

Co-Correcting: Combat Noisy Labels in Space Debris Detection

Abstract
1. Introduction
1.1. Background
1.2. Related Work
1.2.1. Classical Methods
1.2.2. Machine Learning Methods
1.2.3. Label-Noise Learning
1.3. Solution and Contributions of This Paper
- We proposed a novel label-noise learning paradigm, termed Co-correcting, to train networks by directly using the data with noisy labels. Empirical results exhibit the excellent performance of Co-correcting compared to other state-of-the-art methods in label-noise learning.
- We are the first to introduce label-noise learning into space debris detection, and take noisy samples as a compromise to train networks. In our pipeline, the noisy training samples are directly sent into Co-correcting, therefore time-consuming manual data cleaning is avoided.
1.4. Organization of This Article
2. Materials and Methods
2.1. Problem Formulation
2.1.1. Space Debris Detection
2.1.2. Label-Noise Learning
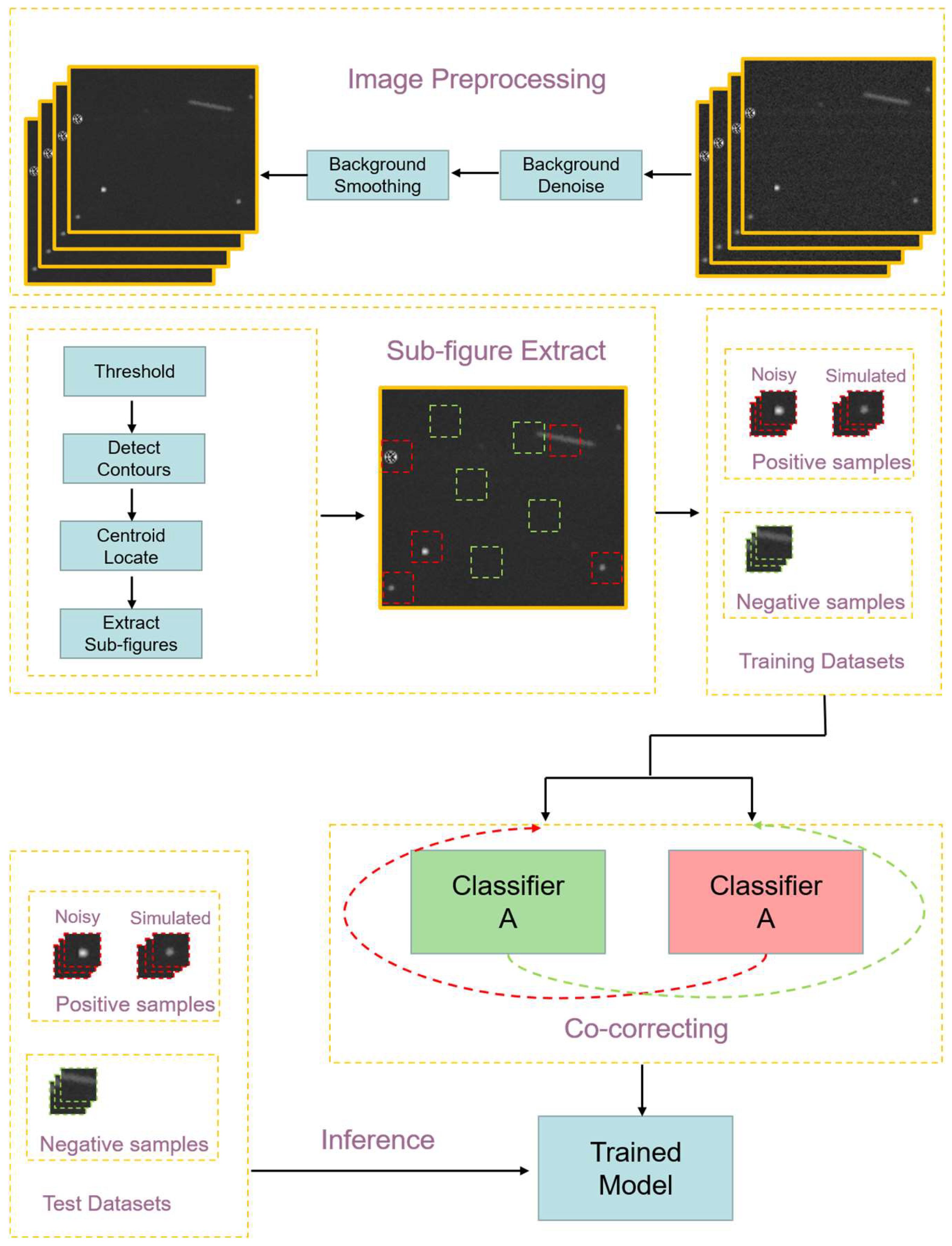
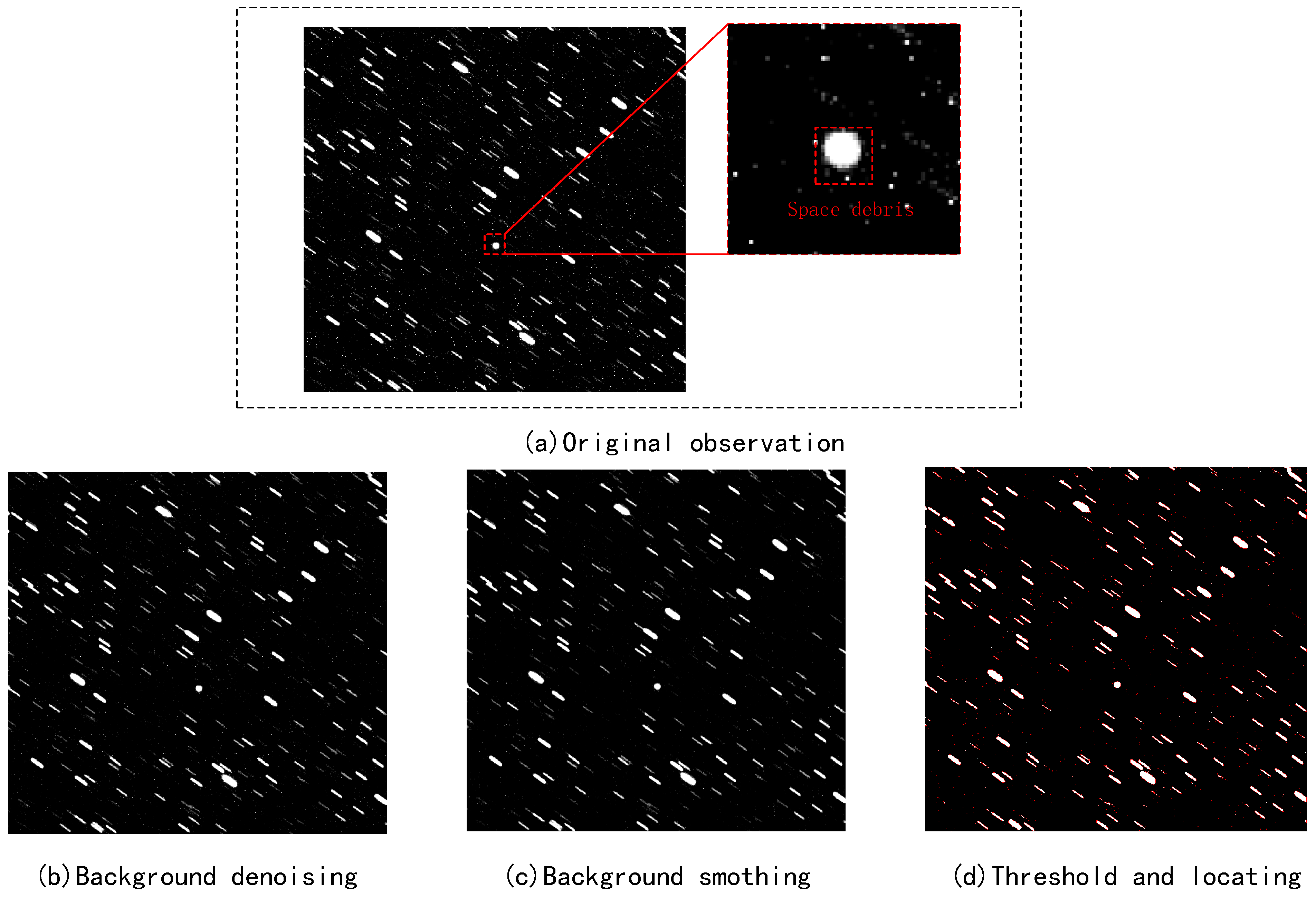
2.2. Preprocessing
2.2.1. Background Denoising
2.2.2. Background Smoothing
2.2.3. Sub-Figure Extraction
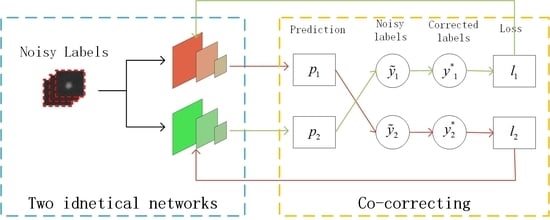
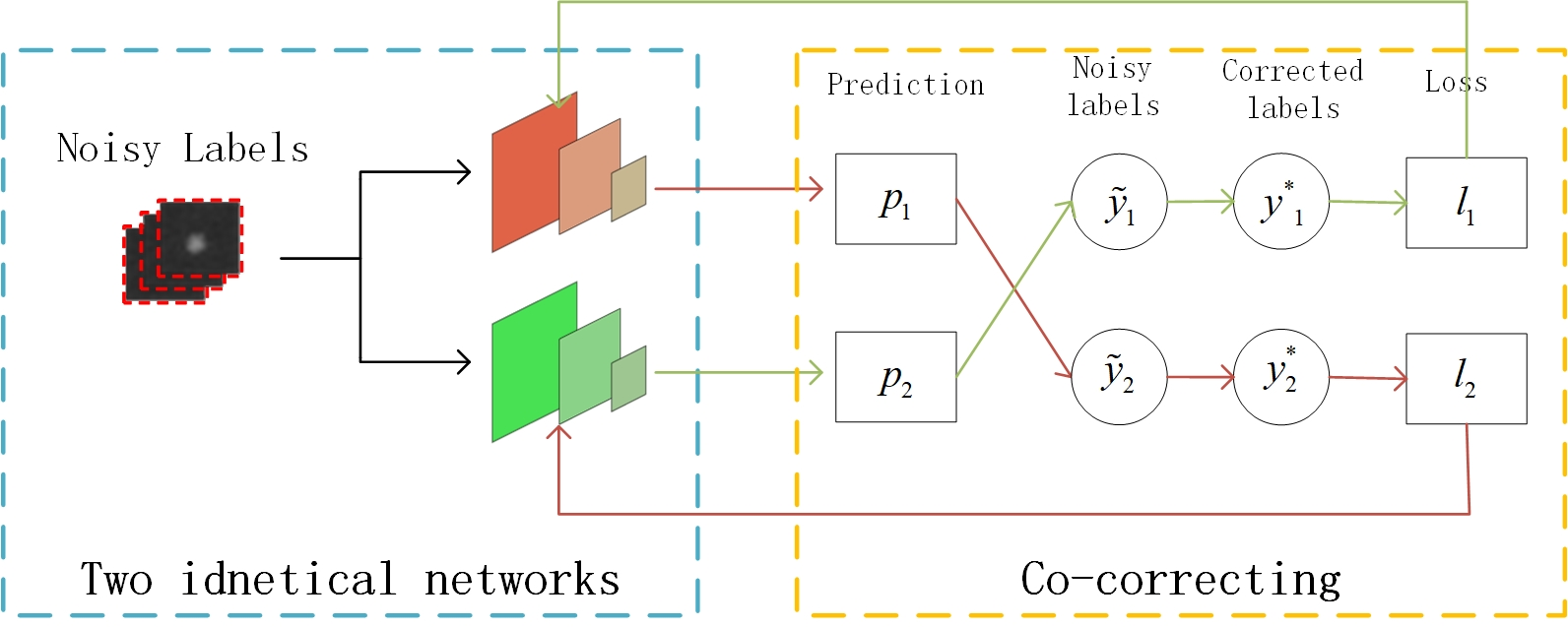
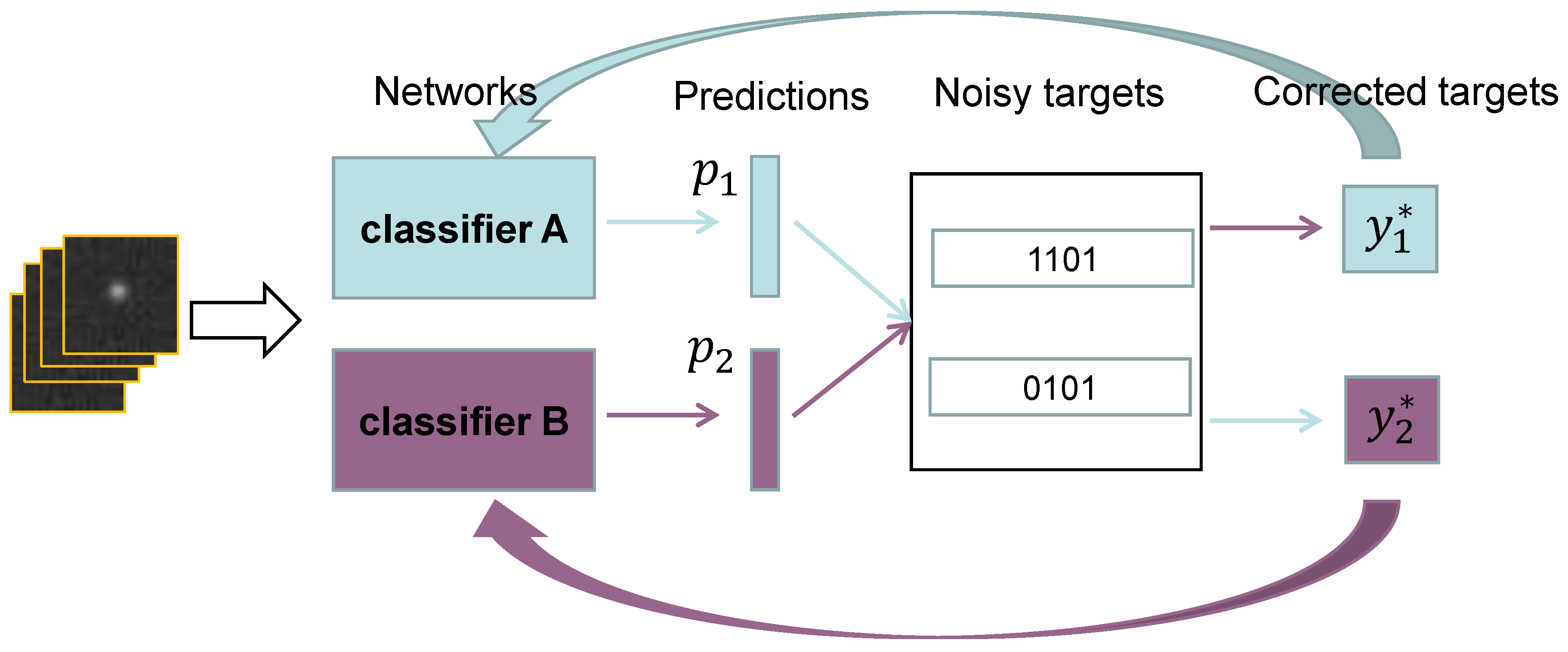
2.3. Co-Correcting
2.3.1. The Structure of Co-Correcting
2.3.2. Loss Function of Co-Correcting
