
Fast Tree Detection and Counting on UAVs for Sequential Aerial Images with Generating Orthophoto Mosaicing


 , ,
, ,  ,
,
Abstract
:1. Introduction
- A novel efficient tree detection and counting framework for UAVs: Compared to the current tree counting pipeline, our method provides a real-time solution for detection tasks with UAVs. High-quality mosaicing is efficiently generated with less calculations; detection and counting task is completed with fast annotation, training and inference analysis pipelines.
- A multiplanar hypothesis-based online pose optimization: A multiplanar hypothesis-based pose optimization method is proposed to estimate camera poses and generate mosaicing simultaneously. The number of parameters about reprojection error is effectively reduced; the method could accelerate the calculation speed and achieve robust stitching performance with sequential low overlap images in the embedded devices.
- Point-supervised-based attention detection framework: A point supervised method could not only estimate the localization of trees but also generate a contour mask that is comparable to full supervised methods. The supervised label information is easy to be obtained, which could be effective for entire learning framework.
- An embedded system with a proposed algorithm on UAVs: An embedded fully automatic system is embedded into the UAV for completing integrated stitching and tree counting tasks; the whole procedure requires no human intervention at all. In addition, buildings or trees could have a greater negative impact on the communication link between the UAV and a ground station; the embedded system could ignore this negative effects and improve work efficiency.
2. Related Work
2.1. Image Mosaicing
2.2. Tree Counting
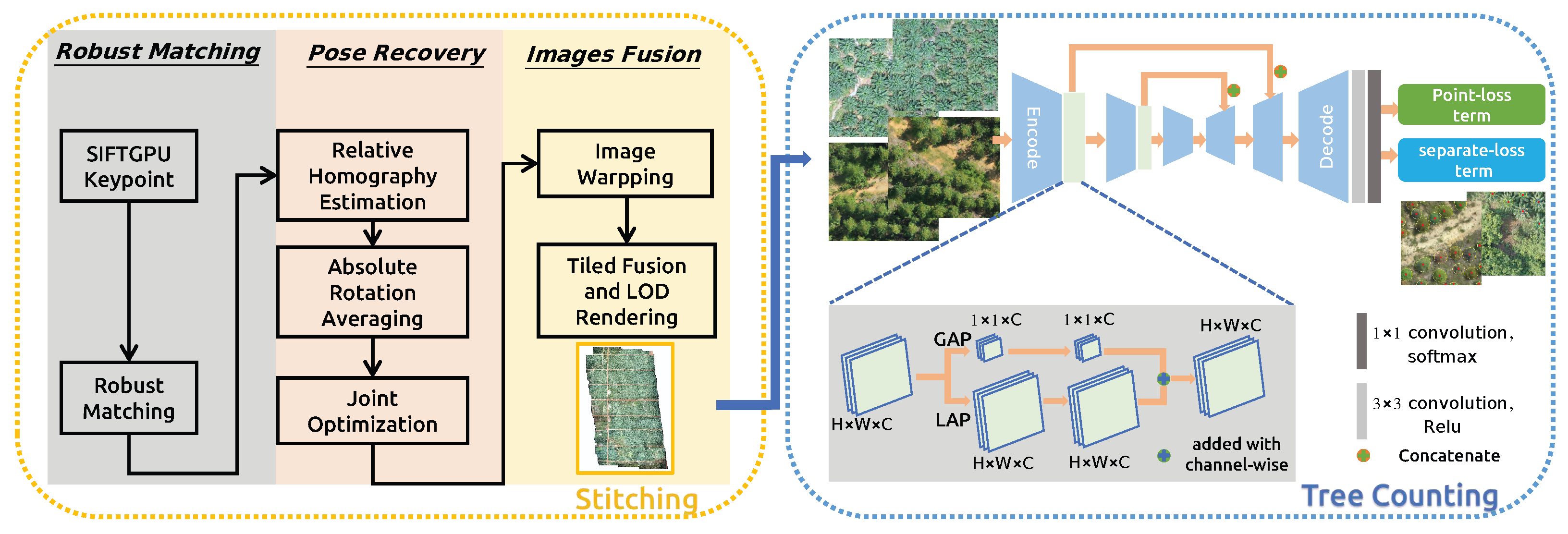
3. Methodology
3.1. Overview
3.2. Real Time Generating Orthophoto Mosaicing
3.2.1. Keypoint Detection and Matching
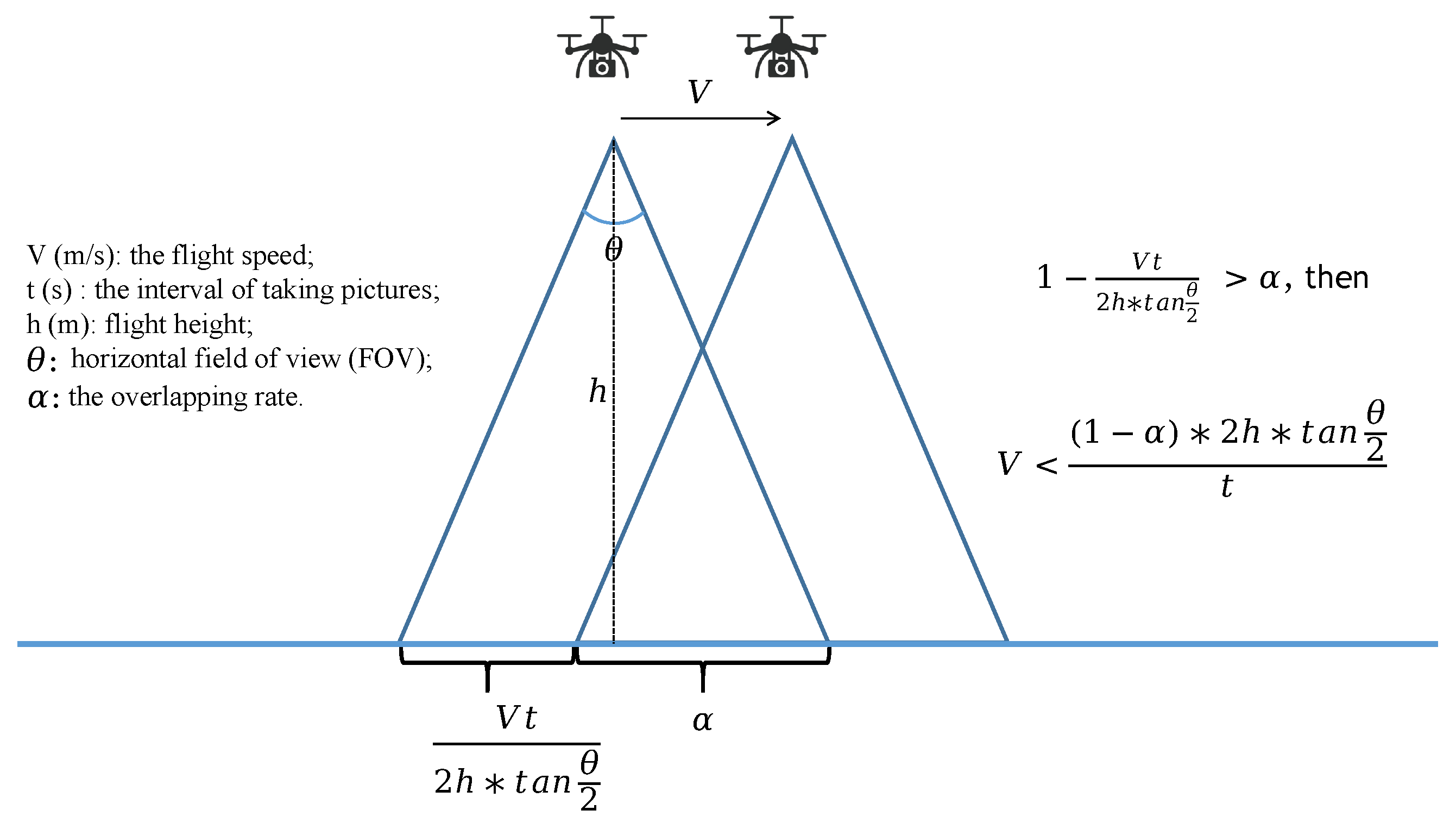
3.2.2. Online Planar Restricted Pose Recovery
3.2.3. Georeferenced Images Fusion with Tiling and LoD
3.3. Weakly Supervised Attention Counting Tree Network
3.3.1. Attention Based Tree Feature Extractor Network
3.3.2. Point Supervised Loss Function
3.4. Application with Fast Orthophoto Mosaicing and Tree Counting
4. Experiments
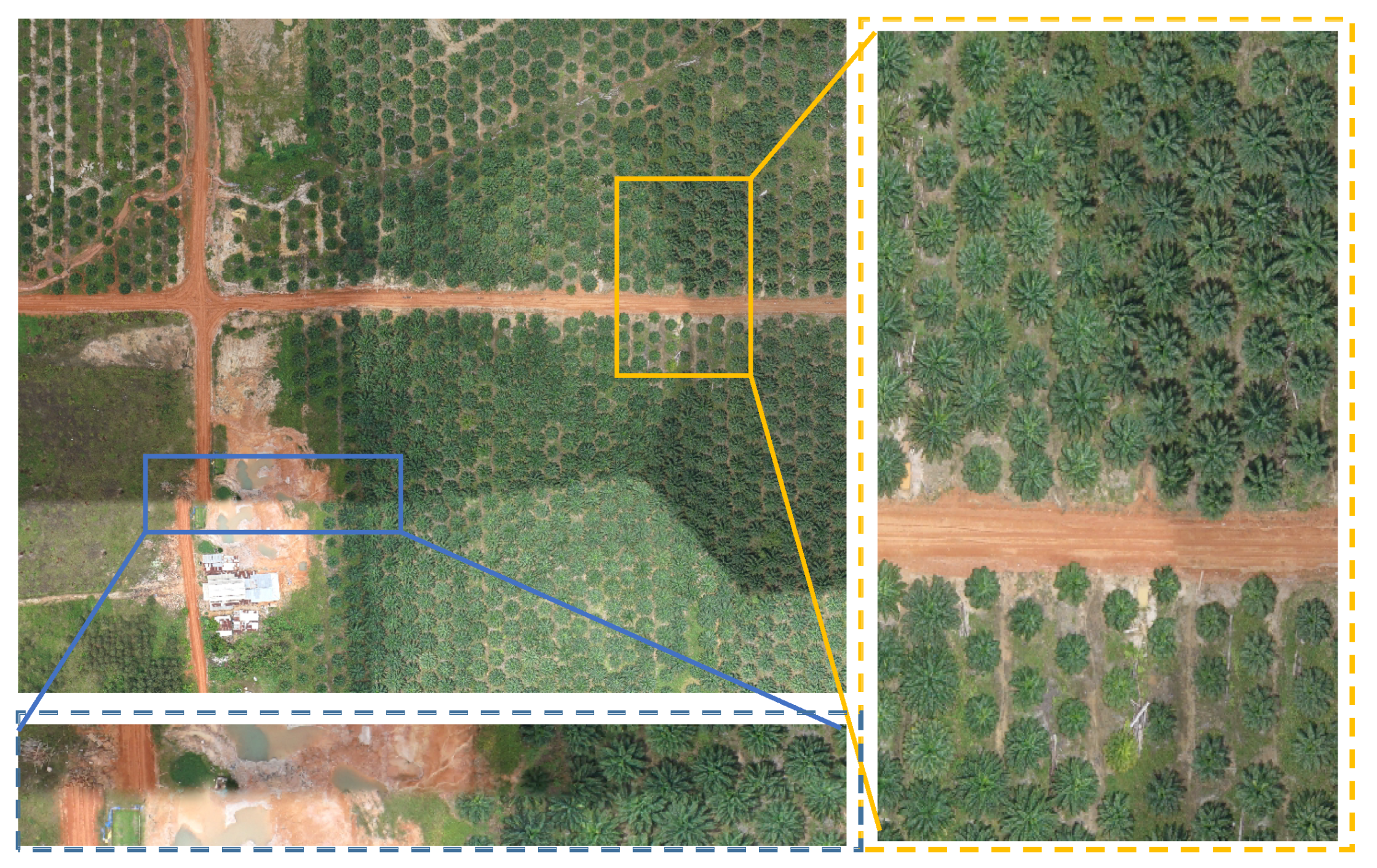
4.1. Results of Generating Orthophoto Mosaicing and DOM Quality Comparison
4.1.1. Comparision Experiments
4.1.2. Computation Performance Analysis
4.1.3. Discussion of the Potential Uncertainties
4.2. Results of Point Supervised Tree Detection
4.2.1. Evaluation Metric
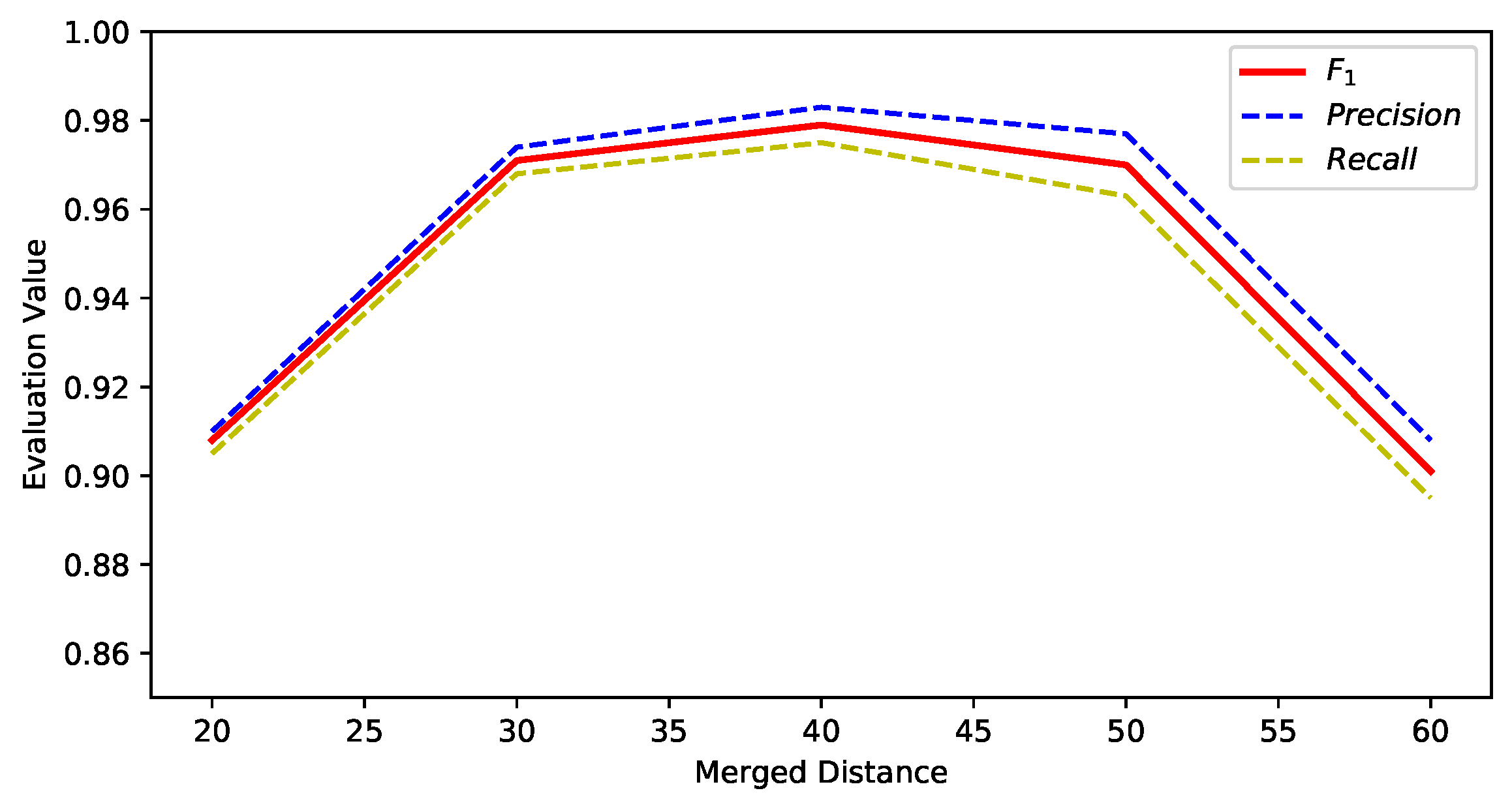
4.2.2. Merged Distance Parameter Setting
4.2.3. Comparision Experiments
4.2.4. Ablation Study
4.2.5. Time Statistics
