
Targeted Universal Adversarial Examples for Remote Sensing


Abstract
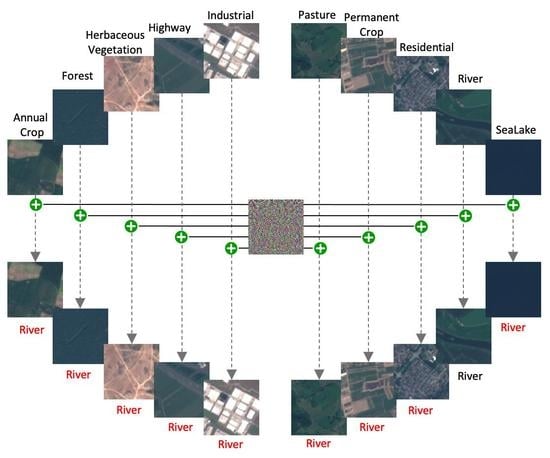
1. Introduction
- 1.
- To the best of our knowledge, we are the first to study targeted universal adversarial examples in remote sensing data, without accessing the victim models in evaluation. Compared to universal adversarial examples, our research helps reveal and understand the vulnerabilities of deep learning models in remote sensing applications at a fine-grained level.
- 2.
- We propose two variants of universal adversarial examples: targeted universal adversarial example(s) (TUAE) for all images and source-targeted universal adversarial example(s) (STUAE) for limited source images.
- 3.
- Extensive experiments with various deep learning models on three benchmark datasets of remote sensing showed strong attackability of our methods in the scene classification task.

2. Related Work
2.1. Adversarial Attacks
2.1.1. Fast Gradient Sign Method (FGSM)
2.1.2. Iterative Fast Gradient Sign Method (I-FGSM)
2.1.3. C&W Attack
2.1.4. Projected Gradient Descent (PGD) Attack
2.2. Universal Attacks
3. Methodology
3.1. Targeted Universal Adversarial Examples
3.1.1. Problem Definition
3.1.2. Loss Design
| Algorithm 1 Targeted universal attack. | |
| Require: Dataset , Victim model f, Targeted class t, Loss function , Number of iterations I, Perturbation magnitude | |
| initialize | ▹ Random initialization |
| while do | |
| sample | ▹ Mini batch |
| ▹ Craft adversarial examples | |
| ▹ Calculate gradients | |
| ▹ Update | |
| ▹ Projection | |
| end while | |
3.2. Source-Targeted Universal Adversarial Examples
3.2.1. Problem Definition
3.2.2. Loss Design
| Algorithm 2 Source-targeted universal attack. | |
| Require: Dataset , Victim model f, Specified class s, Targeted class t, Loss function , Number of iterations I, Perturbation magnitude , hyperparameter | |
| initialize | ▹Random initialization |
| while do | |
| sample | ▹ Mini batch |
| ▹ Craft adversarial examples | |
| ▹ Generate mask | |
| ▹ Select specified class samples | |
| ▹ Select other class samples | |
| ▹ Calculate loss | |
| ▹ Calculate gradients | |
| ▹ Update | |
| ▹ Projection | |
| end while | |
4. Experiments
4.1. Data Descriptions
4.2. Experimental Settings and Implementation Details
4.3. Attacks on Scene Classification
4.3.1. Targeted Adversarial Attacks
4.3.2. Source-Targeted Universal Adversarial Examples
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boukabara, S.A.; Eyre, J.; Anthes, R.A.; Holmlund, K.; Germain, K.M.S.; Hoffman, R.N. The Earth-Observing Satellite Constellation: A review from a meteorological perspective of a complex, interconnected global system with extensive applications. IEEE Geosci. Remote Sens. Mag. 2021, 9, 26–42. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L.; Cerra, D.; Pato, M.; Carmona, E.; Prasad, S.; Yokoya, N.; Hänsch, R.; Le Saux, B. Advanced multi-sensor optical remote sensing for urban land use and land cover classification: Outcome of the 2018 IEEE GRSS data fusion contest. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1709–1724. [Google Scholar] [CrossRef]
