
Towards Automated Detection and Localization of Red Deer Cervus elaphus Using Passive Acoustic Sensors during the Rut

 , , , , ,
, , , , ,  and
and
Abstract
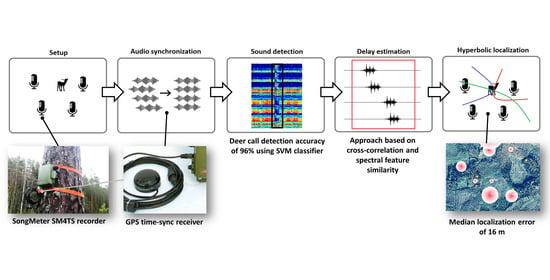
:
1. Introduction
2. Related Work
3. Methods
- Setup—recorder deployment in the area of interest and data gathering during the deer rutting period.
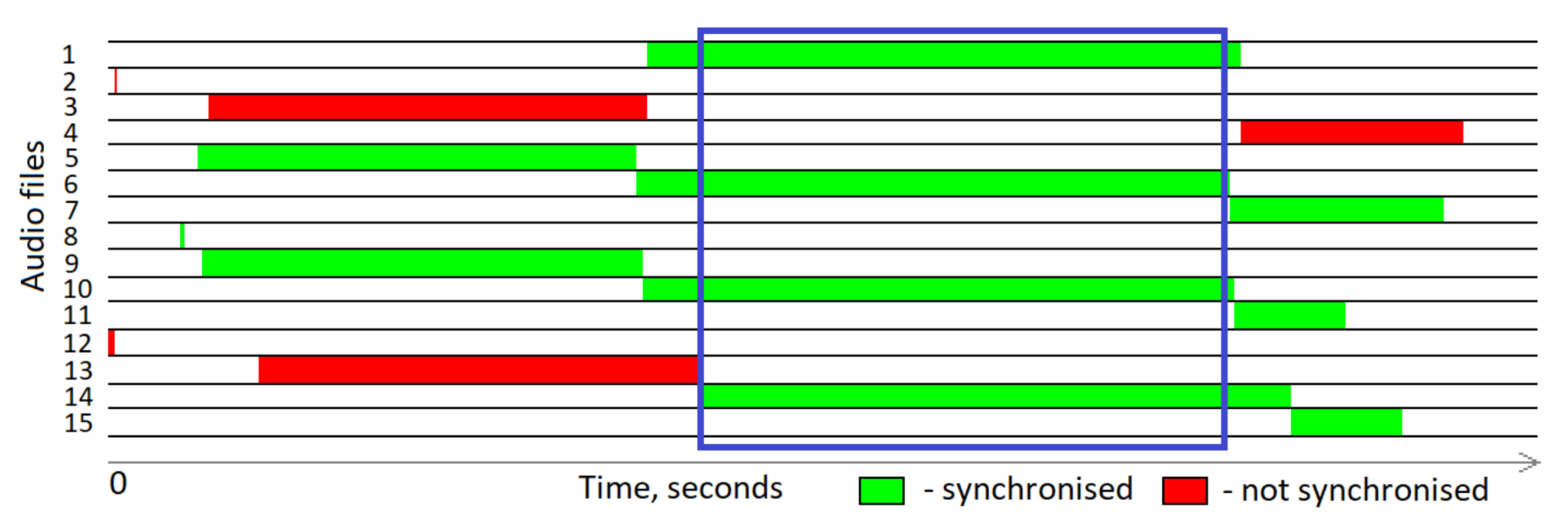
- Audio synchronization—synchronization of multiple microphone clocks using GPS time-sync receiver and filtration of only synchronized audio record for deer call localization.
- Sound detection—application of the best-performing binary classifier for deer call detection. The classifier has been trained on various deer vocalizations and environment sounds and is used to find audio timestamps where deer calls are heard in all recorders in a given time window.
- Delay estimation—precise assessment of deer call starts in synchronized audio signals from multiple microphones and calculation of acoustic signal arrival delays. This step is applied only for deer calls detected in all four microphones. The reference signal is selected as the signal where deer sounds were detected first; afterwards, this signal is used to find a signal delay in the other three recorders. Signal delay can be calculated using cross-correlation or the proposed spectral similarity methods.
- Hyperbolic localization—geospatial localization of signal source from obtained signal delay values and recorder locations.
3.1. Pilot Area
