
Real-Time UAV Patrol Technology in Orchard Based on the Swin-T YOLOX Lightweight Model



Abstract

1. Introduction
2. Materials and Methods
2.1. Data Acquisition and Preprocessing
2.1.1. UAV Remote Sensing Image Acquisition
2.1.2. UAV Remote Sensing Image Data Enhancement
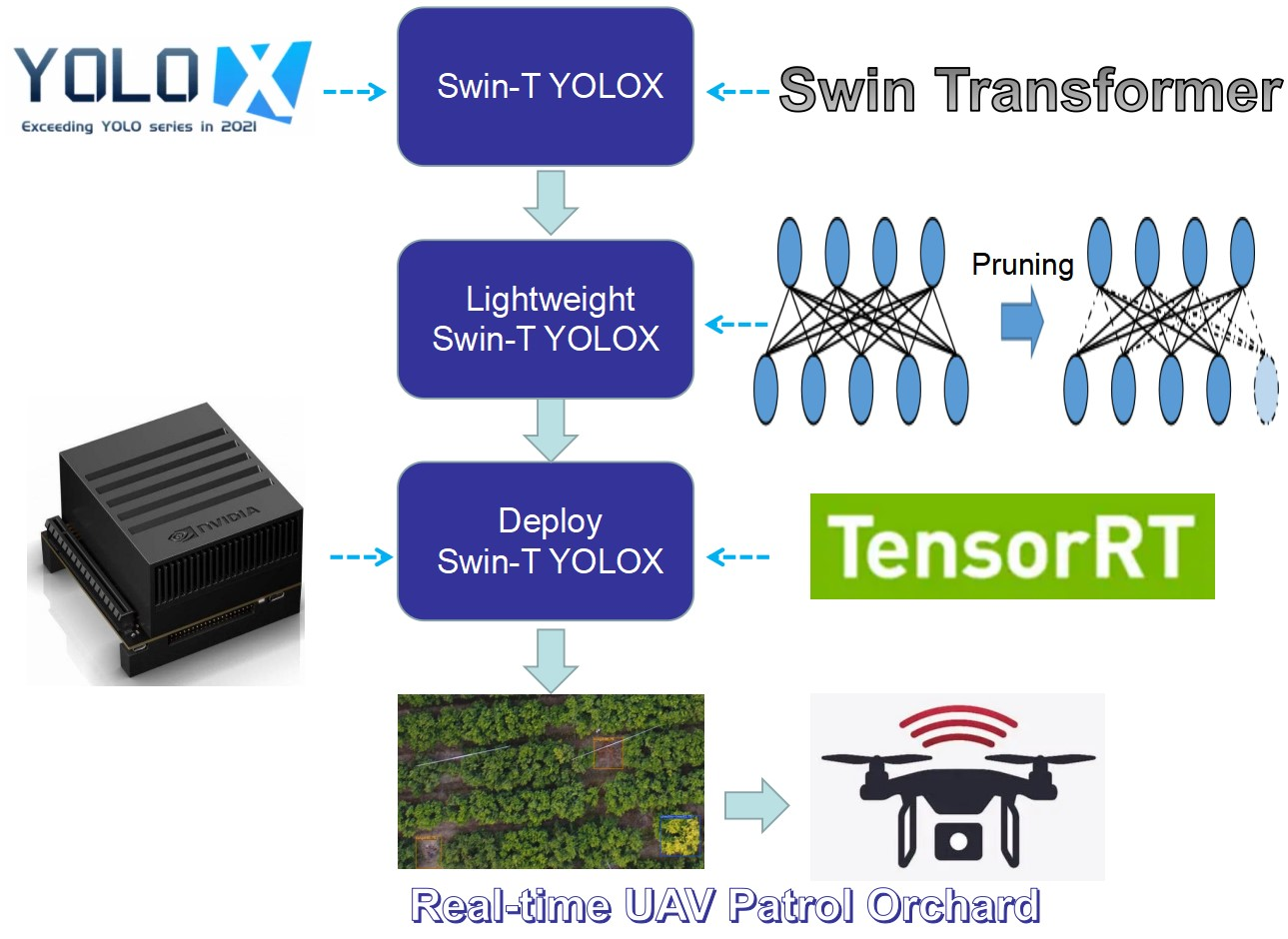
2.2. Proposed Swin-T YOLOX Lightweight Network
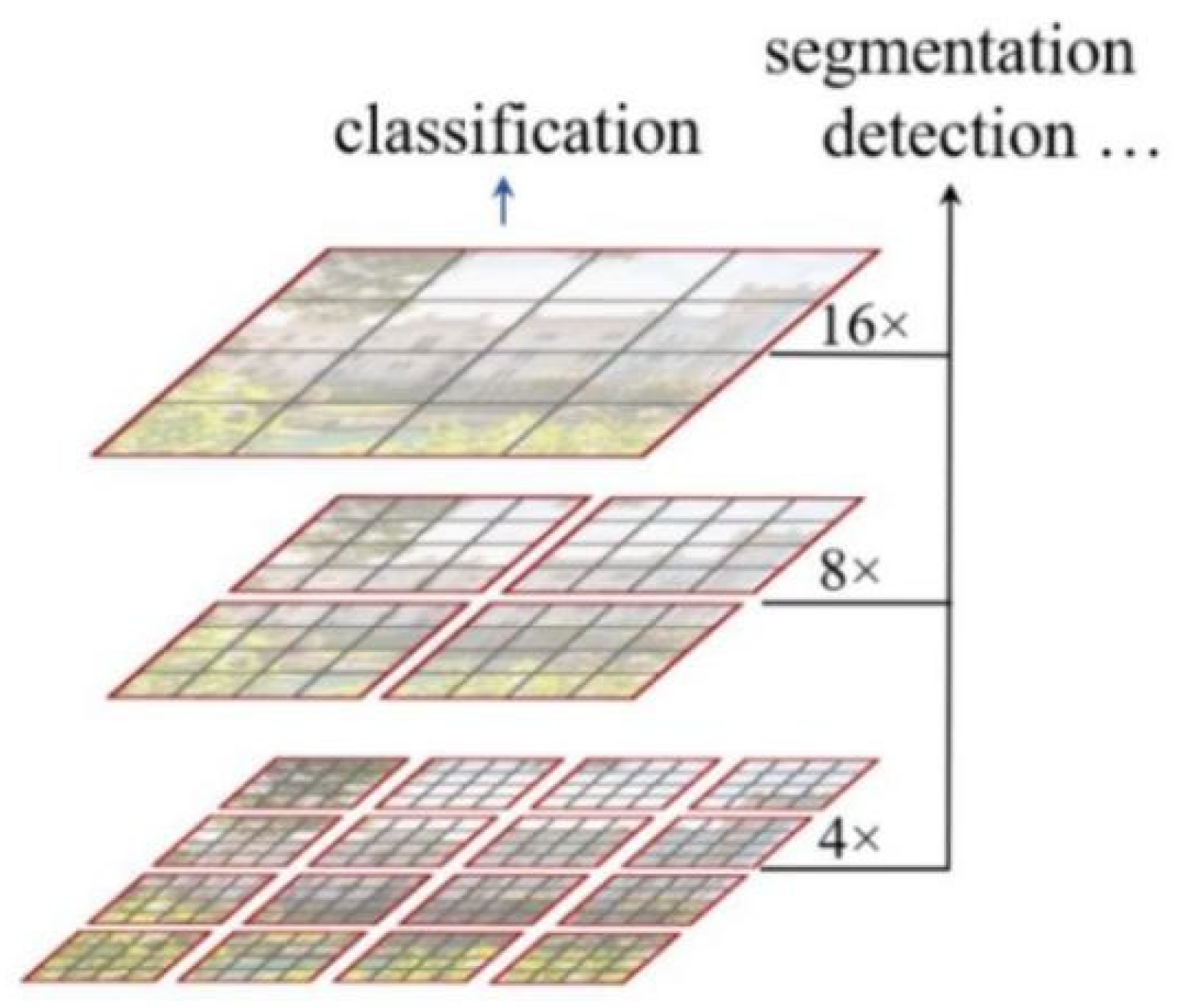
2.2.1. Swin-T YOLOX Algorithm
2.2.2. Lightweight of Swin-T YOLOX Model
2.2.3. Deployment Based on Swin-T YOLOX Lightweight Model
3. Experiments and Result
3.1. Model Evaluation Metrics
3.2. Performance of UAV Patrol Orchard Anomaly Detection
3.3. Performance Comparison of Model Pruning Schemes
3.4. Comparison of Model Deployment Schemes
4. Discussion
4.1. Data Process
4.2. Method of Model Lightweight
4.3. Application and Future Work Directions
- (1)
- A lightweight network Swin-T YOLOX is proposed to be used for real-time UAV patrol orchard task. In this algorithm, the Swin Transformer is used to replace Darknet53 as the backbone network of YOLOX, which can significantly improve the model accuracy;
- (2)
- Layer pruning technology is used to reduce the number of parameters and calculation amount of the Swin-T YOLOX;
- (3)
- Deploy the Swin-T YOLOX model to the Jetson Xavier NX edge computing platform using the TensorRt optimizer, and test the detection performance of the algorithm on the embedded platform.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, H.; Zhou, W.; Li, J. Current Status, Problems and Development Trend of the Wisdom Agriculture Research in China. J. Anhui Agric. Sci. 2016, 44, 279–282. [Google Scholar]
- Wang, L.; Li, K.; Shan, H. Design of Small-scale Intelligent Orchard System. Agric. Eng. 2021, 11, 55–61. [Google Scholar]
