1. Introduction
With the development of remote sensing and information processing technology, HSI technology has become the focus in the remote sensing community. The hyperspectral image is a precise remote sensing means that contains rich spatial texture information and spectral reflectance information [
1], which has unique advantages in subtle recognition and detection missions. e.g., vegetation cover monitoring [
2], atmospheric environmental research [
3], and marine monitoring [
4].
Based on the recent literature reviewed in [
5], HSI classification is the most vibrant field of research in the hyperspectral community (i.e., each pixel in hyperspectral images is appointed a unique category). Within the initial stage of HSI classification, most methods take spectral features, such as independent component analysis (ICA) [
6] and support vector machines (SVM) [
7], as the primary classification basis. However, the HSI classification results obtained by these methods are unsatisfactory since the spatial features are not well exploited. Due to the characteristics of spatial homogeneity and heterogeneity and mixed pixels of HSI, it is difficult to fully utilize the features of HSI by spectral feature extraction alone. The spatial features can improve the classification performance of HSI [
8]; increasingly, classification strategies that combine spatial features have been proposed. For example, a hyperspectral data preprocessing method based on mathematical morphology was proposed in [
9] in which extended morphological profiles (EMPs) were utilized to exact spatial construction information through morphological manipulation.
With the rapid development of deep learning (DL) [
10], DL has been presented in numerous computer vision tasks and has made worthwhile breakthroughs. As a typical deep learning(DL) model, a convolutional neural network (CNN) has been considered to create full utilization of the spatial and spectral features of HSI [
11], and researchers have proposed a series of HSI classification methods based on CNN. Hu et al. [
12] used a deep CNN model for HSI classification and achieved good performance. Chen et al. [
13] proposed a 3D-CNN model for HSI classification, which performs superior to a 1D-CNN and a 2D-CNN. Cheng et al. [
14] designed a spatial–spectral random patch network, which made adequate utilization of the spatial and spectral information and achieved satisfactory performance. However, due to the scarcity of labeled samples in HSI, DL-based strategies cannot obtain satisfactory accuracy. The collection and labeling of HSI are complicated, time-consuming, and high-cost. Therefore, the number of labeled training samples is greatly limited, and the shortage of training samples is one of the main obstacles to productive HSI classification methods.
Some recent works have begun to explore self-supervised or semi-supervised strategies for HSI classification to solve this problem. Semi-supervised learning methods aim to improve performance by simultaneously using a few labeled samples and a large number of unlabeled samples. Several semi-supervised methods have been used for HSI classification, which are roughly categorized into three classes: (1) self-training [
15,
16,
17]; e.g., Li et al. [
16] iteratively enlarged the training sample set and retrained the classifier, and the selection of training samples was based on the region information, so the risk of assigning wrong labels was primarily reduced. (2) generative models [
18,
19,
20]; e.g., Feng et al. [
19] proposed a semi-supervised dual-branch convolutional autoencoder with self-attention. (3) graph-based methods [
21,
22,
23]; e.g., Ding et al. [
23] proposed a semi-supervised locality-preserving dense graph neural network (GNN) for HSI classification in which autoregressive moving average filters and context-aware learning are integrated. Moreover, the self-supervised learning methods are also applied to the few-shot HSI classification [
24,
25,
26,
27]. In [
26], a self-supervised contrastive fruitful disymmetrical expanded network is presented for HSI classification. In [
27], a self-supervised learning strategy with flexible distillation is proposed for HSI classification. Nevertheless, these approaches suffer from some limitations. Self-training requires high-confidence samples with their “pseudo-labels” to update the training set, and the performance will get worse once the “pseudo-labels” are incorrect. Methods based on a graph should construct a structural graph, but it is troublesome due to the fact that the latent spatial–spectral structural information is not easy to learn.
In view of these limitations, we attempt to incorporate a self-supervised strategy into a semi-supervised framework and propose a unified SSRNet. The proposed SSRNet is designed as two branches: a semi-supervised and a self-supervised branch. The semi-supervised component consists of a residual feature extraction network (RNet) that extracts discriminative spectral–spatial features from HSI cubes. Since random perturbation is proved to be an effective way for robust classification [
28,
29,
30,
31], we implement perturbation by spectral feature shift in this framework. The self-supervised component consists of two auxiliary tasks: a spectral order forecast and a masked bands reconstruction, which can learn the discriminative features of HSI.
