
Reliable Label-Supervised Pixel Attention Mechanism for Weakly Supervised Building Segmentation in UAV Imagery


Abstract
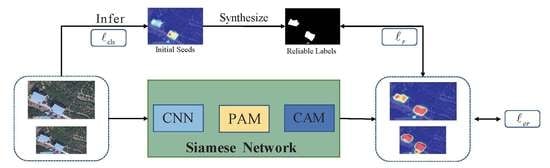
:
1. Introduction
- 1.
- We propose a new, weakly supervised building segmentation network, RSPA, which can produce better pseudo-labels to train segmentation networks, resulting in better segmentation results.
- 2.
- We use the initial seeds to synthesize reliable labels, then use reliable labels as the constraints of the network to address CAM over-activation. PAM is proposed to capture long-range contextual information and find inter-pixel similarities. This can significantly enable the CAM to obtain more discriminative regions of the object.
- 3.
- The proposed reliable label loss takes full advantage of the complementary relationship between the modified CAM and reliable labels.
2. Related Works
2.1. Fully Supervised Building Segmentation
2.2. Weakly Supervised Semantic Segmentation
2.2.1. Weakly Supervised Semantic Segmentation of Natural Images
2.2.2. Weakly Supervised Semantic Segmentation of Remote Sensing Images
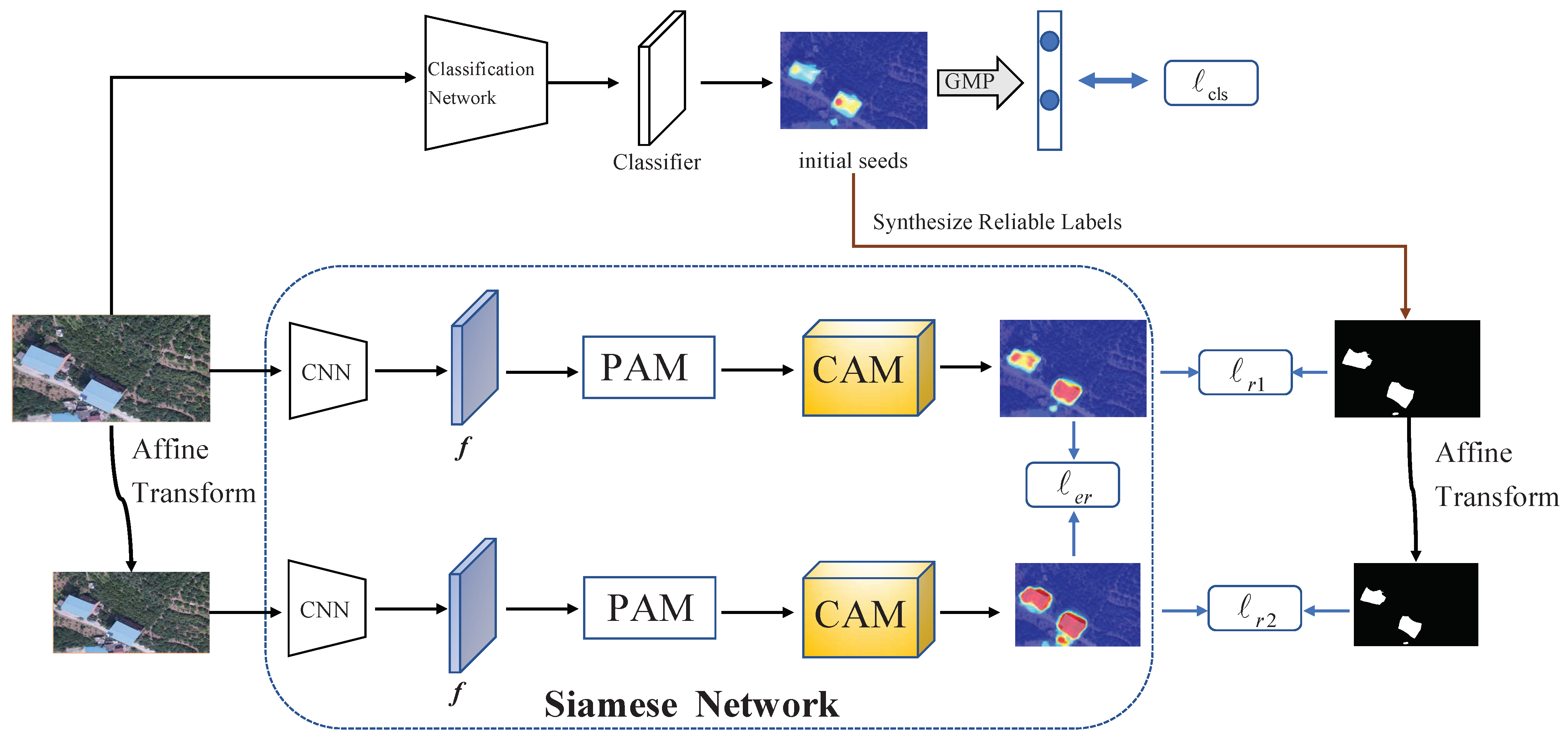
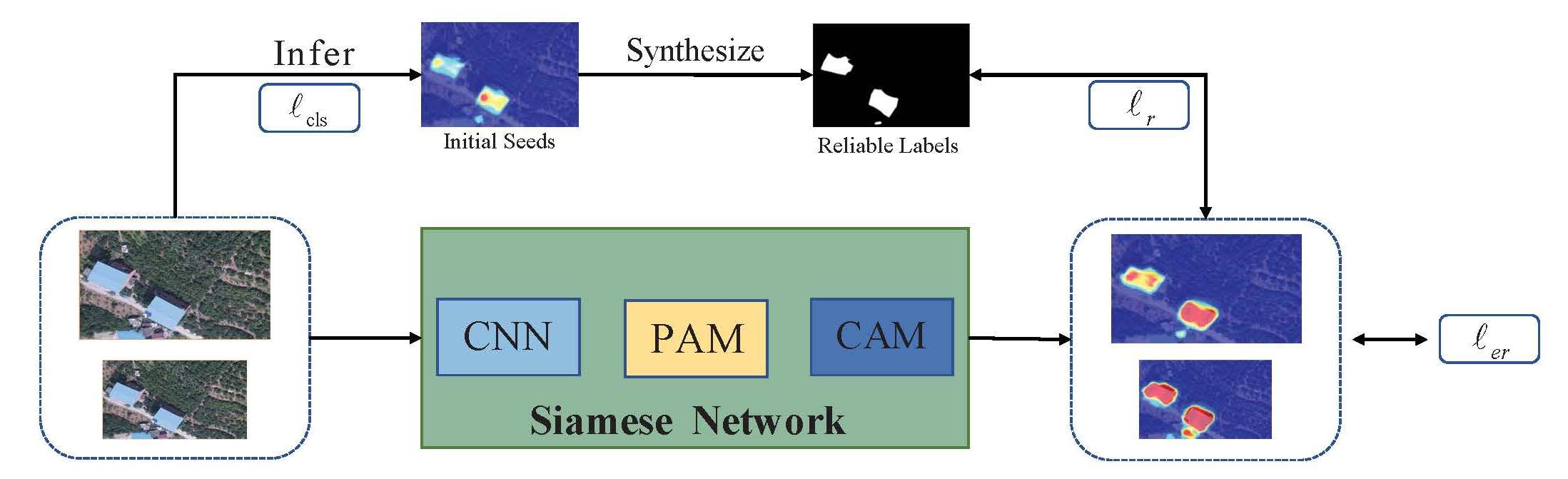
3. Methodology
3.1. Class Activation Map (CAM)
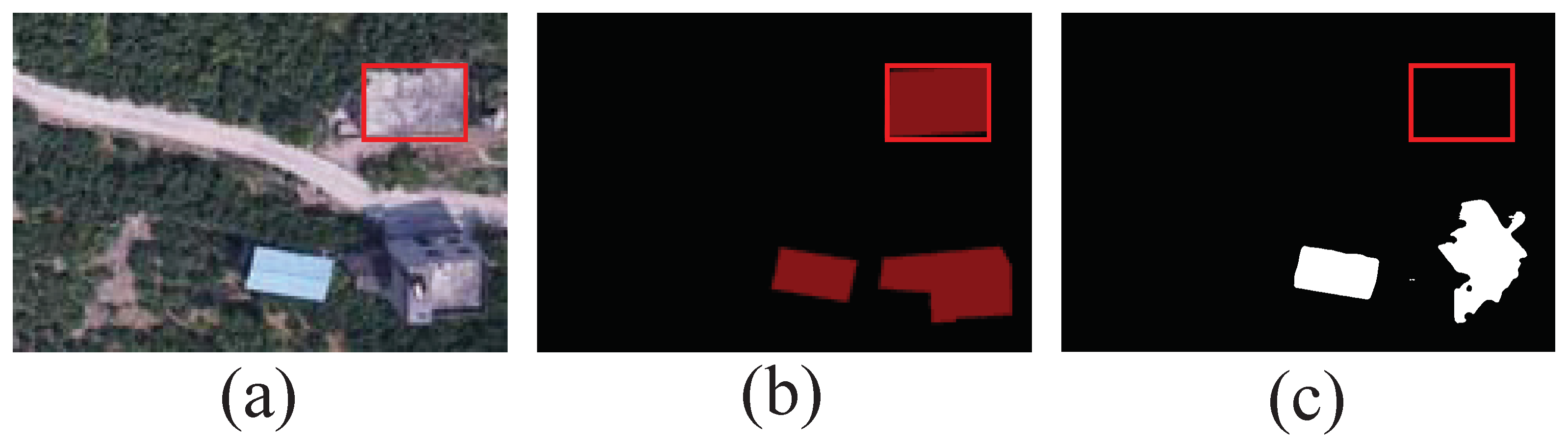
3.2. Synthesizing Reliable Labels
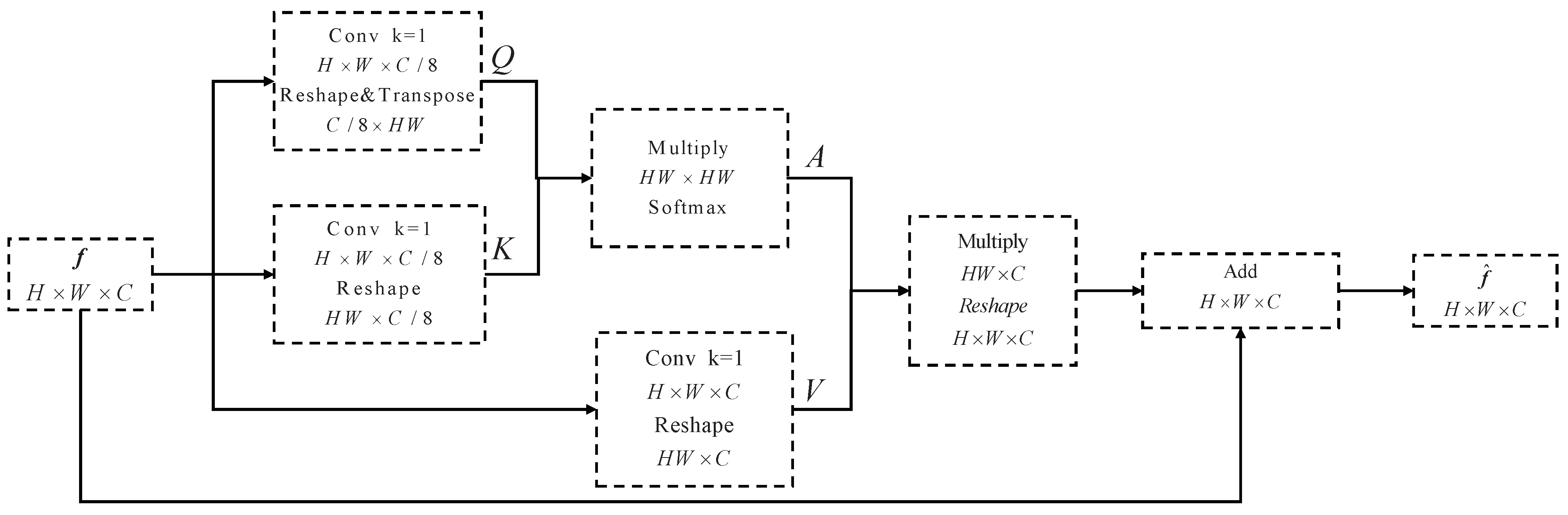
3.3. Pixel Attention Module (PAM)
3.4. Loss Design
- Classification loss: We use GMP at the end of the network to obtain the prediction probability vector p for image classification. To train the classification network, we use the binary cross-entropy loss function:where 0 and 1 denote background and foreground labels, respectively; denotes the classification label of sample i; and represents the number of training samples. As our network uses a Siamese network structure, the output includes two predictive probability vectors, and , where denotes the prediction probability vector of the original image and comes from the branch with the transformed image. The classification loss is the sum of the two branch results:
- Reliable label loss: The introduction of the PAM has the advantage of mining more discriminative regions, but it may also inevitably lead to over-activation. To take full advantage of the complementary relationship between the modified CAM and reliable labels, we use the Mean Square Error (MSE) as the loss function. In contrast to the Mean Absolute Error (MAE), MSE is sensitive to outliers, which correspond to over-activation. This advantage of MSE can allow us to address the over-activation of modified CAMs while preserving the complementary parts of the modified CAM and reliable labels. In the experimental results, we provide the quantitative results of reliable labels under different losses. In this paper, the loss function is defined as the pixel-level difference between the reliable labels and modified CAM, as follows:where M denotes the modified CAM and R denotes reliable label. Considering the two-branch structure of the Siamese Network, Equation (10) can be divided intowhere denotes the affine transformation, denotes the CAM obtained from the original input image, and denotes the CAM which comes from the branch with transformed image. The Reliable Label loss is the sum of the two branch results:
- Equivariant regularization loss (ER): In order to maintain the consistency of the output, equivariant regularization loss is considered:
4. Experiments
4.1. Preparation for Experiments
4.1.1. Data Set
4.1.2. Evaluation Metrics
4.1.3. Implementation Details
4.2. Analysis of the RSPA
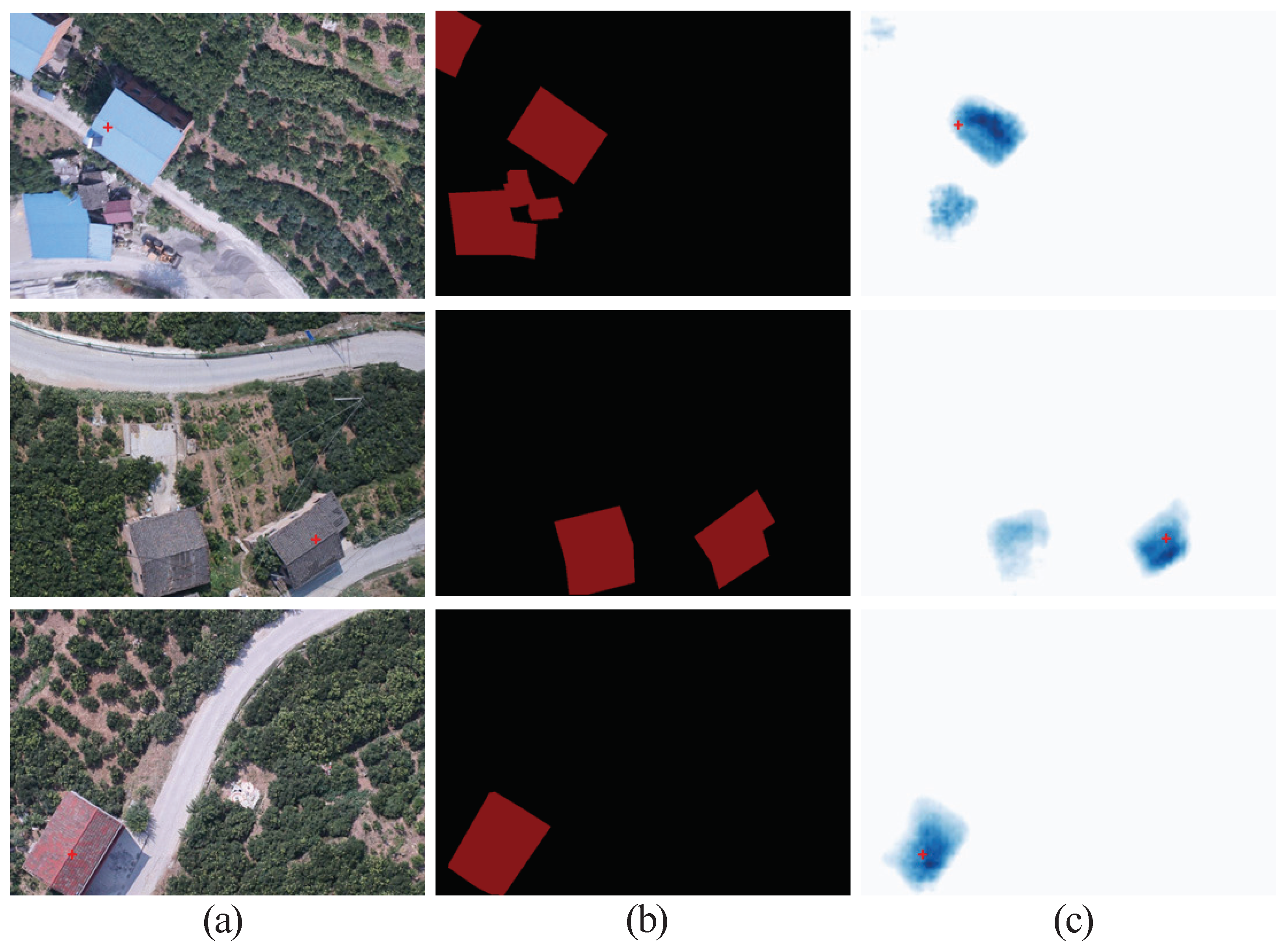
4.2.1. Improving the Quality of the Initial Seeds
4.2.2. Comparison with Baseline (SEAM)
4.2.3. Visualization of Pixel Attention Module
