3.1. Multiple Collocation Formalism
Suppose we have a set of
collocated measurements made by
observation systems,
, with
the collocation index,
, and
the observation system index,
. Assuming that linear calibration is sufficient for intercalibration and omitting the collocation index
, we can pose the following simplified observation error model
where
is the signal common to all observation systems (also referred to as the truth),
the calibration scaling,
the calibration bias, and
a random measurement error with zero average and variance
. It is assumed that
is uncorrelated with the common signal
,
, where the brackets 〈 〉 stand for averaging over all measurements
. In the literature, this condition is also referred to as error orthogonality. Of course, the assumptions made on linearity and error orthogonality should be checked first by inspecting scatter plots. Note that
is an uncalibrated measurement while
is calibrated, so (1) actually constitutes an inverse calibration transformation.
Without loss of generality, we can select the first observation system as calibration reference, so
and
. By forming first moments (averages) and second moments from (1) and introducing covariances, the general collocation problem can be cast in the form [
3,
16]
with
the averages of the observations, and
with
the (co-)variances of the observations,
the (mixed) second moments of the observations,
the common variance, and
the error covariances. Note that
and
are symmetric in their indices.
At this point, it must be emphasized that the approach outlined above is geared toward ocean surface vector winds. Their statistical properties in time and space are well-studied. In particular, their spectra follow power laws, and the observing systems with highest resolution show the largest variations. Therefore, buoy winds are widely accepted as calibration standard. This need not be the case for other quantities, and slightly different approaches have been developed to account for this. Nevertheless, much of what follows can be easily adapted to those approaches.
Equations (2) and (3) completely define the multiple collocation problem for error model (1). Once the calibration scalings are known, the calibration biases follow from (2). The remaining unknowns, in particular the essential unknowns (the calibration scalings , the error variances , and the common variance ), must be obtained from the covariance Equation (3).
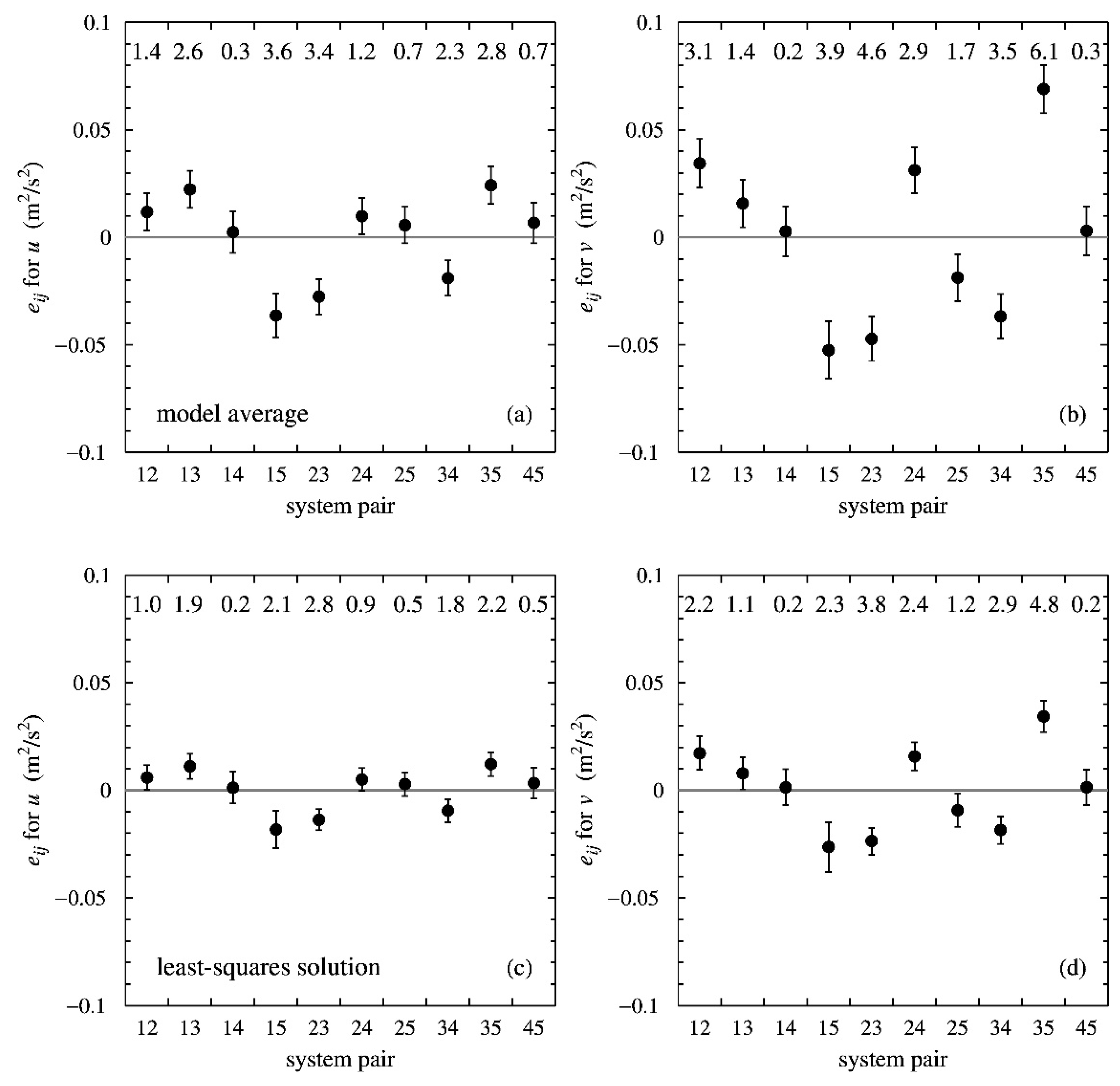
For triple collocation, , there are six equations. Setting the off-diagonal error covariances to zero, the covariance equations can be solved analytically for the essential unknowns. For quadruple and higher-order collocations, there are more equations than essential unknowns: the number of equations is while the number of essential unknowns equals .
The common approach is to solve (3) as an overdetermined system with a least-squares method by introducing new variables
