1. Introduction
Remote-sensing time-series datasets are an important product and can be applied to research and applications in global changes, such as vegetation phenology changes, land degradation, etc. The successful application of remote-sensing time-series datasets are significant for earth science to expand the growth to a deeper level and to better understand the Earth [
1,
2].
Time-series analysis usually requires the data to be dense and has equal time intervals to facilitate the process. However, remote-sensing acquisitions often provide sparse time series due to sensor resolution limitations and environmental factors [
3], such as cloud noise for optical data. In this case, it is difficult to conduct time-series analysis and construct remote-sensing sequence image datasets.
A conventional method to solve missing data is a linear fitting method, and only uses 1D data for transformation. Seaquist et al. [
4] used the ordinary kriging (OK) method to improve the accuracy of a normalized difference vegetable index (NDVI). Berterretche et al. [
5] used a spatial interpolation method to interpolate leaf-area index (LAI) data. Bhattacharjee et al. [
6] compared the accuracy of remote-sensing data using different spatial interpolation methods and concluded that the accuracy of OK was better than inverse distance weight (IDW). The above methods can use the spatial information of remote-sensing images for spatial transformation, and cannot use temporal information of remote-sensing images for temporal transformation.
Zhou et al. [
7] used NDVI data of moderate-resolution imaging spectroradiometer (MODIS) satellite to conduct simulation experiments and evaluate the Savitzky–Golay (SG) filtering [
8] and harmonic analysis of time-series (HANTS) model [
9] refactoring effect at different time intervals. According to the daily harmonic changes of land surface temperature (LST), Crosson et al. [
10] used the LST data of MODIS Terra and Aqua to repair missing LST points by harmonic analysis. The above methods provide better 1D data fitting for the construction of time-series data at different time intervals and are not suitable for the transformation of high-dimensional time-series data.
The emergence of the enhanced spatial and temporal adaptive reflectance fusion model (ESTARTFM) [
11], spatial and temporal adaptive reflectance fusion model (STARTFM) [
12], a virtual image pair-based spatio-temporal fusion (VIPSTF) [
13], and global dense feature fusion convolutional network [
14] had provided ideas for research on sequence construction. These models can obtain high spatio-temporal resolution fusion data, but they cannot elaborate on the spatio-temporal evolution of sequence images and rely heavily on the situation of the original data itself.
Remote-sensing sequence images are a kind of short-range complex and nonlinear 2D data [
15], and spatio-temporal information must be considered during construction. It is difficult to construct 2D images in the same way that construction is applied to 1D data. It is difficult to use the conventional linear fitting method for construction. The deep learning method can better simulate complex and diverse nonlinear data information, so it is a better choice for time-series image transformation.
Yuval et al. [
16] presented benthic mapping and accelerated segmentation through photogrammetry and multi-level superpixels, and showed the accuracy of repeated surveys using orthorectification and sparse label augmentation. This approach is appropriate for any person who is interested in using photogrammetry for ecological surveys, especially diver-based underwater surveys. Kalajdjieski et al. [
17] proposed a novel approach evaluating four different architectures that utilize camera images to estimate the air pollution in those areas. These images were further enhanced with weather data to boost the classification accuracy. The proposed approach exploits the deep learning method combined with data augmentation techniques to mitigate the class imbalance problem. In principle, this approach is suitable for every application where image data is correlated with sensor data, and using them in combination can be beneficial for the learning task. In particular, the adoption of this method in multi-class classification settings with imbalanced classes is particularly beneficial. Wang et al. [
18] proposed an unsupervised data augmentation and effective spectral structure extraction method for all hyperspectral samples. This method not only improves the classification accuracy greatly with the newly added training samples but also further improves the classification accuracy of the classifier by optimizing the augmented testing samples. However, as discussed previously, these data augmentation methods cannot make full use of the spatio-temporal features of the original data, and the transfer learning ability of its mapping model is weak. So these methods are not well-suited for remote-sensing time-series data transformation.
Long et al. [
19] used frame interpolation as a supervision signal to learn the Convolutional Neural Network (CNN) models for optical flow. However, their main target is optical flow and the interpolated frames tend to be blurry. Liu et al. [
20] developed a CNN model for frame interpolation that had an explicit sub-network for motion estimation. Their method obtains not only good interpolation results but also promising unsupervised flow estimation results on KITTI 2012. Niklaus et al. [
21] used a deep fully convolutional neural network to estimate spatially adaptive 2D or separable 1D convolution kernels for each output pixel and convolves input frames with them to render the intermediate frame. The convolution kernel can capture local motion between input frames and the coefficients for pixel synthesis. However, as discussed previously, these CNN-based single-frame interpolation methods are not well-suited for multi-frame interpolation.
