
A Low-Grade Road Extraction Method Using SDG-DenseNet Based on the Fusion of Optical and SAR Images at Decision Level



Abstract
:
1. Introduction
- (1)
- A novel SDG-DenseNet network for low-grade road extraction in optical images is proposed. The stem block is taken as the starting module to expand the receptive field and preserve image information, while the stem block also reduces the number of parameters. A novel D-dense block is introduced to construct the encoder and decoder of the network, which applies the dilated convolution in all parts from the encoder to the decoder to improve the receptive field of the network. Moreover, in order to make the dilated convolution run through the entire network, this paper introduces a GIRM module combining the dilated convolution and a double self-attention mechanism. The introduction of the GIRM module aims to enhance the network’s ability to obtain global information. The segmentation effect of the novel network is better than that of many existing networks;
- (2)
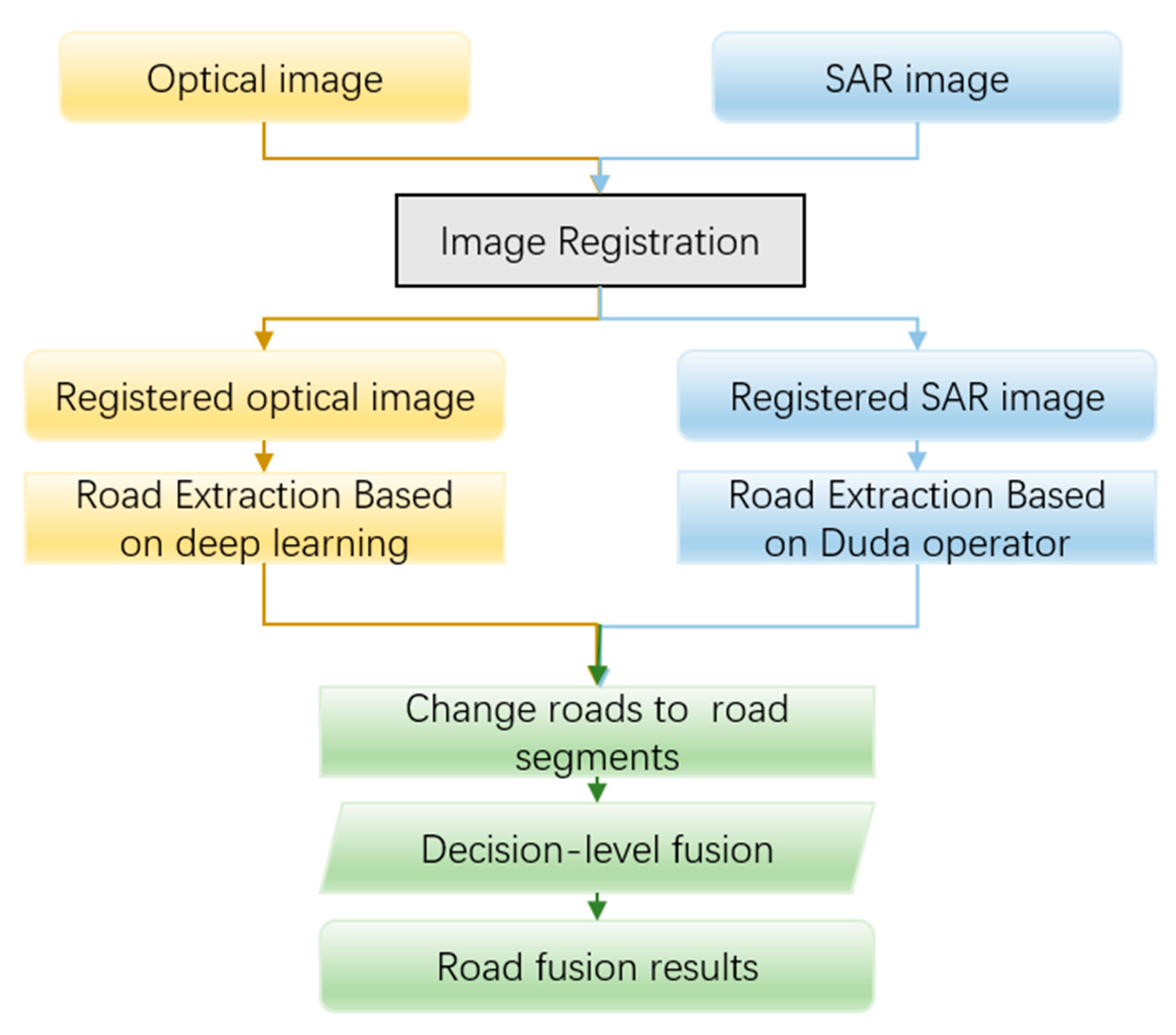
- A decision-level fusion method is proposed for the low-grade road extraction based on optical images and SAR images, which repairs some interrupted roads in the optical image extraction results. The extraction accuracy of decision-level fusion methods is higher than that of optical image-based deep learning methods in practical application scenarios.
2. Methods
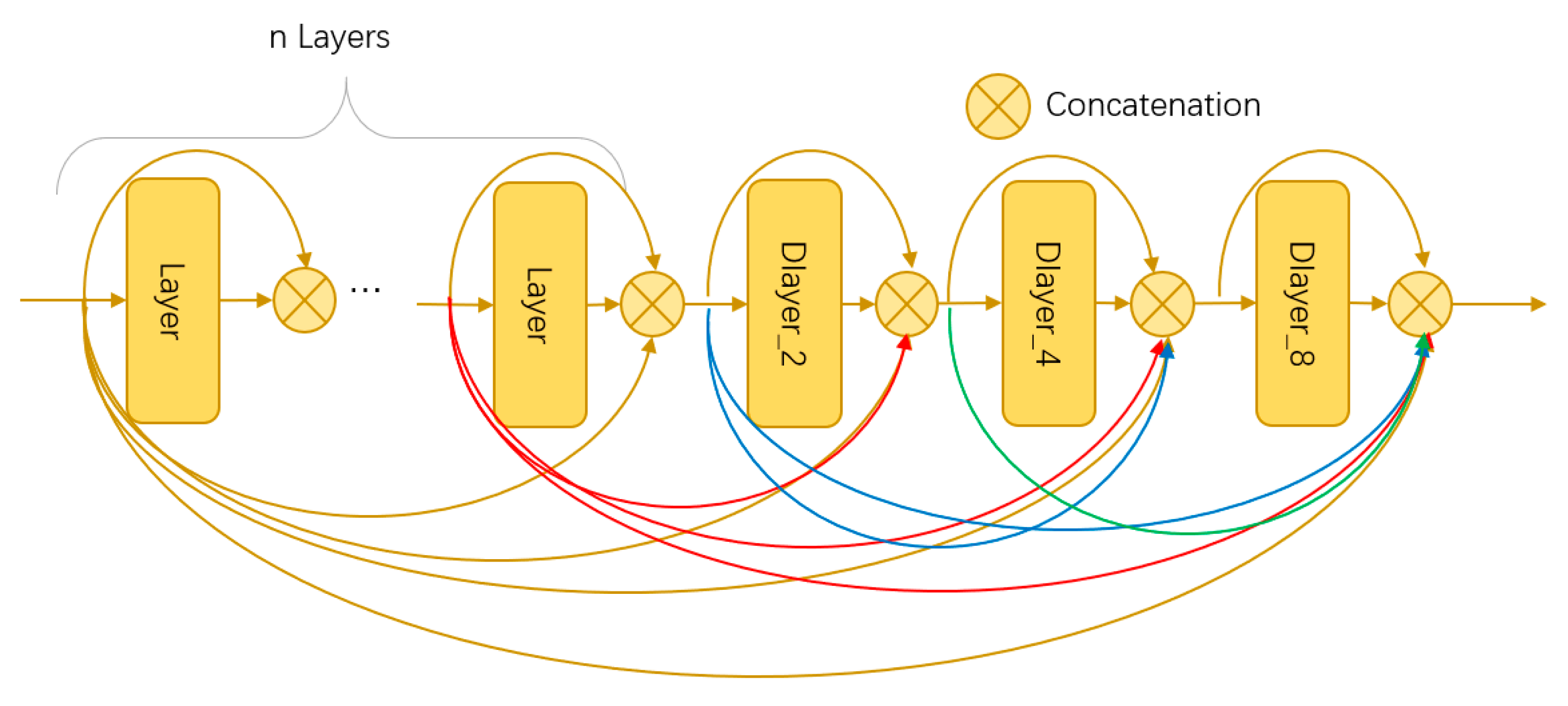
2.1. Architecture of SDG-DenseNet Network
