
Instance Segmentation in Very High Resolution Remote Sensing Imagery Based on Hard-to-Segment Instance Learning and Boundary Shape Analysis



Abstract
:
1. Introduction
- We propose an ensemble workflow to strengthen the learning of hard-to-segment instances and edges, especially sharp edges, and explore our method on two datasets with different feature distributions and spatial resolutions.
- For hard instance mining, we adopt a pixel-level Dice metric that reliably describes the segmentation quality of each instance to achieve online hard instance learning. To the best of our knowledge, it is the first attempt to calculate and apply the segmentation difficulty of instances for hard instance learning.
- Edges of different shapes are explored and weighted by the shape-penalty map discriminatively, which effectively improves the performance of instance segmentation detectors.
2. Related Work
2.1. Instance Segmentation
2.2. Hard Example Mining
2.3. Edge Enhancement
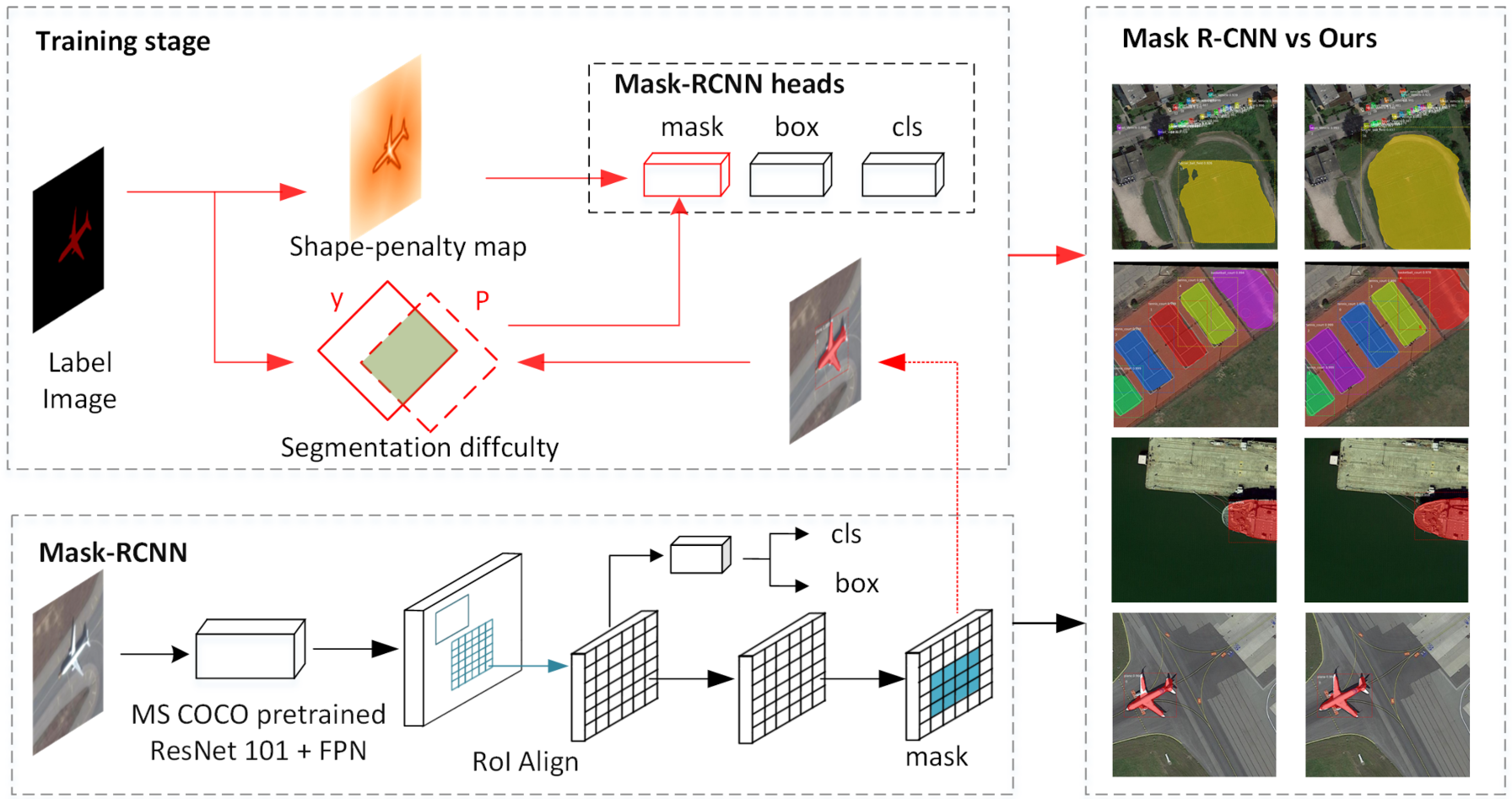
3. The Method
3.1. Motivation
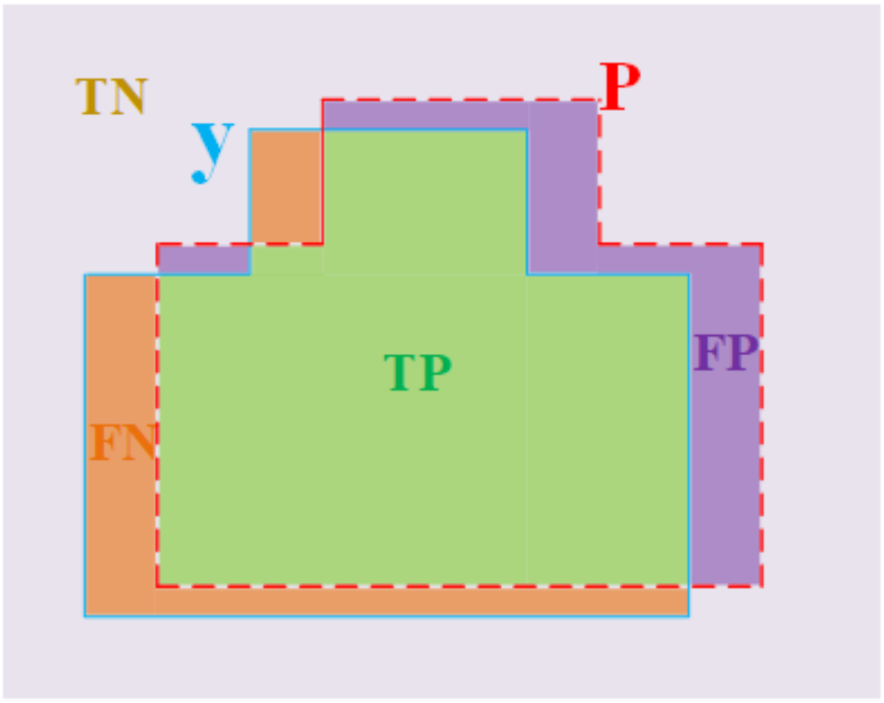
3.2. Hard-to-Segment Instance Learning
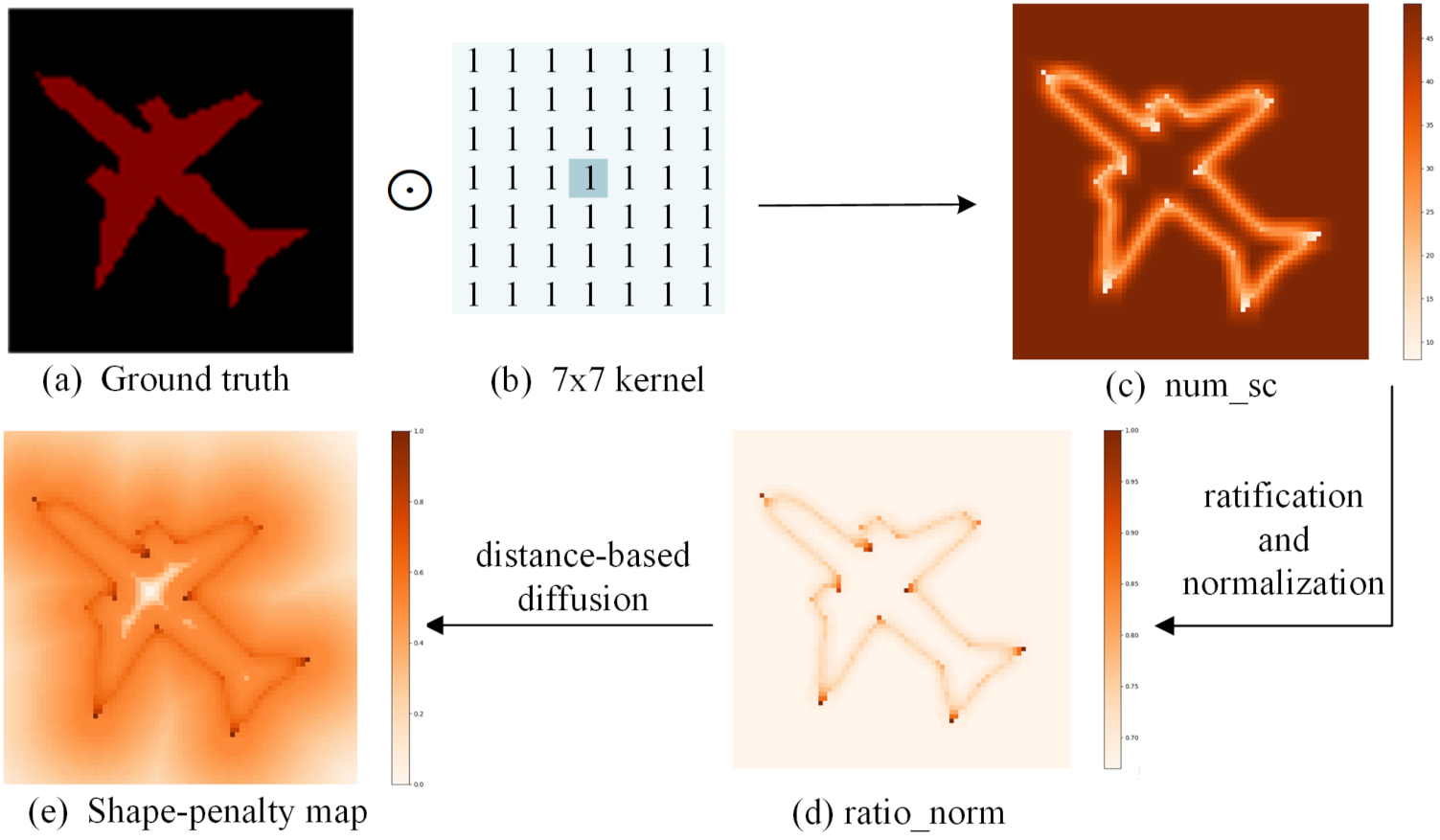
3.3. Shape-Penalty Map for Edge Enhancement
3.4. Mask R-CNN Improved by Our Method
3.4.1. Architecture
3.4.2. Training and Inference
4. Experiments and Results
4.1. Datasets
4.1.1. iSAID-Reduce100
4.1.2. JKGW_WHU
4.2. Experimental Setup
4.3. Experimental Results
4.3.1. Instance Segmentation on iSAID-Reduce100
4.3.2. Instance Segmentation on JKGW_WHU
4.3.3. Quantitative Comparison with Advanced Methods
