
Semantic Segmentation of Panoramic Images for Real-Time Parking Slot Detection


Abstract
:1. Introduction
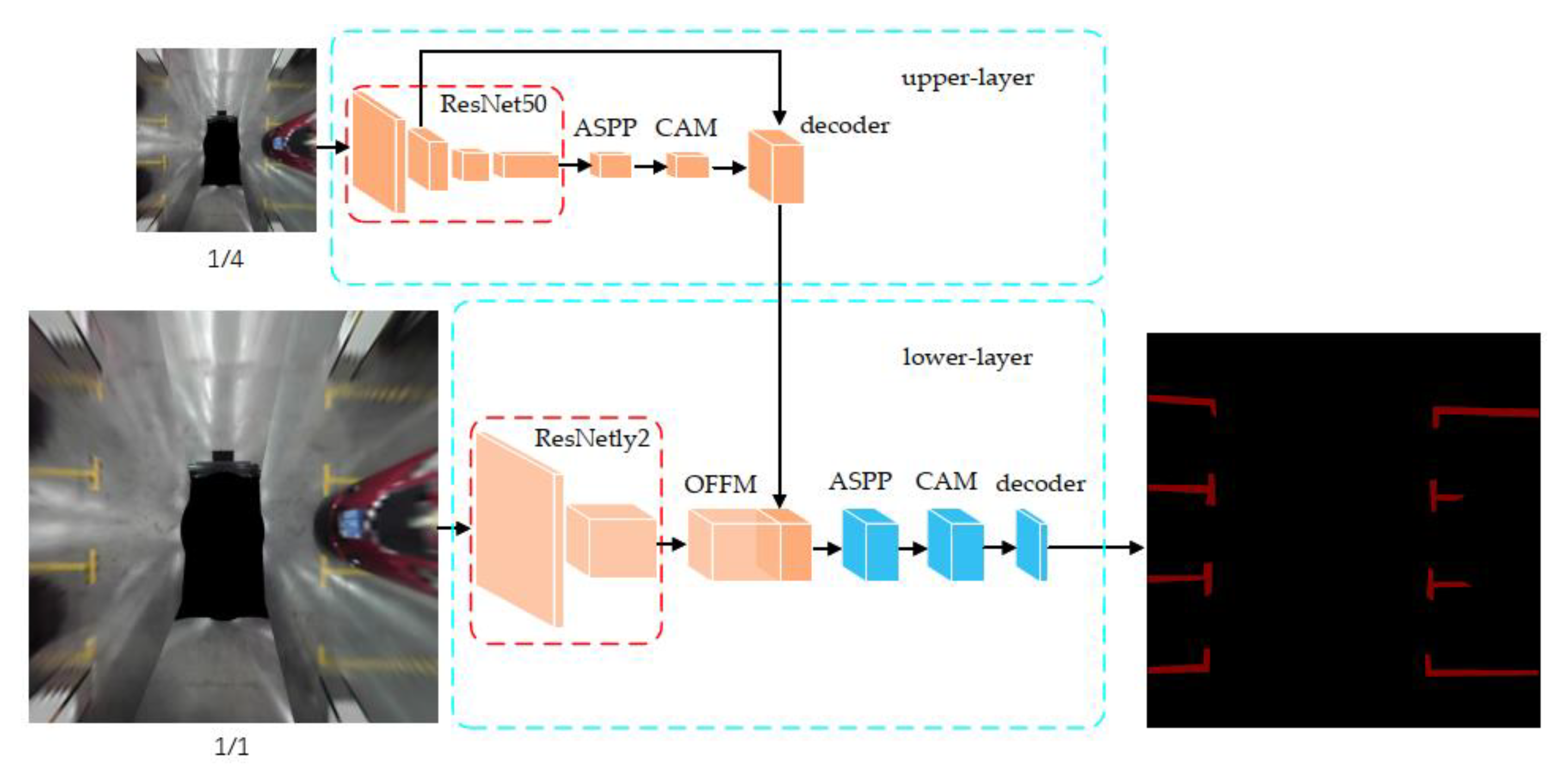
- By cascading multi-scale image information, the number of parameters in the network is effectively reduced, thereby improving computational efficiency. Due to the multi-layers network structure, the upper-layer is responsible for rapid primary information extraction while the lower-layer extracts more details to ensure accuracy. Therefore, based on inheriting the previous advantages of semantic segmentation networks, the proposed network structure maintains recognition accuracy while achieving real-time parking slot detection.
