
MS-IAF: Multi-Scale Information Augmentation Framework for Aircraft Detection

 , ,
, ,
Abstract
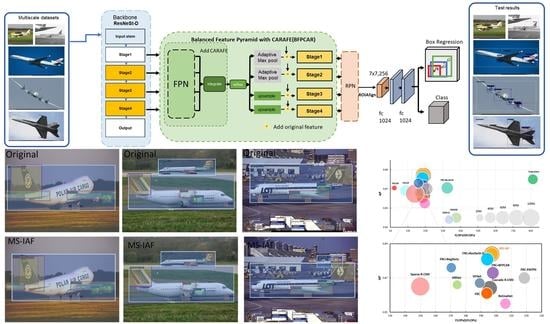
:
1. Introduction
- (1)
- We provided a multi-scale object dataset AP-DATA (containing 7000 images of multi-scale aircrafts taken from different angles and in complex backgrounds, where a portion of the multi-scale objects are obscured and the whole aircrafts and their key parts come with mixed annotation).
- (2)
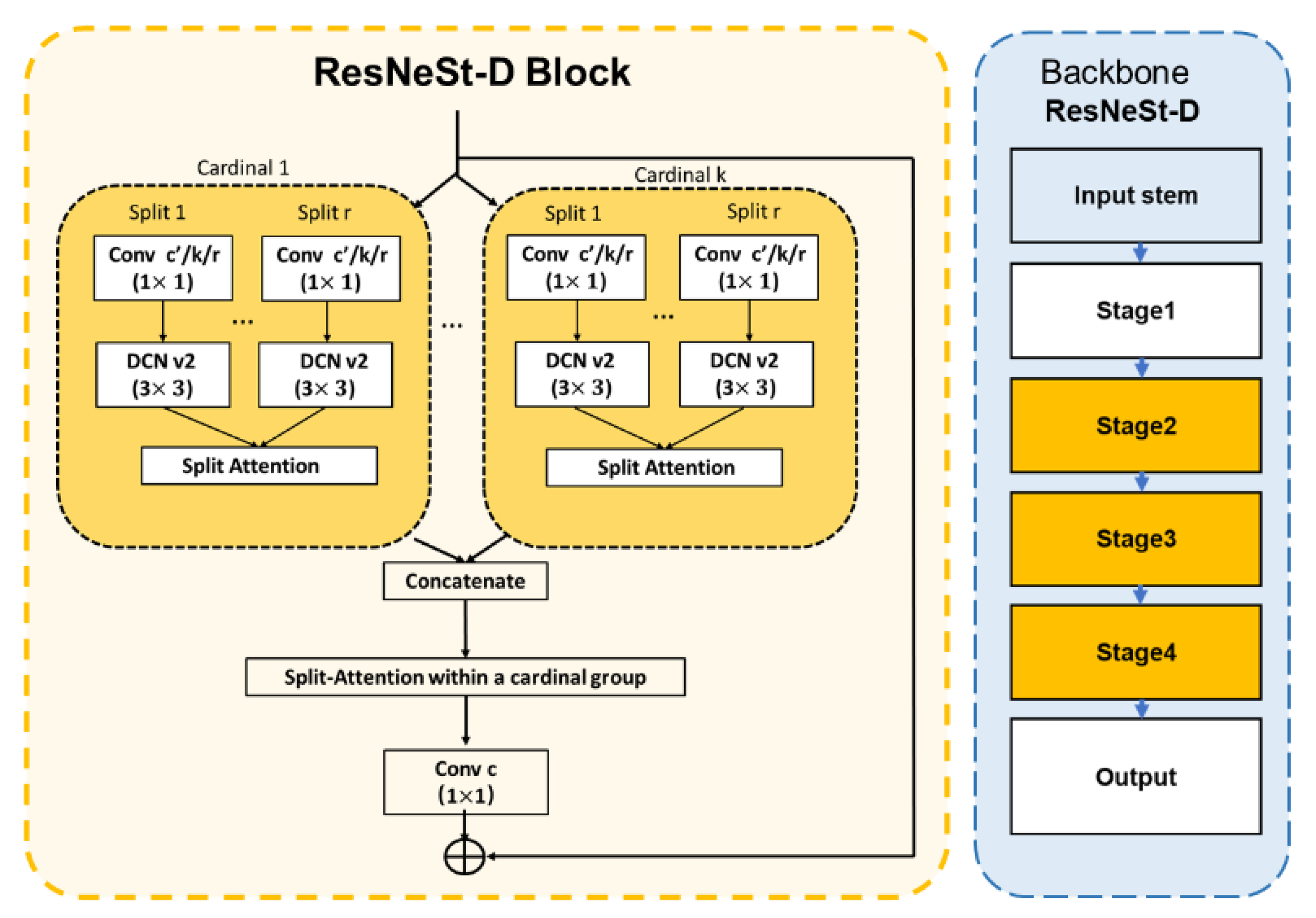
- We proposed a ResNeSt-D backbone, which stacks scattered attention in a multi-path manner and makes the receptive field more suitable for the object.
