
Incremental Learning with Neural Network Algorithm for the Monitoring Pre-Convective Environments Using Geostationary Imager


Abstract
1. Introduction
2. Data
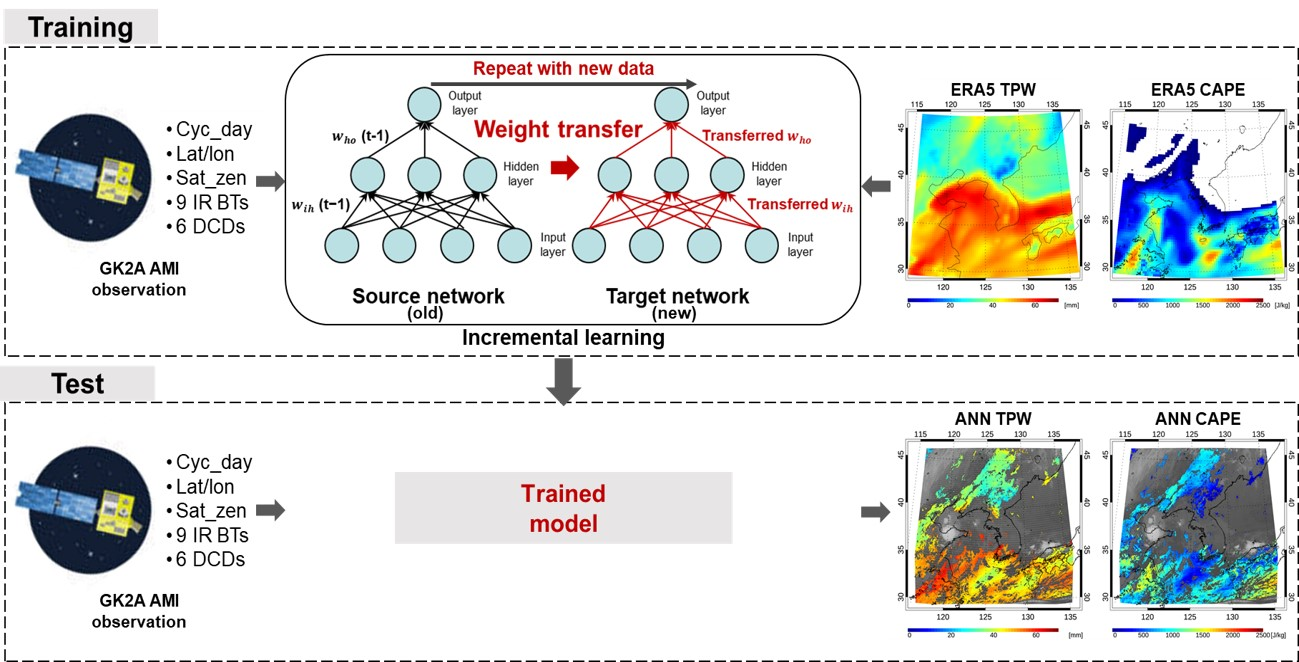
2.1. Study Area
2.2. GK2A Satellite Data
2.3. Radiosonde Observations
2.4. Numerical Weather Prediction Data
2.5. Digital Elevation Model Data
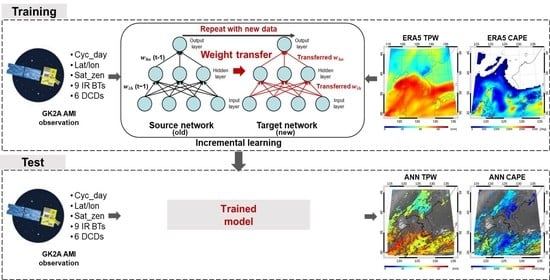
3. Methods
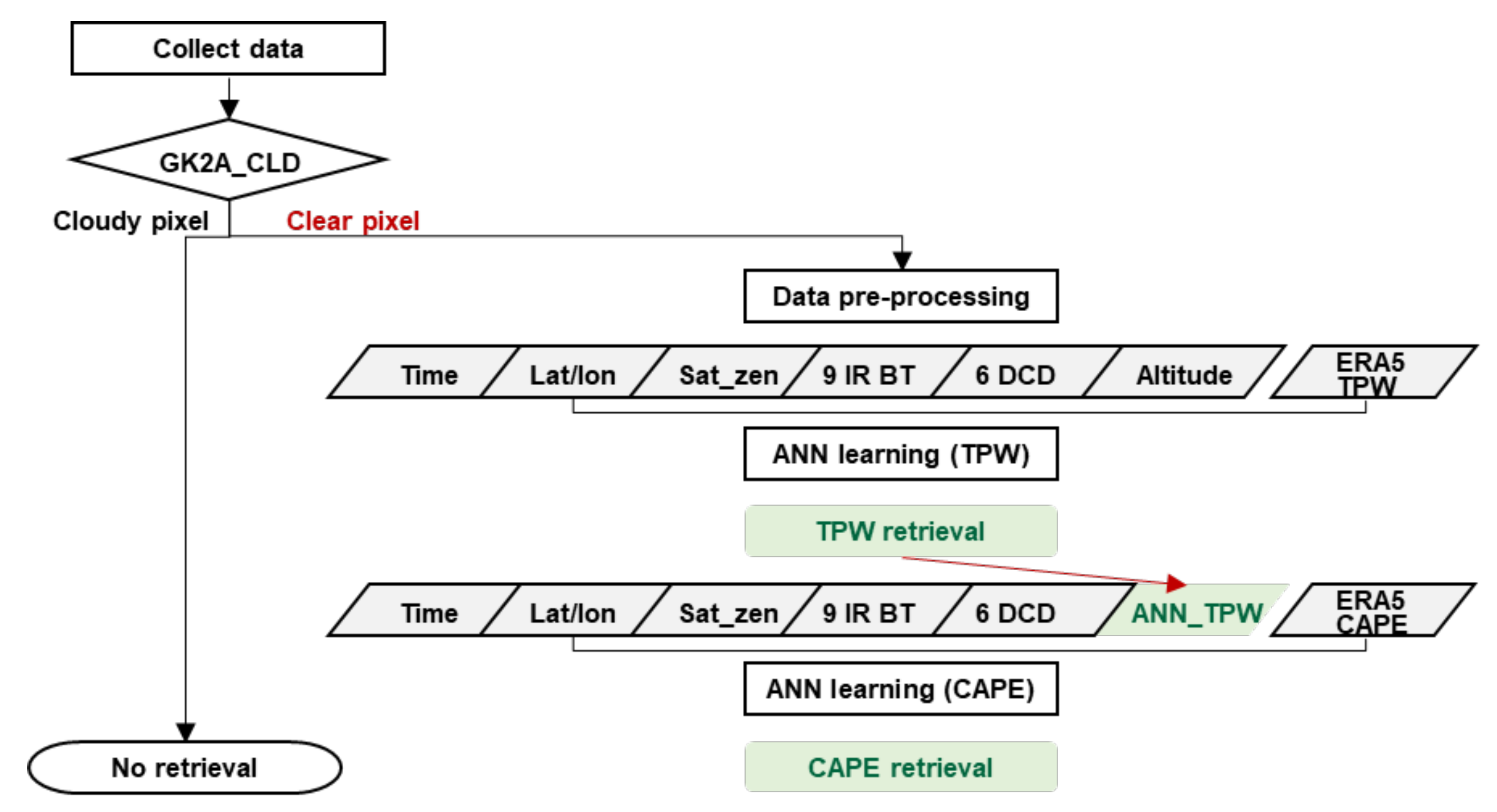
3.1. Retrieval Algorithm Descriptions
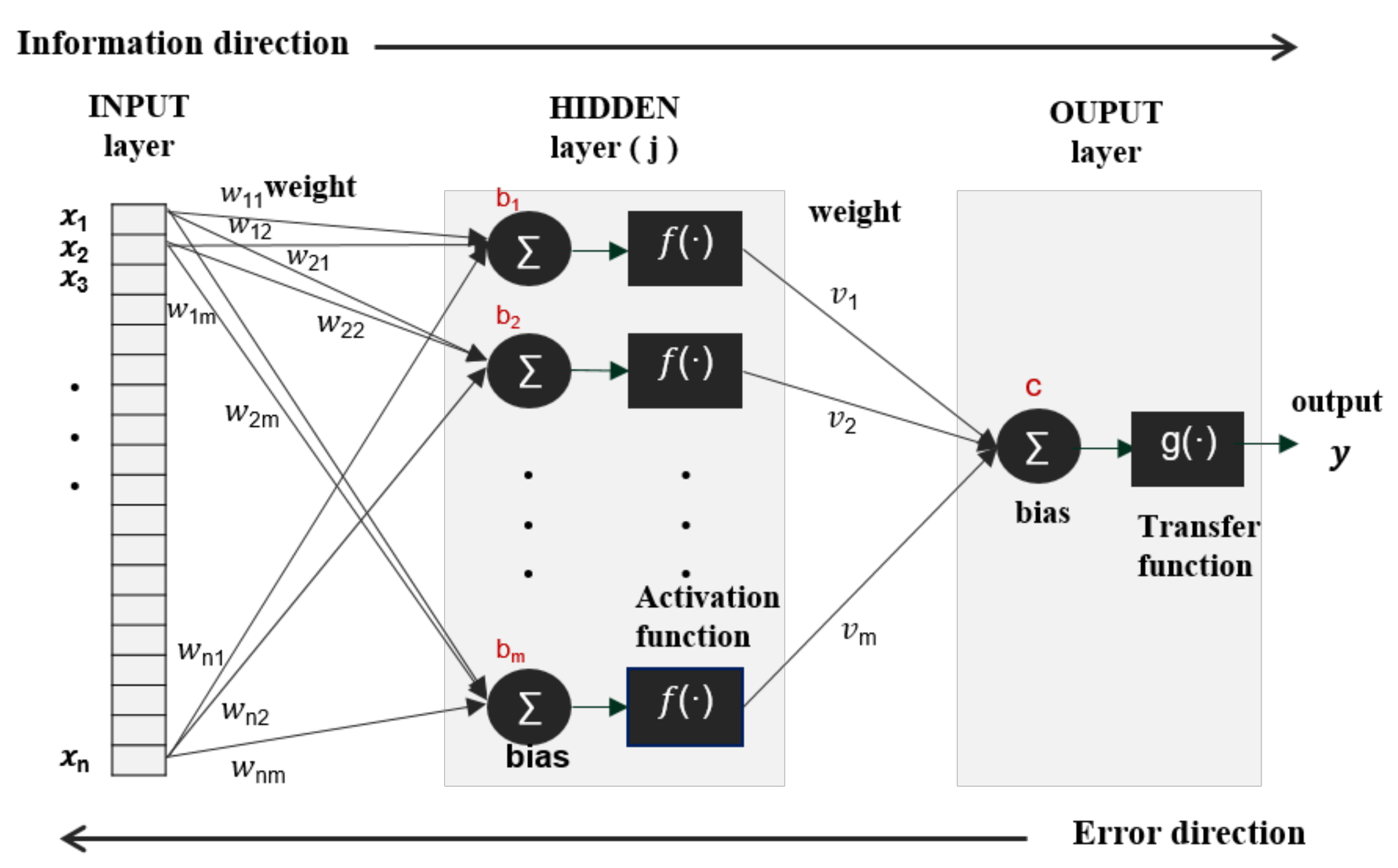
3.2. Conventional ANN Approach (Static Learning)
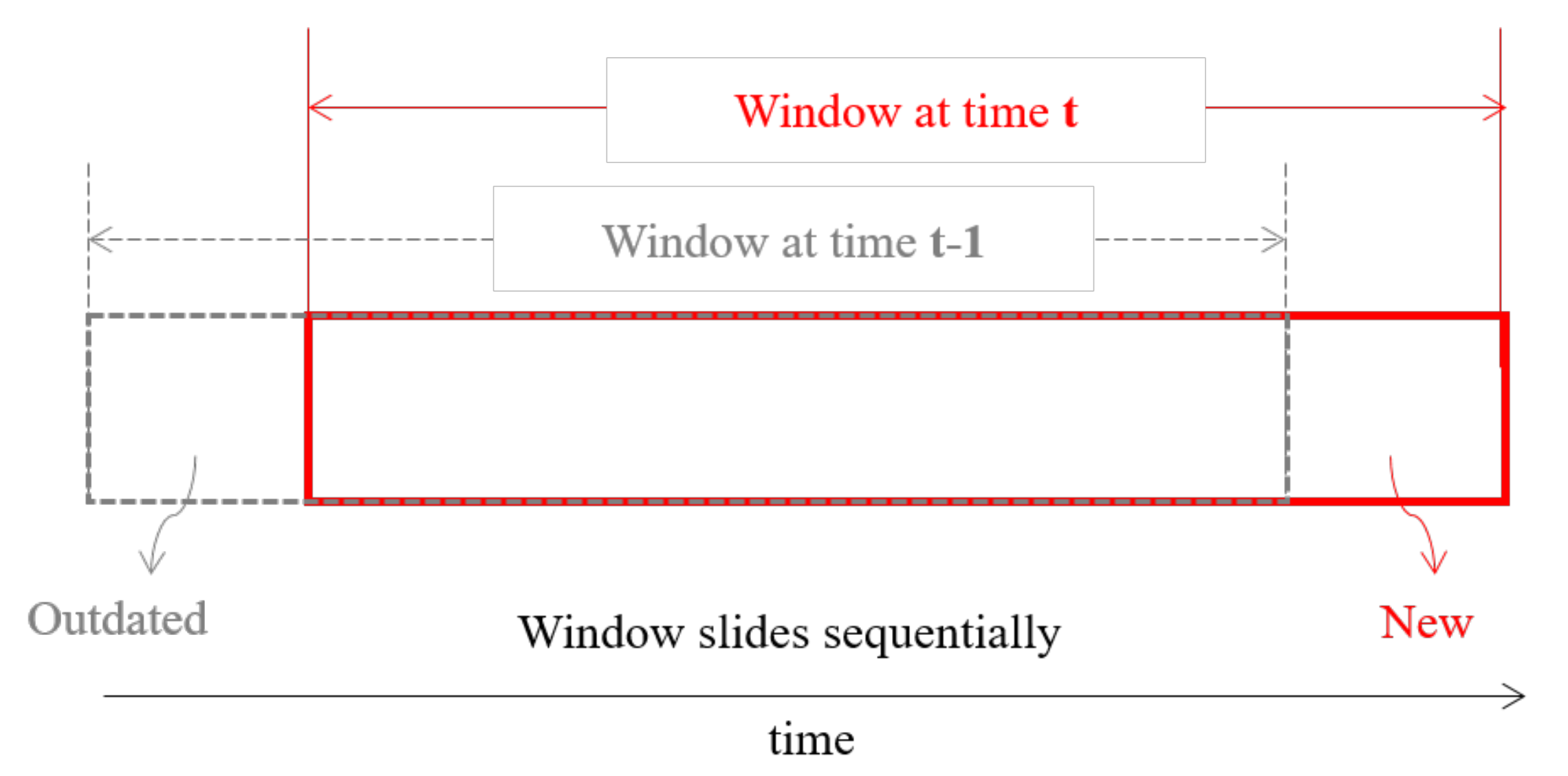
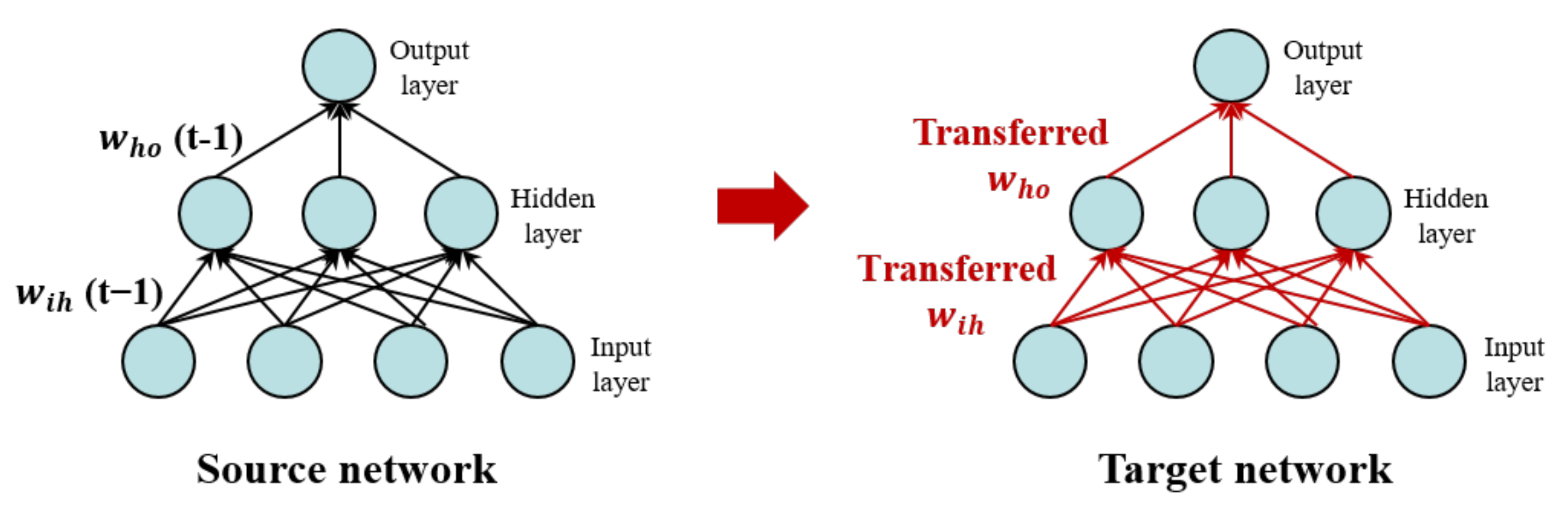
3.3. Incremental Learning Strategies
3.4. Preparation of Learning Dataset
3.5. Accuracy Assessment
4. Results
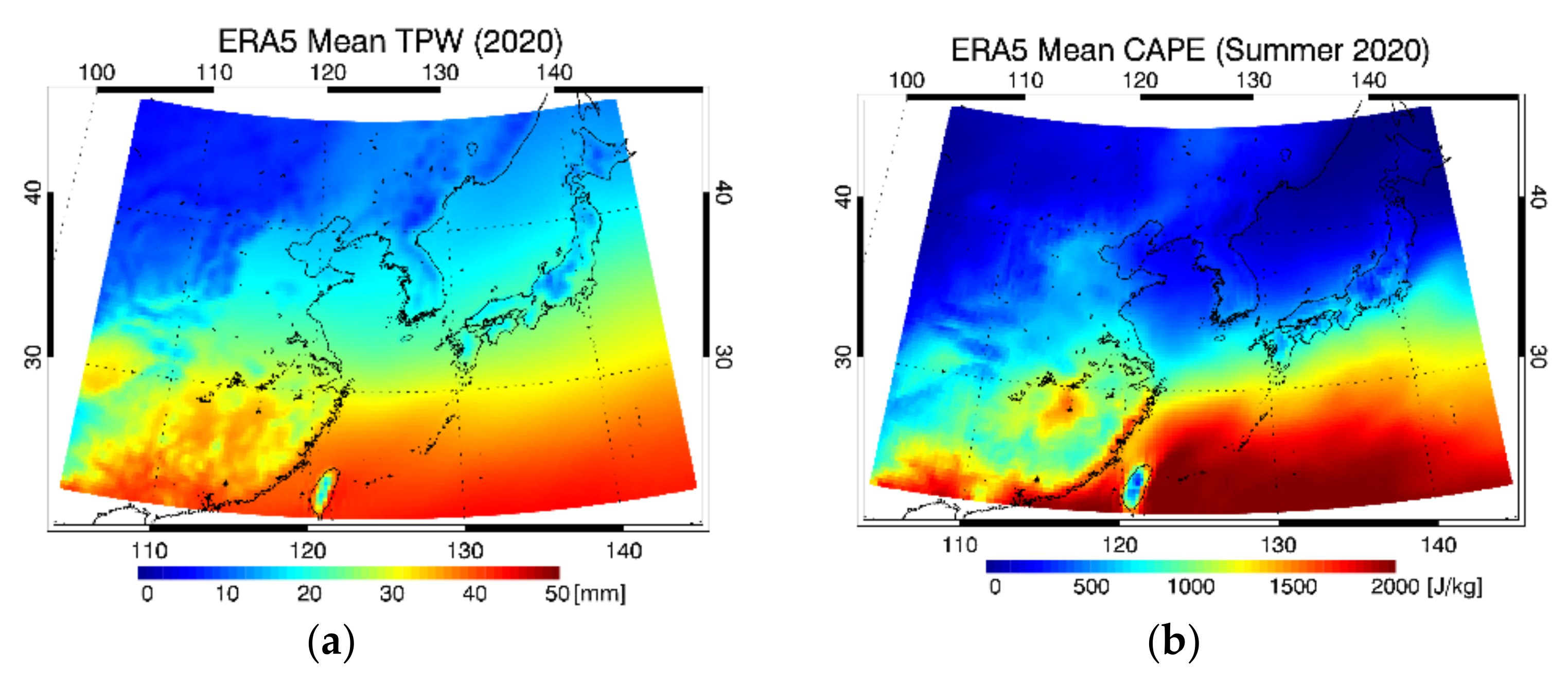
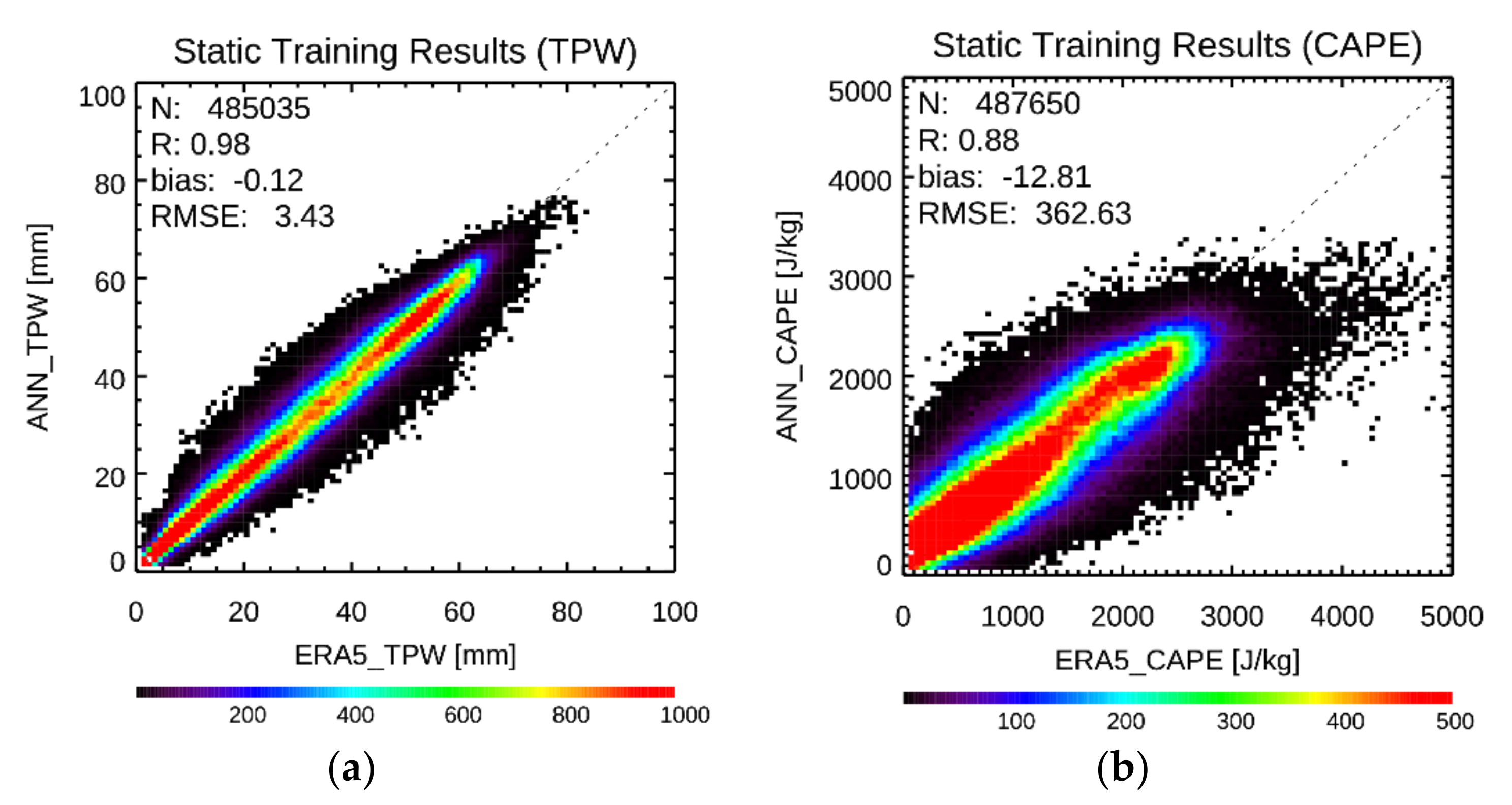
4.1. Model Performance
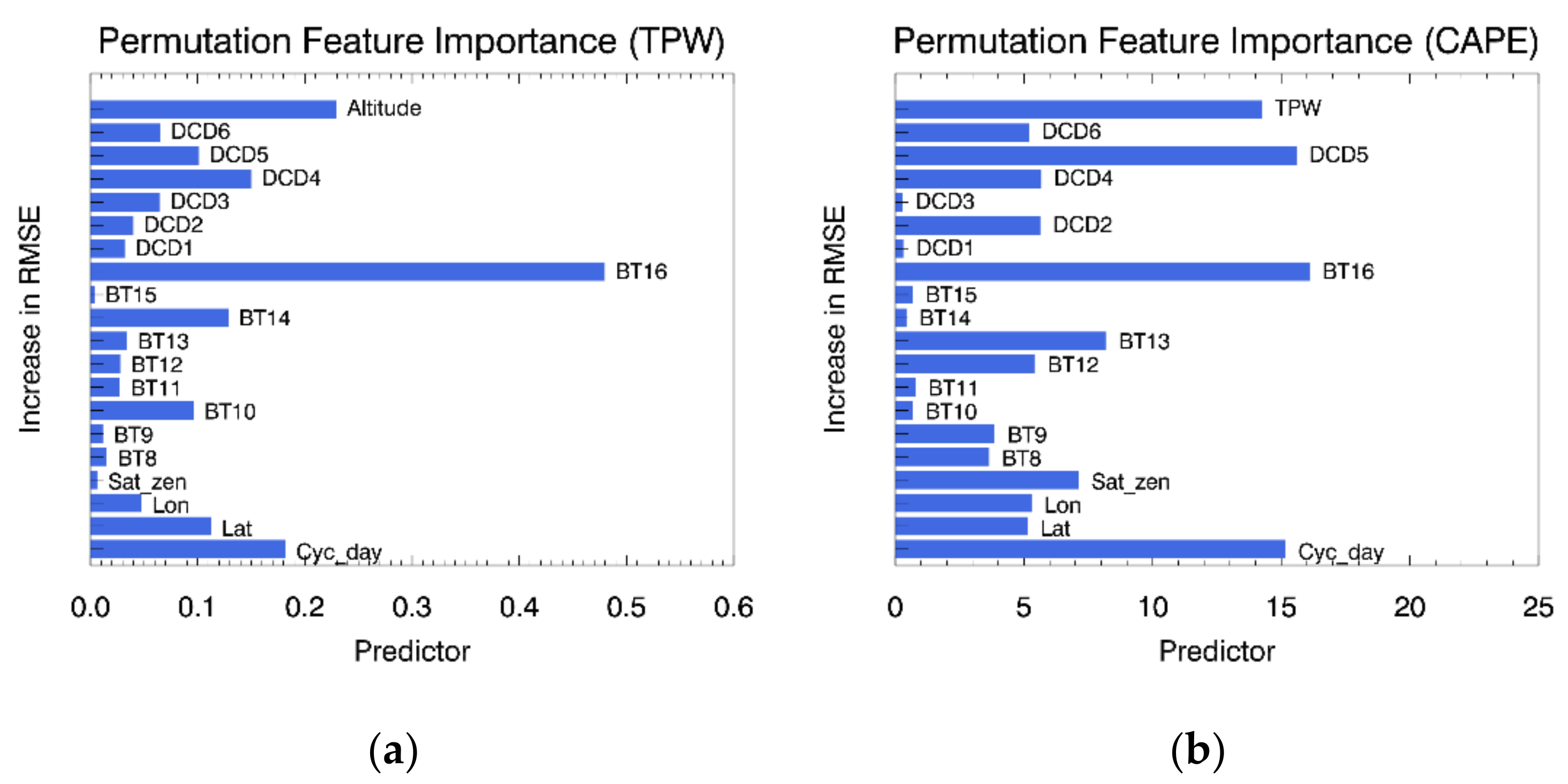
4.2. Feature Contributions
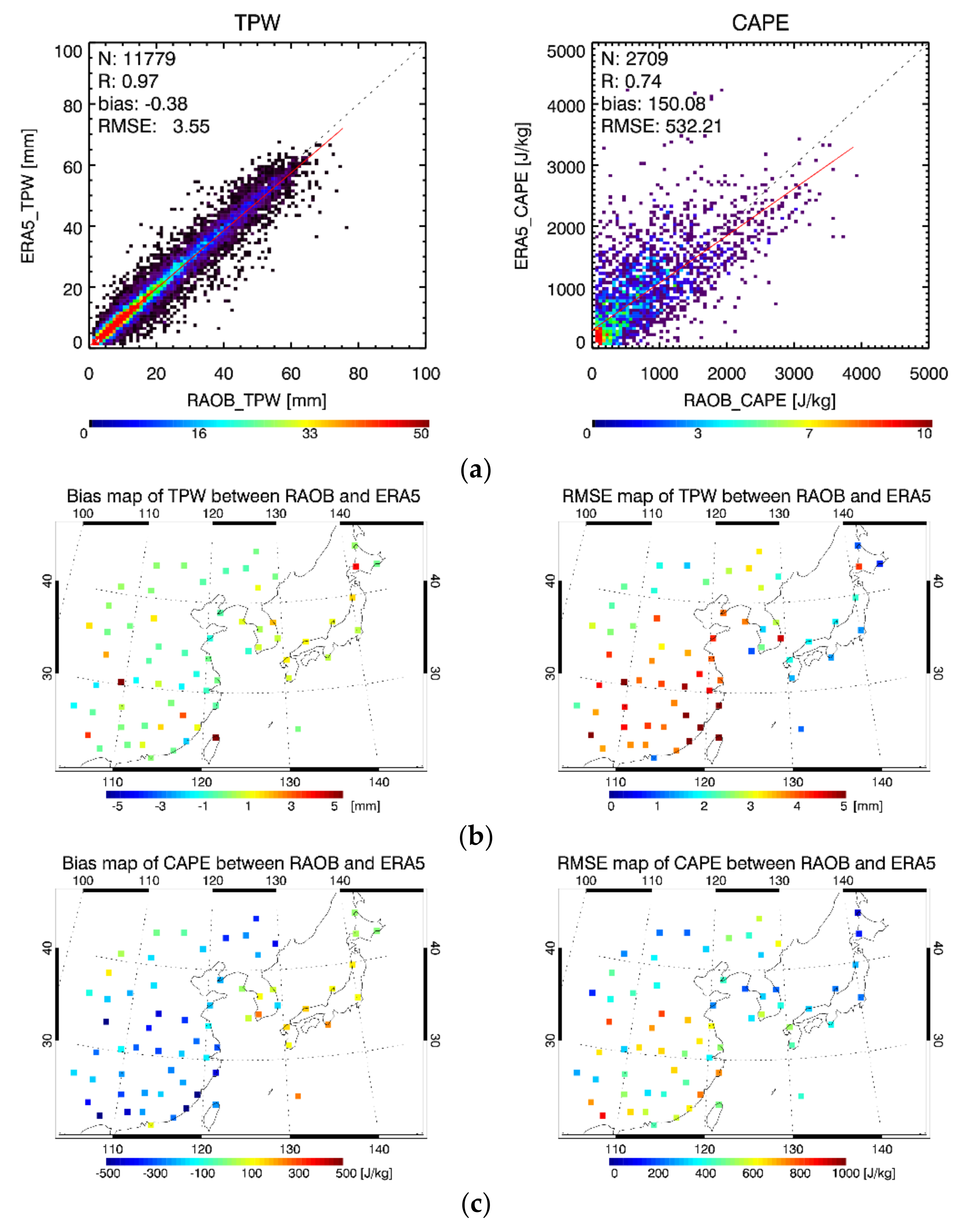
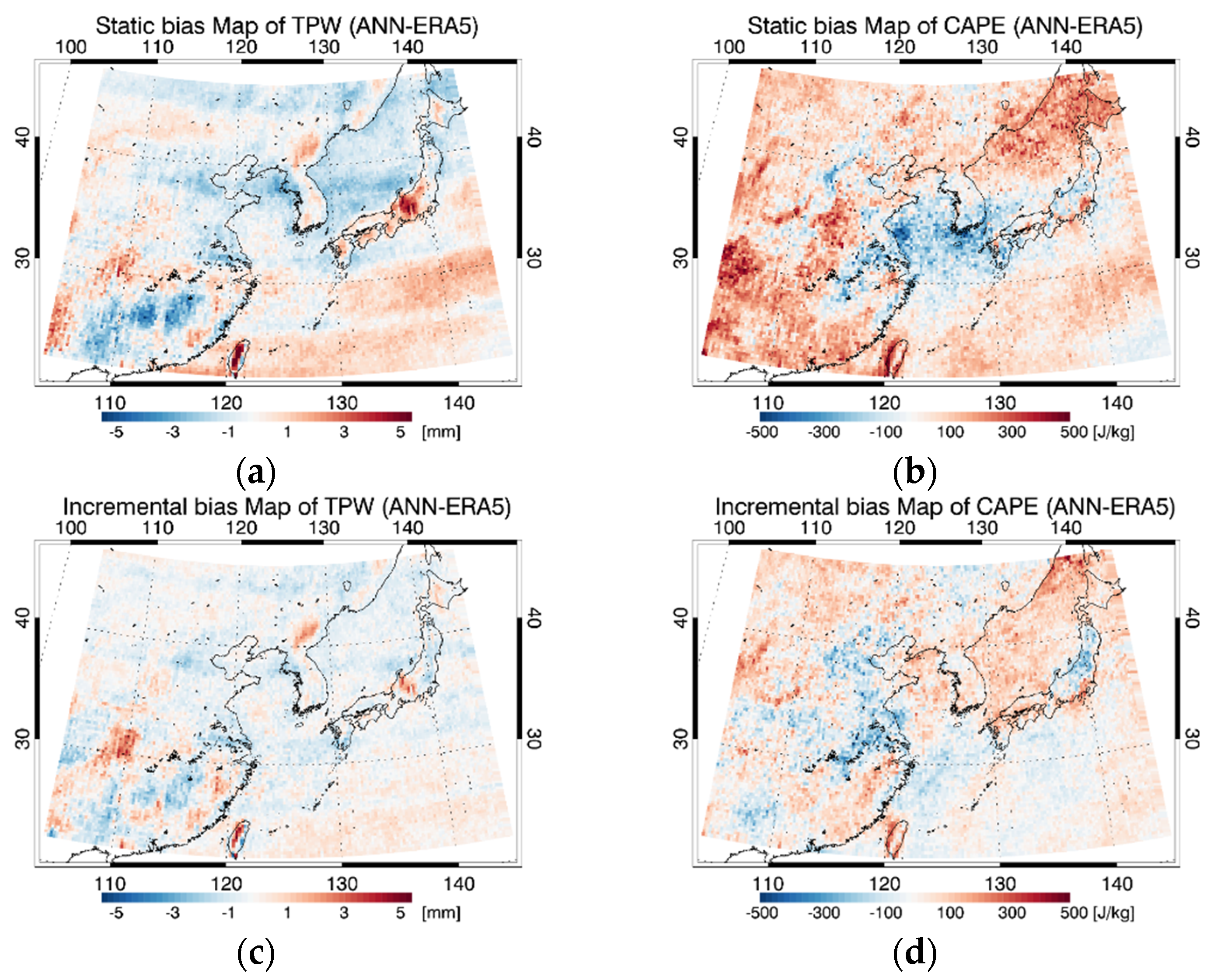
4.3. Evaluation Results and Comparison
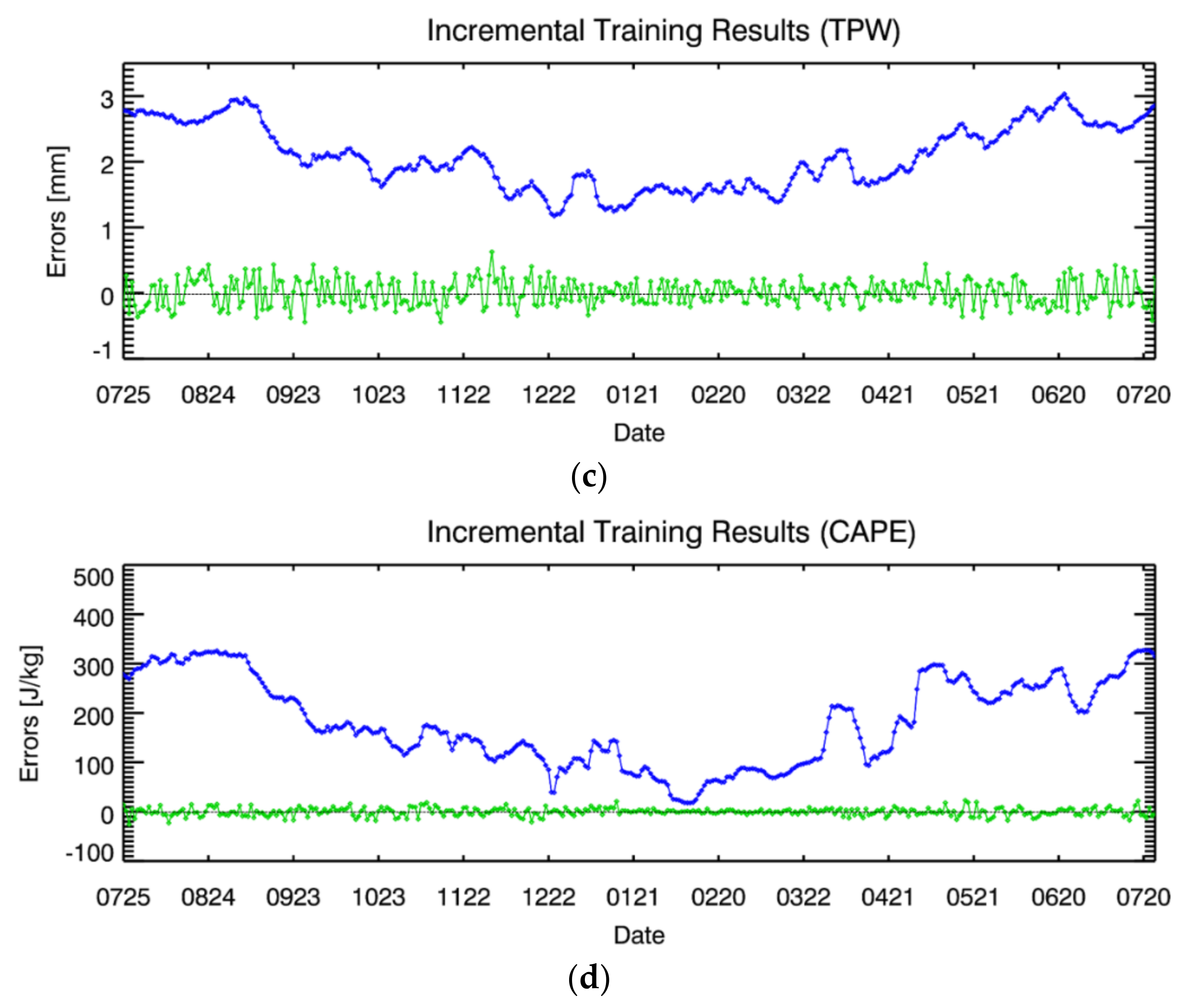
4.4. Error Analysis
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Comparison with State-of-the-Are Methods

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyper- Parameter | TPW (mm) | CAPE (J/kg) | |||||