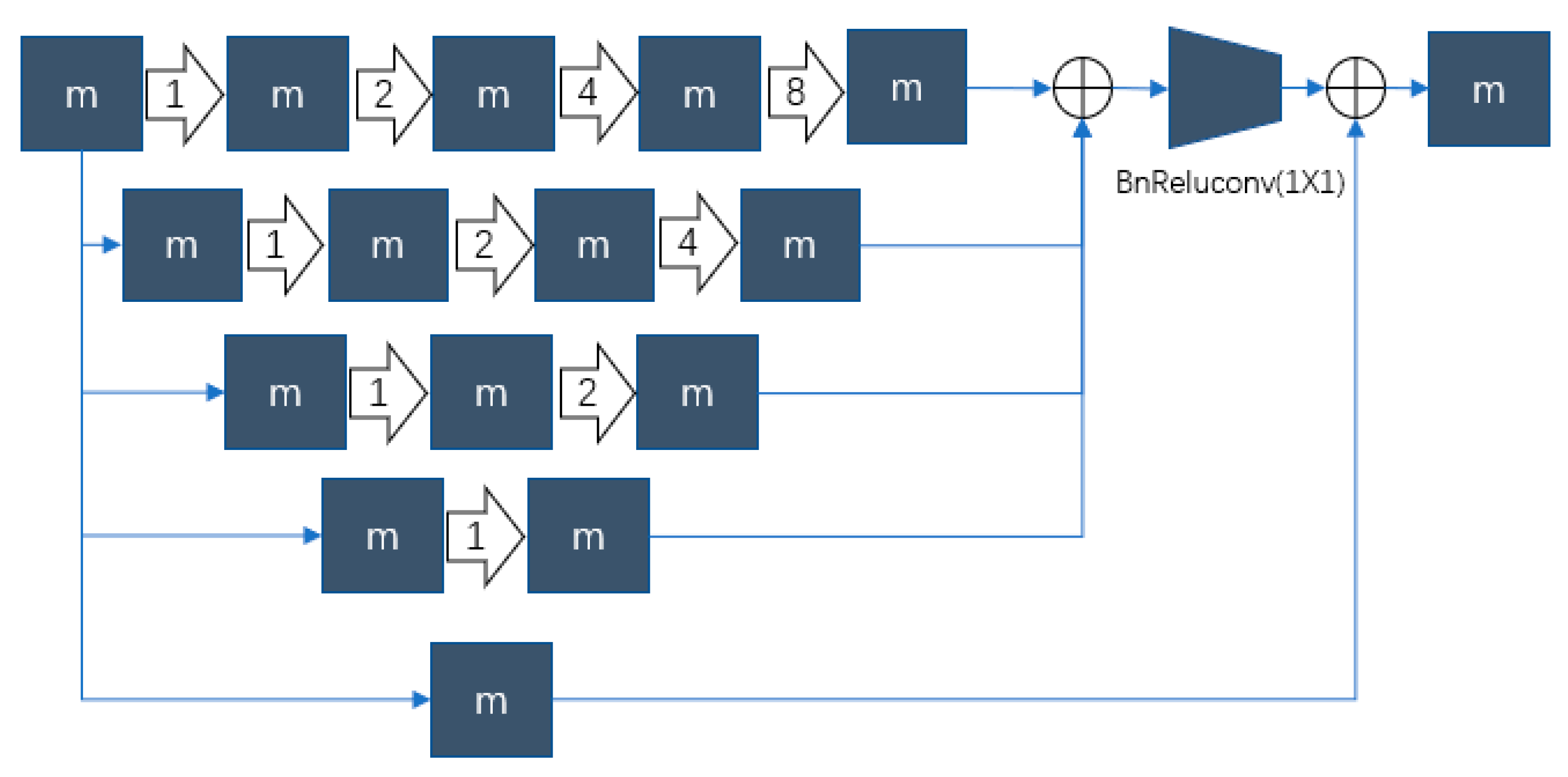
2.2. Improved D-Dense Block and Stem Block
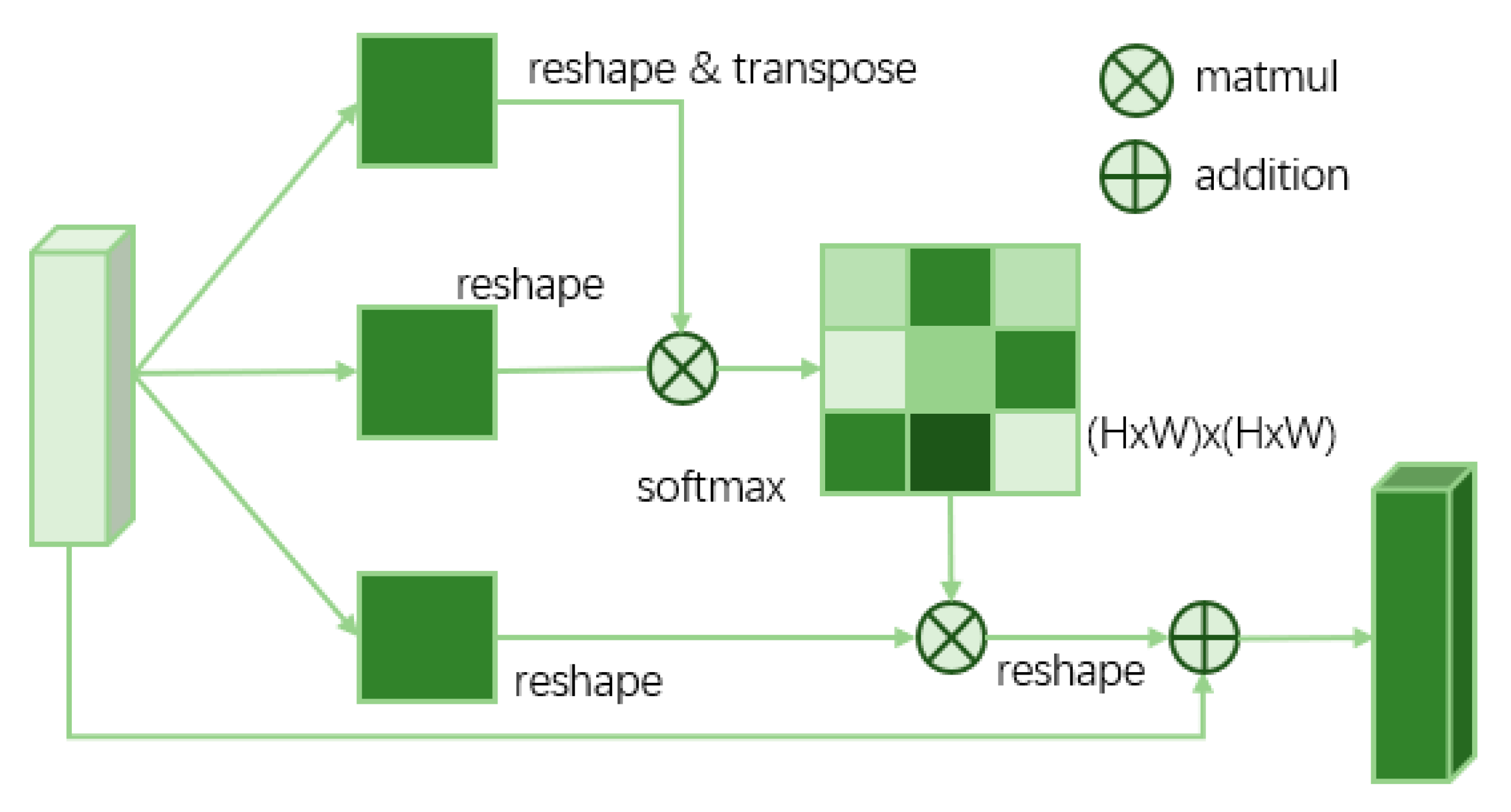
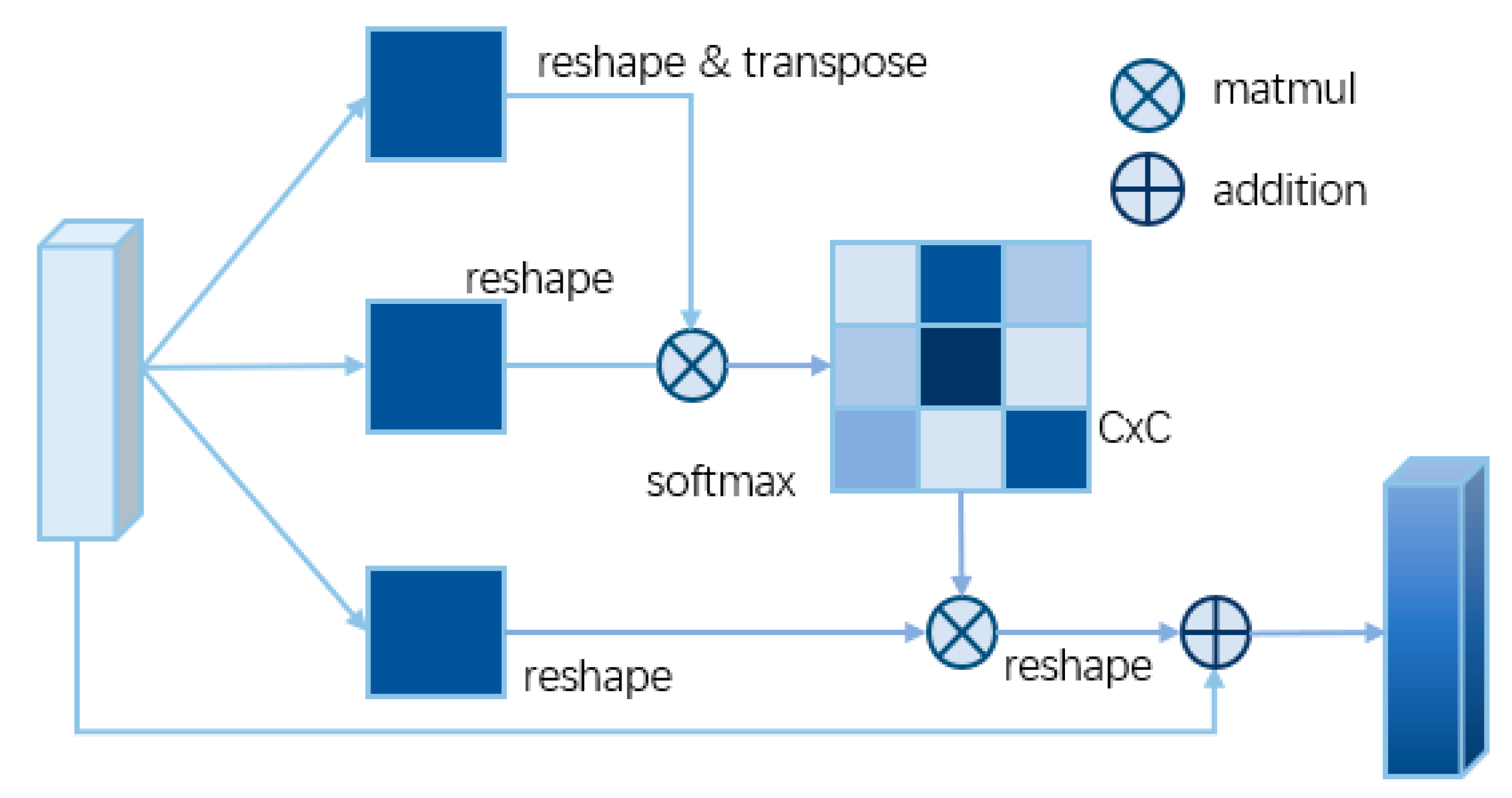
2.3. Global Information Recovery Module (GIRM) Based on d-Blockplus and Attention Mechanism
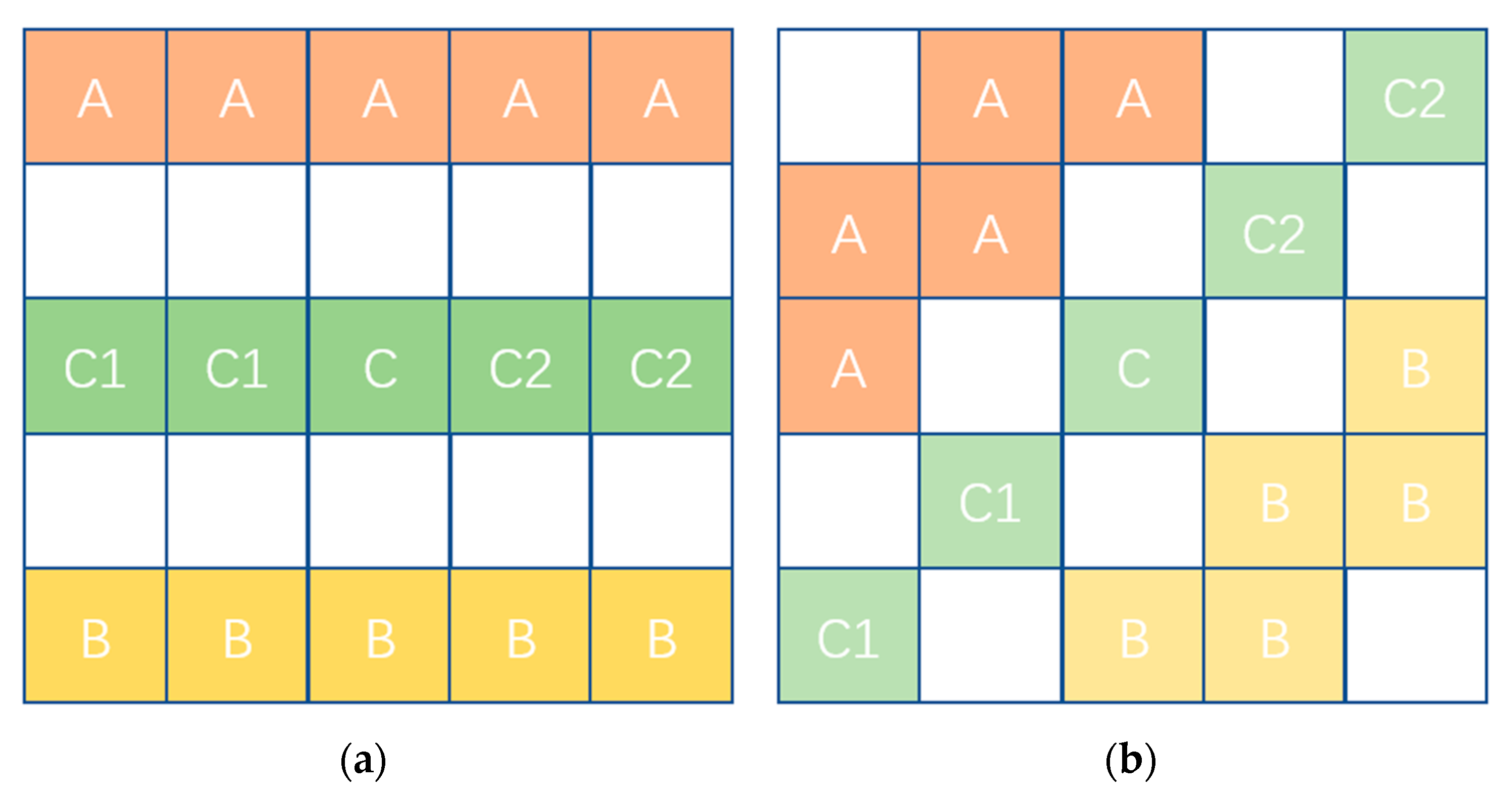
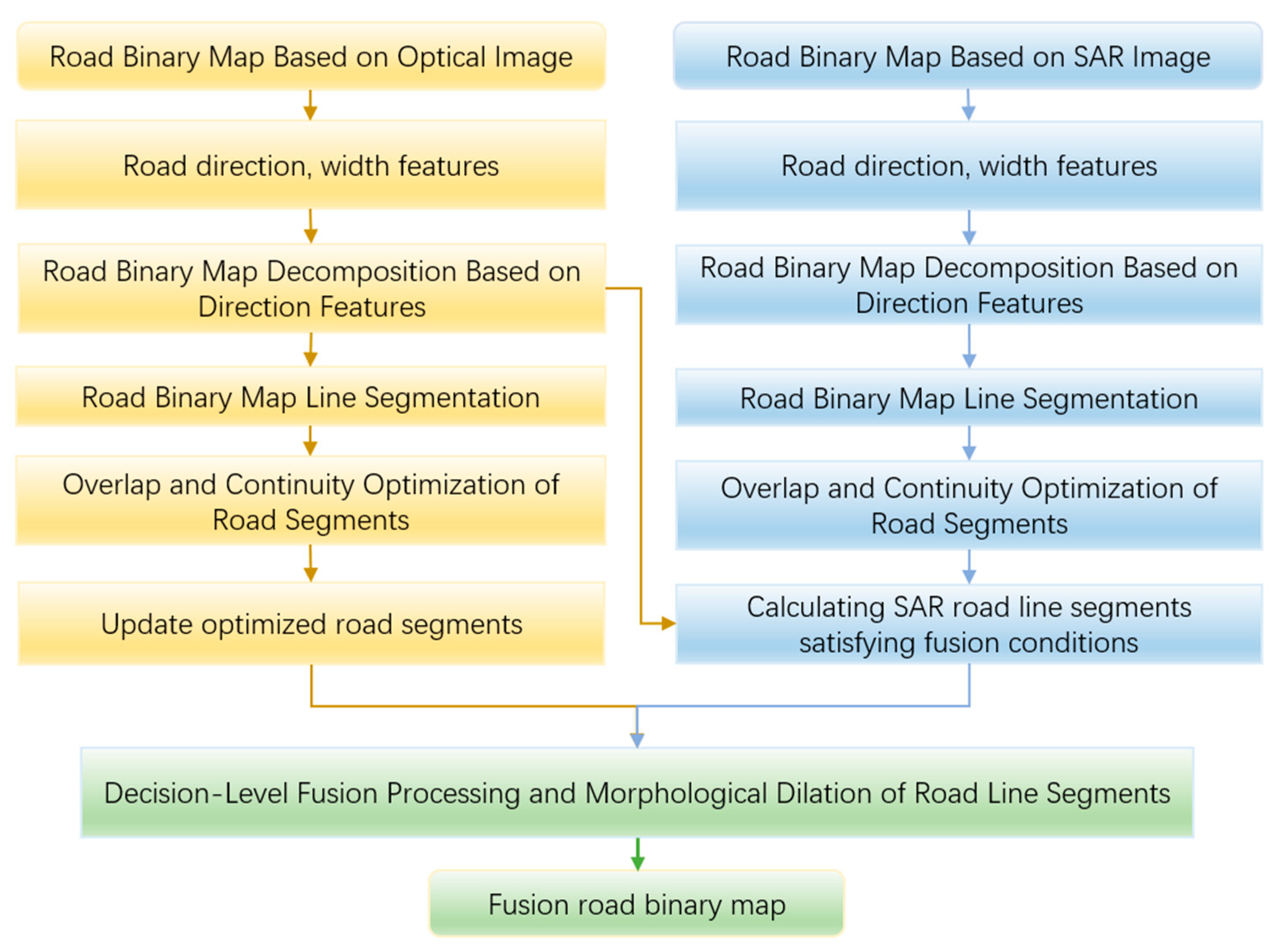
2.4. Decision-Level Fusion Algorithm for Low Grade Roads
3. Experiments
3.1. Dataset and Data Augmentation
3.2. Hybrid Loss Function and Implementation Details
3.3. Decision-Level Fusion Experiment
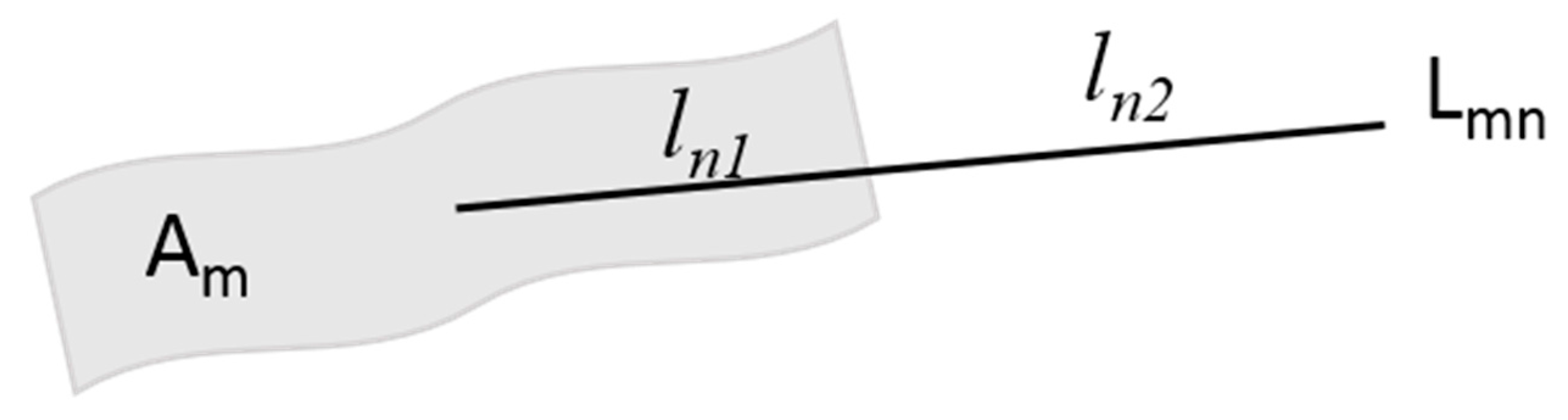
3.4. Evaluation Metrics
4. Results and Discussion
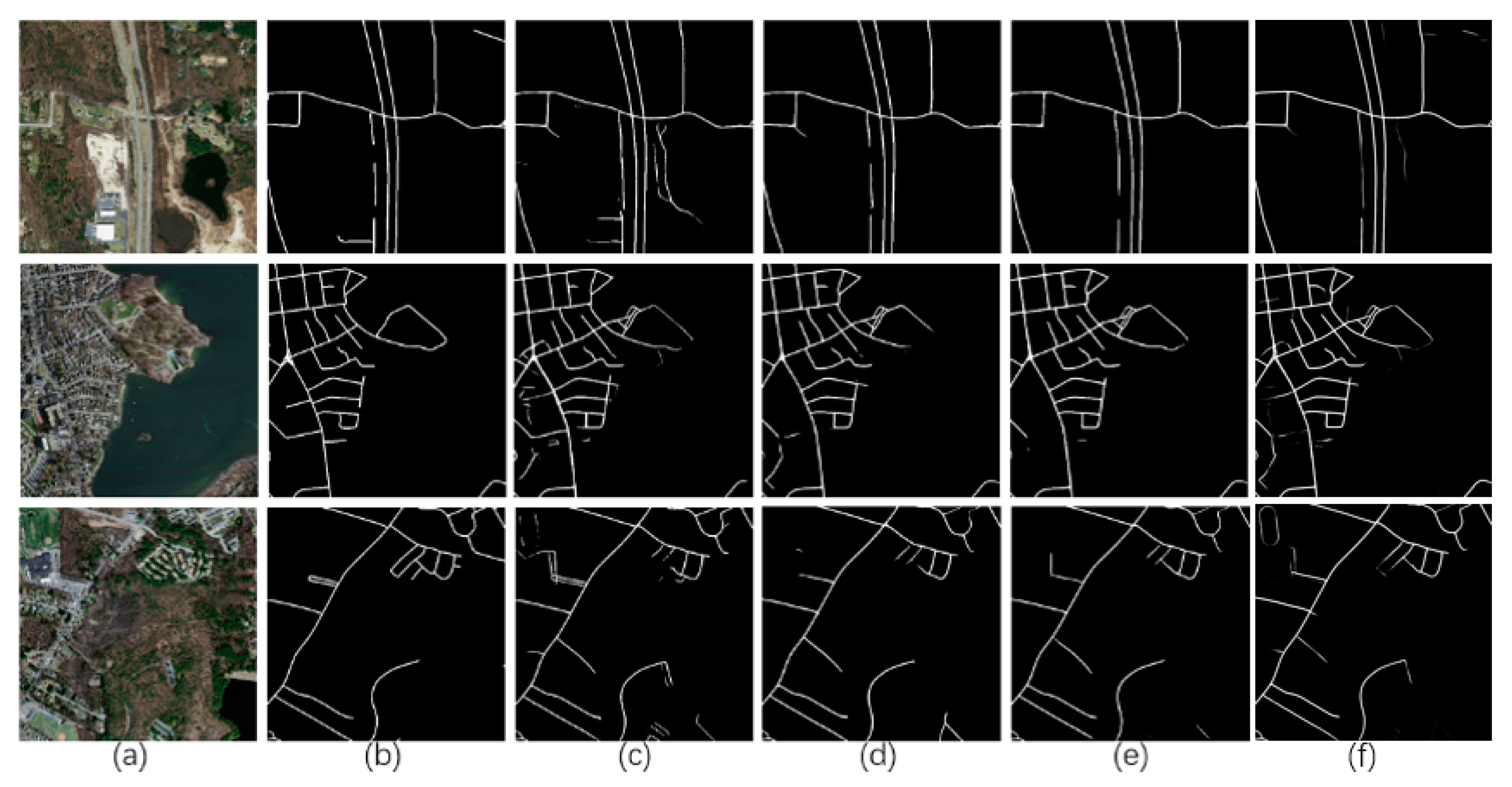
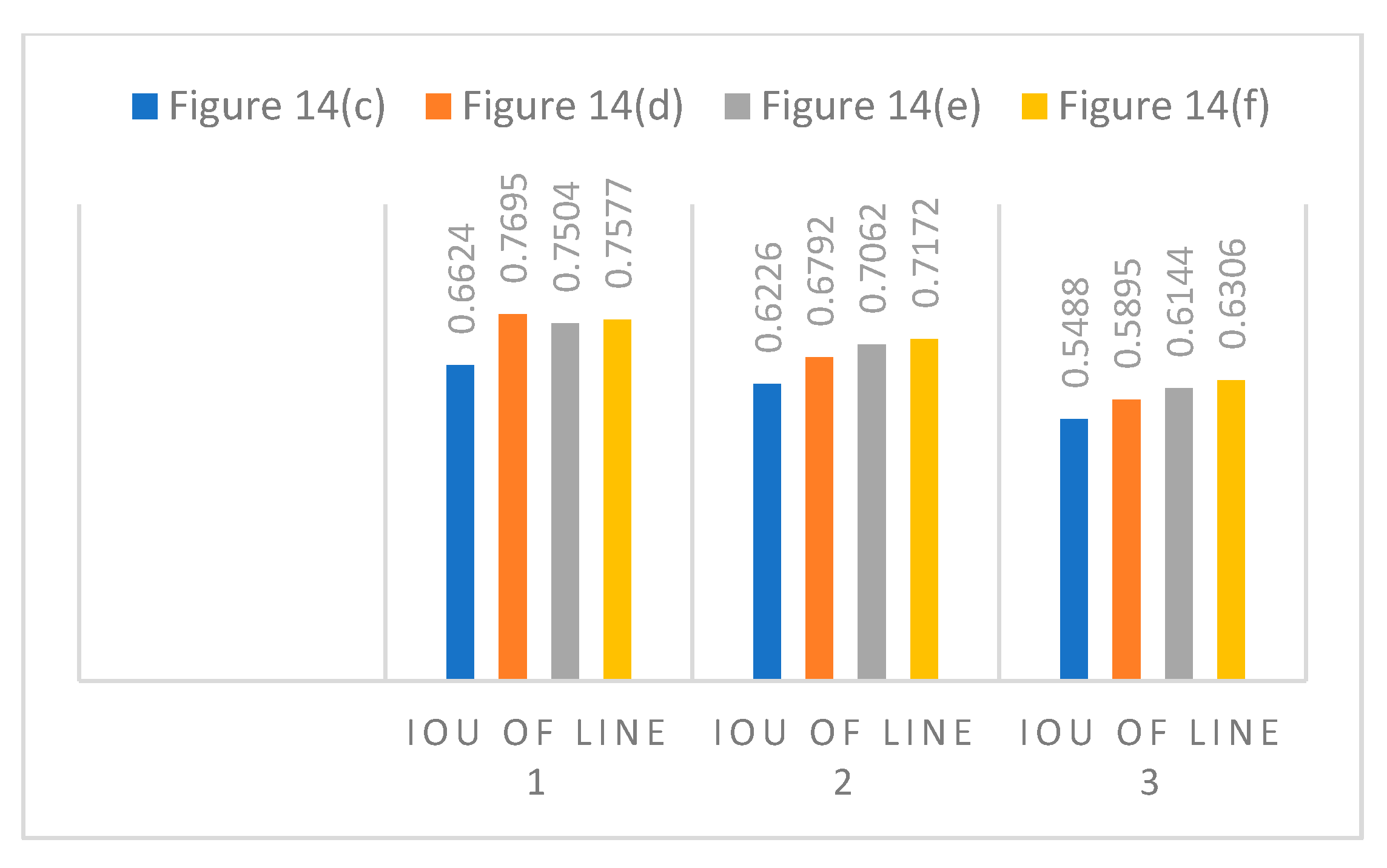
4.1. Results of the Massachusetts Roads Dataset
4.2. Results on Massachusetts Roads Dataset of Different Methods
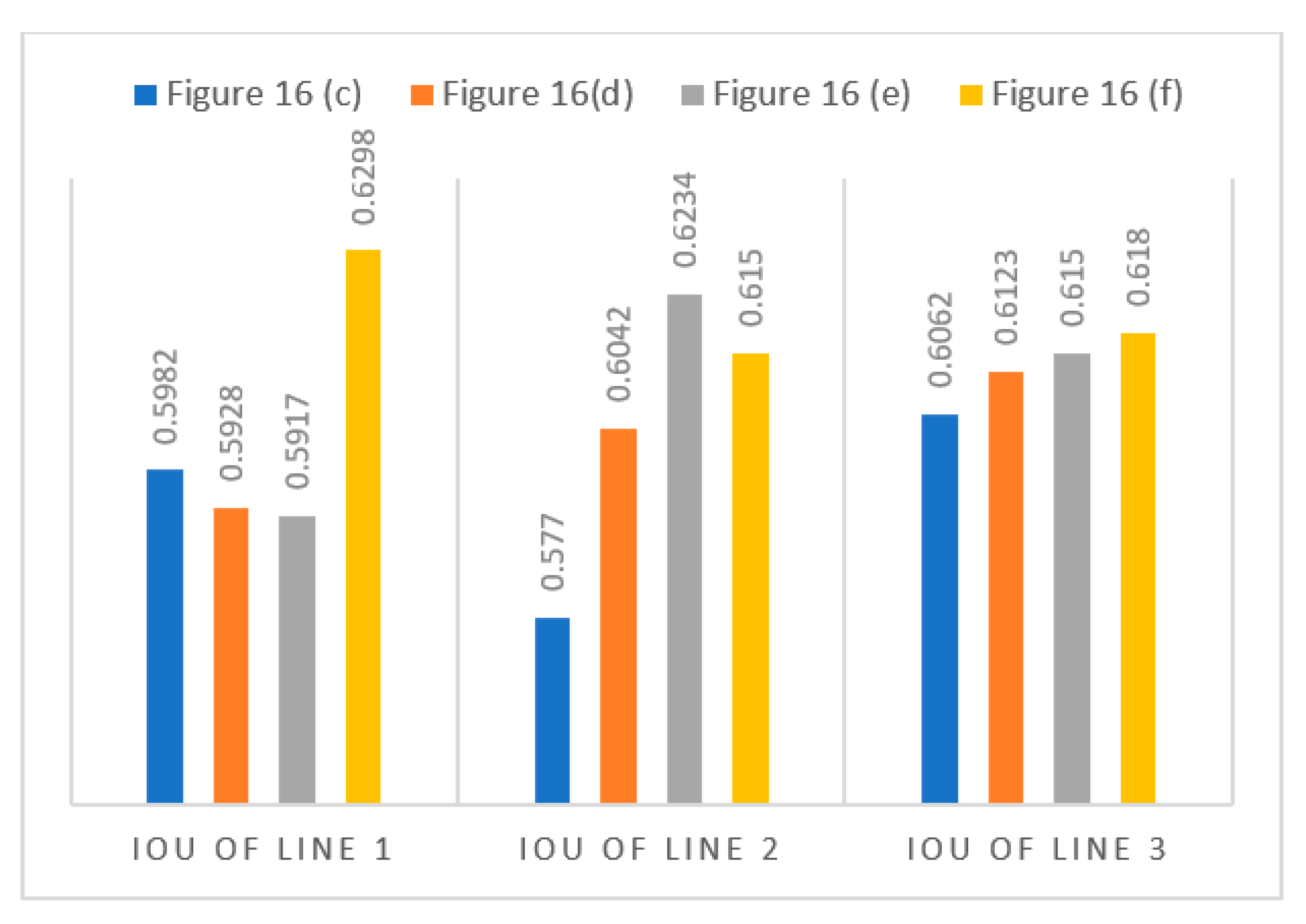
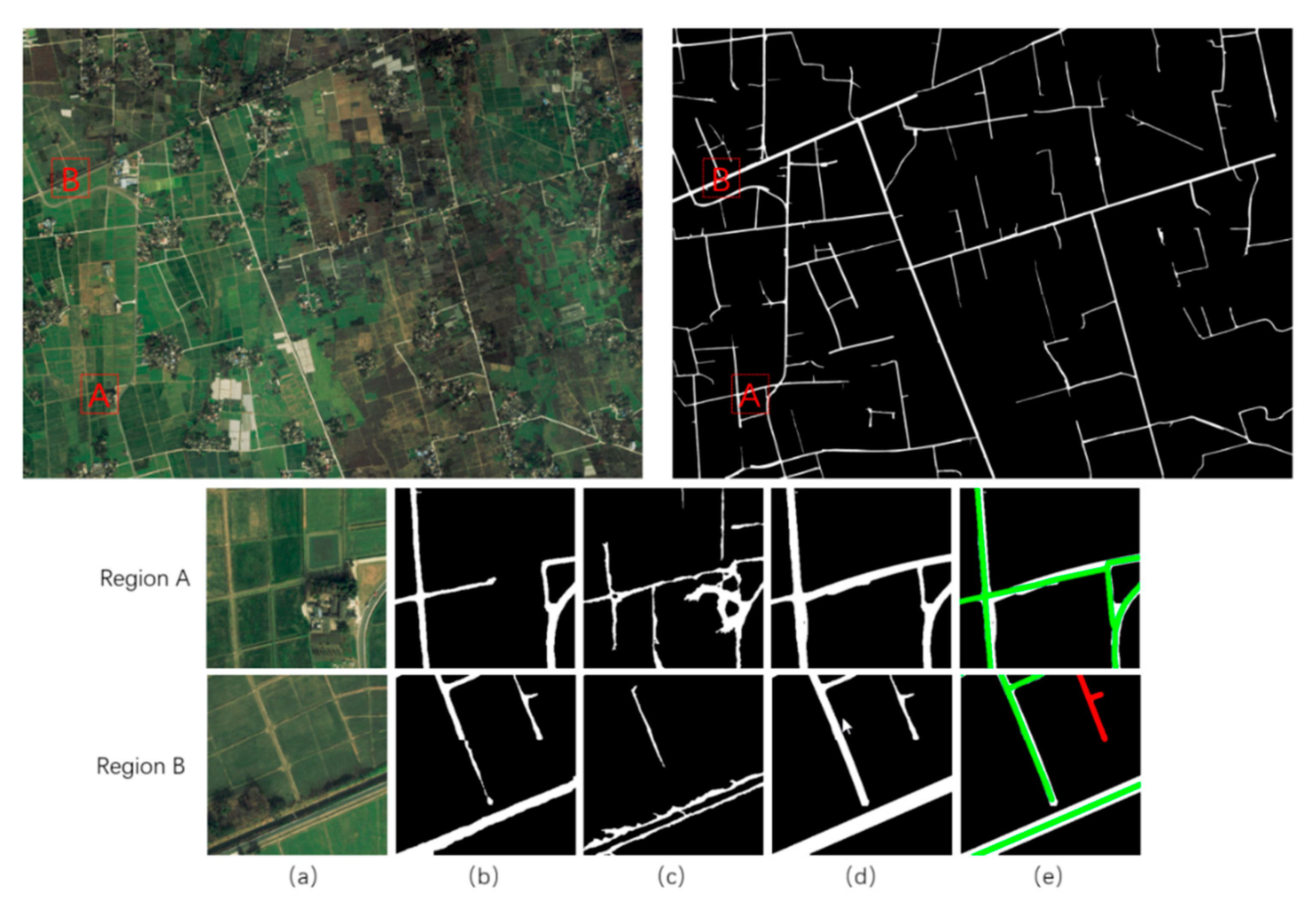
4.3. Results of Low-Grade Roads on the Chongzhou–Wuzhen Dataset
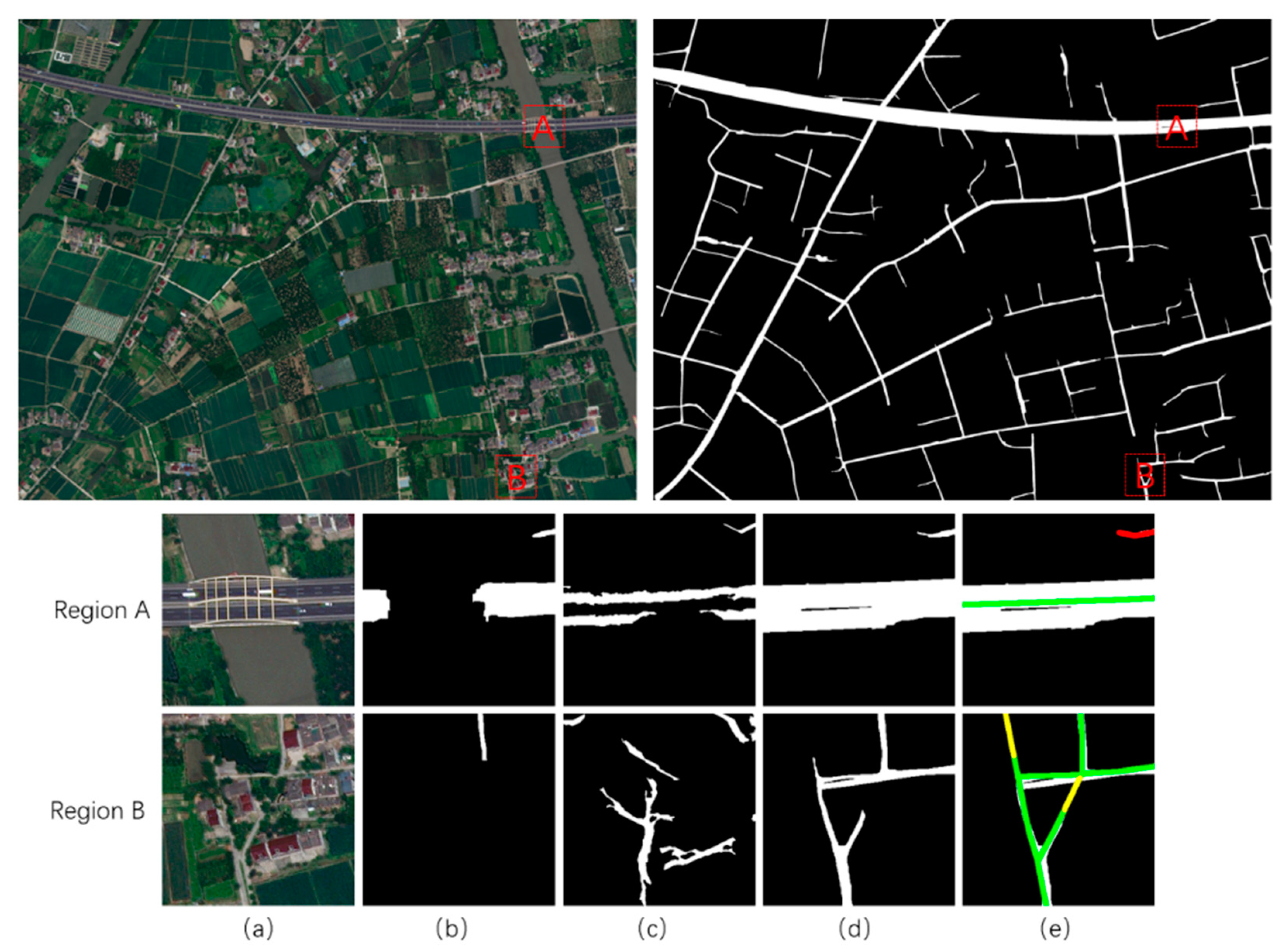
4.4. Extraction Results of Low-Grade Roads on Large-Scale Images of the Fusion Method
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhou, L.; Zhang, C.; Wu, M. D-linknet: Linknet with pretrained encoder and dilated convolution for high resolution satellite imagery road extraction. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 182–186. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Wei, Y.; Zhang, K.; Ji, S. Simultaneous Road Surface and Centerline Extraction From Large-Scale Remote Sensing Images Using CNN-Based Segmentation and Tracing. IEEE Trans. Geosci. Remote Sens. 2020, 58, 8919–8931. [Google Scholar] [CrossRef]