Taking into account the limitations of the above conventional methods and video interpolation methods, Pan et al. [
22] used the convolutional long short-term memory network to conduct the prediction of NDVI. This method can perform prediction based on the state information of time-series, and it belongs to the method of multi-scene transformation. However, its predicted results are affected by the length and missing degree of sequence images. Zhu et al. [
23] adopted the cycle-consistent generative adversarial network to conduct style conversion between different pictures. This method can perform bidirectional transformation between different pictures, and its generated results are not affected by the missing degree of sequence images. However, the spectral transformation ability of this method is lower than other deep convolution networks and its results are affected by the noise degree of sequence images.
To improve the accuracy of remote-sensing time-series data transformation, this paper is inspired by the idea of Niklaus, Pan, and Zhu et al., and employs the advantage of different deep convolutional neural networks to make up for the missing remote-sensing data. The major novelty of this paper can be summarized as follows:
We are one of the first attempts to use the advantage of the different convolution networks to conduct spectral transformation for filling in missing areas of sequence images and produce full remote-sensing sequence images.
We combine the temporal and spatial neighborhood of sequence images to consider the construction of scene-based remote-sensing sequence images. It does not rely on other high-temporal-resolution remote-sensing data, and only construct datasets based on the sequence itself. This provides a new idea for the construction of remote-sensing datasets.
This paper shows that the data-driven models can better simulate complex and nonlinear spectral transformation, then get the generated result based on this transformation. High-quality remote-sensing sequence datasets can be produced using different deep convolution networks. This enriches the research and development of the remote-sensing field.
The rest of the paper is organized as follows.
Section 1 reviews related studies regarding remote-sensing time-series data transformation.
Section 2 describes the experimental datasets and different deep convolution networks.
Section 3 presents the experiments and results, including a generalization of deep convolution networks in the time dimension, visual comparisons, and quantitative evaluation of constructed datasets with single and multiple networks.
