
MAEANet: Multiscale Attention and Edge-Aware Siamese Network for Building Change Detection in High-Resolution Remote Sensing Images


Abstract
1. Introduction
2. Methods
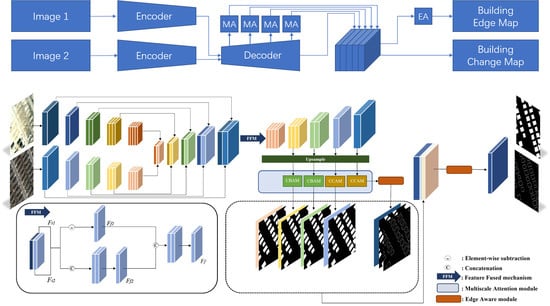
2.1. Overview of MAEANet Network
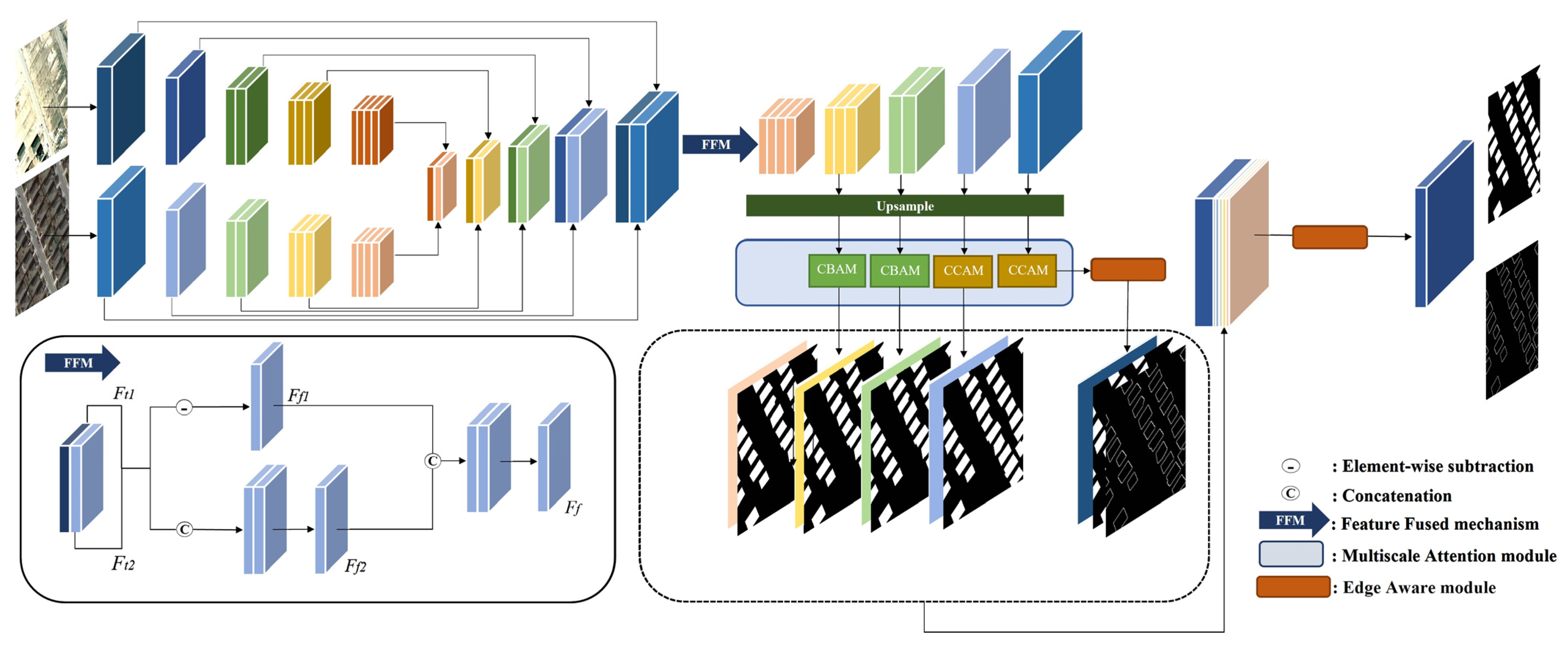
2.2. Siam-fusedNet
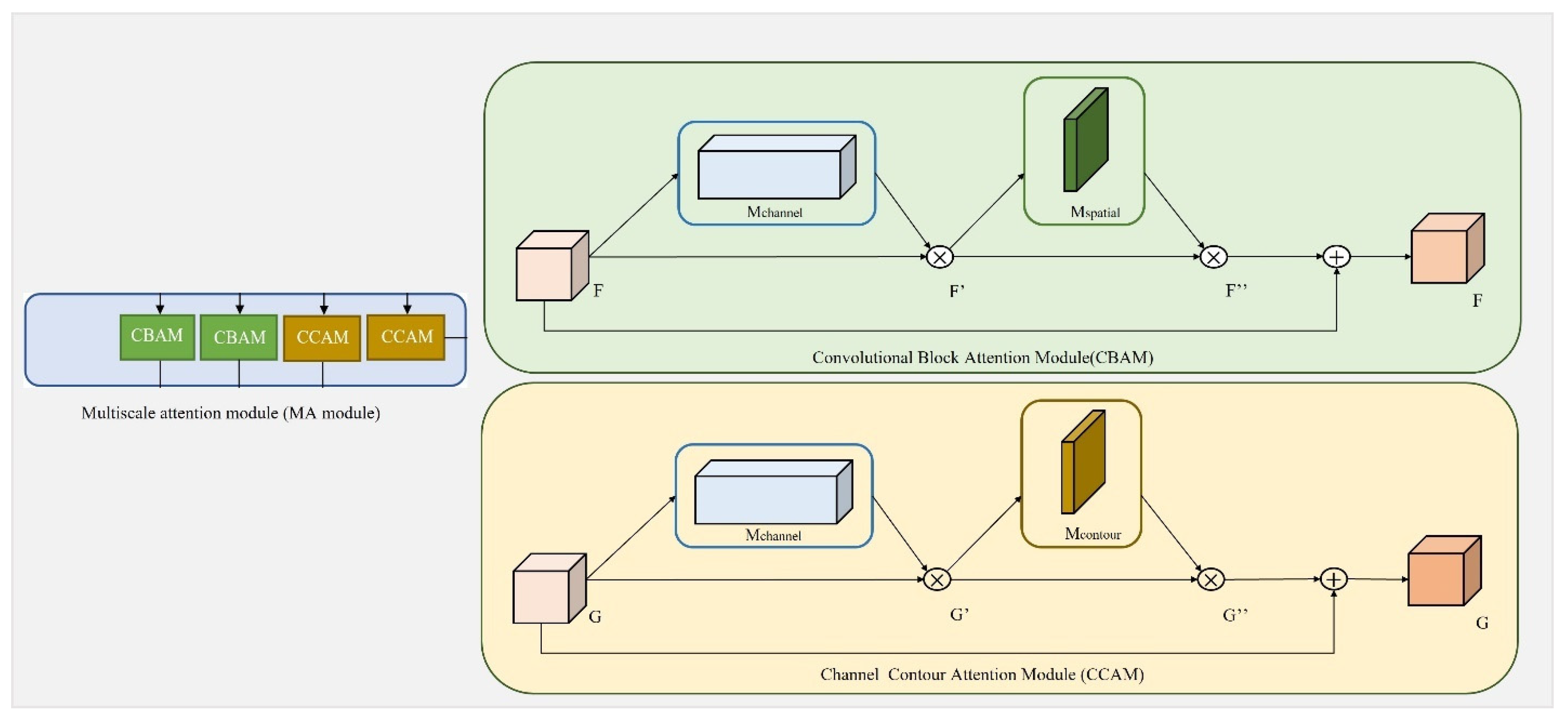
2.3. Multiscale Attention (MA) Module
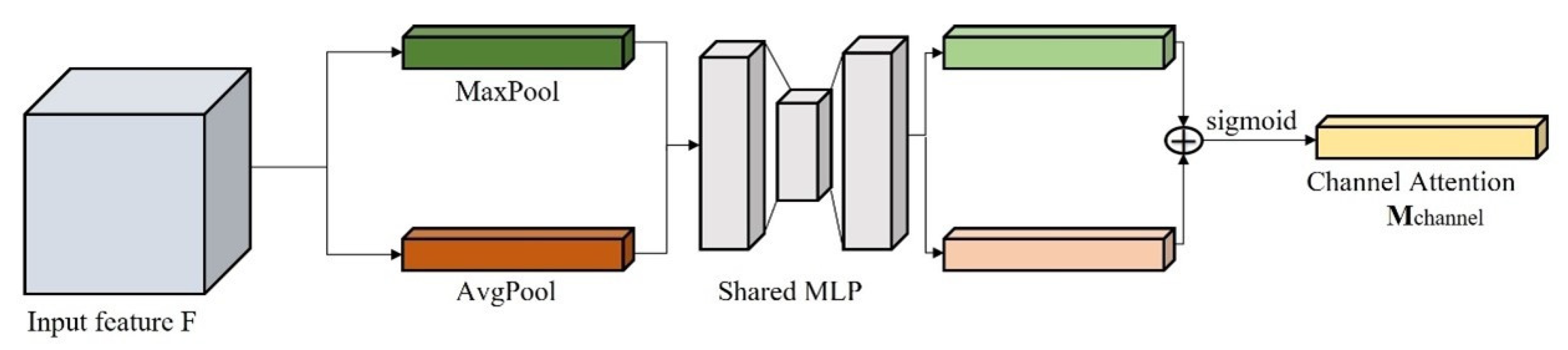
2.3.1. Channel Attention Mechanism
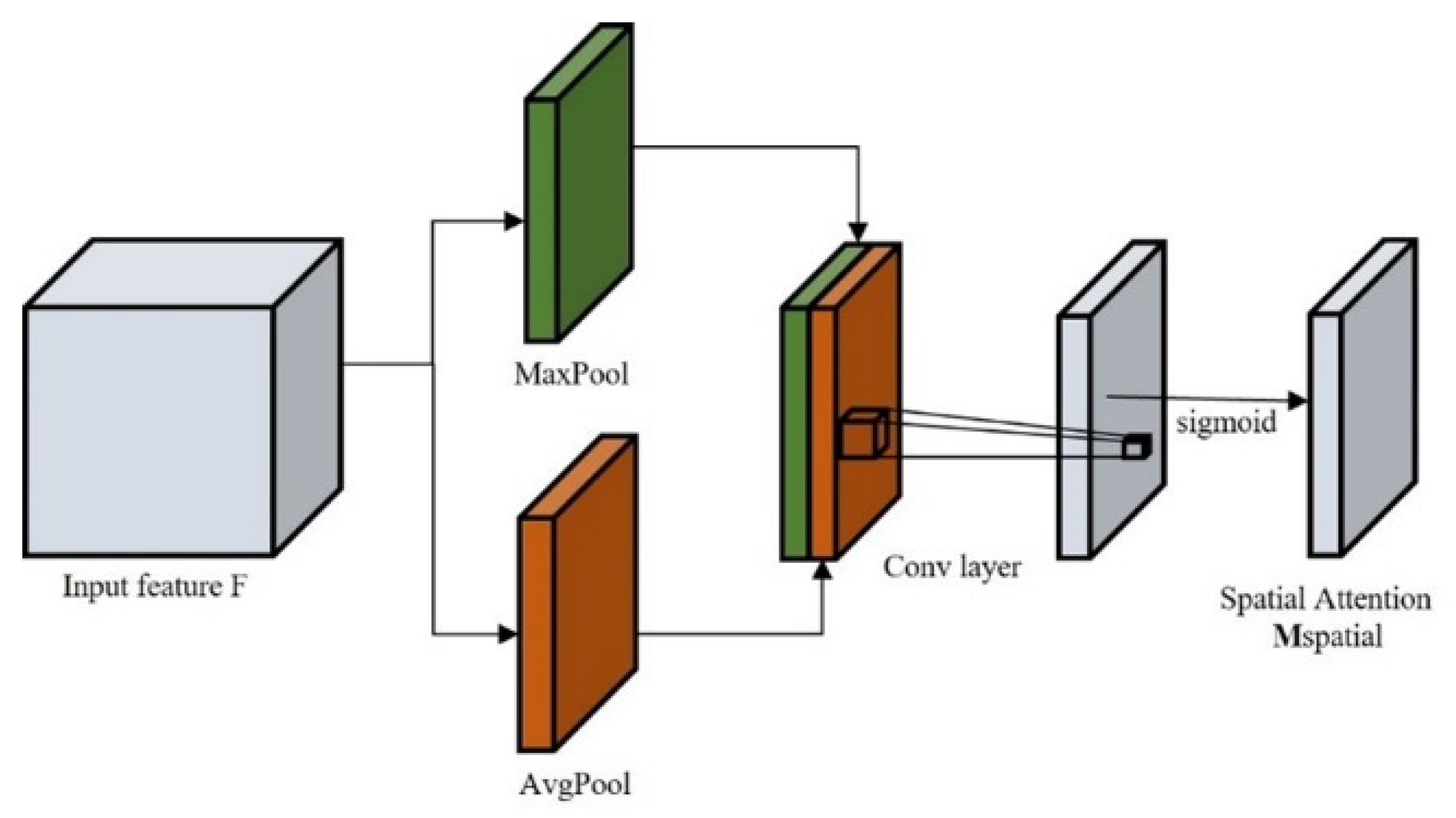
2.3.2. Spatial Attention Mechanism
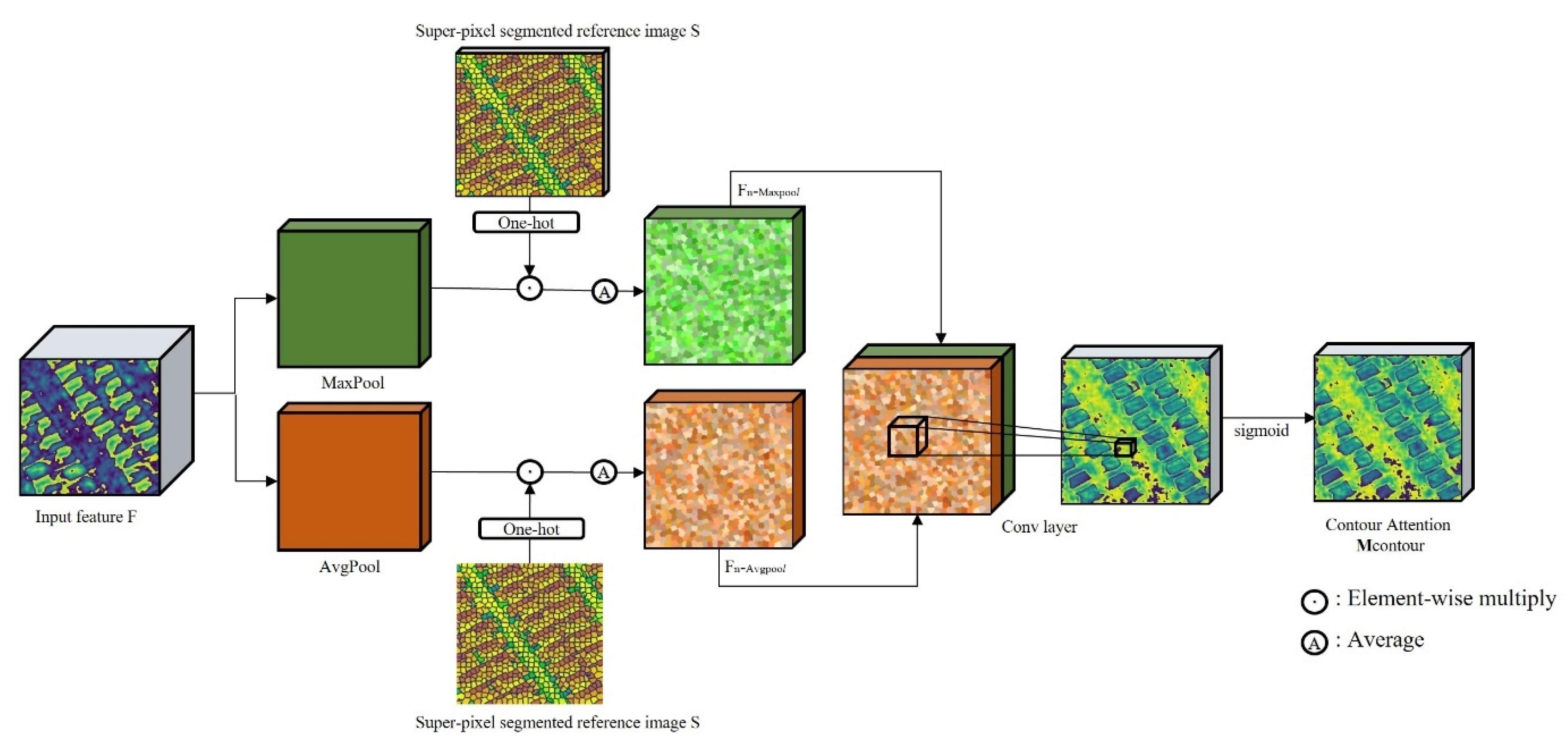
2.3.3. Contour Attention Mechanism

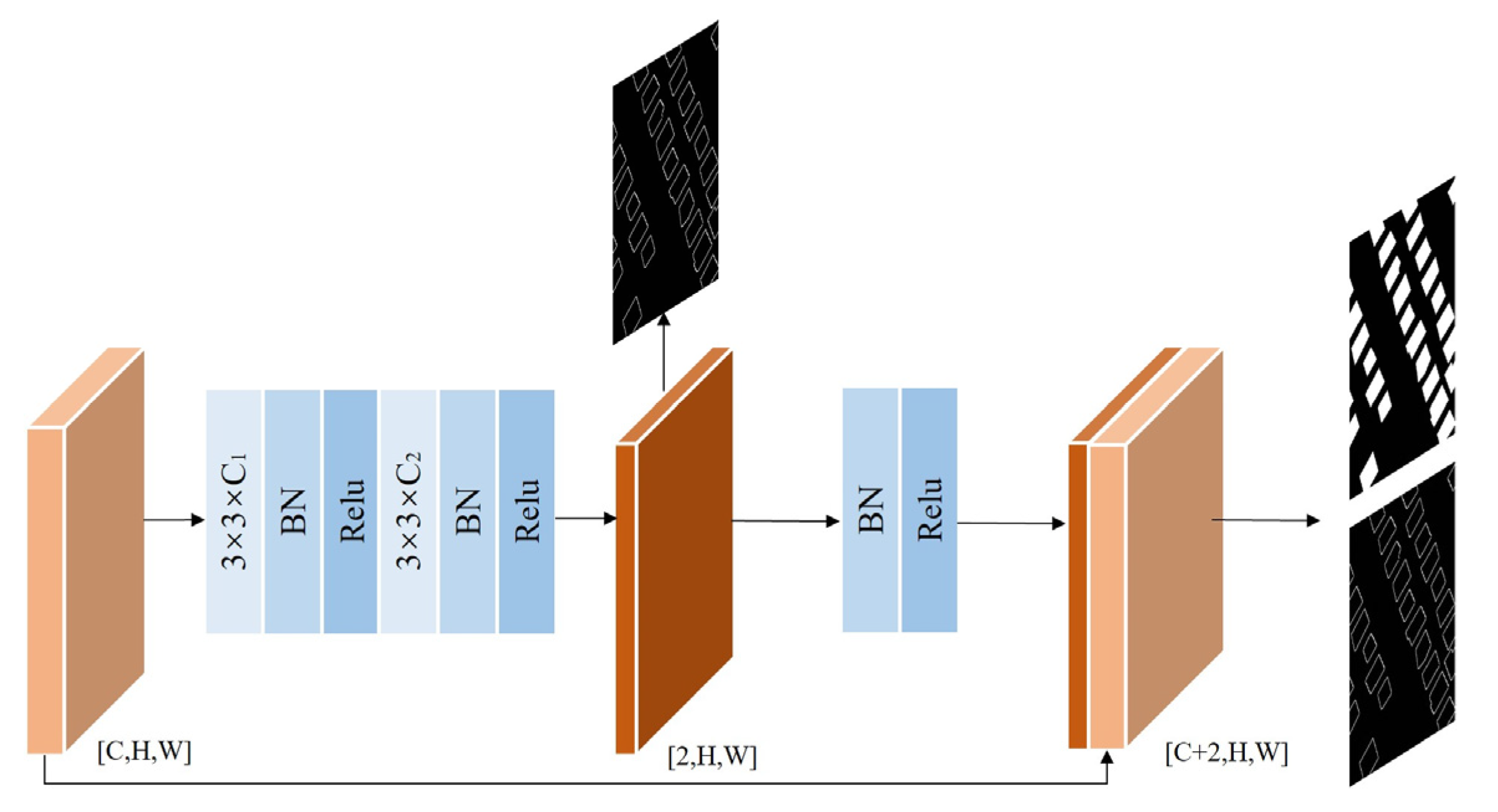
2.4. Edge Aware Module
2.5. Loss Function Details
3. Experiments and Results
3.1. Data Description
3.2. Comparison Methods
3.3. Implementation Details and Evaluation Metrics
3.4. Ablation Study for the Proposed MAEANet
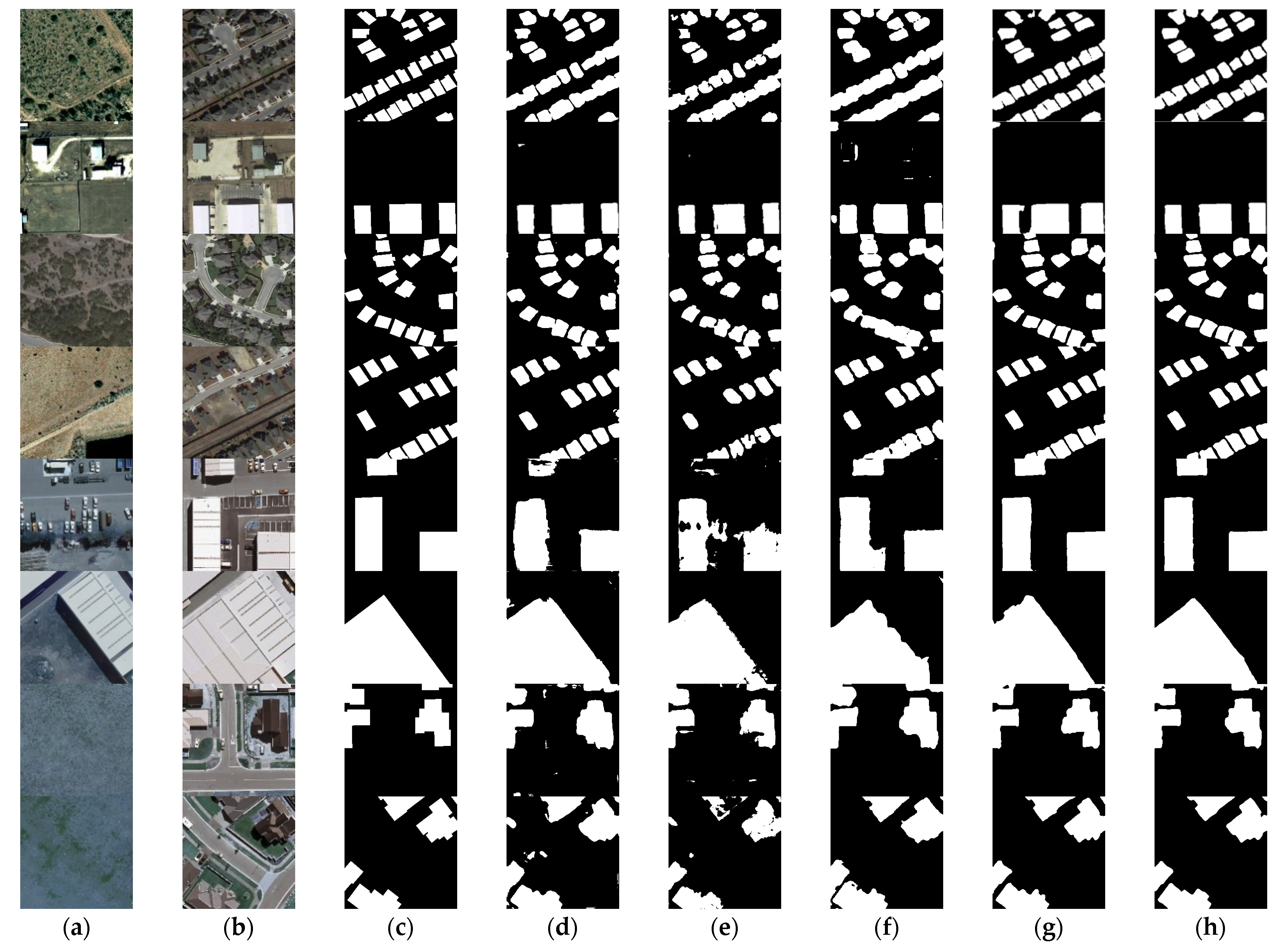
3.5. Comparison Experiments
4. Discussion
4.1. Quantitative Comparison of Binary Edge Prediction Results
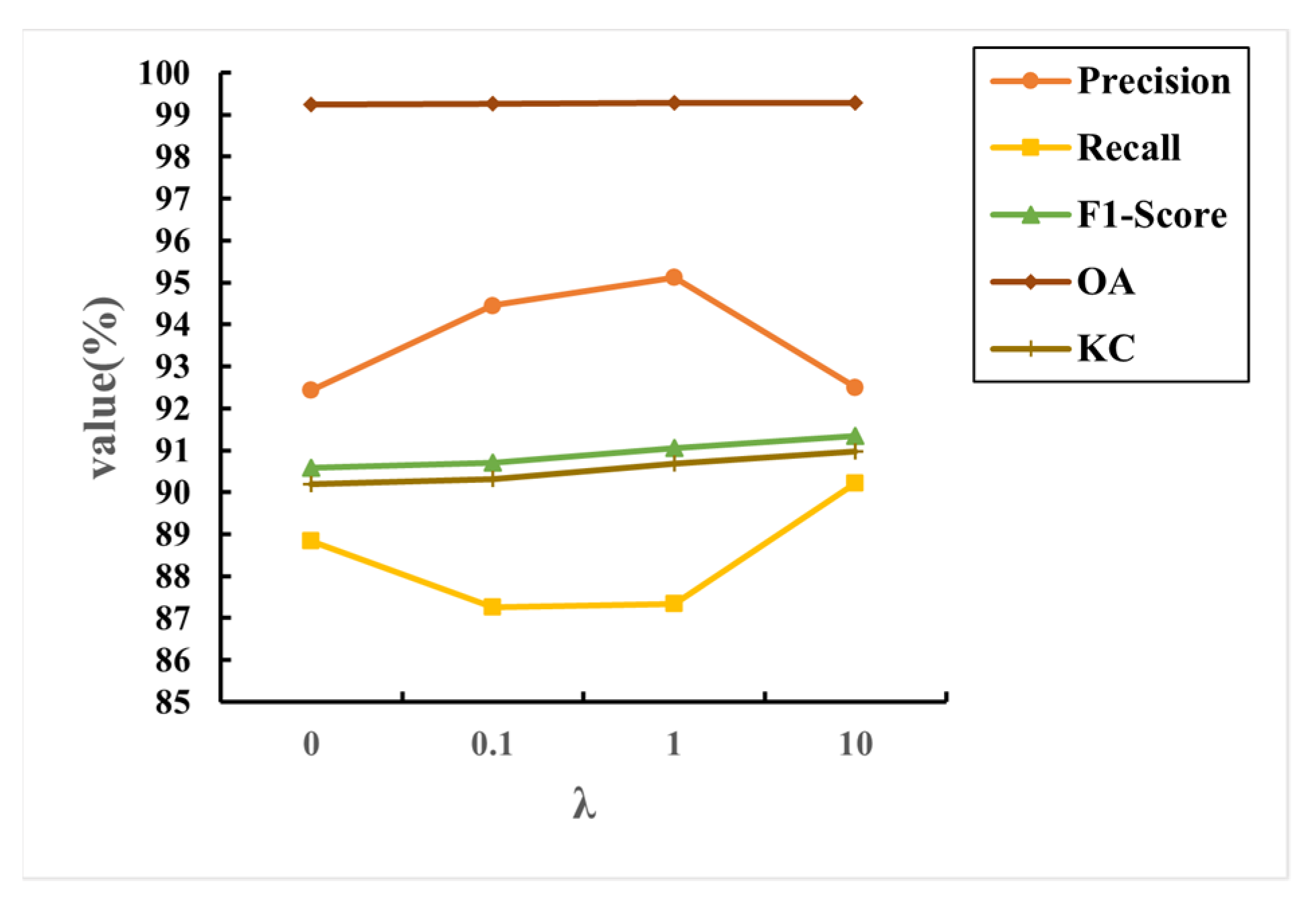
4.2. The Experiments on the Hybrid Loss
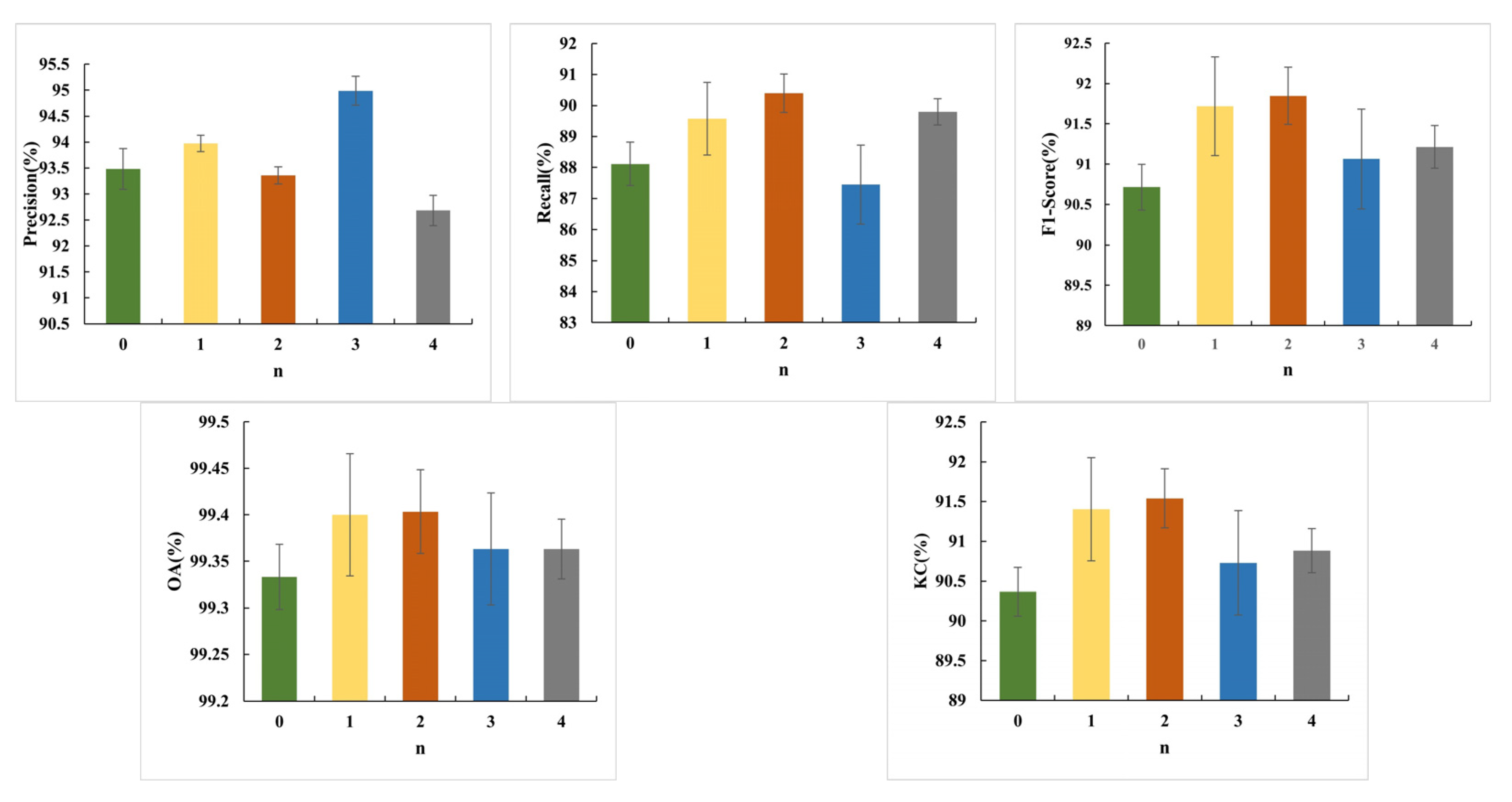
4.3. How to Combine the CBAM and CCAM in the MA Module?
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, H.; Wang, M.; Wang, F.; Yang, G.; Zhang, Y.; Jia, J.; Wang, S. A Novel Squeeze-and-Excitation W-Net for 2D and 3D Building Change Detection with Multi-Source and Multi-Feature Remote Sensing Data. Remote Sens. 2021, 13, 440. [Google Scholar] [CrossRef]
