
Triple Collocation Analysis of Satellite Precipitation Estimates over Australia

Abstract
:
1. Introduction
- Is TCA a reasonable validation method for precipitation over Australia?
- Is the additive or multiplicative error model more appropriate for precipitation TCA over Australia?
2. Materials and Methods
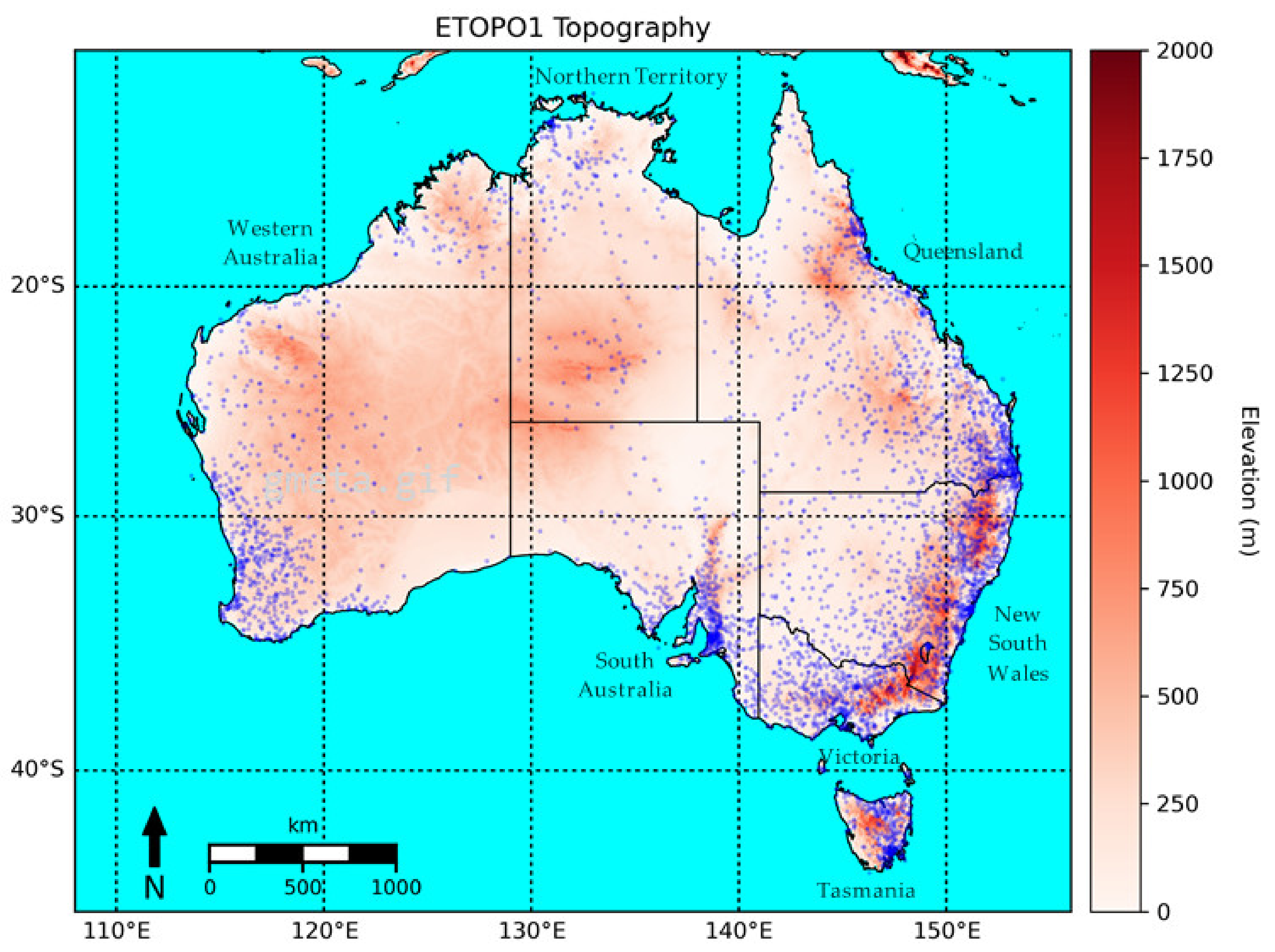
2.1. Study Area and Study Period
2.2. Datasets
2.3. Method
2.4. Evaluation of Satisfaction of Triple Collocation Assumptions
- Linearity between datasets
- Stationarity of datasets
- Independence of errors between the datasets
2.4.1. Linearity between Datasets
2.4.2. Stationarity of Datasets
2.4.3. Independence of Errors
2.4.4. Summary
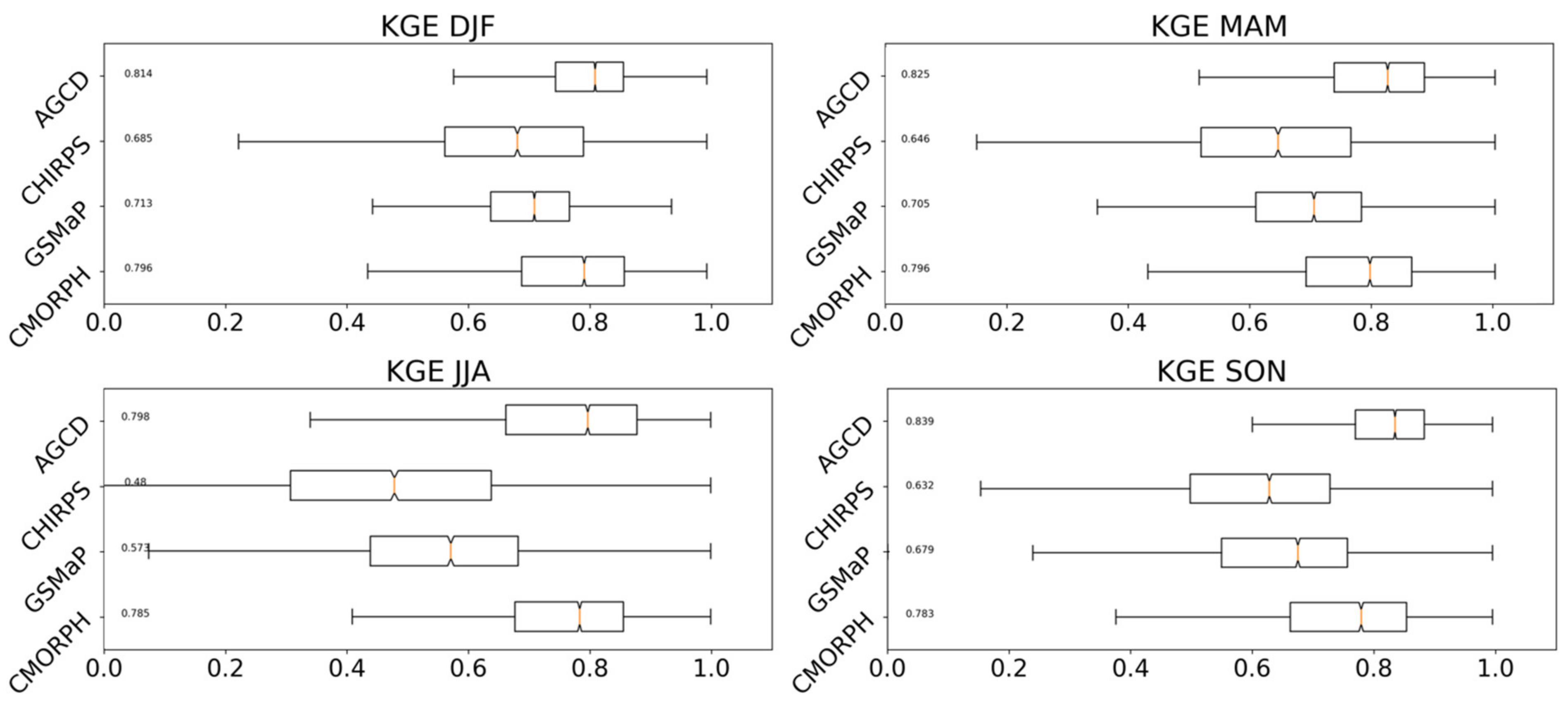
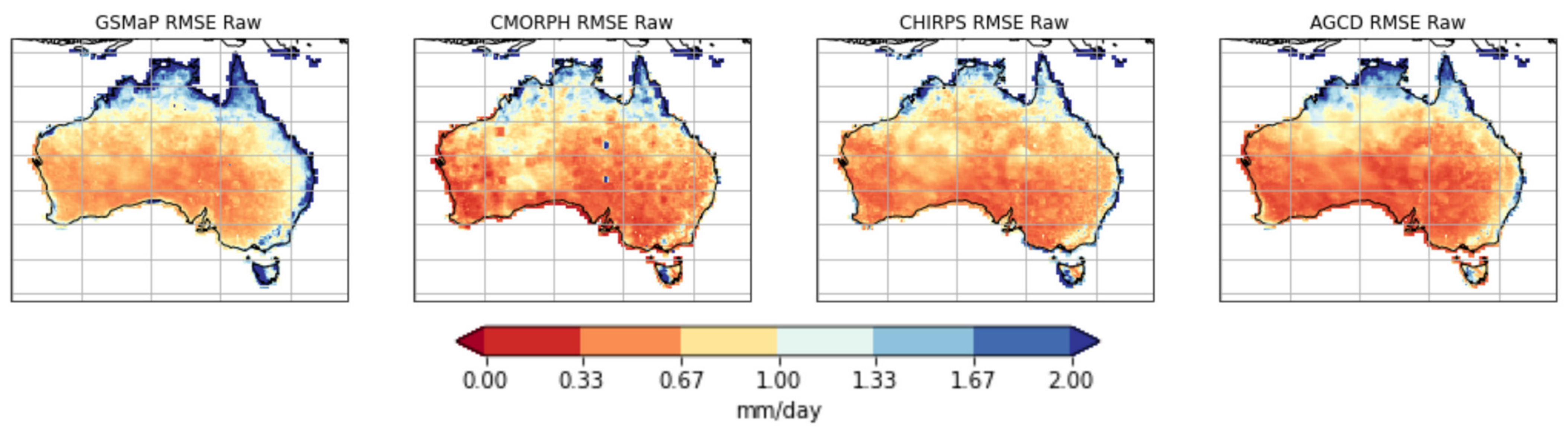
3. Results
3.1. Gauge Analysis
3.2. Gridded Analysis
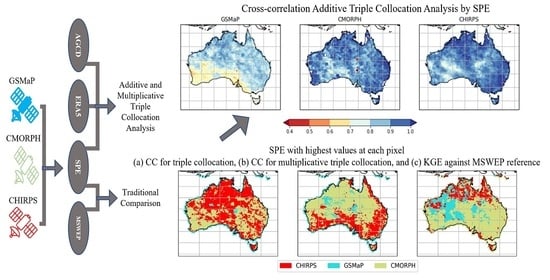
3.3. Collocation Analysis
4. Discussion
4.1. Dataset Deficiencies
4.2. How Does TCA Compare to Traditional Verification Methods of Precipitation over Australia?
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ADFT | Augmented Dickey–Fuller Test |
| AGCD | Australian Gridded Climate Dataset |
| BOM | Bureau of Meteorology |
| CC | Correlation co-efficient |
| CHIRPS | Climate Hazards Group Infrared Precipitation with Stations |
| CMORPH-BLD | Climate Prediction Center morphing technique (Blended) |
| CMORPH-CRT | Climate Prediction Center morphing technique (Corrected) |
| CPC | Climate Prediction Center |
| DJF | December, January, and February |
| ECMWF | European Centre for Medium-Range Weather Forecasts |
