1. Introduction
With the development of sensor technologies, huge amounts of remote-sensing (RS) images with varied resolutions, spectral characteristics, and modalities are easily available, which has opened up the era of RS big data. Thus, it is crucial to develop skills and techniques to excavate useful knowledge from the increasingly accumulated data. Change detection (CD) is the process of identifying Earth surface changes by using co-registered images acquired in the same area but different dates. Due to the advantages of large coverage areas and short revisit period, RS change detection techniques have been widely used in the areas of land mapping, urban planing, resource investigation, disaster monitoring, and environment assessment [
1,
2,
3,
4,
5].
In the past few decades, a large amount of research has been conducted on CD [
6,
7,
8], which basically evolves with the development of machine learning and pattern recognition, and falls into two categories: traditional change detection (TCD) and deep learning change detection (DLCD). In the former case, feature engineering and pattern classification techniques are mostly investigated to extract change information, and the workflow mainly consists of (1) difference image generation, (2) threshold segmentation or classification, and (3) change map generation. The analysis unit can be independent pixels or spatially continuous super-pixels (i.e., image objects). Pixel-based TCD are mainly designed for middle- and low-resolution RS images, where ground objects can be delineated by a single pixel. In this case, it is possible to generate change map by directly comparing pixel spectral or textural values. In addition, feature engineering can be introduced to generate more discriminative features through principal component analysis (PCA) [
9], multivariate alteration detection (MAD) [
10], or slow feature analysis (SFA) [
11]. However, “salt and pepper” noise easily arises as pixels are treated independently without considering spatial context. To overcome the limitation, neighbouring windows [
12] or Markov random fields [
13,
14] are further employed to include spatial prior constraints. On the contrary, object-based TCD aims to address CD issues in high-resolution RS images, where intra-class heterogeneity increase and inter-class heterogeneity decrease significantly. In this case, image objects, which are usually generated by segmentation algorithms, are more meaningful to delineate ground objects. Change map can be thus generated by comparing object features [
15] or class categories [
16,
17]. Note that spatial context can be included naturally within image objects, and rich object features (such as shape, geometry, topology, etc.) can be extracted for comprehensive change analysis. However, it is difficult to determine a proper scale for high-resolution RS images with complex scenes. Taking the limitations of pixel-based CD (PBCD) and object-based CD (OBCD) into account, it is naturally to design CD techniques by combining their advantages. For example, in [
18], a novel unsupervised algorithm-level fusion scheme is proposed to improve the accuracy of PBCD using spatial context information. In addition, 3D change detection is becoming increasingly popular due to the usage of height information through stereo images [
19] or Light Detection and Ranging (LiDAR) points [
20].
Recently, due to the availability of big data and powerful computational resources (especially GPUs), deep learning has achieved tremendous success in the areas of computer vision and image understanding, which also leads to many breakthroughs in RS community [
21,
22,
23]. The advantages of deep learning can be mainly summarized into two aspects: (1) strong feature representation ability, hierarchical features can be learned automatically by training deep neural network (DNN), which makes it unnecessary to design hand-craft features using complex feature engineering; and (2) powerful non-linear modeling ability, DNN is capable of fitting arbitrarily complex functions, which far outperforms traditional classifiers such as decision tree, support vector machine (SVM), and random forest. As a result, deep learning has dominated the contemporary CD methods. In the early stage, deep features are used to replace hand-craft features, difference image (DI) can be thus generated for change analysis. Note that deep features can be extracted directly from pre-trained DNN models or specially designed models which are trained from scratch. For example, Hou et al. [
24] proposed to extract deep features using pretrained VGG16 network, low-rank decomposition was then applied on the difference images to generate saliency change maps. Zhang et al. [
25] proposed a deep belief network (DBN) to learn deep features directly from raw images, polar domain transformation and fuzzy clustering method were then used to generate change map. In [
26,
27], Siamese–CNN architectures were employed to learn robust features through contrastive loss or triplet loss. However, DIs have to be generated before change analysis, which inevitably leads to error accumulation effect. To address the limitations, numerous end-to-end CD networks are proposed, where change map can be learned directly from bi-temporal images. The network input can be pixel patches or image clips. In the former case, small convolution neural network (CNN) with fully connected (FC) layer is usually adopted, and the change type of the center pixel is determined by the corresponding patch classification result, which is mainly used for small datasets. Rodrigo et al. [
28] first proposed two CNN architectures for end-to-end CD, which are trained from scratch using
patches. In [
29], 2D affinity matrix is constructed for end-to-end hyperspectral image CD. However, it is difficult to define a proper patch size, and the pixel patches contain massive redundant information, which easily leads to over-fitting effect and huge computational consumption. To overcome the drawbacks, fully convolutional network (FCN)-based CD methods are proposed by dealing with image clips directly, where the change type of each pixel can be determined all at once through network inference. Due to its efficiency and effectiveness, plenty of FCN architectures are introduced to improve end-to-end CD performance, such as SegNet [
30,
31], UNet [
32,
33,
34,
35,
36,
37], UNet++ [
38,
39,
40,
41,
42,
43], UNet3+ [
44], DeepLab [
45,
46], HRNet [
47,
48,
49], etc. Note that in FCN-based CD, bi-temporal images can be stacked as a novel image with double bands or fed into two independent branches (i.e., Siamese architecture) before network training.