- Fan, Y.; Zhang, Z.; Chen, G.; Li, B. Research on Monitoring and Analysis System of Corn Growth in Precision Agriculture Based on Internet of Things. J. Agric. Mech. Res. 2018, 40, 223–227. [Google Scholar]
- Zhang, K.; Zhang, S.; Lian, X. Design of cruise inspection system for four-rotor autonomous aircraft in orchard. J. Chin. Agric. Mech. 2017, 38, 81–85. [Google Scholar]
- Gao, X.; Xie, J.; Hu, D. Application of Quadrotor UAV in the Inspection System of Citrus Orchard. Process Autom. Instrum. 2016, 36, 26–30. [Google Scholar]
- Nikolaos, S.; Haluk, B.; Volkan, I. Vision-based monitoring of orchards with UAVs. Comput. Electron. Agric. 2019, 163, 104814. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Shi, T.; Zhang, X.; Guo, L. Research on remote sensing recognition of wild planted Lonicera japonica based on deep convolutional neural network. China J. Chin. Mater. Med. 2020, 45, 5658–5662. [Google Scholar]
- Deng, X.; Tong, Z.; Lan, Y. Detection and location of dead trees with pine wilt disease based on deep learning and UAV remote sensing. AgriEngineering 2020, 2, 294–307. [Google Scholar] [CrossRef]
- Mo, J.; Lan, Y.; Yang, D. Deep learning-based instance segmentation method of litchi canopy from UAV-acquired images. Remote Sens. 2021, 13, 3919. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 20–23 June 2014. [Google Scholar]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. (IJCV) 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (CVPR), Boston, MA, USA, 7–10 June 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 10–16 October 2016. [Google Scholar]
- Zheng, G.; Songtao, L.; Feng, W.; Zeming, L.; Jian, S. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. In Proceedings of the International Conference on Learning Representations (ICLR), Online, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Wang, H.; Hu, X.; Zhang, Q. Structured pruning for efficient convolutional neural networks via incremental regularization. IEEE J. Sel. Top. Signal Process. 2019, 14, 775–788. [Google Scholar] [CrossRef]
