
Offshore Oil Slick Detection: From Photo-Interpreter to Explainable Multi-Modal Deep Learning Models Using SAR Images and Contextual Data

 , ,
, ,  , , and
, , and
Abstract
:1. Introduction
1.1. Offshore Oil Slick Detection and the Related Literature
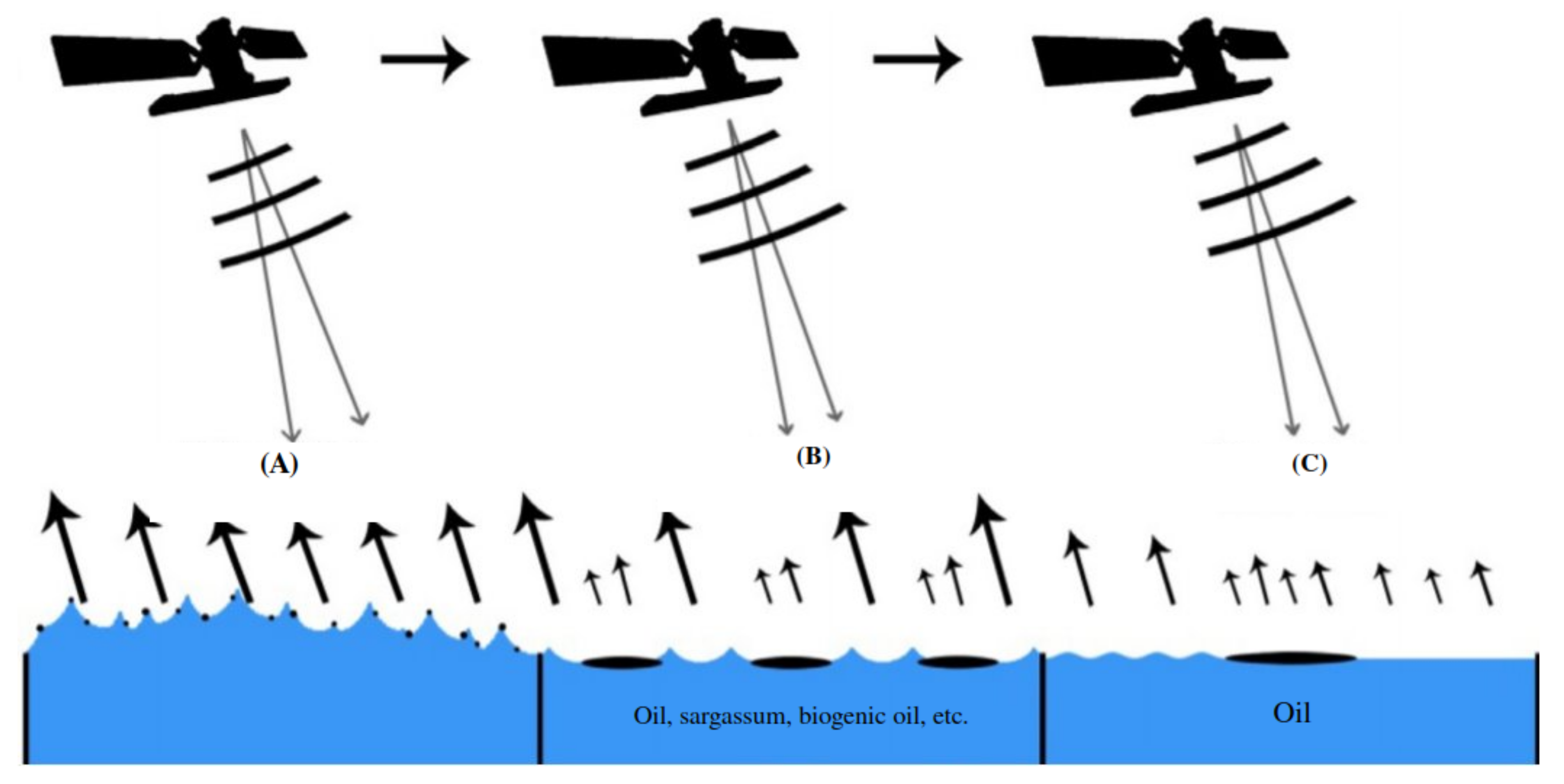
1.1.1. Oil Slick Observation on the Sea Surface
1.1.2. Contextual Data: Impact on Oil Slick Detection
1.1.3. Classical Methods for Oil Slick Detection
1.1.4. Deep Learning Methods for Oil Slick Detection
2. Materials and Methods
2.1. Oil Slicks Segmentation Methods
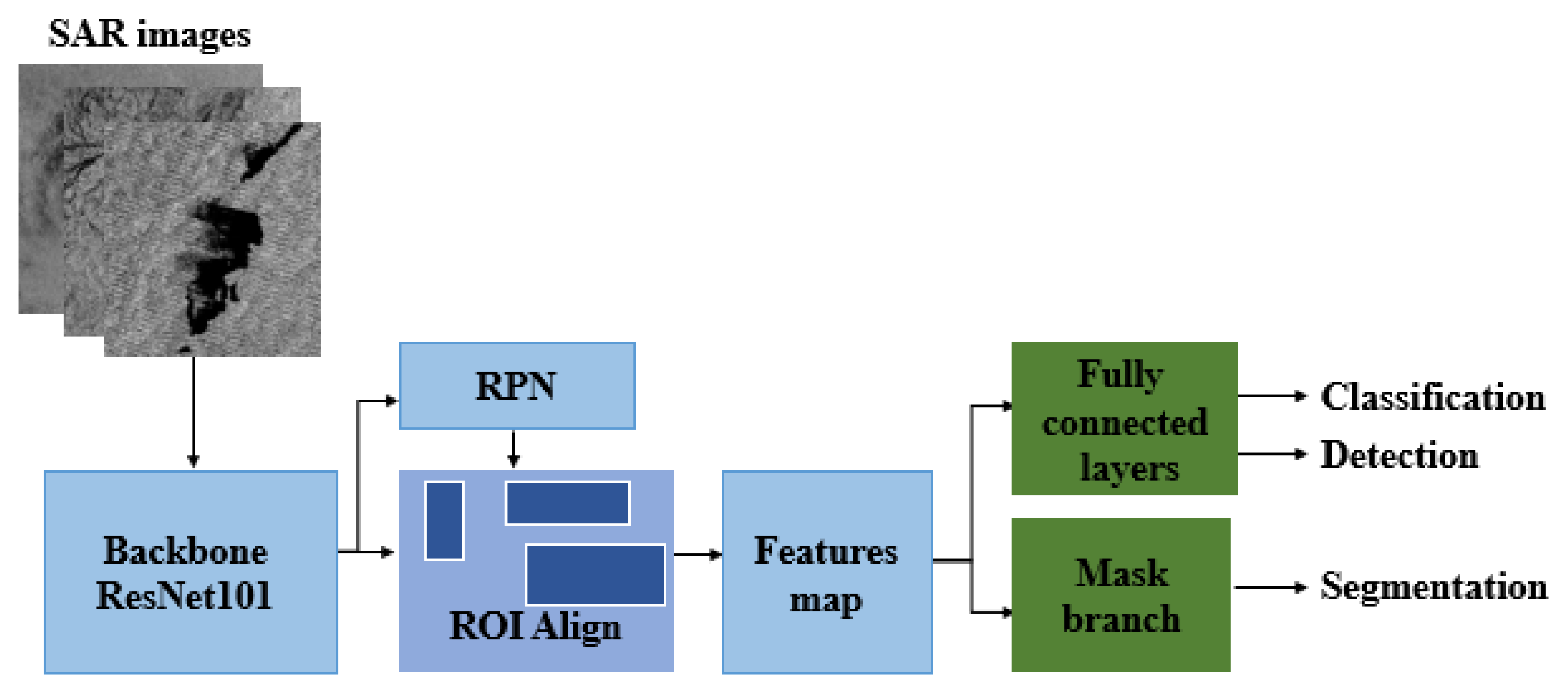
2.1.1. Instance Segmentation: Mask R-CNN
2.1.2. Model Parameters Configuration
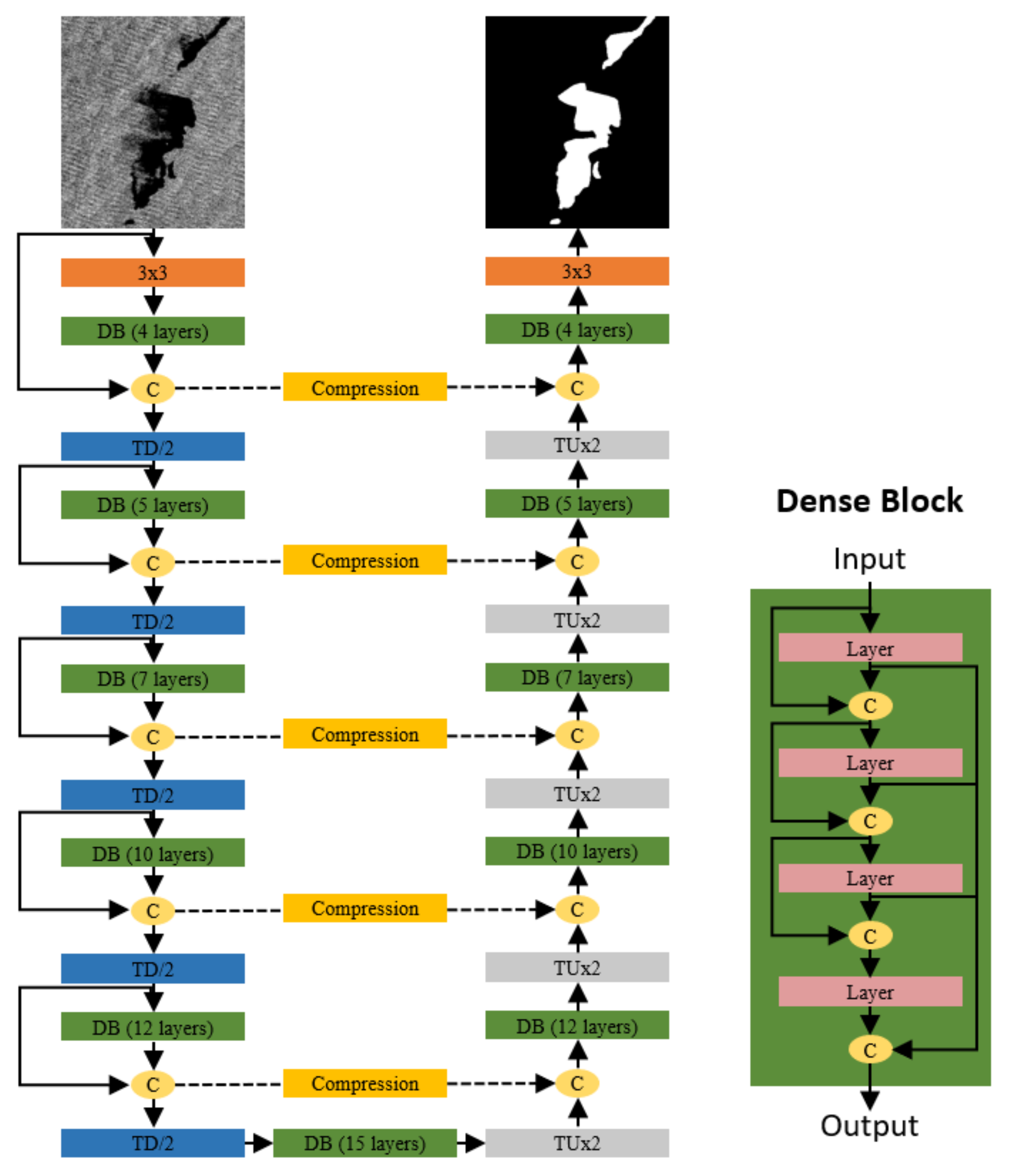
2.1.3. Semantic Segmentation: FC-DenseNet
2.1.4. Model Parameters Configuration
- Optimizer: Different gradient-based optimization algorithms of objective functions have been introduced so far, such as Stochastic Gradient Descent (SGD) [39], Adam [40], and RMSprop [40]. Driven by the work of Kingma et al. [40], we use the Adam algorithm in our work. It is computationally efficient, requires little memory, is invariant to the diagonal scaling of gradients, and is well suited to large problems in terms of data and/or parameters. We consider an initial learning rate of 0.00005 to begin the learning. Subsequently, a learning rate decay policy is applied: it is reduced by a factor of ten if the validation loss has not improved in the last 150 epochs. This latency time does not result in an over-fitting, thanks to the dropout existing in all the model layers.