|---|---|---|---|---|---|---|---|
| Bias | RMSE | R | Bias | RMSE | R | ||
| ANN | 881 | 0.01 | 3.43 | 0.98 | −29.28 | 415.12 | 0.84 |
| CNN | 1685 | −0.22 | 3.36 | 0.98 | −69.59 | 407.89 | 0.85 |
| RNN | 4071 | −0.20 | 3.32 | 0.98 | −38.34 | 411.21 | 0.85 |
References
- Koutavarapu, R.; Umakanth, N.; Satyanarayana, T.; Kumar, M.S.; Rao, M.C.; Lee, D.-Y.; Shim, J. Study of Statistical Estimated Parameters Using ERA5 Reanalysis Data over Khulna Region during Monsoon Season. Acta Geophys. 2021, 69, 1963–1978. [Google Scholar] [CrossRef]
- Botes, D.; Mecikalski, J.R.; Jedlovec, G.J. Atmospheric Infrared Sounder (AIRS) Sounding Evaluation and Analysis of the Pre-Convective Environment: Pre-Convective Airs Sounding Analysis. J. Geophys. Res. 2012, 117, 1–22. [Google Scholar] [CrossRef]
- Kwon, T.-Y.; Kim, J.-S.; Kim, B.-G. Comparison of the Properties of Yeongdong and Yeongseo Heavy Rain. Atmosphere 2013, 23, 245–264. [Google Scholar] [CrossRef]
- Kim, Y.-C.; Ham, S.-J. Heavy Rainfall prediction using convective instability index. J. Korean Soc. Aviat. Aeronaut. 2009, 17, 17–23. [Google Scholar]