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Fu, H.; Yu, L.; Cracknell, A. Deep learning-based oil palm tree detection and counting for high-resolution remote sensing images. Remote Sens. 2017, 9, 22. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; Dong, R.; Fu, H.; Yu, L. Large-scale oil palm tree detection from high-resolution satellite images using two-stage convolutional neural networks. Remote Sens. 2019, 11, 11. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; He, C.; Fu, H.; Zheng, J.; Dong, R.; Xia, M.; Yu, L.; Luk, W. A real-time tree crown detection approach for large-scale remote sensing images on FPGAs. Remote Sens. 2019, 11, 1025. [Google Scholar] [CrossRef] [Green Version]
- Bhattacharyya, R.; Bhattacharyya, A. Crown Detection and Counting Using Satellite Images. In Emerging Technology in Modelling and Graphics; Springer: Berlin/Heidelberg, Germany, 2020; pp. 765–773. [Google Scholar]
- Zheng, J.; Fu, H.; Li, W.; Wu, W.; Yu, L.; Yuan, S.; Tao, W.Y.W.; Pang, T.K.; Kanniah, K.D. Growing status observation for oil palm trees using Unmanned Aerial Vehicle (UAV) images. ISPRS J. Photogramm. Remote Sens. 2021, 173, 95–121. [Google Scholar] [CrossRef]
- Vallet, J.; Panissod, F.; Strecha, C.; Tracol, M. Photogrammetric Performance of an Ultra Light Weight Swinglet UAV. ISPRS-Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2011, 3822, 253–258. [Google Scholar]