4.4. Architecture Design Analysis
4.4.1. Architecture
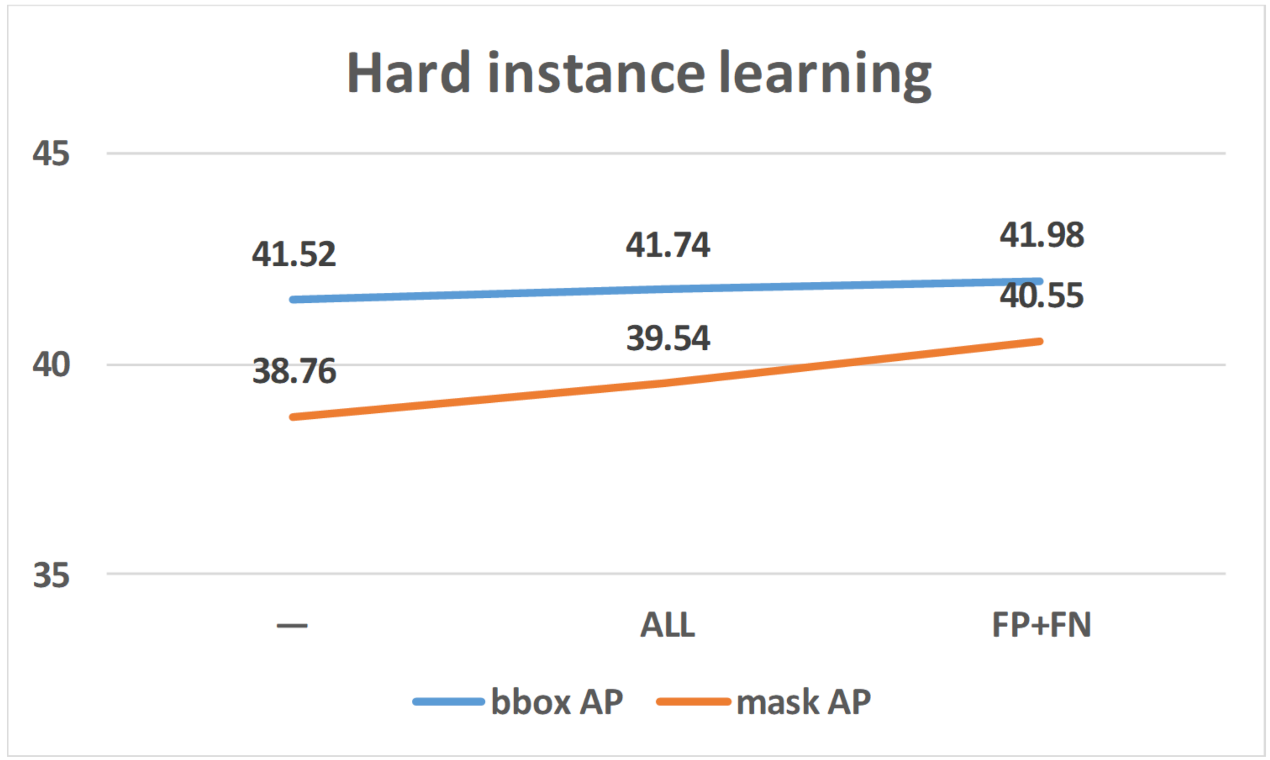
4.4.2. Hard-to-Segment Instance Learning
4.4.3. Edge Enhancement Based on the Shape-Penalty Map
4.4.4. Timing
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Tang, P.; Wang, X.; Huang, Z.; Bai, X.; Liu, W. Deep patch learning for weakly supervised object classification and discovery. Pattern Recognit. 2017, 71, 446–459. [Google Scholar] [CrossRef] [Green Version]
- Kwon, S. CLSTM: Deep Feature-Based Speech Emotion Recognition Using the Hierarchical ConvLSTM Network. Mathematics 2020, 8, 133. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, T.Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar] [CrossRef] [Green Version]
- Shrivastava, A.; Gupta, A.; Girshick, R.B. Training Region-Based Object Detectors with Online Hard Example Mining. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 761–769. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar] [CrossRef] [Green Version]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015—18th International Conference Munich, Munich, Germany, 5–9 October 2015; Volume 9351, pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. arXiv 2016, arXiv:1606.00915. [Google Scholar] [CrossRef] [PubMed]
- Dai, J.; He, K.; Sun, J. Instance-Aware Semantic Segmentation via Multi-task Network Cascades. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 3150–3158. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar] [CrossRef]