- (3)
- We proposed a BFPCAR feature fusion module to overcome the loss of information during information fusion in non-adjacent layers and introduced a larger receptive field to obtain semantic features.
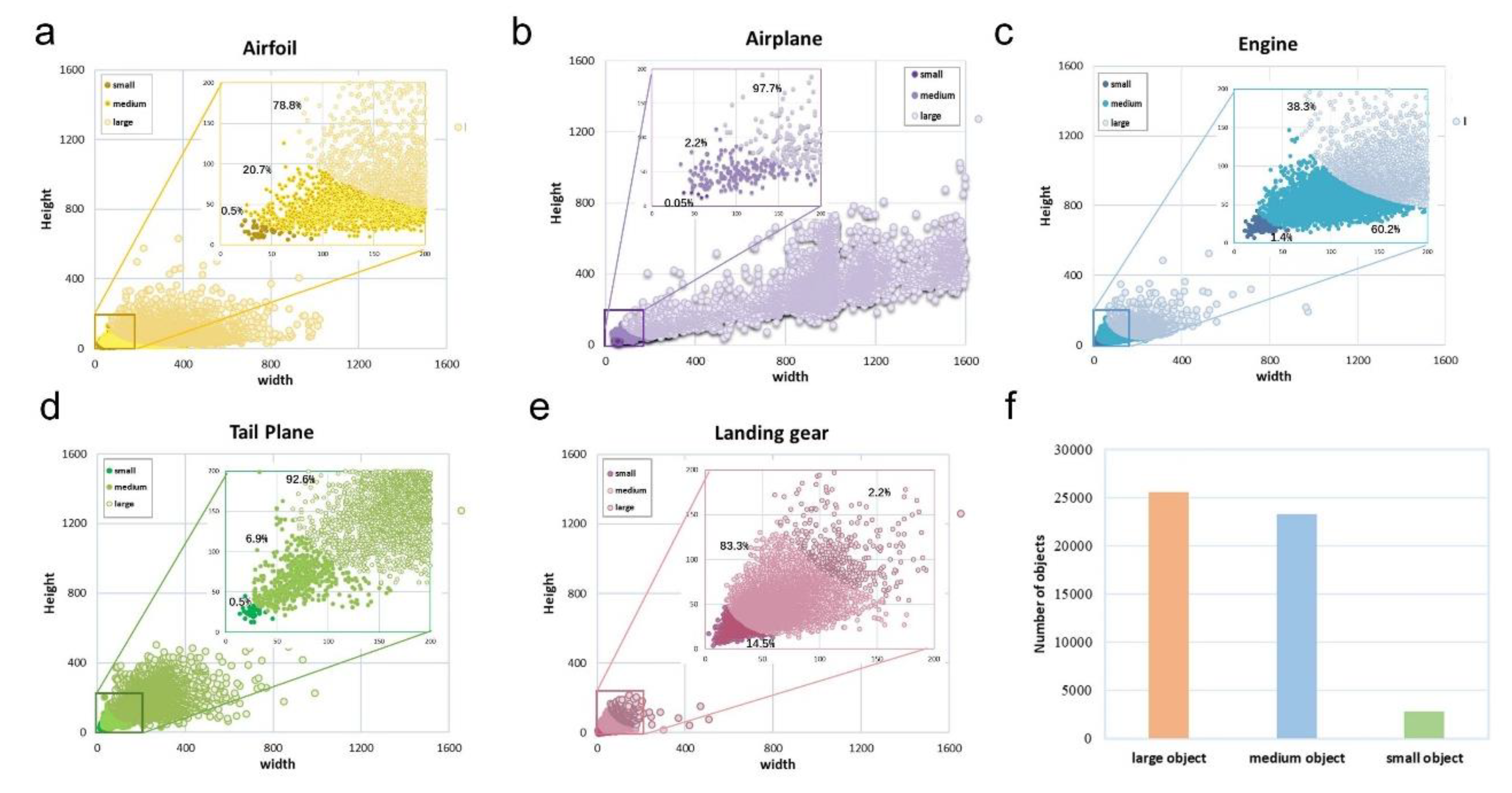
2. AP-DATA Data Set
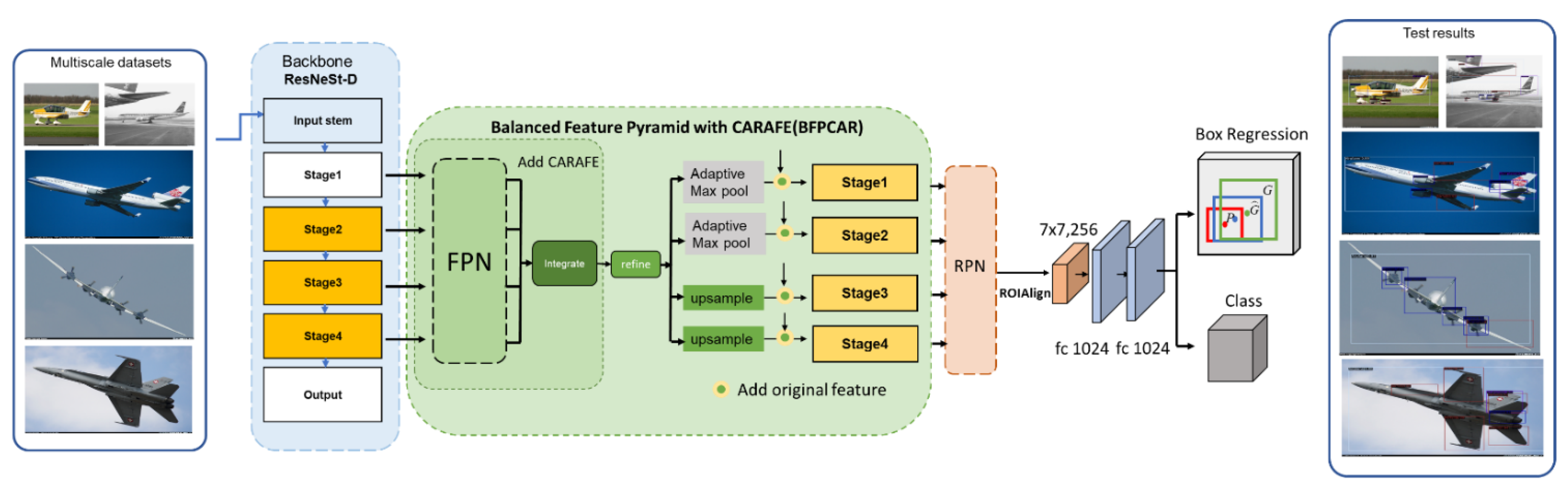
3. Framework of the Model
3.1. Optimization of Backbone
3.2. Multi-Scale Feature Fusion
4. Experiment
4.1. Experimental Results
4.2. Robustness Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Y.; Zhang, X.Y.; Bian, J.W.; Zhang, L.; Cheng, M.M. SAMNet: Stereoscopically Attentive Multi-Scale Network for Lightweight Salient Object Detection. IEEE Trans. Image Process. 2021, 30, 3804–3814. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.; Wan, L.; Zhu, J.; Xu, G.; Deng, M. Multi-Scale Spatial and Channel-Wise Attention for Improving Object Detection in Remote Sensing Imagery. IEEE Geosci. Remote Sens. Lett. 2020, 17, 681–685. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep Learning Approach for Car Detection in UAV Imagery. Remote Sens. 2017, 9, 312. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Liu, Y.; Liu, T.; Lin, Z.; Wang, S. DAGN: A Real-Time UAV Remote Sensing Image Vehicle Detection Framework. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1884–1888. [Google Scholar] [CrossRef]
- Wu, X.; Li, W.; Hong, D.; Tao, R.; Du, Q. Deep Learning for Unmanned Aerial Vehicle-Based Object Detection and Tracking: A Survey. IEEE Geosci. Remote Sens. Mag. 2022, 10, 91–124. [Google Scholar] [CrossRef]
- Zhang, Q.; Liu, H. Multi-Scale Defect Detection of Printed Circuit Board Based on Feature Pyramid Network. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence and Computer Applications, ICAICA 2021, Dalian, China, 28–30 June 2021; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2021; pp. 911–914. [Google Scholar]
