
A Review of Image Super-Resolution Approaches Based on Deep Learning and Applications in Remote Sensing

 ,
, 
 , ,
, ,
Abstract
1. Introduction
- We provide a comprehensive introduction to the deep-learning-based super-resolution process, including problem definitions, datasets, learning strategies, and evaluation methods, to give this review a detailed background.
- We classify the SR algorithms according to their design principles. In addition, we analyze the effectiveness of several performance metrics of representative SR algorithms on benchmark datasets, and some remote sensing image super-resolution methods proposed in recent years are also introduced. The visual effects of classical SR methods on remote sensing images are shown and discussed.
- We analyze the current issues and challenges of super-resolution remote sensing images from multiple perspectives and present valuable suggestions, in addition to clarifying future trends and directions for development.
2. Background
2.1. Deep-Learning-Based Super-Resolution
2.2. Training and Test Datasets
2.3. Evaluation Methods
2.3.1. Image Quality Assessment
Peak Signal-to-Noise Ratio (PSNR)
Structural Similarity (SSIM)
Mean Opinion Score (MOS)
2.3.2. Model Reconstruction Efficiency
Storage Efficiency (Params)
Execution Time
Computational Efficiency (Mult & Adds)
3. Deep Architectures for Super-Resolution
3.1. Network Design
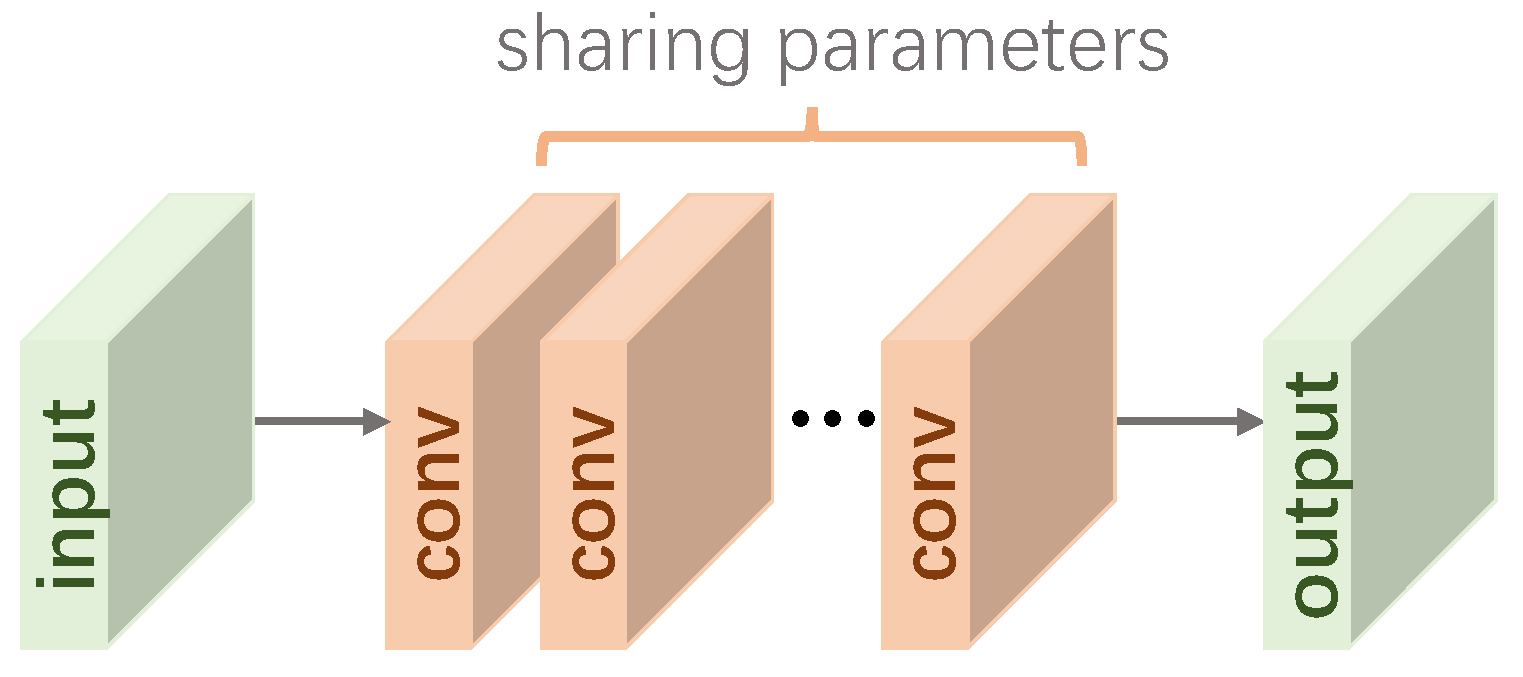
3.1.1. Recursive Learning
3.1.2. Residual Learning
3.1.3. Multi-Scale Learning
3.1.4. Attention Mechanism
Channel Attention
Non-Local Attention
Other Attention
3.1.5. Feedback Mechanism
3.1.6. Frequency Information-Based Models
3.1.7. Sparsity-Based Models
3.2. Learning Strategies
3.2.1. Loss Function
Pixel Loss
Perceptual Loss
Content Loss
Texture Loss
Adversarial Loss
3.2.2. Regularization
L1∖L2 Regularization
Dropout
Early Stopping
Data Augmentation
3.2.3. Batch Normalization
3.3. Other Improvement Methods
3.3.1. Knowledge-Distillation-Based Models
3.3.2. Adder-Operation-Based Models
3.3.3. Transformer-Based Models
3.3.4. Reference-Based Models
4. Analyses and Comparisons of Various Models
4.1. Details of the Representative Models
4.2. Results and Discussion
5. Remote Sensing Applications
5.1. Supervised Remote Sensing Image Super-Resolution
5.2. Unsupervised Remote Sensing Image Super-Resolution
6. Current Challenges and Future Directions
6.1. Network Design
6.2. Learning Strategies
6.3. Evaluation Methods
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jo, Y.; Kim, S.J. Practical single-image super-resolution using look-up table. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 691–700. [Google Scholar]
- Loghmani, G.B.; Zaini, A.M.E.; Latif, A. Image Zooming Using Barycentric Rational Interpolation. J. Math. Ext. 2018, 12, 67–86. [Google Scholar]
- Cherifi, T.; Hamami-Metiche, L.; Kerrouchi, S. Comparative study between super-resolution based on polynomial interpolations and Whittaker filtering interpolations. In Proceedings of the 2020 1st International Conference on Communications, Control Systems and Signal Processing (CCSSP), El-Oued, Algeria, 16–17 March 2020; pp. 235–241. [Google Scholar]
- Xu, Y.; Li, J.; Song, H.; Du, L. Single-Image Super-Resolution Using Panchromatic Gradient Prior and Variational Model. Math. Probl. Eng. 2021, 2021, 9944385. [Google Scholar] [CrossRef]
- Huang, Y.; Li, J.; Gao, X.; He, L.; Lu, W. Single image super-resolution via multiple mixture prior models. IEEE Trans. Image Process. 2018, 27, 5904–5917. [Google Scholar] [CrossRef] [PubMed]
- Yang, Q.; Zhang, Y.; Zhao, T.; Chen, Y.Q. Single image super-resolution using self-optimizing mask via fractional-order gradient interpolation and reconstruction. ISA Trans. 2018, 82, 163–171. [Google Scholar] [CrossRef]
- Xiong, M.; Song, Y.; Xiang, Y.; Xie, B.; Deng, Z. Anchor neighborhood embedding based single-image super-resolution reconstruction with similarity threshold adjustment. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence and Information Systems, Chongqing, China, 28–30 May 2021; pp. 1–8. [Google Scholar]
- Hardiansyah, B.; Lu, Y. Single image super-resolution via multiple linear mapping anchored neighborhood regression. Multimed. Tools Appl. 2021, 80, 28713–28730. [Google Scholar] [CrossRef]
- Liu, J.; Liu, Y.; Wu, H.; Wang, J.; Li, X.; Zhang, C. Single image super-resolution using feature adaptive learning and global structure sparsity. Signal Process. 2021, 188, 108184. [Google Scholar] [CrossRef]
- Yang, B.; Wu, G. Efficient Single Image Super-Resolution Using Dual Path Connections with Multiple Scale Learning. arXiv 2021, arXiv:2112.15386. [Google Scholar]
- Yang, Q.; Zhang, Y.; Zhao, T. Example-based image super-resolution via blur kernel estimation and variational reconstruction. Pattern Recognit. Lett. 2019, 117, 83–89. [Google Scholar] [CrossRef]
- Wang, L.; Du, J.; Gholipour, A.; Zhu, H.; He, Z.; Jia, Y. 3D dense convolutional neural network for fast and accurate single MR image super-resolution. Comput. Med. Imaging Graph. Off. J. Comput. Med. Imaging Soc. 2021, 93, 101973. [Google Scholar] [CrossRef]
- Yutani, T.; Yono, O.; Kuwatani, T.; Matsuoka, D.; Kaneko, J.; Hidaka, M.; Kasaya, T.; Kido, Y.; Ishikawa, Y.; Ueki, T.; et al. Super-Resolution and Feature Extraction for Ocean Bathymetric Maps Using Sparse Coding. Sensors 2022, 22, 3198. [Google Scholar] [CrossRef]
