
WiFi Access Points Line-of-Sight Detection for Indoor Positioning Using the Signal Round Trip Time


Abstract
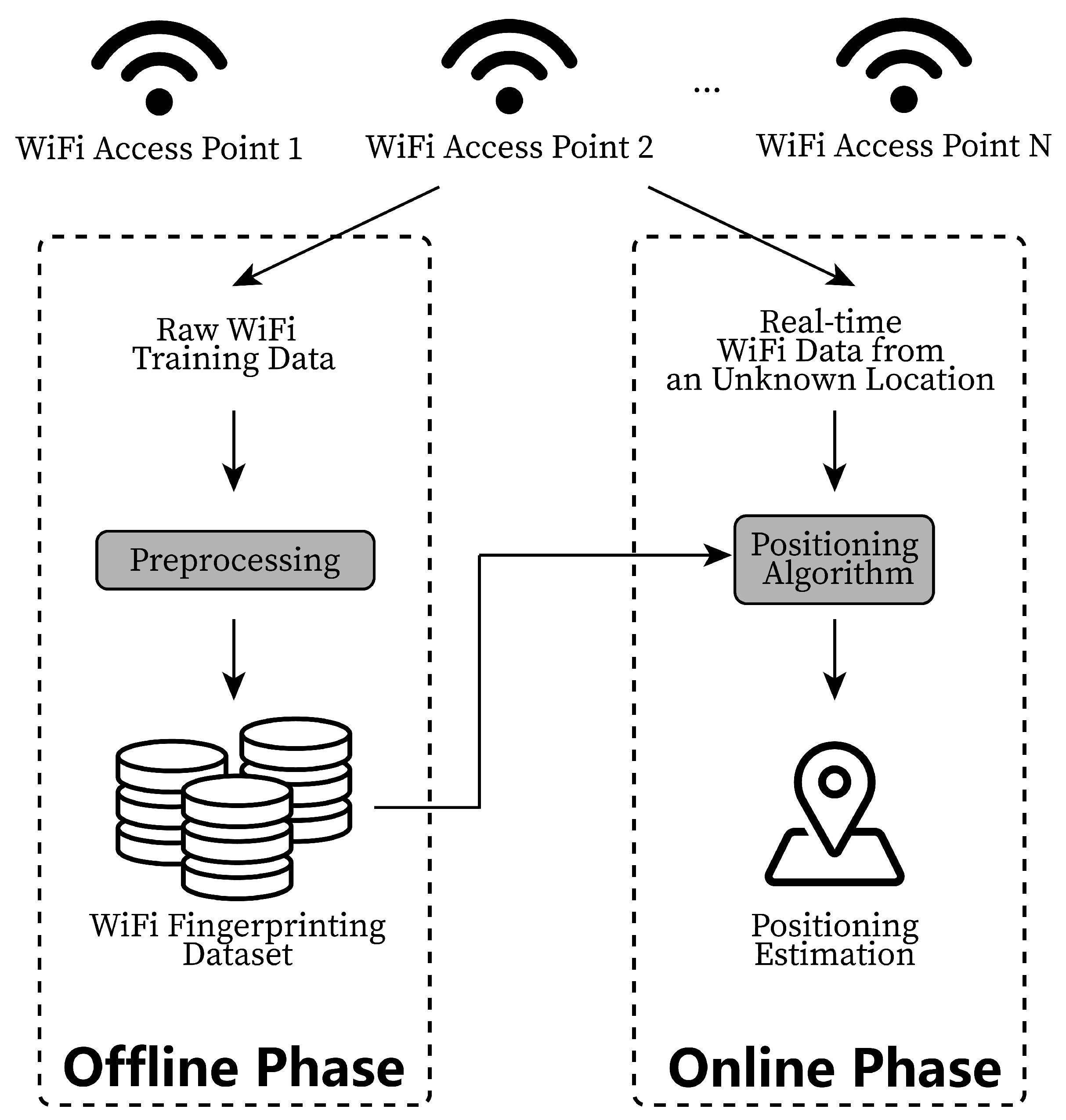
1. Introduction
- A novel feature selection framework was proposed to identify the LOS conditions of WiFi APs with high accuracy even with few data samples, while using fewer Machine Learning features than existing state-of-the-arts.
- A large-scale real-world dataset for a campus floor was collected and made available for further research. To the best of our knowledge, this was the first publicly available dataset that contains both WiFi RSS and RTT signal measures, as well as LOS conditions of each AP for every location.
- We analyzed our framework on such dataset to evaluate the efficiency and to provide a baseline performance for further research.