2.3.3. Small-Loss Selection
2.3.4. Algorithm Description
| Algorithm 1: Co-correcting |
| Input: Networks and , training dataset D, learning rate , noisy rate and epoch and , iteration |
| Output: Networks and |
|
3. Results
3.1. Experiments Setting
3.1.1. Dataset
3.1.2. Baselines
3.1.3. Measurement
3.1.4. Network Structure and Optimizer
3.1.5. Selection Setting
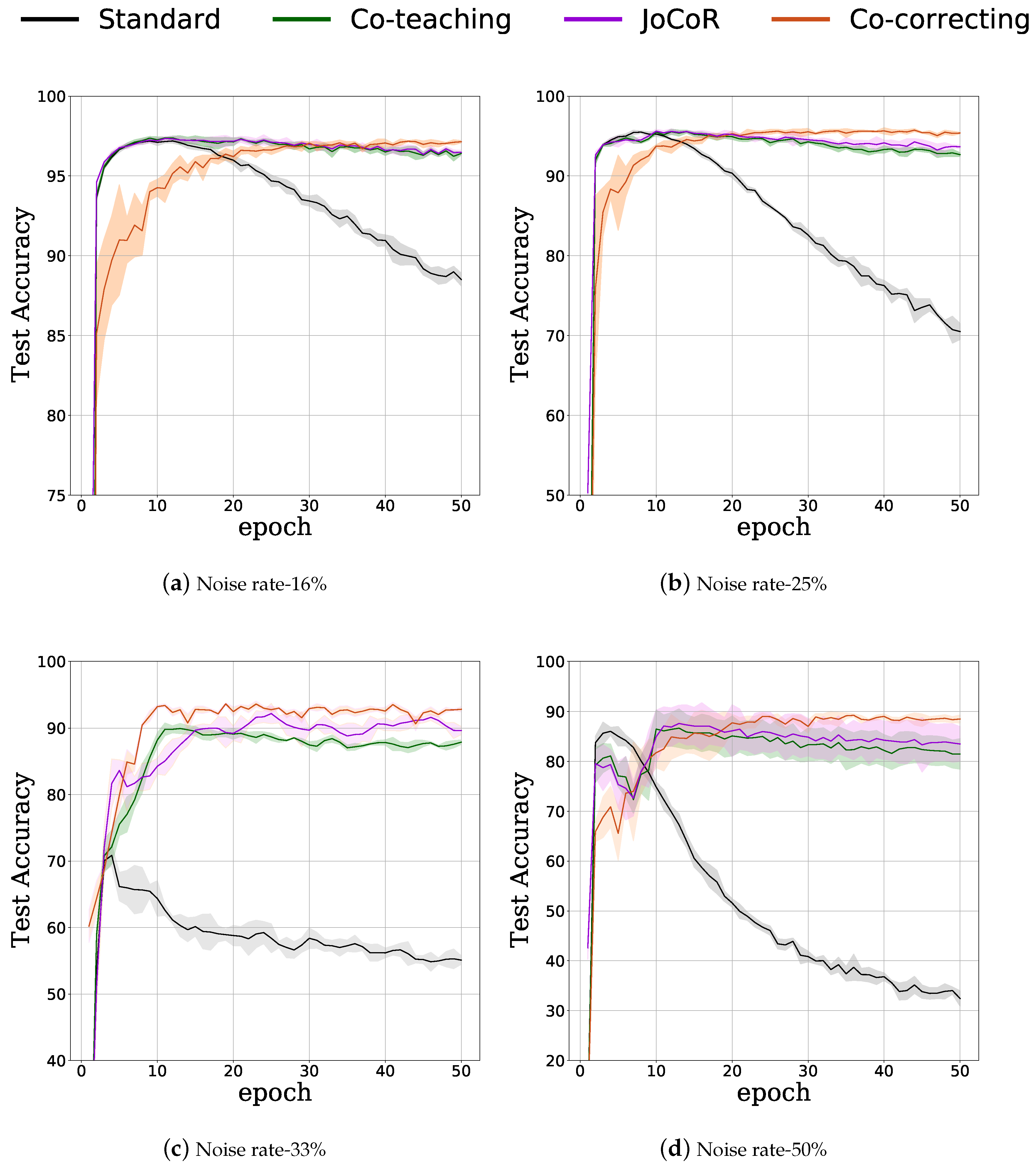
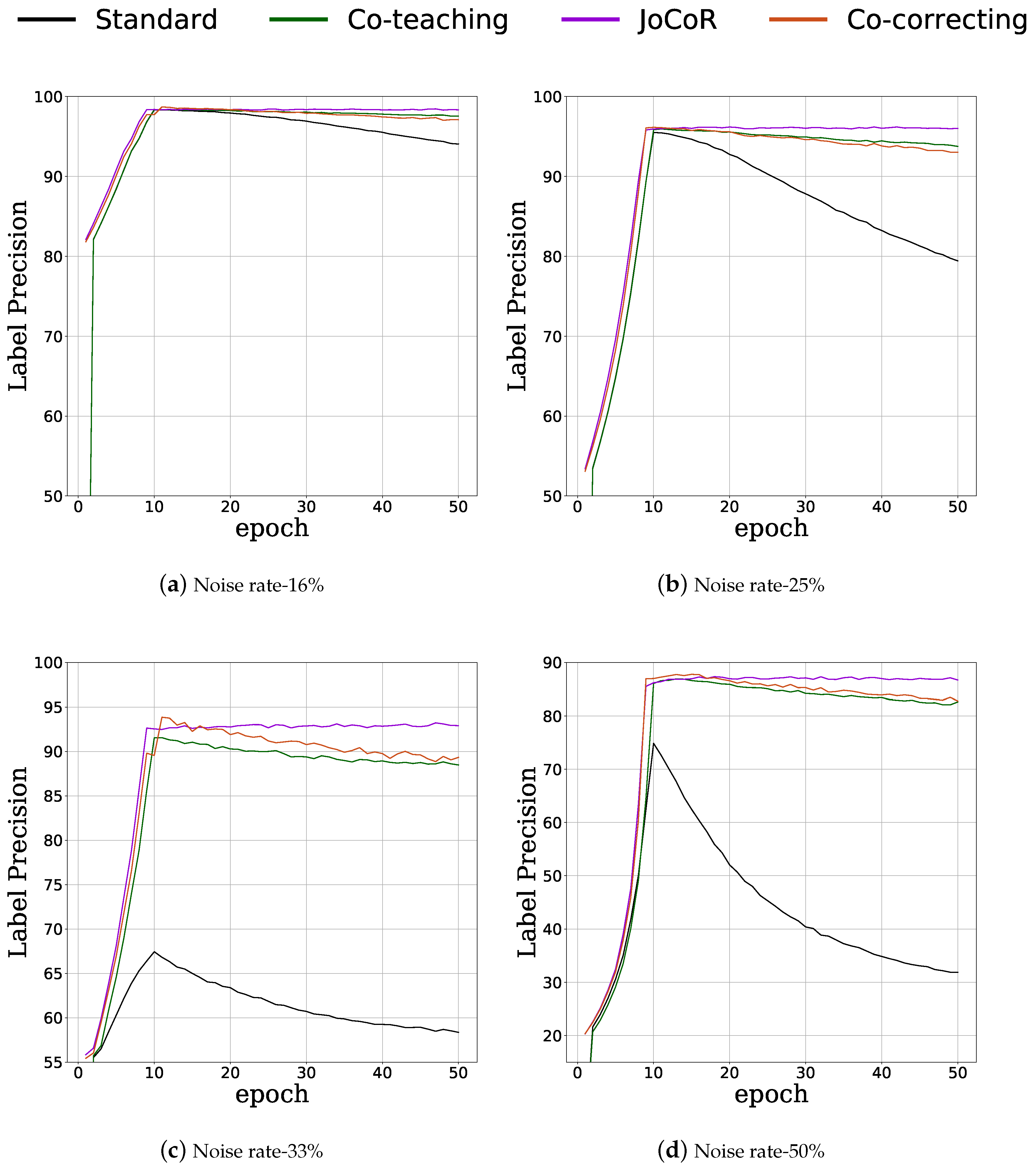
3.2. Feasibility of Label-Noise Learning in Space Debris Detection
3.3. Detection Results of Co-Correcting
4. Discussion
4.1. The Memorization Effect of Network
4.2. The Feasibility of Label-Noise Learning in Label-Noise Learning
4.3. The Performance of Co-Correcting in Space Debris Detection
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Schildknecht, T. Optical surveys for space debris. Astron. Astrophys. Rev. 2007, 14, 41–111. [Google Scholar] [CrossRef]
- Thiele, S.; Boley, A. Investigating the risks of debris-generating ASAT tests in the presence of megaconstellations. arXiv 2021, arXiv:2111.12196. [Google Scholar]
- Jiang, Y. Debris cloud of India anti-satellite test to Microsat-R satellite. Heliyon 2020, 6, e04692. [Google Scholar] [CrossRef] [PubMed]
