


Towards Classification of Architectural Styles of Chinese Traditional Settlements Using Deep Learning: A Dataset, a New Framework, and Its Interpretability

Abstract
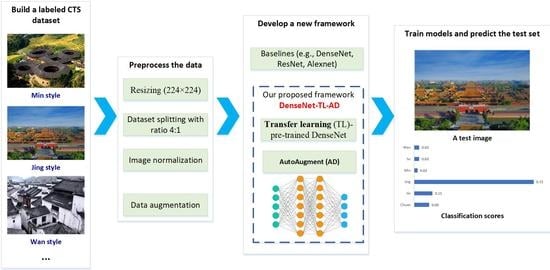
1. Introduction
- Established a first new architectural style dataset for Chinese traditional settlement style classification and benchmarked the dataset with several representative CNNs.
- Developed a new DL framework to classify CTS styles effectively by introducing transfer learning and AutoAugment to the baselines, e.g., DenseNet.
- Interpreted the CNNs by the CAM visualization technique to reveal how the CNNs think a given image belongs to a particular architectural style.
2. Literature Review
2.1. Classification of Architectural Style for Heritage Preservation
2.2. Convolutional Neural Networks
2.3. Effective Techniques to Address the Overfitting Problem
2.3.1. Transfer Learning
2.3.2. Data Augmentation
3. Methodology
3.1. Building a Labeled CTS Dataset
3.1.1. Overview of the CTSs
3.1.2. Representative Architectural Styles of the CTSs
3.1.3. Data Collection and Preprocessing
- (1)
- Data collection and rigorous quality inspection
- (2)
- Data preprocessing
3.2. Benchmarking the CTS Dataset Using Representative CNNs
3.3. The Proposed Framework DenseNet-TL-Aug
3.3.1. Transfer Learning
3.3.2. AutoAugment
3.4. Model Evaluation Metrics
- Confusion matrix (CM). A CM is a summary table of prediction results on a classifier which allows presenting the performance of the classifier visually. Typically, each row represents an actual class, while each column represents a predicted class (shown in Figure 5). CM not only enables the visualization of the performance but also allows easy identification of the confusion between classes, i.e., misclassifying one class with another class. In addition, most concise classification performance metrics, e.g., accuracy, precision, and recall, are calculated based on the components of CM, such as the number of true positives (TP), the number of false positives (FP), the number of true negatives (TN) and the number of false negatives (FN).Figure 5. A confusion matrix table.

- Overall accuracy (OA), precision, recall, and F1 score. OA is the rate of correctly predicted data points concerning the total number of data points (Equation (1)). However, OA is not sufficient for evaluating a classifier, especially when dealing with imbalanced datasets (i.e., some classes in the dataset are much more frequent than others). Therefore, we consider using more classification metrics including mean accuracy, precision, recall, and F1 score. Mean accuracy is the mean of the accuracy over all classes (Equation (2)). Precision is the accuracy of the positive predictions (Equation (3)), while recall is the ratio of positive data points that are correctly detected by the classifier (Equation (4)). To integrate the precision and recall into a single metric, the F1 score is often used which computes the harmonic mean of precision and recall (Equation (5)). Typically, the classifier gets a high F1 score if both recall, and precision are high.

