DeepForest: Novel Deep Learning Models for Land Use and Land Cover Classification Using Multi-Temporal and -Modal Sentinel Data of the Amazon Basin



Abstract
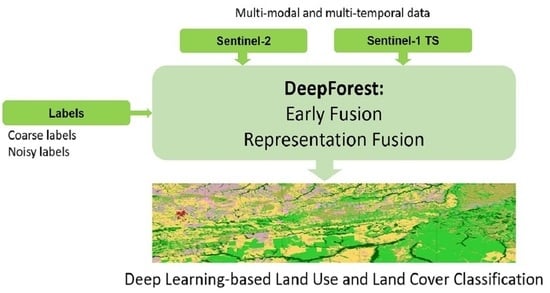
1. Introduction
2. Materials and Methods
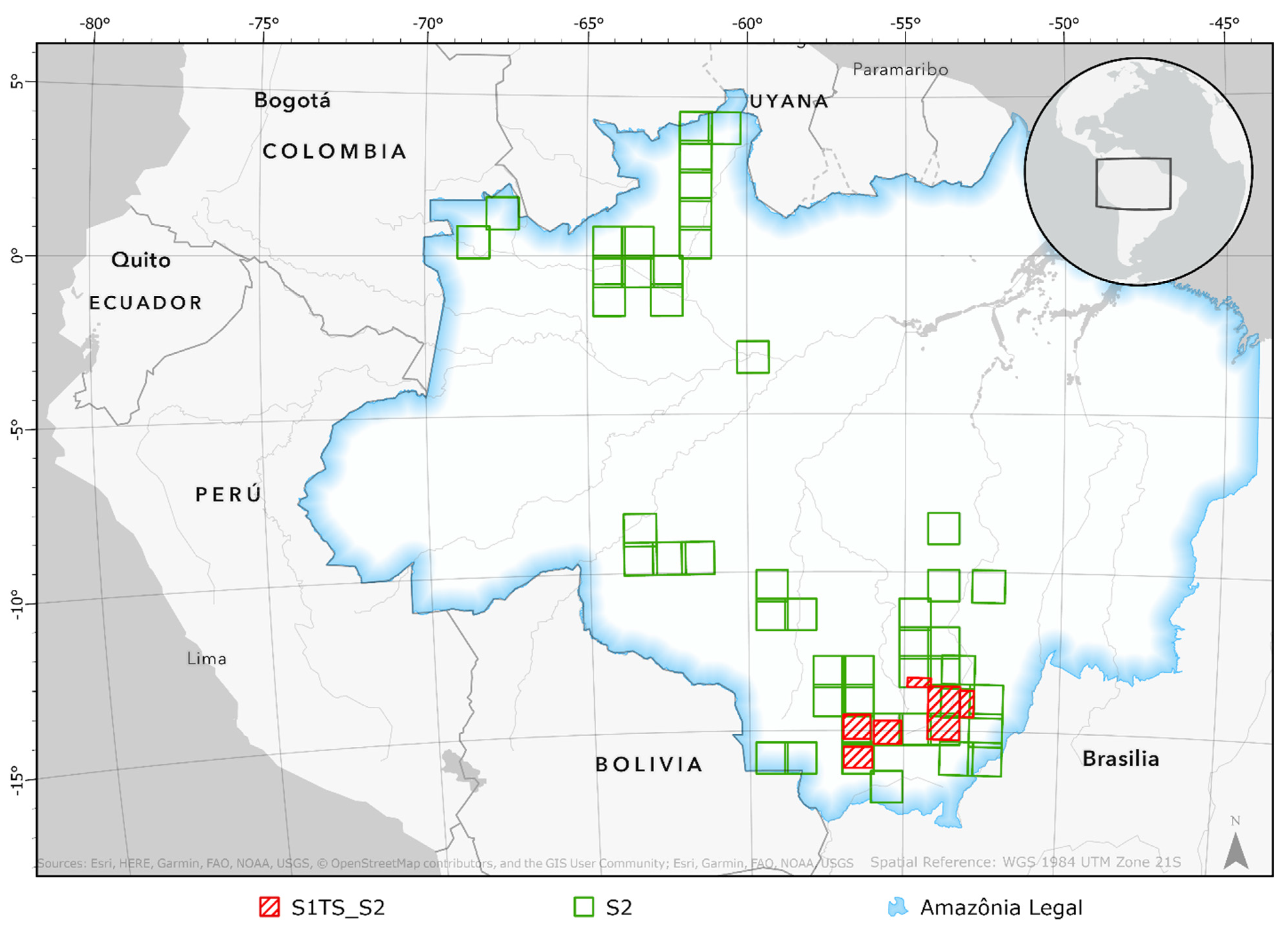
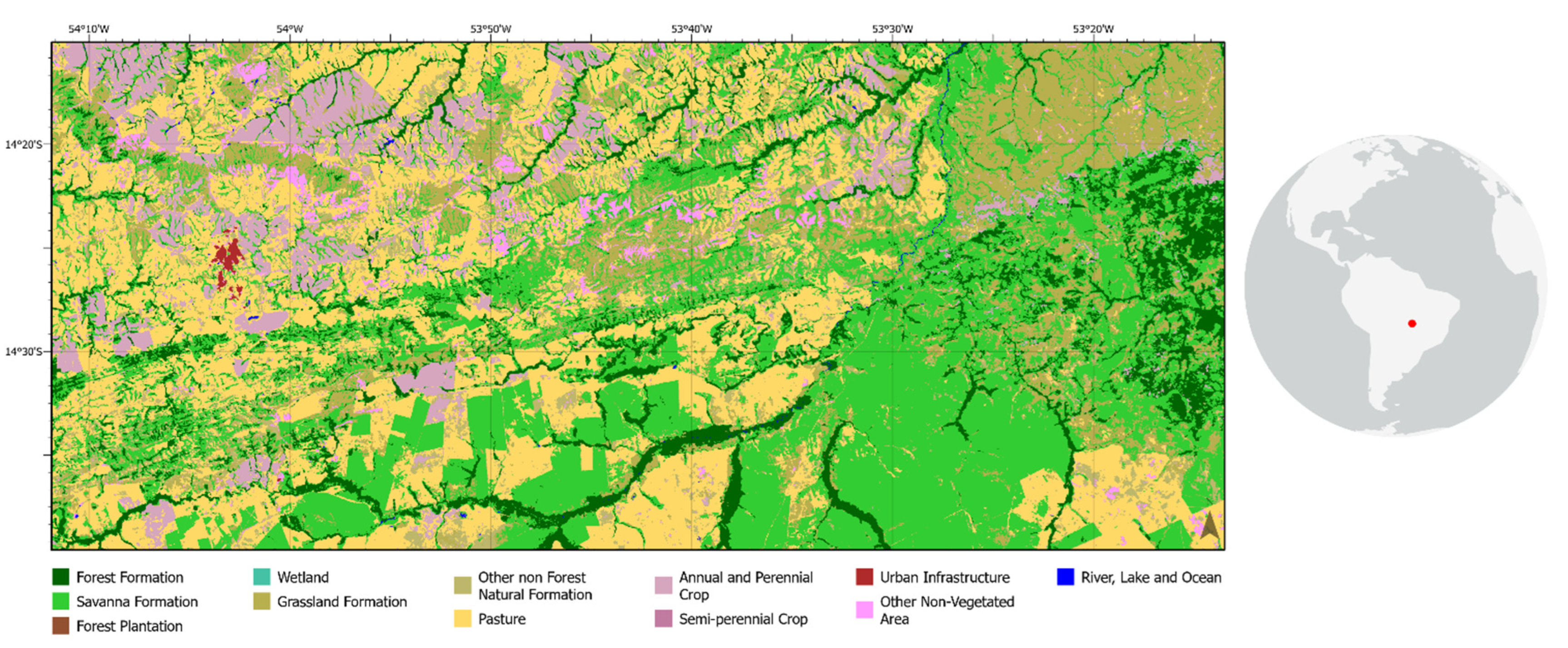
2.1. Study Area
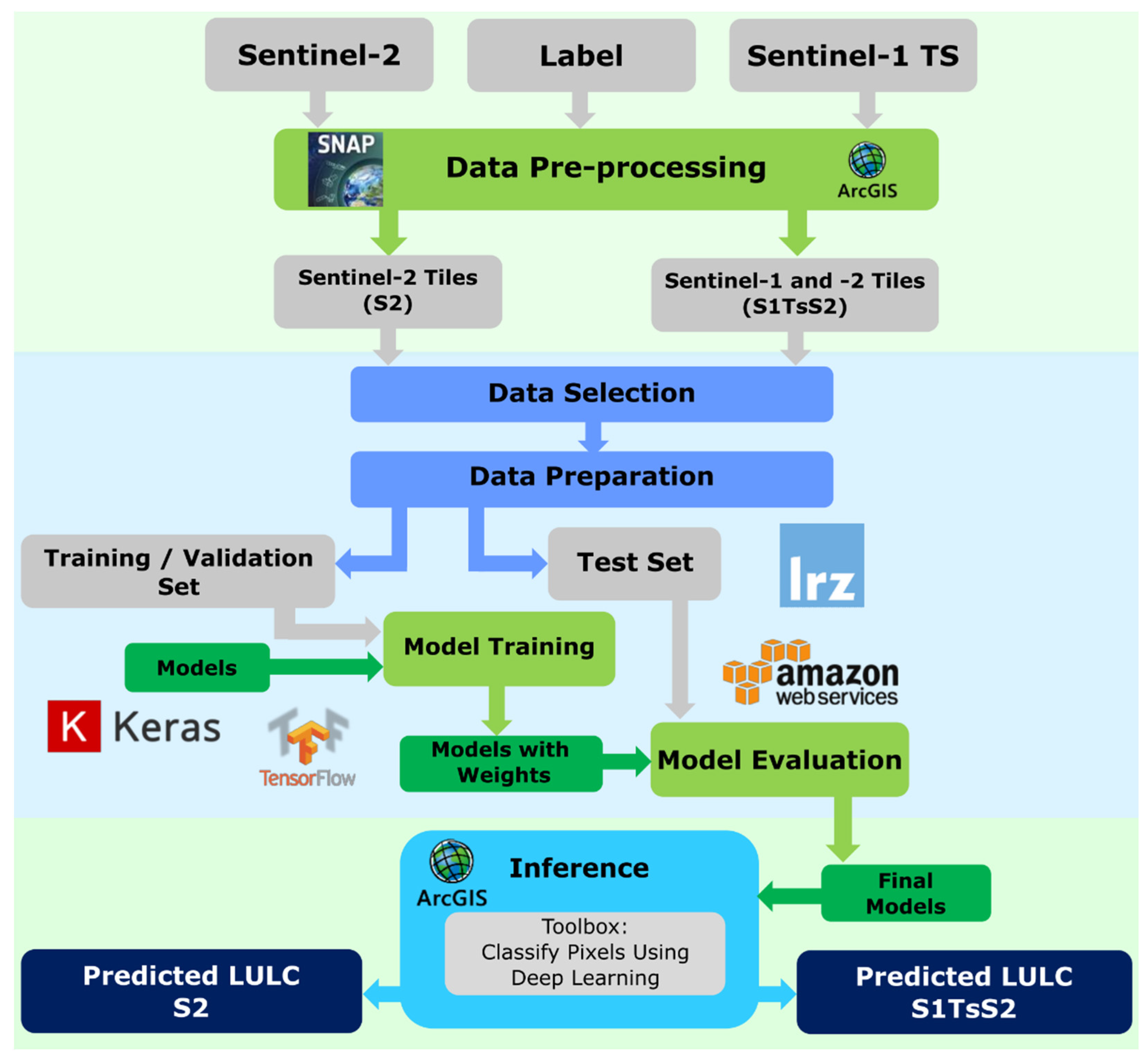
2.2. Data and Pre-Processing
2.3. Deep-Learning Approaches and Experiments
- Investigation of the performance of SotA architectures with Sentinel-2 and SAR Sentinel-1 data regarding LULC classification. We trained and tested U-Net and DeepLab on both the multispectral data and the fused datasets;