- Yang, F.; Wang, H.; Jin, Z. A fusion network for road detection via spatial propagation and spatial transformation. Pattern Recognit. 2020, 100, 107141. [Google Scholar] [CrossRef]
- Zhou, M.; Sui, H.; Chen, S.; Wang, J.; Chen, X. BT-RoadNet: A boundary and topologically-aware neural network for road extraction from high-resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2020, 168, 288–306. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, C.; Li, J.; Xie, N.; Han, Y.; Du, J. Reconstruction Bias U-Net for Road Extraction From Optical Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 2284–2294. [Google Scholar] [CrossRef]
- He, X.; Zemel, R.S.; Carreira-Perpiñán, M.Á. Multiscale conditional random fields for image labeling. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Washington, DC, USA, 27 June–2 July 2004; Volume 2. [Google Scholar]
- Shotton, J.; Winn, J.; Rother, C.; Criminisi, A. Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context. Int. J. Comput. Vis. 2009, 81, 2–23. [Google Scholar] [CrossRef] [Green Version]
- Krähenbühl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Galleguillos, C.; Belongie, S. Context based object categorization: A critical survey. Comput. Vis. Image Underst. 2010, 114, 712–722. [Google Scholar] [CrossRef] [Green Version]
- Farabet, C.; Couprie, C.; Najman, L.; Lecun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [Green Version]