- Loss function: An extreme imbalance is observed between foreground (slicks) and background (sea) classes on the considered data collections. A set of losses has been experimented with, such as focal loss [36], dice loss [41], and cross-entropy. The main objective is to select a loss taking into account the class imbalance, focusing the training on difficult cases. The loss chosen based on the experiment is the sum of the dice loss and the cross-entropy.
- Batch size: Batch size, rather than optimizing the network from one sample at a time, leading to non-optimal solutions, averaging the errors over a set of samples has proven to be more efficient. We use a batch of 4 samples due to hardware limitations.
- Model depth and width: We experiment FC-DenseNet with various hyper-parameter combinations controlling model depth (number of dense blocks) and width (number of neurons per layer, also referred to as growth rate). Experiments show that a higher depth gives the best results. We chose to set the number of dense blocks to 5 and the number of feature maps per layer to 16. Thus, the total number of parameters of the corresponding model is about 8 M.
2.1.5. FC-DenseNet Model Enhancements
- Layer initialization: The choice of initial parameter values for gradient-based optimization is very crucial. Following [42], we chose random orthogonal initial weights to start with complementary operators and to accelerate the convergence compared to a Gaussian initialization. Such an approach indeed leads to faithful gradient propagation, even in deep non-linear networks, by combating exploding and vanishing gradients. Further, regarding the initialization of the last linear classification layer, it is common to use a bias b = 0. However, Lin et al. [36] point out that this could cause instability during training for obtaining class probabilities. Therefore, for training, we initialize the bias of the last layer as , where where C is the number of classes.
- Non-linearity: In the original FC-DenseNet model, is considered as an activation function. Its main advantage is the non-saturation of its gradient, which leads to faster convergence of the training process [43]. Improved versions of ReLU activation have been proposed, such as Leaky-ReLU [44]. Such activation enables the transformation of the negative input signal instead of canceling it as for ReLU. This activation can interest classical model structures with no or few skip connections to avoid losing important information. However, the dense blocks of the model allow all the data to be shared across layers with dense connections, thus maximizing feature reuse before applying activation functions and justifying the use of RELU.
- Model regularization: Original FC-DenseNet relies on batch normalization with large batch size. However, small batch size is required to handle large images while working with limited GPU memory. In this situation, batch normalization is discarded. A chosen alternative is the use of Spectrum Restricted Isometry (SRIP) weights regularization [45] for all but the last layer. This regularization technique does not induce additional computation at test time and provides notable advantages: it ensures feature normalization while maintaining the orthogonality of neuron parameters throughout the training, which is complementary to the initialization strategy [45]. This approach then ensures that neural kernels act in a complementary way, which is relevant when dealing with few feature maps per layer as for the FC-DenseNet structure.
- Skip connection compression: It aims at reducing the size of the features passed from the encoding part to the decoding one. Actually, for the vanilla FC-DenseNet, the dimensions of the low-level features outing from the encoder to be fused with the decoder features are higher than their counterpart. A compression then allows for a balance of feature dimensions and reduces model complexity on the decoder side. In this work, compression consists of 1 × 1 convolutions. The compression ratio is adjusted so that the feature maps of the skip connections and the previous dense block have the same size before they are concatenated.
- Upsampling: Transposed convolutions are generally considered but tend to introduce checkerboard artifacts on the outputs [46]. An alternative is to separate upsampling to a higher resolution from convolutions to compute features. We then first resize the image using nearest-neighbor interpolation and then apply 2D convolution layers as proposed in [47].
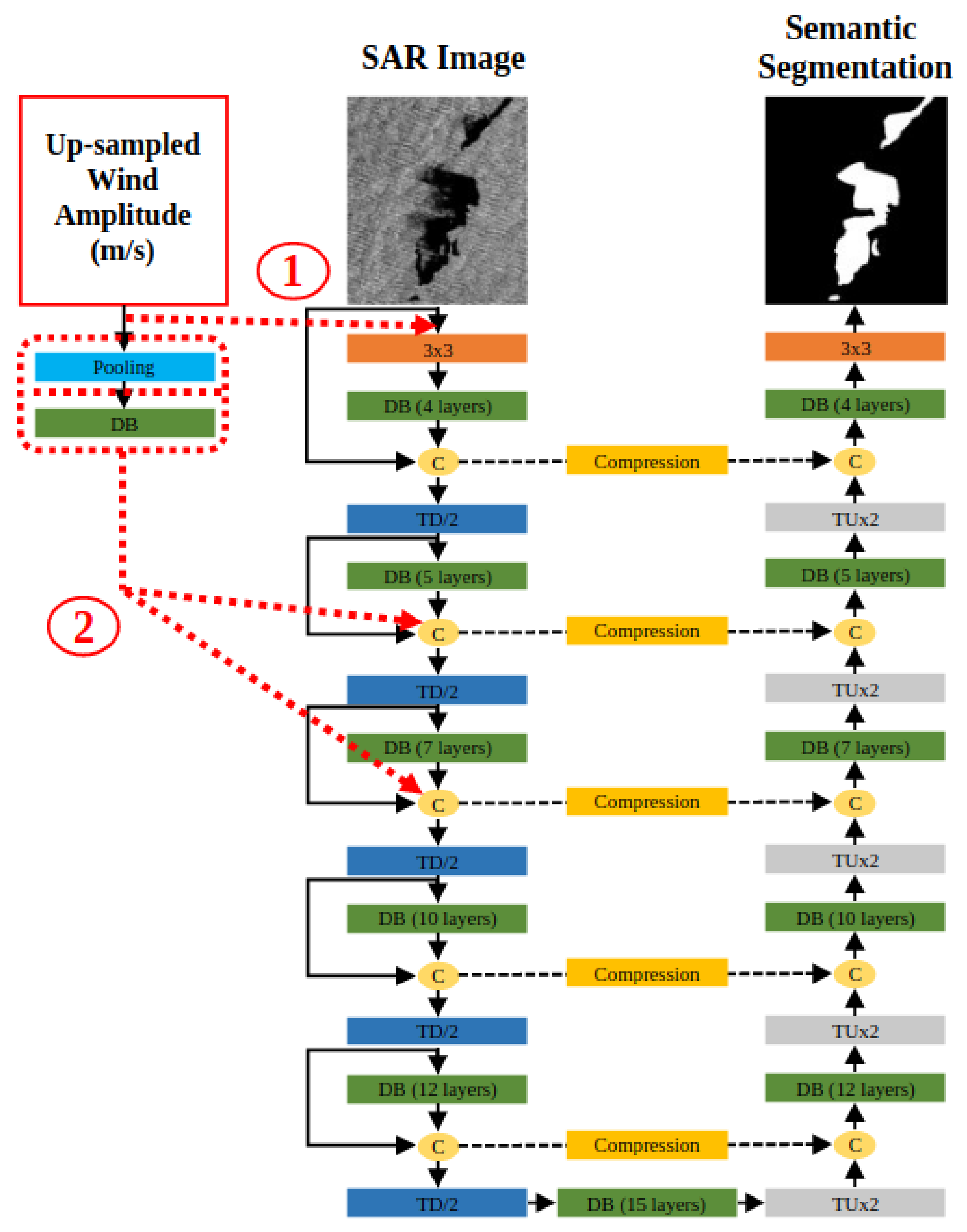
2.1.6. Detecting from Heterogeneous Sources, Fuse-FC-DenseNet
- (1)
- Early fusion: Wind and SAR modalities are considered at the same level. Thus, the network input consists of the SAR data channel and the corresponding wind speed channel, resampled during the data processing step to match the SAR image resolution.
- (2)
- Late fusion: The SAR and wind modalities are considered as two specific input channels with their separate layers before their fusion. In this approach, while keeping the enhanced FC-DenseNet structure for the SAR data, the wind modality is introduced in subsequent dense blocks along the model encoding path. The merging process is performed after the second or third block so that the wind features at their original scale are fused with the SAR features when the latter reach a similar resolution after a few downscaling steps along the encoding section. As for the general DenseNet approach, this fusion operation consists of concatenating the features of each channel. Regarding the processing of wind channels, several strategies can be investigated. In this paper, we consider two approaches: (i) applying a simple average pooling to adjust feature scales and (ii) applying mean clustering and then extracting higher-level features with a dense block.
2.2. Experimental Data
- Sentinel-1 SAR data: Acquired by the European Space Agency (ESA) organization in Interferometric Wide-swath Mode, C-band (5.40 GHz) and with a 10 m resolution per pixel. The level of signal backscattered by the sea surface is higher for vertically polarized waves (V) than for horizontally polarized waves (H) [48]. Hence, vertical polarizations for transmission and reception (VV channel) are selected as they are generally preferred to the HH channel for ocean studies [49]. A set of 1428 images is considered in this study.
