



A Method with Adaptive Graphs to Constrain Multi-View Subspace Clustering of Geospatial Big Data from Multiple Sources



Abstract
:1. Introduction
- (1)
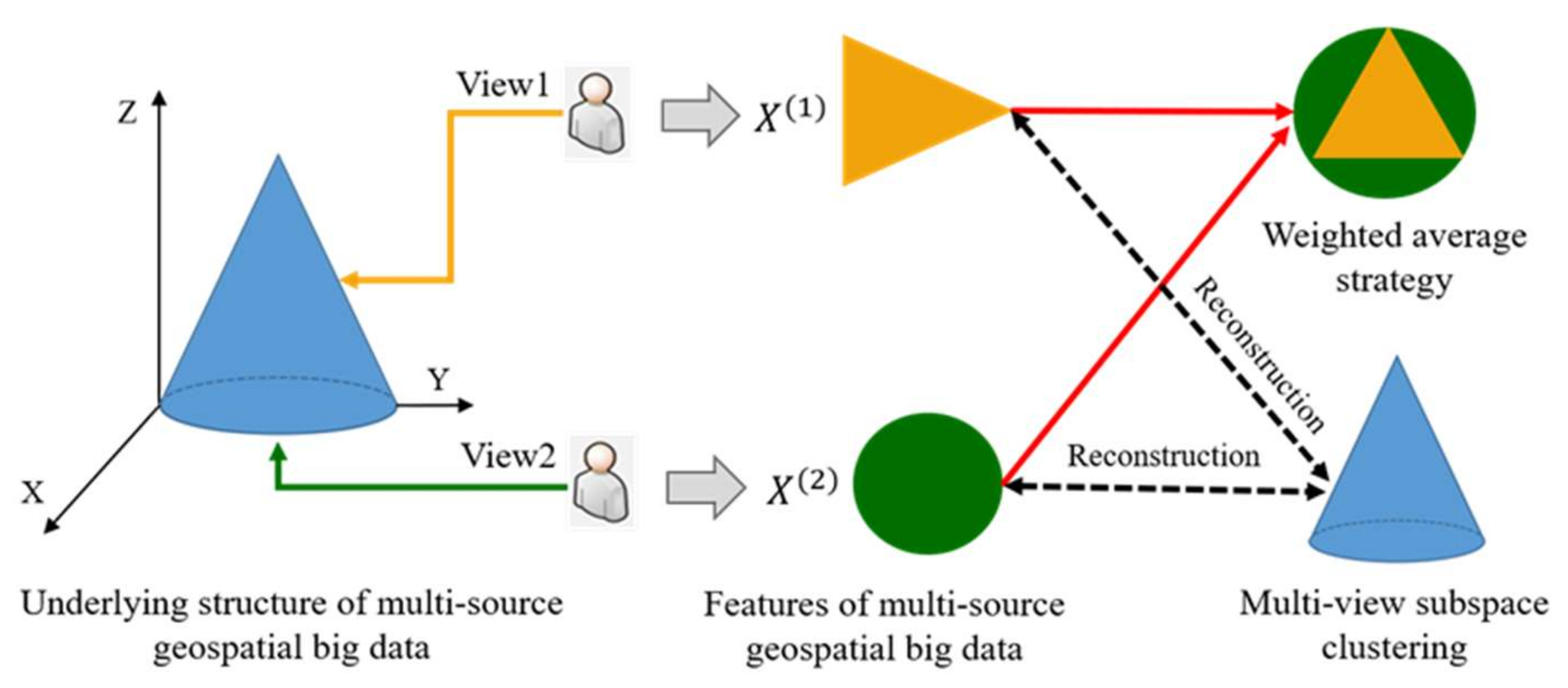
- We used a multi-view learning strategy to fuse the information embedded in multi-source geospatial big data. Compared with the weighted average strategy, multi-view subspace clustering is more suitable for integrating different and/or overlapping dimensions of human activities reflected by multi-source geospatial big data.
- (2)
- We used autoencoder networks [24] to map high-dimensional and noisy original geospatial big data into a latent representation. The latent representation of each type of geospatial big data was used to construct the low-dimensional subspace. Therefore, the influence of feature redundancy and noise on subspace construction can be reduced; moreover, the non-linear relationship between each type of data and its latent representation can be captured.
- (3)
- We used a shared nearest neighbor method [25] to construct adaptive graphs for high-dimensional, non-uniform, and noisy geospatial big data. The adaptive graphs can be used as constraints to obtain a more robust subspace shared by multi-source geospatial big data. Therefore, the quality of multi-view subspace clustering can be improved.
2. Related Work
3. Method
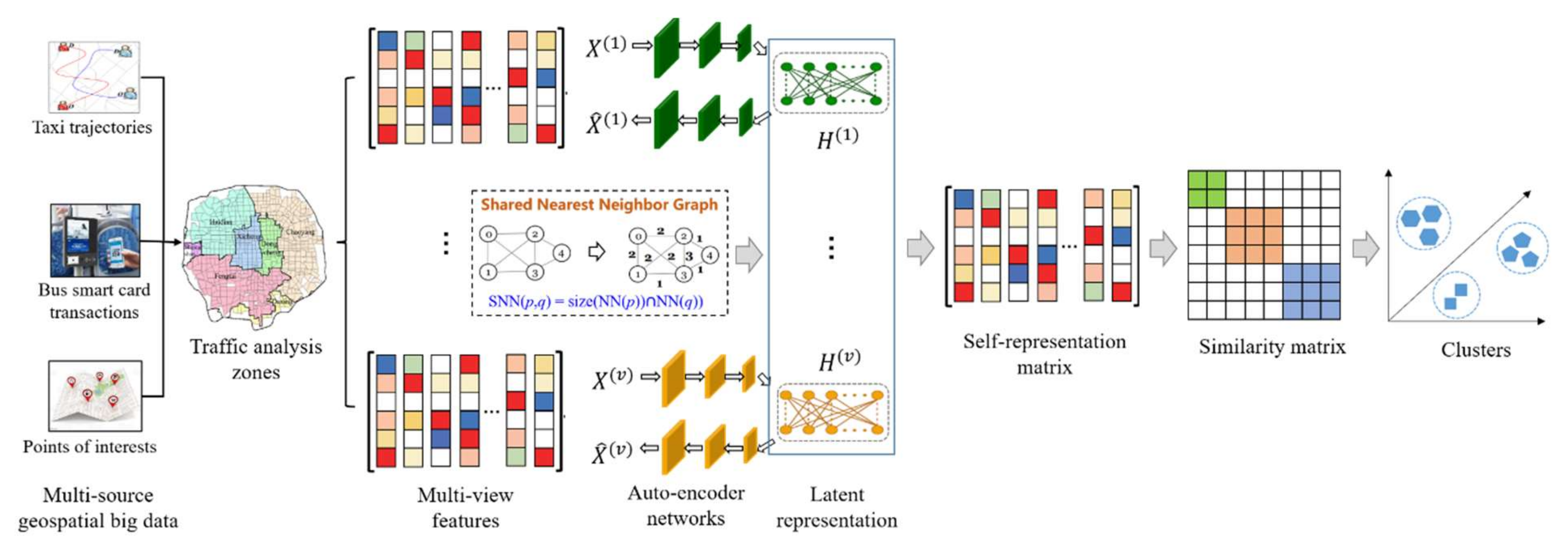
3.1. Clustering Feature Extraction of Multi-Source Geospatial Big Data
3.2. Construction of Shared Nearest Neighbor Graph
3.3. Latent Representation Based on Autoencoder Networks
3.4. Multi-View Subspace Clustering with an Adaptive Graph Constraint
| Algorithm 1 The agc2msc method |
| Input: multi-view dataset , unified adjacency matrix , parameters and . |
| Initial: Learning rate: lr = 0.001 Optimizer: Adam Epoch = 20,000 |
| 1: While pre-training not converged do: 2: Update and by formula (A3)–(A5) in Appendix A. 3: Obtain Z. 4: End pre-training. 5: While training not converged do: 6: Update and by formula (A3)–(A5) in Appendix A. 7: Obtain Z. 8: End training. |
| 9: Return the shared subspace representation matrix Z. |
| Perform spectral clustering by employing the similarity matrix . |
| Output: Clustering results. |
4. Experiments
4.1. Benchmark Datasets
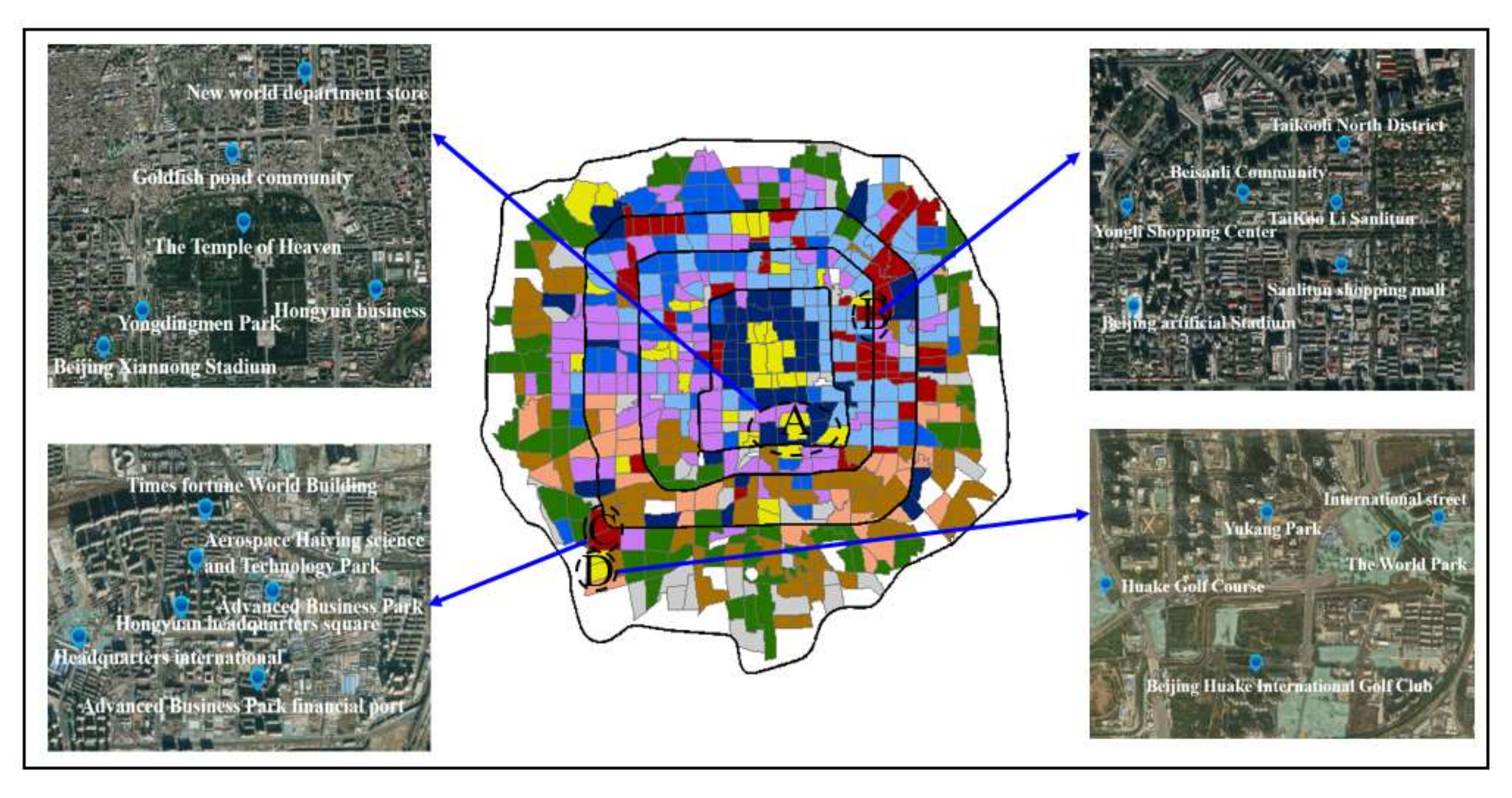
4.2. Case Study of Beijing Multi-Source Geospatial Big Data
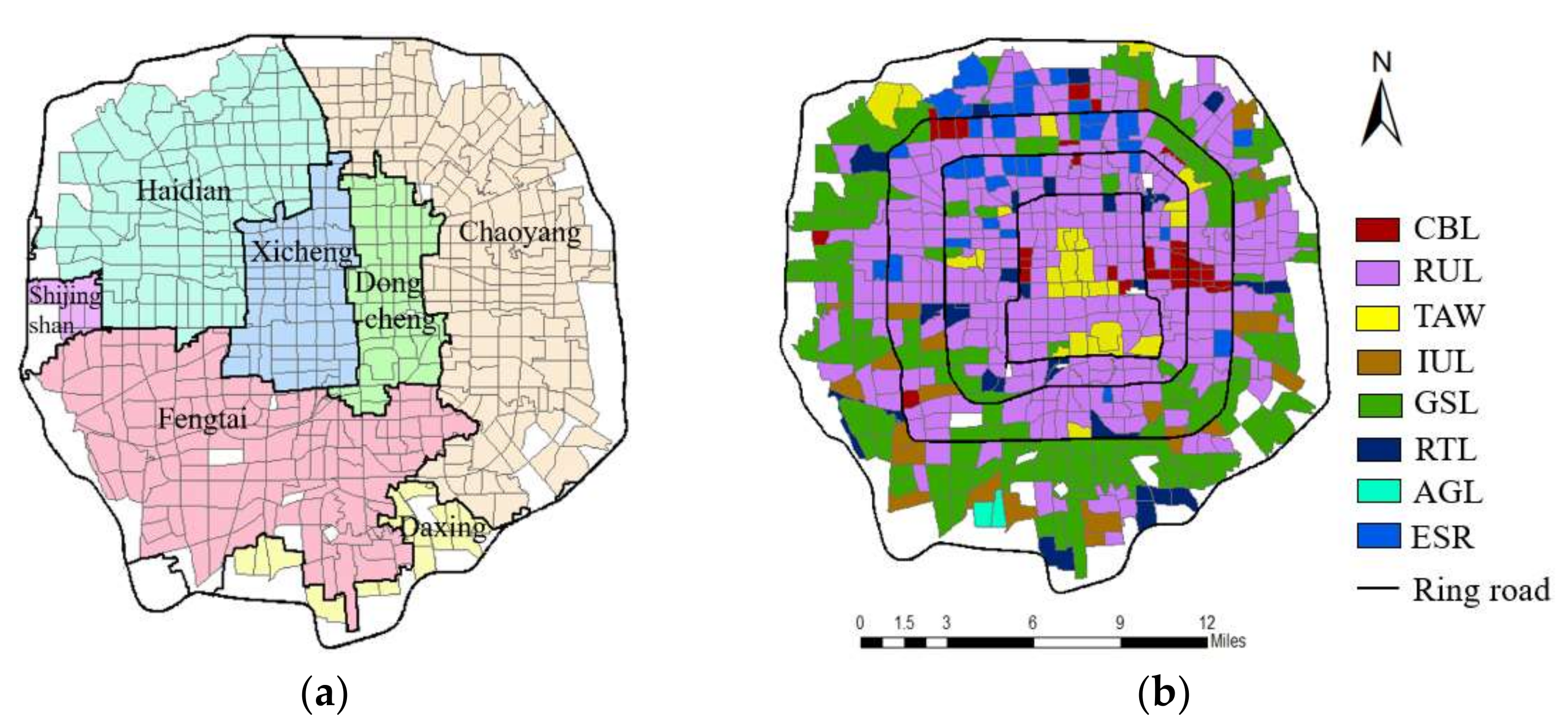
4.2.1. Study Area and Dataset
- (1)
- Traffic analysis zones. The study area was divided into 577 traffic analysis zones (Figure 4a). A traffic analysis zone is usually a socio-economically homogenous region that consists of one or more census blocks, block groups, or census tracts [60]. Existing work have found that traffic analysis zones are the suitable spatial units used in transportation and urban planning models [5,14,61]. Therefore, this study performs the clustering methods at the scale (or resolution) of traffic analysis zones. The traffic analysis zones were defined by the transport and urban planning authority, which were provided by Beijing Municipal Commission of Planning and Natural Resources.
- (2)
- Land use planning map: Figure 4b displays the governmental land-use map obtained from the Beijing Municipal Commission of Planning and Natural Resources. The current land classification (GB/T 21010-2017) identifies eight land use types: commercial and business land (CBL), residential land (RUL), tourist attraction and water (TAW), industrial land (IUL), green space land (GSL), road and transportation land (RTL), agricultural land (AGL), and education and scientific research land (ESR).
- (3)
- Taxi trajectory and bus smart-card transaction data: We collected GPS trajectories from more than 33,000 taxis and bus smart-card transaction data from 834 lines during the week (9:00–24:00 from 9 May 2016 to 15 May 2016). Each taxi trajectory contains the records of taxi ID, location, the status (occupied or not), and sampling time. We extracted the origin and destination points from each taxi trajectory. The numbers of taxi origin and destination pairs on workdays and weekends are 792,497 and 237,441, respectively. Each record of bus smart-card transaction data contains bus ID, the transaction time, pick-up station and drop-off station. For each bus smart-card transaction, the pick-up and drop-off stations were identified as the origin and destination points of that transaction. There are 14,157,913 and 4,157,948 bus origin and destination pairs on workdays and weekends, respectively. The origin and destination points of taxi trajectories and bus smart-card transactions were matched to traffic analysis zones according to their locations. The feature vectors constructed for the taxi GPS trajectory and bus smart-card transaction data had 64 dimensions;