- Furthermore, we propose new approaches including spatial-temporal dependencies and different fusion strategies to take the multi-temporal nature of the data into consideration;
- Finally, we compared the results obtained from different data combinations used in all experiments.
2.3.1. State-of-the-Art Architectures
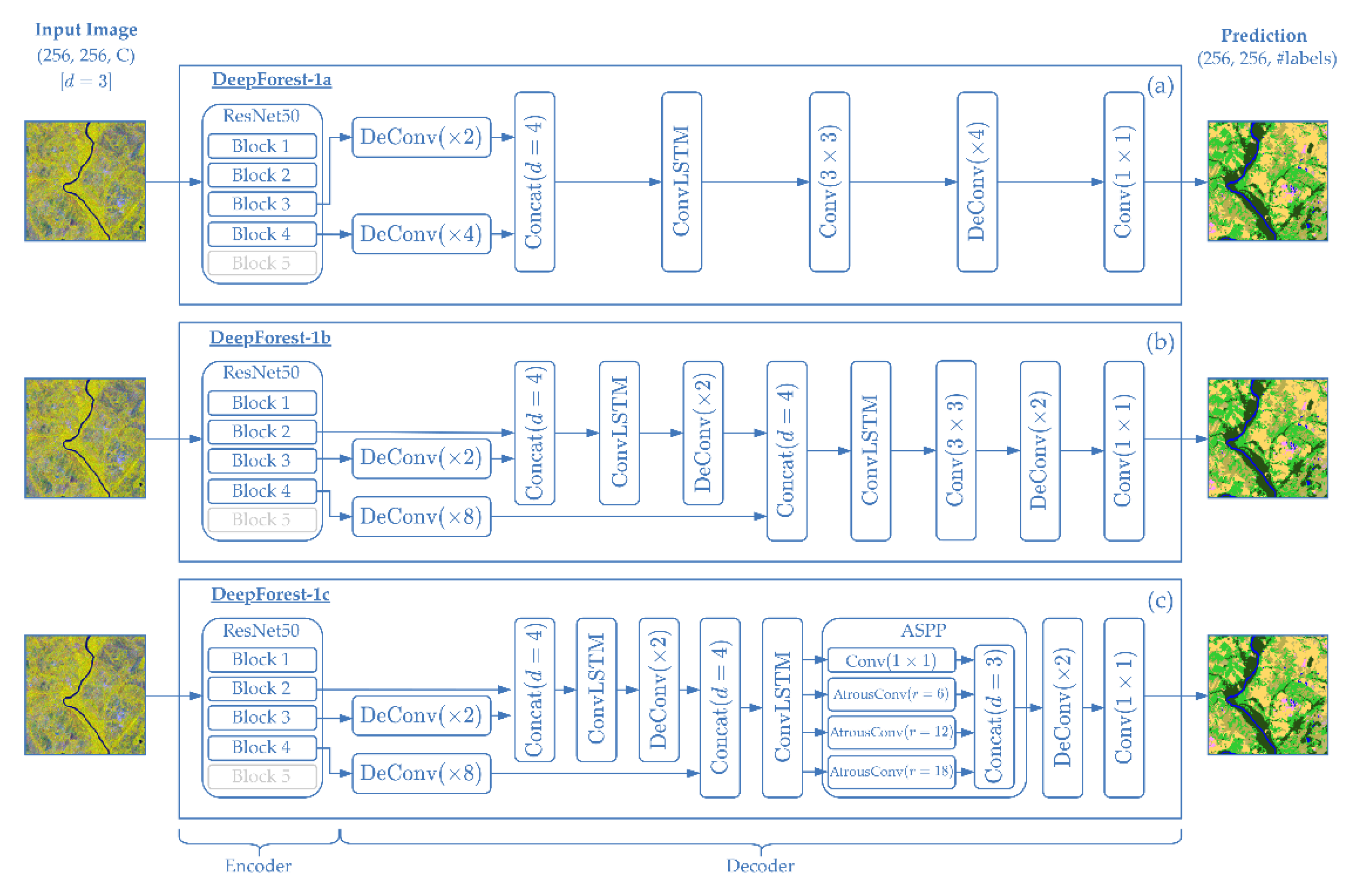
2.3.2. Early Fusion Approach: DeepForest-1
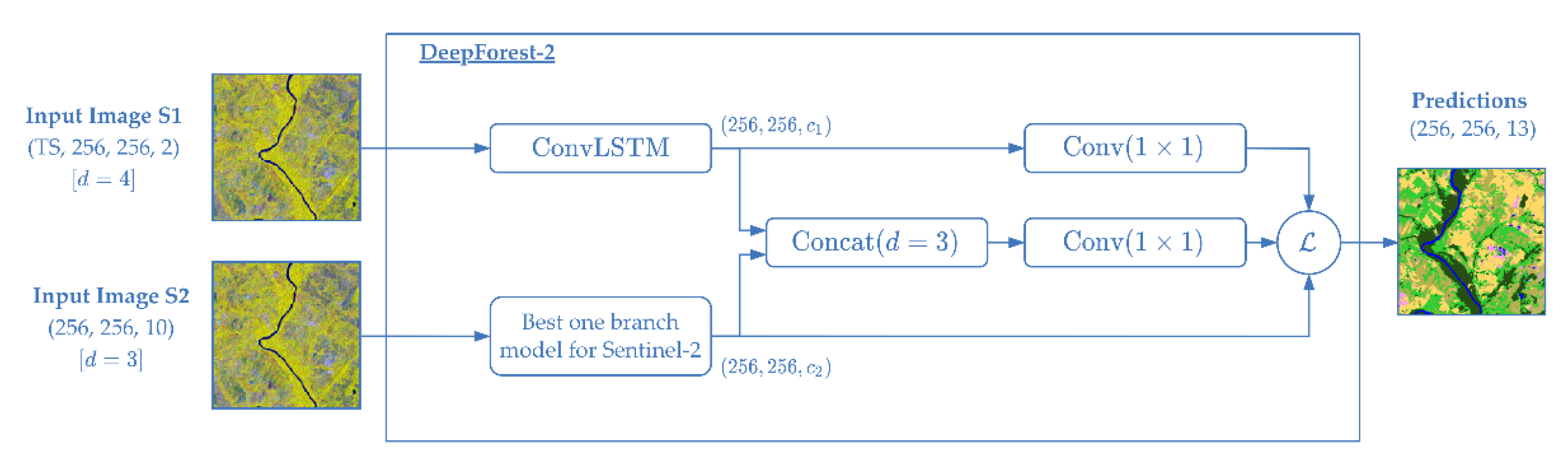
2.3.3. Representation Fusion: DeepForest-2
2.3.4. Loss Function
2.4. Evaluation Metrics
3. Results
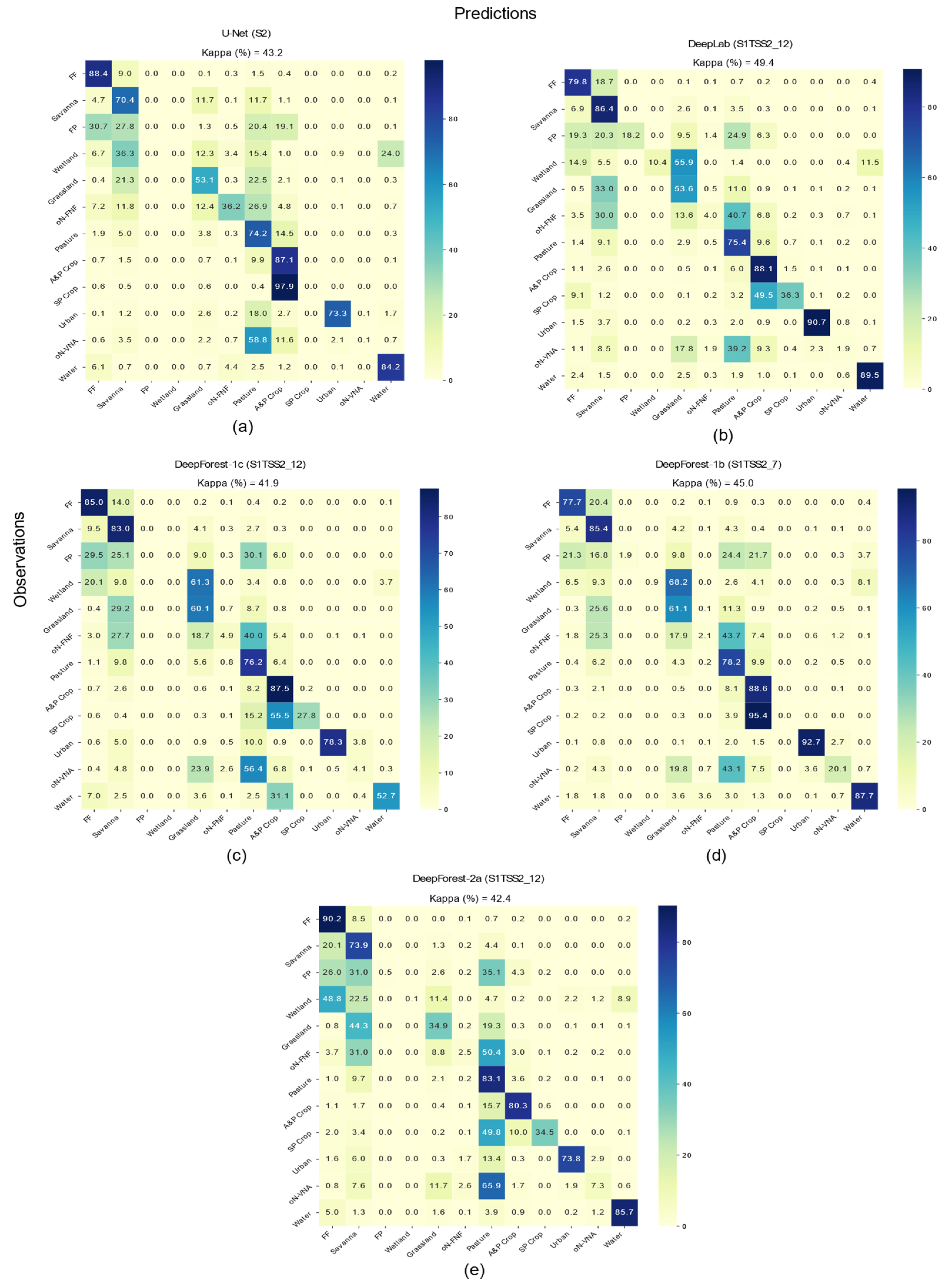
3.1. Quantitative Results on Multispectral Data
3.2. Quantitative Results on Multi-Modal-Data
3.3. Quantitative Results on Reduced Multi-Modal Data