- Jung, S.-P.; Kwon, T.-Y.; Han, S.-O.; Jeong, J.-H.; Shim, J.; Choi, B.-C. Thermodynamic Characteristics Associated with Localized Torrential Rainfall Events in the Southwest Region of the Korean Peninsula. Asia-Pac. J. Atmos. Sci. 2015, 51, 229–237. [Google Scholar] [CrossRef]
- McNulty, R.P. Severe and Convective Weather: A Central Region Forecasting Challenge. Weather Forecast. 1995, 10, 187–202. [Google Scholar] [CrossRef]
- Kulikov, M.Y.; Belikovich, M.V.; Skalyga, N.K.; Shatalina, M.V.; Dementyeva, S.O.; Ryskin, V.G.; Shvetsov, A.A.; Krasil’nikov, A.A.; Serov, E.A.; Feigin, A.M. Skills of Thunderstorm Prediction by Convective Indices over a Metropolitan Area: Comparison of Microwave and Radiosonde Data. Remote Sens. 2020, 12, 604. [Google Scholar] [CrossRef]
- Gartzke, J.; Knuteson, R.; Przybyl, G.; Ackerman, S.; Revercomb, H. Comparison of Satellite-, Model-, and Radiosonde-Derived Convective Available Potential Energy in the Southern Great Plains Region. J. Appl. Meteor. Climatol. 2017, 56, 1499–1513. [Google Scholar] [CrossRef]
- Bevis, M.; Businger, S.; Herring, T.A.; Rocken, C.; Anthes, R.A.; Ware, R.H. GPS Meteorology: Remote Sensing of Atmospheric Water Vapor Using the Global Positioning System. J. Geophys. Res. Atmos. 1992, 97, 15787–15801. [Google Scholar] [CrossRef]
