
IoT Enabled Deep Learning Based Framework for Multiple Object Detection in Remote Sensing Images





Abstract
:1. Introduction
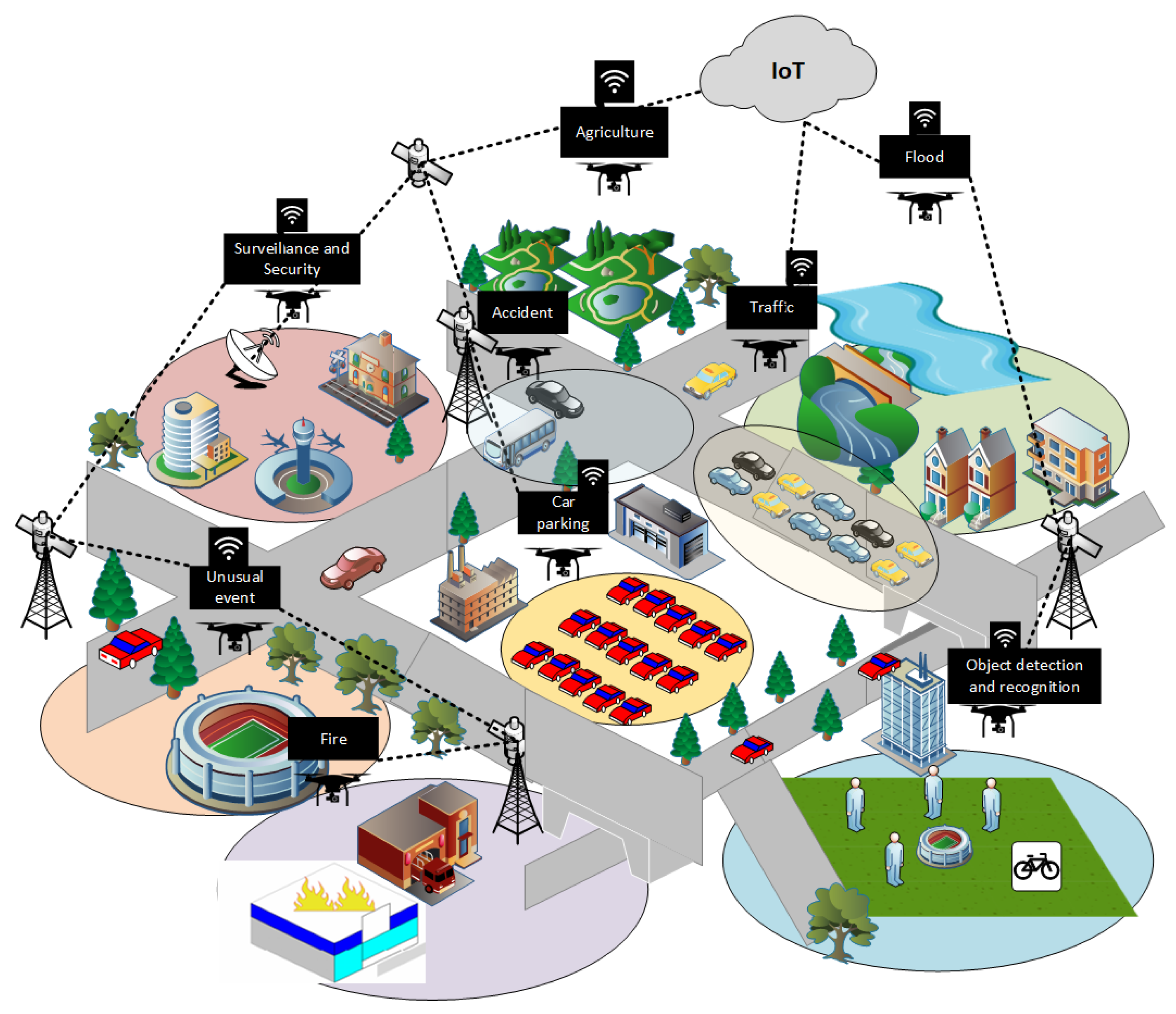
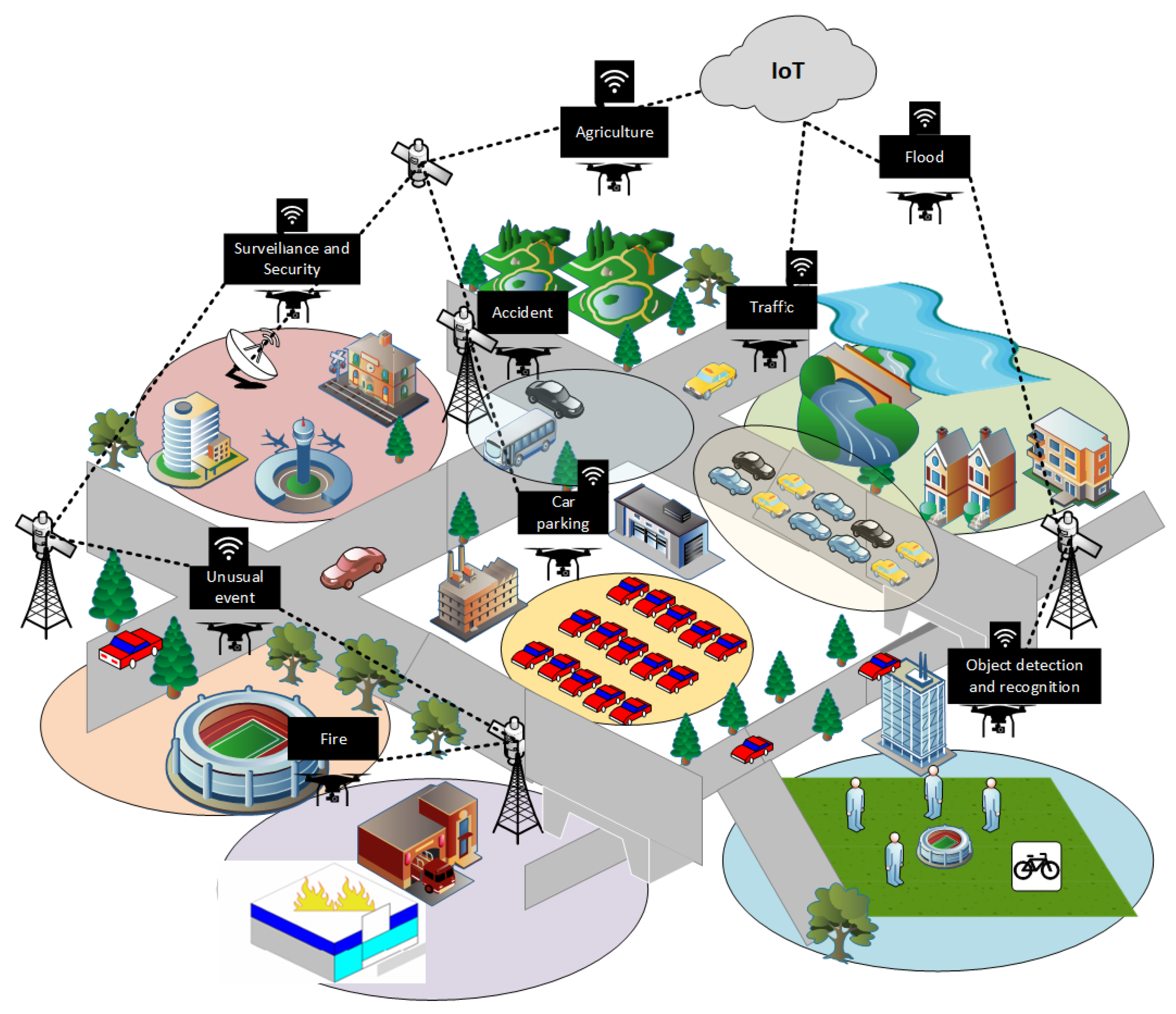
- To introduce an IoT-enabled solution for smart surveillance applications in smart cities using an aerial drone.
- To apply artificial intelligence and develop a system based on the deep learning model for multiple object detection.
- To apply data augmentation techniques and deep transfer learning to increase and enhance the performance of an aerial drone surveillance system.
- To explore training and testing of the deep learning architecture with different CNN classifies using aerial drone images.
- To investigate and analyze the results of the segmentation architecture with different classification models with aerial drone data in terms of efficiency.
