
Triplet-Metric-Guided Multi-Scale Attention for Remote Sensing Image Scene Classification with a Convolutional Neural Network

 , ,
, ,
Abstract
:1. Introduction
- Large diversity within classes: some scenes in the same class can be very different. As shown in Figure 1, in the first row, four scenes of the palace are different in appearance, shape, color, etc..
- High similarity between classes: some scenes from different categories express similar geographical features. From the second row of Figure 1, we can see that the forest and sparse residential (freeway and runway) areas have strong similarities, such as spatial distribution, appearance, and texture.
- The large variance of object/scene scales: when collecting remote sensing images, the scale of object/scene can change arbitrarily due to the different ground sample distances. In the third row of Figure 1, from airplane01 to airplane02, and from storage tank01 to storage tank02, there are large spatial scale variations.
- Coexistence of multi-class objects: there may be multiple different objects in a scene. For example, the basketball court and tennis court, listed in the last row of Figure 1, also have buildings and trees, alongside being semantically related regions.
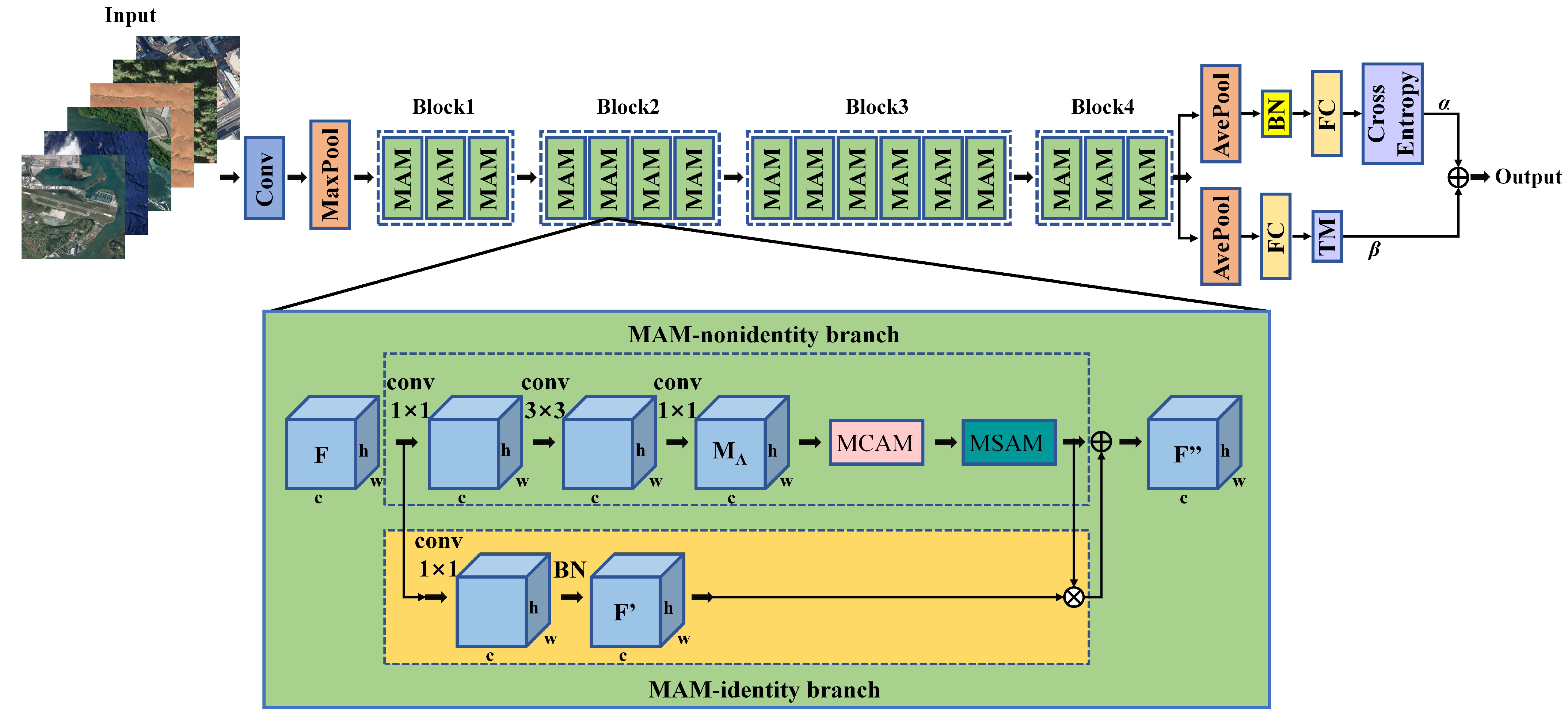
- We propose a multi-scale attention module (MAM) for RSISC. It can emphasize salient features from multi-scale convolutional activation features and capture the contextual information.