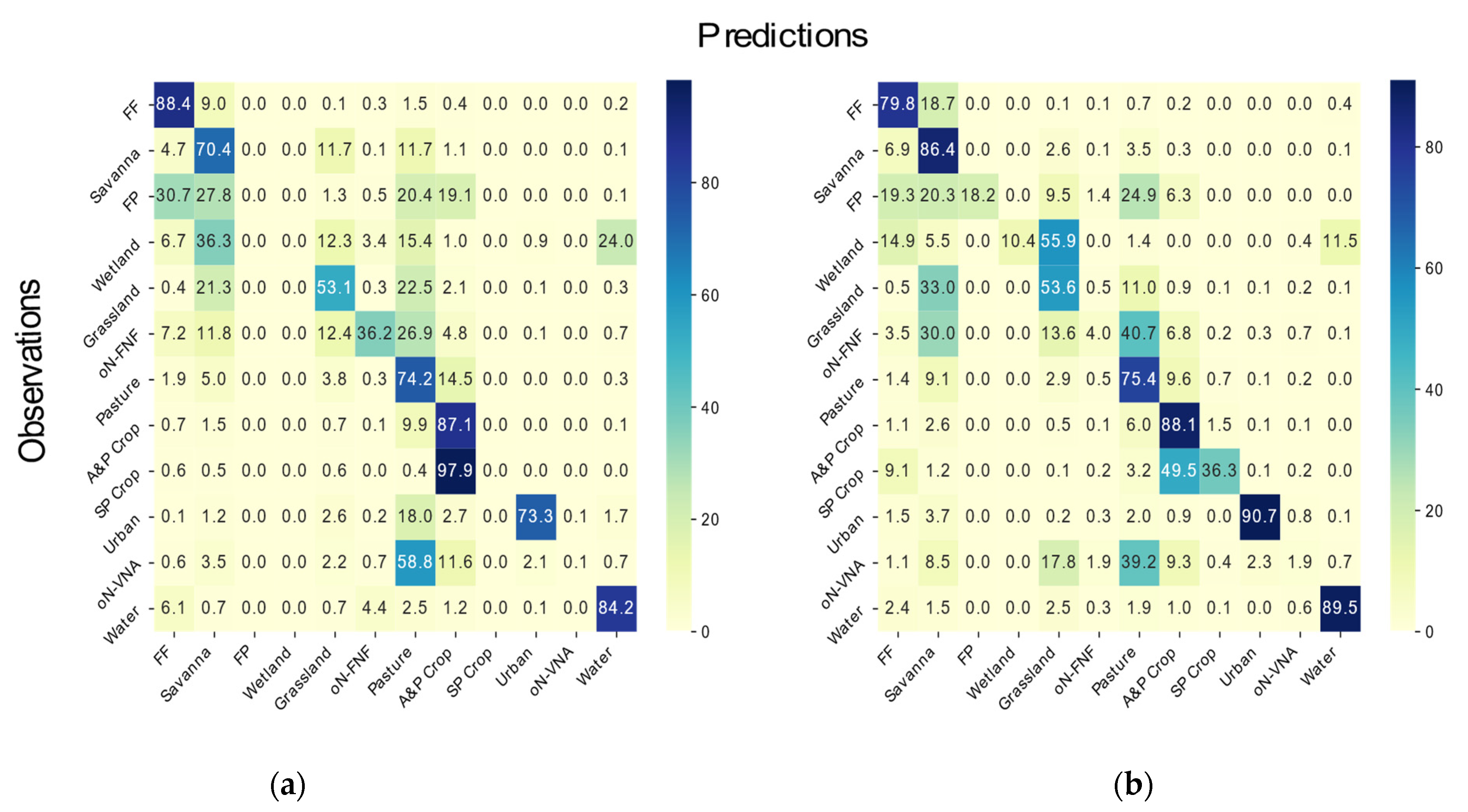
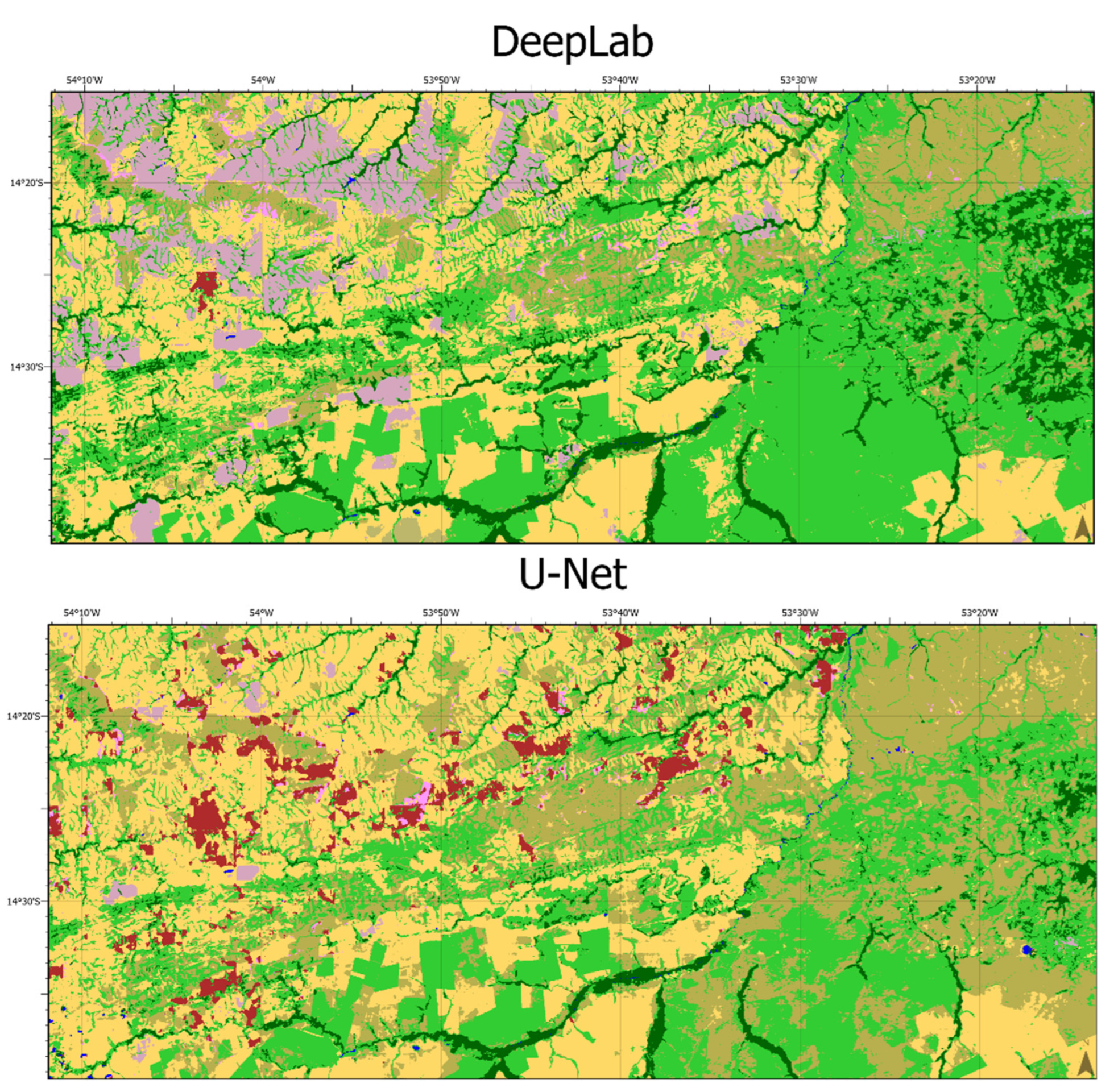
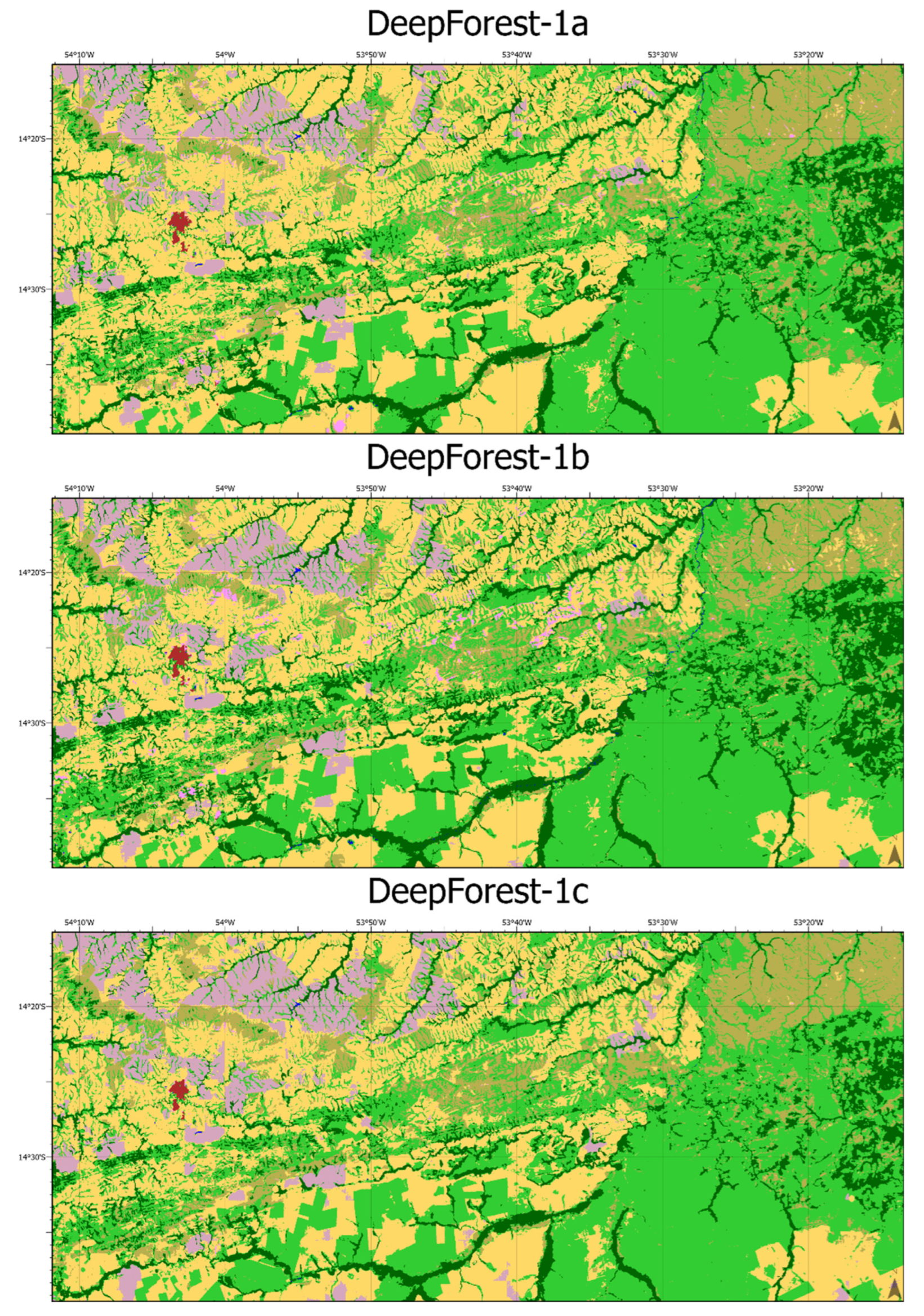
3.4. Qualitative Assessment
4. Discussion
4.1. Effect of the Synergy between Sentinel-1 and Sentinel-2 Data
4.2. Classification Scheme and Label Quality
4.3. Discussion of the Results Compared to Related Studies
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

References
- The World Bank New Project to Implement Sustainable Landscapes in the Brazilian Amazon. Available online: https://www.worldbank.org/en/news/press-release/2017/12/14/brazil-amazon-new-project-implement-sustainable-landscapes (accessed on 21 May 2022).
