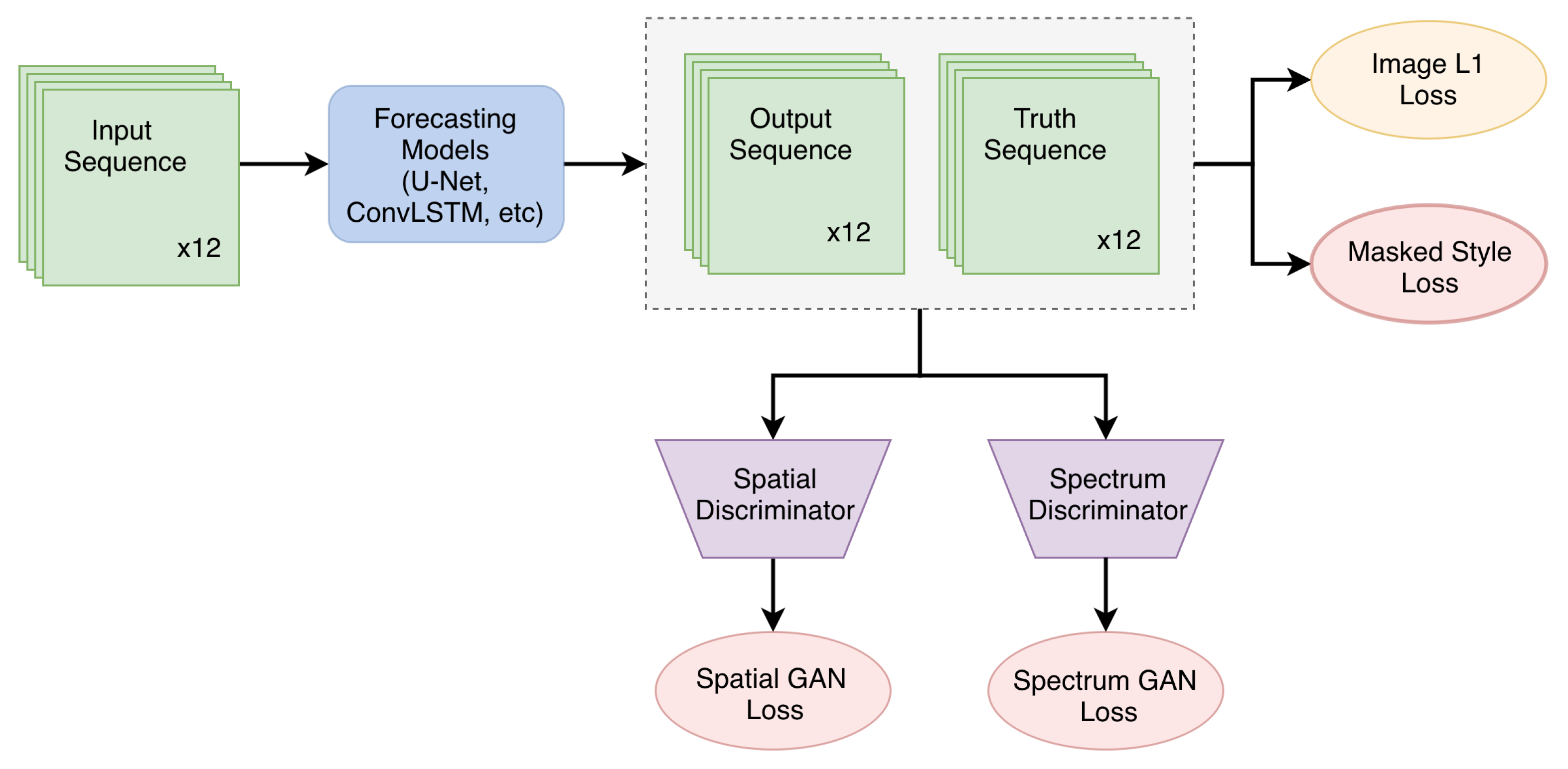
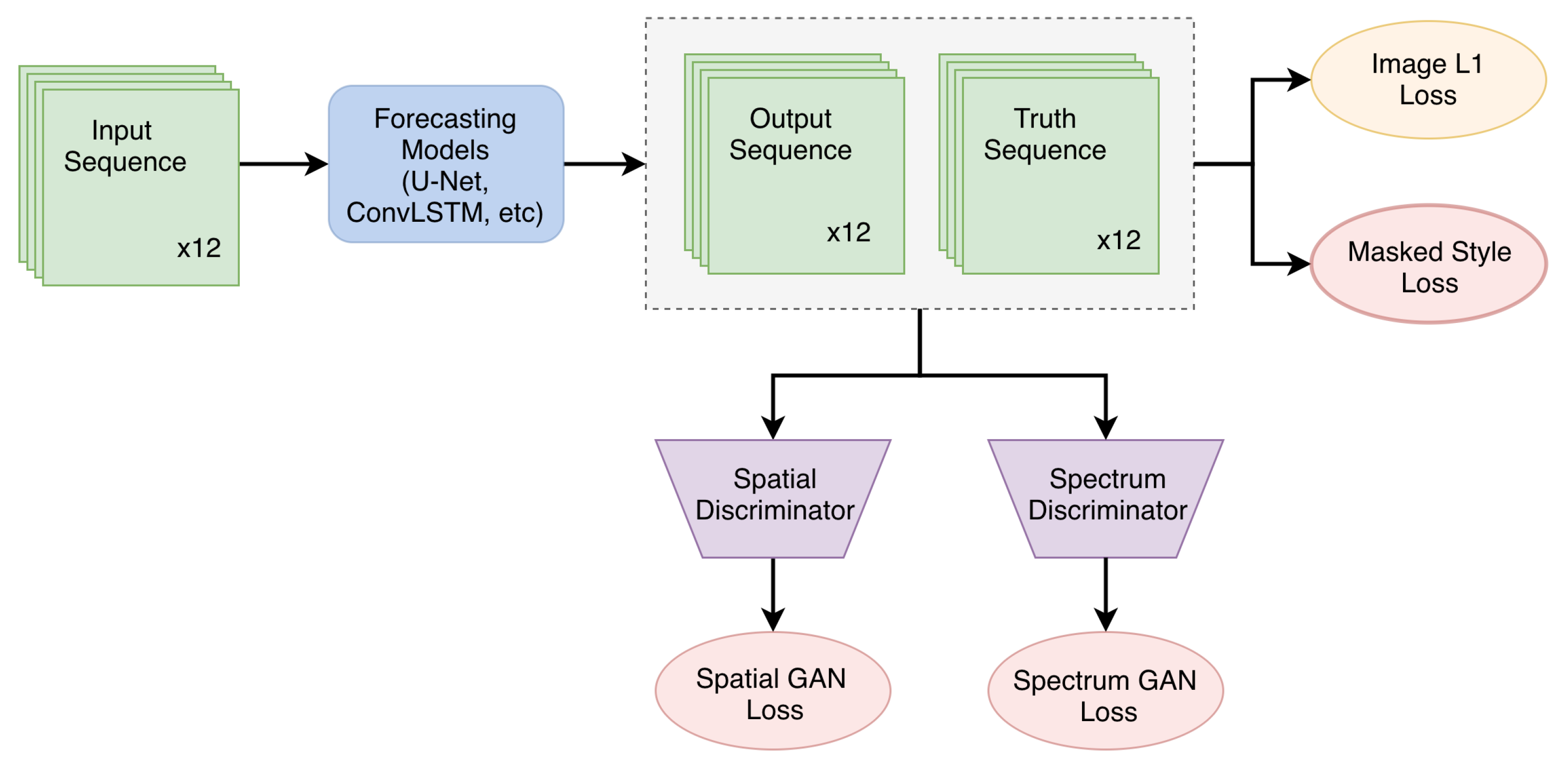
4.2. Experimental Setup
We designed two experimental settings, i.e., short-term prediction setting and long-term prediction setting. In the short-term setting, the model is trained to predict 1 h extrapolations given 1 h observations in the past (i.e., the last 12 frames are predicted based on the first 12 frames). Since there are 49 frames in each event sequence, we can split an event into 3 sequences with intervals equal to 12 frames, which results in 44,778 sequences for training and validation, and 12,159 sequences for testing. In order to show the generalizability of our method for predicting sharp images in a longer lead time, we further designed a long-term setting, in which future 2 h frames (in total 24 frames) are extrapolated conditioned on past 1 h frames (in total 12 frames).
The original value range of vil imagery is [0, 255], and we normalize it to [0, 1] during training. Considering the cloud movement caused by wind and pressure, a large spatial context is needed for the accurate prediction of the target. Therefore, the whole image (384 km × 384 km) is used to train the model, but the center part with a size 256 km × 256 km is used for testing. This leaves 64 km of spatial context on each of the four sides.
Both U-Net baseline and ConvLSTM baseline are trained with L1 loss, and the proposed losses are additionally applied in corresponding ablation studies. The batch size, learning rate, and maximum epochs were set to 16, , and 30, respectively. All experiments were optimized by AdamW using PyTorch and performed using 8 NVIDIA Tesla P100 (16 G) GPUs.