2. Related Work
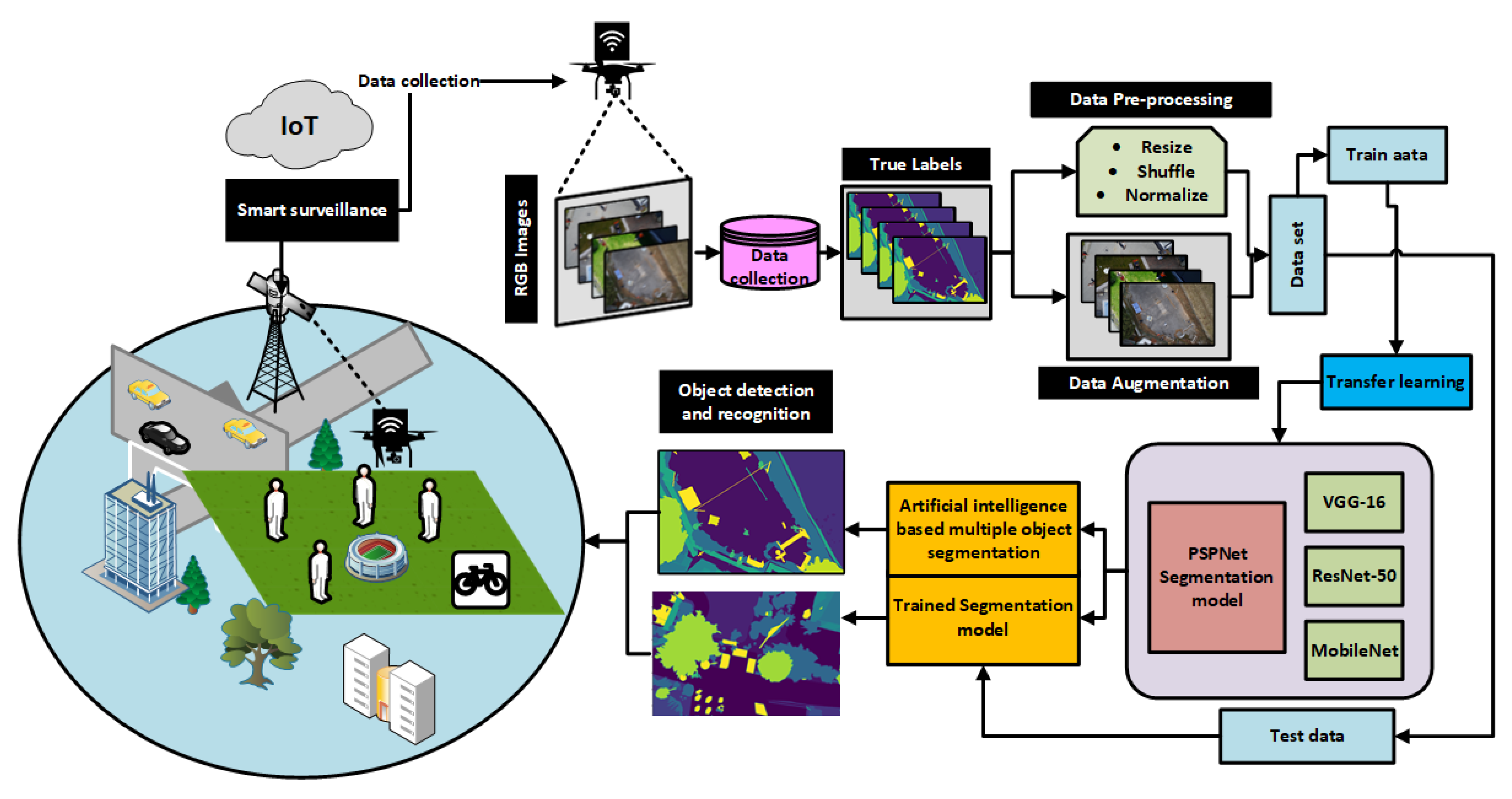
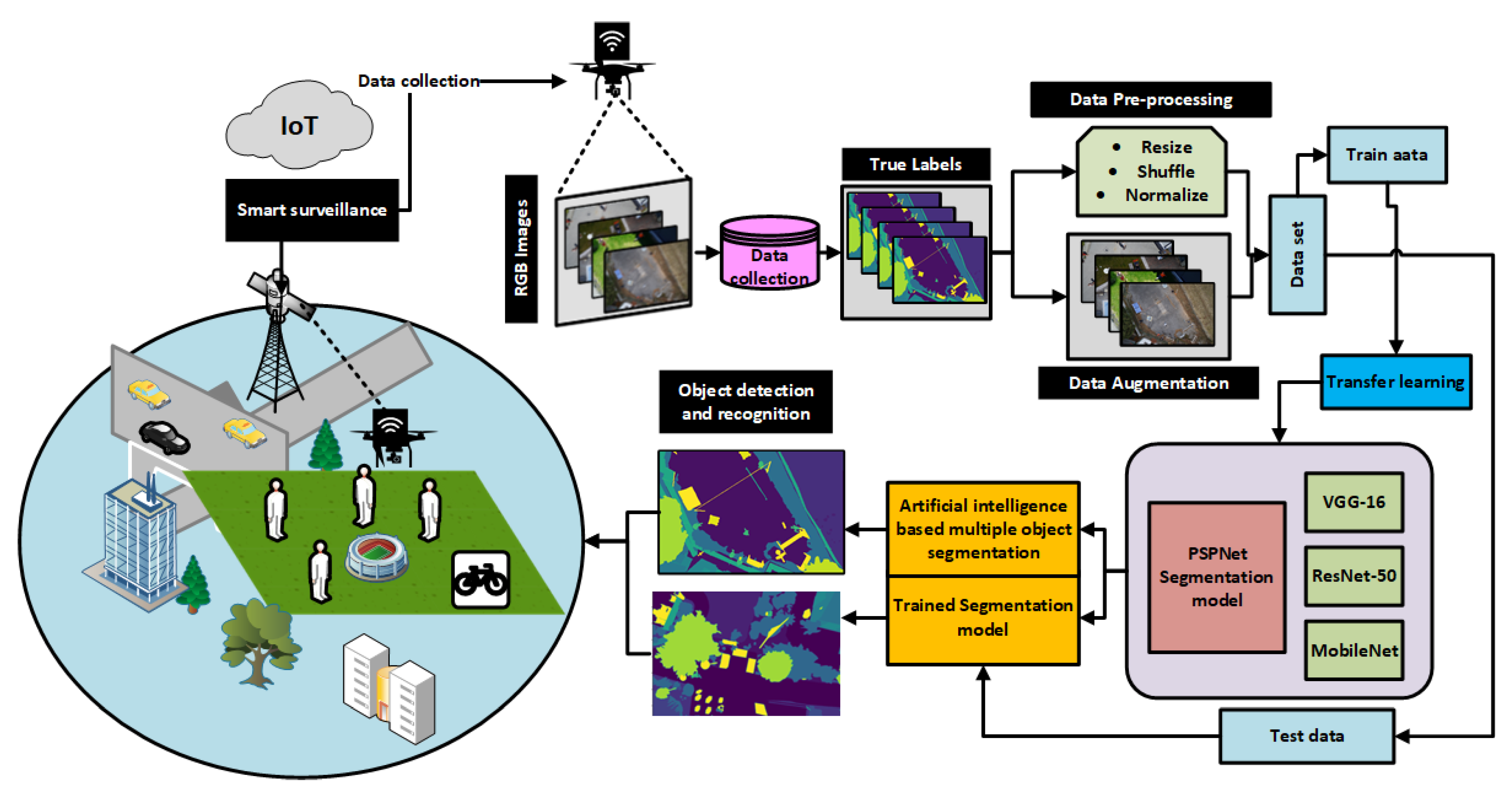
3. IoT-Enabled Leep Learning Based Solution for Object Detection Using Aerial Drone
3.1. Pre-Processing and Data Augmentation
3.2. CNN Based Classifiers as Base Architectures
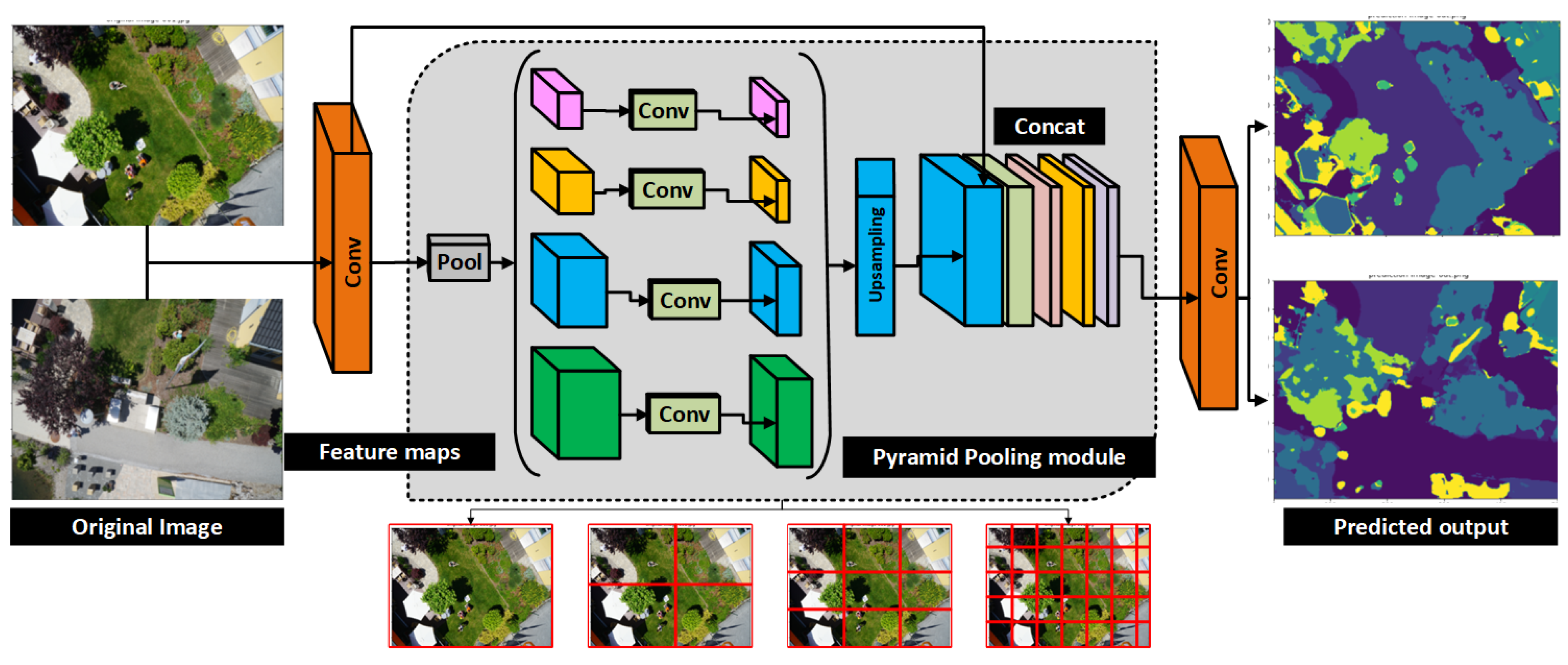
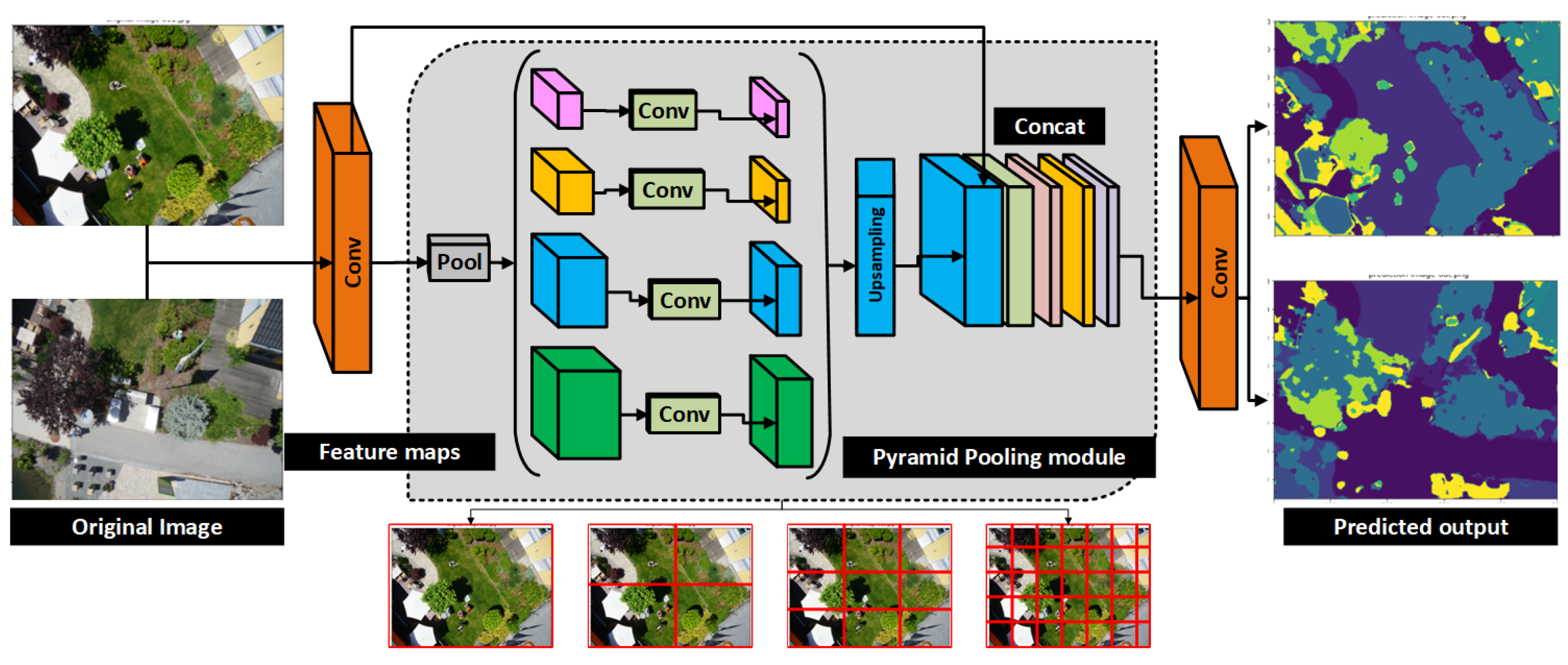
3.3. Semantic Segmentation Model
4. Experimental and Performance Results
4.1. Data Set
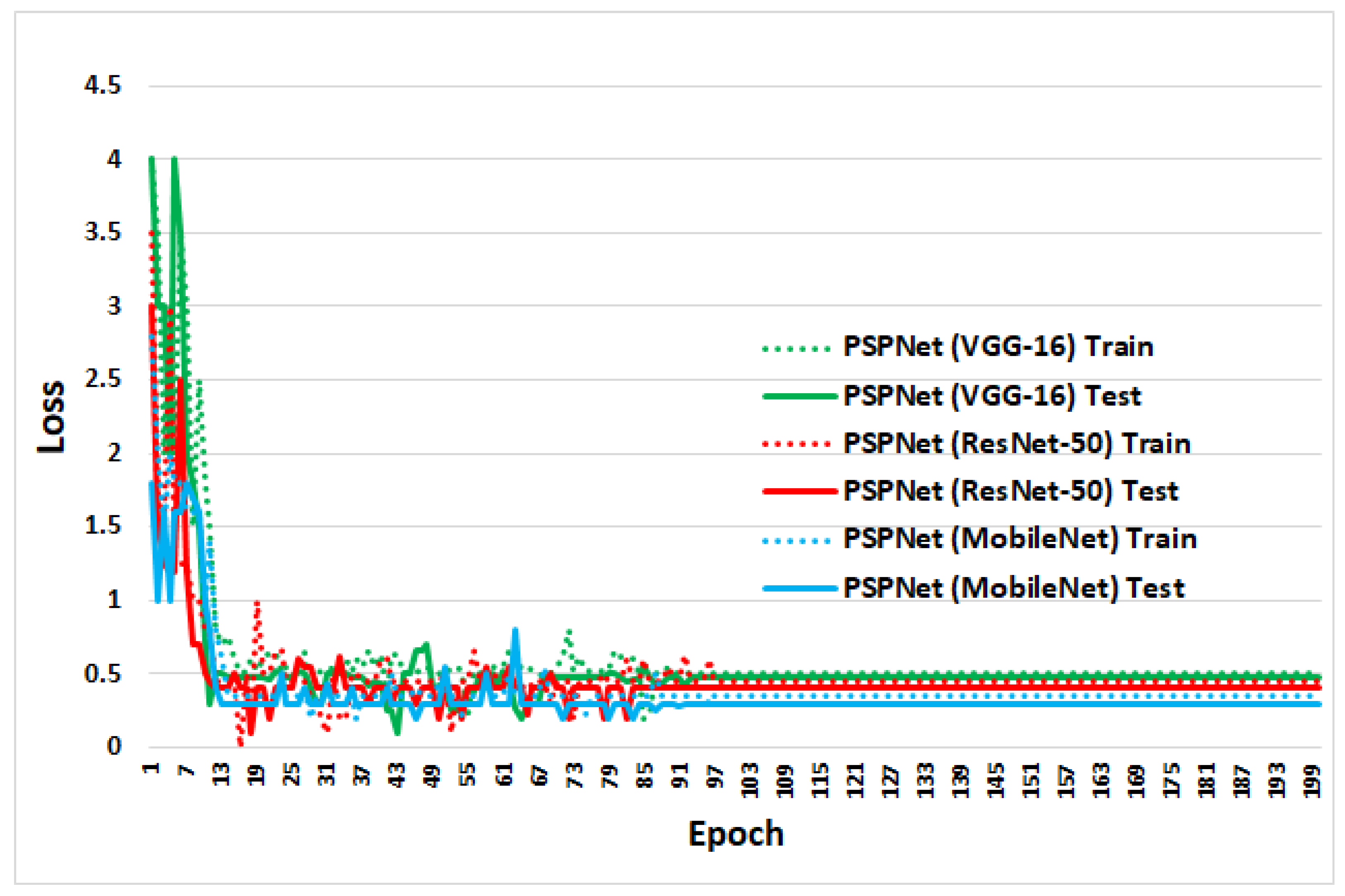
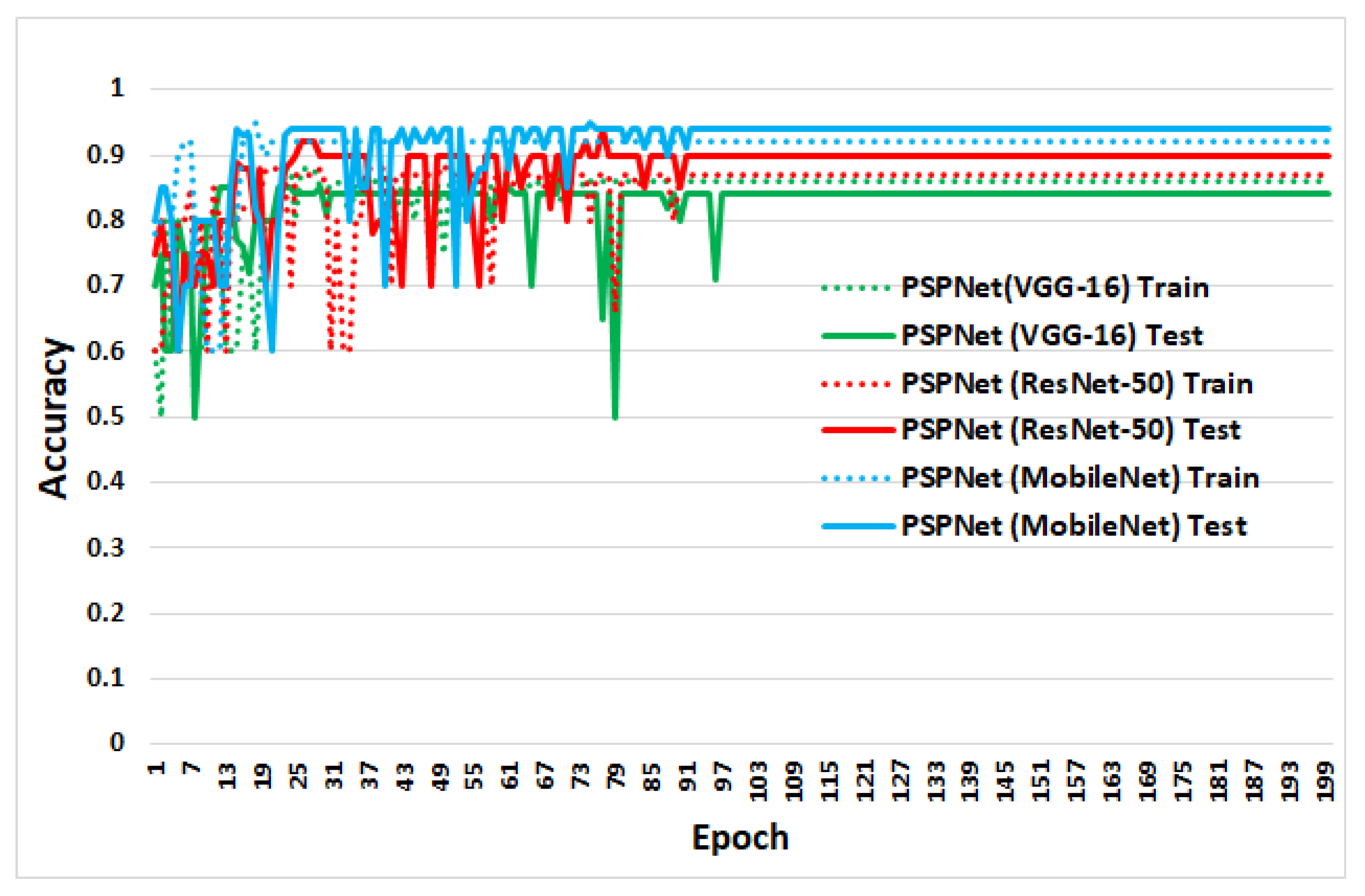
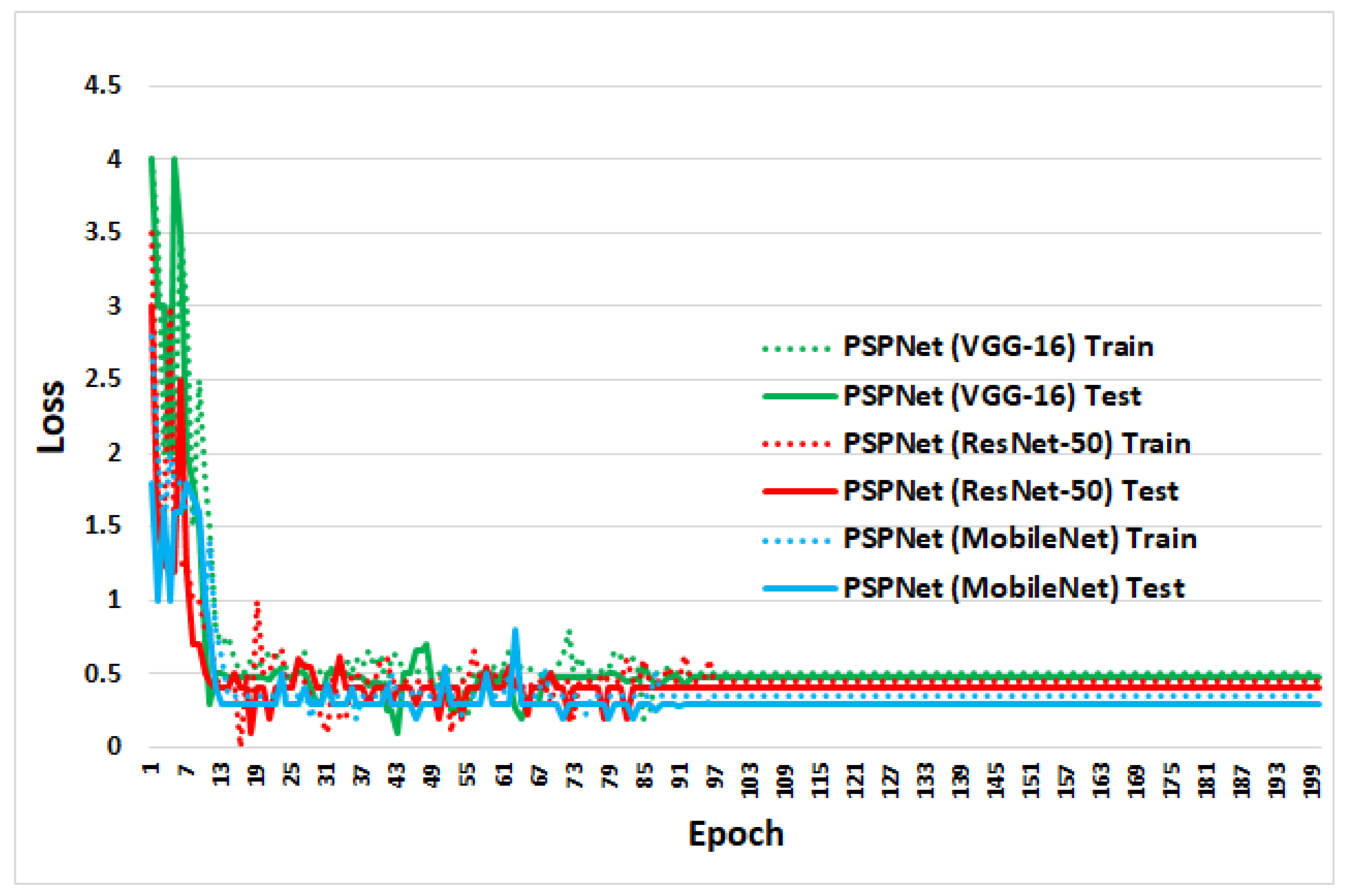
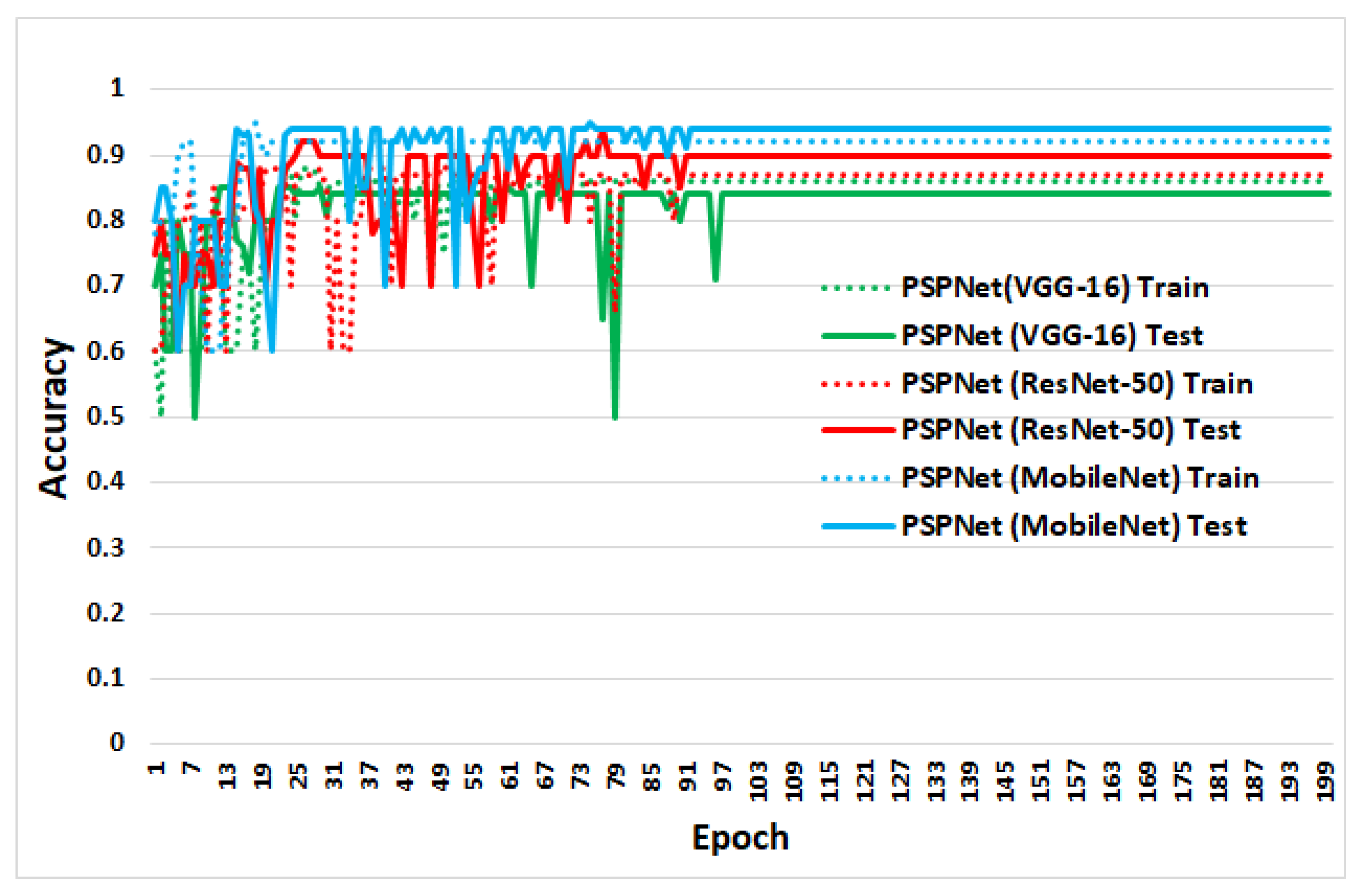
4.2. Training and Testing
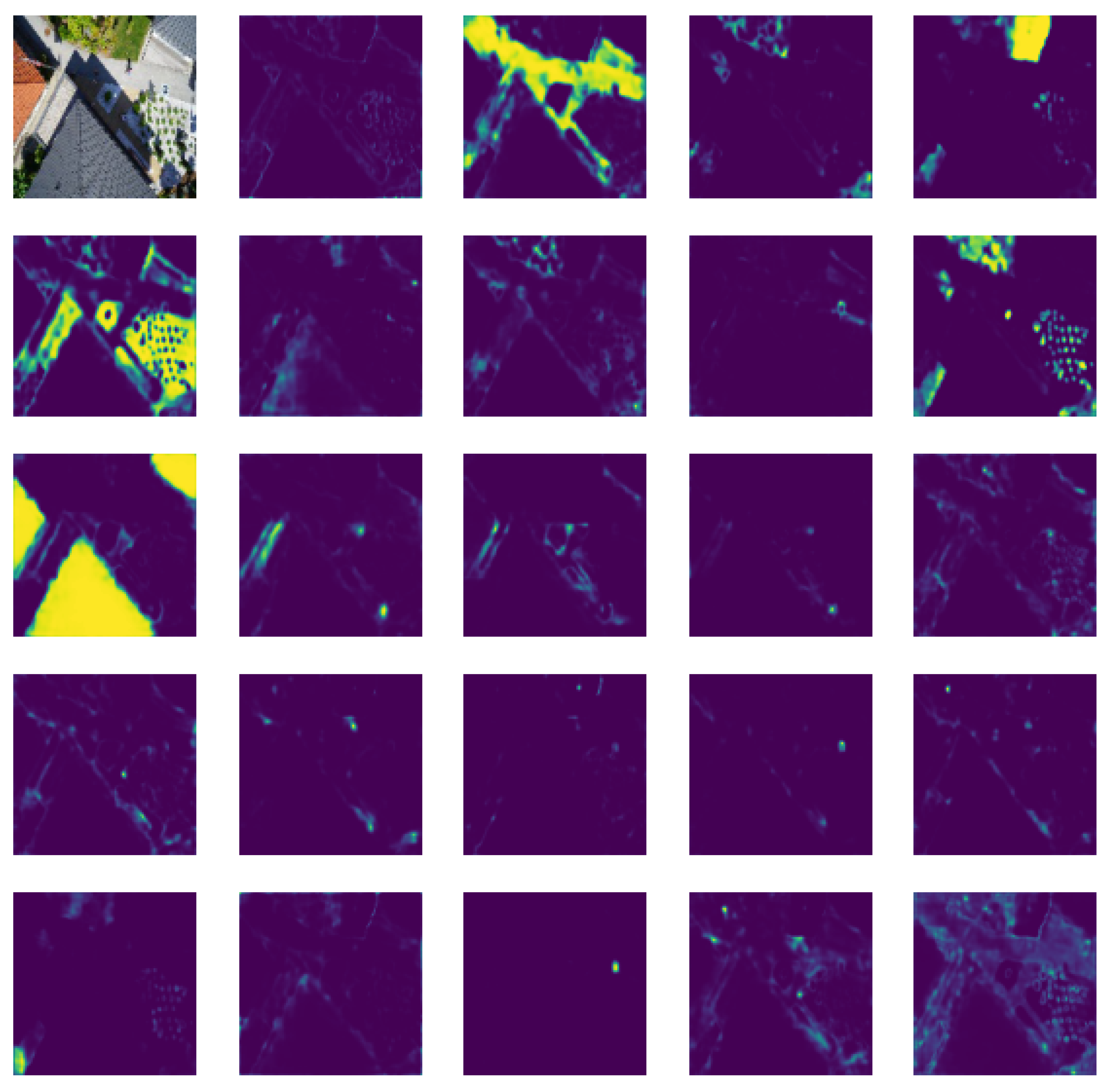
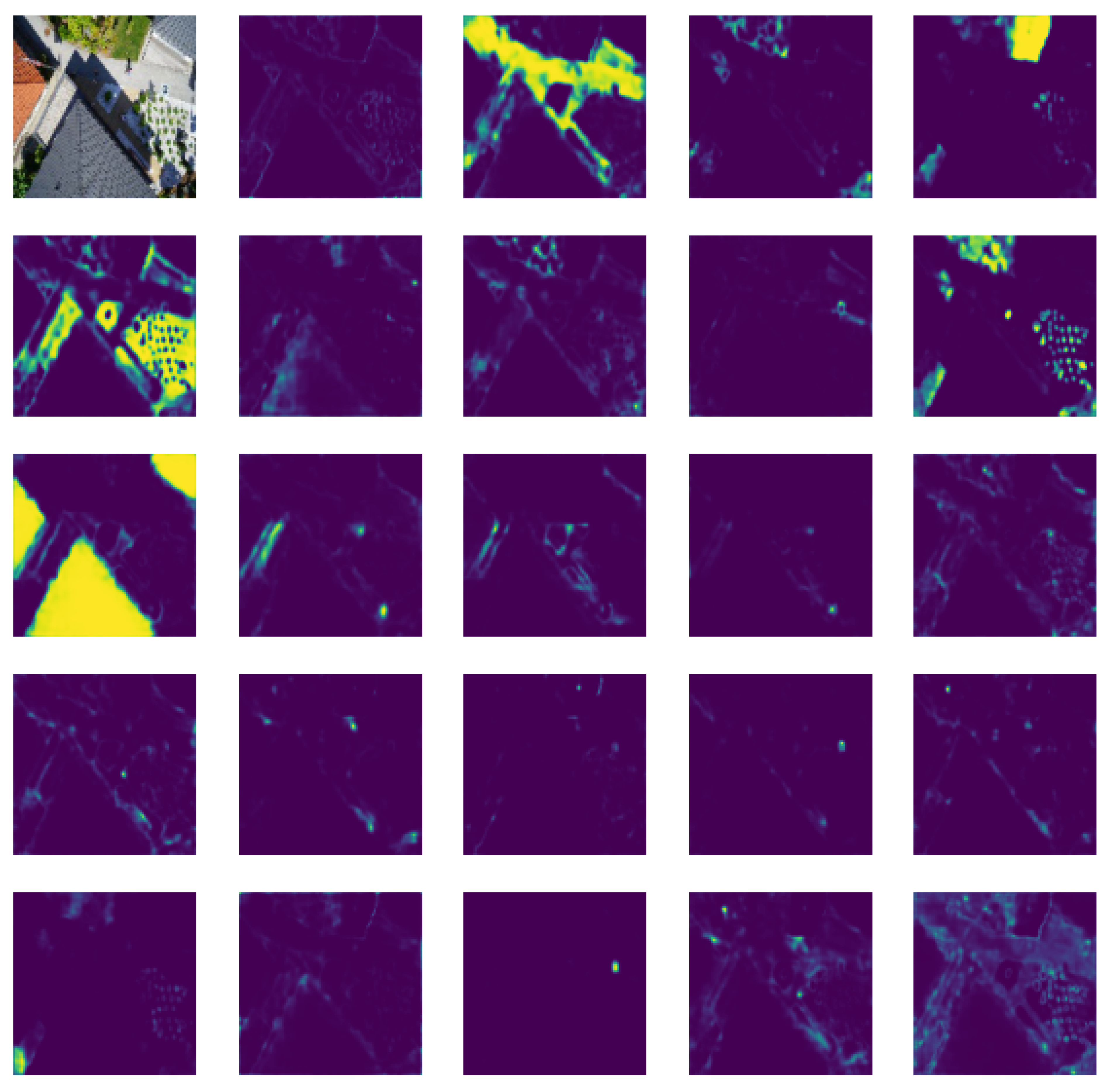
4.3. Segmentation Results
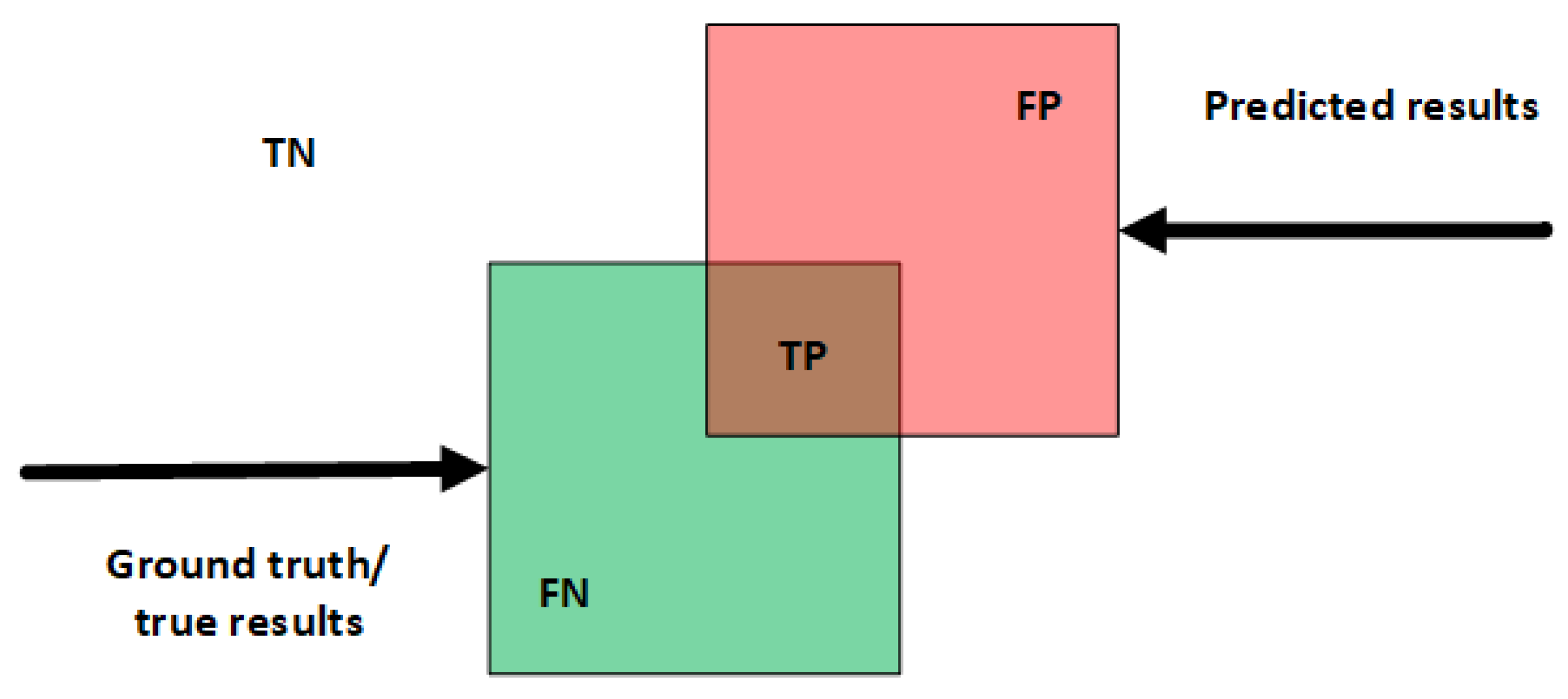
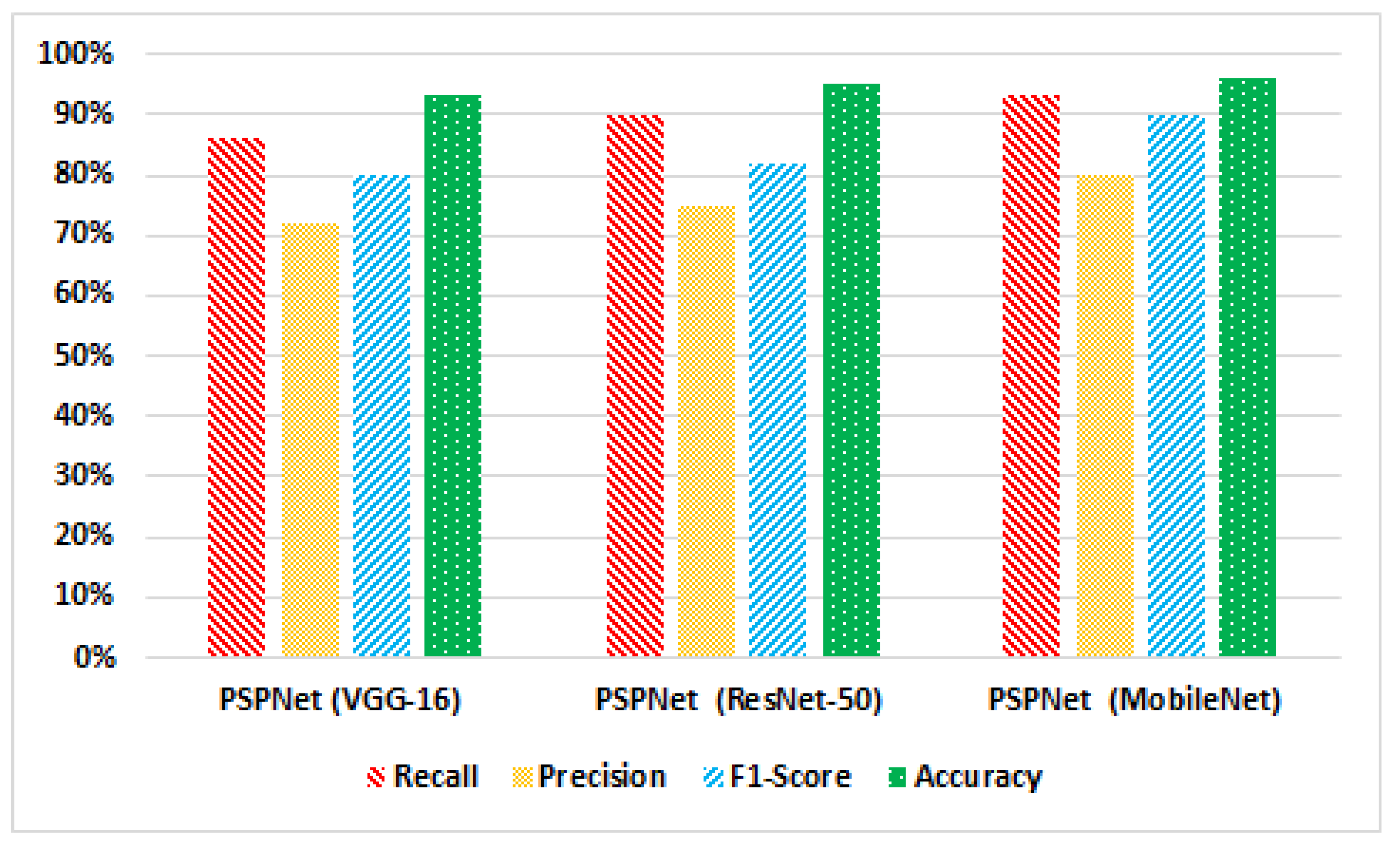
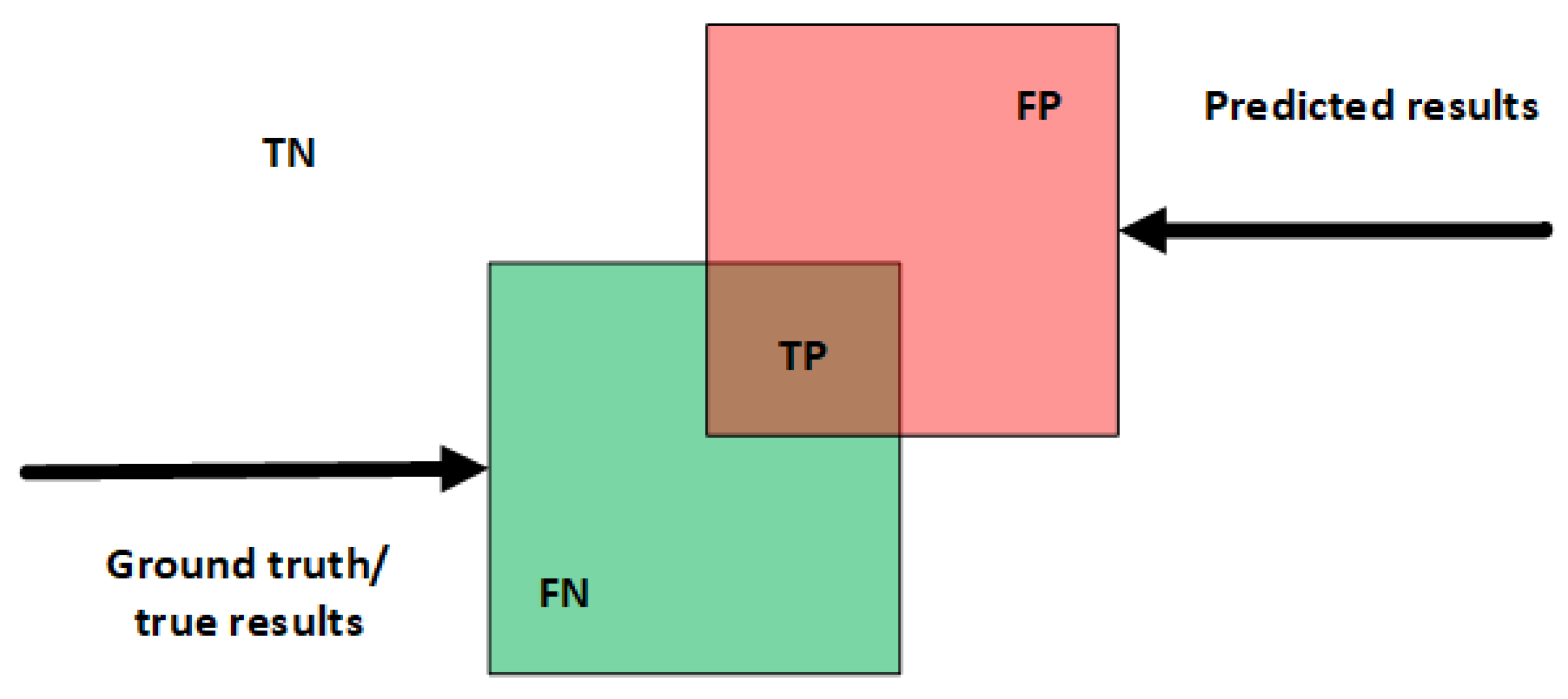
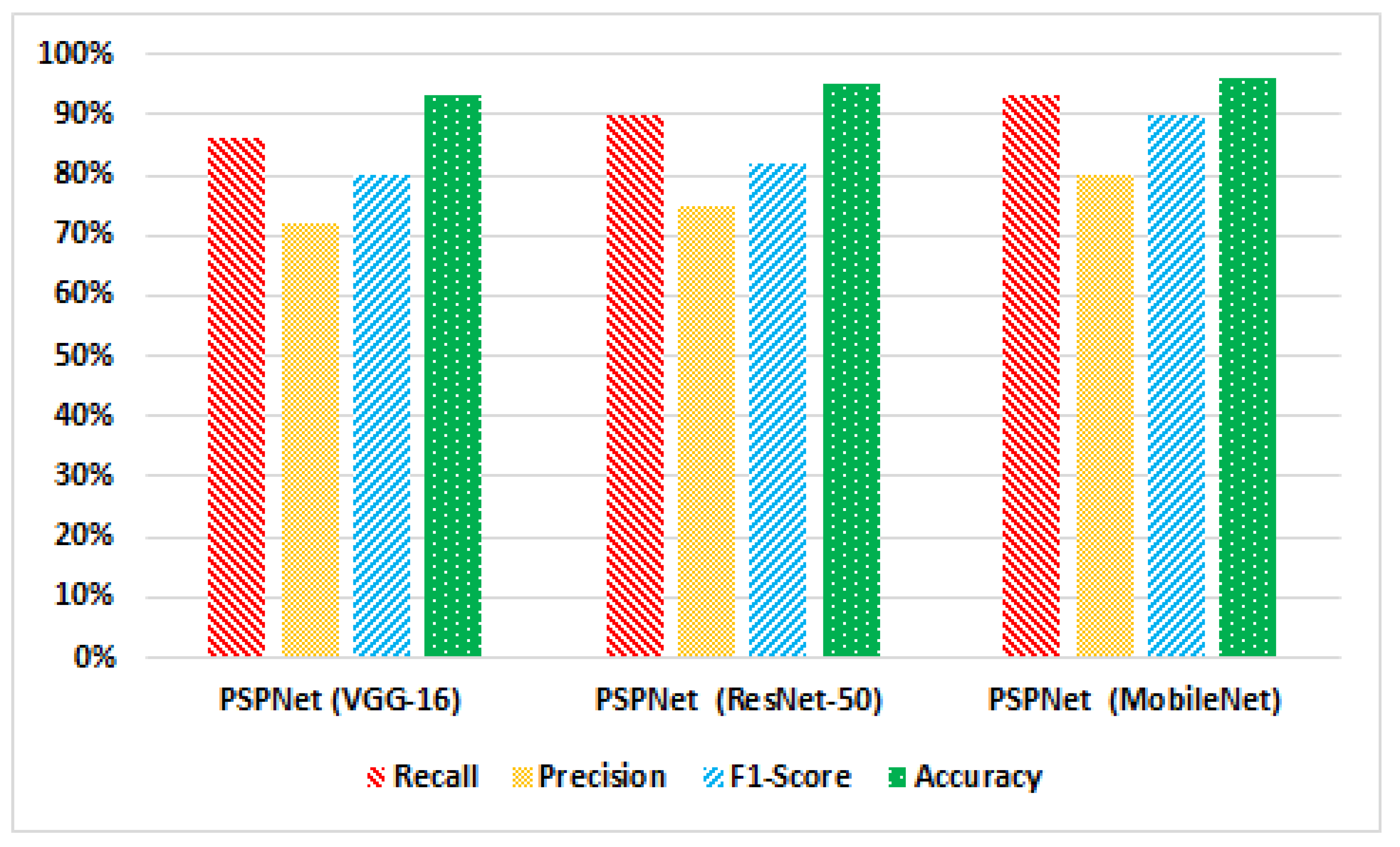
4.4. Performance Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yang, C.; Wong, D.; Miao, Q.; Yang, R. Advanced GeoInformation Science; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Ahmed, I.; Din, S.; Jeon, G.; Piccialli, F. Exploring deep learning models for overhead view multiple object detection. IEEE Internet Things J. 2019, 7, 5737–5744. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Nawaz, M.; Haseeb, K.; Khan, S.; Jeon, G. Efficient topview person detector using point based transformation and lookup table. Comput. Commun. 2019, 147, 188–197. [Google Scholar] [CrossRef]