- Xi, J.; Xiang, Y.; Ersoy, O.K.; Cong, M.; Wei, X.; Gu, J. Space debris detection using feature learning of candidate regions in optical image sequences. IEEE Access 2020, 8, 150864–150877. [Google Scholar] [CrossRef]
- Schirru, L.; Pisanu, T.; Podda, A. The Ad Hoc Back-End of the BIRALET Radar to Measure Slant-Range and Doppler Shift of Resident Space Objects. Electronics 2021, 10, 577. [Google Scholar] [CrossRef]
- Ionescu, L.; Rusu-Casandra, A.; Bira, C.; Tatomirescu, A.; Tramandan, I.; Scagnoli, R.; Istriteanu, D.; Popa, A.E. Development of the Romanian Radar Sensor for Space Surveillance and Tracking Activities. Sensors 2022, 22, 3546. [Google Scholar] [CrossRef] [PubMed]
- Ender, J.; Leushacke, L.; Brenner, A.; Wilden, H. Radar techniques for space situational awareness. In Proceedings of the 2011 12th International Radar Symposium (IRS), Leipzig, Germany, 7–9 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 21–26. [Google Scholar]
- Mohanty, N.C. Computer tracking of moving point targets in space. IEEE Trans. Pattern Anal. Mach. Intell. 1981, 5, 606–611. [Google Scholar] [CrossRef] [PubMed]
- Reed, I.S.; Gagliardi, R.M.; Shao, H. Application of three-dimensional filtering to moving target detection. IEEE Trans. Aerosp. Electron. Syst. 1983, 6, 898–905. [Google Scholar] [CrossRef]
- Reed, I.S.; Gagliardi, R.M.; Stotts, L.B. A recursive moving-target-indication algorithm for optical image sequences. IEEE Trans. Aerosp. Electron. Syst. 1990, 26, 434–440. [Google Scholar] [CrossRef]