- Pulella, A.; Aragão Santos, R.; Sica, F.; Posovszky, P.; Rizzoli, P. Multi-Temporal Sentinel-1 Backscatter and Coherence for Rainforest Mapping. Remote Sens. 2020, 12, 847. [Google Scholar] [CrossRef]
- Carreiras, J.M.B.; Jones, J.; Lucas, R.M.; Shimabukuro, Y.E. Mapping Major Land Cover Types and Retrieving the Age of Secondary Forests in the Brazilian Amazon by Combining Single-Date Optical and Radar Remote Sensing Data. Remote Sens. Environ. 2017, 194, 16–32. [Google Scholar] [CrossRef]
- Le Quéré, C.; Capstick, S.; Corner, A.; Cutting, D.; Johnson, M.; Minns, A.; Schroeder, H.; Walker-Springett, K.; Whitmarsh, L.; Wood, R. Towards a Culture of Low-Carbon Research for the 21st Century. Tyndall Cent. Clim. Chang. Res. Work. Pap. 2015, 161, 1–25. [Google Scholar]
- Heckenberger, M.J.; Christian Russell, J.; Toney, J.R.; Schmidt, M.J. The Legacy of Cultural Landscapes in the Brazilian Amazon: Implications for Biodiversity. Phil. Trans. R. Soc. B 2007, 362, 197–208. [Google Scholar] [CrossRef]
- The Nature Conservancy The Amazon Is Our Planet’s Greatest Life Reserve and Our World’s Largest Tropical Rainforest. Available online: https://www.nature.org/en-us/get-involved/how-to-help/places-we-protect/amazon-rainforest/ (accessed on 18 February 2022).
- PRODES—Coordenação-Geral de Observação Da Terra. Available online: http://www.obt.inpe.br/OBT/assuntos/programas/amazonia/prodes/prodes/ (accessed on 10 December 2021).