It is worth noting that, attention mechanism, which aims to focus on saliency areas based on human visual system, has been widely used in FCN-based CD architectures [
39,
50,
51,
52]. In general, two types of attention units are mostly employed, namely channel attention (CA) and spatial attention (SA). The former aims to assign different weights to different feature channels based on their importance, while the latter aims to force the network to focus on the areas of interest. To exploit spatial–temporal dependency, Chen et al. [
53] proposed a self-attention mechanism to generate more discriminative features. Multi-scale sub-regions are further generated to capture spatial–temporal dependencies for different objects at various scales. In a similar way, Shi et al. [
54] proposed a convolutional block attention module (CBAM), which consists of both CA and SA modules. A metric learning module is then used to generate change map. In [
55], to enhance high-frequency information of buildings, a spatial-wise attention and high-frequency enhancement module is introduced to better detect the edges of changed buildings. Similarly, Xiang et al. [
44] proposed a multi-receptive field position enhancement module (MRPEM) based on coordinate attention, leading to enhanced local relationship and long-distance dependency of features. Fang et al. [
43] proposed SNUNet-CD, where an ensemble channel attention module (ECAM) is employed for mitigating the semantic gap in deep supervision. In a similar work, EUNet-CD [
41] is proposed by repeatly adopting SA and CA units to refine the multi-scale features. In [
56], a novel deeply supervised attention-guided network named DSANet is proposed by introducing SA-guided cross-layer addition and skip-connection module.
Different from CNN architectures with limited receptive fields, transformer architectures, which are composed of self-attention units and feed-forward network, are capable of capturing global information and modeling long-range dependencies. In the past few years, it has demonstrated significant advantages over CNN counterparts in the areas of both natural language processing and image understanding. Due to its excellent global modeling ability, transformer architectures are also drawing increasing attention in CD areas. Based on the intuition that high-level concepts of changes could be represented by semantic tokens, Chen et al. [
57] proposed a bitemporal image transformer (BIT) to model spatial–temporal contexts, where a transformer-based encoder is used to learn high-level semantic tokens, and a transformer-based decoder is further adopted to refine original deep features by using the context-rich tokens. To overcome the limitation of single-scale tokens, Ke et al. [
58] proposed a hybrid transformer for RS image CD by establishing heterogeneous semantic tokens, which fully models the representation attentions at hybrid scales. A hybrid difference transformer decoder is further introduced to strengthen multi-scale global dependencies of high-level features. To aggregate rich context information effectively for CD, Liu et al. [
59] proposed a multi-scale context aggregation network (MSCANet), where transformer-based encoder and decoder are adopted for refining feature maps from each scale. In [
60], a multi-scale swin transformer is introduced to refine multi-scale features, thus generating more discriminative features for CD. Note that in the above-mentioned methods, CNN-based backbones are used for feature extraction, while transformers are only used for modeling global long-range dependencies. In [
61], a pure transformer-based architecture termed ChangeFormer is first proposed for CD, which unifies hierarchically structured transformer-based encoder and multi-layer perception (MLP)-based decoder in a Siamese network architecture. In this way, multi-scale long-range dependencies can be efficiently modeled for accurate CD. Zhang et al. [
62] also proposed a pure transformer network named SwinUNet for RS images CD, where swin-transformer blocks are adopted to serve as the basic units for all the encoder, decoder and fusion modules.