4.2.4. Handling over-Activation
4.2.5. Reliable Label Loss
4.3. Comparison with State-of-the-Art
4.3.1. Accuracy of Pseudo-Labels
4.3.2. Accuracy of Segmentation Maps
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Peng, C.; Ma, J. Semantic segmentation using stride spatial pyramid pooling and dual attention decoder. Pattern Recognit. 2020, 107, 107498. [Google Scholar] [CrossRef]
- Peng, C.; Tian, T.; Chen, C.; Guo, X.; Ma, J. Bilateral attention decoder: A lightweight decoder for real-time semantic segmentation. Neural Netw. 2021, 137, 188–199. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing And Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Fu, K.; Lu, W.; Diao, W.; Yan, M.; Sun, H.; Zhang, Y.; Sun, X. WSF-NET: Weakly supervised feature-fusion network for binary segmentation in remote sensing image. Remote Sens. 2020, 10, 1970. [Google Scholar] [CrossRef] [Green Version]
- Pathak, D.; Krahenbuhl, P.; Darrell, T. Constrained convolutional neural networks for weakly supervised segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1796–1804. [Google Scholar]
- Pinheiro, P.O.; Collobert, R. From image-level to pixel-level labeling with convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1713–1721. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Wang, Y.; Zhang, J.; Kan, M.; Shan, S.; Chen, X. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 12275–12284. [Google Scholar]
- Peng, C.; Zhang, K.; Ma, Y.; Ma, J. Cross Fusion Net: A Fast Semantic Segmentation Network for Small-Scale Semantic Information Capturing in Aerial Scenes. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Wei, S.; Ji, S.; Lu, M. Toward automatic building footprint delineation from aerial images using CNN and regularization. IEEE Trans. Geosci. Remote Sens. 2020, 58, 2178–2189. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully Convolutional Networks for Multisource Building Extraction from an Open Aerial and Satellite Imagery Data Set. IEEE Trans. Geosci. Remote Sens. 2019, 57, 574–586. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Pan, B.; Xu, X.; Shi, Z.; Zhang, N.; Luo, H.; Lan, X. DSSNet: A Simple Dilated Semantic Segmentation Network for Hyperspectral Imagery Classification. IEEE Geosci. Remote. Sens. Lett. 2020, 17, 1968–1972. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. A scale robust convolutional neural network for automatic building extraction from aerial and satellite imagery. Int. J. Remote Sens. 2019, 40, 3308–3322. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, J.; Jiang, Y.; Luo, L.; Gong, W. ASF-Net: Adaptive Screening Feature Network for Building Footprint Extraction from Remote-Sensing Images. Int. J. Remote Sens. 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Wei, Y.; Feng, J.; Liang, X.; Cheng, M.M.; Zhao, Y.; Yan, S. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1568–1576. [Google Scholar]
- Bearman, A.; Russakovsky, O.; Ferrari, V.; Fei-Fei, L. What’s the point: Semantic segmentation with point supervision. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2016; pp. 549–565. [Google Scholar]
- Wang, S.; Chen, W.; Xie, S.M.; Azzari, G.; Lobell, D.B. Weakly supervised deep learning for segmentation of remote sensing imagery. Remote Sens. 2020, 12, 207. [Google Scholar] [CrossRef] [Green Version]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3159–3167. [Google Scholar]
- Vernaza, P.; Chandraker, M. Learning random-walk label propagation for weakly-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7158–7166. [Google Scholar]
- Wu, W.; Qi, H.; Rong, Z.; Liu, L.; Su, H. Scribble-supervised segmentation of aerial building footprints using adversarial learning. IEEE Access. 2018, 6, 58898–58911. [Google Scholar] [CrossRef]
