
A Comprehensive Clear-Sky Database for the Development of Land Surface Temperature Algorithms



Abstract
:1. Introduction
2. Materials and Methods
2.1. Model Data
- Atmospheric profiles, including temperature, specific humidity, and ozone on model levels (137 levels from the surface up to a height of 80 km).
- Surface variables, including 2-m temperature (T2 m), surface pressure (SP), skin temperature (Tskin), land-sea mask, geopotential, and the logarithm of surface pressure (the last two are used to obtain the height and pressure of each model level).
- Vertically integrated or column variables, namely total column water vapor (TCWV) and total cloud cover (TCC).
2.2. Satellite Data
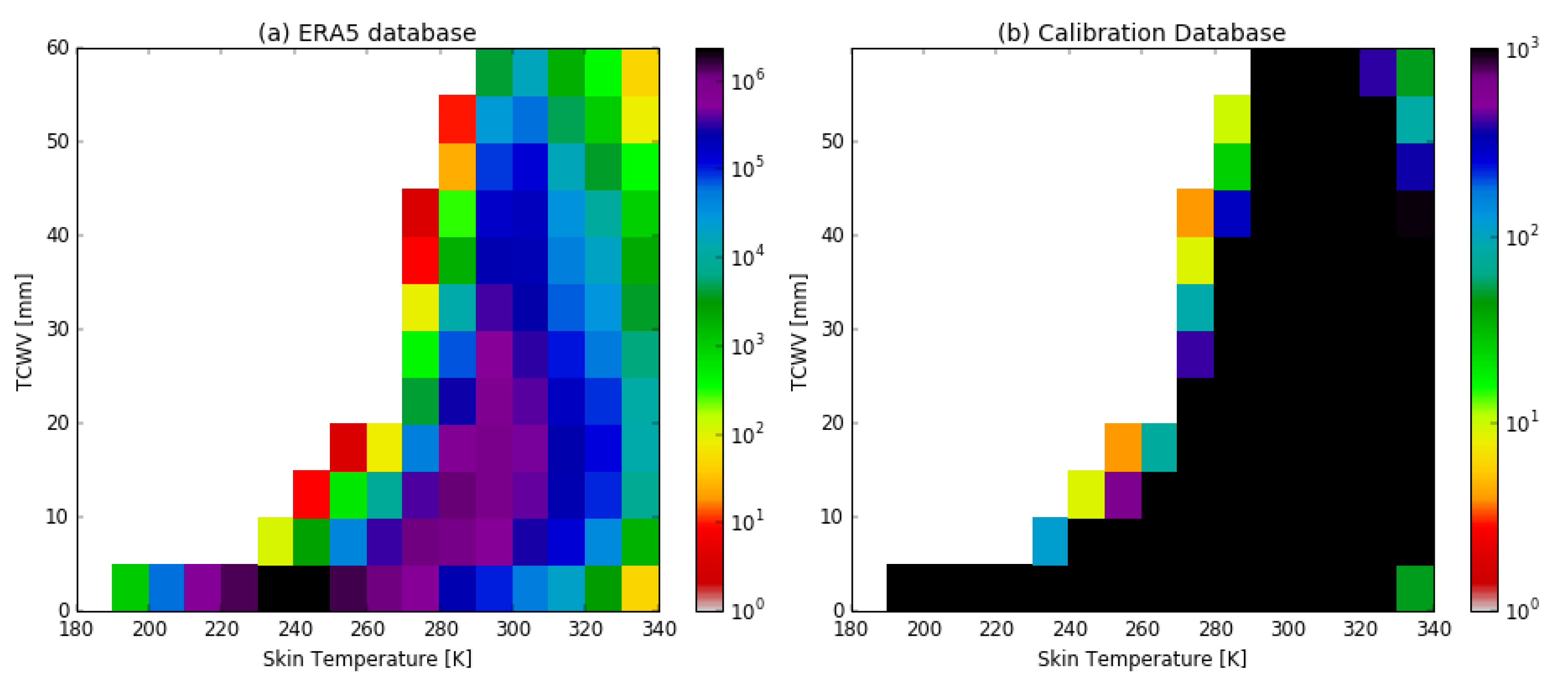
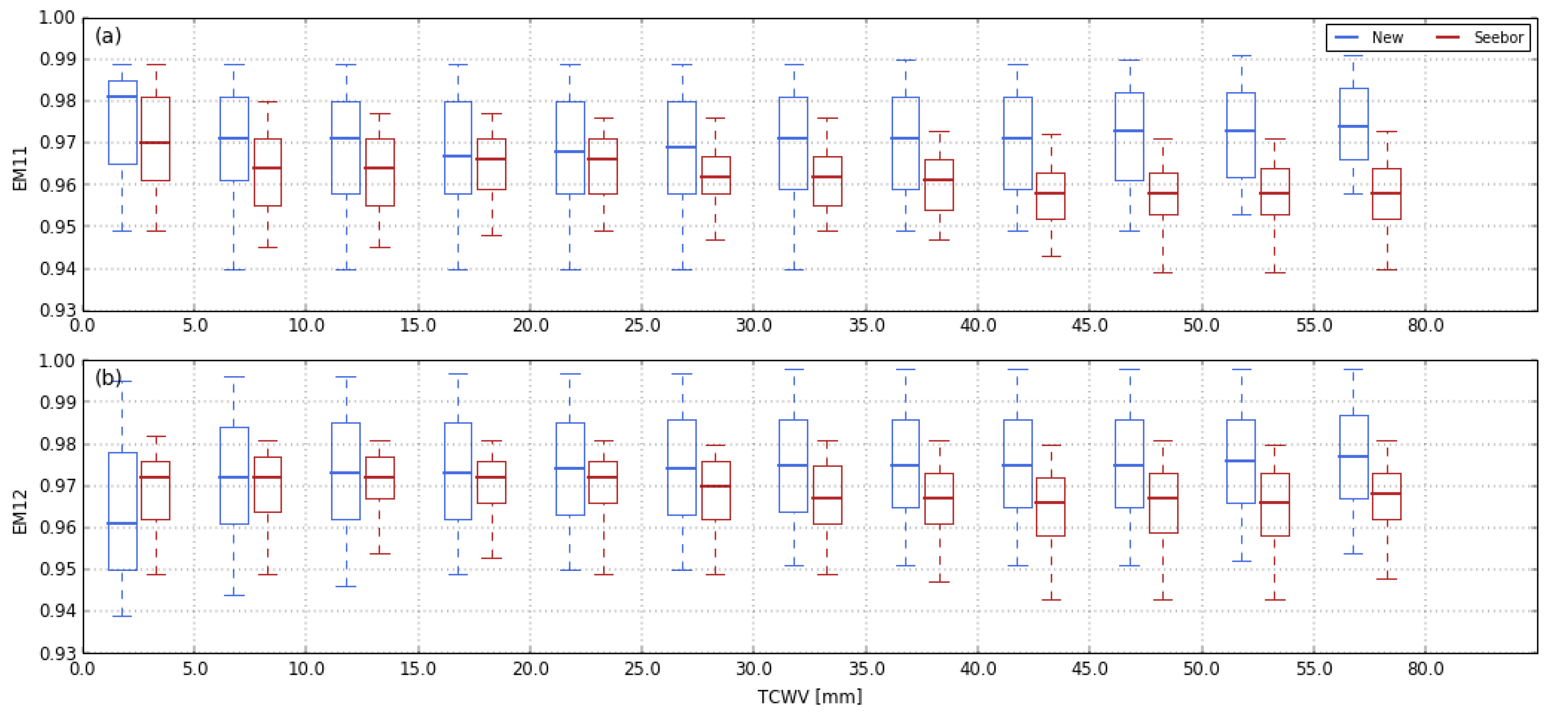
2.3. Profile Selection Methodology
- For a given TCWV and Tskin class, a pair of profiles of and is randomly selected from the original database and put in the calibration database.
- A new pair of profiles is then selected randomly from the original database. The distances and are calculated between the new profiles and each pair of profiles already in the calibration database. The minimum values, and , are then computed.
- The new pair of profiles are stored in the database if and meet the threshold criteria for the minimum acceptable distance:
- 4.
- Steps 2 and 3 are repeated until all profiles in the original database have been tested.
