
Vegetation Mapping with Random Forest Using Sentinel 2 and GLCM Texture Feature—A Case Study for Lousã Region, Portugal




Abstract
:1. Introduction
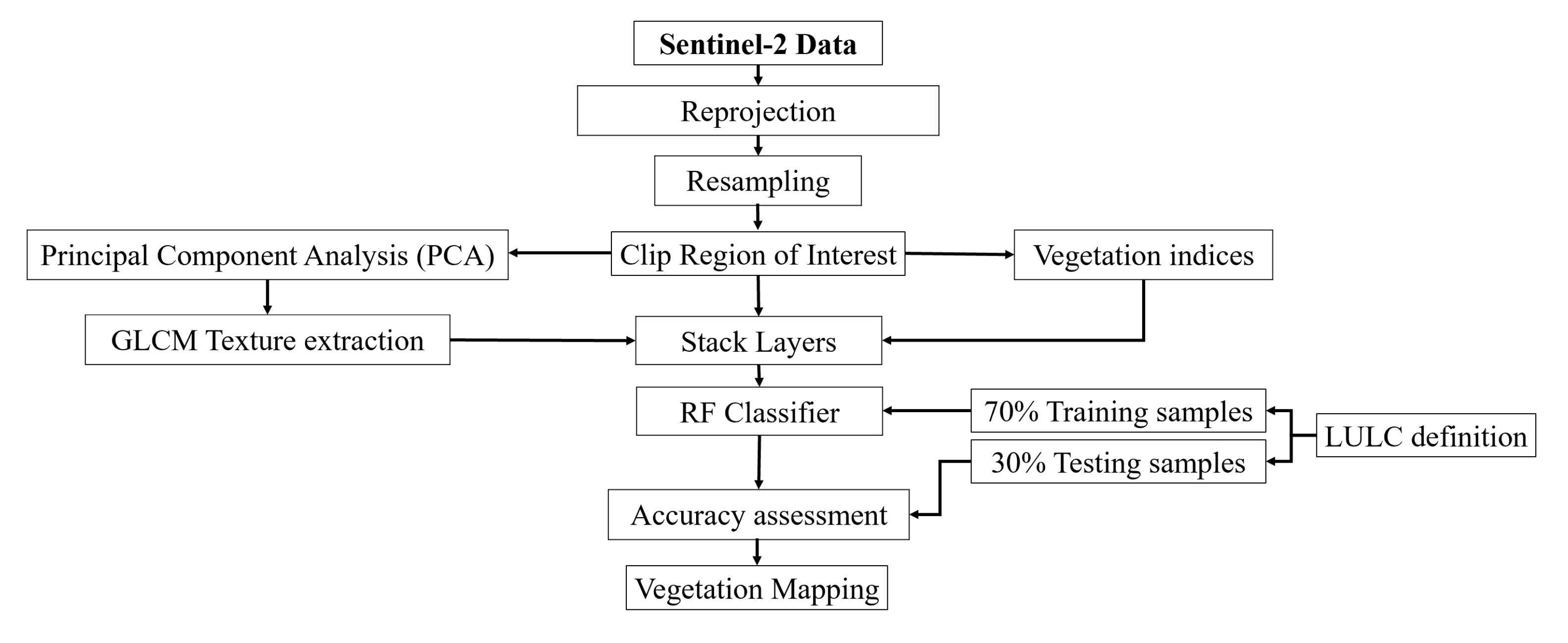
2. Materials and Methods
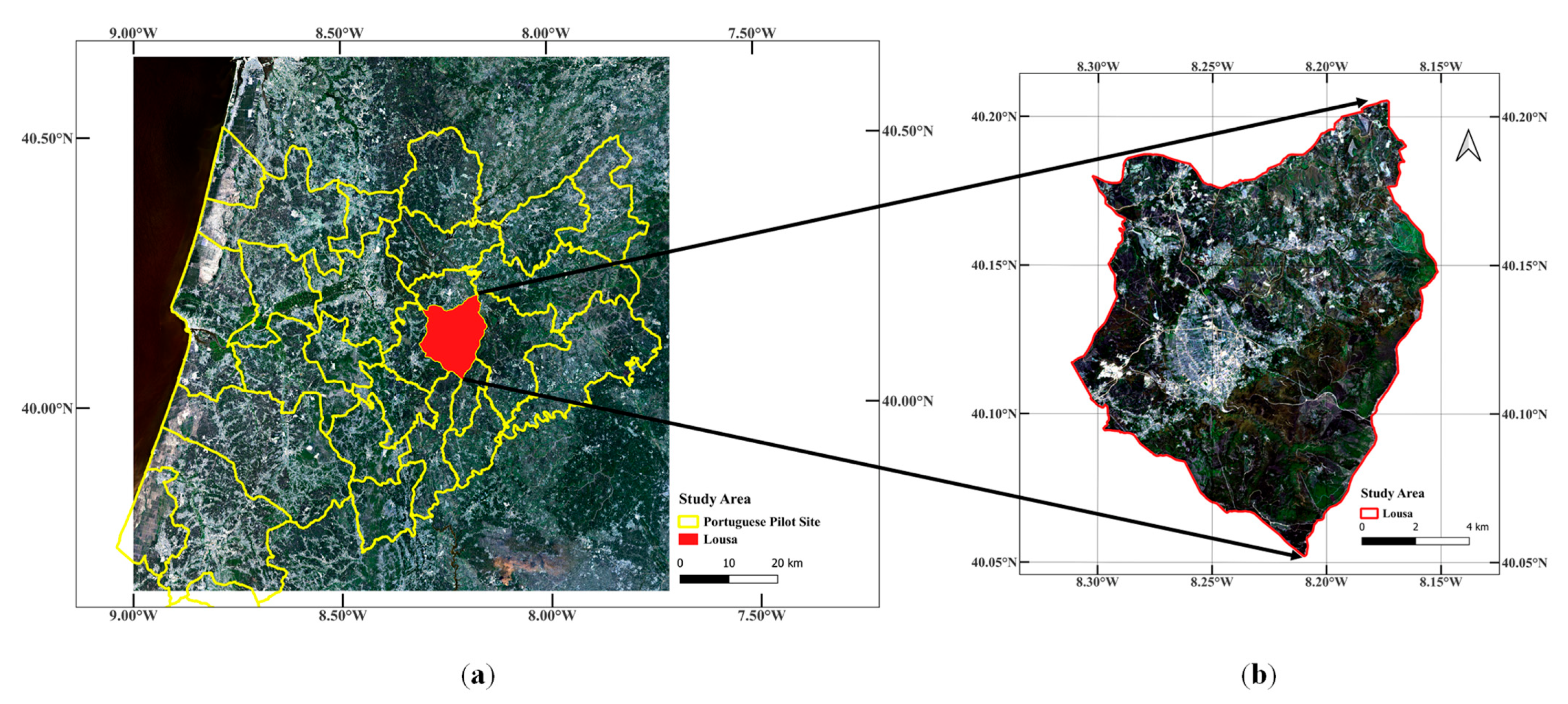
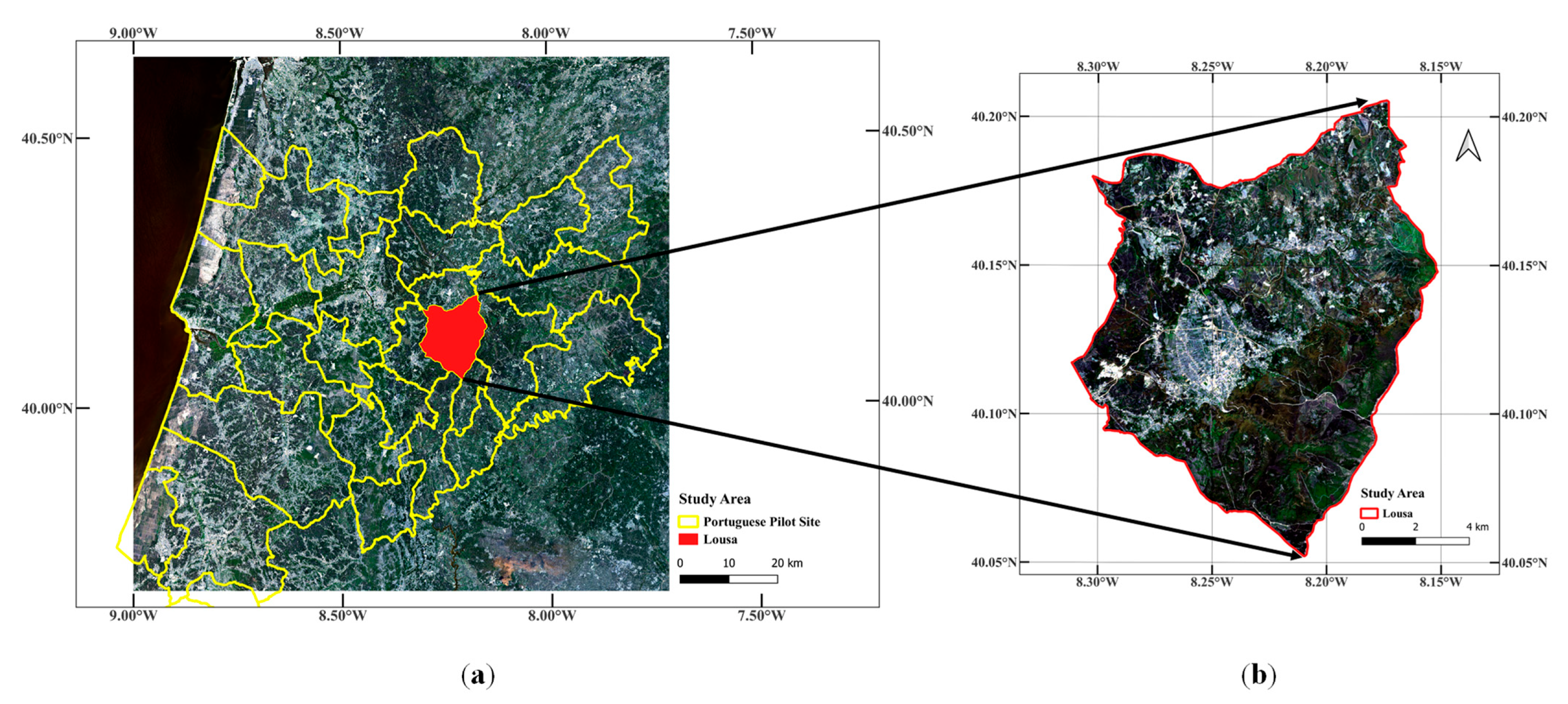
2.1. Study Area
2.2. Materials, Data and Model Algorithm
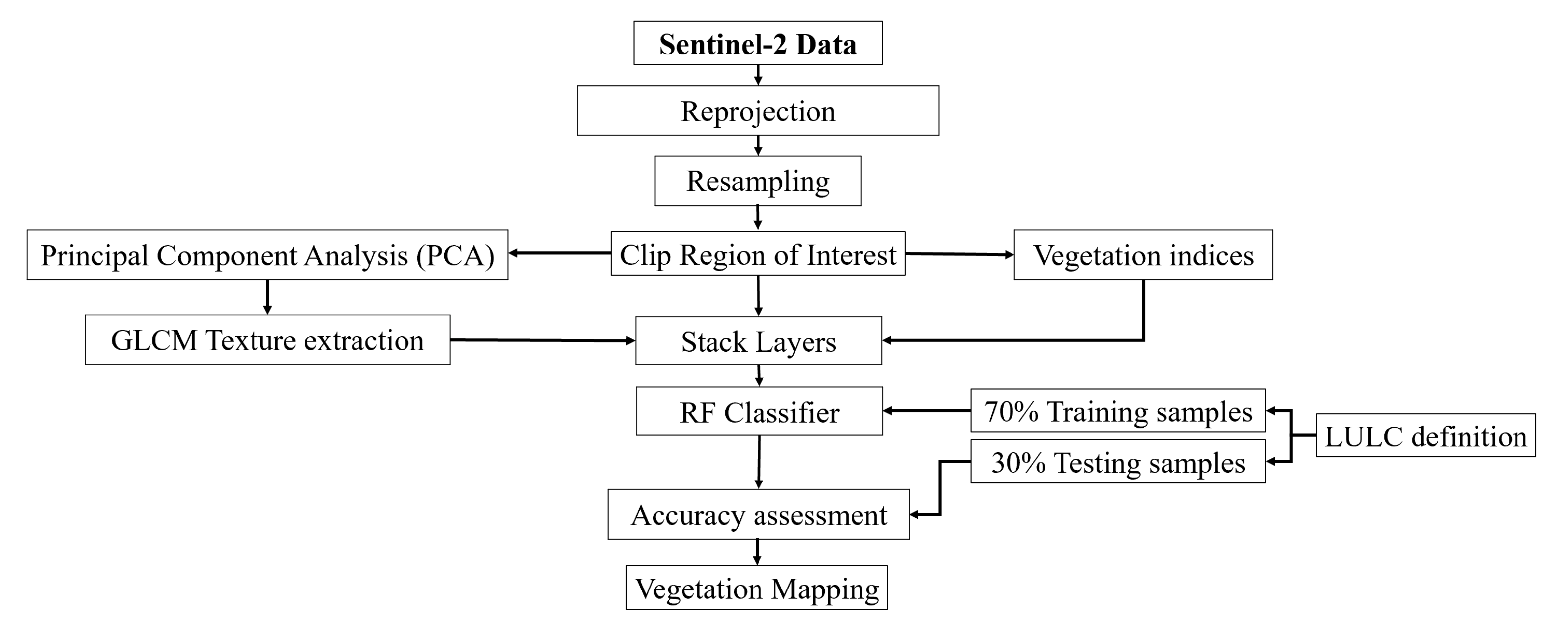
2.2.1. Dataset and Preprocessing
2.2.2. Reference Data
2.2.3. Image Classification
2.2.4. Accuracy Assessment
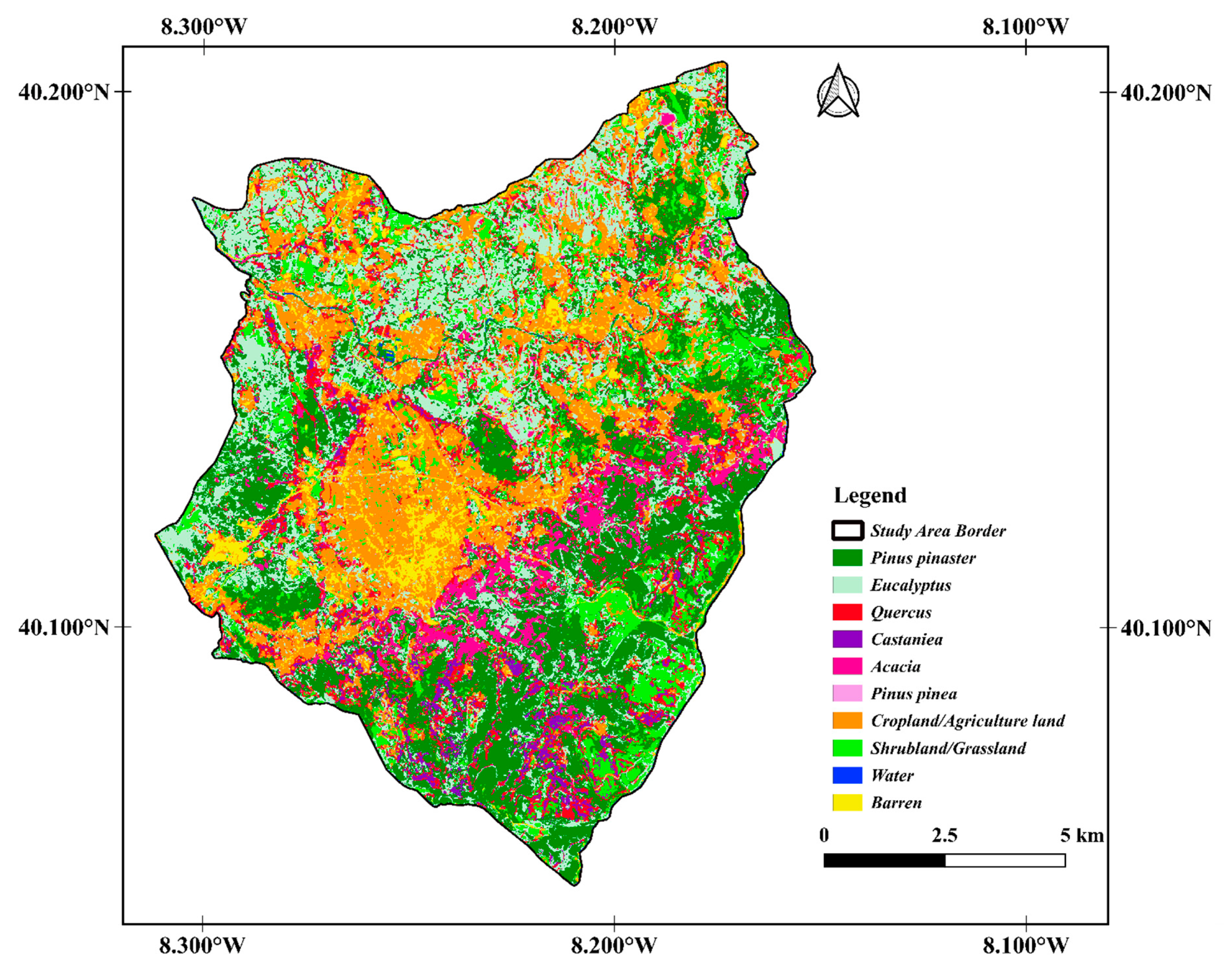
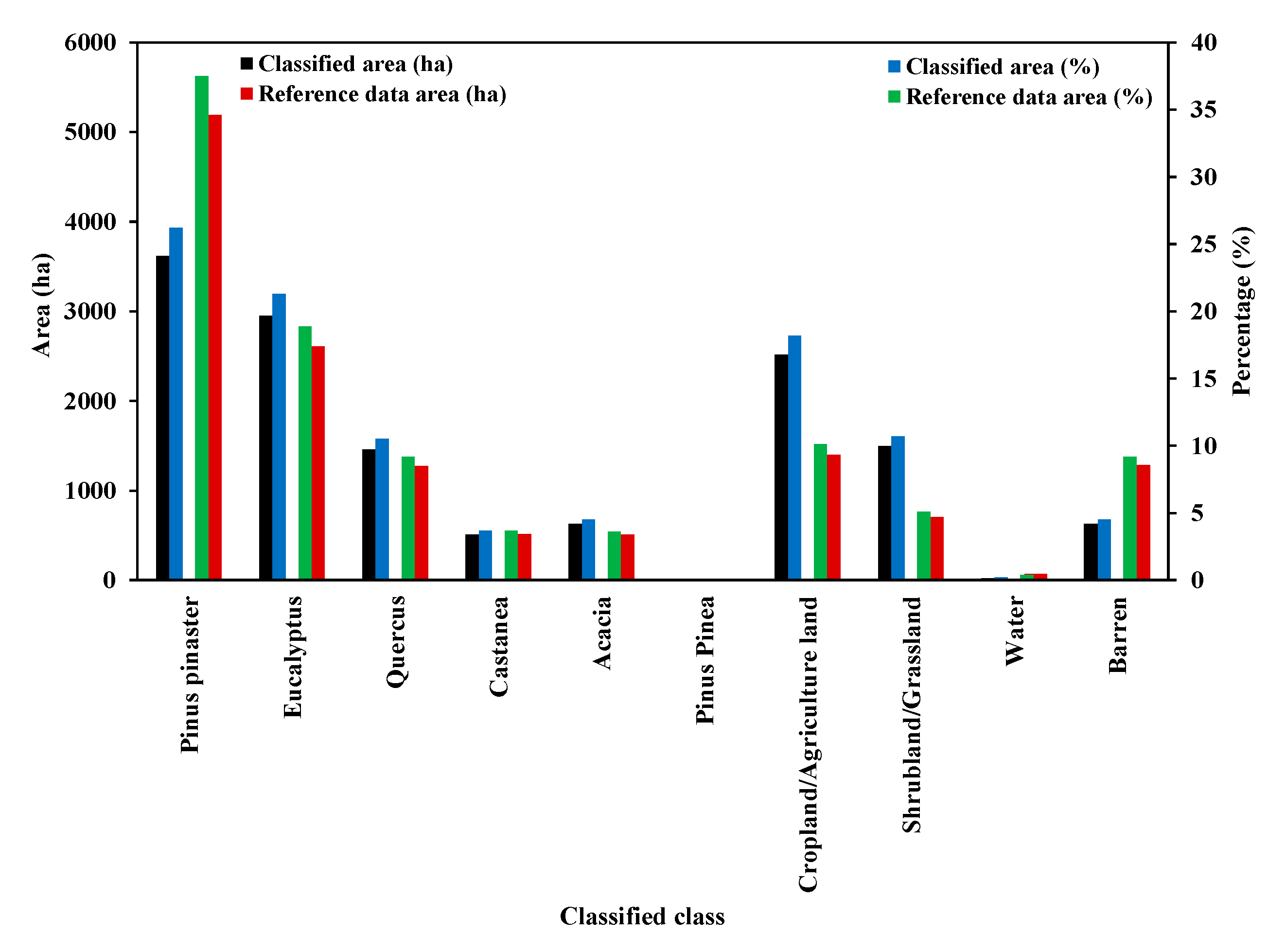
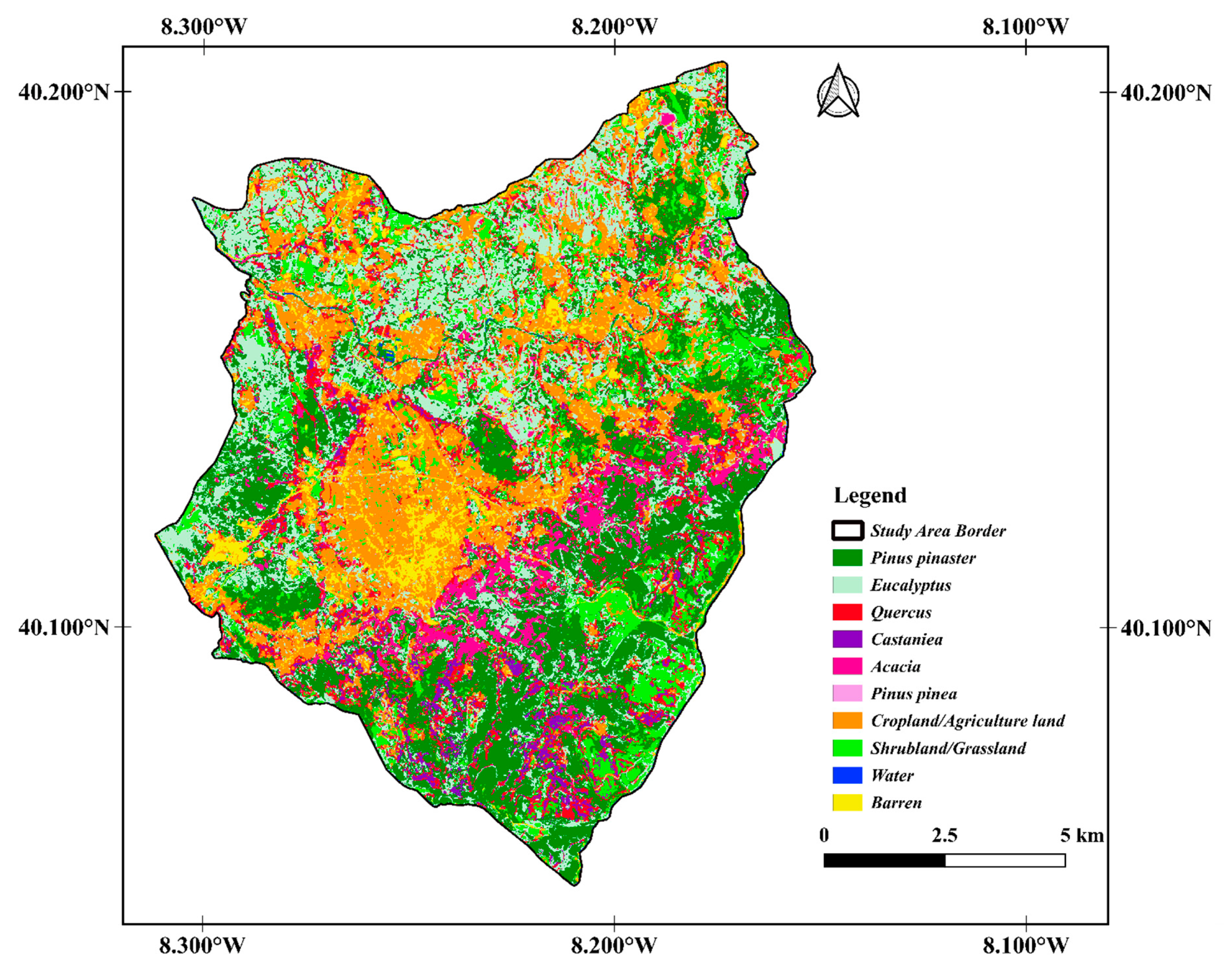
3. Results
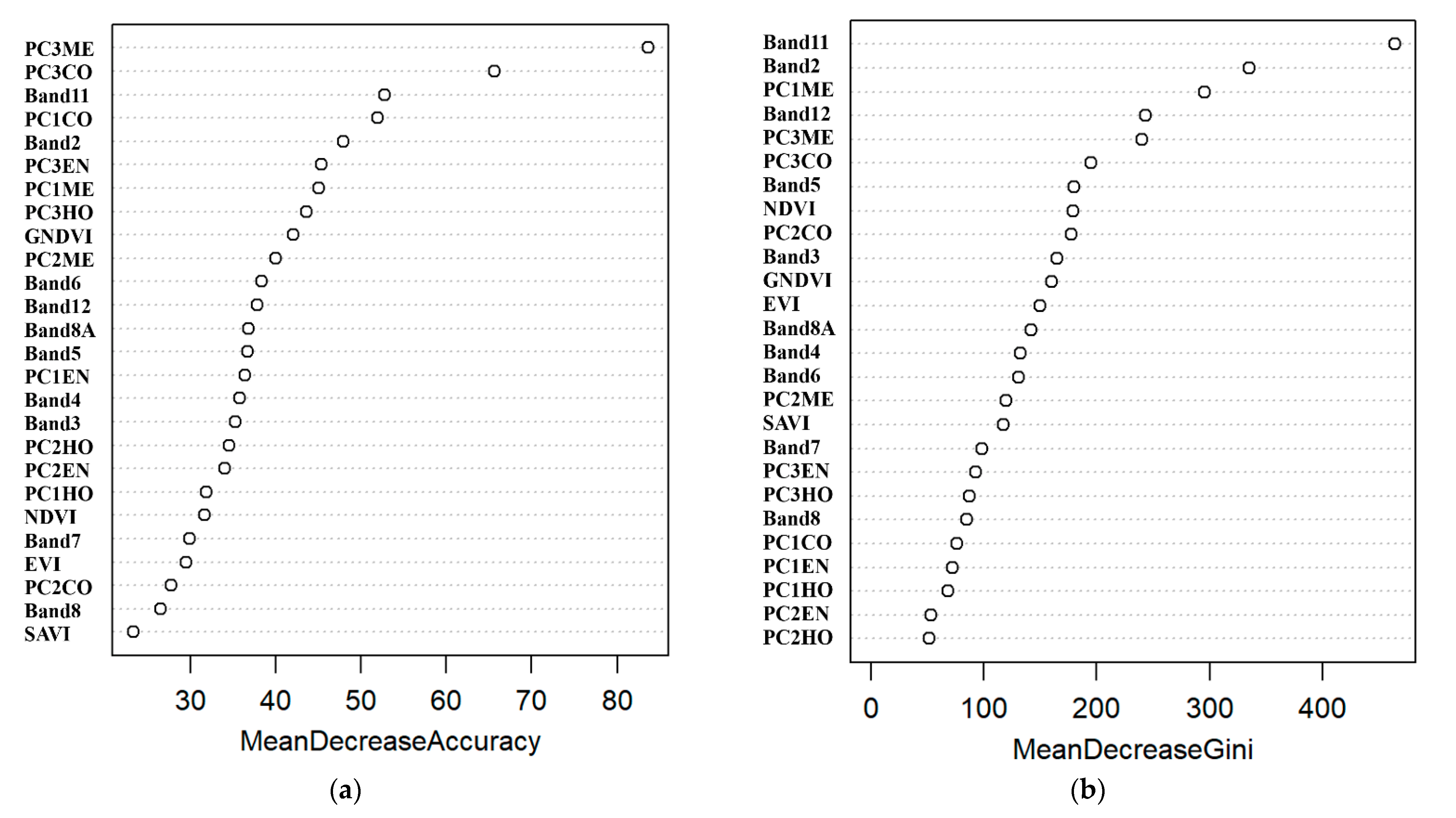
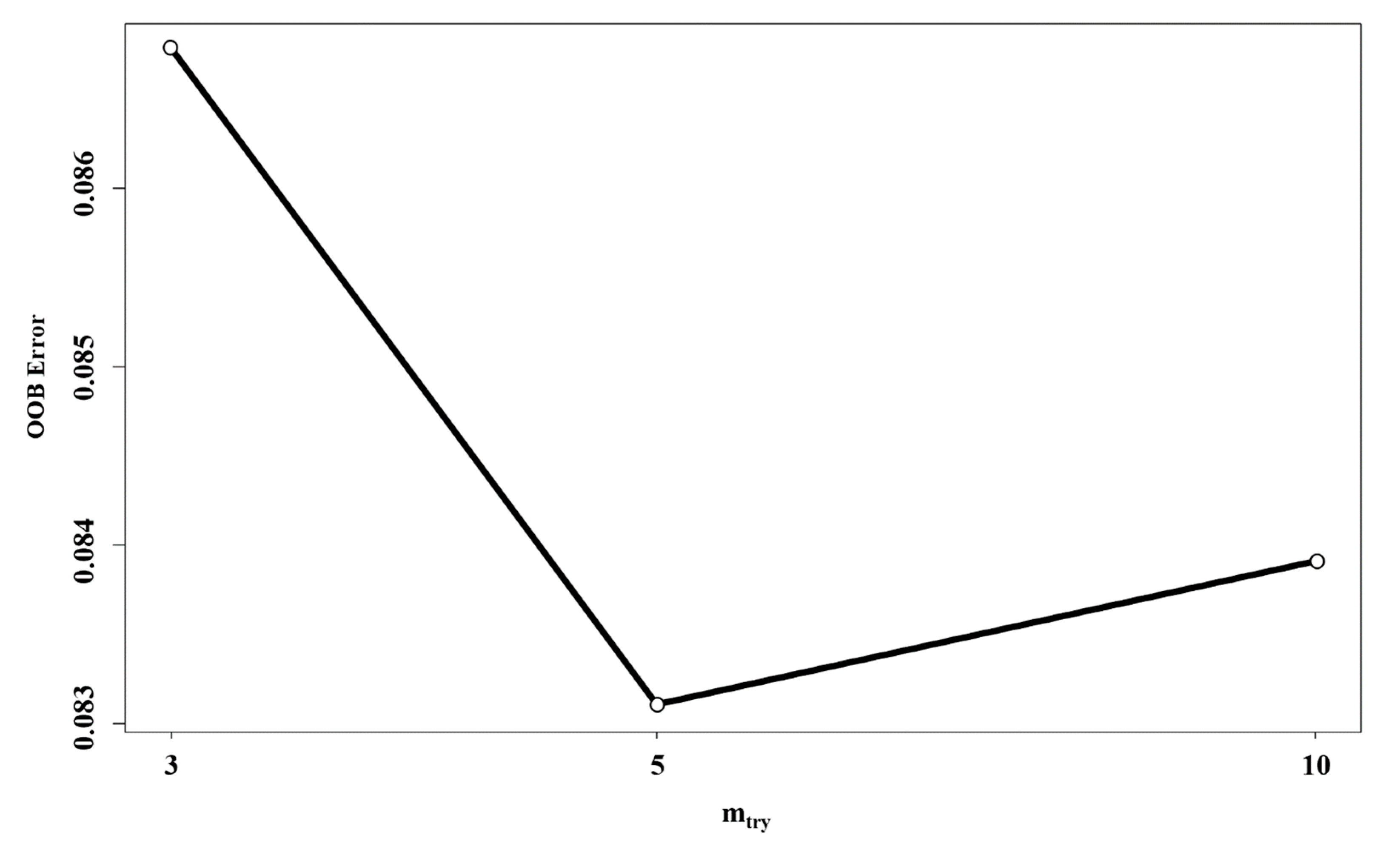
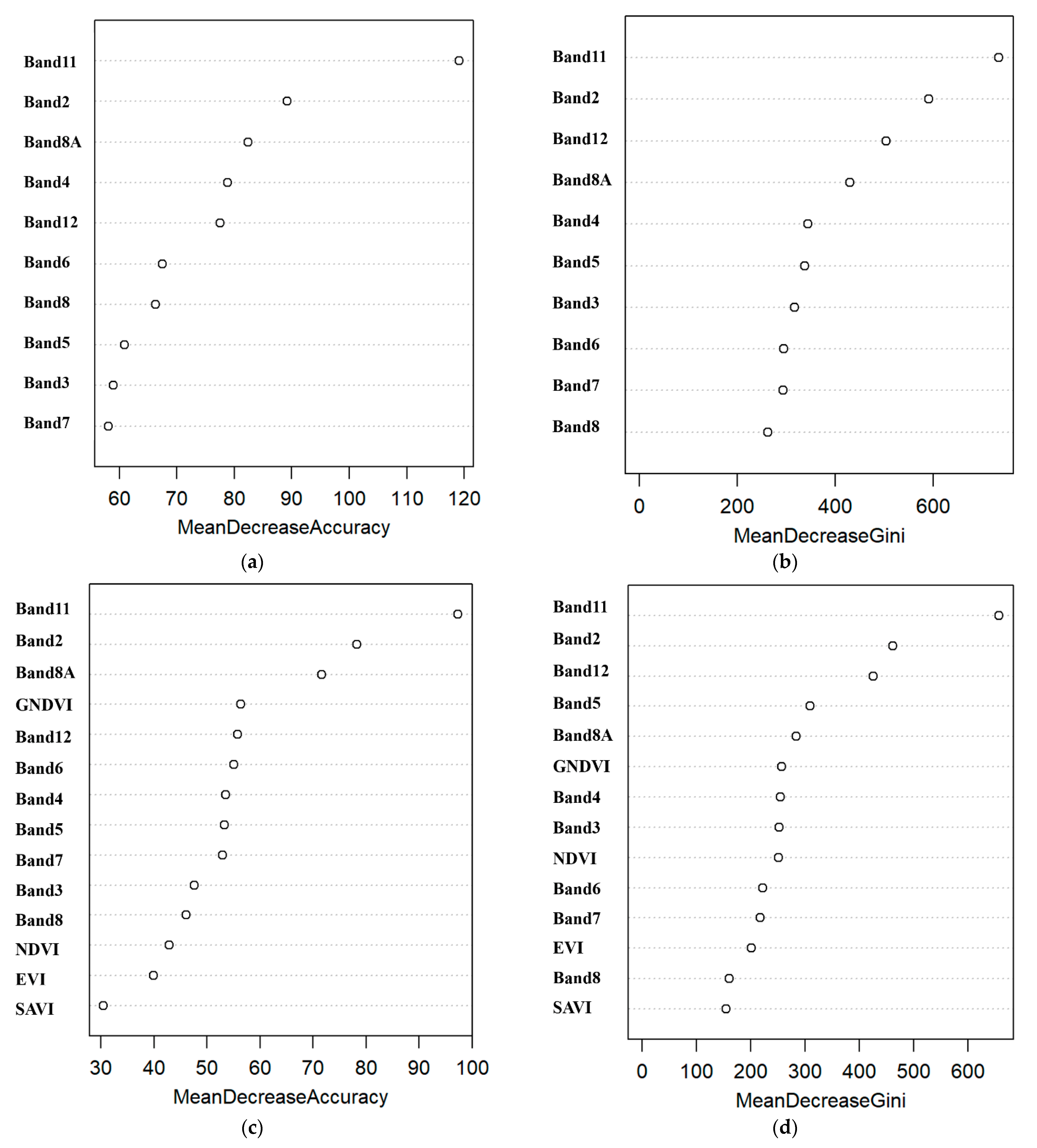
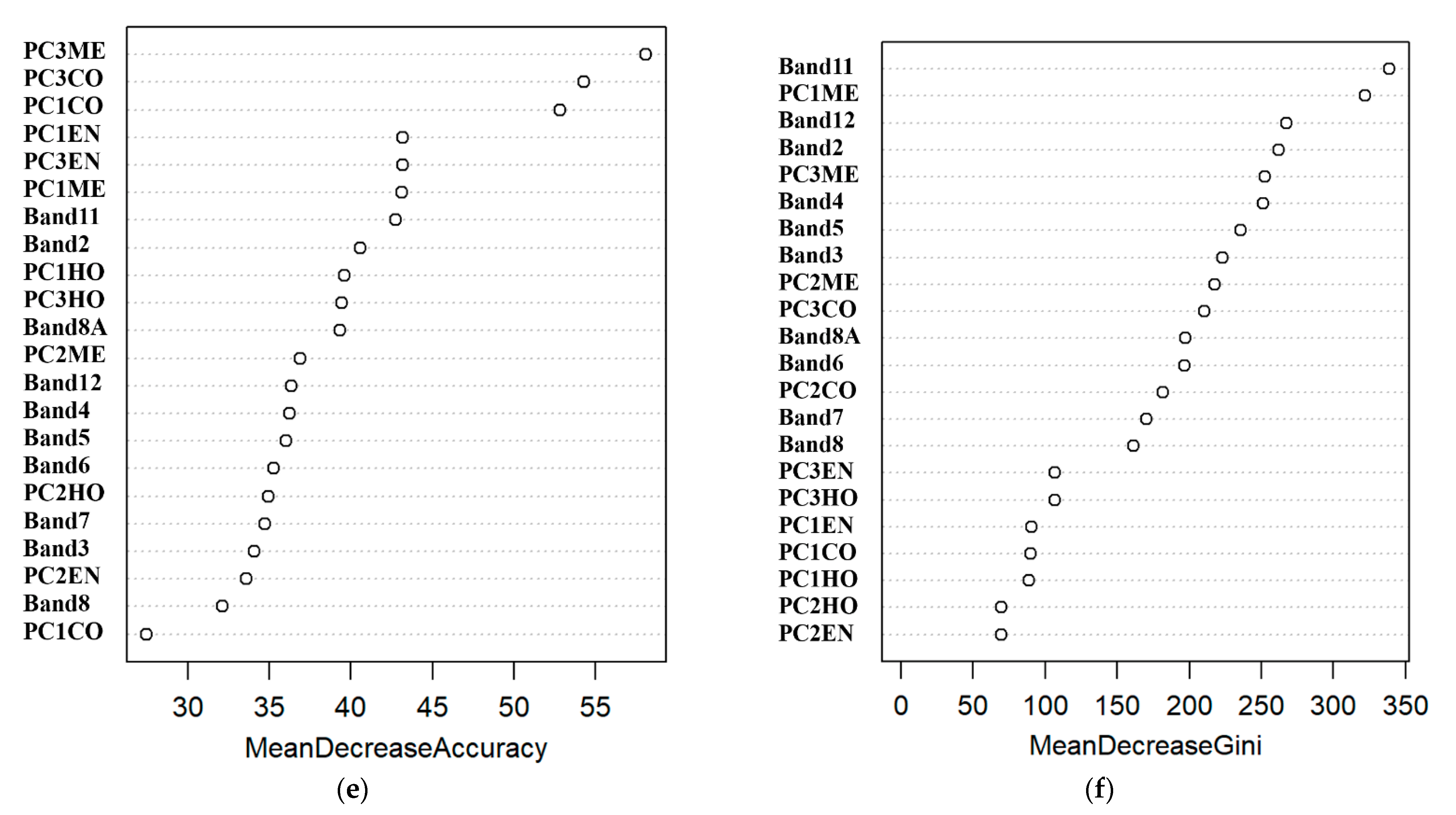