- Huang, Z.; Huang, L.; Gong, Y.; Huang, C.; Wang, X. Mask scoring r-cnn. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6409–6418. [Google Scholar]
- Dai, J.; He, K.; Li, Y.; Ren, S.; Sun, J. Instance-Sensitive Fully Convolutional Networks. In Proceedings of the Computer Vision—ECCV 2016—14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9910, pp. 534–549. [Google Scholar] [CrossRef] [Green Version]
- Arnab, A.; Torr, P.H.S. Pixelwise Instance Segmentation with a Dynamically Instantiated Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 879–888. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.C.; Hermans, A.; Papandreou, G.; Schroff, F.; Wang, P.; Adam, H. Masklab: Instance segmentation by refining object detection with semantic and direction features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4013–4022. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Takikawa, T.; Acuna, D.; Jampani, V.; Fidler, S. Gated-SCNN: Gated Shape CNNs for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 27 October–2 November 2019; pp. 5228–5237. [Google Scholar] [CrossRef] [Green Version]
- Chen, L.; Barron, J.T.; Papandreou, G.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Task-Specific Edge Detection Using CNNs and a Discriminatively Trained Domain Transform. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; pp. 4545–4554. [Google Scholar] [CrossRef] [Green Version]
- Kervadec, H.; Bouchtiba, J.; Desrosiers, C.; Granger, E.; Dolz, J.; Ayed, I.B. Boundary loss for highly unbalanced segmentation. In Proceedings of the International Conference on Medical Imaging with Deep Learning, PMLR, London, UK, 8–10 July 2019; pp. 285–296. [Google Scholar]