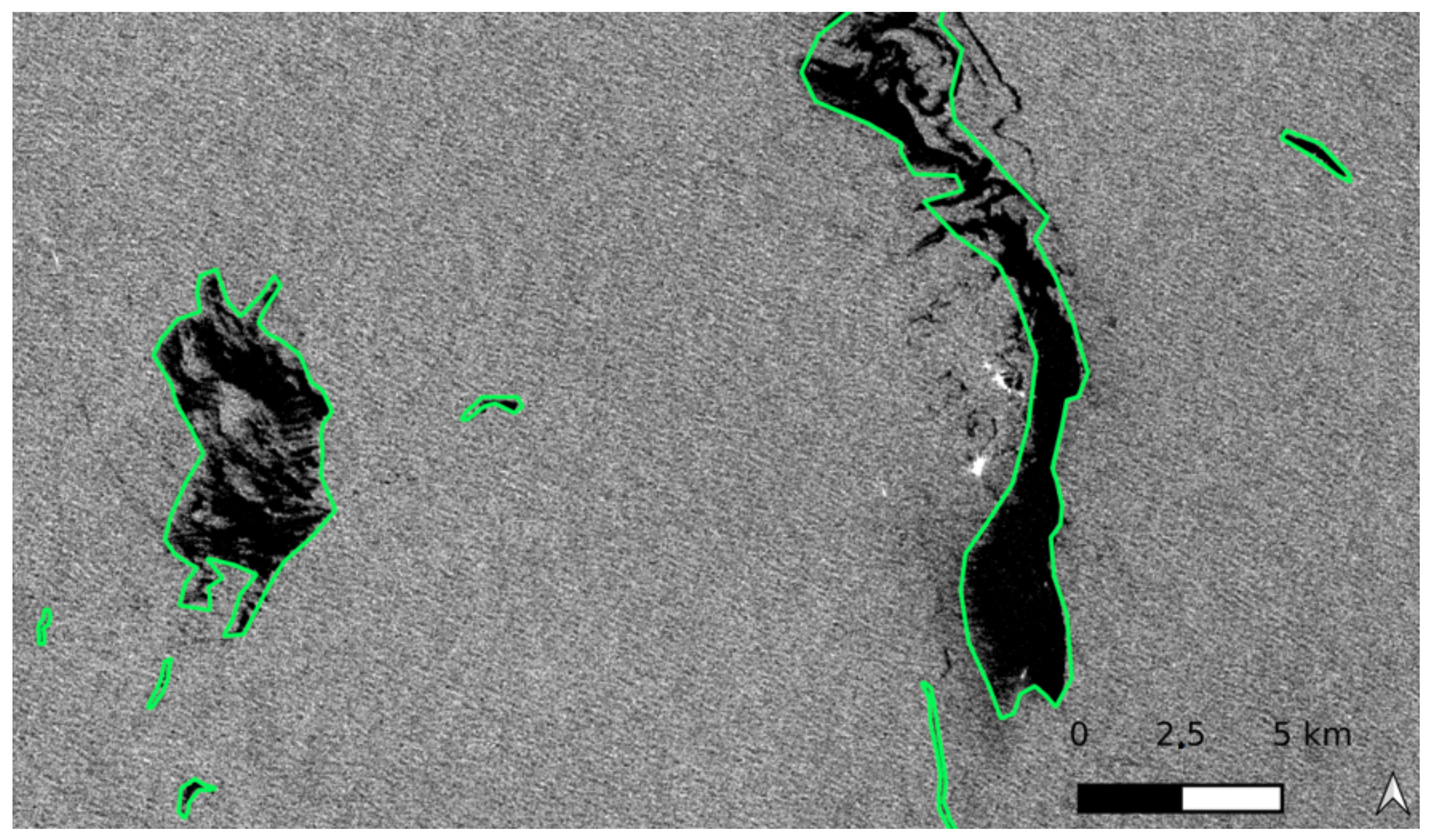
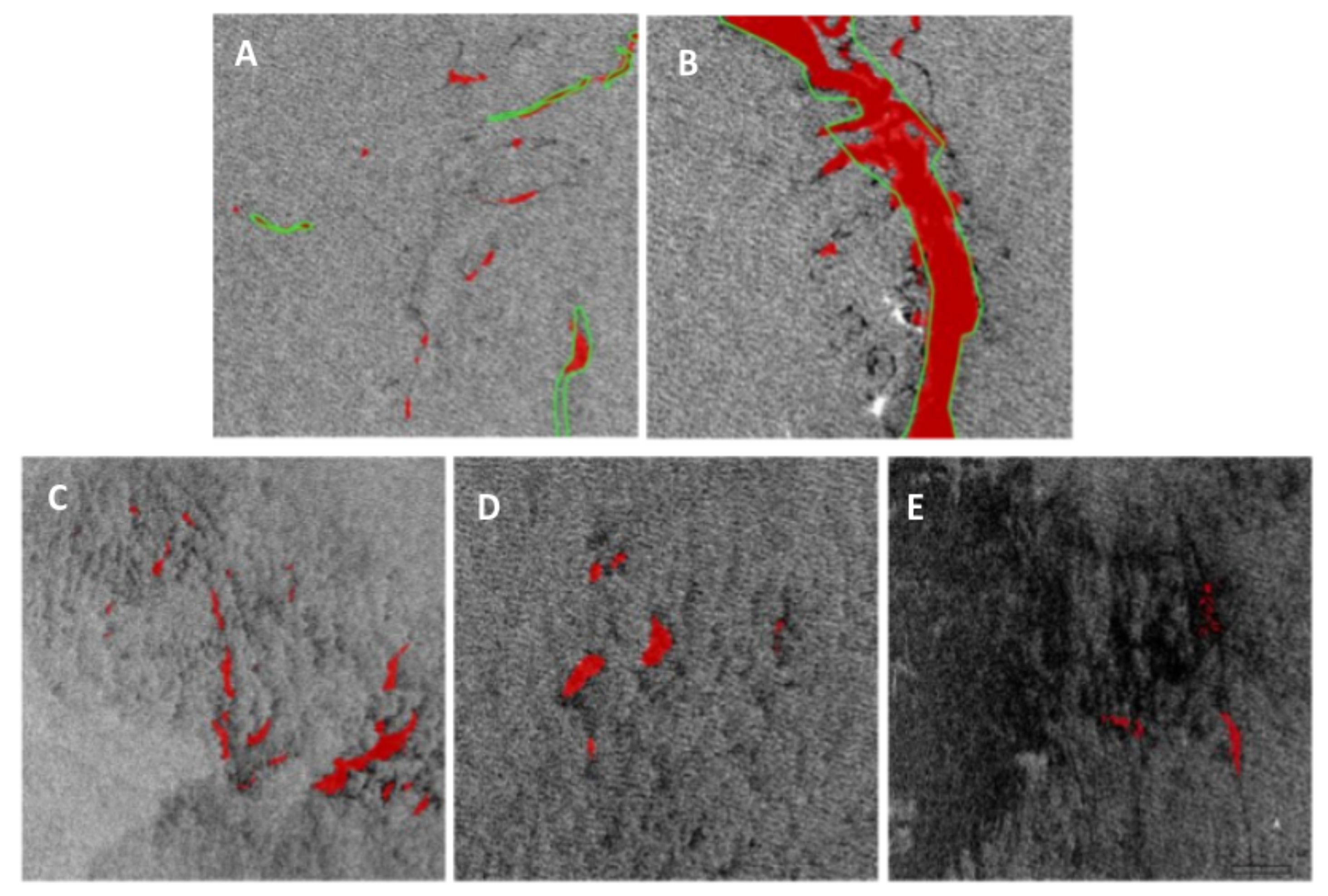
- Slick annotation (Ground Truth): Human experts performed manual annotation of natural and anthropogenic oil slicks. The considered classes are: sea, spill, and seep. Importantly, this study is based on real-world monitoring scenarios. Under these conditions, the photo-interpreters cannot provide accurate annotations on object boundaries due to the fuzzy contours of the slicks and the annotation rhythm. Therefore, the annotations show sharp transitions that do not reflect the actual slick shape. Further, slick annotation is performed by five photo-interpreters, revealing a diversity of annotation criteria. For example, some slick annotations do not match the black slick perfectly and are shifted by a few pixels. Others account for small slick patches separated from the main slick and displaced. The difference is shown in Figure 2a–j. Figure 7 shows an example of image annotation. One can then consider that annotation is noisy but satisfies operational monitoring requirements.
- Wind speed information: Wind speed estimates for each SAR image are also provided. The estimation is performed based on empirical Geophysical Model Functions (GMFs), relying on the relationship between the backscatter and the wind speed. For C-band and VV polarization, several variants of GMFs named CMODs have been developed [50]. The CMOD5 variant is a version that has been used successfully as an improvement of the above variants. It is formulated as Equation (2):where the variables are:
- : backscatter value of the model CMOD5,
- V: wind speed (m/s),
- : relative direction between the radar look direction and the wind direction,
- : angle of incidence,
- : functions of wind speed V and incidence angle .
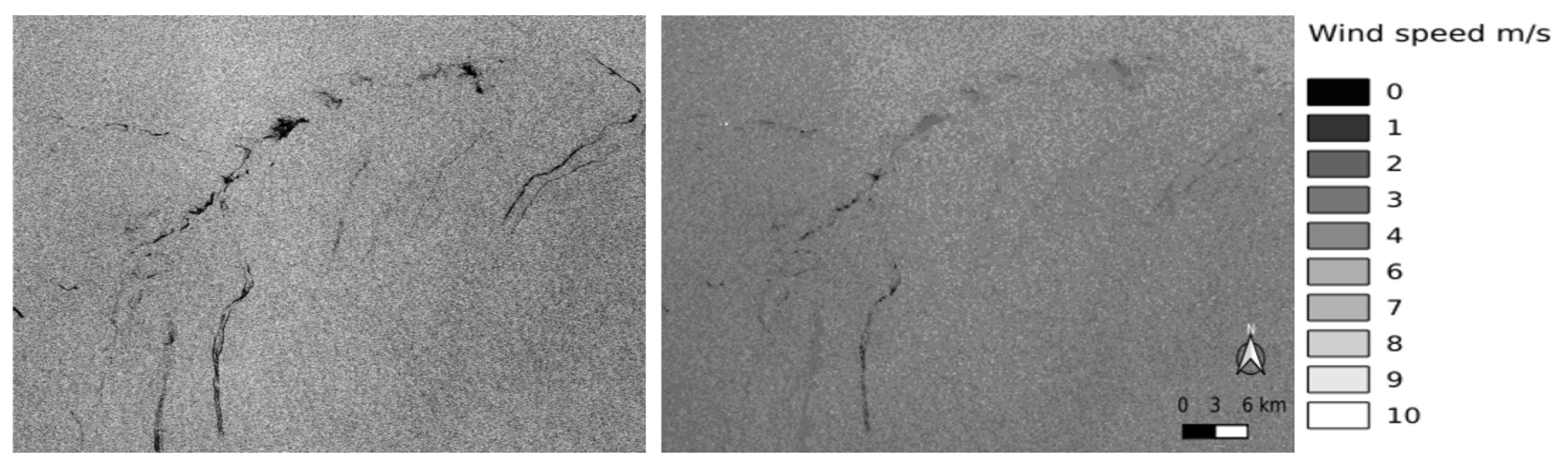
CMOD5 estimates the radar backscatter in a scene as a function of the surface wind speed (V) and the angle that the wind makes with respect to the direction of the pulse () and the incidence angle () [51]. However, for surfaces such as slick areas, the wind speed is underestimated due to the wave damping effect. This discrepancy has been considered at the model performance assessment step.In our context, SAR and wind resolutions are 10 and 100 m per pixel, respectively, such that wind is upsampled by a factor of 10 using linear interpolation when required. An example of a Sentinel-1 SAR image before and after adaptation to CMOD5 is shown in Figure 8. - Infrastructure Position: This information is known using global referencing, which represents support for photo-interpreter analysis [4]. Through the use of infrastructure position, we further improve the evaluation of model performance in terms of detecting anthropogenic oil. The types of infrastructure considered are pipelines, wells, ports, platforms and ships. For each of them, there is a possibility of leakage accorded to the experts. The location of the infrastructures is associated with the SAR images, as shown in Figure 9.
