
Few-Shot Multi-Class Ship Detection in Remote Sensing Images Using Attention Feature Map and Multi-Relation Detector



Abstract
:
1. Introduction
- (1)
- Less training data. For newer types of ships, less labeled data are available for training.
- (2)
- Intraclass diversity and interclass similarity between different ships. As shown in Figure 1, ships of the same type often show great differences in different environments, and some ships of different categories may be relatively similar.
- (3)
- Large scale differences between ships. There are large differences in size between ships.
- (1)
- We introduce the few-shot object detection framework of [25] to the remote sensing domain and propose a few-shot multi-class ship detection algorithm with attention feature map and multi-relation detector. It solves the problem of insufficient training sample in real remote sensing ship detection application. Different from most ship detection works, treating all ships as one category, our model can achieve fine-grained classification of the detected ships.
- (2)
- We consider the advantage of one-stage object detection, we remove the regional proposal network in [25], and we use YOLO as the weight-shared framework to speed up ship detection.
- (3)
- We perform extensive experiments to evaluate our method. Experimental results show that our model achieves state-of-the-art performance, and every part of the algorithm is effective.
2. Related Works
2.1. Object Detection in Computer Vision
2.2. Ship Detection in Remote Sensing Images
2.3. Few-Shot Object Detection
2.4. Few-Shot Learning in Remote Sensing Images
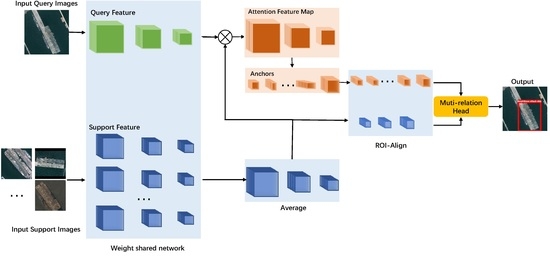
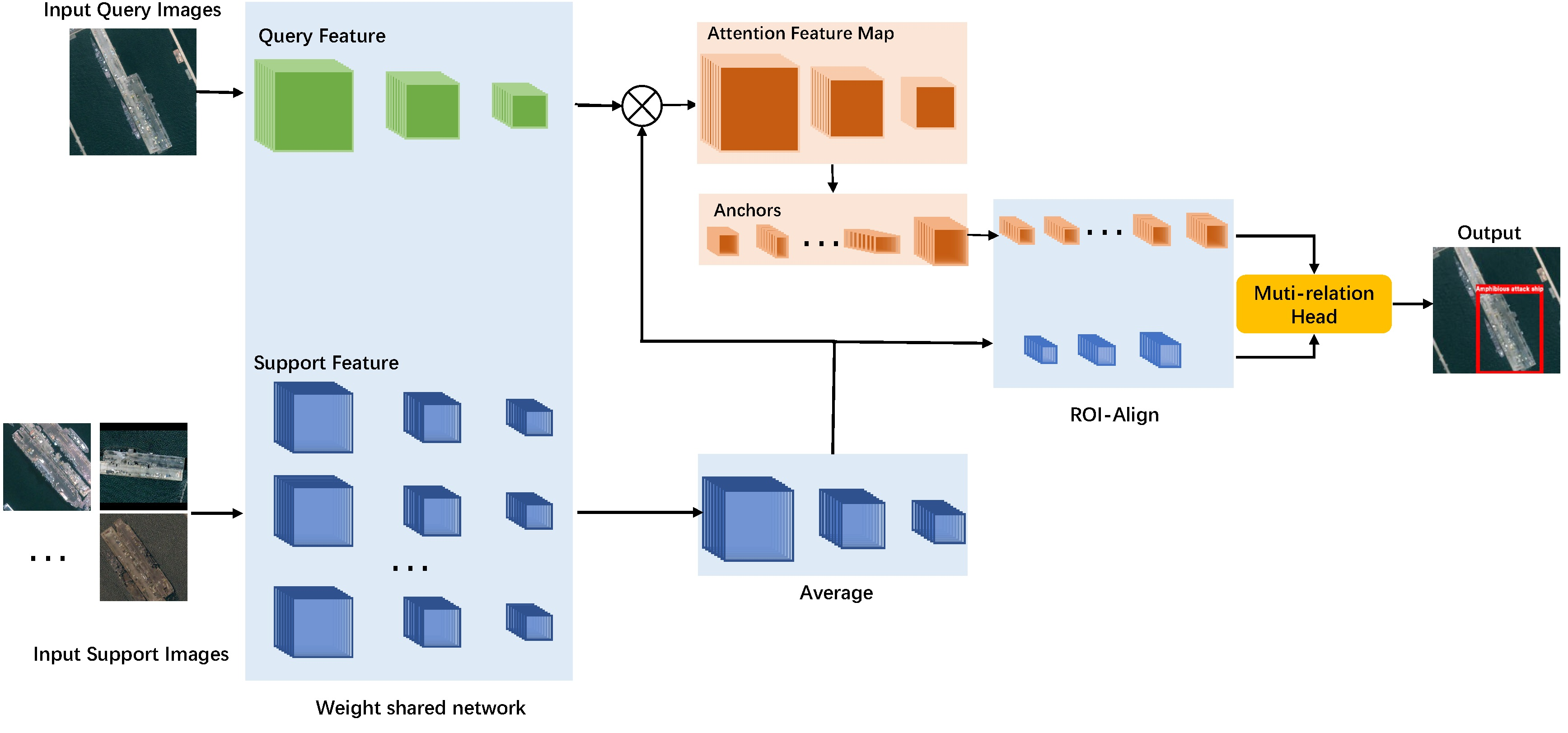
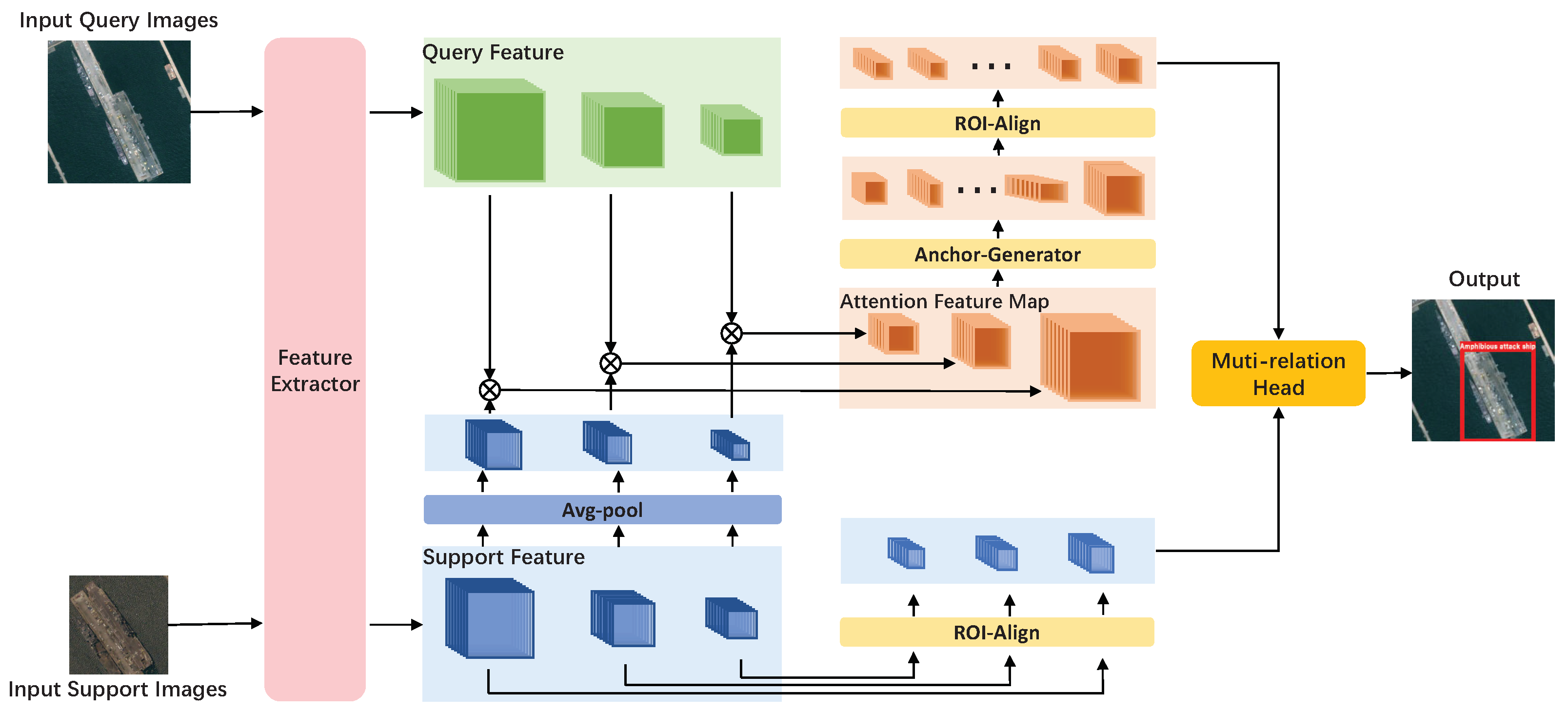
3. Methods
3.1. Introduction of Settings
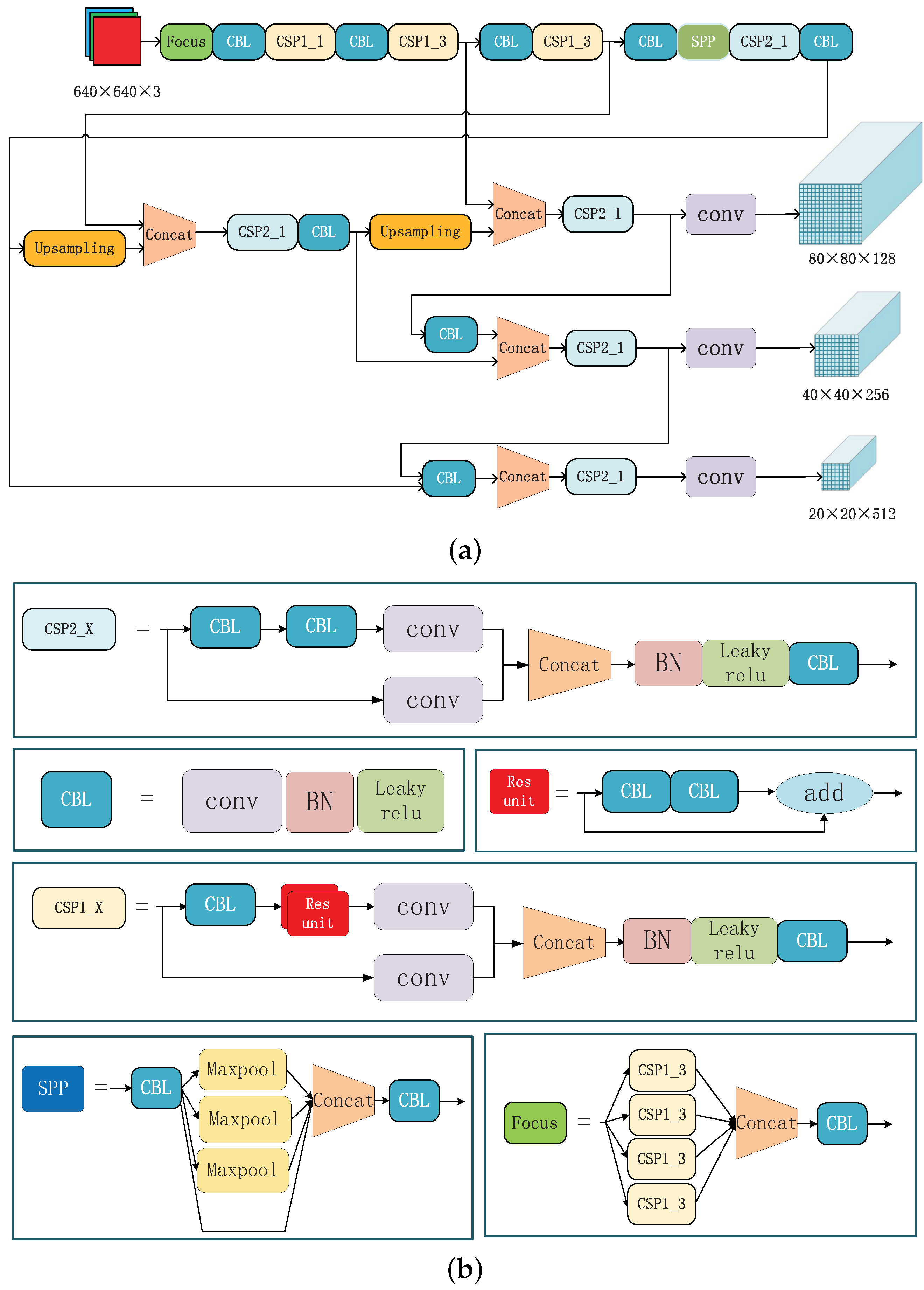
3.2. Feature Extractor
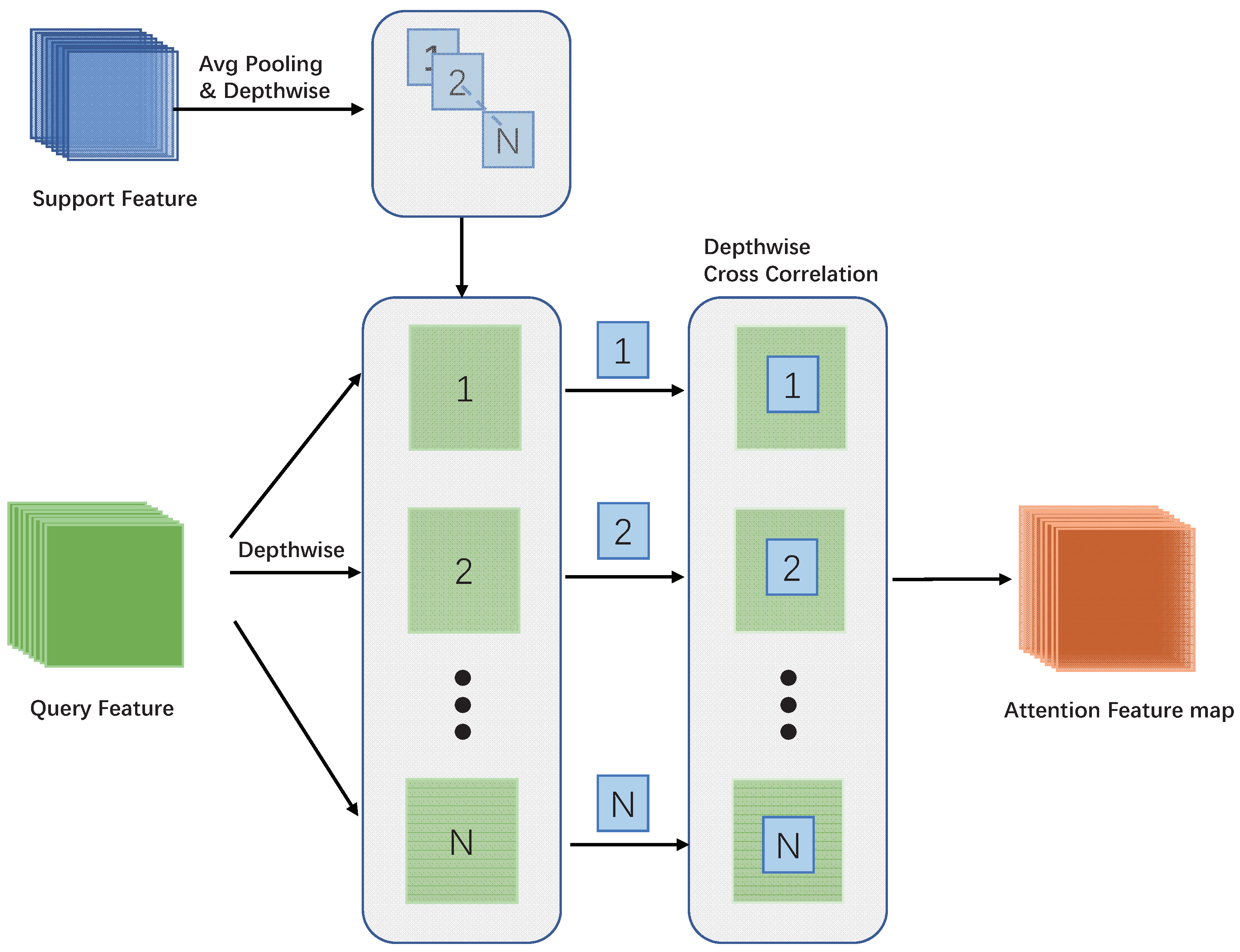
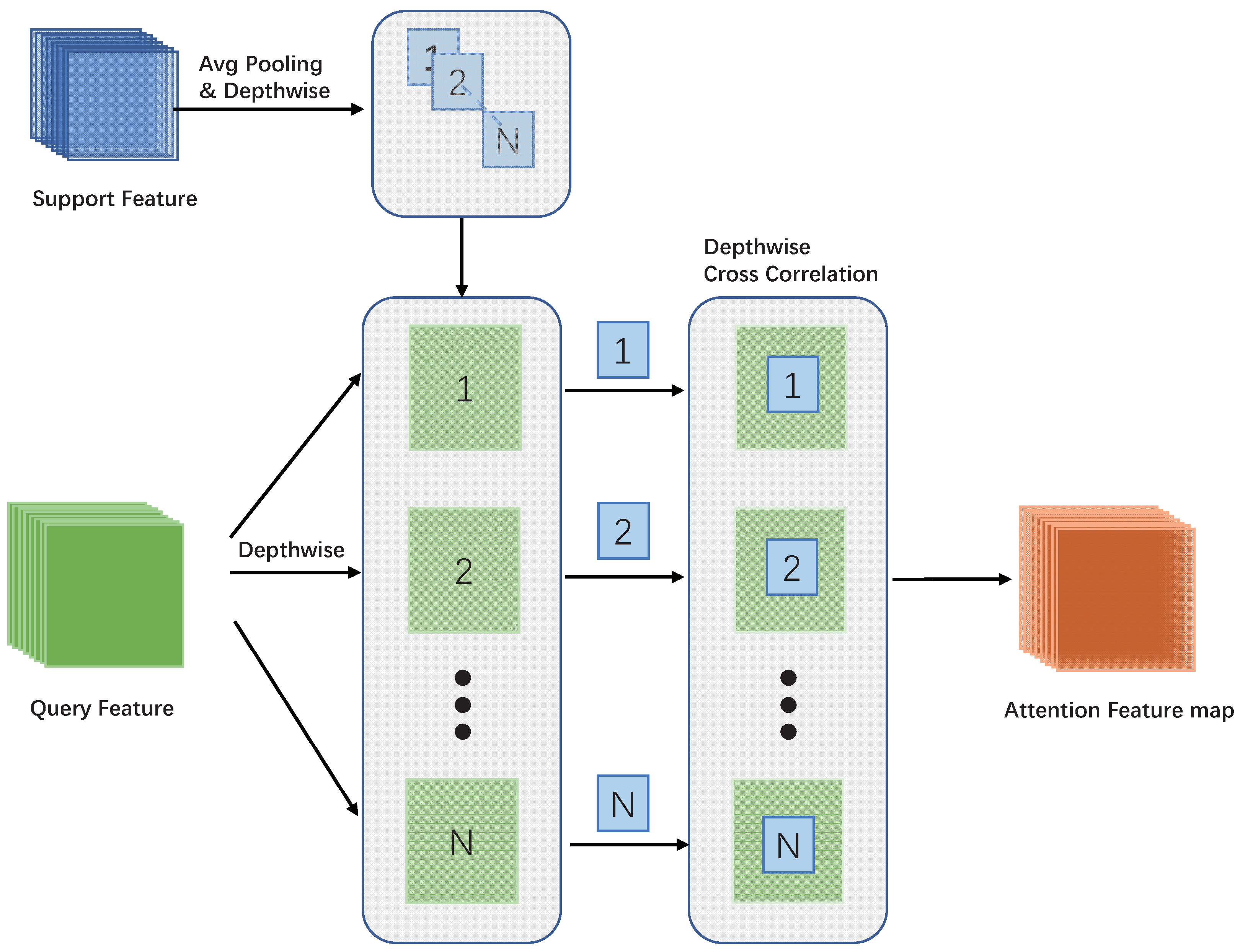
3.3. Attention Feature Map
3.4. Multi-Relation Head
- Global-relation head. Firstly, we concatenate and to find the concatenated feature whose size is . Then we perform global average pooling on and becomes a vector. Then we input to a network which contains MLP with two fully connected layers with ReLU and a final fully connected layer and generate a matching score.
- Local relation head. Firstly, we use a weight shared convolution kernel to perform channel-wise convolutional operation on and . Then, we use the two feature maps to perform depth-wise convolutional. Then, we find a matching score after a fully connected layer.
- Patch relation head. We concatenate and firstly, and find the concatenated feature whose size is . Then we put into a module and the structure of the module is shown as Table 1. The size of the output of the module is . Finally, we put the output into a fully connected layer to generate matching score and put the output into another fully connected layer to generate bounding box information.
