1. Introduction
Vehicle detection and identification(VDI) systems are in growing demand as development of information and communication technology [
1] increases, and the need for sophisticated signal processing and data analysis techniques is becoming increasingly apparent [
2]. A growing number of novel applications such as smart navigation, traffic monitoring and transportation infrastructure monitoring have been accompanied by a corresponding improvement in overall system performance and efficiency [
3]. Accurate and rapid detection of moving vehicles is fundamental in these applications.
Vehicle detection aims to detect a vehicle passing by a deployed sensor. Vehicle detection and classification systems are mainly based on ultrasonic sensors, acoustic sensors, infrared sensors, inductive loops, magnetic sensors, video sensors, laser sensors and microwave radars [
4]. Currently, video sensors and image detection techniques are frequently adopted for vehicle detection [
5,
6]. However, these image-based methods require the camera to be placed directly towards the road, and the lens cannot be blocked. In our scenario, the sensors are mostly placed in the field or forests, where vehicles may come from all directions and objects such as weeds and trees are likely to disturb the view.
Acoustic communications are attractive because they do not require extra hardware on either transmitter and receiver sides, which facilitates numerous tasks in IoT and other applications [
7]. Therefore, in our intelligent sensor system, the acoustic signals are collected using acoustic sensors and processed on the chips. The vehicle detection task can be solved as an acoustic event classification task. Vehicle detection and identification using features extracted from vehicle audio with supervised learning have been widely explored, such as support vector machine classifiers, k-nearest neighbor classifiers, Gaussian mixture models, hidden Markov models, etc. [
3].
Recently, deep neural networks have shown promising results in many pattern recognition applications [
8], such as acoustic event classification. The vehicle detection task can be considered as a binary acoustic event classification of a vehicle or a non-vehicle. Deep neural networks are powerful pattern classifiers which enable the networks to learn the highly nonlinear relationships between the input features and the output targets [
9]. Convolutional neural networks (CNNs) have also been widely used for remote sensing recognition tasks [
10,
11,
12] and acoustic event classification tasks [
13], as CNNs have shared-weight architecture based on convolution kernels which is efficient in extracting acoustic features for acoustic classification.
Many feature extraction techniques have been studied for analyzing acoustic characteristics over decades, including temporal domain, frequency domain, cepstral domain, wavelet domain and time-frequency domain [
14]. Mel frequency cepstral coefficients (MFCC), a kind of cepstral domain feature, are widely used for acoustic classification [
15]. Recent works exploring CNN-based approaches have shown significant improvements over hand-crafted feature-based methods such as MFCC [
16,
17,
18,
19,
20,
21]. In our practical application, the locations of the sensors deployed are different, and therefore the distances between the sensors and road are uncertain. MFCCs are relatively independent of the absolute signal level [
22]; thus, MFCCs are appropriate for vehicle detection in our case as the amplitudes of the vehicle signals vary with the distance between the sensors and roads.
However, the performance of deep neural networks is highly dependent on the availability of large quantities of training data in order to learn a nonlinear function from input to output that generalizes well and yields high classification accuracy on unseen data [
23]. The recordings for vehicles of specific types are limited, such as an armored vehicle. To solve this problem, data augmentation is applied to the original recordings to generate more samples for training. Data augmentation is a common strategy adopted to increase the quantity of training data, avoid overfitting and improve robustness of the models [
24]. Commonly used strategies for acoustic data augmentation are vocal tract length perturbation, tempo perturbation, speed perturbation [
24], time shifting, pitch shifting, time streching [
25] and spectrogram augmentation [
26].
After a neural network for vehicle detection is trained, it has to be migrated to the hardware platform where the computation cost and battery life is limited. Typical approaches include linear quantization of network weights and inputs [
27] and a reduction in the number of parameters [
28]. Depthwise separable convolutions are a form of factorized convolutions which factorize a standard convolution into a depthwise convolution and a
convolution called a pointwise convolution [
29]. The computational cost can be reduced using depthwise separable convolution with only a small reduction in accuracy.
