
Gated Path Aggregation Feature Pyramid Network for Object Detection in Remote Sensing Images

Abstract
:1. Introduction
- Aiming at the problem of redundant noise information generated by PAFPN in the feature fusion process, we use an additional gating function, namely GPAFPN. The experiments are conducted to explore which gating function is more suitable.
- For the problem of missed target detection, replacing maxpooling with SSAC structure can not only prevent sample features from being replaced by other features, but also ensure that the receptive field and computational cost remain unchanged. The experiments explore which feature layer is the most appropriate to derive the top layer.
- A quantitative analysis with the mainstream attention mechanism on the NWPU VHR-10 [25] dataset is performed and the optimal mechanism is selected. Comparing with a series of popular networks, our proposed GPANet shows significant improvement.
2. Materials and Methods
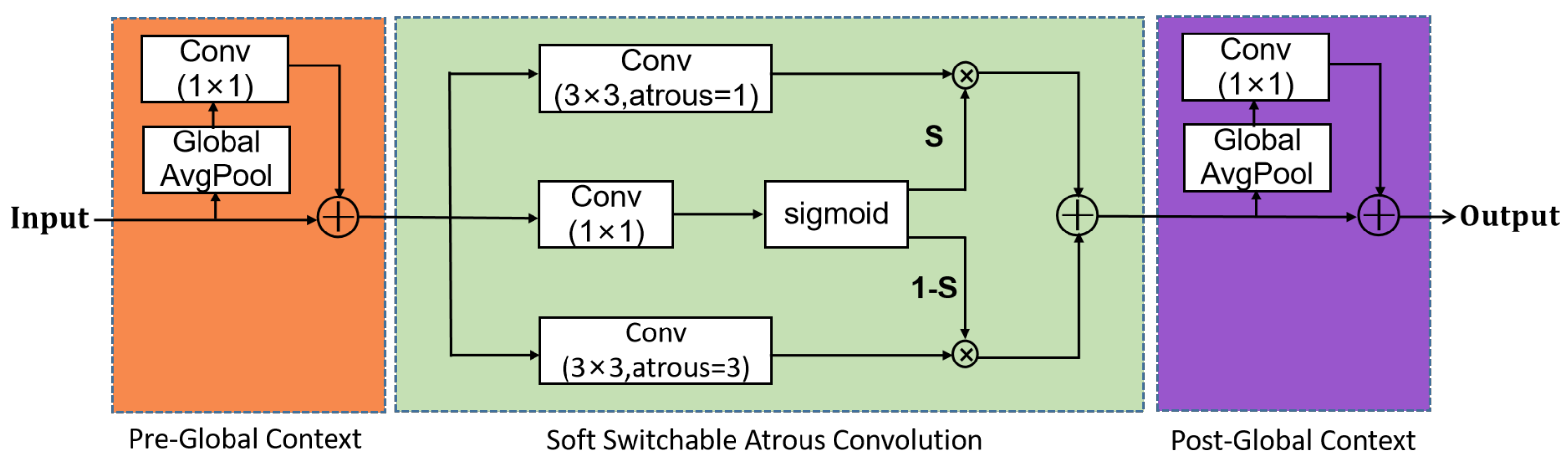
2.1. Soft Switchable Atrous Convolution Module
2.1.1. Atrous Convolution
2.1.2. Soft Switchable Atrous Convolution
2.1.3. Global Context
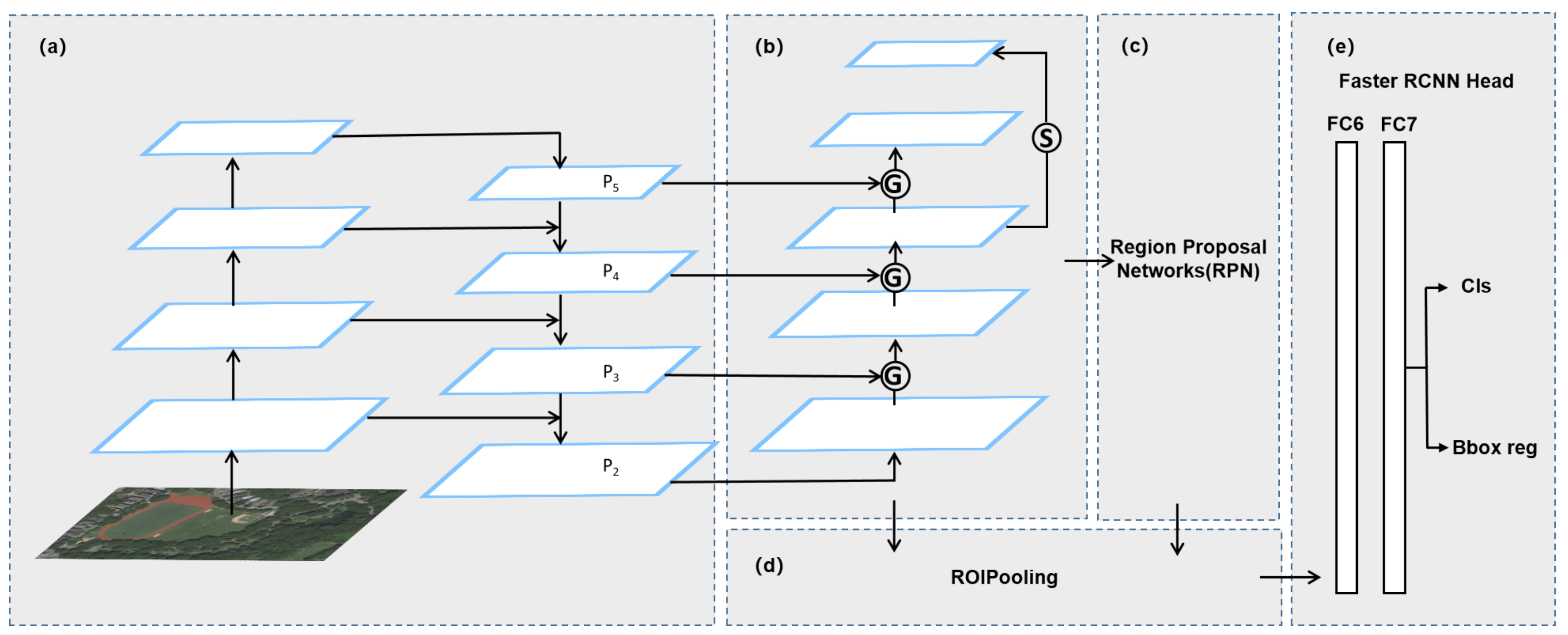
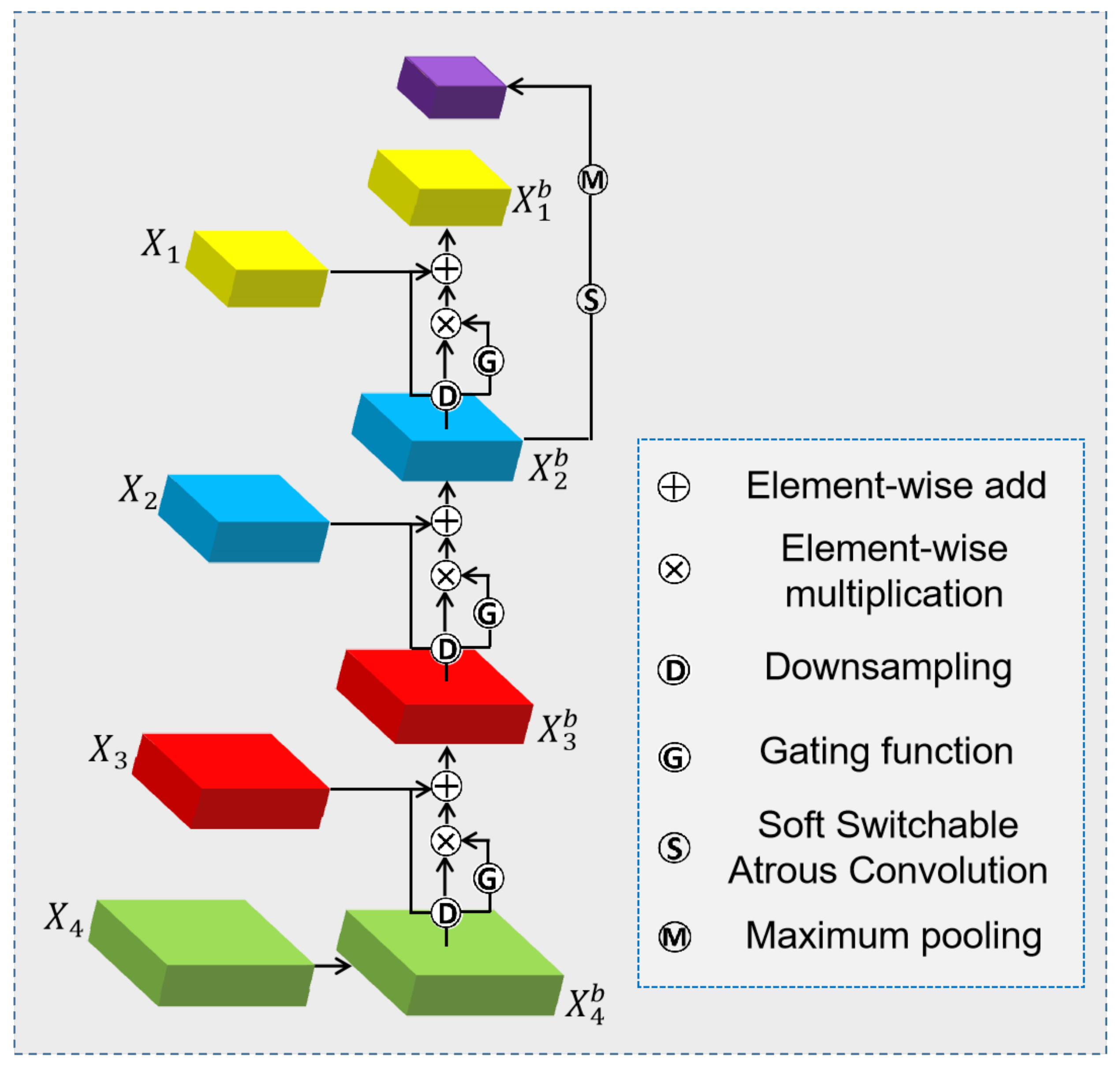
2.2. Bottom-Up Gating Function
2.3. Top-Level Features after Fine-Tuning
3. Experiments and Analysis
3.1. Dataset Description
3.2. Experimental Training Details
3.3. Evaluation Criteria
4. Discussions
4.1. The Effect of the Attention Mechanism
4.2. The Top Layer Derived from Different Feature Layers
4.3. Comparison of Other Models