- Verhoeven, G. Taking computer vision aloft—Archaeological three-dimensional reconstructions from aerial photographs with photoscan. Archaeol. Prospect. 2011, 18, 67–73. [Google Scholar] [CrossRef]
- Zhao, Y.; Liu, G.; Xu, S.; Bu, S.; Jiang, H.; Wan, G. Fast Georeferenced Aerial Image Stitching With Absolute Rotation Averaging and Planar-Restricted Pose Graph. IEEE Trans. Geosci. Remote. Sens. 2020, 59, 3502–3517. [Google Scholar] [CrossRef]
- Bu, S.; Zhao, Y.; Wan, G.; Liu, Z. Map2dfusion: Real-time incremental UAV image mosaicing-based on monocular slam. In Proceedings of the 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Daejeon, Korea, 9–14 October 2016; pp. 4564–4571. [Google Scholar]
- Botterill, T.; Mills, S.; Green, R. Real-time aerial image mosaicing. In Proceedings of the 2010 25th International Conference of Image and Vision Computing New Zealand, Queenstown, New Zealand, 8–9 November 2010; pp. 1–8. [Google Scholar]
- de Souza, R.H.C.; Okutomi, M.; Torii, A. Real-time image mosaicing using non-rigid registration. In Pacific-Rim Symposium on Image and Video Technology; Springer: Berlin/Heidelberg, Germany, 2011; pp. 311–322. [Google Scholar]
- Schönberger, J.L.; Frahm, J.M. Structure-from-Motion Revisited. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Snavely, N. Bundler: Structure from Motion (SFM) for Unordered Image Collections. 2008. Available online: http://phototour.cs.washington.edu/bundler/ (accessed on 3 January 2022).