- Eigen, D.; Fergus, R. Predicting depth, surface normal and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2650–2658. [Google Scholar]
- Pinheiro PH, O.; Collobert, R. Recurrent convolutional neural networks for scene labeling. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014. [Google Scholar]
- Chen, L.C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3640–3649. [Google Scholar]
- Lin, G.; Shen, C.; Van Den Hengel, A.; Reid, I. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3194–3203. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. RefineNet: Multi-path refinement networks with identity mappings for high-resolution semantic segmentation. arXiv 2016, arXiv:1611.06612. [Google Scholar]
- Pohlen, T.; Hermans, A.; Mathias, M.; Leibe, B. Full-resolution residual networks for semantic segmentation in street scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4151–4160. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Amirul Islam, M.; Rochan, M.; Bruce ND, B.; Wang, Y. Gated feedback refinement network for dense image labeling. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3751–3759. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Hu, C.; Bai, X.; Qi, L.; Chen, P.; Xue, G.; Mei, L. Vehicle color recognition with spatial pyramid deep learning. IEEE Trans. Intell. Transp. Syst. 2015, 16, 2925–2934. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–17 June 2019; pp. 3146–3154. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018. ECCV 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11211. [Google Scholar]
- Wan, J.; Xie, Z.; Xu, Y.; Chen, S.; Qiu, Q. DA-RoadNet: A Dual-Attention Network for Road Extraction From High Resolution Satellite Imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6302–6315. [Google Scholar] [CrossRef]
- Bentabet, L.; Jodouin, S.; Ziou, D.; Vaillancourt, J. Road vectors update using SAR imagery: A snake-based method. IEEE Trans. Geosci. Remote Sens. 2003, 41, 1785–1803. [Google Scholar] [CrossRef]
- Sun, Z.; Geng, H.; Lu, Z.; Scherer, R.; Woźniak, M. Review of Road Segmentation for SAR Images. Remote Sens. 2021, 13, 1011. [Google Scholar] [CrossRef]
- Jiang, Y.H.; Pi, Y.J. SAR image road detection based on Hough transform and genetic algorithm. Radar Sci. Technol. 2005, 3, 156–162. [Google Scholar]
- Wei, X.; Lv, X.; Zhang, K. Road Extraction in SAR Images Using Ordinal Regression and Road-Topology Loss. Remote Sens. 2021, 13, 2080. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 2–4 February 2017. [Google Scholar]
- Rahman, M.A.; Wang, Y. Optimizing intersection-over-union in deep neural networks for image segmentation. In Proceedings of the International Symposium on Visual Computing, Las Vegas, NV, USA, 12–14 December 2016; pp. 234–244. [Google Scholar]
- Jégou, S.; Drozdzal, M.; Vazquez, D.; Romero, A.; Bengio, Y. The one hundred layers tiramisu: Fully convolutional densenets for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 11–19. [Google Scholar]