- Cai, Q.; Li, J.; Li, H.; Yang, Y.H.; Wu, F.; Zhang, D. TDPN: Texture and Detail-Preserving Network for Single Image Super-Resolution. IEEE Trans. Image Process. 2022, 31, 2375–2389. [Google Scholar] [CrossRef] [PubMed]
- Keys, R. Cubic convolution interpolation for digital image processing. IEEE Trans. Acoust. Speech, Signal Process. 1981, 29, 1153–1160. [Google Scholar] [CrossRef]
- Dai, S.; Han, M.; Xu, W.; Wu, Y.; Gong, Y.; Katsaggelos, A.K. SoftCuts: A Soft Edge Smoothness Prior for Color Image Super-Resolution. IEEE Trans. Image Process. 2009, 18, 969–981. [Google Scholar] [PubMed]
- Chang, H.; Yeung, D.Y.; Xiong, Y. Super-resolution through neighbor embedding. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 1, p. 1. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Deeply-recursive convolutional network for image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1637–1645. [Google Scholar]
- Liebel, L.; Körner, M. Single-image super resolution for multispectral remote sensing data using convolutional neural networks. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 883–890. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Guo, Y.; Chen, J.; Wang, J.; Chen, Q.; Cao, J.; Deng, Z.; Xu, Y.; Tan, M. Closed-loop matters: Dual regression networks for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5407–5416. [Google Scholar]
- Wang, Z.; Chen, J.; Hoi, S.C. Deep learning for image super-resolution: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3365–3387. [Google Scholar] [CrossRef]
- Tian, C.; Zhang, X.; Lin, J.C.W.; Zuo, W.; Zhang, Y. Generative Adversarial Networks for Image Super-Resolution: A Survey. arXiv 2022, arXiv:2204.13620. [Google Scholar]
- Chen, H.; He, X.; Qing, L.; Wu, Y.; Ren, C.; Sheriff, R.E.; Zhu, C. Real-world single image super-resolution: A brief review. Inf. Fusion 2022, 79, 124–145. [Google Scholar] [CrossRef]
- Liu, H.; Ruan, Z.; Zhao, P.; Dong, C.; Shang, F.; Liu, Y.; Yang, L.; Timofte, R. Video super-resolution based on deep learning: A comprehensive survey. Artif. Intell. Rev. 2022, 1–55. [Google Scholar] [CrossRef]
- Yan, B.; Bare, B.; Ma, C.; Li, K.; Tan, W. Deep Objective Quality Assessment Driven Single Image Super-Resolution. IEEE Trans. Multimed. 2019, 21, 2957–2971. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Abiodun, O.I.; Jantan, A.; Omolara, A.E.; Dada, K.V.; Mohamed, N.A.; Arshad, H. State-of-the-art in artificial neural network applications: A survey. Heliyon 2018, 4, e00938. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.C.; Vincent, P. Representation Learning: A Review and New Perspectives. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1798–1828. [Google Scholar] [CrossRef]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Vancouver, BC, Canada, 9–12 July 2001; Volume 2, pp. 416–423. [Google Scholar]
- Arbelaez, P.; Maire, M.; Fowlkes, C.; Malik, J. Contour detection and hierarchical image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 898–916. [Google Scholar] [CrossRef] [PubMed]
- Agustsson, E.; Timofte, R. Ntire 2017 challenge on single image super-resolution: Dataset and study. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–16 July 2017; pp. 126–135. [Google Scholar]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 7–10 September 2012; pp. 135.1–135.10. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On single image scale-up using sparse-representations. In Proceedings of the International Conference on Curves and Surfaces, Avignon, France, 24–30 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 711–730. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single image super-resolution from transformed self-exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Xia, G.S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Dai, D.; Yang, W. Satellite image classification via two-layer sparse coding with biased image representation. IEEE Geosci. Remote Sens. Lett. 2010, 8, 173–176. [Google Scholar] [CrossRef]
- Wang, X.; Yu, K.; Dong, C.; Loy, C.C. Recovering realistic texture in image super-resolution by deep spatial feature transform. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 606–615. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279. [Google Scholar]
- Cheng, G.; Han, J.; Lu, X. Remote Sensing Image Scene Classification: Benchmark and State of the Art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]
- Zhao, L.; Tang, P.; Huo, L. Feature significance-based multibag-of-visual-words model for remote sensing image scene classification. J. Appl. Remote Sens. 2016, 10, 035004. [Google Scholar] [CrossRef]
- Yang, J.; Wright, J.; Huang, T.S.; Ma, Y. Image super-resolution via sparse representation. IEEE Trans. Image Process. 2010, 19, 2861–2873. [Google Scholar] [CrossRef] [PubMed]
- Fujimoto, A.; Ogawa, T.; Yamamoto, K.; Matsui, Y.; Yamasaki, T.; Aizawa, K. Manga109 dataset and creation of metadata. In Proceedings of the 1st International Workshop on Comics Analysis, Processing and Understanding, Cancun, Mexico, 4 December 2016; pp. 1–5. [Google Scholar]
