
Integrating Hybrid Pyramid Feature Fusion and Coordinate Attention for Effective Small Sample Hyperspectral Image Classification

 , , and
, , and
Abstract
:
1. Introduction
- A network that integrates hybrid pyramid feature fusion and coordinate attention is introduced for HSIC under small sample training conditions. This model can extract more robust spectral-spatial feature information during training small samples and has better classification performance than several other advanced models;
- A hybrid pyramid feature fusion is proposed, which can fuse the feature information of different levels and scales, effectively enhancing the spectral-spatial feature information and enhancing the performance of the small sample HSIC result;
- A coordinate attention mechanism is introduced for HSIC, which can not only weight spectral dimensions, but also capture position sensitive and direction-aware features in hyperspectral images, in order to enhance feature information extracted from small sample training.
2. The Proposed Method
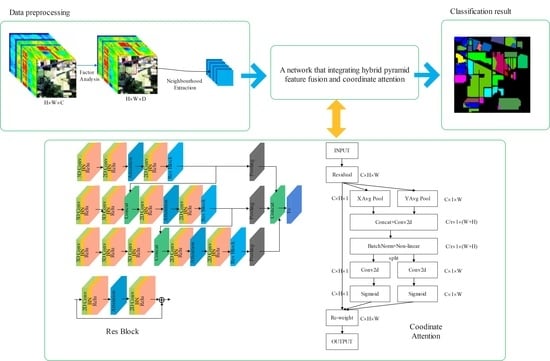
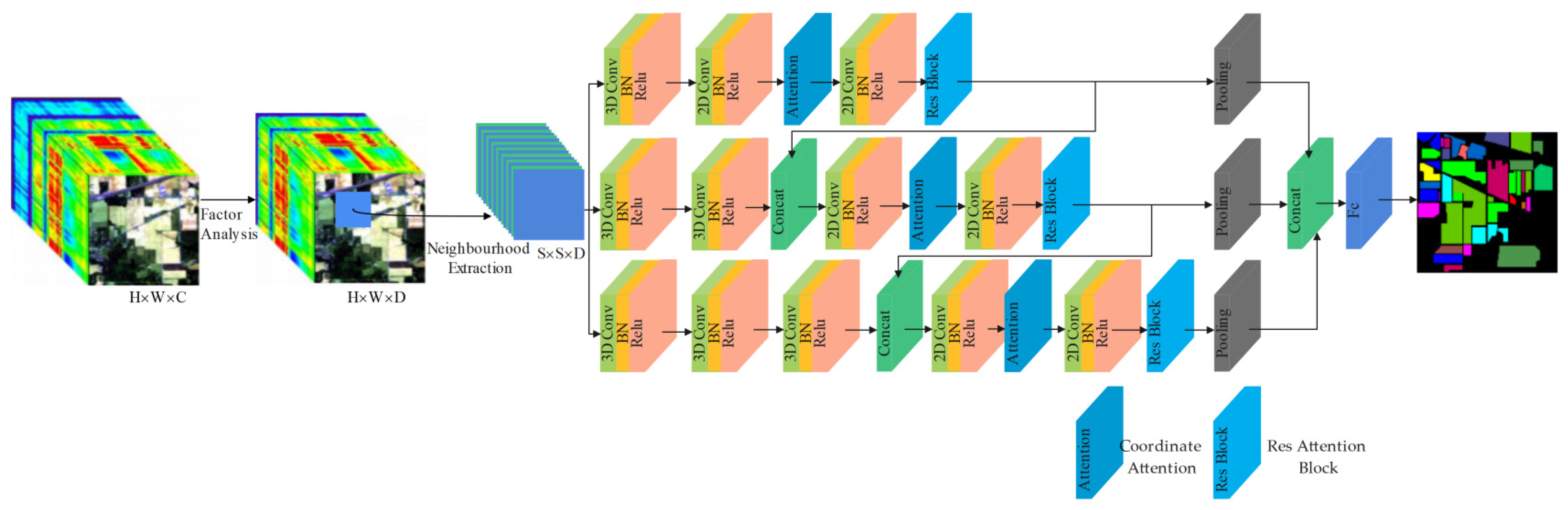
2.1. The Framework of Proposed Model
2.1.1. Data Preprocessing
2.1.2. Hybrid Pyramid Feature Fusion Network
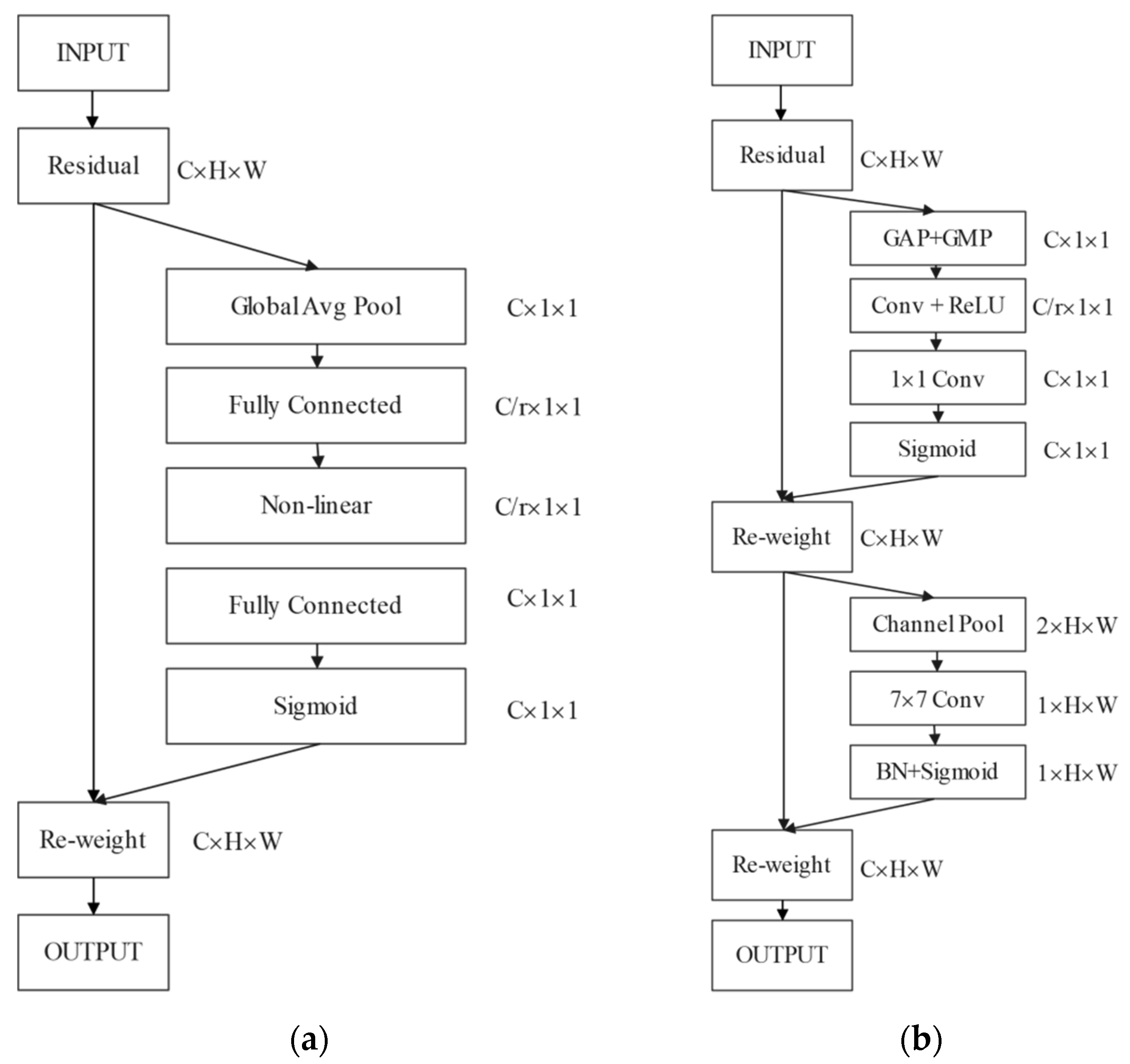
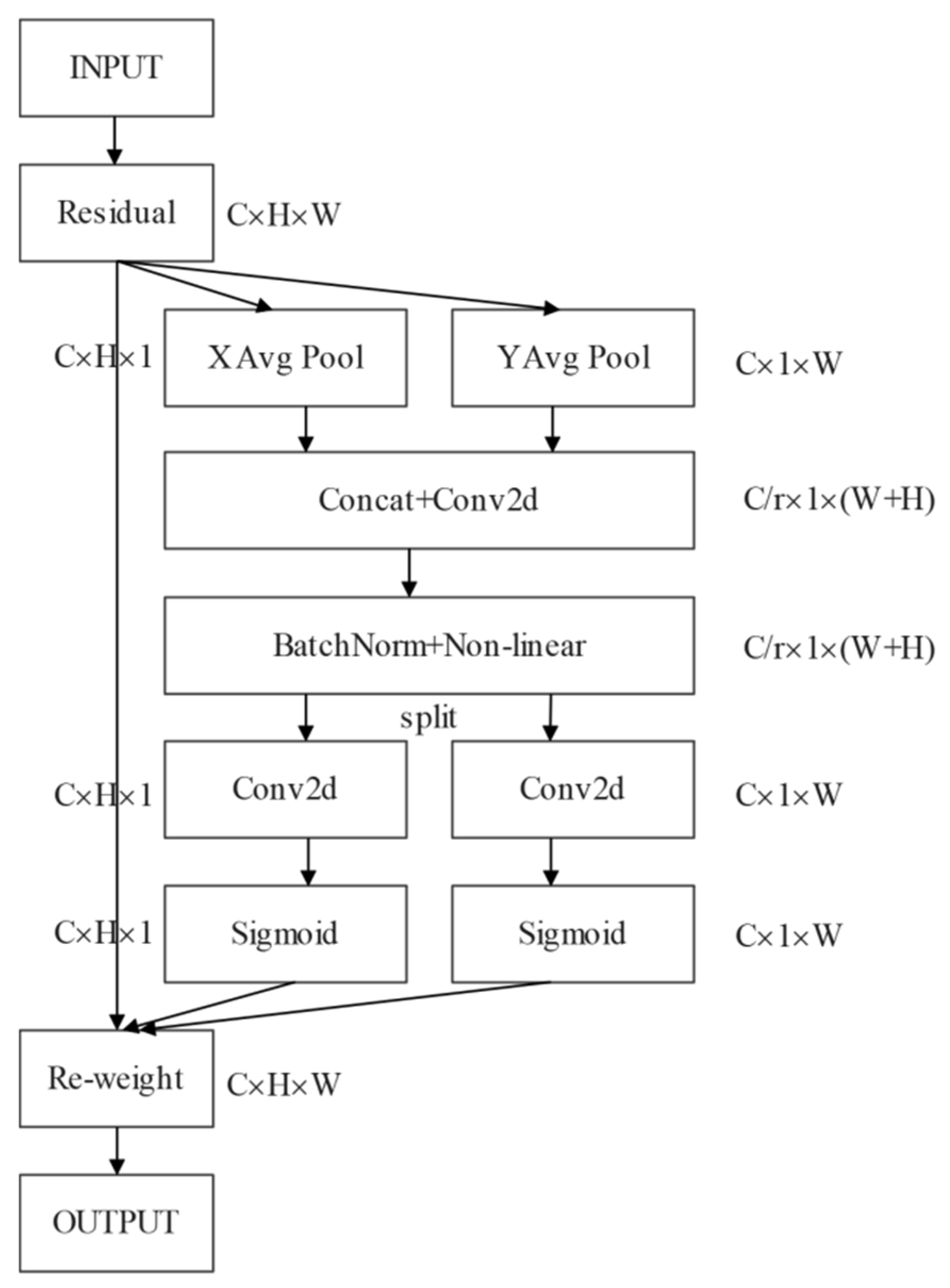
2.1.3. Coordinate Attention Mechanism
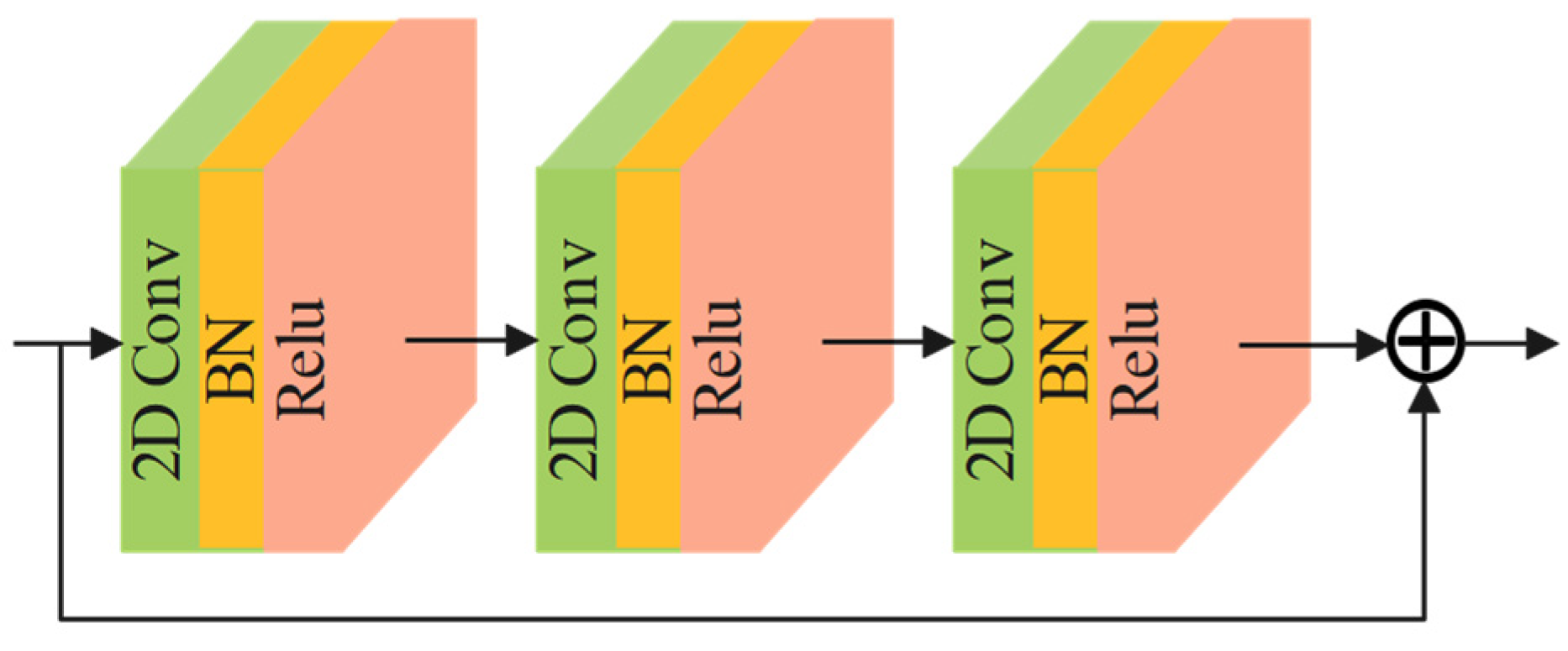
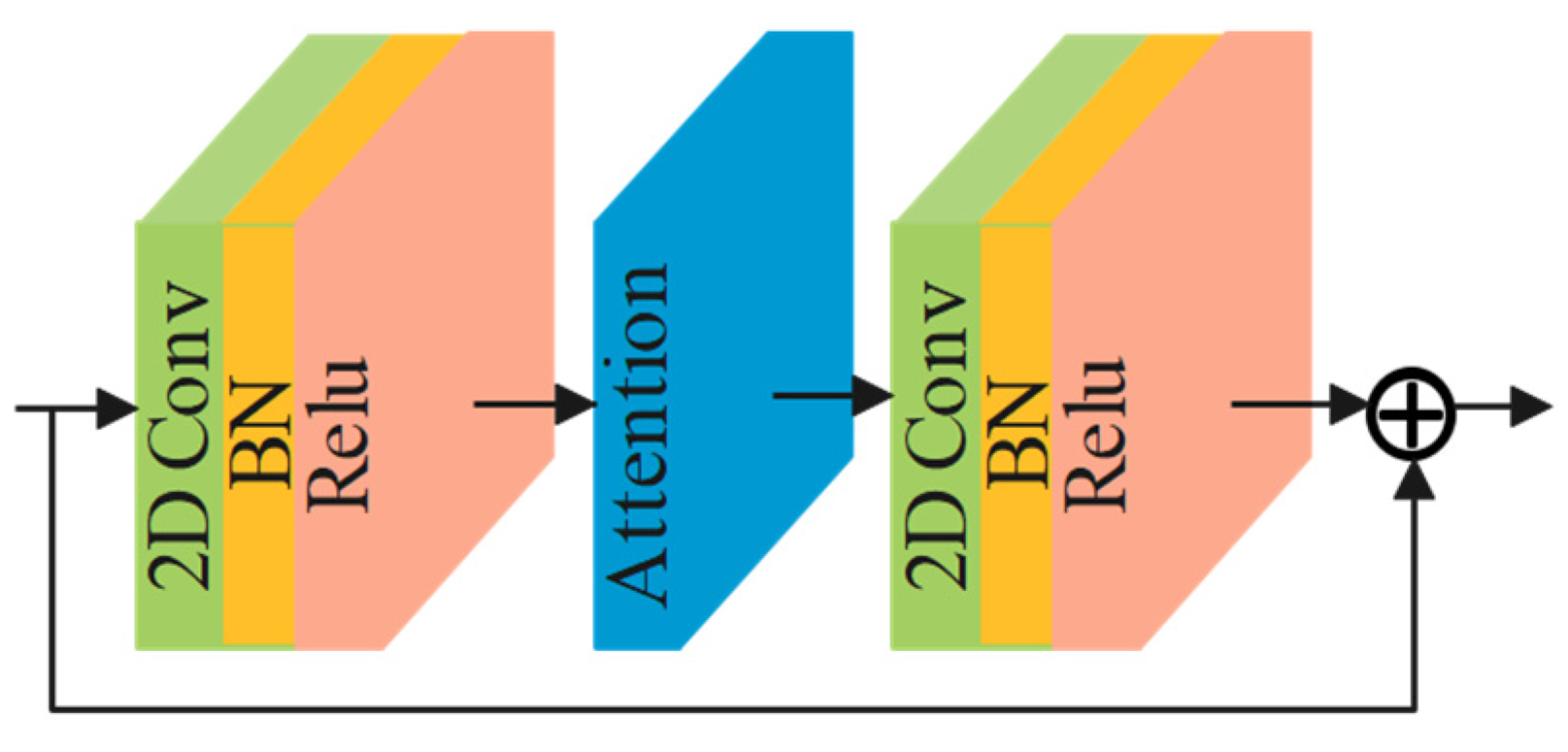
2.1.4. Residual Attention Block
2.2. Loss Function
3. Experiments and Analysis
3.1. Data Description
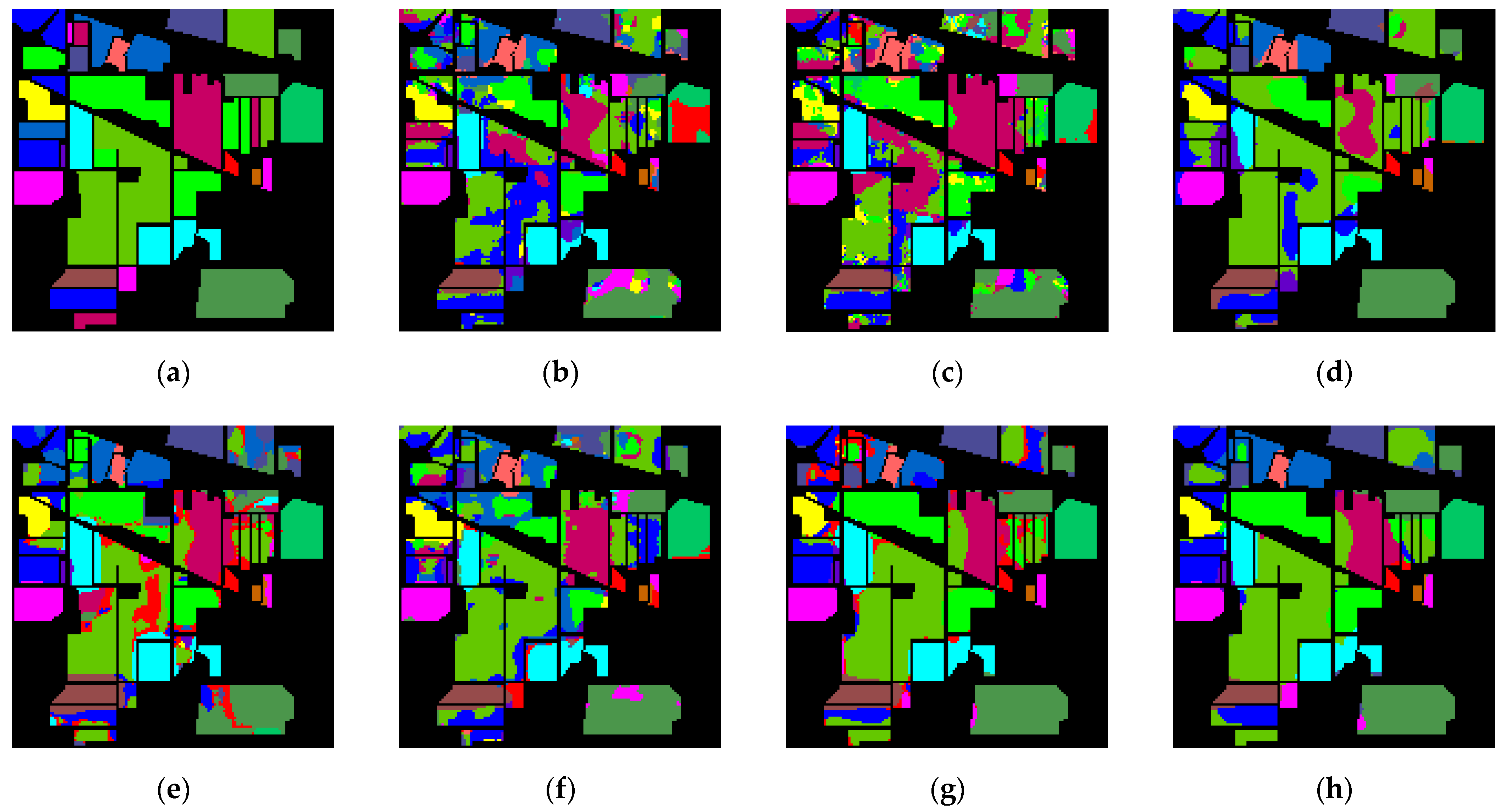
- The Indian Pines (IP) dataset contains a hyperspectral image. The spatial size is and the spectral dimension is 224. The pixels in this image have 16 categories, of which 10,249 pixels are labeled. This image deleted 24 spectral dimensions and only used another 200 spectral dimensions to classify. Figure 7a–c are the pseudo-color composite image, ground-truth image and corresponding color label of the IP dataset, respectively. The number of samples used for training and testing in the IP dataset is shown in Table 1.
- The University of Pavia (PU) dataset contains a hyperspectral image. The spatial size is and the spectral dimension is 115. The pixels in this image have 9 categories, of which 42,776 pixels are labeled. This image deleted 12 spectral dimensions and only used another 103 spectral dimensions to classify. Figure 8a–c shows the pseudo-color composite image, ground-truth image and corresponding color label of the PU dataset, respectively. The number of samples used for training and testing in the PU dataset is shown in Table 2.