- LeCun, Y.A.; Bottou, L.; Orr, G.B.; Orr, G.B.; Muller, K.R. Efficient Backprop in Neural Networks: Tricks of the Trade; Springer: Berlin/Heidelberg, Germany, 2012; pp. 9–48. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef] [Green Version]
- Xiao, F.; Chen, Y.; Tong, L.; He, L.; Tan, L.; Wu, B. Road detection in high-resolution SAR images using Duda and path operators. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1266–1269. [Google Scholar] [CrossRef]
- Mnih, V.; Hinton, G.E. Learning to Detect Roads in High-Resolution Aerial Images. In Proceedings of the Computer Vision—ECCV 2010—11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part VI. Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Sun, T.; Chen, Z.; Yang, W.; Wang, Y. Stacked u-nets with multi-output for road extraction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 202–206. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual U-Net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Lan, M.; Zhang, J.; Tao, D. Stagewise Unsupervised Domain Adaptation with Adversarial Self-Training for Road Segmentation of Remote-Sensing Images. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5609413. [Google Scholar] [CrossRef]
- Zhang, Z.; Wang, Y. JointNet: A common neural network for road and building extraction. Remote Sens. 2019, 11, 696. [Google Scholar] [CrossRef] [Green Version]
- Dey, M.S.; Chaudhuri, U.; Banerjee, B.; Bhattacharya, A. Dual-Path Morph-UNet for Road and Building Segmentation From Satellite Images. IEEE Geosci. Remote Sens. Lett. 2022, 19, 3004005. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data | Satellites | Resolution Ratio | Date | Scale | Area |