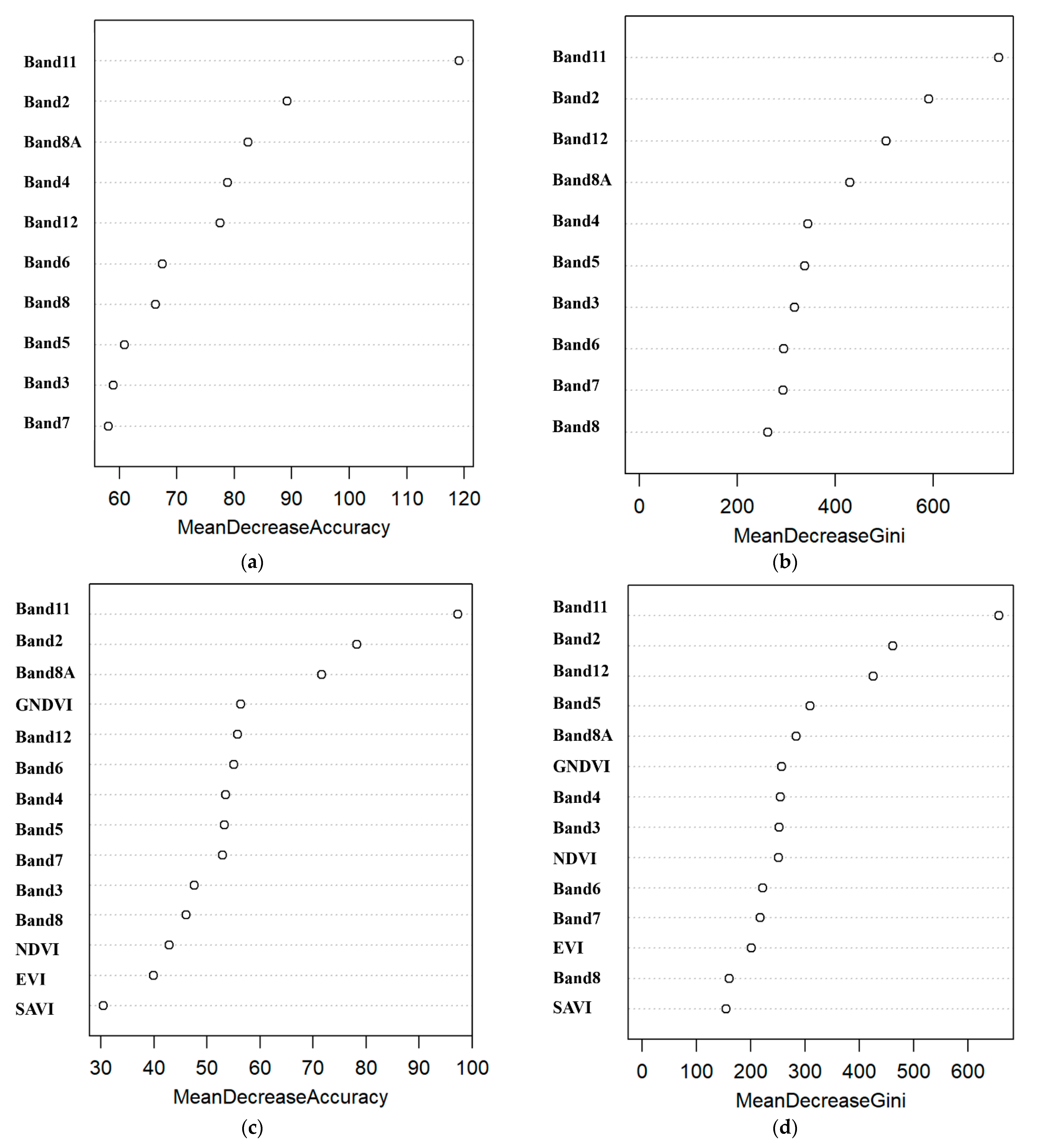
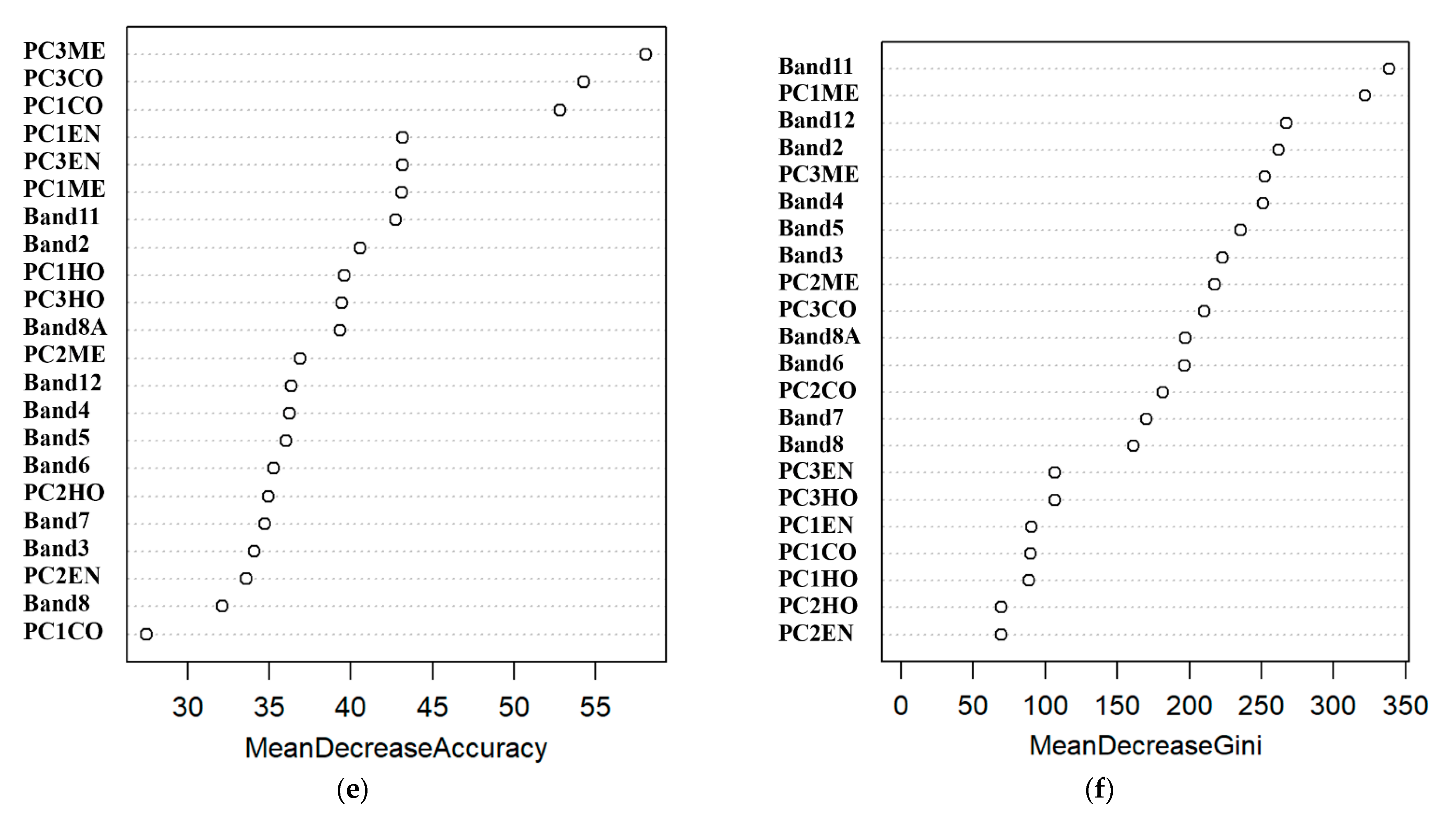
3.1. Importance of Independent Variables
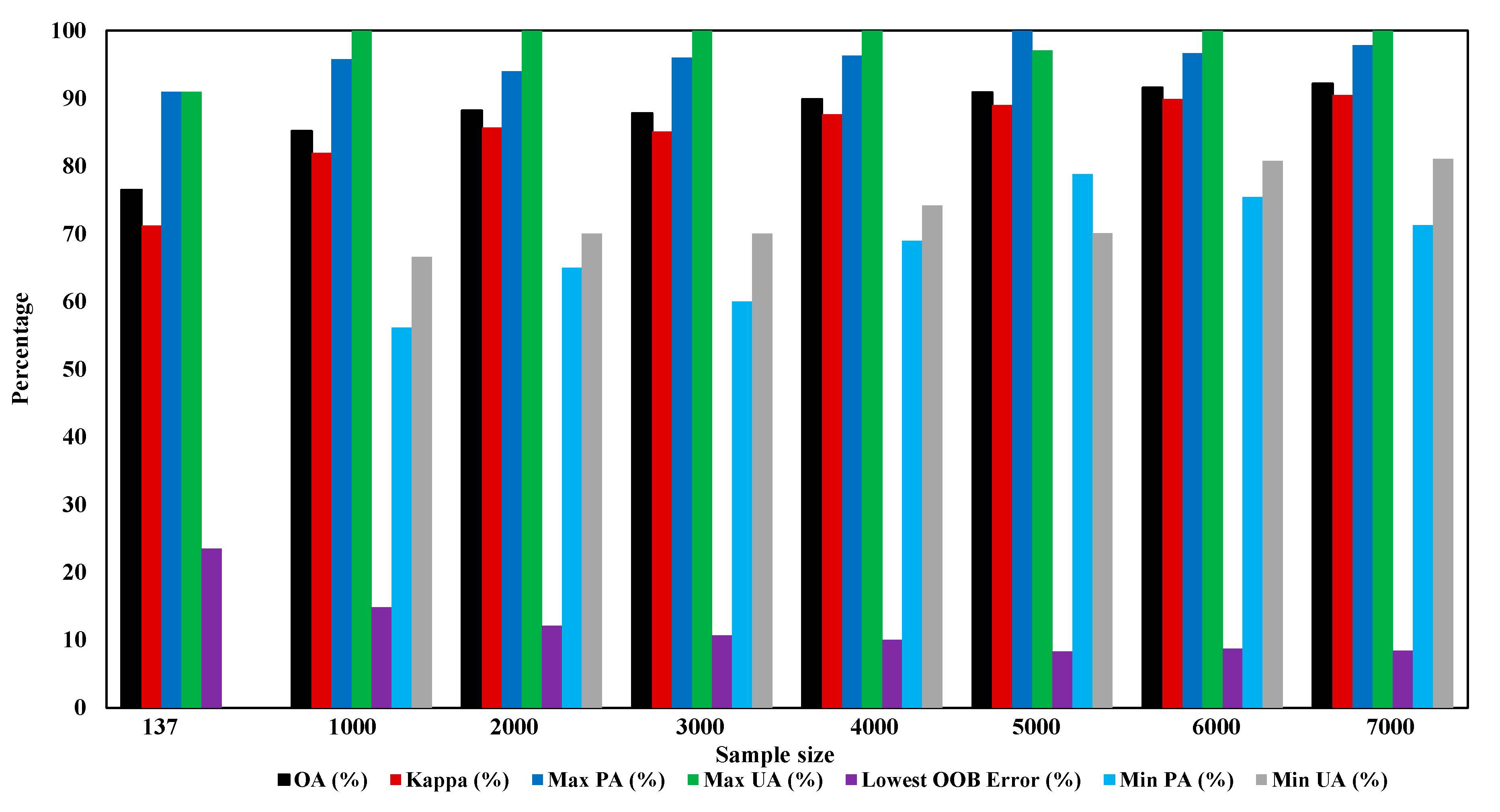
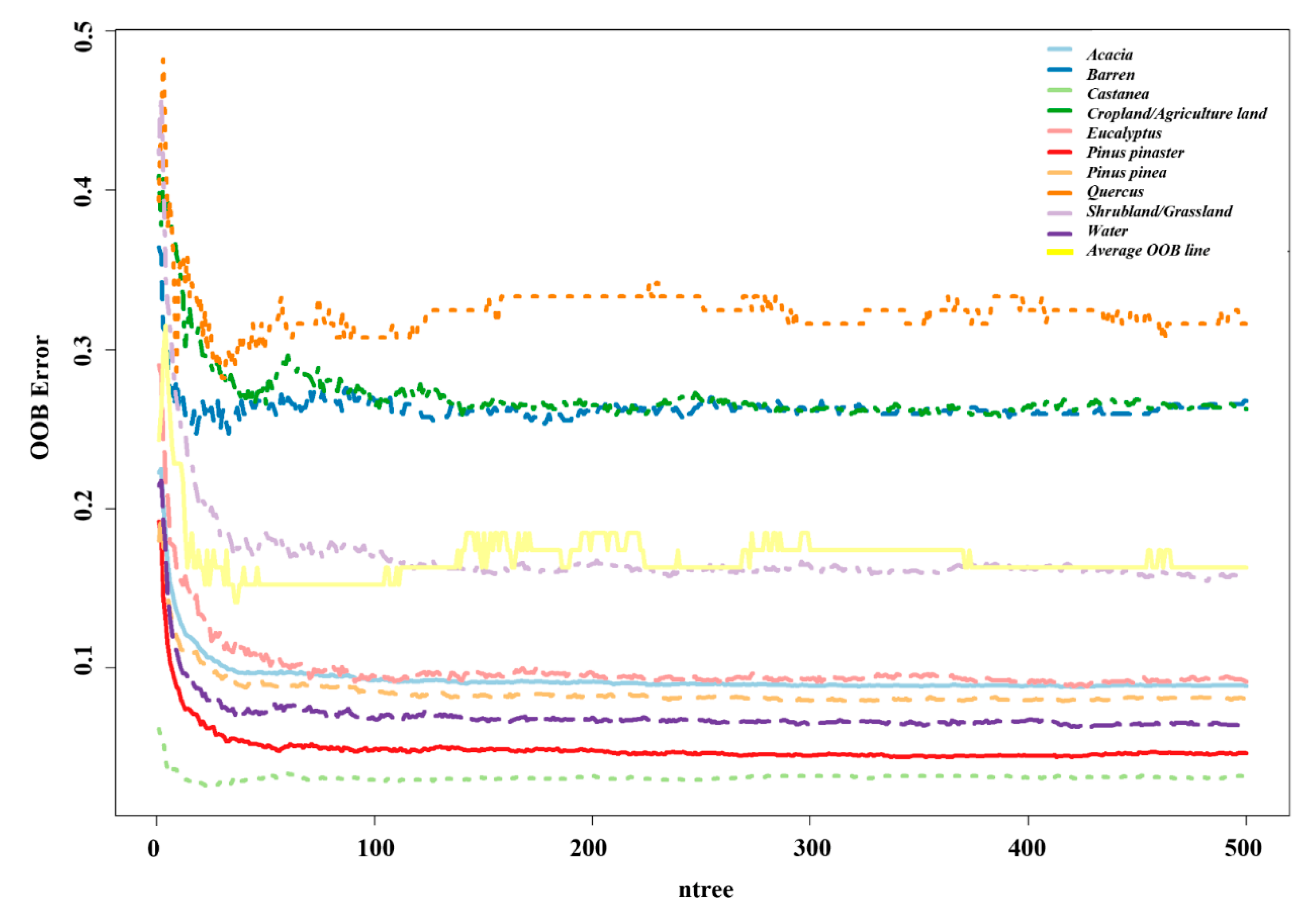
3.2. Effect of Bootstrap Sample Size
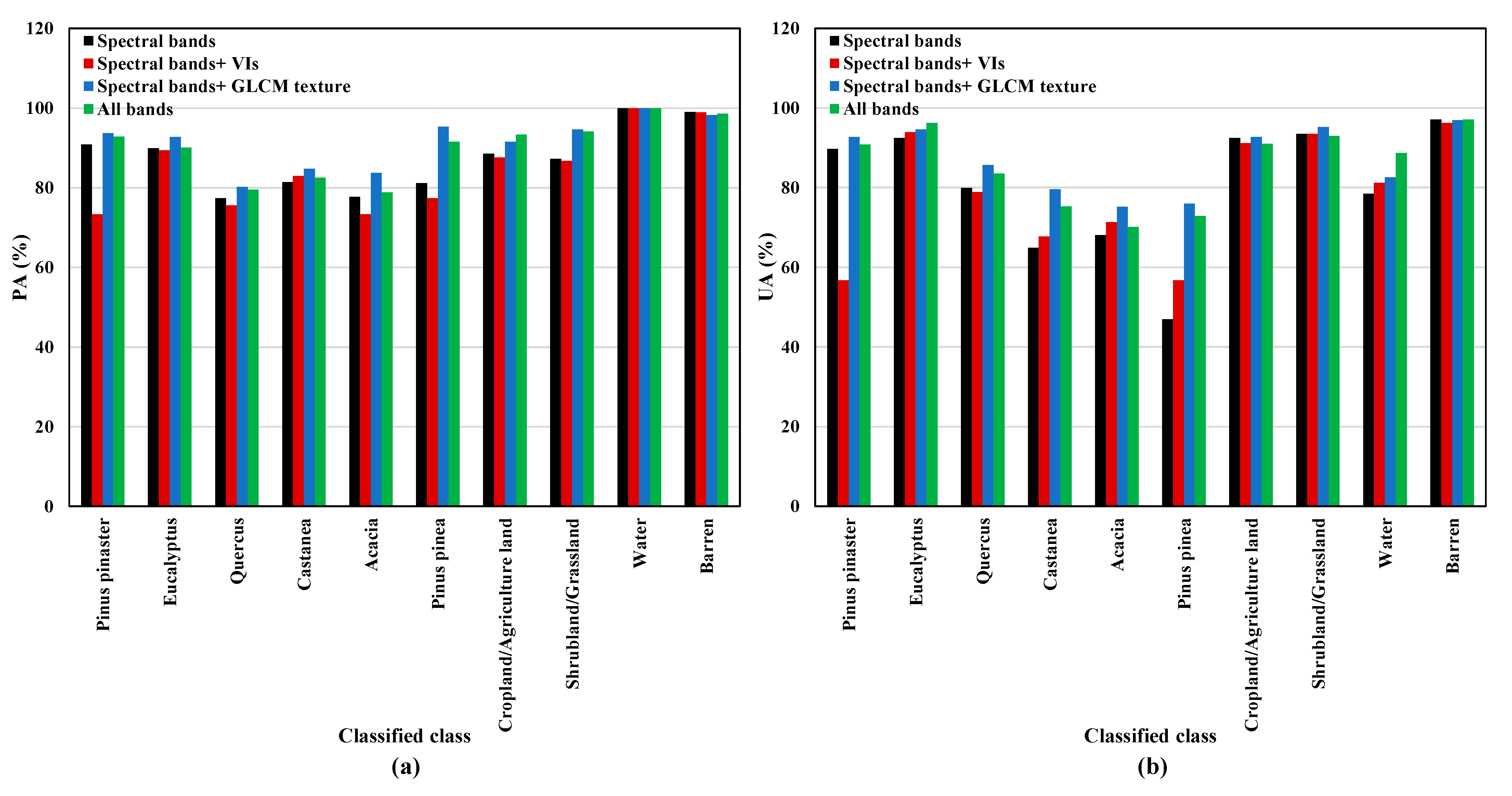
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| B2 | S2A band2 |
| B3 | S2A band3 |
| B4 | S2A band4 |
| B8 | S2A band8 |
| N | Number of grey levels |
| P | Normalized symmetric GLCM of dimension N × N |
| P (i, j) | Normalized grey level value in the cell i, j of the co-occurrence matrix |
| d | Distance |
| θ | Direction |
| Mean of Px | |
| Mean of Py | |
| Standard deviation of Px | |
| Standard deviation of Py |
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PC Layer | Percent of Eigenvalues (%) | Accumulative of Eigenvalues (%) |