- Barniv, Y. Dynamic programming solution for detecting dim moving targets. IEEE Trans. Aerosp. Electron. Syst. 1985, 1, 144–156. [Google Scholar] [CrossRef]
- Buzzi, S.; Lops, M.; Venturino, L. Track-before-detect procedures for early detection of moving target from airborne radars. IEEE Trans. Aerosp. Electron. Syst. 2005, 41, 937–954. [Google Scholar] [CrossRef]
- Kouprianov, V. Distinguishing features of CCD astrometry of faint GEO objects. Adv. Space Res. 2008, 41, 1029–1038. [Google Scholar] [CrossRef]
- Tagawa, M.; Hanada, T.; Oda, H.; Kurosaki, H.; Yanagisawa, T. Detection algorithm of small and Fast orbital objects using Faint Streaks; application to geosynchronous orbit objects. In Proceedings of the 40th COSPAR Scientific Assembly, Moscow, Russia, 2–10 August 2014; Volume 40, p. PEDAS–1. [Google Scholar]
- Virtanen, J.; Poikonen, J.; Säntti, T.; Komulainen, T.; Torppa, J.; Granvik, M.; Muinonen, K.; Pentikäinen, H.; Martikainen, J.; Näränen, J.; et al. Streak detection and analysis pipeline for space-debris optical images. Adv. Space Res. 2016, 57, 1607–1623. [Google Scholar] [CrossRef]
- Yanagisawa, T.; Kurosaki, H.; Banno, H.; Kitazawa, Y.; Uetsuhara, M.; Hanada, T. Comparison between four detection algorithms for GEO objects. In Proceedings of the Advanced Maui Optical and Space Surveillance Technologies Conference, Maui, HI, USA, 11–14 September 2012; Volume 1114, p. 9197. [Google Scholar]