- Chen, J.; Liu, H.; Hou, J.; Yang, M.; Deng, M. Improving Building Change Detection in VHR Remote Sensing Imagery by Combining Coarse Location and Co-Segmentation. ISPRS Int. J. Geo-Inf. 2018, 7, 213. [Google Scholar] [CrossRef]
- He, Y.; Ma, W.; Ma, Z.; Fu, W.; Chen, C.; Yang, C.-F.; Liu, Z. Using Unmanned Aerial Vehicle Remote Sensing and a Monitoring Information System to Enhance the Management of Unauthorized Structures. Appl. Sci. 2019, 9, 4954. [Google Scholar] [CrossRef]
- Jiang, H.; Peng, M.; Zhong, Y.; Xie, H.; Hao, Z.; Lin, J.; Ma, X.; Hu, X. A Survey on Deep Learning-Based Change Detection from High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 1552. [Google Scholar] [CrossRef]
- Asokan, A.; Anitha, J. Change Detection Techniques for Remote Sensing Applications: A Survey. Earth Sci. Inf. 2019, 12, 143–160. [Google Scholar] [CrossRef]
- Wen, D.; Huang, X.; Bovolo, F.; Li, J.; Ke, X.; Zhang, A.; Benediktsson, J.A. Change Detection from Very-High-Spatial-Resolution Optical Remote Sensing Images: Methods, Applications, and Future Directions. IEEE Geosci. Remote Sens. Mag. 2021, 9, 68–101. [Google Scholar] [CrossRef]
- Johnson, R.D.; Kasischke, E.S. Change Vector Analysis: A Technique for the Multispectral Monitoring of Land Cover and Condition. Int. J. Remote Sens. 1998, 19, 411–426. [Google Scholar] [CrossRef]
- Lv, Z.Y.; Liu, T.F.; Zhang, P.; Benediktsson, J.A.; Lei, T.; Zhang, X. Novel Adaptive Histogram Trend Similarity Approach for Land Cover Change Detection by Using Bitemporal Very-High-Resolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 9554–9574. [Google Scholar] [CrossRef]