|---|---|---|
| PC1 | 92.5 | 92.5 |
| PC2 | 6.3 | 98.8 |
| PC3 | 0.6 | 99.4 |


Appendix B
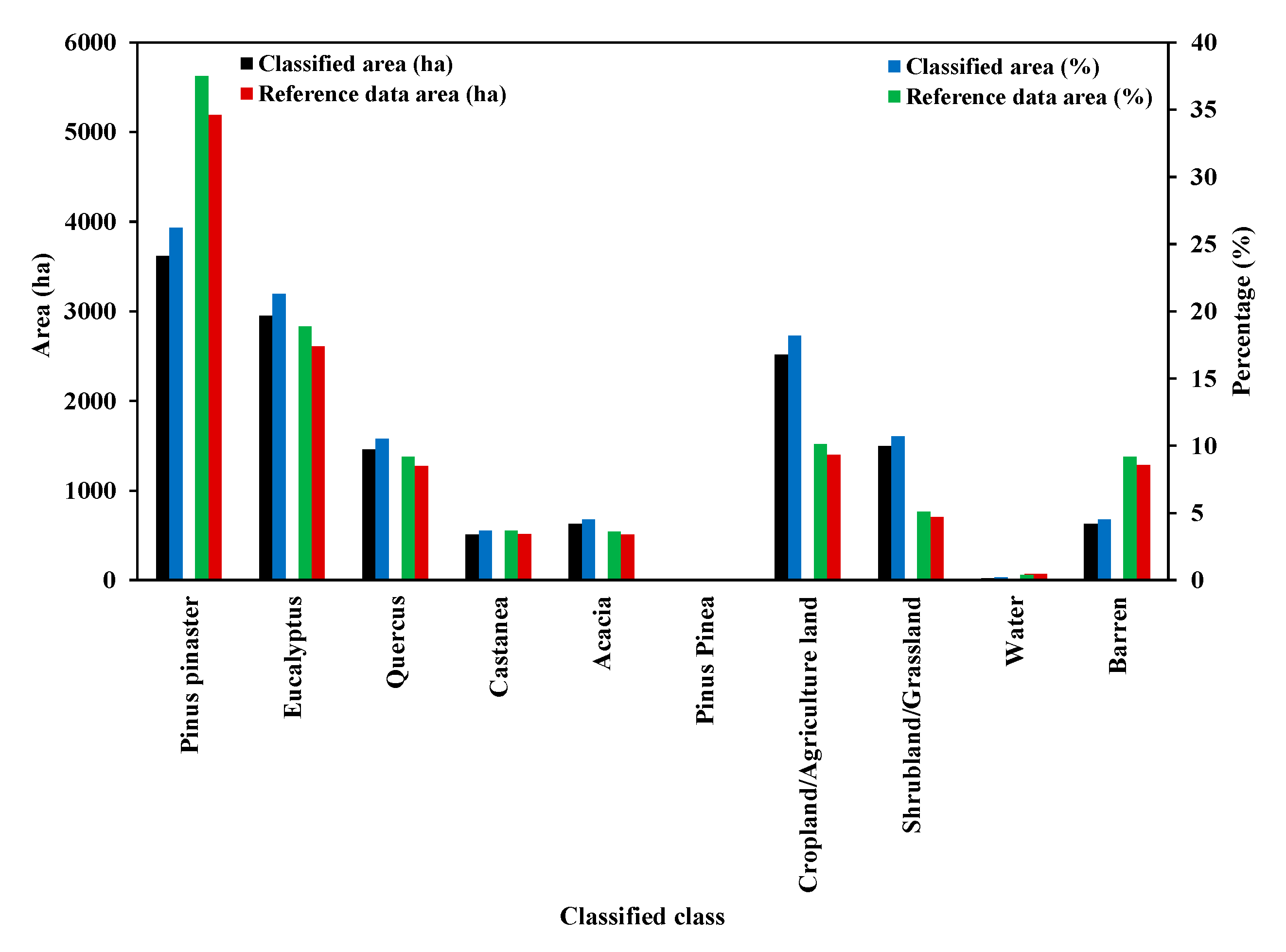
| Class ID | Classified Class | Classified Area (ha) | Percentage (%) | The Difference with Reference Data Area (ha) | The Difference with Reference Data Area (%) |
|---|---|---|---|---|---|
| 1 | Pinus pinaster | 3619.1867 | 26.2 | −1570.9833 | −11.3 |
| 2 | Eucalyptus | 2951.4365 | 21.3 | +339.4865 | +2.4 |
| 3 | Quercus | 1453.5870 | 10.5 | −180.227 | −1.3 |
| 4 | Castanea | 506.3817 | 3.7 | −4.5483 | −0.0 |
| 5 | Acacia | 626.2897 | 4.5 | +120.0297 | +0.9 |
| 6 | Pinus pinea | 17.1625 | 0.1 | +5.9825 | +0.0 |
| 7 | Cropland/Agriculture land | 2518.3886 | 18.2 | +1119.0689 | +8.1 |
| 8 | Shrubland/Grassland | 1499.6008 | 10.7 | +798.0708 | +5.6 |