- Ghamisi, P.; Rasti, B.; Yokoya, N.; Wang, Q.; Hofle, B.; Bruzzone, L.; Bovolo, F.; Chi, M.; Anders, K.; Gloaguen, R.; et al. Multisource and multitemporal data fusion in remote sensing: A comprehensive review of the state of the art. IEEE Geosci. Remote Sens. Mag. 2019, 7, 6–39. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep learning for unmanned aerial vehicle-based object detection and tracking: A survey. IEEE Geosci. Remote Sens. Mag. 2021, 10, 91–124. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Tiede, D.; Wendt, L.; Sudmanns, M.; Lang, S. Transferable instance segmentation of dwellings in a refugee camp-integrating CNN and OBIA. Eur. J. Remote Sens. 2021, 54, 127–140. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. Conference Track Proceedings. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Carlini, N.; Wagner, D. Towards Evaluating the Robustness of Neural Networks. In Proceedings of the 2017 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2017. [Google Scholar]
- Madry, A.; Makelov, A.; Schmidt, L.; Tsipras, D.; Vladu, A. Towards Deep Learning Models Resistant to Adversarial Attacks. Conference Track Proceedings. In Proceedings of the 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Xiao, C.; Li, B.; Zhu, J.; He, W.; Liu, M.; Song, D. Generating Adversarial Examples with Adversarial Networks. In Proceedings of the Twenty-Seventh International Joint Conference on Artificial Intelligence, IJCAI 2018, Stockholm, Sweden, 13–19 July 2018. [Google Scholar]
- Bai, T.; Zhao, J.; Zhu, J.; Han, S.; Chen, J.; Li, B.; Kot, A. AI-GAN: Attack-Inspired Generation of Adversarial Examples. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AL, USA, 19–22 September 2021; pp. 2543–2547. [Google Scholar] [CrossRef]
- Akhtar, N.; Mian, A. Threat of Adversarial Attacks on Deep Learning in Computer Vision: A Survey. arXiv 2018, arXiv:1801.00553. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial Machine Learning at Scale. Conference Track Proceedings. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- Czaja, W.; Fendley, N.; Pekala, M.; Ratto, C.; Wang, I.J. Adversarial examples in remote sensing. In Proceedings of the 26th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Washington, DC, USA, 6–9 November 2018; pp. 408–411. [Google Scholar]
- Xu, Y.; Du, B.; Zhang, L. Assessing the threat of adversarial examples on deep neural networks for remote sensing scene classification: Attacks and defenses. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1604–1617. [Google Scholar] [CrossRef]