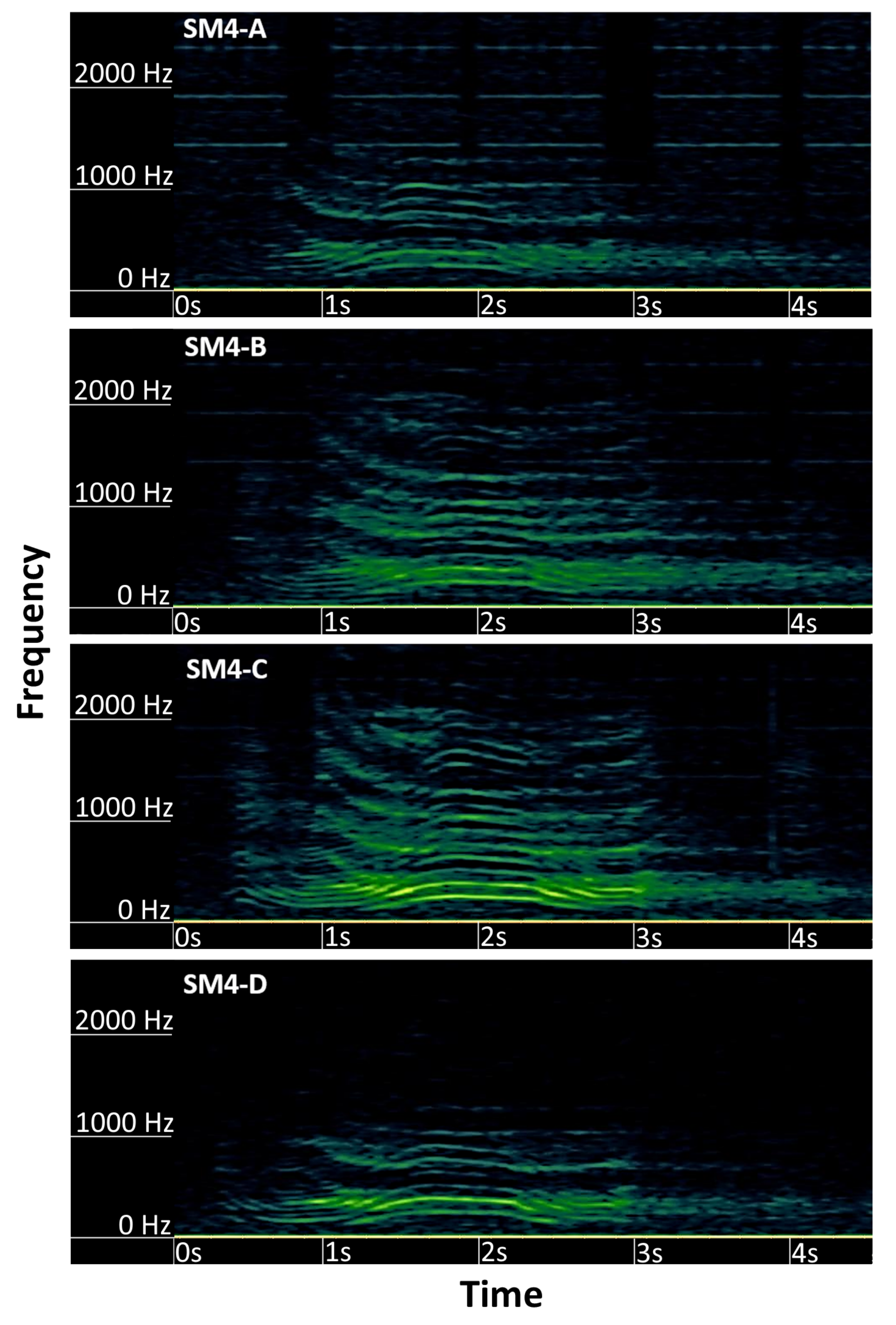
3.2. Deer Sound Acquisition
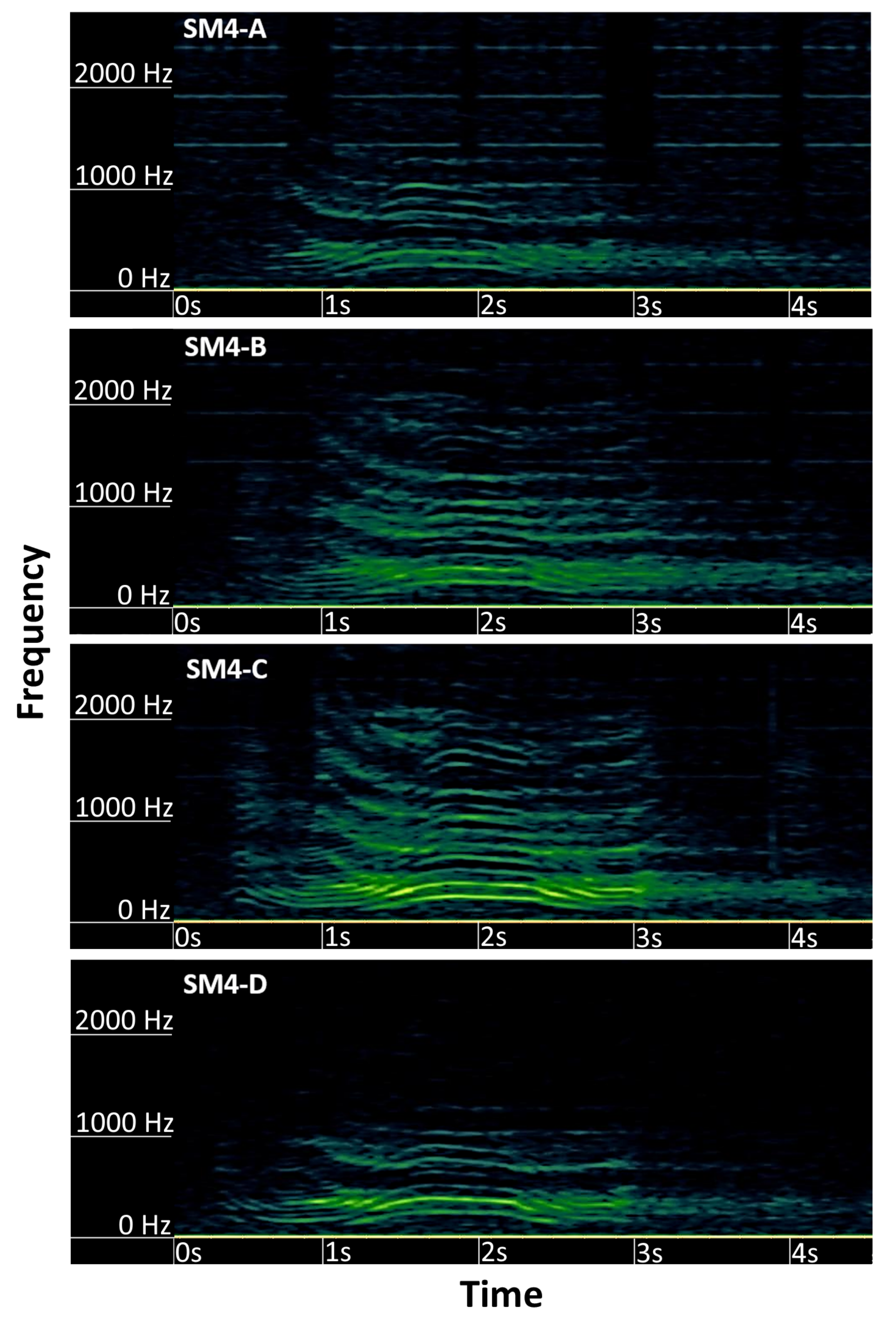
3.3. Deer Sound Detection
- Loudness normalization in accordance with EBU R 128 Standard.
- Stereo to mono conversion.
- Wind noise reduction using 150 Hz high-pass filter.
3.3.1. Semiautomatic Approach for Dataset Creation
- Linear spectrum (feature count: 2000).
- Mel spectrum (no. of bandpass filters in filterbank: 32).
- Bark spectrum (no. of bandpass filters in filterbank: 32).
- Equivalent rectangular bandwidth (ERB) (no. of ERB bands: 28).
| Algorithm 1 Spectral similarity search. |
| 1: Fs = 8000 Hz |
| 2: windowSize = 5 |
| 3: Aref—audio reference file |
| 4: Atest—audio test file |
| 5: Arefn ← gainNormalization(Aref) |
| 6: Atestn ← gainNormalization(Atest) |
| 7: Areff ← audioFeatureExtractor(Arefn) |
| 8: Atestf ← audioFeatureExtractor(Atestn) |
| 9: Areffm ← moveMean(Areff, windowSize, rows) |
| 10: Atestfm ← moveMean(Atestf, windowSize, rows) |
| 11: score = zeros(size(Atestfm,rows) − size(Areffm,rows)) |
| 12: for i = 1,2,…,size(score) do |
| 13: score(i) = psnr(Areffm, Atestfm(i:i + size(Areffm) :)) |
| 14: end for |
| 15: scoreSorted, scoreSortedIdx = sortAscend(score) |
| 16: audioIdx = featureSetep2sampleTime(scoreSortedIdx) |
| 17: for i = 1, 2,…,50 do |
| 18: saveAudio = Atest(audioIdx(i):audioIdx(i) + 2Fs) |
| 19: end for |
3.3.2. Automatic Approach for Deer Sound Detection
- Mel spectrum (no. of bandpass filters in filterbank: 32).