- We add triplet metric (TM) regularization in the objective function. It optimizes the learning of MAM and guides the MAM to pay attention to task-related salient features by constraining the distance of positive pairs to be smaller than negative pairs.
- We make MAM and TM collaborate. This strategy allows for the better determination of the contribution of different features in global decision and enforces learning a more discriminative classification model.
2. Materials and Methods
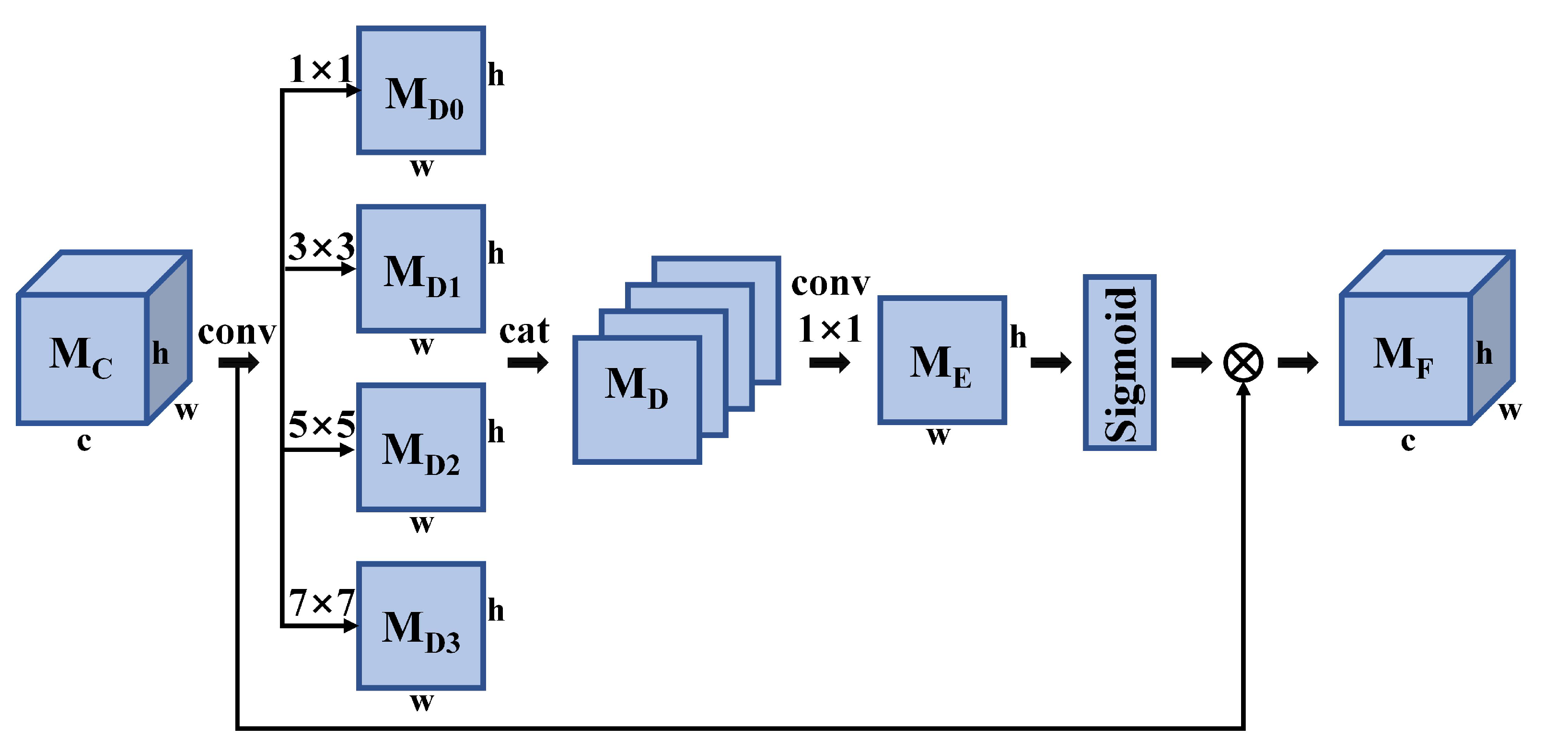
2.1. Multi-Scale Channel Attention Module (MCAM)
2.2. Multi-Scale Spatial Attention Module (MSAM)
2.3. Multi-Scale Attention Module (MAM)
2.4. Triplet Metric (TM)
3. Experiment and Analysis
3.1. Datasets
3.2. Experimental Setup
3.3. Evaluation Metrics
3.4. Compared to State-of-the-Art Methods
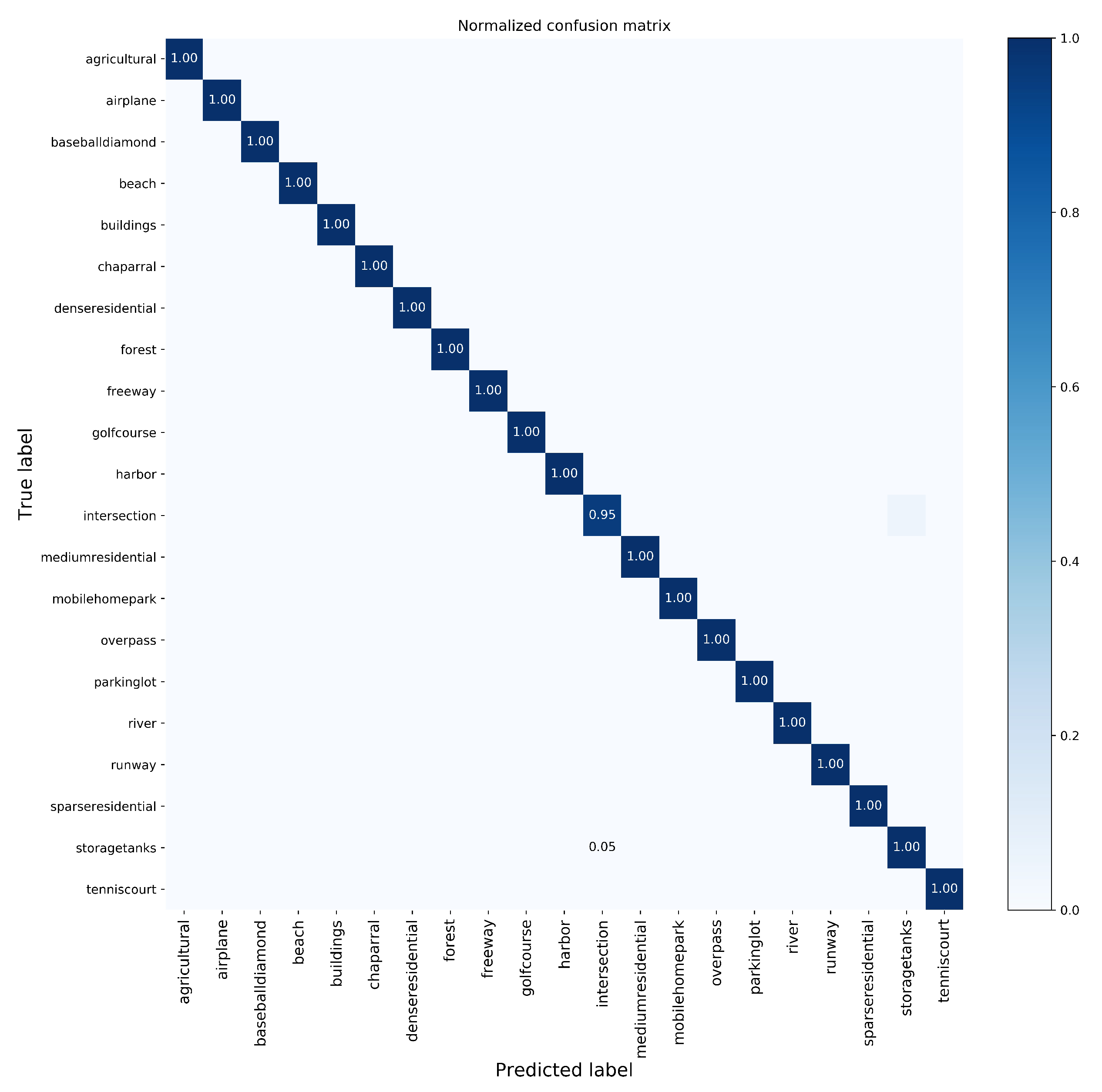
- The CM of the UC Merced dataset is shown in Figure 8, from which we can see that only the scene class “storagetanks” resulted in classification accuracy of less than 1: 0.95. A “storagetanks” scene was misclassified into “intersection”, since there can be similar objects and appearances. However, our method correctly classified the categories that are easy to be misclassified, e.g., “sparse residential”, “medium residential”, and “dense residential”.
- The CMs for AID are in Figure 9. With the 20% training ratio, for all 30 categories, only the “school” category has a classification accuracy of less than 90% and is more easily confused with “commercial” and “playground”. For the 50% training ratio, classification accuracies of four categories are less than 90%, but three of them are close to 90%.
- Figure 10 shows the CMs on the NWPU-RESISC45 dataset when training ratios were 10% and 20%, respectively. With the 10% training ratio, it achieved a classification accuracy of greater than 90% on 37 of 45 scenes and greater than 80% on almost all scenes. With the 20% training ratio, it achieved a classification accuracy of greater than 90% on 40 of 45 scenes and greater than 80% on all scenes. At two different training ratios, we found that the “church” scene and “palace” scene can easily be misclassified into each other because of the similar layout and architectural style.