2. Related Work
3. System Architecture and Problem Formulation
3.1. System Architecture
- Step 1: A feature preprocessing method is proposed to extract the statistical features from raw WiFi training data. The mean, median, standard deviation, Kurtosis, and Skewness are calculated. Then, several Machine Learning feature selection models are used to analyze the importance of each feature and generate different sets of features.
- Step 2: Each feature set will be assigned an initial weight based on its macro F1 score and accuracy. These weights will be fed into the Feature Selector in the next step, and used for generating an initial set of features.
- Step 3: A multi-scale selection (MSS) method is used to reduce the weights of the uninformative features. The MSS method uses several scales of the datasets to select the features from different perspectives. In doing so, features that are important in both long-term time and short-term periods would be selected. The process is repeated until an optimal set of features is decided.
- Step 4: Using the selected set of features from the previous step, a LOS identifier (e.g., Random Forest Classifier) is employed to make LOS detections for the WiFi APs.
3.2. Problem Formulation
4. Feature Preprocessing and Feature Selection Algorithms
4.1. Feature Preprocessing
| Algorithm 1 Feature preprocessing and initial weights assignment |
|
4.1.1. Statistical Feature Extraction
4.1.2. Importance Filter
4.2. Initial Weights Assignment
4.3. Feature Selector and Testing Data Validation
4.3.1. Multi-Scale Selection (MSS)
| Algorithm 2 Feature selector with multi-scale selection. |
|
4.3.2. Final Feature Set and Testing Data Validation
5. Experimental Setup and Empirical Results
5.1. Test Bed and the Proposed Dataset
5.2. The Impact of NLOS Scenarios in Indoor Positioning
5.3. The Importance of Feature Selection
5.4. Sampling Size
5.5. The Performance of the Proposed Framework
6. Discussion
- The dataset was collected in a campus floor. Each AP was surrounded by complex interiors and in different LOS/NLOS conditions.
- The testbed of 92 × 15 m2 was evenly divided into 0.6 × 0.6 m grids which served as reference points. Each grid was carefully labeled with ground-truth coordinates by two human surveyors. Reference points for training and testing are not overlapping.
- At each reference point, more than 120 scans of both WiFi RTT and RSS signal measurements were collected. During collection, the influence of the human body was taken into consideration.
- Each data sample was meticulously labeled with LOS conditions of all the APs in the testbed.
- With more than 77,000 samples, the dataset provides good coverage for the evaluation of any WiFi RSS-based, RTT-based or hybrid indoor positioning systems. The real-world indoor environment guarantees the generalization of the proposed framework.
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nguyen, K.A.; Luo, Z.; Li, G.; Watkins, C. A review of smartphones-based indoor positioning: Challenges and applications. IET Cyber-Syst. Robot. 2021, 3, 1–30. [Google Scholar] [CrossRef]
- Huang, C.; He, R.; Ai, B.; Molisch, A.F.; Lau, B.K.; Haneda, K.; Liu, B.; Wang, C.X.; Yang, M.; Oestges, C.; et al. Artificial intelligence enabled radio propagation for communications—Part II: Scenario identification and channel modeling. IEEE Trans. Antennas Propag. 2022, 70, 3955–3969. [Google Scholar] [CrossRef]
- Liu, F.; Liu, J.; Yin, Y.; Wang, W.; Hu, D.; Chen, P.; Niu, Q. Survey on WiFi-based indoor positioning techniques. IET Commun. 2020, 14, 1372–1383. [Google Scholar] [CrossRef]
- Nguyen, K.A.; Luo, Z. On assessing the positioning accuracy of Google Tango in challenging indoor environments. In Proceedings of the 2017 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Sapporo, Japan, 18–21 September 2021; IEEE: Piscataway, NJ, USA, 2017; pp. 1–8. [Google Scholar]
