
A Land Cover Background-Adaptive Framework for Large-Scale Road Extraction





Abstract
1. Introduction
2. Study Area and Dataset
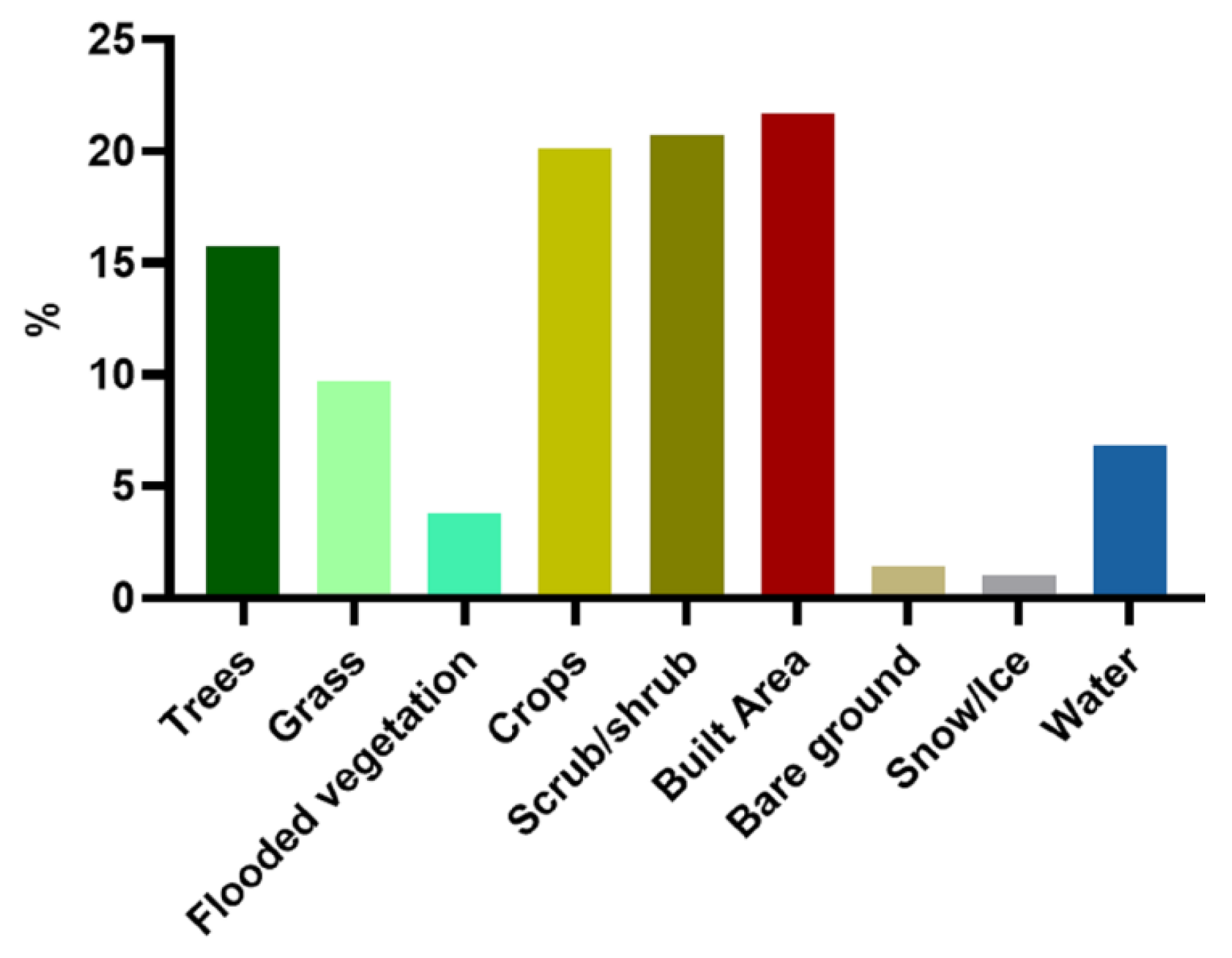
2.1. Study Area
2.2. Dataset
3. Methods