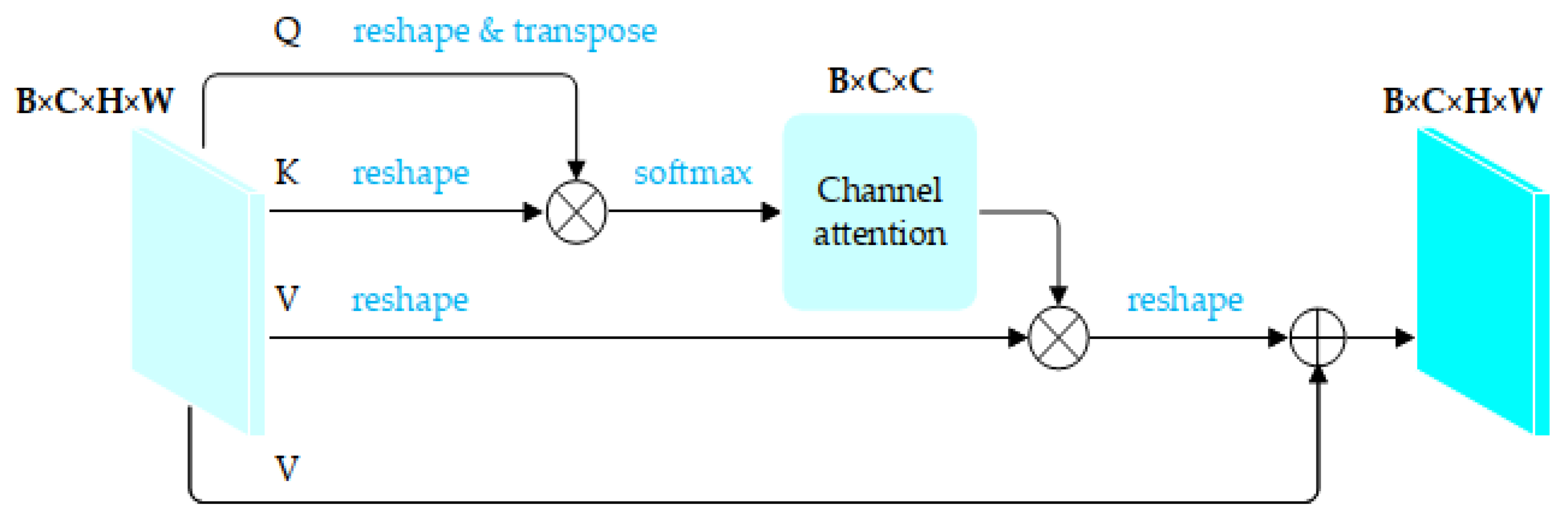
- Using the self-attention mechanism for channel domains, the ability to recognize small lines in the image is effectively improved. Pixel accuracy and the mIoU of the network are improved.
- The adaptive weighted loss function based on weighted cross-entropy is proposed to solve the imbalance of data and classification effectively. The average improvement in mIoU is almost 2% for small proportion categories.