3.5. Interpreting the CNNs Using the Grad-CAM
| Algorithm 1: Grad-CAM visualization technique for interpreting a CNN classifier | |
| Input: given input images X, a pre-trained model M, and a specified class k Output: the class activation heatmaps H for a particular class | |
| 1 | Load a pre-trained model M |
| 2 | Preprocessing given input images X to obtain X’ (in batch form) |
| 3 | for each image x in X’: |
| 4 | create a classifier that maps 𝑥 to the activations of the last convolutional layer L |
| 5 | create a model that maps the activations of the last convolutional layer to the final predictions |
| 6 | compute gradients of the top predicted class for x w.r.t. the activations of the last convolution layer L |
| 7 | apply pooling and importance weighting to the gradient tensor to obtain the heatmap of class activation |
| 8 | normalize the heatmap between 0 and 1 |
| 9 | generate an image that superimposes the original image on the heatmap |
| 10 | end for |
4. Experiments and Results
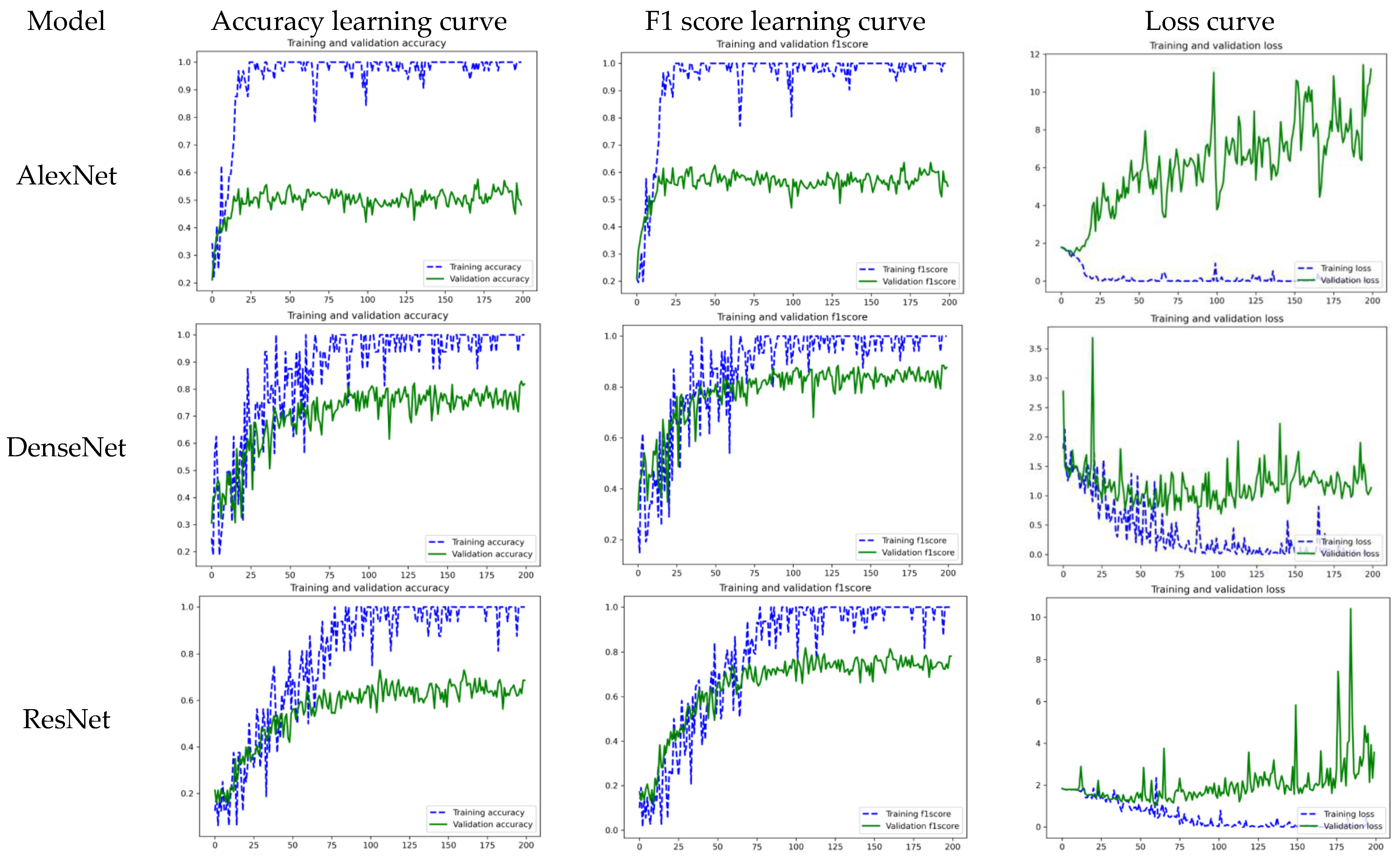
4.1. Results of the Baselines
4.2. Result of the Proposed Framework
4.3. Results of the Grad-CAM Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- China Intangible Cultural Heritage, China-Ich. (n.d.). Available online: https://www.culturalheritagechina.org (accessed on 18 December 2020).