- Blau, Y.; Mechrez, R.; Timofte, R.; Michaeli, T.; Zelnik-Manor, L. The 2018 PIRM challenge on perceptual image super-resolution. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Chen, C.; Xiong, Z.; Tian, X.; Zha, Z.J.; Wu, F. Camera lens super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 1652–1660. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Everingham, M.; Eslami, S.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep learning face attributes in the wild. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Zhao, T.; Chen, W.; Niu, Y.; Hu, J.F. SPQE: Structure-and-Perception-Based Quality Evaluation for Image Super-Resolution. arXiv 2022, arXiv:2205.03584. [Google Scholar]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The Unreasonable Effectiveness of Deep Features as a Perceptual Metric. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]
- Tai, Y.; Yang, J.; Liu, X. Image super-resolution via deep recursive residual network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar]
- Ahn, N.; Kang, B.; Sohn, K.A. Fast, accurate, and lightweight super-resolution with cascading residual network. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 252–268. [Google Scholar]
- Qiu, Y.; Wang, R.; Tao, D.; Cheng, J. Embedded block residual network: A recursive restoration model for single-image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 4180–4189. [Google Scholar]
- Li, J.; Yuan, Y.; Mei, K.; Fang, F. Lightweight and Accurate Recursive Fractal Network for Image Super-Resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27 October–2 November 2019; pp. 3814–3823. [Google Scholar]
- Luo, Z.; Huang, Y.; Li, S.; Wang, L.; Tan, T. Efficient Super Resolution by Recursive Aggregation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 8592–8599. [Google Scholar]
- Gao, G.; Wang, Z.; Li, J.; Li, W.; Yu, Y.; Zeng, T. Lightweight Bimodal Network for Single-Image Super-Resolution via Symmetric CNN and Recursive Transformer. arXiv 2022, arXiv:2204.13286. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar]
- Li, J.; Fang, F.; Mei, K.; Zhang, G. Multi-scale Residual Network for Image Super-Resolution. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 517–532. [Google Scholar]
- Liu, J.; Zhang, W.; Tang, Y.; Tang, J.; Wu, G. Residual feature aggregation network for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2359–2368. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 630–645. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced deep residual networks for single image super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Qin, J.; He, Z.; Yan, B.; Jeon, G.; Yang, X. Multi-Residual Feature Fusion Network for lightweight Single Image Super-Resolution. In Proceedings of the 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 14–17 December 2021; pp. 1511–1518. [Google Scholar]
- Park, K.; Soh, J.W.; Cho, N.I. A Dynamic Residual Self-Attention Network for Lightweight Single Image Super-Resolution. IEEE Trans. Multimed. 2021. [Google Scholar] [CrossRef]
- Sun, L.; Liu, Z.; Sun, X.; Liu, L.; Lan, R.; Luo, X. Lightweight Image Super-Resolution via Weighted Multi-Scale Residual Network. IEEE/CAA J. Autom. Sin. 2021, 8, 1271–1280. [Google Scholar] [CrossRef]
- Liu, D.; Li, J.; Yuan, Q. A Spectral Grouping and Attention-Driven Residual Dense Network for Hyperspectral Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2021, 59, 7711–7725. [Google Scholar] [CrossRef]
- Liu, J.; Tang, J.; Wu, G. Residual Feature Distillation Network for Lightweight Image Super-Resolution. In Proceedings of the European conference on computer vision (ECCV), Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 41–55. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep Laplacian Pyramid Networks for Fast and Accurate Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Chen, X.; Sun, C. Multiscale Recursive Feedback Network for Image Super-Resolution. IEEE Access 2022, 10, 6393–6406. [Google Scholar] [CrossRef]
- Qin, J.; Huang, Y.; Wen, W. Multi-scale feature fusion residual network for Single Image Super-Resolution. Neurocomputing 2020, 379, 334–342. [Google Scholar] [CrossRef]
- Pandey, G.; Ghanekar, U. Single image super-resolution using multi-scale feature enhancement attention residual network. Optik 2021, 231, 166359. [Google Scholar] [CrossRef]
- Zhang, X.; Zeng, H.; Guo, S.; Zhang, L. Efficient Long-Range Attention Network for Image Super-resolution. arXiv 2022, arXiv:2203.06697. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B.; Fu, Y. Image super-resolution using very deep residual channel attention networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 286–301. [Google Scholar]
- Niu, B.; Wen, W.; Ren, W.; Zhang, X.; Yang, L.; Wang, S.; Zhang, K.; Cao, X.; Shen, H. Single image super-resolution via a holistic attention network. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 191–207. [Google Scholar]
- Dai, T.; Cai, J.; Zhang, Y.; Xia, S.T.; Zhang, L. Second-order attention network for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11065–11074. [Google Scholar]
- Magid, S.A.; Zhang, Y.; Wei, D.; Jang, W.D.; Lin, Z.; Fu, Y.; Pfister, H. Dynamic high-pass filtering and multi-spectral attention for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4288–4297. [Google Scholar]
- Liu, D.; Wen, B.; Fan, Y.; Loy, C.C.; Huang, T.S. Non-local recurrent network for image restoration. Adv. Neural Inf. Process. Syst. 2018, 31. Available online: http://s.dic.cool/S/tamTpxhq (accessed on 28 September 2022).