|---|---|---|---|---|---|
| 1 | WorldView-4 | 0.6 m | 13 May 2018 (optical) | 3469 × 4786 | Chongzhou, Sichuan |
| 2 | WorldView-2 | 0.5 m | 27 July 2018 (optical) | 2800 × 3597 | Wuzhen, Zhejiang |
| 3 | WorldView-2 | 0.5 m | 27 July 2018 (optical) | 2800 × 1798 | Wuzhen, Zhejiang |
| Data | Satellites | Resolution Ratio | Date | Scale | Area |
|---|---|---|---|---|---|
| 1 | WorldView-4 | 0.6 m | 13 May 2018 (optical) | 3469 × 4786 | Chongzhou, Sichuan |
| TerraSAR-X | 0.8 m | 20 September 2018 (SAR) | |||
| 2 | WorldView-2 | 0.5 m | 27 July 2018 (optical) | 2800 × 3597 | Wuzhen, Zhejiang |
| TerraSAR-X | 0.9 m | 24 March 2019 (SAR) |
| Model’s Description | F1 | IoU | COR | COM |
|---|---|---|---|---|
| D-LinkNet | 0.7688 | 0.6286 | 0.7712 | 0.7727 |
| DenseNet | 0.7786 | 0.6423 | 0.7780 | 0.7854 |
| S-DenseNet | 0.7810 | 0.6462 | 0.8153 | 0.7557 |
| SD-DenseNet | 0.7894 | 0.6562 | 0.8190 | 0.7667 |
| SDG-DenseNet | 0.7963 | 0.6647 | 0.8186 | 0.7767 |
| Method | F1 | IoU | COR | COM |
|---|---|---|---|---|
| Residual Unet [46] | * | 0.6340 | * | * |
| Joint-Net [48] | 0.7805 | 0.6310 | 0.8536 | 0.7190 |
| Dual Path Morph-Unet [49] | * | 0.6440 | * | * |
| DA-RoadNet [32] | 0.7819 | 0.6419 | 0.8524 | 0.7124 |
| SDG-DenseNet (ours) | 0.7963 | 0.6647 | 0.8186 | 0.7767 |
| Model’s Description | IoU | Model Size |
|---|---|---|
| D-LinkNet | 0.5236 | 0.98 GB |
| S-DenseNet | 0.5558 | 81.7 MB |