- Liu, Z.; Min, M.; Li, J.; Sun, F.; Di, D.; Ai, Y.; Li, Z.; Qin, D.; Li, G.; Lin, Y.; et al. Local Severe Storm Tracking and Warning in Pre-Convection Stage from the New Generation Geostationary Weather Satellite Measurements. Remote Sens. 2019, 11, 383. [Google Scholar] [CrossRef]
- Lee, J.; Lee, S.-W.; Han, S.-O.; Lee, S.-J.; Jang, D.-E. The Impact of Satellite Observations on the UM-4DVar Analysis and Prediction System at KMA. Atmosphere 2011, 21, 85–93. [Google Scholar] [CrossRef]
- Mecikalski, J.R.; Rosenfeld, D.; Manzato, A. Evaluation of Geostationary Satellite Observations and the Development of a 1–2 h Prediction Model for Future Storm Intensity. J. Geophys. Res. Atmos. 2016, 121, 6374–6392. [Google Scholar] [CrossRef]
- Kim, D.; Gu, M.; Oh, T.-H.; Kim, E.-K.; Yang, H.-J. Introduction of the Advanced Meteorological Imager of Geo-Kompsat-2a: In-Orbit Tests and Performance Validation. Remote Sens. 2021, 13, 1303. [Google Scholar] [CrossRef]
- Li, Z.; Li, J.; Menzel, W.P.; Schmit, T.J.; Nelson, J.P.; Daniels, J.; Ackerman, S.A. GOES Sounding Improvement and Applications to Severe Storm Nowcasting. Geophys. Res. Lett. 2008, 35. [Google Scholar] [CrossRef]
- Jin, X.; Li, J.; Schmit, T.J.; Li, J.; Goldberg, M.D.; Gurka, J.J. Retrieving Clear-Sky Atmospheric Parameters from SEVIRI and ABI Infrared Radiances. J. Geophys. Res. Atmos. 2008, 113. [Google Scholar] [CrossRef]