- Ahmad, M.; Ahmed, I.; Khan, F.A.; Qayum, F.; Aljuaid, H. Convolutional neural network–based person tracking using overhead views. Int. J. Distrib. Sens. Netw. 2020, 16, 1550147720934738. [Google Scholar] [CrossRef]
- Ullah, K.; Ahmed, I.; Ahmad, M.; Rahman, A.U.; Nawaz, M.; Adnan, A. Rotation invariant person tracker using top view. J. Ambient. Intell. Humaniz. Comput. 2019, 1–17. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Jeon, G. A real-time efficient object segmentation system based on U-Net using aerial drone images. J. Real-Time Image Process. 2021, 18, 1745–1758. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Khan, F.A.; Asif, M. Comparison of deep-learning-based segmentation models: Using top view person images. IEEE Access 2020, 8, 136361–136373. [Google Scholar] [CrossRef]
- Pires de Lima, R.; Marfurt, K. Convolutional neural network for remote-sensing scene classification: Transfer learning analysis. Remote Sens. 2020, 12, 86. [Google Scholar] [CrossRef] [Green Version]
- Ahmed, I.; Ahmad, M.; Rodrigues, J.J.; Jeon, G.; Din, S. A deep learning-based social distance monitoring framework for COVID-19. Sustain. Cities Soc. 2021, 65, 102571. [Google Scholar] [CrossRef]
- Ahmad, M.; Ahmed, I.; Ullah, K.; Khan, I.; Khattak, A.; Adnan, A. Person Detection from Overhead View: A Survey. Int. J. Adv. Comput. Sci. Appl. 2019, 10. [Google Scholar] [CrossRef]