2. Related Work
3. Proposed Method
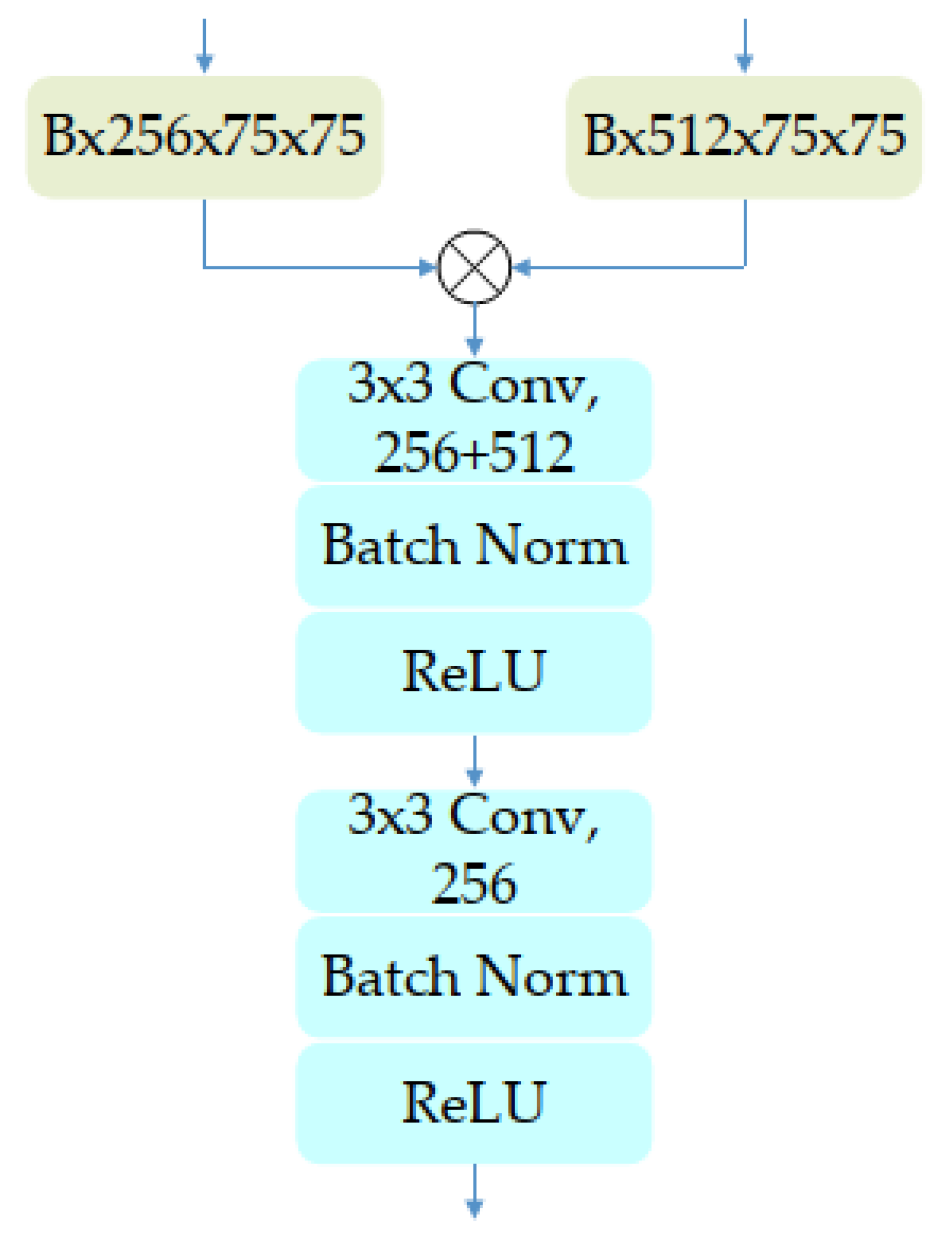
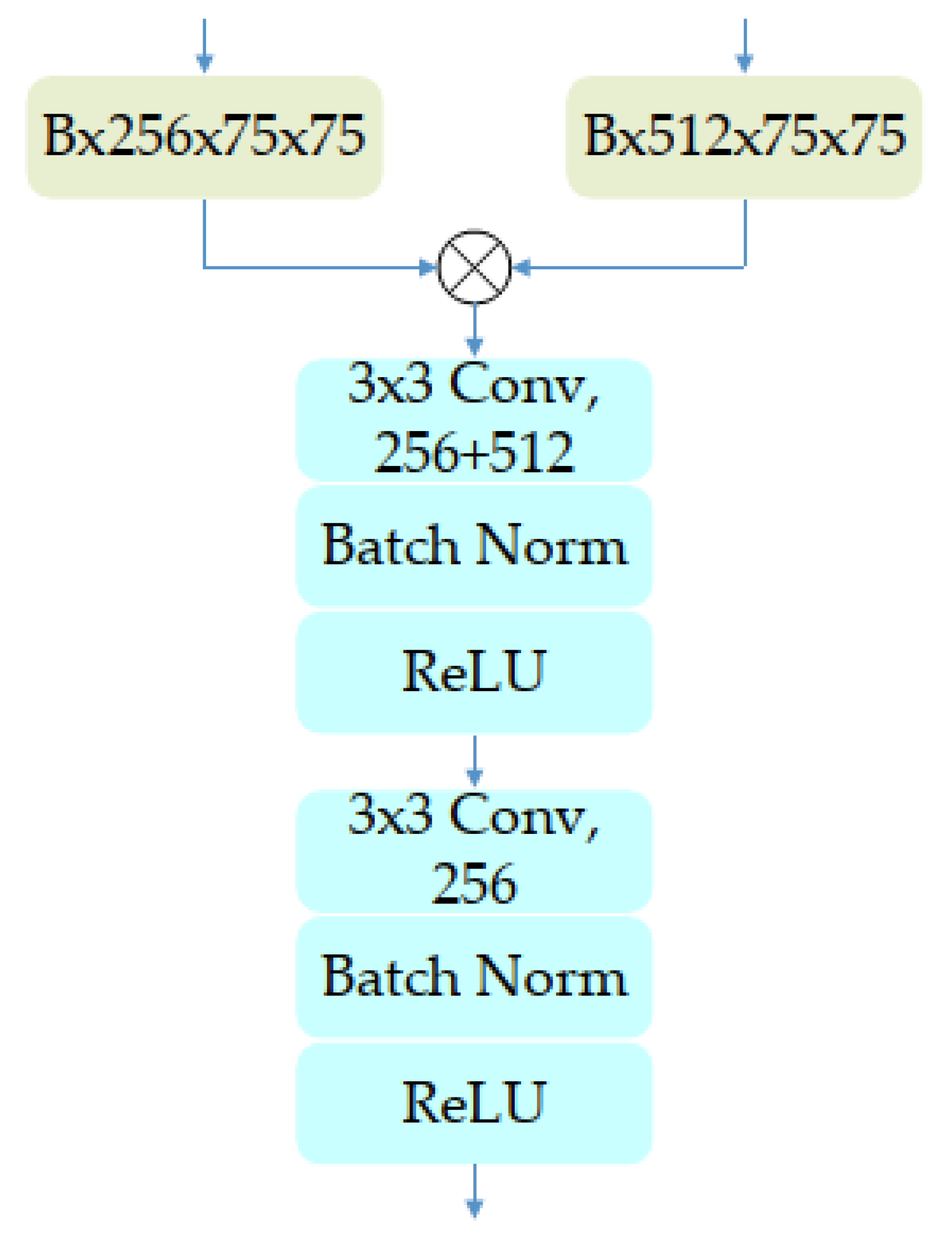
3.1. Multi-Layers Network Structure
3.2. Self-Attention Mechanism for Channel Domain
3.3. Adaptive Weighted Cross-Entropy Loss Function
4. Experiments and Results
4.1. Ablation Study
- 1.
- The total amount of trainable parameters for ResNetly2 with 600 600 input size is 1,444,928, which is about 6% of the original ResNet50 with the same input size because the network structures of these two comparison items are different;
- 2.
- The total amount of trainable parameters for those two entire ResNet50s, with either 600 600 or 300 300 input sizes, is 25,557,032 and the total number of integer floating-point calculations for the entire ResNet50 with 300 300 input size is about 23.2% of that with 600 600 input size because the input size is only 1/4 of the original input. This brings compression of all feature map sizes.
- This work decomposes a traditional single-layer network problem into two sub-problems. There is no causal relationship between the calculations of the upper-layer and the lower-layer, and these calculations can be processed in parallel; limited by the ResNetly2_600 branch, processing time is 64% of that of the single-layer network (Table 2);
- Usually, the cost of splitting a complex problem into two simpler independent problems indicates an increment in total processing cost, which is the general cost of problem simplification. In contrast, the total amount of calculation of the two-layers network structure is 66.55% of that of the traditional method (Table 1), which contributes to a computationally efficient architecture.
