1. Introduction
Earthquakes are events of episodic nature, which can have a grave impact on human life and cause immense property loss. The Centre for Research on the Epidemiology of Disasters (CRED) and UN Office for Disaster Risk Reduction (UNDRR) [
1] report on the cost of disasters for the period 2000–2019 declared earthquakes as the deadliest type of disaster for the first two decades of the 21st century, and highlight their potential for massive damage to infrastructure. Given that earthquakes are unpredictable, both in terms of time and magnitude, responding appropriately after the event is often critical to minimize the number of casualties. The success of emergency response operations relies on efficient organizational management and rapid reaction. A mandatory precondition to fulfill these requirements is to gain Situational Awareness: to know what has happened, when and where. The suitability of Machine Learning (ML) [
2] techniques in different phases of disaster mitigation has been exhibited in recent studies. Harirchian et al. [
3] assess the seismic vulnerability given a set of quantifiable parameters. The regional seismicity can also be monitored using ML if the automatically captured ambient noise data are subjected to Convolutional Neural Network (CNN)-based classifiers in order to detect earthquake events [
4]. In the post-disaster phase, ML approaches have been employed to locate and measure post-earthquake urban damage, confirming the relevance of this field for such kinds of applications [
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15]. Pre-event seismic vulnerability assessment, earthquake magnitude evaluation and post-event damage detection are complementary aspects of disaster mitigation and, if combined, can provide valuable insights to local stakeholders for traffic network disruption modeling, restoration planning and cost estimation [
16].
To identify the locations that require immediate relief, remotely sensed data are commonly used because they can provide an overview of a large region at once, and acquiring them does not pose the same risks as collecting ground-truth data [
11]. In the context of emergency mapping, remotely sensed data usually refer to imagery acquired via satellite, Unmanned Aerial Vehicles (UAVs) or other aerial platforms [
17]. As the availability of this kind of data and the processing power of modern computational systems have been constantly increasing, the possibility of automating the identification and assessment of post-disaster damage is also being explored [
18]. For this reason, computer vision methods are employed, aiming to minimize the time overhead and the error that is introduced by the human factor [
9]. Recent studies have demonstrated that ML algorithms outperform traditional Remote Sensing techniques in image classification tasks [
19]. One of the main obstacles to overcome in the identification of earthquake damage is the small number of training samples [
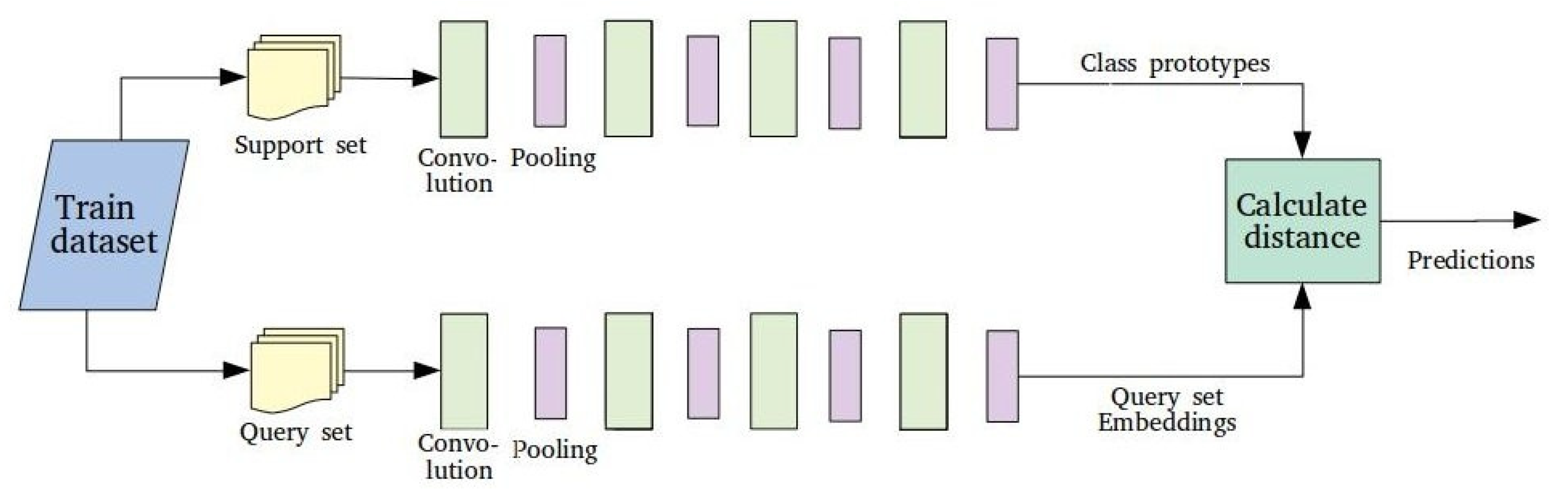
6]. The methodology that we follow in this study is based on Few-Shot Learning (FSL), which is a type of ML method, where the available data for the target classification task contains only a limited number of examples with supervised information [
20]. Since destructive seismic events rarely happen but reacting quickly in such cases is crucial, FSL is competent when it comes to extracting knowledge from a narrow amount of data, and thus, the required effort for data gathering is also reduced. However, an FSL problem is not easy to solve. The lack of data requires a different approach than other ML problems, which rely on having a plethora of samples to train the model. The suggested solutions may vary in terms of algorithm, model parameters and data handling [
20].
