

Shift Pooling PSPNet: Rethinking PSPNet for Building Extraction in Remote Sensing Images from Entire Local Feature Pooling


Abstract
1. Introduction
1.1. Related Works
1.2. Innovation and Contribution of This Paper
2. Method
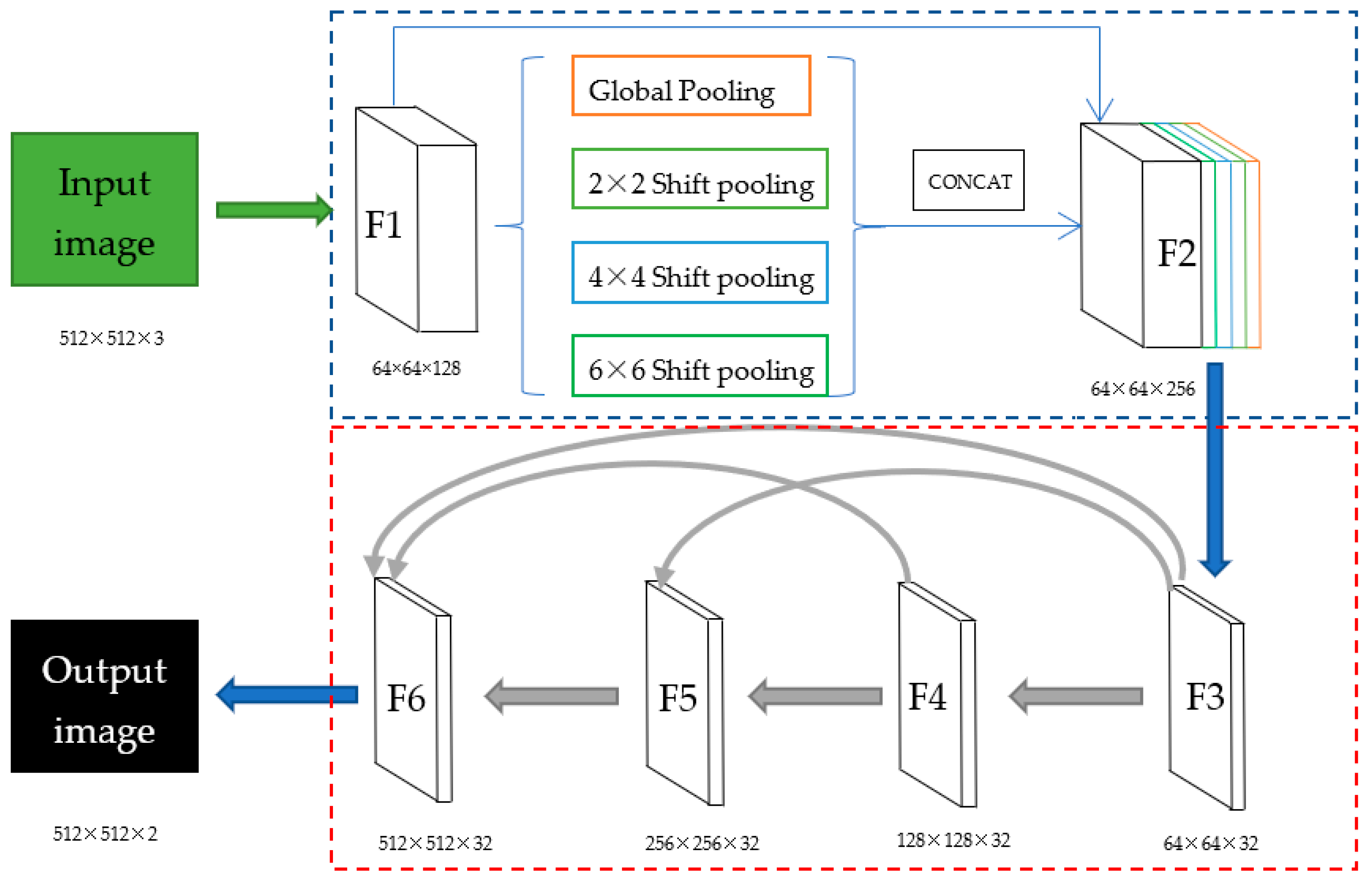
2.1. Architecture of Shift Pooling PSPNet
2.2. Shift Pooling
| Algorithm 1: Horizontal shift pooling |
| Input: feature map, pool_factor, depth |
| Output: feature map |
| 1: Divide the size of the feature map by pool_factor to obtain the pooling size and stride. (For example, If the pool_factor is 2, the pooling size is half of the feature map size, and the stride equals pooling size.) |
| 2: Obtain the size of padding on the left and right of the feature map; the value is half of the pooling size. |
| 3: Pad the feature map on the left and right symmetrically to obtain feature map 1. 4: Maxpool feature map 1 with size and stride obtained by step 1 to obtain feature map 2. 5: Feature map 2 is convoluted with a 1 × 1 kernel into a feature map 3 with the same width and height, but the channel is deep. 6: Through batch normalization and activation layers, feature map 4 is obtained. 7: Upsample feature map 4 to the size of feature map 1 to obtain feature map 5. |
| 8: Crop off the left and right padding parts of feature map 5 to obtain feature map 6. |
| 9: Return feature map 6. |
| Algorithm 2: Vertical shift pooling |
| Input: feature map, pool_factor, depth |
| Output: feature map |
| 1: Divide the size of the feature map by pool_factor to obtain the pooling size and stride. |
| 2: Obtain the size of padding on the top and bottom of the feature map; the value is half of the pooling size. |
| 3: Pad the feature map on the top and bottom symmetrically to obtain feature map 1. 4: Maxpool feature map 1 with size and stride obtained by step 1 to obtain feature map 2. 5: Feature map 2 is convoluted with a 1 × 1 kernel into feature map 3 with same width and height, but the channel is deep. 6: Through batch normalization and activation layers, feature map 4 is obtained. 7: Upsample feature map 4 to the size of feature map 1 to obtain feature map 5. |
| 8: Crop off top and bottom padding parts of feature map 5 to obtain feature map 6. |
| 9: Return feature map 6. |
| Algorithm 3: Horizontal and vertical shift pooling |
| Input: feature map, pool_factor, depth |
| Output: feature map |
| 1: Divide the size of the feature map by pool_factor to obtain the pooling size and stride. |
| 2: Obtain the size of padding on the left, right, top, and bottom of the feature map; the value is half of the pooling size. |