To summarize, the contributions of the proposed methods are threefold as follows:
(1) Self-supervised learning is integrated into a semi-supervised framework for HSI classification by designing a unified multi-task SSRNet. SSRNet has competitive performance, especially under few labeled samples conditions.
(2) A semi-supervised data random perturbation strategy is proposed. This perturbation strategy is the bidirectional movement of some randomly selected spectral segments along the spatial dimension, respectively, on the HSI feature maps.
(3) Two types of self-supervised auxiliary tasks are presented for SSRNet. The two auxiliary tasks, i.e., masked bands reconstruction and spectral order forecast, can help the network learn the discriminative features.
2. Methodology
This section will present the proposed SSRNet, including the semi-supervised and self-supervised branches. In the semi-supervised branch, we amplify the mean-teacher [
29] framework with one kind of random perturbation, i.e., spectral feature shift. Furthermore, we design a residual feature extraction network (RNet) for learning spectral–spatial features. In the self-supervised branch, two auxiliary tasks: masked bands reconstruction and spectral order forecast, are explored to help in training the proposed SSRNet.
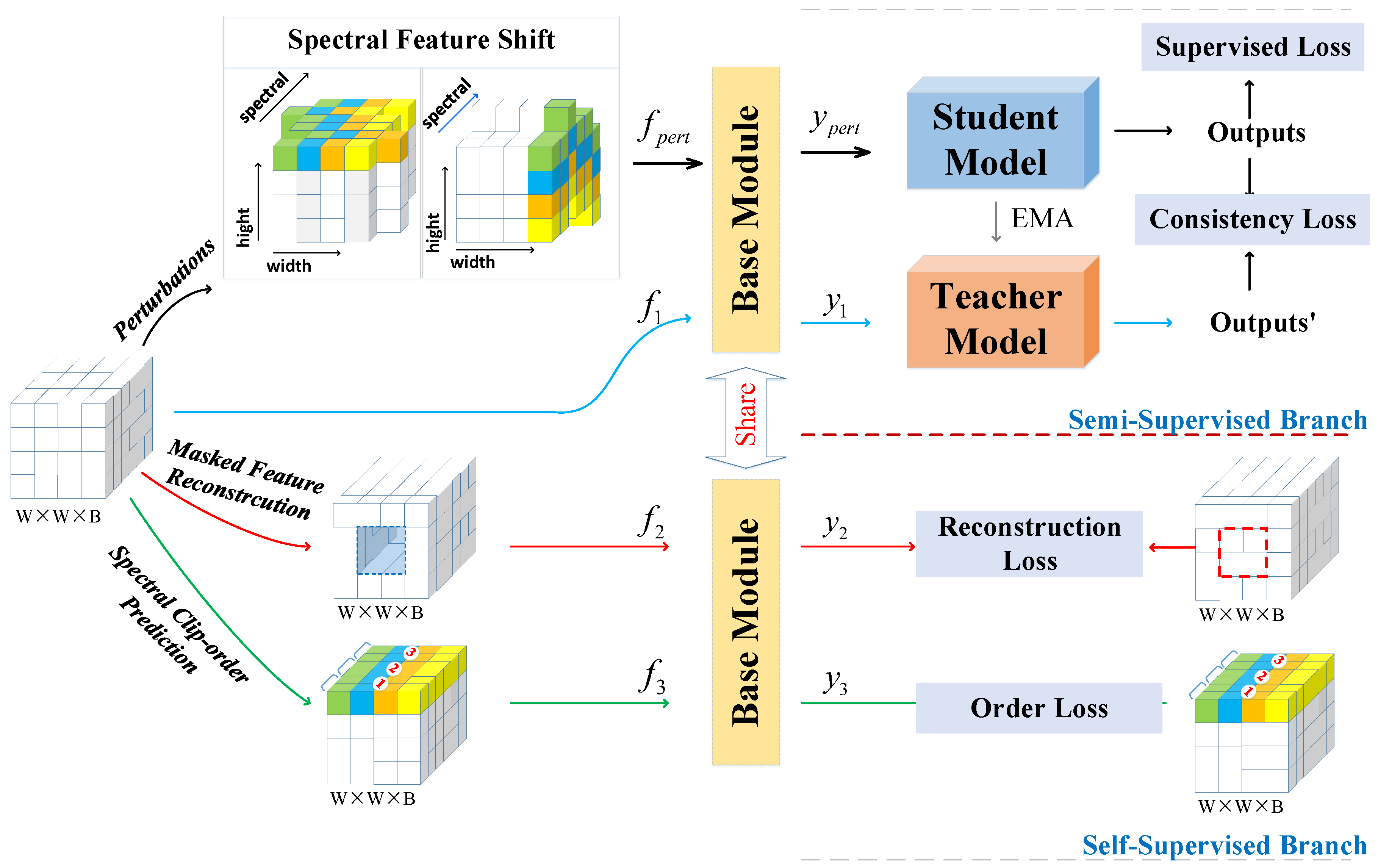
Figure 1 illustrates the outline of the SSRNet.