| 9 | Water | 21.9260 | 0.2 | −42.914 | −0.2 |
| 10 | Barren | 625.9895 | 4.5 | −655.2805 | −4.7 |
| Sample Size | 137 | 1000 | 2000 | 3000 | 4000 | 5000 | 6000 | 7000 |
|---|---|---|---|---|---|---|---|---|
| OA (%) | 76.5 | 85.2 | 88.2 | 87.8 | 89.9 | 90.9 | 91.6 | 92.2 |
| Kappa (%) | 71.2 | 82 | 85.7 | 85.1 | 87.7 | 89 | 89.9 | 90.5 |
| Max PA (%) | 91 Barren | 95.8 Barren | 94 Eucalyptus | 96 Barren | 96.3 Barren | 100 water | 96.7 Barren | 97.9 Barren |
| Min PA (%) | 0 Water & Pinus pinea | 56.1 Pinus pinea | 65 Acacia | 60 Acacia | 69 Castanea | 78.8 Acacia | 75.4 Castanea | 71.3 Pinus pinea |
| Max UA (%) | 91 Barren | 100 Water | 100 Water | 100 Water | 100 Pinus pinea | 97.1 Barren | 100 Water | 100 Water/Pinuspinea |
| Min UA (%) | 0 Water & Pinus pinea | 66.6 Quercus | 70 Quercus | 70 Quercus | 74.2 Quercus | 70.1 Acacia | 80.8 Quercus | 81.1 Quercus |