- Bark spectrum (no. of bandpass filters in filterbank: 32).
- Equivalent rectangular bandwidth (ERB) (no. of ERB bands: 28).
- Mel frequency cepstral coefficients (MFCC) (no. of coefficients for window: 13).
- Gammatone cepstral coefficients (GTCC) (no. of coefficients for window: 13).
- Spectral centroid.
- Spectral crest.
- Spectral decrease.
- Spectral entropy.
- Spectral flatness.
- Spectral kurtosis.
- Spectral roll off point.
- Spectral skewness.
- Spectral slope.
- Spectral spread.
- Harmonic ratio.
| Algorithm 2 Feature extraction. |
| 1: Fs = 8000 Hz |
| 2: windowSize = 5 |
| 3: Asample−audio file |
| 4: AsampleNorm ← gainNormalization(Asample) |
| 5: sampleRange = 1:Fs/4:len(AsampleNorm)−Fs/2 |
| 6: fvecList = [] |
| 7: for i = sampleRange do |
| 8: Atmp ← AsampleNorm(i:i + Fs/2) |
| 9: Afvec ← audioFeatureExtractor(Atmp) |
| 10: Astd = std(Atmp) |
| 11: Apv = Astd/ |
| 12: fvecList(i) = [AfvecAstdApv] |
| 13: end for |
| 14: fvecListConcat = [] |
| 15: for i = 3,4,…,size(fvec, List, rows)−2 do |
| 16: ftmp = fvecList(i − 2:i + 2, :) |
| 17: fmean = mean(ftmp, rows) |
| 18: fstd = std(ftmp, rows) |
| 19: fpv = fstd/ |
| 20: fvecListConcat(k,:) = [fmean fstd fpv] |
| 21: end for |
| 22: fvecListMean ← moveMean(f vecListConcat, windowSize, rows) |
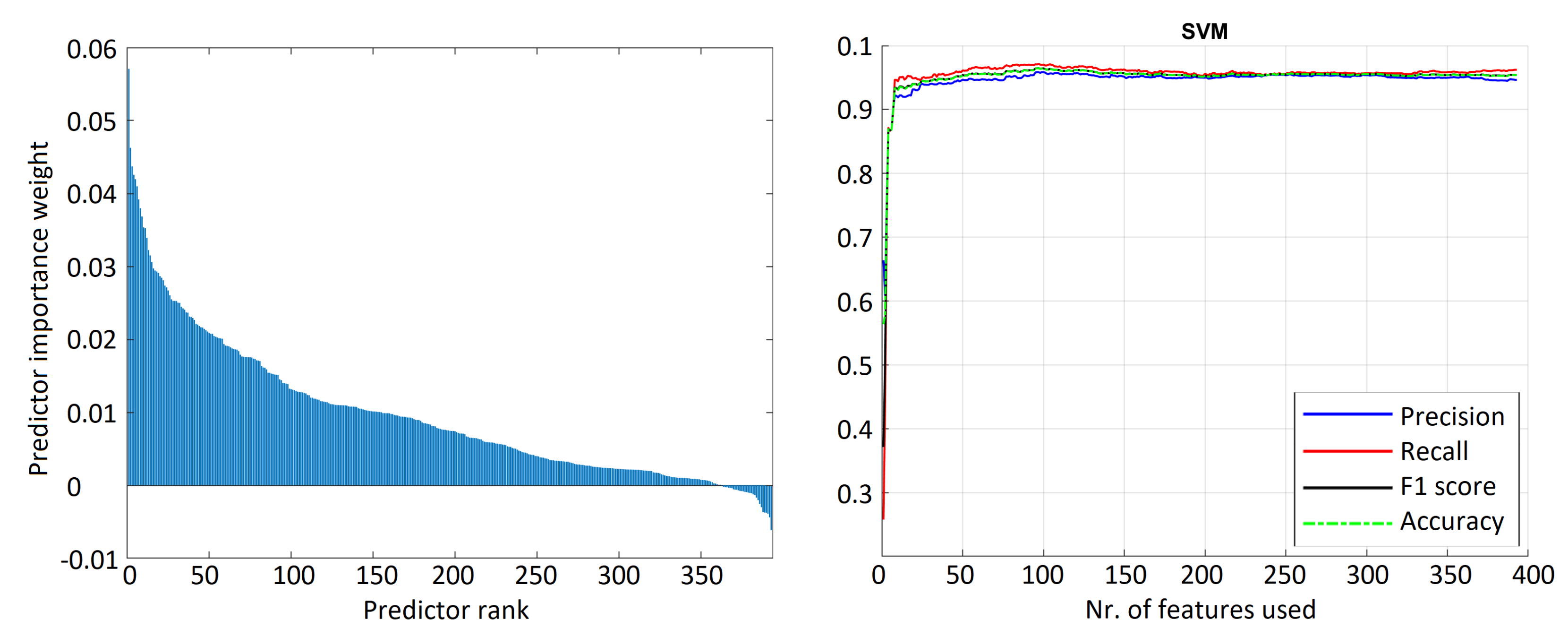
3.3.3. Support Vector Machine (SVM)
3.3.4. Linear Discriminant Analysis (LDA)
3.3.5. K-Nearest Neighbors Algorithm (kNN)
3.3.6. Decision Tree (DT)