This paper aims to solve a practical issue for vehicle detection by using a lightweight CNN model for acoustic classification. To summarize, the main contributions of this paper are as follows:
A spectrogram augmentation method is applied to the mel spectrogram of the acoustic signals to improve the robustness of the proposed model.
A CNN classification model is trained on the original data and the augmented samples to achieve a high classification accuracy of each frame.
Depthwise separable convolution is applied to the original CNN network for model compression. The lightweight model can be migrated to the chips of the intelligent sensor system and realize the task of real-time vehicle detection.
The paper is organized as follows:
Section 2 describes the materials and methods including both hardware structure and algorithm implementation.
Section 3 presents the detailed results of the experiments.
Section 4 discusses the experiment results.
Section 5 presents the conclusion of this paper.
2. Materials and Methods
This section describes the system hardware structure, data collection method, dataset description, feature extraction, data augmentation, two-stage detection method and experiment setup. The codes for the experiments including feature extraction, spectrogram augmentation and deep neural network structures are published in the Github website:
https://github.com/chaoyiwang09/Vehicle-Detection-CNN.git (accessed on 23 August 2022).
2.1. System Hardware Structure
Our implemented system can be divided into the four modules according to their functions: microphone array (MA), preprocessing and sampling (P and S) module, real-time data processing and acquisition (P and A) module and transmission module [
30]. Four microphone arrays are used to collect the acoustic signal in the deployed area. The collected acoustic signals are then sampled in the P and S module to obtain four simultaneous digital signals by the synchronized filters and amplifiers [
31]. The detection algorithm is implemented on the digital signal processors (DSP) chip of the real-time P and A module. The detection results are finally transmitted to a terminal device through radio frequency. The diagram of the system hardware process is shown in
Figure 1.
Four ADMP504 MEMS microphones which are produced by Analog Devices are placed uniformly on the main circuit board. The device for AD sampling is MAXIM MAX11043, a 4-channel 16-bit simultaneous ADC [
32]. The DSP chip, ASDP21479 is used for real-time data processing and acquisition. The printed circuit board layout is shown in
Figure 2. A more detailed description of the hardware structure implemented in the modules can be found in [
31].
2.2. Dataset
The acoustic signals are collected with microphone arrays in the intelligent sensor system deployed in the field. The vehicle recorded includes a small wheeled vehicle, a large wheeled vehicle and a tracked vehicle. The sensors are deployed 30 m, 50 m, 80 m and 150 m away from the road for the small wheeled vehicle. For the tracked vehicle and the large wheeled vehicle, the sensors are deployed 200 m, 250 m and 300 m away from the road. The length of road is 700 m, 350 m on each side of the microphone arrays. The recording scene is illustrated in
Figure 3.
All the recordings are collected at a sample rate of 8k and a bit rate of 16 bits. For each experiment, the start time and end time of the vehicle are recorded. Therefore, the acoustic signals can be truncated by the start time and the end time. The signals of duration from the start time and end time are labeled as 1 for vehicle, while the remaining parts of the signals are labeled as 0 for non-vehicle. There are overall 445 recordings in the dataset; 191 recordings are non-vehicle, the average duration of which are about 104 s. A total of 91 recordings are from the small wheeled vehicle, 101 recordings are from the large wheeled vehicle, and 62 recordings are from the tracked vehicle, and the average duration of them are 40 s, 70 s and 150 s, respectively. The dataset composition is shown in
Table 1.
2.3. Feature Extraction
Mel-scale frequency cepstral coefficients (MFCC) features are extracted as the input features for the binary classifier. MFCC is widely used in acoustic tasks such as voice activity detection [
33]. The diagram of MFCC extraction is illustrated in
Figure 4. The steps of MFCC extractions are:
Pre-emphasis is used to compensate and amplify the high-frequency part from the acoustic signal [
34]. This is calculated by:
where
in our case,
s(
n) is the input acoustic signal, and
s′(
n) is the output signal.