Related research papers that have incorporated FSL for locating ravaged buildings focus on binary classification rather than further dividing buildings into different wreckage levels [
5,
6,
8,
10,
12]. Multi-class categorization, though, can emphasize or even create class imbalances within the data. The present study seeks to fill this gap by leveraging FSL to tackle data deficiency for certain classes in a multi-class problem. There are several means of dealing with data deficiency [
20,
21] and imbalance [
22]. Applications that track disaster-related damage with ML can benefit from the existence of pre-event data, but on some occasions, this kind of data may be impossible to acquire. For this reason, we examine how efficient can a model be that is based only on post-event data. The purpose of this study is to implement and evaluate the effect of different FSL approaches on an imbalanced dataset. More precisely, we explore how can the supervised classification of a highly imbalanced dataset be elaborated, to what extent are the representatives of the majority and minority classes successfully detected and how indicative is the map overlay of the predictions for the severity of damage suffered by a geographic region.
The rest of the document is organized as follows.
Section 2 reviews related studies, considers the applied research approaches and analyzes the theoretical background that is necessary to follow the present study.
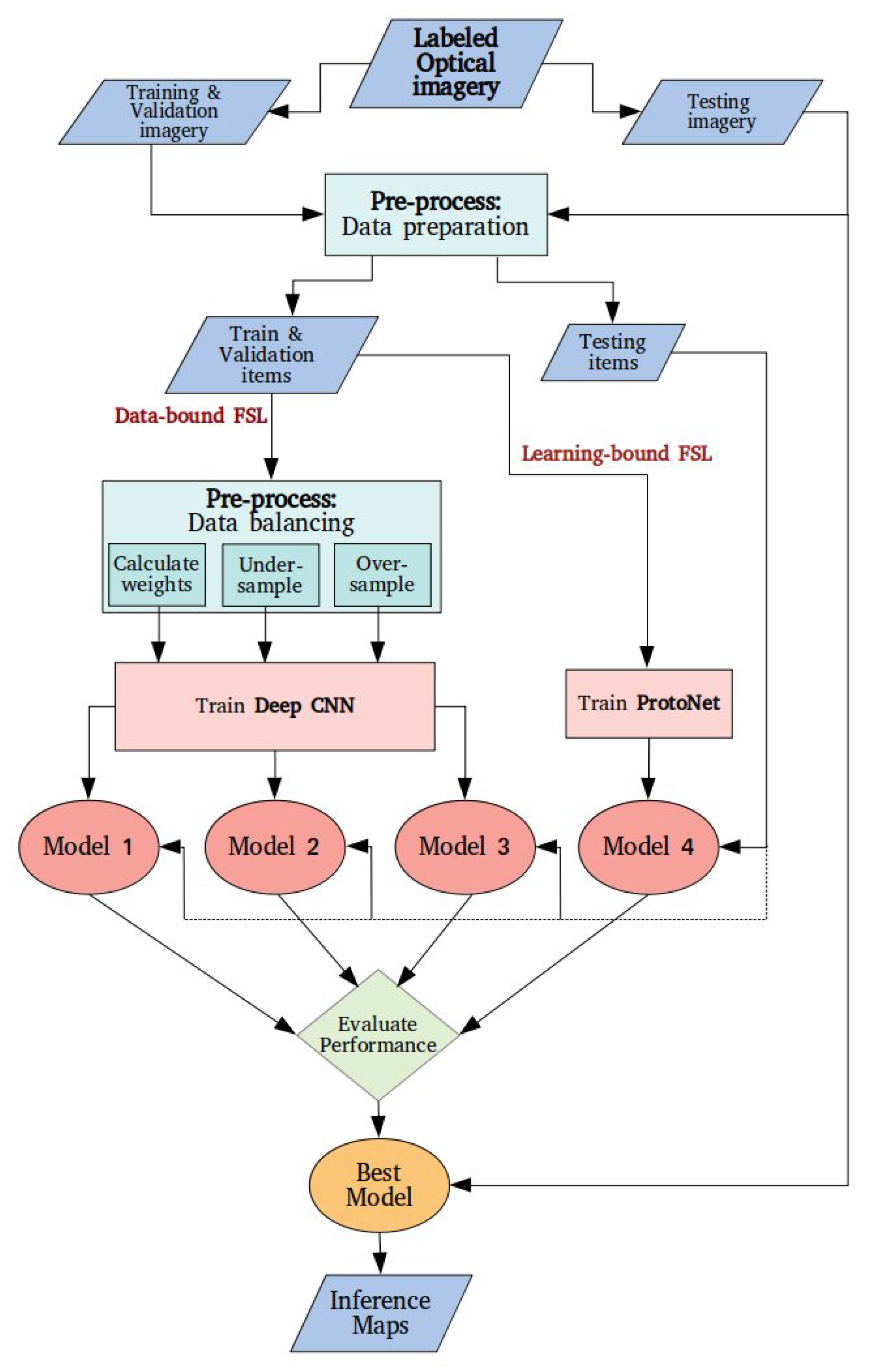