- Lee, S.J.; Ahn, M.-H.; Chung, S.-R. Atmospheric Profile Retrieval Algorithm for Next Generation Geostationary Satellite of Korea and Its Application to the Advanced Himawari Imager. Remote Sens. 2017, 9, 1294. [Google Scholar] [CrossRef]
- Basili, P.; Bonafoni, S.; Mattioli, V.; Pelliccia, F.; Ciotti, P.; Carlesimo, G.; Pierdicca, N.; Venuti, G.; Mazzoni, A. Neural-Network Retrieval of Integrated Precipitable Water Vapor over Land from Satellite Microwave Radiometer. In Proceedings of the 2010 11th Specialist Meeting on Microwave Radiometry and Remote Sensing of the Environment, Washington, DC, USA, 1–4 March 2010; pp. 161–166. [Google Scholar]
- Lee, Y.; Han, D.; Ahn, M.-H.; Im, J.; Lee, S.J. Retrieval of Total Precipitable Water from Himawari-8 AHI Data: A Comparison of Random Forest, Extreme Gradient Boosting, and Deep Neural Network. Remote Sens. 2019, 11, 1741. [Google Scholar] [CrossRef]
- Mallet, C.; Moreau, E.; Casagrande, L.; Klapisz, C. Determination of Integrated Cloud Liquid Water Path and Total Precipitable Water from SSM/I Data Using a Neural Network Algorithm. Int. J. Remote Sens. 2002, 23, 661–674. [Google Scholar] [CrossRef]