- Nunez, J.; Nunez, A.; Montojo, F.J.; Condominas, M. Improving space debris detection in GEO ring using image deconvolution. Adv. Space Res. 2015, 56, 218–228. [Google Scholar] [CrossRef]
- Stoveken, E.; Schildknecht, T. Algorithms for the optical detection of space debris objects. In Proceedings of the 4th European Conference on Space Debris, Darmstadt, Germany, 18–20 April 2005; pp. 18–20. [Google Scholar]
- Wei, M.; Chen, H.; Yan, T.; Wu, Q.; Xu, B. The detecting methods of geostationary orbit objects. In Proceedings of the 2010 Third International Symposium on Intelligent Information Technology and Security Informatics, Jinggangshan, China, 2–4 April 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 645–648. [Google Scholar]
- Silha, J.; Schildknecht, T.; Hinze, A.; Flohrer, T.; Vananti, A. An optical survey for space debris on highly eccentric and inclined MEO orbits. Adv. Space Res. 2017, 59, 181–192. [Google Scholar] [CrossRef]
- Schildknecht, T.; Musci, R.; Ploner, M.; Beutler, G.; Flury, W.; Kuusela, J.; de Leon Cruz, J.; Palmero, L.D.F.D. Optical observations of space debris in GEO and in highly-eccentric orbits. Adv. Space Res. 2004, 34, 901–911. [Google Scholar] [CrossRef]