4. Experiments and Results
4.1. Datasets
4.2. Experimental Setup
4.3. Evaluation Indicators
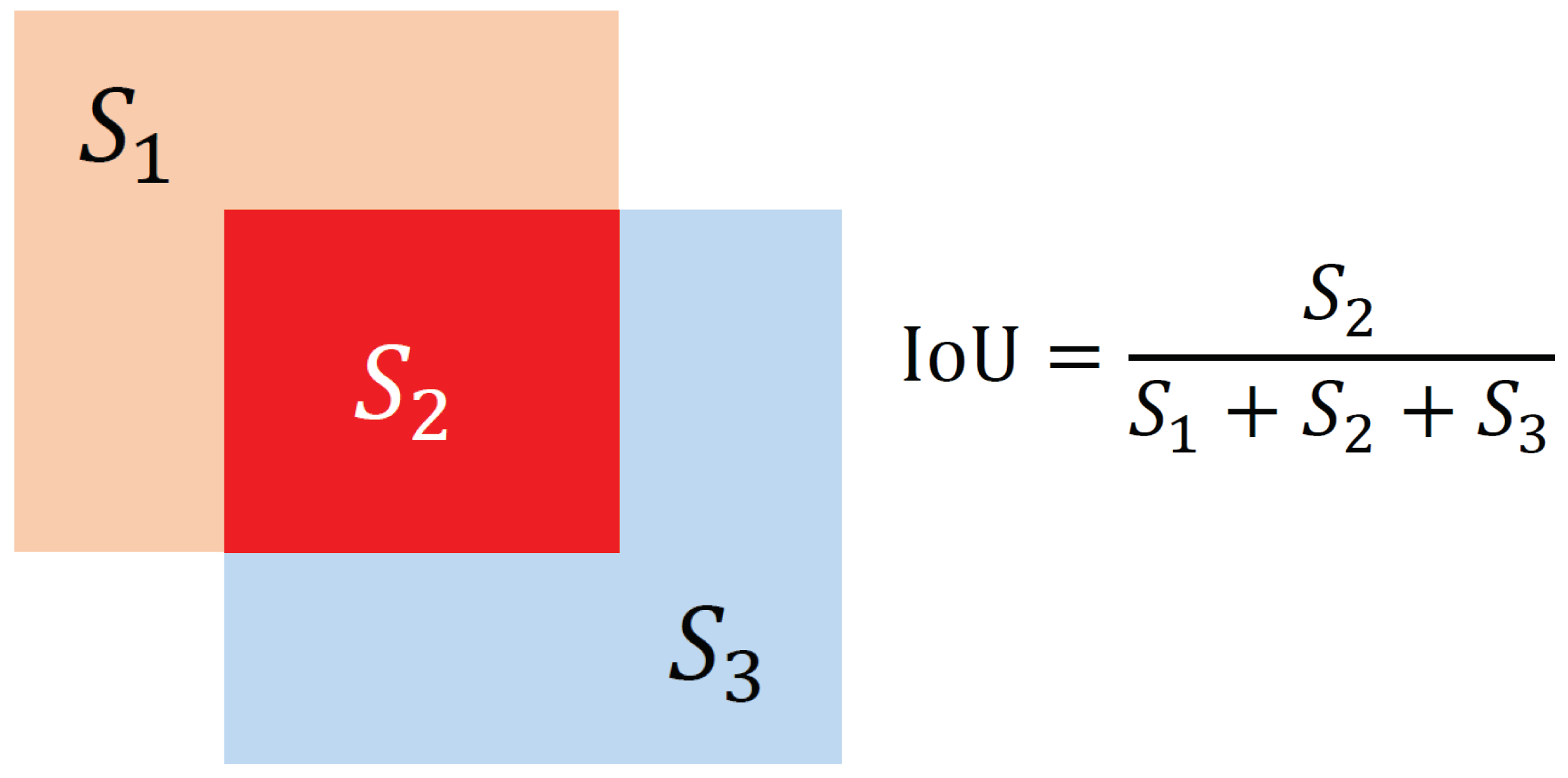
- IoU (Intersection over Union): IOU refers to the ratio of the area of the overlapping part of the prediction box and the ground-truth box to the area occupied by their union. The calculation process of IoU is shown in Figure 7, where represents the area of the orange area, represents the area of the red area, and represents the area of the blue area.
- Precision and Recall: When the confidence of the prediction box is greater than the confidence threshold, the prediction box is called Positive. Otherwise, it is called Negative. When the IoU of the prediction box and the ground truth box is greater than the threshold, the prediction box is called True, otherwise it is called False. Based on this, the discrimination methods of TP, FP, TN, and FN are shown in Table 4.Therefore, the calculation method of the precision rate and the recall rate is shown as:
- Drawing PR curve and calculating mAP. After obtaining the PR curve, the area enclosed by the PR curve and the coordinate axis is the AP value of each category. After obtaining the AP value of each category, the AP of all categories is added and averaged, where mAP 50 means that the IoU threshold is taken as 0.5 during the calculation.