| ERA5 | Fifth-generation ECMWF reanalysis |
| FEWS NET | Famine Early Warning Systems Network |
| GSMaP | Global Satellite Mapping of Precipitation |
| GSMaP-GNRT | Global Satellite Mapping of Precipitation (Gauge Near Real-time Adjusted) |
| JAXA | Japan Aerospace Exploration Agency |
| JJA | June, July, and August |
| KGE | Kling–Gupta efficiency |
| MAM | March, April, and May |
| MSWEP | Multi-Source Weighted-Ensemble Precipitation |
| NOAA | National Oceanographic and Atmospheric Administration |
| RMSE | Root-mean-squared-error |
| SON | September, October, and November |
| SPE | Satellite precipitation estimate |
| TCA | Triple collocation analysis |
| USA | United States of America |
| Var. ratio | Variance ratio |
References
- Dinku, T. The Value of Satellite Rainfall Estimates in Agriculture and Food Security. In Satellite Precipitation Measurement; Advances in Global Change Research; Springer: Cham, Switzerland, 2020; pp. 1113–1129. [Google Scholar]
- Funk, C.; Peterson, P.; Landsfeld, M.; Pedreros, D.; Verdin, J.; Shukla, S.; Husak, G.; Rowland, J.; Harrison, L.; Hoell, A.; et al. The climate hazards infrared precipitation with stations—A new environmental record for monitoring extremes. Sci. Data 2015, 2, 150066. [Google Scholar] [CrossRef] [Green Version]
- Tarnavsky, E.; Bonifacio, R. Drought Risk Management Using Satellite-Based Rainfall Estimates. In Satellite Precipitation Measurement; Advances in Global Change Research; Springer: Cham, Switzerland, 2020; pp. 1029–1053. [Google Scholar]