3. Results
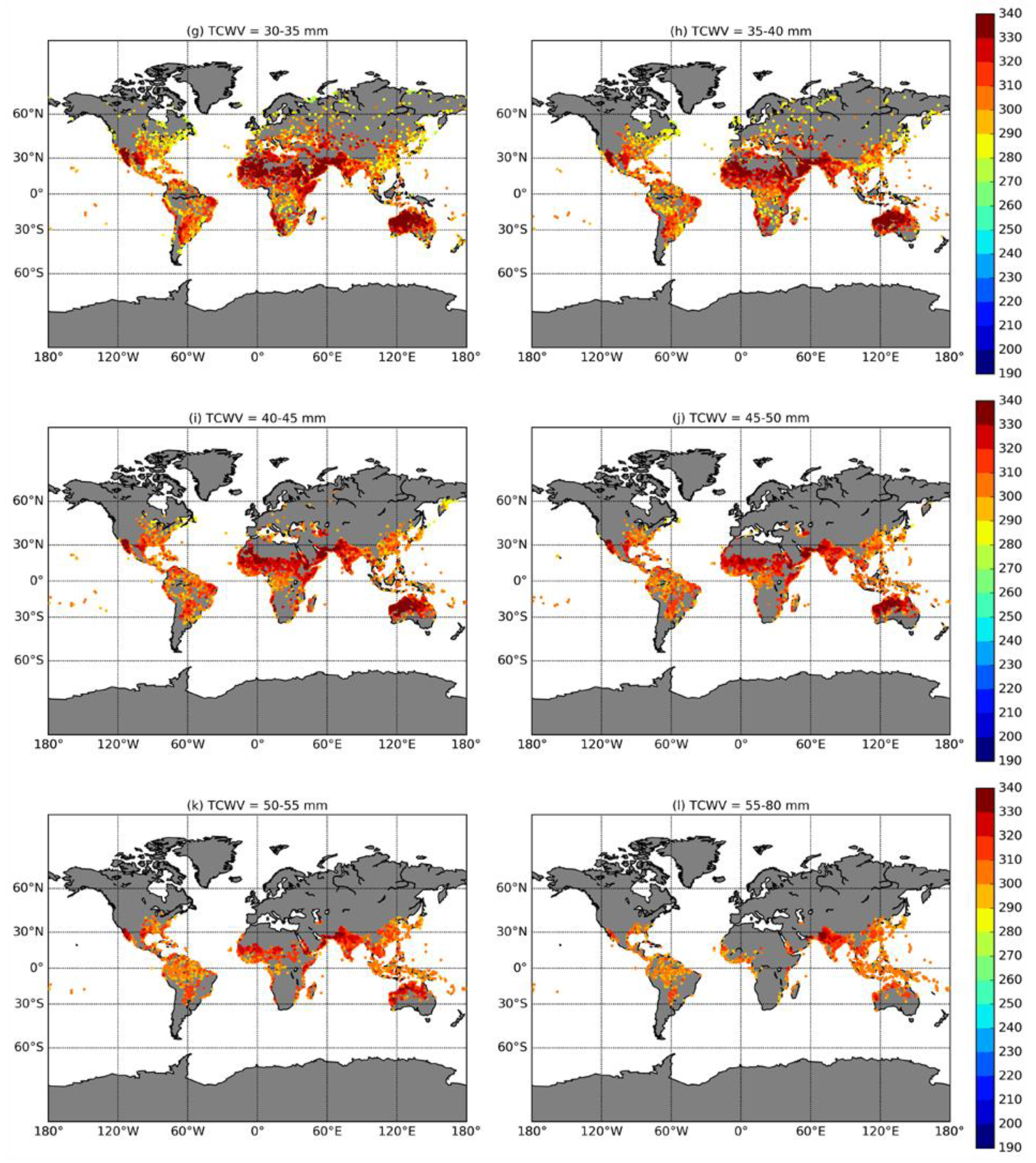
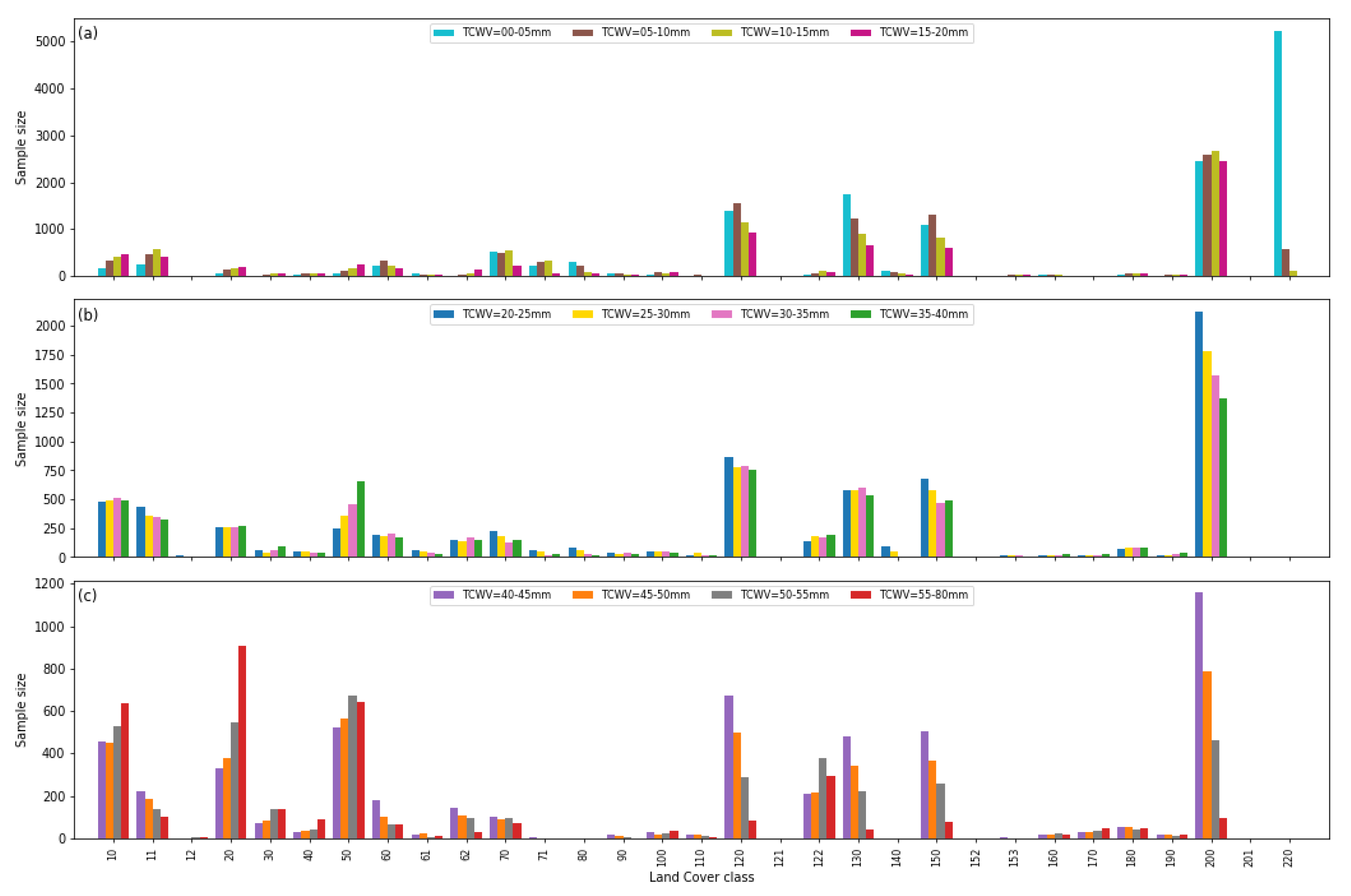
3.1. Spatial Distribution
3.2. Temporal Distribution
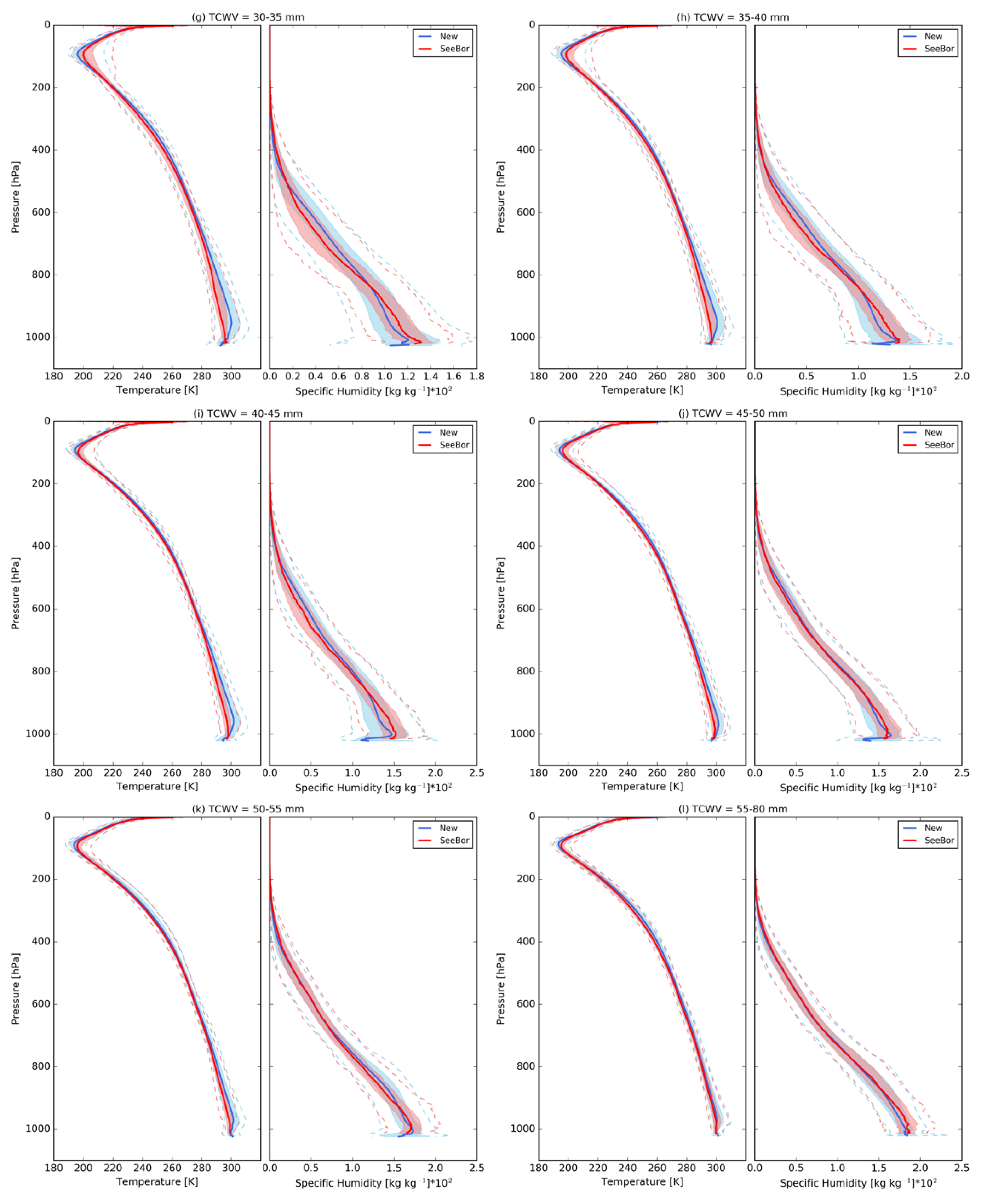
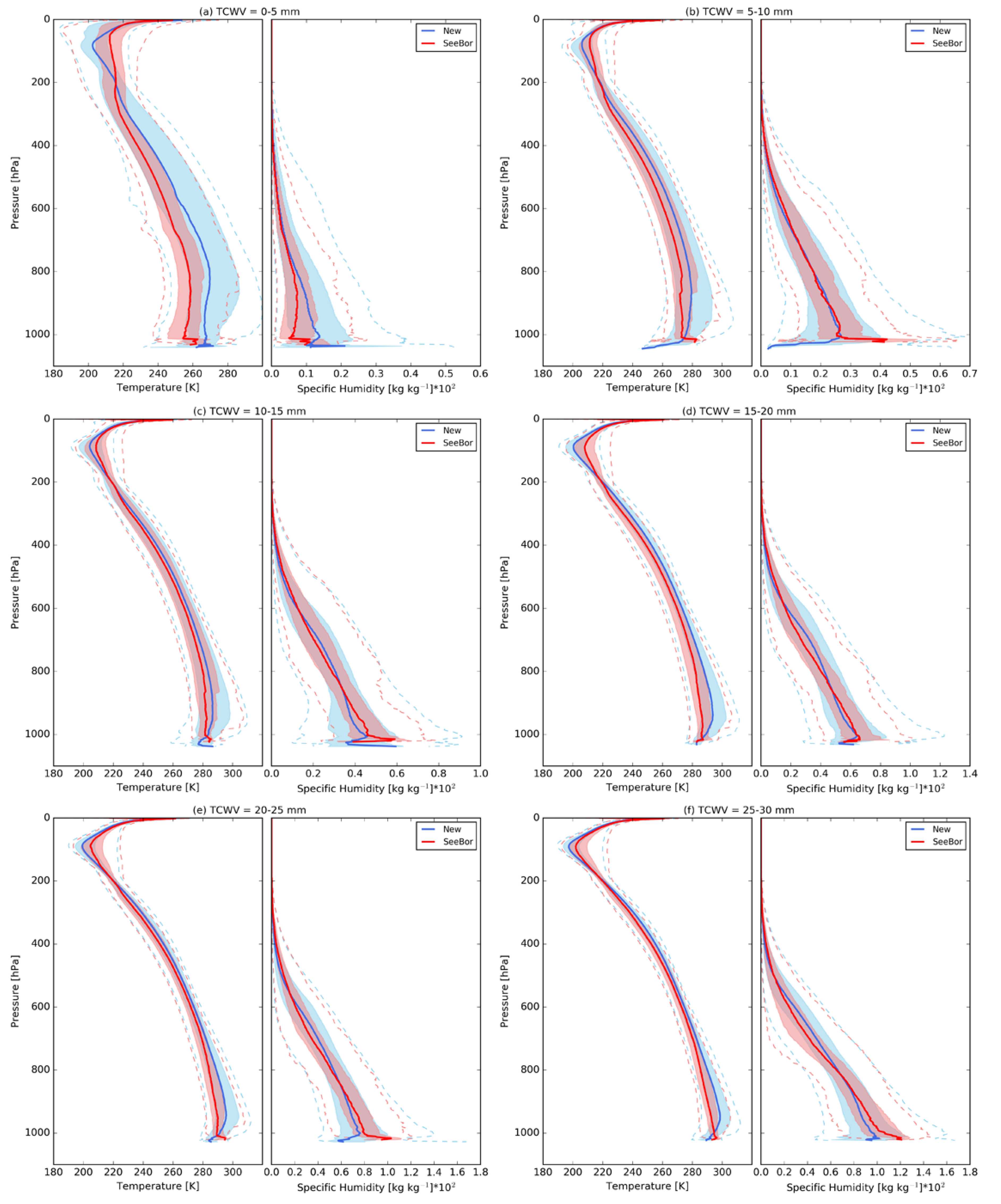
3.3. Vertical Distribution