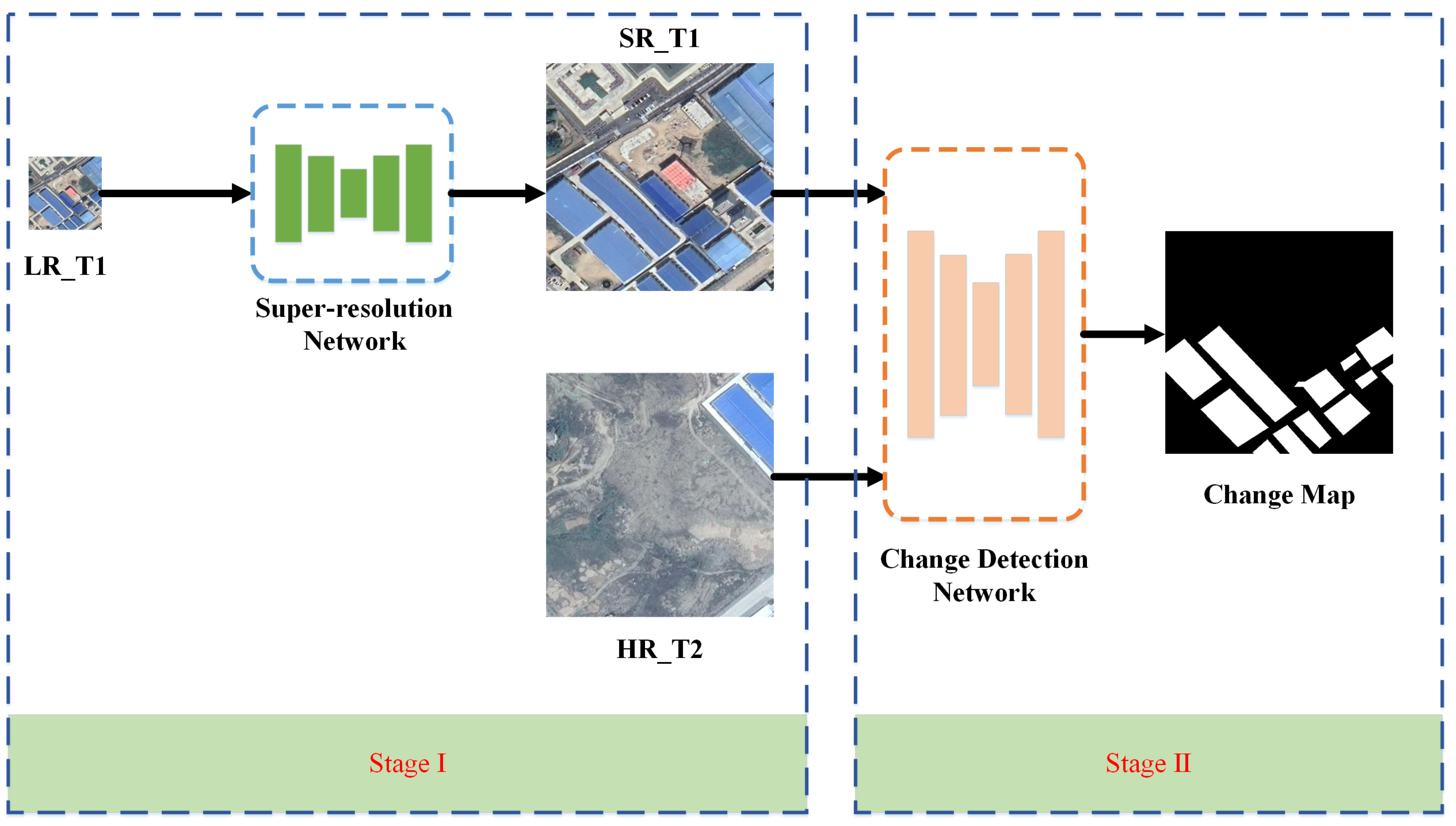
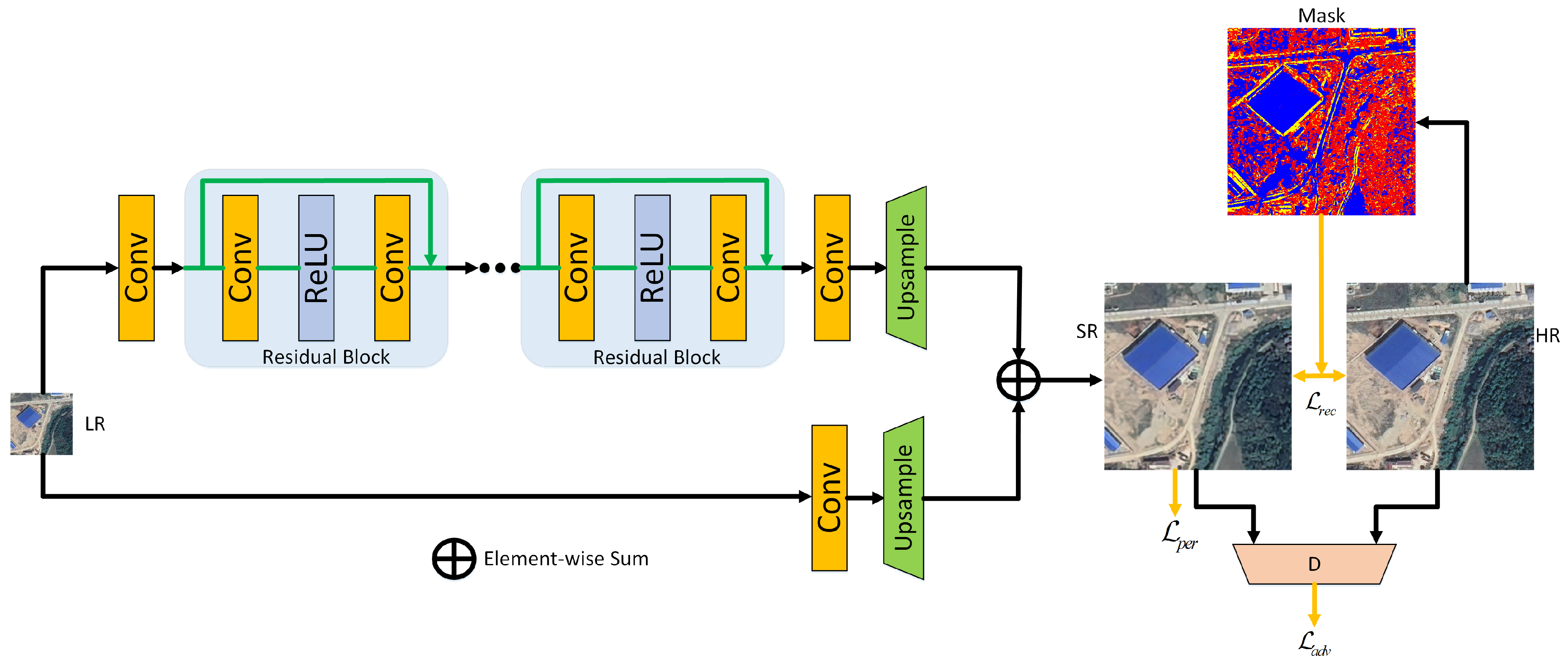
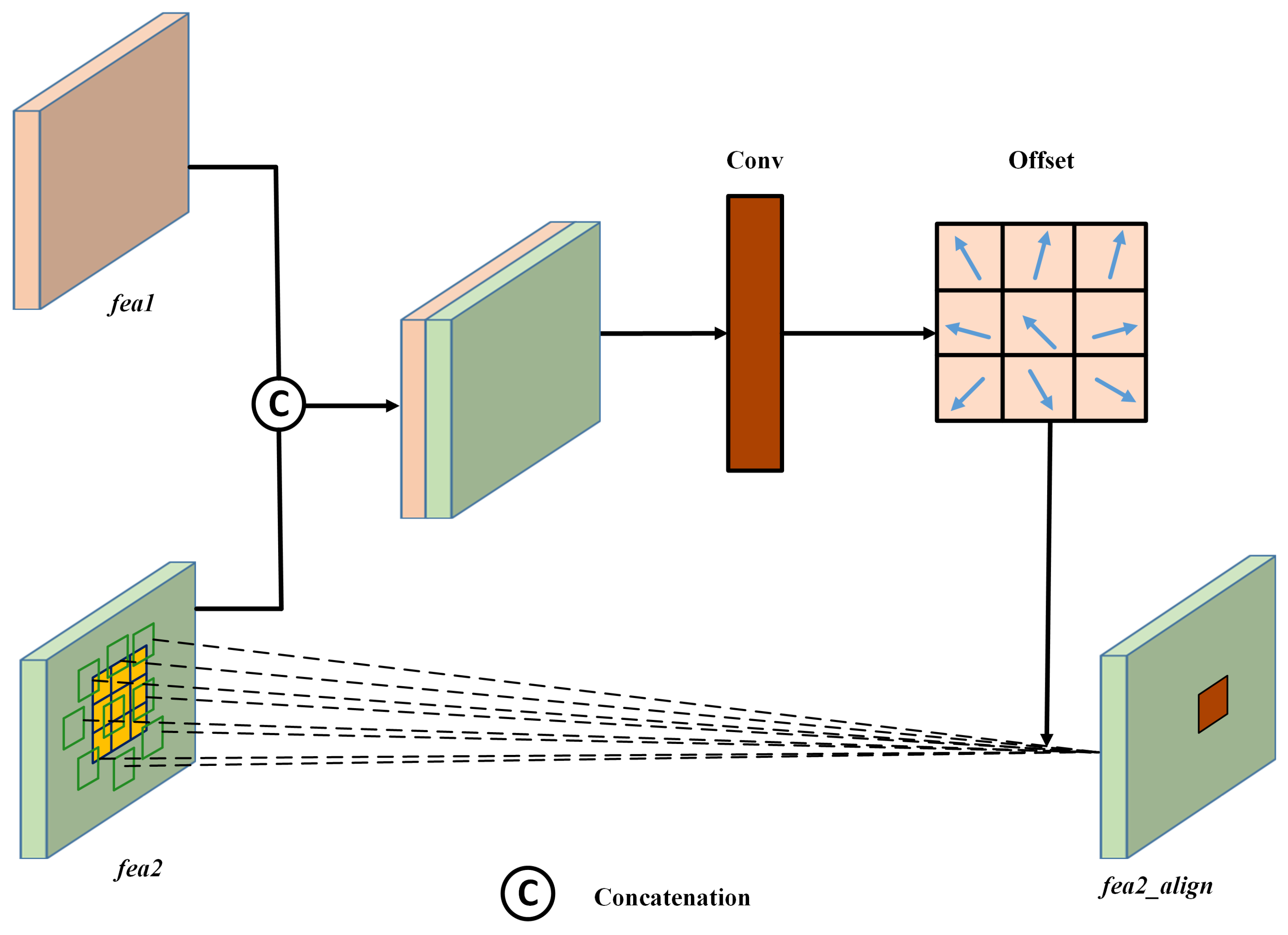
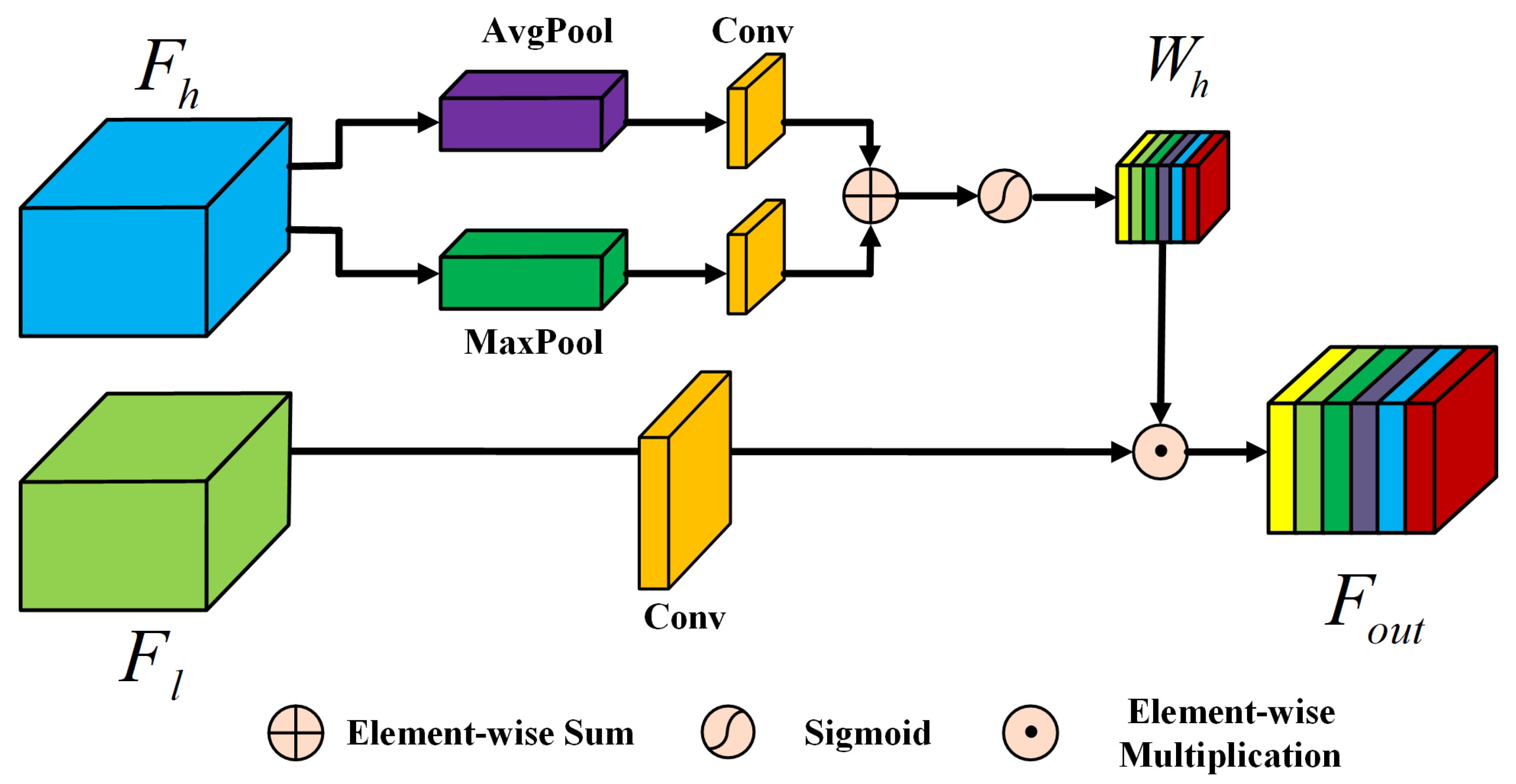
Despite the tremendous success of the above-mentioned DLCD methods, they heavily rely on co-registered bi-temporal images with equivalent resolutions. However, in real-world scenes, such images are difficult to acquire due to the limitation of imaging conditions and revisit period. Meanwhile, accurate co-registration between bi-temporal is especially challenging due to widespread object changes, leading to inevitable co-registration errors. To address the issues, a novel resolution- and alignment-aware change detection network (RACDNet) is proposed. First, a light-weighted super-resolution network based on WDSR is proposed. To better recover high-frequency detailed information, gradient weight is calculated and assigned to different regions, thus forcing the network to concentrate on difficult reconstruction areas. To mitigate over-smooth effect, adversarial loss and perceptual loss are further introduced to improve visual perceptual quality of the reconstructed images. Then, a novel Siamese–UNet is proposed for effective CD, which follows the classic encoder-decoder architecture. To align bi-temporal deep features, deformable convolution unit (DCU) is used by warping the feature maps with the learned offsets. At the end of the encoder, atrous convolution unit (ACU) is adopted to enlarge the receptive field. To bridge the semantic gap between encoder and decoder, an effective attention unit (AU) is embedded. To sum up, our contributions are three-fold:
- (1)
A novel super-resolution network is proposed, which is simple yet effective in recovering high-frequency details in RS imagery.
- (2)
An alignment-aware CD network is proposed, where bi-temporal deep features can be aligned explicitly by using DCUs, ACU and attention mechanism are further introduced to improve CD performance.