- Li, X.; Chen, Y.; Deng, X.; Zhang, Y.; Chen, L. Evaluation and Hydrological Utility of the GPM IMERG Precipitation Products over the Xinfengjiang River Reservoir Basin, China. Remote Sens. 2021, 13, 866. [Google Scholar] [CrossRef]
- Stanley, T.; Kirschbaum, D.B.; Pascale, S.; Kapnick, S. Extreme Precipitation in the Himalayan Landslide Hotspot. In Satellite Precipitation Measurement; Advances in Global Change Research; Springer: Cham, Switzerland, 2020; pp. 1087–1111. [Google Scholar]
- LeRoy, A.; Berndt, E.; Molthan, A.; Zavodsky, B.; Smith, M.; LaFontaine, F.; McGrath, K.; Fuell, K. Operational Applications of Global Precipitation Measurement Observations. In Satellite Precipitation Measurement; Advances in Global Change Research; Springer: Cham, Switzerland, 2020; pp. 919–940. [Google Scholar]
- Chua, Z.-W.; Kuleshov, Y.; Watkins, A. Evaluation of Satellite Precipitation Estimates over Australia. Remote Sens. 2020, 12, 678. [Google Scholar] [CrossRef] [Green Version]
- Beck, H.E.; Pan, M.; Roy, T.; Weedon, G.P.; Pappenberger, F.; van Dijk, A.I.J.M.; Huffman, G.J.; Adler, R.F.; Wood, E.F. Daily evaluation of 26 precipitation datasets using Stage-IV gauge-radar data for the CONUS. Hydrol. Earth Syst. Sci. 2019, 23, 207–224. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Yong, B. Evaluation and Hydrological Utility of the Latest GPM IMERG V5 and GSMaP V7 Precipitation Products over the Tibetan Plateau. Remote Sens. 2018, 10, 2022. [Google Scholar] [CrossRef] [Green Version]