- Jiang, Y.; Han, S.; Bai, Y. Building and Infrastructure Defect Detection and Visualization Using Drone and Deep Learning Technologies. J. Perform. Constr. Facil. 2021, 35, 1–15. [Google Scholar] [CrossRef]
- Liu, Y.; Yeoh, J.K.W.; Chua, D.K.H. Deep Learning–Based Enhancement of Motion Blurred UAV Concrete Crack Images. J. Comput. Civ. Eng. 2020, 34, 04020028. [Google Scholar] [CrossRef]
- Muzammul, M.; Li, X. A Survey on Deep Domain Adaptation and Tiny Object Detection Challenges, Techniques and Datasets. arXiv 2021, arXiv:2107.07927. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 3974–3983. [Google Scholar]
- Cheng, G.; Han, J.; Zhou, P.; Li, K. Multi-Class Geospatial Object Detection and Geographic Image Classification Based on Collection of Part Detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-Sign Detection and Classification in the Wild. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Washington, DC, USA, 2016; Volume 2016, pp. 2110–2118. [Google Scholar]
- Han, J.; Liang, K.; Zhou, B.; Zhu, X.; Zhao, J.; Zhao, L. Infrared Small Target Detection Utilizing the Multiscale Relative Local Contrast Measure. IEEE Geosci. Remote Sens. Lett. 2018, 15, 612–616. [Google Scholar] [CrossRef]
- Dong, Z.; Wang, M.; Wang, Y.; Zhu, Y.; Zhang, Z. Object Detection in High Resolution Remote Sensing Imagery Based on Convolutional Neural Networks with Suitable Object Scale Features. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2104–2114. [Google Scholar] [CrossRef]
- Gao, S.-H.; Cheng, M.-M.; Zhao, K.; Zhang, X.-Y.; Yang, M.-H.; Torr, P. Res2Net: A New Multi-Scale Backbone Architecture. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 652–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep High-Resolution Representation Learning for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 3349–3364. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-Resolution Representations for Labeling Pixels and Regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q. v EfficientDet: Scalable and Efficient Object Detection. In Proceeding of the Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Guo, C.; Fan, B.; Zhang, Q.; Xiang, S.; Pan, C. AugFPN: Improving Multi-Scale Feature Learning for Object Detection. In Proceeding of the Conference on Computer Vision and Pattern Recognition 2020 (CVPR) , Seattle, WA, USA, 14–19 June 2020; pp. 12595–12604. [Google Scholar]
- Cao, J.; Chen, Q.; Guo, J.; Shi, R. Attention-Guided Context Feature Pyramid Network for Object Detection. arXiv 2020, arXiv:2005.11475. [Google Scholar]
- Zhang, T.; Zhang, X.; Shi, J.; Wei, S.; Wang, J.; Li, J. Balanced Feature Pyramid Network for Ship Detection in Synthetic Aperture Radar Images. In Proceedings of the IEEE National Radar Conference—Proceedings, Washington, DC, USA, 28–30 April 2020; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2020; Volume 2020. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient Multi-Scale Training. In Proceedings of the 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), Montreal, QC, Canada, 3–8 December 2018; pp. 1–8. [Google Scholar]
- Singh, B.; Davis, L.S. An Analysis of Scale Invariance in Object Detection—SNIP. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, Y.; Chen, Y.; Wang, N.; Zhang, Z. Scale-Aware Trident Networks for Object Detection. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6054–6063. [Google Scholar]
- Tirin, M.; Marc, Z. Neural Mechanisms of Selective Visual Attention. Annu Rev Psychol. 2017, 68, 47–72. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for Small Object Detection. arXiv 2019, arXiv:1902.07296. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Zhang, H.; Wu, C.; Zhang, Z.; Zhu, Y.; Lin, H.; Zhang, Z.; Sun, Y.; He, T.; Mueller, J.; Manmatha, R.; et al. ResNeSt: Split-Attention Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Fang, F.; Li, L.; Zhu, H.; Lim, J.H. Combining Faster R-CNN and Model-Driven Clustering for Elongated Object Detection. IEEE Trans. Image Process. 