- (4)
- POI data: POI data were collected from the 2017 Gaode Map. A total of 1,210,197 records were classified into 23 categories. Each POI record contained five essential attributes: name, ID, longitude, latitude, and category. For POI data, the information related to urban land use was extracted using two deep-learning language models, i.e., Word2vec and Doc2vec. We also matched POIs to traffic analysis zones according to the locations of POIs. A 64-dimensional feature vector was constructed for each traffic analysis zone.
4.2.2. Baseline Methods
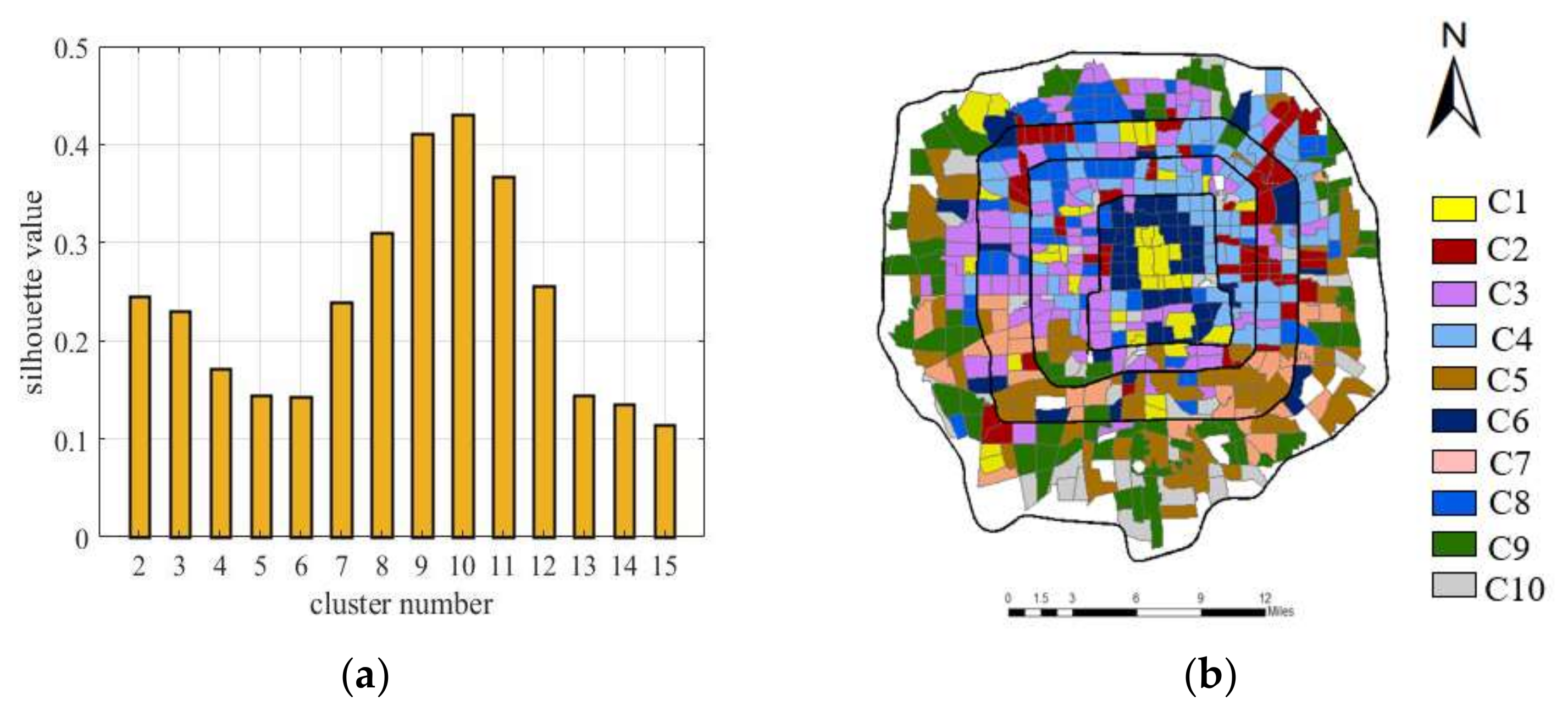
4.2.3. Clustering Results of agc2msc
- (i)
- Frequency density (FD) and category rate (CR) of POIs in each cluster (Table 2):
- (ii)
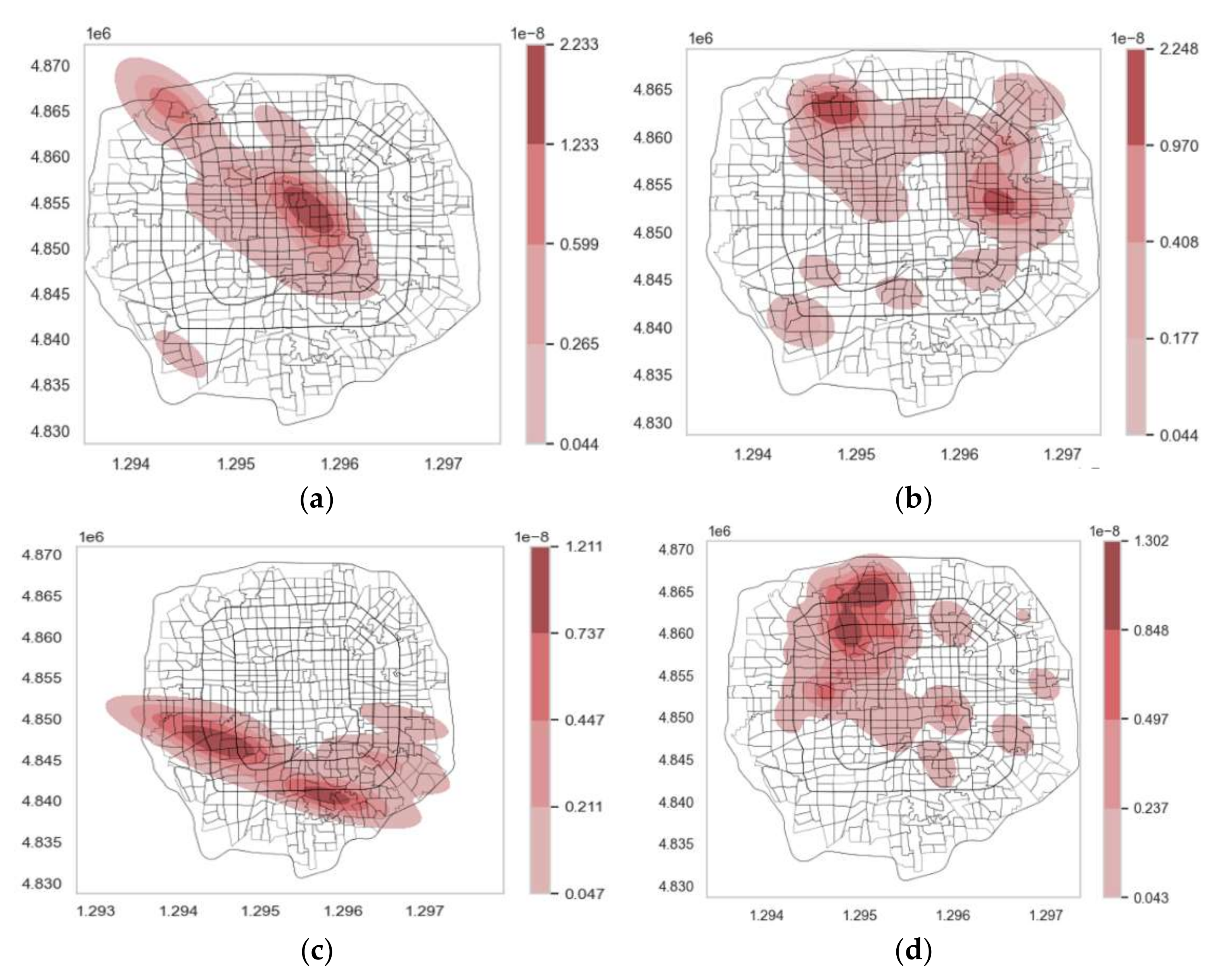
- Arriving/leaving transition matrices: As shown in Figure 6, the horizontal axes represent the time over the day from 8:00 to 24:00, and the vertical axes represent the clusters for which passengers either arrive or leave. The colour for a grid represents the number of pick-ups or drop-offs in a cluster.
Tourist Attraction and Water Areas (C1)
Commercial and business areas (C2)
Developed Residential Areas (C3)
Emerging Residential Areas (C4)
Less Developed Residential Areas (C5)
Residential/Commercial/Entertainment Areas (C6)
Industrial Areas (C7)
Education and Scientific Research Areas (C8)
Green Space Areas (C9)
Road and Transportation Areas (C10)
4.2.4. Quantitative Comparison and Analysis
5. Discussion
- (i)
- Compared with the single-view spectral clustering method, the complementary information of multi-source geospatial big data can be incorporated accurately using agc2msc. Therefore, agc2msc can alleviate the bias problem caused by a single type of geospatial big data and comprehensively describe urban structures and organizations in cities.
- (ii)
- Compared with the weighted average spectral clustering strategy, agc2msc can fuse the shared and complementary information among different types of geospatial big data. The underlying structure of the multi-source data can be reconstructed accurately using agc2msc. Therefore, agc2msc can capture the complementarity of multi-source geospatial big data more accurately.
- (iii)
- Compared with the multi-view subspace clustering method, agc2msc can construct appropriate neighboring relationships for high-dimensional, noisy, and non-uniform geospatial big data. A more robust shared subspace can be obtained under the constraint of a shared nearest neighbor graph.
- (i)
- Actually, these clusters can reveal urban function zones in a city. By fusing multi-source geospatial big data, we can obtain a comprehensive view of urban function zones naturally formulated according to human activities. The clusters identified by agc2msc may be further used for public services, business site selection, and human-centric urban planning [30]. The more complex land-use types identified in this study can also provide a reference for urban planning and city development. For instance, residential areas can be divided into three types: developed residential areas; emerging residential areas; less developed residential areas; and a mix of residential, commercial, and entertainment areas. Scientific and research areas were also identified. Existing remote sensing techniques are hard to obtain this complex division. The clustering results obtained by agc2msc may help urban planners make more strategic decisions and improve the quality of land-use mapping.
- (ii)
- Some calibrations may be presented for urban land-use planning. Although the detection rate of the proposed method is relatively low (overall accuracy is 68.11%), the clustering results are useful for infer the actual land use which cannot be captured by land use planning map. In fact, the actual land use types may differ from the Beijing land use planning map (Figure 4b). The land use planning map was obtained based on the physical characteristics of ground components (e.g., spectral, shape, and texture); therefore, the land use planning map is hard to reflect the actual way of how people use spaces [3,26]. We give some examples to illustrate that the actual land use types of some traffic analysis zones are not consistent with those in Beijing land-use planning map.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Solution and Optimization of the Objective Function
