




High-Performance Segmentation for Flood Mapping of HISEA-1 SAR Remote Sensing Images

 , ,
, ,  and
and 
Abstract
1. Introduction
- A high-resolution floodwater detection dataset based on HISEA-1 imagery is constructed. It contains many diverse types of water bodies, including those involved in flooding events.
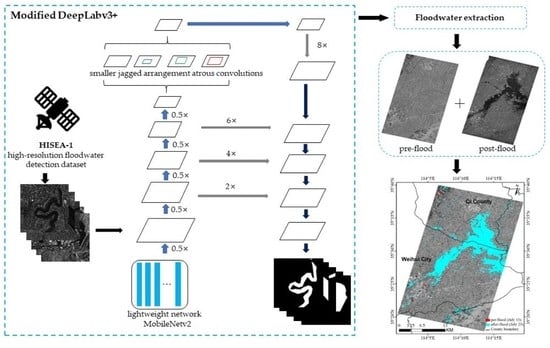
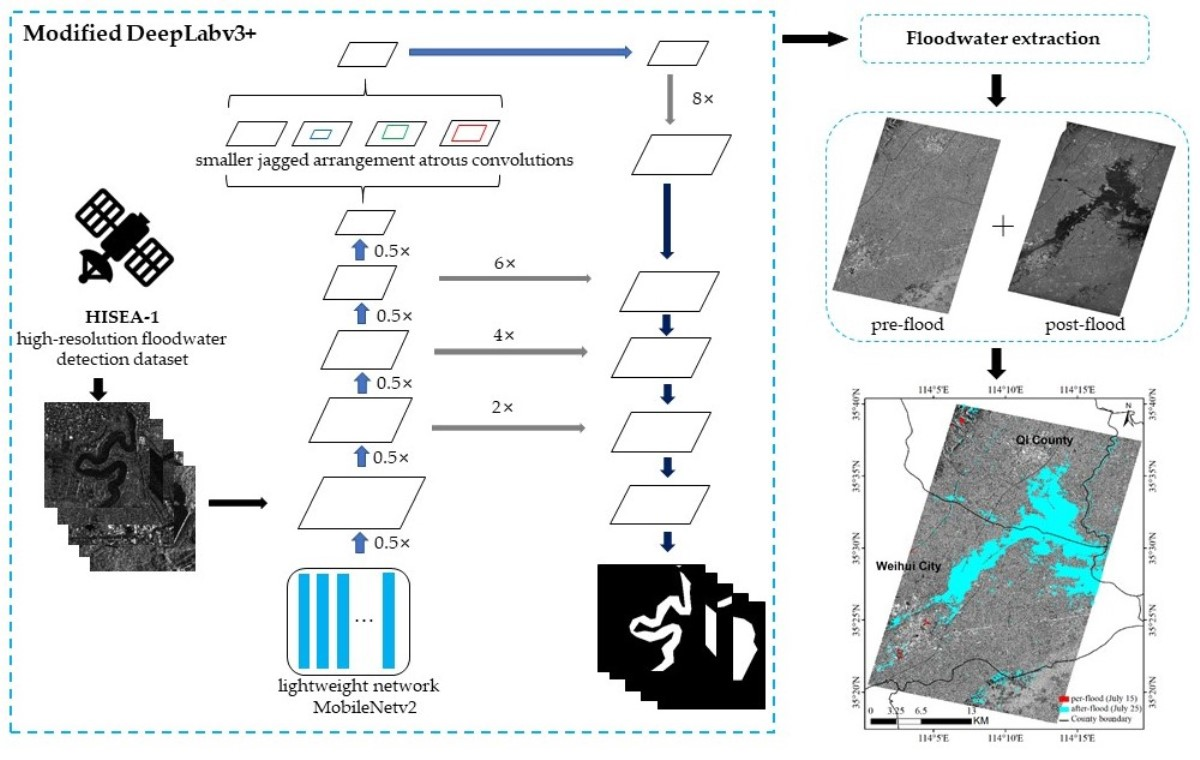
- A Modified DeepLabv3+ Model is proposed to achieve accurate and fast extraction of floodwaters. The improvements include (1) using a lightweight network called MobileNetv2 as the backbone to improve floodwater detection efficiency, (2) employing small jagged arrangement atrous convolutions to capture features at small scales and improve pixels utilization, and (3) increasing the upsampling layers to refine the segmented boundaries of water bodies.
- Two flooding events in China and the United States are analyzed to monitor the dynamic changes and flood levels of water bodies in the affected area.