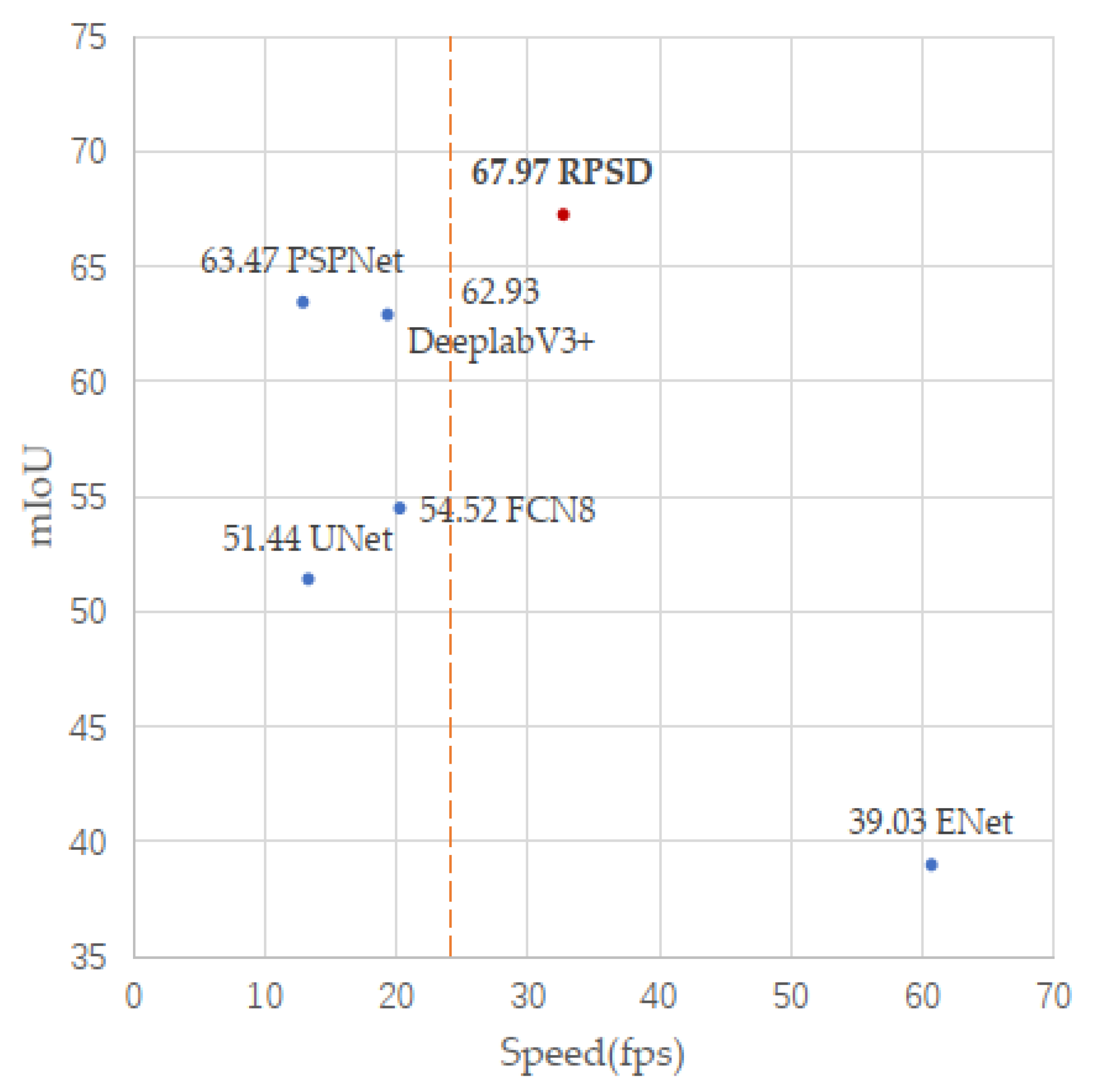
4.2. Results with the PSV Dataset
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Arnott, R.; Williams, P. Cruising for parking around a circle. Transp. Res. Part B Methodol. 2017, 104, 357–375. [Google Scholar] [CrossRef] [Green Version]
- Wada, M.; Yoon, K.S.; Hashimoto, H. Development of advanced parking assistance system. IEEE Trans. Ind. Electron. 2003, 50, 4–17. [Google Scholar] [CrossRef]
- Allianz, S.E. A Sudden Bang When Parking. 2015. Available online: https://www.allianz.com/en/press/news/commitment/community/150505-a-sudden-bang-when-parking.html (accessed on 28 April 2020).