4. Discussion
4.1. Impact of Multiple Kernels Using Different Combinations
4.2. Effects of Different Components in the Proposed TMGMA
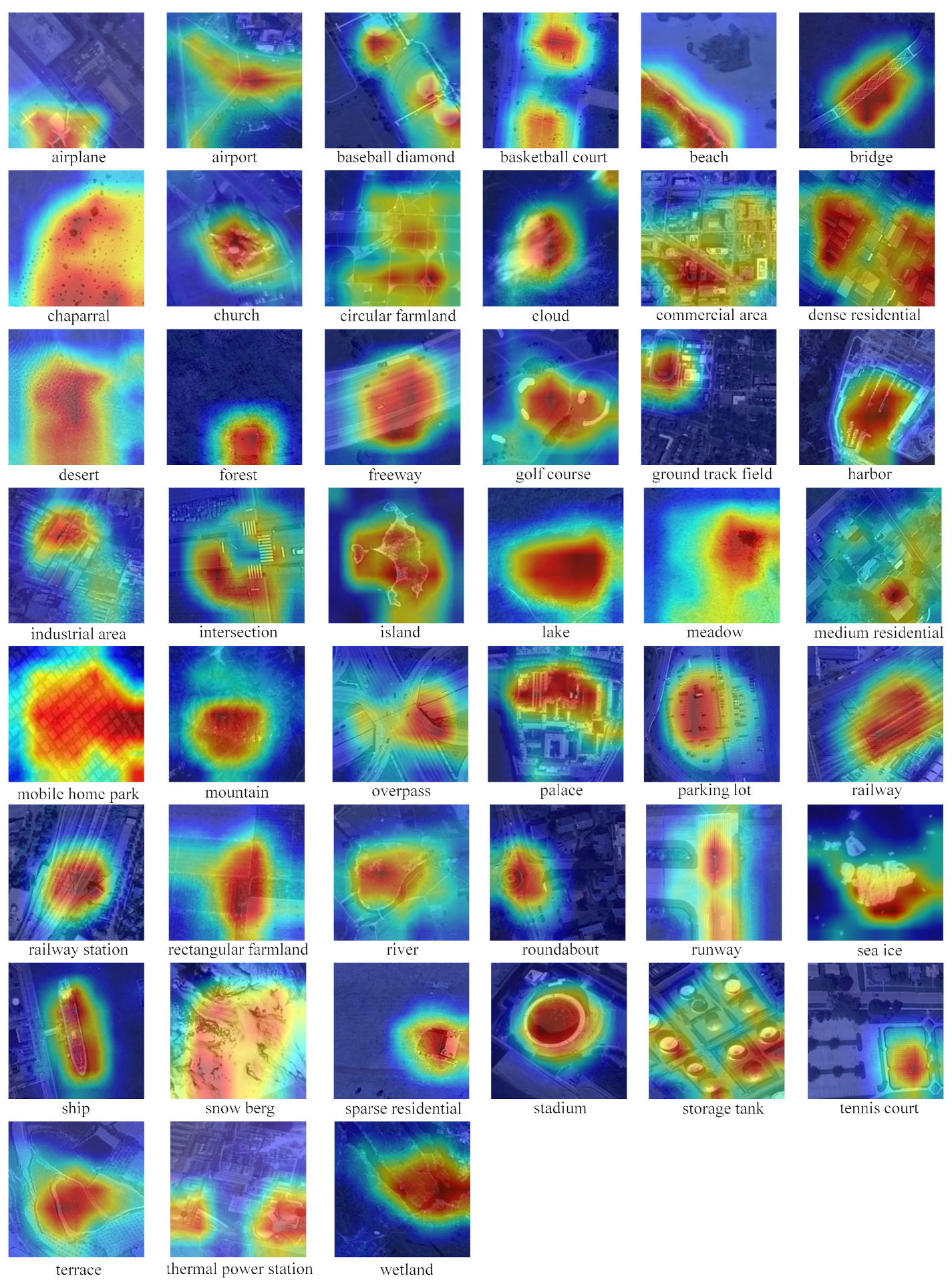
4.3. Visualization Using Grad-CAM
4.4. Visualization Using t-SNE
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yang, K.; Liu, Z.; Lu, Q.; Xia, G. Multi-scale weighted branch network for remote sensing image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 1–10. [Google Scholar]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Atkinson, P.M. Joint deep learning for land cover and land use classification. Remote Sens. Environ. 2019, 221, 173–187. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Guo, L.; Zhao, T.; Han, J.; Li, H.; Fang, J. Automatic landslide detection from remote-sensing imagery using a scene classification method based on BoVW and pLSA. Int. J. Remote Sens. 2013, 34, 45–59. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using random forests. Remote Sens. Eviron. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Lv, Y.; Zhang, X.; Xiong, W.; Cui, Y.; Cai, M. An end-to-end local-global-fusion feature extraction network for remote sensing image scene classification. Remote Sens. 2019, 11, 3006. [Google Scholar] [CrossRef] [Green Version]
- Du, Z.; Li, X.; Lu, X. Local structure learning in high resolution remote sensing image retrieval. Neurocomputing 2016, 207, 813–822. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Cheng, G.; Han, J.; Guo, L.; Liu, Z.; Bu, S.; Ren, J. Effective and efficient midlevel visual elements-oriented land-use classification using VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4238–4249. [Google Scholar] [CrossRef] [Green Version]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote sensing scene classification using multilayer stacked covariance pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Cao, R.; Fang, L.; Lu, T.; He, N. Self-attention-based deep feature fusion for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2020, 18, 43–47. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Liu, L.; Fieguth, P.; Guo, Y.; Wang, X.; Pietikäinen, M. Local binary features for texture classification: Taxonomy and experimental study. Pattern Recognit. 2017, 62, 135–160. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Olshausen, B.A.; Field, D.J. Sparse coding with an overcomplete basis set: A strategy employed by V1? Vis. Res. 1997, 37, 3311–3325. [Google Scholar] [CrossRef] [Green Version]
- AWold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, Q.; Zhong, Y.; Zhao, B.; Xia, G.S.; Zhang, L. Bag-of-visual-words scene classifier with local and global features for high spatial resolution remote sensing imagery. IEEE Geosci. Remote Sens. Lett. 2016, 13, 747–751. [Google Scholar] [CrossRef]
- Zhao, B.; Zhong, Y.; Zhang, L. A spectral–structural bag-of-features scene classifier for very high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2016, 116, 73–85. [Google Scholar] [CrossRef]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, S.; Zhang, Y.; Chen, W. RS-DARTS: A convolutional neural architecture search for remote sensing image scene classification. Remote Sens. 2022, 14, 141. [Google Scholar] [CrossRef]
- Längkvist, M.; Kiselev, A.; Alirezaie, M.; Loutfi, A. Classification and segmentation of satellite orthoimagery using convolutional neural networks. Remote Sens. 2016, 8, 329. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Wang, Q.; Li, X. Feature sparsity in convolutional neural networks for scene classification of remote sensing image. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGRASS), Yokohama, Japan, 28 July–2 August 2019; pp. 3017–3020. [Google Scholar]
- Li, J.; Lin, D.; Wang, Y.; Xu, G.; Zhang, Y.; Ding, C.; Zhou, Y. Deep discriminative representation learning with attention map for scene classification. Remote Sens. 2020, 12, 1366. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Yu, D.; Xu, Q.; Guo, H.; Zhao, C.; Lin, Y.; Li, D. An efficient and lightweight convolutional neural network for remote sensing image scene classification. Sensors 2020, 20, 1999. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, Z.; Li, J.; Luo, Z.; Li, J.; Chen, C. Remote sensing image scene classification based on an enhanced attention module. IEEE Geosci. Remote Sens. Lett. 2020, 18, 1926–1930. [Google Scholar] [CrossRef]
- Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision transformers for remote sensing image classification. Remote Sens. 2021, 13, 516. [Google Scholar] [CrossRef]
- Wang, D.; Lan, J. A Deformable Convolutional Neural Network with Spatial-Channel Attention for Remote Sensing Scene Classification. Remote Sens. 2021, 13, 5076. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Qin, Q. Scene classification based on multiscale convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7109–7121. [Google Scholar] [CrossRef] [Green Version]
- He, N.; Fang, L.; Li, S.; Plaza, J.; Plaza, A. Skip-connected covariance network for remote sensing scene classification. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1461–1474. [Google Scholar] [CrossRef] [Green Version]
- Wang, S.; Guan, Y.; Shao, L. Multi-granularity canonical appearance pooling for remote sensing scene classification. IEEE Trans. Image Process. 2020, 29, 5396–5407. [Google Scholar] [CrossRef] [Green Version]
- Zhu, Q.; Zhong, Y.; Zhang, L.; Li, D. Adaptive deep sparse semantic modeling framework for high spatial resolution image scene classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6180–6195. [Google Scholar] [CrossRef]
- Bi, Q.; Qin, K.; Li, Z.; Zhang, H.; Xu, K.; Xia, G. A multiple-instance densely-connected ConvNet for aerial scene classification. IEEE Trans. Image Process. 2020, 29, 4911–4926. [Google Scholar] [CrossRef] [PubMed]
- Fang, J.; Yuan, Y.; Lu, X.; Feng, Y. Robust space–frequency joint representation for remote sensing image scene classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7492–7502. [Google Scholar] [CrossRef]
- Qi, K.; Yang, C.; Hu, C.; Shen, Y.; Shen, S.; Wu, H. Rotation invariance regularization for remote sensing image scene classification with convolutional neural networks. Remote Sens. 2021, 13, 569. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural machine translation by jointly learning to align and translate. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015; pp. 1–15. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Qin, Z.; Zhang, P.; Wu, F.; Li, X. Fcanet: Frequency channel attention networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Virtual, 11–17 October 2021; pp. 783–792. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. Eca-net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 14–19 June 2020. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I.S. Bam: Bottleneck attention module. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; pp. 1–14. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Li, B.; Guo, Y.; Yang, J.; Wang, L.; Wang, Y.; An, W. Gated recurrent multiattention network for VHR remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2021, 60, 5606113. [Google Scholar] [CrossRef]
- Shi, C.; Zhao, X.; Wang, L. A multi-branch feature fusion strategy based on an attention mechanism for remote sensing image scene classification. Remote Sens. 2021, 13, 1950. [Google Scholar] [CrossRef]
- Tang, X.; Ma, Q.; Zhang, X.; Liu, F.; Ma, J.; Jiao, L. Attention consistent network for remote sensing scene classification. IEEE J-STARS 2021, 14, 2030–2045. [Google Scholar] [CrossRef]
- Song, H.O.; Xiang, Y.; Jegelka, S.; Savarese, S. Deep metric learning via lifted structured feature embedding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4004–4012. [Google Scholar]
- Tian, Y.; Chen, C.; Shah, M. Cross-view image matching for geo-localization in urban environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 14–19 June 2017; pp. 3608–3616. [Google Scholar]
- Cheng, G.; Zhou, P.; Han, J. Duplex metric learning for image set classification. IEEE Trans. Image Process. 2017, 27, 281–292. [Google Scholar] [CrossRef]
- Zhang, J.; Lu, C.; Wang, J.; Yue, X.G.; Lim, S.J.; Al-Makhadmeh, Z.; Tolba, A. Training convolutional neural networks with multi-size images and triplet loss for remote sensing scene classification. Sensors 2020, 20, 1188. [Google Scholar] [CrossRef] [Green Version]