- Zaitoun, N.M.; Aqel, M.J. Survey on image segmentation techniques. Procedia Comput. Sci. 2015, 65, 797–806. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image segmentation using deep learning: A survey. IEee Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, I.; Ahmad, M.; Rodrigues, J.J.; Jeon, G. Edge computing-based person detection system for top view surveillance: Using CenterNet with transfer learning. Appl. Soft Comput. 2021, 107, 107489. [Google Scholar] [CrossRef]
- Guzzo, A.; Sacca, D.; Serra, E. An effective approach to inverse frequent set mining. In Proceedings of the 2009 Ninth IEEE International Conference on Data Mining, Miami Beach, FL, USA, 6–9 December 2009; pp. 806–811. [Google Scholar]
- Ahmed, I.; Ahmad, M.; Jeon, G.; Piccialli, F. A framework for pandemic prediction using big data analytics. Big Data Res. 2021, 25, 100190. [Google Scholar] [CrossRef]
- Guzzo, A.; Moccia, L.; Saccà, D.; Serra, E. Solving inverse frequent itemset mining with infrequency constraints via large-scale linear programs. ACM Trans. Knowl. Discov. Data (TKDD) 2013, 7, 1–39. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Ahmad, A.; Jeon, G. Top view multiple people tracking by detection using deep SORT and YOLOv3 with transfer learning: Within 5G infrastructure. Int. J. Mach. Learn. Cybern. 2020, 12, 3053–3067. [Google Scholar] [CrossRef]
- Ahmed, I.; Jeon, G.; Chehri, A.; Hassan, M.M. Adapting Gaussian YOLOv3 with transfer learning for overhead view human detection in smart cities and societies. Sustain. Cities Soc. 2021, 70, 102908. [Google Scholar] [CrossRef]