2. Materials
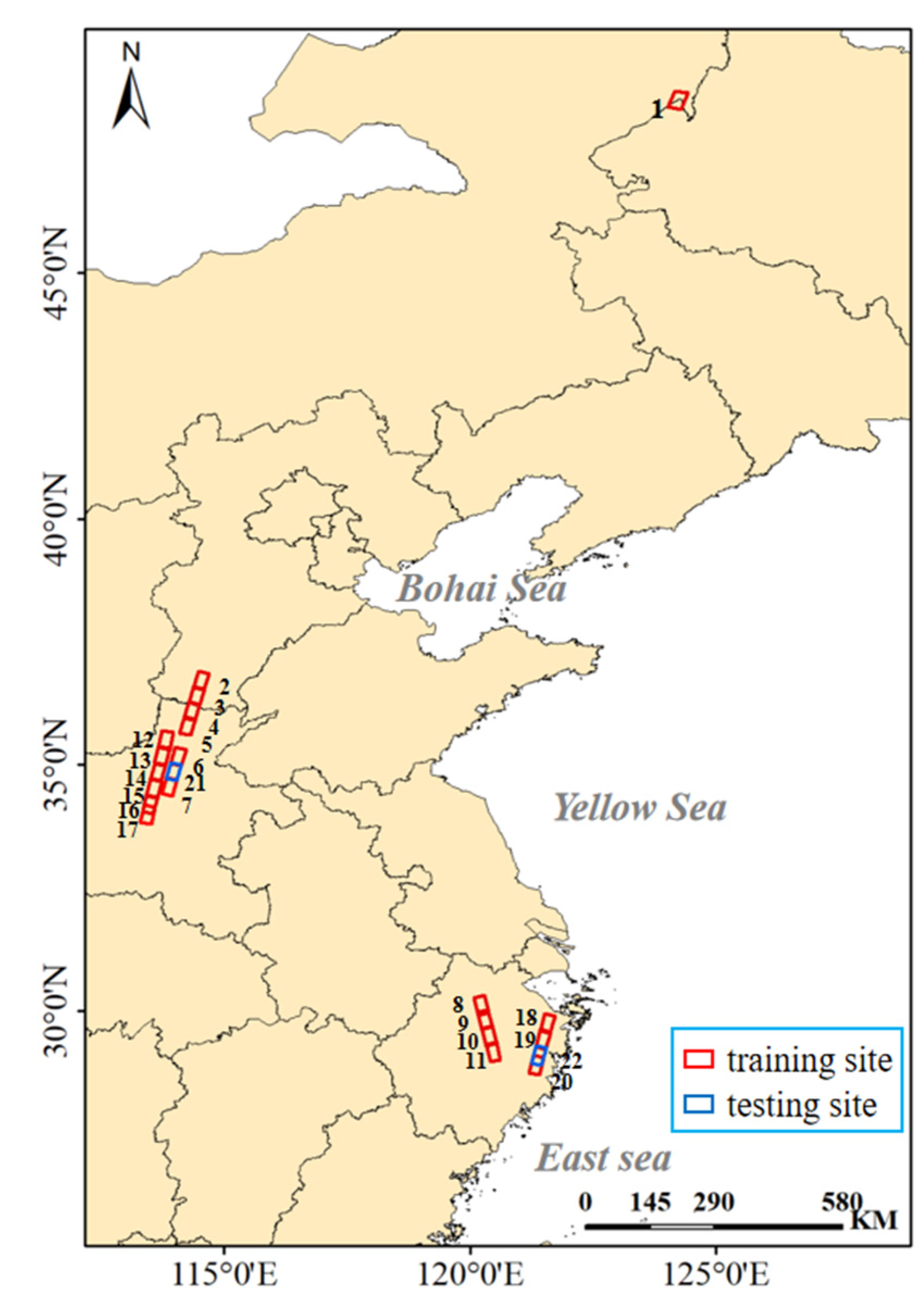
2.1. Water Body Extraction Images
2.2. Image Preprocessing
2.3. Dataset Generation
- Employment of an online annotation tool LabelMe [28] to manually label water bodies and construct sample sets referring to the optical image at the same time.
- Batch-convert all marked json files to png image format.
- Due to limitations of graphics processing unit (GPU) capabilities, all samples were resized to 256 × 256 sub-images without overlapping parts.
3. Methodology
3.1. Using Lightweight Network MobileNetv2 as Encoder
3.2. Employing Smaller Jagged Arrangement Atrous Convolutions in ASPP
3.3. Adding More Upsampling Layers in Decoder
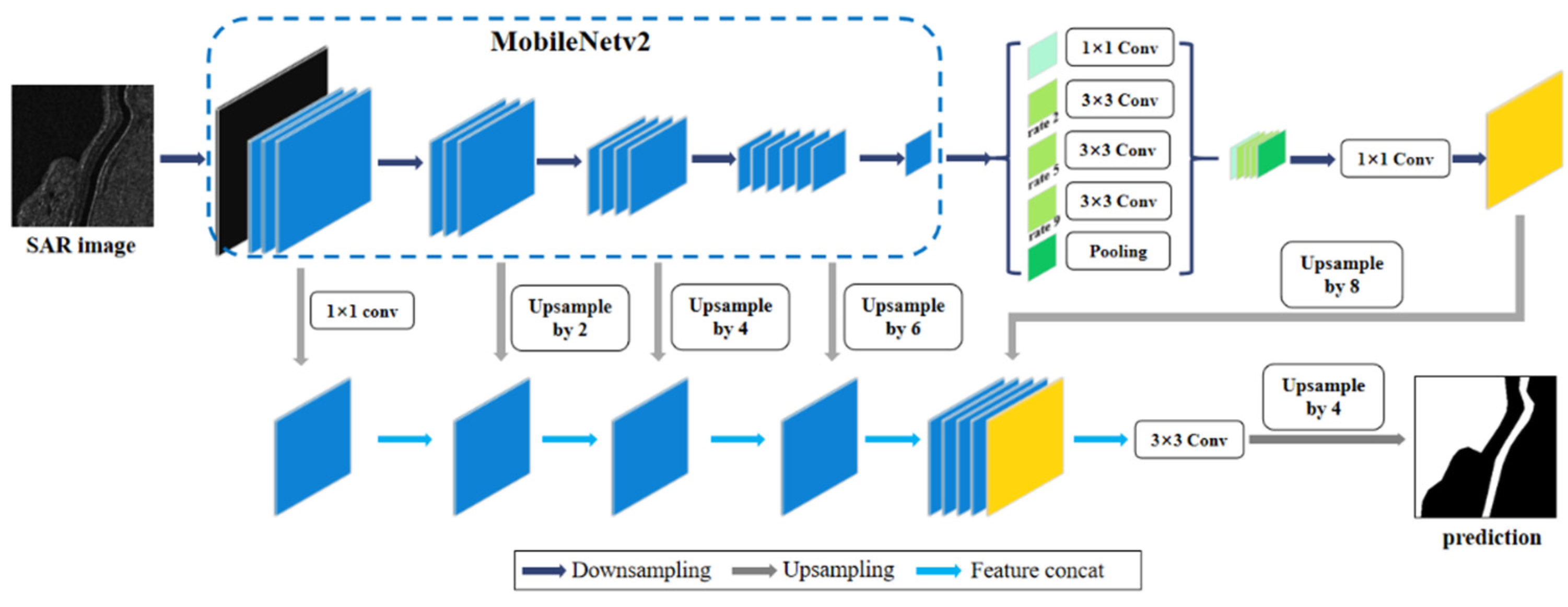
3.4. Modified DeepLabv3+ Model for Water Extraction
3.5. Metrics
4. Results
4.1. Experimental Setup
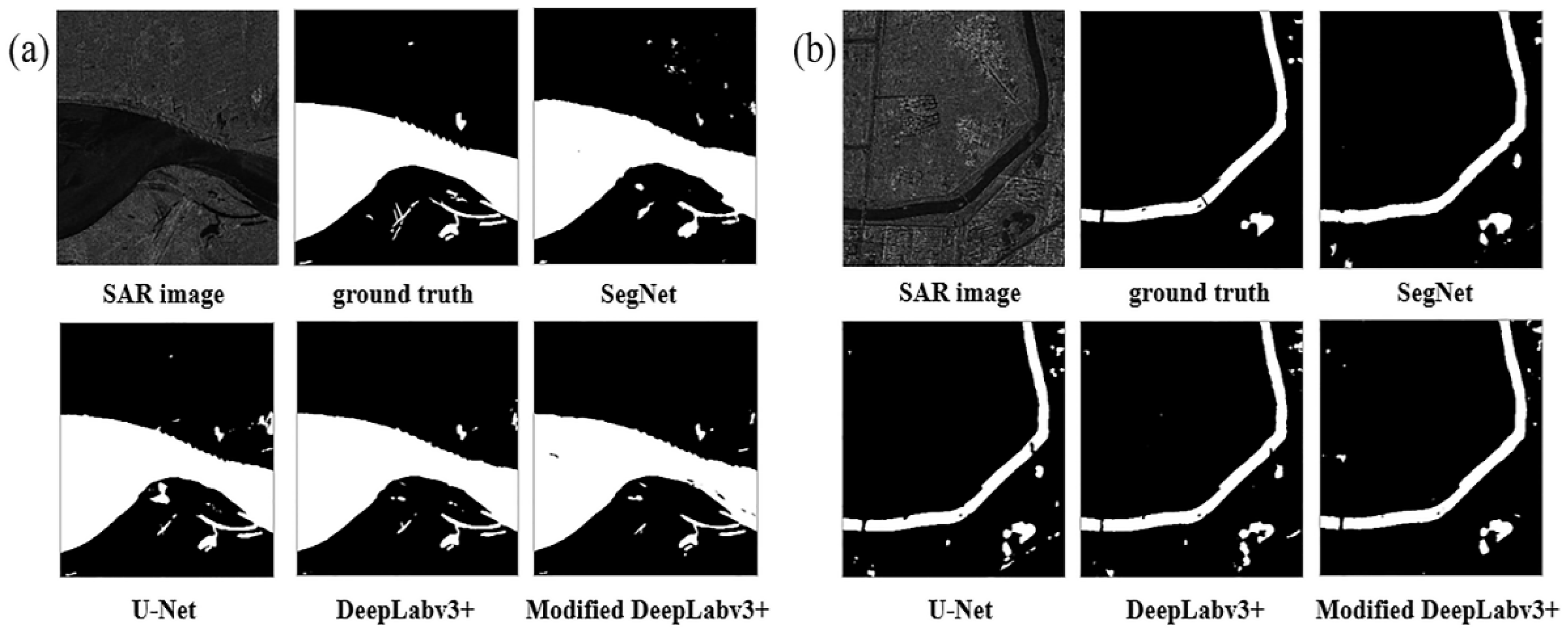
4.2. Comparison with Other Models
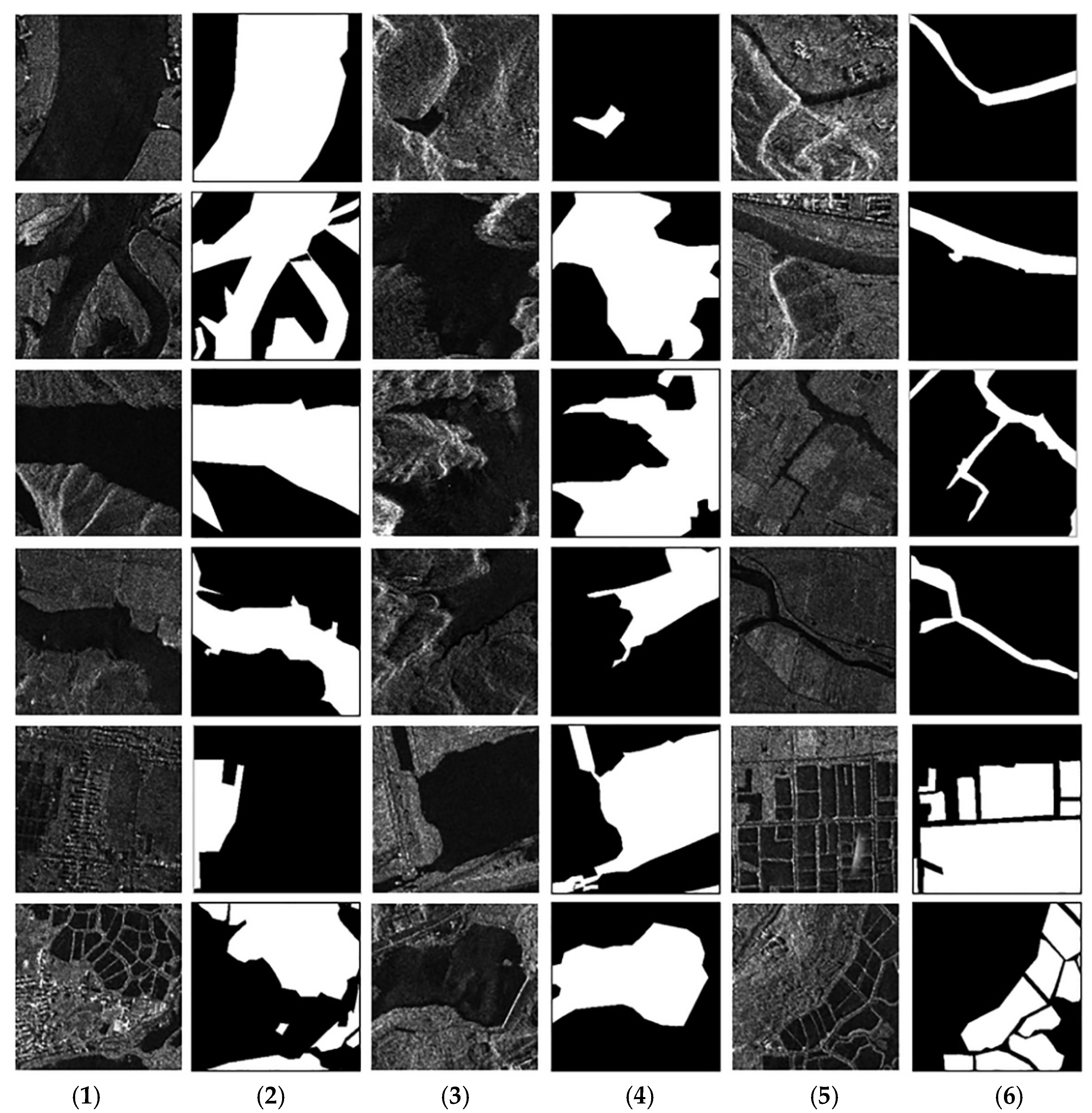
4.3. Performance for Various Water Body Types
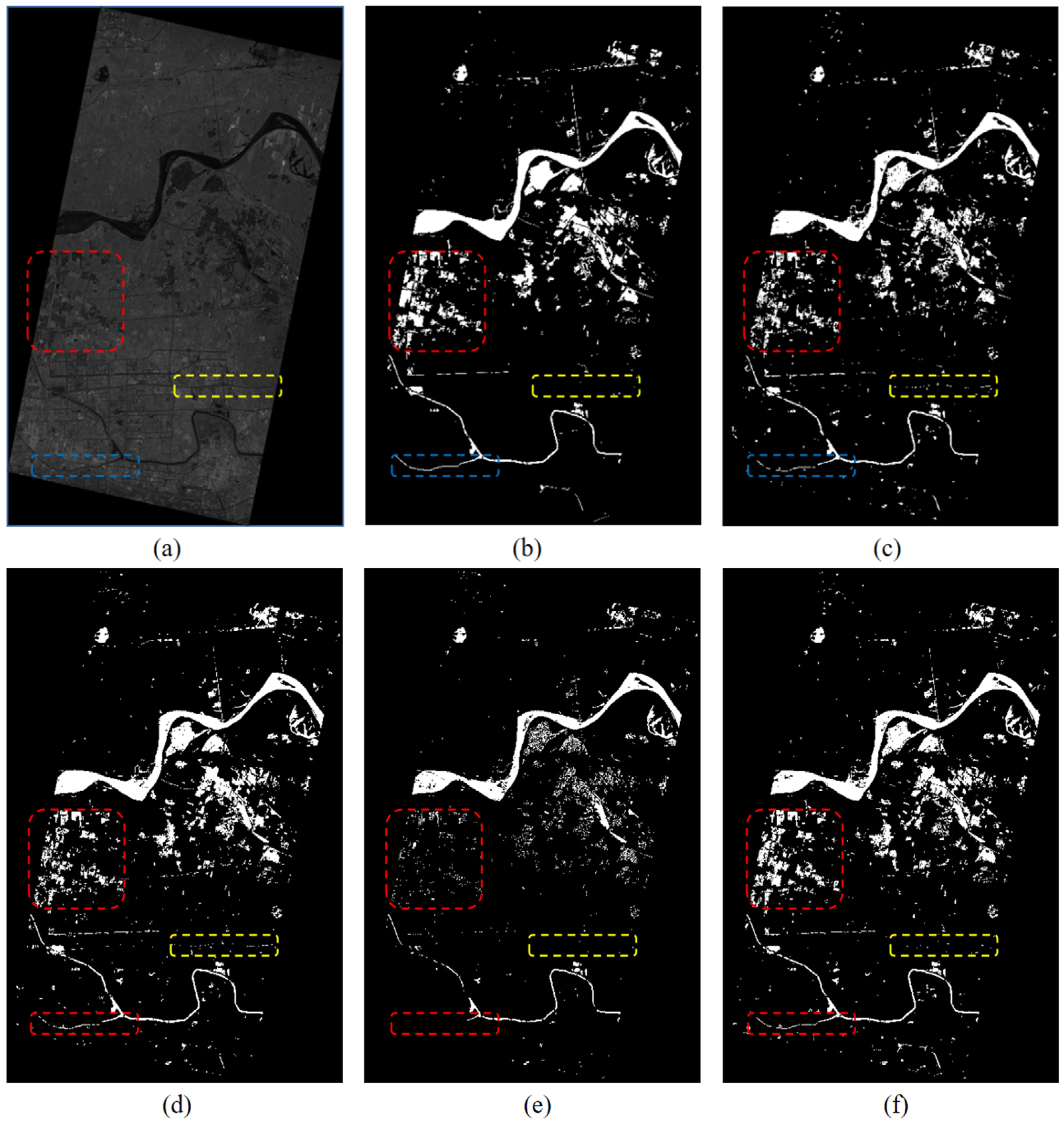
4.4. Performance for Large-Scale Floodwater Extraction
5. Spatiotemporal Analysis of Two Flood Events
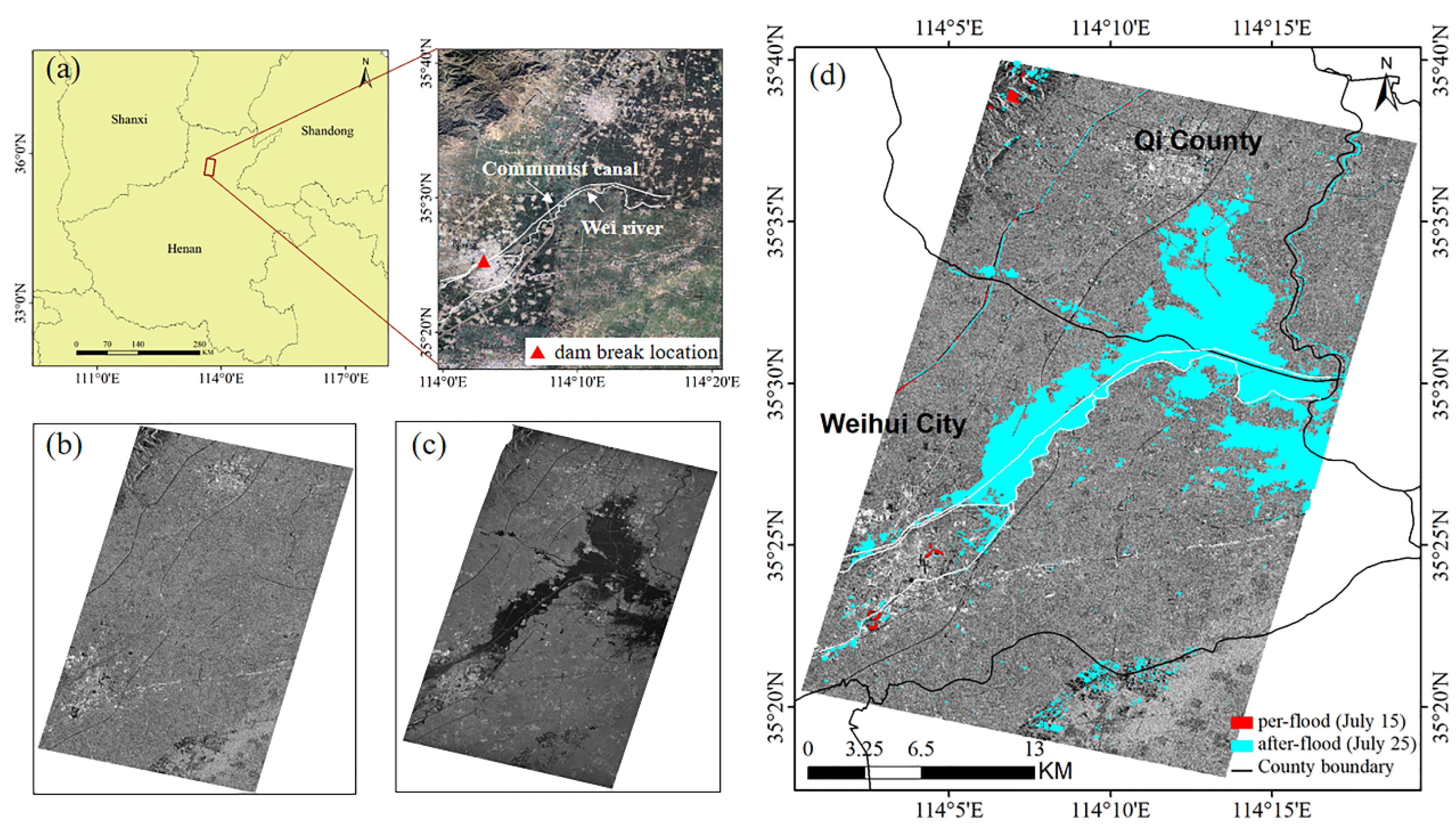
5.1. Severe Floods Caused by Extremely Heavy Rainfall in Henan Province, China
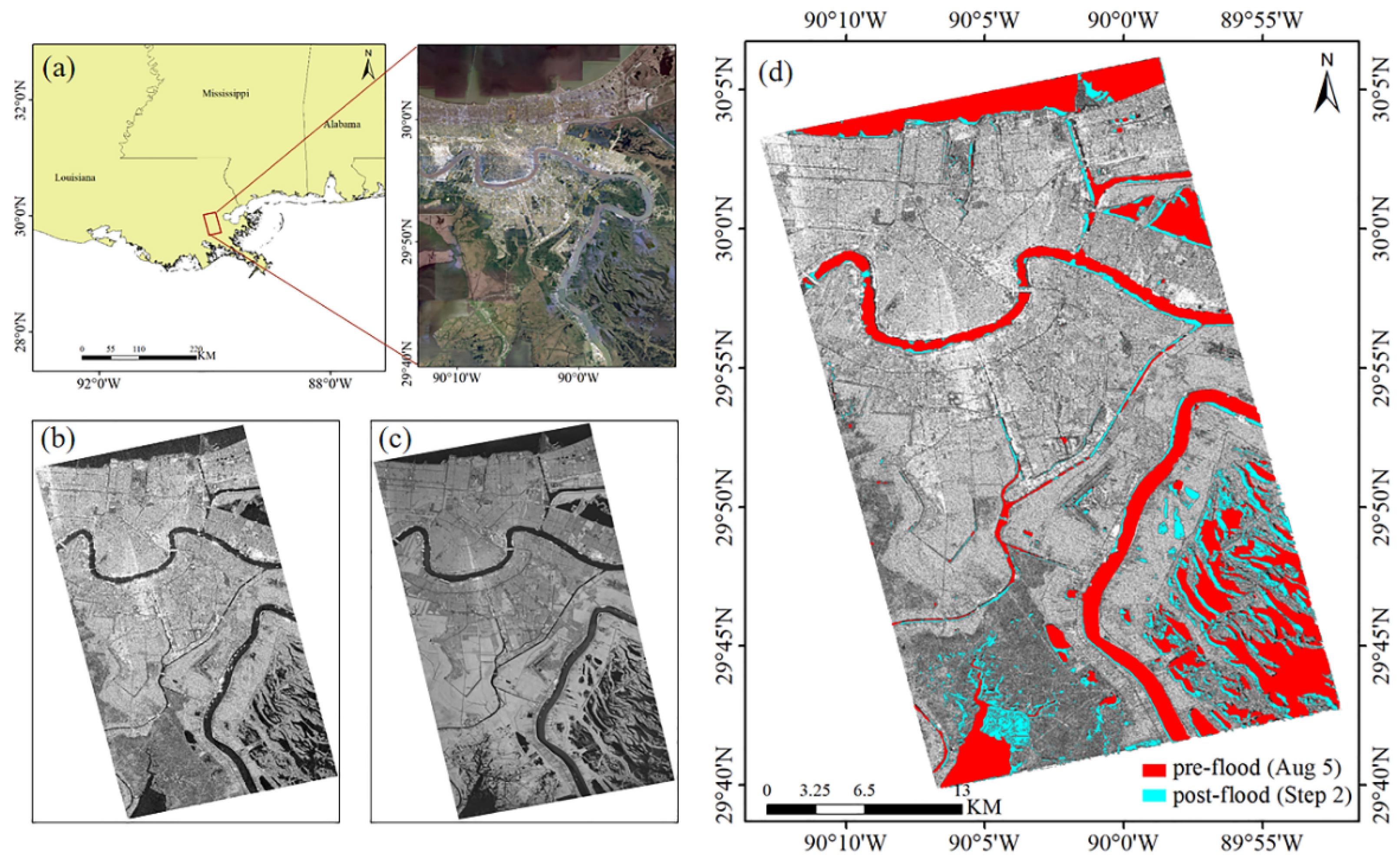
5.2. Flood Disaster Caused by Hurricane Ida in New Orleans, Louisiana, USA
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, Y.; Zhao, S.-S. Floods losses and hazards in China from 2001 to 2020. Clim. Chang. Res. 2022, 18, 154–165. [Google Scholar] [CrossRef]
- Xia, J.; Wang, H.; Gan, Y.; Zhang, L. Research progress in forecasting methods of rainstorm and flood disaster in China. Torrential Rain Disasters 2019, 5, 416–421. [Google Scholar]