- Mei, Y.; Fan, Y.; Zhou, Y.; Huang, L.; Huang, T.S.; Shi, H. Image super-resolution with cross-scale non-local attention and exhaustive self-exemplars mining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5690–5699. [Google Scholar]
- Zhang, Y.; Wei, D.; Qin, C.; Wang, H.; Pfister, H.; Fu, Y. Context reasoning attention network for image super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4278–4287. [Google Scholar]
- Mei, Y.; Fan, Y.; Zhou, Y. Image super-resolution with non-local sparse attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3517–3526. [Google Scholar]
- Li, K.; Hariharan, B.; Malik, J. Iterative instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3659–3667. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human Pose Estimation with Iterative Error Feedback. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Deep back-projection networks for super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–21 June 2018; pp. 1664–1673. [Google Scholar]
- Haris, M.; Shakhnarovich, G.; Ukita, N. Recurrent back-projection network for video super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3897–3906. [Google Scholar]
- Li, Z.; Yang, J.; Liu, Z.; Yang, X.; Jeon, G.; Wu, W. Feedback Network for Image Super-Resolution. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3862–3871. [Google Scholar]
- Xie, W.; Song, D.; Xu, C.; Xu, C.; Zhang, H.; Wang, Y. Learning frequency-aware dynamic network for efficient super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4308–4317. [Google Scholar]
- Kong, X.; Zhao, H.; Qiao, Y.; Dong, C. Classsr: A general framework to accelerate super-resolution networks by data characteristic. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12016–12025. [Google Scholar]
- Liu, D.; Wang, Z.; Wen, B.; Yang, J.; Han, W.; Huang, T.S. Robust single image super-resolution via deep networks with sparse prior. IEEE Trans. Image Process. 2016, 25, 3194–3207. [Google Scholar] [CrossRef]
- Gao, X.; Xiong, H. A hybrid wavelet convolution network with sparse-coding for image super-resolution. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 1439–1443. [Google Scholar]
- Wang, L.; Dong, X.; Wang, Y.; Ying, X.; Lin, Z.; An, W.; Guo, Y. Exploring sparsity in image super-resolution for efficient inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 4917–4926. [Google Scholar]
- Zhang, Z.; Wang, Z.; Lin, Z.L.; Qi, H. Image Super-Resolution by Neural Texture Transfer. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7974–7983. [Google Scholar]
- MadhuMithraK, K.; Ramanarayanan, S.; Ram, K.; Sivaprakasam, M. Reference-Based Texture Transfer For Single Image Super-Resolution Of Magnetic Resonance Images. In Proceedings of the 2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI), Nice, France, 13–16 April 2021; pp. 579–583. [Google Scholar]
- Yang, F.; Yang, H.; Fu, J.; Lu, H.; Guo, B. Learning Texture Transformer Network for Image Super-Resolution. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 5790–5799. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Aitken, A.P.; Tejani, A.; Totz, J.; Wang, Z.; Shi, W. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 105–114. [Google Scholar]
- Moradi, R.; Berangi, R.; Minaei, B. A survey of regularization strategies for deep models. Artif. Intell. Rev. 2019, 53, 3947–3986. [Google Scholar] [CrossRef]
- Kukačka, J.; Golkov, V.; Cremers, D. Regularization for Deep Learning: A Taxonomy. arXiv 2017, arXiv:1710.10686. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Srivastava, N. Improving neural networks with dropout. Univ. Tor. 2013, 182, 7. [Google Scholar]
- Konda, K.R.; Bouthillier, X.; Memisevic, R.; Vincent, P. Dropout as data augmentation. arXiv 2015, arXiv:1506.08700. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2012, 60, 84–90. [Google Scholar] [CrossRef]
- Li, M.; Soltanolkotabi, M.; Oymak, S. Gradient Descent with Early Stopping is Provably Robust to Label Noise for Overparameterized Neural Networks. arXiv 2020, arXiv:1903.11680. [Google Scholar]
- Prechelt, L. Early stopping-but when? In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 1998; pp. 55–69. [Google Scholar]