- Hayder, Z.; He, X.; Salzmann, M. Boundary-aware instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5696–5704. [Google Scholar]
- Chen, Z.; Zhou, H.; Xie, X.; Lai, J. Contour Loss: Boundary-Aware Learning for Salient Object Segmentation. arXiv 2019, arXiv:1908.01975. [Google Scholar] [CrossRef] [PubMed]
- Calivá, F.; Iriondo, C.; Martinez, A.M.; Majumdar, S.; Pedoia, V. Distance Map Loss Penalty Term for Semantic Segmentation. arXiv 2019, arXiv:1908.03679. [Google Scholar]
- Pinheiro, P.O.; Collobert, R.; Dollár, P. Learning to segment object candidates. arXiv 2015, arXiv:1506.06204. [Google Scholar]
- Li, Y.; Qi, H.; Dai, J.; Ji, X.; Wei, Y. Fully Convolutional Instance-Aware Semantic Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4438–4446. [Google Scholar] [CrossRef] [Green Version]
- Kirillov, A.; Levinkov, E.; Andres, B.; Savchynskyy, B.; Rother, C. InstanceCut: From Edges to Instances with MultiCut. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 7322–7331. [Google Scholar] [CrossRef] [Green Version]
- Arbeláez, P.A.; Pont-Tuset, J.; Barron, J.T.; Marqués, F.; Malik, J. Multiscale Combinatorial Grouping. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2014, Columbus, OH, USA, 23–28 June 2014; pp. 328–335. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; He, K.; Sun, J. Convolutional feature masking for joint object and stuff segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2015, Boston, MA, USA, 7–12 June 2015; pp. 3992–4000. [Google Scholar] [CrossRef] [Green Version]