Appendix B. Experiments on Benchmark Datasets
Appendix B.1. Benchmark Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Datasets | Samples | Clusters | Views | Dimensions |
|---|---|---|---|---|
| ORL | 400 | 40 | 3 | 4096/3304/6750 |
| Yale | 165 | 15 | 3 | 4096/3304/6750 |
| MSRCV1 | 210 | 7 | 6 | 1032/48/512/100/256/210 |
| Caltech101 | 441 | 7 | 6 | 1032/32/512/64/256/441 |
- (i)
- ORL: This dataset contains 400 gray images of 40 different individuals; it was created by Olivetti research laboratory in Cambridge, UK from April 1992 to April 1994. The dataset contains a total of 40 directories. Each directory represents 10 facial pictures taken by the same person at different times and in different environments (e.g., light/no light, glasses/no glasses, changes in different facial expressions, etc.). All the pictures are stored in the form of gray-scale image and Portable Gray Map format, and the picture size is 92 × 112. Three types of features were used in the experiment, i.e., intensity (4096 dimensions), Local Binary Pattern (3304 dimensions) and Gabor (6750 dimensions), representing three different views of observation.
- (ii)
- Yale: This dataset was created by Yale University and contains a total of 165 grayscale images from 15 different individuals. The dataset contains a total of 15 directories. Each directory represents 11 face images of the same person under different expressions, gestures and illumination. The size of each image is 100 × 100. Variations of images include central light/edge light, wearing glasses/not wearing glasses, happiness/sadness, surprise/blink, etc. Similar to ORL dataset, three different types of features were extracted in the experiment as three different views of observation, namely intensity (4096 dimension), Local Binary Pattern (3304 dimension) and Gabor (6750 dimension).
- (iii)
- MSRCV1: This dataset contains 210 images from 7 categories collected from 6 different views, and each category contains 30 images. From the collected samples, it can be seen that seven categories include human face, animals, trees, scenery, bicycles, cars, planes. Six types of high-dimensional features were extracted in the experiment: Centrist (view1), Charcot Marie Tooth (view2), Gist (view3), Histogram of Oriented Gradient (view4), Local Binary Pattern (view5), and Scale-invariant feature transform (view6).
- (iv)
- Caltech101-7: Caltech101 is a dataset widely used in image classification in deep learning, which contains 101 types of images. In this study, the subset of this dataset (i.e., Caltech101-7) was used in the experiment. In Caltech101-7, a total of 441 images of 7 categories were selected, including face, coin, Garfield, motorcycle, Snoopy, parking sign and chair. Six types of high-dimensional features were extracted for experiment, which was similar to those of MSRCV1.
Appendix B.2. Baselines
- (1)
- : This method performs the standard spectral clustering [28] on the most informative view.
- (2)
- : This method performs single-view algorithm LRR [34] on the most informative view.
- (3)
- FeatConcate [46]: This method directly concatenates the features from different views, and then applies the concatenated features to single-view clustering algorithm.
- (4)
- RMSC [63]: This method firstly recovers a shared low-rank transition probability matrix, and then uses a Markov chain to cluster.
- (5)
- gLMSC [18]: This method firstly calculates an underlying latent representation shared by multi-view features, and then applies the latent representation to subspace clustering.
- (6)
- DiMSC [38]: This method extends the existing single-view subspace clustering into multi-view domain and exploits the complementary information of multi-view representations by enforcing Hilbert Schmidt Independence Criterion term.
- (7)
- CSMSC [39]: This method exploits both the consistent and specific information among multi-view features by pursuing a view-consistent representation matrix and a set of view-specific self-representation matrices.
- (8)
- DSS-MSC [22]: This method decomposes the underlying latent representation into shared component and view-specific components, which exploit the underlying correlations cross multiple views and simultaneously capture specific property for each independent view.
- (9)
- MSCNLG [23]: This method introduces artificial neural network under each view to obtain a set of latent representations and integrates local and global graph information into self-expressive layers.