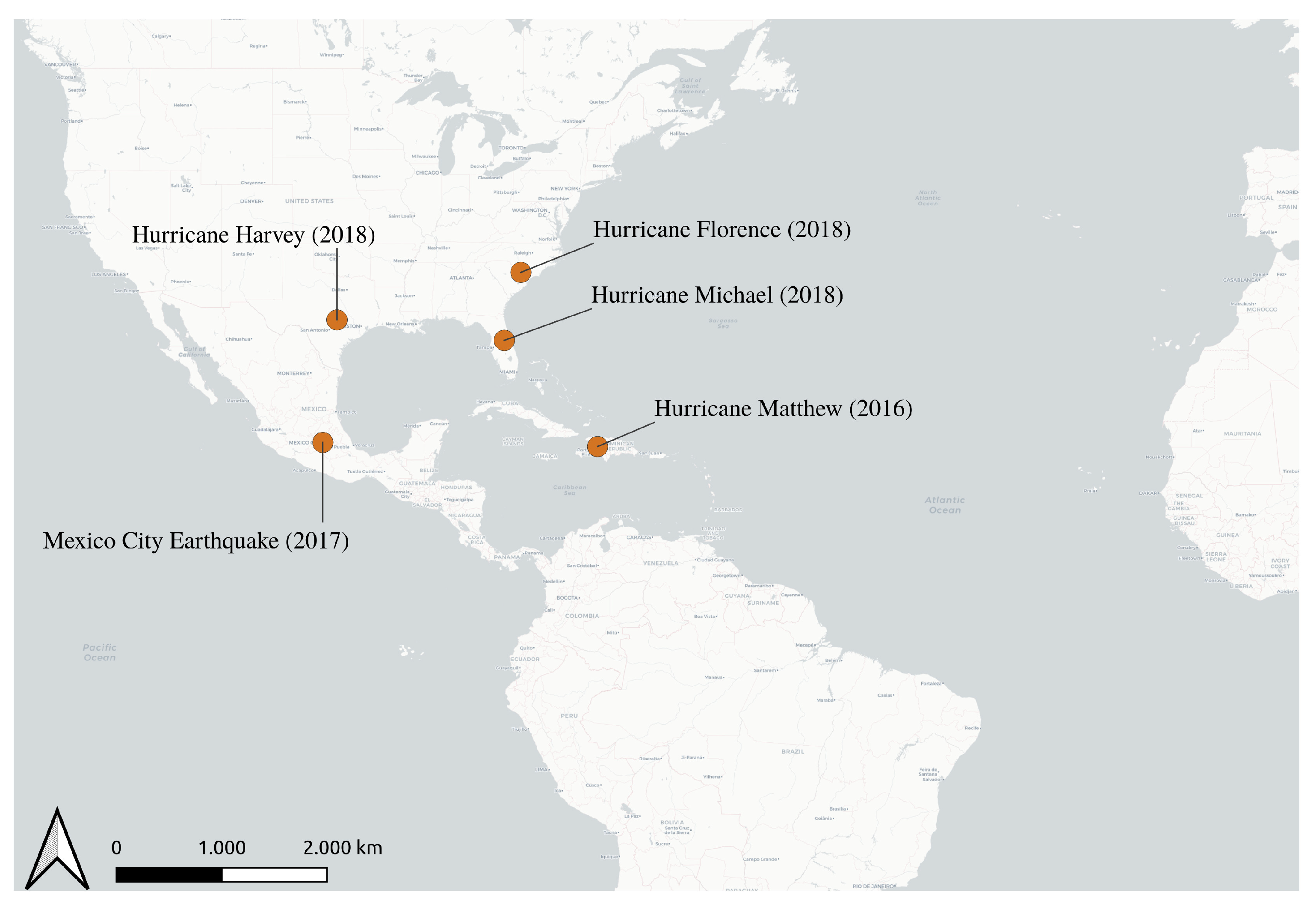
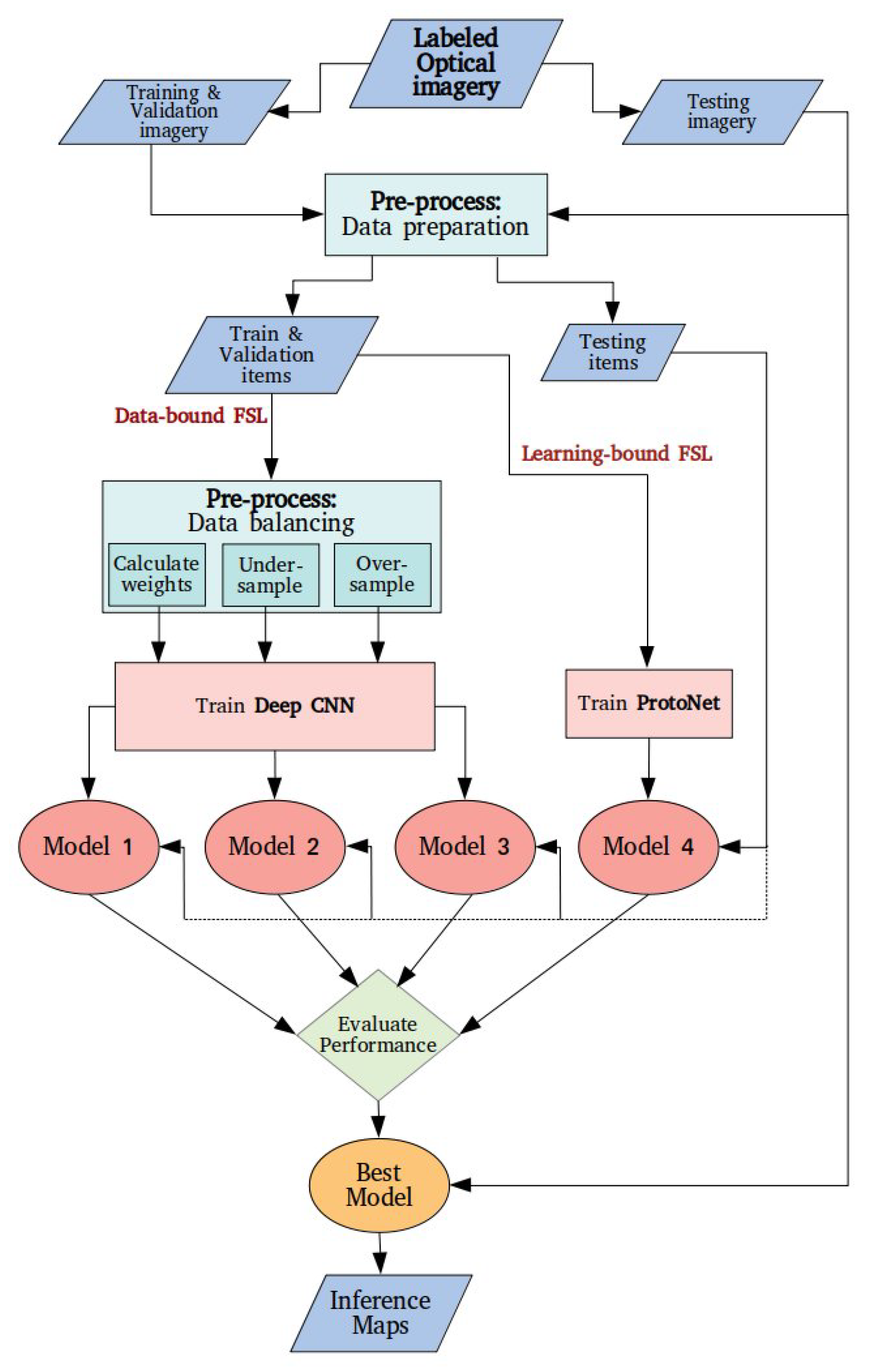
Section 3 presents the data and the methodological workflow.
Section 4 explains the results of the study and is followed by
Section 5, which discusses the results and proposes future research directions. Finally,
Section 6 concludes the work.
5. Discussion
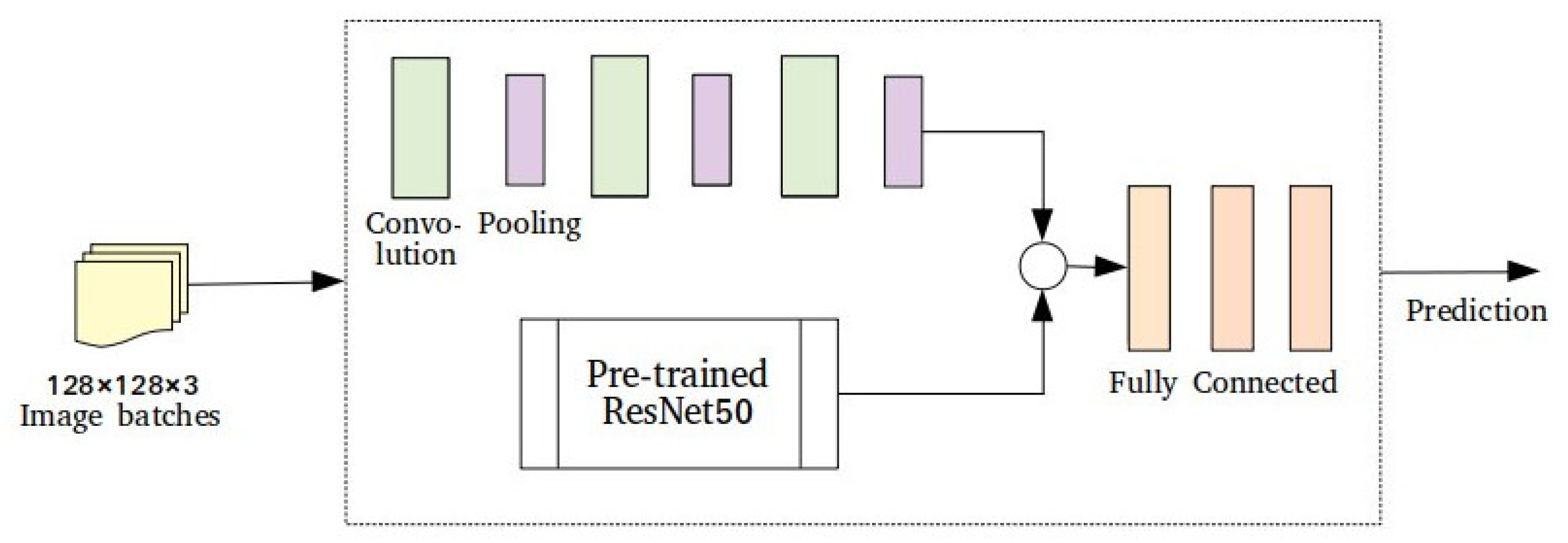
Previous work indicates that the common trend for urban damage assessment with Remote Sensing is to use Deep Learning. The data shortage is mostly addressed with data augmentation, but pre-trained models and unsupervised learning have also been put to the test. All these approaches are considered Few-Shot Learning, demonstrating the applicability of this Machine Learning family of strategies in relevant problems. In this study, we took into consideration the type of input imagery (labeled optical imagery) and the intended number of output classes (four-level damage scale) to select the appropriate methodological components. According to the conclusions drawn by the literature review, we confronted the data shortage in two distinct ways: (1) balancing and augmenting the dataset to make it suitable for training a Deep Architecture and (2) metric Few-Shot Learning with Prototypical Networks. More data from hurricane incidents were incorporated in the analysis as a first step of expanding the dataset with data from related problems. Subsequently, four different models were developed and compared.