- The Salinas (SA) dataset contains a hyperspectral image that has a spatial size of and a spectral dimension of 224. The pixels in this image have 16 categories, of which 54,129 pixels are labeled. This image deleted 20 spectral dimensions that and only used another 204 spectral dimensions to classify. Figure 9a–c are the pseudo-color composite image, ground-truth image and corresponding color label of the SA dataset, respectively. The number of samples used for training and testing in the SA dataset is shown in Table 3.
3.2. Experimental Configuration
3.3. Experimental Results
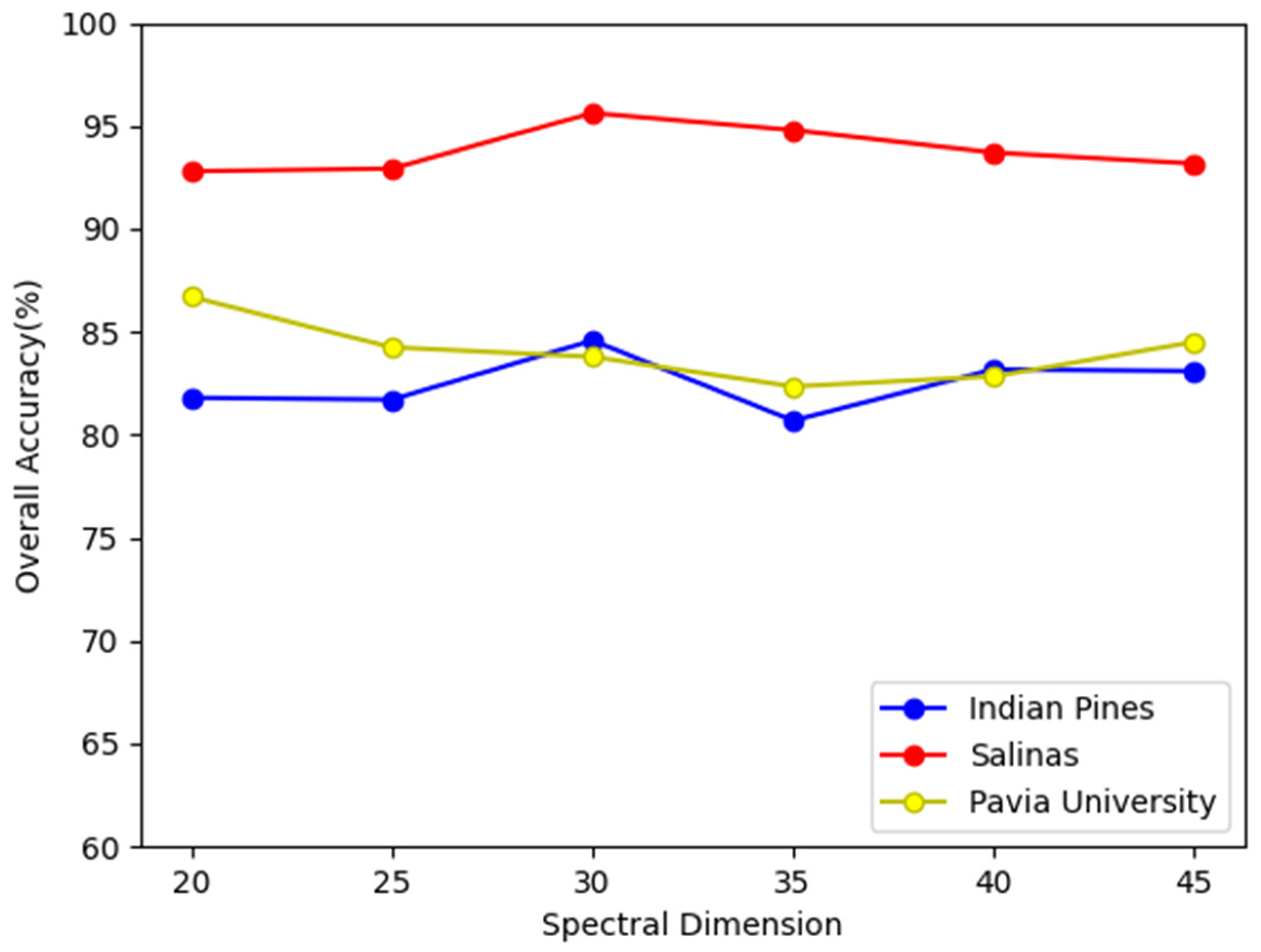
3.3.1. Analysis of Parameters
3.3.2. Ablation Studies
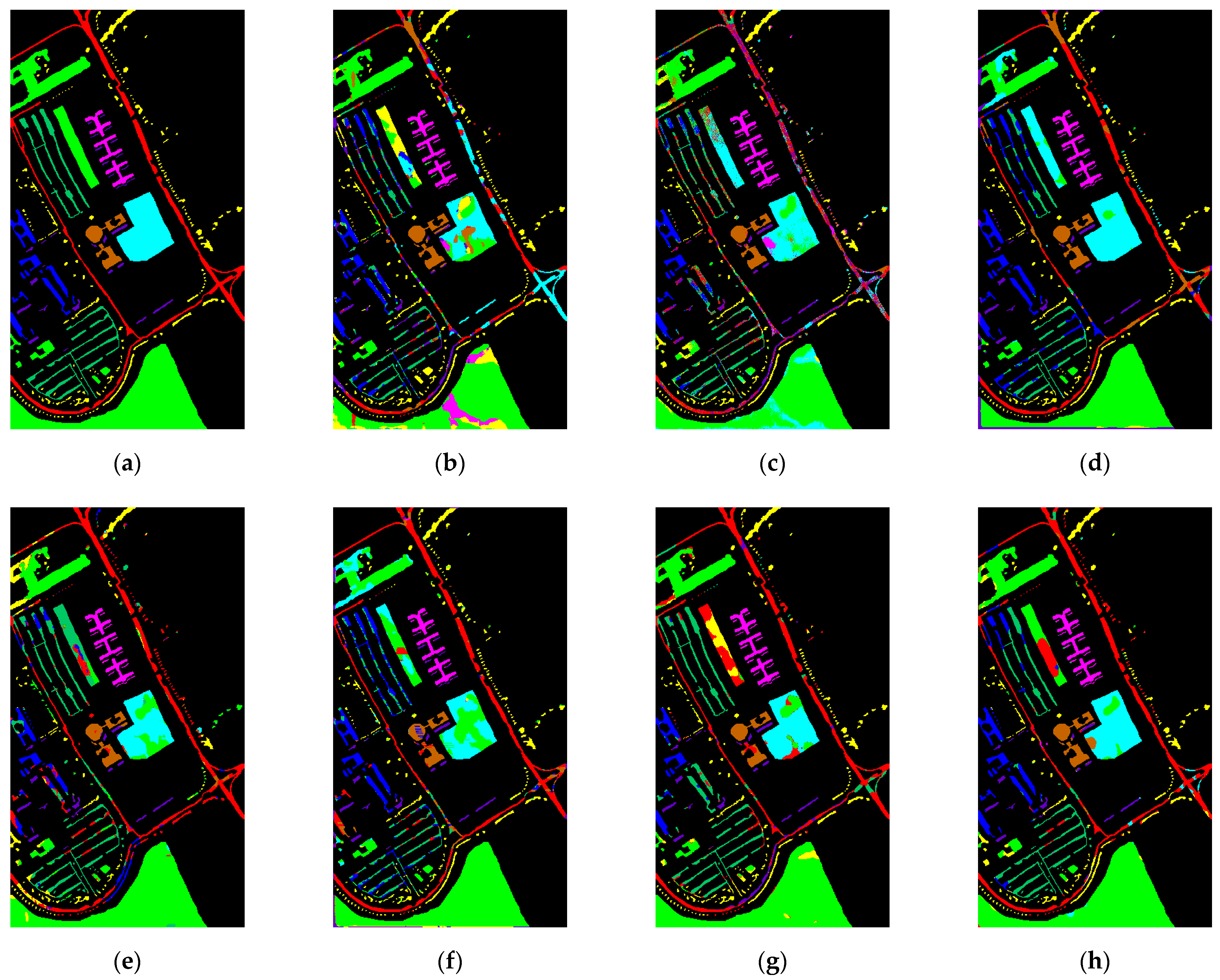
3.3.3. Comparison with Other Methods
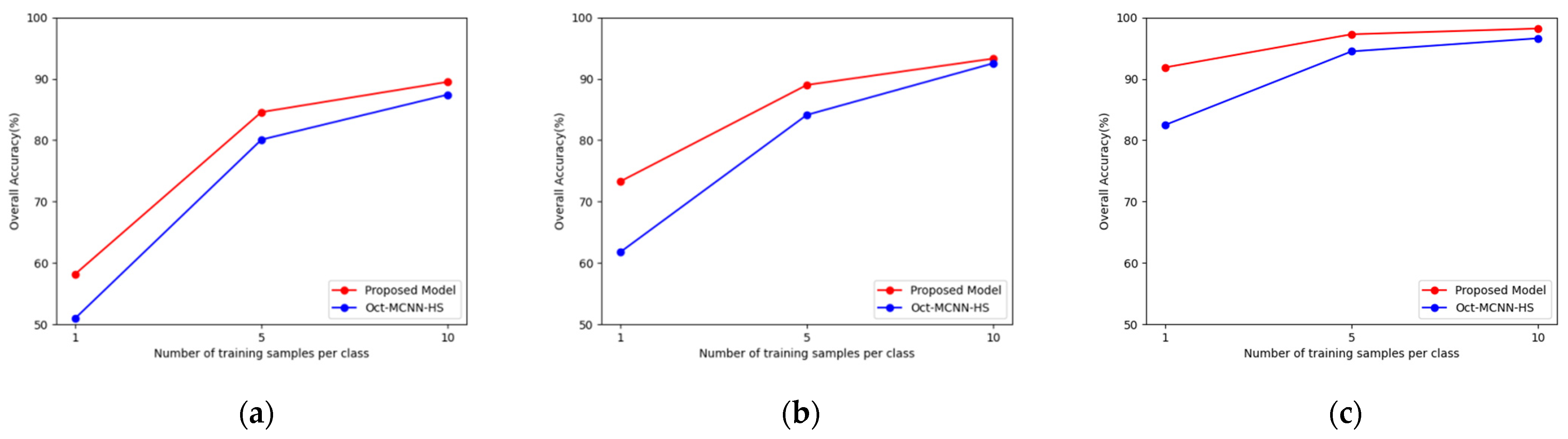
3.3.4. Performance Comparison of Different Training Samples
4. Discussion
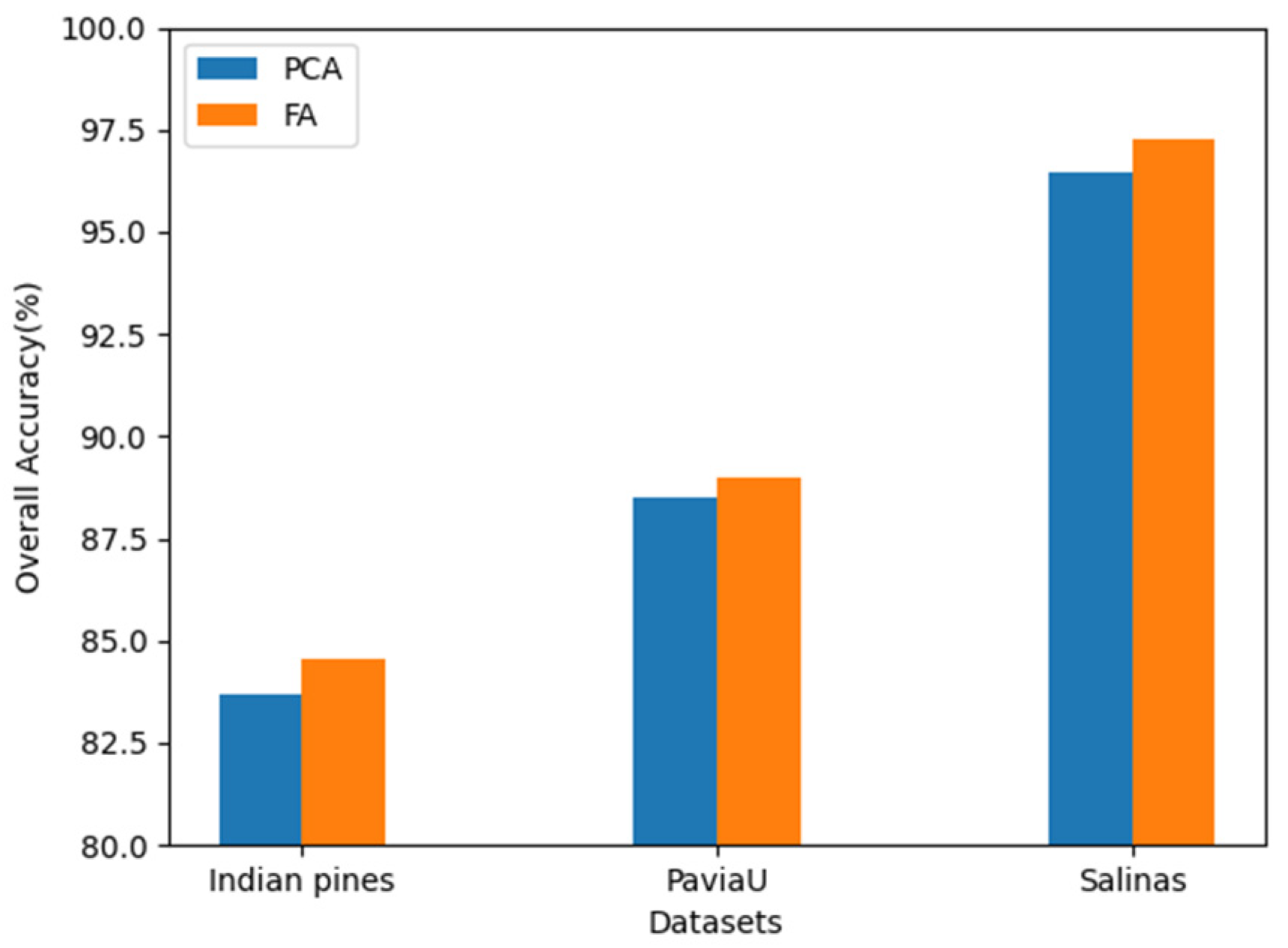
4.1. The Influence of Different Dimensionality Reduction Method
4.2. The Influence of the Hybrid Pyramid Feature Fusion Method
4.3. The Influence of the Different Attention Modules
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ahmad, M.; Shabbir, S.; Roy, S.K.; Hong, D.; Wu, X.; Yao, J.; Khan, A.M.; Mazzara, M.; Distefano, S.; Chanussot, J. Hyperspectral Image Classification—Traditional to Deep Models: A Survey for Future Prospects. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2022, 15, 968–999. [Google Scholar] [CrossRef]
- Dalponte, M.; Ørka, H.O.; Gobakken, T.; Gianelle, D.; Næsset, E. Tree species classification in boreal forests with hyperspectral data. IEEE Trans. Geosci. Remote Sens. 2012, 51, 2632–2645. [Google Scholar] [CrossRef]
- Camino, C.; González-Dugo, V.; Hernández, P.; Sillero, J.; Zarco-Tejada, P.J. Improved nitrogen retrievals with airborne-derived fluorescence and plant traits quantified from VNIR-SWIR hyperspectral imagery in the context of precision agriculture. Int. J. Appl. Earth Obs. Geoinf. 2018, 70, 105–117. [Google Scholar] [CrossRef]
- Murphy, R.J.; Whelan, B.; Chlingaryan, A.; Sukkarieh, S. Quantifying leaf-scale variations in water absorption in lettuce from hyperspectral imagery: A laboratory study with implications for measuring leaf water content in the context of precision agriculture. Precis. Agric. 2019, 20, 767–787. [Google Scholar] [CrossRef]
- Makki, I.; Younes, R.; Francis, C.; Bianchi, T.; Zucchetti, M. A survey of landmine detection using hyperspectral imaging. ISPRS J. Photogramm. Remote Sens. 2017, 124, 40–53. [Google Scholar] [CrossRef]
- Shimoni, M.; Haelterman, R.; Perneel, C. Hypersectral imaging for military and security applications: Combining myriad processing and sensing techniques. IEEE Geosci. Remote Sens. Mag. 2019, 7, 101–117. [Google Scholar] [CrossRef]
- Nigam, R.; Bhattacharya, B.K.; Kot, R.; Chattopadhyay, C. Wheat blast detection and assessment combining ground-based hyperspectral and satellite based multispectral data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 473–475. [Google Scholar] [CrossRef] [Green Version]
- Bajjouk, T.; Mouquet, P.; Ropert, M.; Quod, J.-P.; Hoarau, L.; Bigot, L.; Le Dantec, N.; Delacourt, C.; Populus, J. Detection of changes in shallow coral reefs status: Towards a spatial approach using hyperspectral and multispectral data. Ecol. Indic. 2019, 96, 174–191. [Google Scholar] [CrossRef]
- Chen, X.; Lee, H.; Lee, M. Feasibility of using hyperspectral remote sensing for environmental heavy metal monitoring. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 1–4. [Google Scholar] [CrossRef] [Green Version]
- Scafutto, R.D.P.M.; de Souza Filho, C.R.; de Oliveira, W.J. Hyperspectral remote sensing detection of petroleum hydrocarbons in mixtures with mineral substrates: Implications for onshore exploration and monitoring. ISPRS J. Photogramm. Remote Sens. 2017, 128, 146–157. [Google Scholar] [CrossRef]
- Camps-Valls, G.; Tuia, D.; Bruzzone, L.; Benediktsson, J.A. Advances in hyperspectral image classification: Earth monitoring with statistical learning methods. IEEE Signal Processing Mag. 2013, 31, 45–54. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. On combining multiple features for hyperspectral remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2011, 50, 879–893. [Google Scholar] [CrossRef]