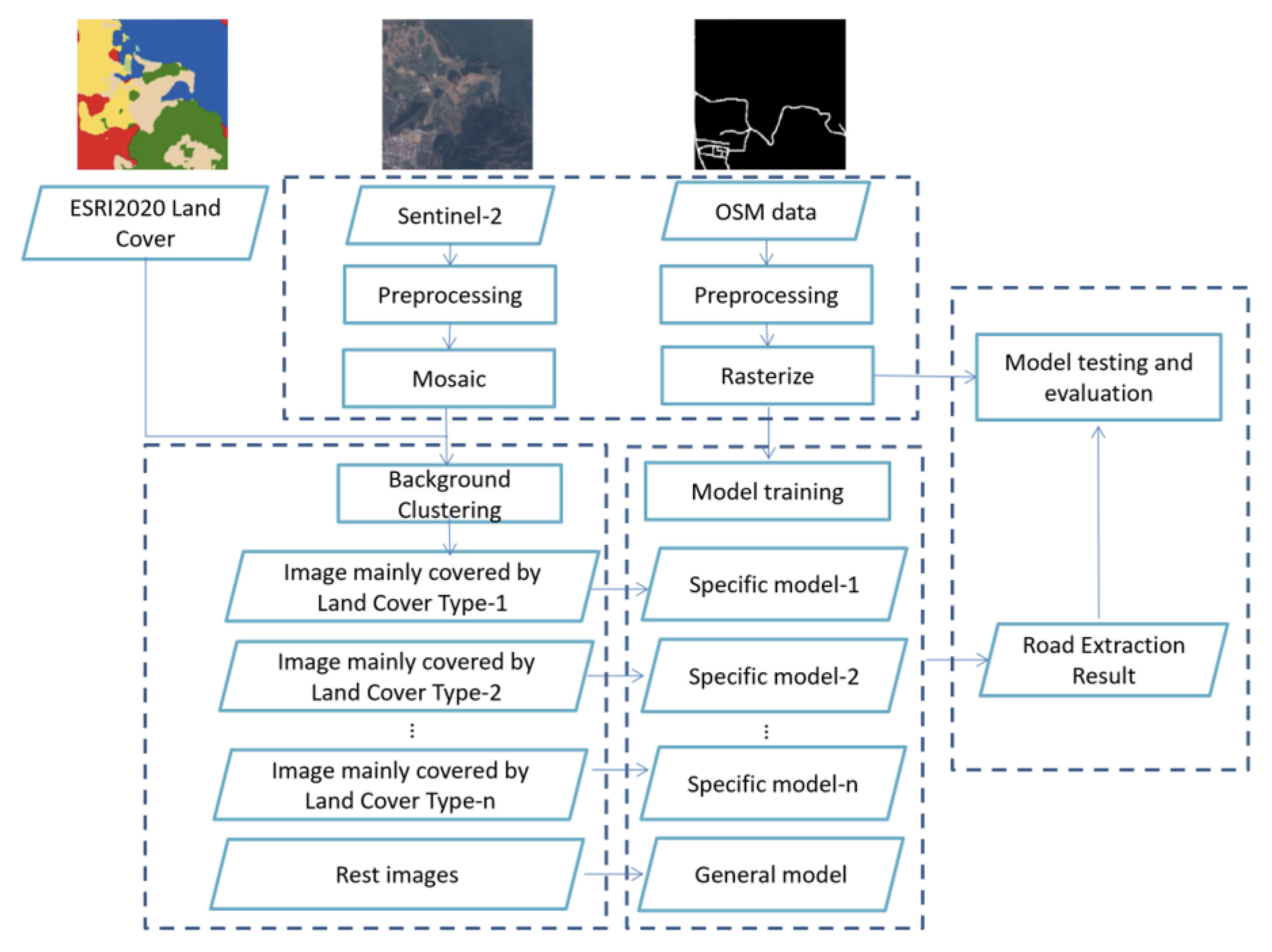
3.1. The Land Cover Background-Adaptive Framework
- (a)
- Preprocessing:
- (b)
- Land cover background clustering:
- (c)
- Model training:

- (d)
- Model testing and evaluation:
3.2. Land Cover Background Clustering
3.3. Validation and Accuracy Assessment
4. Results
4.1. Land Cover Background Clustering
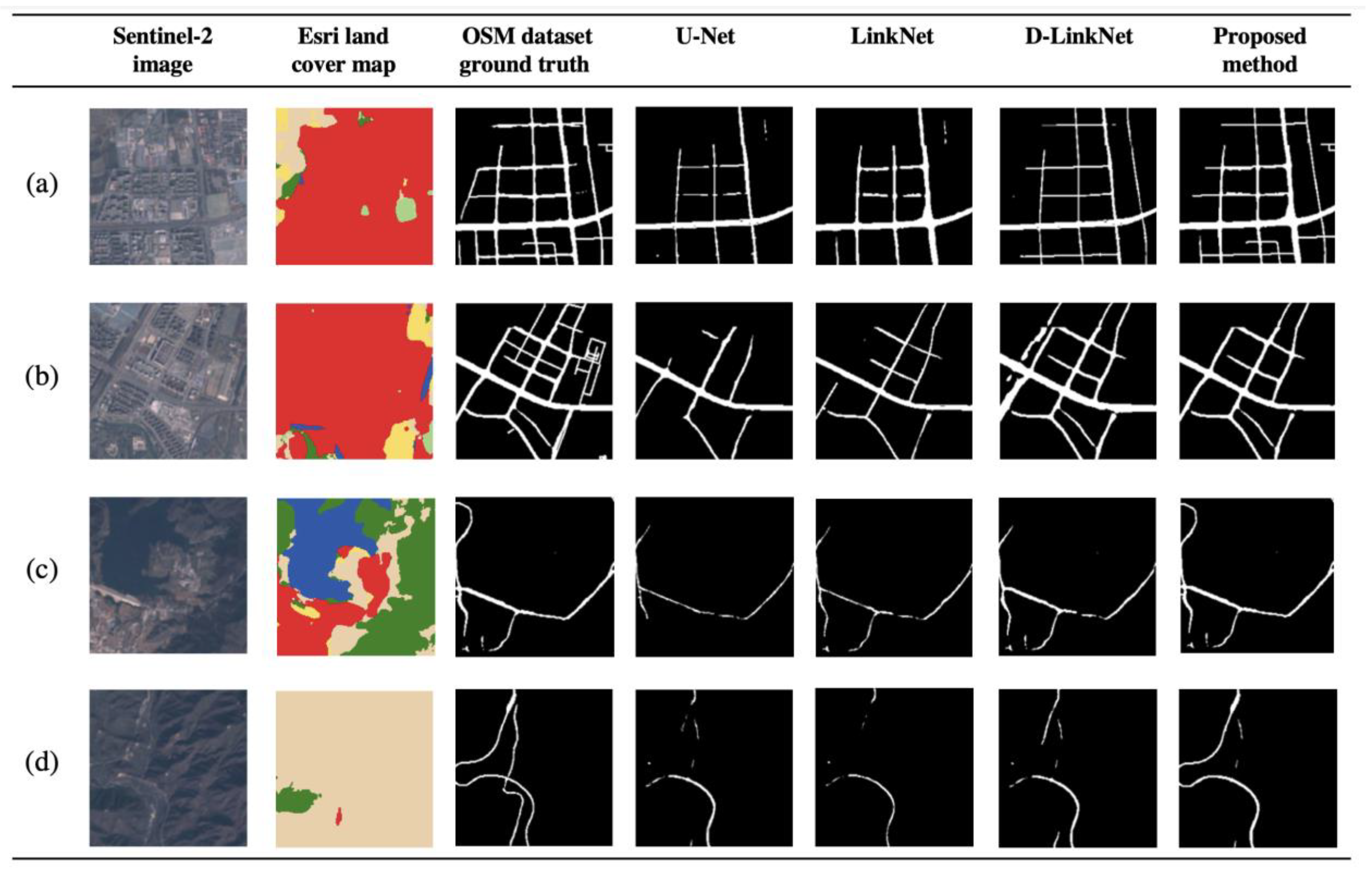
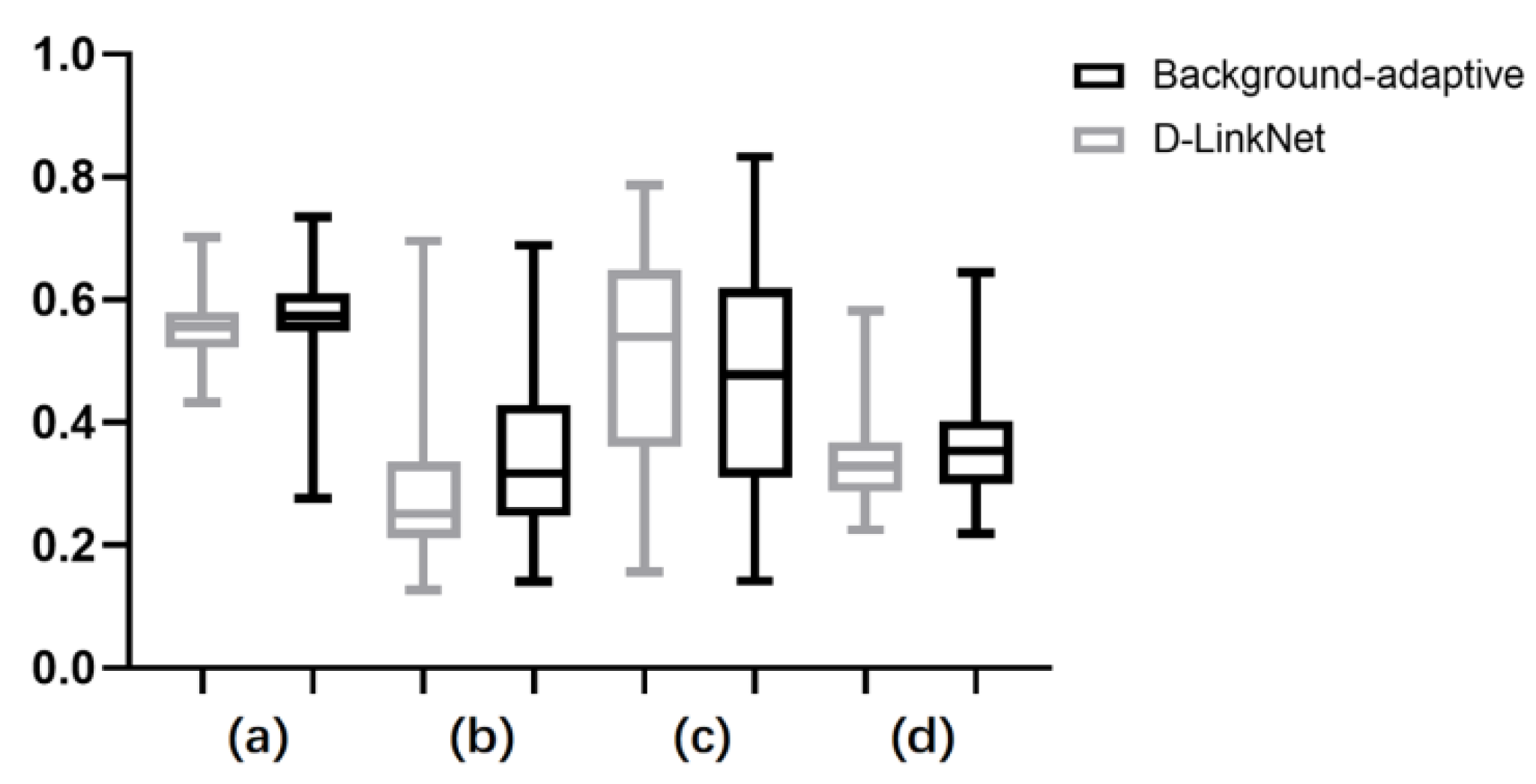