- Byrne, G.F.; Crapper, P.F.; Mayo, K.K. Monitoring Land-Cover Change by Principal Component Analysis of Multitemporal Landsat Data. Remote Sens. Environ. 1980, 10, 175–184. [Google Scholar] [CrossRef]
- Im, J.; Jensen, J. A Change Detection Model Based on Neighborhood Correlation Image Analysis and Decision Tree Classification. Remote Sens. Environ. 2005, 99, 326–340. [Google Scholar] [CrossRef]
- Wessels, K.; van den Bergh, F.; Roy, D.; Salmon, B.; Steenkamp, K.; MacAlister, B.; Swanepoel, D.; Jewitt, D. Rapid Land Cover Map Updates Using Change Detection and Robust Random Forest Classifiers. Remote Sens. 2016, 8, 888. [Google Scholar] [CrossRef]
- Wang, J.; Li, K.; Shao, Y.; Zhang, F.; Wang, Z.; Guo, X.; Qin, Y.; Liu, X. Analysis of Combining SAR and Optical Optimal Parameters to Classify Typhoon-Invasion Lodged Rice: A Case Study Using the Random Forest Method. Sensors 2020, 20, 7346. [Google Scholar] [CrossRef] [PubMed]
- Nemmour, H.; Chibani, Y. Multiple Support Vector Machines for Land Cover Change Detection: An Application for Mapping Urban Extensions. ISPRS J. Photogramm. Remote Sens. 2006, 61, 125–133. [Google Scholar] [CrossRef]
- Cross, G.R.; Jain, A.K. Markov Random Field Texture Models. IEEE Trans. Pattern Anal. Mach. Intell. 1983, PAMI-5, 25–39. [Google Scholar] [CrossRef]
- Li, Y.; Li, C.; Li, X.; Wang, K.; Rahaman, M.M.; Sun, C.; Chen, H.; Wu, X.; Zhang, H.; Wang, Q. A Comprehensive Review of Markov Random Field and Conditional Random Field Approaches in Pathology Image Analysis. Arch. Computat. Methods Eng. 2022, 29, 609–639. [Google Scholar] [CrossRef]