2.1. The Overall Framework of the Proposed SSRNet
The HSI data cube is denoted by . M and N signify the width and height of the HSI individually. L is the number of spectral bands. The corresponding category label set of each pixel in D is in which C means the amount of the land cover categories. First, principal component analysis (PCA) is utilized to decrease the spectral dimension of HSI, while keeping the same spatial size. We signify the data cube after PCA by in which X is the input after PCA and B is the number of spectral bands after PCA, i.e., B andis set as 30 in our framework. Then, the HSI is split into overlapping 3D-patches centering on each pixel, which is represented by . I is the input data for the SSRNet, and the label of each 3D-patch is determined by the label of the center pixel. Furthermore, the W, i.e., patch size, is set as 11.
Figure 1 illustrates the schematic diagrams of the proposed SSRNet. First, we utilized PCA to reduce the spectral dimensionality of HSI. Then, adjacent cubes of each pixel were taken as the center to form a new data representation. There is a random perturbation of HSI data in the semi-supervised branch: spectral-feature shift. The base module takes the perturbed data and the unperturbed data as inputs. The student and teacher models have a unified model framework and distinctive weight updating strategies. RNet is made up of a base module, a student model and a teacher model. The self-supervised branch consists of two additional tasks: masked bands reconstruction and spectral order forecast. Lastly, a multi-task framework is explored for optimization.
2.2. Semi-Supervised Learning Branch
This section will introduce the semi-supervised branch of the SSRNet and provide a brief description of the mean-teacher framework. Then, we present the RNet, which includes the base module (BM) and residual feature extraction module (REM). Afterward, we give one type of data random perturbation method called spectral-feature shift.
2.2.1. Mean-Teacher Framework
The mean-teacher framework is extended from a supervised learning paradigm with two models: a student model
and a teacher model
. For the student model, the weights
are optimized by the HSI supervised losses in the same way as that for supervised learning. The student model is RNet in our proposed SSRNet. The teacher model shares the unified model architecture with the student, but its weights