- Malisiewicz, T.; Gupta, A.; Efros, A.A. Ensemble of exemplar-SVMs for object detection and beyond. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2011, Barcelona, Spain, 6–13 November 2011; pp. 89–96. [Google Scholar] [CrossRef] [Green Version]
- Felzenszwalb, P.F.; Girshick, R.B.; McAllester, D.A.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dollár, P.; Tu, Z.; Perona, P.; Belongie, S.J. Integral Channel Features. In Proceedings of the British Machine Vision Conference, BMVC 2009, London, UK, 7–10 September 2009; pp. 1–11. [Google Scholar] [CrossRef] [Green Version]
- Cheng, T.; Wang, X.; Huang, L.; Liu, W. Boundary-preserving mask r-cnn. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 660–676. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.A. V-Net: Fully Convolutional Neural Networks for Volumetric Medical Image Segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016. [Google Scholar]
- Wu, S.; Li, X. Iou-balanced loss functions for single-stage object detection. arXiv 2019, arXiv:1908.05641. [Google Scholar]
- Waqas Zamir, S.; Arora, A.; Gupta, A.; Khan, S.; Sun, G.; Shahbaz Khan, F.; Zhu, F.; Shao, L.; Xia, G.S.; Bai, X. isaid: A large-scale dataset for instance segmentation in aerial images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019; pp. 28–37. [Google Scholar]
- Abdulla, W. Mask R-CNN for Object Detection and Instance Segmentation on Keras and TensorFlow. Available online: https://github.com/matterport/Mask_RCNN (accessed on 20 June 2019).