- Schildknecht, T.; Hugentobler, U.; Ploner, M. Optical surveys of space debris in GEO. Adv. Space Res. 1999, 23, 45–54. [Google Scholar] [CrossRef]
- Schildknecht, T.; Hugentobler, U.; Verdun, A. Algorithms for ground based optical detection of space debris. Adv. Space Res. 1995, 16, 47–50. [Google Scholar] [CrossRef]
- Sun, R.Y.; Zhao, C.Y. A new source extraction algorithm for optical space debris observation. Res. Astron. Astrophys. 2013, 13, 604. [Google Scholar] [CrossRef]
- Kong, S.; Zhou, J.; Ma, W. Effect analysis of optical masking algorithm for geo space debris detection. Int. J. Opt. 2019, 2019, 2815890. [Google Scholar] [CrossRef]
- Hu, J.; Hu, Y.; Lu, X. A new method of small target detection based on neural network. In Proceedings of the MIPPR 2017: Automatic Target Recognition and Navigation, Wuhan, China, 28–29 October 2017; SPIE: Bellingham, WA, USA, 2018; Volume 10608, pp. 111–119. [Google Scholar]
- Varela, L.; Boucheron, L.; Malone, N.; Spurlock, N. Streak detection in wide field of view images using Convolutional Neural Networks (CNNs). In Proceedings of the Advanced Maui Optical and Space Surveillance Technologies Conference, Maui, HI, USA, 17–20 September 2019; p. 89. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Jia, P.; Liu, Q.; Sun, Y. Detection and classification of astronomical targets with deep neural networks in wide-field small aperture telescopes. Astron. J. 2020, 159, 212. [Google Scholar] [CrossRef]