- Liu, Z.; Li, J.; Shen, Z.; Huang, G.; Yan, S.; Zhang, C. Learning efficient convolutional networks through network slimming. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Qi, P.; Sha, E.H.M.; Zhuge, Q. Accelerating framework of transformer by hardware design and model compression co-optimization. In Proceedings of the IEEE/ACM International Conference On Computer Aided Design (ICCAD), Wuxi, China, 22–23 December 2021. [Google Scholar]
- Yu, S.; Chen, T.; Shen, J. Unified visual transformer compression. In Proceedings of the International Conference on Learning Representations (ICLR), Online, 25–29 April 2022. [Google Scholar]
- Hou, Z.; Kung, S.Y. Multi-dimensional model compression of vision transformer. In Proceedings of the IEEE International Conference on Multimedia and Expo (ICME), Taiyuan, China, 27–28 August 2022. [Google Scholar]
- Mao, J.; Yang, H.; Li, A.; Li, H.; Chen, Y. TPrune: Efficient transformer pruning for mobile devices. ACM Transact. Cyber-Phys. Syst. 2021, 5, 1–22. [Google Scholar] [CrossRef]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. In Proceedings of the International Conference on Learning Representations (ICLR), SAN Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Li, Z.; Wallace, E.; Shen, S. Train big, then compress: Rethinking model size for efficient training and inference of transformers. In Proceedings of the International Conference on International Conference on Machine Learning (ICML), Online, 13–18 July 2020. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Number of Layers | Hidden Dimensions | Number of Attention Heads | Model Parameters |
|---|---|---|---|---|
| Swin-T | 12 | 768 | 24 | 29 M |
| Swin-S | 24 | 768 | 24 | 50 M |