4.4. Evaluation Metrics
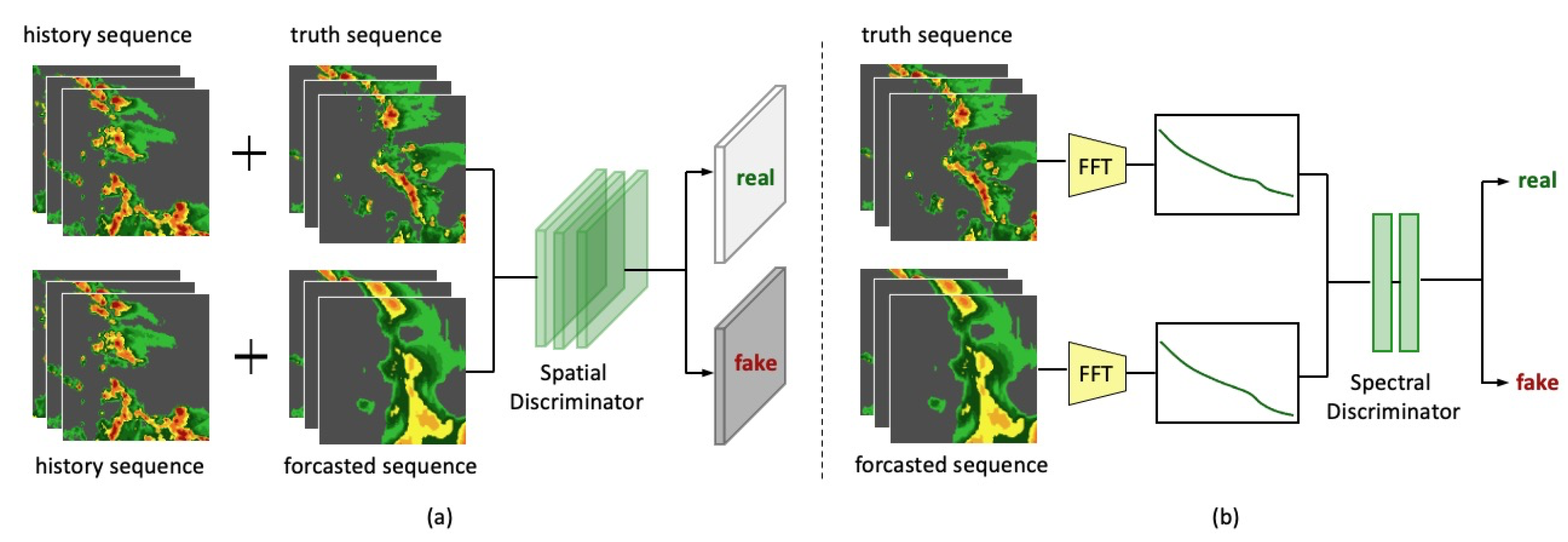
We used two types of metric to evaluate model performance, i.e., forecast-specific metrics (CSI and BIAS) and perceptual-specific metrics (LPIPS and the proposed PSDS). Critical success index (CSI) and BIAS are commonly used metrics in forecast evaluation. In addition, since the main contribution of this paper is to tackle the blurring issue in radar extrapolation, we employed LPIPS and PSDS metrics for evaluating the sharpness of generated images and we will focus more on the performance of different methods on these two metrics.
As for CSI and BIAS, we first binarize the truth and prediction images at four thresholds, i.e.,
. Then, we calculate true positive (TP, prediction = truth = 1), false positive (FP, prediction = 1, truth = 0), false negative (FN, prediction = 0, truth = 1), and true negative (TN, prediction = truth = 0). Finally, CSI and BIAS are computed as follows. As can be seen from the definitions, the range of CSI is
, and the higher the better; the range of BIAS is
, and the closer it is to 1 the better.
LPIPS was proposed by Zhang et al. [
22] to measure the perceptual similarity between two images, and has been shown to be more consistent with human judgment compared to traditional metrics (PSNR, SSIM [
26], and FSIM [
36]). The LPIPS metric can be obtained by computing the cosine distance of deep features in pre-trained networks, such as SqueezeNet [
37], AlexNet [
38], and VGGNet [
39]. We use AlexNet in this paper. As the LPIPS measures deep feature distance, the lower it is the better.