- Mur-Artal, R.; Montiel, J.; Tardos, J.D. ORB-SLAM: A Versatile and Accurate Monocular SLAM System. arXiv 2015, arXiv:1502.00956. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. Orb-slam2: An open-source slam system for monocular, stereo, and rgb-d cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 611–625. [Google Scholar] [CrossRef]
- Forster, C.; Zhang, Z.; Gassner, M.; Werlberger, M.; Scaramuzza, D. Svo: Semidirect visual odometry for monocular and multicamera systems. IEEE Trans. Robot. 2017, 33, 249–265. [Google Scholar] [CrossRef] [Green Version]
- Moulon, P.; Monasse, P.; Marlet, R. Global fusion of relative motions for robust, accurate and scalable structure from motion. In Proceedings of the 2013 IEEE International Conference on Computer Vision (ICCV), Sydney, Australia, 1–8 December2013; pp. 3248–3255. [Google Scholar]
- Sweeney, C. Theia Multiview Geometry Library: Tutorial & Reference. Available online: http://theia-sfm.org (accessed on 10 January 2022).
- Aliero, M.M.; Mukhtar, N.; Al-Doksi, J. The usefulness of unmanned airborne vehicle (UAV) imagery for automated palm oil tree counting. J. For. Res. 2014, 1, 1–12. [Google Scholar]
- Wang, Y.; Zhu, X.; Wu, B. Automatic detection of individual oil palm trees from UAV images using HOG features and an SVM classifier. Int. J. Remote Sens. 2019, 40, 7356–7370. [Google Scholar] [CrossRef]
- Soula, A.; Tbarki, K.; Ksantini, R.; Said, S.B.; Lachiri, Z. A novel incremental Kernel Nonparametric SVM model (iKN-SVM) for data classification: An application to face detection. Eng. Appl. Artif. Intell. 2020, 89, 103468. [Google Scholar] [CrossRef]
- Gao, L.; Li, J.; Khodadadzadeh, M.; Plaza, A.; Zhang, B.; He, Z.; Yan, H. Subspace-based support vector machines for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2014, 12, 349–353. [Google Scholar]
- Puissant, A.; Rougier, S.; Stumpf, A. Object-oriented mapping of urban trees using Random Forest classifiers. Int. J. Appl. Earth Obs. Geoinf. 2014, 26, 235–245. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision & Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Fernández-Sanjurjo, M.; Bosquet, B.; Mucientes, M.; Brea, V.M. Real-time visual detection and tracking system for traffic monitoring. Eng. Appl. Artif. Intell. 2019, 85, 410–420. [Google Scholar] [CrossRef]
- Tan, J. Complex object detection using deep proposal mechanism. Eng. Appl. Artif. Intell. 2020, 87, 103234. [Google Scholar] [CrossRef]
- Kwasniewska, A.; Ruminski, J.; Szankin, M.; Kaczmarek, M. Super-resolved thermal imagery for high-accuracy facial areas detection and analysis. Eng. Appl. Artif. Intell. 2020, 87, 103263. [Google Scholar] [CrossRef]
- Wei, X.; Yang, Z.; Liu, Y.; Wei, D.; Jia, L.; Li, Y. Railway track fastener defect detection-based on image processing and deep learning techniques: A comparative study. Eng. Appl. Artif. Intell. 2019, 80, 66–81. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2015, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep Learning Classification of Land Cover and Crop Types Using Remote Sensing Data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep Learning in Agriculture: A Survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Liu, Q.; Xiang, X.; Wang, Y.; Luo, Z.; Fang, F. Aircraft detection in remote sensing image-based on corner clustering and deep learning. Eng. Appl. Artif. Intell. 2020, 87, 103333. [Google Scholar] [CrossRef]