- UNESCO—China. (n.d.). Available online: https://ich.unesco.org/en/state (accessed on 18 December 2020).
- Convention for the Safeguarding of the Intangible Cultural Heritage 2003. Int. J. Cult. Prop. 2005, 12, 447–458. [CrossRef]
- Preservation of China’s Intangible Cultural Heritage, EESD: The Encyclopedia of Education for Sustainable Development. (n.d.). Available online: http://www.encyclopediaesd.com/blog-1/2016/5/25/preservation-of-chinas-intangible-cultural-heritage (accessed on 18 December 2020).
- Ahmad, Y. The Scope and Definitions of Heritage: From Tangible to Intangible. Int. J. Herit. Stud. 2006, 12, 292–300. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Fiorucci, M.; Khoroshiltseva, M.; Pontil, M.; Traviglia, A.; Del Bue, A.; James, S. Machine Learning for Cultural Heritage: A Survey. Pattern Recognit. Lett. 2020, 133, 102–108. [Google Scholar] [CrossRef]
- Obeso, A.M.; Benois-Pineau, J.; Acosta, A.Á.R.; Vázquez, M.S.G. Architectural style classification of Mexican historical buildings using deep convolutional neural networks and sparse features. J. Electron. Imaging 2016, 26, 011016. [Google Scholar] [CrossRef]
- Cao, J.; Cui, H.; Zhang, Z.; Zhao, A. Mural classification model based on high- and low-level vision fusion. Herit Sci. 2020, 8, 121. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. Available online: http://arxiv.org/abs/1409.1556 (accessed on 15 October 2019).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. 2015. Available online: https://arxiv.org/abs/1512.03385 (accessed on 24 October 2018).
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2018, arXiv:1608.06993. Available online: http://arxiv.org/abs/1608.06993 (accessed on 5 December 2020).
- Tan, C.; Sun, F.; Kong, T.; Zhang, W.; Yang, C.; Liu, C. A Survey on Deep Transfer Learning; Springer: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Strategies from Data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Fu, J.; Zhou, J.; Deng, Y. Heritage values of ancient vernacular residences in traditional villages in Western Hunan, China: Spatial patterns and influencing factors. Build. Environ. 2021, 188, 107473. [Google Scholar] [CrossRef]
- İpekoğlu, B. An architectural evaluation method for conservation of traditional dwellings. Build. Environ. 2006, 41, 386–394. [Google Scholar] [CrossRef]
- Bienvenido-Huertas, D.; León-Muñoz, M.; Martín-del-Río, J.J.; Rubio-Bellido, C. Analysis of climate change impact on the preservation of heritage elements in historic buildings with a deficient indoor microclimate in warm regions. Build. Environ. 2021, 200, 107959. [Google Scholar] [CrossRef]
- Li, G.; Jiang, G.; Jiang, C.; Bai, J. Differentiation of spatial morphology of rural settlements from an ethnic cultural perspective on the Northeast Tibetan Plateau, China. Habitat Int. 2018, 79, 1–9. [Google Scholar] [CrossRef]
- Potosyan, A.H. Geographical features and development regularities of rural areas and settlements distribution in mountain countries. Ann. Agrar. Sci. 2017, 52, 32–40. [Google Scholar] [CrossRef]
- Wu, S.; Di, B.; Ustin, S.L.; Stamatopoulos, C.A.; Li, J.; Zuo, Q.; Wu, X.; Ai, N. Classification and detection of dominant factors in geospatial patterns of traditional settlements in China. J. Geogr. Sci. 2022, 32, 873–891. [Google Scholar] [CrossRef]