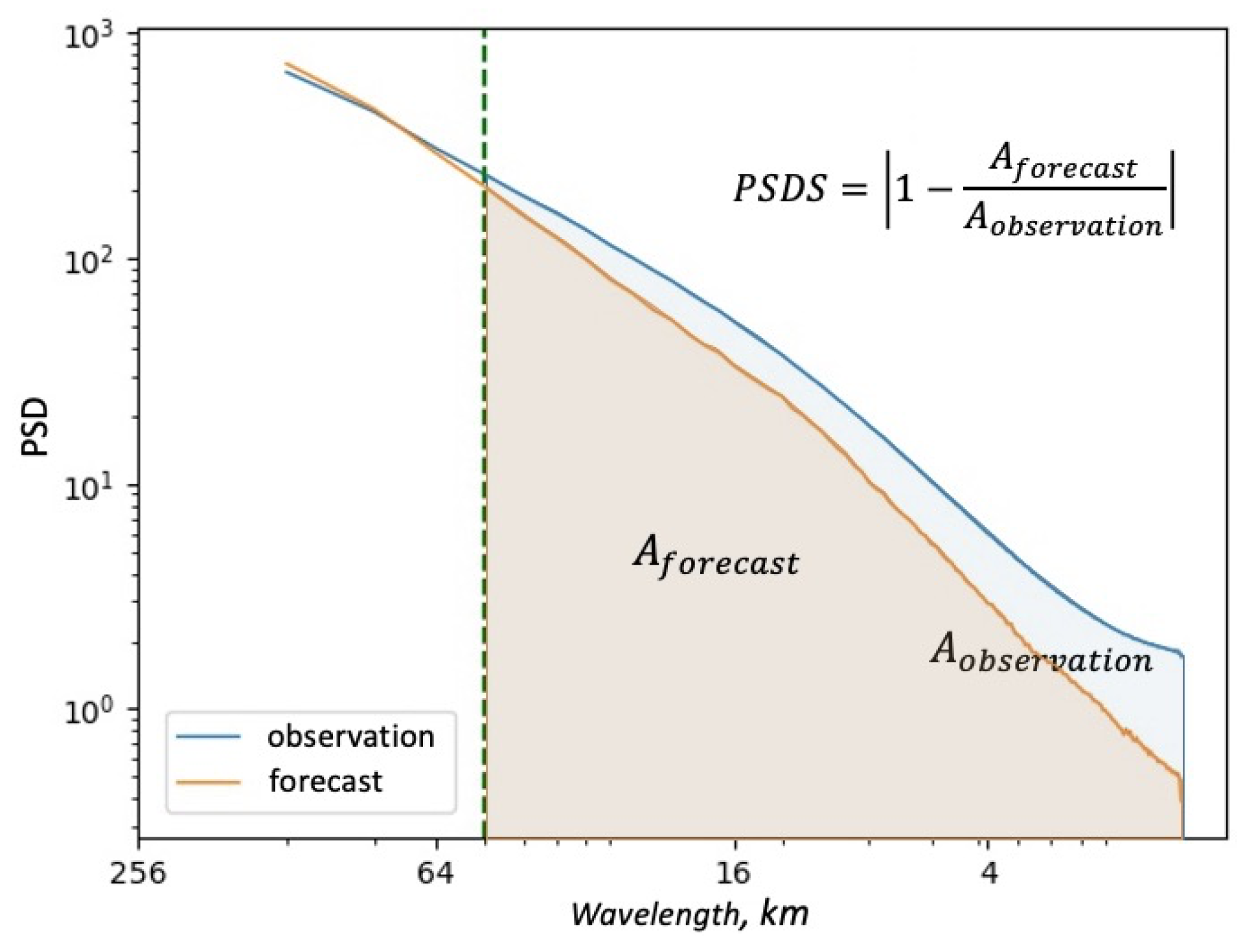
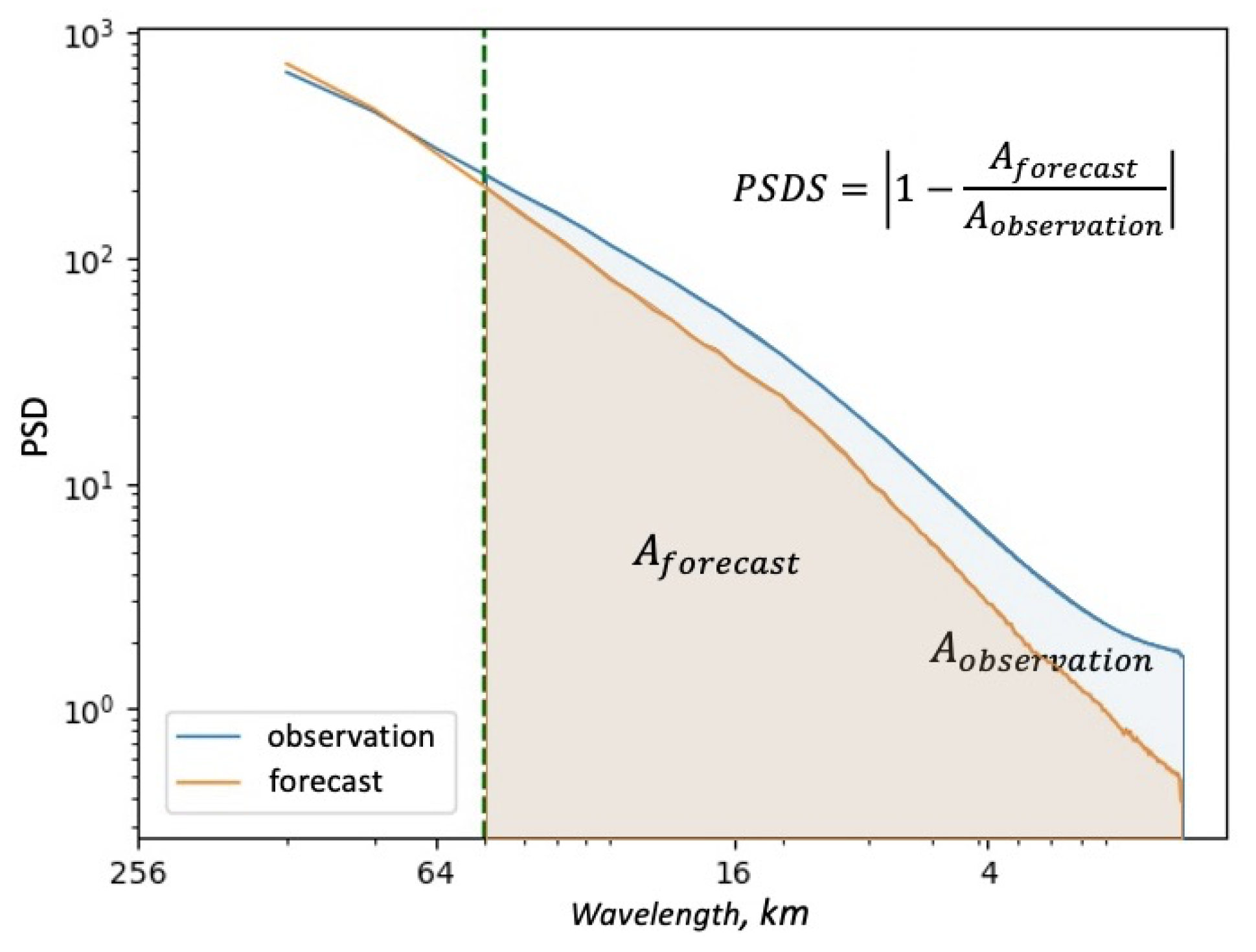
In addition, the proposed PSDS metric is also applied to evaluate the perceptual quality. In contrast with the LPIPS metric that measures the similarity of images in the feature space of pre-trained CNN models, the proposed PSDS measures their distances from the spectrum perspective (the lower the better). Therefore, these two metrics can be complementary to each other to better quantify the visual quality. One can refer to
Section 3.3 for more details about the PSDS metric.
4.5. Experimental Results
In this subsection, we first describe ablation experiments with UNet and ConvLSTM baselines to investigate the effectiveness of each newly proposed component. Then, we discuss the influence of the weight of the masked style loss on both forecast performance and perceptual quality. All of the above experiments were conducted using the short-term prediction setting, in which 1 h future radar frames are predicted given 1 h past radar frames. Finally, we performed experiments using the long-term setting, in which we performed 2 h extrapolation given 1 h past radar sequences, to further verify our method’s generalizability for longer lead time.
Table 1 and
Table 2 show UNet-based and ConvLSTM-based ablation study results on each proposed component (spatial GAN, spectrum GAN, and masked style loss) on the SEVIR dataset, respectively. We compare CSI, LPIPS, and PSDS metrics in the same table so as to observe the model’s forecast performance and perceptual quality at the same time. In addition, BIAS for both UNet-based and ConvLSTM-based models is reported in