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Li, X.; He, H.; Li, X.; Li, D.; Cheng, G.; Shi, J.; Weng, L.; Tong, Y.; Lin, Z. Pointflow: Flowing semantics through points for aerial image segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 4217–4226. [Google Scholar]
- Dong, R.; Xu, D.; Zhao, J.; Jiao, L.; An, J. Sig-NMS-based faster R-CNN combining transfer learning for small target detection in VHR optical remote sensing imagery. IEEE Trans. Geosci. Electron. 2019, 57, 8534–8545. [Google Scholar] [CrossRef]
- Zhu, B.; Wang, J.; Jiang, Z.; Zong, F.; Liu, S.; Li, Z.; Sun, J. Autoassign: Differentiable label assignment for dense object detection. arXiv 2020, arXiv:2007.03496. [Google Scholar]
- Xu, C.; Li, C.; Cui, Z.; Zhang, T.; Yang, J. Hierarchical semantic propagation for object detection in remote sensing imagery. IEEE Trans. Geosci. Electron. 2020, 58, 4353–4364. [Google Scholar] [CrossRef]
- Xie, X.; Cheng, G.; Wang, J.; Yao, X.; Han, J. Oriented r-cnn for object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 3520–3529. [Google Scholar]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z.; Fu, K. Scrdet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 8232–8241. [Google Scholar]
- Yang, X.; Liu, Q.; Yan, J.; Li, A.; Zhang, Z.; Yu, G. R3det: Refined single-stage detector with feature refinement for rotating object. arXiv 2019, arXiv:1908.05612. [Google Scholar] [CrossRef]
- Zhu, Y.; Du, J.; Wu, X. Adaptive period embedding for representing oriented objects in aerial images. IEEE Trans. Geosci. Electron. 2020, 58, 7247–7257. [Google Scholar] [CrossRef]