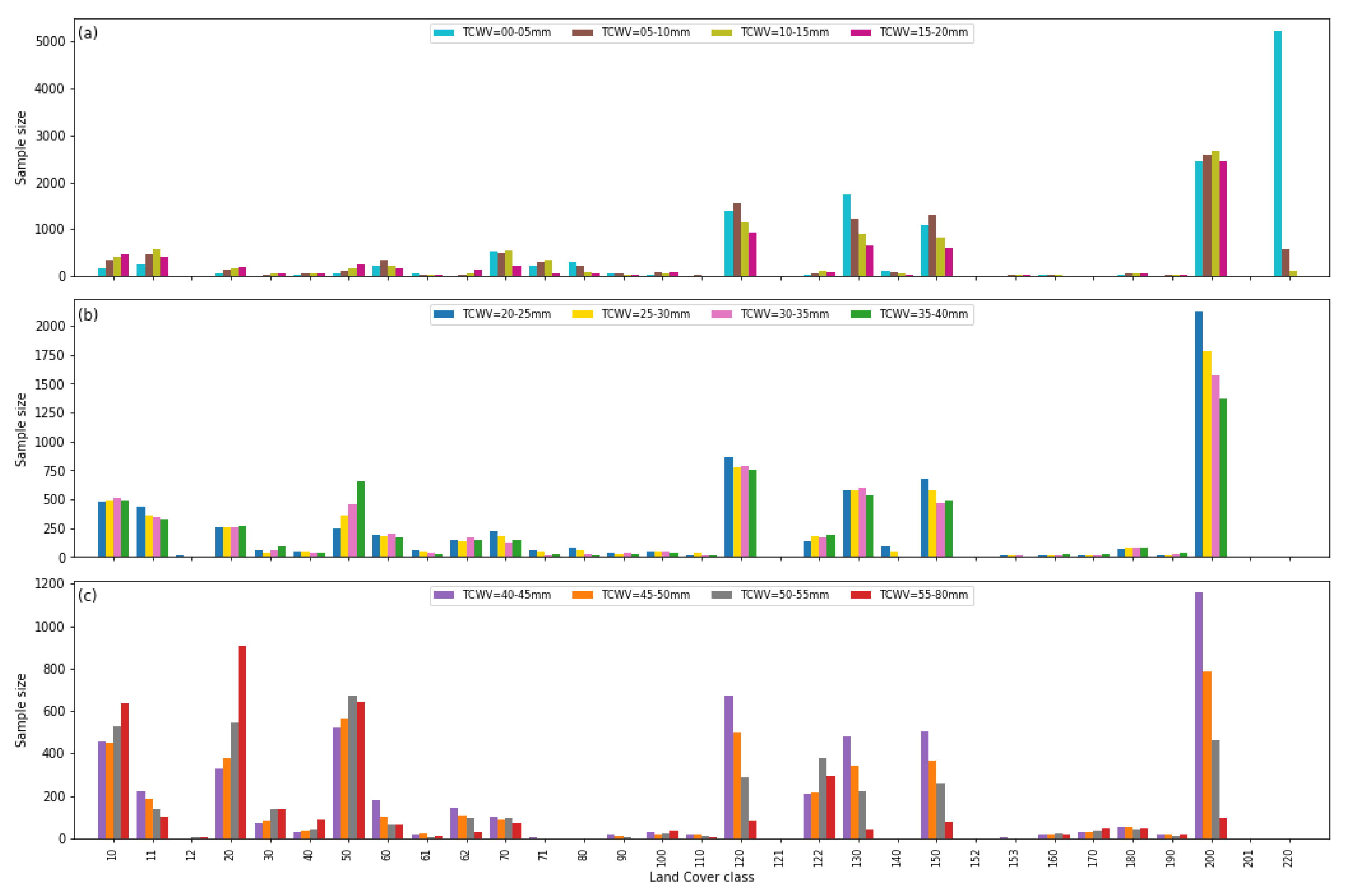
3.4. Distribution of Surface Conditions
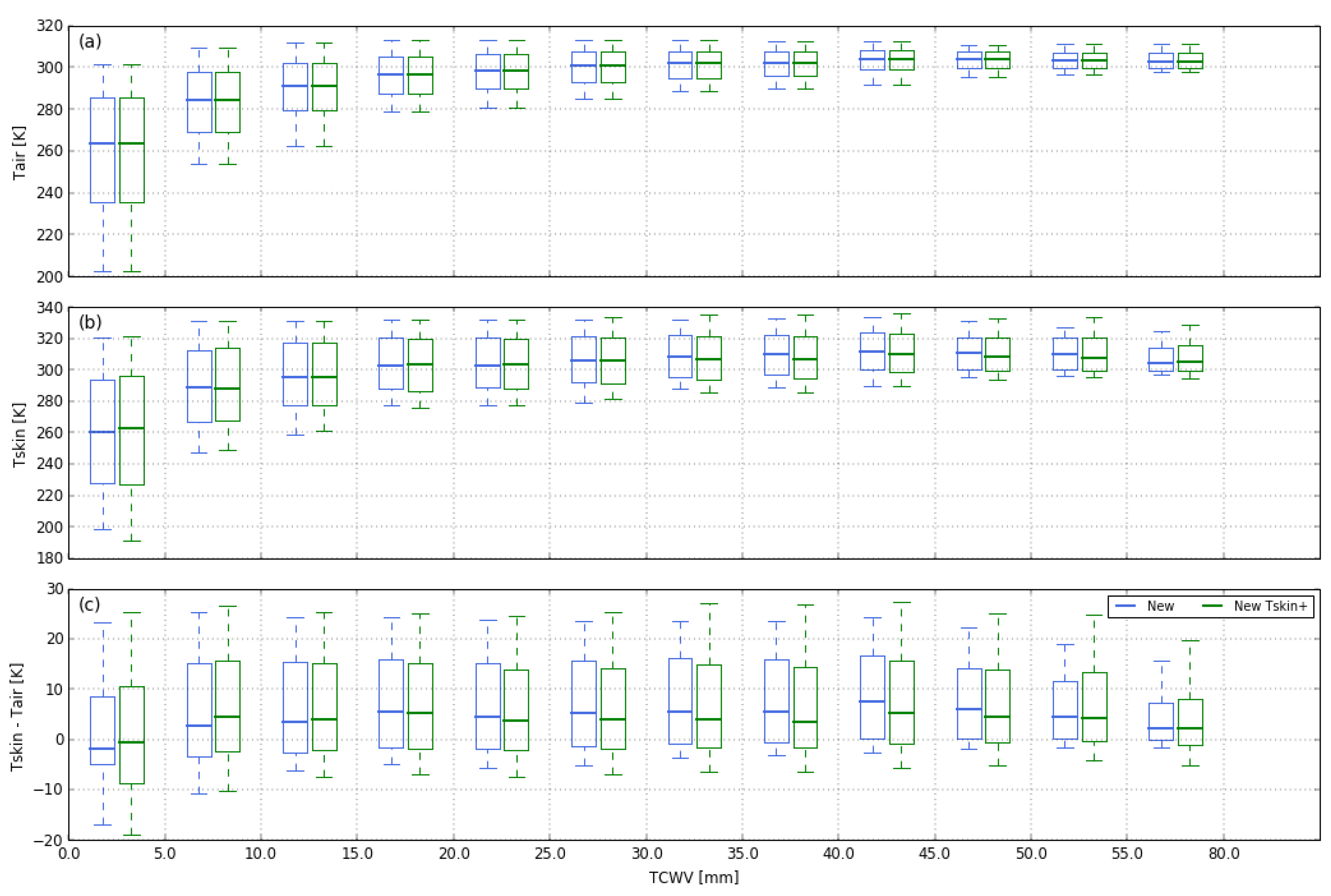
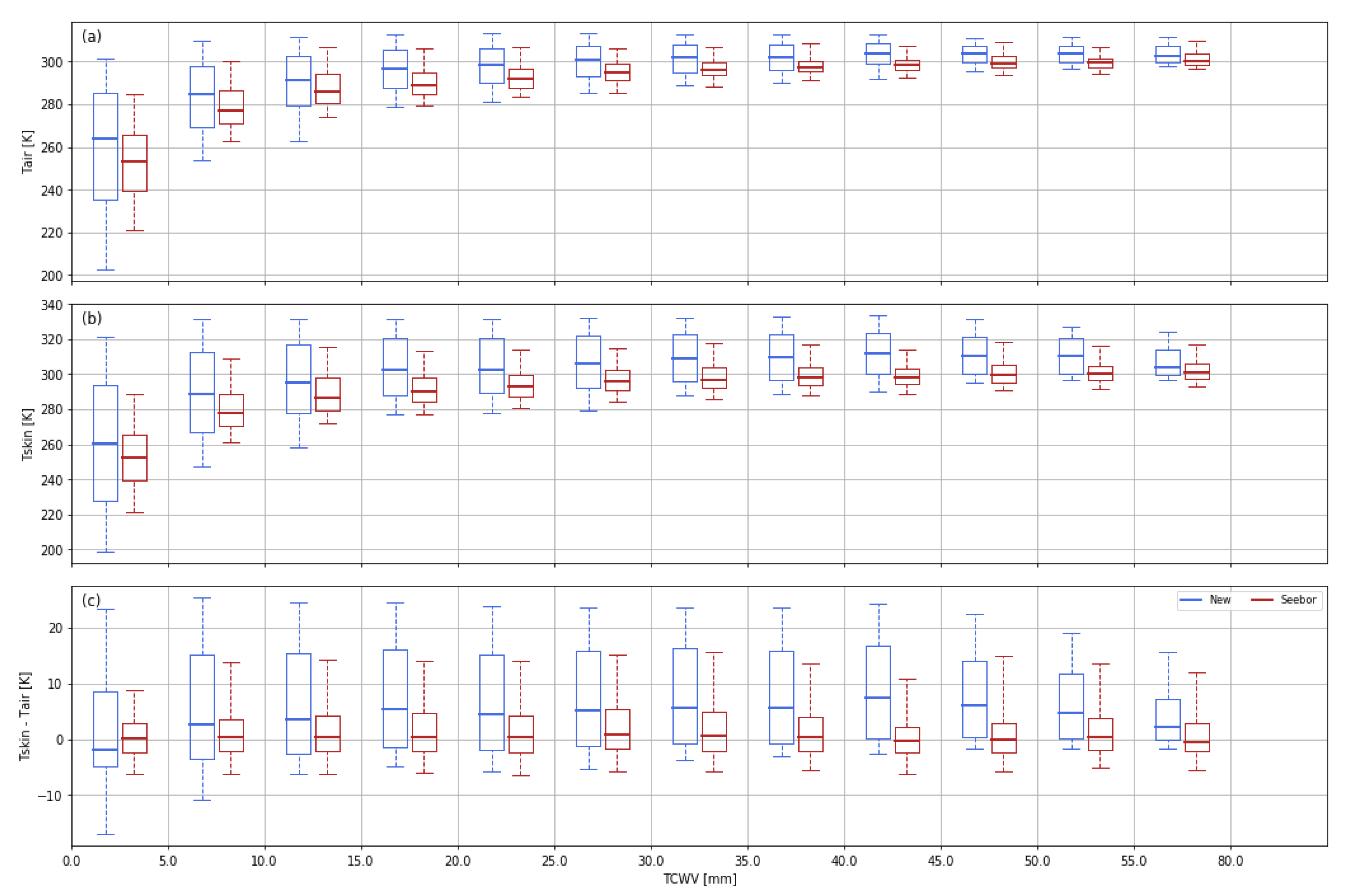
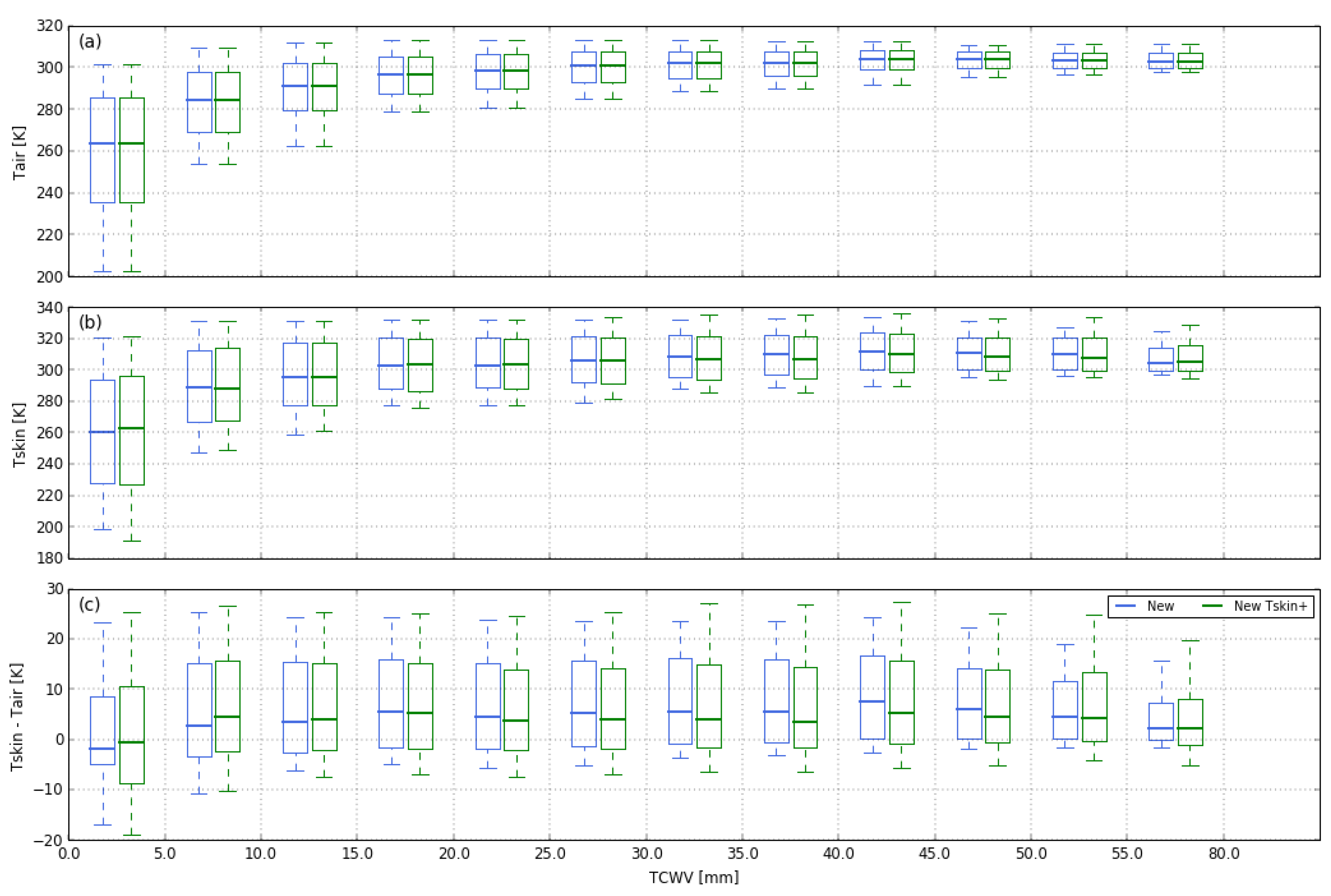
3.4.1. Surface Temperature
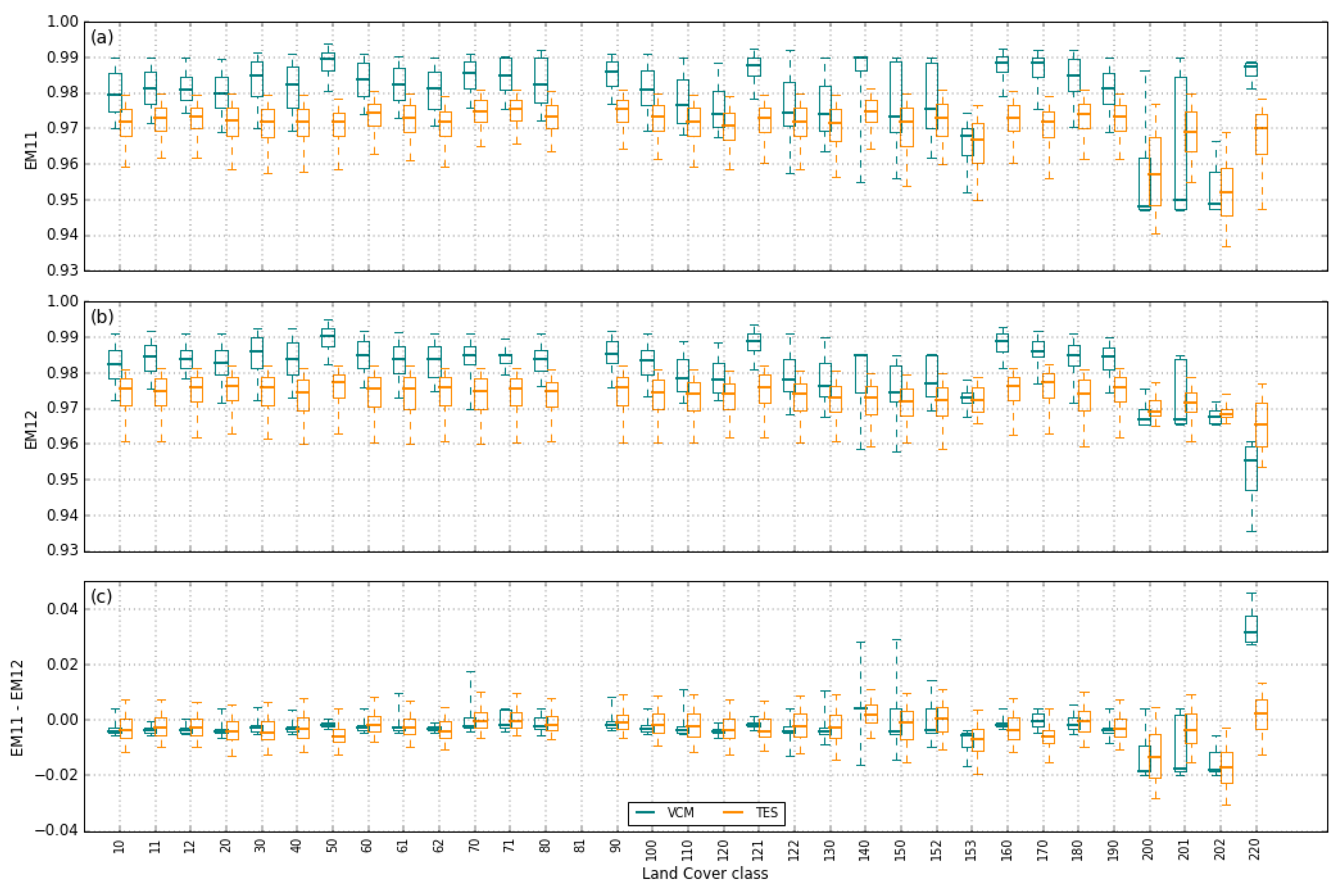