- Yang, J.; Price, B.; Cohen, S.; Lee, H.; Yang, M.-H. Object Contour Detection with a Fully Convolutional Encoder-Decoder Network. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 193–202. [Google Scholar]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention Receptive Pyramid Network for Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Cheng, G.; Li, Z.; Han, J.; Yao, X.; Guo, L. Exploring Hierarchical Convolutional Features for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6712–6722. [Google Scholar] [CrossRef]
- Wang, D.; Chen, X.; Jiang, M.; Du, S.; Xu, B.; Wang, J. ADS-Net:An Attention-Based Deeply Supervised Network for Remote Sensing Image Change Detection. Int. J. Appl. Earth Obs. Geoinf. 2021, 101, 102348. [Google Scholar] [CrossRef]
- Zhang, C.; Yue, P.; Tapete, D.; Jiang, L.; Shangguan, B.; Huang, L.; Liu, G. A Deeply Supervised Image Fusion Network for Change Detection in High Resolution Bi-Temporal Remote Sensing Images. ISPRS J. Photogramm. Remote Sens. 2020, 166, 183–200. [Google Scholar] [CrossRef]
- Jiang, H.; Hu, X.; Li, K.; Zhang, J.; Gong, J.; Zhang, M. PGA-SiamNet: Pyramid Feature-Based Attention-Guided Siamese Network for Remote Sensing Orthoimagery Building Change Detection. Remote Sens. 2020, 12, 484. [Google Scholar] [CrossRef]