The signals are split into short parts by windowing. In our case, the window length of each frame is set to 200 milliseconds, the window step is 200 milliseconds, and no overlap is applied to each frame. A rectangular window is chosen for short time Fourier Transformation.
Mel filter banks are applied and a logarithm is taken to the extracted mel frequency features. The mel cepstral coefficients are calculated as follows for a given
f in Hz:
Discrete cosine transformation is applied.
The zeroth cepstral coefficient is replaced with the log of the total frame energy.
Delta, a first order difference calculation and double-delta, a second order difference calculation, are finally calculated.
For each frame, 13 cepstral coefficients are extracted, and the output dimension of one frame is 39-dimensional after the delta step. Overall 100,000 samples are kept for the training set, the duration of which is about 5.6 h. A total of 20,000 samples are extracted for the validation set, and 20,000 samples are extracted for the test set. For the training set, validation set, and training set, half of the features are labeled as vehicle, and the others are labeled as non-vehicle.
2.4. Data Augmentation
Data augmentation is a strategy to increase the diversity of available data and make it possible to train models without collecting new data [
35]. Our augmentation method is applied to the mel spectrogram domain. Frequency masks are applied to the mel spectrogram. Frequency masking is applied so that
f consecutive mel frequency channels
are masked, where
f is first chosen from a uniform distribution from 0 to the frequency mask parameter
F, and
is chosen from
;
v is the number of mel frequency channels [
26]. The mean value and standard deviation of the mel spectrogram of the training data are calculated. Then, the frequency masking coefficient
X is generated with a Gaussian distribution of the same mean value and standard deviation of the original training set. The formulas can be written as:
where
,
, F is a frequency mask parameter,
v is the number of mel frequency channels,
,
is the mean value, and
is the standard deviation of the mel spectrogram in the training data.
We mainly apply the masking procedure on the frequency domain rather than the time domain because the environment noise such as wind noise has a large influence on some specific frequency bands, and we aim to increase the robustness against environment noise and expect the system to detect correctly even if a frequency band is masked or interrupted.
Figure 5 shows the original and masked log mel spectrogram of a recording. The upper figure is the original log mel spectrogram, and the lower is the masked log mel spectrogram. For the augmented data, the cepstral features ranging from 512 Hz to 1024 Hz are masked. After the log result of the mel spectrogram is calculated and discrete cosine transform is applied to the log-mel spectrogram, augmented MFCC features are calculated. Then, the augmented data are appended to the original training data. Finally 100,000 samples are augmented, and there are overall 200,000 samples in the training set.
2.5. Depthwise Separable Convolution
Depthwise separable (DS) convolutions are a form of factorized convolutions which factorize a standard convolution into a depthwise convolution and a
convolution called a pointwise convolution [
29]. The key insight is that different filter channels in regular convolutions are strongly coupled and may involve plenty of redundancy [
36].
Depthwise convolution with one filter per input channel can be written as:
where
is the depthwise convolution kernel of size
, and
filter in
is applied to
channel in a feature map
F to produce the
channel of the filtered output feature map
.
The standard convolutions have the computational cost of:
where
is the kernel size,
for 1-dimensional convolution,
for 2-dimensional convolution, M is the number of input channels, N is the number of output channels, and
is the spatial width.
The depthwise separable convolutions have the cost of:
Therefore, after applying depthwise separable convolutions, we obtain the reduction in computation of:
2.6. Two-Stage Detection Method
The older version of the algorithm in our system for vehicle detection is based on a two-stage detection method by log-sum detection and subspace-based target detection (SBTD) [
32].
The first stage is to compare the log-sum energy of the high-frequency part of the acoustic signal and the low-frequency part of the acoustic signal [
32]. If the log-sum energy of the high-frequency part is less than the low-frequency part, a result of non-vehicle is returned. Otherwise, the program will proceed to the next stage, subspace-based target detection (SBTD). The steps of the subspace-based target detection(SBTD) are:
Estimate the covariance matrix
:
where X is the received signal, and H denotes the Hermitian transpose.
Obtain the eigenvalues of the covariance matrix by eigenvalue decomposition.