- Feng, X.; Nguyen, K.A.; Luo, Z. An analysis of the properties and the performance of WiFi RTT for indoor positioning in non-line-of-sight environments. In Proceedings of the 17th International Conference on Location Based Services, Munich, Germany, 12–14 September 2022. [Google Scholar]
- Nie, Z.; Liu, F.; Gao, Y. Real-time precise point positioning with a low-cost dual-frequency GNSS device. Gps Solut. 2020, 24, 9. [Google Scholar] [CrossRef]
- Marra, A.D.; Becker, H.; Axhausen, K.W.; Corman, F. Developing a passive GPS tracking system to study long-term travel behavior. Transp. Res. Part C Emerg. Technol. 2019, 104, 348–368. [Google Scholar] [CrossRef]
- Zein, Y.; Darwiche, M.; Mokhiamar, O. GPS tracking system for autonomous vehicles. Alex. Eng. J. 2018, 57, 3127–3137. [Google Scholar] [CrossRef]
- Zhang, E.; Masoud, N. Increasing GPS localization accuracy with reinforcement learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 2615–2626. [Google Scholar] [CrossRef]
- Gondelach, D.J.; Linares, R. Real-time thermospheric density estimation via radar and GPS tracking data assimilation. Space Weather 2021, 19, e2020SW002620. [Google Scholar] [CrossRef]
- Xu, B.; Jia, Q.; Hsu, L.T. Vector tracking loop-based GNSS NLOS detection and correction: Algorithm design and performance analysis. IEEE Trans. Instrum. Meas. 2019, 69, 4604–4619. [Google Scholar] [CrossRef]
- Wen, F.; Wymeersch, H.; Peng, B.; Tay, W.P.; So, H.C.; Yang, D. A survey on 5G massive MIMO localization. Digit. Signal Process. 2019, 94, 21–28. [Google Scholar] [CrossRef]
- He, J.; Wymeersch, H.; Kong, L.; Silvén, O.; Juntti, M. Large intelligent surface for positioning in millimeter wave MIMO systems. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Virtual Event, 25–28 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- De Bast, S.; Guevara, A.P.; Pollin, S. CSI-based positioning in massive MIMO systems using convolutional neural networks. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Virtual Event, 25–28 May 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Lin, Y.; Jin, S.; Matthaiou, M.; You, X. Channel estimation and user localization for IRS-assisted MIMO-OFDM systems. IEEE Trans. Wirel. Commun. 2021, 21, 2320–2335. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, S.; Li, H.; Gao, F.; Jin, S. Sparse Bayesian learning for the time-varying massive MIMO channels: Acquisition and tracking. IEEE Trans. Commun. 2018, 67, 1925–1938. [Google Scholar] [CrossRef]
- Zhang, J.; Salmi, J.; Lohan, E.S. Analysis of kurtosis-based LOS/NLOS identification using indoor MIMO channel measurement. IEEE Trans. Veh. Technol. 2013, 62, 2871–2874. [Google Scholar] [CrossRef]
- Chen, J.; Yin, X.; Cai, X.; Wang, S. Measurement-based massive MIMO channel modeling for outdoor LoS and NLoS environments. IEEE Access 2017, 5, 2126–2140. [Google Scholar] [CrossRef]
- Huang, C.; Molisch, A.F.; Wang, R.; Tang, P.; He, R.; Zhong, Z. Angular information-based NLOS/LOS identification for vehicle to vehicle MIMO system. In Proceedings of the 2019 IEEE International Conference on Communications Workshops (ICC Workshops), Shanghai, China, 22–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Zhang, Q.; Yang, H.H.; Quek, T.Q.; Lee, J. Heterogeneous cellular networks with LoS and NLoS transmissions—The role of massive MIMO and small cells. IEEE Trans. Wirel. Commun. 2017, 16, 7996–8010. [Google Scholar] [CrossRef]
- Zeng, T.; Chang, Y.; Zhang, Q.; Hu, M.; Li, J. CNN-based LOS/NLOS identification in 3-D massive MIMO systems. IEEE Commun. Lett. 2018, 22, 2491–2494. [Google Scholar] [CrossRef]
- Li, J.; Chang, Y.; Zeng, T.; Xiong, Y. Channel correlation based identification of LOS and NLOS in 3D massive MIMO systems. In Proceedings of the 2019 IEEE Wireless Communications and Networking Conference (WCNC), Marrakesh, Morocco, 15–18 April 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Ridolfi, M.; Kaya, A.; Berkvens, R.; Weyn, M.; Joseph, W.; Poorter, E.D. Self-calibration and collaborative localization for uwb positioning systems: A survey and future research directions. ACM Comput. Surv. (CSUR) 2021, 54, 1–27. [Google Scholar] [CrossRef]