Table 3 and
Table 4.
For UNet-based experiments, as shown in
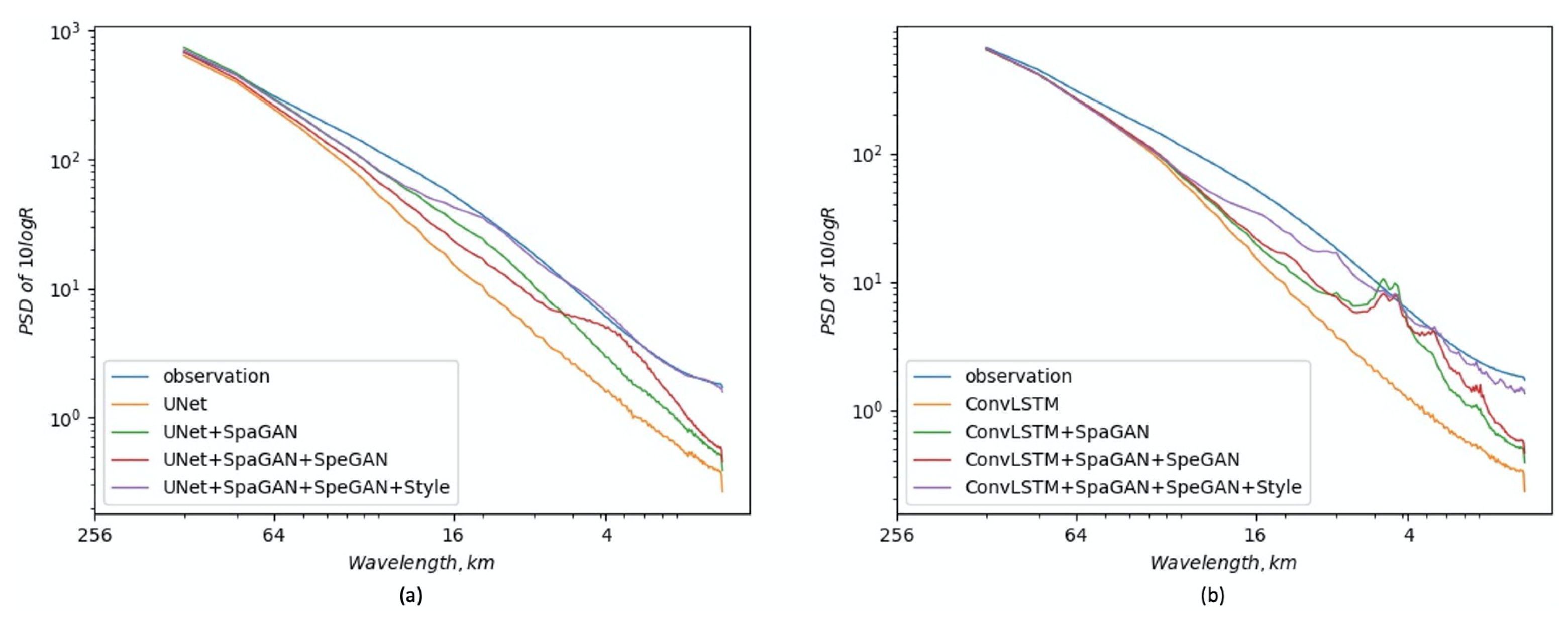
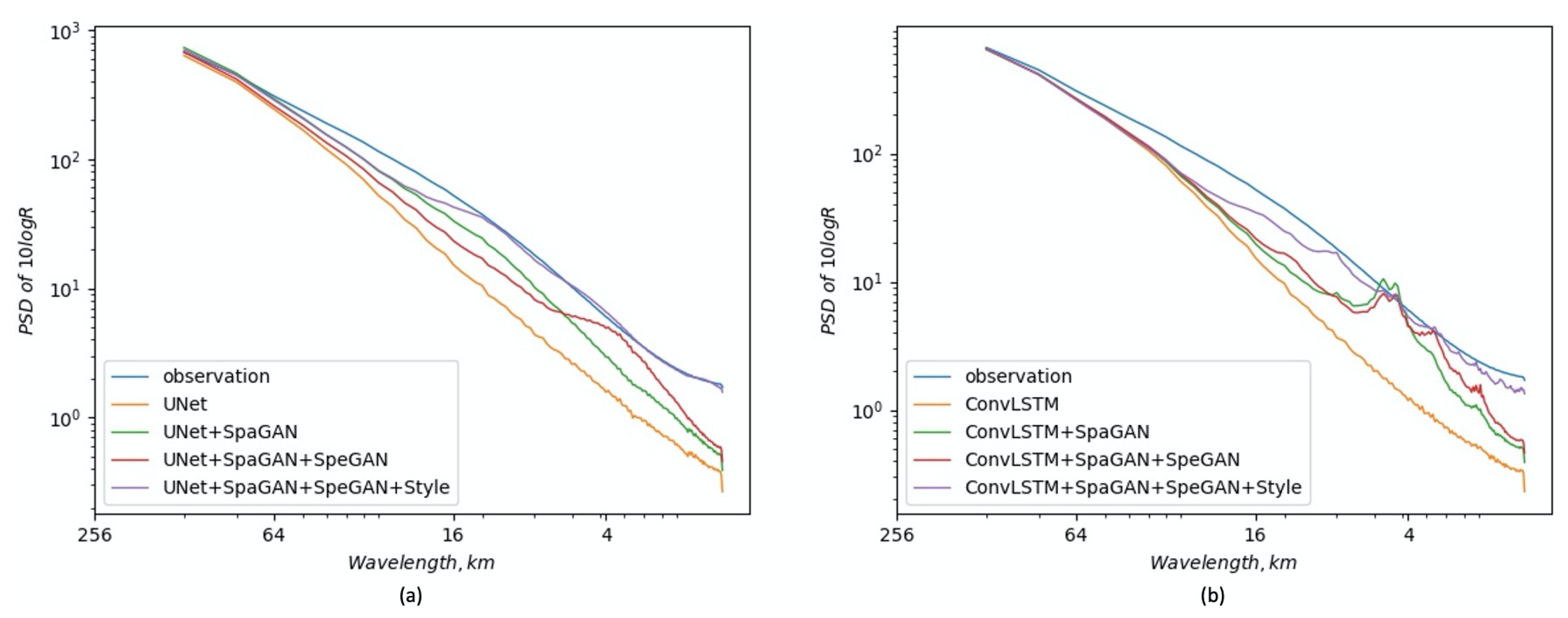
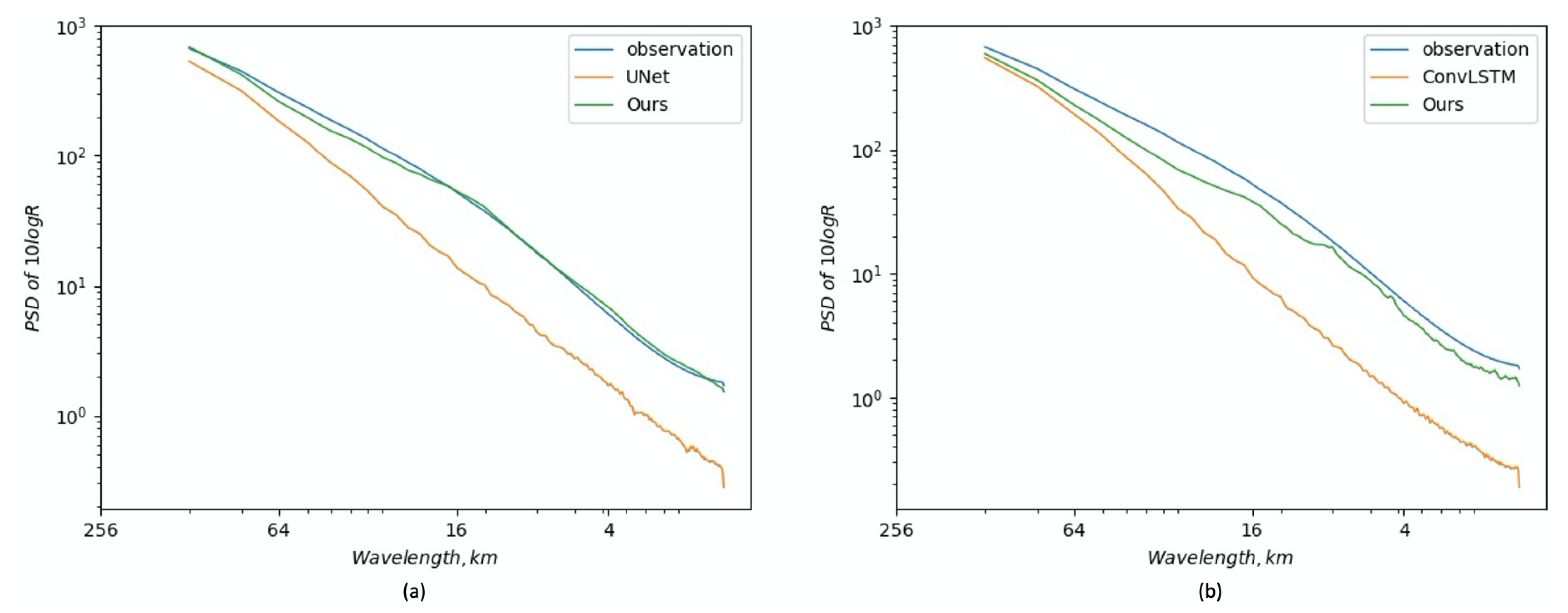
Table 1 (Row 1 and Row 2), the spatial GAN provides comparable performance to UNet baseline on CSI score. Specifically, some gains are observed for thresholds 133, 160, and 181, and a slight drop for threshold 174. Nevertheless, it achieves great improvements on LPIPS and PSDS scores (the lower the better), and the improvements can also be observed in the PSD curve. As can be seen in
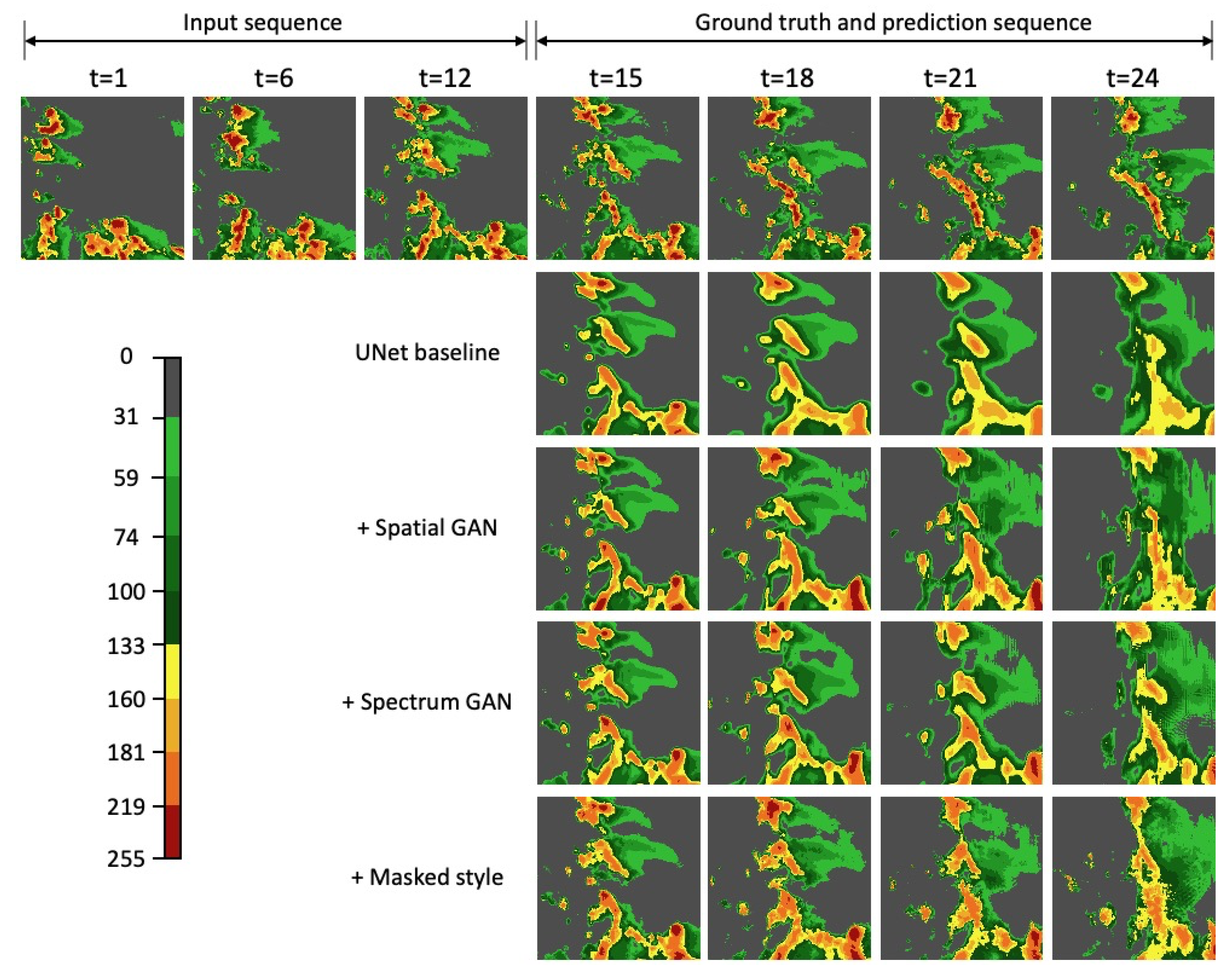
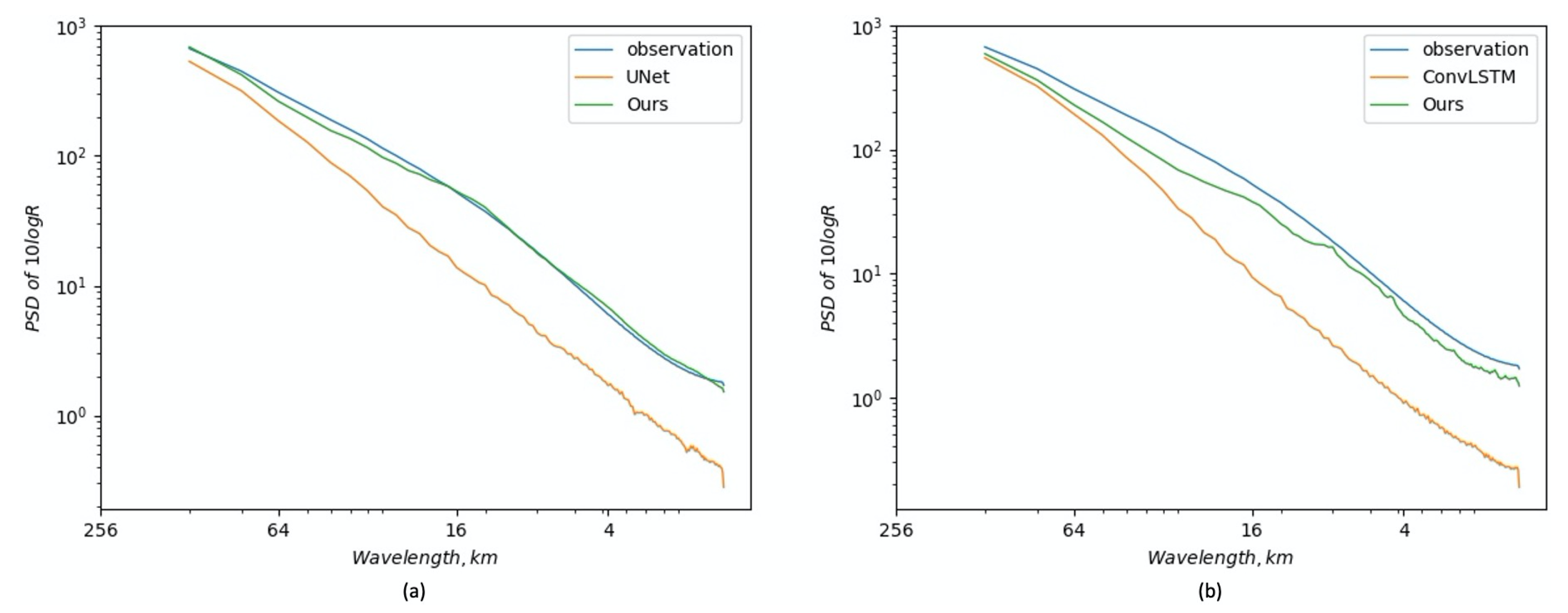
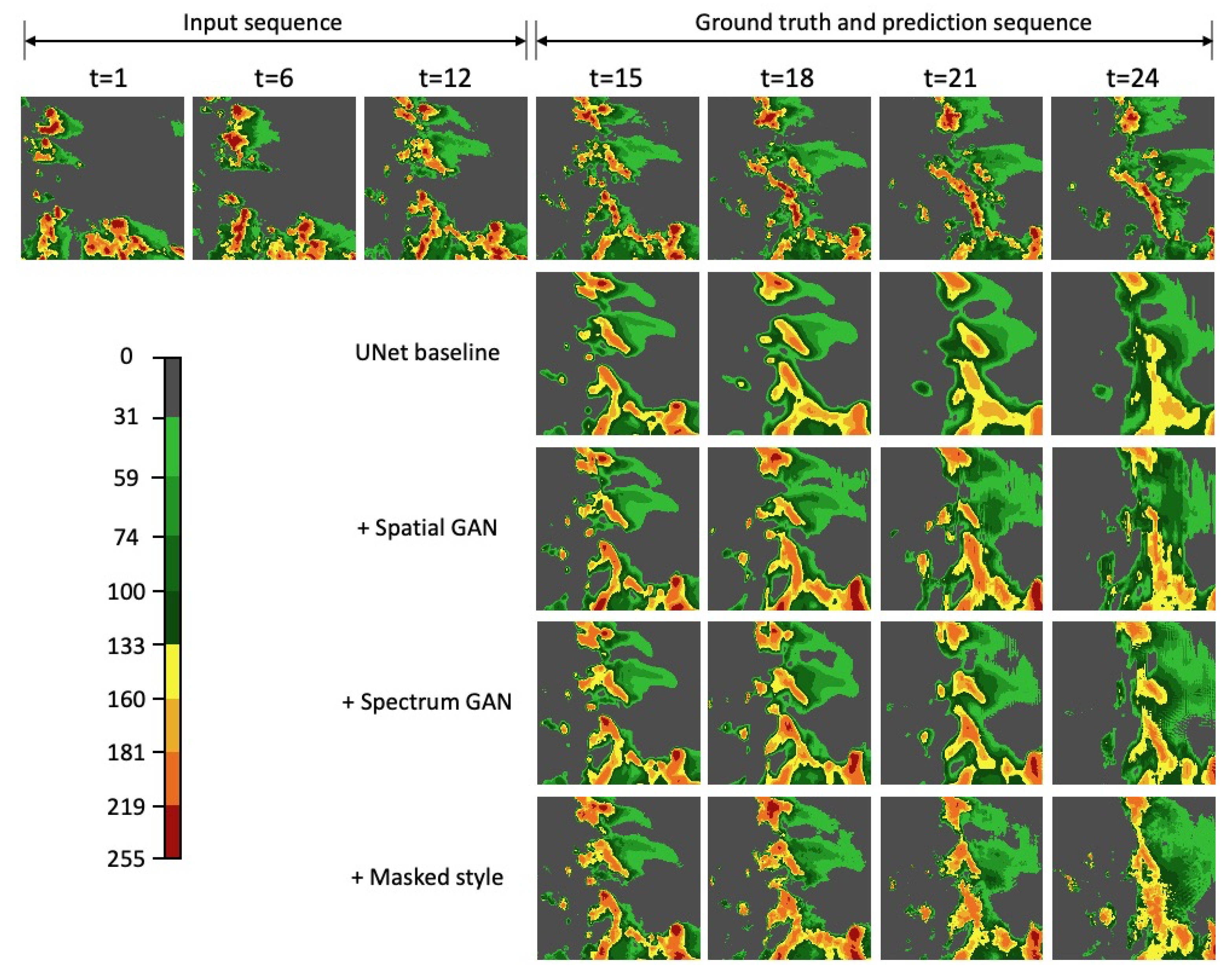
Figure 4a, a substantial loss of power is apparent at wavelengths below 64 km for the UNet baseline. However, after adopting the spatial GAN, corresponding spectral power at small and medium scales is recovered significantly. We also visualize the extrapolation results in
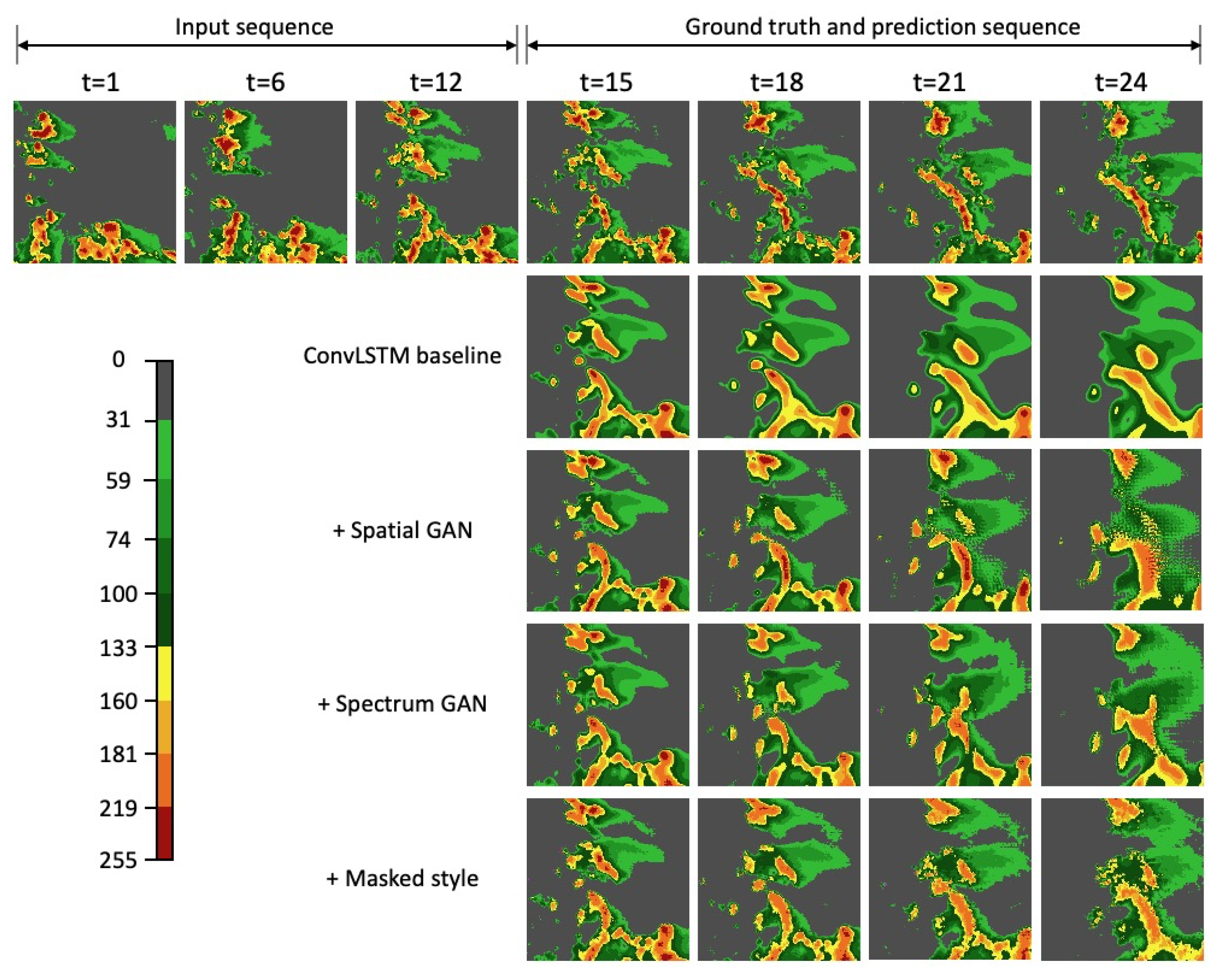
Figure 5. More details can be observed with the spatial GAN compared to the UNet baseline. Row 3 in
Table 1 shows the results of further adding the spectrum GAN, which imposes additional supervision on the frequency domain. As shown in
Table 1, the spectrum GAN provides remarkable improvements on CSI and PSDS scores. In the spectrum domain as shown in