- Guo, Q.; Zhang, J.; Zhu, S.; Zhong, C.; Zhang, Y. Deep Multiscale Siamese Network with Parallel Convolutional Structure and Self-Attention for Change Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–12. [Google Scholar] [CrossRef]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change Detection from Remotely Sensed Images: From Pixel-Based to Object-Based Approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Shi, Q.; Liu, M.; Li, S.; Liu, X.; Wang, F.; Zhang, L. A Deeply Supervised Attention Metric-Based Network and an Open Aerial Image Dataset for Remote Sensing Change Detection. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Chen, H.; Shi, Z. A Spatial-Temporal Attention-Based Method and a New Dataset for Remote Sensing Image Change Detection. Remote Sens. 2020, 12, 1662. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Learning Spectral-Spatial-Temporal Features via a Recurrent Convolutional Neural Network for Change Detection in Multispectral Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 57, 924–935. [Google Scholar] [CrossRef]
- Chen, H.; Wu, C.; Du, B.; Zhang, L.; Wang, L. Change Detection in Multisource VHR Images via Deep Siamese Convolutional Multiple-Layers Recurrent Neural Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2848–2864. [Google Scholar] [CrossRef]
- Liu, R.; Kuffer, M.; Persello, C. The Temporal Dynamics of Slums Employing a CNN-Based Change Detection Approach. Remote Sens. 2019, 11, 2844. [Google Scholar] [CrossRef]
- Zheng, Z.; Wan, Y.; Zhang, Y.; Xiang, S.; Peng, D.; Zhang, B. CLNet: Cross-Layer Convolutional Neural Network for Change Detection in Optical Remote Sensing Imagery. ISPRS J. Photogramm. Remote Sens. 2021, 175, 247–267. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Shao, J.; Li, Z. SNUNet-CD: A Densely Connected Siamese Network for Change Detection of VHR Images. IEEE Geosci. Remote Sens. Lett. 2021, 19, 1–5. [Google Scholar] [CrossRef]