- Chen, L.; Zhu, G.; Li, Q.; Li, H. Adversarial example in remote sensing image recognition. arXiv 2019, arXiv:1910.13222. [Google Scholar]
- Chan-Hon-Tong, A.; Lenczner, G.; Plyer, A. Demotivate adversarial defense in remote sensing. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021; pp. 3448–3451. [Google Scholar]
- Xu, Y.; Du, B.; Zhang, L. Self-attention context network: Addressing the threat of adversarial attacks for hyperspectral image classification. IEEE Trans. Image Process. 2021, 30, 8671–8685. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Ghamisi, P. Universal Adversarial Examples in Remote Sensing: Methodology and Benchmark. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]
- Benz, P.; Zhang, C.; Imtiaz, T.; Kweon, I.S. Double targeted universal adversarial perturbations. In Proceedings of the Asian Conference on Computer Vision, Kyoto, Japan, 30 November–4 December 2020. [Google Scholar]
- Carlini, N.; Athalye, A.; Papernot, N.; Brendel, W.; Rauber, J.; Tsipras, D.; Goodfellow, I.; Madry, A.; Kurakin, A. On Evaluating Adversarial Robustness. arXiv 2019, arXiv:1902.06705. [Google Scholar]
- Moosavi-Dezfooli, S.M.; Fawzi, A.; Fawzi, O.; Frossard, P. Universal adversarial perturbations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1765–1773. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 14, 1–9. [Google Scholar] [CrossRef]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing network design spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10428–10436. [Google Scholar]
- Kim, H. Torchattacks: A pytorch repository for adversarial attacks. arXiv 2020, arXiv:2010.01950. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Target Class | FGSM | I-FGSM | C&W | PGD | TUAE |
|---|---|---|---|---|---|---|
| AlexNet | 0 | 0.00% | 99.67% | 39.48% | 99.69% | 99.48% |
| 1 | 0.02% | 76.85% | 23.94% | 82.11% | 99.52% | |
| 2 | 0.00% | 97.91% | 35.76% | 98.57% | 99.80% | |
| 3 | 0.54% | 100.00% | 49.06% | 99.96% | 99.91% | |
| 4 | 1.87% | 94.04% | 16.94% | 98.54% | 99.94% | |
| 5 | 0.00% | 98.57% | 30.50% | 98.61% | 99.78% | |
| 6 | 0.00% | 99.81% | 51.81% | 99.69% | 99.54% | |
| 7 | 99.85% | 100.00% | 23.17% | 100.00% | 100.00% | |
| 8 | 0.00% | 99.96% | 41.61% | 99.93% | 97.54% | |
| 9 | 0.00% | 92.57% | 22.94% | 91.19% | 99.26% | |
| DenseNet121 | 0 | 0.26% | 99.96% | 50.94% | 100.00% | 100.00% |
| 1 | 0.00% | 95.93% | 47.11% | 99.19% | 100.00% | |
| 2 | 0.00% | 98.24% | 56.33% | 96.07% | 100.00% | |
| 3 | 0.00% | 99.93% | 47.33% | 100.00% | 100.00% | |
| 4 | 0.46% | 100.00% | 35.22% | 100.00% | 100.00% | |
| 5 | 0.00% | 100.00% | 54.63% | 100.00% | 100.00% | |
| 6 | 0.02% | 100.00% | 80.94% | 100.00% | 100.00% | |
| 7 | 99.93% | 100.00% | 61.87% | 100.00% | 100.00% | |
| 8 | 0.00% | 99.78% | 35.37% | 99.87% | 100.00% | |
| 9 | 0.09% | 100.00% | 34.69% | 100.00% | 100.00% | |
| RegNet_x_400mf | 0 | 33.69% | 100.00% | 55.22% | 100.00% | 100.00% |