- Sarabia, R.; Aquino, A.; Ponce, J.M.; López, G.; Andújar, J.M. Automated Identification of Crop Tree Crowns From UAV Multispectral Imagery by Means of Morphological Image Analysis. Remote Sens. 2020, 12, 748. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Wang, L.; Jiang, K.; Xue, L.; An, F.; Chen, B.; Yun, T. Individual tree crown segmentation-based on aerial image using superpixel and topological features. J. Appl. Remote Sens. 2020, 14, 022210. [Google Scholar] [CrossRef]
- Liu, T.; Abdelrahman, A.; Morton, J.; Wilhelm, V.L. Comparing fully convolutional networks, random forest, support vector machine, and patch-based deep convolutional neural networks for object-based wetland mapping using images from small unmanned aircraft system. Giscience Remote Sens. 2018, 55, 243–264. [Google Scholar] [CrossRef]
- Chen, S.W.; Shivakumar, S.S.; Dcunha, S.; Das, J.; Okon, E.; Qu, C.; Taylor, C.J.; Kumar, V. Counting Apples and Oranges With Deep Learning: A Data-Driven Approach. IEEE Robot. Autom. Lett. 2017, 2, 781–788. [Google Scholar] [CrossRef]
- Wang, Z.; Underwood, J.; Walsh, K.B. Machine vision assessment of mango orchard flowering. Comput. Electron. Agric. 2018, 151, 501–511. [Google Scholar] [CrossRef]
- Liu, J.; Gao, C.; Meng, D.; Hauptmann, A.G. Decidenet: Counting varying density crowds through attention guided detection and density estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Ren, S.; Girshick, R.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Freudenberg, M.; Nölke, N.; Agostini, A.; Urban, K.; Wörgötter, F.; Kleinn, C. Large Scale Palm Tree Detection In High Resolution Satellite Images Using U-Net. Remote. Sens. 2019, 11, 312. [Google Scholar] [CrossRef] [Green Version]
- Zhao, T.; Yang, Y.; Niu, H.; Wang, D.; Chen, Y. Comparing U-Net convolutional network with mask R-CNN in the performances of pomegranate tree canopy segmentation. In Multispectral, Hyperspectral, and Ultraspectral Remote Sensing Technology, Techniques and Applications VII; International Society for Optics and Photonics: Bellingham, WA, USA, 2018; Volume 10780, p. 107801J. [Google Scholar]
- Papadopoulos, D.P.; Uijlings, J.R.; Keller, F.; Ferrari, V. Training object class detectors with click supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 6374–6383. [Google Scholar]
- Ribera, J.; Guera, D.; Chen, Y.; Delp, E.J. Locating Objects Without Bounding Boxes. arXiv 2018, arXiv:1806.07564. [Google Scholar]
- Gherardi, R.; Farenzena, M.; Fusiello, A. Improving the efficiency of hierarchical structure-and-motion. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1594–1600. [Google Scholar]
- Turner, D.; Lucieer, A.; Watson, C. An automated technique for generating georectified mosaics from ultra-high resolution unmanned aerial vehicle (UAV) imagery,-based on structure from motion (SfM) point clouds. Remote Sens. 2012, 4, 1392–1410. [Google Scholar] [CrossRef] [Green Version]
- Lati, A.; Belhocine, M.; Achour, N. Robust aerial image mosaicing algorithm-based on fuzzy outliers rejection. Evol. Syst. 2019, 11, 717–729. [Google Scholar] [CrossRef]
- Guizilini, V.; Sales, D.; Lahoud, M.; Jorge, L. Embedded mosaic generation using aerial images. In Proceedings of the 2017 Latin American Robotics Symposium (LARS) and 2017 Brazilian Symposium on Robotics (SBR), Curitiba, Brazil, 8–11 November 2017; pp. 1–6. [Google Scholar]
- Itakura, K.; Hosoi, F. Automatic tree detection from three-dimensional images reconstructed from 360 spherical camera using YOLO v2. Remote Sens. 2020, 12, 988. [Google Scholar] [CrossRef] [Green Version]
- Zheng, J.; Li, W.; Xia, M.; Dong, R.; Fu, H.; Yuan, S. Large-scale oil palm tree detection from high-resolution remote sensing images using faster-rcnn. In Proceedings of the IGARSS 2019-2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July 2019–2 August 2019; pp. 1422–1425. [Google Scholar]
