
An Effectively Dynamic Path Optimization Approach for the Tree Skeleton Extraction from Portable Laser Scanning Point Clouds



Abstract
:1. Introduction
2. Related Works
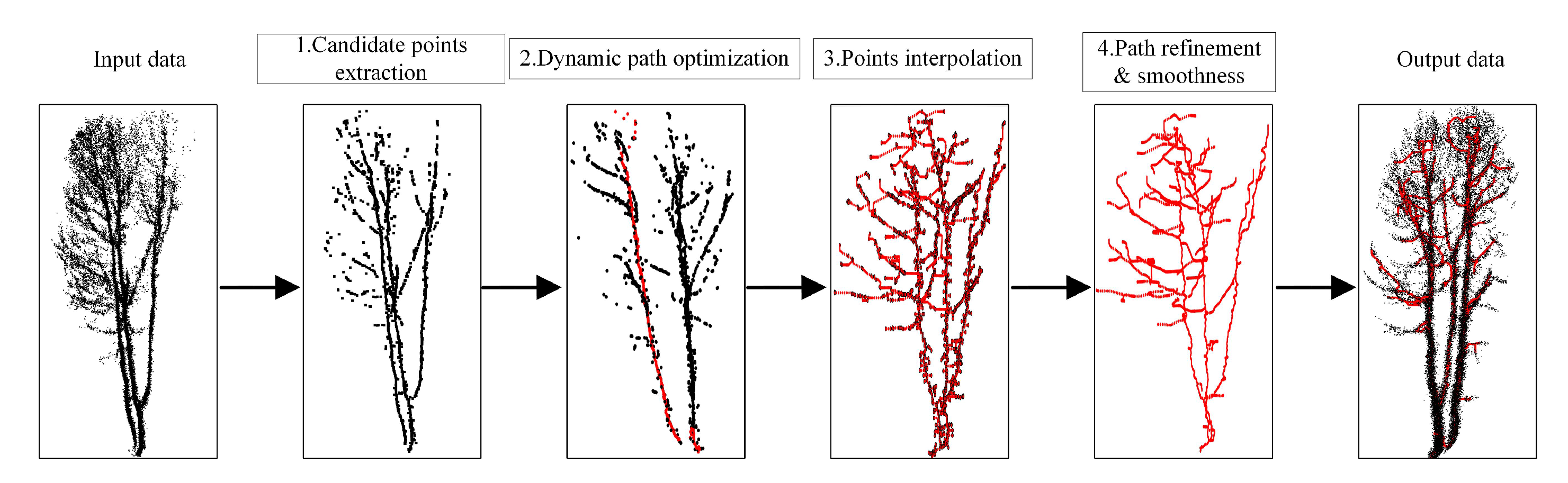
3. Tree Skeleton Extraction
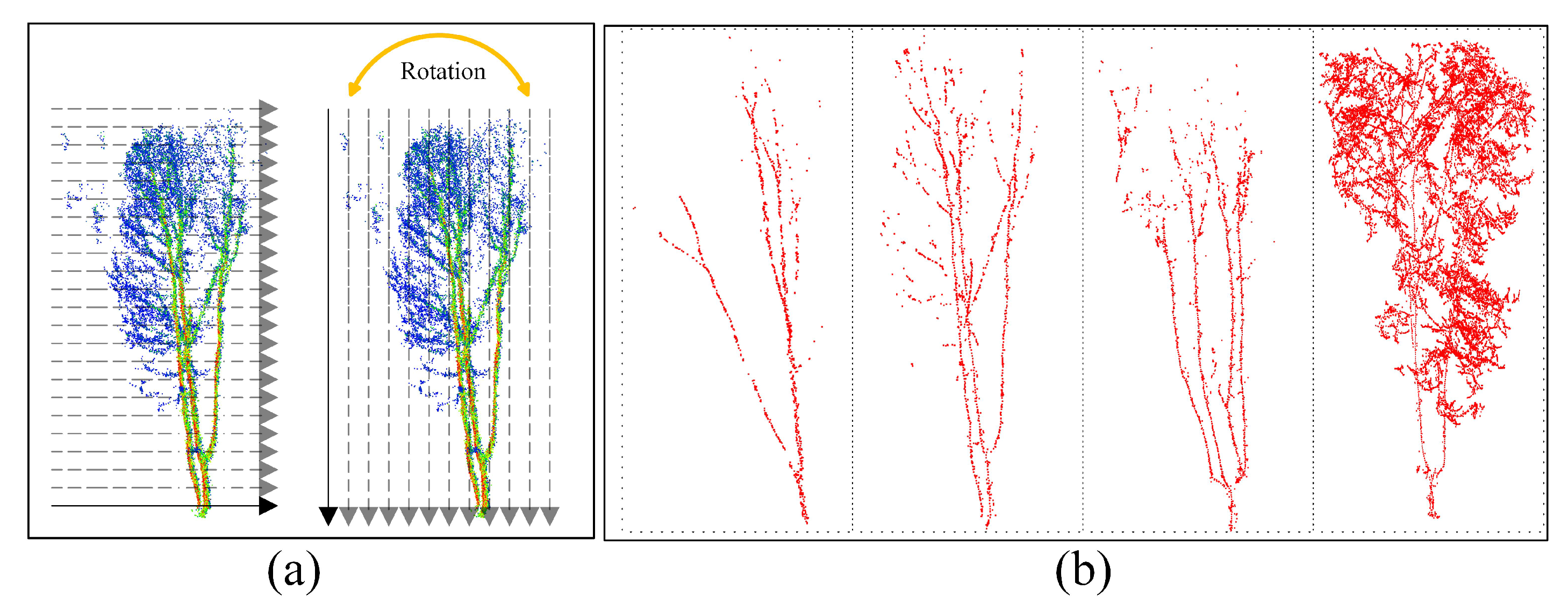
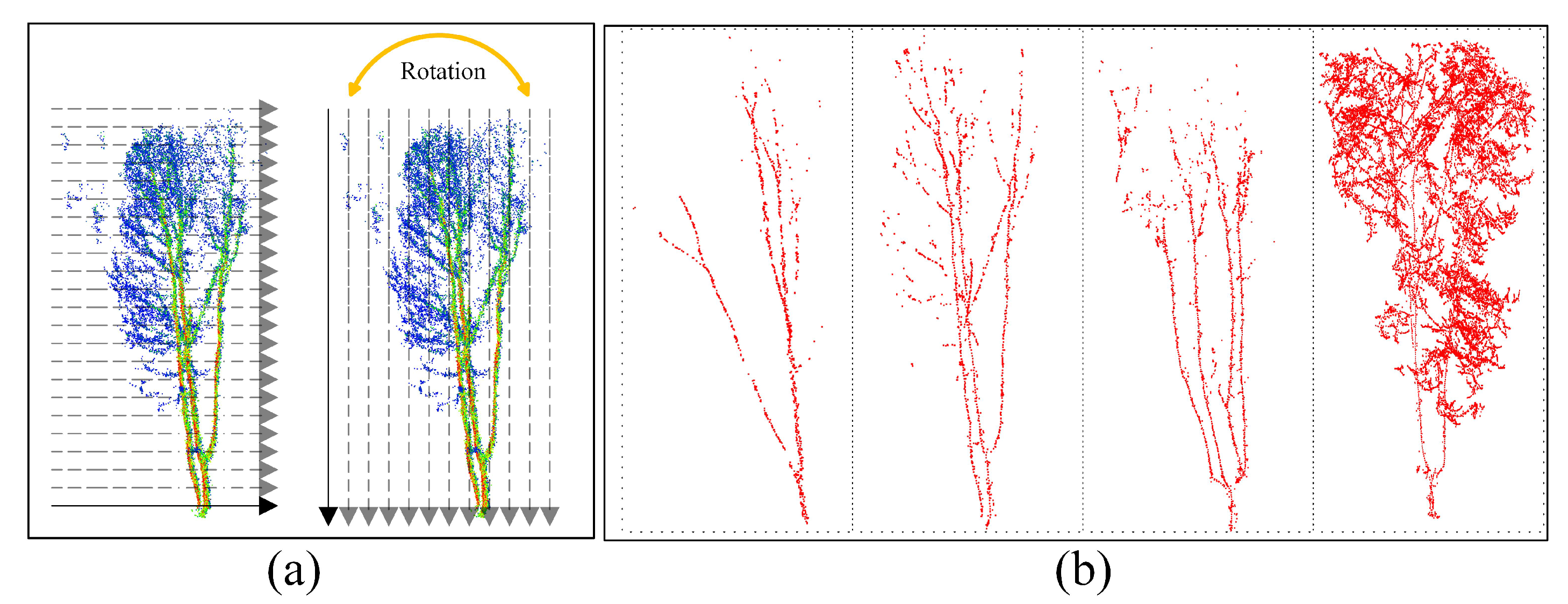
3.1. Candidate Point Extraction
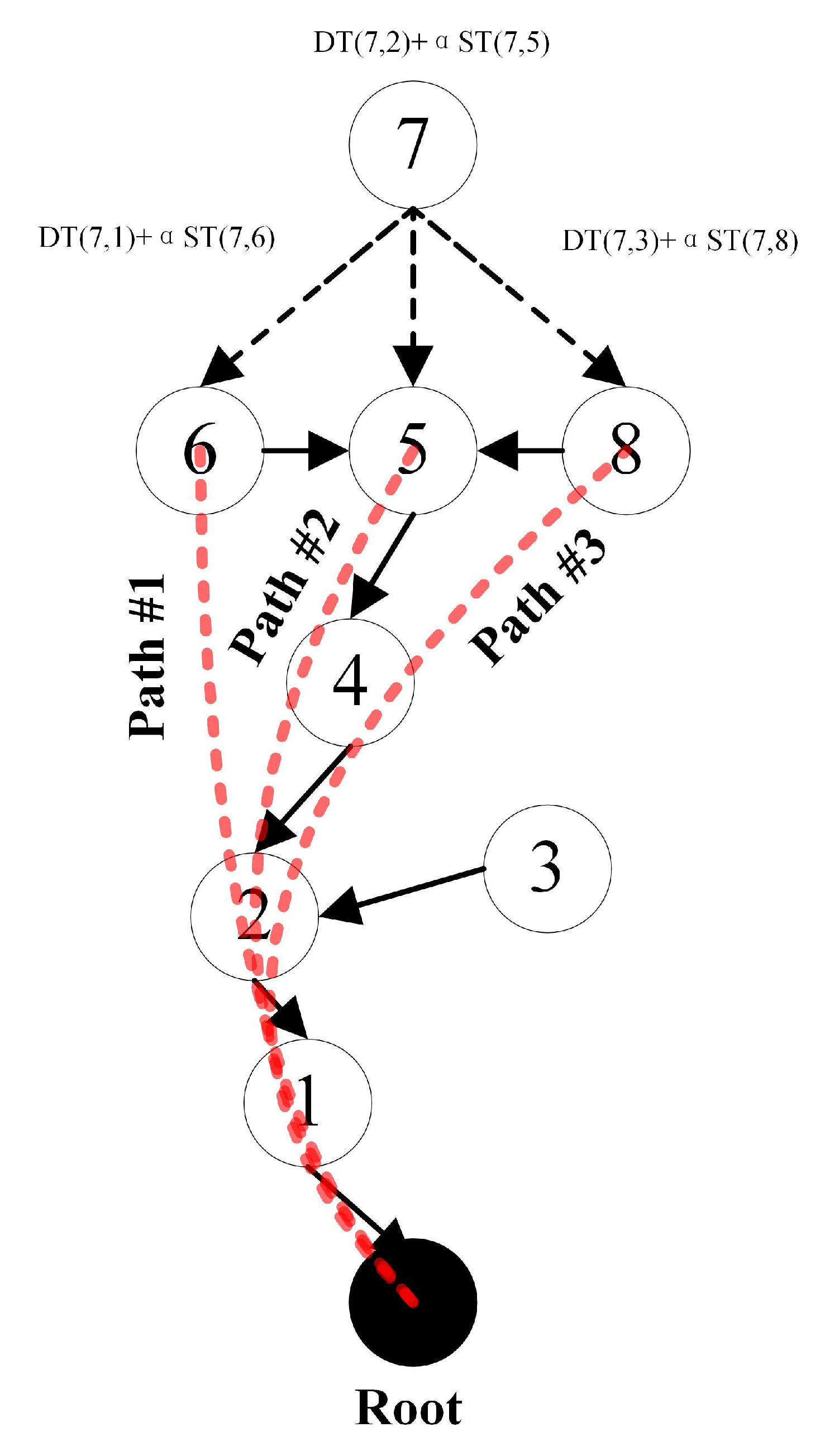
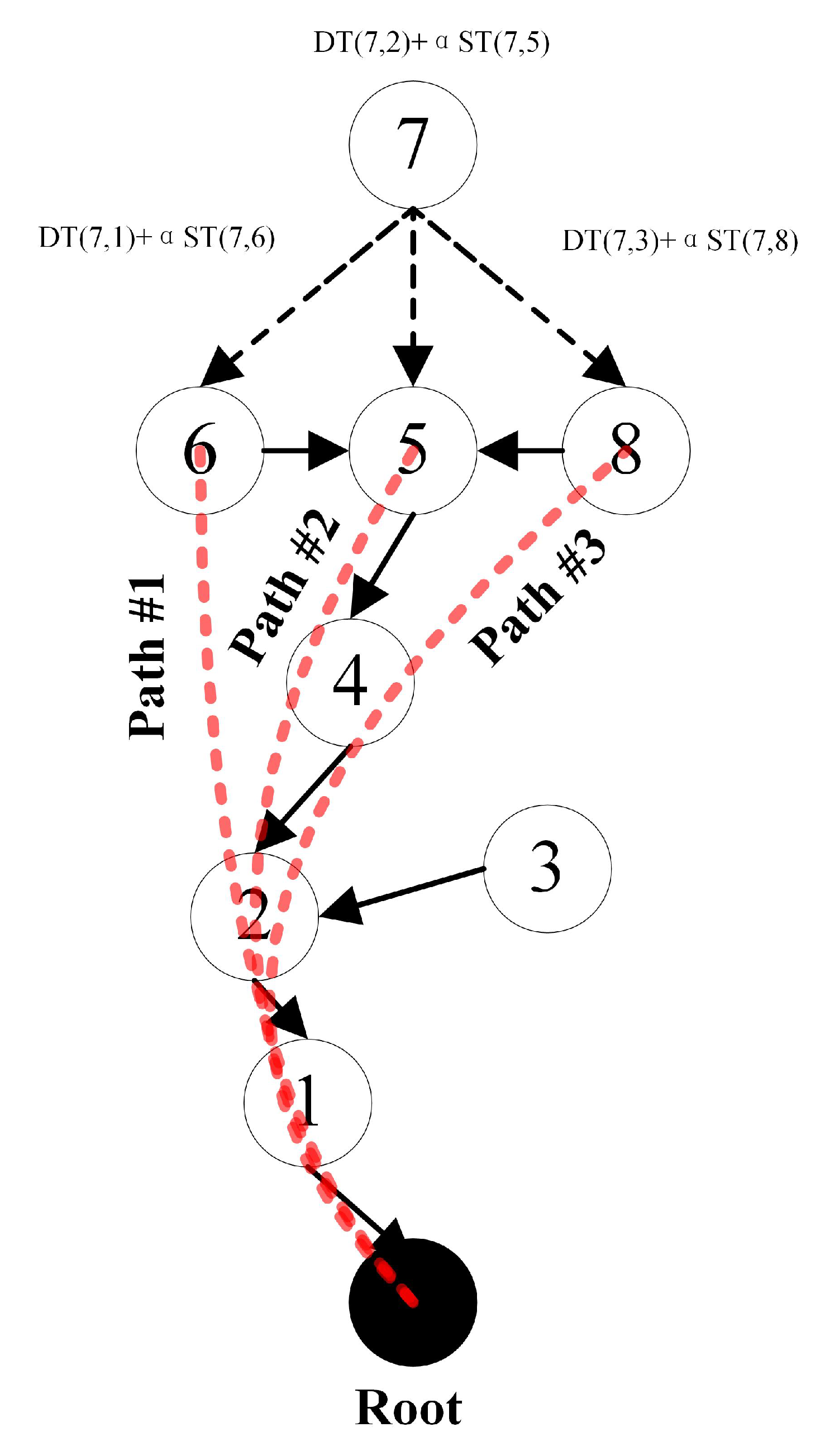
3.2. Dynamic Path Optimization
| Algorithm 1 Dynamic Path Optimization. |
|
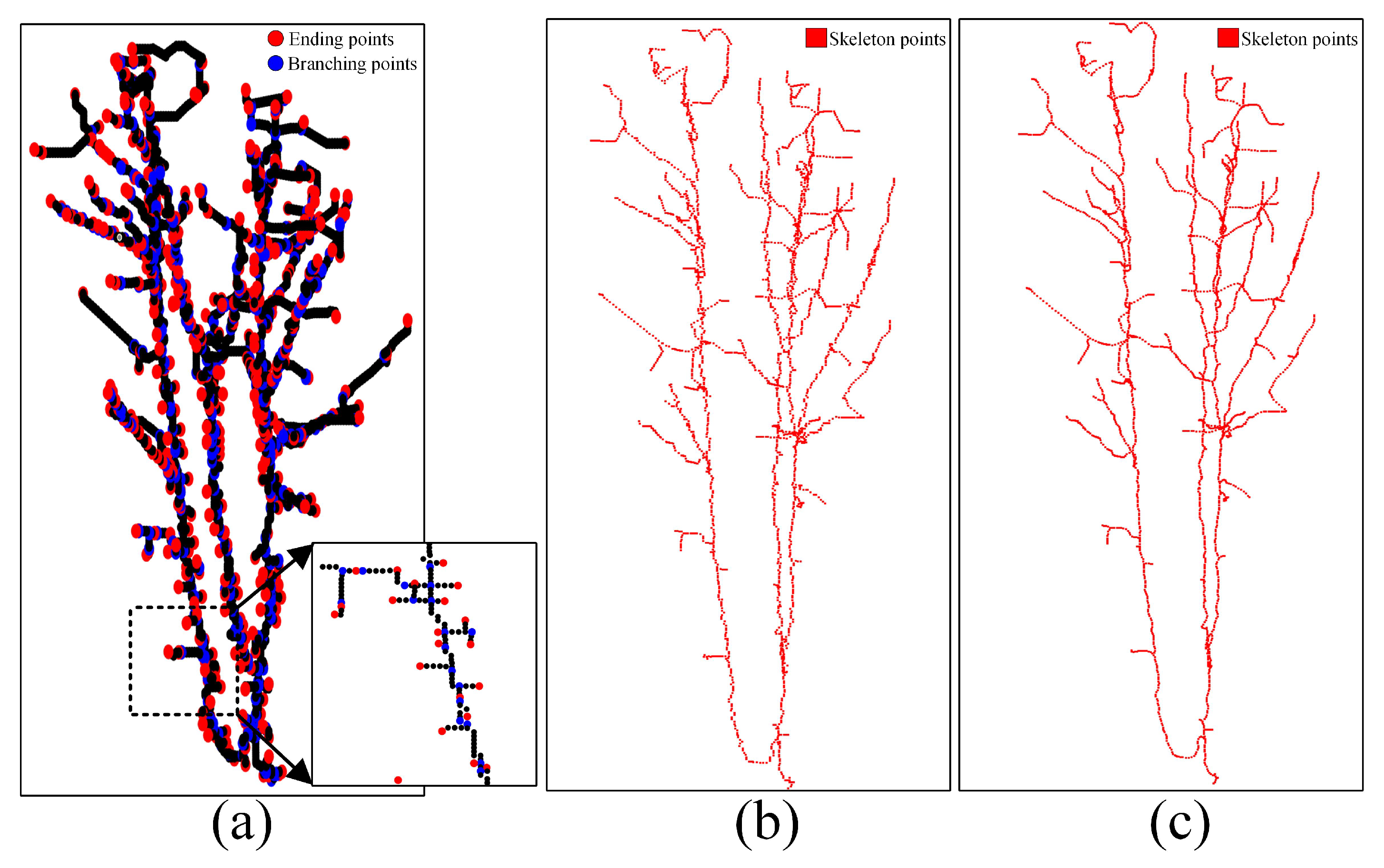
3.3. Points Interpolation
3.4. Path Refinement and Smoothness
4. Experiments and Results
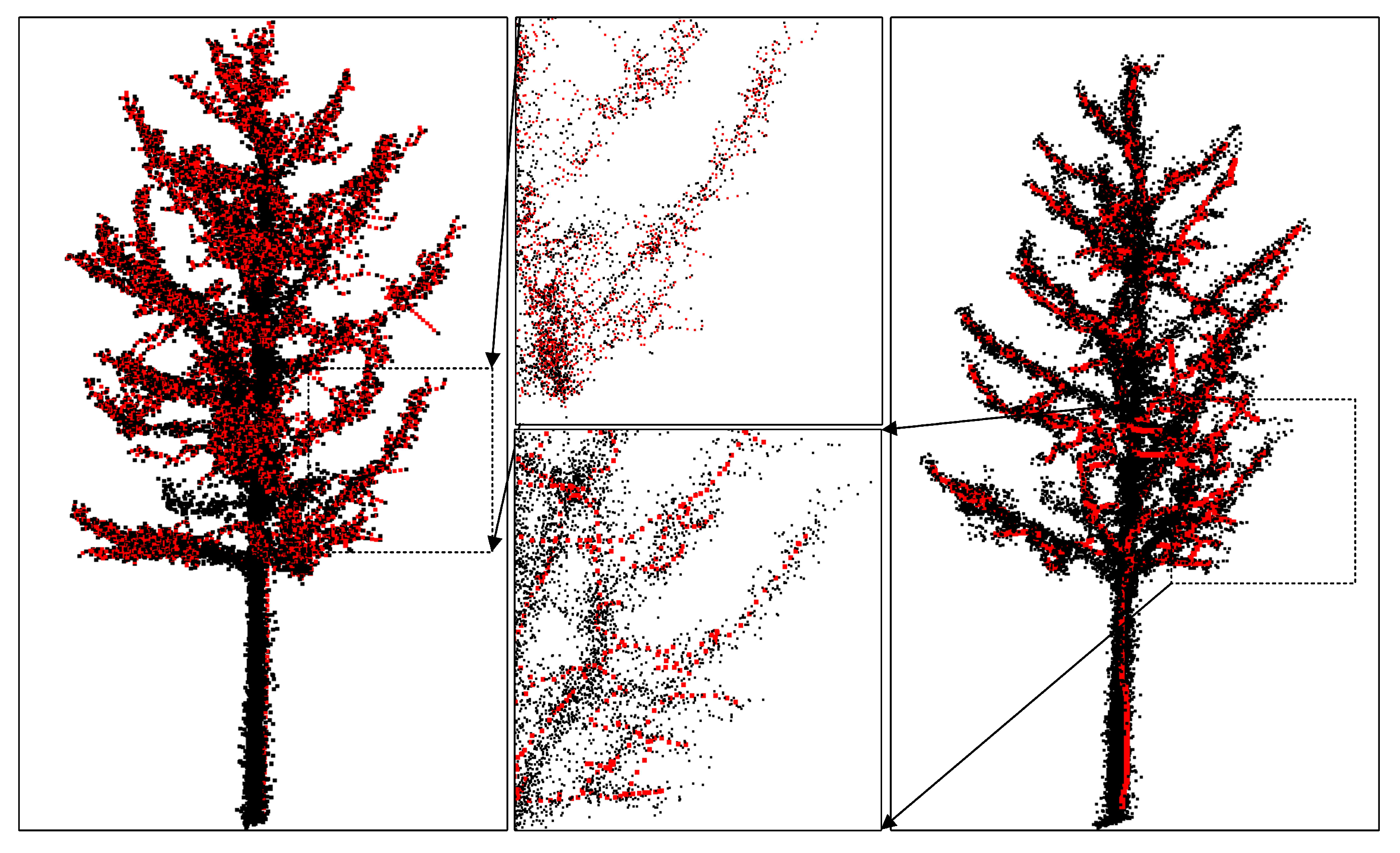
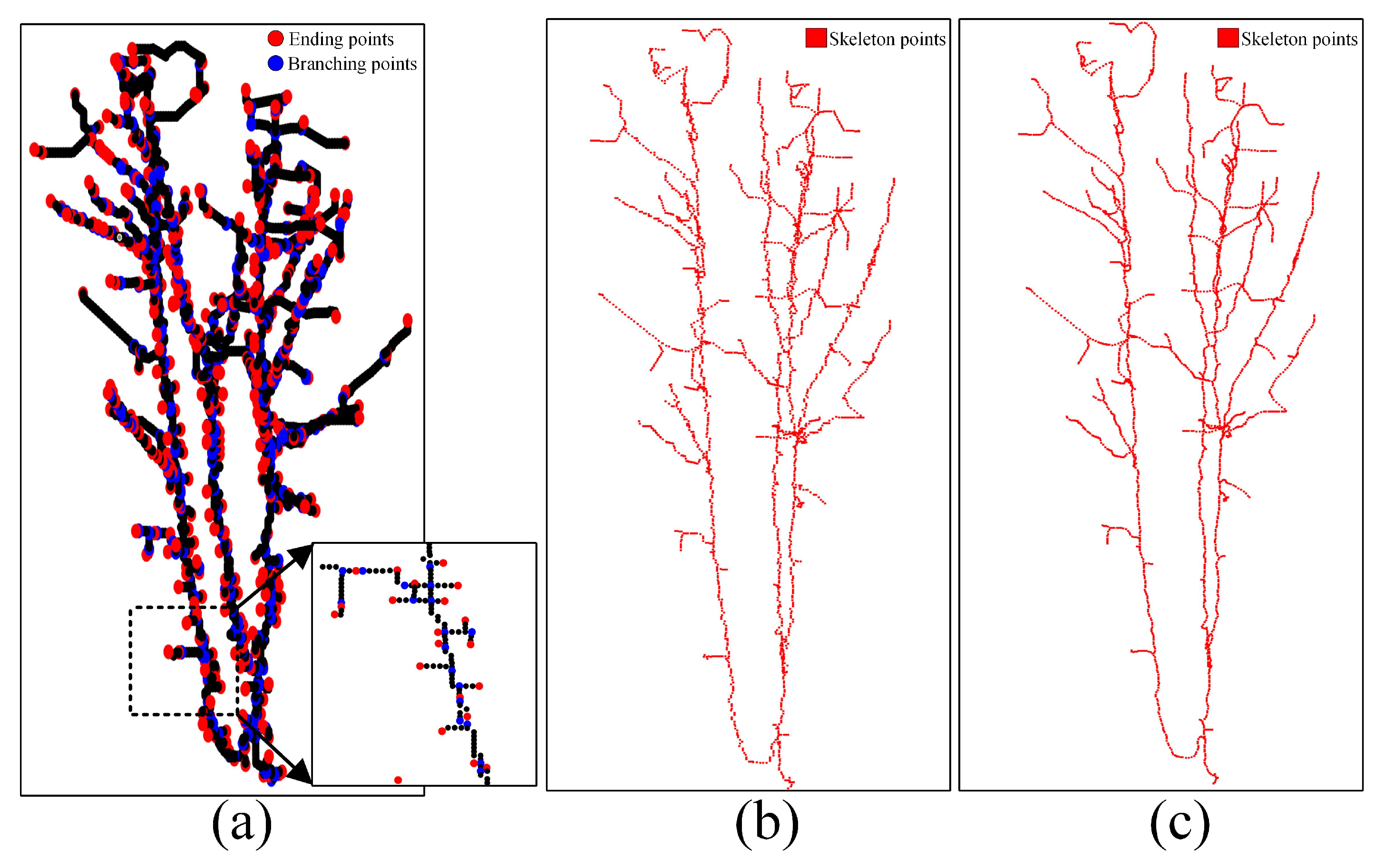
4.1. Visual Evaluation
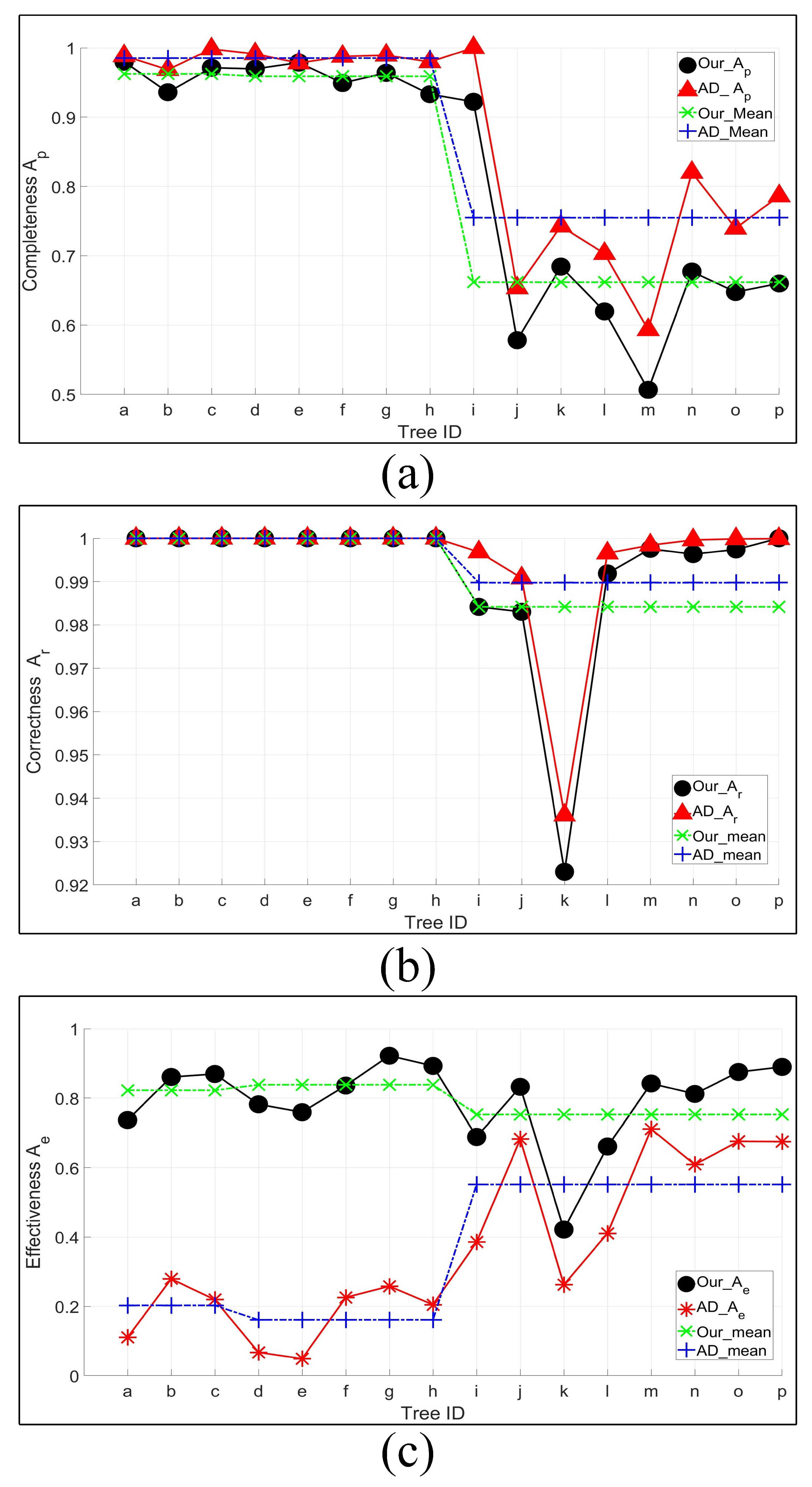
4.2. Quantitative Analysis