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Oveis, A.H.; Giusti, E.; Ghio, S.; Martorella, M. A Survey on the applications of convolutional neural networks for synthetic aperture radar: Recent advances. IEEE Aero. El. Sys. Mag. 2022, 37, 18–42. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote Sensing Scene Classification by Gated Bidirectional Network. IEEE Trans. Geosci. Remote Sens. 2020, 58, 82–96. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone or Features | Method | Training Ratio (80%) |
|---|---|---|
| SIFT | BoVW [8] | 76.81 |
| VGG-16 | SAFF [12] | 97.02 ± 0.78 |
| MSCP [10] | 98.36 ± 0.58 | |
| DCNN [11] | 98.93 ± 0.10 | |
| ACNet [47] | 99.76 ± 0.10 | |
| SCCov [33] | 99.05 ± 0.25 | |
| Fine-tuning | 97.86± 0.12 | |
| TMGMA | 99.29 ± 0.09 | |
| ResNet50 | D-CNN [31] | 99.62 |
| GBNet [59] | 98.57 ± 0.48 | |
| RIR [38] | 99.15 ± 0.40 | |
| Fine-tuning | 99.29 ± 0.24 | |
| CBAM + Fine-tuning [44] | 99.42 ± 0.f23 | |
| TMGMA | 99.76 ± 0.04 |
| Backbone | Method | Training Ratio (20%) | Training Ratio (50%) |
|---|---|---|---|
| VGG-16 | SAFF [12] | 90.25 ± 0.29 | 93.83 ± 0.28 |
| MSCP [10] | 91.52 ± 0.21 | 94.42 ± 0.17 | |
| DCNN [11] | 90.82 ± 0.16 | 96.89 ± 0.10 | |
| SCCov [33] | 93.12 ± 0.25 | 96.10 ± 0.16 | |
| ACNet [47] | 93.33 ± 0.29 | 95.38 ± 0.29 | |
| Fine-tuning | 91.23 ± 0.22 | 94.80 ± 0.14 | |
| TMGMA | 94.65 ± 0.23 | 96.64 ± 0.19 | |
| ResNet50 | D-CNN [31] | 94.63 | 96.43 |
| GBNet [59] | 92.20 ± 0.23 | 95.48 ± 0.12 | |
| RIR [38] | 94.95 ± 0.17 | 96.48 ± 0.21 | |
| Vision Transformer [30] | 94.97 ± 0.01 | - | |
| Fine-tuning | 94.30 ± 0.15 | 95.24 ± 10 | |
| CBAM + Fine-tuning [44] | 94.66 ± 0.27 | 96.10 ± 0.14 | |
| TMGMA | 95.14 ± 0.21 | 96.70 ± 0.15 |
| Backbone | Method | Training Ratio (10%) | Training Ratio (20%) |
|---|---|---|---|
| VGG-16 | SAFF [12] | 84.38 ± 0.19 | 87.86 ± 0.14 |
| MSCP [10] | 85.33 ± 0.21 | 88.93 ± 0.14 | |
| DCNN [11] | 89.22 ± 0.50 | 91.89 ± 0.22 | |
| SCCov [33] | 89.30 ± 0.35 | 92.10 ± 0.25 | |
| ACNet [47] | 91.09 ± 0.13 | 92.42 ± 0.16 | |
| Fine-tuning | 86.78 ± 0.37 | 91.35 ± 0.16 | |
| TMGMA | 91.63 ± 0.21 | 94.24 ± 0.17 | |
| ResNet50 | D-CNN [31] | 89.88 | 94.44 |
| RIR [38] | 92.05 ± 0.23 | 94.06 ± 0.15 | |
| Vision Transformer [30] | 92.60 ± 0.10 | - | |