Section 4 discusses the influence of hyper-parameters on the transformation result.
Section 5 concludes the paper.
3. Results and Analysis
3.1. Experimental Strategy
The size of scenes in sequence in both datasets was 3072 × 5632. To get enough training samples, all scenes in a sequence were cropped as a block with a size of 128 × 128.
This paper mainly conducted three aspects. The first aspect was a generalized application in the time dimension using different deep convolution networks. The second and third aspects were mainly to construct datasets in different time series using single and multiple networks, and this was implemented among multiple sequences. Corresponding experimental data are described in the following paragraphs in detail.
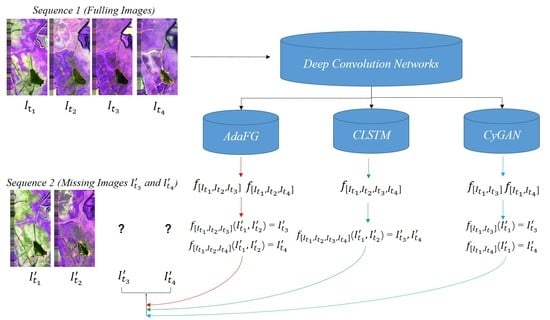
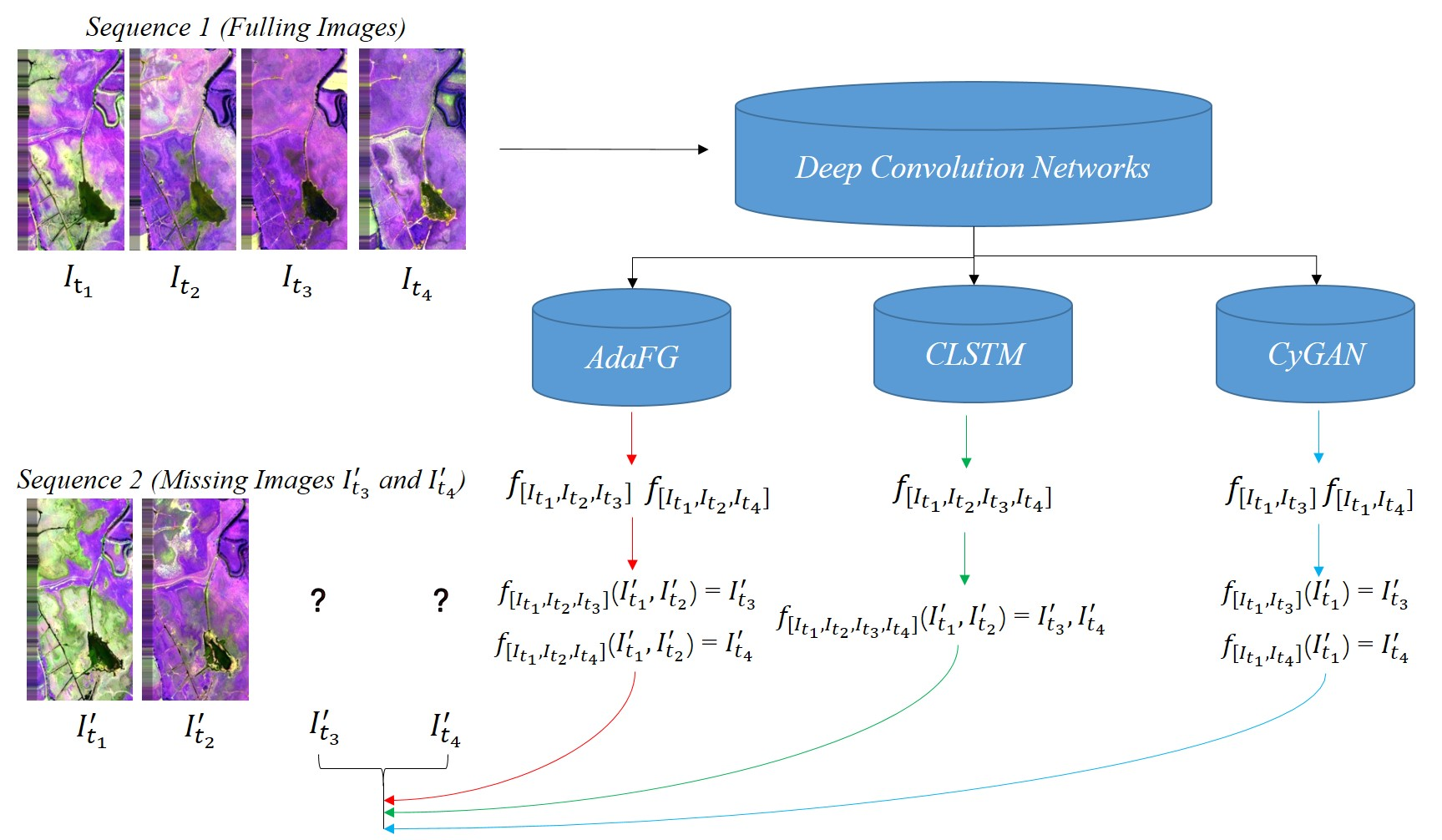
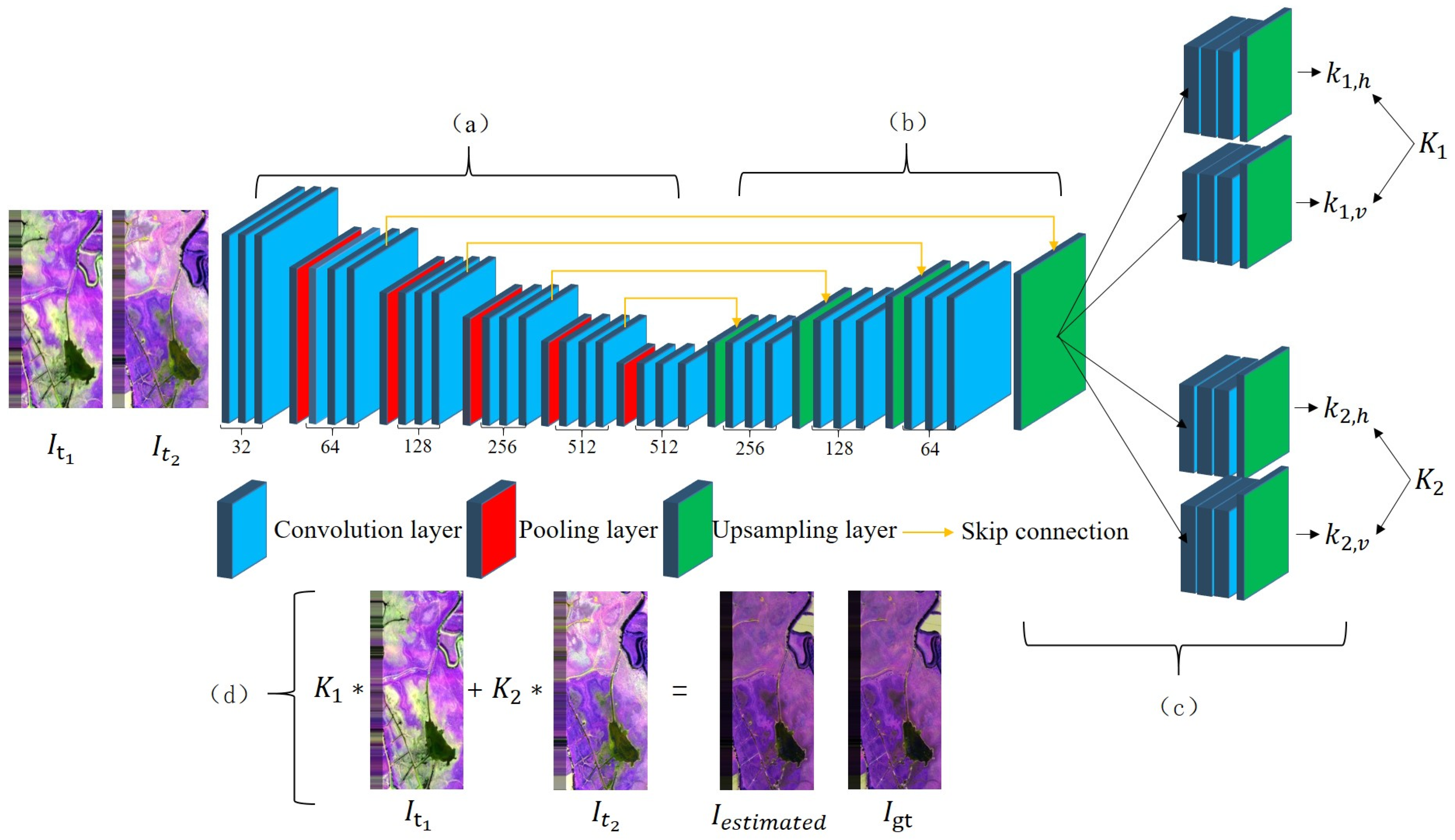
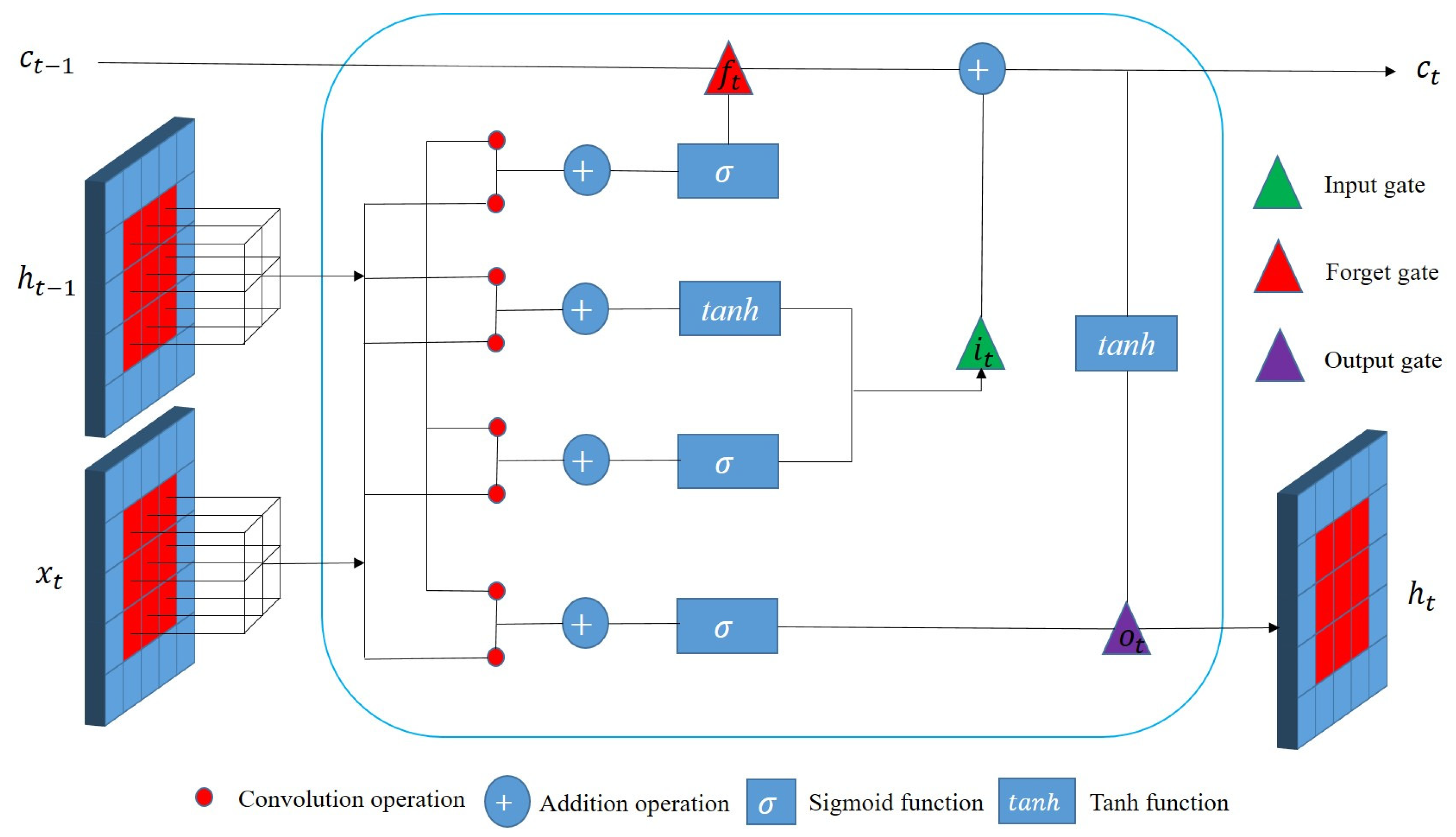
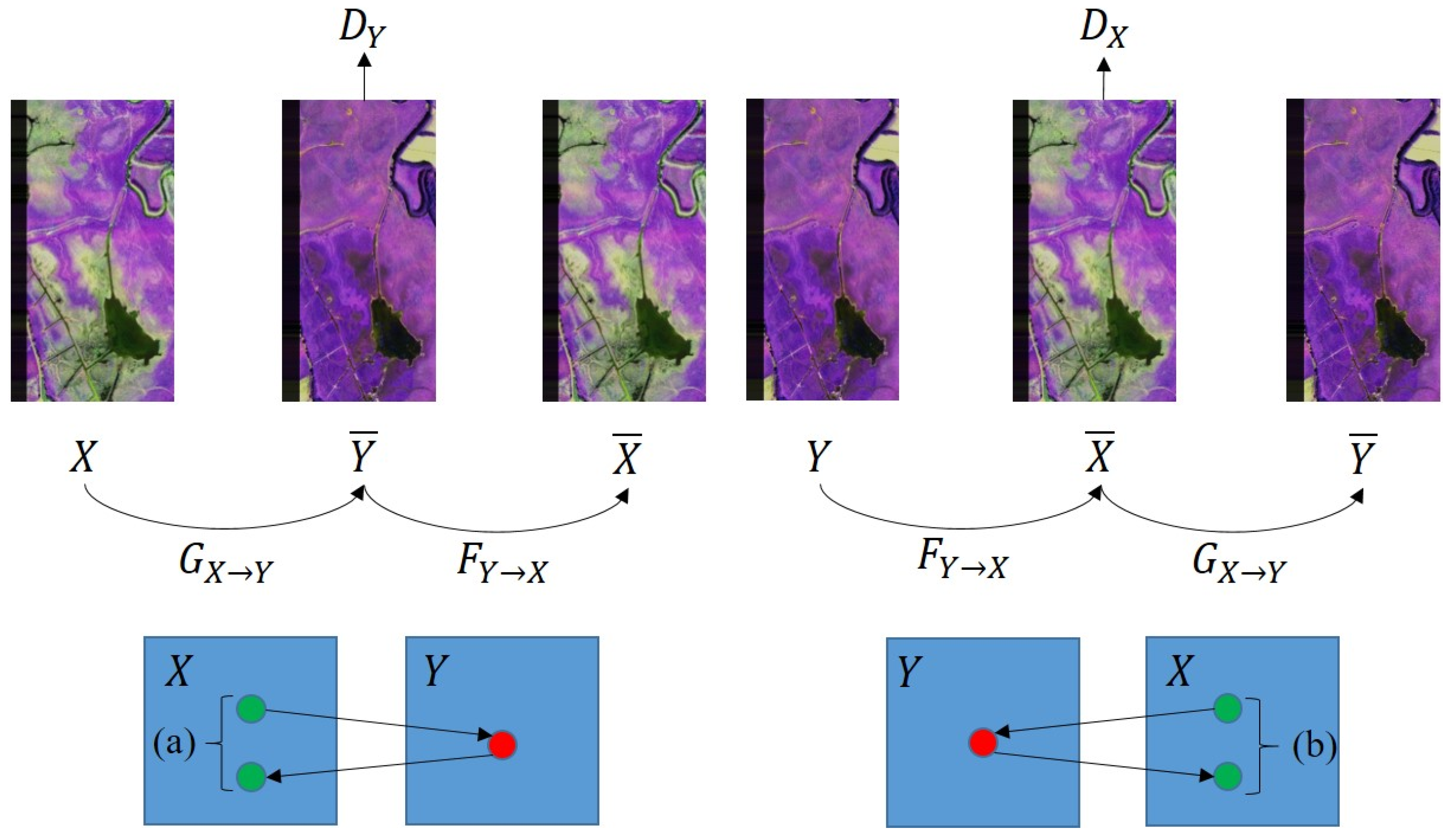
Before describing the experimental data in every aspect, we will first introduce some symbols used below. We represent image scene in different sequences, and , , represent different sequence images acquired at time ( = 1,…,12). In AdaFG network, the mapping model is expressed as , where [] represents training image triples, and represent the training image pairs, represents the reference