- Zaart, A.E.; Ziou, D.; Wang, S. Segmentation of SAR images. Pattern Recognit. 2002, 35, 713–724. [Google Scholar] [CrossRef]
- Liang, J.; Liu, D. A local thresholding approach to flood water delineation using Sentinel-1 SAR imagery. ISPRS J. Photogramm. Remote Sens. 2020, 159, 53–62. [Google Scholar] [CrossRef]
- Chini, M.; Hostache, R.; Giustarini, L.; Matgen, P. A Hierarchical Split-Based Approach for Parametric Thresholding of SAR Images: Flood Inundation as a Test Case. IEEE Trans. Geosci. Remote Sens. 2017, 55, 6975–6988. [Google Scholar] [CrossRef]
- Lang, F.; Yang, J.; Yan, S.; Qin, F. Superpixel Segmentation of Polarimetric Synthetic Aperture Radar (SAR) Images Based on Generalized Mean Shift. Remote Sens. 2018, 10, 1592. [Google Scholar] [CrossRef]
- Zhang, W.; Xiang, D.; Su, Y. Fast Multiscale Superpixel Segmentation for SAR Imagery. IEEE Geosci. Remote Sens. Lett. 2022, 19, 1–5. [Google Scholar] [CrossRef]
- Ijitona, B.; Ren, J.; Hwang, B. SAR Sea Ice Image Segmentation Using Watershed with Intensity-Based Region Merging. IEEE Int. Conf. Comput. Inf. Technol. 2014, 168–172. [Google Scholar] [CrossRef]
- Ciecholewski, M. River channel segmentation in polarimetric SAR images: Watershed transform combined with average contrast maximisation. Expert Syst. Appl. 2017, 82, 196–215. [Google Scholar] [CrossRef]
- Horritt, M.S.; Mason, D.C.; Luckman, A.J. Flood boundary delineation from Synthetic Aperture Radar imagery using a statistical active contour model. Int. J. Remote Sens. 2001, 22, 2489–2507. [Google Scholar] [CrossRef]