2020, 29, 2052–2065. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2016, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Zhu, X.; Hu, H.; Lin, S.; Dai, J. Deformable Convnets V2: More Deformable, Better Results. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; IEEE Computer Society: Washington, DC, USA, 2019; Volume 2019, pp. 9300–9308. [Google Scholar]
- Zhao, Y.; Li, J.; Zhang, Q.; Lian, C.; Shan, P.; Yu, C.; Jiang, Z.; Qiu, Z. Simultaneous Detection of Defects in Electrical Connectors Based on Improved Convolutional Neural Network. IEEE Trans. Instrum. Meas. 2022, 71, 1–10. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, Hawaii, USA, 21–26 July 2017. [Google Scholar]
- Wang, J.; Chen, K.; Xu, R.; Liu, Z.; Loy, C.C.; Lin, D. CARAFE: Content-Aware Reassembly of Features. In Proceedings of the Proceedings of the IEEE International Conference on Computer Vision; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2019; Volume 2019, pp. 3007–3016. [Google Scholar]
- Pang, J.; Chen, K.; Shi, J.; Feng, H.; Ouyang, W.; Lin, D. Libra R-CNN: Towards Balanced Learning for Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Tang, X.; Zhang, H.; Ma, J.; Zhang, X.; Jiao, L. Supervised Adaptive-RPN Network for Object Detection in Remote Sensing Images. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Waikoloa, HI, USA, 26 September–2 October 2020; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2020; pp. 2647–2650. [Google Scholar]
- Sun, P.; Zhang, R.; Jiang, Y.; Kong, T.; Xu, C.; Zhan, W.; Tomizuka, M.; Li, L.; Yuan, Z.; Wang, C.; et al. Sparse R-CNN: End-to-End Object Detection with Learnable Proposals. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 14–19 June 2022. [Google Scholar]
- Cai, Z.; Vasconcelos, N. Cascade R-CNN: Delving into High Quality Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2017, Honolulu, Hawaii, USA, 21–26 July 2017. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 1–17. [Google Scholar]