- Gong, Y.; Xiao, Z.; Tan, X.; Sui, H.; Xu, C.; Duan, H.; Li, D. Context-aware convolutional neural network for object detection in VHR remote sensing imagery. IEEE Trans. Geosci. Electron. 2019, 58, 34–44. [Google Scholar] [CrossRef]
- Lu, X.; Zhang, Y.; Yuan, Y.; Feng, Y. Gated and axis-concentrated localization network for remote sensing object detection. IEEE Trans. Geosci. Electron. 2019, 58, 179–192. [Google Scholar] [CrossRef]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. Augfpn: Improving multi-scale feature learning for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12595–12604. [Google Scholar]
- Li, C.; Cong, R.; Hou, J.; Zhang, S.; Qian, Y.; Kwong, S. Nested network with two-stream pyramid for salient object detection in optical remote sensing images. IEEE Trans. Geosci. Electron. 2019, 57, 9156–9166. [Google Scholar] [CrossRef]
- Zhang, G.; Lu, S.; Zhang, W. CAD-Net: A context-aware detection network for objects in remote sensing imagery. IEEE Trans. Geosci. Electron. 2019, 57, 10015–10024. [Google Scholar] [CrossRef]
- Liu, S.; Huang, D.; Wang, Y. Learning spatial fusion for single-shot object detection. arXiv 2019, arXiv:1911.09516. [Google Scholar]
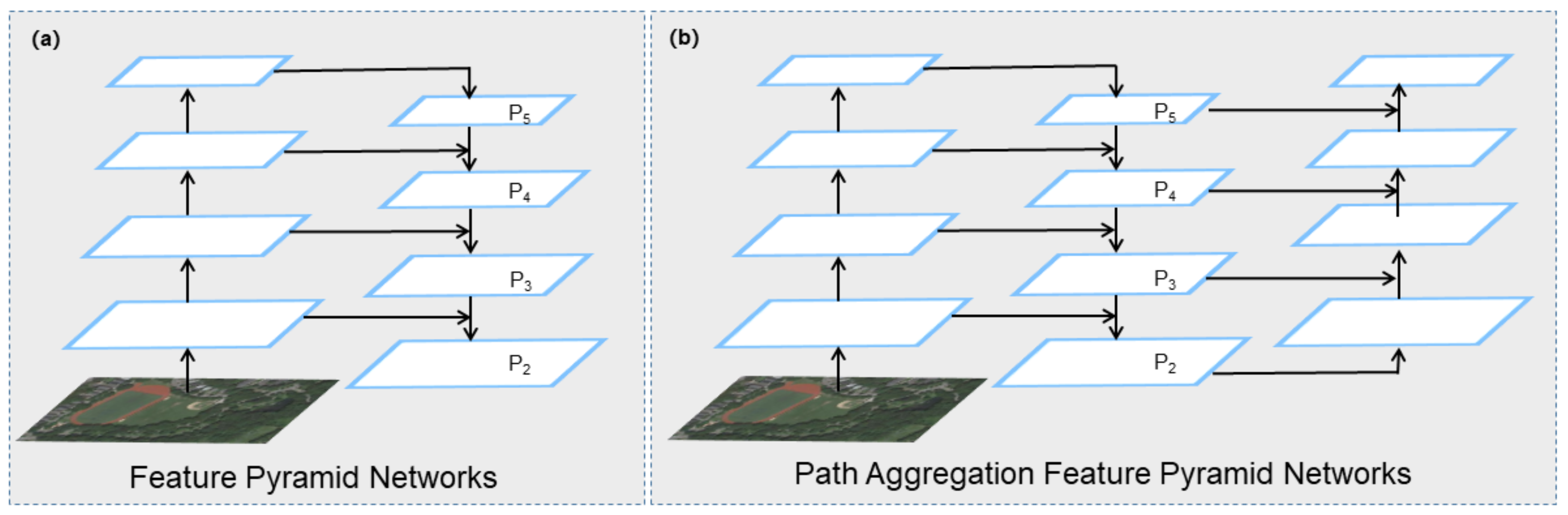
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Qiao, S.; Chen, L.C. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Online, 19–25 June 2021; pp. 10213–10224. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Ghiasi, G.; Lin, T.Y.; Le, Q.V. Nas-fpn: Learning scalable feature pyramid architecture for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–19 June 2019; pp. 7036–7045. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Zhang, Q.L.; Yang, Y.B. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2235–2239. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Electron. 2019, 58, 82–96. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Electron. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. Abstract Number 28. [Google Scholar]
- He, K.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Chen, K.; Wang, J.; Pang, J.; Cao, Y.; Xiong, Y.; Li, X.; Sun, S.; Feng, W.; Liu, Z.; Xu, J. MMDetection: Open MMLab Detection Toolbox and Benchmark. arXiv 2019, arXiv:1906.07155. [Google Scholar]
- Kong, T.; Yao, A.; Chen, Y.; Sun, F. Hypernet: Towards accurate region proposal generation and joint object detection. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 845–853. [Google Scholar]
- Li, K.; Cheng, G.; Bu, S.; You, X. Rotation-insensitive and context-augmented object detection in remote sensing images. IEEE Trans. Geosci. Electron. 2017, 56, 2337–2348. [Google Scholar] [CrossRef]
- Shih, K.J.; Endres, I.; Hoiem, D. Learning discriminative collections of part detectors for object recognition. IEEE Trans Pattern Anal. Mach. Intell. 2014, 37, 1571–1584. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Object Size (pixel) | Number of Original Objects | Enhancement Method | Number after Enhancement |
|---|---|---|---|---|
| airplane | 33–129 | 757 | RFC | 741 |
| ship | 40–128 | 302 | RFC | 741 |
| storage tank | 34–103 | 655 | GC | 663 |