are updated with an exponential moving average (EMA) of the consequences from a sequence of student models of different training iterations. EMA can be formulated as follows:
where
T represents the iteration of the training process, and
is a smoothing coefficient. Its default option is 0.999.
2.2.2. The RNet Overview
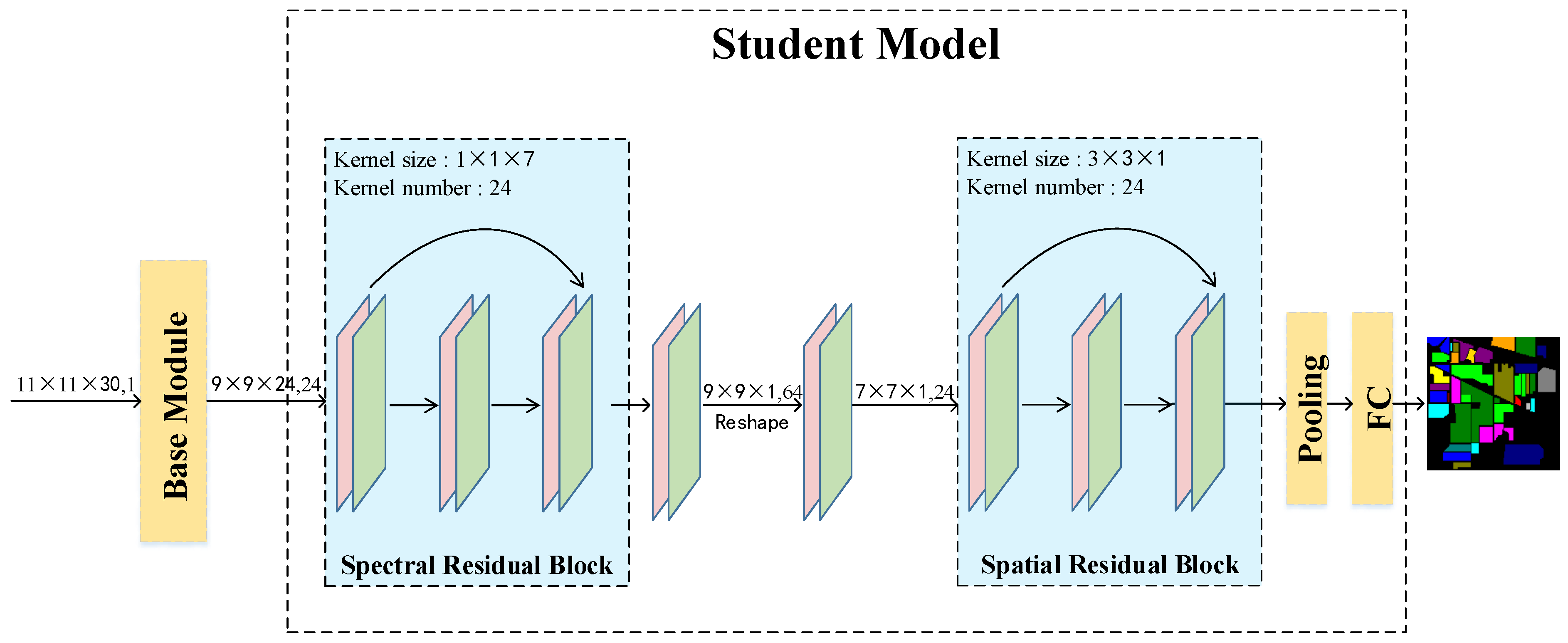
To verify our semi-supervised framework and better clarify our method, we design a residual network (RNet). The RNet is shown in
Figure 2. The RNet comprises two modules: a BM and a residual feature extraction module (REM). The BM copes with the input feature
and outputs feature
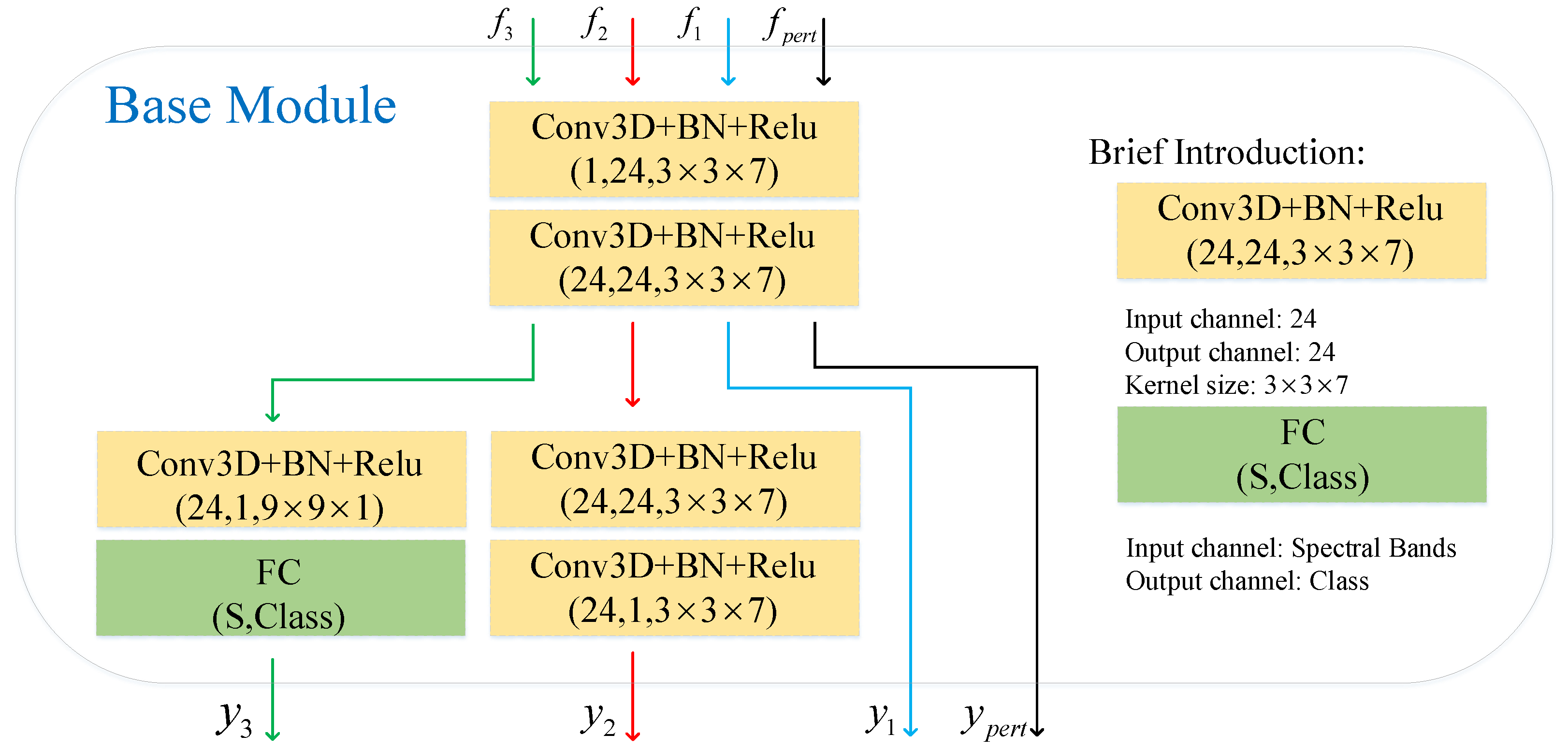
shared by the following REM. The details of the BM are shown in
Figure 3. The REM copes with the input feature
and outputs feature
. Finally,
is sent into the classifier for HSI classification.
The classical CNN model has been applied to hyperspectral classification and has achieved advanced results. However, the classification precision diminishes with the increase in the convolution layers [
32]. This problem can be successfully eased by attaching shortcut connections between other layers to make residual blocks [
33]. According to the spatial correlation and spectral characteristics of HSI, we designed a residual feature extraction module (REM). The residual structure is shown in
Figure 2. We created two kinds of residual feature extraction modules: spectral residual and spatial residual modules. For the spectral residual feature extraction module, the size of the input feature is
and has
n channels. The kernel size of
is applied to the two convolution layers. Meanwhile, the input feature is kept at
unaltered through a padding method. The spectral residual module is formulated as follows:
where
means the input feature of the
i-th convolution layer,
represents the output feature of the
-th convolution layer, and
is the weight parameter of the convolution layers.
2.2.3. Data Random Perturbation
Random perturbation is proved to be effective for robust semi-supervised learning models [
28,
29,
30,
31,
34]. The work in [
29] adds Gaussian noise to intermediate feature maps of the mean-teacher framework. For HSI data, spatial and spectral information are both essential. We propose a primary data random perturbation in our work: spectral feature shift.