- Hecht-Nielsen, R. III.3—Theory of the Backpropagation Neural Network**Based on “Nonindent”. In Neural Networks for Perception, Proceedings of the International Joint Conference on Neural Networks, Washington, DC, USA, 18–22 June 1989; Wechsler, H., Ed.; Academic Press: Cambridge, MA, USA, 1992; pp. 65–93. ISBN 978-0-12-741252-8. [Google Scholar]
- Gamage, S.; Premaratne, U. Detecting and Adapting to Concept Drift in Continually Evolving Stochastic Processes. In Proceedings of the International Conference on Big Data and Internet of Thing, London, UK, 20–22 December 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 109–114. [Google Scholar]
- Andrade, M.; Gasca, E.; Rendón, E. Implementation of Incremental Learning in Artificial Neural Networks. In Proceedings of the 3rd Global Con- ference on Artificial Intelligence, Miami, FL, USA, 18–22 October 2017; EasyChair: Manchester, UK, 2017; Volume 50, pp. 221–232. [Google Scholar]
- Tasar, O.; Tarabalka, Y.; Alliez, P. Incremental Learning for Semantic Segmentation of Large-Scale Remote Sensing Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3524–3537. [Google Scholar] [CrossRef]
- Xiao, T.; Zhang, J.; Yang, K.; Peng, Y.; Zhang, Z. In Proceedings of the 22nd ACM International Conference on Multimedia Virtual Event, Online, 3–7 November 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 177–186.