if the error covariance
is neglected or
if it is included as unknown. Using boldface for vectors and matrices, the covariance equations are written in matrix-vector form as
with
and
a matrix with elements zero or one, see [
9] for more details. The solution reads
provided the inverse of
exists. In cases where no calibration reference is selected, the error variances are included in the variables, e.g., [
9].
3.2. Linearization of the Covariance Equations
The
error variances
only appear in the
diagonal covariance equations, so these are easily calculated when
and
are known. The remaining
off-diagonal covariance equations only contain the
essential variables
and
(
because system 1 is the calibration reference) plus the error covariances
. For quadruple collocations, the authors take all possible sets of
off-diagonal covariance equations, neglect the error covariances in these so the equations take the form
, and solve each set analytically for
and
[
3]. There are 15 possible sets, further referred to as models, of which 12 have a solution. Three models cannot be solved, and such models will be referred to as unsolvable. Besides the essential unknowns, each solvable model also yields two error covariances from the remaining two covariance equations that were not used to solve
and
. See also
Appendix A for an example. The number of models grows rapidly with the number of observing systems, see
Table 1. For quintuple collocation there are already 252 models, and analytical solution is practically impossible.
Taking a closer look at the covariance equations with the error covariances neglected, one sees that the unknowns
and
appear as a product on one side and the coefficients
, calculated from the data, on the other. By taking logarithms on both sides, the unknowns are separated and the equations reduce to an ordinary system of linear equations. Suppose a model has been defined by a selection of
off-diagonal covariance equations
in which the error covariances are neglected, with
and labeled with index
. Setting
,
for
, and
, the off-diagonal covariances read in matrix-vector notation
where the matrix
has for each row the value 1 in the first column,
, and one or two additional values 1 in the remaining columns,
if
, and
. All other elements of
are zero. The determinant of
can thus only take integer values; the zero-value indicating that system (5) has no solution. See
Appendix A for an example.
It may seem awkward to take logarithms, but (5) yields the same solution as the original set of equations as long as all variables are positive. This is certainly the case here. The calibration scalings are generally close to 1, so their logarithms are around 0, and the observed covariances are nonnegative; also when representativeness errors are taken into account (see further down). The common variance is of the same order of magnitude as the . Therefore, problem (5) is well-posed and can be solved numerically with standard methods.