- Guo, Y.; Mo, D.; Mao, L.; Wang, S.; Li, S. Settlement distribution and its relationship with environmental changes from the Neolithic to Shang-Zhou dynasties in northern Shandong, China. J. Geogr. Sci. 2013, 23, 679–694. [Google Scholar] [CrossRef]
- Prieto, A.J.; Silva, A.; de Brito, J.; Macías-Bernal, J.M.; Alejandre, F.J. Multiple linear regression and fuzzy logic models applied to the functional service life prediction of cultural heritage. J. Cult. Herit. 2017, 27, 20–35. [Google Scholar] [CrossRef]
- Liu, P.L.; Liu, C.L. Landscape division of traditional settlement and effect elements of landscape gene in China. Acta Geogr. Sin. 2010, 65, 1496–1506. [Google Scholar]
- Bianco, S.; Mazzini, D.; Schettini, R. Deep Multibranch Neural Network for Painting Categorization. In Image Analysis and Processing—ICIAP 2017; Battiato, S., Gallo, G., Schettini, R., Stanco, F., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 414–423. [Google Scholar] [CrossRef]
- Xu, F.; Ho, H.C.; Chi, G.; Wang, Z. Abandoned rural residential land: Using machine learning techniques to identify rural residential land vulnerable to be abandoned in mountainous areas. Habitat Int. 2019, 84, 43–56. [Google Scholar] [CrossRef]
- Gonthier, N.; Gousseau, Y.; Ladjal, S.; Bonfait, O. Weakly Supervised Object Detection in Artworks. In Computer Vision—ECCV 2018 Workshops; Leal-Taixé, L., Roth, S., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 692–709. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. Available online: http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf (accessed on 7 October 2018).
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Yang, S.; Xiao, W.; Zhang, M.; Guo, S.; Zhao, J.; Shen, F. Image Data Augmentation for Deep Learning: A Survey. arXiv 2022, arXiv:2204.08610. [Google Scholar] [CrossRef]
- Li, R.; Li, X.; Heng, P.-A.; Fu, C.-W. PointAugment: An Auto-Augmentation Framework for Point Cloud Classification. arXiv 2020, arXiv:2002.10876. Available online: http://arxiv.org/abs/2002.10876 (accessed on 13 August 2020).
- Cubuk, E.D.; Zoph, B.; Shlens, J.; Le, Q.V. RandAugment: Practical automated data augmentation with a reduced search space. arXiv 2019, arXiv:1909.13719. Available online: http://arxiv.org/abs/1909.13719 (accessed on 18 December 2020).
- Yu, L.; Liu, J. The Spatial Distribution Dataset of 2555 Chinese Traditional Villages. J. Glob. Chang. Data Discov. 2018, 2, 144–150. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]
- Zoph, B.; Ghiasi, G.; Lin, T.-Y.; Cui, Y.; Liu, H.; Cubuk, E.D.; Le, Q.V. Rethinking Pre-training and Self-training. arXiv 2020, arXiv:2006.06882. Available online: http://arxiv.org/abs/2006.06882 (accessed on 16 December 2020).
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A Simple Framework for Contrastive Learning of Visual Representations. arXiv 2020, arXiv:2002.05709. Available online: http://arxiv.org/abs/2002.05709 (accessed on 22 November 2020).
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Zhang, Z.; Lin, H.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. arXiv 2020, arXiv:2004.08955. Available online: http://arxiv.org/abs/2004.08955 (accessed on 15 December 2020).