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yun, T.; Jiang, K.; Li, G.; Eichhorn, M.P.; Fan, J.; Liu, F.; Chen, B.; An, F.; Cao, L. Individual tree crown segmentation from airborne LiDAR data using a novel Gaussian filter and energy function minimization-based approach. Remote Sens. Environ. 2021, 256, 112307. [Google Scholar] [CrossRef]
- Yun, T.; Cao, L.; An, F.; Chen, B.; Xue, L.; Li, W.; Pincebourde, S.; Smith, M.J.; Eichhorn, M.P. Simulation of multi-platform LiDAR for assessing total leaf area in tree crowns. Agric. For. Meteorol. 2019, 276, 107610. [Google Scholar] [CrossRef]
- Hu, C.; Pan, Z.; Zhong, T. Leaf and wood separation of poplar seedlings combining locally convex connected patches and K-means++ clustering from terrestrial laser scanning data. J. Appl. Remote Sens. 2020, 14, 1. [Google Scholar] [CrossRef]
- Li, Q.; Yuan, P.; Liu, X.; Zhou, H. Street tree segmentation from mobile laser scanning data. Int. J. Remote. Sens. 2020, 41, 7145–7162. [Google Scholar] [CrossRef]
- Xia, S.; Wang, R. Semiautomatic construction of 2-D façade footprints from mobile LIDAR data. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4005–4020. [Google Scholar] [CrossRef]
- Wang, D.; Hollaus, M.; Puttonen, E.; Pfeifer, N. Automatic and self-adaptive stem reconstruction in landslide-affected forests. Remote Sens. 2016, 8, 974. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Wan, P.; Wang, T.; Cai, S.; Chen, Y.; Jin, X.; Yan, G. A novel approach for the detection of standing tree stems from plot-level terrestrial laser scanning data. Remote Sens. 2019, 11, 211. [Google Scholar] [CrossRef] [Green Version]