- Horgan, J.; Hughes, C.; McDonald, J.; Yogamani, S. Vision-Based Driver Assistance Systems: Survey, Taxonomy and Advances. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 2032–2039. [Google Scholar]
- SAE. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles; SAE International: Warrendale, PA, USA, 2021. [Google Scholar]
- Kotb, A.O.; Shen, Y.-C.; Huang, Y. Smart Parking Guidance, Monitoring and Reservations: A Review. IEEE Intell. Transp. Syst. Mag. 2017, 9, 6–16. [Google Scholar] [CrossRef]
- Banzhaf, H.; Nienhüser, D.; Knoop, S.; Zöllner, J.M. The future of parking: A survey on automated valet parking with an outlook on high density parking. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 1827–1834. [Google Scholar]
- Lin, T.; Rivano, H.; Le Mouel, F. A Survey of Smart Parking Solutions. IEEE Trans. Intell. Transp. Syst. 2017, 18, 3229–3253. [Google Scholar] [CrossRef] [Green Version]
- Wada, M.; Yoon, K.; Hashimoto, H.; Matsuda, S. Development of advanced parking assistance system using human guidance. In Proceedings of the 1999 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (Cat. No. 99TH8399), Atlanta, GA, USA, 19–23 September 1999; pp. 997–1002. [Google Scholar]
- Zadobrischi, E. Analysis and Experiment of Wireless Optical Communications in Applications Dedicated to Mobile Devices with Applicability in the Field of Road and Pedestrian Safety. Sensors 2022, 22, 1023. [Google Scholar] [CrossRef] [PubMed]
- Zadobrischi, E.; Dimian, M. Inter-Urban Analysis of Pedestrian and Drivers through a Vehicular Network Based on Hybrid Communications Embedded in a Portable Car System and Advanced Image Processing Technologies. Remote Sens. 2021, 13, 1234. [Google Scholar] [CrossRef]
- Naudts, D.; Maglogiannis, V.; Hadiwardoyo, S.; van den Akker, D.; Vanneste, S.; Mercelis, S.; Hellinckx, P.; Lannoo, B.; Marquez-Barja, J.; Moerman, I. Vehicular Communication Management Framework: A Flexible Hybrid Connectivity Platform for CCAM Services. Future Internet 2021, 13, 81. [Google Scholar] [CrossRef]
- Zhang, L.; Huang, J.; Li, X.; Xiong, L. Vision-based Parking-slot Detection: A DCNN-based Approach and A Large-scale Benchmark Dataset. IEEE Trans. Image Process. 2018, 27, 5350–5364. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. NIPS 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Zhang, L.; Li, X.; Huang, J.; Shen, Y.; Wang, D. Vision-Based Parking-Slot Detection: A Benchmark and a Learning-Based Approach. Symmetry 2018, 10, 64. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 3431–3440. [Google Scholar]
- Li, W.; Cao, L.; Yan, L.; Li, C.; Feng, X.; Zhao, P. Vacant Parking Slot Detection in the Around View Image Based on Deep Learning. Sensors 2020, 20, 2138. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schneider, L.; Cordts, M.; Rehfeld, T.; Pfeiffer, D.; Enzweiler, M.; Franke, U.; Pollefeys, M.; Roth, S. Semantic stixels: Depth is not enough. In Proceedings of the 2016 IEEE Intelligent Vehicles Symposium (IV), Gothenburg, Sweden, 19–22 June 2016; pp. 110–117. [Google Scholar]
- Wu, Z.; Sun, W.; Wang, M.; Wang, X.; Ding, L.; Wang, F. PSDet: Efficient and Universal Parking Slot Detection. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October 2020–13 November 2020; pp. 290–297. [Google Scholar]
- Wu, Y.; Yang, T.; Zhao, J.; Guan, L.; Jiang, W. Vh-hfcn based parking slot and lane markings segmentation on panoramic surround view. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1767–1772. [Google Scholar]
- Jiang, W.; Wu, Y.; Guan, L.; Zhao, J. Dfnet: Semantic segmentation on panoramic images with dynamic loss weights and residual fusion block. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5887–5892. [Google Scholar]
