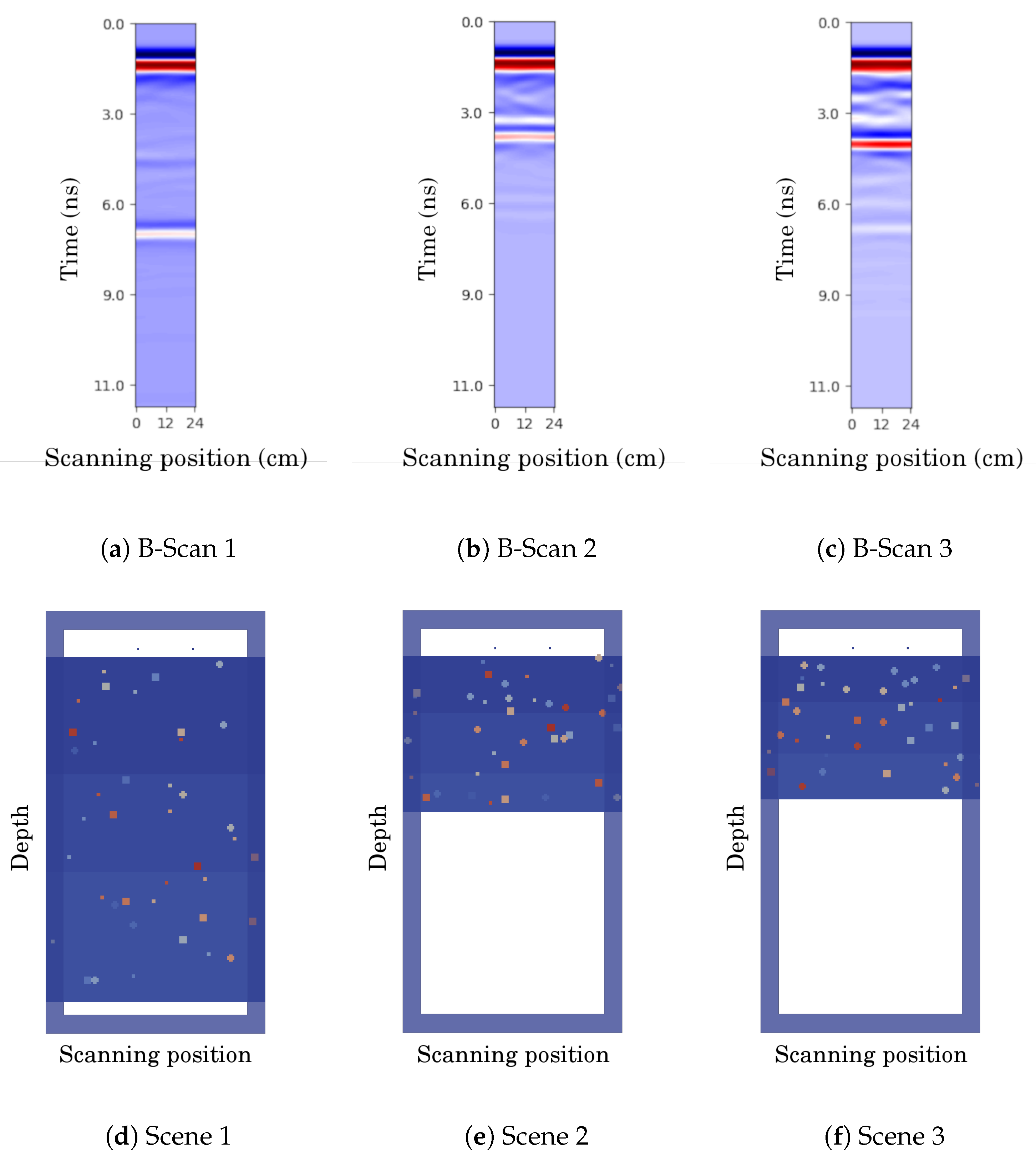
4.1. Evaluation on Simulated Data
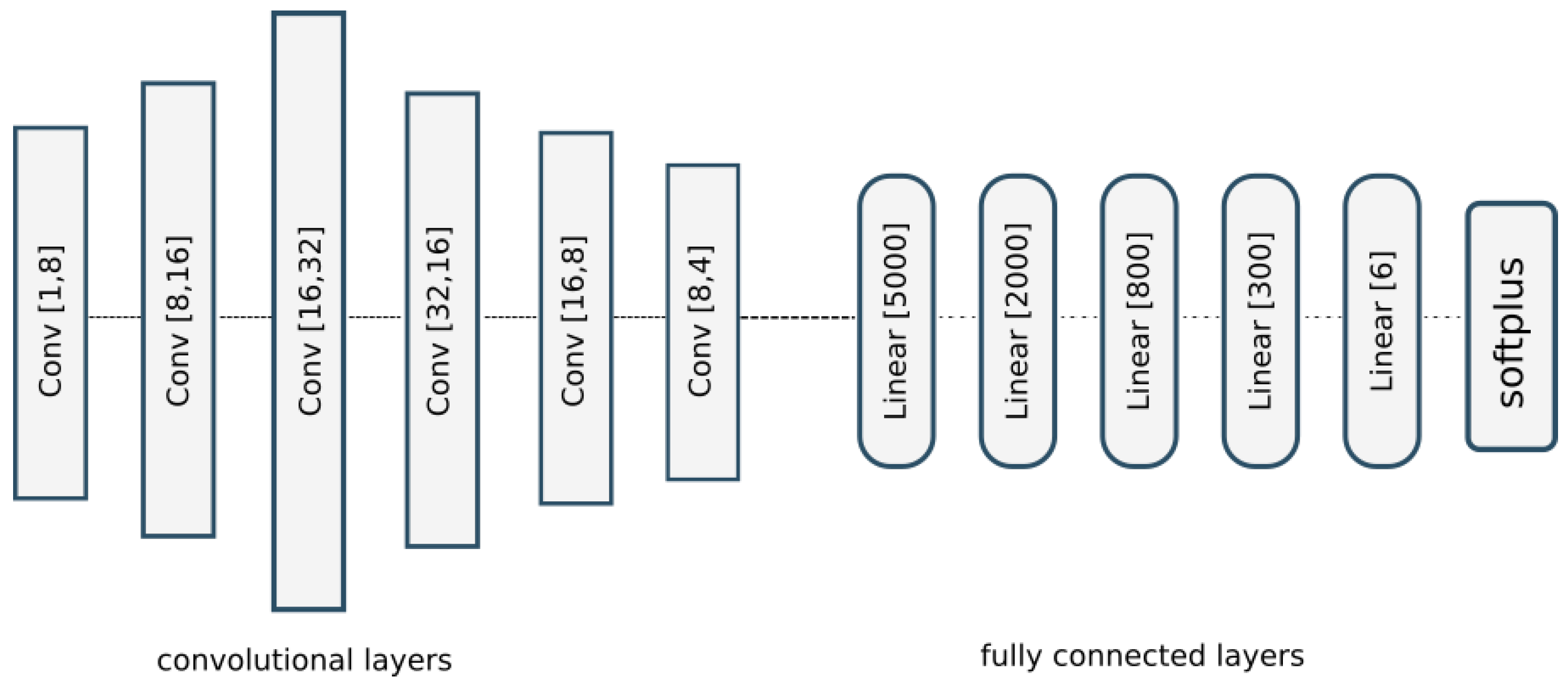
The previously described simulated data were used to train the convolutional neural network from
Section 2.1. We split the dataset into training and testing sets in a ratio of 80 to 20. The CNN was trained for 1500 epochs. The network parameters were optimized with the ADAM optimizer with a step length of 0.001.