- Zoph, B.; Cubuk, E.D.; Ghiasi, G.; Lin, T.Y.; Shlens, J.; Le, Q.V. Learning data augmentation strategies for object detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 566–583. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random erasing data augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–8 February 2020; Volume 34, pp. 13001–13008. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Hinton, G.E.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Lee, W.; Lee, J.; Kim, D.; Ham, B. Learning with Privileged Information for Efficient Image Super-Resolution. arXiv 2020, arXiv:2007.07524. [Google Scholar]
- Zhang, Y.; Chen, H.; Chen, X.; Deng, Y.; Xu, C.; Wang, Y. Data-free knowledge distillation for image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7852–7861. [Google Scholar]
- Chen, H.; Wang, Y.; Xu, C.; Shi, B.; Xu, C.; Tian, Q.; Xu, C. AdderNet: Do we really need multiplications in deep learning? In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1468–1477. [Google Scholar]
- Song, D.; Wang, Y.; Chen, H.; Xu, C.; Xu, C.; Tao, D. Addersr: Towards energy efficient image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15648–15657. [Google Scholar]
- Vaswani, A.; Ramachandran, P.; Srinivas, A.; Parmar, N.; Hechtman, B.; Shlens, J. Scaling local self-attention for parameter efficient visual backbones. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 12894–12904. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning (PMLR), Virtual, 18–24 July 2021; pp. 10347–10357. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Raghu, M.; Unterthiner, T.; Kornblith, S.; Zhang, C.; Dosovitskiy, A. Do vision transformers see like convolutional neural networks? Adv. Neural Inf. Process. Syst. 2021, 34, 12116–12128. [Google Scholar]
- Chen, X.; Wang, X.; Zhou, J.; Dong, C. Activating More Pixels in Image Super-Resolution Transformer. arXiv 2022, arXiv:2205.04437. [Google Scholar]
- Lu, Z.; Li, J.; Liu, H.; Huang, C.; Zhang, L.; Zeng, T. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–24 June 2022; pp. 457–466. [Google Scholar]
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 1833–1844. [Google Scholar]
- Cai, Q.; Qian, Y.; Li, J.; Lv, J.; Yang, Y.H.; Wu, F.; Zhang, D. HIPA: Hierarchical Patch Transformer for Single Image Super Resolution. arXiv 2022, arXiv:2203.10247. [Google Scholar]
- Haut, J.M.; Fernández-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A.J. Remote Sensing Image Superresolution Using Deep Residual Channel Attention. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9277–9289. [Google Scholar] [CrossRef]
- Ma, W.; Pan, Z.; Guo, J.; Lei, B. Achieving Super-Resolution Remote Sensing Images via the Wavelet Transform Combined With the Recursive Res-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3512–3527. [Google Scholar]
- Shao, Z.; Wang, L.; Wang, Z.; Deng, J. Remote sensing image super-resolution using sparse representation and coupled sparse autoencoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2663–2674. [Google Scholar] [CrossRef]
- Ma, W.; Pan, Z.; Yuan, F.; Lei, B. Super-resolution of remote sensing images via a dense residual generative adversarial network. Remote Sens. 2019, 11, 2578. [Google Scholar] [CrossRef]
- Dong, X.; Xi, Z.; Sun, X.; Gao, L. Transferred Multi-Perception Attention Networks for Remote Sensing Image Super-Resolution. Remote Sens. 2019, 11, 2857. [Google Scholar] [CrossRef]
- Pan, Z.; Ma, W.; Guo, J.; Lei, B. Super-Resolution of Single Remote Sensing Image Based on Residual Dense Backprojection Networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7918–7933. [Google Scholar] [CrossRef]
- Dong, X.; Xi, Z.; Sun, X.; Yang, L. Remote Sensing Image Super-Resolution via Enhanced Back-Projection Networks. In Proceedings of the IGARSS 2020 - 2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1480–1483. [Google Scholar]
- Wang, P.; Bayram, B.; Sertel, E. Super-resolution of remotely sensed data using channel attention based deep learning approach. Int. J. Remote Sens. 2021, 42, 6048–6065. [Google Scholar] [CrossRef]
- Wang, Z.; Li, L.; Xue, Y.; Jiang, C.; Wang, J.; Sun, K.; Ma, H. FeNet: Feature Enhancement Network for Lightweight Remote-Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–12. [Google Scholar] [CrossRef]
- Huang, B.; Guo, Z.; Wu, L.; He, B.; Li, X.; Lin, Y. Pyramid Information Distillation Attention Network for Super-Resolution Reconstruction of Remote Sensing Images. Remote Sens. 2021, 13, 5143. [Google Scholar] [CrossRef]
- Zhang, J.; Xu, T.; Li, J.; Jiang, S.; Zhang, Y. Single-Image Super Resolution of Remote Sensing Images with Real-World Degradation Modeling. Remote Sens. 2022, 14, 2895. [Google Scholar] [CrossRef]