- Wei, H.; Feng, L.; Chen, X.; An, B. Combating noisy labels by agreement: A joint training method with co-regularization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13726–13735. [Google Scholar]
- Arpit, D.; Jastrzebski, S.K.; Ballas, N.; Krueger, D.; Bengio, E.; Kanwal, M.S.; Maharaj, T.; Fischer, A.; Courville, A.C.; Bengio, Y.; et al. A Closer Look at Memorization in Deep Networks. In Proceedings of the ICML, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Han, B.; Yao, J.; Gang, N.; Zhou, M.; Tsang, I.; Zhang, Y.; Sugiyama, M. Masking: A new perspective of noisy supervision. In Proceedings of the NeurIPS, Montreal, QC, Canada, 3–8 December 2018; pp. 5839–5849. [Google Scholar]
- Li, M.; Soltanolkotabi, M.; Oymak, S. Gradient descent with early stopping is provably robust to label noise for overparameterized neural networks. In Proceedings of the International Conference on Artificial Intelligence and Statistics PMLR, Online, 26–28 August 2020; pp. 4313–4324. [Google Scholar]
- Yu, X.; Han, B.; Yao, J.; Niu, G.; Tsang, I.W.; Sugiyama, M. How does Disagreement Help Generalization against Label Corruption? In Proceedings of the ICML, Long Beach, CA, USA, 9–15 June 2019.