Appendix B.3. Evaluation Metrics and Clustering Results
| Method | NMI | ACC | F-Score | AR | Precision | Recall |
|---|---|---|---|---|---|---|
| 0.884 ± 0.002 | 0.726 ± 0.025 | 0.664 ± 0.005 | 0.655 ± 0.005 | 0.610 ± 0.006 | 0.728 ± 0.005 | |
| 0.895 ± 0.006 | 0.773 ± 0.003 | 0.731 ± 0.004 | 0.724 ± 0.020 | 0.701 ± 0.001 | 0.754 ± 0.002 | |
| FeatConcate | 0.831 ± 0.003 | 0.648 ± 0.033 | 0.564 ± 0.007 | 0.553 ± 0.007 | 0.522 ± 0.007 | 0.614 ± 0.008 |
| RMSC | 0.872 ± 0.012 | 0.723 ± 0.025 | 0.654 ± 0.028 | 0.645 ± 0.029 | 0.607 ± 0.033 | 0.709 ± 0.027 |
| gLMSC | 0.924 ± 0.011 | 0.830 ± 0.017 | 0.771 ± 0.028 | 0.765 ± 0.044 | 0.728 ± 0.010 | 0.819 ± 0.010 |
| DiMSC | 0.940 ± 0.003 | 0.838 ± 0.001 | 0.807 ± 0.003 | 0.802 ± 0.000 | 0.764 ± 0.012 | 0.856 ± 0.004 |
| CSMSC | 0.942 ± 0.005 | 0.868 ± 0.012 | 0.831 ± 0.001 | 0.615 ± 0.005 | 0.673 ± 0.002 | 0.610 ± 0.006 |
| DSS-MSC | 0.928 ± 0.010 | 0.795 ± 0.010 | 0.766 ± 0.010 | 0.762 ± 0.010 | 0.719 ± 0.010 | 0.823 ± 0.010 |
| MSCNLG | 0.936 ± 0.002 | 0.885 ± 0.003 | 0.857 ± 0.004 | 0.825 ± 0.002 | 0.885 ± 0.002 | 0.885 ± 0.002 |
| agc2msc | 0.943 ± 0.002 | 0.893 ± 0.002 | 0.871 ± 0.002 | 0.831 ± 0.002 | 0.890 ± 0.002 | 0.890 ± 0.002 |
| Method | NMI | ACC | F-Score | AR | Precision | Recall |
|---|---|---|---|---|---|---|
| 0.654 ± 0.009 | 0.616 ± 0.030 | 0.475 ± 0.043 | 0.440 ± 0.011 | 0.457 ± 0.011 | 0.495 ± 0.010 | |
| 0.709 ± 0.011 | 0.697 ± 0.001 | 0.547 ± 0.007 | 0.515 ± 0.004 | 0.529 ± 0.003 | 0.567 ± 0.004 | |
| FeatConcate | 0.648 ± 0.030 | 0.607 ± 0.043 | 0.471 ± 0.039 | 0.434 ± 0.042 | 0.447 ± 0.043 | 0.497 ± 0.032 |
| RMSC | 0.872 ± 0.012 | 0.723 ± 0.025 | 0.654 ± 0.028 | / | / | / |
| gLMSC | 0.735 ± 0.021 | 0.752 ± 0.026 | 0.564 ± 0.019 | 0.551 ± 0.011 | 0.543 ± 0.015 | 0.571 ± 0.013 |
| DiMSC | 0.727 ± 0.010 | 0.709 ± 0.003 | 0.564 ± 0.002 | 0.535 ± 0.001 | 0.543 ± 0.001 | 0.586 ± 0.003 |
| CSMSC | 0.784 ± 0.001 | 0.752 ± 0.007 | 0.640 ± 0.004 | 0.615 ± 0.005 | 0.673 ± 0.002 | 0.610 ± 0.006 |
| DSS-MSC | 0.779 ± 0.021 | 0.782 ± 0.013 | 0.613 ± 0.012 | 0.601 ± 0.009 | 0.529 ± 0.010 | 0.622 ± 0.015 |
| MSCNLG | 0.879 ± 0.002 | 0.903 ± 0.002 | 0.831 ± 0.002 | 0.790 ± 0.002 | 0.903 ± 0.002 | 0.903 ± 0.002 |
| agc2msc | 0.913 ± 0.002 | 0.925 ± 0.002 | 0.871 ± 0.002 | 0.835 ± 0.002 | 0.922 ± 0.002 | 0.922 ± 0.002 |
| Method | NMI | ACC | F-Score | AR | Precision | Recall |
|---|---|---|---|---|---|---|
| 0.574 ± 0.032 | 0.668 ± 0.051 | 0.535 ± 0.043 | 0.536 ± 0.010 | 0.571 ± 0.009 | 0.612 ± 0.009 | |
| 0.569 ± 0.008 | 0.676 ± 0.009 | 0.524 ± 0.009 | 0.502 ± 0.010 | 0.543 ± 0.009 | 0.587 ± 0.007 | |
| FeatConcate | 0.613 ± 0.042 | 0.672 ± 0.031 | 0.575 ± 0.024 | 0.505 ± 0.032 | 0.566 ± 0.021 | 0.586 ± 0.027 |
| RMSC | 0.650 ± 0.022 | 0.750 ± 0.048 | 0.628 ± 0.023 | / | / | / |
| gLMSC | 0.752 ± 0.011 | 0.848 ± 0.013 | 0.738 ± 0.018 | 0.721 ± 0.017 | 0.744 ± 0.012 | 0.743 ± 0.011 |
| DiMSC | 0.692 ± 0.002 | 0.810 ± 0.002 | 0.685 ± 0.002 | 0.634 ± 0.002 | 0.679 ± 0.002 | 0.691 ± 0.002 |
| CSMSC | 0.756 ± 0.002 | 0.857 ± 0.002 | 0.756 ± 0.002 | 0.717 ± 0.002 | 0.750 ± 0.002 | 0.762 ± 0.002 |
| DSS-MSC | 0.743 ± 0.015 | 0.846 ± 0.011 | 0.726 ± 0.021 | 0.681 ± 0.014 | 0.711 ± 0.011 | 0.743 ± 0.013 |
| MSCNLG | 0.850 ± 0.002 | 0.921 ± 0.002 | 0.862 ± 0.002 | 0.830 ± 0.002 | 0.922 ± 0.002 | 0.922 ± 0.002 |
| agc2msc | 0.893 ± 0.002 | 0.943 ± 0.002 | 0.900 ± 0.002 | 0.869 ± 0.002 | 0.945 ± 0.002 | 0.942 ± 0.002 |
| Method | NMI | ACC | F-Score | AR | Precision | Recall |
|---|---|---|---|---|---|---|
| 0.589 ± 0.009 | 0.629 ± 0.007 | 0.576 ± 0.009 | 0.523 ± 0.012 | 0.586 ± 0.014 | 0.566 ± 0.003 | |
| 0.639 ± 0.002 | 0.646 ± 0.003 | 0.649 ± 0.002 | 0.580 ± 0.001 | 0.631 ± 0.001 | 0.623 ± 0.003 | |
| FeatConcate | 0.603 ± 0.017 | 0.641 ± 0.020 | 0.601 ± 0.023 | 0.526 ± 0.034 | 0.624 ± 0.021 | 0.579 ± 0.024 |
| gLMSC | 0.694 ± 0.013 | 0.722 ± 0.012 | 0.683 ± 0.009 | 0.620 ± 0.002 | 0.670 ± 0.002 | 0.695 ± 0.002 |
| DiMSC | 0.679 ± 0.002 | 0.746 ± 0.002 | 0.709 ± 0.002 | 0.653 ± 0.002 | 0.717 ± 0.002 | 0.702 ± 0.002 |
| CSMSC | 0.701 ± 0.002 | 0.732 ± 0.002 | 0.702 ± 0.002 | 0.630 ± 0.002 | 0.680 ± 0.002 | 0.702 ± 0.002 |
| DSS-MSC | 0.691 ± 0.002 | 0.737 ± 0.001 | 0.703 ± 0.006 | 0.635 ± 0.002 | 0.698 ± 0.002 | 0.710 ± 0.002 |
| MSCNLG | 0.758 ± 0.002 | 0.764 ± 0.002 | 0.760 ± 0.002 | 0.687 ± 0.002 | 0.748 ± 0.002 | 0.748 ± 0.002 |
| agc2msc | 0.805 ± 0.002 | 0.790 ± 0.002 | 0.793 ± 0.002 | 0.710 ± 0.002 | 0.762 ± 0.002 | 0.762 ± 0.002 |
Appendix B.4. Parameter Settings and Parameter Sensitivity
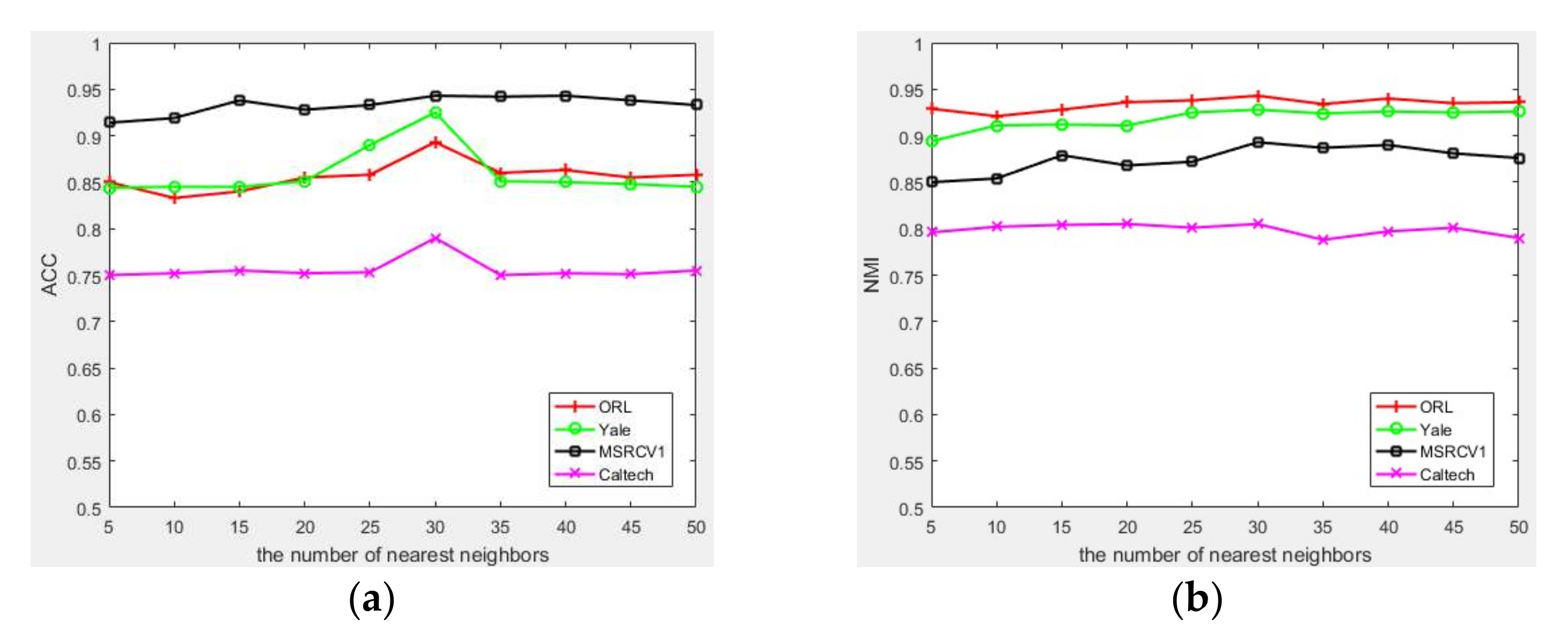
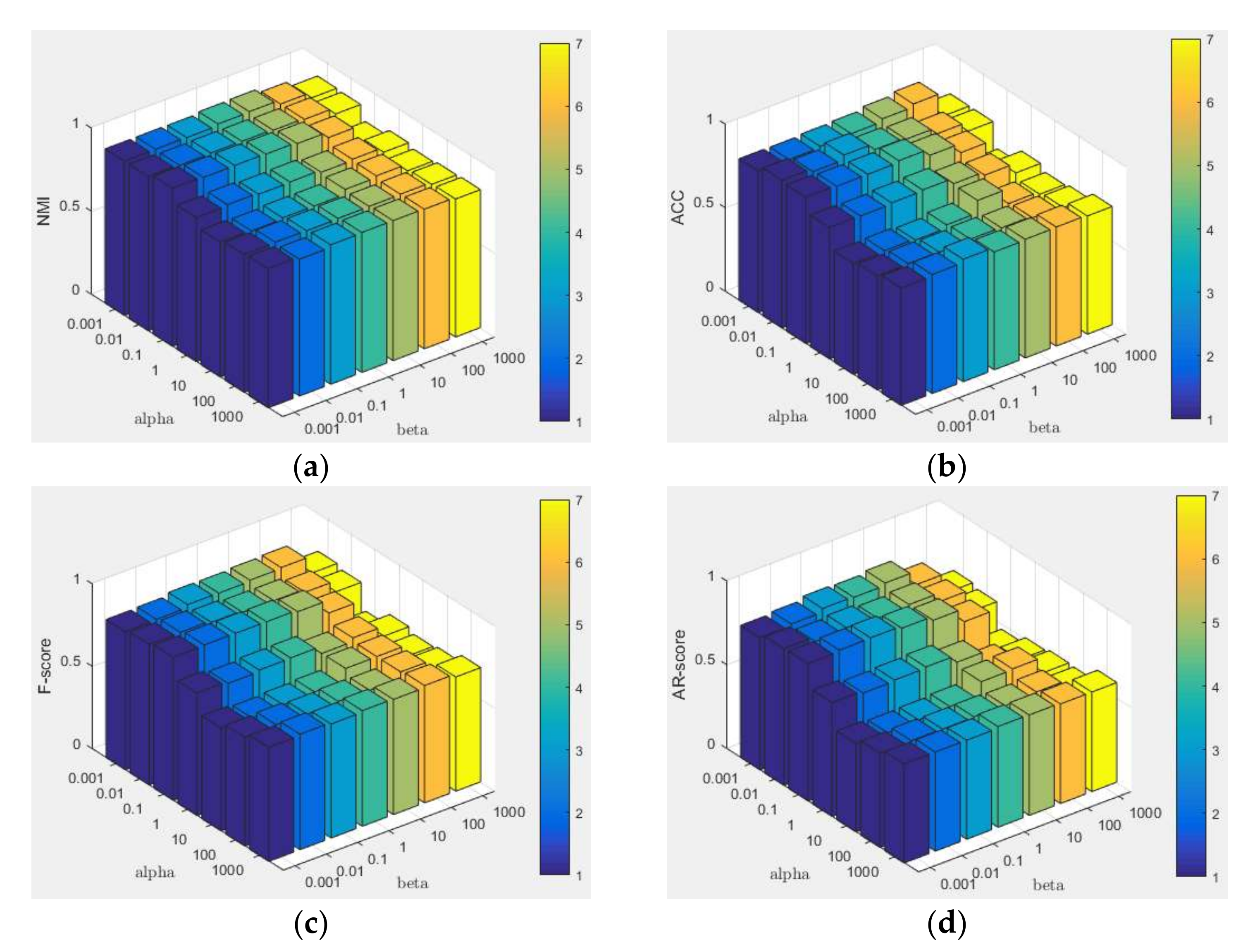
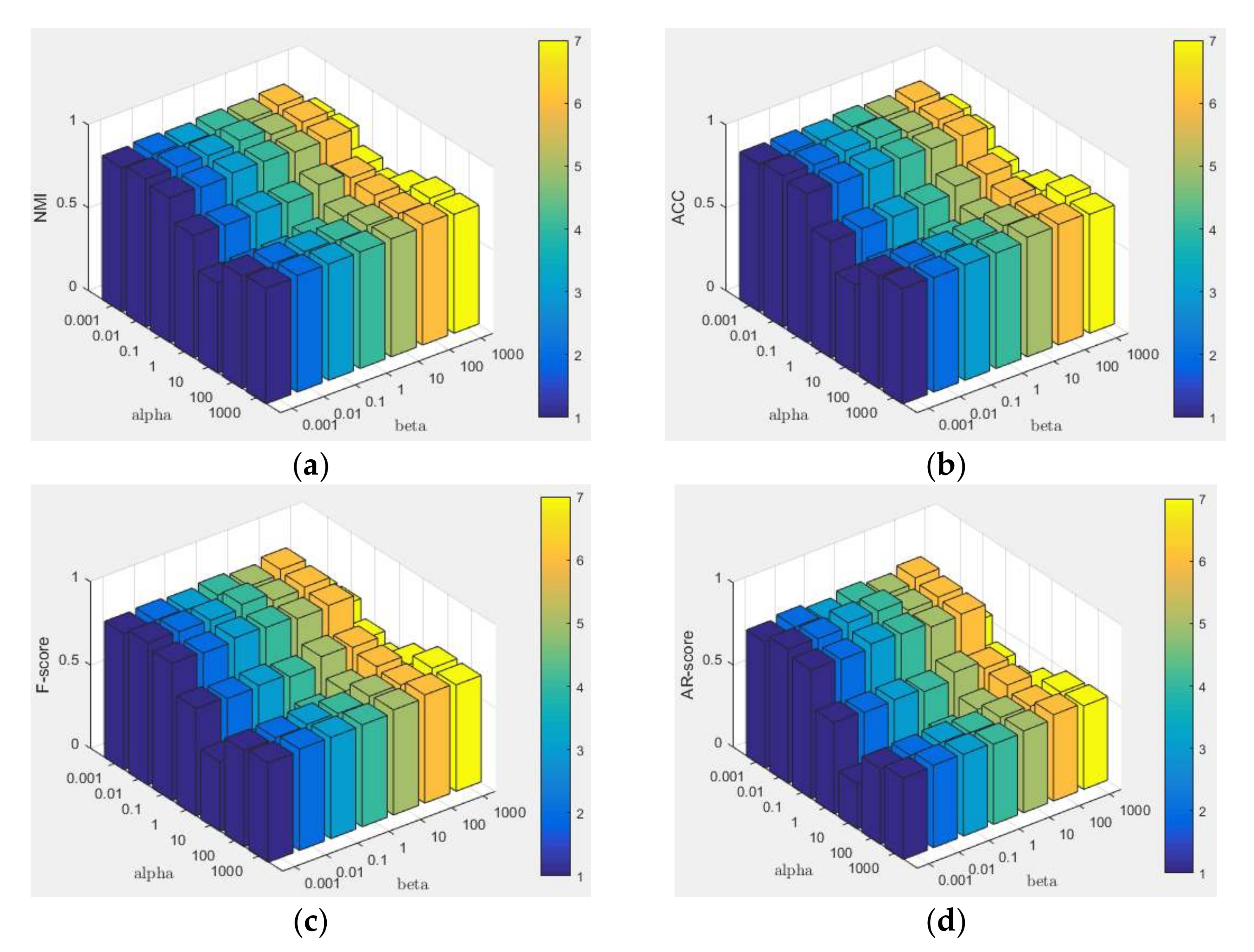
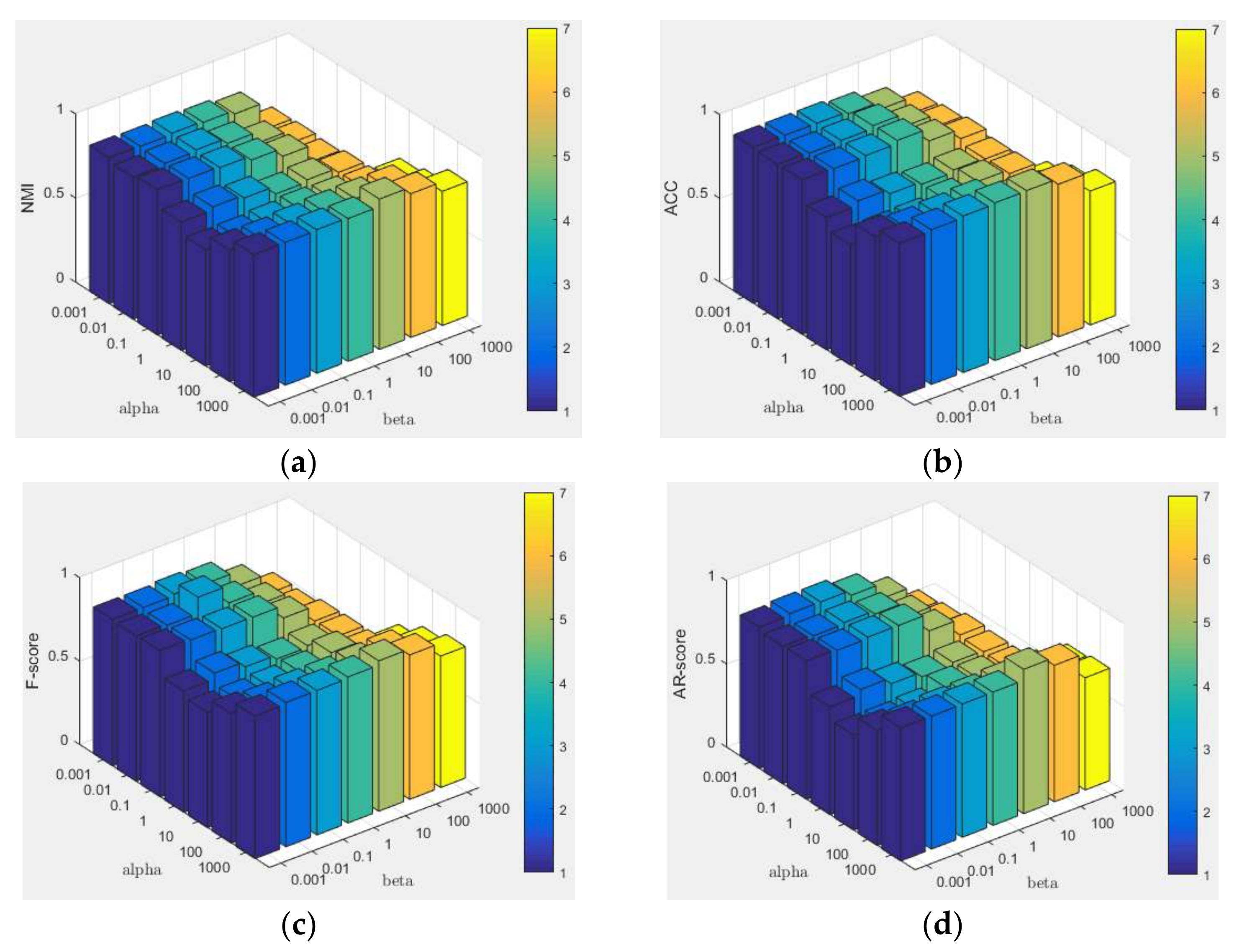

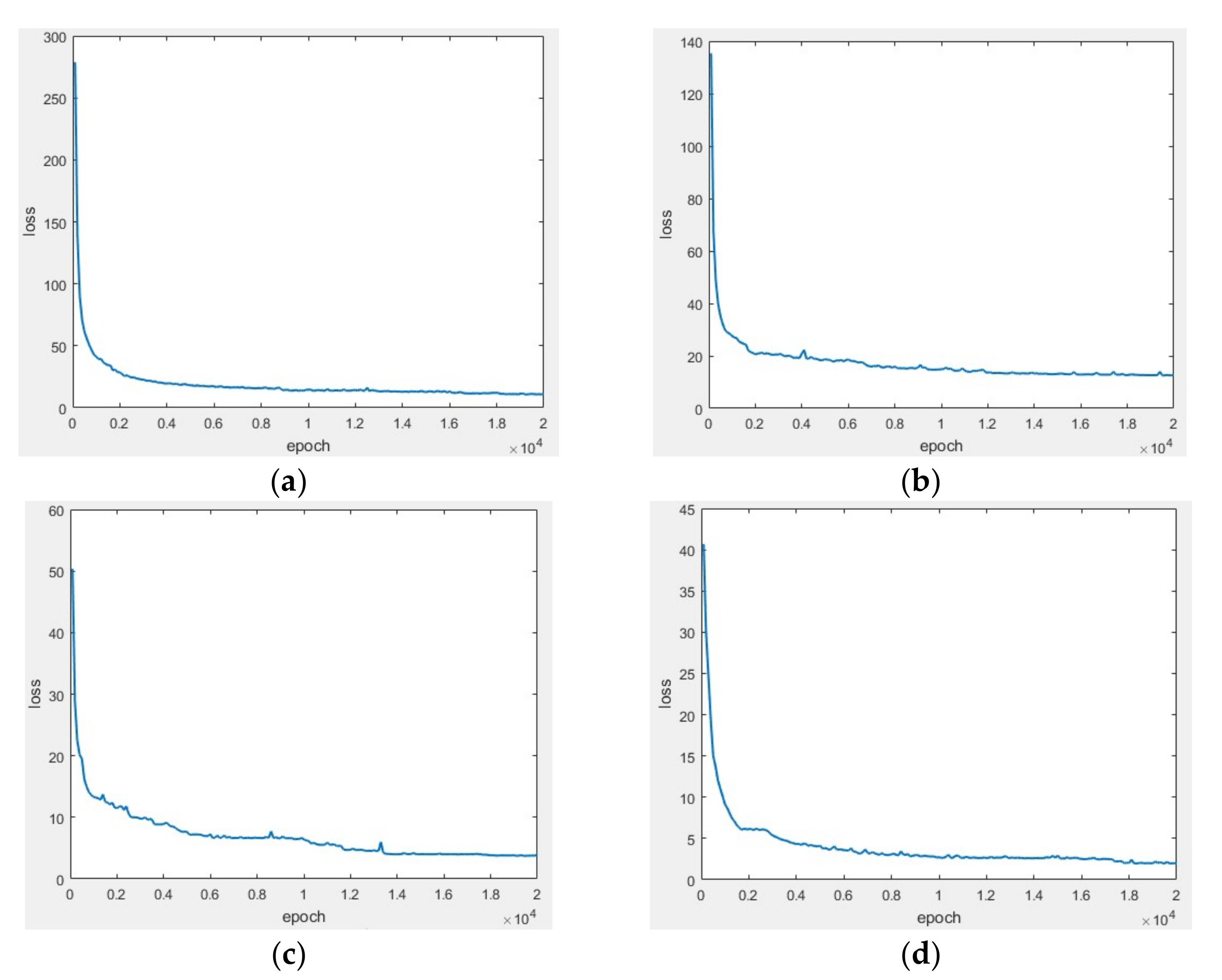
Appendix B.5. Convergence Analysis
References
- Pan, G.; Qi, G.; Wu, Z.; Zhang, D.; Li, S. Land-use classification using taxi gps traces. IEEE Trans. Intell. Transp. Syst. 2013, 14, 113–123. [Google Scholar] [CrossRef]