4.2. Large-Scale Road Extraction Results
5. Discussion
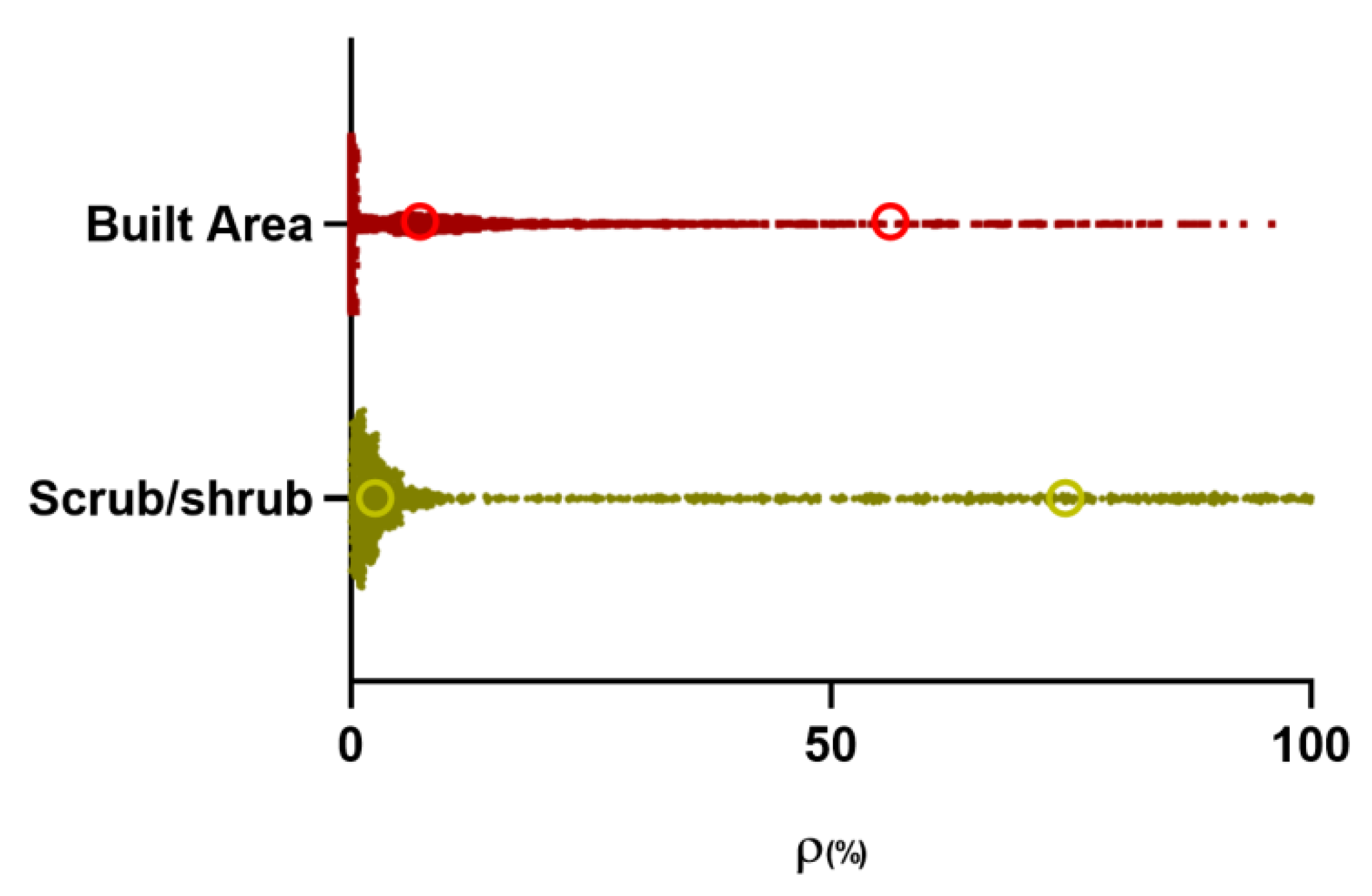
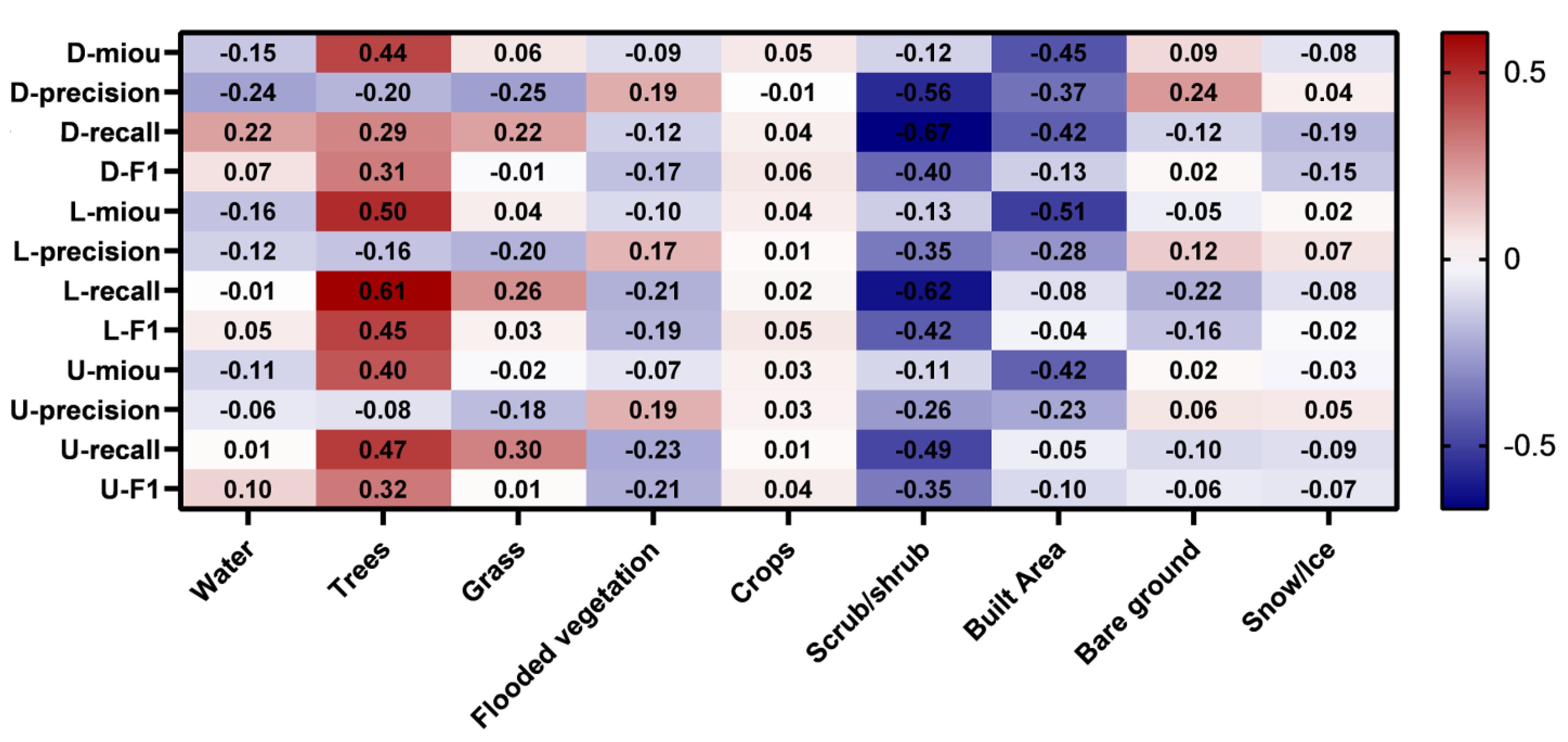
5.1. Effects of Land Cover Types on Road Extraction Performance
5.2. Advantages and Limitations of the Proposed Framework
6. Conclusions
- An obvious negative correlation between the proportion of Scrub/shrubs and Built Area and the road extraction accuracy is quantitively discovered for the one belt and road region.