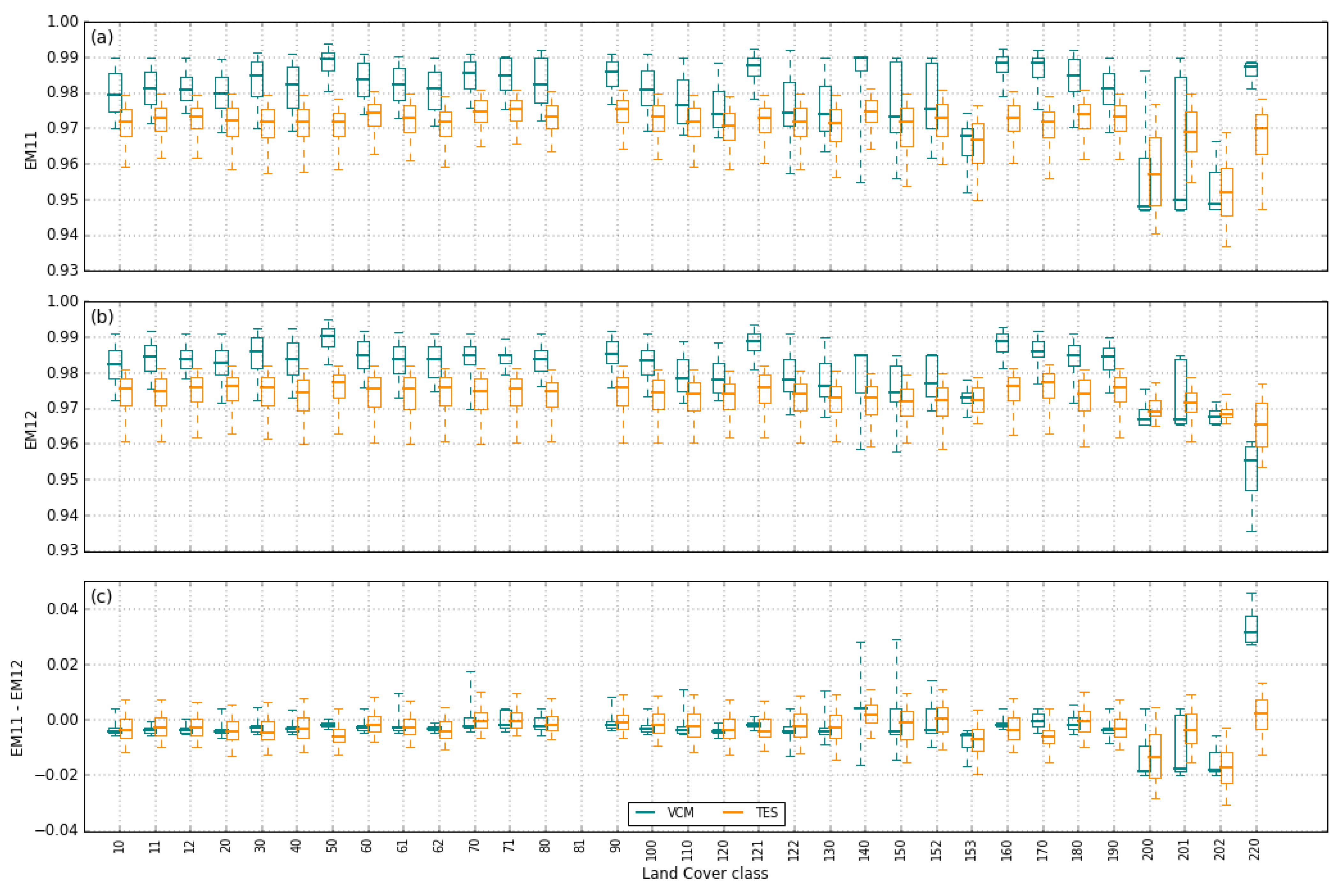
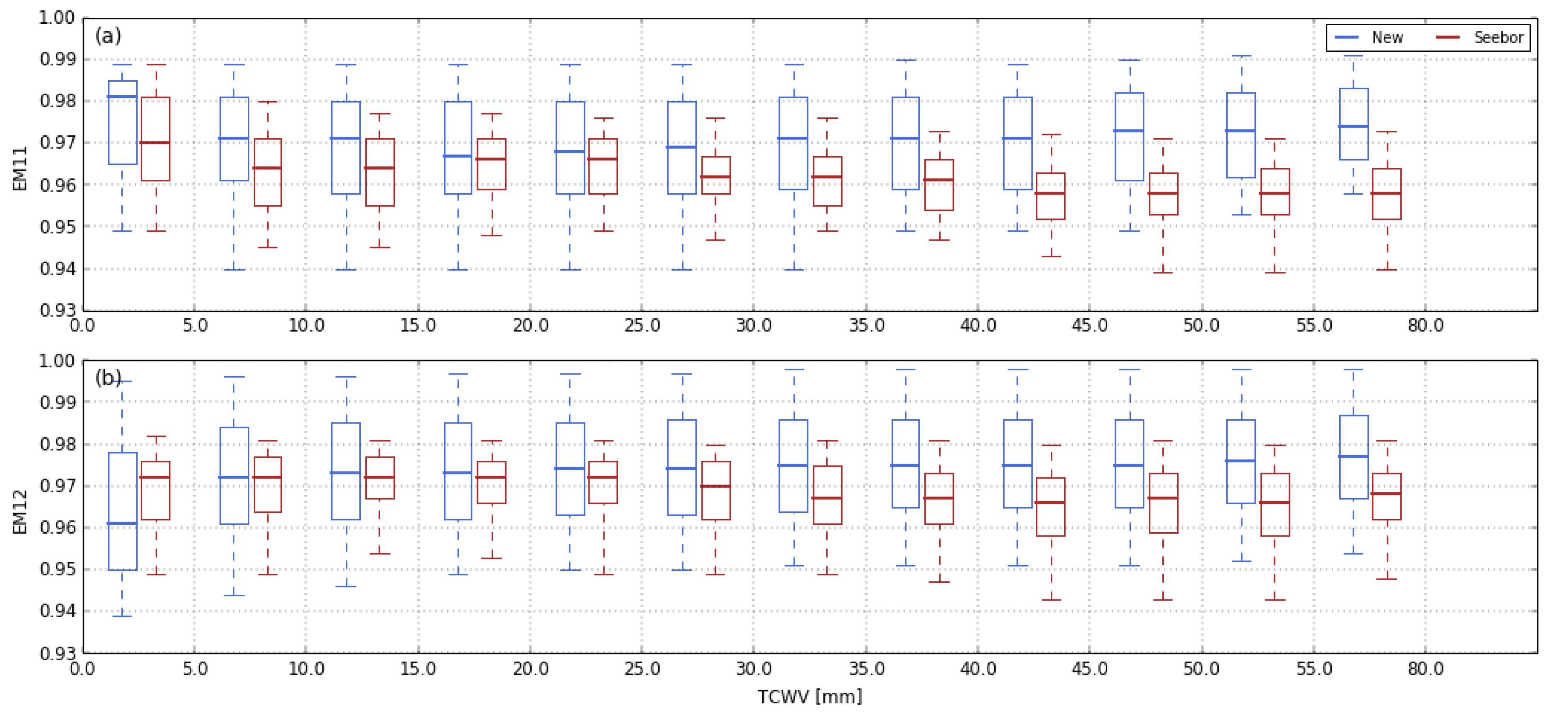
3.4.2. Surface Emissivity
- Five emissivity values are set for the ~11 µm channel taking equally spaced values in the emissivity range selected based on landcover (as described above);
- For each emissivity value prescribed in 1), five values of emissivity difference are set, taking equally spaced values in the selected emissivity difference range, which are used to compute the emissivities of the ~12 µm channel. Values above 0.99 are discarded.