- Jin, R.; Yin, J.; Zhou, W.; Yang, J. Level Set Segmentation Algorithm for High-Resolution Polarimetric SAR Images Based on a Heterogeneous Clutter Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4565–4579. [Google Scholar] [CrossRef]
- Braga, M.; Marques, P.; Rodrigues, A.; Medeiros, S. A Median Regularized Level Set for Hierarchical Segmentation of SAR Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1171–1175. [Google Scholar] [CrossRef]
- Pulvirenti, L.; Pierdicca, N.; Chini, M.; Guerriero, L. An algorithm for operational flood mapping from Synthetic Aperture Radar (SAR) data using fuzzy logic. Nat. Hazards Earth Syst. Sci. 2011, 2, 529–540. [Google Scholar] [CrossRef]
- Kuenzer, C.; Guo, H.; Schlegel, I.; Tuan, V.; Li, X.; Dech, S. Varying Scale and Capability of Envisat ASAR-WSM, TerraSAR-X Scansar and TerraSAR-X Stripmap Data to Assess Urban Flood Situations: A Case Study of the Mekong Delta in Can Tho Province. Remote Sens. 2013, 5, 5122–5142. [Google Scholar] [CrossRef]
- Inglada, J.; Mercier, G. A New Statistical Similarity Measure for Change Detection in Multitemporal SAR Images and Its Extension to Multiscale Change Analysis. IEEE Trans. Geosci. Remote Sens. 2007, 45, 1432–1445. [Google Scholar] [CrossRef]
- Long, S.; Fatoyinbo, T.E.; Policelli, F. Flood extent mapping for Namibia using change detection and thresholding with SAR. Environ. Res. Lett. 2014, 9, 206–222. [Google Scholar] [CrossRef]
- Clement, M.A.; Kilsby, C.G.; Moore, P. Multi-temporal synthetic aperture radar flood mapping using change detection. J. Flood Risk Manag. 2018, 11, 152–168. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. In Proceedings of the International Conference on Learning Representations 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. Preprint arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Kang, W.; Xiang, Y.; Wang, F.; Wan, L.; You, H. Flood Detection in Gaofen-3 SAR Images via Fully Convolutional Networks. Sensors 2018, 18, 2915. [Google Scholar] [CrossRef] [PubMed]
- Nemni, E.; Bullock, J.; Belabbes, S.; Bromley, L. Fully Convolutional Neural Network for Rapid Flood Segmentation in Synthetic Aperture Radar Imagery. Remote Sens. 2020, 12, 2532. [Google Scholar] [CrossRef]
- Bai, Y.; Wu, W.; Yang, Z.; Yu, J.; Zhao, B.; Liu, X.; Yang, H.; Mas, E.; Koshimura, S. Enhancement of Detecting Permanent Water and Temporary Water in Flood Disasters by Fusing Sentinel-1 and Sentinel-2 Imagery Using Deep Learning Algorithms: Demonstration of Sen1Floods11 Benchmark Datasets. Remote Sens. 2021, 13, 2220. [Google Scholar] [CrossRef]
- Xue, S.; Geng, X.; Meng, L.; Xie, T.; Huang, L.; Yan, X.-H. HISEA-1: The First C-Band SAR Miniaturized Satellite for Ocean and Coastal Observation. Remote Sens. 2021, 13, 2076. [Google Scholar] [CrossRef]
- Torralba, A.; Russell, B.C.; Yuen, J. LabelMe: Online Image Annotation and Applications. Proc. IEEE 2010, 98, 1467–1484. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Wang, P.Q.; Chen, P.F.; Yuan, Y.; Liu, D.; Huang, Z.H.; Hou, X.D.; Cottrell, G. Understanding Convolution for Semantic Segmentation. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV 2018), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1451–1460. [Google Scholar] [CrossRef]
- Pistrika, A.K.; Jonkman, S.N. Damage to residential buildings due to flooding of New Orleans after hurricane Katrina. Nat. Hazards 2010, 54, 413–434. [Google Scholar] [CrossRef]