In this work, the inverse of
is calculated using Gaussian elimination, and the solution reads
. This has the advantage that the analytical solution can be reconstructed, since in components
which implies that after exponentiating
so the analytical solutions for the common variance
and the calibration scalings
are products of observed covariances raised to a power determined by the components of
. The error variances are given by
, and from (7) and (8), it follows that
Note that in (10), factors may cancel in the exponent.
The same logarithmic transformation can also be applied to all off-diagonal covariance equations and solved with the least-squares method, having the advantage that the solution is given directly in the logarithms of the basic unknowns rather than combinations of them. If the number of equations permits, error covariances can be included by adding extra variables with .
The determinant of
in the least-squares solution equals the number of soluble models for quadruple and quintuple collocations. In the determined cases, matrices
have only integer elements, see
Appendix A; in the overdetermined case, the Moore–Penrose pseudoinverse
also contains rational numbers. In
Appendix B, it is shown that the least-squares solution is the geometric mean of all model solutions, a consequence of the fact that in logarithmic space the overdetermined solution is the arithmetic average of the determined ones.
A solution method equivalent to the least-squares solution is minimizing a quadratic cost function
defined as
to
and
using a standard conjugate-gradient method.
3.3. Iterative Solution
The covariance equations for each possible model are solved in an iterative scheme that starts with assuming that the data are already perfectly calibrated, so
and
,
, where the superscript
stands for the iteration index. The relation between the calibrated measured values in iteration
,
, and the original values,
, is
In each iteration, the averages and covariances are recalculated from the calibrated data and the covariance equations are solved, but now the solution does not yield the calibration coefficients
and
themselves, but their updates
and
. Of course,
and
because system 1 is chosen as calibration reference. The calibration coefficients are updated as
Iteration has converged when and , with . This usually takes about ten steps.
This iteration scheme has two advantages. First, in each iteration, the standard deviation of the difference between each pair of calibrated measurements,
, can be calculated, and this can be used in the next iteration to detect (and exclude) outliers. The iteration starts with a large value
m
2s
−2, and collocations are excluded whenever
(hence the name “4-sigma test”).
Second, it allows for proper inclusion of representativeness errors calculated as differences in spatial variances of the uncalibrated data. Suppose the observation systems are sorted to decreasing spatial resolution and that
is the representativeness error of higher resolution system
with respect to lower resolution system
. As shown in [
3], the (calibrated) representativeness errors can be incorporated in the observed covariances by the substitution
In other words, the known representativeness errors are put to the other side of the covariance Equation (3) together with the known covariances . Error covariances that are known a priori can be incorporated in this way.
3.4. Representativeness Errors
In general, the representativeness errors cannot be retrieved from the error covariances. The number of off-diagonal covariance equations is
, so the number of error covariances that can be retrieved is
. The number of representativeness errors is
, so there is always one off-diagonal covariance equation lacking. This can be circumvented when the two coarsest resolution systems have the same spatial and temporal resolution. In the case considered here, one could try ECMWF forecasts with different analysis times. However, as already remarked in [
3], this would introduce an additional error covariance between the two forecasts, and the resulting model has no solution.
As a consequence, the representativeness errors must be estimated in a different way. In this study, they are obtained from differences in spatial variance as a function of sample length (further referred to as scale) [
13].