3.5. Brightness Temperature Distribution
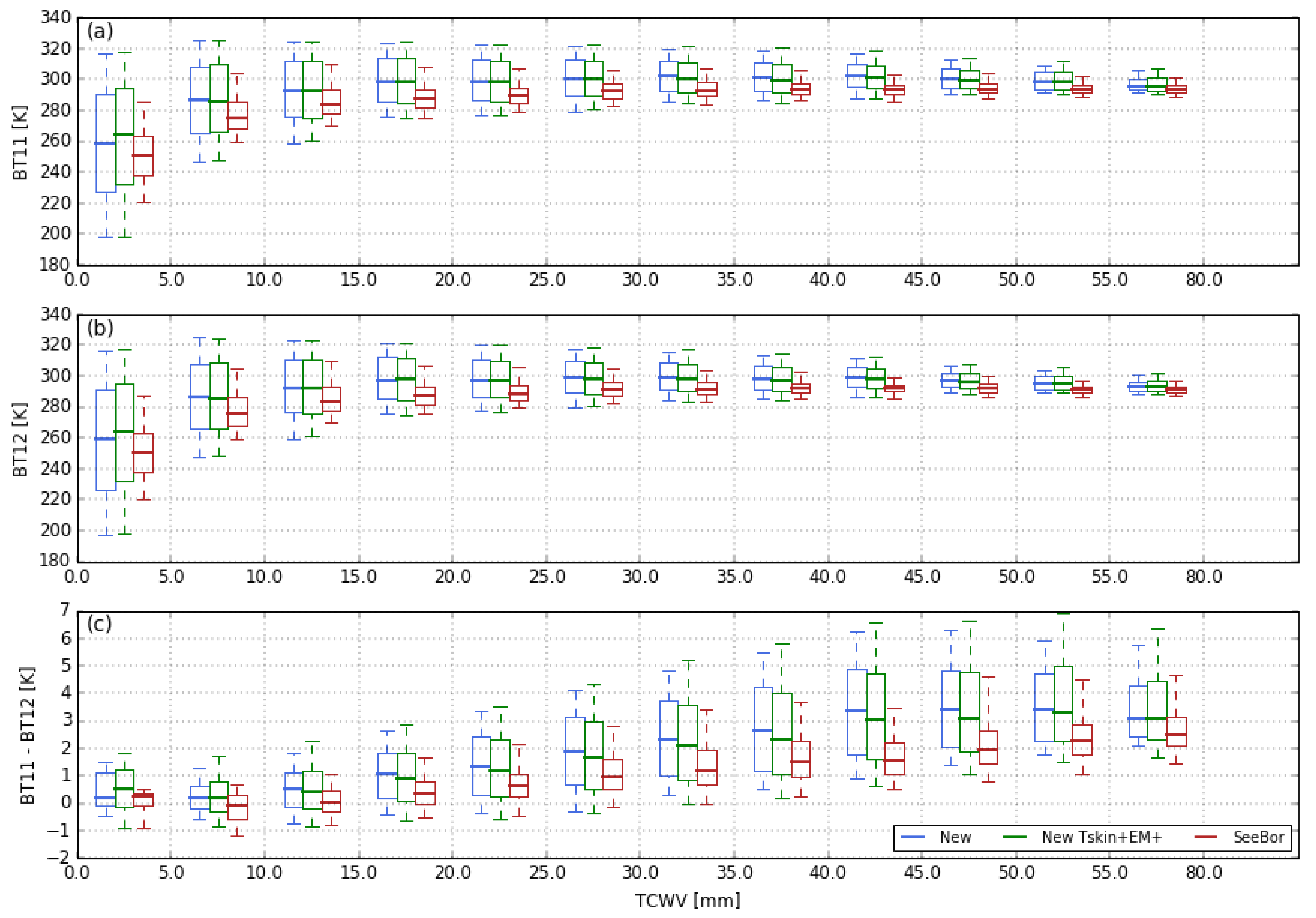
4. Impact on Algorithm Calibration
5. Discussion
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Balsamo, G.; Agusti-Panareda, A.; Albergel, C.; Arduini, G.; Beljaars, A.; Bidlot, J.; Blyth, E.; Bousserez, N.; Boussetta, S.; Brown, A.; et al. Satellite and In Situ Observations for Advancing Global Earth Surface Modelling: A Review. Remote Sens. 2018, 10, 2038. [Google Scholar] [CrossRef] [Green Version]
- Trigo, I.F.; Boussetta, S.; Viterbo, P.; Balsamo, G.; Beljaars, A.; Sandu, I. Comparison of model land skin temperature with remotely sensed estimates and assessment of surface-atmosphere coupling. J. Geophys. Res. Atmos. 2015, 120, 12096–12111. [Google Scholar] [CrossRef] [Green Version]
- Mildrexler, D.J.; Zhao, M.; Running, S.W. Satellite Finds Highest Land Skin Temperatures on Earth. Bull. Am. Meteorol. Soc. 2011, 92, 855–860. [Google Scholar] [CrossRef] [Green Version]
- Miralles, D.G.; van den Berg, M.J.; Teuling, A.J.; de Jeu, R.A.M. Soil moisture-temperature coupling: A multiscale observational analysis. Geophys. Res. Lett. 2012, 39. [Google Scholar] [CrossRef] [Green Version]
- Su, Z. The Surface Energy Balance System (SEBS) for estimation of turbulent heat fluxes. Hydrol. Earth Syst. Sci. 2002, 6, 85–100. [Google Scholar] [CrossRef]
- Bojinski, S.; Verstraete, M.; Peterson, T.C.; Richter, C.; Simmons, A.; Zemp, M. The Concept of Essential Climate Variables in Support of Climate Research, Applications, and Policy. Bull. Am. Meteorol. Soc. 2014, 95, 1431–1443. [Google Scholar] [CrossRef]
- Li, Z.-L.; Tang, B.-H.; Wu, H.; Ren, H.; Yan, G.; Wan, Z.; Trigo, I.F.; Sobrino, J. A Satellite-derived land surface temperature: Current status and perspectives. Remote Sens. Environ. 2013, 131, 14–37. [Google Scholar] [CrossRef] [Green Version]
- Johannsen, F.; Ermida, S.; Martins, J.P.A.; Trigo, I.F.; Nogueira, M.; Dutra, E. Cold Bias of ERA5 Summertime Daily Maximum Land Surface Temperature over Iberian Peninsula. Remote Sens. 2019, 11, 2570. [Google Scholar] [CrossRef] [Green Version]
- Orth, R.; Dutra, E.; Trigo, I.F.; Balsamo, G. Advancing land surface model development with satellite-based Earth observations. Hydrol. Earth Syst. Sci. 2017, 21, 2483–2495. [Google Scholar] [CrossRef] [Green Version]
- Nogueira, M.; Boussetta, S.; Balsamo, G.; Albergel, C.; Trigo, I.F.; Johannsen, F.; Miralles, D.G.; Dutra, E. Upgrading Land-Cover and Vegetation Seasonality in the ECMWF Coupled System: Verification With FLUXNET Sites, METEOSAT Satellite Land Surface Temperatures, and ERA5 Atmospheric Reanalysis. J. Geophys. Res. Atmos. 2021, 126, e2020JD034163. [Google Scholar] [CrossRef]
- Kogan, F.N.; Kogan, F.N. Operational Space Technology for Global Vegetation Assessment. Bull. Am. Meteorol. Soc. 2001, 82, 1949–1964. [Google Scholar] [CrossRef]
- Kumar, D.; Shekhar, S. Statistical analysis of land surface temperature–vegetation indexes relationship through thermal remote sensing. Ecotoxicol. Environ. Saf. 2015, 121, 39–44. [Google Scholar] [CrossRef] [PubMed]
- Bento, V.A.; Gouveia, C.M.; DaCamara, C.C.; Trigo, I.F. A climatological assessment of drought impact on vegetation health index. Agric. For. Meteorol. 2018, 259, 286–295. [Google Scholar] [CrossRef]
- Albright, T.P.; Pidgeon, A.M.; Rittenhouse, C.D.; Clayton, M.K.; Flather, C.H.; Culbert, P.D.; Radeloff, V.C. Heat waves measured with MODIS land surface temperature data predict changes in avian community structure. Remote Sens. Environ. 2011, 115, 245–254. [Google Scholar] [CrossRef] [Green Version]
- Jiménez, C.; Michel, D.; Hirschi, M.; Ermida, S.; Prigent, C. Applying multiple land surface temperature products to derive heat fluxes over a grassland site. Remote Sens. Appl. Soc. Environ. 2017, 6. [Google Scholar] [CrossRef] [Green Version]
- Mokhtari, A.; Noory, H.; Pourshakouri, F.; Haghighatmehr, P.; Afrasiabian, Y.; Razavi, M.; Fereydooni, F.; Sadeghi Naeni, A. Calculating potential evapotranspiration and single crop coefficient based on energy balance equation using Landsat 8 and Sentinel-2. ISPRS J. Photogramm. Remote Sens. 2019, 154, 231–245. [Google Scholar] [CrossRef]
- Andersson, E.; Bauer, P.; Beljaars, A.; Chevallier, F.; Hólm, E.; Janisková, M.; Kallberg, P.; Kelly, G.; Lopez, P.; McNally, A.; et al. Assimilation and modeling of the atmospheric hydrological cycle in the ECMWF forecasting system. Bull. Am. Meteorol. Soc. 2005. [Google Scholar] [CrossRef] [Green Version]
- Bechtel, B.; Daneke, C. Classification of Local Climate Zones Based on Multiple Earth Observation Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2012, 5, 1191–1202. [Google Scholar] [CrossRef]
- Fu, P.; Weng, Q. A time series analysis of urbanization induced land use and land cover change and its impact on land surface temperature with Landsat imagery. Remote Sens. Environ. 2016, 175, 205–214. [Google Scholar] [CrossRef]
- Rogan, J.; Ziemer, M.; Martin, D.; Ratick, S.; Cuba, N.; DeLauer, V. The impact of tree cover loss on land surface temperature: A case study of central Massachusetts using Landsat Thematic Mapper thermal data. Appl. Geogr. 2013, 45, 49–57. [Google Scholar] [CrossRef]
- Maimaitiyiming, M.; Ghulam, A.; Tiyip, T.; Pla, F.; Latorre-Carmona, P.; Halik, Ü.; Sawut, M.; Caetano, M. Effects of green space spatial pattern on land surface temperature: Implications for sustainable urban planning and climate change adaptation. ISPRS J. Photogramm. Remote Sens. 2014, 89, 59–66. [Google Scholar] [CrossRef] [Green Version]
- Peng, J.; Jia, J.; Liu, Y.; Li, H.; Wu, J. Seasonal contrast of the dominant factors for spatial distribution of land surface temperature in urban areas. Remote Sens. Environ. 2018, 215, 255–267. [Google Scholar] [CrossRef]
- Sobrino, J.A.; Julien, Y.; García-Monteiro, S. Surface Temperature of the Planet Earth from Satellite Data. Remote Sens. 2020, 12, 218. [Google Scholar] [CrossRef] [Green Version]
- Zhou, C.; Wang, K. Land surface temperature over global deserts: Means, variability, and trends. J. Geophys. Res. Atmos. 2016, 121, 357. [Google Scholar] [CrossRef]
- Bechtel, B. A New Global Climatology of Annual Land Surface Temperature. Remote Sens. 2015, 7, 2850–2870. [Google Scholar] [CrossRef] [Green Version]
- Trigo, I.F.; Monteiro, I.T.; Olesen, F.; Kabsch, E. An assessment of remotely sensed land surface temperature. J. Geophys. Res. 2008, 113, 1–12. [Google Scholar] [CrossRef]