- Ahmed, I.; Ahmad, M.; Ahmad, A.; Jeon, G. IoT-based crowd monitoring system: Using SSD with transfer learning. Comput. Electr. Eng. 2021, 93, 107226. [Google Scholar] [CrossRef]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chaudhuri, D.; Kushwaha, N.; Samal, A. Semi-automated road detection from high resolution satellite images by directional morphological enhancement and segmentation techniques. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1538–1544. [Google Scholar] [CrossRef]
- Stankov, K.; He, D.C. Detection of buildings in multispectral very high spatial resolution images using the percentage occupancy hit-or-miss transform. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 4069–4080. [Google Scholar] [CrossRef]
- Stankov, K.; He, D.C. Building detection in very high spatial resolution multispectral images using the hit-or-miss transform. IEEE Geosci. Remote Sens. Lett. 2012, 10, 86–90. [Google Scholar] [CrossRef]
- Leninisha, S.; Vani, K. Water flow based geometric active deformable model for road network. ISPRS J. Photogramm. Remote Sens. 2015, 102, 140–147. [Google Scholar] [CrossRef]
- Drăguţ, L.; Csillik, O.; Eisank, C.; Tiede, D. Automated parameterisation for multi-scale image segmentation on multiple layers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 119–127. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ming, D.; Li, J.; Wang, J.; Zhang, M. Scale parameter selection by spatial statistics for GeOBIA: Using mean-shift based multi-scale segmentation as an example. ISPRS J. Photogramm. Remote Sens. 2015, 106, 28–41. [Google Scholar] [CrossRef]