| baseball diamond | 49–179 | 390 | FG | 862 |
| tennis court | 45–127 | 524 | RF | 636 |
| basketball court | 52–179 | 159 | FG | 846 |
| ground track field | 192–418 | 163 | FG | 732 |
| harbor | 68–222 | 224 | RF | 640 |
| bridge | 98–363 | 124 | FG | 696 |
| vehicle | 42–91 | 598 | RFC | 591 |
| Total of the target quantity | – | 3896 | – | 7148 |
| Enhancement method | Parameters |
|---|---|
| R (Rotation) | |
| F (Flip) | Horizontal or vertical |
| G (GaussianBlur) | |
| C (Cropping) |
| Parameters | Value |
|---|---|
| Learning Rate | 0.0025 |
| Image Resize | |
| Momentum | 0.9 |
| Weight Decay | 0.0005 |
| Anchor Size | |
| Ratios | |
| Strides | |
| Warmup | Linear |
| epochs | 12 |
| Batch size | 2 |
| Backbone | Method | mAP |
|---|---|---|
| Resnet-34 | FPN | 0.5900 |
| PAFPN | 0.6030 | |
| PAFPN+ECA | 0.5950 | |
| PAFPN+CBMA | 0.6010 | |
| PAFPN+SE | 0.6060 | |
| Resnet-50 | FPN | 0.5980 |
| PAFPN | 0.6120 | |
| PAFPN+ECA | 0.6100 | |
| PAFPN+CBMA | 0.6080 | |
| PAFPN+SE | 0.6200 |
| Feature Level | SSAC | mAP | ||
|---|---|---|---|---|
| 0.6200 | 0.9210 | 0.6800 | ||
| ✓ | 0.6180 | 0.9190 | 0.6820 | |
| 0.6170 | 0.9200 | 0.6820 | ||
| ✓ | 0.6220 | 0.9270 | 0.6880 | |
| 0.6130 | 0.9210 | 0.6810 | ||
| ✓ | 0.6170 | 0.9210 | 0.6740 |
| Method | mAP | Ship | Airplane | Storage Tank | Vehicle | Harbor | Tennis Court | Baseball Diamond | Bridge | Basketball Court | Ground Track Field |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Hyper | 0.887 | 0.898 | 0.997 | 0.987 | 0.887 | 0.804 | 0.907 | 0.909 | 0.689 | 0.903 | 0.893 |