Figure 4a, the PSD curve of adding the spectrum GAN shows great power improvement at small scales (below 10 km) compared to the model without the spectrum GAN. Furthermore, in
Figure 5, we can see that details become richer by further adding the spectrum GAN, which is especially obvious at a lead time of 1 h (t = 24 in
Figure 5). It is also worth noting that the LPIPS score becomes slightly higher when adding the spectrum GAN, which does not agree with the PSDS score and visual impression. This phenomenon encourages joint analysis of different metrics, such as LPIPS, PSD, and the proposed PSDS, which are important for quantifying the visual performance of models comprehensively. Finally, as shown in
Table 1 Row 3 and Row 4, further adding the masked style loss improves the perceptual quality significantly from
to
for LPIPS, and from
to
for PSDS, with only a slight drop in CSI scores. As shown in
Figure 4a, the PSD curve of adding all proposed components achieves conspicuous improvements at scales below 16 km, and almost coincides with the observation curve. Qualitative results in
Figure 5 show that we are able to achieve realistic and sharp extrapolations by further adding the masked style loss, and the prediction shows rich details even in a lead time of 1 h. In addition,
Table 3 compares the BIAS between UNet baseline and the proposed method. As can be seen, the BIAS values at high thresholds [133, 160, 181] are far below 1 for UNet baseline, which means the model has difficulty in predicting high-intensity rainfall. However, by adding the proposed