- Bai, B.; Fu, W.; Lu, T.; Li, S. Edge-Guided Recurrent Convolutional Neural Network for Multitemporal Remote Sensing Image Building Change Detection. IEEE Trans. Geosci. Remote Sens. 2021, 60, 1–13. [Google Scholar] [CrossRef]
- Shi, C.; Zhang, Z.; Zhang, W.; Zhang, C.; Xu, Q. Learning Multiscale Temporal–Spatial–Spectral Features via a Multipath Convolutional LSTM Neural Network for Change Detection with Hyperspectral Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. ISBN 978-3-319-24573-7. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zhang, L.; Hu, X.; Zhang, M.; Shu, Z.; Zhou, H. Object-Level Change Detection with a Dual Correlation Attention-Guided Detector. ISPRS J. Photogramm. Remote Sens. 2021, 177, 147–160. [Google Scholar] [CrossRef]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef]
- Tong, H.; Tong, F.; Zhou, W.; Zhang, Y. Purifying SLIC Superpixels to Optimize Superpixel-Based Classification of High Spatial Resolution Remote Sensing Image. Remote Sens. 2019, 11, 2627. [Google Scholar] [CrossRef]
- Csillik, O. Fast Segmentation and Classification of Very High Resolution Remote Sensing Data Using SLIC Superpixels. Remote Sens. 2017, 9, 243. [Google Scholar] [CrossRef]
- Connolly, C.; Fleiss, T. A Study of Efficiency and Accuracy in the Transformation from RGB to CIELAB Color Space. IEEE Trans. Image Process. 1997, 6, 1046–1048. [Google Scholar] [CrossRef]