3.3.7. Long Short-Term Memory (LSTM)
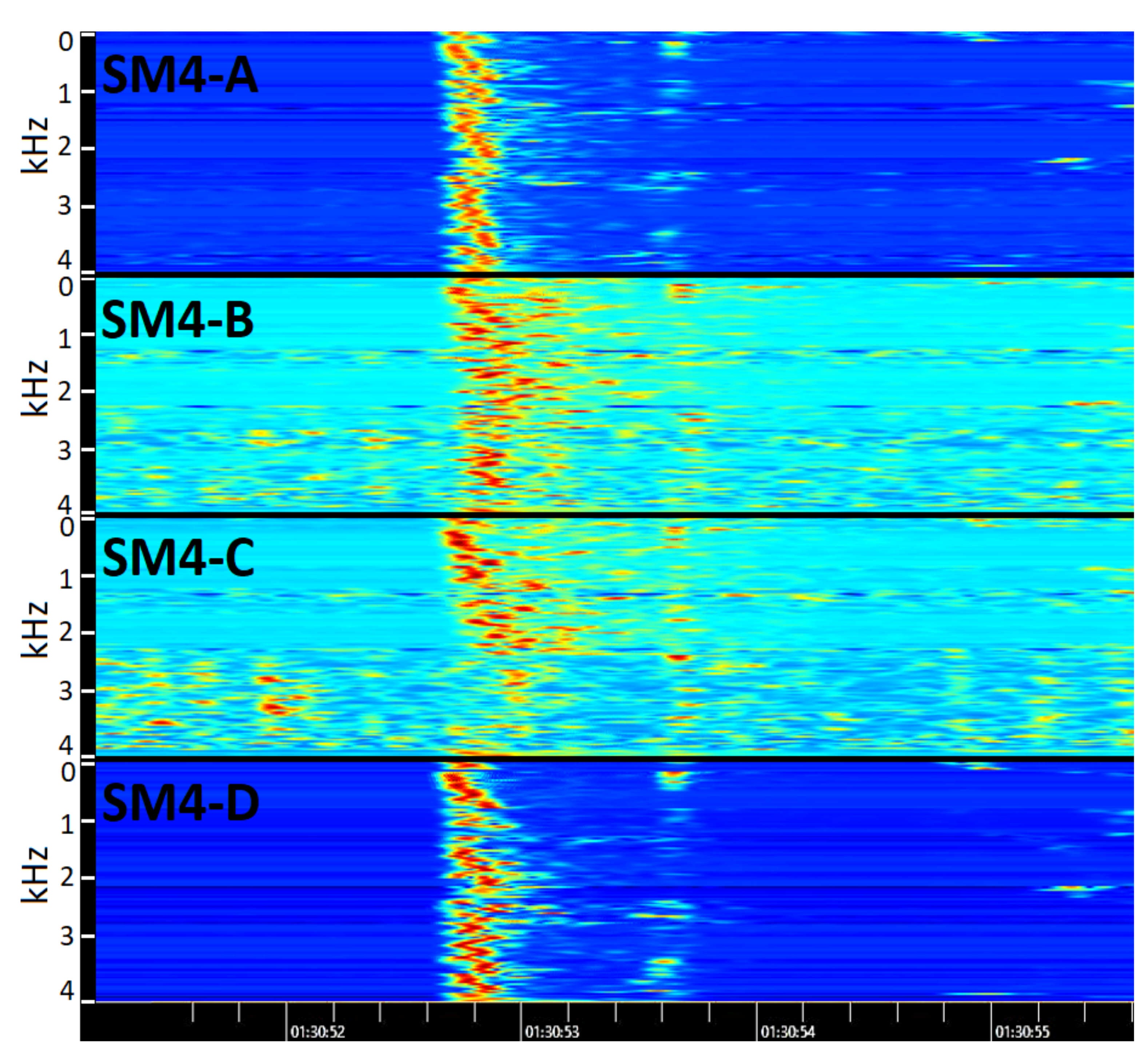
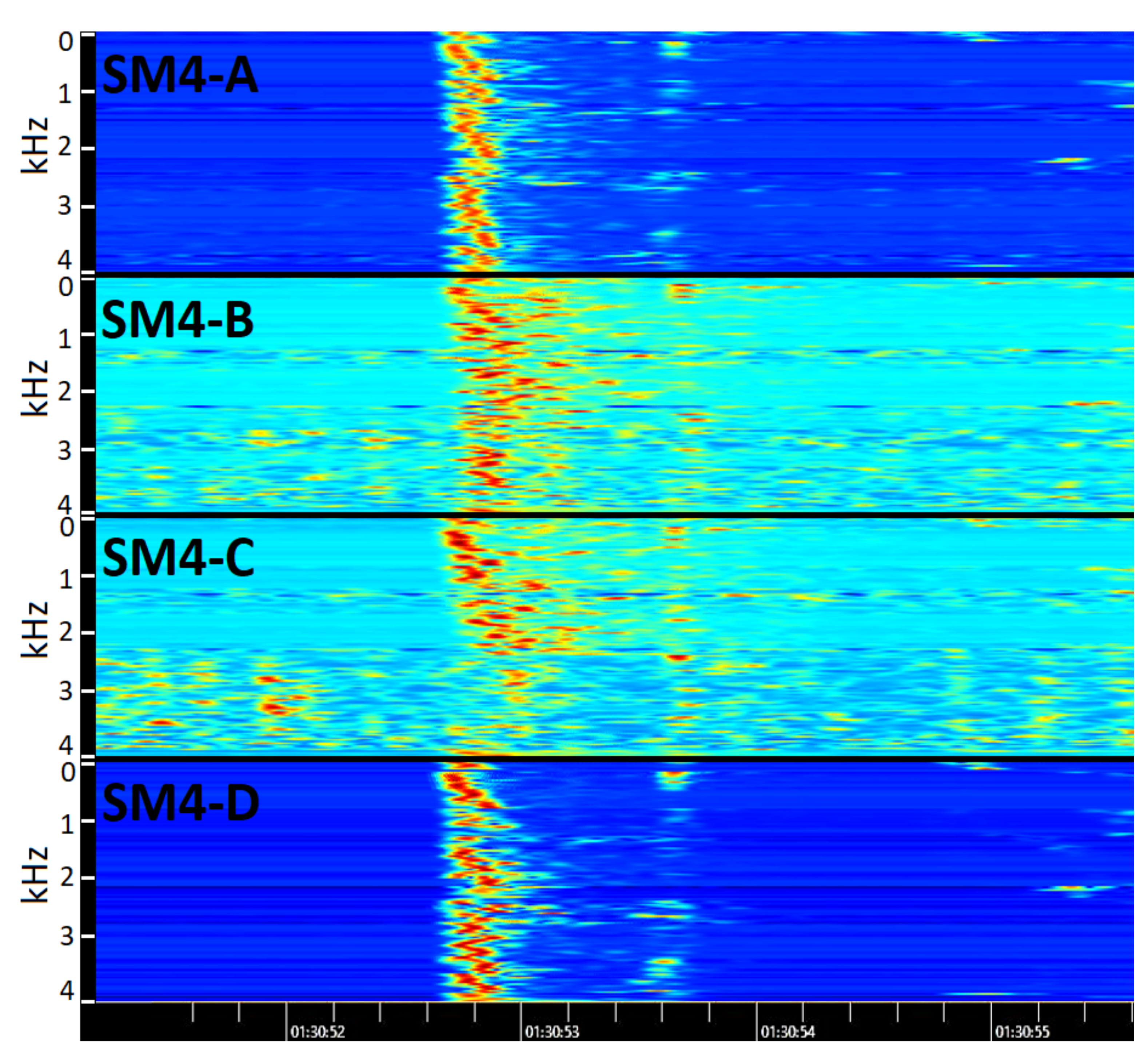
3.4. Audio Delay Calculation
3.4.1. Manual Detection
3.4.2. Cross-Correlation
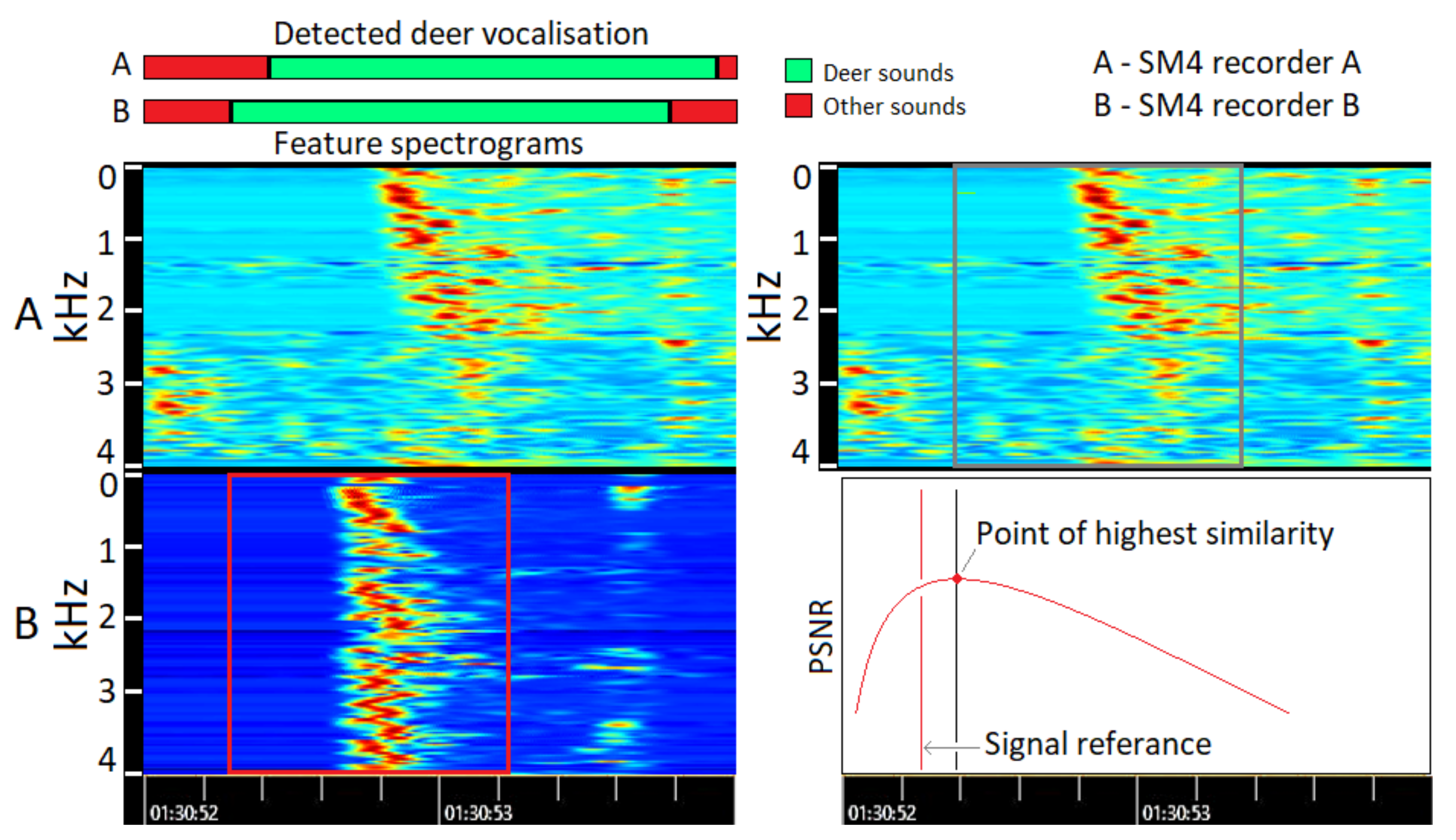
3.4.3. Spectral Similarity
3.4.4. Audio Delay Estimation—Spectral Selected
- Select a reference signal.
- Extract spectral features of the reference signal.
- Generate white Gaussian noise with SNR of 30 dB.
- Add white Gaussian noise to the reference signal.
- Extract spectral features from the noise added signal.
- Perform cross-correlation between reference and noise added signal for each spectral feature individually.
- Select features with the highest correlation coefficient at the expected time delay.