- Long, Y.; Shen, Z. Discovering functional zones using bus smart card data and points of interest in Beijing. In Geospatial Analysis to Support Urban Planning in Beijing; Long, Y., Shen, Z., Eds.; Springer: Berlin, Germany, 2015; Volume 116, pp. 193–217. [Google Scholar]
- Pei, T.; Sobolevsky, S.; Ratti, C.; Shaw, S.L.; Li, T.; Zhou, C. A new insight into land use classification based on aggregated mobile phone data. Int. J. Geogr. Inf. Sci. 2014, 28, 1988–2007. [Google Scholar] [CrossRef]
- Comito, C.; Pizzuti, C.; Procopio, N. Online clustering for topic detection in social data streams. In Proceedings of the IEEE 28th International Conference on Tools with Artificial Intelligence, San Jose, CA, USA, 6–8 November 2016; pp. 362–369. [Google Scholar]
- Yao, Y.; Li, X.; Liu, X.; Liu, P.; Liang, Z.; Zhang, J.; Mai, K. Sensing spatial distribution of urban land use by integrating points-of-interest and Google Word2Vec model. Int. J. Geogr. Inf. Sci. 2017, 31, 825–848. [Google Scholar] [CrossRef]
- Song, C.; Qu, Z.; Blumm, N.; Barabási, A.L. Limits of predictability in urban mobility. Science 2010, 327, 1018–1021. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, X.; Gao, S.; Gong, L.; Kang, C.; Zhi, Y.; Shi, L. Social Sensing: A new approach to Understanding Our Socioeconomic Environments. Ann. Assoc. Am. Geogr. 2015, 105, 512–530. [Google Scholar] [CrossRef]
- Yin, J.; Dong, J.; Hamm, N.; Li, Z.; Wang, J.; Xing, H.; Fu, P. Integrating remote sensing and geospatial big data for urban land use mapping: A review. Int. J. Appl. Earth. Obs. 2021, 103, 102514. [Google Scholar] [CrossRef]
- Yuan, J.; Zheng, Y.; Xie, X. Discovering regions of different functions in a city using human mobility and POIs. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; pp. 186–194. [Google Scholar]
- Song, C.; Pei, T.; Ma, T.; Du, Y.; Shu, H.; Guo, S.; Fan, Z. Detecting arbitrarily shaped clusters in origin-destination flows using ant colony optimization. Int. J. Geogr. Inf. Sci. 2019, 33, 134–154. [Google Scholar] [CrossRef]
- Zhang, X.; Xu, Y.; Tu, W.; Ratti, C. Do different datasets tell the same story about urban mobility—A comparative study of public transit and taxi usage. J. Transp. Geogr. 2018, 70, 78–90. [Google Scholar] [CrossRef]
- Zhai, W.; Bai, X.; Shi, Y.; Han, Y.; Peng, Z.R.; Gu, C. Beyond Word2vec: An approach for urban functional region extraction and identification by combining Place2vec and POIs. Comput. Environ. Urban Syst. 2019, 74, 1–12. [Google Scholar] [CrossRef]
- Hu, S.; He, Z.; Wu, L.; Yin, L.; Xu, Y.; Cui, H. A framework for extracting urban functional regions based on multiprototype word embeddings using points-of-interest data. Comput. Environ. Urban Syst. 2020, 80, 101442. [Google Scholar] [CrossRef]
- Ye, C.; Zhang, F.; Mu, L.; Gao, Y.; Liu, Y. Urban function recognition by integrating social media and street-level imagery. Environ. Plan. B-Urban Anal. City Sci. 2021, 48, 1430–1444. [Google Scholar] [CrossRef]
- Yue, M.; Kang, C.; Andris, C.; Qin, K.; Liu, Y.; Meng, Q. Understanding the interplay between bus, metro, and cab ridership dynamics in Shenzhen, China. Trans. GIS 2018, 22, 855–871. [Google Scholar] [CrossRef]
- Tu, W.; Zhu, T.; Xia, J.; Zhou, Y.; Lai, Y.; Jiang, J.; Li, Q. Portraying the spatial dynamics of urban vibrancy using multi-source urban big data. Comput. Environ. Urban. Syst. 2020, 80, 101428. [Google Scholar] [CrossRef]
- Liu, J.; Li, J.; Li, W.; Wu, J. Rethinking big data: A review on the data quality and usage issues. ISPRS-J. Photogramm. Remote Sens. 2016, 115, 134–142. [Google Scholar] [CrossRef]
- Zhang, C.; Fu, H.; Hu, Q.; Cao, X.; Xie, Y.; Tao, D.; Xu, D. Generalized Latent Multi-View Subspace Clustering. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 86–99. [Google Scholar] [CrossRef] [PubMed]
- Liu, Q.; Huan, W.; Deng, M.; Zheng, X.; Yuan, H. Inferring Urban Land Use from Multi-Source Urban Mobility Data Using Latent Multi-View Subspace Clustering. ISPRS Int. J. Geo-Inf. 2021, 10, 274. [Google Scholar] [CrossRef]
- Sagiroglu, S.; Sinanc, D. Big Data: A Review. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems, San Diego, CA, USA, 20–24 May 2013; pp. 42–47. [Google Scholar]
- Fan, Y.; He, R.; Hu, B.G. Global and local consistent multi-view subspace clustering. In Proceedings of the Asian Conference on Pattern Recognition (ACPR), Kuala Lumpur, Malaysia, 3–6 November 2015; pp. 564–568. [Google Scholar]
- Zhou, T.; Zhang, C.; Peng, X.; Bhaskar, H.; Yang, J. Dual Shared-Specific Multi-view Subspace Clustering. IEEE T. Cybern. 2019, 50, 3517–3530. [Google Scholar] [CrossRef]
- Zheng, Q.; Zhu, J.; Ma, Y.; Li, Z.; Tian, Z. Multi-view subspace clustering networks with local and global graph information. Neurocomputing 2021, 449, 15–23. [Google Scholar] [CrossRef]
- Tschannen, M.; Bachem, O.; Lucic, M. Recent advances in autoencoder-based representation learning. arXiv 2018, arXiv:1812.05069. [Google Scholar]
- Jarvis, R.A.; Patrick, E.A. Clustering using a similarity measure based on shared near neighbors. IEEE Trans. Comput. 1973, 100, 1025–1034. [Google Scholar] [CrossRef]