- Poulose, A.; Han, D.S. UWB indoor localization using deep learning LSTM networks. Appl. Sci. 2020, 10, 6290. [Google Scholar] [CrossRef]
- Yu, K.; Wen, K.; Li, Y.; Zhang, S.; Zhang, K. A novel NLOS mitigation algorithm for UWB localization in harsh indoor environments. IEEE Trans. Veh. Technol. 2018, 68, 686–699. [Google Scholar] [CrossRef]
- Macoir, N.; Bauwens, J.; Jooris, B.; Van Herbruggen, B.; Rossey, J.; Hoebeke, J.; De Poorter, E. Uwb localization with battery-powered wireless backbone for drone-based inventory management. Sensors 2019, 19, 467. [Google Scholar] [CrossRef]
- Poulose, A.; Emeršič, Ž.; Eyobu, O.S.; Han, D.S. An accurate indoor user position estimator for multiple anchor uwb localization. In Proceedings of the 2020 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 21–23 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 478–482. [Google Scholar]
- Musa, A.; Nugraha, G.D.; Han, H.; Choi, D.; Seo, S.; Kim, J. A decision tree-based NLOS detection method for the UWB indoor location tracking accuracy improvement. Int. J. Commun. Syst. 2019, 32, e3997. [Google Scholar] [CrossRef]
- Barral, V.; Escudero, C.J.; García-Naya, J.A.; Maneiro-Catoira, R. NLOS identification and mitigation using low-cost UWB devices. Sensors 2019, 19, 3464. [Google Scholar] [CrossRef]
- Park, J.; Nam, S.; Choi, H.; Ko, Y.; Ko, Y.B. Improving deep learning-based UWB LOS/NLOS identification with transfer learning: An empirical approach. Electronics 2020, 9, 1714. [Google Scholar] [CrossRef]
- Hajiakhondi-Meybodi, Z.; Mohammadi, A.; Hou, M.; Plataniotis, K.N. DQLEL: Deep Q-Learning for Energy-Optimized LoS/NLoS UWB Node Selection. IEEE Trans. Signal Process. 2022, 70, 2532–2547. [Google Scholar] [CrossRef]
- Cui, Z.; Gao, Y.; Hu, J.; Tian, S.; Cheng, J. LOS/NLOS identification for indoor UWB positioning based on Morlet wavelet transform and convolutional neural networks. IEEE Commun. Lett. 2020, 25, 879–882. [Google Scholar] [CrossRef]
- Li, H.; Zeng, X.; Li, Y.; Zhou, S.; Wang, J. Convolutional neural networks based indoor Wi-Fi localization with a novel kind of CSI images. China Commun. 2019, 16, 250–260. [Google Scholar] [CrossRef]
- Dang, X.; Tang, X.; Hao, Z.; Ren, J. Discrete Hopfield neural network based indoor Wi-Fi localization using CSI. EURASIP J. Wirel. Commun. Netw. 2020, 2020, 1–16. [Google Scholar] [CrossRef]
- Wang, X.; Wang, X.; Mao, S. Deep convolutional neural networks for indoor localization with CSI images. IEEE Trans. Netw. Sci. Eng. 2018, 7, 316–327. [Google Scholar] [CrossRef]
- Dang, X.; Tang, X.; Hao, Z.; Liu, Y. A device-free indoor localization method using CSI with Wi-Fi signals. Sensors 2019, 19, 3233. [Google Scholar] [CrossRef] [PubMed]
- Tong, X.; Wan, Y.; Li, Q.; Tian, X.; Wang, X. CSI fingerprinting localization with low human efforts. IEEE/ACM Trans. Netw. 2020, 29, 372–385. [Google Scholar] [CrossRef]
- Feng, X.; Nguyen, K.A.; Luo, Z. A survey of deep learning approaches for WiFi-based indoor positioning. J. Inf. Telecommun. 2022, 6, 163–216. [Google Scholar] [CrossRef]
- Li, Z.; Tian, Z.; Zhou, M.; Zhang, Z.; Jin, Y. Awareness of line-of-sight propagation for indoor localization using Hopkins statistic. IEEE Sen. J. 2018, 18, 3864–3874. [Google Scholar] [CrossRef]
- Zhou, Z.; Yang, Z.; Wu, C.; Sun, W.; Liu, Y. LiFi: Line-of-sight identification with WiFi. In Proceedings of the IEEE INFOCOM 2014-IEEE Conference on Computer Communications, Toronto, ON, Canada, 27 April–2 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 2688–2696. [Google Scholar]
- Wu, C.; Yang, Z.; Zhou, Z.; Qian, K.; Liu, Y.; Liu, M. PhaseU: Real-time LOS identification with WiFi. In Proceedings of the 2015 IEEE Conference on Computer Communications (INFOCOM), Hong Kong, China, 26 April–1 May 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 2038–2046. [Google Scholar]
- Zhou, Z.; Yang, Z.; Wu, C.; Shangguan, L.; Cai, H.; Liu, Y.; Ni, L.M. WiFi-based indoor line-of-sight identification. IEEE Trans. Wirel. Commun. 2015, 14, 6125–6136. [Google Scholar] [CrossRef]