- Song, C.; Huang, Y.; Ouyang, W.; Wang, L. Box-driven class-wise region masking and filling rate guided loss for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 3136–3145. [Google Scholar]
- Rafique, M.U.; Jacobs, N. Weakly Supervised Building Segmentation from Aerial Images. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 3955–3958. [Google Scholar]
- Guo, R.; Sun, X.; Chen, K.; Zhou, X.; Yan, Z.; Diao, W.; Yan, M. Jmlnet: Joint multi-label learning network for weakly supervised semantic segmentation in aerial images. Remote Sens. 2020, 12, 3169. [Google Scholar] [CrossRef]
- Hou, Q.; Jiang, P.; Wei, Y.; Cheng, M.M. Self-erasing network for integral object attention. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–8 December 2018; pp. 549–559. [Google Scholar]
- Zhang, X.; Wei, Y.; Feng, J.; Yang, Y.; Huang, T.S. Adversarial complementary learning for weakly supervised object localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1325–1334. [Google Scholar]
- Ahn, J.; Kwak, S. Learning pixel-level semantic affinity with image-level supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4981–4990. [Google Scholar]
- Ahn, J.; Cho, S.; Kwak, S. Weakly supervised learning of instance segmentation with inter-pixel relations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 2209–2218. [Google Scholar]
- Sun, G.; Wang, W.; Dai, J.; Van Gool, L. Mining cross-image semantics for weakly supervised semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 347–365. [Google Scholar]
- Chen, L.; Wu, W.; Fu, C.; Han, X.; Zhang, Y. Weakly supervised semantic segmentation with boundary exploration. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 347–362. [Google Scholar]
- Yao, Y.; Chen, T.; Xie, G.S.; Zhang, C.; Shen, F.; Wu, Q.; Tang, Z.; Zhang, J. Non-salient region object mining for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 2623–2632. [Google Scholar]