- Borbas, E.E.; Seemann, S.W.; Huang, H.L.; Li, J.; Menzel, W.P. Global profile training database for satellite regression retrievals with estimates of skin temperature and emissivity. In Proceedings of the International TOVS Study Conference-XIV, Beijing, China, 25–31 May 2005. [Google Scholar]
- Wan, Z.; Dozier, J. A generalized split-window algorithm for retrieving land-surface temperature from space. Geosci. Remote Sens. IEEE Trans. 1996, 34, 892–905. [Google Scholar]
- Malakar, N.K.; Hulley, G.C. A water vapor scaling model for improved land surface temperature and emissivity separation of MODIS thermal infrared data. Remote Sens. Environ. 2016, 182, 252–264. [Google Scholar] [CrossRef]
- Ghent, D.J.; Corlett, G.K.; Göttsche, F.-M.; Remedios, J.J. Global Land Surface Temperature From the Along-Track Scanning Radiometers. J. Geophys. Res. Atmos. 2017, 122, 193. [Google Scholar] [CrossRef] [Green Version]
- Martins, J.; Trigo, I.; Bento, V.; da Camara, C. A Physically Constrained Calibration Database for Land Surface Temperature Using Infrared Retrieval Algorithms. Remote Sens. 2016, 8, 808. [Google Scholar] [CrossRef] [Green Version]
- Achard, V. Trois problèmes clés de l’analyse 3D de la structure thermodynamique de l’atmosphère par satellite: Mesure du contenu en ozone; classification des masses d’air; modélisation hyper rapide du transfert radiatif. Ph.D. Thesis, University of Paris, Paris, France, 1991. [Google Scholar]
- Chedin, A.; Scott, N.A.; Wahiche, C.; Moulinier, P.; Chedin, A.; Scott, N.A.; Wahiche, C.; Moulinier, P. The Improved Initialization Inversion Method: A High Resolution Physical Method for Temperature Retrievals from Satellites of the TIROS-N Series. J. Clim. Appl. Meteorol. 1985, 24, 128–143. [Google Scholar] [CrossRef] [Green Version]
- Chevallier, F.; Chéruy, F.; Scott, N.A.; Chédin, A. A Neural Network Approach for a Fast and Accurate Computation of a Longwave Radiative Budget. J. Appl. Meteorol. 1998, 37, 1385–1397. [Google Scholar] [CrossRef]
- Escobar-Munoz, J. Base de données pour la restitution de variables atmosphériques à l’échelle globale. Étude sur l’inversion par réseaux de neurones des données des sondeurs verticaux atmosphériques satellitaires présents et à venir. Ph.D. Thesis, University of Paris, Paris, France, 1993. [Google Scholar]
- Moulinier, P. Analyse Statistique d’un Vaste Echantillonnage de Situations Atmosphériques sur l’ensemble du Globe. Laboratoire de Météorologie Dynamique Internal note No. 123; École Polytechnique: Paris, France, 1983. [Google Scholar]
- Seemann, S.W.; Li, J.; Menzel, W.P.; Gumley, L.E. Operational Retrieval of Atmospheric Temperature, Moisture, and Ozone from MODIS Infrared Radiances. J. Appl. Meteorol. 2003, 42, 1072–1091. [Google Scholar] [CrossRef]
- Chevallier, F.; Chédin, A.; Cheruy, F.; Morcrette, J.-J. TIGR-like atmospheric-profile databases for accurate radiative-flux computation. Q. J. R. Meteorol. Soc. 2000, 126, 777–785. [Google Scholar] [CrossRef]
- Chevallier, F. Sampled database of 60-Level atmospheric profiles from the ECMWF analyses; NWPSAF Research Report No NWPSAF-EC-TR-004 (v1.0); Reading: Shinfield Park, UK, 2002. [Google Scholar]
- Saunders, R.; Hocking, J.; Turner, E.; Rayer, P.; Rundle, D.; Brunel, P.; Vidot, J.; Roquet, P.; Matricardi, M.; Geer, A.; et al. An update on the RTTOV fast radiative transfer model (currently at version 12). Geosci. Model Dev. 2018, 11, 2717–2737. [Google Scholar] [CrossRef] [Green Version]
- Chevallier, F.; Di Michele, S.; McNally, A. Diverse Profile Datasets from the ECMWF 91-Level Short-Range Forecasts; NWPSAF Research Report No NWPSAF-EC-TR-010 (v1.0); Reading: Shinfield Park, UK, 2006. [Google Scholar]
- Aires, F.; Prigent, C. Sampling techniques in high-dimensional spaces for the development of satellite remote sensing database. J. Geophys. Res. 2007, 112, D20301. [Google Scholar] [CrossRef] [Green Version]
- Mattar, C.; Durán-Alarcón, C.; Jiménez-Muñoz, J.C.; Santamaría-Artigas, A.; Olivera-Guerra, L.; Sobrino, J.A. Global Atmospheric Profiles from Reanalysis Information (GAPRI): A new database for earth surface temperature retrieval. Int. J. Remote Sens. 2015, 36, 5045–5060. [Google Scholar] [CrossRef]
- Choi, Y.-Y.; Suh, M.-S. Development of Himawari-8/Advanced Himawari Imager (AHI) Land Surface Temperature Retrieval Algorithm. Remote Sens. 2018, 10, 2013. [Google Scholar] [CrossRef] [Green Version]
- Duguay-Tetzlaff, A.; Bento, V.A.; Göttsche, F.M.; Stöckli, R.; Martins, J.P.A.; Trigo, I.; Olesen, F.; Bojanowski, J.S.; da Camara, C.; Kunz, H. Meteosat land surface temperature climate data record: Achievable accuracy and potential uncertainties. Remote Sens. 2015, 7, 13139–13156. [Google Scholar] [CrossRef] [Green Version]
- Freitas, S.C.; Trigo, I.F.; Macedo, J.; Barroso, C.; Silva, R.; Perdigão, R.; Freitas, S.C.; Trigo, I.F.; Macedo, J.; Barroso, C.; et al. Land surface temperature from multiple geostationary satellites. Int. J. Remote Sens. 2013, 1161. [Google Scholar] [CrossRef]
- Hulley, G.C.; Hook, S.J.; Abbott, E.; Malakar, N.; Islam, T.; Abrams, M. The ASTER Global Emissivity Dataset (ASTER GED): Mapping Earth’s emissivity at 100 meter spatial scale. Geophys. Res. Lett. 2015, 42. [Google Scholar] [CrossRef]
- Islam, T.; Hulley, G.C.; Malakar, N.K.; Radocinski, R.G.; Guillevic, P.C.; Hook, S.J. A Physics-Based Algorithm for the Simultaneous Retrieval of Land Surface Temperature and Emissivity From VIIRS Thermal Infrared Data. IEEE Trans. Geosci. Remote Sens. 2017, 55, 563–576. [Google Scholar] [CrossRef]
- Jiang, G.-M.; Zhou, W.; Liu, R. Development of Split-Window Algorithm for Land Surface Temperature Estimation From the VIRR/FY-3A Measurements. IEEE Geosci. Remote Sens. Lett. 2013, 10, 952–956. [Google Scholar] [CrossRef]
- Liu, X.; Tang, B.-H.; Yan, G.; Li, Z.-L.; Liang, S. Retrieval of Global Orbit Drift Corrected Land Surface Temperature from Long-term AVHRR Data. Remote Sens. 2019, 11, 2843. [Google Scholar] [CrossRef] [Green Version]
- Hulley, G.; Malakar, N.; Freepartner, R. Moderate Resolution Imaging Spectroradiometer (MODIS) Land Surface Temperature and Emissivity Product (MxD21) Algorithm Theoretical Basis Document Collection-6. Jet Propuls. Lab. Calif. Inst. Technol. 2016. [Google Scholar]