- Chang, T.; Jiang, S.; Sun, Y.; Jia, A.; Wang, W. Multi-bandwidth NLOS Identification Based on Deep Learning Method. In Proceedings of the 2021 15th European Conference on Antennas and Propagation (EuCAP), Dusseldorf, Germany, 22–26 March 2021; IIEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Jiokeng, K.; Jakllari, G.; Tchana, A.; Beylot, A.L. When FTM discovered MUSIC: Accurate WiFi-based ranging in the presence of multipath. In Proceedings of the IEEE INFOCOM 2020-IEEE Conference on Computer Communications, Toronto, ON, Canada, 6–9 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1857–1866. [Google Scholar]
- Zheng, Q.; He, R.; Ai, B.; Huang, C.; Chen, W.; Zhong, Z.; Zhang, H. Channel non-line-of-sight identification based on convolutional neural networks. IEEE Wirel. Commun. Lett. 2020, 9, 1500–1504. [Google Scholar] [CrossRef]
- Ramadan, M.; Sark, V.; Gutierrez, J.; Grass, E. NLOS identification for indoor localization using random forest algorithm. In Proceedings of the WSA 2018 22nd International ITG Workshop on Smart Antennas, Bochum, Germany, 14–16 March 2018; VDE: Berlin, Germany, 2018; pp. 1–5. [Google Scholar]
- Li, X.; Cai, X.; Hei, Y.; Yuan, R. NLOS identification and mitigation based on channel state information for indoor WiFi localisation. IET Commun. 2017, 11, 531–537. [Google Scholar] [CrossRef]
- Sharma, S.; Mohammadmoradi, H.; Heydariaan, M.; Gnawali, O. Device-free activity recognition using ultra-wideband radios. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1029–1033. [Google Scholar]
- Bocus, M.; Piechocki, R.; Chetty, K. A Comparison of UWB CIR and WiFi CSI for Human Activity Recognition. In Proceedings of the IEEE Radar Conference (RadarCon), Atlanta, GA, USA, 10–14 May 2021. [Google Scholar]
- Han, S.; Li, Y.; Meng, W.; Li, C.; Liu, T.; Zhang, Y. Indoor localization with a single Wi-Fi access point based on OFDM-MIMO. IEEE Syst. J. 2018, 13, 964–972. [Google Scholar] [CrossRef]
- Chen, L.; Ahriz, I.; Le Ruyet, D.; Sun, H. Probabilistic indoor position determination via channel impulse response. In Proceedings of the 2018 IEEE 29th Annual International Symposium on Personal, Indoor and Mobile Radio Communications (PIMRC), Bologna, Italy, 9–12 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 829–834. [Google Scholar]
- Wang, Y.; Liu, J.; Chen, Y.; Gruteser, M.; Yang, J.; Liu, H. E-eyes: Device-free location-oriented activity identification using fine-grained wifi signatures. In Proceedings of the 20th Annual International Conference on Mobile Computing and Networking, Maui, HI, USA, 7–11 September 2014; pp. 617–628. [Google Scholar]
- Wang, H.; Zhang, D.; Ma, J.; Wang, Y.; Wang, Y.; Wu, D.; Gu, T.; Xie, B. Human respiration detection with commodity wifi devices: Do user location and body orientation matter? In Proceedings of the 2016 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 25–36. [Google Scholar]
- Menezes, C. Wi-Fi FTM RTT Based Positioning System. 2021. Available online: https://contest.embarcados.com.br/wp-content/uploads/2021/11/Wi-Fi-FTM-RTT-Based-Positioning-System-Chronos-3-2.pdf (accessed on 14 November 2022).
- Yu, Y.; Chen, R.; Chen, L.; Guo, G.; Ye, F.; Liu, Z. A robust dead reckoning algorithm based on Wi-Fi FTM and multiple sensors. Remote Sens. 2019, 11, 504. [Google Scholar] [CrossRef]
- Yu, Y.; Chen, R.; Chen, L.; Xu, S.; Li, W.; Wu, Y.; Zhou, H. Precise 3-D indoor localization based on Wi-Fi FTM and built-in sensors. IEEE Internet Things J. 2020, 7, 11753–11765. [Google Scholar] [CrossRef]
- Schepers, D.; Singh, M.; Ranganathan, A. Here, there, and everywhere: Security analysis of wi-fi fine timing measurement. In Proceedings of the 14th ACM Conference on Security and Privacy in Wireless and Mobile Networks, Virtual Conference, 28 June–2 July 2021; pp. 78–89. [Google Scholar]
- Shao, W.; Luo, H.; Zhao, F.; Tian, H.; Yan, S.; Crivello, A. Accurate indoor positioning using temporal–spatial constraints based on Wi-Fi fine time measurements. IEEE Internet Things J. 2020, 7, 11006–11019. [Google Scholar] [CrossRef]