| 3: Pad the feature map on the left and right symmetrically, then pad the top and bottom symmetrically again to obtain feature map 1. 4: Maxpool feature map 1 with the size and stride obtained by step 1 to obtain feature map 2. 5: Feature map 2 is convoluted with a 1 × 1 kernel into a feature map 3 with same width and height, but the channel is deep. 6: Through batch normalization and activation layers, feature map 4 is obtained. 7: Upsample feature map 4 to the size of feature map 1 to obtain feature map 5. |
| 8: Crop off the left, right, top, and bottom padding parts of feature map 5 to obtain feature map 6. |
| 9: Return feature map 6. |
3. Experiment and Results
3.1. WHU Building Dataset and Preprocessing
3.2. Massachusetts Building Dataset and Preprocessing
3.3. Hardware and Settings for Experiment
3.4. Evaluation Metrics
3.5. Results on WHU Building Dataset
3.6. Results on Massachusetts Building Dataset
4. Discussion
4.1. Ablation Experiment
4.2. Feature Visualization
4.3. Generalizations Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random Forest Classification of Multisource Remote Sensing and Geographic Data. In Proceedings of the IGARSS 2004, 2004 IEEE International Geoscience and Remote Sensing Symposium, Anchorage, AK, USA, 20–24 September 2004; Volume 2, pp. 1049–1052. [Google Scholar] [CrossRef]
- Oommen, T.; Baise, L.G. A New Approach to Liquefaction Potential Mapping using Satellite Remote Sensing and Support Vector Machine Algorithm. In Proceedings of the IGARSS 2008–2008 IEEE International Geoscience and Remote Sensing Symposium, Boston, MA, USA, 6–11 July 2008; pp. III-51–III-54. [Google Scholar] [CrossRef]
- Shen, W.; Wu, G.; Sun, Z.; Xiong, W.; Fu, Z.; Xiao, R. Study on classification methods of remote sensing image based on decision tree technology. In Proceedings of the 2011 International Conference on Computer Science and Service System (CSSS), Nanjing, China, 27–29 June 2011; pp. 4058–4061. [Google Scholar] [CrossRef]
- Zhou, Y.; Chen, H.; Zhu, Q. The research of classification algorithm based on fuzzy clustering and neural network. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Toronto, ON, Canada, 24–28 June 2002; Volume 4, pp. 2525–2527. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. Available online: https://arxiv.org/abs/1409.1556 (accessed on 3 July 2021).
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. Convolutional networks for biomedical image segmentation. In Proceedings of the 2015 Medical Image Computing and Computer Assisted Intervention, Piscataway, NJ, USA, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. Comput. Sci. 2014, 357–361. Available online: https://arxiv.org/abs/1412.7062 (accessed on 13 July 2021).
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Rethinking Atrous Convolution for Semantic Image Segmentation. 2017. Available online: https://arxiv.org/abs/1706.05587 (accessed on 13 July 2021).