- Bazi, Y.; Melgani, F. Gaussian process approach to remote sensing image classification. IEEE Trans. Geosci. Remote Sens. 2009, 48, 186–197. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X. Riemannian manifold learning based k-nearest-neighbor for hyperspectral image classification. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium-IGARSS, Melbourne, Australia, 21–26 July 2013; pp. 1975–1978. [Google Scholar]
- Cheng, G.; Li, Z.; Han, J.; Yao, X.; Guo, L. Exploring hierarchical convolutional features for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6712–6722. [Google Scholar] [CrossRef]
- Li, J.; Marpu, P.R.; Plaza, A.; Bioucas-Dias, J.M.; Benediktsson, J.A. Generalized composite kernel framework for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4816–4829. [Google Scholar] [CrossRef]
- Wu, Z.; Shi, L.; Li, J.; Wang, Q.; Sun, L.; Wei, Z.; Plaza, J.; Plaza, A. GPU parallel implementation of spatially adaptive hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 11, 1131–1143. [Google Scholar] [CrossRef]
- Chen, Y.; Nasrabadi, N.M.; Tran, T.D. Hyperspectral image classification using dictionary-based sparse representation. IEEE Trans. Geosci. Remote Sens. 2011, 49, 3973–3985. [Google Scholar] [CrossRef]
- Ghamisi, P.; Maggiori, E.; Li, S.; Souza, R.; Tarablaka, Y.; Moser, G.; De Giorgi, A.; Fang, L.; Chen, Y.; Chi, M. New frontiers in spectral-spatial hyperspectral image classification: The latest advances based on mathematical morphology, Markov random fields, segmentation, sparse representation, and deep learning. IEEE Geosci. Remote Sens. Mag. 2018, 6, 10–43. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Liu, C.; Li, S. Recent advances on spectral–spatial hyperspectral image classification: An overview and new guidelines. IEEE Trans. Geosci. Remote Sens. 2017, 56, 1579–1597. [Google Scholar] [CrossRef]
- Zhou, Y.; Peng, J.; Chen, C.P. Extreme learning machine with composite kernels for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 8, 2351–2360. [Google Scholar] [CrossRef]
- Han, Y.; Shi, X.; Yang, S.; Zhang, Y.; Hong, Z.; Zhou, R. Hyperspectral Sea Ice Image Classification Based on the Spectral-Spatial-Joint Feature with the PCA Network. Remote Sens. 2021, 13, 2253. [Google Scholar] [CrossRef]
- Wang, J.; Chang, C.-I. Independent component analysis-based dimensionality reduction with applications in hyperspectral image analysis. IEEE Trans. Geosci. Remote Sens. 2006, 44, 1586–1600. [Google Scholar] [CrossRef]
- Chakraborty, T.; Trehan, U. SpectralNET: Exploring Spatial-Spectral WaveletCNN for Hyperspectral Image Classification. arXiv 2021, arXiv:2104.00341. [Google Scholar]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Deep learning for classification of hyperspectral data: A comparative review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef] [Green Version]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature extraction for hyperspectral imagery: The evolution from shallow to deep: Overview and toolbox. IEEE Geosci. Remote Sens. Mag. 2020, 8, 60–88. [Google Scholar] [CrossRef]
- Hang, R.; Liu, Q.; Hong, D.; Ghamisi, P. Cascaded recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5384–5394. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Li, T.; Zhang, J.; Zhang, Y. Classification of hyperspectral image based on deep belief networks. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 5132–5136. [Google Scholar]
- Makantasis, K.; Karantzalos, K.; Doulamis, A.; Doulamis, N. Deep supervised learning for hyperspectral data classification through convolutional neural networks. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 4959–4962. [Google Scholar]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D–2-D CNN feature hierarchy for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 277–281. [Google Scholar] [CrossRef] [Green Version]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Gao, H.; Chen, Z.; Li, C. Sandwich convolutional neural network for hyperspectral image classification using spectral feature enhancement. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 3006–3015. [Google Scholar] [CrossRef]