4.4. Results
4.5. Ablation Study
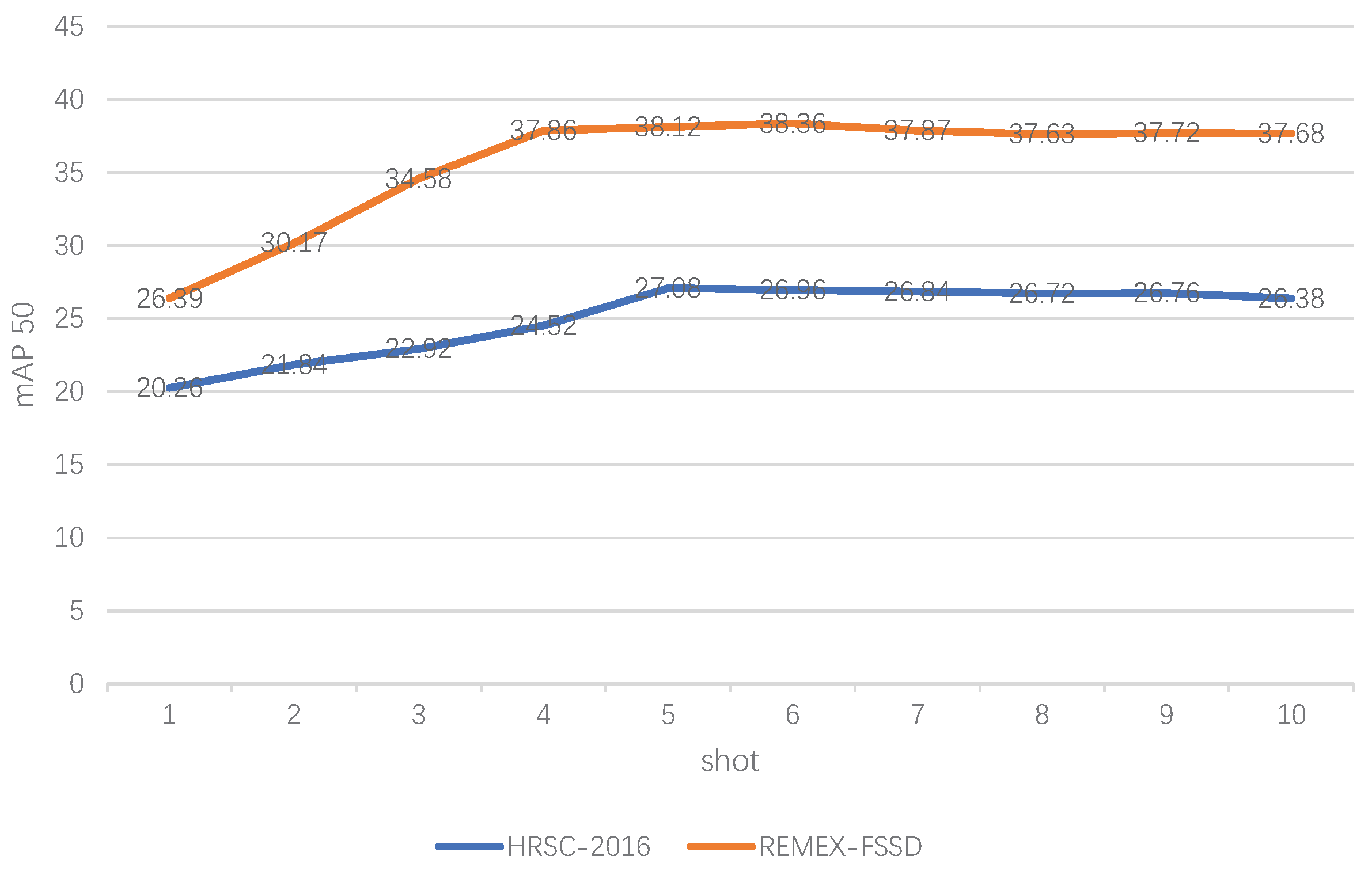
4.5.1. Number of Training Samples
4.5.2. Role of Different Modules
4.5.3. Combinations of Different Relation Heads
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In European Conference on Computer Vision; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In European Conference on Computer Vision; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Swizterland, 2014; pp. 740–755. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef] [Green Version]
- Etten, A.V. You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery. arXiv 2018, arXiv:1805.09512. [Google Scholar]
- Li, Q.; Mou, L.; Liu, Q.; Wang, Y.; Zhu, X.X. HSF-Net: Multiscale Deep Feature Embedding for Ship Detection in Optical Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7147–7161. [Google Scholar] [CrossRef]
- Nie, S.; Jiang, Z.; Zhang, H.; Cai, B.; Yao, Y. Inshore Ship Detection Based on Mask R-CNN. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 693–696. [Google Scholar] [CrossRef]
- Snell, J.; Swersky, K.; Zemel, R. Prototypical networks for few-shot learning. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Vinyals, O.; Blundell, C.; Lillicrap, T.; Wierstra, D. Matching networks for one shot learning. In Proceedings of the 30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; Volume 29. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 1126–1135. [Google Scholar]
- Nichol, A.; Achiam, J.; Schulman, J. On first-order meta-learning algorithms. arXiv 2018, arXiv:1803.02999. [Google Scholar]
- Shi, J.; Jiang, Z.; Zhang, H. Few-Shot Ship Classification in Optical Remote Sensing Images Using Nearest Neighbor Prototype Representation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3581–3590. [Google Scholar] [CrossRef]
- Li, X.; Deng, J.; Fang, Y. Few-Shot Object Detection on Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–14. [Google Scholar] [CrossRef]
- Huang, Z.; Pan, Z.; Lei, B. Transfer Learning with Deep Convolutional Neural Network for SAR Target Classification with Limited Labeled Data. Remote Sens. 2017, 9, 907. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zhoa, J.; Liang, X. Zero-shot Learning Based on Semantic Embedding for Ship Detection. In Proceedings of the 2020 3rd International Conference on Unmanned Systems (ICUS), Harbin, China, 27–28 November 2020; pp. 1152–1156. [Google Scholar]
- Tang, J.; Deng, C.; Huang, G.B.; Zhao, B. Compressed-Domain Ship Detection on Spaceborne Optical Image Using Deep Neural Network and Extreme Learning Machine. IEEE Trans. Geosci. Remote Sens. 2015, 53, 1174–1185. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Ship Detection in Spaceborne Optical Image With SVD Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Yang, F.; Xu, Q.; Li, B. Ship Detection From Optical Satellite Images Based on Saliency Segmentation and Structure-LBP Feature. IEEE Geosci. Remote Sens. Lett. 2017, 14, 602–606. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Fan, Q.; Zhuo, W.; Tang, C.K.; Tai, Y.W. Few-Shot Object Detection with Attention-RPN and Multi-Relation Detector. In Proceedings of IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR); Seattle, WA, USA, 13–19 June 2020.