Spectral feature shift is the bidirectional movement of some randomly selected spectral segments along the horizontal and vertical dimensions on the feature maps, respectively. The schematic diagrams of the spectral feature shift are shown in
Figure 1. Therefore, spectral feature shift can significantly boost the multifariousness of the input features and make the semi-supervised learning model more robust. First, we randomly select
spectral bands. Then,
spectral bands are bidirectionally offset in the horizontal spatial dimension, and the other
spectral bands are bidirectionally offset in the vertical spatial dimension. We use
to mean the rank of the spectral shift. Moreover, we will discuss the influence of
size on HSI classification accuracy in
Section 3.
Each mini-batch incorporates both labeled HSI data and unlabeled HSI data during the training process. Moreover, we take a dropout method to avoid overfitting. The dropout strategy is a simple and effective technique that prevents overfitting by discarding a certain percentage of units during the training process [
35]. In the mean-teacher framework, the labeled samples are trained using supervised loss. Unlabeled samples have no ground truth labels, so their supervised loss is undefined. Consistency regularization utilizes unlabeled HSI data based on the assumption that the model should output similar forecasts when fed perturbed forms of the same input. The consistency loss is utilized to the labeled HSI data and unlabeled HSI data in the semi-supervised branch. Therefore, the total loss in the semi-supervised branch is:
where
means the label of
i-th training sample and
indicates the predictive label,
denotes the training samples with labels in each mini-batch, and
means the
i-th training sample of spectral feature shift and
is the output of the student model. Here,
represents the
i-th training sample and
is the output of the teacher model. It should be noted that only the training samples of the student network will be perturbed by the spectral feature shift. The hyper-parameters
are set to 1.
is consistency loss for spectral feature shift random perturbation, and
is
-loss.
is supervised loss for the labeled data, and
is typical cross entropy loss.