- Zhang, H.; Wang, Y.; Dayoub, F.; Sünderhauf, N. VarifocalNet: An IoU-Aware Dense Object Detector. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 8514–8523. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Chen, Q.; Wang, Y.; Yang, T.; Zhang, X.; Cheng, J.; Sun, J. You Only Look One-Level Feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2021, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2018, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Radosavovic, I.; Kosaraju, R.P.; Girshick, R.; He, K.; Dollár, P. Designing Network Design Spaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2020, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Köpüklü, O.; Kose, N.; Gunduz, A.; Rigoll, G. Resource Efficient 3D Convolutional Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 1–10. [Google Scholar]
- Cao, J.; Zhang, J.; Huang, W. Traffic Sign Detection and Recognition Using Multi-Scale Fusion and Prime Sample Attention. IEEE Access 2021, 9, 3579–3591. [Google Scholar] [CrossRef]

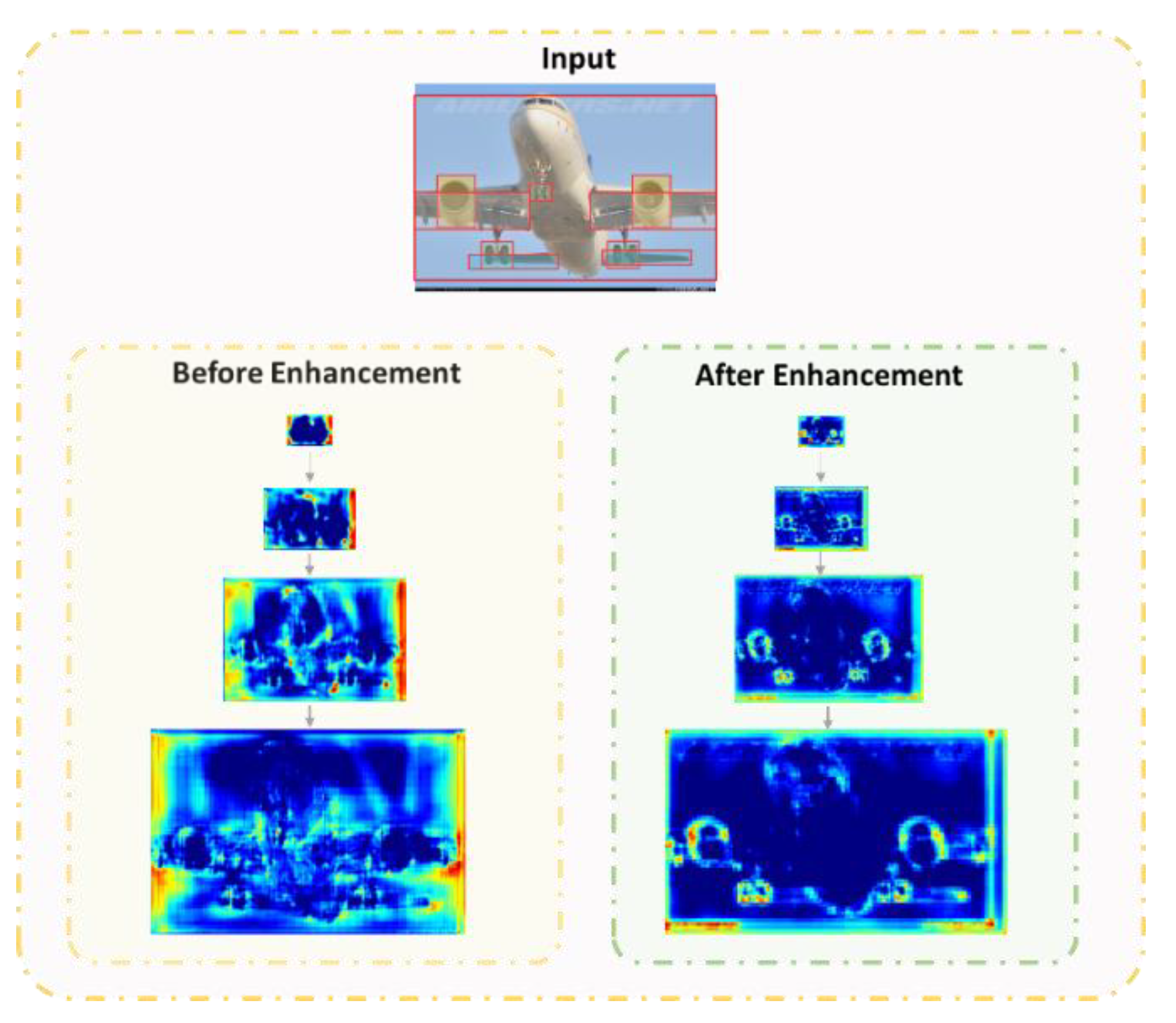

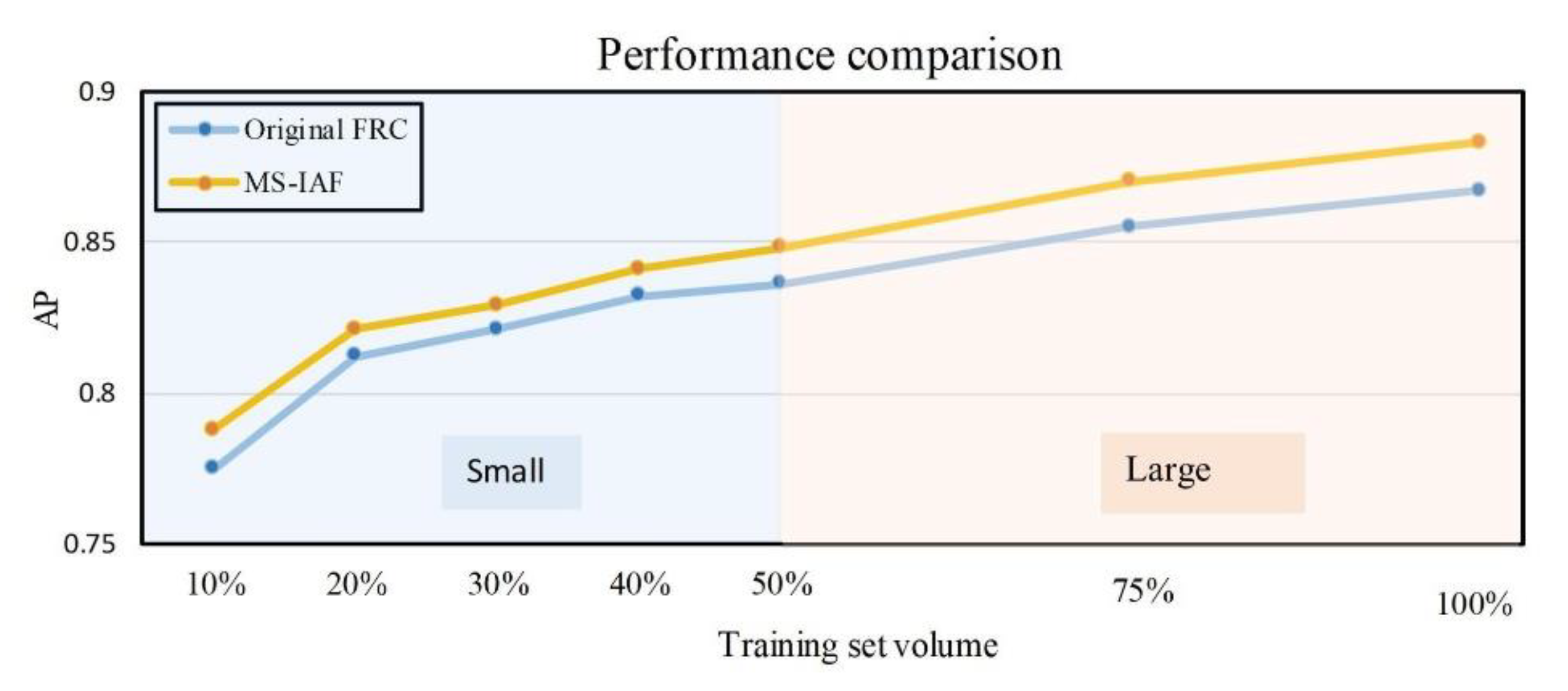




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object | Quantity |
|---|---|
| Aircraft | 7850 |
| Airfoil | 8160 |
| Engine | 10,127 |
| Tail Plane | 7703 |
| Landing gear | 17,759 |
| Model | Backbone | Small | Medium | Large | AP | FLOPs (GFLOPS) | Params (M) | |||
|---|---|---|---|---|---|---|---|---|---|---|
| APS | ARS | APM | ARM | APL | ARL | |||||
| Sparse R-CNN [40] | ResNet-50 | 0.435 | 0.657 | 0.631 | 0.868 | 0.864 | 0.944 | 0.865 ± 0.013 | 149.9 | 105.95 |
| HRNet [19] | ResNet-50 | 0.416 | 0.523 | 0.651 | 0.828 | 0.871 | 0.963 | 0.866 ± 0.012 | 174.25 | 27.1 |
| Cascade R-CNN [41] | ResNet-50 | 0.416 | 0.488 | 0.654 | 0.840 | 0.877 | 0.943 | 0.864 ± 0.09 | 195.82 | 69.84 |
| SSD 300 [42] | VGG-16 | 0.248 | 0.448 | 0.561 | 0.861 | 0.872 | 0.960 | 0.840 ± 0.002 | 386.25 | 34.31 |