| Lowest OOB Error (%) | 23.5 | 14.83 | 12.1 | 10.7 | 10 | 8.3 | 8.7 | 8.4 |
| Optimum mtry | 10 | 10 | 5 | 10 | 10 | 5 | 5 | 5 |
| ntree | Not stable | Stable | Stable | Stable | Stable | Stable | Stable | Stable |
References
- Xavier, A.C.; Rudorff, B.F.T.; Shimabukuro, Y.E.; Berka, L.M.S.; Moreira, M.A. Multi-temporal analysis of MODIS data to classify sugarcane crop. Int. J. Remote Sens. 2006, 27, 755–768. [Google Scholar] [CrossRef]
- World Bank. Investment in Disaster Risk Management in Europe Makes Economic Sense; World Bank: Washington, DC, USA, 2021. [Google Scholar] [CrossRef]
- Costa, H.; de Rigo, D.; Libertà, G.; Houston Durrant, T.; San-Miguel-Ayanz, J. European Wildfire Danger and Vulnerability in a Changing Climate: Towards Integrating Risk Dimensions; Publications Office of the European Union: Mercier, Luxembourg, 2020. [Google Scholar] [CrossRef]
- Benali, A.; Fernandes, P. Understanding the impact of different landscape-level fuel management strategies on wildfire hazard Understanding the impact of different landscape-level fuel management strategies on wildfire hazard. Forests 2021, 12, 522. [Google Scholar] [CrossRef]
- Monteiro-Henriques, T.; Fernandes, P.M. Regeneration of native forest species in Mainland Portugal: Identifying main drivers. Forests 2018, 9, 694. [Google Scholar] [CrossRef]
- Instituto Português do Mar e da Atmosfera (IPMA) May Climatological Bulletin. Available online: https://www.ipma.pt/pt/media/noticias/news.detail.jsp?f=/pt/media/noticias/textos/Boletim_climatologico_maio.html (accessed on 15 June 2022).