2.3. Self-Supervised Learning Branch
Motivated by recent advances in self-supervised learning of HSI classification [
32,
36,
37,
38,
39], we hypothesize that the semi-supervised HSI classification method could significantly benefit from self-supervised learning strategies. Furthermore, based on this motivation, we propose two auxiliary tasks in the self-supervised branch: masked bands reconstruction and spectral order forecast.
2.3.1. Masked Bands Reconstruction
As shown in
Figure 1, the critical thought of this self-supervised auxiliary task is to generate the feature
by stochastically masking the HSI feature
at a few areas on the spatial dimensions. Then the BM utilizes
to reconstruct
. The schematic diagrams of the BM are shown in
Figure 3. Masked bands reconstruction generates self-supervised signs from the original HSI feature
, which could learn discriminative representations simply and effectively. The loss formula for the masked features auxiliary reconstruction task is:
where
represents the
i-th training sample of randomly masking the feature at some area along the spatial dimension,
means the reconstruction of the
i-th training sample, and
N represents the number of mini-batches.
At the same time, the SSRNet is trained in a multi-task pattern.In the pretext task of reconstruction of masked bands, the BM will be driven to notice and aggregate features from the context to predict the discarded areas. In this way, the learned features spontaneously conduct semi-supervised HSI classification. We use
to mean the rank of the mask. Moreover, we will discuss the influence of
size on HSI classification accuracy in
Section 3.
2.3.2. Spectral Order Forecast
As shown in
Figure 1, this auxiliary task needs to predict spectral feature sequences corrected in stochastically scrambled feature maps. The spectral order forecast is formulated as a classification task. The input is an HSI patch of clip spectral order, and the output is a probability distribution of the spectral order. The loss presentation for the spectral order forecast auxiliary task is:
where
means the
i-th sample label for the correct spectral order,
represents the
i-th sample label for the predicted spectral order. Spectral order forecast can utilize the spectral order of features to learn discriminative spectral representations.
2.4. Overall Loss
Loss function is designed for masked bands reconstruction, and is -loss, while is cross entropy loss. Finally, the total loss function is made up of the , and the . Hyper-parameters and are set to 0.0001 and 0.001. A multi-task framework is exploited for optimization.
3. Experiments
In this section, we describe the experiment we performed to demonstrate the effectiveness of the proposed SSRNet for HSI classification. First, a brief introduction of the datasets used in the experiment is given, and then the experimental setup and comparison with other advanced methods follow. Lastly, we analyze the running time of the SSRNet and perform an ablation study to affirm the effectiveness of each component.
3.1. Dataset Description
Four widely used HSI datasets were used in the experiments, including Indian Pines, University of Pavia (PaviaU), Salinas and Houston 2013 datasets. We will give a short introduction of datasets as follows:
(1) Indian Pines: The dataset was collected by Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor over Northwestern Indiana. The data contain 200 spectral bands in the wavelength within range of 0.4 to 2.5 and 16 land cover categories. The spatial size is pixels with resolution of 20 m/pixel. The total number of valid samples is 10,249 excluding background samples.
(2) University of Pavia: The dataset was captured by the ROSIS-03 sensor in the University of Pavia, Italy. The dataset consists of 103 spectral bands with the wavelength range of 0.43 to 0.86 and nine land cover classes, and its spatial size is pixels, with a total of 42,776 labeled samples excluding background classes.
(3) Salinas: The dataset was collected by the AVIRIS sensor over Salinas Valley, California, USA. and consists of 204 spectral bands in the wavelength range of 0.4 to 2.5 and 16 land cover classes. The spatial size is with the spatial resolution is 3.7 m/pixel. The total number of valid samples is 54,129, excluding background classes.
(4) Houston 2013: The dataset was acquired by the ITRES CASI-1500 sensor at the Houston University campus and its surrounding area, which contains 144 spectral bands in the wavelength range of 0.38 to 1.05 and 15 land cover classes, and its spatial size is , with a total of 15,029 labeled samples, excluding background classes. The spatial resolution is 2.5 m/pixel.