3.4.5. Audio Delay Estimation—Spectral 2 Stage
| Algorithm 3 Similarity score calculation in Spectral 2 stage approach. |
| 1: Sref−reference spectrogram |
| 2: Cref ← spectrogram2blocks(Sref, 5, 5) |
| 3: Wref = (5, 5) |
| 4: for i = 1, 2,…, 5 do |
| 5: for j = 1, 2,…, 5 do |
| 6: Wref (i, j) = std(Cref (i, j)) |
| 7: end for |
| 8: end for |
| 9: Wrefnorm = Wref/∑ Wref |
| 10: Stest−test spectrogram |
| 11: Ctest ← spectrogram2blocks(Stest, 5, 5) |
| 12: score = 0 |
| 13: for i = 1, 2,…, 5 do |
| 14: for j = 1, 2,…, 5 do |
| 15: score + = PSNR(Ctest (i, j), Cref (i, j) ∗ Wrefnorm (i, j)) |
| 7: end for |
| 8: end for |
3.5. Hyperbolic Localization
3.6. Controlled Tests
4. Results
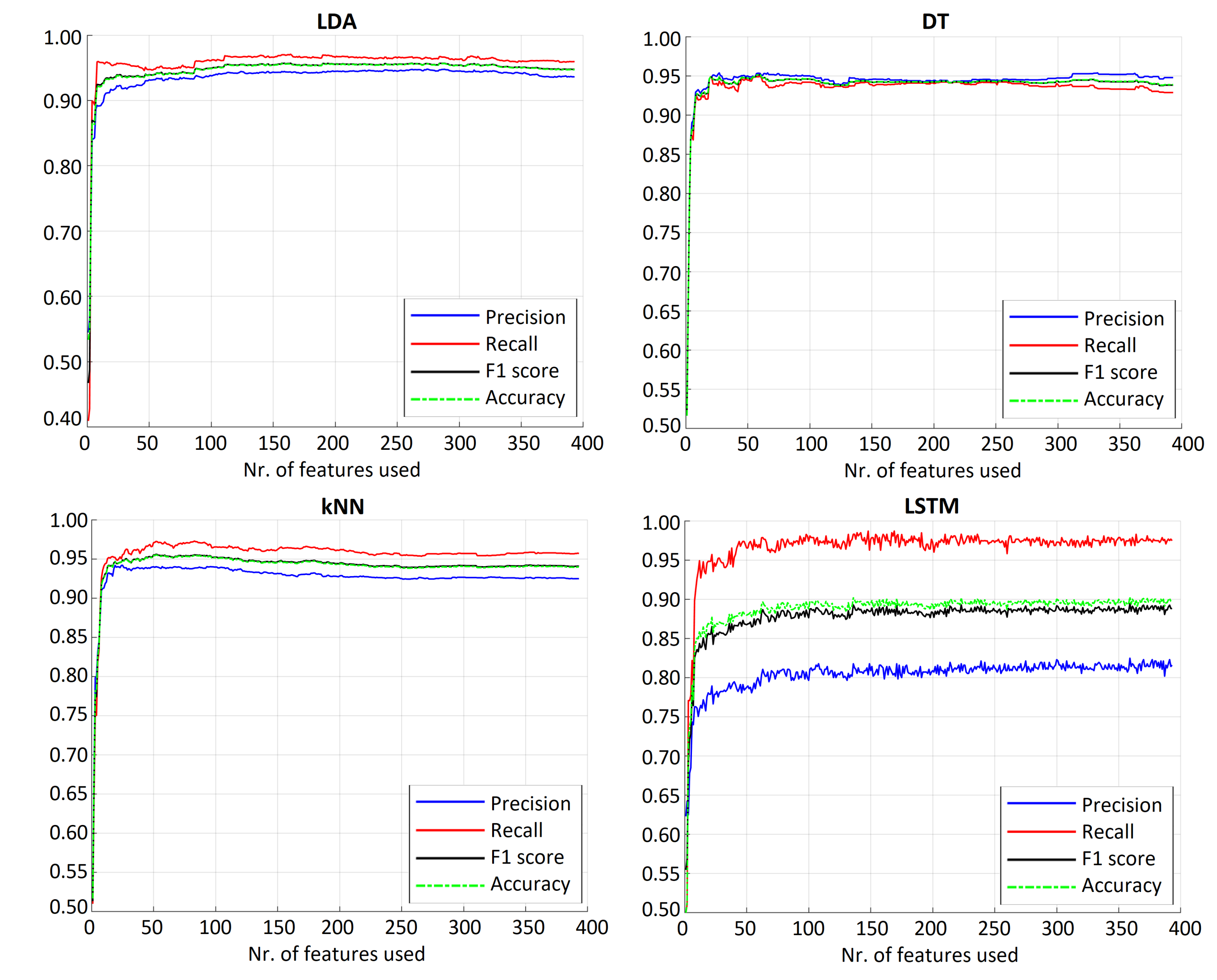
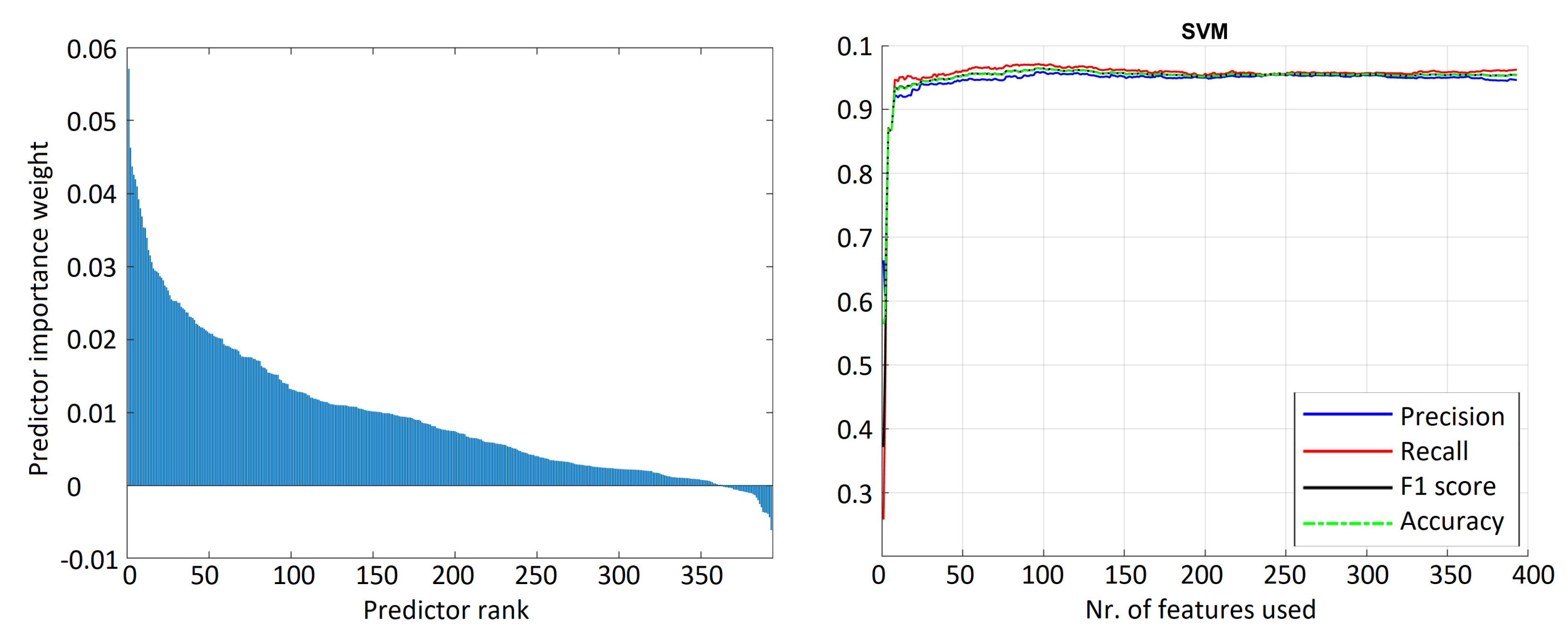
4.1. Deer Sound Detection Results
4.2. Sound Localization Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DOA | Direction-of-arrival |
| DT | Decision tree |
| ERB | Equivalent rectangular bandwidth |
| FSIM | Feature-based similarity index |
| GPS | Global positioning system |
| GTCC | Gammatone cepstral coefficients |
| ISSM | Information theoretic-based statistic similarity measure |
| KNN | K-nearest neighbors algorithm |
| LDA | Linear discriminant analysis |
| LSTM | Long short-term memory |
| MFCC | Mel frequency cepstral coefficients |
| PAM | Passive acoustic monitoring |
| SNR | Signal-to-noise ratio |
| PSNR | Peak signal-to-noise ratio |
| RMSE | Root mean square error |
| SSIM | Structural similarity index |
| STD | Standard deviation |
| SVM | Support vector machine |
References
- Blumstein, D.T.; Mennill, D.J.; Clemins, P.; Girod, L.; Yao, K.; Patricelli, G.; Deppe, J.L.; Krakauer, A.H.; Clark, C.; Cortopassi, K.A.; et al. Acoustic monitoring in terrestrial environments using microphone arrays: Applications, technological considerations and prospectus. J. Appl. Ecol. 2011, 48, 758–767. [Google Scholar] [CrossRef]
- Buxton, R.T.; McKenna, M.F.; Clapp, M.; Meyer, E.; Stabenau, E.; Angeloni, L.M.; Crooks, K.; Wittemyer, G. Efficacy of extracting indices from large-scale acoustic recordings to monitor biodiversity. Conserv. Biol. 2018, 32, 1174–1184. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Qiang, M.; Luan, X.; Xu, P.; He, G.; Yin, X.; Xi, L.; Jin, X.; Shao, J.; Chen, X.; et al. The application of the Internet of Things to animal ecology. Integr. Zool. 2015, 10, 572–578. [Google Scholar] [CrossRef] [PubMed]
- Gibb, R.; Browning, E.; Glover-Kapfer, P.; Jones, K.E. Emerging opportunities and challenges for passive acoustics in ecological assessment and monitoring. Methods Ecol. Evol. 2019, 10, 169–185. [Google Scholar] [CrossRef] [Green Version]
- Darras, K.; Batáry, P.; Furnas, B.J.; Grass, I.; Mulyani, Y.A.; Tscharntke, T. Autonomous sound recording outperforms human observation for sampling birds: A systematic map and user guide. Ecol. Appl. 2019, 29, e01954. [Google Scholar] [CrossRef] [Green Version]
- Kalan, A.K.; Mundry, R.; Wagner, O.J.; Heinicke, S.; Boesch, C.; Kühl, H.S. Towards the automated detection and occupancy estimation of primates using passive acoustic monitoring. Ecol. Indic. 2015, 54, 217–226. [Google Scholar] [CrossRef]
- Stevenson, B.C.; Borchers, D.L.; Altwegg, R.; Swift, R.J.; Gillespie, D.M.; Measey, G.J. A general framework for animal density estimation from acoustic detections across a fixed microphone array. Methods Ecol. Evol. 2015, 6, 38–48. [Google Scholar] [CrossRef]
- Rhinehart, T.A.; Chronister, L.M.; Devlin, T.; Kitzes, J. Acoustic localization of terrestrial wildlife: Current practices and future opportunities. Ecol. Evol. 2020, 10, 6794–6818. [Google Scholar] [CrossRef]
- Sugai, L.S.M.; Silva, T.S.F.; Ribeiro, J.W., Jr.; Llusia, D. Terrestrial passive acoustic monitoring: Review and perspectives. BioScience 2019, 69, 15–25. [Google Scholar] [CrossRef]