As revealed by the quantitative evaluation to which the models were subjected, oversampling achieved the highest precision and f-score values for all classes and the highest recall values for all classes except
Minor damage, amongst all three data-balancing strategies for Deep Learning architectures. This outcome is consistent with related studies that have used the xBD dataset for model training. Valentijn et al. [
14] have compared cost-sensitive learning with a combination of over and undersampling and conclude that the latter is more effective in the classification outcome. Bai et al. [
15] mention that after preliminary experiments, they chose to use oversampling to train their models. Contrarily Ji et al. [
6] used a different dataset to train a binary CNN-based classifier and found cost-sensitive learning more effective as a balancing operation.
The comparison of the four models demonstrates that Prototypical Network models can outperform Deep Learning models in damage classification problems with data scarcity. However, in accordance with other studies from the literature, it was not easy to acquire very high accuracy results for a small dataset with slight inter-class disparities in a multi-class classification task. Furthermore, although the xBD dataset is not uncommon in the recent damage classification studies, its use of it in research that focuses on FSL has not been encountered in the literature. As a consequence, similar studies exploit the entirety of the xBD for model training. Valentijn et al. [
14], who trained a model based on Inception-v3 with xBD, report on recall as the following:
No damage: 0.867,
Minor damage: 0.541,
Major damage: 0.607 and
Destroyed: 0.679. As shown in
Table 9, the recall of the ProtoNets model is 0.69 for
No damage, 0.52 for
Minor damage, 0.57 for
Major damage and 0.75 for
Destroyed. The results are not only comparable but also can surpass the performance of a model trained with the entire dataset. Bai et al. [
15], who also trained their proposed architecture with xBD, report on the same evaluation metrics as the present paper, namely precision, recall and f-score, and distinguish between localization and classification metrics, so the comparison with the values of
Table 9 is more straight-forward. For
No damage, the results for precision, recall and f-score are 90.64%, 87.07% and 89.85%, respectively, and are significantly higher than the respective values in
Table 9. On the contrary, the calculated metrics for
Minor damage (precision: 35.51%, recall: 49.50%, f-score: 41.36%) are significantly lower than the values of
Table 9. For
Major damage, the Bai et al. [
15] performance metrics (precision: 65.80%, recall: 64.93%, f-score: 65.36%) are higher than Model 4. Finally, for
Destroyed, the precision in Bai et al. [
15] is 87.08%, which is higher than Model 4, but the other two metrics (recall: 57.87%, f-score: 69.55%) are lower than Model 4. As a general remark, Model 4, which is based on ProtoNets, exhibits more consistent behavior across the four classes, but it performs significantly lower for
No damage.
Based on the intuitive interpretation gained by the visual mapping of the predictions of Model 4 compared to the ground truth, we can deduce that the tested model has plenty of room for improvement but seems promising for tackling the problem of post-earthquake urban damage assessment. The most confounding aspect of the results is when
No damage buildings are misinterpreted as
Destroyed and vice versa because in a real case scenario it could lead to consuming critical resources and time for assisting the wrong locations. It must be stated that such misclassifications seem to be more rare as the area of the polygon increases. In the broader context of emergency response, the significance of the damage classification output should be validated by other data sources. Seismic vulnerability reports, smart building structural monitoring [
46] and earthquake magnitude measurements based on environmental noise [
4] can be ancillary information to earth observation-based damage classification. The aforementioned information sources, along with ground-truth verification, should be taken into account for the response planning by the local authorities, as the traffic network capacity and the citizen mobility demands change dramatically during the recovery process [
16].