2.2.1. Data Preprocessing
- SAR Data: The preprocessing of initial SAR data consists of low-level transformations to improve the qualitative and quantitative interpretation of image components, thus facilitating the visibility of slicks for photo-interpreters. SAR preprocessing can be grouped into four processes: radiometric calibration, geo-referencing, filtering, and masking [18].
- (1)
- First, radiometric correction and calibration: Its purpose is to remove or minimize radiometric distortions and to ensure the correlation of pixel values with the backscatter coefficient of the reflecting surface [52]. Thus, quantitative measurements (backscattered microwave energy) restored from image pixel values can be compared with object characteristics in multi-temporal SAR images acquired with different sensors and SAR modes [53].
- (2)
- A geo-referencing step of the SAR data is then performed to correct eventual geometric distortions and to locate each pixel of the image on the Earth [54]. This step is also applied to all the considered data sources to ensure their alignment.
- (3)
- A speckle noise filtering step is then performed. As reported by [3,55], such noise must be reduced in order to facilitate the analysis and interpretation of the data. An optimal speckle filtering technique should preserve useful radiometric information and avoid the loss of features, such as the local mean of backscatter, texture, edges, and point targets [56]. Several filter types have been used in previous studies to reduce speckles and enhance SAR images for oil slicks, such as Lee, Frost, Kuan, median, and Lopez [57]. The considered preprocessing pipeline relies on such filters, but its detailed implementation remains confidential.
- (4)
- The final preprocessing step consists of masking the land and shorelines from the SAR images. This process restricts sea surface analysis and prevents land from interfering with oil slick detection [58].
- Wind data: For each 10 m resolution SAR image, the associated wind intensity map is provided with the same geographic coverage but at 100 m resolution. Therefore, to align the two modalities, bi-linear interpolation is applied to the wind map. However, the wind speed is underestimated over the slick areas due to the wave damping effect. Then, specifically for the test set and evaluation process but not for the training set, the wind speed, in the vicinity of 50 m around the annotated slicks, is merged within the slick area, relying on iterative median filtering.
- Infrastructure data: It is based on the infrastructure position; a map that represents the proximity of existing infrastructure in the neighborhood for each pixel is realized. These distance maps will be considered only in the evaluation process.
2.2.2. Preparation of the Training/Validation Datasets
- (1)
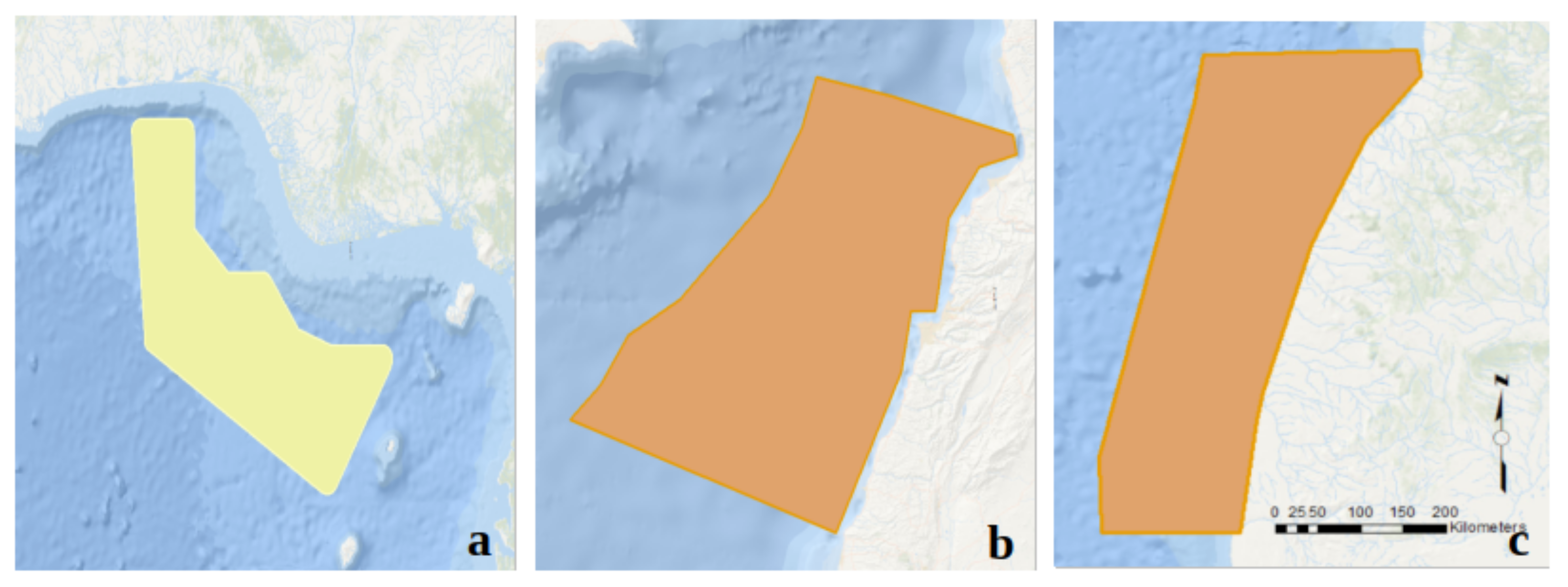
- Dataset Splitting: Following our previous study [28], both training and validation sets rely on the same geographical areas. However, they do not share the same images; each has a different capture date and sea coverage. A third area (Nigeria) is chosen for testing to validate the generalization capability of the model.
- (2)
- Image Crop Selection: We built a collection of smaller image crops of pixels from the large images of the training and validation datasets. This resolution is a compromise between the size of the layer, the field of view of the model, and the memory constraints of the GPUs (NVidia V100 16 Gb).The crop selection strategy takes into account the slick annotations and ensures the presence of slicks within crops following the logical function presented in Equation (3):where ∧ and ¬ are the logical AND and NOT operators, respectively, X is a random crop in a large SAR image, Y is the corresponding annotation, a Boolean function that checks if there is a border (no data area) inside the crop, is the entropy function used to check the sea and slick classes statistics within the crop, and T is a threshold fixed heuristically to .Further, to make the model robust against slick lookalikes, an additional crop selection of such potential patterns is built from the slick-free image areas. Since no specific annotation reports them, we rely on a heuristic reported in Equation (4), the objective of which is to choose crops with contrasting patterns:where ∧ is the logical OR operator, and correspond to the ones described in Equation (3), and is a Boolean function that randomly selects the crop that probably contains lookalikes based on the normalized variance of the pixel values. A minimal variance threshold fixed on the basis of experiments must be reached to highlight a contrasted area.
- (3)
- Data Augmentation: It is applied to increase the variability in the dataset artificially. It is comprised of random horizontal and vertical flipping and ±90 random rotation in both training and validation datasets [59].Table 3 outlines the details of the training and validation datasets. A total of 85% of the crops in the dataset belong to the training set. We notice that the oil slicks are small to medium in size compared to the large sea area, covering less than 11% of the total area. This emphasizes the strong imbalance in the number of slicks pixels and the clean sea pixels that include lookalikes.
2.2.3. Test Dataset
2.3. Performance Assessments
2.3.1. Standard Metrics
2.3.2. Prediction Explanation Methods
- Class Activation Maps (CAM)-based methods, e.g., Grad-CAM [63,64], are designed to generate heat maps of the input, indicating which areas most influence the network decision. It relies on a linear combination of activation maps of a given layer, weighted with the gradient of the class score, with regard to the feature map activation. CAM-based methods have some drawbacks: first, explanation precision is limited given that the produced heatmap is computed based on low-resolution activation maps and further upsampled to match the original image size. Second, it does not provide information on negative contributions (inhibition effects).
- Local Interpretable Model-agnostic Explanations (LIME) [65] is a model-agnostic method that aims to locally (e.g., for one set of inputs) approximate the complex model to a more easily understandable one. This method aims to produce visual artifacts that provide a good understanding of the model choice. However, the LIME method can be criticized for its lack of stability and the discrepancy of its results with human intuition.
- Layer-wise Relevance Propagation (LRP) [66] uses calculation rules to backpropagate the score of a specified output of the network until the first layer, thus showing areas that affected the network decision for the specific output. This method is specific to neural networks and may not provide a trustworthy comparison when applied to different network architectures, as the score backpropagation will proceed differently. Moreover, the backpropagation through FC-DenseNet architecture can lead to conflicts caused by skip connections.
- SHapley Additive exPlanation (SHAP) [12] is a game-theory-inspired method that attempts to enhance interpretability by computing the importance values of each input feature on individual predictions. By definition, the Shapley value calculated by SHAP is the average marginal contribution of an input feature to a model output across all possible coalitions. Different methods are proposed for estimating Shapley values, such as KernelSHAP or DeepSHAP [12]. They provide results demonstrating the expressiveness of SHAP values in terms of discrimination ability between different output classes and better alignment with human intuition compared to many other existing methods [62]. Several works have adopted the SHAP method for image classification or object detection [67,68].