| SSD 512 [42] | VGG-16 | 0.393 | 0.635 | 0.601 | 0.923 | 0.860 | 0.966 | 0.838 ± 0.005 | 344.86 | 24.98 |
| VFNet [43] | ResNet-50 | 0.367 | 0.580 | 0.653 | 0.942 | 0.855 | 0.988 | 0.867 ± 0.011 | 189.17 | 32.49 |
| YOLOX [44] | Darknet53 | 0.433 | 0.617 | 0.648 | 0.877 | 0.835 | 0.900 | 0.871 ± 0.016 | 33.31 | 8.94 |
| YOLOF [45] | ResNet-50 | 0.376 | 0.453 | 0.643 | 0.901 | 0.873 | 0.981 | 0.868 ± 0.013 | 98.26 | 42.16 |
| RetinaNet [46] | Resnet-50 | 0.405 | 0.613 | 0.613 | 0.908 | 0.846 | 0.980 | 0.855 ± 0.016 | 206.13 | 36.19 |
| Faster R C-NN+PAFPN [47] | ResNet-50 | 0.399 | 0.479 | 0.663 | 0.843 | 0.903 | 0.960 | 0.870 ± 0.009 | 218.58 | 44.68 |
| TridentNet [26] | ResNet-50 | 0.380 | 0.503 | 0.666 | 0.861 | 0.865 | 0.949 | 0.880 ± 0.007 | 822.13 | 32.8 |
| FRC [30] | ResNeSt | 0.415 | 0.494 | 0.642 | 0.848 | 0.872 | 0.963 | 0.871 ± 0.004 | 220.17 | 43.03 |
| FRC [48] | RegNetX | 0.394 | 0.499 | 0.665 | 0.853 | 0.897 | 0.960 | 0.876 ± 0.006 | 170.41 | 31.49 |
| Original FRC | ResNet-50 | 0.397 | 0.442 | 0.624 | 0.826 | 0.869 | 0.936 | 0.861 ± 0.014 | 193.8 | 41.14 |
| FRC +BFPCAR | ResNet-50 | 0.409 | 0.486 | 0.641 | 0.850 | 0.885 | 0.954 | 0.873 ± 0.009 | 197.81 | 47.01 |
| FRC | ResNeSt-D | 0.436 | 0.521 | 0.694 | 0.869 | 0.879 | 0.954 | 0.881 ± 0.011 | 194.16 | 46.52 |
| MS-IAF | ResNeSt-D | 0.434 | 0.507 | 0.644 | 0.885 | 0.885 | 0.961 | 0.884 ± 0.009 | 197.12 | 52.12 |
| Model | Light:1 | Fog:1 | Cloud:1 | Snow:1 | Stains:1 |
|---|---|---|---|---|---|
| FRC | 0.890 | 0.882 | 0.888 | 0.880 | 0.897 |
| HRNet | 0.896 | 0.887 | 0.887 | 0.886 | 0.892 |
| Cascade R-CNN | 0.901 | 0.903 | 0.898 | 0.900 | 0.891 |
| RetinaNet | 0.903 | 0.903 | 0.900 | 0.892 | 0.900 |
| TridentNet | 0.906 | 0.904 | 0.899 | 0.903 | 0.906 |
| MS-IAF | 0.911 | 0.907 | 0.914 | 0.906 | 0.907 |
| Model | Light:2 | Fog:2 | Cloud:2 | Snow:2 | Stains:2 |
| FRC FPN | 0.862 | 0.866 | 0.871 | 0.861 | 0.876 |