- Li, X.; Cheng, X.; Chen, W.; Chen, G.; Liu, S. Identification of forested landslides using LiDar data, object-based image analysis, and machine learning algorithms. Remote Sens. 2015, 7, 9705–9726. [Google Scholar] [CrossRef] [Green Version]
- Contreras, D.; Blaschke, T.; Tiede, D.; Jilge, M. Monitoring recovery after earthquakes through the integration of remote sensing, GIS, and ground observations: The case of L’Aquila (Italy). Cartogr. Geogr. Inf. Sci. 2016, 43, 115–133. [Google Scholar] [CrossRef]
- Arı, Ç.; Aksoy, S. Detection of compound structures using a Gaussian mixture model with spectral and spatial constraints. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6627–6638. [Google Scholar] [CrossRef]
- Benedek, C.; Shadaydeh, M.; Kato, Z.; Szirányi, T.; Zerubia, J. Multilayer Markov random field models for change detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2015, 107, 22–37. [Google Scholar] [CrossRef] [Green Version]
- Dong, Y.; Du, B.; Zhang, L. Target detection based on random forest metric learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1830–1838. [Google Scholar] [CrossRef]
- Wang, J.; Song, J.; Chen, M.; Yang, Z. Road network extraction: A neural-dynamic framework based on deep learning and a finite state machine. Int. J. Remote Sens. 2015, 36, 3144–3169. [Google Scholar] [CrossRef]