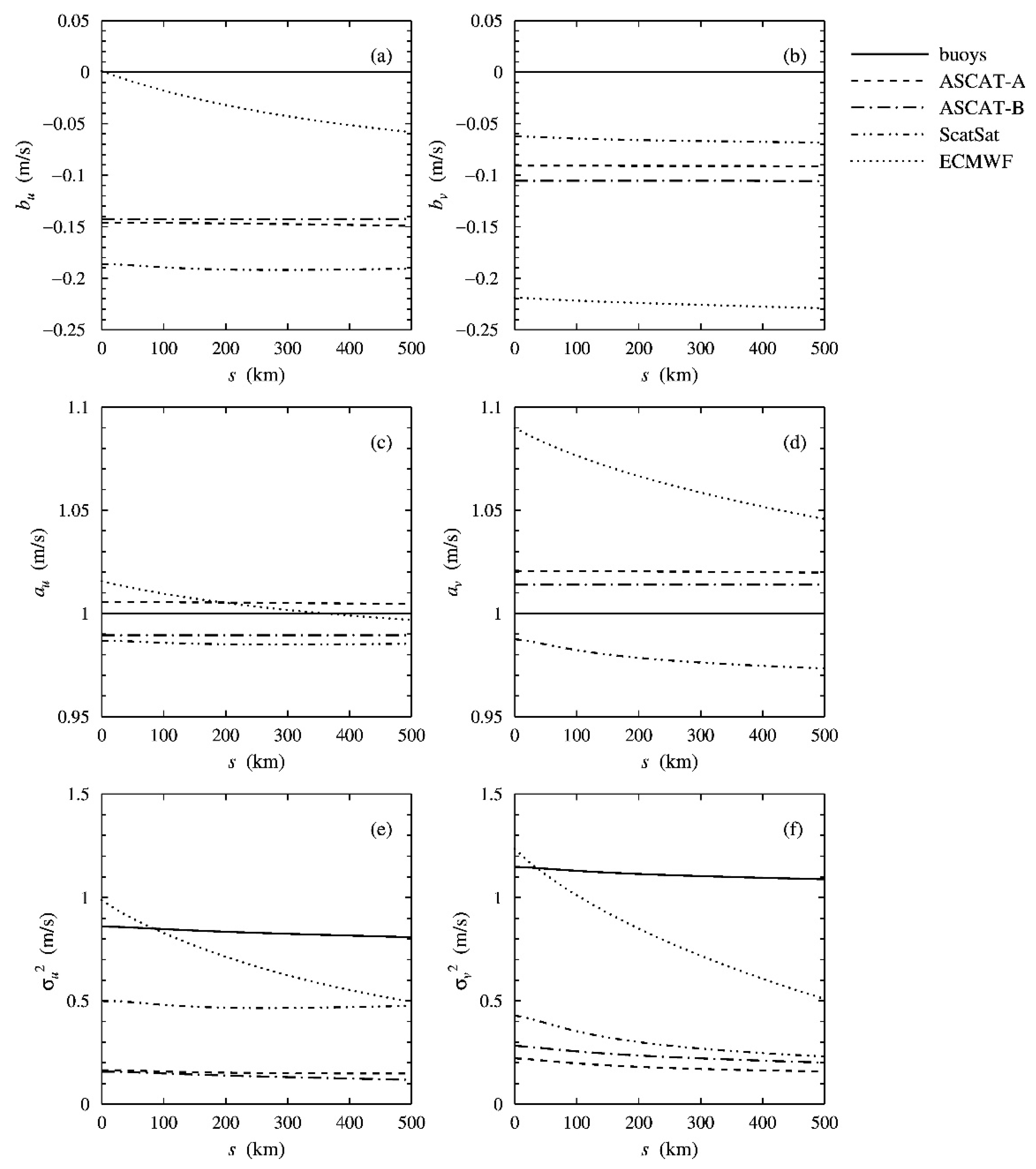
Figure 1 shows the difference in spatial variance
, as a function of scale
for ASCAT-B, ASCAT-A, and ScatSat.
Figure 1 is the same as Figure 2 in [
3]. In the terminology of Equation (15), the ScatSat representativeness error with respect to the ECMWF model,
, is defined as
, the height of the dotted curve. The representativeness error
of ASCAT-A relative to ScatSat equals the vertical distance between the dotted curve and the solid curve, and that of ASCAT-B relative to ASCAT-A,
, by the vertical distance between the dashed and the solid curve. The representativeness error of ASCAT-B relative to the ECMWF background equals
, the height of the dashed curve, in
Figure 1. The representativeness errors increase with scale.
Previous work indicated that the optimum scale for calculating the representativeness errors is about 200 km for the zonal wind component and about 100 km for the meridional wind component . Both correspond to a spatial representativeness wind vector component variance of about 0.3 m2 s−2 for the ASCATs.