| HRNet | 0.870 | 0.866 | 0.874 | 0.866 | 0.873 |
| Cascade R-CNN | 0.872 | 0.876 | 0.878 | 0.863 | 0.874 |
| RetinaNet | 0.880 | 0.881 | 0.879 | 0.869 | 0.872 |
| TridentNet | 0.886 | 0.893 | 0.894 | 0.871 | 0.902 |
| MS-IAF | 0.907 | 0.907 | 0.904 | 0.871 | 0.908 |
| Model | Light:3 | Fog:3 | Cloud:3 | Snow:3 | Stains:3 |
| FRC FPN | 0.837 | 0.859 | 0.846 | 0.759 | 0.729 |
| HRNet | 0.844 | 0.861 | 0.851 | 0.820 | 0.731 |
| Cascade R-CNN | 0.849 | 0.86 | 0.857 | 0.822 | 0.733 |
| RetinaNet | 0.851 | 0.866 | 0.859 | 0.839 | 0.739 |
| TridentNet | 0.853 | 0.870 | 0.856 | 0.833 | 0.741 |
| MS-IAF | 0.862 | 0.874 | 0.860 | 0.844 | 0.744 |
| Model | Light:4 | Fog:4 | Cloud:4 | Snow:4 | Stains:4 |
| FRC FPN | 0.824 | 0.855 | 0.773 | 0.704 | 0.663 |
| HRNet | 0.829 | 0.859 | 0.779 | 0.706 | 0.659 |
| Cascade R-CNN | 0.833 | 0.858 | 0.786 | 0.711 | 0.667 |
| RetinaNet | 0.836 | 0.863 | 0.787 | 0.715 | 0.672 |
| TridentNet | 0.836 | 0.866 | 0.774 | 0.710 | 0.677 |
| MS-IAF | 0.839 | 0.869 | 0.788 | 0.721 | 0.679 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, Y.; Li, J.; Li, W.; Shan, P.; Wang, X.; Li, L.; Fu, Q. MS-IAF: Multi-Scale Information Augmentation Framework for Aircraft Detection. Remote Sens. 2022, 14, 3696. https://doi.org/10.3390/rs14153696
Zhao Y, Li J, Li W, Shan P, Wang X, Li L, Fu Q. MS-IAF: Multi-Scale Information Augmentation Framework for Aircraft Detection. Remote Sensing. 2022; 14(15):3696. https://doi.org/10.3390/rs14153696
Chicago/Turabian StyleZhao, Yuliang, Jian Li, Weishi Li, Peng Shan, Xiaoai Wang, Lianjiang Li, and Qiang Fu. 2022. "MS-IAF: Multi-Scale Information Augmentation Framework for Aircraft Detection" Remote Sensing 14, no. 15: 3696. https://doi.org/10.3390/rs14153696
APA StyleZhao, Y., Li, J., Li, W., Shan, P., Wang, X., Li, L., & Fu, Q. (2022). MS-IAF: Multi-Scale Information Augmentation Framework for Aircraft Detection. Remote Sensing, 14(15), 3696. https://doi.org/10.3390/rs14153696