- G. Braga, J.R.; Peripato, V.; Dalagnol, R.; P Ferreira, M.; Tarabalka, Y.; OC Aragão, L.E.; F de Campos Velho, H.; Shiguemori, E.H.; Wagner, F.H. Tree crown delineation algorithm-based on a convolutional neural network. Remote Sens. 2020, 12, 1288. [Google Scholar] [CrossRef] [Green Version]
- Wagner, F.H.; Dalagnol, R.; Tagle Casapia, X.; Streher, A.S.; Phillips, O.L.; Gloor, E.; Aragão, L.E. Regional mapping and spatial distribution analysis of canopy palms in an amazon forest using deep learning and VHR images. Remote Sens. 2020, 12, 2225. [Google Scholar] [CrossRef]
- Zhang, C.; Atkinson, P.M.; George, C.; Wen, Z.; Diazgranados, M.; Gerard, F. Identifying and mapping individual plants in a highly diverse high-elevation ecosystem using UAV imagery and deep learning. ISPRS J. Photogramm. Remote Sens. 2020, 169, 280–291. [Google Scholar] [CrossRef]
- Ferreira, M.P.; de Almeida, D.R.A.; de Almeida Papa, D.; Minervino, J.B.S.; Veras, H.F.P.; Formighieri, A.; Santos, C.A.N.; Ferreira, M.A.D.; Figueiredo, E.O.; Ferreira, E.J.L. Individual tree detection and species classification of Amazonian palms using UAV images and deep learning. For. Ecol. Manag. 2020, 475, 118397. [Google Scholar] [CrossRef]
- Xiao, C.; Qin, R.; Huang, X. Treetop detection using convolutional neural networks trained through automatically generated pseudo labels. Int. J. Remote Sens. 2020, 41, 3010–3030. [Google Scholar] [CrossRef]
- Brandt, M.; Tucker, C.J.; Kariryaa, A.; Rasmussen, K.; Abel, C.; Small, J.; Chave, J.; Rasmussen, L.V.; Hiernaux, P.; Diouf, A.A.; et al. An unexpectedly large count of trees in the West African Sahara and Sahel. Nature 2020, 587, 78–82. [Google Scholar] [CrossRef]
- Khan, F.A.; Khelifi, F.; Tahir, M.A.; Bouridane, A. Dissimilarity Gaussian mixture models for efficient offline handwritten text-independent identification using SIFT and RootSIFT descriptors. IEEE Trans. Inf. Forensics Secur. 2018, 14, 289–303. [Google Scholar] [CrossRef]
- Chatterjee, A.; Madhav Govindu, V. Efficient and robust large-scale rotation averaging. In Proceedings of the IEEE International Conference on Computer Vision 2013, Sydney, Australia, 1–8 December 2013; pp. 521–528. [Google Scholar]
- Russell, B.C.; Torralba, A.; Murphy, K.P.; Freeman, W.T. LabelMe: A database and web-based tool for image annotation. Int. J. Comput. Vis. 2008, 77, 157–173. [Google Scholar] [CrossRef]
- Soydaner, D. Attention mechanism in neural networks: Where it comes and where it goes. Neural Comput. Appl. 2022, 34, 13371–13385. [Google Scholar] [CrossRef]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the point: Semantic segmentation with point supervision. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 549–565. [Google Scholar]
- Saarinen, K. Color image segmentation by a watershed algorithm and region adjacency graph processing. In Proceedings of the 1st International Conference on Image Processing, Austin, TX, USA, 13–16 November 1994. [Google Scholar]
- Borji, A.; Cheng, M.M.; Jiang, H.; Li, J. Salient object detection: A benchmark. IEEE Trans. Image Process. 2015, 24, 5706–5722. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Sindagi, V.A.; Patel, V.M. Ha-ccn: Hierarchical attention-based crowd counting network. IEEE Trans. Image Process. 2019, 29, 323–335. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Salzmann, M.; Fua, P. Context-aware crowd counting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5099–5108. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Bilen, H.; Vedaldi, A. Weakly supervised deep detection networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2846–2854. [Google Scholar]