- Ebert, E.E.; Janowiak, J.E.; Kidd, C. Comparison of Near-Real-Time Precipitation Estimates from Satellite Observations and Numerical Models. Bull. Am. Meteorol. Soc. 2007, 88, 47–64. [Google Scholar] [CrossRef] [Green Version]
- Massari, C.; Crow, W.; Brocca, L. An assessment of the performance of global rainfall estimates without ground-based observations. Hydrol. Earth Syst. Sci. 2017, 21, 4347–4361. [Google Scholar] [CrossRef] [Green Version]
- Alemohammad, S.H.; McColl, K.A.; Konings, A.G.; Entekhabi, D.; Stoffelen, A. Characterization of precipitation product errors across the United States using multiplicative triple collocation. Hydrol. Earth Syst. Sci. 2015, 19, 3489–3503. [Google Scholar] [CrossRef] [Green Version]
- Tian, Y.; Huffman, G.J.; Adler, R.F.; Tang, L.; Sapiano, M.; Maggioni, V.; Wu, H. Modeling errors in daily precipitation measurements: Additive or multiplicative? Geophys. Res. Lett. 2013, 40, 2060–2065. [Google Scholar] [CrossRef] [Green Version]
- Gruber, A.; Su, C.-H.; Zwieback, S.; Crow, W.; Dorigo, W.; Wagner, W. Recent advances in (soil moisture) triple collocation analysis. Int. J. Appl. Earth Obs. Geoinf. 2016, 45, 200–211. [Google Scholar] [CrossRef]
- Stoffelen, A. Toward the true near-surface wind speed: Error modeling and calibration using triple collocation. J. Geophys. Res. Ocean. 1998, 103, 7755–7766. [Google Scholar] [CrossRef]
- Roebeling, R.A.; Wolters, E.L.A.; Meirink, J.F.; Leijnse, H. Triple Collocation of Summer Precipitation Retrievals from SEVIRI over Europe with Gridded Rain Gauge and Weather Radar Data. J. Hydrometeorol. 2012, 13, 1552–1566. [Google Scholar] [CrossRef]