- Toole, J.L.; Ulm, M.; González, M.C.; Bauer, D. Inferring land use from mobile phone activity. In Proceedings of the ACM SIGKDD International Workshop on Urban Computing, Beijing, China, 12–16 August 2012; pp. 1–8. [Google Scholar]
- Krishna, K.; Murty, M. Genetic K-means algorithm. IEEE Trans. Syst. Man Cybern. 1999, 29, 433–439. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. In Advances in Neural Information Processing Systems; MIT Press: Vancouver, BC, Canada, 2002; Volume 14, pp. 849–856. [Google Scholar]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining; 1996; Volume 96, pp. 226–231. [Google Scholar]
- Yuan, N.J.; Zheng, Y.; Xie, X.; Wang, Y.; Zheng, K.; Xiong, H. Discovering urban functional zones using latent activity trajectories. IEEE Trans. Knowl. Data Eng. 2015, 27, 712–725. [Google Scholar] [CrossRef]
- Gao, H.; Nie, F.; Li, X.; Huang, H. Multi-view subspace clustering. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; pp. 4238–4246. [Google Scholar]
- Parsons, L.; Haque, E.; Liu, H. Subspace clustering for high dimensional data: A review. Acm Sigkdd Explor. Newsl. 2004, 6, 90–105. [Google Scholar] [CrossRef]
- Vidal, R. Subspace clustering. IEEE Signal. Process. Mag. 2011, 28, 52–68. [Google Scholar] [CrossRef]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 171–184. [Google Scholar] [CrossRef]
- Elhamifar, E.; Vidal, R. Sparse subspace clustering: Algorithm, theory, and applications. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 2765–2781. [Google Scholar] [CrossRef]
- Hu, H.; Lin, Z.; Feng, J.; Zhou, J. Smooth representation clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 24–17 June 2014; pp. 3834–3841. [Google Scholar]
- Li, C. Structured sparse subspace clustering: A joint affinity learning and subspace clustering framework. IEEE Trans. Image Process. 2017, 26, 2988–3001. [Google Scholar] [CrossRef]
- Cao, X.; Zhang, C.; Fu, H.; Liu, S.; Zhang, H. Diversity-induced multi-view subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 586–594. [Google Scholar]
- Luo, S.; Zhang, C.; Zhang, W.; Cao, X. Consistent and specific multi-view subspace clustering. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 3730–3737. [Google Scholar]
- Zhu, P.; Hui, B.; Zhang, C.; Du, D.; Wen, L.; Hu, Q. Multi-view Deep Subspace Clustering Networks. arXiv 2019, arXiv:1908.01978. 2019. [Google Scholar]
- Zhang, C.; Hu, Q.; Fu, H.; Zhu, P.; Cao, X. Latent multi-view subspace clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4279–4287. [Google Scholar]
- Yu, X.; Liu, H.; Wu, Y.; Zhang, C. Intrinsic self-representation for multi-view subspace clustering. Sci. China Inf. Sci. 2021, 51, 1625–1639. [Google Scholar]
- Wang, X.; Liu, H.; Qian, X.; Jiang, Y.; Deng, Z.; Wang, S. Cascaded hidden space feature mapping, fuzzy clustering, and nonlinear switching regression on large datasets. IEEE Trans. Fuzzy Syst. 2018, 26, 640–655. [Google Scholar] [CrossRef]
- Wang, X.; Lei, Z.; Guo, X.; Zhang, C.; Shi, H.; Li, S.Z. Multi-view subspace clustering with intactness-aware similarity. Pattern Recognit. 2019, 88, 50–63. [Google Scholar] [CrossRef]
- Zhu, W.; Lu, J.; Zhou, J. Structured General and Specific Multi-view Subspace Clustering. Pattern Recognit. 2019, 93, 392–403. [Google Scholar] [CrossRef]
- Zheng, Q.; Zhu, J.; Li, Z.; Pang, S.; Wang, J.; Li, Y. Feature concatenation multi-view subspace clustering. Neurocomputing 2020, 379, 89–102. [Google Scholar] [CrossRef] [Green Version]
- Xia, S.; Xiong, Z.; Luo, Y.; Zhang, G. Effectiveness of the Euclidean distance in high dimensional spaces. Optik 2015, 126, 5614–5619. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, W.; Deng, M.; Cai, J.; Liu, Y. An adaptive detection of multilevel co-location patterns based on natural neighborhoods. Int. J. Geogr. Inf. Sci. 2021, 35, 556–581. [Google Scholar] [CrossRef]
- Wang, Q.; Cheng, J.; Gao, Q.; Zhao, G.; Jiao, L. Deep multi-view subspace clustering with unified and discriminative learning. IEEE Trans. Multimed. 2020, 23, 3483–3493. [Google Scholar] [CrossRef]
- Comito, C.; Talia, D. GDIS: A service-based architecture for data integration on Grids. In On the Move to Meaningful Internet Systems 2004: OTM 2004 Workshops; Meersman, R., Tari, Z., Corsaro, A., Eds.; OTM 2004. Lecture Notes in Computer Science; Springer: Berlin, Heidelberg, 2004; Volume 3292. [Google Scholar]
- Lee, J.; Kang, M. Geospatial big data: Challenges and opportunities. Big Data Res. 2015, 2, 74–81. [Google Scholar] [CrossRef]
- Liu, X.; Tian, Y.; Zhang, X.; Wan, Z. Identification of urban functional regions in chengdu based on taxi trajectory time series data. ISPRS Int. J. Geo-Inf. 2020, 9, 158. [Google Scholar] [CrossRef]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 9–12 December 2013; p. 26. [Google Scholar]
- Lau, J.; Baldwin, T. An empirical evaluation of doc2vec with practical insights into document embedding generation. arXiv 2016, arXiv:1607.05368. [Google Scholar]
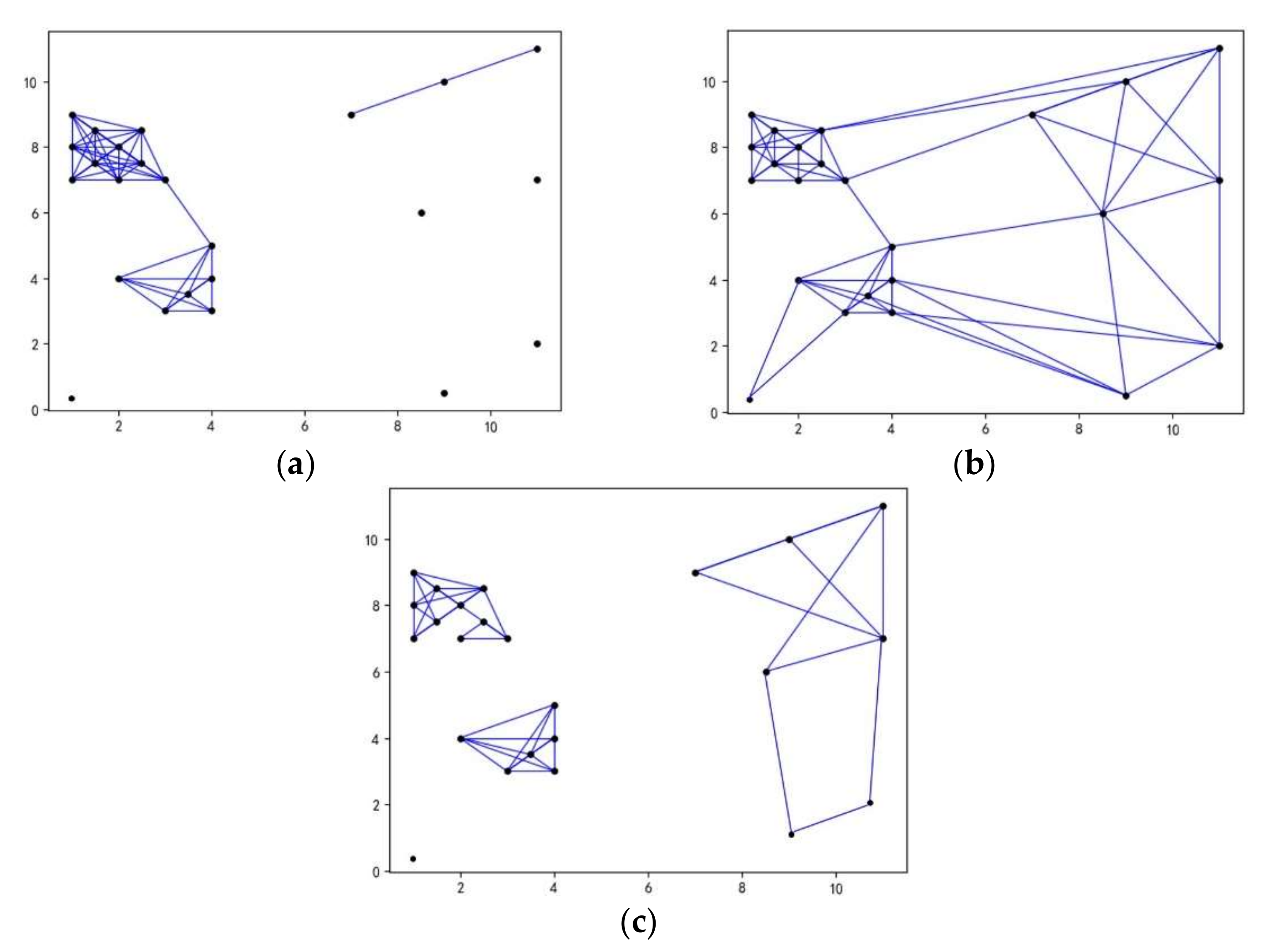