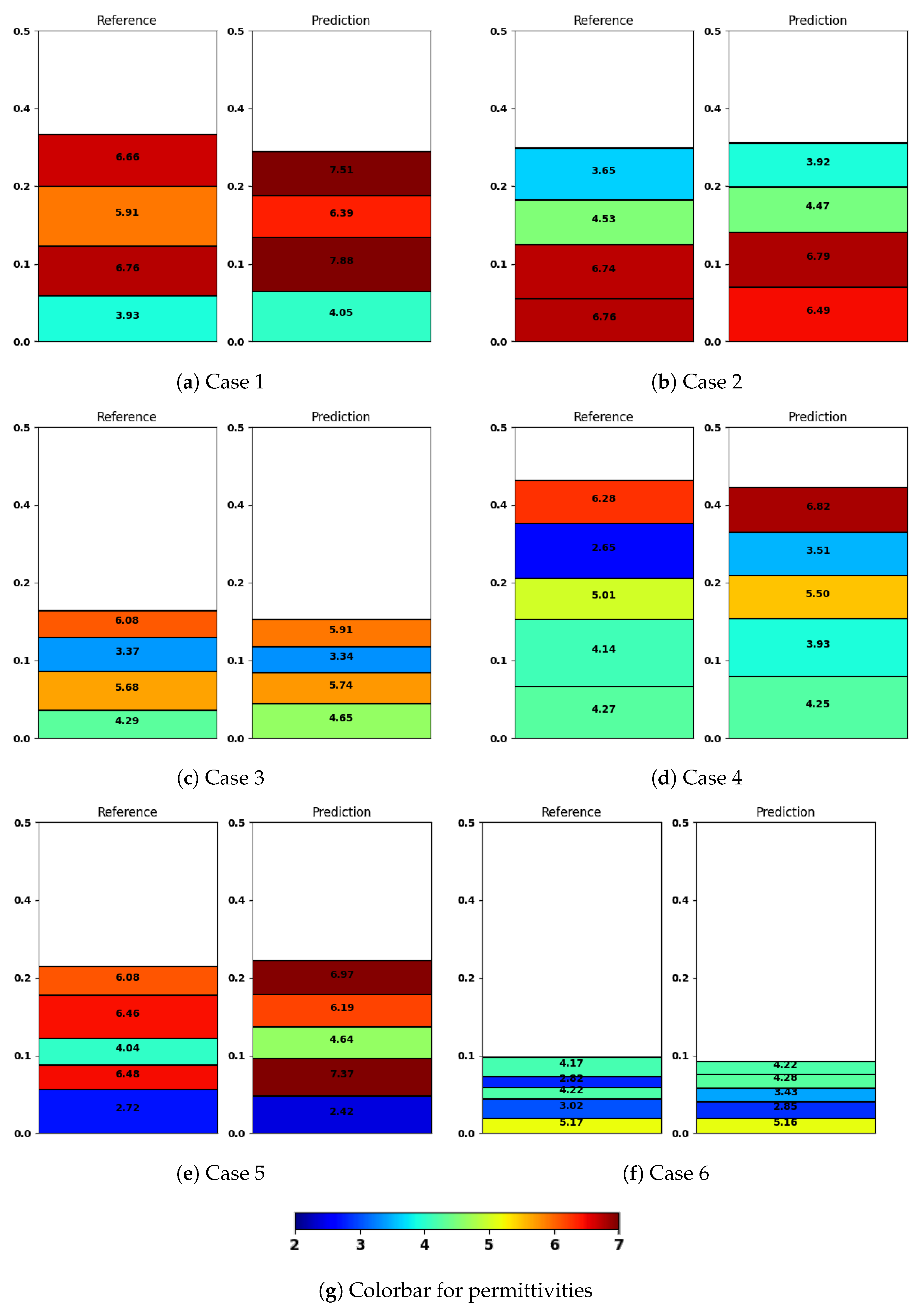
The results of the CNN’s performance are visualized in
Figure 7, where we show six examples from the test dataset (left) together with the output of our trained model (right). We omitted the structures with few layers in this visualization in order to showcase the more complex cases, but we provide such results in
Table 2. We observe that low permittivity layers negatively affect the quality of prediction in further layers, as can be seen in
Figure 7a,b,e. In Case 1 from
Figure 7a, the first layer has a permittivity of 3.93, which is predicted fairly close by the model to be 4.05. However, the prediction error in subsequent layers is already more significant, ranging from 0.48 to 1.12. A similar situation appears in Case 5 from
Figure 7e. The first layer has a permittivity of 2.72, and its thickness and permittivity are predicted quite well by the model, but the further layers have a visible divergence from the reference configuration both in terms of thicknesses and permittivities. The opposite situation can be observed in Case 2 from
Figure 7b. The first layer has a quite high permittivity—6.76. The range of prediction errors for the further layers stays between 0.05 and 0.27, and even around 0.05–0.06 for the first layers, which is a significantly better prediction than with the previously mentioned cases. A similar behavior can be observed in cases
Figure 7c,d. In Case 6 from
Figure 7f, we can also see an accurate prediction of the first layers with high permittivity. However, due to the second layer having a low permittivity value of 3.02, the prediction errors in the further layers rapidly increase, going from 0.79 to 1.46.