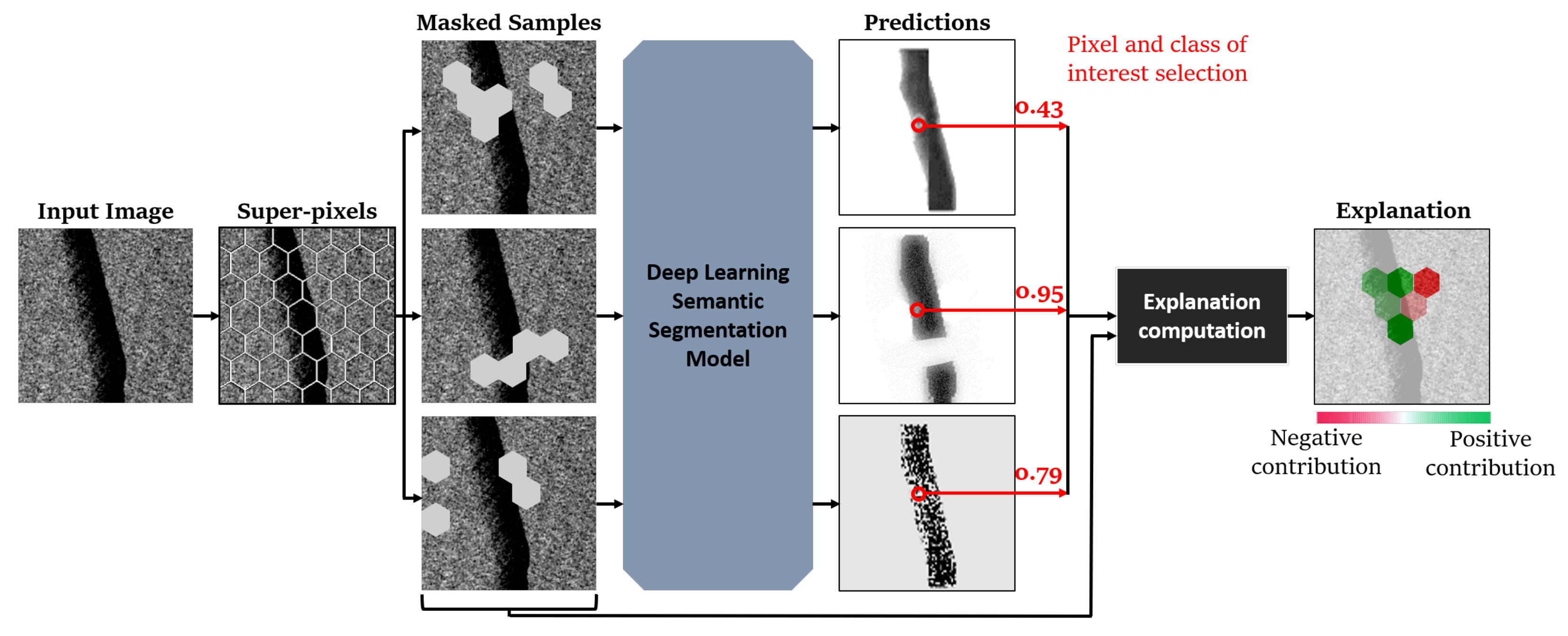
- (1)
- The first step aims at creating groups of pixels, or super-pixels, from the input image. The method result shows the contribution of each super-pixel in the model’s decision. Experiments have shown that relying on super-pixels of equal size and shape generates clearer explanations. Moreover, hexagonal super-pixels allow for a more natural explanation than square super-pixels, mainly due to the higher number of direct neighbors of each super-pixels. Thus, explanations presented in this paper rely on a grid of super-pixels shaped as a regular hexagon.
- (2)
- Then, masking is applied to the input image super-pixels in order to generate several masked samples, as shown in Figure 11. Note that masking super-pixels with the zero value is often considered in this step but is avoided in our case, as it would introduce ambiguity with the target (dark oil slicks). Thus, the explanations presented in this paper are based on a grid of super-pixels shaped like a regular hexagon.
- (3)
- The third step is to feed the resulting masked samples through a semantic black-box image segmentation model, which yields prediction probability maps for each sample.
- (4)
- The fourth step is to select the pixel and class of interest (e.g., the pixel highlighted in red in Figure 11 and the class “slick”), for which the explanation of the model decision is to be conducted.
- (5)
- After that, explanation computation based on Shapley values computation rules is applied [69], considering the mask and the pixel-level decision for every sample. In more detail, the Kernel SHAP algorithm estimates the impact of each super-pixel on the probability that the selected pixel belongs to the selected class (e.g., slick).