- Wild, A.; Chua, Z.-W.; Kuleshov, Y. Evaluation of Satellite Precipitation Estimates over the South West Pacific Region. Remote Sens. 2021, 13, 3929. [Google Scholar] [CrossRef]
- Amante, C.; Eakins, B.W. ETOPO1 1 Arc-Minute Global Relief Model: Procedures, Data Sources and Analysis. In NOAA Technical Memorandum NESDIS NGDC-24; US Department Commerce: Boulder, CO, USA, 2009. [Google Scholar] [CrossRef]
- Masunaga, H.; Schröder, M.; Furuzawa, F.A.; Kummerow, C.; Rustemeier, E.; Schneider, U. Inter-product biases in global precipitation extremes. Environ. Res. Lett. 2019, 14, 125016. [Google Scholar] [CrossRef]
- Prat, O.P.; Nelson, B.R. Satellite Precipitation Measurement and Extreme Rainfall. In Satellite Precipitation Measurement; Advances in Global Change Research; Springer: Cham, Switzerland, 2020; pp. 761–790. [Google Scholar]
- Tashima, T.; Kubota, T.; Mega, T.; Ushio, T.; Oki, R. Precipitation Extremes Monitoring Using the Near-Real-Time GSMaP Product. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 5640–5651. [Google Scholar] [CrossRef]
- Kubota, T.; Aonashi, K.; Ushio, T.; Shige, S.; Takayabu, Y.N.; Kachi, M.; Arai, Y.; Tashima, T.; Masaki, T.; Kawamoto, N.; et al. Global Satellite Mapping of Precipitation (GSMaP) Products in the GPM Era. In Satellite Precipitation Measurement; Advances in Global Change Research; Springer: Cham, Switzerland, 2020; pp. 355–373. [Google Scholar]
- Chua, Z.-W.; Kuleshov, Y.; Watkins, A.B. Drought Detection over Papua New Guinea Using Satellite-Derived Products. Remote Sens. 2020, 12, 3859. [Google Scholar] [CrossRef]