- Liu, P.; Liu, X.; Liu, M.; Shi, Q.; Yang, J.; Xu, X.; Zhang, Y. Building footprint extraction from high-resolution images via spatial residual inception convolutional neural network. Remote Sens. 2019, 11, 830. [Google Scholar] [CrossRef]
- Liu, Y.; Zhou, J.; Qi, W.; Li, X.; Gross, L.; Shao, Q.; Zhao, Z.; Ni, L.; Fan, X.; Li, Z. ARC-Net: An Efficient Network for Building Extraction From High-Resolution Aerial Images. IEEE Access 2020, 8, 154997–155010. [Google Scholar] [CrossRef]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic Segmentation of Urban Buildings from VHR Remote Sensing Imagery Using a Deep Convolutional Neural Network. Remote Sens. 2019, 11, 1774. [Google Scholar] [CrossRef]
- Diakogiannis, F.I.; Waldner, F.; Caccetta, P.; Wu, C. Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data. ISPRS J. Photogramm. Remote Sens. 2020, 162, 94–114. [Google Scholar] [CrossRef]
- Ye, Z.; Fu, Y.; Gan, M.; Deng, J.; Comber, A.; Wang, K. Building extraction from very high resolution aerial imagery using joint attention deep neural network. Remote Sens. 2019, 11, 2970. [Google Scholar] [CrossRef]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Zheng, S.; Lu, J.; Zhao, H.; Zhu, X.; Luo, Z.; Wang, Y.; Fu, Y.; Feng, J.; Xiang, T.; Torr, P.H.S.; et al. Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Yuan, W.; Xu, W. MSST-Net: A Multi-Scale Adaptive Network for Building Extraction from Remote Sensing Images Based on Swin Transformer. Remote Sens. 2021, 13, 4743. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021. [Google Scholar]
- Pan, X.; Yang, F.; Gao, L.; Chen, Z.; Zhang, B.; Fan, H.; Ren, J. Building extraction from high-resolution aerial imagery using a generative adversarial network with spatial and channel attention mechanisms. Remote Sens. 2019, 11, 917. [Google Scholar] [CrossRef]
- Protopapadakis, E.; Doulamis, A.; Doulamis, N.; Maltezos, E. Stacked autoencoders driven by semi-supervised learning for building extraction from near infrared remote sensing imagery. Remote Sens. 2021, 13, 371. [Google Scholar] [CrossRef]
- Wang, Y.; Zhao, L.; Liu, L.; Hu, H.; Tao, W. URNet: A U-Shaped Residual Network for Lightweight Image Super-Resolution. Remote Sens. 2021, 13, 3848. [Google Scholar] [CrossRef]
- Liu, H.; Cao, F.; Wen, C.; Zhang, Q. Lightweight multi-scale residual networks with attention for image super-resolution. Knowl.-Based Syst. 2020, 203, 106103. [Google Scholar] [CrossRef]
- Cheng, D.; Liao, R.; Fidler, S.; Urtasun, R. Darnet: Deep active ray network for building segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7431–7439. [Google Scholar]
- Yuan, W.; Xu, W. NeighborLoss: A Loss Function Considering Spatial Correlation for Semantic Segmentation of Remote Sensing Image. IEEE Access 2021, 9, 75641–75649. [Google Scholar] [CrossRef]
- Chen, M.; Wu, J.; Liu, L.; Zhao, W.; Tian, F.; Shen, Q.; Zhao, B.; Du, R. DR-Net: An Improved Network for Building Extraction from High Resolution Remote Sensing Image. Remote Sens. 2021, 13, 294. [Google Scholar] [CrossRef]
- Miao, Y.; Jiang, S.; Xu, Y.; Wang, D. Feature Residual Analysis Network for Building Extraction from Remote Sensing Images. Appl. Sci. 2022, 12, 5095. [Google Scholar] [CrossRef]
- Hou, Q.; Zhang, L.; Cheng, M.-M.; Feng, J. Strip Pooling: Rethinking Spatial Pooling for Scene Parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 30 March 2020. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Chen, J.; Zhang, D.; Wu, Y.; Chen, Y.; Yan, X. A Context Feature Enhancement Network for Building Extraction from High-Resolution Remote Sensing Imagery. Remote Sens. 2022, 14, 2276. [Google Scholar] [CrossRef]
- ZWang, Z.; Du, B.; Guo, Y. Domain Adaptation With Neural Embedding Matching. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 2387–2397. [Google Scholar] [CrossRef]