- (6)
- Finally, a heat map explanation is generated, highlighting the areas (super-pixel) of the input image that contributed positively (excited) and negatively (inhibited) to the model decision.
3. Results
3.1. Evaluation of SAR Data Experiments
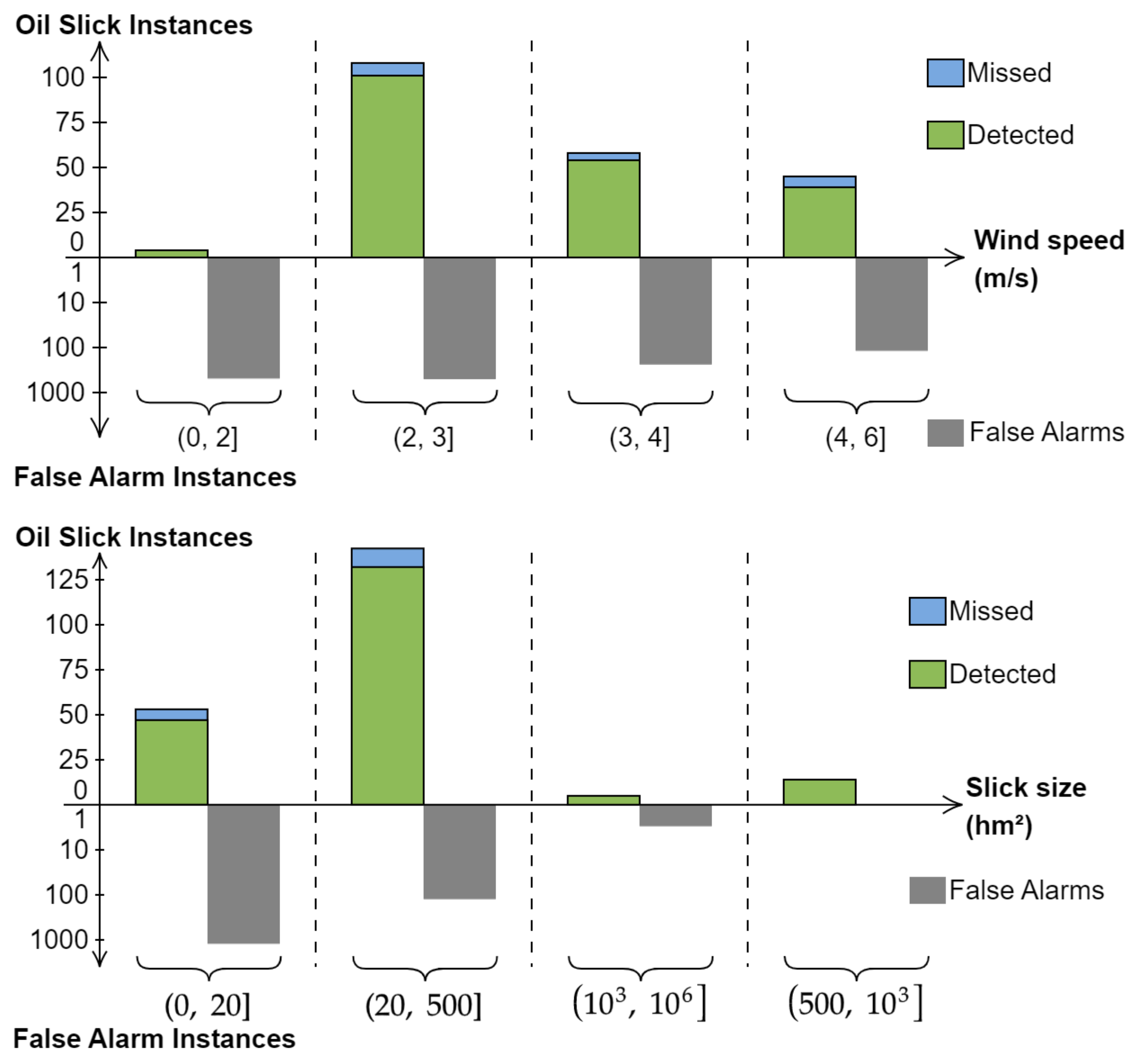
3.1.1. Evaluation of Models Based on SAR Data
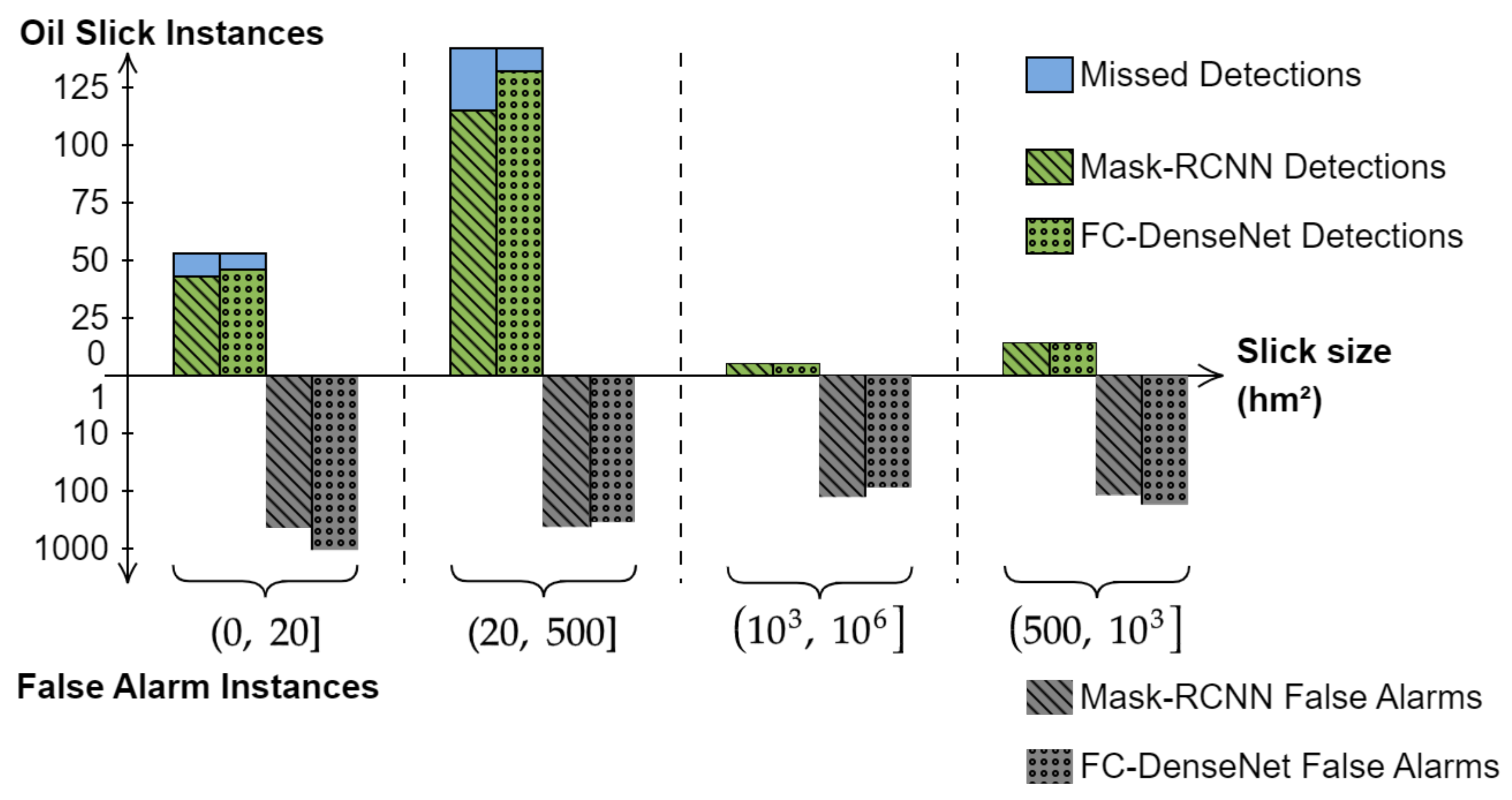
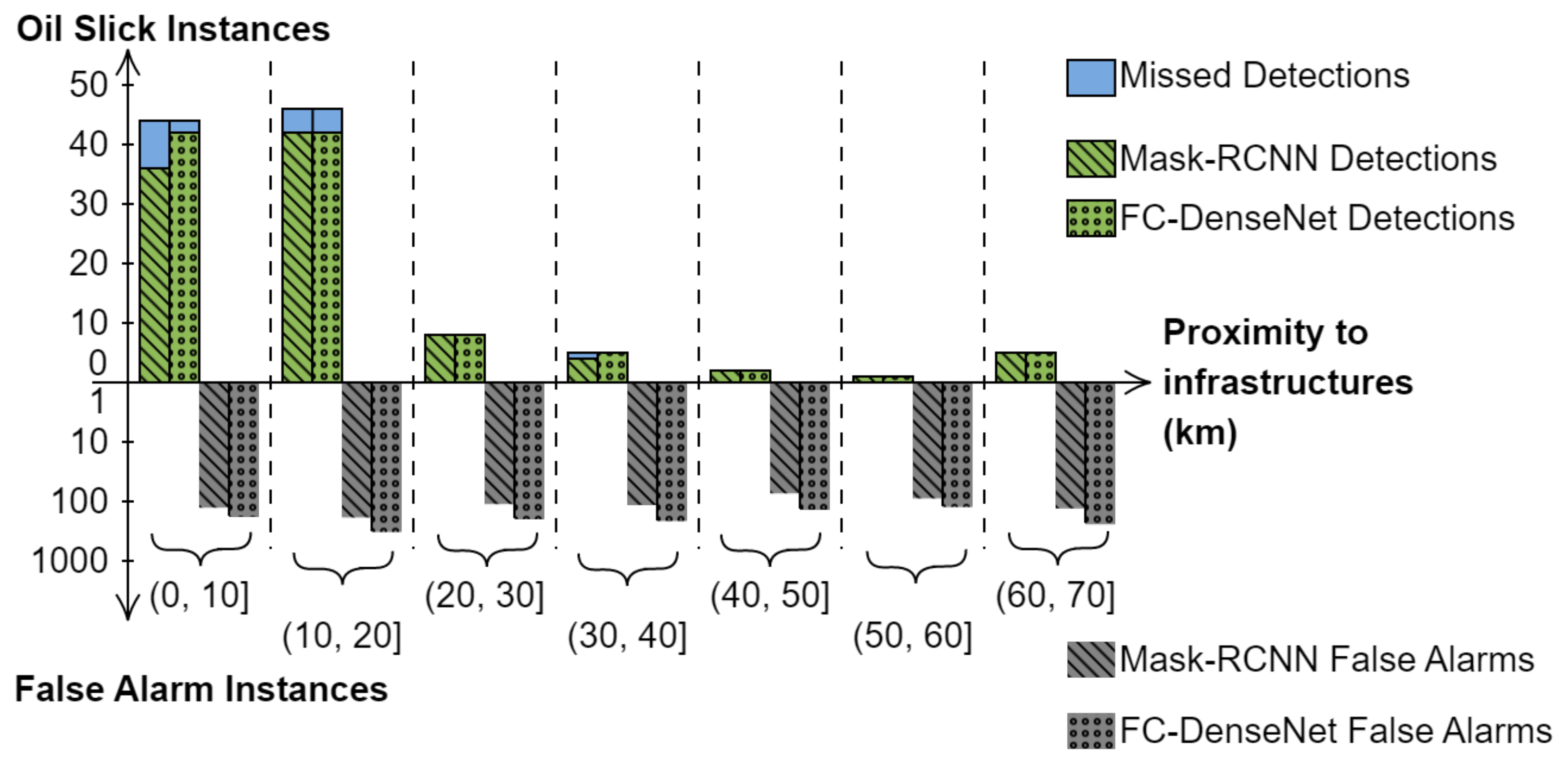
3.1.2. Evaluation Based on Contextual Data
3.2. Evaluation of Data Fusion Models
3.2.1. Early Fusion Experiment
3.2.2. Late Fusion Experiments
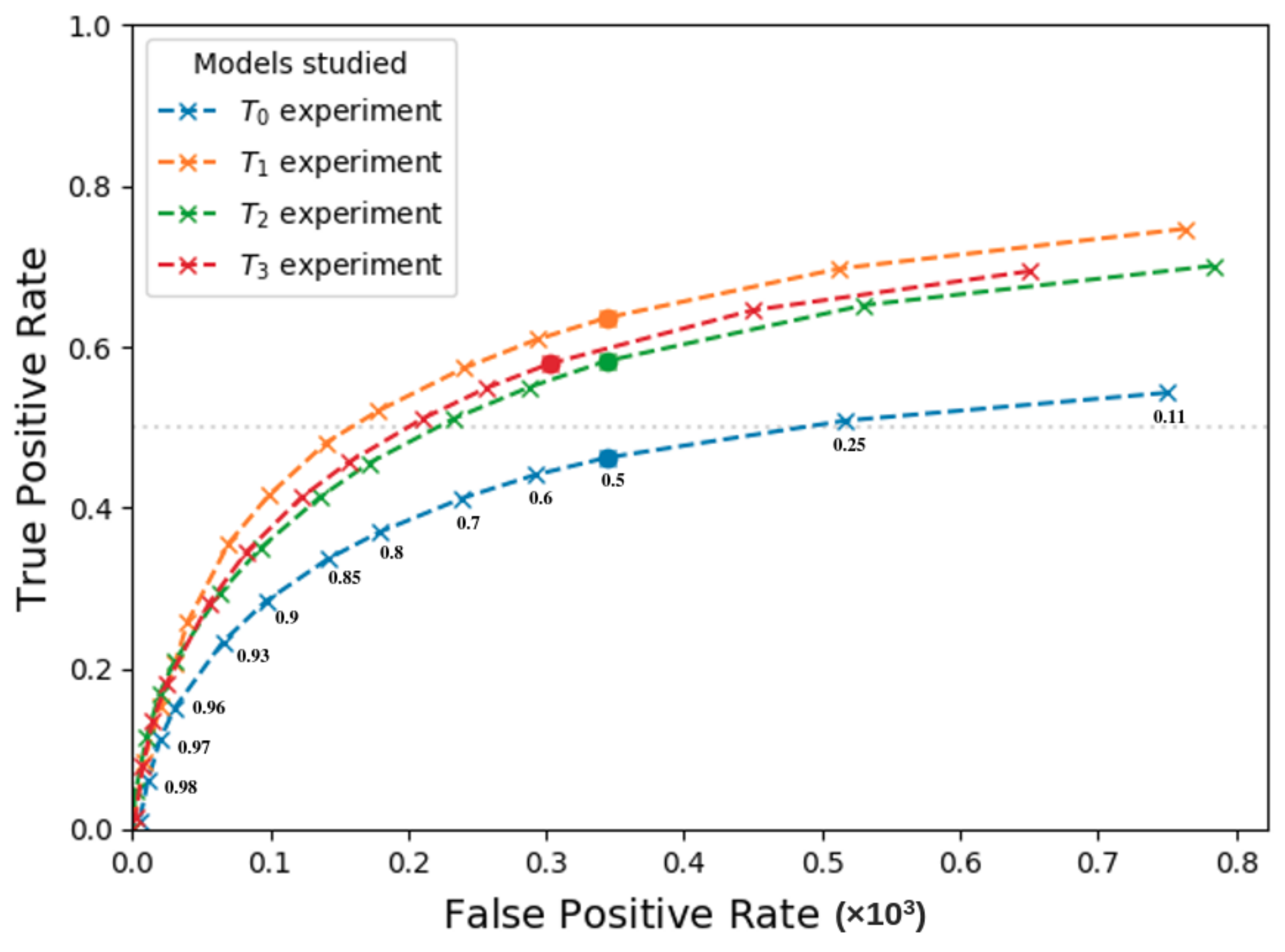
3.2.3. ROC Curves Analysis
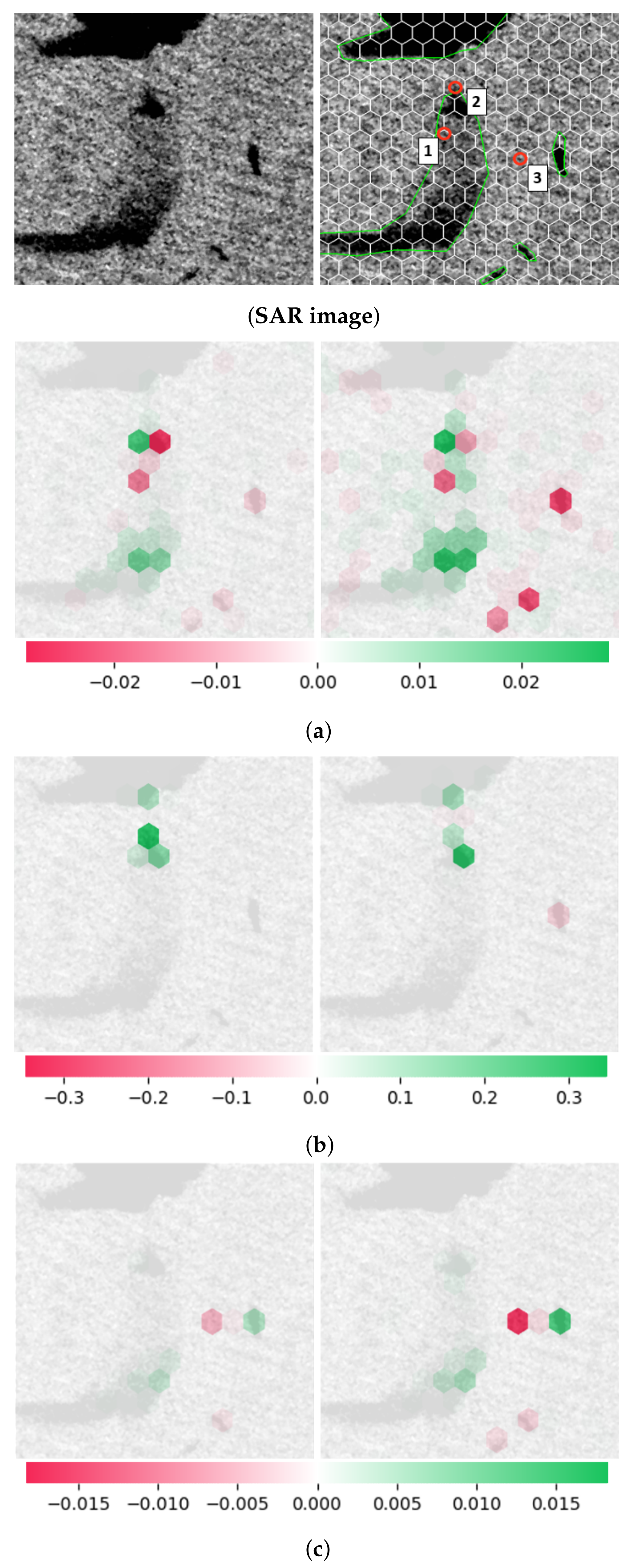
3.3. SHAP Explanation
- For a pixel classified as sea, as for explained pixels in Figure 22a,c and Figure 23a: the surface affecting the decision of the networks is large and depends on the presence of slicks (or lookalikes) in the entire image. Specifically, a general observation reveals that the prediction is mainly influenced by the presence of oil slicks in the vicinity of the explained pixel: a positive impact (reinforcing the classification of the pixel as slick) in the case of a relatively close slick and a negative one in the case of a distant slick. However, their contribution to the decision is extremely low and always countered by the considered pixel area. As a result, the prediction associated with the slick class is always close to .