- Hang, R.; Zhou, F.; Liu, Q.; Ghamisi, P. Classification of hyperspectral images via multitask generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2020, 59, 1424–1436. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. Adv. Neural Inf. Processing Syst. 2014, 27. [Google Scholar]
- Hang, R.; Li, Z.; Liu, Q.; Ghamisi, P.; Bhattacharyya, S.S. Hyperspectral image classification with attention-aided CNNs. IEEE Trans. Geosci. Remote Sens. 2020, 59, 2281–2293. [Google Scholar] [CrossRef]
- Mei, X.; Pan, E.; Ma, Y.; Dai, X.; Huang, J.; Fan, F.; Du, Q.; Zheng, H.; Ma, J. Spectral-spatial attention networks for hyperspectral image classification. Remote Sens. 2019, 11, 963. [Google Scholar] [CrossRef] [Green Version]
- Zhu, M.; Jiao, L.; Liu, F.; Yang, S.; Wang, J. Residual spectral–spatial attention network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 449–462. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Learning to pay attention on spectral domain: A spectral attention module-based convolutional network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 110–122. [Google Scholar] [CrossRef]
- Roy, S.K.; Manna, S.; Song, T.; Bruzzone, L. Attention-based adaptive spectral–spatial kernel ResNet for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 59, 7831–7843. [Google Scholar] [CrossRef]
- Wu, H.; Li, D.; Wang, Y.; Li, X.; Kong, F.; Wang, Q. Hyperspectral Image Classification Based on Two-Branch Spectral–Spatial-Feature Attention Network. Remote Sens. 2021, 13, 4262. [Google Scholar] [CrossRef]
- Laban, N.; Abdellatif, B.; Ebeid, H.M.; Shedeed, H.A.; Tolba, M.F. Reduced 3-d deep learning framework for hyperspectral image classification. In Proceedings of the International Conference on Advanced Machine Learning Technologies and Applications, Cairo, Egypt, 28–30 March 2019; pp. 13–22. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, attend and tell: Neural image caption generation with visual attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. Gcnet: Non-local networks meet squeeze-excitation networks and beyond. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Liu, J.-J.; Hou, Q.; Cheng, M.-M.; Wang, C.; Feng, J. Improving convolutional networks with self-calibrated convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10096–10105. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Hou, Q.; Zhang, L.; Cheng, M.-M.; Feng, J. Strip pooling: Rethinking spatial pooling for scene parsing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4003–4012. [Google Scholar]
- Zhong, X.; Gong, O.; Huang, W.; Li, L.; Xia, H. Squeeze-and-excitation wide residual networks in image classification. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 395–399. [Google Scholar]
- Wang, H.; Zhu, Y.; Green, B.; Adam, H.; Yuille, A.; Chen, L.-C. Axial-deeplab: Stand-alone axial-attention for panoptic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 108–126. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Zheng, J.; Feng, Y.; Bai, C.; Zhang, J. Hyperspectral image classification using mixed convolutions and covariance pooling. IEEE Trans. Geosci. Remote Sens. 2020, 59, 522–534. [Google Scholar] [CrossRef]
- Feng, Y.; Zheng, J.; Qin, M.; Bai, C.; Zhang, J. 3D Octave and 2D Vanilla Mixed Convolutional Neural Network for Hyperspectral Image Classification with Limited Samples. Remote Sens. 2021, 13, 4407. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Class | Name | Train Samples | Test Samples | Total Samples |
|---|---|---|---|---|
| 1 | Alfalfa | 5 | 41 | 46 |
| 2 | Corn-no till | 5 | 1423 | 1428 |
| 3 | Corn-min till | 5 | 825 | 830 |
| 4 | Corn | 5 | 232 | 237 |
| 5 | Grass-pasture | 5 | 478 | 483 |
| 6 | Grasstrees | 5 | 725 | 730 |
| 7 | Grass-pasture-mowed | 5 | 23 | 28 |
| 8 | Background | 5 | 473 | 478 |
| 9 | Oats | 5 | 15 | 20 |
| 10 | Soybean-no till | 5 | 967 | 972 |
| 11 | Soybean-min till | 5 | 2450 | 2455 |
| 12 | Soybean-clean | 5 | 588 | 593 |
| 13 | Wheat | 5 | 200 | 205 |