- Marschner, F.J.; Anderson, J.R. Major Land Uses in the United States; U.S. Geological Survey: Reston, VA, USA, 1967; pp. 158–159. Available online: https://pubs.er.usgs.gov/publication/70046790 (accessed on 10 December 2021).
- Vali, A.; Comai, S.; Matteucci, M. Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Nasrallah, A.; Baghdadi, N.; El Hajj, M.; Darwish, T.; Belhouchette, H.; Faour, G.; Darwich, S.; Mhawej, M. Sentinel-1 Data for Winter Wheat Phenology Monitoring and Mapping. Remote Sens. 2019, 11, 2228. [Google Scholar] [CrossRef]
- Sica, F.; Pulella, A.; Nannini, M.; Pinheiro, M.; Rizzoli, P. Repeat-Pass SAR Interferometry for Land Cover Classification: A Methodology Using Sentinel-1 Short-Time-Series. Remote Sens. Environ. 2019, 232, 111277. [Google Scholar] [CrossRef]
- Colditz, R.R. An Evaluation of Different Training Sample Allocation Schemes for Discrete and Continuous Land Cover Classification Using Decision Tree-Based Algorithms. Remote Sens. 2015, 7, 9655–9681. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support Vector Machines in Remote Sensing: A Review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random Forest in Remote Sensing: A Review of Applications and Future Directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Mapbiomas Brasil. Available online: https://mapbiomas.org/en (accessed on 17 March 2022).
- Steinhausen, M.J.; Wagner, P.D.; Narasimhan, B.; Waske, B. Combining Sentinel-1 and Sentinel-2 Data for Improved Land Use and Land Cover Mapping of Monsoon Regions. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 595–604. [Google Scholar] [CrossRef]
- Foerster, S.; Kaden, K.; Foerster, M.; Itzerott, S. Crop Type Mapping Using Spectral–Temporal Profiles and Phenological Information. Comput. Electron. Agric. 2012, 89, 30–40. [Google Scholar] [CrossRef]
- Souza, J.; Siqueira, J.V.; Sales, M.H.; Fonseca, A.V.; Ribeiro, J.G.; Numata, I.; Cochrane, M.A.; Barber, C.P.; Roberts, D.A.; Barlow, J. Ten-Year Landsat Classification of Deforestation and Forest Degradation in the Brazilian Amazon. Remote Sens. 2013, 5, 5493–5513. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional Networks for Images, Speech, and Time Series. In The Handbook of Brain Theory and Neural Networks; MIT Press: Cambridge, MA, USA, 1998; pp. 255–258. ISBN 978-0-262-51102-5. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.-S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep Learning in Remote Sensing: A Comprehensive Review and List of Resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Sr, C.S.C. Comprehensive Survey of Deep Learning in Remote Sensing: Theories, Tools, and Challenges for the Community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef]
- Yuan, X.; Shi, J.; Gu, L. A Review of Deep Learning Methods for Semantic Segmentation of Remote Sensing Imagery. Expert Syst. Appl. 2021, 169, 114417. [Google Scholar] [CrossRef]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very Deep Convolutional Neural Networks for Complex Land Cover Mapping Using Multispectral Remote Sensing Imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef]
- Schmitt, M.; Prexl, J.; Ebel, P.; Liebel, L.; Zhu, X.X. Weakly Supervised Semantic Segmentation of Satellite Images for Land Cover Mapping—Challenges and Opportunities. arXiv 2020, arXiv:2002.08254. [Google Scholar] [CrossRef]
- Schmitt, M.; Hughes, L.H.; Qiu, C.; Zhu, X.X. SEN12MS—A Curated Dataset of Georeferenced Multi-Spectral Sentinel-1/2 Imagery for Deep Learning and Data Fusion. arXiv 2019, arXiv:1906.07789. [Google Scholar] [CrossRef]
- Loveland, T.R.; Belward, A.S. The IGBP-DIS Global 1km Land Cover Data Set, DISCover: First Results. Int. J. Remote Sens. 1997, 18, 3289–3295. [Google Scholar] [CrossRef]
- Neves, A.K.; Körting, T.S.; Fonseca, L.M.G.; Girolamo Neto, C.D.; Wittich, D.; Costa, G.A.O.P.; Heipke, C. Semantic segmentation of Brazilian savanna vegetation using high spatial resolution satellite data and U-net. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 5, 505–511. [Google Scholar] [CrossRef]
- Espinoza Villar, J.C.; Ronchail, J.; Guyot, J.L.; Cochonneau, G.; Naziano, F.; Lavado, W.; De Oliveira, E.; Pombosa, R.; Vauchel, P. Spatio-Temporal Rainfall Variability in the Amazon Basin Countries (Brazil, Peru, Bolivia, Colombia, and Ecuador). Int. J. Climatol. 2009, 29, 1574–1594. [Google Scholar] [CrossRef]
- Arvor, D.; Funatsu, B.M.; Michot, V.; Dubreuil, V. Monitoring Rainfall Patterns in the Southern Amazon with PERSIANN-CDR Data: Long-Term Characteristics and Trends. Remote Sens. 2017, 9, 889. [Google Scholar] [CrossRef]
- Peterson, J. Rainforest Weather & Climate. Available online: https://sciencing.com/rainforest-weather-climate-19521.html (accessed on 14 August 2022).
- JEC Assessment: Mato Grosso. 2021. Available online: https://www.andgreen.fund/wp-content/uploads/2022/02/JECA-Mato-Grosso-Full_compressed.pdf (accessed on 8 November 2021).
- Yale University. The Amazon Basin Forest | Global Forest Atlas. Available online: https://web.archive.org/web/20190630052510/https://globalforestatlas.yale.edu/region/amazon (accessed on 20 September 2022).