- Bruzzone, L.; Fernàndez Prieto, D. An Incremental-Learning Neural Network for the Classification of Remote-Sensing Images. Pattern Recognit. Lett. 1999, 20, 1241–1248. [Google Scholar] [CrossRef]
- Li, X.; Du, Z.; Huang, Y.; Tan, Z. A Deep Translation (GAN) Based Change Detection Network for Optical and SAR Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2021, 179, 14–34. [Google Scholar] [CrossRef]
- Zhan, Y.; Qin, J.; Huang, T.; Wu, K.; Hu, D.; Zhao, Z.; Wang, Y.; Cao, Y.; Jiao, R.; Medjadba, Y.; et al. Hyperspectral Image Classification Based on Generative Adversarial Networks with Feature Fusing and Dynamic Neighborhood Voting Mechanism. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 811–814. [Google Scholar]
- Tuller, S.E. World Distribution of Mean Monthly and Annual Precipitable Water. Mon. Weather Rev. 1968, 96, 785–797. [Google Scholar] [CrossRef]
- Durre, I.; Vose, R.S.; Wuertz, D.B. Overview of the Integrated Global Radiosonde Archive. J. Clim. 2006, 19, 53–68. [Google Scholar] [CrossRef]
- Dai, A.; Wang, J.; Thorne, P.W.; Parker, D.E.; Haimberger, L.; Wang, X.L. A New Approach to Homogenize Daily Radiosonde Humidity Data. J. Clim. 2011, 24, 965–991. [Google Scholar] [CrossRef]
- Zhang, W.; Lou, Y.; Haase, J.S.; Zhang, R.; Zheng, G.; Huang, J.; Shi, C.; Liu, J. The Use of Ground-Based GPS Precipitable Water Measurements over China to Assess Radiosonde and ERA-Interim Moisture Trends and Errors from 1999 to 2015. J. Clim. 2017, 30, 7643–7667. [Google Scholar] [CrossRef]
- Persson, A. User Guide to ECMWF Forecast Products. 2001; p. 107. Available online: https://ghrc.nsstc.nasa.gov/uso/ds_docs/tcsp/tcspecmwf/ECMWFUserGuideofForecastProductsm32.pdf (accessed on 5 December 2021).
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 Global Reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Hensley, S.; Rosen, P.; Gurrola, E. The SRTM Topographic Mapping Processor. In Proceedings of the IGARSS 2000. IEEE 2000 International Geoscience and Remote Sensing Symposium. Taking the Pulse of the Planet: The Role of Remote Sensing in Managing the Environment. Proceedings (Cat. No.00CH37120), Honolulu, HI, USA, 24–28 July 2000; IEEE: Honolulu, HI, USA, July 2000; Volume 3, pp. 1168–1170. [Google Scholar]
- Berry, P.A.M.; Garlick, J.D.; Smith, R.G. Near-Global Validation of the SRTM DEM Using Satellite Radar Altimetry. Remote Sens. Environ. 2007, 106, 17–27. [Google Scholar] [CrossRef]
- Blackwell, W.J. A Neural-Network Technique for the Retrieval of Atmospheric Temperature and Moisture Profiles from High Spectral Resolution Sounding Data. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2535–2546. [Google Scholar] [CrossRef]
- Koenig, M.; de Coning, E. The MSG Global Instability Indices Product and Its Use as a Nowcasting Tool. Weather Forecast. 2009, 24, 272–285. [Google Scholar] [CrossRef]
- Martinez, M.A.; Velazquez, M.; Manso, M.; Mas, I. Application of LPW and SAI SAFNWC/MSG Satellite Products in Pre-Convective Environments. Atmos. Res. 2007, 83, 366–379. [Google Scholar] [CrossRef]
- Atkinson, P.M.; Tatnall, A.R.L. Introduction Neural Networks in Remote Sensing. Int. J. Remote Sens. 1997, 18, 699–709. [Google Scholar] [CrossRef]
- Chollet, F. Deep Learning with Python; Simon and Schuster: New York, NY, USA, 2017; ISBN 978-1-63835-204-4. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A System for Large-Scale Machine Learning; UNSENIX: Berkeley, CA, USA, 2016; pp. 265–283. [Google Scholar]
- Blackwell, W.J.; Chen, F.W. Neural Networks in Atmospheric Remote Sensing; Artech House: Norwood, MA, USA, 2009; ISBN 978-1-59693-373-6. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Jin, J.; Li, M.; Jin, L. Data Normalization to Accelerate Training for Linear Neural Net to Predict Tropical Cyclone Tracks. Math. Probl. Eng. 2015, 2015, e931629. [Google Scholar] [CrossRef]
- Casillas, J.; Wang, S.; Yao, X. Concept Drift Detection in Histogram-Based Straightforward Data Stream Prediction. In Proceedings of the 2018 IEEE International Conference on Data Mining Workshops (ICDMW), Singapore, 17–20 November 2018; pp. 878–885. [Google Scholar]
- Gepperth, A.; Hammer, B. Incremental Learning Algorithms and Applications. In Proceedings of the European Symposium on Artificial Neural Networks (ESANN), Bruges, Belgium, 27–29 April 2016. [Google Scholar]
- Gama, J.; Medas, P.; Castillo, G.; Rodrigues, P. Learning with Drift Detection. In Advances in Artificial Intelligence—SBIA 2004, Proceedings of the 17th Brazilian Symposium on Artificial Intelligence, Sao Luis, Brazil, 29 September–1 Ocotber 2004; Bazzan, A.L.C., Labidi, S., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; pp. 286–295. [Google Scholar]
- Guha, S.; Koudas, N.; Shim, K. Approximation and Streaming Algorithms for Histogram Construction Problems. ACM Trans. Database Syst. 2006, 31, 396–438. [Google Scholar] [CrossRef]
- Sebastião, R.; Gama, J.; Mendonça, T. Constructing Fading Histograms from Data Streams. Prog. Artif. Intell. 2014, 3, 15–28. [Google Scholar] [CrossRef][Green Version]
- Wang, H.; Fan, W.; Yu, P.S.; Han, J. Mining Concept-Drifting Data Streams Using Ensemble Classifiers. In Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 24 August 2003; Association for Computing Machinery: New York, NY, USA, 2003; pp. 226–235. [Google Scholar]
- Oskoei, M.A.; Hu, H. Support Vector Machine-Based Classification Scheme for Myoelectric Control Applied to Upper Limb. IEEE Trans. Biomed. Eng. 2008, 55, 1956–1965. [Google Scholar] [CrossRef]
- Smith, L.H.; Hargrove, L.J.; Lock, B.A.; Kuiken, T.A. Determining the Optimal Window Length for Pattern Recognition-Based Myoelectric Control: Balancing the Competing Effects of Classification Error and Controller Delay. IEEE Trans. Neural Syst. Rehabil. Eng. 2011, 19, 186–192. [Google Scholar] [CrossRef]
- Ebell, K.; Orlandi, E.; Hünerbein, A.; Löhnert, U.; Crewell, S. Combining Ground-Based with Satellite-Based Measurements in the Atmospheric State Retrieval: Assessment of the Information Content. J. Geophys. Res. Atmos. 2013, 118, 6940–6956. [Google Scholar] [CrossRef]
- Schmit, T.J.; Lindstrom, S.S.; Gerth, J.J.; Gunshor, M.M. Applications of the 16 Spectral Bands on the Advanced Baseline Imager (ABI). 2018. Available online: http://nwafiles.nwas.org/jom/articles/2018/2018-JOM4/2018-JOM4.pdf (accessed on 5 December 2021).