3.2. Experiment Setup
To assess the effectiveness of the SSRNet, we contrasted the SSRNet with other advanced HSI classification methods, including the traditional feature extraction method, SVM with RBF kernel [
7], and other deep-learning-based classifiers: SSRN [
40], SSLSTM [
41], DBMA [
42], HybridSN [
43], CDCNN [
44] and 3D-CAE [
37]. Our proposed SSRNet and all DL-based methods were executed with PyTorch, and SVM was executed with sklearn. To make full utilization of unlabeled samples to improve learning performance, we randomly selected 10 labeled samples and 20% unlabeled samples for each class as training samples, and the rest as testing samples. For other supervised methods, we selected 10 labeled samples for each class as training samples. Details of training samples and testing samples of the dataset are listed in
Table 1,
Table 2,
Table 3 and
Table 4. The batch size was 16, the optimizer was Adam [
45] with a learning rate of 0.0005, and the number of epochs was 80. Moreover, all experimTents at the same computing platform were configured with NVIDIA GeForce GTX1660 SUPER GPU and with 8 GB of memory. Next, the above methods will be briefly introduced.
(1) SVM [
7] is a traditional classification method, and all spectral bands are taken as the input of the SVM with a radial basis function (RBF) kernel.
(2) SSRN [
40] is a fully supervised method based on ResNet and 3D CNN in which the patch size is set to be
.
(3) SSLSTM [
41] is a method using spectral–spatial long short-term memory (LSTM) networks.
(4) DBMA [
42] is a supervised method based on a 3D CNN, attention mechanism and DenseNet in which the patch size is set to be
.
(5) HybridSN [
43] is a supervised method of mixing a 3D CNN and a 2D CNN in which the patch size is set to be
.
(6) CDCNN [
44] is a supervised method based on a 2D CNN and ResNet in which the patch size is set to be
.
(7) 3D-CAE [
37] is a self-supervised method based on a 3D convolutional autoencoder in which the patch size is set to be
.
3.3. Experimental Results
The results of overall accuracy (OA), average accuracy (AA), and Kappa coefficient (Kappa) are demonstrated in
Table 5,
Table 6,
Table 7 and
Table 8. Each experiment was repeated 10 times in which the mean and the standard deviation of each index were reported.
Figure 4,
Figure 5,
Figure 6 and
Figure 7 illustrates the classification maps of our SSRNet and other compared methods. The proposed methods outperform the compared methods on four datasets.
For instance, in the Indian Pines dataset, the SSRNet achieved the best OA of 81.65%, our SSRNet yielded over 20% higher than SVM (54.22%) and CDCNN (58.50%), and over 4% higher than other advanced deep-learning-based methods SSRN (77.48%) and DBMA (70.73%). In the University of Pavia, our proposed SSRNet was over 20% higher than the traditional SVM (64.32%), which was higher than the counterpart of SSRN (85.24%), CDCNN (74.39%) and DBMA (85.66%). Especially in the Salinas dataset, the SSRNet achieved the best OA of 93.47%, over 4% higher than advanced DBMA, but the OA of the other methods did not reach above 90%. Compared with self-supervised methods, the SSRNet was superior to the 3D-CAE in all four datasets, especially in the Indian Pines dataset, where the OA of SSRNet yielded over 20% higher than the 3D-CAE. We also made a visual comparison utilizing classification maps obtained by those methods. Other methods have classification errors in almost every land cover, and SSLSTM, CDCNN and 3D-CAE have obvious classification errors in the class of Broccoli-green-weeds-2 in the Salinas dataset. It can be observed that the SSRNet restored the distribution of surface objects well and maintained the best boundary region for these four datasets, which further validates the outstanding performance of the SSRNet.
3.4. Ablation Study
3.4.1. Complementarity between Components
The proposed SSRNet consists of two branches: semi-supervised and self-supervised. Spectral feature shift (S) proposes a random data perturbation strategy in the semi-supervised branch. Two auxiliary tasks are proposed in the self-supervised branch: masked bands reconstruction (R) and spectral order forecast (O). To prove the validity of our proposed three components, we made exhaustive ablation studies to evaluate different components of the SSRNet on the Indian Pines dataset and the Houston 2013 dataset. Ablation studies include the following:
SSRNet-S-R-O: The spectral feature shift in the semi-supervised branch is discarded, and two self-supervised auxiliary tasks are discarded;
SSRNet-S: Only the spectral feature shift in the semi-supervised branch is discarded;
SSRNet-R: Only the masked bands reconstruction in the self-supervised branch is discarded;
SSRNet-O: Only the spectral order forecast in the self-supervised branch is discarded;
SSRNet (ALL): No components are discarded.