- Ertöz, L.; Steinbach, M.; Kumar, V. Finding clusters of different sizes, shapes, and densities in noisy, high dimensional data. In Proceedings of the 2003 SIAM International Conference on Data mining, Society for Industrial and Applied Mathematics, San Francisco, CA, USA, 1–3 May 2003; pp. 47–58. [Google Scholar]
- Tan, P.N.; Steinbach, M.; Karpatne, A.; Kumar, V. Introduction to Data Mining; Pearson Education: London, UK, 2006; pp. 622–630. [Google Scholar]
- Liu, Q.; Deng, M.; Bi, J.; Yang, W. A novel method for discovering spatio-temporal clusters of different sizes, shapes, and densities in the presence of noise. Int. J. Digit. Earth 2014, 7, 138–157. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]
- Martínez, L.; Viegas, J.; Silva, E. A traffic analysis zone definition: A new methodology and algorithm. Transportation 2009, 36, 581–599. [Google Scholar] [CrossRef]
- Yang, B.; Tian, Y.; Wang, J.; Hu, X.; An, S. How to improve urban transportation planning in big data era? A practice in the study of traffic analysis zone delineation. Transp. Policy 2022, 127, 1–14. [Google Scholar] [CrossRef]
- Cherry, J.M.; Adler, C.; Ball, C.; Chervitz, S.A.; Dwight, S.S.; Hester, E.T.; Botstein, D. SGD: Saccharomyces genome database. Nucleic Acids Res. 1998, 26, 73–79. [Google Scholar] [CrossRef]
- Xia, R.; Pan, Y.; Du, L.; Yin, J. Robust multi-view spectral clustering via low-rank and sparse decomposition. In Proceedings of the AAAI Conference on Artificial Intelligence, Québec, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]


| Notations | Meaning |
|---|---|
| The number of pick-ups in the hour on weekdays | |
| The number of pick-ups in the hour on weekends | |
| The number of drop-offs in the hour on weekdays | |
| The number of drop-offs in the hour on weekends | |
| k nearest neighbors of | |
| The number of data points | |
| The number of views | |
| The adjacency matrix of the view | |
| W | The unified adjacency matrix |
| The shared nearest neighbor similarity between point and point | |
| A multi-view dataset | |
| Feature matrix of the view | |
| Output of the decoder network of the view | |
| The dimension of the feature matrix in the view | |
| Latent representation of the view | |
| Combination of weights and bias in the layer of the view | |
| The total number of layers in autoencoder networks | |
| Output of the layer of the autoencoder in the view | |
| The weight of the layer of the autoencoder in the view | |
| The bias of the layer of the autoencoder in the view | |
| Shared subspace representation matrix | |
| The subspace representation of point | |
| Diagonal matrix | |
| Similarity matrix | |
| trade-off parameters | |
| The number of traffic analysis zones | |
| I | Indicator function |
| FD | Frequency density |
| CR | Category rate |
| C1 | C2 | C3 | C4 | C5 | C6 | C7 | C8 | C9 | C10 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| POI | FD | CR | FD | CR | FD | CR | FD | CR | FD | CR | FD | CR | FD | CR | FD | CR | FD | CR | FD | CR |
| Tourist attraction | 7.40 | 2.36% | 0.98 | 0.15% | 1.52 | 0.18% | 1.35 | 0.16% | 0.48 | 0.07% | 0.71 | 0.24% | 0.02 | 0.00% | 0.20 | 0.15% | 0.23 | 0.06% | 0.09 | 0.01% |
| Scenic spots | 13.73 | 4.39% | 1.63 | 0.24% | 1.88 | 0.22% | 2.42 | 0.28% | 1.23 | 0.17% | 1.16 | 0.40% | 0.95 | 0.20% | 0.49 | 0.38% | 5.41 | 1.30% | 0.22 | 0.03% |
| Hot place name | 0.19 | 0.06% | 0.01 | 0.00% | 0.02 | 0.00% | 0.01 | 0.00% | 0.04 | 0.01% | 0.00 | 0.00% | 0.04 | 0.01% | 0.00 | 0.00% | 0.01 | 0.00% | 0.01 | 0.00% |
| Cultural relics | 0.09 | 0.03% | 0.01 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.01 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% |
| Company/enterprise | 27.94 | 8.92% | 81.01 | 12.14% | 125.66 | 14.97% | 80.48 | 9.35% | 26.20 | 3.64% | 156.95 | 53.62% | 49.82 | 10.46% | 18.48 | 14.17% | 7.65 | 1.85% | 62.20 | 7.54% |
| Building | 1.65 | 0.53% | 4.20 | 0.63% | 5.75 | 0.69% | 5.79 | 0.67% | 1.70 | 0.24% | 7.17 | 2.45% | 1.67 | 0.35% | 0.36 | 0.28% | 2.10 | 0.51% | 0.60 | 0.07% |
| Shopping | 59.43 | 18.98% | 123.68 | 18.54% | 205.46 | 24.48% | 137.73 | 15.99% | 132.65 | 18.42% | 138.59 | 47.35% | 44.75 | 9.39% | 20.11 | 15.42% | 70.44 | 16.99% | 92.94 | 11.27% |
| Shopping mall | 0.97 | 0.31% | 7.67 | 1.15% | 6.39 | 0.76% | 4.34 | 0.50% | 2.98 | 0.41% | 2.20 | 0.75% | 0.99 | 0.21% | 0.13 | 0.10% | 1.75 | 0.42% | 0.40 | 0.05% |
| Theater | 0.25 | 0.08% | 1.32 | 0.20% | 1.82 | 0.22% | 0.97 | 0.11% | 0.82 | 0.11% | 1.72 | 0.59% | 0.36 | 0.08% | 0.07 | 0.05% | 2.32 | 0.56% | 0.60 | 0.07% |
| Accommodation | 6.93 | 2.21% | 7.63 | 1.14% | 36.71 | 4.37% | 23.21 | 2.69% | 16.73 | 2.32% | 20.95 | 7.16% | 8.52 | 1.79% | 2.40 | 1.84% | 12.96 | 3.13% | 2.10 | 0.25% |
| Catering service | 87.58 | 16.74% | 186.14 | 22.18% | 87.27 | 18.31% | 44.23 | 15.11% | 23.97 | 18.39% | 142.00 | 21.29% | 91.38 | 18.90% | 67.64 | 21.60% | 96.67 | 23.32% | 75.39 | 22.57% |
| Hotel | 21.43 | 2.49% | 28.19 | 3.36% | 12.53 | 2.63% | 6.42 | 2.19% | 3.45 | 2.65% | 20.26 | 3.04% | 13.77 | 1.46% | 9.24 | 2.95% | 15.76 | 3.80% | 16.60 | 2.12% |