- Na, Y.; Kim, J.H.; Lee, K.; Park, J.; Hwang, J.Y.; Choi, J.P. Domain Adaptive Transfer Attack (DATA)-based Segmentation Networks for Building Extraction from Aerial Images. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5171–5182. [Google Scholar] [CrossRef]
- Ji, S.P.; Wei, S.Q. Building extraction via convolutional neural networks from an open remote sensing building dataset. Acta Geod. Cartogr. Sin. 2019, 48, 448–459. [Google Scholar]
- Lashgari, E.; Liang, D.; Maoz, U. Data augmentation for deep-learning-based electroencephalography. J. Neurosci. Methods 2020, 346, 108885. [Google Scholar] [CrossRef]
- Liu, W.; Zhang, C.; Lin, G.; Liu, F. CRNet: Cross-reference networks for few-shot segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4164–4172. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Params (M) |
|---|---|
| PSPNet | 42.57 |
| PSPNet + shift pooling | 42.62 |
| PSPNet + our decoder | 42.64 |
| PSPNet + shift pooling + our decoder (shift pooling PSPNet) | 42.69 |
| Methods | mIoU | F1-Score | Accuracy |
|---|---|---|---|
| SETR | 83.5 | 83.1 | 96.3 |
| MSST-Net | 88.0 | 88.2 | 97.4 |
| SegNet | 83.8 | 83.5 | 96.4 |
| DeepLab V3 | 84.6 | 84.3 | 96.7 |
| PSPNet | 86.7 | 86.8 | 97.0 |
| SPNet | 87.3 | 87.5 | 97.2 |
| BiSeNet V2 | 87.6 | 87.8 | 97.3 |
| CFENet | 88.1 | 88.2 | 97.5 |
| Ours | 89.1 | 89.4 | 97.7 |
| Methods | mIoU | F1-Score | Accuracy |
|---|---|---|---|
| SETR | 67.9 | 63.5 | 90.2 |
| MSST-Net | 71.0 | 68.6 | 90.9 |
| SegNet | 69.9 | 66.7 | 90.7 |
| DeepLab V3 | 67.5 | 63.8 | 89.3 |
| PSPNet | 71.8 | 70.0 | 90.8 |
| SPNet | 70.6 | 68.0 | 90.6 |
| BiSeNet V2 | 72.2 | 70.3 | 91.2 |
| CFENet | 71.4 | 68.7 | 91.4 |
| Ours | 75.4 | 74.3 | 92.6 |
| Methods | mIoU | F1-Score | Accuracy |
|---|---|---|---|
| PSPNet | 71.8 | 70.0 | 90.8 |
| PSPNet + Our decoder | 72.8 | 71.1 | 91.4 |
| PSPNet + shift pooling | 73.8 | 72.6 | 91.7 |
| PSPNet + Our decoder + shift pooling (shift pooling PSPNet) | 75.4 | 74.3 | 92.6 |
| Methods | Backbone | mIoU | F1-Score | Accuracy |
|---|---|---|---|---|
| PSPNet | ResNet50 | 72.1 | 70.2 | 91.2 |
| Shift pooling PSPNet | 75.3 | 74.4 | 92.4 | |
| PSPNet | ResNet101 | 71.8 | 70.0 | 90.8 |
| Shift pooling PSPNet | 75.4 | 74.3 | 92.6 | |
| PSPNet | ResNet152 | 71.9 | 69.9 | 91.1 |
| Shift pooling PSPNet | 75.7 | 74.8 | 92.5 |
| Methods | mIoU of Validation Dataset | mIoU of Test Dataset | Test Validation |
|---|---|---|---|
| SETR | 82.8 | 83.5 | 0.7 |
| MSST-Net | 88.1 | 88.0 | -0.1 |
| SegNet | 86.3 | 83.8 | -2.5 |
| DeepLab V3 | 85.2 | 84.6 | -0.6 |
| PSPNet | 87.4 | 86.7 | -0.7 |
| SPNet | 87.9 | 87.3 | -0.6 |
| BiSeNet V2 | 87.4 | 87.6 | 0.2 |
| CFENet | 89.0 | 88.1 | -0.9 |
| Ours | 89.6 | 89.1 | -0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, W.; Wang, J.; Xu, W. Shift Pooling PSPNet: Rethinking PSPNet for Building Extraction in Remote Sensing Images from Entire Local Feature Pooling. Remote Sens. 2022, 14, 4889. https://doi.org/10.3390/rs14194889
Yuan W, Wang J, Xu W. Shift Pooling PSPNet: Rethinking PSPNet for Building Extraction in Remote Sensing Images from Entire Local Feature Pooling. Remote Sensing. 2022; 14(19):4889. https://doi.org/10.3390/rs14194889
Chicago/Turabian StyleYuan, Wei, Jin Wang, and Wenbo Xu. 2022. "Shift Pooling PSPNet: Rethinking PSPNet for Building Extraction in Remote Sensing Images from Entire Local Feature Pooling" Remote Sensing 14, no. 19: 4889. https://doi.org/10.3390/rs14194889
APA StyleYuan, W., Wang, J., & Xu, W. (2022). Shift Pooling PSPNet: Rethinking PSPNet for Building Extraction in Remote Sensing Images from Entire Local Feature Pooling. Remote Sensing, 14(19), 4889. https://doi.org/10.3390/rs14194889