image, t1 and t2 represent the month of training image pairs acquired, and t3 represents the month of the reference image acquired. represents output image with mapping model and input scenes and . In CLSTM network, the mapping model is expressed as , where [] represents training image multi-group, represent the training images, represents the reference image, t1,…,tn represent the month of training images acquired, and tn+1 represents the month of the reference image acquired. represents output image with mapping model and input scenes . In CyGAN network, the output image is expressed as , where represents a mapping model trained by training image pair [] with reference image . in the brackets represents the input used to generate the output image.
Table 2 shows the sequences used in the first aspect and the dates of all scenes acquired in them.
Figure 6 shows the visual effect of training and testing images using different deep convolution networks in the first aspect.
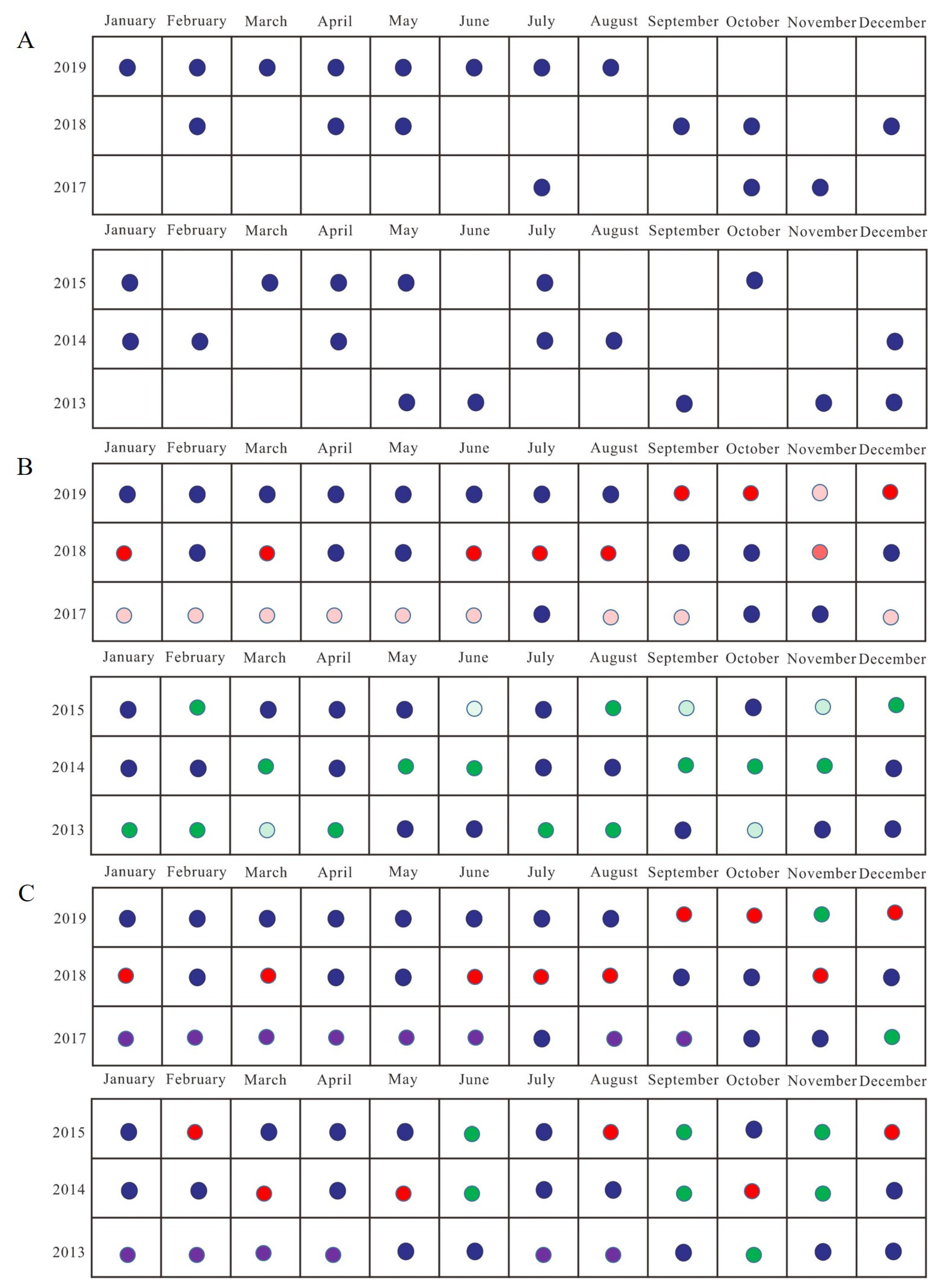
The second and third aspects mainly constructed remote-sensing sequence datasets with multiple sequences. The remote-sensing sequence here mainly reflected two aspects: non-equidistant missing images in the same sequence and non-equidistant missing images of the same scene in a different sequence. It