- Kolström, M.; Vile, T.; Lindner, M. Climate Change Impacts and Adaptation in European Forests. EFI Policy Brief 2011, 6, 14. [Google Scholar]
- Aragoneses, E.; Chuvieco, E. Generation and mapping of fuel types for fire risk assessment. Fire 2021, 4, 59. [Google Scholar] [CrossRef]
- Xie, Y.; Sha, Z.; Yu, M. Remote sensing imagery in vegetation mapping: A review. J. Plant Ecol. 2008, 1, 9–23. [Google Scholar] [CrossRef]
- Chaves, M.E.D.; Picoli, M.C.A.; Sanches, I.D. Recent applications of Landsat 8/OLI and Sentinel-2/MSI for land use and land cover mapping: A systematic review. Remote Sens. 2020, 12, 3062. [Google Scholar] [CrossRef]
- Zeng, L.; Wardlow, B.D.; Xiang, D.; Hu, S.; Li, D. A review of vegetation phenological metrics extraction using time-series, multispectral satellite data. Remote Sens. Environ. 2020, 237, 111511. [Google Scholar] [CrossRef]
- Kaplan, G. Broad-Leaved and Coniferous Forest Classification in Google Earth Engine Using Sentinel Imagery. Environ. Sci. Proc. 2021, 3, 64. [Google Scholar] [CrossRef]
- ESA. Sentinel-2 User Handbook. 2015. Available online: https://sentinel.esa.int/documents/247904/685211/Sentinel-2_User_Handbook (accessed on 10 November 2021).
- Wessel, M.; Brandmeier, M.; Tiede, D. Evaluation of different machine learning algorithms for scalable classification of tree types and tree species based on Sentinel-2 data. Remote Sens. 2018, 10, 1419. [Google Scholar] [CrossRef]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Hernandez, I.; Benevides, P.; Costa, H.; Caetano, M. Exploring sentinel-2 for land cover and crop mapping in portugal. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.—ISPRS Arch. 2020, 43, 83–89. [Google Scholar] [CrossRef]
- Costa, H.; Benevides, P.; Moreira, F.D.; Moraes, D.; Caetano, M. Spatially Stratified and Multi-Stage Approach for National Land Cover Mapping Based on Sentinel-2 Data and Expert Knowledge. Remote Sens. 2022, 14, 1865. [Google Scholar] [CrossRef]
- Persson, M.; Lindberg, E.; Reese, H. Tree species classification with multi-temporal Sentinel-2 data. Remote Sens. 2018, 10, 1794. [Google Scholar] [CrossRef]
- Pacheco, A.D.P.; Junior, J.A.D.S.; Ruiz-Armenteros, A.M.; Henriques, R.F.F. Assessment of k-nearest neighbor and random forest classifiers for mapping forest fire areas in central portugal using landsat-8, sentinel-2, and terra imagery. Remote Sens. 2021, 13, 1345. [Google Scholar] [CrossRef]
- Sheykhmousa, M.; Mahdianpari, M.; Ghanbari, H.; Mohammadimanesh, F.; Ghamisi, P.; Homayouni, S. Support Vector Machine Versus Random Forest for Remote Sensing Image Classification: A Meta-Analysis and Systematic Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 6308–6325. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Costa, H.; Almeida, D.; Vala, F.; Marcelino, F.; Caetano, M. Land cover mapping from remotely sensed and auxiliary data for harmonized official statistics. ISPRS Int. J. Geo-Inf. 2018, 7, 157. [Google Scholar] [CrossRef]
- Liu, H.; Gong, P.; Wang, J.; Wang, X.; Ning, G.; Xu, B. Production of global daily seamless data cubes and quantification of global land cover change from 1985 to 2020—iMap World 1.0. Remote Sens. Environ. 2021, 258, 112364. [Google Scholar] [CrossRef]
- Incêndios, C.; Base, I.; Florestal, G.T. Plano Municipal de Defesa da Floresta Contra Incêndios; Município de Vila Nova de Poiares: Vila Nova de Poiares, Portugal, 2020. [Google Scholar]
- Viegas, D.X.; Figueiredo Almeida, M.; Ribeiro, L.M.; Raposo, J.; Viegas, M.T.; Oliveira, R.; Alves, D.; Pinto, C.; Jorge, H.; Rodrigues, A.; et al. O Complexo de Incêndios de Pedrogão Grande E Concelhos Limítrofes, Iniciado a 17 de Junho de 2017. Iniciado A 2017, 2017, 238. [Google Scholar]
- Zheng, H.; Du, P.; Chen, J.; Xia, J.; Li, E.; Xu, Z.; Li, X.; Yokoya, N. Performance evaluation of downscaling sentinel-2 imagery for Land Use and Land Cover classification by spectral-spatial features. Remote Sens. 2017, 9, 1274. [Google Scholar] [CrossRef]
- Noi Phan, T.; Kuch, V.; Lehnert, L.W. Land cover classification using google earth engine and random forest classifier-the role of image composition. Remote Sens. 2020, 12, 2411. [Google Scholar] [CrossRef]
- Xia, H.; Zhao, W.; Li, A.; Bian, J.; Zhang, Z. Subpixel inundation mapping using landsat-8 OLI and UAV data for a wetland region on the zoige plateau, China. Remote Sens. 2017, 9, 31. [Google Scholar] [CrossRef]
- Gitelson, A.A.; Kaufman, Y.J.; Merzlyak, M.N. Use of a green channel in remote sensing of global vegetation from EOS—MODIS. Remote Sens. Environ. 1996, 58, 289–298. [Google Scholar] [CrossRef]
- Bhatnagar, S.; Gill, L.; Regan, S.; Waldren, S.; Ghosh, B. A nested drone-satellite approach to monitoring the ecological conditions of wetlands. ISPRS J. Photogramm. Remote Sens. 2021, 174, 151–165. [Google Scholar] [CrossRef]
- Somvanshi, S.S.; Kumari, M. Comparative analysis of different vegetation indices with respect to atmospheric particulate pollution using sentinel data. Appl. Comput. Geosci. 2020, 7, 100032. [Google Scholar] [CrossRef]
- Agarwal, A.; Kumar, S.; Singh, D. Development of neural network based adaptive change detection technique for land terrain monitoring with satellite and drone images. Def. Sci. J. 2019, 69, 474–480. [Google Scholar] [CrossRef]
- Gitelson, A.; Merzlyak, M.N. Quantitative estimation of chlorophyll-a using reflectance spectra: Experiments with autumn chestnut and maple leaves. J. Photochem. Photobiol. B 1994, 22, 247–252. [Google Scholar] [CrossRef]
- Alam, M.J.; Rahman, K.M.; Asna, S.M.; Muazzam, N.; Ahmed, I.; Chowdhury, M.Z. Comparative studies on IFAT, ELISA & DAT for serodiagnosis of visceral leishmaniasis in Bangladesh. Bangladesh Med. Res. Counc. Bull. 1996, 22, 27–32. [Google Scholar]
- Gini, R.; Sona, G.; Ronchetti, G.; Passoni, D.; Pinto, L. Improving tree species classification using UAS multispectral images and texture measures. ISPRS Int. J. Geo-Inf. 2018, 7, 315. [Google Scholar] [CrossRef]
- Guo, Q.; Wu, W.; Massart, D.L.; Boucon, C.; De Jong, S. Feature selection in principal component analysis of analytical data. Chemom. Intell. Lab. Syst. 2002, 61, 123–132. [Google Scholar] [CrossRef]
- Xiao, B. Principal component analysis for feature extraction of image sequence. In Proceedings of the 2010 International Conference on Computer and Communication Technologies in Agriculture Engineering, Chengdu, China, 12–13 June 2010. [Google Scholar]
- Kattenborn, T.; Lopatin, J.; Förster, M.; Christian, A.; Ewald, F. Remote Sensing of Environment UAV data as alternative to fi eld sampling to map woody invasive species based on combined Sentinel-1 and Sentinel-2 data. Remote Sens. Environ. 2019, 227, 61–73. [Google Scholar] [CrossRef]
- Chatziantoniou, A.; Petropoulos, G.P.; Psomiadis, E. Co-Orbital Sentinel 1 and 2 for LULC mapping with emphasis on wetlands in a mediterranean setting based on machine learning. Remote Sens. 2017, 9, 1259. [Google Scholar] [CrossRef]
- Humeau-Heurtier, A. Texture feature extraction methods: A survey. IEEE Access 2019, 7, 8975–9000. [Google Scholar] [CrossRef]
- Xu, J.L.; Gowen, A.A. Spatial-spectral analysis method using texture features combined with PCA for information extraction in hyperspectral images. J. Chemom. 2020, 34, e3132. [Google Scholar] [CrossRef]
- Zhang, X.; Cui, J.; Wang, W.; Lin, C. A study for texture feature extraction of high-resolution satellite images based on a direction measure and gray level co-occurrence matrix fusion algorithm. Sensors 2017, 17, 1474. [Google Scholar] [CrossRef]
- Held, M.; Committee, T.I.B. GLCM texture: A tutorial. In Proceedings of the 17th International Symposium on Ballistics, Midrand, South Africa, 23–27 March 1998; Volume 2, pp. 267–274. [Google Scholar]
- Feng, Q.; Liu, J.; Gong, J. Urban flood mapping based on unmanned aerial vehicle remote sensing and random forest classifier-A case of yuyao, China. Water 2015, 7, 1437–1455. [Google Scholar] [CrossRef]
- Nizalapur, V.; Vyas, A. Texture analysis for land use land cover (LULC) classification in parts of Ahmedabad, Gujarat. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci.—ISPRS Arch. 2020, 43, 275–279. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I. Textural Features for Image Classification. SEG Tech. Program Expand. Abstr. 1973, 3, 610–621. [Google Scholar] [CrossRef]
- Portugal Directorate-General for the Territory (DGT)-Carta de Uso e Ocupação do Solo de Portugal Continental (COS2018). Available online: https://www.dgterritorio.gov.pt/Carta-de-Uso-e-Ocupacao-do-Solo-para-2018 (accessed on 10 December 2021).
- ICNF 6º Inventário Florestal Nacional (IFN6; 2015)- Relatório Final. Instituto da Conservação da Natureza e das Florestas Lisboa, Portugal. Available online: https://geocatalogo.icnf.pt/catalogo_tema3.html (accessed on 10 December 2021).