- Kuleshov, Y.; Kurino, T.; Kubota, T.; Tashima, T.; Xie, P. WMO Space-based Weather and Climate Extremes Monitoring Demonstration Project (SEMDP): First Outcomes of Regional Cooperation on Drought and Heavy Precipitation Monitoring for Australia and Southeast Asia. In Rainfall-Extremes, Distribution and Properties; IntechOpen: London, UK, 2019; pp. 51–57. [Google Scholar]
- Tarnavsky, E.; Chavez, E.; Boogaard, H. Agro-meteorological risks to maize production in Tanzania: Sensitivity of an adapted Water Requirements Satisfaction Index (WRSI) model to rainfall. Int. J. Appl. Earth Obs. Geoinf. 2018, 73, 77–87. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Hamed, M.M.; Nashwan, M.S.; Shahid, S. Performance evaluation of reanalysis precipitation products in Egypt using fuzzy entropy time series similarity analysis. Int. J. Climatol. 2021, 41, 5431–5446. [Google Scholar] [CrossRef]
- Tang, G.; Clark, M.P.; Papalexiou, S.M.; Ma, Z.; Hong, Y. Have satellite precipitation products improved over last two decades? A comprehensive comparison of GPM IMERG with nine satellite and reanalysis datasets. Remote Sens. Environ. 2020, 240, 111697. [Google Scholar] [CrossRef]
- Beck, H.E.; van Dijk, A.I.J.M.; Levizzani, V.; Schellekens, J.; Miralles, D.G.; Martens, B.; de Roo, A. MSWEP: 3-hourly 0.25° global gridded precipitation (1979–2015) by merging gauge, satellite, and reanalysis data. Hydrol. Earth Syst. Sci. 2017, 21, 589–615. [Google Scholar] [CrossRef] [Green Version]