- Jain, A.; Ramaprasad, R.; Narang, P.; Mandal, M.; Chamola, V.; Yu, F.; Guizani, M. AI-enabled Object Detection in UAVs: Challenges, Design Choices, and Research Directions. IEEE Netw. 2021, 35, 129–135. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. In Proceedings of the Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 180–196. [Google Scholar]
- Garg, P.; Chakravarthy, A.S.; Mandal, M.; Narang, P.; Chamola, V.; Guizani, M. Isdnet: Ai-enabled instance segmentation of aerial scenes for smart cities. ACM Trans. Internet Technol. 2020, 21, 1–18. [Google Scholar] [CrossRef]
- Abdollahi, A.; Pradhan, B.; Alamri, A.M. An ensemble architecture of deep convolutional Segnet and Unet networks for building semantic segmentation from high-resolution aerial images. Geocarto Int. 2022, 37, 3355–3370. [Google Scholar] [CrossRef]
- Marcu, A.; Costea, D.; Licaret, V.; Leordeanu, M. Towards automatic annotation for semantic segmentation in drone videos. arXiv 2019, arXiv:1910.10026. [Google Scholar]
- Maulik, U.; Chakraborty, D. Remote Sensing Image Classification: A survey of support-vector-machine-based advanced techniques. IEEE Geosci. Remote Sens. Mag. 2017, 5, 33–52. [Google Scholar] [CrossRef]
- Song, J.; Gao, S.; Zhu, Y.; Ma, C. A survey of remote sensing image classification based on CNNs. Big Earth Data 2019, 3, 232–254. [Google Scholar] [CrossRef]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Object detection in optical remote sensing images: A survey and a new benchmark. ISPRS J. Photogramm. Remote Sens. 2020, 159, 296–307. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1529–1537. [Google Scholar]