We designed two data selection methods, one was 20% unlabeled samples and 10 labeled samples for each class, and the other was 20% unlabeled samples and 20 labeled samples for each class.
Table 9 demonstrates that the three components are complementary. Moreover, perfect precision is achieved when integrated with three components (i.e., SSRNet (ALL)).
3.4.2. Choice of Hyper-Parameters
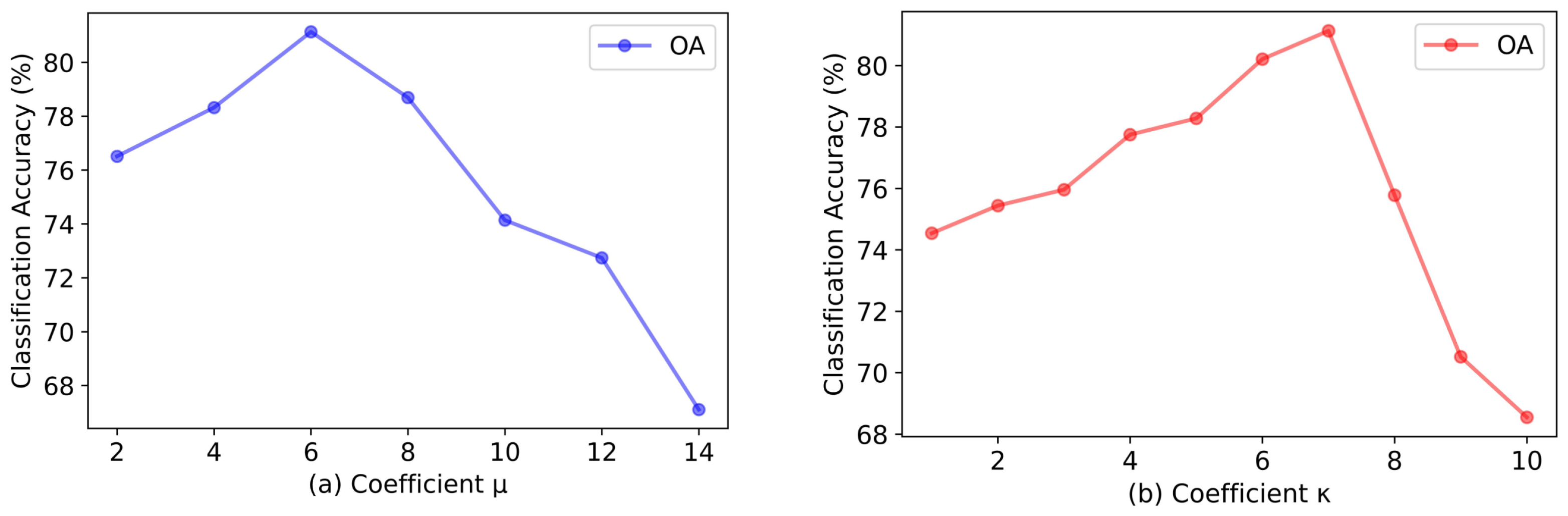
Figure 8 shows the OA of the spectral feature shift perturbation and the masked bands reconstruction auxiliary task under different hyper-parameter choices on the Indian Pines dataset in which the coefficient
is used to denote the level of spectral feature shift, and the coefficient
was used to mean the rank of mask. The adjustment of hyper-parameter has a certain effect of HSI classification precision. Moreover,
and
seem to be the best parameters.
3.4.3. Choice of Patch Size
Table 10 shows the OA of the SSRNet with various patch sizes, which varied from 7 × 7 to 13 × 13 with an interval of 2. As the patch size increased, the OA of the Salinas dataset kept increasing. For the other three datasets, the OA began to decline after 11 × 11, where they reached the highest OA of 83.96%, 90.99% and 85.54%, respectively. It has been found that the 11 × 11 patch size is most suitable.
3.5. Investigation on Running Time
The whole training time and testing time of our SSRNet and other methods are reported in
Table 11,
Table 12,
Table 13 and
Table 14. The SVM consumed less training and testing time than the deep-learning-based methods because the deep-learning-based methods have more parameters and larger input feature maps generally. Moreover, since our proposed SSRNet aims to improve learning performance by using fewer labeled samples and a large number of unlabeled samples, it requires more training time, but testing time still has one advantage compared with other methods. Considering the classification accuracy, our proposed SSRNet is competitive.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}