- Zhang, W.; Jin, F.F.; Stuecker, M.F.; Wittenberg, A.T.; Timmermann, A.; Ren, H.L.; Kug, J.S.; Cai, W.; Cane, M. Unraveling El Nino’s impact on the East Asian Monsoon and Yangtze River summer flooding. Geophys. Res. Lett. 2016, 43, 11375–11382. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Segmentation Techniques | Characteristic, Advantage | Limitation, Disadvantage |
|---|---|---|
| Threshold-based | Low computation complexity; no need for prior knowledge | Spatial details are not considered; not good if no clear peaks |
| Superpixel-based | Groups of pixels that look similar | Challenging in detailed information and superpixel number |
| Watershed-based | Region-based; detected boundaries are continuous | Complex calculation of gradients; over-segmentation |
| Active contour methods | Good performance for complicated boundaries | Dependent on initial contour |
| Classification-based | Pixel-level classification; more choice of classification methods | Dependent on classifying effect; some models need to be trained |
| Image ID | Time Date | Central Location | Study Area | Orbit Direction | Incidence Angle Mid-Swath | Image Size |
|---|---|---|---|---|---|---|
| Training region | ||||||
| No. 1 | 21 July 2021 | 48°30′N/124°12′E | Inner Mongolia | Descending | 24.5° | 9819 × 13,833 |
| No. 2 | 25 July 2021 | 36°42′N/114°31′E | Hebei | Descending | 28.5° | 9926 × 13,862 |
| No. 3 | 25 July 2021 | 36°24′N/114°26′E | Hebei | Descending | 28.5° | 9924 × 13,863 |
| No. 4 | 25 July 2021 | 36°6′N/114°20′E | Henan | Descending | 28.5° | 9921 × 13,863 |
| No. 5 | 25 July 2021 | 35°47′N/114°15′E | Henan | Descending | 28.5° | 9917 × 13,862 |