Note that the spatial variances
and
should be divided by the square of the calibration scaling before calculating the representativeness errors and applying (15) in order not to mix up calibrated and uncalibrated quantities when applying the iterative scheme presented in
Section 3.3. Note also that the curves for ASCAT-A and ASCAT-B are not identical. This is due to the time difference of about 50 min in the local overpass time between the two sensors, mainly due to a different orbit phase. They, therefore, sample different weather at a particular phase of the diurnal cycle (both sensors are in a mid-morning sun-synchronous orbit). When mesoscale turbulent processes play a role, ASCAT-A and ASCAT-B can give quite different wind fields [
18].
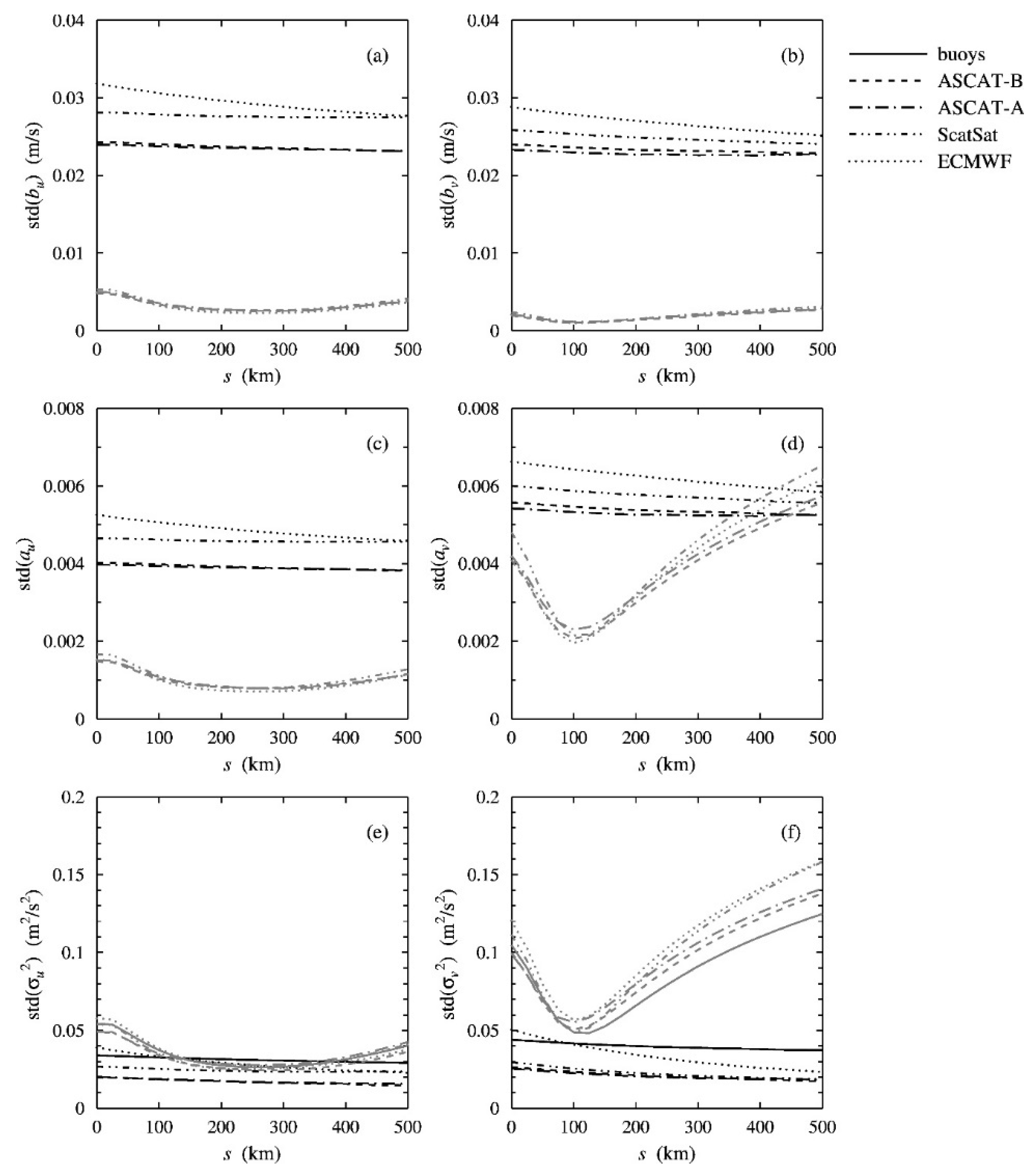
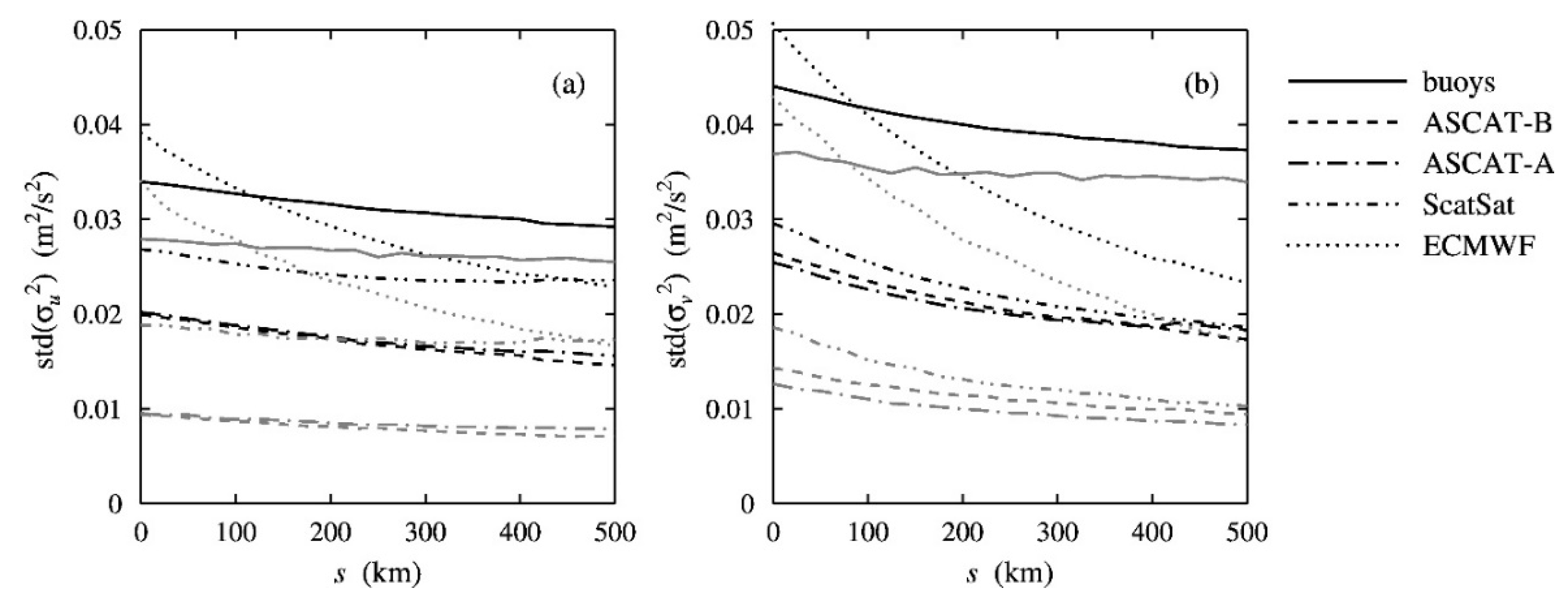
3.5. Precision Estimate
The primary source of uncertainty is in the wind components . The calibration scalings and common variance are functions of the covariances which are second-order statistics. To calculate the precision in the covariances would require fourth-order statistics, but these are very sensitive to outliers and give no usable results for data sets with the size considered here. Therefore, a different approach is followed in this work.
The first step is to run a quintuple collocation analysis on the original data to calculate calibration coefficients and the error variances. Then, the reference system is adopted as common signal and a synthetic data set is constructed using (1) with Gaussian random errors. This yields a data set that is not precisely equivalent to the original data set because the observation errors of the reference system are part of the signal, but it is close enough for a good precision estimate. Next, a quintuple collocation analysis is performed on the synthetic data set. The process is repeated a sufficient number of times (10,000 in the cases presented here), and the first and second moments of each variable are updated. Finally, averages and standard deviations are calculated for each model separately. The averages lie close to the values used to construct the synthetic data (no results shown), while the standard deviations give the precision estimates. Finally, the model results are averaged over all models. The same procedure, except for the model averaging, is also followed for the least-squares solution.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}