- (3)
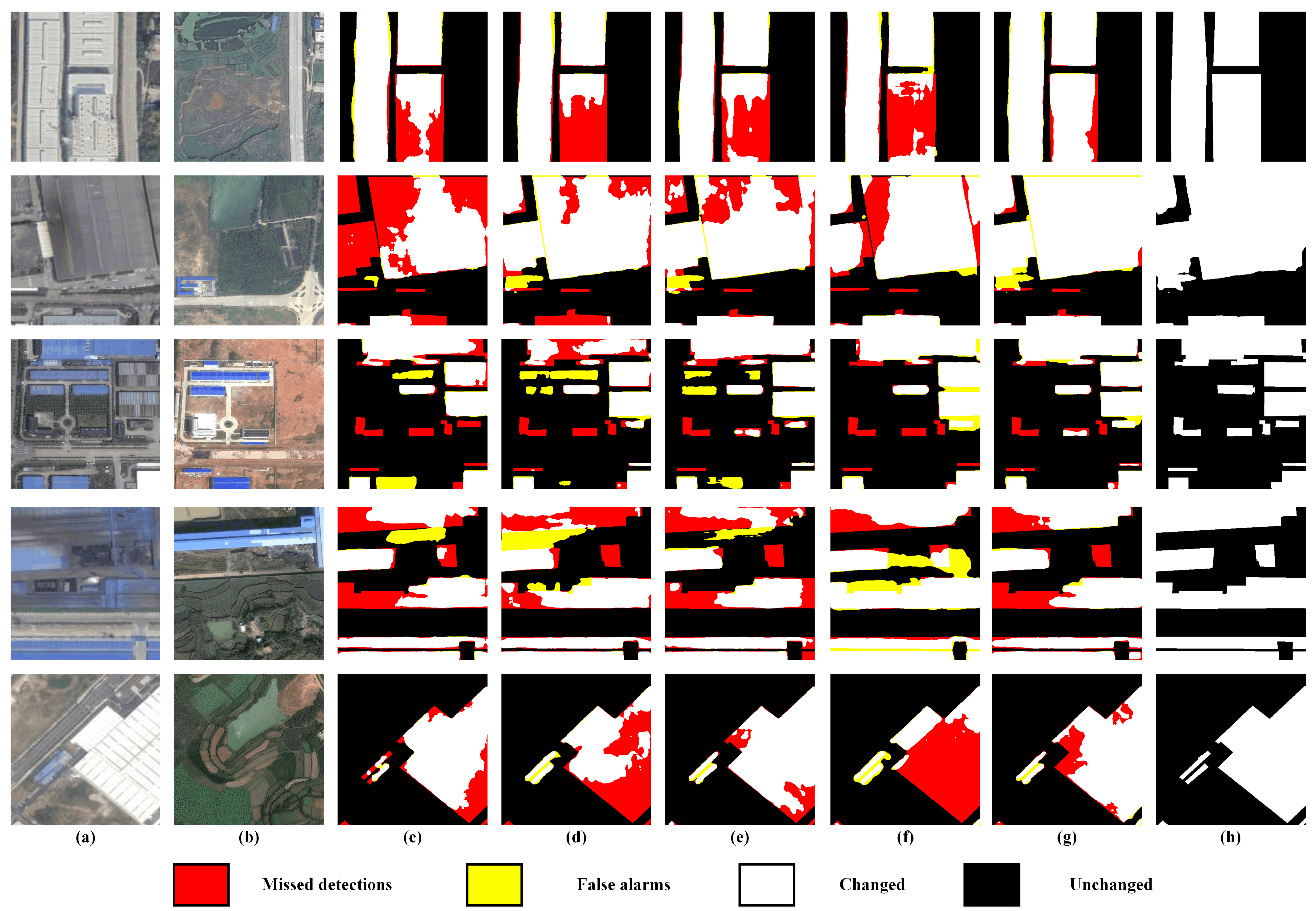
We, for the first time, create a novel multi-resolution change detection dataset (MRCDD), which is beneficial for future multi-resolution CD research. Extensive experiments and analysis are conducted on the MRCDD to demonstrate the effectiveness of our proposed method. The code and dataset will be open to public via
https://github.com/daifeng2016/Multi-resolution-Change-Detection (accessed on 31 July 2022).
The rest of the article is organized as follows.
Section 2 describes the preliminary work. The proposed RACDNet is illustrated in detail in
Section 3. Experiments and results of the proposed method are presented and analyzed in
Section 4.
Section 5 presents the discussions of the proposed method. Finally,
Section 6 draws the conclusions of this paper.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}