- Xu, S.; Zhou, K.; Sun, Y.; Yun, T. Separation of Wood and Foliage for Trees from Ground Point Clouds using a Novel Least-cost Path Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 6414–6425. [Google Scholar] [CrossRef]
- Fu, L.; Li, Z.; Ye, Q.; Yin, H.; Liu, Q.; Chen, X.; Fan, X.; Yang, W.; Yang, G. Learning robust discriminant subspace based on joint L2, p-and L2, s-Norm distance metrics. IEEE Trans. Neural Netw. Learn. Syst. 2020. [Google Scholar] [CrossRef] [PubMed]
- Ye, Q.; Huang, P.; Zhang, Z.; Zheng, Y.; Fu, L.; Yang, W. Multiview Learning With Robust Double-Sided Twin SVM. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef] [PubMed]
- Gaillard, M.; Miao, C.; Schnable, J.; Benes, B. Sorghum segmentation by skeleton extraction. In Computer Vision–ECCV 2020 Workshops; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2020; Volume 12540. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, G.; Jiang, Y.; Xu, B.; Li, X.; Zhu, Y.; Lei, L.; Chen, R.; Dong, Z.; Yang, H. Apple tree branch information extraction from terrestrial laser scanning and backpack-lidar. Remote Sens. 2020, 12, 3592. [Google Scholar] [CrossRef]
- Xu, H.; Gossett, N.; Chen, B. Knowledge and heuristic-based modeling of laser-scanned trees. ACM Trans. Graph. (TOG) 2007, 26, 19-es. [Google Scholar] [CrossRef]
- Bucksch, A.; Lindenbergh, R. CAMPINO—A skeletonization method for point cloud processing. ISPRS J. Photogramm. Remote Sens. 2008, 63, 115–127. [Google Scholar] [CrossRef]
- Livny, Y.; Yan, F.; Olson, M.; Chen, B.; Zhang, H.; El-Sana, J. Automatic reconstruction of tree skeletal structures from point clouds. In ACM SIGGRAPH Asia 2010 Papers; Association for Computing Machinery: New York, NY, USA, 2010; pp. 1–8. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Zhang, L.; Fang, T.; Mathiopoulos, P.T.; Qu, H.; Chen, D.; Wang, Y. A structure-aware global optimization method for reconstructing 3-D tree models from terrestrial laser scanning data. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5653–5669. [Google Scholar] [CrossRef]
- Du, S.; Lindenbergh, R.; Ledoux, H.; Stoter, J.; Nan, L. AdTree: Accurate, detailed, and automatic modelling of laser-scanned trees. Remote Sens. 2019, 11, 2074. [Google Scholar] [CrossRef] [Green Version]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | H (m) | S | P | Our_P | AD_P | AD_Ratio | Our_Ratio |
|---|---|---|---|---|---|---|---|
| a | 7.80 | 1 | 22,520 | 1566 | 25,930 | 1.151 | 0.070 |
| b | 8.42 | 1 | 71,220 | 1982 | 79,783 | 1.120 | 0.028 |
| c | 7.62 | 1 | 127,868 | 1620 | 133,979 | 1.048 | 0.013 |
| d | 9.43 | 2 | 413,249 | 2763 | 37,841 | 0.092 | 0.007 |
| e | 9.56 | 2 | 945,333 | 2648 | 35,585 | 0.038 | 0.003 |
| f | 8.20 | 2 | 632,514 | 1891 | 28,243 | 0.045 | 0.003 |
| g | 7.75 | 2 | 789,197 | 2796 | 34,505 | 0.044 | 0.004 |
| h | 7.41 | 2 | 614,486 | 2168 | 35,970 | 0.059 | 0.004 |
| i | 18.58 | 3 | 31,977 | 6311 | 27,701 | 0.866 | 0.197 |
| j | 21.49 | 3 | 424,618 | 10,639 | 45,431 | 0.107 | 0.025 |
| k | 21.01 | 3 | 1,175,513 | 8485 | 34,928 | 0.030 | 0.007 |
| l | 21.09 | 3 | 1,531,635 | 9122 | 38,248 | 0.025 | 0.006 |
| m | 23.15 | 3 | 1,528,382 | 10,722 | 40,953 | 0.027 | 0.007 |
| n | 24.68 | 3 | 16,407 | 7381 | 21,818 | 1.330 | 0.450 |
| o | 25.42 | 3 | 95,923 | 9609 | 40,107 | 0.418 | 0.100 |
| p | 23.61 | 3 | 1,316,136 | 11,414 | 43,361 | 0.033 | 0.009 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, S.; Li, X.; Yun, J.; Xu, S. An Effectively Dynamic Path Optimization Approach for the Tree Skeleton Extraction from Portable Laser Scanning Point Clouds. Remote Sens. 2022, 14, 94. https://doi.org/10.3390/rs14010094
Xu S, Li X, Yun J, Xu S. An Effectively Dynamic Path Optimization Approach for the Tree Skeleton Extraction from Portable Laser Scanning Point Clouds. Remote Sensing. 2022; 14(1):94. https://doi.org/10.3390/rs14010094
Chicago/Turabian StyleXu, Sheng, Xin Li, Jiayan Yun, and Shanshan Xu. 2022. "An Effectively Dynamic Path Optimization Approach for the Tree Skeleton Extraction from Portable Laser Scanning Point Clouds" Remote Sensing 14, no. 1: 94. https://doi.org/10.3390/rs14010094
APA StyleXu, S., Li, X., Yun, J., & Xu, S. (2022). An Effectively Dynamic Path Optimization Approach for the Tree Skeleton Extraction from Portable Laser Scanning Point Clouds. Remote Sensing, 14(1), 94. https://doi.org/10.3390/rs14010094