components, the BIAS values for high thresholds are improved, and the values for all thresholds fall in a reasonable range around 1. Overall, by leveraging the spatial GAN, spectrum GAN, and masked style loss, we can achieve not only significant improvements in visual quality (from 0.3795 to 0.2680 in terms of LPIPS, and from 0.7245 to 0.1586 in terms of PSDS), but also a remarkable performance boost at high VIL thresholds; specifically,
,
, and
performance gains at thresholds 133, 160, and 181, respectively. These results demonstrate the effectiveness of the proposed methods for producing realistic radar extrapolation and improving performance at high rainfall regions.
For ConvLSTM-based experiments, similar results were obtained. As shown in
Table 2 Row 1 and Row 4, our methods improve the visual performance significantly from
to
for LPIPS, and from
to
for PSDS. Moreover, CSI scores at high thresholds
achieve improvements of
,
, and
, respectively, with only a small drop of
at a low threshold of 74. Improvements in BIAS values also verify our method’s effectiveness in high rainfall region prediction, as shown in
Table 4.
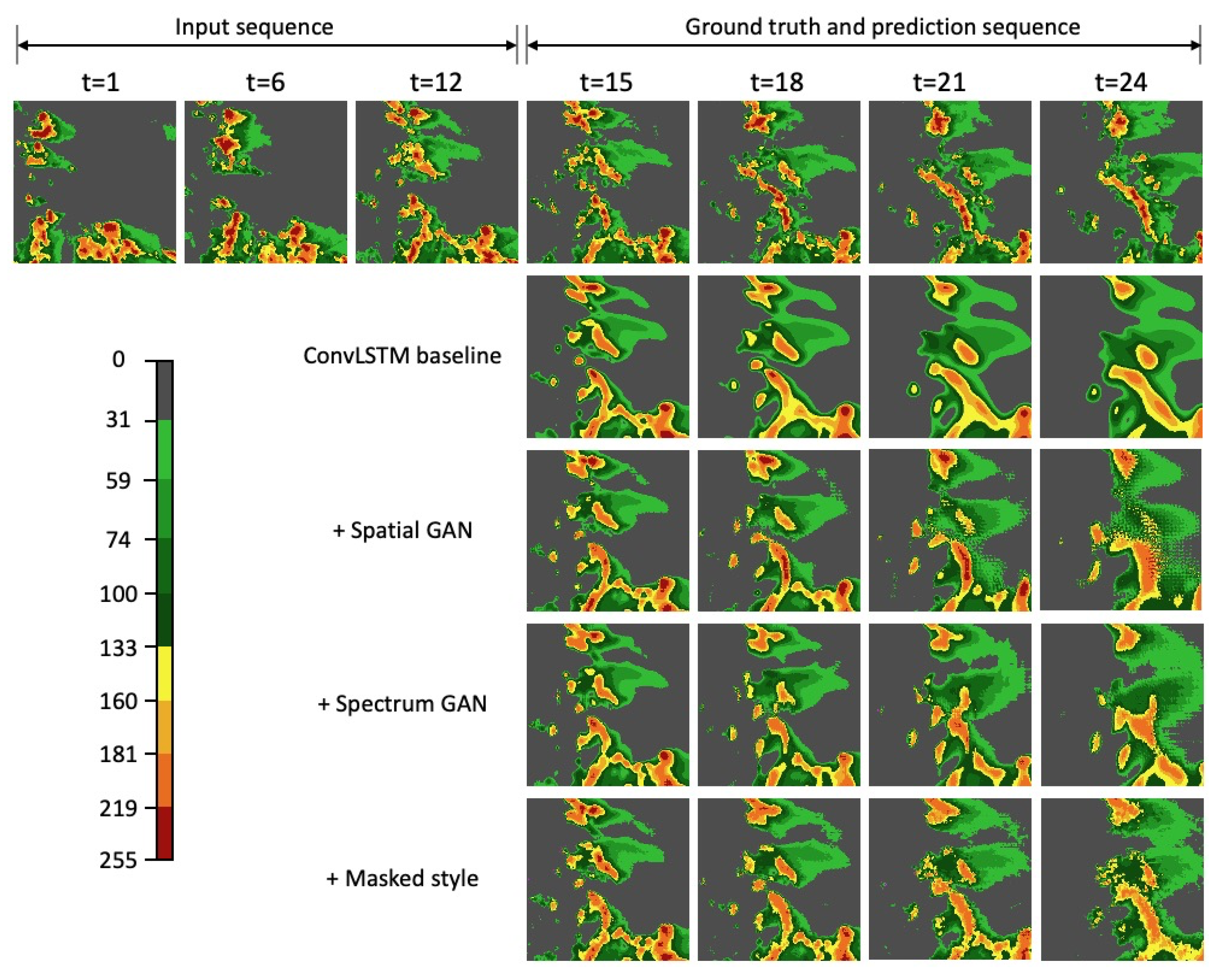
Figure 4b shows the comparison of PSD curves. By adding all components, the PSD curve recovers most spectral power at scales below 16 km. In addition, we visualize some extrapolation results in
Figure 6. As we can see, the predicted radar maps become sharper and achieve more detail with progressively adding the spatial GAN, spectrum GAN, and masked style loss.