| 1 | 0.00% | 84.93% | 11.43% | 95.85% | 99.98% | |
| 2 | 0.00% | 93.63% | 25.56% | 95.93% | 99.98% | |
| 3 | 0.00% | 99.67% | 33.61% | 99.57% | 99.98% | |
| 4 | 0.00% | 99.94% | 30.87% | 99.98% | 100.00% | |
| 5 | 0.00% | 100.00% | 29.76% | 99.98% | 100.00% | |
| 6 | 0.00% | 99.98% | 69.63% | 99.98% | 100.00% | |
| 7 | 0.00% | 100.00% | 67.69% | 100.00% | 100.00% | |
| 8 | 0.00% | 100.00% | 32.15% | 100.00% | 100.00% | |
| 9 | 66.76% | 100.00% | 34.65% | 100.00% | 100.00% | |
| ResNet18 | 0 | 0.06% | 96.65% | 41.46% | 98.85% | 100.00% |
| 1 | 7.76% | 99.98% | 51.94% | 100.00% | 99.94% | |
| 2 | 0.00% | 99.96% | 50.52% | 99.96% | 99.89% | |
| 3 | 2.46% | 99.81% | 48.17% | 99.98% | 100.00% | |
| 4 | 5.11% | 100.00% | 34.48% | 100.00% | 99.98% | |
| 5 | 0.00% | 99.89% | 42.33% | 99.65% | 99.98% | |
| 6 | 0.00% | 99.93% | 61.31% | 99.91% | 99.94% | |
| 7 | 93.74% | 100.00% | 57.24% | 100.00% | 100.00% | |
| 8 | 0.22% | 99.98% | 41.65% | 99.98% | 100.00% | |
| 9 | 0.02% | 99.91% | 20.48% | 99.98% | 99.69% |
| Target Class | Source Class | Victim Model | |||||||
|---|---|---|---|---|---|---|---|---|---|
| AlexNet | DenseNet121 | RegNet_x_400mf | ResNet18 | ||||||
| SR | OR | SR | OR | SR | OR | SR | OR | ||
| 5 | 9 | 96.33% | 12.38% | 98.67% | 12.35% | 96.00% | 12.56% | 95.00% | 12.71% |
| 6 | 9 | 83.83% | 12.38% | 96.17% | 12.38% | 94.00% | 12.56% | 97.33% | 12.69% |
| 4 | 9 | 87.00% | 12.02% | 94.20% | 12.10% | 89.40% | 12.31% | 96.40% | 12.47% |
| 3 | 4 | 98.20% | 12.14% | 98.40% | 12.12% | 100.00% | 12.31% | 99.40% | 12.47% |
| 0 | 9 | 97.50% | 11.84% | 99.25% | 11.82% | 93.75% | 11.94% | 98.75% | 12.20% |
| 4 | 7 | 93.80% | 12.02% | 97.80% | 12.04% | 87.80% | 12.08% | 97.80% | 12.27% |
| 8 | 9 | 95.50% | 12.40% | 97.67% | 12.38% | 99.83% | 12.56% | 99.67% | 12.73% |
| 6 | 1 | 92.40% | 12.08% | 94.00% | 12.12% | 96.80% | 12.31% | 98.20% | 12.43% |
| 3 | 7 | 97.17% | 12.35% | 99.67% | 12.35% | 98.83% | 12.56% | 99.83% | 12.69% |
| 7 | 4 | 94.67% | 11.00% | 97.00% | 12.40% | 95.33% | 12.52% | 98.50% | 12.46% |
| Target Class | Source Class | Victim Model | |||||||
|---|---|---|---|---|---|---|---|---|---|
| AlexNet | DenseNet121 | RegNet_x_400mf | ResNet18 | ||||||
| SR | OR | SR | OR | SR | OR | SR | OR | ||
| 0 | 1 | 89.68% | 3.61% | 90.97% | 3.80% | 81.29% | 3.78% | 94.19% | 3.82% |
| 8 | 11 | 72.80% | 4.64% | 71.20% | 4.23% | 72.80% | 4.74% | 67.20% | 3.63% |
| 9 | 1 | 90.97% | 2.97% | 94.19% | 3.01% | 94.84% | 3.03% | 97.42% | 2.95% |
| 11 | 9 | 88.00% | 2.74% | 92.67% | 2.56% | 94.00% | 2.58% | 99.33% | 2.78% |
| 13 | 10 | 82.16% | 2.91% | 80.54% | 2.95% | 80.00% | 2.91% | 79.46% | 2.97% |
| 14 | 13 | 94.29% | 2.96% | 93.57% | 3.13% | 97.86% | 3.13% | 92.86% | 2.82% |
| 15 | 13 | 97.14% | 3.58% | 93.57% | 3.50% | 100.00% | 3.46% | 97.14% | 3.46% |
| 16 | 18 | 84.87% | 3.88% | 88.11% | 3.55% | 91.89% | 3.78% | 94.05% | 4.36% |