- Souza, C.M.; Azevedo, T. ATBD_R Algorithm Theoretical Base Document & Results. In MapBiomas General “Handbook”; MapBiomas: São Paulo, Brazil, 2017; Volume 24. [Google Scholar] [CrossRef]
- Zhou, Z.-H. A Brief Introduction to Weakly Supervised Learning. Natl. Sci. Rev. 2018, 5, 44–53. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Scharvogel, D.; Brandmeier, M.; Weis, M. A Deep Learning Approach for Calamity Assessment Using Sentinel-2 Data. Forests 2020, 11, 1239. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. Adv. Neural Inf. Process. Syst. 2015, 28, 9. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 June 2015; pp. 448–456. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Alencar, A.; Shimbo, J.Z.; Lenti, F.; Balzani Marques, C.; Zimbres, B.; Rosa, M.; Arruda, V.; Castro, I.; Fernandes Márcico Ribeiro, J.P.; Varela, V.; et al. Mapping Three Decades of Changes in the Brazilian Savanna Native Vegetation Using Landsat Data Processed in the Google Earth Engine Platform. Remote Sens. 2020, 12, 924. [Google Scholar] [CrossRef]
- Costa, O.B.d.; Matricardi, E.A.T.; Pedlowski, M.A.; Cochrane, M.A.; Fernandes, L.C. Spatiotemporal Mapping of Soybean Plantations in Rondônia, Western Brazilian Amazon. Acta Amaz. 2017, 47, 29–38. [Google Scholar] [CrossRef][Green Version]
- Becker, W.R.; Richetti, J.; Mercante, E.; Esquerdo, J.C.D.M.; da Silva Junior, C.A.; Paludo, A.; Johann, J.A. Agricultural Soybean and Corn Calendar Based on Moderate Resolution Satellite Images for Southern Brazil. Semin. Cienc. Agrar. 2020, 41, 2419–2428. [Google Scholar] [CrossRef]
- Susan, S.; Kumar, A. The Balancing Trick: Optimized Sampling of Imbalanced Datasets—A Brief Survey of the Recent State of the Art. Eng. Rep. 2021, 3, e12298. [Google Scholar] [CrossRef]
- Tulbure, M.G.; Hostert, P.; Kuemmerle, T.; Broich, M. Regional Matters: On the Usefulness of Regional Land-Cover Datasets in Times of Global Change. Remote Sens. Ecol. Conserv. 2022, 8, 272–283. [Google Scholar] [CrossRef]
- De Alban, J.D.T.; Connette, G.M.; Oswald, P.; Webb, E.L. Combined Landsat and L-Band SAR Data Improves Land Cover Classification and Change Detection in Dynamic Tropical Landscapes. Remote Sens. 2018, 10, 306. [Google Scholar] [CrossRef]
- Masolele, R.N.; De Sy, V.; Herold, M.; Marcos, D.; Verbesselt, J.; Gieseke, F.; Mullissa, A.G.; Martius, C. Spatial and Temporal Deep Learning Methods for Deriving Land-Use Following Deforestation: A Pan-Tropical Case Study Using Landsat Time Series. Remote Sens. Environ. 2021, 264, 112600. [Google Scholar] [CrossRef]
- Mercier, A.; Betbeder, J.; Rumiano, F.; Baudry, J.; Gond, V.; Blanc, L.; Bourgoin, C.; Cornu, G.; Ciudad, C.; Marchamalo, M.; et al. Evaluation of Sentinel-1 and 2 Time Series for Land Cover Classification of Forest–Agriculture Mosaics in Temperate and Tropical Landscapes. Remote Sens. 2019, 11, 979. [Google Scholar] [CrossRef]
- Ienco, D.; Interdonato, R.; Gaetano, R.; Ho Tong Minh, D. Combining Sentinel-1 and Sentinel-2 Satellite Image Time Series for Land Cover Mapping via a Multi-Source Deep Learning Architecture. ISPRS J. Photogramm. Remote Sens. 2019, 158, 11–22. [Google Scholar] [CrossRef]
- Wang, Y.; Albrecht, C.; Ait Ali Braham, N.; Mou, L.; Zhu, X. Self-Supervised Learning in Remote Sensing: A Review. IEEE Geosci. Remote Sens. Mag. 2022, 15, 2–36. [Google Scholar] [CrossRef]
- Xue, Z.; Yu, X.; Yu, A.; Liu, B.; Zhang, P.; Wu, S. Self-Supervised Feature Learning for Multimodal Remote Sensing Image Land Cover Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–15. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Number of Tiles | Number of Bands | Tile Size [px] | |
|---|---|---|---|---|
| Training | Test | |||
| S2 | 35,000 | 8750 | 10 | 256 × 256 |
| S1TsS2_12 | 18,074 | 4517 | 34 | 256 × 256 |
| S1TsS2_7 | 18,074 | 4517 | 24 | 256 × 256 |
| LRZ | EC2 | |
|---|---|---|
| GPU (Memory) | NVIDIA V100 (16 GB) | NVIDIA T4 (16 GB) |
| RAM (GB) | 500 | 200 |
| Operating System | Linux | Windows |
| DL Framework | Tensorflow 1.15.2 + Keras | |
| F1 [%] | IoU [%] | |||||||
|---|---|---|---|---|---|---|---|---|
| UN | DLab | DF 1a | DF 1b | UN | DLab | DF 1a | DF 1b | |
| FF | 92.0 | 90.1 | 87.7 | 91.2 | 85.1 | 82.0 | 78.2 | 83.8 |
| Savanna | 65.8 | 60.5 | 41.2 | 39.7 | 49.0 | 43.4 | 26.0 | 24.7 |
| FP | 0.0 | 2.8 | 0.0 | 0.0 | 0.0 | 1.4 | 0.0 | 0.0 |
| Wetland | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Grassland | 48.8 | 38.6 | 25.5 | 21.1 | 32.3 | 23.9 | 14.6 | 11.8 |
| oN-FNF | 50.4 | 45.0 | 33.6 | 39.5 | 33.7 | 29.0 | 20.1 | 24.6 |
| Pasture | 72.8 | 64.6 | 73.2 | 61.5 | 57.2 | 47.7 | 57.7 | 44.4 |
| A&P Crop | 76.2 | 54.8 | 73.5 | 68.1 | 61.5 | 37.7 | 58.1 | 51.6 |
| SP Crop | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Urban | 69.4 | 61.5 | 0.0 | 0.0 | 53.1 | 44.4 | 0.0 | 0.0 |
| oN-VNA | 0.3 | 8.8 | 2.6 | 0.0 | 0.14 | 4.6 | 1.3 | 0.0 |
| Water | 86.0 | 85.7 | 76.7 | 78.8 | 75.4 | 75.0 | 62.2 | 65.0 |
| Macro Average | 46.8 | 42.7 | 34.5 | 33.3 | 37.3 | 32.4 | 26.5 | 27.8 |
| Weighted Average | 77.9 | 71.9 | 69.9 | 68.4 | 66.0 | 59.1 | 57.5 | 56.5 |
| U-Net | DeepLab | DeepForest-1a | DeepForest-1b | |||||
| Overall Accuracy [%] | 77.9 | 72.7 | 72.7 | 71.4 | ||||