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7310–7311. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | bbox AP (%) | Mask AP (%) |
|---|---|---|---|
| BCE Loss [15] | ResNet-101 | 41.52 | 38.76 |
| Focal Loss [20] | ResNet-101 | 40.83 | 37.80 |
| ContourLoss [25] | ResNet-101 | 41.76 | 40.19 |
| Distance-Penalty Loss [26] | ResNet-101 | 41.48 | 41.02 |
| Hard-to-segment instance learning | ResNet-101 | 41.98 | 40.55 |
| Shape-penalty map | ResNet-101 | 42.36 | 41.02 |
| The proposed method | ResNet-101 | 42.57 | 41.54 |
| Method | Backbone | bbox AP (%) | Mask AP (%) |
|---|---|---|---|
| BCE [15] | ResNet-101 | 92.43 | 92.35 |
| Focal Loss [20] | ResNet-101 | 92.47 | 92.54 |
| ContourLoss [25] | ResNet-101 | 93.17 | 93.15 |
| Distance-penalty Loss [26] | ResNet-101 | 93.17 | 93.36 |
| Hard-to-segment instance learning | ResNet-101 | 93.90 | 93.85 |
| Shape-penalty map | ResNet-101 | 92.51 | 93.45 |
| The proposed method | ResNet-101 | 94.10 | 94.12 |
| iSAID-Reduce100 | JKGW_WHU | ||||
|---|---|---|---|---|---|
| Method | Backbone | bbox AP (%) | Mask AP (%) | bbox AP (%) | Mask AP (%) |
| Mask R-CNN [15] | ResNet-101 | 41.47 | 35.24 | 92.97 | 93.20 |
| Mask Scoring R-CNN [16] | ResNet-101 | 41.27 | 36.14 | 92.17 | 92.30 |
| BMask R-CNN [35] | ResNet-101 | 39.02 | 36.46 | 91.23 | 91.32 |
| The proposed method | ResNet-101 | 41.52 | 38.42 | 93.64 | 95.77 |
| Method | Backbone | bbox AP | Mask AP |
|---|---|---|---|
| BCE Loss | ResNet-50 | 39.36% | 32.57% |
| The proposed method | ResNet-50 | 40.71% | 39.56% |
| BCE Loss | ResNet-101 | 41.52% | 38.76% |
| The proposed method | ResNet-101 | 42.57% | 41.54% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, Y.; Zhang, F.; Jia, X.; Mao, Z.; Huang, X.; Li, D. Instance Segmentation in Very High Resolution Remote Sensing Imagery Based on Hard-to-Segment Instance Learning and Boundary Shape Analysis. Remote Sens. 2022, 14, 23. https://doi.org/10.3390/rs14010023
Gong Y, Zhang F, Jia X, Mao Z, Huang X, Li D. Instance Segmentation in Very High Resolution Remote Sensing Imagery Based on Hard-to-Segment Instance Learning and Boundary Shape Analysis. Remote Sensing. 2022; 14(1):23. https://doi.org/10.3390/rs14010023
Chicago/Turabian StyleGong, Yiping, Fan Zhang, Xiangyang Jia, Zhu Mao, Xianfeng Huang, and Deren Li. 2022. "Instance Segmentation in Very High Resolution Remote Sensing Imagery Based on Hard-to-Segment Instance Learning and Boundary Shape Analysis" Remote Sensing 14, no. 1: 23. https://doi.org/10.3390/rs14010023
APA StyleGong, Y., Zhang, F., Jia, X., Mao, Z., Huang, X., & Li, D. (2022). Instance Segmentation in Very High Resolution Remote Sensing Imagery Based on Hard-to-Segment Instance Learning and Boundary Shape Analysis. Remote Sensing, 14(1), 23. https://doi.org/10.3390/rs14010023