| 17 | 13 | 91.43% | 3.93% | 92.86% | 4.01% | 97.86% | 4.01% | 97.86% | 3.89% |
| 19 | 3 | 90.00% | 4.33% | 89.50% | 4.52% | 81.00% | 4.40% | 92.00% | 4.42% |
| Target Class | Source Class | Victim Model | |||||||
|---|---|---|---|---|---|---|---|---|---|
| AlexNet | DenseNet121 | RegNet_x_400mf | ResNet18 | ||||||
| SR | OR | SR | OR | SR | OR | SR | OR | ||
| 9 | 3 | 96.00% | 6.60% | 98.00% | 7.70% | 100.00% | 7.20% | 100.00% | 7.70% |
| 0 | 3 | 90.00% | 6.70% | 98.00% | 6.70% | 92.00% | 6.20% | 100.00% | 7.10% |
| 2 | 3 | 86.00% | 7.10% | 100.00% | 7.40% | 98.00% | 11.20% | 98.00% | 8.90% |
| 1 | 3 | 78.00% | 7.80% | 100.00% | 7.90% | 94.00% | 9.10% | 98.00% | 6.60% |
| 7 | 16 | 70.00% | 8.80% | 78.00% | 8.50% | 80.00% | 8.90% | 70.00% | 10.10% |
| 7 | 5 | 92.00% | 6.30% | 42.00% | 6.10% | 78.00% | 7.80% | 70.00% | 9.90% |
| 18 | 9 | 70.00% | 10.50% | 66.00% | 9.40% | 82.00% | 11.30% | 72.00% | 9.60% |
| 20 | 2 | 80.00% | 13.50% | 62.00% | 7.20% | 54.00% | 7.30% | 76.00% | 11.60% |
| 16 | 17 | 56.00% | 8.60% | 54.00% | 9.80% | 64.00% | 7.90% | 54.00% | 9.30% |
| 20 | 9 | 52.00% | 16.30% | 54.00% | 8.10% | 64.00% | 10.00% | 68.00% | 12.90% |
| Target Class | Source Class | Victim Model | |||||||
|---|---|---|---|---|---|---|---|---|---|
| AlexNet | DenseNet121 | RegNet_x_400mf | ResNet18 | ||||||
| 5 | 9 | 12.38% | 61.60% | 12.35% | 65.06% | 12.56% | 98.23% | 12.71% | 71.50% |
| 6 | 9 | 12.38% | 69.04% | 12.38% | 78.35% | 12.56% | 99.15% | 12.69% | 85.65% |
| 4 | 9 | 12.02% | 88.56% | 12.10% | 91.27% | 12.31% | 100.00% | 12.47% | 99.88% |
| 3 | 4 | 12.14% | 99.98% | 12.12% | 100.00% | 12.31% | 99.98% | 12.47% | 100.00% |
| 0 | 9 | 11.84% | 66.58% | 11.82% | 69.88% | 11.94% | 99.88% | 12.20% | 69.04% |
| 4 | 7 | 12.02% | 99.50% | 12.04% | 100.00% | 12.08% | 99.75% | 12.27% | 100.00% |
| 8 | 9 | 12.40% | 63.48% | 12.38% | 59.75% | 12.56% | 89.02% | 12.73% | 93.40% |
| 6 | 1 | 12.08% | 76.10% | 12.12% | 87.25% | 12.31% | 96.06% | 12.43% | 93.60% |
| 3 | 7 | 12.35% | 99.77% | 12.35% | 100.00% | 12.56% | 99.50% | 12.69% | 99.96% |
| 7 | 4 | 11.00% | 100.00% | 12.40% | 100.00% | 12.52% | 100.00% | 12.46% | 100.00% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bai, T.; Wang, H.; Wen, B. Targeted Universal Adversarial Examples for Remote Sensing. Remote Sens. 2022, 14, 5833. https://doi.org/10.3390/rs14225833
Bai T, Wang H, Wen B. Targeted Universal Adversarial Examples for Remote Sensing. Remote Sensing. 2022; 14(22):5833. https://doi.org/10.3390/rs14225833
Chicago/Turabian StyleBai, Tao, Hao Wang, and Bihan Wen. 2022. "Targeted Universal Adversarial Examples for Remote Sensing" Remote Sensing 14, no. 22: 5833. https://doi.org/10.3390/rs14225833
APA StyleBai, T., Wang, H., & Wen, B. (2022). Targeted Universal Adversarial Examples for Remote Sensing. Remote Sensing, 14(22), 5833. https://doi.org/10.3390/rs14225833