- For a pixel classified as slick, as for the explained pixel in Figure 22b, Figure 23c, and Figure 24b: the prediction is based on a limited area centered around the considered pixel. The maximal SHAP value in these cases is the highest observed (about 0.5). Typically, the network prediction for the pixel is impacted by one input feature containing mainly black pixels, which is enough to classify the pixel as a slick, with a probability above .
- For a pixel located on a slick edge or within a narrow slick, as for the explained pixel in Figure 23b,d: networks tend to detect and base their decision on the slick edge or the narrow slick length. This shows that networks can detect the slick edges around the selected pixel in all observed images, which significantly influences their decision. The impact of each area containing a slick edge tends to decrease as the area moves away from the pixel.
4. Discussion
Explainable Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| EM | ElectroMagnetic |
| FA | False Alarms |
| FC-DenseNet | Fully Convolutional DenseNet |
| GMF | Geophysical Model Functions |
| Mask R-CNN | Mask Region Based Convolutional Neural Network |
| SAR | Synthetic Aperture Radar |
| SHAP | SHapley Additive exPlanation |
| ROC | Receiver Operating Characteristic |
| RS | Remote Sensing |
References
- Girard-Ardhuin, F.; Mercier, G.; Garello, R. Oil slick detection by SAR imagery: Potential and limitation. In Proceedings of the Oceans 2003. Celebrating the Past… Teaming Toward the Future (IEEE Cat. No. 03CH37492), San Diego, CA, USA, 22–26 September 2003; Volume 1, pp. 164–169. [Google Scholar]
- Alpers, W.; Holt, B.; Zeng, K. Oil spill detection by imaging radars: Challenges and pitfalls. Remote Sens. Environ. 2017, 201, 133–147. [Google Scholar] [CrossRef]
- Fingas, M.; Brown, C. Review of oil spill remote sensing. Mar. Pollut. Bull. 2014, 83, 9–23. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brekke, C.; Solberg, A.H. Oil spill detection by satellite remote sensing. Remote Sens. Environ. 2005, 95, 1–13. [Google Scholar] [CrossRef]
- Angelliaume, S.; Dubois-Fernandez, P.C.; Jones, C.E.; Holt, B.; Minchew, B.; Amri, E.; Miegebielle, V. SAR imagery for detecting sea surface slicks: Performance assessment of polarization-dependent parameters. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4237–4257. [Google Scholar] [CrossRef] [Green Version]
- Solberg, A.S.; Storvik, G.; Solberg, R.; Volden, E. Automatic detection of oil spills in ERS SAR images. IEEE Trans. Geosci. Remote Sens. 1999, 37, 1916–1924. [Google Scholar] [CrossRef] [Green Version]
- Espedal, H. Satellite SAR oil spill detection using wind history information. Int. J. Remote Sens. 1999, 20, 49–65. [Google Scholar] [CrossRef]
- Karathanassi, V.; Topouzelis, K.; Pavlakis, P.; Rokos, D. An object-oriented methodology to detect oil spills. Int. J. Remote Sens. 2006, 27, 5235–5251. [Google Scholar] [CrossRef]
- Nirchio, F.; Sorgente, M.; Giancaspro, A.; Biamino, W.; Parisato, E.; Ravera, R.; Trivero, P. Automatic detection of oil spills from SAR images. Int. J. Remote Sens. 2005, 26, 1157–1174. [Google Scholar] [CrossRef]
- Benoit, A.; Ghattas, B.; Amri, E.; Fournel, J.; Lambert, P. Deep learning for semantic segmentation. In Multi-Faceted Deep Learning; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Krestenitis, M.; Orfanidis, G.; Ioannidis, K.; Avgerinakis, K.; Vrochidis, S.; Kompatsiaris, I. Oil spill identification from satellite images using deep neural networks. Remote Sens. 2019, 11, 1762. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, S.; Lee, S.I. A unified approach to interpreting model predictions. arXiv 2017, arXiv:1705.07874. [Google Scholar]
- Li, X.; Nunziata, F.; Garcia, O. Oil spill detection from single-and multipolarization SAR imagery. In Reference Module in Earth Systems and Environmental Sciences; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Espedal, H.; Hamre, T.; Wahl, T.; Sandven, S. Oil Spill Detection Using Satellite Based SAR, Pre-Operational Phase A; Technical Report; Nansen Environmental and Remote Sensing Center: Bergen, Norway, 1995. [Google Scholar]
- Wang, P.; Zhang, H.; Patel, V.M. SAR image despeckling using a convolutional neural network. IEEE Signal Process. Lett. 2017, 24, 1763–1767. [Google Scholar] [CrossRef] [Green Version]
- La, T.V.; Messager, C.; Honnorat, M.; Channelliere, C. Detection of convective systems through surface wind gust estimation based on Sentinel-1 images: A new approach. Atmos. Sci. Lett. 2018, 19, e863. [Google Scholar] [CrossRef]
- Najoui, Z.; Deffontaines, B.; Xavier, J.P.; Riazanoff, S.; Aurel, G. Wind Speed and instrument modes influence on the detectability of oil slicks using SAR images: A stochastic approach. Remote Sens. Environ. 2017. Available online: www-igm.univ-mlv.fr/~riazano/publications/NAJOUI_Zhour_thesis_paper1_Oil_slicks_detectability_from_SAR_images_draft31.pdf (accessed on 2 February 2022).
- Al-Ruzouq, R.; Gibril, M.B.A.; Shanableh, A.; Kais, A.; Hamed, O.; Al-Mansoori, S.; Khalil, M.A. Sensors, Features, and Machine Learning for Oil Spill Detection and Monitoring: A Review. Remote Sens. 2020, 12, 3338. [Google Scholar] [CrossRef]
- Chehresa, S.; Amirkhani, A.; Rezairad, G.A.; Mosavi, M.R. Optimum features selection for oil spill detection in SAR image. J. Indian Soc. Remote Sens. 2016, 44, 775–787. [Google Scholar] [CrossRef]
- Topouzelis, K.; Karathanassi, V.; Pavlakis, P.; Rokos, D. Detection and discrimination between oil spills and look-alike phenomena through neural networks. ISPRS J. Photogramm. Remote Sens. 2007, 62, 264–270. [Google Scholar] [CrossRef]
- Hamedianfar, A.; Barakat, A.; Gibril, M. Large-scale urban mapping using integrated geographic object-based image analysis and artificial bee colony optimization from worldview-3 data. Int. J. Remote Sens. 2019, 40, 6796–6821. [Google Scholar] [CrossRef]
- Guo, H.; Wu, D.; An, J. Discrimination of oil slicks and lookalikes in polarimetric SAR images using CNN. Sensors 2017, 17, 1837. [Google Scholar] [CrossRef] [Green Version]
- Yaohua, X.; Xudong, M. A sar oil spill image recognition method based on densenet convolutional neural network. In Proceedings of the 2019 International Conference on Robots & Intelligent System (ICRIS), Haikou, China, 15–16 June 2019; pp. 78–81. [Google Scholar]
- Chen, Y.; Li, Y.; Wang, J. An end-to-end oil-spill monitoring method for multisensory satellite images based on deep semantic segmentation. Sensors 2020, 20, 725. [Google Scholar] [CrossRef] [Green Version]
- Gallego, A.J.; Gil, P.; Pertusa, A.; Fisher, R. Segmentation of oil spills on side-looking airborne radar imagery with autoencoders. Sensors 2018, 18, 797. [Google Scholar] [CrossRef] [Green Version]
- Bianchi, F.M.; Espeseth, M.M.; Borch, N. Large-scale detection and categorization of oil spills from SAR images with deep learning. Remote Sens. 2020, 12, 2260. [Google Scholar] [CrossRef]
- Cantorna, D.; Dafonte, C.; Iglesias, A.; Arcay, B. Oil spill segmentation in SAR images using convolutional neural networks. A comparative analysis with clustering and logistic regression algorithms. Appl. Soft Comput. 2019, 84, 105716. [Google Scholar] [CrossRef]
- Emna, A.; Alexandre, B.; Bolon, P.; Véronique, M.; Bruno, C.; Georges, O. Offshore Oil Slicks Detection From SAR Images Through The Mask-RCNN Deep Learning Model. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Amri, E.; Courteille, H.; Benoit, A.; Bolon, P.; Dubucq, D.; Poulain, G.; Credoz, A. Deep learning based automatic detection of offshore oil slicks using SAR data and contextual information. In Proceedings of the Remote Sensing of the Ocean, Sea Ice, Coastal Waters, and Large Water Regions 2021, Online, 13–17 September 2021; Volume 11857, pp. 35–42. [Google Scholar]
- Orfanidis, G.; Ioannidis, K.; Avgerinakis, K.; Vrochidis, S.; Kompatsiaris, I. A deep neural network for oil spill semantic segmentation in Sar images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3773–3777. [Google Scholar]
- Yu, X.; Zhang, H.; Luo, C.; Qi, H.; Ren, P. Oil spill segmentation via adversarial f-divergence learning. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4973–4988. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 11–19. [Google Scholar]
- Lin, T.; Maire, M.; Belongie, S.J.; Bourdev, L.D.; Girshick, R.B.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. 2017. Available online: https://github.com/matterport/Mask_RCNN (accessed on 2 February 2022).