| F1 [%] | IoU [%] | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| UN | DLab | DF 1a | DF 1b | DF 1c | DF 2a | DF 2b | UN | DLab | DF 1a | DF 1b | DF 1c | DF 2a | DF 2b | |
| FF | 32.6 | 80.9 | 81.5 | 81.1 | 82.1 | 77.5 | 71.8 | 19.5 | 67.9 | 68.8 | 68.2 | 69.7 | 63.2 | 56.0 |
| Savanna | 60.0 | 74.4 | 77.1 | 74.3 | 77.8 | 71.6 | 73.2 | 42.8 | 64.6 | 62.7 | 59.1 | 63.7 | 55.8 | 57.7 |
| FP | 0.0 | 30.3 | 0.0 | 0.0 | 0.0 | 0.9 | 0.0 | 0.0 | 17.9 | 0.0 | 0.0 | 0.0 | 0.5 | 0.0 |
| Wetland | 0.0 | 18.1 | 0.6 | 0.0 | 1.8 | 0.1 | 5.0 | 0.0 | 9.9 | 0.3 | 0.0 | 0.9 | 0.1 | 2.6 |
| Grassland | 52.2 | 59.8 | 58.7 | 53.0 | 60.1 | 46.4 | 47.2 | 35.4 | 42.7 | 41.5 | 36.1 | 43.0 | 30.2 | 30.9 |
| oN-FNF | 2.6 | 7.4 | 3.3 | 5.6 | 8.8 | 4.7 | 2.2 | 1.3 | 3.8 | 1.7 | 2.9 | 4.6 | 2.4 | 1.2 |
| Pasture | 67.6 | 75.5 | 76.4 | 74.8 | 76.2 | 75.3 | 71.5 | 51.0 | 60.7 | 61.8 | 59.8 | 61.5 | 60.4 | 55.6 |
| A&P Crop | 61.9 | 81.6 | 83.6 | 85.0 | 83.2 | 84.1 | 82.9 | 44.8 | 69.0 | 71.8 | 73.9 | 71.3 | 72.6 | 70.8 |
| SP Crop | 0.0 | 13.8 | 0.0 | 0.4 | 32.2 | 26.2 | 12.0 | 0.0 | 7.4 | 0.0 | 0.2 | 19.2 | 15.1 | 6.4 |
| Urban | 43.0 | 85.5 | 88.0 | 86.5 | 85.2 | 77.7 | 72.7 | 27.4 | 74.6 | 78.6 | 76.2 | 74.2 | 63.5 | 57.1 |
| oN-VNA | 15.0 | 28.4 | 21.9 | 25.8 | 7.7 | 12.7 | 8.0 | 8.1 | 16.6 | 12.3 | 14.8 | 4.0 | 6.8 | 4.2 |
| Water | 84.9 | 88.8 | 89.0 | 88.2 | 67.6 | 89.5 | 88.8 | 73.8 | 79.9 | 80.2 | 78.9 | 51.1 | 81.0 | 79.8 |
| Macro Average | 35.0 | 54.1 | 48.3 | 47.9 | 48.6 | 47.2 | 44.6 | 25.3 | 42.9 | 40.0 | 39.2 | 38.6 | 37.6 | 35.2 |
| Weighted Average | 52.2 | 69.4 | 71.0 | 69.4 | 71.5 | 67.1 | 65.5 | 37.1 | 60.6 | 57.8 | 55.8 | 58.3 | 53.2 | 51.3 |
| UN | DLab | DF-1a | DF-1b | DF-1c | DF-2a | DF-2b | ||||||||
| Overall Accuracy [%] | 56.7 | 74.4 | 74.3 | 72.9 | 74.4 | 70.9 | 69.0 | |||||||
| F1 [%] | IoU [%] | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DeepLab | DF-1b | DF-1c | DF-2b | DeepLab | DF-1b | DF-1c | DF-2b | |||||||||
| 7 Ms | 12 Ms | 7 Ms | 12 Ms | 7 Ms | 12 Ms | 7 Ms | 12 Ms | 7 Ms | 12 Ms | 7 Ms | 12 Ms | 7 Ms | 12 Ms | 7 Ms | 12 Ms | |
| FF | 71.2 | 80.9 | 81.9 | 81.1 | 44.2 | 82.1 | 55.2 | 71.8 | 55.3 | 67.9 | 69.3 | 68.2 | 28.4 | 69.7 | 38.1 | 56.0 |
| Savanna | 75.8 | 74.4 | 79.6 | 74.3 | 72.2 | 77.8 | 73.4 | 73.2 | 61.0 | 64.6 | 66.1 | 59.1 | 56.5 | 63.7 | 58.0 | 57.7 |
| FP | 0.0 | 30.3 | 3.7 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 17.9 | 1.9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Wetland | 27.0 | 18.1 | 1.7 | 0.0 | 0.0 | 1.8 | 0.0 | 5.0 | 15.6 | 9.9 | 0.9 | 0.0 | 0.0 | 0.9 | 0.0 | 2.6 |
| Grassland | 58.0 | 59.8 | 61.9 | 53.0 | 60.3 | 60.1 | 56.5 | 47.2 | 40.8 | 42.7 | 44.8 | 36.1 | 43.2 | 43.0 | 39.4 | 30.9 |
| oN-FNF | 2.0 | 7.4 | 4.0 | 5.6 | 3.2 | 8.8 | 1.3 | 2.2 | 1.0 | 3.8 | 2.0 | 2.9 | 1.6 | 4.6 | 0.6 | 1.2 |
| Pasture | 71.9 | 75.5 | 76.0 | 74.8 | 76.1 | 76.2 | 73.8 | 71.5 | 56.0 | 60.7 | 61.3 | 59.8 | 61.4 | 61.5 | 58.5 | 55.6 |
| A&P Crop | 74.1 | 81.6 | 81.3 | 85.0 | 83.1 | 83.2 | 79.5 | 82.9 | 58.8 | 69.0 | 68.6 | 73.9 | 71.0 | 71.3 | 66.4 | 70.8 |
| SP Crop | 0.1 | 13.8 | 0.0 | 0.4 | 0.1 | 32.2 | 0.0 | 12.0 | 0.0 | 7.4 | 0.0 | 0.2 | 0.0 | 19.2 | 0.0 | 6.4 |
| Urban | 79.0 | 85.5 | 80.3 | 86.5 | 84.6 | 85.2 | 71.2 | 72.7 | 65.3 | 74.4 | 67.1 | 76.2 | 73.3 | 74.2 | 55.3 | 57.1 |
| oN-VNA | 18.0 | 28.4 | 26.8 | 25.8 | 23.9 | 7.7 | 26.1 | 8.0 | 9.9 | 16.0 | 15.5 | 14.8 | 13.6 | 4.0 | 15.0 | 4.2 |
| Water | 86.0 | 88.8 | 67.6 | 88.2 | 88.9 | 67.6 | 89.3 | 88.8 | 76.0 | 79.9 | 80.1 | 78.9 | 79.5 | 51.1 | 80.6 | 79.8 |
| Macro Average | 46.9 | 53.7 | 47.1 | 47.9 | 44.7 | 48.5 | 43.9 | 44.6 | 36.6 | 42.9 | 39.8 | 39.2 | 35.7 | 38.6 | 34.3 | 35.2 |
| Weighted Average | 67.5 | 71.0 | 72.6 | 70.4 | 64.3 | 72.2 | 65.0 | 66.5 | 52.9 | 58.8 | 59.6 | 56.7 | 50.0 | 58.9 | 50.4 | 52.1 |
| DeepLab | DeepForest-1b | DeepForest-1c | DeepForest-2b | |||||||||||||
| 7 Months | 12 Months | 7 Months | 12 Months | 7 Months | 12 Months | 7 Months | 12 Months | |||||||||
| Overall Accuracy [%] | 69.9 | 74.4 | 75.0 | 72.9 | 67.8 | 74.4 | 68.1 | 69.0 | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cherif, E.; Hell, M.; Brandmeier, M. DeepForest: Novel Deep Learning Models for Land Use and Land Cover Classification Using Multi-Temporal and -Modal Sentinel Data of the Amazon Basin. Remote Sens. 2022, 14, 5000. https://doi.org/10.3390/rs14195000
Cherif E, Hell M, Brandmeier M. DeepForest: Novel Deep Learning Models for Land Use and Land Cover Classification Using Multi-Temporal and -Modal Sentinel Data of the Amazon Basin. Remote Sensing. 2022; 14(19):5000. https://doi.org/10.3390/rs14195000
Chicago/Turabian StyleCherif, Eya, Maximilian Hell, and Melanie Brandmeier. 2022. "DeepForest: Novel Deep Learning Models for Land Use and Land Cover Classification Using Multi-Temporal and -Modal Sentinel Data of the Amazon Basin" Remote Sensing 14, no. 19: 5000. https://doi.org/10.3390/rs14195000
APA StyleCherif, E., Hell, M., & Brandmeier, M. (2022). DeepForest: Novel Deep Learning Models for Land Use and Land Cover Classification Using Multi-Temporal and -Modal Sentinel Data of the Amazon Basin. Remote Sensing, 14(19), 5000. https://doi.org/10.3390/rs14195000