| Swin-B | 24 | 1024 | 32 | 88 M |
| Swin-L | 24 | 1536 | 48 | 197 M |
| Model | Model Parameters | mAP@0.5 | mAP@ [0.5:0.95] |
|---|---|---|---|
| DarkNet53 + YOLOX-M | 25.3 M | 92.1% | 66.3% |
| DarkNet53 + YOLOX-L | 54.3 M | 93.0% | 69.9% |
| Swin-T YOLOX(proposed) | 29.0 M | 93.3% | 73.6% |
| The Number of Pruning Layers | mAP@0.5 | Model Parameters (M) | Calculation (G) |
|---|---|---|---|
| None | 93.3% | 45.89 | 209.70 |
| 12 layer | 93.3% | 38.81 | 182.80 |
| 11~12 layer | 94.1% | 31.72 | 155.90 |
| 10~12 layer | 94.0% | 29.95 | 146.35 |
| 9~12 layer | 92.4% | 28.18 | 136.79 |
| Platform | Model | Speed (fps) | Accuracy |
|---|---|---|---|
| GPU server | Swin-T YOLOX | 22 | 93.3% |
| GPU server | Lightweigh Swin-T YOLOX | 48 | 94.0% |
| Jetson | Swin-T YOLOX | 10 | 93.4% |
| Jetson | Lightweigh Swin-T YOLOX | 20 | 93.9% |
| Jetson + TensorRT | Swin-T YOLOX | 24 | 93.2% |
| Jetson + TensorRT | Lightweigh Swin-T YOLOX | 40 | 94.0% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lan, Y.; Lin, S.; Du, H.; Guo, Y.; Deng, X. Real-Time UAV Patrol Technology in Orchard Based on the Swin-T YOLOX Lightweight Model. Remote Sens. 2022, 14, 5806. https://doi.org/10.3390/rs14225806
Lan Y, Lin S, Du H, Guo Y, Deng X. Real-Time UAV Patrol Technology in Orchard Based on the Swin-T YOLOX Lightweight Model. Remote Sensing. 2022; 14(22):5806. https://doi.org/10.3390/rs14225806
Chicago/Turabian StyleLan, Yubin, Shaoming Lin, Hewen Du, Yaqi Guo, and Xiaoling Deng. 2022. "Real-Time UAV Patrol Technology in Orchard Based on the Swin-T YOLOX Lightweight Model" Remote Sensing 14, no. 22: 5806. https://doi.org/10.3390/rs14225806
APA StyleLan, Y., Lin, S., Du, H., Guo, Y., & Deng, X. (2022). Real-Time UAV Patrol Technology in Orchard Based on the Swin-T YOLOX Lightweight Model. Remote Sensing, 14(22), 5806. https://doi.org/10.3390/rs14225806