- Sugai, L.S.M.; Desjonqueres, C.; Silva, T.S.F.; Llusia, D. A roadmap for survey designs in terrestrial acoustic monitoring. Remote Sens. Ecol. Conserv. 2020, 6, 220–235. [Google Scholar] [CrossRef] [Green Version]
- McComb, K. Roaring by red deer stags advances the date of oestrus in hinds. Nature 1987, 330, 648–649. [Google Scholar] [CrossRef]
- Volodin, I.A.; Volodina, E.V.; Golosova, O.S. Automated monitoring of vocal rutting activity in red deer (Cervus elaphus). Russ. J. Theriol. 2016, 15, 91–99. [Google Scholar] [CrossRef]
- Rusin, I.Y.; Volodin, I.A.; Sitnikova, E.F.; Litvinov, M.N.; Andronova, R.S.; Volodina, E.V. Roaring dynamics in rutting male red deer Cervus elaphus from five Russian populations. Russ. J. Theriol. 2021, 20, 44–58. [Google Scholar] [CrossRef]
- Enari, H.; Enari, H.; Okuda, K.; Yoshita, M.; Kuno, T.; Okuda, K. Feasibility assessment of active and passive acoustic monitoring of sika deer populations. Ecol. Indic. 2017, 79, 155–162. [Google Scholar] [CrossRef]
- Enari, H.; Enari, H.S.; Okuda, K.; Maruyama, T.; Okuda, K.N. An evaluation of the efficiency of passive acoustic monitoring in detecting deer and primates in comparison with camera traps. Ecol. Indic. 2019, 98, 753–762. [Google Scholar] [CrossRef]
- Reby, D.; André-Obrecht, R.; Galinier, A.; Farinas, J.; Cargnelutti, B. Cepstral coefficients and hidden Markov models reveal idiosyncratic voice characteristics in red deer (Cervus elaphus) stags. J. Acoust. Soc. Am. 2006, 120, 4080–4089. [Google Scholar] [CrossRef] [Green Version]
- Heinicke, S.; Kalan, A.K.; Wagner, O.J.; Mundry, R.; Lukashevich, H.; Kühl, H.S. Assessing the performance of a semi-automated acoustic monitoring system for primates. Methods Ecol. Evol. 2015, 6, 753–763. [Google Scholar] [CrossRef]
- Digby, A.; Towsey, M.; Bell, B.D.; Teal, P.D. A practical comparison of manual and autonomous methods for acoustic monitoring. Methods Ecol. Evol. 2013, 4, 675–683. [Google Scholar] [CrossRef]
- Aide, T.M.; Corrada-Bravo, C.; Campos-Cerqueira, M.; Milan, C.; Vega, G.; Alvarez, R. Real-time bioacoustics monitoring and automated species identification. PeerJ 2013, 1, e103. [Google Scholar] [CrossRef] [Green Version]
- Mac Aodha, O.; Gibb, R.; Barlow, K.E.; Browning, E.; Firman, M.; Freeman, R.; Harder, B.; Kinsey, L.; Mead, G.R.; Newson, S.E.; et al. Bat detective—Deep learning tools for bat acoustic signal detection. PLoS Comput. Biol. 2018, 14, e1005995. [Google Scholar] [CrossRef] [Green Version]
- Pavlovs, I.; Aktas, K.; Avots, E.; Vecvanags, A.; Filipovs, J.; Brauns, A.; Done, G.; Jakovels, D.; Anbarjafari, G. Ungulate Detection and Species Classification from Camera Trap Images Using RetinaNet and Faster R-CNN. Entropy 2022, 24, 353. [Google Scholar]
- Cristianini, N.; Shawe-Taylor, J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods; Cambridge University Press: Cambridge, UK, 2000. [Google Scholar]
- Fisher, R.A. The use of multiple measurements in taxonomic problems. Ann. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Hart, P.E.; Stork, D.G.; Duda, R.O. Pattern Classification; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Li, B.; Friedman, J.; Olshen, R.; Stone, C. Classification and regression trees. Biometrics 1984, 40, 358–361. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Spiesberger, J.L. Hyperbolic location errors due to insufficient numbers of receivers. J. Acoust. Soc. Am. 2001, 109, 3076–3079. [Google Scholar] [CrossRef]
- Watkins, W.A.; Schevill, W.E. Sound source location by arrival-times on a non-rigid three-dimensional hydrophone array. In Deep Sea Research and Oceanographic Abstracts; Elsevier: Amsterdam, The Netherlands, 1972; Volume 19, pp. 691–706. [Google Scholar]
- Murphy, C.; Singh, H. Rectilinear coordinate frames for deep sea navigation. In Proceedings of the 2010 IEEE/OES Autonomous Underwater Vehicles, Monterey, CA, USA, 1–3 September 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1–10. [Google Scholar]