- Kluczek, M.; Zagajewski, B. Airborne HySpex Hyperspectral Versus Multitemporal Sentinel-2 Images for Mountain Plant Communities Mapping. Remote Sens. 2022, 14, 1209. [Google Scholar] [CrossRef]
- Wójtowicz, A.; Piekarczyk, J.; Czernecki, B.; Ratajkiewicz, H. A random forest model for the classification of wheat and rye leaf rust symptoms based on pure spectra at leaf scale. J. Photochem. Photobiol. B 2021, 223, 112278. [Google Scholar] [CrossRef] [PubMed]
- Adeli, S.; Quackenbush, L.J.; Salehi, B.; Mahdianpari, M. The Importance of Seasonal Textural Features for Object-Based Classification of Wetlands: New York State Case Study. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2022, 43, 471–477. [Google Scholar] [CrossRef]
- Hanes, C.C.; Wotton, M.; Woolford, D.G.; Martell, D.L.; Flannigan, M. Mapping organic layer thickness and fuel load of the boreal forest in Alberta, Canada. Geoderma 2022, 417, 115827. [Google Scholar] [CrossRef]
- Immitzer, M.; Vuolo, F.; Atzberger, C. First experience with Sentinel-2 data for crop and tree species classifications in central Europe. Remote Sens. 2016, 8, 166. [Google Scholar] [CrossRef]
- Wang, H.; Zhao, Y.; Pu, R.; Zhang, Z. Mapping Robinia pseudoacacia forest health conditions by using combined spectral, spatial, and textural information extracted from IKONOS imagery and random forest classifier. Remote Sens. 2015, 7, 9020–9044. [Google Scholar] [CrossRef]
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef]
- Story, M.; Congalton, R.G. Remote Sensing Brief Accuracy Assessment: A User’s Perspective. Photogramm. Eng. Remote Sens. 1986, 52, 397–399. [Google Scholar]
- Thomlinson, J.R.; Bolstad, P.V.; Cohen, W.B. Coordinating methodologies for scaling landcover classifications from site-specific to global: Steps toward validating global map products. Remote Sens. Environ. 1999, 70, 16–28. [Google Scholar] [CrossRef]
- Blatchford, M.L.; Mannaerts, C.M.; Zeng, Y. Determining representative sample size for validation of continuous, large continental remote sensing data. Int. J. Appl. Earth Obs. Geoinf. 2021, 94, 102235. [Google Scholar] [CrossRef]
- Moraes, D.; Benevides, P.; Costa, H.; Moreira, F.D.; Caetano, M. Influence of Sample Size in Land Cover Classification Accuracy Using Random Forest and Sentinel-2 Data in Portugal. In Proceedings of the 2021 IEEE International Geoscience and Remote Sensing Symposium IGARSS, Brussels, Belgium, 11–16 July 2021. [Google Scholar]


| Vegetation Indices | Formulation | Application |
|---|---|---|
| NDVI | Detection of vegetation communities in various seasons [30] Estimating changes in vegetation state [29] Determining the density of greenness [32] | |
| GNDVI | Determining water and nitrogen uptake in the crop canopy [29,33] | |
| EVI | Detection of vegetation communities in various seasons [30] Land cover classification [27] | |
| SAVI | Minimizing soil brightness influences [31,34] Land cover classification [27] |
| Texture Metrics | Formulation | Application |
|---|---|---|
| ME | Weighting pixel value based on the frequency of its occurrence in conjunction with a specific neighbor pixel value [43,44] Calculating the mean processing window value [45] | |
| EN | Assessing the disorder of the GLCM [40] Reflecting the complexity of the texture distribution [42] | |
| HO | Measuring the level of homogeneity in pairs of pixels [40] | |
| CO | Measuring grey level linear relation between pixels [40,42,46] |
| Species | Area (ha) | Percentage of the Study Area (%) |
|---|---|---|
| Pinus pinaster | 5190.17 | 37.5 |
| Eucalyptus | 2611.95 | 18.9 |
| Quercus | 1273.36 | 9.2 |
| Castanea | 510.93 | 3.7 |
| Acacia | 506.26 | 3.6 |
| Pinus pinea | 11.18 | 0.1 |
| Reference | Total | PA | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Classification | Classes | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | N° Pixels | % | |
| 1 | Pinus pinaster | 2136 | 40 | 36 | 18 | 63 | 0 | 0 | 5 | 4 | 0 | 2302 | 92.8 | |
| 2 | Eucalyptus | 101 | 2052 | 13 | 11 | 4 | 11 | 26 | 51 | 1 | 7 | 2277 | 90.1 | |
| 3 | Quercus | 32 | 10 | 580 | 64 | 7 | 0 | 17 | 20 | 0 | 0 | 730 | 79.5 | |
| 4 | Castanea | 24 | 2 | 41 | 333 | 1 | 0 | 0 | 1 | 0 | 0 | 402 | 82.5 | |
| 5 | Acacia | 30 | 2 | 6 | 9 | 176 | 0 | 0 | 0 | 0 | 0 | 223 | 78.8 | |
| 6 | Pinus pinea | 0 | 0 | 0 | 0 | 0 | 43 | 0 | 3 | 0 | 1 | 47 | 91.5 | |
| 7 | Cropland/Agriculture land | 10 | 5 | 5 | 6 | 0 | 2 | 638 | 1 | 0 | 17 | 684 | 93.3 | |
| 8 | Shrubland/Grassland | 19 | 21 | 13 | 1 | 0 | 3 | 11 | 1083 | 0 | 0 | 1151 | 94.1 | |
| 9 | Water | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 39 | 0 | 39 | 100 | |
| 10 | Barren | 0 | 2 | 1 | 0 | 0 | 0 | 9 | 0 | 0 | 831 | 843 | 98.6 | |
| Total | N° Pixels | 2352 | 2134 | 695 | 442 | 251 | 59 | 701 | 1164 | 44 | 856 | 8706 | ||
| UA | % | 90.8 | 96.2 | 83.5 | 75.3 | 70.1 | 72.9 | 91 | 93 | 88.6 | 97.1 | |||
| OA | 90.9% | |||||||||||||
| K | 89% | |||||||||||||
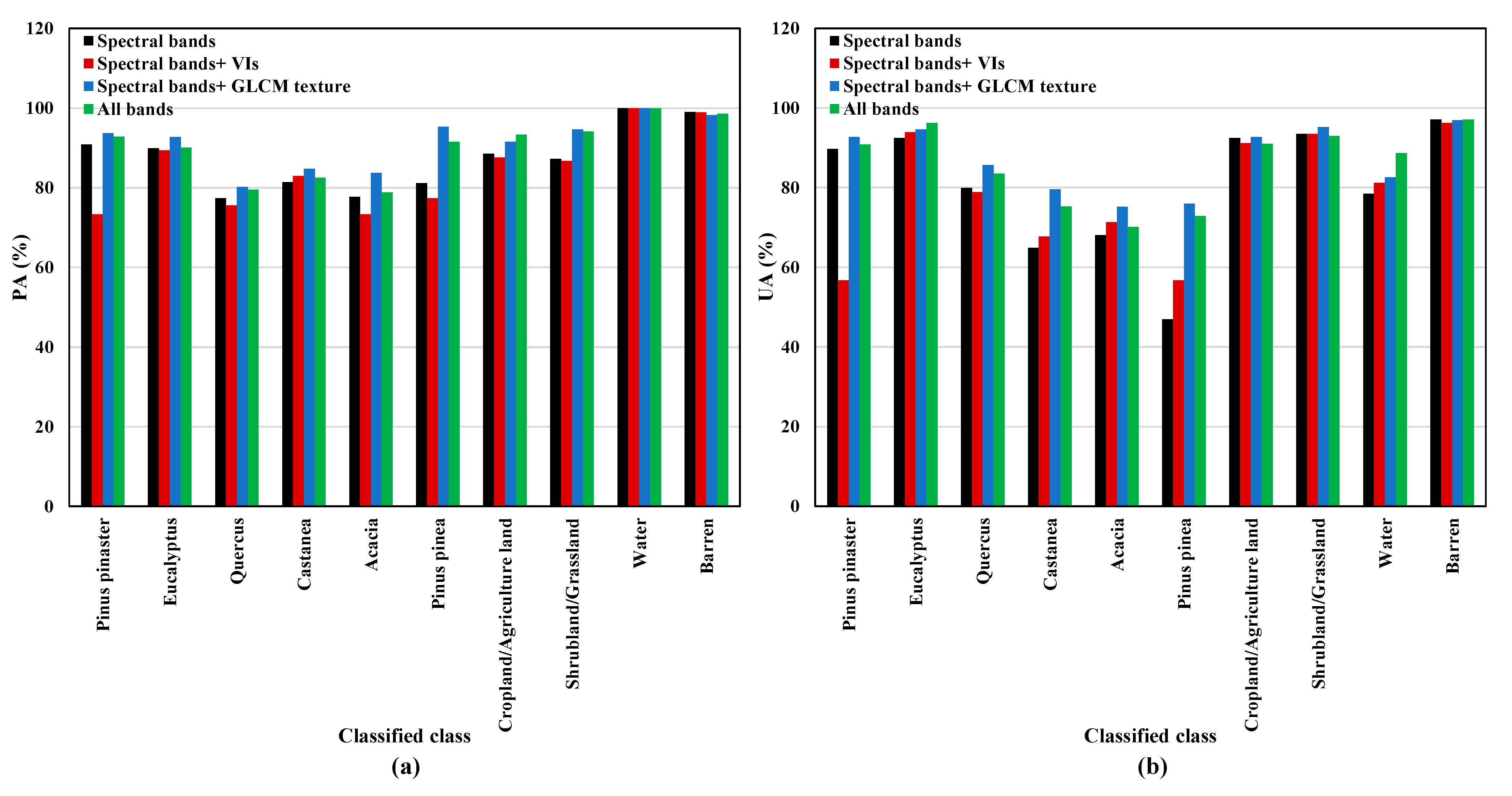
| All Bands | Spectral Bands | Spectral Bands + Vis | Spectral Bands + GLCM Texture | |
|---|---|---|---|---|
| OA (%) | 90.8 | 88 | 88.6 | 92 |
| Kappa (%) | 89 | 86 | 86.1 | 90.2 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mohammadpour, P.; Viegas, D.X.; Viegas, C. Vegetation Mapping with Random Forest Using Sentinel 2 and GLCM Texture Feature—A Case Study for Lousã Region, Portugal. Remote Sens. 2022, 14, 4585. https://doi.org/10.3390/rs14184585
Mohammadpour P, Viegas DX, Viegas C. Vegetation Mapping with Random Forest Using Sentinel 2 and GLCM Texture Feature—A Case Study for Lousã Region, Portugal. Remote Sensing. 2022; 14(18):4585. https://doi.org/10.3390/rs14184585
Chicago/Turabian StyleMohammadpour, Pegah, Domingos Xavier Viegas, and Carlos Viegas. 2022. "Vegetation Mapping with Random Forest Using Sentinel 2 and GLCM Texture Feature—A Case Study for Lousã Region, Portugal" Remote Sensing 14, no. 18: 4585. https://doi.org/10.3390/rs14184585
APA StyleMohammadpour, P., Viegas, D. X., & Viegas, C. (2022). Vegetation Mapping with Random Forest Using Sentinel 2 and GLCM Texture Feature—A Case Study for Lousã Region, Portugal. Remote Sensing, 14(18), 4585. https://doi.org/10.3390/rs14184585