- Evans, A.; Jones, D.; Smalley, R.; Lellyett, S. An Enhanced Gridded Rainfall Dataset Scheme for Australia; Bureau of Meteorology: Melbourne, Australia, 2020; ISBN 978-1-925738-12-4.
- Kling, H.; Fuchs, M.; Paulin, M. Runoff conditions in the upper Danube basin under an ensemble of climate change scenarios. J. Hydrol. 2012, 424–425, 264–277. [Google Scholar] [CrossRef]
- Chen, F.; Crow, W.T.; Ciabatta, L.; Filippucci, P.; Panegrossi, G.; Marra, A.C.; Puca, S.; Massari, C. Enhanced Large-Scale Validation of Satellite-Based Land Rainfall Products. J. Hydrometeorol. 2021, 22, 245–257. [Google Scholar] [CrossRef]
- Robeson, S.M.; Ensor, L.A. Statistical Characteristics of Daily Precipitation: Comparisons of Gridded and Point Datasets. J. Appl. Meteorol. Climatol. 2008, 47, 2468–2476. [Google Scholar] [CrossRef]
- Nashwan, M.S.; Shahid, S.; Dewan, A.; Ismail, T.; Alias, N. Performance of five high resolution satellite-based precipitation products in arid region of Egypt: An evaluation. Atmos. Res. 2020, 236, 104809. [Google Scholar] [CrossRef]


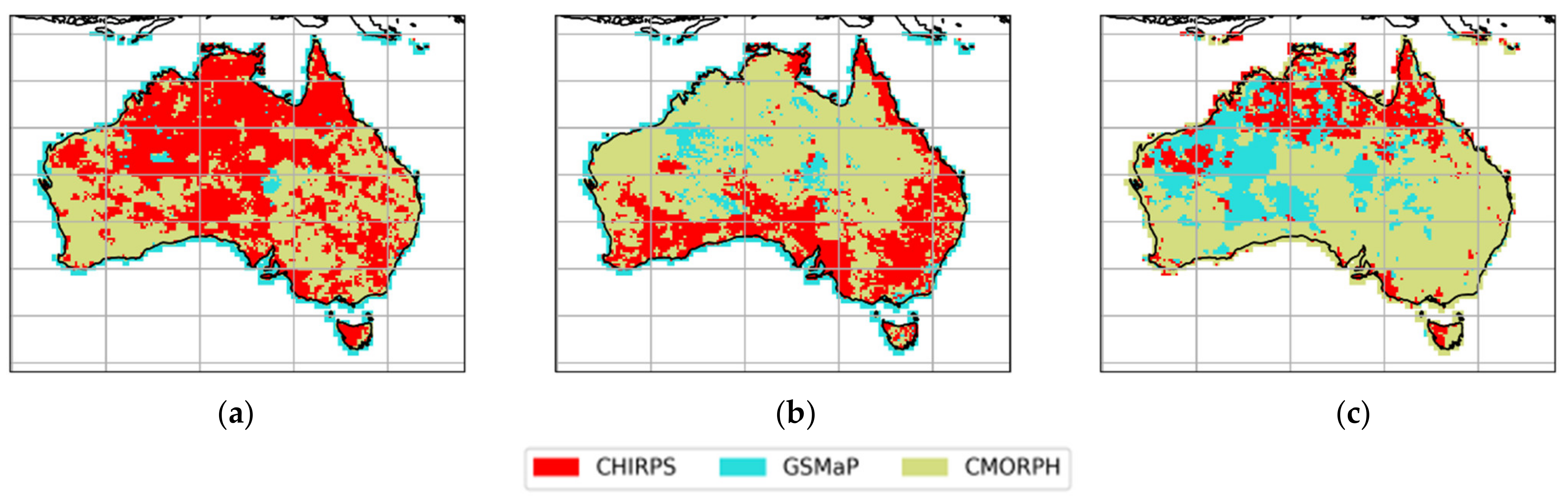
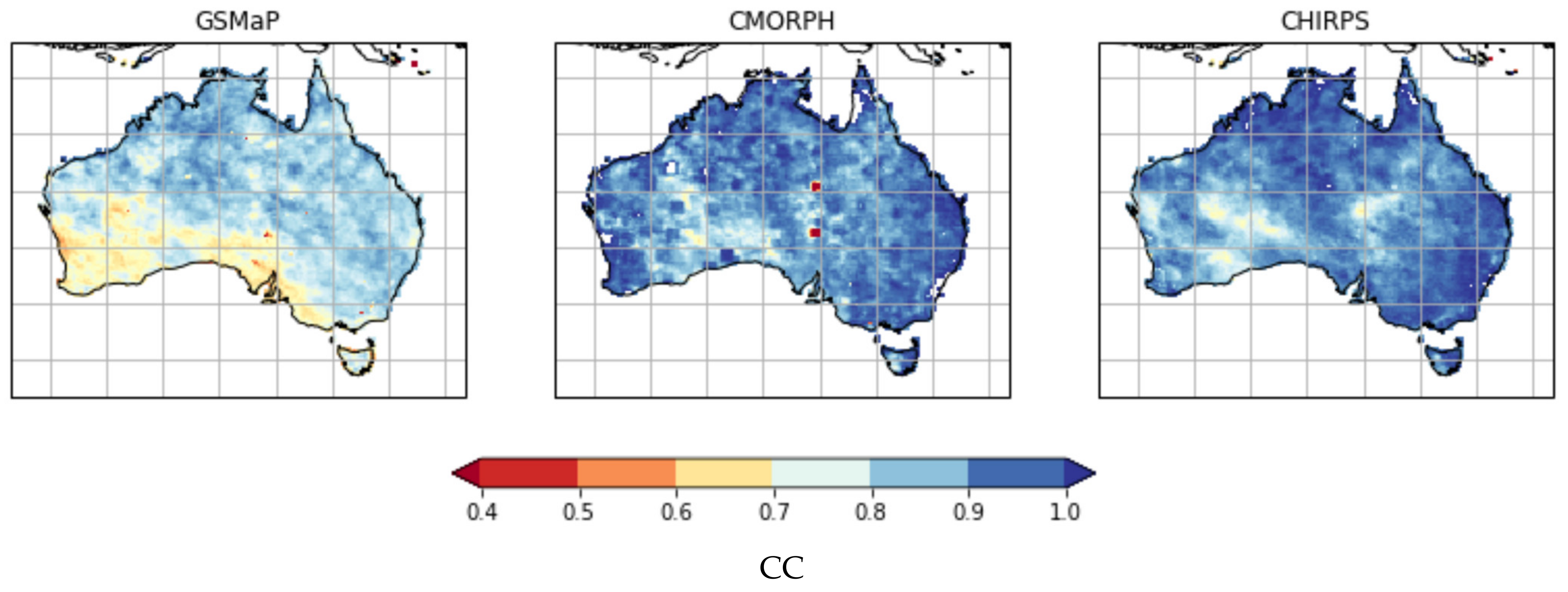

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Raw | Anomaly | DJF | MAM | JJA | SON |
|---|---|---|---|---|---|---|
| GSMaP | −3.16 * | −6.75 ** | −5.76 ** | −3.09 * | −7.30 ** | −2.42 |
| CMORPH | −2.46 | −2.43 | −2.23 | −2.46 | −1.08 | −2.00 |
| CHIRPS | −3.18 * | −8.20 ** | −3.56 ** | −3.95 ** | −7.19 ** | −2.38 |
| ERA5 | −1.52 | −6.22 ** | −1.53 | −1.53 | −1.53 | −1.52 |
| AGCD | −2.55 | −2.64 * | −6.54 ** | −3.67 ** | −6.84 ** | −2.14 |
| GSMaP | CMORPH | CHIRPS | AGCD | MSWEP | |