| Dwelling | 14.67 | 4.68% | 10.69 | 1.60% | 51.81 | 6.17% | 35.75 | 4.15% | 34.62 | 4.81% | 41.76 | 14.27% | 3.70 | 0.78% | 4.88 | 3.74% | 20.06 | 4.84% | 4.15 | 0.50% |
| Courier service | 1.37 | 0.44% | 2.49 | 0.37% | 6.01 | 0.72% | 4.50 | 0.52% | 2.24 | 0.31% | 3.95 | 1.35% | 2.84 | 0.60% | 1.35 | 1.03% | 0.88 | 0.21% | 2.88 | 0.35% |
| Living service | 57.59 | 18.39% | 62.10 | 9.31% | 290.73 | 34.64% | 135.26 | 15.71% | 126.32 | 17.54% | 141.91 | 48.49% | 63.49 | 13.32% | 17.95 | 13.77% | 59.67 | 14.40% | 13.87 | 1.68% |
| Hair dressing | 15.98 | 5.10% | 29.12 | 4.37% | 80.77 | 9.62% | 29.77 | 3.46% | 34.72 | 4.82% | 37.33 | 12.75% | 18.77 | 3.94% | 3.27 | 2.51% | 13.86 | 3.34% | 13.97 | 1.69% |
| Health care treatment | 8.15 | 2.60% | 7.96 | 1.19% | 29.38 | 3.50% | 16.36 | 1.90% | 15.60 | 2.17% | 19.17 | 6.55% | 10.67 | 2.24% | 2.78 | 2.13% | 9.84 | 2.37% | 17.10 | 2.07% |
| Bank | 2.62 | 0.84% | 6.22 | 0.93% | 14.53 | 1.73% | 11.83 | 1.37% | 7.47 | 1.04% | 8.15 | 2.79% | 3.16 | 0.66% | 0.74 | 0.57% | 4.02 | 0.97% | 2.15 | 0.26% |
| Courier service | 5.09 | 1.62% | 7.42 | 1.11% | 14.95 | 1.78% | 8.75 | 1.02% | 8.15 | 1.13% | 3.44 | 1.17% | 6.35 | 1.33% | 2.14 | 1.64% | 5.60 | 1.35% | 4.74 | 0.57% |
| Moving company | 1.09 | 0.35% | 0.75 | 0.11% | 2.24 | 0.27% | 3.71 | 0.43% | 1.18 | 0.16% | 2.14 | 0.73% | 1.01 | 0.21% | 0.36 | 0.28% | 1.04 | 0.25% | 0.22 | 0.03% |
| Intermediary agency | 3.25 | 1.04% | 3.63 | 0.54% | 5.34 | 0.64% | 9.19 | 1.07% | 2.60 | 0.36% | 1.52 | 0.52% | 0.36 | 0.08% | 0.29 | 0.22% | 2.04 | 0.49% | 0.40 | 0.05% |
| Doorplate | 9.86 | 3.15% | 6.36 | 0.95% | 10.58 | 1.26% | 10.97 | 1.27% | 12.11 | 1.68% | 9.27 | 3.17% | 8.77 | 1.84% | 4.02 | 3.08% | 5.97 | 1.44% | 8.59 | 1.04% |
| Recreation place | 2.78 | 0.89% | 4.75 | 0.71% | 6.66 | 0.79% | 6.38 | 0.74% | 8.69 | 1.21% | 1.52 | 0.52% | 3.16 | 0.66% | 0.94 | 0.72% | 3.22 | 0.78% | 11.28 | 1.37% |
| Clothing factory | 11.30 | 3.61% | 20.14 | 3.02% | 68.46 | 8.16% | 28.60 | 3.32% | 28.80 | 4.00% | 4.97 | 1.70% | 42.39 | 8.90% | 1.14 | 0.87% | 15.03 | 3.63% | 5.18 | 0.63% |
| Industry | 1.25 | 0.40% | 0.59 | 0.09% | 0.67 | 0.08% | 0.33 | 0.04% | 0.33 | 0.05% | 1.05 | 0.36% | 1.84 | 0.39% | 0.45 | 0.35% | 0.39 | 0.09% | 0.33 | 0.04% |
| Educational service | 12.30 | 3.93% | 30.58 | 4.58% | 43.57 | 5.19% | 43.12 | 5.01% | 31.33 | 4.35% | 7.38 | 2.52% | 15.07 | 3.16% | 21.47 | 16.46% | 22.66 | 5.47% | 8.12 | 0.98% |
| Scientific institution | 4.28 | 1.37% | 3.27 | 0.49% | 8.54 | 1.02% | 7.16 | 0.83% | 4.61 | 0.64% | 2.19 | 0.75% | 1.29 | 0.27% | 4.63 | 3.55% | 1.81 | 0.44% | 1.17 | 0.14% |
| Sports leisure service | 9.24 | 2.95% | 20.26 | 3.04% | 28.19 | 3.36% | 23.77 | 2.76% | 26.60 | 3.69% | 6.42 | 2.19% | 12.53 | 2.63% | 3.45 | 2.65% | 15.76 | 3.80% | 3.32 | 0.40% |
| Natural place name | 0.00 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.00 | 0.00% | 0.10 | 0.02% | 0.00 | 0.00% |
| Road ancillary facility | 2.12 | 0.68% | 2.76 | 0.41% | 3.94 | 0.47% | 4.10 | 0.48% | 3.72 | 0.52% | 1.34 | 0.46% | 1.73 | 0.36% | 1.05 | 0.80% | 5.25 | 1.27% | 11.13 | 1.35% |
| Sinopec | 0.19 | 0.06% | 0.06 | 0.01% | 0.02 | 0.00% | 0.07 | 0.01% | 0.06 | 0.01% | 0.26 | 0.09% | 0.02 | 0.00% | 0.05 | 0.04% | 0.17 | 0.04% | 0.20 | 0.02% |
| Gas station | 0.28 | 0.09% | 0.34 | 0.05% | 0.05 | 0.01% | 0.31 | 0.04% | 0.37 | 0.05% | 0.60 | 0.21% | 0.35 | 0.07% | 0.25 | 0.19% | 0.28 | 0.07% | 0.58 | 0.07% |
| Long-distance bus | 0.00 | 0.00% | 0.01 | 0.00% | 0.03 | 0.00% | 0.05 | 0.01% | 0.03 | 0.00% | 0.02 | 0.01% | 0.05 | 0.01% | 0.01 | 0.01% | 0.04 | 0.01% | 0.06 | 0.01% |
| Railway station | 0.00 | 0.00% | 0.04 | 0.01% | 0.05 | 0.01% | 0.01 | 0.00% | 0.06 | 0.01% | 0.05 | 0.02% | 0.02 | 0.00% | 0.02 | 0.01% | 0.10 | 0.02% | 0.20 | 0.02% |
| Methods | Single-View Method (Taxi) | Single-View Method (Bus) | Single-View Method (POI) | Weighted Average Method | gLMSC | agc2msc |
|---|---|---|---|---|---|---|
| Overall accuracy | 44.53% | 45.93% | 50.95% | 53.15% | 64.82% | 68.11% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Q.; Huan, W.; Deng, M. A Method with Adaptive Graphs to Constrain Multi-View Subspace Clustering of Geospatial Big Data from Multiple Sources. Remote Sens. 2022, 14, 4394. https://doi.org/10.3390/rs14174394
Liu Q, Huan W, Deng M. A Method with Adaptive Graphs to Constrain Multi-View Subspace Clustering of Geospatial Big Data from Multiple Sources. Remote Sensing. 2022; 14(17):4394. https://doi.org/10.3390/rs14174394
Chicago/Turabian StyleLiu, Qiliang, Weihua Huan, and Min Deng. 2022. "A Method with Adaptive Graphs to Constrain Multi-View Subspace Clustering of Geospatial Big Data from Multiple Sources" Remote Sensing 14, no. 17: 4394. https://doi.org/10.3390/rs14174394
APA StyleLiu, Q., Huan, W., & Deng, M. (2022). A Method with Adaptive Graphs to Constrain Multi-View Subspace Clustering of Geospatial Big Data from Multiple Sources. Remote Sensing, 14(17), 4394. https://doi.org/10.3390/rs14174394