| 14 | Woods | 5 | 1260 | 1265 |
| 15 | Buildings-grass-trees-drives | 5 | 381 | 386 |
| 16 | Stone-steel-towers | 5 | 88 | 93 |
| Total | 80 | 10,169 | 10,249 |
| Class | Name | Train Samples | Test Samples | Total Samples |
|---|---|---|---|---|
| 1 | Asphalt | 5 | 6626 | 6631 |
| 2 | Meadows | 5 | 18,644 | 18,649 |
| 3 | Gravel | 5 | 2094 | 2099 |
| 4 | Trees | 5 | 3059 | 3064 |
| 5 | Painted metal sheets | 5 | 1340 | 1345 |
| 6 | Bare soil | 5 | 5024 | 5029 |
| 7 | Bitumen | 5 | 1325 | 1330 |
| 8 | Self-blocking bricks | 5 | 3677 | 3682 |
| 9 | Shadows | 5 | 942 | 947 |
| Total | 45 | 42,731 | 42,776 |
| Class | Name | Train Samples | Test Samples | Total Samples |
|---|---|---|---|---|
| 1 | Brocoli_green_weeds_1 | 5 | 2004 | 2009 |
| 2 | Brocoli_green_weeds_2 | 5 | 3721 | 3726 |
| 3 | Fallow | 5 | 1971 | 1976 |
| 4 | Fallow rough plow | 5 | 1389 | 1394 |
| 5 | Fallow smooth | 5 | 2673 | 2678 |
| 6 | Stubble | 5 | 3954 | 3959 |
| 7 | Celery | 5 | 3574 | 3579 |
| 8 | Grapes untrained | 5 | 11,266 | 11,271 |
| 9 | Soil vineyard develop | 5 | 6198 | 6203 |
| 10 | Corn senesced green weeds | 5 | 3273 | 3278 |
| 11 | Lettuce_romaine_4wk | 5 | 1063 | 1068 |
| 12 | Lettuce_romaine_5wk | 5 | 1922 | 1927 |
| 13 | Lettuce_romaine_6wk | 5 | 911 | 916 |
| 14 | Lettuce_romaine_7wk | 5 | 1065 | 1070 |
| 15 | Vineyard untrained | 5 | 7263 | 7268 |
| 16 | Vineyard vertical trellis | 5 | 1802 | 1807 |
| Total | 80 | 54,049 | 54,129 |
| Proposed Network Configuration | ||
|---|---|---|
| Part 1 | Part 2 | Part 3 |
| Input:(15 × 15 × 30 × 1) | ||
| 3DConv-(3,3,3,8), stride = 1, padding = 0 | 3DConv-(3,3,3,8), stride = 1, padding = 0 3DConv-(3,3,3,16), stride = 1, padding = 0 | 3DConv-(3,3,3,8), stride = 1, padding = 0 3DConv-(3,3,3,16), stride = 1, padding = 0 3DConv-(3,3,3,32), stride = 1, padding = 0 |
| Output10:(13 × 13 × 28 × 8) | Output20:(11 × 11 × 26 × 16) | Output30:(9 × 9 × 24 × 32) |
| Reshape | ||
| Output11:(13 × 13 × 224) | Output21:(11 × 11 × 416) | Output31:(9 × 9 × 768) |
| Concat(Output15,Output21) | Concat(Output25,Output31) | |
| 2DConv-(1,1,128), stride = 1, padding = 0 | 2DConv-(1,1,128), stride = 1, padding = 0 | 2DConv-(1,1,128), stride = 1, padding = 0 |
| Output12:(13 × 13 × 128) | Output22:(11 × 11 × 128) | Output32:(9 × 9 × 128) |
| Coordinate Attention | Coordinate Attention | Coordinate Attention |
| Output13:(13 × 13 × 128) | Output23:(11 × 11 × 128) | Output33:(9 × 9 × 128) |
| 2DConv-(3,3,64), stride = 1, padding = 0 | 2DConv-(3,3,64), stride = 1, padding = 0 | 2DConv-(3,3,64), stride = 1, padding = 0 |
| Output14:(11 × 11 × 64) | Output24:(9 × 9 × 64) | Output34:(7 × 7 × 64) |
| ResAttentionBlock | ResAttentionBlock | ResAttentionBlock |
| Output15:(11 × 11 × 64) | Output25:(9 × 9 × 64) | Output35:(7 × 7 × 64) |
| Global Average Pooling | ||
| Output16:(1 × 1 × 64) | Output26:(1 × 1 × 64) | Output36:(1 × 1 × 64) |
| Concat(Output16,Output26,Output36) | ||
| Flatten | ||
| FC-(192,16) | ||
| Output:(16) | ||
| Dataset | Spatial Size | Spectral Dimension |
|---|---|---|
| IP | 30 | |
| PU | 20 | |
| SA | 30 |
| Methods | IP | PU | SA | |||
|---|---|---|---|---|---|---|
| OA (%) | AA (%) | OA (%) | AA (%) | OA (%) | AA (%) | |
| Baseline | 79.59 | 86.62 | 86.33 | 84.65 | 95.52 | 97.65 |
| Baseline + hybrid pyramid feature fusion | 82.48 | 88.04 | 87.51 | 86.27 | 95.72 | 97.73 |
| Baseline + coordinate attention | 82.76 | 87.44 | 88.15 | 85.85 | 95.91 | 97.68 |
| proposed | 84.58 | 89.68 | 89.00 | 87.37 | 97.26 | 97.80 |
| Class | 3D-CNN | HybridSN | SSRN | MCNN-CP | A2S2K-ResNet | Oct-MCNN-HS | Proposed |
|---|---|---|---|---|---|---|---|
| 1 | 95.12 | 100.00 | 97.56 | 100.00 | 100.00 | 97.56 | 100.00 |
| 2 | 46.38 | 54.60 | 35.98 | 51.09 | 35.49 | 70.41 | 68.10 |
| 3 | 44.48 | 56.97 | 64.24 | 69.09 | 47.03 | 77.58 | 86.30 |
| 4 | 78.02 | 64.66 | 82.76 | 75.00 | 90.95 | 74.14 | 85.34 |
| 5 | 67.99 | 68.20 | 62.97 | 73.43 | 69.25 | 84.10 | 91.63 |
| 6 | 82.21 | 93.24 | 81.93 | 85.93 | 80.28 | 97.52 | 95.93 |
| 7 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 8 | 44.19 | 87.95 | 97.89 | 99.79 | 95.35 | 100.00 | 100.00 |