- The Fuzzy C-means clustering algorithm is proven to achieve better land cover background clustering results than other hard clustering algorithms.
- The proposed land cover background adaptive model achieves better road extraction results than compared models on large-scale road extraction tasks, obtaining improvements in the mIoU index by 0.0174, precision by 0.0617, and F1 score by 0.0244.
- The efficiency of the proposed framework in the training and inferring process is comparable to those of deep learning-based road extraction algorithms.
- The GEE and Google Colaboratory are proved to be ideal cloud-based platforms for large-scale remote sensing studies using deep learning algorithms.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carrara, S.; Longden, T. Freight futures: The potential impact of road freight on climate policy. Transp. Res. Part D Transp. Environ. 2017, 55, 359–372. [Google Scholar] [CrossRef]
- Xing, X.; Huang, Z.; Cheng, X.; Zhu, D.; Kang, C.; Zhang, F.; Liu, Y. Mapping human activity volumes through remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5652–5668. [Google Scholar] [CrossRef]
- Tsou, J.Y.; Gao, Y.; Zhang, Y.; Sun, G.; Ren, J.; Li, Y. Evaluating urban land carrying capacity based on the ecological sensitivity analysis: A case study in Hangzhou, China. Remote Sens. 2017, 9, 529. [Google Scholar] [CrossRef]
- Peng, D.; Bruzzone, L.; Zhang, Y.; Guan, H.; Ding, H.; Huang, X. SemiCDNet: A semisupervised convolutional neural network for change detection in high resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5891–5906. [Google Scholar] [CrossRef]
- Zhang, B.; Wu, Y.; Zhao, B.; Chanussot, J.; Hong, D.; Yao, J.; Gao, L. Progress and challenges in intelligent remote sensing satellite systems. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 1814–1822. [Google Scholar] [CrossRef]
- Shi, S.; Zhong, Y.; Zhao, J.; Lv, P.; Liu, Y.; Zhang, L. Land-use/land-cover change detection based on class-prior object-oriented conditional random field framework for high spatial resolution remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2020, 60, 5600116. [Google Scholar] [CrossRef]
- Buono, A.; Nunziata, F.; Mascolo, L.; Migliaccio, M. A multipolarization analysis of coastline extraction using X-band COSMO-SkyMed SAR data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2811–2820. [Google Scholar] [CrossRef]
- Bai, Y.; Sun, G.; Li, Y.; Ma, P.; Li, G.; Zhang, Y. Comprehensively analyzing optical and polarimetric SAR features for land-use/land-cover classification and urban vegetation extraction in highly-dense urban area. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102496. [Google Scholar] [CrossRef]
- Zheng, K.; Wei, M.; Sun, G.; Anas, B.; Li, Y. Using vehicle synthesis generative adversarial networks to improve vehicle detection in remote sensing images. ISPRS Int. J. Geo-Inf. 2019, 8, 390. [Google Scholar] [CrossRef]
- Li, H.; Li, S.; Song, S. Modulation Recognition Analysis Based on Neural Networks and Improved Model. In Proceedings of the 2021 13th International Conference on Advanced Infocomm Technology (ICAIT), Yanji, China, 15–18 October 2021. [Google Scholar] [CrossRef]
- Tang, R.; Fong, S.; Wong, R.K.; Wong, K.K.L. Dynamic group optimization algorithm with embedded chaos. IEEE Access 2018, 6, 22728–22743. [Google Scholar] [CrossRef]
- Bajcsy, R.; Tavakoli, M. Computer recognition of roads from satellite pictures. IEEE Trans. Syst. Man Cybern. 1976, SMC-6, 623–637. [Google Scholar] [CrossRef]
- Mena, J.B.; Malpica, J.A. An automatic method for road extraction in rural and semi-urban areas starting from high resolution satellite imagery. Pattern Recognit. Lett. 2005, 26, 1201–1220. [Google Scholar] [CrossRef]
- Kirthika, A.; Mookambiga, A. Automated road network extraction using artificial neural network. In Proceedings of the 2011 International Conference on Recent Trends in Information Technology (ICRTIT), Chennai, India, 3–5 June 2011. [Google Scholar] [CrossRef]