- Yue, X.; Chen, X.; Zhang, W.; Ma, H.; Wang, L.; Zhang, J.; Wang, M.; Jiang, B. Super-Resolution Network for Remote Sensing Images via Preclassification and Deep–Shallow Features Fusion. Remote Sens. 2022, 14, 925. [Google Scholar] [CrossRef]
- Xu, Y.; Luo, W.; Hu, A.; Xie, Z.; Xie, X.; Tao, L. TE-SAGAN: An Improved Generative Adversarial Network for Remote Sensing Super-Resolution Images. Remote Sens. 2022, 14, 2425. [Google Scholar] [CrossRef]
- Guo, M.; Zhang, Z.; Liu, H.; Huang, Y. NDSRGAN: A Novel Dense Generative Adversarial Network for Real Aerial Imagery Super-Resolution Reconstruction. Remote Sens. 2022, 14, 1574. [Google Scholar] [CrossRef]
- Qin, X.; Gao, X.; Yue, K. Remote Sensing Image Super-Resolution using Multi-Scale Convolutional Neural Network. In Proceedings of the 2018 11th UK-Europe-China Workshop on Millimeter Waves and Terahertz Technologies (UCMMT), Hangzhou, China, 5–7 September 2018; Volume 1, pp. 1–3. [Google Scholar]
- Yu, Y.; Li, X.; Liu, F. E-DBPN: Enhanced deep back-projection networks for remote sensing scene image superresolution. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5503–5515. [Google Scholar] [CrossRef]
- Zhang, D.; Shao, J.; Li, X.; Shen, H.T. Remote sensing image super-resolution via mixed high-order attention network. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5183–5196. [Google Scholar] [CrossRef]
- Zhang, S.; Yuan, Q.; Li, J.; Sun, J.; Zhang, X. Scene-adaptive remote sensing image super-resolution using a multiscale attention network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4764–4779. [Google Scholar] [CrossRef]
- Arefin, M.R.; Michalski, V.; St-Charles, P.L.; Kalaitzis, A.; Kim, S.; Kahou, S.E.; Bengio, Y. Multi-image super-resolution for remote sensing using deep recurrent networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 206–207. [Google Scholar]
- Wang, S.; Zhou, T.; Lu, Y.; Di, H. Contextual Transformation Network for Lightweight Remote-Sensing Image Super-Resolution. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Jiang, W.; Zhao, L.; Wang, Y.J.; Liu, W.; Liu, B.D. U-Shaped Attention Connection Network for Remote-Sensing Image Super-Resolution. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Pla, F. A new deep generative network for unsupervised remote sensing single-image super-resolution. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6792–6810. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, H.; Zhou, F.; Jiang, Z. Unsupervised remote sensing image super-resolution using cycle CNN. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3117–3120. [Google Scholar]
- Zhang, N.; Wang, Y.; Zhang, X.; Xu, D.; Wang, X. An unsupervised remote sensing single-image super-resolution method based on generative adversarial network. IEEE Access 2020, 8, 29027–29039. [Google Scholar] [CrossRef]
- Zhang, N.; Wang, Y.; Zhang, X.; Xu, D.; Wang, X.; Ben, G.; Zhao, Z.; Li, Z. A multi-degradation aided method for unsupervised remote sensing image super resolution with convolution neural networks. IEEE Trans. Geosci. Remote Sens. 2020, 60, 1–14. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Amount | Resolution | Format | Short Description |
|---|---|---|---|---|
| BSD300 [32] | 300 | (435, 367) | JPG | animal, scenery, decoration, plant, etc. |
| BSD500 [33] | 500 | (432, 370) | JPG | animal, scenery, decoration, plant, etc. |
| DIV2K [34] | 1000 | (1972, 1437) | PNG | people, scenery, animal, decoration, etc. |
| Set5 [35] | 5 | (313, 336) | PNG | baby, butterfly, bird, head, woman |
| Set14 [36] | 14 | (492, 446) | PNG | baboon, bridge, coastguard, foreman, etc. |
| T91 [45] | 91 | (264, 204) | PNG | flower, face, fruit, people, etc. |
| BSD100 [32] | 100 | (481,321) | JPG | animal, scenery, decoration, plant, etc. |
| Urban100 [37] | 100 | (984, 797) | PNG | construction, architecture, scenery, etc. |
| Manga109 [46] | 109 | (826, 1169) | PNG | comics |
| PIRM [47] | 200 | (617, 482) | PNG | animal, people, scenery, decoration, etc. |
| City100 [48] | 100 | (840,600) | RAW | city scene |
| OutdoorScene [41] | 10624 | (553, 440) | PNG | scenes outside |
| AID [38] | 10000 | (600, 600) | JPG | airport, bare land, beach, desert, etc. |
| RSSCN7 [39] | 2800 | (400, 400) | JPG | farmlands, parking lots, residential areas, lakes etc. |
| WHU-RS19 [40] | 1005 | (600, 600) | TIF | bridge, forest, pond, port, etc. |
| UC Merced [42] | 2100 | (256, 256) | PNG | farmland, bushes, highways, overpasses, etc. |