- Banin, L.; Bar-Shalom, O.; Dvorecki, N.; Amizur, Y. Scalable Wi-Fi client self-positioning using cooperative FTM-sensors. IEEE Trans. Instrum. Meas. 2018, 68, 3686–3698. [Google Scholar] [CrossRef]
- Yu, Y.; Chen, R.; Liu, Z.; Guo, G.; Ye, F.; Chen, L. Wi-Fi fine time measurement: Data analysis and processing for indoor localisation. J. Navig. 2020, 73, 1106–1128. [Google Scholar] [CrossRef]
- Pajovic, M.; Wang, P.; Koike-Akino, T.; Sun, H.; Orlik, P.V. Fingerprinting-based indoor localization with commercial mmWave WiFi-part I: RSS and beam indices. In Proceedings of the 2019 IEEE Global Communications Conference (GLOBECOM), Big Island, HI, USA, 9–13 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Guo, X.; Elikplim, N.R.; Ansari, N.; Li, L.; Wang, L. Robust WiFi localization by fusing derivative fingerprints of RSS and multiple classifiers. IEEE Trans. Ind. Inform. 2019, 16, 3177–3186. [Google Scholar] [CrossRef]
- Zhang, L.; Chen, Z.; Cui, W.; Li, B.; Chen, C.; Cao, Z.; Gao, K. Wifi-based indoor robot positioning using deep fuzzy forests. IEEE Internet Things J. 2020, 7, 10773–10781. [Google Scholar] [CrossRef]
- Xue, J.; Liu, J.; Sheng, M.; Shi, Y.; Li, J. A WiFi fingerprint based high-adaptability indoor localization via machine learning. China Commun. 2020, 17, 247–259. [Google Scholar] [CrossRef]
- Choi, J.S.; Lee, W.H.; Lee, J.H.; Lee, J.H.; Kim, S.C. Deep learning based NLOS identification with commodity WLAN devices. IEEE Trans. Veh. Technol. 2017, 67, 3295–3303. [Google Scholar] [CrossRef]
- Si, M.; Wang, Y.; Xu, S.; Sun, M.; Cao, H. A Wi-Fi FTM-based indoor positioning method with LOS/NLOS identification. Appl. Sci. 2020, 10, 956. [Google Scholar] [CrossRef]
- Xu, S.; Chen, R.; Yu, Y.; Guo, G.; Huang, L. Locating smartphones indoors using built-in sensors and Wi-Fi ranging with an enhanced particle filter. IEEE Access 2019, 7, 95140–95153. [Google Scholar] [CrossRef]
- Sun, M.; Wang, Y.; Xu, S.; Qi, H.; Hu, X. Indoor positioning tightly coupled Wi-Fi FTM ranging and PDR based on the extended Kalman filter for smartphones. IEEE Access 2020, 8, 49671–49684. [Google Scholar] [CrossRef]
- Dong, Y.; Arslan, T.; Yang, Y. Real-time NLOS/LOS Identification for Smartphone-based Indoor Positioning Systems using WiFi RTT and RSS. IEEE Sens. J. 2021, 22, 5199–5209. [Google Scholar] [CrossRef]
- Carpi, F.; Davoli, L.; Martalò, M.; Cilfone, A.; Yu, Y.; Wang, Y.; Ferrari, G. RSSI-based methods for LOS/NLOS channel identification in indoor scenarios. In Proceedings of the 2019 16th International Symposium on Wireless Communication Systems (ISWCS), Oulu, Finland, 27–30 August 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 171–175. [Google Scholar]
- Han, K.; Yu, S.M.; Kim, S.L. Smartphone-based indoor localization using Wi-Fi fine timing measurement. In Proceedings of the 2019 International Conference on Indoor Positioning and Indoor Navigation (IPIN), Pisa, Italy, 30 September–3 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–5. [Google Scholar]
- Xiao, Z.; Wen, H.; Markham, A.; Trigoni, N.; Blunsom, P.; Frolik, J. Non-line-of-sight identification and mitigation using received signal strength. IEEE Trans. Wirel. Commun. 2014, 14, 1689–1702. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: A corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef] [PubMed]
- Koya, S.K.; Brusatori, M.; Yurgelevic, S.; Huang, C.; Werner, C.W.; Kast, R.E.; Shanley, J.; Sherman, M.; Honn, K.V.; Maddipati, K.R.; et al. Accurate identification of breast cancer margins in microenvironments of ex vivo basal and luminal breast cancer tissues using Raman spectroscopy. Prostaglandins Other Lipid Mediat. 2020, 151, 106475. [Google Scholar] [CrossRef] [PubMed]
- Huang, N.; Lu, G.; Xu, D. A permutation importance-based feature selection method for short-term electricity load forecasting using random forest. Energies 2016, 9, 767. [Google Scholar] [CrossRef]