- He, C.; Fang, P.; Zhang, Z.; Xiong, D.; Liao, M. An end-to-end conditional random fields and skip-connected generative adversarial segmentation network for remote sensing images. Remote Sens. 2019, 11, 1604. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| S.No | Model Name | ||
|---|---|---|---|
| 1 | U-Net (VGG-16) | 81% | 82% |
| 2 | U-Net (ResNet-50) | 80% | 78% |
| 3 | U-Net (MobileNet) | 83% | 82% |
| 4 | PSPNet (VGG-16) | 80% | 82% |
| 5 | PSPNet (ResNet-50) | 81% | 83% |
| 6 | PSPNet (MobileNet) | 83% | 85% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahmed, I.; Ahmad, M.; Chehri, A.; Hassan, M.M.; Jeon, G. IoT Enabled Deep Learning Based Framework for Multiple Object Detection in Remote Sensing Images. Remote Sens. 2022, 14, 4107. https://doi.org/10.3390/rs14164107
Ahmed I, Ahmad M, Chehri A, Hassan MM, Jeon G. IoT Enabled Deep Learning Based Framework for Multiple Object Detection in Remote Sensing Images. Remote Sensing. 2022; 14(16):4107. https://doi.org/10.3390/rs14164107
Chicago/Turabian StyleAhmed, Imran, Misbah Ahmad, Abdellah Chehri, Mohammad Mehedi Hassan, and Gwanggil Jeon. 2022. "IoT Enabled Deep Learning Based Framework for Multiple Object Detection in Remote Sensing Images" Remote Sensing 14, no. 16: 4107. https://doi.org/10.3390/rs14164107
APA StyleAhmed, I., Ahmad, M., Chehri, A., Hassan, M. M., & Jeon, G. (2022). IoT Enabled Deep Learning Based Framework for Multiple Object Detection in Remote Sensing Images. Remote Sensing, 14(16), 4107. https://doi.org/10.3390/rs14164107