| 9 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 | 100.00 |
| 10 | 43.33 | 74.97 | 37.54 | 55.02 | 59.46 | 52.74 | 57.70 |
| 11 | 43.88 | 39.22 | 83.63 | 62.53 | 75.88 | 79.63 | 88.82 |
| 12 | 45.07 | 21.09 | 58.16 | 62.07 | 51.02 | 56.46 | 74.49 |
| 13 | 94.50 | 98.50 | 98.00 | 100.00 | 98.50 | 100.00 | 100.00 |
| 14 | 61.75 | 68.73 | 92.14 | 75.56 | 90.71 | 96.90 | 96.98 |
| 15 | 87.14 | 23.10 | 97.38 | 76.64 | 58.79 | 98.69 | 98.43 |
| 16 | 100.00 | 100.00 | 100.00 | 76.14 | 100.00 | 90.91 | 93.18 |
| OA (%) | 54.69 | 58.64 | 71.20 | 68.21 | 68.18 | 80.09 | 84.58 |
| AA (%) | 70.88 | 71.95 | 80.64 | 78.89 | 78.29 | 86.04 | 89.68 |
| Kappa × 100 | 49.47 | 53.68 | 86.71 | 64.02 | 63.86 | 77.32 | 82.36 |
| Class | 3D-CNN | HybridSN | SSRN | MCNN-CP | A2S2K-ResNet | Oct-MCNN-HS | Proposed |
|---|---|---|---|---|---|---|---|
| 1 | 36.69 | 43.40 | 65.88 | 81.54 | 83.25 | 80.44 | 88.03 |
| 2 | 74.51 | 76.15 | 80.19 | 85.36 | 87.12 | 86.20 | 92.58 |
| 3 | 82.71 | 74.07 | 94.22 | 60.17 | 75.21 | 60.08 | 96.51 |
| 4 | 91.27 | 74.47 | 86.99 | 38.57 | 88.62 | 89.47 | 74.83 |
| 5 | 99.93 | 100.00 | 100.00 | 100.00 | 99.93 | 100.00 | 100.00 |
| 6 | 52.81 | 75.80 | 96.14 | 71.10 | 56.33 | 79.60 | 86.58 |
| 7 | 100.00 | 97.58 | 100.00 | 95.92 | 88.68 | 88.45 | 100.00 |
| 8 | 54.12 | 58.69 | 60.62 | 77.92 | 50.97 | 90.37 | 81.15 |
| 9 | 38.43 | 58.70 | 79.19 | 69.00 | 88.96 | 75.69 | 66.67 |
| OA (%) | 66.73 | 70.33 | 80.51 | 78.29 | 79.80 | 84.12 | 89.00 |
| AA (%) | 70.05 | 73.21 | 84.80 | 75.51 | 79.90 | 83.37 | 87.37 |
| Kappa × 100 | 58.07 | 62.32 | 75.38 | 71.48 | 73.36 | 79.37 | 85.56 |
| Class | 3D-CNN | HybridSN | SSRN | MCNN-CP | A2S2K-ResNet | Oct-MCNN-HS | Proposed |
|---|---|---|---|---|---|---|---|
| 1 | 100.00 | 99.80 | 98.50 | 99.15 | 99.80 | 98.60 | 97.75 |
| 2 | 99.87 | 98.82 | 99.73 | 100.00 | 96.69 | 100.00 | 100.00 |
| 3 | 96.09 | 91.83 | 24.71 | 98.22 | 75.14 | 100.00 | 99.95 |
| 4 | 78.62 | 94.74 | 98.85 | 89.20 | 99.86 | 96.33 | 100.00 |
| 5 | 97.19 | 95.96 | 96.07 | 85.82 | 88.89 | 98.73 | 94.50 |
| 6 | 98.43 | 99.72 | 94.66 | 98.99 | 95.17 | 100.00 | 99.67 |
| 7 | 100.00 | 99.16 | 99.94 | 94.80 | 99.94 | 100.00 | 99.55 |
| 8 | 95.97 | 78.80 | 82.53 | 73.64 | 60.18 | 83.66 | 93.91 |
| 9 | 97.76 | 99.82 | 99.79 | 98.52 | 99.84 | 100.00 | 99.98 |
| 10 | 75.65 | 73.60 | 59.98 | 86.95 | 77.51 | 91.90 | 92.33 |
| 11 | 100.00 | 100.00 | 99.81 | 100.00 | 97.37 | 100.00 | 100.00 |
| 12 | 97.97 | 99.38 | 90.69 | 87.67 | 99.32 | 90.11 | 93.13 |
| 13 | 99.78 | 99.01 | 100.00 | 93.96 | 98.13 | 98.90 | 100.00 |
| 14 | 94.84 | 99.62 | 87.04 | 99.72 | 99.62 | 97.28 | 97.56 |
| 15 | 63.13 | 99.37 | 45.93 | 71.25 | 94.78 | 92.70 | 98.18 |
| 16 | 77.91 | 97.00 | 94.78 | 98.17 | 95.17 | 99.33 | 98.34 |
| OA (%) | 90.60 | 92.53 | 82.44 | 87.58 | 87.29 | 94.47 | 97.26 |
| AA (%) | 92.08 | 95.23 | 85.81 | 92.25 | 92.34 | 96.72 | 97.80 |
| Kappa × 100 | 89.51 | 91.73 | 80.44 | 86.25 | 85.92 | 93.86 | 96.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ding, C.; Chen, Y.; Li, R.; Wen, D.; Xie, X.; Zhang, L.; Wei, W.; Zhang, Y. Integrating Hybrid Pyramid Feature Fusion and Coordinate Attention for Effective Small Sample Hyperspectral Image Classification. Remote Sens. 2022, 14, 2355. https://doi.org/10.3390/rs14102355
Ding C, Chen Y, Li R, Wen D, Xie X, Zhang L, Wei W, Zhang Y. Integrating Hybrid Pyramid Feature Fusion and Coordinate Attention for Effective Small Sample Hyperspectral Image Classification. Remote Sensing. 2022; 14(10):2355. https://doi.org/10.3390/rs14102355
Chicago/Turabian StyleDing, Chen, Youfa Chen, Runze Li, Dushi Wen, Xiaoyan Xie, Lei Zhang, Wei Wei, and Yanning Zhang. 2022. "Integrating Hybrid Pyramid Feature Fusion and Coordinate Attention for Effective Small Sample Hyperspectral Image Classification" Remote Sensing 14, no. 10: 2355. https://doi.org/10.3390/rs14102355
APA StyleDing, C., Chen, Y., Li, R., Wen, D., Xie, X., Zhang, L., Wei, W., & Zhang, Y. (2022). Integrating Hybrid Pyramid Feature Fusion and Coordinate Attention for Effective Small Sample Hyperspectral Image Classification. Remote Sensing, 14(10), 2355. https://doi.org/10.3390/rs14102355