- Li, K.; Ma, Z.; Robinson, D.; Ma, J. Identification of typical building daily electricity usage profiles using Gaussian mixture model-based clustering and hierarchical clustering. Appl. Energy 2018, 231, 331–342. [Google Scholar] [CrossRef]
- Briggs, C.; Fan, Z.; Andras, P. Federated learning with hierarchical clustering of local updates to improve training on non-IID data. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–9. [Google Scholar]
- Aksu, D.; Üstebay, S.; Aydin, M.A.; Atmaca, T. Intrusion detection with comparative analysis of supervised learning techniques and fisher score feature selection algorithm. In Proceedings of the International Symposium on Computer and Information Sciences, Kuala Lumpur, Malaysia, 13–14 August 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 141–149. [Google Scholar]
- Sun, L.; Fu, S.; Wang, F. Decision tree SVM model with Fisher feature selection for speech emotion recognition. EURASIP J. Audio Speech Music Process. 2019, 2019, 2. [Google Scholar] [CrossRef]
- Guyon, I.; Weston, J.; Barnhill, S.; Vapnik, V. Gene selection for cancer classification using support vector machines. Mach. Learn. 2002, 46, 389–422. [Google Scholar] [CrossRef]
- Xue, Y.; Zhang, L.; Wang, B.; Zhang, Z.; Li, F. Nonlinear feature selection using Gaussian kernel SVM-RFE for fault diagnosis. Appl. Intell. 2018, 48, 3306–3331. [Google Scholar] [CrossRef]
- Nitta, G.R.; Rao, B.Y.; Sravani, T.; Ramakrishiah, N.; Balaanand, M. LASSO-based feature selection and naïve Bayes classifier for crime prediction and its type. Serv. Oriented Comput. Appl. 2019, 13, 187–197. [Google Scholar] [CrossRef]
- Kang, C.; Huo, Y.; Xin, L.; Tian, B.; Yu, B. Feature selection and tumor classification for microarray data using relaxed Lasso and generalized multi-class support vector machine. J. Theor. Biol. 2019, 463, 77–91. [Google Scholar] [CrossRef]
- Leo, B. Manual On Setting Up, Using, Furthermore, Understanding Random Forests V3.1. Stat. Dep. Univ. Calif. Berkeley 2002, 1, 58. [Google Scholar]
- Louppe, G.; Wehenkel, L.; Sutera, A.; Geurts, P. Understanding variable importances in forests of randomized trees. In Proceedings of the 2016 the 26th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013. [Google Scholar]
- Han, H.; Guo, X.; Yu, H. Variable selection using mean decrease accuracy and mean decrease gini based on random forest. In Proceedings of the 2016 7th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 26–28 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 219–224. [Google Scholar]
- Liu, Y.; Mu, Y.; Chen, K.; Li, Y.; Guo, J. Daily activity feature selection in smart homes based on pearson correlation coefficient. Neural Process. Lett. 2020, 51, 1771–1787. [Google Scholar] [CrossRef]
- Bahassine, S.; Madani, A.; Al-Sarem, M.; Kissi, M. Feature selection using an improved Chi-square for Arabic text classification. J. King Saud Univ.-Comput. Inf. Sci. 2020, 32, 225–231. [Google Scholar] [CrossRef]
- Choi, J.; Choi, Y.S.; Talwar, S. Unsupervised learning techniques for trilateration: From theory to android app implementation. IEEE Access 2019, 7, 134525–134538. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Sensor | Identification Technique | Test Bed | Accuracy | Notes |
|---|---|---|---|---|---|
| Huang et al. [19] | MIMO | SVM | Public roads | 96% | The authors focused on identifying LOS conditions in vehicle to vehicle localization system and tested the system in large-scale outdoor space. |
| Zeng et al. [21] | MIMO | CNN | Unspecified | 97% | By constructing the coordinated tap energy matrix, the system achieved better results than previous models. |
| Li et al. [22] | MIMO | Binary hypothesis test | Simulation | 97% | By leveraging time-space-frequency channel correlation, the authors improved 5G New Radio (NR) capacity and spectral efficiency. |
| Musa et al. [28] | UWB | Recursive decision tree | Small apartment | 90% | The proposed method was tested in seven common indoor environments and performed best in small apartment. |