- Simler, C. An improved road and building detector on VHR images. In Proceedings of the 2011 IEEE international geoscience and remote sensing symposium (IGARSS), Vancouver, BC, Canada, 24–29 July 2011. [Google Scholar] [CrossRef]
- Shi, W.; Miao, Z.; Wang, Q.; Zhang, H. Spectral–spatial classification and shape features for urban road centerline extraction. IEEE Geosci. Remote Sens. Lett. 2013, 11, 788–792. [Google Scholar] [CrossRef]
- Yin, D.; Du, S.; Wang, S.; Guo, Z. A direction-guided ant colony optimization method for extraction of urban road information from very-high-resolution images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 4785–4794. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Shukla, N.; Chakraborty, S.; Alamri, A. Deep learning approaches applied to remote sensing datasets for road extraction: A state-of-the-art review. Remote Sens. 2020, 12, 1444. [Google Scholar] [CrossRef]
- Lian, R.; Wang, W.; Mustafa, N.; Huang, L. Road extraction methods in high-resolution remote sensing images: A comprehensive review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5489–5507. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to detect roads in high-resolution aerial images. In Proceedings of the European Conference on Computer Vision, Heraklion, Greece, 5–11 September 2010. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual U-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef]
- Chaurasia, A.; Culurciello, E. Linknet: Exploiting encoder representations for efficient semantic segmentation. In Proceedings of the 2017 IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017. [Google Scholar] [CrossRef]
- Zhou, L.; Zhang, C.; Wu, M. D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar] [CrossRef]
- Oehmcke, S.; Thrysøe, C.; Borgstad, A.; Salles, M.A.V.; Brandt, M.; Gieseke, F. Detecting hardly visible roads in low-resolution satellite time series data. In Proceedings of the 2019 IEEE International Conference on Big Data, Los Angeles, CA, USA, 9–12 December 2019. [Google Scholar] [CrossRef]
- Zhou, G.; Chen, W.; Gui, Q.; Li, X.; Wang, L. Split depth-wise separable graph-convolution network for road extraction in complex environments from high-resolution remote-sensing images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5614115. [Google Scholar] [CrossRef]
- Li, S.; Liao, C.; Ding, Y.; Hu, H.; Jia, Y.; Chen, M.; Xu, B.; Ge, X.; Liu, T.; Wu, D. Cascaded Residual Attention Enhanced Road Extraction from Remote Sensing Images. ISPRS Int. J. Geo-Inf. 2021, 11, 9. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, M.; Sun, G.; Chen, J.; Zhu, X.; Yang, J. Weakly supervised training for eye fundus lesion segmentation in patients with diabetic retinopathy. Math. Biosci. Eng. 2022, 19, 5293–5311. [Google Scholar] [CrossRef]
- Karra, K.; Kontgis, C.; Statman-Weil, Z.; Mazzariello, J.C.; Mathis, M.; Brumby, S.P. Global land use/land cover with Sentinel 2 and deep learning. In Proceedings of the 2021 IEEE international geoscience and remote sensing symposium (IGARSS), Brussels, Belgium, 11–16 July 2021. [Google Scholar] [CrossRef]
- Radoux, J.; Chomé, G.; Jacques, D.C.; Waldner, F.; Bellemans, N.; Matton, N.; Lamarche, C.; D’Andrimont, R.; Defourny, P. Sentinel-2’s Potential for Sub-Pixel Landscape Feature Detection. Remote Sens. 2016, 8, 488. [Google Scholar] [CrossRef]
- Sun, G.; Liang, H.; Li, Y.; Zhang, H. Analysing the Influence of Land Cover Type on the Performance of Large-scale Road Extraction. In Proceedings of the 2021 10th International Conference on Computing and Pattern Recognition, Shanghai, China, 15–17 October 2021. [Google Scholar] [CrossRef]
- Gorelick, N.; Hancher, M.; Dixon, M.; Ilyushchenko, S.; Thau, D.; Moore, R. Google Earth Engine: Planetary-scale geospatial analysis for everyone. Remote Sens. Environ. 2017, 202, 18–27. [Google Scholar] [CrossRef]