- Zadobrischi, E.; Dimian, M.; Negru, M. The Utility of DSRC and V2X in Road Safety Applications and Intelligent Parking: Similarities, Differences, and the Future of Vehicular Communication. Sensors 2021, 21, 7237. [Google Scholar] [CrossRef] [PubMed]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018. [Google Scholar]
- Lee, S.; Kim, J.; Shin Yoon, J.; Shin, S.; Bailo, O.; Kim, N.; Lee, T.-H.; Seok Hong, H.; Han, S.-H.; So Kweon, I. Vpgnet: Vanishing point guided network for lane and road marking detection and recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1947–1955. [Google Scholar]
- Wang, Z.; Ren, W.; Qiu, Q. Lanenet: Real-time lane detection networks for autonomous driving. arXiv 2018, arXiv:1807.01726. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection cnns by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Yan, M.; Wang, J.; Li, J.; Zhang, K.; Yang, Z. Traffic scene semantic segmentation using self-attention mechanism and bi-directional GRU to correlate context. Neurocomputing 2020, 386, 293–304. [Google Scholar] [CrossRef]
- Li, J.; Jiang, F.; Yang, J.; Kong, B.; Gogate, M.; Dashtipour, K.; Hussain, A. Lane-DeepLab: Lane semantic segmentation in automatic driving scenarios for high-definition maps. Neurocomputing 2021, 465, 15–25. [Google Scholar] [CrossRef]
- Aznar-Poveda, J.; Egea-López, E.; García-Sánchez, A.-J. Cooperative Awareness Message Dissemination in EN 302 637-2: An Adaptation for Winding Roads. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–5. [Google Scholar]
- Jang, C.; Kim, C.; Lee, S.; Kim, S.; Lee, S.; Sunwoo, M. Re-Plannable Automated Parking System With a Standalone Around View Monitor for Narrow Parking Lots. IEEE Trans. Intell. Transp. Syst. 2020, 21, 777–790. [Google Scholar] [CrossRef]
- Kumar, V.R.; Hiremath, S.A.; Bach, M.; Milz, S.; Witt, C.; Pinard, C.; Yogamani, S.; Mäder, P. Fisheyedistancenet: Self-supervised scale-aware distance estimation using monocular fisheye camera for autonomous driving. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 574–581. [Google Scholar]
- Lai, C.; Luo, W.; Chen, S.; Li, Q.; Yang, Q.; Sun, H.; Zheng, N. Zynq-based full HD around view monitor system for intelligent vehicle. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1079–1082. [Google Scholar]
- Liu, Y.-C.; Lin, K.-Y.; Chen, Y.-S. Bird’s-eye view vision system for vehicle surrounding monitoring. In Proceedings of the International Workshop on Robot Vision, Auckland, New Zealand, 18–20 February 2008; pp. 207–218. [Google Scholar]
- Andrew, A.M. Multiple view geometry in computer vision. Kybernetes 2001, 30, 1333–1341. [Google Scholar] [CrossRef]
- Liu, W.; Xu, Z. Some practical constraints and solutions for optical camera communication. Philos. Trans. A Math. Phys. Eng. Sci. 2020, 378, 20190191. [Google Scholar] [CrossRef] [Green Version]
- Hughes, C.; Jones, E.; Glavin, M.; Denny, P. Validation of polynomial-based equidistance fish-eye models. In Proceedings of the IET Irish Signals and Systems Conference (ISSC 2009), Dublin, Ireland, 10–11 June 2009. [Google Scholar]
- Zhang, Z. A flexible new technique for camera calibration. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1330–1334. [Google Scholar] [CrossRef] [Green Version]
- Hughes, C.; Denny, P.; Jones, E.; Glavin, M. Accuracy of fish-eye lens models. Appl. Opt. 2010, 49, 3338–3347. [Google Scholar] [CrossRef] [Green Version]
- Suhr, J.K.; Jung, H.G. Fully-automatic recognition of various parking slot markings in Around View Monitor (AVM) image sequences. In Proceedings of the 2012 15th International IEEE Conference on Intelligent Transportation Systems, Anchorage, AK, USA, 16–19 September 2012; pp. 1294–1299. [Google Scholar]
- Suhr, J.K.; Jung, H.G. Sensor Fusion-Based Vacant Parking Slot Detection and Tracking. IEEE Trans. Intell. Transp. Syst. 2014, 15, 21–36. [Google Scholar] [CrossRef]