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Gao, J.; Li, X. Weakly Supervised Adversarial Domain Adaptation for Semantic Segmentation in Urban Scenes. IEEE Trans. Image Process. 2019, 28, 4376–4386. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Li, X.; Zhou, N.; Yang, L.; Peng, L.; Xiao, S. A Sample Update-Based Convolutional Neural Network Framework for Object Detection in Large-Area Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2019, 16, 947–951. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef] [Green Version]
- Liu, R.W.; Yuan, W.; Chen, X.; Lu, Y. An enhanced CNN-enabled learning method for promoting ship detection in maritime surveillance system. Ocean Eng. 2021, 235, 109435. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhao, L.; Xiong, B.; Kuang, G. Attention Receptive Pyramid Network for Ship Detection in SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 2738–2756. [Google Scholar] [CrossRef]
- Karlinsky, L.; Shtok, J.; Harary, S.; Schwartz, E.; Aides, A.; Feris, R.; Giryes, R.; Bronstein, A.M. RepMet: Representative-Based Metric Learning for Classification and Few-Shot Object Detection. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 5192–5201. [Google Scholar] [CrossRef]
- Kang, B.; Liu, Z.; Wang, X.; Yu, F.; Feng, J.; Darrell, T. Few-Shot Object Detection via Feature Reweighting. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 8419–8428. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Huang, T.E.; Darrell, T.; Gonzalez, J.E.; Yu, F. Frustratingly Simple Few-Shot Object Detection. arXiv 2020, arXiv:2003.06957. [Google Scholar]
- Chen, H.; Wang, Y.; Wang, G.; Qiao, Y. LSTD: A Low-Shot Transfer Detector for Object Detection. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32, pp. 2836–2843. [Google Scholar]
- Dong, X.; Zheng, L.; Ma, F.; Yang, Y.; Meng, D. Few-Example Object Detection with Model Communication. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1641–1654. [Google Scholar] [CrossRef] [Green Version]
- Fan, Z.; Ma, Y.; Li, Z.; Sun, J. Generalized Few-Shot Object Detection without Forgetting. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 4525–4534. [Google Scholar] [CrossRef]
- Zhu, C.; Chen, F.; Ahmed, U.; Shen, Z.; Savvides, M. Semantic Relation Reasoning for Shot-Stable Few-Shot Object Detection. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 8778–8787. [Google Scholar] [CrossRef]
- Ward, C.M.; Harguess, J.; Hilton, C. Ship Classification from Overhead Imagery using Synthetic Data and Domain Adaptation. In Proceedings of the OCEANS 2018 MTS/IEEE Charleston, Charleston, SC, USA, 22–25 October 2018; pp. 1–5. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Zhong, Y.; Zhang, L. An Efficient and Robust Integrated Geospatial Object Detection Framework for High Spatial Resolution Remote Sensing Imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef] [Green Version]
- Ai, J.; Tian, R.; Luo, Q.; Jin, J.; Tang, B. Multi-Scale Rotation-Invariant Haar-Like Feature Integrated CNN-Based Ship Detection Algorithm of Multiple-Target Environment in SAR Imagery. IEEE Trans. Geosci. Remote Sens. 2019, 57, 10070–10087. [Google Scholar] [CrossRef]
- Rostami, M.; Kolouri, S.; Eaton, E.; Kim, K. Deep Transfer Learning for Few-Shot SAR Image Classification. Remote Sens. 2019, 11, 1374. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Zhang, H.; Jiang, Z. Few shot object detection in remote sensing images. In Proceedings of the Image and Signal Processing for Remote Sensing XXVII; Bruzzone, L., Bovolo, F., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2021; Volume 11862, pp. 76–81. [Google Scholar] [CrossRef]