| NWHU-RESISC45 [43] | 31,500 | (256, 256) | PNG | airports, basketball courts, residential areas, ports, etc. |
| RSC11 [44] | 1232 | (512, 512) | TIF | grasslands, overpasses, roads, residential areas, etc. |
| Models | Scale | Set5 | Set14 | BSD100 | Urban100 | Manga109 | Train Data | Param. |
|---|---|---|---|---|---|---|---|---|
| PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | PSNR/SSIM | ||||
| SRCNN [18] | ×2 | 36.66/0.9542 | 32.45/0.9067 | 31.36 0.8879 | 29.50/0.8946 | 35.60/0.9663 | T91 + ImageNet | 57 K |
| VDSR [21] | ×2 | 37.53/0.9587 | 33.03/0.9124 | 31.90/0.8960 | 30.76/0.9140 | -/- | BSD + T91 | 665 K |
| DRCN [19] | ×2 | 37.63/0.9588 | 33.04/0.9118 | 31.85/0.8942 | 30.75/0.9133 | -/- | T91 | 1.8 M |
| DRRN [57] | ×2 | 37.74/0.9591 | 33.23/0.9136 | 32.05/0.8973 | 31.23/0.9188 | -/- | BSD + T91 | 297 K |
| CARN [58] | ×2 | 37.76/0.9590 | 33.52/0.9166 | 32.09/0.8978 | 31.92/0.9256 | -/- | BSD + T91 + DIV2K | 1.6 M |
| EDSR [68] | ×2 | 38.11/0.9601 | 33.92/0.9195 | 32.32/0.9013 | 32.93/0.9351 | -/- | DIV2K | 43 M |
| ELAN [79] | ×2 | 38.17/0.9611 | 33.94/0.9207 | 32.30/0.9012 | 32.76/0.9340 | 39.11/0.9782 | DIV2K | 8.3 M |
| MSRN [65] | ×2 | 38.08/0.9605 | 33.74/0.9170 | 32.23/0.9013 | 32.22/0.9326 | 38.82/0.9868 | DIV2K | 6.5 M |
| RCAN [81] | ×2 | 38.27/0.9614 | 34.12/0.9216 | 32.41/0.9027 | 33.34/0.9384 | 39.44/0.9786 | DIV2K | 16 M |
| HAN [82] | ×2 | 38.27/0.9614 | 34.16/0.9217 | 32.41/0.9027 | 33.35/0.9385 | 39.46/0.9785 | DIV2K | 16.1 M |
| RDN [64] | ×2 | 38.30/0.9616 | 34.10/0.9218 | 32.40/0.9022 | 33.09/0.9368 | 39.38/0.9784 | DIV2K | 22.6 M |
| NLSN [88] | ×2 | 38.34/0.9618 | 34.08/0.9231 | 32.43/0.9027 | 33.42/0.9394 | 39.59/0.9789 | DIV2K | 16.1 M |
| RFANet [66] | ×2 | 38.26/0.9615 | 34.16/0.9220 | 32.41/0.9026 | 33.33/0.9389 | 39.44/0.9783 | DIV2K | 11 M |
| SAN [83] | ×2 | 38.31/0.9620 | 34.07/0.9213 | 32.42/0.9028 | 33.10/0.9370 | 39.32/0.9792 | DIV2K | 15.7 M |
| SMSR [98] | ×2 | 38.00/0.9601 | 33.64/0.9179 | 32.17/0.8990 | 32.19/0.9284 | 38.76/0.9771 | DIV2K | 1 M |
| ESRT [126] | ×2 | -/- | -/- | -/- | -/- | -/- | DIV2K | 751 K |
| TDPN [14] | ×2 | 38.31/0.9621 | 34.16/0.9225 | 32.52/0.9045 | 33.36/0.9386 | 39.57/0.9795 | DIV2K | 12.8 M |
| SwinIR [127] | ×2 | 38.42/0.9623 | 34.46/0.9250 | 32.53/0.9041 | 33.81/0.9427 | 39.92/0.9797 | DIV2K + Flickr2K | 12 M |
| SRCNN [18] | ×3 | 32.75/0.9090 | 29.30/0.8215 | 28.41/0.7863 | 26.24/0.7989 | 30.48/0.9117 | T91 + ImageNet | 57 K |
| VDSR [21] | ×3 | 33.66/0.9213 | 29.77/0.8314 | 28.82/0.7976 | 27.14/0.8279 | -/- | BSD + T91 | 665 K |
| DRCN [19] | ×3 | 33.82/0.9226 | 29.76/0.8311 | 28.80/0.7963 | 27.15/0.8276 | -/- | T91 | 1.8 M |
| DRRN [57] | ×3 | 34.03/0.9244 | 29.96/0.8349 | 28.95/0.8004 | 27.53/0.8378 | -/- | BSD + T91 | 297 K |
| CARN [58] | ×3 | 34.29/0.9255 | 30.29/0.8407 | 29.06/0.8034 | 28.06/0.8493 | -/- | BSD + T91 + DIV2K | 1.6 M |
| EDSR [68] | ×3 | 34.65/0.9282 | 30.52/0.8462 | 27.71/0.7420 | 29.25/0.8093 | -/- | DIV2K | 43 M |
| ELAN [79] | ×3 | 34.61/0.9288 | 30.55/0.8463 | 29.21/0.8081 | 28.69/0.8624 | 34.00/0.9478 | DIV2K | 8.3 M |
| MSRN [65] | ×3 | 34.38/0.9262 | 30.34/0.8395 | 29.08/0.8041 | 28.08/0.8554 | 33.44/0.9427 | DIV2K | 6.5 M |
| RCAN [81] | ×3 | 34.74/0.9299 | 30.65/0.8482 | 29.32/0.8111 | 29.09/0.8702 | 34.44/0.9499 | DIV2K | 16 M |
| HAN [82] | ×3 | 34.75/0.9299 | 30.67/0.8483 | 29.32/0.8110 | 29.10/0.8705 | 34.48/0.9500 | DIV2K | 16.1 M |
| RDN [64] | ×3 | 34.78/0.9300 | 30.67/0.8482 | 29.33/0.8105 | 29.00/0.8683 | 34.43/0.9498 | DIV2K | 22.6 M |
| NLSN [88] | ×3 | 34.85/0.9306 | 30.70/0.8485 | 29.34/0.8117 | 29.25/0.8726 | 34.57 0.9508 | DIV2K | 16.1 M |
| RFANet [66] | ×3 | 34.79/0.9300 | 30.67/0.8487 | 29.34/0.8115 | 29.15/0.8720 | 34.59/0.9506 | DIV2K | 11 M |
| SAN [83] | ×3 | 34.75/0.9300 | 30.59/0.8476 | 30.59/0.8476 | 28.93/0.8671 | 34.30/0.9494 | DIV2K | 15.7 M |
| SMSR [98] | ×3 | 34.40/0.9270 | 30.33/0.8412 | 29.10/0.8050 | 28.25/0.8536 | 33.68/0.9445 | DIV2K | 1 M |
| ESRT [126] | ×3 | 34.42/0.9268 | 30.43/0.8433 | 29.15/0.8063 | 28.46/0.8574 | 33.95/0.9455 | DIV2K | 751 K |
| TDPN [14] | ×3 | 34.86/0.9312 | 30.79/0.8501 | 29.45/0.8126 | 29.26/0.8724 | 34.48/0.9508 | DIV2K+Flickr2K | 12.8 M |
| SwinIR [127] | ×3 | 34.97/0.9318 | 30.93/0.8534 | 29.46/0.8145 | 29.75/0.8826 | 35.12/0.9537 | DIV2K + Flickr2K | 12 M |
| SRCNN [18] | ×4 | 30.48/0.8628 | 27.50/0.7513 | 26.90/0.7101 | 24.52/0.7221 | 27.58/0.8555 | T91 + ImageNet | 57 K |