- Goldberger, J.; Ben-Reuven, E. Training deep neural-networks using a noise adaptation layer. In Proceedings of the ICLR (Poster). OpenReview.net, Toulon, France, 24–26 April 2017. [Google Scholar]
- Xia, X.; Liu, T.; Wang, N.; Han, B.; Gong, C.; Niu, G.; Sugiyama, M. Are anchor points really indispensable in label-noise learning? Adv. Neural Inf. Process. Syst. 2019, 32, 6838–6849. [Google Scholar]
- Natarajan, N.; Dhillon, I.S.; Ravikumar, P.K.; Tewari, A. Learning with noisy labels. Adv. Neural Inf. Process. Syst. 2013, 26, 1196–1204. [Google Scholar]
- Menon, A.K.; Van Rooyen, B.; Natarajan, N. Learning from binary labels with instance-dependent noise. Mach. Learn. 2018, 107, 1561–1595. [Google Scholar] [CrossRef]
- Jiang, L.; Zhou, Z.; Leung, T.; Li, L.J.; Fei-Fei, L. Mentornet: Learning data-driven curriculum for very deep neural networks on corrupted labels. In Proceedings of the International Conference on Machine Learning, PMLR, Stockholm, Sweden, 10–15 July 2018; pp. 2304–2313. [Google Scholar]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.W.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In Proceedings of the NeurIPS, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Malach, E.; Shalev-Shwartz, S. Decoupling “when to update” from “how to update”. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 961–971. [Google Scholar]
- Elad, M. On the origin of the bilateral filter and ways to improve it. IEEE Trans. Image Process. 2002, 11, 1141–1151. [Google Scholar] [CrossRef] [PubMed]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| 2-Layer CNN |
|---|
| gray Image |
| , 16 BN, ReLU Max-pool |
| , 16 BN, ReLU Max-pool |
| Dense , ReLU Dense , ReLU |
| Dense |
| Noise rate | Standard | Co-Teaching | JoCoR | Co-Correcting |
|---|---|---|---|---|
| Noise rate 16 % | ||||
| Noise rate 25 % | ||||
| Noise rate 33 % | ||||
| Noise rate 50 % |
| Noise Rate | Standard | Co-Teaching | JoCoR | Co-Correcting |
|---|---|---|---|---|
| Noise rate 16 % | ||||
| Noise rate 25 % | ||||
| Noise rate 33 % | ||||
| Noise rate 50 % |
| Noise Rate (%) | Total Number | Detection Number | Detection Probability (%) | False Alarms | False Alarms Rate (%) |
|---|---|---|---|---|---|
| 300 | 299 | 1 | |||
| 300 | 298 | 2 | |||
| 300 | 297 | 3 | |||
| 300 | 294 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Niu, Z.; Sun, Q.; Li, Y. Co-Correcting: Combat Noisy Labels in Space Debris Detection. Remote Sens. 2022, 14, 5261. https://doi.org/10.3390/rs14205261
Li H, Niu Z, Sun Q, Li Y. Co-Correcting: Combat Noisy Labels in Space Debris Detection. Remote Sensing. 2022; 14(20):5261. https://doi.org/10.3390/rs14205261
Chicago/Turabian StyleLi, Hui, Zhaodong Niu, Quan Sun, and Yabo Li. 2022. "Co-Correcting: Combat Noisy Labels in Space Debris Detection" Remote Sensing 14, no. 20: 5261. https://doi.org/10.3390/rs14205261
APA StyleLi, H., Niu, Z., Sun, Q., & Li, Y. (2022). Co-Correcting: Combat Noisy Labels in Space Debris Detection. Remote Sensing, 14(20), 5261. https://doi.org/10.3390/rs14205261