- Tang, P.; Wang, X.; Bai, S.; Shen, W.; Bai, X.; Liu, W.; Yuille, A. Pcl: Proposal cluster learning for weakly supervised object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 42, 176–191. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wan, F.; Liu, C.; Ke, W.; Ji, X.; Jiao, J.; Ye, Q. C-MIL: Continuation multiple instance learning for weakly supervised object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2199–2208. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequence | Images | Resolution | Dataset Size | Time Cost | Peak Source Usage | ||
|---|---|---|---|---|---|---|---|
| Ours | Pix4DMapper | Ours | Pix4DMapper | ||||
| acacia | 8 | 6000 × 4000 | 162 MB | 12 s | 4 min 20 s | 100%CPU, 57%GPU, 53%RAM | 100%CPU, 72%GPU, 74%RAM |
| oil-palm | 189 | 6000 × 3376 | 1.8 GB | 2 min 19 s | 94 min 24 s | 100%CPU, 67%GPU, 70%RAM | 100%CPU, 80%GPU, 92%RAM |
| Methods | Acacia | Oil-Palm | ||
|---|---|---|---|---|
| MAE | RMSE | MAE | RMSE | |
| MCNN [67] | 12.32 | 52.06 | 4.48 | 5.53 |
| HA-CCN [68] | 4.12 | 18.42 | 3.67 | 4.81 |
| CAN [69] | 3.35 | 12.06 | 2.49 | 4.12 |
| Ours | 2.135 | 3.274 | 2.068 | 3.159 |
| Methods | Annotation | Acacia | Oil-Palm | ||||
|---|---|---|---|---|---|---|---|
| TPR | Prec | TPR | Prec | ||||
| Faster R-CNN [42] | boundingbox | 0.972 | 0.978 | 0.975 | 0.965 | 0.942 | 0.953 |
| FPN [70] | boundingbox | 0.974 | 0.976 | 0.976 | 0.979 | 0.988 | 0.984 |
| WSDDN [71] | image level | 0.702 | 0.776 | 0.715 | 0.736 | 0.758 | 0.9750 |
| PCL [72] | image level | 0.751 | 0.785 | 0.773 | 0.747 | 0.764 | 0.759 |
| C-MIL [73] | image level | 0.826 | 0.879 | 0.868 | 0.847 | 0.864 | 0.858 |
| Ours | point level | 0.979 | 0.985 | 0.982 | 0.974 | 0.952 | 0.963 |
| Methods | Acacia | Oil-Palm | ||||
|---|---|---|---|---|---|---|
| TPR | Prec | TPR | Prec | |||
| ATFENet + | 0.062 | 0.147 | 0.087 | 0.075 | 0.141 | 0.098 |
| ATFENet + | 0.979 | 0.985 | 0.982 | 0.974 | 0.952 | 0.963 |
| Methods | Acacia | Oil-Palm | ||||
|---|---|---|---|---|---|---|
| TPR | Prec | TPR | Prec | |||
| Center-click | 0.979 | 0.985 | 0.982 | 0.974 | 0.952 | 0.963 |
| Random-click | 0.971 | 0.978 | 0.974 | 0.966 | 0.947 | 0.956 |
| Sequence | Number of Trees | Time Cost | ||
|---|---|---|---|---|
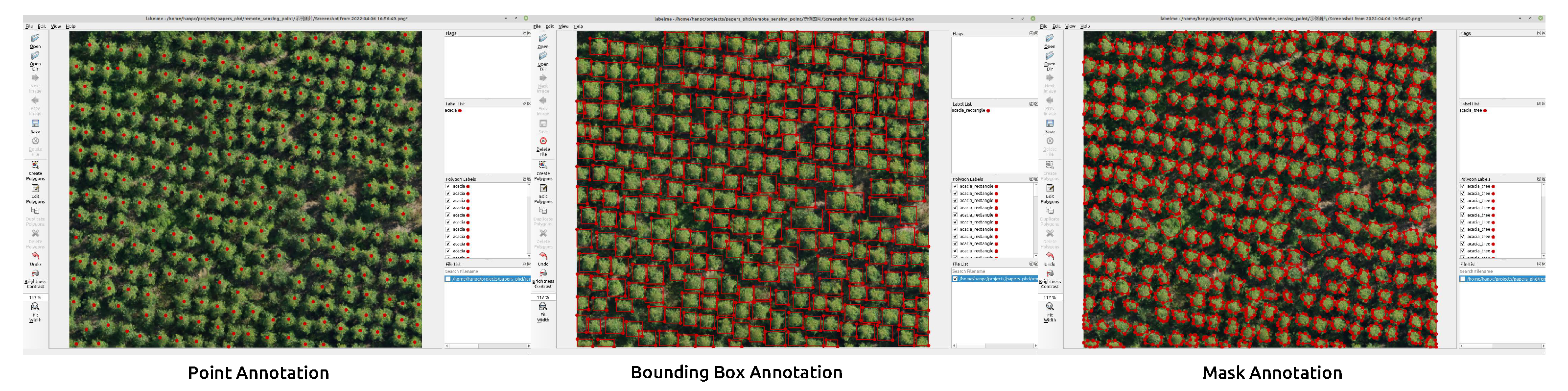
| Mask Annotation | Bounding Box | Point Annotation | ||
| acacia | nearly 300 | 45 min 47 s | 18 min 7 s | 8 min 56 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, P.; Ma, C.; Chen, J.; Chen, L.; Bu, S.; Xu, S.; Zhao, Y.; Zhang, C.; Hagino, T. Fast Tree Detection and Counting on UAVs for Sequential Aerial Images with Generating Orthophoto Mosaicing. Remote Sens. 2022, 14, 4113. https://doi.org/10.3390/rs14164113
Han P, Ma C, Chen J, Chen L, Bu S, Xu S, Zhao Y, Zhang C, Hagino T. Fast Tree Detection and Counting on UAVs for Sequential Aerial Images with Generating Orthophoto Mosaicing. Remote Sensing. 2022; 14(16):4113. https://doi.org/10.3390/rs14164113
Chicago/Turabian StyleHan, Pengcheng, Cunbao Ma, Jian Chen, Lin Chen, Shuhui Bu, Shibiao Xu, Yong Zhao, Chenhua Zhang, and Tatsuya Hagino. 2022. "Fast Tree Detection and Counting on UAVs for Sequential Aerial Images with Generating Orthophoto Mosaicing" Remote Sensing 14, no. 16: 4113. https://doi.org/10.3390/rs14164113
APA StyleHan, P., Ma, C., Chen, J., Chen, L., Bu, S., Xu, S., Zhao, Y., Zhang, C., & Hagino, T. (2022). Fast Tree Detection and Counting on UAVs for Sequential Aerial Images with Generating Orthophoto Mosaicing. Remote Sensing, 14(16), 4113. https://doi.org/10.3390/rs14164113