- Suhr, J.K.; Jung, H.G. Automatic Parking Space Detection and Tracking for Underground and Indoor Environments. IEEE Trans. Ind. Electron. 2016, 63, 5687–5698. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6230–6239. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Zhao, H.; Qi, X.; Shen, X.; Shi, J.; Jia, J. Icnet for real-time semantic segmentation on high-resolution images. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 405–420. [Google Scholar]
- Yang, T.; Wu, Y.; Zhao, J.; Guan, L. Semantic Segmentation via Highly Fused Convolutional Network with Multiple Soft Cost Functions. Cogn. Syst. Res. 2018, 53, 20–30. [Google Scholar] [CrossRef] [Green Version]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-attention generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 7354–7363. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1743–1751. [Google Scholar]
- Sun, K.; Zhao, Y.; Jiang, B.; Cheng, T.; Xiao, B.; Liu, D.; Mu, Y.; Wang, X.; Liu, W.; Wang, J. High-resolution representations for labeling pixels and regions. arXiv 2019, arXiv:1904.04514. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation; Springer: Cham, Switzerland, 2019. [Google Scholar]
- Hu, P.; Perazzi, F.; Heilbron, F.C.; Wang, O.; Lin, Z.; Saenko, K.; Sclaroff, S.; Letters, A. Real-time semantic segmentation with fast attention. IEEE Robot. Autom. Lett. 2020, 6, 263–270. [Google Scholar] [CrossRef]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The Cityscapes Dataset for Semantic Urban Scene Understanding. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2009, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Total Params | Total Flops (GFlops) | Total MAdd (GMAdd) |
|---|---|---|---|
| ResNet50_600 | 25,557,032 | 28.58 | 57.04 |
| ResNetly2_600 | 1,444,928 | 12.39 | 24.7 |
| ResNet50_300 | 25,557,032 | 6.63 | 13.23 |
| Methods | Total Time (s) | Speed (fps) |
|---|---|---|
| ResNet50_600 | 100.89 | 99.12 |
| ResNetly2_600 | 63.66 | 157.08 |
| ResNet50_300 | 31.39 | 318.57 |
| Methods | Pixel_Accu | mIoU | Speed (ms) |
|---|---|---|---|
| w/o Att. | 98.34% | 47.06% | 20 |
| Channel-att. | 98.41% | 48.15% | 21 |
| Methods | White Dashed | Yellow Solid |
|---|---|---|
| w/o apt weight loss | 25.38% | 49.93% |
| apt weight loss | 27.19% | 51.25% |
| Methods | Background | Parking | White Solid | White Dashed | Yellow Solid | Yellow Dashed | Pixel Accu | mIoU | Speed (fps) |
|---|---|---|---|---|---|---|---|---|---|
| FCN8 [28] | 98.05 | 49.59 | 49.13 | 27.75 | 50.43 | 52.15 | 98.07 | 54.52 | 20.24 |
| U-Net [29] | 98.91 | 62.30 | 61.28 | 11.01 | 25.87 | 49.24 | 98.87 | 51.44 | 13.28 |
| ENet [36] | 98.56 | 50.26 | 45.97 | 0.00 | 0.00 | 39.45 | 98.42 | 39.03 | 60.71 |
| DeeplabV3+ [33] | 98.82 | 60.51 | 60.72 | 32.00 | 70.29 | 55.20 | 98.84 | 62.93 | 19.31 |
| PSPNet [30] | 98.92 | 63.56 | 62.38 | 35.02 | 68.16 | 52.77 | 98.93 | 63.47 | 12.87 |
| VH-HFCN [10] | 96.22 | 36.16 | 39.56 | 21.46 | 47.64 | 38.03 | 96.25 | 46.51 | <2.78 1 |
| DFNet [27] | 98.45 | 58.40 | 59.80 | 49.90 | 68.32 | 64.32 | 98.47 | 66.53 | 9.09 2 |
| RPSD (this work) | 99.00 | 65.36 | 64.95 | 36.37 | 71.59 | 70.57 | 99.01 | 67.97 | 32.69 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lai, C.; Yang, Q.; Guo, Y.; Bai, F.; Sun, H. Semantic Segmentation of Panoramic Images for Real-Time Parking Slot Detection. Remote Sens. 2022, 14, 3874. https://doi.org/10.3390/rs14163874
Lai C, Yang Q, Guo Y, Bai F, Sun H. Semantic Segmentation of Panoramic Images for Real-Time Parking Slot Detection. Remote Sensing. 2022; 14(16):3874. https://doi.org/10.3390/rs14163874
Chicago/Turabian StyleLai, Cong, Qingyu Yang, Yixin Guo, Fujun Bai, and Hongbin Sun. 2022. "Semantic Segmentation of Panoramic Images for Real-Time Parking Slot Detection" Remote Sensing 14, no. 16: 3874. https://doi.org/10.3390/rs14163874
APA StyleLai, C., Yang, Q., Guo, Y., Bai, F., & Sun, H. (2022). Semantic Segmentation of Panoramic Images for Real-Time Parking Slot Detection. Remote Sensing, 14(16), 3874. https://doi.org/10.3390/rs14163874