| RICA | 0.871 | 0.908 | 0.997 | 0.906 | 0.871 | 0.803 | 0.903 | 0.929 | 0.685 | 0.801 | 0.908 |
| CA-CNN | 0.910 | 0.906 | 0.999 | 0.900 | 0.890 | 0.890 | 0.902 | 0.997 | 0.793 | 0.909 | 0.909 |
| COPD | 0.807 | 0.817 | 0.891 | 0.973 | 0.833 | 0.734 | 0.733 | 0.894 | 0.629 | 0.734 | 0.830 |
| RICNN | 0.726 | 0.773 | 0.884 | 0.853 | 0.711 | 0.686 | 0.408 | 0.881 | 0.615 | 0.585 | 0.867 |
| Fast-RCNN | 0.827 | 0.906 | 0.909 | 0.893 | 0.698 | 0.882 | 1.000 | 0.473 | 0.803 | 0.859 | 0.849 |
| Faster-RCNN | 0.827 | 0.906 | 0.909 | 0.905 | 0.781 | 0.801 | 0.897 | 0.982 | 0.615 | 0.696 | 1.000 |
| GPANet | 0.927 | 0.921 | 0.995 | 0.993 | 0.892 | 0.924 | 0.923 | 0.995 | 0.832 | 0.846 | 0.923 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zheng, Y.; Zhang, X.; Zhang, R.; Wang, D. Gated Path Aggregation Feature Pyramid Network for Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 4614. https://doi.org/10.3390/rs14184614
Zheng Y, Zhang X, Zhang R, Wang D. Gated Path Aggregation Feature Pyramid Network for Object Detection in Remote Sensing Images. Remote Sensing. 2022; 14(18):4614. https://doi.org/10.3390/rs14184614
Chicago/Turabian StyleZheng, Yuchao, Xinxin Zhang, Rui Zhang, and Dahan Wang. 2022. "Gated Path Aggregation Feature Pyramid Network for Object Detection in Remote Sensing Images" Remote Sensing 14, no. 18: 4614. https://doi.org/10.3390/rs14184614
APA StyleZheng, Y., Zhang, X., Zhang, R., & Wang, D. (2022). Gated Path Aggregation Feature Pyramid Network for Object Detection in Remote Sensing Images. Remote Sensing, 14(18), 4614. https://doi.org/10.3390/rs14184614