- Yao, Q.; Gong, X. Saliency guided self-attention network for weakly and semi-supervised semantic segmentation. IEEE Access. 2020, 8, 14413–14423. [Google Scholar] [CrossRef]
- Lee, S.; Lee, M.; Lee, J.; Shim, H. Railroad is not a train: Saliency as pseudo-pixel supervision for weakly supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 5495–5505. [Google Scholar]
- Zeng, Y.; Zhuge, Y.; Lu, H.; Zhang, L. Joint learning of saliency detection and weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 7223–7233. [Google Scholar]
- Chen, J.; He, F.; Zhang, Y.; Sun, G.; Deng, M. SPMF-Net: Weakly supervised building segmentation by combining superpixel pooling and multi-scale feature fusion. Remote Sens. 2020, 12, 1049. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J.; Liu, Y.; Wu, P.; Shi, Z.; Pan, B. Mining Cross-Domain Structure Affinity for Refined Building Segmentation in Weakly Supervised Constraints. Remote Sens. 2022, 14, 1227. [Google Scholar] [CrossRef]
- Krahenbuhl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. In Proceedings of the 24th International Conference on Neural Information Processing Systems, Granada, Spain, 12–15 December 2011. [Google Scholar]
- Wu, Z.; Shen, C.; Van Den Hengel, A. Wider or deeper: Revisiting the resnet model for visual recognition. Pattern Recognit. 2019, 90, 119–133. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.-J.; Li, K.; Li, F.-F. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Chen, L.C.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. In Proceedings of the International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Lee, J.; Kim, E.; Yoon, S. Anti-adversarially manipulated attributions for weakly and semi-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 4071–4080. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Initial Seeds |