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2020, arXiv:1905.11946. Available online: http://arxiv.org/abs/1905.11946 (accessed on 15 December 2020).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typical Photographs | Style | Description |
|---|---|---|
 | Chuan | Chuan style is widely distributed in Sichuan, Yunnan, Guizhou province of China, mostly in the ethnic minority areas. To keep ventilation, dry, and prevent poisonous wild animals in the humid environment, the residents build the house as column or semi-column structures, such as the dai bamboo houses and the stilted buildings. |
 | Jin | Jin style is named after the abbreviation of Shanxi, most of the areas are around Shanxi province. The architecture is represented as cave dwellings in the rural area and is well designed with blue brick walls in the urban area showing the steady and preciseness of Shanxi merchants. |
 | Jing | Jing style is usually in the form of a quadrangle courtyard, which is the most typical style of northern China. The most representative, of course, is the Forbidden City, which is over 600 years old. Additionally, the quadrangle courtyards with carved or painted ornaments in Beijing Hutong are like a miniature of the Forbidden City, highlighting the stately peculiarity. |
 | Min | Min style originated from the ancient construction technology of raw soil in the Central Plains and has been inherited for more than 500 years in the south of Fujian (Min). This bunker-style architecture is still in use today. It can not only prevent fire and shock but also resist the invasion of the enemy. |
 | Su | Su style is the epitome of southern and northern architectural styles, and the garden layout is one of its prominent features. The architecture with glazed tile windows, high ridge roof, and brick gate tower, faultlessly reflect the artistic characteristics of purity, lightness, elegance, and simplicity of Jiangnan Water Town. |
 | Wan | The Wan style is representative of the southern folk dwellings of China. The Hui style, one of the most familiar styles in the Wan style, was inscribed on the World Heritage List in 2000. The typical features of the Wan style architecture are high walls and deep courtyards with black tiles and white walls, which are full of quietly elegant characteristics, showing the infinite charm of the Wan style. |
| Chuan | Jin | Jing | Min | Su | Wan | Total | |
|---|---|---|---|---|---|---|---|
| The number of images | 214 | 193 | 194 | 215 | 188 | 222 | 1226 |
| Class | Chuan | Jin | Jing | Min | Su | Wan | Total |
|---|---|---|---|---|---|---|---|
| Training | 169 | 147 | 166 | 175 | 145 | 178 | 980 |
| Test | 45 | 46 | 28 | 40 | 43 | 44 | 246 |
| Total | 214 | 193 | 194 | 215 | 188 | 222 | 1226 |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| AlexNet | 57.53% | 77.21% | 57.53% | 63.56% |
| DenseNet | 82.92% | 97.08% | 82.92% | 88.56% |
| ResNet | 73.02% | 94.80% | 73.02% | 81.41% |
| Model | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| AlexNet | 57.53% | 77.21% | 57.53% | 63.56% |
| AlexNet-TL-Aug (ours) | 86.98% (+29.5%) | 93.48% | 86.98% | 89.73% |
| DenseNet | 82.92% | 97.08% | 82.92% | 88.56% |
| DenseNet-TL-Aug (ours) | 94.15% (+11.2%) | 96.53% | 94.15% | 95.06% |
| ResNet | 73.02% | 94.80% | 73.02% | 81.41% |
| ResNet-TL-Aug (ours) | 89.98% (+11.2%) | 94.01% | 89.98% | 91.68% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, Q.; Yin, C.; Deng, Y.; Liu, P. Towards Classification of Architectural Styles of Chinese Traditional Settlements Using Deep Learning: A Dataset, a New Framework, and Its Interpretability. Remote Sens. 2022, 14, 5250. https://doi.org/10.3390/rs14205250
Han Q, Yin C, Deng Y, Liu P. Towards Classification of Architectural Styles of Chinese Traditional Settlements Using Deep Learning: A Dataset, a New Framework, and Its Interpretability. Remote Sensing. 2022; 14(20):5250. https://doi.org/10.3390/rs14205250
Chicago/Turabian StyleHan, Qing, Chao Yin, Yunyuan Deng, and Peilin Liu. 2022. "Towards Classification of Architectural Styles of Chinese Traditional Settlements Using Deep Learning: A Dataset, a New Framework, and Its Interpretability" Remote Sensing 14, no. 20: 5250. https://doi.org/10.3390/rs14205250
APA StyleHan, Q., Yin, C., Deng, Y., & Liu, P. (2022). Towards Classification of Architectural Styles of Chinese Traditional Settlements Using Deep Learning: A Dataset, a New Framework, and Its Interpretability. Remote Sensing, 14(20), 5250. https://doi.org/10.3390/rs14205250