| SD-DenseNet | 0.5796 | 106 MB |
| SDG-DenseNet | 0.5901 | 265 MB |
| Tested Data | Extraction Results Based on SDG-DenseNet (WorldView Optical Image) | Extraction Results Based on Decision-Level Fusion Method (SAR and Optical Image) | ||||
|---|---|---|---|---|---|---|
| Metrics | F1 | COR | COM | F1 | COR | COM |
| Area 1 | 0.7376 | 0.8567 | 0.6476 | 0.8528 | 0.9336 | 0.7849 |
| Area 2 | 0.8047 | 0.7923 | 0.8176 | 0.8885 | 0.8680 | 0.9100 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Li, Y.; Si, Y.; Peng, B.; Xiao, F.; Luo, S.; He, L. A Low-Grade Road Extraction Method Using SDG-DenseNet Based on the Fusion of Optical and SAR Images at Decision Level. Remote Sens. 2022, 14, 2870. https://doi.org/10.3390/rs14122870
Zhang J, Li Y, Si Y, Peng B, Xiao F, Luo S, He L. A Low-Grade Road Extraction Method Using SDG-DenseNet Based on the Fusion of Optical and SAR Images at Decision Level. Remote Sensing. 2022; 14(12):2870. https://doi.org/10.3390/rs14122870
Chicago/Turabian StyleZhang, Jinglin, Yuxia Li, Yu Si, Bo Peng, Fanghong Xiao, Shiyu Luo, and Lei He. 2022. "A Low-Grade Road Extraction Method Using SDG-DenseNet Based on the Fusion of Optical and SAR Images at Decision Level" Remote Sensing 14, no. 12: 2870. https://doi.org/10.3390/rs14122870
APA StyleZhang, J., Li, Y., Si, Y., Peng, B., Xiao, F., Luo, S., & He, L. (2022). A Low-Grade Road Extraction Method Using SDG-DenseNet Based on the Fusion of Optical and SAR Images at Decision Level. Remote Sensing, 14(12), 2870. https://doi.org/10.3390/rs14122870