- Hao, P.; He, M. Ship Detection Based on Small Sample Learning. J. Coast. Res. 2020, 108, 135–139. [Google Scholar] [CrossRef]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015; Volume 2, pp. 1–8. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-Scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3974–3983. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Random Access Memories: A New Paradigm for Target Detection in High Resolution Aerial Remote Sensing Images. IEEE Trans. Image Process. 2018, 27, 1100–1111. [Google Scholar] [CrossRef]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A High Resolution Optical Satellite Image Dataset for Ship Recognition and Some New Baselines. In Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods–Volume 1: ICPRAM, INSTICC, SciTePress, Porto, Portugal, 24–26 February 2017; pp. 324–331. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. In Proceedings of the International Conference for Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Filter Shape | Stride/Padding |
|---|---|---|
| Avg Pool | ||
| Conv | ||
| Conv | ||
| Conv | ||
| Avg Pool |
| Dataset | Categories Numbers | Categories | Categories Number of Ships | Categories of Ships | Ship Numbers |
|---|---|---|---|---|---|
| NWPU VHR-10 | 10 | Airplane, storage tanks, ship, baseball fields, ground runways, etc. | 1 | Ship | 302 |
| DOTA | 15 | Airplane, bridge, swimming pool, ship, roundabout, etc. | 1 | Ship | 6300 |
| LEVIR | 3 | Airplane, ship, oilpot | 1 | Ship | 3025 |
| HRSC2016 | 19 | Medical boat, Ticonderoga, Nimitz, Perry, Austin, etc. | 19 | Medical boat, Ticonderoga, Nimitz, Perry, Austin, etc. | 2010 |
| Category | Aircraft Carrier | Amphibious Attack Ship | Destroyer | Others | Total |
| Number | 1357 | 3675 | 26,961 | 24,546 | 56,539 |
| Positive | Negative | |
|---|---|---|
| True | TP | TN |
| False | FP | FN |
| Method | mAP 50 | Class 1 | Class 2 | Class 3 | Class 4 | Class 5 |
|---|---|---|---|---|---|---|
| Faster-RCNN [5] | 2.1 | 2.3 | 1.7 | 3.4 | 0.3 | 2.8 |
| YOLO [1] | 1.94 | 2.1 | 1.4 | 3.0 | 0.4 | 2.8 |
| Faster-RCNN + AF | 3.52 | 4.1 | 2.8 | 5.1 | 1.6 | 3.3 |
| YOLO + AF | 3.78 | 3.9 | 3.4 | 5.5 | 1.2 | 4.9 |
| FSOD [25] | 15.68 | 16.9 | 14.7 | 19.2 | 10.3 | 17.3 |
| TFA/FC [37] | 23.59 | 26.63 | 23.37 | 28.13 | 18.68 | 21.14 |
| TFA/COS [37] | 26.82 | 28.81 | 26.7 | 32.49 | 21.37 | 24.73 |
| Ours | 27.08 | 31.5 | 25.6 | 34.9 | 17.3 | 26.1 |
| Method | mAP 50 |
|---|---|
| Faster-RCNN [5] | 10.7 |
| YOLO [1] | 8.24 |
| FSOD [25] | 26.73 |
| TFA/fc [37] | 34.33 |
| TFA/cos [37] | 35.74 |
| Ours | 38.12 |
| Dataset | HRSC2016 | REMEX-FSSD |
|---|---|---|
| 1 | 27.08 | 38.12 |
| 2 | 27.06 | 38.11 |
| 3 | 27.10 | 38.10 |
| 4 | 27.04 | 38.14 |
| 5 | 27.10 | 38.12 |
| Average | 27.076 | 38.118 |
| Standard deviation | 0.023 | 0.013 |
| Method | HRSC2016 (FPS) | REMEX-FSSD (FPS) |
|---|---|---|
| Faster-RCNN [5] | 11.9 | 13.2 |
| YOLO [1] | 30.6 | 36.1 |
| FSOD [25] | 10.8 | 11.9 |
| TFA/cos [37] | 12.1 | 13.3 |
| Ours | 27.8 | 33.2 |
| YOLO | AF | MR | mAP50 |
|---|---|---|---|
| √ | - | - | 1.94 |
| √ | √ | - | 3.78 |
| √ | - | √ | 11.36 |
| √ | √ | √ | 27.08 |
| Global R | Local R | Patch R | mAP50 |
|---|---|---|---|
| - | - | - | 3.78 |
| √ | - | - | 21.63 |
| - | √ | - | 23.26 |
| - | - | √ | 20.17 |
| √ | √ | - | 26.73 |
| √ | - | √ | 22.37 |
| - | √ | √ | 25.82 |
| √ | √ | √ | 27.08 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, H.; Zhang, X.; Meng, G.; Guo, C.; Jiang, Z. Few-Shot Multi-Class Ship Detection in Remote Sensing Images Using Attention Feature Map and Multi-Relation Detector. Remote Sens. 2022, 14, 2790. https://doi.org/10.3390/rs14122790
Zhang H, Zhang X, Meng G, Guo C, Jiang Z. Few-Shot Multi-Class Ship Detection in Remote Sensing Images Using Attention Feature Map and Multi-Relation Detector. Remote Sensing. 2022; 14(12):2790. https://doi.org/10.3390/rs14122790
Chicago/Turabian StyleZhang, Haopeng, Xingyu Zhang, Gang Meng, Chen Guo, and Zhiguo Jiang. 2022. "Few-Shot Multi-Class Ship Detection in Remote Sensing Images Using Attention Feature Map and Multi-Relation Detector" Remote Sensing 14, no. 12: 2790. https://doi.org/10.3390/rs14122790
APA StyleZhang, H., Zhang, X., Meng, G., Guo, C., & Jiang, Z. (2022). Few-Shot Multi-Class Ship Detection in Remote Sensing Images Using Attention Feature Map and Multi-Relation Detector. Remote Sensing, 14(12), 2790. https://doi.org/10.3390/rs14122790