While the obtained results from Model 4 seem promising, there are certain limitations to the extent a 50-shot metric-learning approach on satellite imagery of this resolution can reach. Randomly picking 50 representatives of each class to train a ProtoNet model may have led to excluding important information carried by the data. Additionally, satellite imagery of higher resolution is usually private, and thus, very difficult to acquire. The model’s ability to assess damage is also limited to disasters of a magnitude similar to the events in the training data set.
Since the outcome is encouraging, further research on this subject is recommended. Although remotely sensed imagery of higher resolution is difficult to obtain, we anticipate that a similar study with satellite or UAV imagery of higher resolution should be pursued. UAVs can also provide oblique perspectives of the buildings, which may hold important information in the context of structural damage and have been already applied in similar applications [
7]. Furthermore, instead of picking at random a few examples from the available data, certain data sampling techniques, such as Near-Miss and Condensed Nearest Neighbor Rule, can be employed to determine the most useful samples to train a model. We strongly believe that Prototypical Networks in the context of urban damage assessment deserve more exploration. The number of shots, the prototyping function and the distance function are parameters to experiment with, and that could improve the existing results.
6. Conclusions
This study employed Very-High Resolution pan-sharpened satellite imagery and Machine Learning in order to identify the level of structural destruction induced by a catastrophic earthquake incident. Aiming to approximate a real case scenario, where the available labeled post-event data are limited, and the pre-event data are possibly nonexistent, the different explored possibilities tackle data insufficiency and imbalance by implementing Few-Shot Learning strategies and pave the way for a new approach to the difficult problem of multi-class damage classification that is formulated upon limited data.
The classification of an imbalanced dataset can be solved either by adjusting the weight matrix, in a way trying to normalize the number of examples for every class (cost-sensitive learning) or by selecting the same number of representatives for each class to build the training set. For a balanced Deep CNN training, three different models were created: Model 1 with cost-sensitive learning, Model 2 with undersampling and Model 3 with oversampling. For Model 4, a 50-shot ProtoNet was trained. This process resulted in four models, each having been trained with a different dataset in terms of the total number of examples and the class proportions. Nevertheless, all models were evaluated based on the same balanced set of completely unseen data. The first method was eventually inefficient in our case while using a balanced dataset when training image classification models immediately added up to the overall performance. Undersampling may cause a loss of decisive information for the classification process, and thus, it is not as considerable as oversampling for training a Deep CNN model. However, for Prototypical Networks, randomly picking a few samples per class was enough for creating the most effective and efficient model.
The four models were compared using precision, recall and f-score. Model 4, built upon Prototypical Networks, showed the most consistent performance according to the three metrics, although Model 3 (data oversampling in the pre-processing stage) exhibited almost equally good results for most classes. Taking a closer look, all four approaches have a different impact on each class. It can be argued that such an eminently imbalanced dataset cannot fully support the training of a multi-class predictive model with cost-sensitive learning since Model 1 is entirely unable to detect the minority class. As stated before, undersampling also leads to dismissing valuable information and hence, the resulting Model 2 has a limited predictive ability over certain classes but performs very well for the minority class. Oversampling seems to be more competent for creating a Deep CNN-based predictive model but has a borderline performance for the majority class. Model 4 seems to achieve a robust performance for all classes, being able to correctly predict more than half of their instances. Consequently, Model 4 was used for creating damage assessment maps to provide an idea of the model’s practical applicability.
The predictions of Model 4 were overlaid with the satellite imagery and compared with the true polygon labels to obtain a qualitative impression of how close the output of the model is to reality. Even though the model is in the right direction for damage assessment, it would not be advisable to base on it an estimation about how gravely an area was affected (
Figure 6,
Figure 7 and
Figure 8). Improvements must still be made so that the possible misinterpretations between
No damage and
Destroyed buildings are eliminated. This phenomenon seems less frequent for polygons of a larger area.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}