- Xia, L.; Zhang, X.; Zhang, J.; Yang, H.; Chen, T. Building Extraction from Very-High-Resolution Remote Sensing Images Using Semi-Supervised Semantic Edge Detection. Remote Sens. 2021, 13, 2187. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | MA | EA | Precision (%) | Recall (%) | F1-Score (%) | OA (%) | KC (%) | |
|---|---|---|---|---|---|---|---|---|
| LEVIR CD | Siam-fusedNet | × | × | 85.80 | 91.95 | 88.77 | 88.15 | 98.81 |
| MAEANet | √ | × | 89.36 | 90.24 | 89.80 | 89.25 | 98.95 | |
| MAEANet | × | √ | 89.43 | 89.48 | 89.45 | 88.89 | 98.93 | |
| MAEANet | √ | √ | 88.84 | 91.00 | 89.90 | 89.35 | 98.95 | |
| BCDD | Siam-fusedNet | × | × | 94.02 | 86.66 | 90.19 | 99.28 | 89.81 |
| MAEANet | √ | × | 92.61 | 89.36 | 90.95 | 99.31 | 90.61 | |
| MAEANet | × | √ | 93.31 | 88.74 | 90.96 | 99.32 | 90.62 | |
| MAEANet | √ | √ | 92.82 | 90.38 | 91.58 | 99.36 | 91.25 |
| Method | LEVIR CD | BCDD | ||||
|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score (%) | Precision (%) | Recall (%) | F1-Score (%) | |
| MSPSNet [22] | 88.74 | 87.44 | 88.09 | 75.84 | 78.59 | 77.19 |
| SNUNet [31] | 88.14 | 77.31 | 82.37 | 76.73 | 72.12 | 74.35 |
| STANet [25] | 81.30 | 89.90 | 85.40 | 81.90 | 85.90 | 83.80 |
| EGRCNN [32] | 86.43 | 89.87 | 88.11 | 90.74 | 88.92 | 89.82 |
| MAEANet | 88.84 | 91.00 | 89.90 | 92.82 | 90.38 | 91.58 |
| Precision (%) | Recall (%) | F1-Score (%) | OA (%) | KC (%) | |
|---|---|---|---|---|---|
| MSPSNet | 71.57 ± 2.54 (+16.5) | 79.23 ± 0.11 (+8.54) | 75.19 ± 1.39 (+12.73) | 92.03 ± 0.40 (+4.29) | 70.46 ± 1.10 (+15.29) |