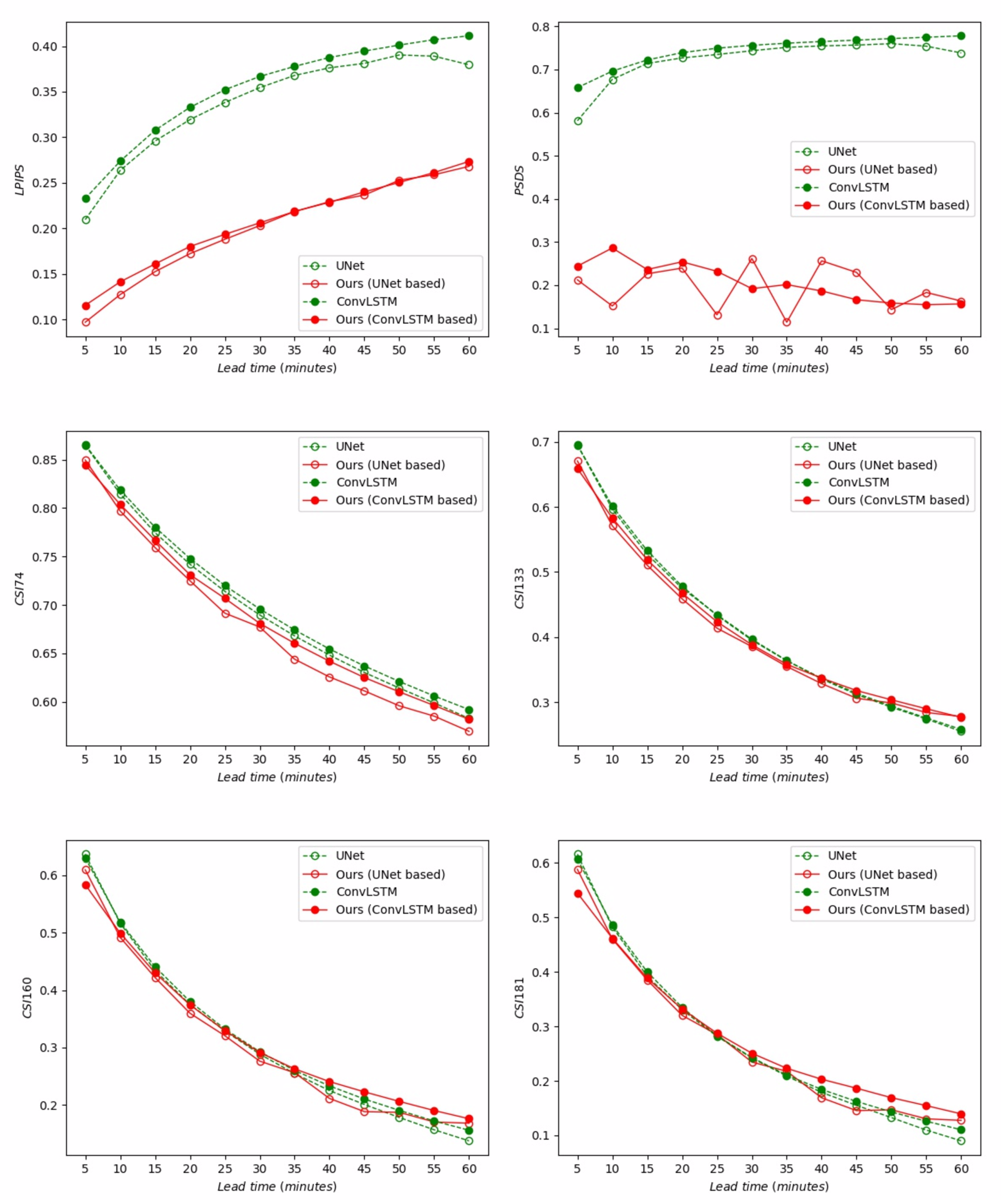
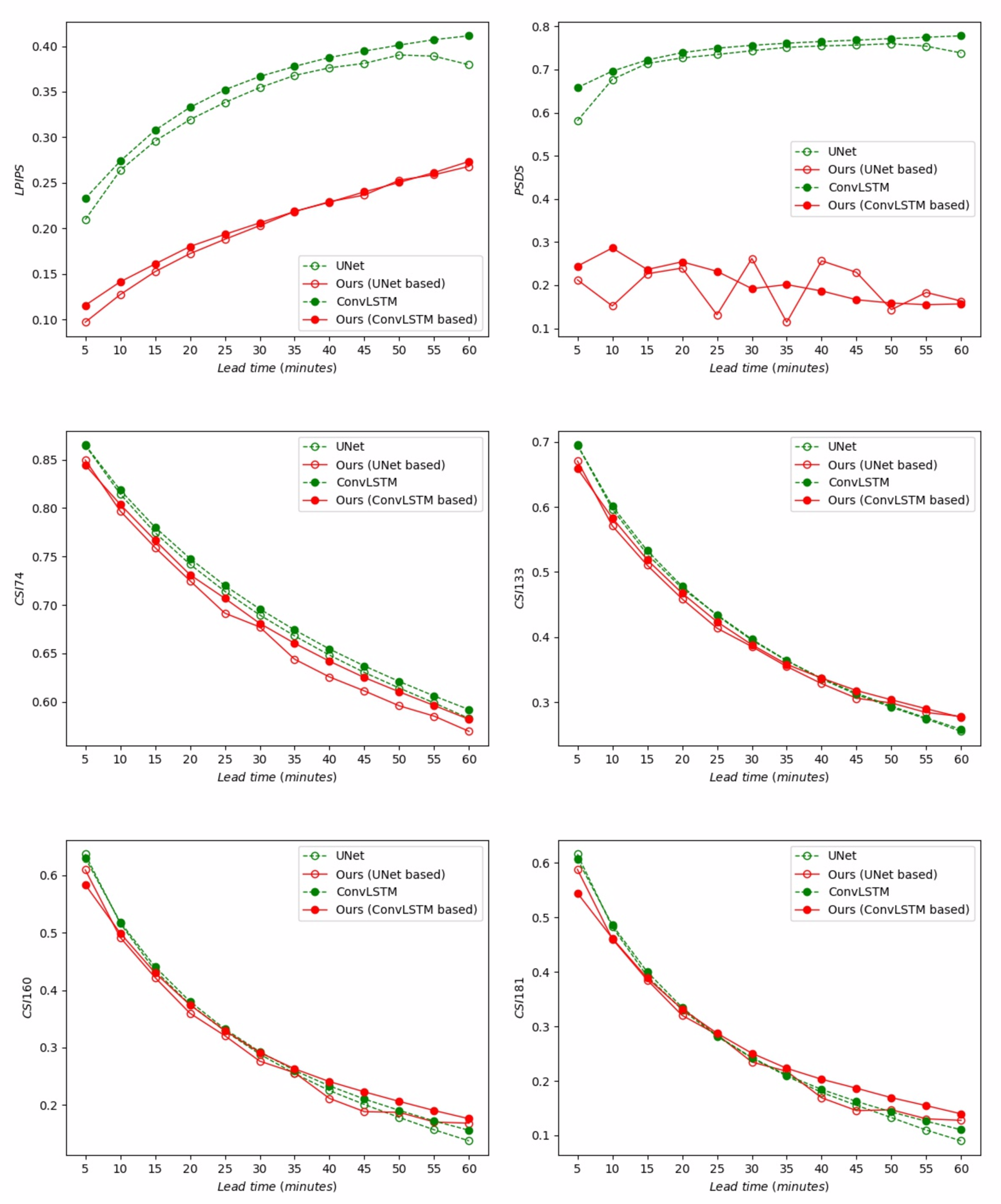
Moreover, we show the LPIPS, PSDS, and CSI curves against different lead times for UNet baseline, ConvLSTM baseline, and our methods in
Figure 7. We can see a significant gap between LPIPS curves of baselines and our methods, and the performance of PSDS curves is similar, which justifies the effectiveness of the proposed methods for improving image sharpness and producing perceptually realistic nowcasting. As can be seen from the CSI curves, our methods show a slight drop for the low threshold 74, but begin to surpass the baselines at higher thresholds (
) and longer lead times (e.g., from 30 min to 60 min).
We then investigated the effect of the magnitude of the style weight (
in Equation (
5)). As shown in
Table 5, we can see a tradeoff between forecast performance and perceptual quality when tuning the weight. For instance, with the decrease in the style weight from 5 × 10
to 1 × 10
in
Table 5 Row 2 and Row 3, CSI scores gradually improve at all thresholds, but LPIPS and PSDS scores also increase, which means details are gradually lost. We set the weight to 1 × 10
for all other experiments in this paper to obtain satisfactory perceptual quality without too much loss of forecast capability. We visualize 1 h extrapolation results of different style weights in
Figure 8. We can see that the highest weight 5 × 10
provides the most realistic extrapolation, and local details are getting lost with the decrease in the style weight. However, it is worth noting that, no matter how big the magnitude of the style weight is, applying the masked style loss can significantly improve the sharpness of prediction in comparison with baselines and produce realistic radar extrapolation.
Finally, we performed comparison experiments in the long-term prediction setting to verify our method’s generalizability in extrapolating to longer lead times.