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]
- Bottou, L. Stochastic gradient descent tricks. In Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 421–436. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Cardoso, M.J. Generalised dice overlap as a deep learning loss function for highly unbalanced segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Berlin/Heidelberg, Germany, 2017; pp. 240–248. [Google Scholar]
- Saxe, A.M.; McClelland, J.L.; Ganguli, S. Exact solutions to the nonlinear dynamics of learning in deep linear neural networks. arXiv 2013, arXiv:1312.6120. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Bansal, N.; Chen, X.; Wang, Z. Can we gain more from orthogonality regularizations in training deep cnns? arXiv 2018, arXiv:1810.09102. [Google Scholar]
- Hénaff, O.J.; Simoncelli, E.P. Geodesics of learned representations. arXiv 2015, arXiv:1511.06394. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Valenzuela, G.R. Theories for the interaction of electromagnetic and oceanic waves—A review. Bound.-Layer Meteorol. 1978, 13, 61–85. [Google Scholar] [CrossRef]
- Goodman, R. Overview and future trends in oil spill remote sensing. Spill Sci. Technol. Bull. 1994, 1, 11–21. [Google Scholar] [CrossRef]
- Attema, E. An experimental campaign for the determination of the radar signature of the ocean at C-band. In Proceedings of the Third International Colloquium on Spectral Signatures of Objects in Remote Sensing, Les Arcs, France, 16–20 December 1986; pp. 791–799. [Google Scholar]
- Mouche, A. Sentinel-1 Ocean Wind Fields (OWI) Algorithm Definition; Sentinel-1 IPF Reference:(S1-TN-CLS-52-9049) Report; CLS: Brest, France, 2010; pp. 1–75. [Google Scholar]
- Freeman, A.; Curlander, J.C. Radiometric correction and calibration of SAR images. Photogramm. Eng. Remote Sens. 1989, 55, 1295–1301. [Google Scholar]
- Lihai, Y.; Jialong, G.; Kai, J.; Yang, W. Research on efficient calibration techniques for airborne SAR systems. In Proceedings of the 2009 2nd Asian-Pacific Conference on Synthetic Aperture Radar, Shanxi, China, 26–30 October 2009; pp. 266–269. [Google Scholar]
- Moreira, A.; Prats-Iraola, P.; Younis, M.; Krieger, G.; Hajnsek, I.; Papathanassiou, K.P. A tutorial on synthetic aperture radar. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–43. [Google Scholar] [CrossRef] [Green Version]
- Lillesand, T.; Kiefer, R.W.; Chipman, J. Remote Sensing and Image Interpretation; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Gao, F.; Xue, X.; Sun, J.; Wang, J.; Zhang, Y. A SAR image despeckling method based on two-dimensional S transform shrinkage. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3025–3034. [Google Scholar] [CrossRef]
- Tong, S.; Liu, X.; Chen, Q.; Zhang, Z.; Xie, G. Multi-feature based ocean oil spill detection for polarimetric SAR data using random forest and the self-similarity parameter. Remote Sens. 2019, 11, 451. [Google Scholar] [CrossRef] [Green Version]
- Singha, S.; Vespe, M.; Trieschmann, O. Automatic Synthetic Aperture Radar based oil spill detection and performance estimation via a semi-automatic operational service benchmark. Mar. Pollut. Bull. 2013, 73, 199–209. [Google Scholar] [CrossRef]
- Wang, J.; Perez, L. The effectiveness of data augmentation in image classification using deep learning. Convolutional Neural Netw. Vis. Recognit. 2017, 11, 1–8. [Google Scholar]
- Powers, D.M. Evaluation: From precision, recall and F-measure to ROC, informedness, markedness and correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable ai: A review of machine learning interpretability methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Vinogradova, K.; Dibrov, A.; Myers, G. Towards interpretable semantic segmentation via gradient-weighted class activation mapping (student abstract). In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13943–13944. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should i trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Montavon, G.; Samek, W.; Müller, K.R. Methods for interpreting and understanding deep neural networks. Digit. Signal Process. 2018, 73, 1–15. [Google Scholar] [CrossRef]
- Van der Velden, B.H.; Janse, M.H.; Ragusi, M.A.; Loo, C.E.; Gilhuijs, K.G. Volumetric breast density estimation on MRI using explainable deep learning regression. Sci. Rep. 2020, 10, 18095. [Google Scholar] [CrossRef]
- Knapič, S.; Malhi, A.; Salujaa, R.; Främling, K. Explainable Artificial Intelligence for Human Decision-Support System in Medical Domain. arXiv 2021, arXiv:2105.02357. [Google Scholar]
- Shapley, L.S. 17. A Value for n-Person Games; Princeton University Press: Princeton, NJ, USA, 2016. [Google Scholar]
- Yu, S.; Chen, M.; Zhang, E.; Wu, J.; Yu, H.; Yang, Z.; Ma, L.; Gu, X.; Lu, W. Robustness study of noisy annotation in deep learning based medical image segmentation. Phys. Med. Biol. 2020, 65, 175007. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wind Speed m/s | Reference | Year |
|---|---|---|
| 1.5 to 6 | [3] | 2014 |
| 2 to 7 | [16] | 2018 |
| 2.09 to 8.33 | [17] | 2017 |
| 3 to 7–10 | [4] | 2005 |
| Architecture | Crop Number | Image Size | Spill & Seep | TL |
|---|---|---|---|---|
| OFCN/UNet [26] | 713 | 160 × 160 | spill | - |
| Fully CNNs [27] | - | 128 × 128, 2048 × 2048 | spill | - |
| Mask R-CNN [28,29] | 9302 | 512 × 512 | spill and seep | ✓ |
| DeepLab [30] | 677 | 1252 × 609 | spill | - |
| DeepLabv3+ [11] | 1002 | 321 × 321 | spill | ✓ |
| AutoEncoders [25] | - | 256 × 256, 384 × 384 | spill | - |
| GANs [31] | - | 256 × 256 | spill | - |
| Spill | Seep | Sea | Total | |
|---|---|---|---|---|
| Image crops number | 1.964 | 244 | 860 | 3.068 |
| Studied area surface (hm2) | 251,200 | 21,900 | 7,769,500 | 8,042,600 |
| Surface rate | 3.12% | 0.27% | 96.6% | 100% |
| Spill | Seep | Sea | Total | |
|---|---|---|---|---|
| Slick instances number | 150 | 64 | - | 214 |
| Studied area surface (hm2) | 49,771 | 25,622 | 267,112,507 | 267,187,900 |
| Surface rate | 3.12% | 0.27% | 96.6% | 100% |
| Metrics | FC-DenseNet | Mask R-CNN | |
|---|---|---|---|
| Instance level | Good detection number | 198 | 177 |
| Miss-detection number | 16 | 37 | |
| False-detection number | 1658 | 1103 | |
| Pixel level | IoU Slick | 0.3 | 0.06 |
| Precision | 0.42 | 0.33 | |
| Recall | 0.53 | 0.06 | |
| Name | Description |
|---|---|
| Enhanced FC-DenseNet baseline model relying exclusively on SAR data | |
| Early fusion of upsampled wind data at the same level as the SAR data | |
| Average pooling of the wind data and fusion with SAR data after dense block 2 (late fusion) | |
| Average pooling and Denseblock applied to the wind data prior fusion with the SAR data after dense block 2 (late fusion) | |
| Average pooling and Denseblock applied to the wind data prior fusion with the SAR data after dense block 3 (late fusion) |
| Metrics | Only SAR | Early Fusion | Late Fusion | |||
|---|---|---|---|---|---|---|
| Instance level | Good detection number | 198 | 198 | 200 | 201 | 192 |
| Miss-detection number | 16 | 16 | 14 | 13 | 22 | |
| False-detection number | 1658 | 1357 | 1376 | 1430 | 1094 | |
| Pixel level | IoU slick | 0.30 | 0.22 | 0.31 | 0.28 | 0.21 |
| Precision | 0.42 | 0.35 | 0.42 | 0.38 | 0.24 | |
| Recall | 0.53 | 0.38 | 0.55 | 0.49 | 0.60 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amri, E.; Dardouillet, P.; Benoit, A.; Courteille, H.; Bolon, P.; Dubucq, D.; Credoz, A. Offshore Oil Slick Detection: From Photo-Interpreter to Explainable Multi-Modal Deep Learning Models Using SAR Images and Contextual Data. Remote Sens. 2022, 14, 3565. https://doi.org/10.3390/rs14153565
Amri E, Dardouillet P, Benoit A, Courteille H, Bolon P, Dubucq D, Credoz A. Offshore Oil Slick Detection: From Photo-Interpreter to Explainable Multi-Modal Deep Learning Models Using SAR Images and Contextual Data. Remote Sensing. 2022; 14(15):3565. https://doi.org/10.3390/rs14153565
Chicago/Turabian StyleAmri, Emna, Pierre Dardouillet, Alexandre Benoit, Hermann Courteille, Philippe Bolon, Dominique Dubucq, and Anthony Credoz. 2022. "Offshore Oil Slick Detection: From Photo-Interpreter to Explainable Multi-Modal Deep Learning Models Using SAR Images and Contextual Data" Remote Sensing 14, no. 15: 3565. https://doi.org/10.3390/rs14153565
APA StyleAmri, E., Dardouillet, P., Benoit, A., Courteille, H., Bolon, P., Dubucq, D., & Credoz, A. (2022). Offshore Oil Slick Detection: From Photo-Interpreter to Explainable Multi-Modal Deep Learning Models Using SAR Images and Contextual Data. Remote Sensing, 14(15), 3565. https://doi.org/10.3390/rs14153565