|---|---|---|---|---|---|
| KGE | 0.587 | 0.808 | 0.741 | 0.933 | 0.871 |
| Pearson | 0.727 | 0.917 | 0.903 | 0.980 | 0.944 |
| Bias Ratio | 0.972 | 1.067 | 1.108 | 1.022 | 1.071 |
| Var. Ratio | 0.847 | 0.897 | 0.836 | 0.945 | 0.945 |
| RMSE | 1.391 | 0.856 | 0.837 | 0.371 | 0.623 |
| GSMaP | CMORPH | CHIRPS | AGCD | |
|---|---|---|---|---|
| KGE | 0.743 | 0.835 | 0.708 | 0.861 |
| Pearson | 0.815 | 0.915 | 0.887 | 0.906 |
| Bias Ratio | 1.016 | 1.076 | 0.973 | 0.998 |
| Variance Ratio | 0.990 | 0.997 | 0.787 | 0.990 |
| RMSE | 0.789 | 0.640 | 0.647 | 0.570 |
| GSMaP | CMORPH | CHIRPS | |
|---|---|---|---|
| CC | 0.839 | 0.929 | 0.932 |
| M CC | 0.668 | 0.796 | 0.748 |
| σ | 0.647 | 0.527 | 0.329 |
| M σ | 1.988 | 1.537 | 0.169 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wild, A.; Chua, Z.-W.; Kuleshov, Y. Triple Collocation Analysis of Satellite Precipitation Estimates over Australia. Remote Sens. 2022, 14, 2724. https://doi.org/10.3390/rs14112724
Wild A, Chua Z-W, Kuleshov Y. Triple Collocation Analysis of Satellite Precipitation Estimates over Australia. Remote Sensing. 2022; 14(11):2724. https://doi.org/10.3390/rs14112724
Chicago/Turabian StyleWild, Ashley, Zhi-Weng Chua, and Yuriy Kuleshov. 2022. "Triple Collocation Analysis of Satellite Precipitation Estimates over Australia" Remote Sensing 14, no. 11: 2724. https://doi.org/10.3390/rs14112724
APA StyleWild, A., Chua, Z.-W., & Kuleshov, Y. (2022). Triple Collocation Analysis of Satellite Precipitation Estimates over Australia. Remote Sensing, 14(11), 2724. https://doi.org/10.3390/rs14112724