| No. 6 | 25 July 2021 | 35°10′N/114°3′E | Henan | Descending | 28.5° | 9918 × 13,863 |
| No. 7 | 25 July 2021 | 34°34′N/113°53′E | Henan | Descending | 28.5° | 9286 × 13,640 |
| No. 8 | 25 July 2021 | 30°7′N/120°12′E | Zhejiang | Ascending | 26.5° | 9487 × 14,504 |
| No. 9 | 25 July 2021 | 29°49′N/120°17′E | Zhejiang | Ascending | 26.5° | 9476 × 14,503 |
| No. 10 | 25 July 2021 | 29°30′N/120°30′E | Zhejiang | Ascending | 26.5° | 9471 × 14,501 |
| No. 11 | 25 July 2021 | 29°9′N/120°27′E | Zhejiang | Ascending | 26.5° | 9482 × 14,502 |
| No. 12 | 26 July 2021 | 35°29′N/113°48′E | Henan | Descending | 16.25° | 9157 × 14,163 |
| No. 13 | 26 July 2021 | 35°11′N/113°43′E | Henan | Descending | 16.25° | 9202 × 14,174 |
| No. 14 | 26 July 2021 | 34°50′N/113°38′E | Henan | Descending | 16.25° | 9199 × 14,176 |
| No. 15 | 26 July 2021 | 34°31′N/113°34′E | Henan | Descending | 16.25° | 9175 × 14,174 |
| No. 16 | 26 July 2021 | 34°12′N/113°29′E | Henan | Descending | 16.25° | 9183 × 14,177 |
| No. 17 | 26 July 2021 | 33°59′N/113°26′E | Henan | Descending | 16.25° | 9200 × 14,196 |
| No. 18 | 27 July 2021 | 29°45′N/121°34′E | Zhejiang | Descending | 29.5° | 9856 × 14,508 |
| No. 19 | 27 July 2021 | 29°25′N/121°28′E | Zhejiang | Descending | 29.5° | 9856 × 14,508 |
| No. 20 | 27 July 2021 | 28°54′N/121°20′E | Zhejiang | Descending | 29.5° | 9842 × 14,506 |
| Testing region | ||||||
| No. 21 | 25 July 2021 | 34°51′N/113°58′E | Henan | Descending | 28.5° | 9286 × 13,643 |
| No. 22 | 27 July 2021 | 29°6′N/121°23′E | Zhejiang | Descending | 29.5° | 9833 × 14,502 |
| Models | Accuracy | F1 | mIoU | Detection Time (s) |
|---|---|---|---|---|