| SNUNet | 70.41 ± 2.37 (+17.66) | 80.30 ± 0.19 (+7.47) | 75.02 ± 1.28 (+12.9) | 91.85 ± 0.41 (+4.47) | 70.16 ± 0.93 (+15.59) |
| STANet | 73.54 ± 2.32 (+14.53) | 75.30 ± 0.69 (+12.47) | 74.31 ± 0.90 (+13.61) | 92.08 ± 0.52 (+4.24) | 69.62 ± 0.50 (+16.13) |
| EGRCNN | 84.51 ± 1.25 (+3.56) | 86.50 ± 0.47 (+1.27) | 85.49 ± 0.86 (+2.43) | 95.53 ± 0.27 (+0.79) | 82.84 ± 0.67 (+2.91) |
| MAEANet | 88.07 ± 0.83 | 87.77 ± 0.11 | 87.92 ± 0.44 | 96.32 ± 0.30 | 85.75 ± 0.25 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, B.; Huang, Y.; Su, X.; Guo, H. MAEANet: Multiscale Attention and Edge-Aware Siamese Network for Building Change Detection in High-Resolution Remote Sensing Images. Remote Sens. 2022, 14, 4895. https://doi.org/10.3390/rs14194895
Yang B, Huang Y, Su X, Guo H. MAEANet: Multiscale Attention and Edge-Aware Siamese Network for Building Change Detection in High-Resolution Remote Sensing Images. Remote Sensing. 2022; 14(19):4895. https://doi.org/10.3390/rs14194895
Chicago/Turabian StyleYang, Bingjie, Yuancheng Huang, Xin Su, and Haonan Guo. 2022. "MAEANet: Multiscale Attention and Edge-Aware Siamese Network for Building Change Detection in High-Resolution Remote Sensing Images" Remote Sensing 14, no. 19: 4895. https://doi.org/10.3390/rs14194895
APA StyleYang, B., Huang, Y., Su, X., & Guo, H. (2022). MAEANet: Multiscale Attention and Edge-Aware Siamese Network for Building Change Detection in High-Resolution Remote Sensing Images. Remote Sensing, 14(19), 4895. https://doi.org/10.3390/rs14194895