- Ebel, P.; Meraner, A.; Schmitt, M.; Zhu, X.X. Multisensor data fusion for cloud removal in global and all-season sentinel-2 imagery. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5866–5878. [Google Scholar] [CrossRef]
- Venkatappa, M.; Sasaki, N.; Shrestha, R.P.; Tripathi, N.K.; Ma, H.-O. Determination of Vegetation Thresholds for Assessing Land Use and Land Use Changes in Cambodia using the Google Earth Engine Cloud-Computing Platform. Remote Sens. 2019, 11, 1514. [Google Scholar] [CrossRef]
- Demetriou, D. Uncertainty of OpenStreetMap data for the road network in Cyprus. In Proceedings of the Fourth International Conference on Remote Sensing and Geoinformation of the Environment (RSCy2016), Paphos, Cyprus, 4–8 April 2016. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Groenen, P.J.F.; Kaymak, U.; van Rosmalen, J. Fuzzy clustering with minkowski distance functions. In Advances in Fuzzy Clustering and Its Applications; Valente de Oliveira, J., Pedrycz, W., Eds.; John Wiley & Sons, Ltd.: Chichester, UK, 2007; pp. 53–68. [Google Scholar] [CrossRef]
- Bezdek, J.C.; Ehrlich, R.; Full, W. FCM: The fuzzy c-means clustering algorithm. Comput. Geosci. 1984, 10, 191–203. [Google Scholar] [CrossRef]
- Krishna, K.; Murty, M.N. Genetic K-means algorithm. IEEE Trans. Syst. Man Cybern. Part B 1999, 29, 433–439. [Google Scholar] [CrossRef]
- Ester, M. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. In Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining (KDD-96), Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- Ulku, I.; Akagündüz, E. A survey on deep learning-based architectures for semantic segmentation on 2D images. Appl. Artif. Intell. 2022, 36, 2032924. [Google Scholar] [CrossRef]
- Nahler, G. Correlation Coefficient. In Dictionary of Pharmaceutical Medicine; Springer: Vienna, Austria, 2009; pp. 40–41. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Data Time | Data Type | Spatial Resolution (m) |
|---|---|---|---|
| Sentinel-2 | 1 January 2019 – 31 December 2019 | Multispectral bands: Blue (496.6 nm (S2A)/492.1 nm (S2B)), Green (560 nm (S2A)/559 nm (S2B)), Red (664.5 nm (S2A)/665 nm (S2B)), NIR (835.1nm (S2A)/833 nm (S2B)) | 10 |
| Esri 2020 Land Cover Dataset | 2020 | Land use type classification map: water, trees, grass, flooded vegetation, crops, scrub/shrub, built area, bare ground, snow/ice, and clouds | 10 |
| OSM | 2019 | Road data in vector format | - |
| K-Means | DBSCAN | FCM | |
|---|---|---|---|
| mIoU | 0.5533 | 0.5547 | 0.5694 |
| Precision | 0.2945 | 0.3287 | 0.3467 |
| Recall | 0.1867 | 0.3456 | 0.4646 |
| F1 Score | 0.2285 | 0.3369 | 0.3601 |
| Processing Time(s) | 0.0364 | 3.5536 | 1.6075 |
| U-Net | LinkNet | D-LinkNet | Background-Adaptive | |
|---|---|---|---|---|
| mIoU | 0.5103 | 0.3098 | 0.5520 | 0.5694 |
| Precision | 0.3098 | 0.2927 | 0.2850 | 0.3467 |
| Recall | 0.3054 | 0.3776 | 0.5076 | 0.4646 |
| F1 Score | 0.2194 | 0.3008 | 0.3357 | 0.3601 |
| Time (s) | 0.5695 | 1.0893 | 1.1352 | 1.3160 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Y.; Liang, H.; Sun, G.; Yuan, Z.; Zhang, Y.; Zhang, H. A Land Cover Background-Adaptive Framework for Large-Scale Road Extraction. Remote Sens. 2022, 14, 5114. https://doi.org/10.3390/rs14205114
Li Y, Liang H, Sun G, Yuan Z, Zhang Y, Zhang H. A Land Cover Background-Adaptive Framework for Large-Scale Road Extraction. Remote Sensing. 2022; 14(20):5114. https://doi.org/10.3390/rs14205114
Chicago/Turabian StyleLi, Yu, Hao Liang, Guangmin Sun, Zifeng Yuan, Yuanzhi Zhang, and Hongsheng Zhang. 2022. "A Land Cover Background-Adaptive Framework for Large-Scale Road Extraction" Remote Sensing 14, no. 20: 5114. https://doi.org/10.3390/rs14205114
APA StyleLi, Y., Liang, H., Sun, G., Yuan, Z., Zhang, Y., & Zhang, H. (2022). A Land Cover Background-Adaptive Framework for Large-Scale Road Extraction. Remote Sensing, 14(20), 5114. https://doi.org/10.3390/rs14205114