| SegNet | 0.9447 | 0.8603 | 0.8441 | 187.2 |
| U-Net | 0.9517 | 0.8801 | 0.8636 | 140.4 |
| DeepLabv3+ | 0.9427 | 0.8551 | 0.8390 | 140.0 |
| Modified DeepLabv3+ | 0.9574 | 0.8936 | 0.8779 | 46.8 |
| Models | Accuracy | F1 | mIoU | Detection Time (s) |
|---|---|---|---|---|
| SegNet | 0.9750 | 0.9035 | 0.8984 | 23.5 |
| U-Net | 0.9777 | 0.9148 | 0.9090 | 24.5 |
| DeepLabv3+ | 0.9765 | 0.9068 | 0.9032 | 25.5 |
| Modified DeepLabv3+ | 0.9820 | 0.9283 | 0.9376 | 10 |
| Models | Accuracy | F1 | mIoU | Detection Time (min) |
|---|---|---|---|---|
| SegNet | 0.9807 | 0.8493 | 0.8589 | 10.5 |
| U-Net | 0.9832 | 0.8720 | 0.8776 | 10.4 |
| DeepLabv3+ | 0.9710 | 0.7218 | 0.7673 | 10.3 |
| Modified DeepLabv3+ | 0.9851 | 0.8864 | 0.8901 | 4.9 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lv, S.; Meng, L.; Edwing, D.; Xue, S.; Geng, X.; Yan, X.-H. High-Performance Segmentation for Flood Mapping of HISEA-1 SAR Remote Sensing Images. Remote Sens. 2022, 14, 5504. https://doi.org/10.3390/rs14215504
Lv S, Meng L, Edwing D, Xue S, Geng X, Yan X-H. High-Performance Segmentation for Flood Mapping of HISEA-1 SAR Remote Sensing Images. Remote Sensing. 2022; 14(21):5504. https://doi.org/10.3390/rs14215504
Chicago/Turabian StyleLv, Suna, Lingsheng Meng, Deanna Edwing, Sihan Xue, Xupu Geng, and Xiao-Hai Yan. 2022. "High-Performance Segmentation for Flood Mapping of HISEA-1 SAR Remote Sensing Images" Remote Sensing 14, no. 21: 5504. https://doi.org/10.3390/rs14215504
APA StyleLv, S., Meng, L., Edwing, D., Xue, S., Geng, X., & Yan, X.-H. (2022). High-Performance Segmentation for Flood Mapping of HISEA-1 SAR Remote Sensing Images. Remote Sensing, 14(21), 5504. https://doi.org/10.3390/rs14215504