|---|---|
| CAM (GAP) | 74.9 |
| CAM (GMP) | 78.2 |
| Baseline | CAM | PAM | SN and ER | Reliable Label Loss | mIoU (%) |
|---|---|---|---|---|---|
| ✓ | 79.8 | ||||
| ✓ | 78.2 | ||||
| ✓ | ✓ | 81.6 | |||
| ✓ | ✓ | ✓ | 82.7 | ||
| ✓ | ✓ | ✓ | ✓ | 86.3 |
| Method | OAR | IoU |
|---|---|---|
| AffinityNet [30] | 65.50 | 57.42 |
| IRN [31] | 50.19 | 64.84 |
| SEAM (Baseline) [10] | 48.75 | 65.24 |
| BES [33] | 53.86 | 63.22 |
| AdvCAM [44] | 35.47 | 70.10 |
| Ours | 22.36 | 75.53 |
| Loss Function | mIoU |
|---|---|
| MAE | 84.24 |
| MSE | 86.25 |
| Method | w/o Refinement | w/AffinityNet | w/IRN |
|---|---|---|---|
| AffinityNet [30] | 74.89 | - | - |
| IRN [31] | 79.53 | - | - |
| SEAM (Baseline) [10] | 73.05 | 79.80 | - |
| BES [33] | 78.52 | - | - |
| AdvCAM [44] | 76.17 | - | 82.25 |
| Ours | 86.25 | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Xu, W.; Yu, Y.; Peng, C.; Gong, W. Reliable Label-Supervised Pixel Attention Mechanism for Weakly Supervised Building Segmentation in UAV Imagery. Remote Sens. 2022, 14, 3196. https://doi.org/10.3390/rs14133196
Chen J, Xu W, Yu Y, Peng C, Gong W. Reliable Label-Supervised Pixel Attention Mechanism for Weakly Supervised Building Segmentation in UAV Imagery. Remote Sensing. 2022; 14(13):3196. https://doi.org/10.3390/rs14133196
Chicago/Turabian StyleChen, Jun, Weifeng Xu, Yang Yu, Chengli Peng, and Wenping Gong. 2022. "Reliable Label-Supervised Pixel Attention Mechanism for Weakly Supervised Building Segmentation in UAV Imagery" Remote Sensing 14, no. 13: 3196. https://doi.org/10.3390/rs14133196
APA StyleChen, J., Xu, W., Yu, Y., Peng, C., & Gong, W. (2022). Reliable Label-Supervised Pixel Attention Mechanism for Weakly Supervised Building Segmentation in UAV Imagery. Remote Sensing, 14(13), 3196. https://doi.org/10.3390/rs14133196