| VDSR [21] | ×4 | 31.35/0.8838 | 28.01/0.7674 | 27.29/0.7260 | 25.18/0.7524 | -/- | BSD + T91 | 665 K |
| DRCN [19] | ×4 | 31.53/0.8854 | 28.02/0.7670 | 27.23/0.7233 | 25.14/0.7510 | -/- | T91 | 1.8 M |
| DRRN [57] | ×4 | 31.68/0.8888 | 28.21/0.7720 | 27.38/0.7284 | 25.44/0.7638 | -/- | BSD + T91 | 297 K |
| CARN [58] | ×4 | 32.13/0.8937 | 28.60/0.7806 | 27.58/0.7349 | 26.07/0.7837 | -/- | BSD + T91 + DIV2K | 1.6 M |
| EDSR [68] | ×4 | 32.46/0.8968 | 28.80/0.7876 | 27.71/0.7420 | 26.6 /0.8033 | -/- | DIV2K | 43M |
| ELAN [79] | ×4 | 32.43/0.8975 | 28.78/0.7858 | 27.69/0.7406 | 26.54/0.7982 | 30.92/0.9150 | DIV2K | 8.3 M |
| MSRN [65] | ×4 | 32.07/0.8903 | 28.60/0.7751 | 27.52/0.7273 | 26.04/0.7896 | 30.17/0.9034 | DIV2K | 6.5 M |
| RCAN [81] | ×4 | 32.63/0.9002 | 28.87/0.7889 | 27.77/0.7436 | 26.82/0.8087 | 31.22/0.9173 | DIV2K | 16 M |
| HAN [82] | ×4 | 32.64/0.9002 | 28.90/0.7890 | 27.80/0.7442 | 26.85/0.8094 | 31.42/0.9177 | DIV2K | 16.1 M |
| RDN [64] | ×4 | 32.61/0.9003 | 28.92/0.7893 | 27.80/0.7434 | 26.82/0.8069 | 31.39/0.9184 | DIV2K | 22.6 M |
| NLSN [88] | ×4 | 32.59 0.9000 | 28.87 0.7891 | 27.78 0.7444 | 26.96 0.8109 | 31.27 0.9184 | DIV2K | 16.1 M |
| RFANet [66] | ×4 | 32.66/0.9004 | 28.88/0.7894 | 27.79/0.7442 | 26.92/0.8112 | 31.41/0.9187 | DIV2K | 11 M |
| SAN [83] | ×4 | 32.64/0.9003 | 28.92/0.7888 | 27.78/0.7436 | 26.79/0.8068 | 31.18/0.9169 | DIV2K | 15.7 M |
| SMSR [98] | ×4 | 32.12/0.8932 | 28.55/0.7808 | 27.55/0.7351 | 26.11/0.7868 | 30.54/0.9085 | DIV2K | 1 M |
| ESRT [126] | ×4 | 32.19/0.8947 | 28.69/0.7833 | 27.69/0.7379 | 26.39/0.7962 | 30.75/0.9100 | DIV2K | 751 K |
| TDPN [14] | ×4 | 32.69/0.9005 | 29.01/0.7943 | 27.93/0.7460 | 27.24/0.8171 | 31.58/0.9218 | DIV2K | 12.8 M |
| SwinIR [127] | ×4 | 32.92/0.9044 | 29.09/0.7950 | 27.92/0.7489 | 27.45/0.8254 | 32.03/0.9260 | DIV2K + Flickr2K | 12 M |
| Models | Method | Scale | Dataset | PSNR/SSIM |
|---|---|---|---|---|
| LGCnet [22] | combination of local and global Information | ×2 | UC Merced | 33.48/0.9235 |
| ×3 | 29.28/0.8238 | |||
| ×4 | 27.02/0.7333 | |||
| RS-RCAN [129] | residual channel attention | ×2 | UC Merced | 34.37/0.9296 |
| ×3 | 30.26/0.8507 | |||
| ×4 | 27.88/0.7707 | |||
| WTCRR [130] | wavelet transform, recursive learning and residual learning | ×2 | NWPU-RESISC45 | 35.47/0.9586 |
| ×3 | 31.80/0.9051 | |||
| ×4 | 29.68/0.8497 | |||
| CSAE [131] | sparse representation and coupled sparse autoencoder | ×2 | NWPU-RESISC45 | 29.070/0.9343 |
| ×3 | 25.850/0.8155 | |||
| DRGAN [132] | a dense residual generative adversarial | ×2 | NWPU-RESISC45 | 35.56/0.9631 |
| ×3 | 31.92/0.9102 | |||
| ×4 | 29.76/0.8544 | |||
| MPSR [133] | enhanced residual block (ERB) and residual channel attention group(RCAG) | ×2 | UC Merced | 39.78/0.9709 |
| ×3 | 33.93/0.9199 | |||
| ×4 | 30.34/0.8584 | |||
| RDBPN [134] | residual dense backprojection network | ×4 | UC Merced | 25.48/0.8027 |
| ×8 | 21.63/0.5863 | |||
| EBPN [135] | enhanced back-projection network(EBPN) | ×2 | UC Merced | 39.84/0.9711 |
| ×4 | 30.31/0.8588 | |||
| ×8 | 24.13/0.6571 | |||
| CARS [136] | channel attention | ×4 | Pleiades1A | 30.8971/0.9489 |
| FeNet [137] | a lightweight feature enhancement network) | ×2 | UC Merced | 34.22/0.9337 |
| ×3 | 29.80/0.8481 | |||
| ×4 | 27.45/0.7672 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Yi, J.; Guo, J.; Song, Y.; Lyu, J.; Xu, J.; Yan, W.; Zhao, J.; Cai, Q.; Min, H. A Review of Image Super-Resolution Approaches Based on Deep Learning and Applications in Remote Sensing. Remote Sens. 2022, 14, 5423. https://doi.org/10.3390/rs14215423
Wang X, Yi J, Guo J, Song Y, Lyu J, Xu J, Yan W, Zhao J, Cai Q, Min H. A Review of Image Super-Resolution Approaches Based on Deep Learning and Applications in Remote Sensing. Remote Sensing. 2022; 14(21):5423. https://doi.org/10.3390/rs14215423
Chicago/Turabian StyleWang, Xuan, Jinglei Yi, Jian Guo, Yongchao Song, Jun Lyu, Jindong Xu, Weiqing Yan, Jindong Zhao, Qing Cai, and Haigen Min. 2022. "A Review of Image Super-Resolution Approaches Based on Deep Learning and Applications in Remote Sensing" Remote Sensing 14, no. 21: 5423. https://doi.org/10.3390/rs14215423
APA StyleWang, X., Yi, J., Guo, J., Song, Y., Lyu, J., Xu, J., Yan, W., Zhao, J., Cai, Q., & Min, H. (2022). A Review of Image Super-Resolution Approaches Based on Deep Learning and Applications in Remote Sensing. Remote Sensing, 14(21), 5423. https://doi.org/10.3390/rs14215423