| Park et al. [30] | UWB | MLP and CNN | Campus rooms | 98% | The proposed scheme in unmeasured environment improved the accuracy by 10%. |
| Cui et al. [32] | UWB | MWT-CNN | Office scenario | 100% | The Morlet wave transform (MWT) was leveraged to time-frequency domain characteristics for identification. |
| Li et al. [47] | WiFi | SVM | Real-world building | 94% | The authors investigated the LOS factor of CSI in time-domain CIR samples and selected the features manually. |
| Choi et al. [65] | WiFi | RNN | 45 × 35 m | 93% | The system based on CSI and RSS signal measures was test in the testbed with 5 APs evenly placed. |
| Dong et al. [69] | WiFi | DNN, RF, SVM | 11 × 12 m | 96% | The statistical features of WiFi signals were manually selected by the system. |
| Han et al. [71] | WiFi | SVM | 5 × 15 m | 92% | Only 1 out of 4 APs was placed under NLOS conditions. |
| Xiao et al. [72] | WiFi | Least Square SVM | 55 × 40 m | 95% | The identification algorithm was tested in a 3 AP test bed with multiple NLOS and LOS scenarios. |
| Data Features | Details |
|---|---|
| Testbed | 92 × 15 m |
| Grid size | 0.6 × 0.6 m |
| Total reference points | 642 |
| Data samples per reference point | 120 |
| Total data samples | 77,040 |
| Training samples | 57,960 |
| Testing samples | 19,080 |
| Signal measure | WiFi RSS, WiFi RTT |
| Ground-truth labels | LOS conditions, X and Y co-ordinate |
| (a) WiFi RSS data samples | ||||||
| X | Y | AP1 RSS (dBm) | AP2 RSS (dBm) | ... | AP13 RSS (dBm) | LOS APs |
| 34 | 12 | −200 | −200 | ... | −200 | 8 |
| 34 | 13 | −200 | −200 | ... | −92 | None |
| 35 | 12 | −200 | −200 | ... | −93 | 8 |
| 35 | 13 | −200 | −200 | ... | −91 | None |
| ... | ... | ... | ... | ... | ... | ... |
| 125 | 15 | −74 | −47 | ... | −200 | 2 3 |
| (b) WiFi RTT data samples | ||||||
| X | Y | AP1 RTT (mm) | AP2 RTT (mm) | ... | AP13 RTT (mm) | LOS APs |
| 34 | 12 | 100,000 | 100,000 | ... | 5958 | 8 |
| 34 | 13 | 100,000 | 100,000 | ... | 22,734 | None |
| 35 | 12 | 100,000 | 100,000 | ... | 24,237 | 8 |
| 35 | 13 | 100,000 | 100,000 | ... | 24,907 | None |
| ... | ... | ... | ... | ... | ... | ... |
| 125 | 15 | 10,585 | 598 | ... | 100,000 | 2 3 |
| Features of This AP | All Features | Features by MSS | |
|---|---|---|---|
| AP6 | 0.845 | 0.609 | 0.897 |
| AP8 | 0.89 | 0.933 | 0.933 |
| AP12 | 0.609 | 0.851 | 0.865 |
| All APs | N/A | 0.689 | 0.780 |
| 120-Scans | 60-Scans | 30-Scans | 15-Scans | 10-Scans | 5-Scans | MSS | |
|---|---|---|---|---|---|---|---|
| AP6 | 0.82 | 0.67 | 0.87 | 0.61 | 0.53 | 0.57 | 0.92 |
| AP8 | 0.93 | 0.98 | 0.95 | 0.93 | 0.94 | 0.93 | 0.98 |
| AP12 | 0.82 | 0.88 | 0.85 | 0.85 | 0.85 | 0.92 | 0.87 |
| All APs | 0.62 | 0.60 | 0.64 | 0.69 | 0.70 | 0.72 | 0.78 |
| PI | HC | Fisher | RFE | Lasso | MDI | Pearson | Chi | S-F | Proposed | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Weighted F1 | 0.90 | 0.88 | 0.91 | 0.72 | 0.89 | 0.88 | 0.91 | 0.88 | 0.41 | 0.89 | 0.57 | 0.88 | 0.89 | 0.68 | 0.93 |
| Macro F1 | 0.68 | 0.71 | 0.70 | 0.68 | 0.67 | 0.68 | 0.71 | 0.70 | 0.67 | 0.69 | 0.67 | 0.68 | 0.68 | 0.43 | 0.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Feng, X.; Nguyen, K.A.; Luo, Z. WiFi Access Points Line-of-Sight Detection for Indoor Positioning Using the Signal Round Trip Time. Remote Sens. 2022, 14, 6052. https://doi.org/10.3390/rs14236052
Feng X, Nguyen KA, Luo Z. WiFi Access Points Line-of-Sight Detection for Indoor Positioning Using the Signal Round Trip Time. Remote Sensing. 2022; 14(23):6052. https://doi.org/10.3390/rs14236052
Chicago/Turabian StyleFeng, Xu, Khuong An Nguyen, and Zhiyuan Luo. 2022. "WiFi Access Points Line-of-Sight Detection for Indoor Positioning Using the Signal Round Trip Time" Remote Sensing 14, no. 23: 6052. https://doi.org/10.3390/rs14236052
APA StyleFeng, X., Nguyen, K. A., & Luo, Z. (2022). WiFi Access Points Line-of-Sight Detection for Indoor Positioning Using the Signal Round Trip Time. Remote Sensing, 14(23), 6052. https://doi.org/10.3390/rs14236052