- Robnik-Šikonja, M.; Kononenko, I. Theoretical and empirical analysis of ReliefF and RReliefF. Mach. Learn. 2003, 53, 23–69. [Google Scholar] [CrossRef] [Green Version]
- Hill, A.P.; Prince, P.; Piña Covarrubias, E.; Doncaster, C.P.; Snaddon, J.L.; Rogers, A. AudioMoth: Evaluation of a smart open acoustic device for monitoring biodiversity and the environment. Methods Ecol. Evol. 2018, 9, 1199–1211. [Google Scholar] [CrossRef] [Green Version]
- Hill, A.P.; Prince, P.; Snaddon, J.L.; Doncaster, C.P.; Rogers, A. AudioMoth: A low-cost acoustic device for monitoring biodiversity and the environment. HardwareX 2019, 6, e00073. [Google Scholar] [CrossRef]
- Karlsson, E.C.M.; Tay, H.; Imbun, P.; Hughes, A.C. The Kinabalu Recorder, a new passive acoustic and environmental monitoring recorder. Methods Ecol. Evol. 2021, 12, 2109–2116. [Google Scholar] [CrossRef]
- Wijers, M.; Loveridge, A.; Macdonald, D.W.; Markham, A. CARACAL: A versatile passive acoustic monitoring tool for wildlife research and conservation. Bioacoustics 2021, 30, 41–57. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classifier | Features | Precision | Recall | F1 | Accuracy |
|---|---|---|---|---|---|
| Linear support vector machine | 97 | 95.84 | 97.13 | 96.48 | 96.46 |
| Linear discriminant analysis | 262 | 94.76 | 96.69 | 95.71 | 95.67 |
| Decision tree | 60 | 95.30 | 94.96 | 95.13 | 95.14 |
| K-nearest neighbors algorithm | 52 | 94.00 | 97.23 | 95.59 | 95.52 |
| Long short-term memory | 359 | 82.48 | 97.69 | 89.44 | 90.27 |
| Error in Meters | ||||||
|---|---|---|---|---|---|---|
| Nr. | Inside Grid | Manual | Cross-Correlation | Spectral All | Spectral Selected | Spectral 2 Stage |
| 1 | No | 25.74 | 45.97 | 9.35 | 25.62 | 17.84 |
| 2 | Yes | 3.97 | 5.07 | 11.45 | 2.71 | 3.9 |
| 3 | Yes | 36.50 | 24.85 | 22.93 | 32.66 | 15.01 |
| 4 | No | 43.33 | 257.85 | 18.89 | 12.20 | 1.20 |
| 5 | No | 156.07 | 150.91 | 195.00 | 65.99 | 39.05 |
| 6 | No | 165.65 | 16.29 | 63.96 | 78.78 | 62.41 |
| 7 | No | 37.97 | 26.59 | 100.44 | 15.57 | 16.42 |
| 8 | No | 81.56 | 75.21 | 36.98 | 55.33 | 39.30 |
| 9 | No | 51.63 | 39.41 | 45.31 | 46.61 | 47.17 |
| 10 | No | 188.61 | 486.96 | 148.68 | 239.29 | 98.72 |
| 11 | No | 58.29 | 24.81 | 45.90 | 27.41 | 11.27 |
| 12 | No | 131.14 | 42.71 | 45.90 | 48.00 | 46.17 |
| 13 | Yes | 7.44 | 5.72 | 7.09 | 7.05 | 5.50 |
| 14 | Yes | 13.50 | 869.25 | 24.71 | 5.77 | 1.46 |
| 15 | Yes | 3.34 | 4.11 | 2.51 | 3.38 | 3.38 |
| Median | 43.33 | 39.41 | 36.98 | 27.41 | 16.42 | |
| STD | 63.00 | 240.26 | 55.58 | 58.99 | 26.38 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Avots, E.; Vecvanags, A.; Filipovs, J.; Brauns, A.; Skudrins, G.; Done, G.; Ozolins, J.; Anbarjafari, G.; Jakovels, D. Towards Automated Detection and Localization of Red Deer Cervus elaphus Using Passive Acoustic Sensors during the Rut. Remote Sens. 2022, 14, 2464. https://doi.org/10.3390/rs14102464
Avots E, Vecvanags A, Filipovs J, Brauns A, Skudrins G, Done G, Ozolins J, Anbarjafari G, Jakovels D. Towards Automated Detection and Localization of Red Deer Cervus elaphus Using Passive Acoustic Sensors during the Rut. Remote Sensing. 2022; 14(10):2464. https://doi.org/10.3390/rs14102464
Chicago/Turabian StyleAvots, Egils, Alekss Vecvanags, Jevgenijs Filipovs, Agris Brauns, Gundars Skudrins, Gundega Done, Janis Ozolins, Gholamreza Anbarjafari, and Dainis Jakovels. 2022. "Towards Automated Detection and Localization of Red Deer Cervus elaphus Using Passive Acoustic Sensors during the Rut" Remote Sensing 14, no. 10: 2464. https://doi.org/10.3390/rs14102464
APA StyleAvots, E., Vecvanags, A., Filipovs, J., Brauns, A., Skudrins, G., Done, G., Ozolins, J., Anbarjafari, G., & Jakovels, D. (2022). Towards Automated Detection and Localization of Red Deer Cervus elaphus Using Passive Acoustic Sensors during the Rut. Remote Sensing, 14(10), 2464. https://doi.org/10.3390/rs14102464