Estimate the number of acoustic emissions
K by the eigenvalues of the matrix
, according to some signal number estimation criterion such as minimum description length (MDL) [
37].
Estimate the total signal power:
where
K is the number of acoustic emissions, and
M is the number of channels.
Estimate the noise power:
Compute the SNR by . If the estimated SNR is larger than the threshold T, we regard it as a target invasion, otherwise we consider it as non-target.
The result of the two-stage detection method is compared with the new proposed method in
Section 3.
2.7. Experiment Setup
The two-stage detection method is set up as a baseline system. The optimal threshold for the SBTD stage of the two-stage detection method is decided by maximum likelihood criterion. The calculated optimal threshold is 9.9 dB.
For the proposed deep learning method, the dimension of the input matrix for training is
, with
original features and
augmented features. For each feature, cepstral mean and variance normalization [
38] is applied for feature normalization and avoiding gradient exploding.
To train a model, a cross-entropy loss function is chosen, and stochastic gradient descent is used as the optimizer [
39]. The batch size is 128. Dropout layers are applied to the fully connected layer to avoid overfitting [
40]. Each model is trained for 100 epochs. The learning rate is set to 0.01 constantly.
A fully connected neural network is built for comparison. The deep neural network has three hidden layers. A ReLU activation function and a random dropout of 0.2 for regularization are applied in each layer. The framework structure of the fully connected neural network is shown in
Table 2.
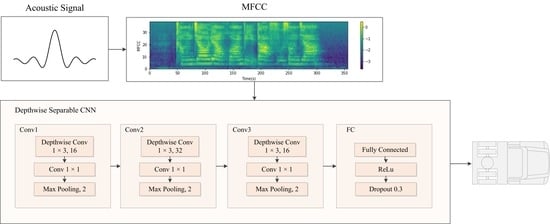
The CNN architecture is comprised of three convolution layers with two max-pooling layers between the three convolution layers and two fully connected layers for the output. The input channel numbers for the first, second and third convolution layers are 1, 16 and 32 respectively; the output channels are 16, 32 and 16, and the kernel sizes are 3, 3 and 3. For each layer, the stride and padding sizes are all set to 1. The kernel sizes for max pooling are 2. The framework structure of the CNN is shown in
Table 3.
A depthwise separable CNN architecture is trained for comparison with the same parameter settings as the original CNN structure. The convolution steps are replaced with depthwise separable convolution.
4. Discussion
The final model migrated to the chips of the sensors is the depthwise separable CNN. The model is lightweight and can be run efficiently on the chips of the sensors. For each frame, the average processing time is about 20 ms; thus, the real-time rate for each frame is . The remaining computational resources can be utilized for other functions such as direction of arrival. The other reason for choosing a depthwise separable convolution network is to prolong the battery life. The intelligent sensor system has to be placed outdoors in the field over weeks. Therefore, the power consumption has to be limited. There is a trade-off between accuracy and model size, and finally the decrease in the accuracy is totally acceptable.
Figure 8 shows the signal and actual detection result of a sample.
Figure 8A is the original time-domain signal of a large wheeled vehicle sample.
Figure 8B shows some detection errors exist near the border region between the silence part and vehicle moving stage.
Figure 8C shows the detection result after applying a smoothing function.
Figure 8D represents the ground truth. The recorded moving time of the vehicle is from the 16th second to the 89th second. It can be seen that most classification errors occur at the border region between the silence part and the vehicle moving stage. This can be solved subsequently using a moving window to smooth. The detection algorithm is processed once every 200 milliseconds for each frame, and the detection result is transmitted every 1 s through the transmission module. Therefore, the following strategy is taken for smoothing: the final detection result follows the majority results of the five frames over a second.
Other classification errors occur when strong environment noise such as wind noise exists, and the distance between sensors and the vehicle is too long. In such cases, the signal-to-noise ratio becomes low, especially for a small wheeled vehicle, and the classification accuracy becomes affected. In the future, we intend to solve this problem by exploring signal processing methods including filtering and signal enhancement.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}