- Yang, J.; Zhou, J.; Göttsche, F.-M.; Long, Z.; Ma, J.; Luo, R. Investigation and validation of algorithms for estimating land surface temperature from Sentinel-3 SLSTR data. Int. J. Appl. Earth Obs. Geoinf. 2020, 91, 102136. [Google Scholar] [CrossRef]
- Zhou, J.; Liang, S.; Cheng, J.; Wang, Y.; Ma, J. The GLASS Land Surface Temperature Product. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 493–507. [Google Scholar] [CrossRef]
- Hersbach, H.; Bell, B.; Berrisford, P.; Hirahara, S.; Horányi, A.; Muñoz-Sabater, J.; Nicolas, J.; Peubey, C.; Radu, R.; Schepers, D.; et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 2020, 146, 1999–2049. [Google Scholar] [CrossRef]
- Chevallier, F. TIGR-Like Sampled Databases of Atmospheric Profiles from the ECMWF 50-Level Forecast Mode. NWPSAF Research Report No1; Reading: Shinfield Park, UK, 2000. [Google Scholar]
- Trigo, I.F.; Ermida, S.L.; Martins, J.P.A.; Gouveia, C.M.; Göttsche, F.-M.; Freitas, S.C. Validation and consistency assessment of land surface temperature from geostationary and polar orbit platforms: SEVIRI/MSG and AVHRR/Metop. ISPRS J. Photogramm. Remote Sens. 2021, 175, 282–297. [Google Scholar] [CrossRef]
- Peres, L.F.; DaCamara, C.C. Emissivity maps to retrieve land-surface temperature from MSG/SEVIRI. IEEE Trans. Geosci. Remote Sens. 2005, 43, 1834–1844. [Google Scholar] [CrossRef]
- Hulley, G.C.; Hook, S.J. MODIS/Aqua Land Surface Temperature/3-Band Emissivity Daily L3 Global 0.05Deg CMG V061 [Data set]. NASA EOSDIS Land Processes DAAC. 2021. Available online: https://www.ecmwf.int/node/8683 (accessed on 15 December 2021).
- CCI; ESA Land Cover. Product User Guide Version 2.0; UCL-Geomatics: London, UK, 2017. [Google Scholar]
- Ermida, S.L.; Trigo, I.F.; Dacamara, C.C.; Göttsche, F.M.; Olesen, F.S.; Hulley, G. Validation of remotely sensed surface temperature over an oak woodland landscape—The problem of viewing and illumination geometries. Remote Sens. Environ. 2014, 148, 16–27. [Google Scholar] [CrossRef]
- Göttsche, F.-M.; Olesen, F.-S.; Bork-Unkelbach, A. Validation of land surface temperature derived from MSG/SEVIRI with in situ measurements at Gobabeb, Namibia. Int. J. Remote Sens. 2013, 34, 3069–3083. [Google Scholar] [CrossRef]
- Jacob, F.; Lesaignoux, A.; Olioso, A.; Weiss, M.; Caillault, K.; Jacquemoud, S.; Nerry, F.; French, A.; Schmugge, T.; Briottet, X.; et al. Reassessment of the temperature-emissivity separation from multispectral thermal infrared data: Introducing the impact of vegetation canopy by simulating the cavity effect with the SAIL-Thermique model. Remote Sens. Environ. 2017, 198, 160–172. [Google Scholar] [CrossRef]
- Jiménez-Muñoz, J.C.; Sobrino, J.A.; Gillespie, A.; Sabol, D.; Gustafson, W.T. Improved land surface emissivities over agricultural areas using ASTER NDVI. Remote Sens. Environ. 2006, 103, 474–487. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. Resampling Methods. In An Introduction to Statistical Learning; Springer Texts in Statistics; Springer: New York, NY, USA, 2021; pp. 197–223. [Google Scholar]
- Xu, Y.; Goodacre, R. On Splitting Training and Validation Set: A Comparative Study of Cross-Validation, Bootstrap and Systematic Sampling for Estimating the Generalization Performance of Supervised Learning. J. Anal. Test. 2018, 2, 249–262. [Google Scholar] [CrossRef] [Green Version]
- Shao, J. Bootstrap Model Selection. J. Am. Stat. Assoc. 1996, 91, 655–665. [Google Scholar] [CrossRef]
- Shao, J. Linear Model Selection by Cross-validation. J. Am. Stat. Assoc. 1993, 88, 486–494. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction, 2nd ed; Springer Series in Statistics; Springer: New York, NY, USA, 2017; ISBN 978-0-387-84857-0. [Google Scholar]
- Ermida, S.L.; Trigo, I.F. Clear-Sky Profile Database for the Development of Land Surface Temperature Algorithms (v0.0.0) [Data Set]; Zenodo: Geneve, Switzerland, 2021. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Description |
|---|---|
| 10 | Cropland, rainfed |
| 11 | Herbaceous cover |
| 12 | Tree or shrub cover |
| 20 | Cropland, irrigated or post-flooding |
| 30 | Mosaic cropland (>50%)/natural vegetation (tree, shrub, herbaceous cover) (<50%) |
| 40 | Mosaic natural vegetation (tree, shrub, herbaceous cover) (>50%) S/cropland (<50%) |
| 50 | Tree cover, broadleaved, evergreen, closed to open (>15%) |
| 60 | Tree cover, broadleaved, deciduous, closed to open (>15%) |
| 61 | Tree cover, broadleaved, deciduous, closed (>40%) |
| 62 | Tree cover, broadleaved, deciduous, open (15–40%) |
| 70 | Tree cover, needle-leaved, evergreen, closed to open (>15%) |
| 71 | Tree cover, needle-leaved, evergreen, closed (>40%) |
| 72 | Tree cover, needle-leaved, evergreen, open (15–40%) |
| 80 | Tree cover, needle-leaved, deciduous, closed to open (>15%) |
| 81 | Tree cover, needle-leaved, deciduous, closed (>40%) |
| 82 | Tree cover, needle-leaved, deciduous, open (15–40%) |
| 90 | Tree cover, mixed leaf type (broadleaved and needle-leaved) |
| 100 | Mosaic tree and shrub (>50%)/herbaceous cover (<50%) |
| 110 | Mosaic herbaceous cover (>50%)/tree and shrub (<50%) |
| 120 | Shrubland |
| 121 | Evergreen shrubland |
| 122 | Deciduous shrubland |
| 130 | Grassland |
| 140 | Lichens and mosses |
| 150 | Sparse vegetation (tree, shrub, herbaceous cover) (<15%) |
| 151 | Sparse tree (<15%) |
| 152 | Sparse shrub (<15%) |
| 153 | Sparse herbaceous cover (<15%) |
| 160 | Tree cover, flooded, fresh, or brackish water |
| 170 | Tree cover, flooded, saline water |
| 180 | Shrub or herbaceous cover, flooded, fresh/saline/brackish water |
| 190 | Urban areas |
| 200 | Bare areas |
| 201 | Consolidated bare areas |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ermida, S.L.; Trigo, I.F. A Comprehensive Clear-Sky Database for the Development of Land Surface Temperature Algorithms. Remote Sens. 2022, 14, 2329. https://doi.org/10.3390/rs14102329
Ermida SL, Trigo IF. A Comprehensive Clear-Sky Database for the Development of Land Surface Temperature Algorithms. Remote Sensing. 2022; 14(10):2329. https://doi.org/10.3390/rs14102329
Chicago/Turabian StyleErmida, Sofia L., and Isabel F. Trigo. 2022. "A Comprehensive Clear-Sky Database for the Development of Land Surface Temperature Algorithms" Remote Sensing 14, no. 10: 2329. https://doi.org/10.3390/rs14102329
APA StyleErmida, S. L., & Trigo, I. F. (2022). A Comprehensive Clear-Sky Database for the Development of Land Surface Temperature Algorithms. Remote Sensing, 14(10), 2329. https://doi.org/10.3390/rs14102329