| Fine-tuning | 90.89 ± 0.12 | 93.36 ± 0.17 | |
| CBAM + Fine-tuning [44] | 91.82 ± 0.13 | 93.94± 0.09 | |
| TMGMA | 92.44 ± 0.19 | 94.70 ± 0.14 |
| Dataset | Components | Accuracy |
|---|---|---|
| NWPU-RESISC45-10% | K1 + K3 | 92.18 |
| K3 + K5 | 92.26 | |
| K5 + K7 | 91.93 | |
| K3 + K5 + K7 | 92.27 | |
| K1 + K3 + K5 + K7 | 92.44 | |
| NWPU-RESISC45-20% | K1 + K3 | 93.97 |
| K3 + K5 | 94.31 | |
| K5 + K7 | 93.61 | |
| K3 + K5 + K7 | 94.59 | |
| K1 + K3 + K5 +K7 | 94.70 |
| Dataset | Components | Accuracy |
|---|---|---|
| NWPU-RESISC45-10% | ResNet50 | 90.89 |
| ResNet50 + MCAM | 91.92 | |
| ResNet50 + MSAM | 91.39 | |
| ResNet50 + MCAM + MSAM | 92.14 | |
| ResNet50 + MAM | 92.25 | |
| ResNet50 + TM | 91.39 | |
| ResNet50 + MAM + TM | 92.44 | |
| NWPU-RESISC45-20% | ResNet50 | 93.36 |
| ResNet50 + MCAM | 93.94 | |
| ResNet50 + MSAM | 93.63 | |
| ResNet50 + MCAM + MSAM | 94.42 | |
| ResNet50 + MAM | 94.53 | |
| ResNet50 + TM | 93.70 | |
| ResNet50 + MAM + TM | 94.70 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, H.; Gao, K.; Min, L.; Mao, Y.; Zhang, X.; Wang, J.; Hu, Z.; Liu, Y. Triplet-Metric-Guided Multi-Scale Attention for Remote Sensing Image Scene Classification with a Convolutional Neural Network. Remote Sens. 2022, 14, 2794. https://doi.org/10.3390/rs14122794
Wang H, Gao K, Min L, Mao Y, Zhang X, Wang J, Hu Z, Liu Y. Triplet-Metric-Guided Multi-Scale Attention for Remote Sensing Image Scene Classification with a Convolutional Neural Network. Remote Sensing. 2022; 14(12):2794. https://doi.org/10.3390/rs14122794
Chicago/Turabian StyleWang, Hong, Kun Gao, Lei Min, Yuxuan Mao, Xiaodian Zhang, Junwei Wang, Zibo Hu, and Yutong Liu. 2022. "Triplet-Metric-Guided Multi-Scale Attention for Remote Sensing Image Scene Classification with a Convolutional Neural Network" Remote Sensing 14, no. 12: 2794. https://doi.org/10.3390/rs14122794
APA StyleWang, H., Gao, K., Min, L., Mao, Y., Zhang, X., Wang, J., Hu, Z., & Liu, Y. (2022). Triplet-Metric-Guided Multi-Scale Attention for Remote Sensing Image Scene Classification with a Convolutional Neural Network. Remote Sensing, 14(12), 2794. https://doi.org/10.3390/rs14122794