- Yu, L.; Wang, S.; Lai, K.K. An Integrated Data Preparation Scheme for Neural Network Data Analysis. IEEE Trans. Knowl. Data Eng. 2006, 18, 217–230. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation Importance: A Corrected Feature Importance Measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef]
- Lee, S.J.; Ahn, M.-H. Synergistic Benefits of Intercomparison Between Simulated and Measured Radiances of Imagers Onboard Geostationary Satellites. IEEE Trans. Geosci. Remote Sens. 2021, 59, 10725–10737. [Google Scholar] [CrossRef]
- Voormansik, T.; Rossi, P.J.; Moisseev, D.; Tanilsoo, T.; Post, P. Thunderstorm Hail and Lightning Detection Parameters Based on Dual-Polarization Doppler Weather Radar Data. Meteorol. Appl. 2017, 24, 521–530. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a Convolutional Neural Network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Medsker, L.; Jain, L.C. (Eds.) Recurrent Neural Networks: Design and Applications; CRC Press: Boca Raton, FL, USA, 1999; ISBN 978-1-00-304062-0. [Google Scholar]
- Baeza-Yates, R.; Liaghat, Z. Quality-Efficiency Trade-Offs in Machine Learning for Text Processing. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 897–904. [Google Scholar]













| Channel | Central Wavelength (μm) | Spatial Resolution at Sub-Satellite Point (km) | |
|---|---|---|---|
| 1 | VIS | 0.470 | 1 |
| 2 | 0.510 | 1 | |
| 3 | 0.640 | 0.5 | |
| 4 | 0.860 | 1 | |
| 5 | NIR | 1.38 | 2 |
| 6 | 1.61 | 2 | |
| 7 | SW038 | 3.83 | 2 |
| 8 | WV063 | 6.24 | 2 |
| 9 | WV069 | 6.95 | 2 |
| 10 | WV073 | 7.34 | 2 |
| 11 | IR087 | 8.59 | 2 |
| 12 | IR096 | 9.63 | 2 |
| 13 | IR105 | 10.4 | 2 |
| 14 | IR112 | 11.2 | 2 |
| 15 | IR123 | 12.4 | 2 |
| 16 | IR133 | 13.3 | 2 |
| Variable | Physical Property |
|---|---|
| ) | Water vapor in upper tropospheric |
| ) | Water vapor in mid and upper tropospheric |
| ) | Water vapor in mid tropospheric |
| ) | SO2, low level moisture, cloud phase |
| ) | Total ozone, upper air flow |
| ) | Land/sea surface temperature, cloud information, fog, Asian dust, amount of water vapor in lower level, atmospheric motion vector |
| ) | |
| ) | |
| ) | Air temperature |
| DCD1 (BT14–BT8) | Moisture in upper tropospheric |
| DCD2 (BT14–BT9) | Moisture in mid and upper tropospheric |
| DCD3 (BT14–BT10) | Moisture in mid tropospheric |
| DCD4 (BT14–BT11) | Amount of water vapor |
| DCD5 (BT14–BT15) | Split-window channels (amount of water vapor) |
| DCD6 (BT10–BT8) | Difference between water vapor channels |
| Cyclic day | Time information |
| Latitude/Longitude | Geographic information |
| Satellite zenith angle | Optical depth |
| Altitude | Topographic information (only use for TPW) |
| Total precipitable water | Amount of water vapor in the air (only use for CAPE) |
| Method | Period and Usage | ||
|---|---|---|---|
| Training | Static learning | 25 July 2019 to 24 July 2020 (00/06/12/18 UTC) | TPW: 80% (487,135) for training and 20% (121,784) for validation CAPE: 80% (492,478) for training and 20% (123,120) for validation |
| Incremental learning | 18 July 2020 to 24 July 2021 (00/06/12/18 UTC) | 8:2 for training and validation | |
| Testing | 25 July 2020 to 24 July 2021 (00/06/12/18 UTC) | ||
| Static NN | Incremental NN | |||||
|---|---|---|---|---|---|---|
| Bias | RMSE | R | Bias | RMSE | R | |
| ERA5_TPW | 0.11 | 3.43 | 0.97 | 0.04 | 3.17 | 0.98 |
| ERA5_CAPE | 3.65 | 516.62 | 0.74 | −9.69 | 461.50 | 0.80 |
| RAOB_TPW | 0.23 | 5.05 | 0.95 | −0.17 | 4.39 | 0.96 |
| RAOB_CAPE | 338.10 | 700.81 | 0.56 | 251.70 | 619.28 | 0.65 |
| Static ANN | Incremental ANN | |
|---|---|---|
| TPW | 0.76 | 0.52 |
| CAPE | 0.79 | 0.32 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, Y.; Ahn, M.-H.; Lee, S.-J. Incremental Learning with Neural Network Algorithm for the Monitoring Pre-Convective Environments Using Geostationary Imager. Remote Sens. 2022, 14, 387. https://doi.org/10.3390/rs14020387
Lee Y, Ahn M-H, Lee S-J. Incremental Learning with Neural Network Algorithm for the Monitoring Pre-Convective Environments Using Geostationary Imager. Remote Sensing. 2022; 14(2):387. https://doi.org/10.3390/rs14020387
Chicago/Turabian StyleLee, Yeonjin, Myoung-Hwan Ahn, and Su-Jeong Lee. 2022. "Incremental Learning with Neural Network Algorithm for the Monitoring Pre-Convective Environments Using Geostationary Imager" Remote Sensing 14, no. 2: 387. https://doi.org/10.3390/rs14020387
APA StyleLee, Y., Ahn, M.-H., & Lee, S.-J. (2022). Incremental Learning with Neural Network Algorithm for the Monitoring Pre-Convective Environments Using Geostationary Imager. Remote Sensing, 14(2), 387. https://doi.org/10.3390/rs14020387