Table 6 and
Table 7 show the results based on UNet and ConvLSTM baselines in terms of CSI, BIAS, LPIPS, and PSDS metrics. As we can see, our methods are able to improve perceptual scores (LPIPS and PSDS) significantly. In addition, it is worth noting that our methods provide remarkable performance gains in high rainfall prediction, as can be seen from CSI and BIAS results in
Table 6 and
Table 7. The BIAS values at thresholds
are far below 1, and values at
are almost close to 0, which means the baselines are unable to predict high rainfall. However, by adding the proposed components, the CSI and BIAS scores obtain significant improvements. The phenomenon can also be observed in
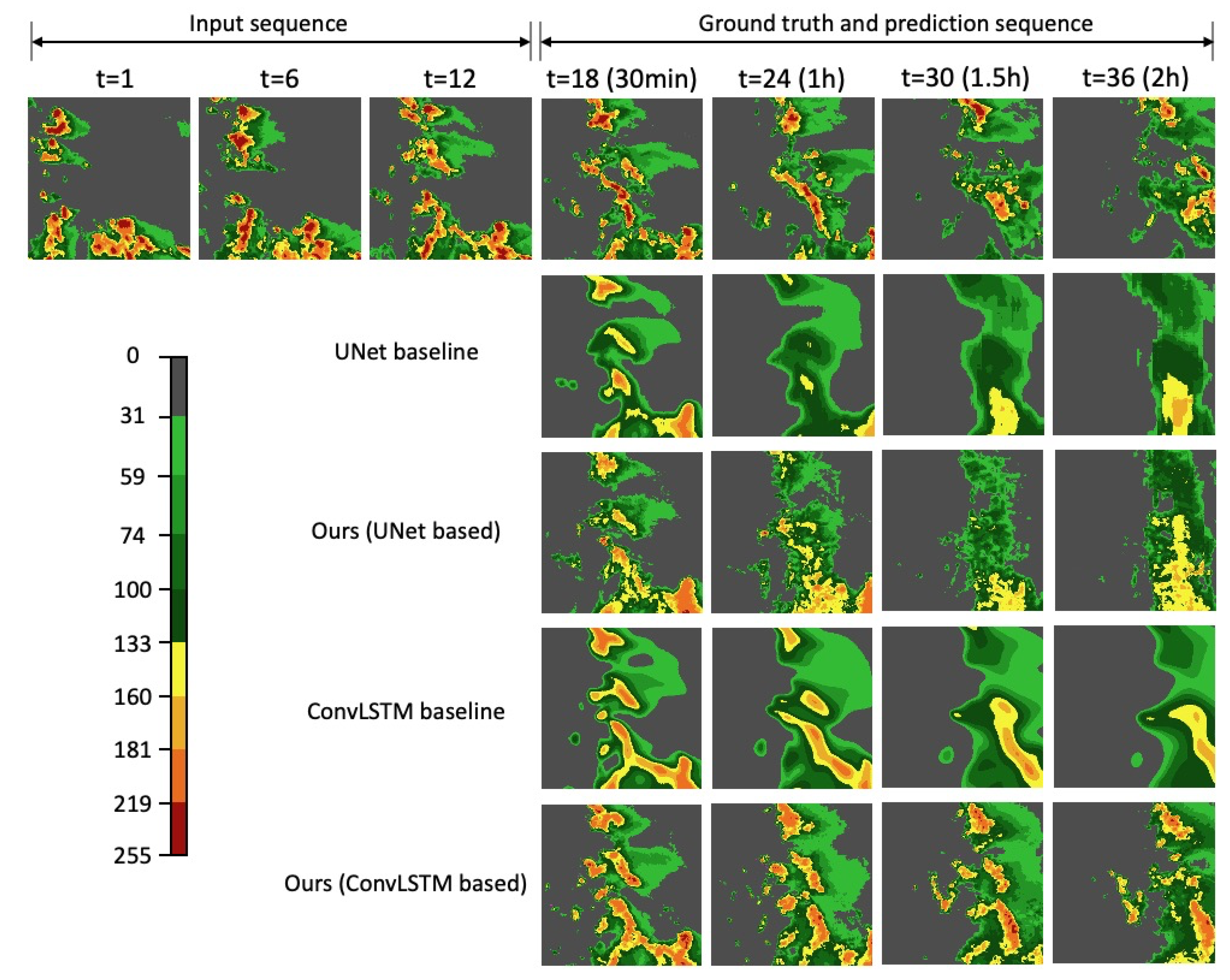
Figure 9 and
Figure 10. ConvLSTM-based models outperform UNet-based models in 2 h extrapolation.
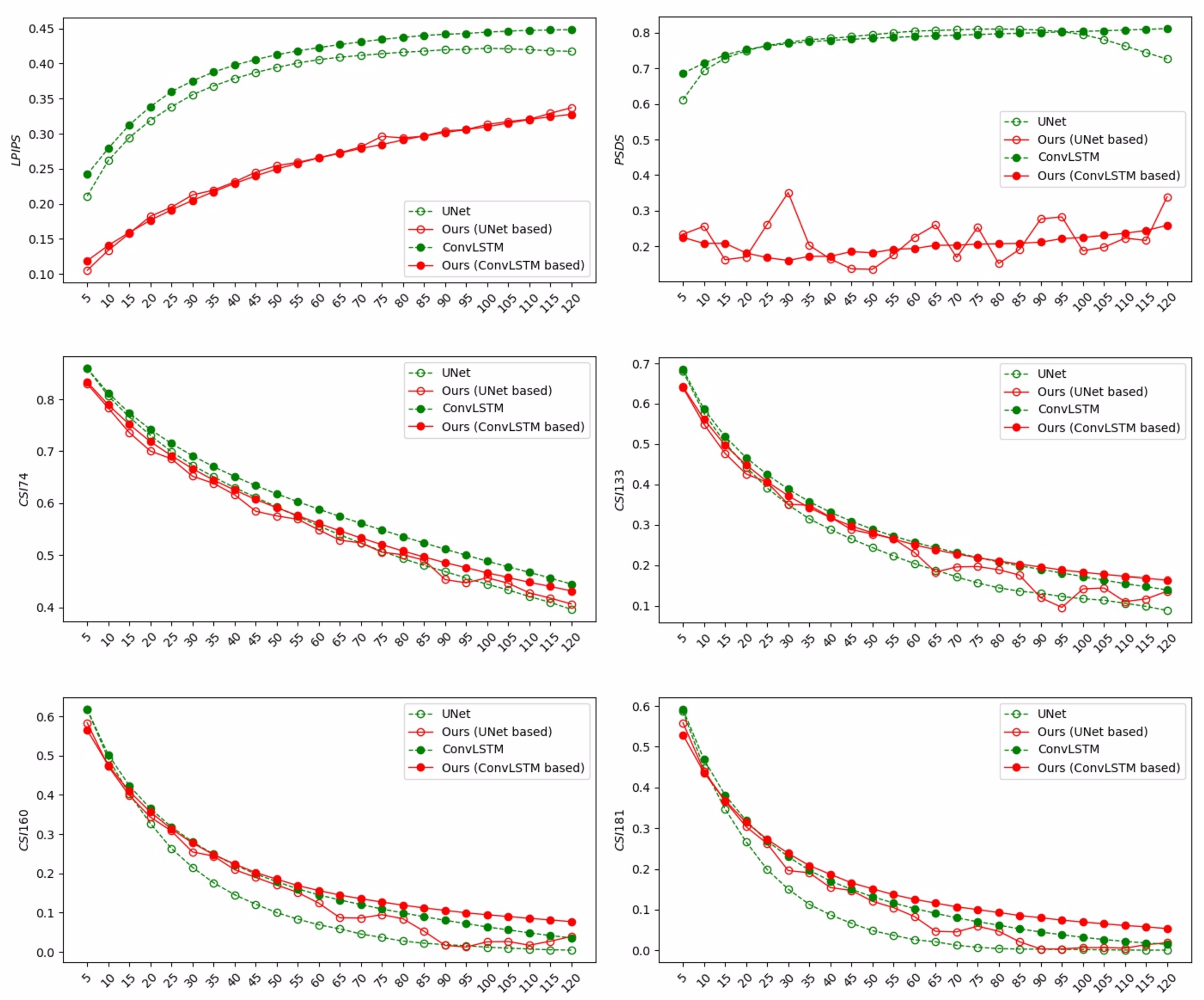
Again, we also show the nowcasting performance against different lead times from 5 to 120 min in terms of LPIPS, PSDS, and CSI scores in
Figure 11. For LPIPS and PSDS, the trends are similar. There are apparent gaps between baselines (both UNet and ConvLSTM) and our methods. In addition, we observe that the PSDS curve of our methods (UNet-based) is not smooth, which means the predicted sequence may have poor time consistency, i.e., flicker between neighboring frames. This issue can be solved by temporal consistency loss [
40,
41,
42], or temporal discriminator [
30], which is outside the scope of this work. For the CSI curve, we can see that our methods decrease the CSI score at a low threshold, i.e., 74. However, the proposed methods improve the performance at a higher intensity (i.e.,
) and longer lead time (e.g., from 30 min to 120 min). It is worth noting that as the lead time increases, the gap between our methods and baselines becomes more and more significant, and it is more obvious at higher thresholds (e.g., 160 and 181). The above results demonstrate that the proposed methods are able to improve the image sharpness of different baseline models significantly as well as improving forecasting performance at high rainfall regions, even in a long lead time up to 2 h.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}