Statistics over the whole dataset are shown in
Table 3, where the average error values in thickness and permittivity are presented. The errors in thickness amounted to 9.3 mm in thickness for the training set and 10.2 mm for the test set. The values are also presented as percentages and compared against average thicknesses and permittivities of the whole dataset—10.1% for the training set and 3.3% for the test set. Given that the estimated vertical resolution for the antenna of central frequency 1 GHz is about 2.5 cm [
20], the achieved results are adequate. Regarding the permittivities, the average training and test errors are 0.71 and 0.81, respectively. As mentioned in the previous section, we used the permittivity range between 1 and 7. This means that achieving average permittivity errors below 1 demonstrates a good model performance.
We also considered a dataset with fewer layers. The statistics are presented in
Table 2. The values show very similar performances. Moreover, on this dataset, we were able to better predict permittivities on average compared to the six-layer cases. However, the results show a slightly higher error value for thickness predictions on the test set.
Additionally, we provide per-layer error values in
Table 4. It can be observed that the prediction of thicknesses worsens at deeper layers, which is to be expected, considering the dissipation of signals going through the previous layers. The effect is, however, not present for permittivities. Their prediction remains stable throughout the layers within the one percent range.
Overall, we can conclude that the proposed network architecture achieves good results on the simulated data.
4.2. Evaluation on Actual Buildings
We evaluated the network architecture on the described real dataset. We tested two modes: one using only the real data as input, and one using transfer learning, where we pre-trained the model on the simulated dataset and then let it train on the collected dataset. The idea of using transfer learning is that the network could generalize beyond the input seen in the real-world training data. This is important because the training data contain only a limited number of typical wall builds.
Both modes were trained for 500 epochs. The results are shown in
Table 5 and
Table 6.
It can be seen that the pre-trained model does not demonstrate better performance. Results on the training part of the collected dataset are slightly better for the untrained model and significantly better on the test dataset for the untrained model, too. The reason for this performance difference lies in the deviation between the simulated and the collected data; the simulated data cover a larger variation of wall builds, and can, therefore, be expected to generalize better to unseen builds, however, at the cost of a lower performance for the wall builds that are actually contained in the data. Evaluating this generalization in more depth is the subject of future work.
Furthermore, the task of generating realistic data that are similar to the output of the target device is difficult due to the problem of reproducing the device model. We used the same antenna frequency in the simulation as the device we utilized, but other factors are as important, including antenna geometry, radiation pattern, etc. These factors made the simulated B-scans considerably different from the ones we collected.
The network that was trained only on the real data demonstrates high performance in terms of material classification accuracy and precision of thickness prediction. As
Table 7 shows, it achieves an accuracy of 92% on the training set and 90% on the test set. The classification was implemented by assigning a material with the closest permittivity value, and thus, depends on the prediction of permittivities. The precision of permittivity prediction is shown in
Table 5. It shows an average error of 0.17 for the training set and 0.29 for the test set, which is a favorable result since the construction materials’ permittivity range is typically 1 to 7. In terms of predicting layer thicknesses, we can see the errors of 12.9 mm and 15.3 mm for training and test sets. These values are higher than the ones obtained from training the CNN on the simulated dataset. However, the demonstrated performance is as expected, considering that the dataset with real scans contains noisier, more complex data and the fact that wall thicknesses can reach 40 cm.





 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