was difficult to find an analysis method to analyze these sequences in a unified and integrated manner. The number of images in a year was relatively small, and the time interval between images was uncertain.
Figure 7A shows available UAV images from 2017 to 2019 and Landsat-8 images from 2013 to 2015 in the second and third aspects. It is obvious that there are many missing images for the frequency of one image per month.
Figure 7B shows one construction strategy with a single network. In UAV datasets, the crimson, red, and light-red points mark the first, second, and third-level generated result, in which training and testing images are listed in
Table 3. In Landsat-8 datasets, the dark-green and light-green points mark the first and second generated result, in which training and testing images are listed in
Table 4.
Figure 7C shows one construction strategy with multiple networks. The red, green, and purple points mark the generated result with AdaFG, CyGAN, and CLSTM network in both datasets, in which training and testing images are listed in
Table 5 and
Table 6.
3.2. Experimental Details
Hyper-parameters selection: We used a separate convolution kernel of size 11 in the AdaFG network, used stacks of 3 × 3 CLSTM network layer, and set
350,
1/32 in CyGAN network. Meanwhile, we used the mean square error (MSE) as the loss function. The optimizer used in the training was Adamax with
= 0.9,
= 0.99, and a learning rate of 0.001. Compared to other network optimizers, Adamax could achieve better convergence of the model [
34].
Time Complexity: We used the python machine learning library to execute the deep convolution networks. To improve computational efficiency, we organized our layer in computer unified device architecture (CUDA). Our deep convolution networks were able to generate a 256 × 256 image block in 4 s. Obtaining the overall scene image (image size 3072 × 5632) took about 18 min under the acceleration of the graphics processing unit (GPU) [
35].
3.3. Experimental Results
3.3.1. Generalization of Networks
Table 7 shows the quantitative evaluation indicator between the generated result and reference image in the first aspect. The table shows that the entropy value produced by using the AdaFG network was higher than that using other networks, and the RMSE [
36] value produced by using the AdaFG network was lower than that using other networks in both datasets.
Figure 8 shows the visual effect and pixel error between the generated result and reference image using different networks in both datasets and illustrates that the generated result using different networks was close to the reference image.
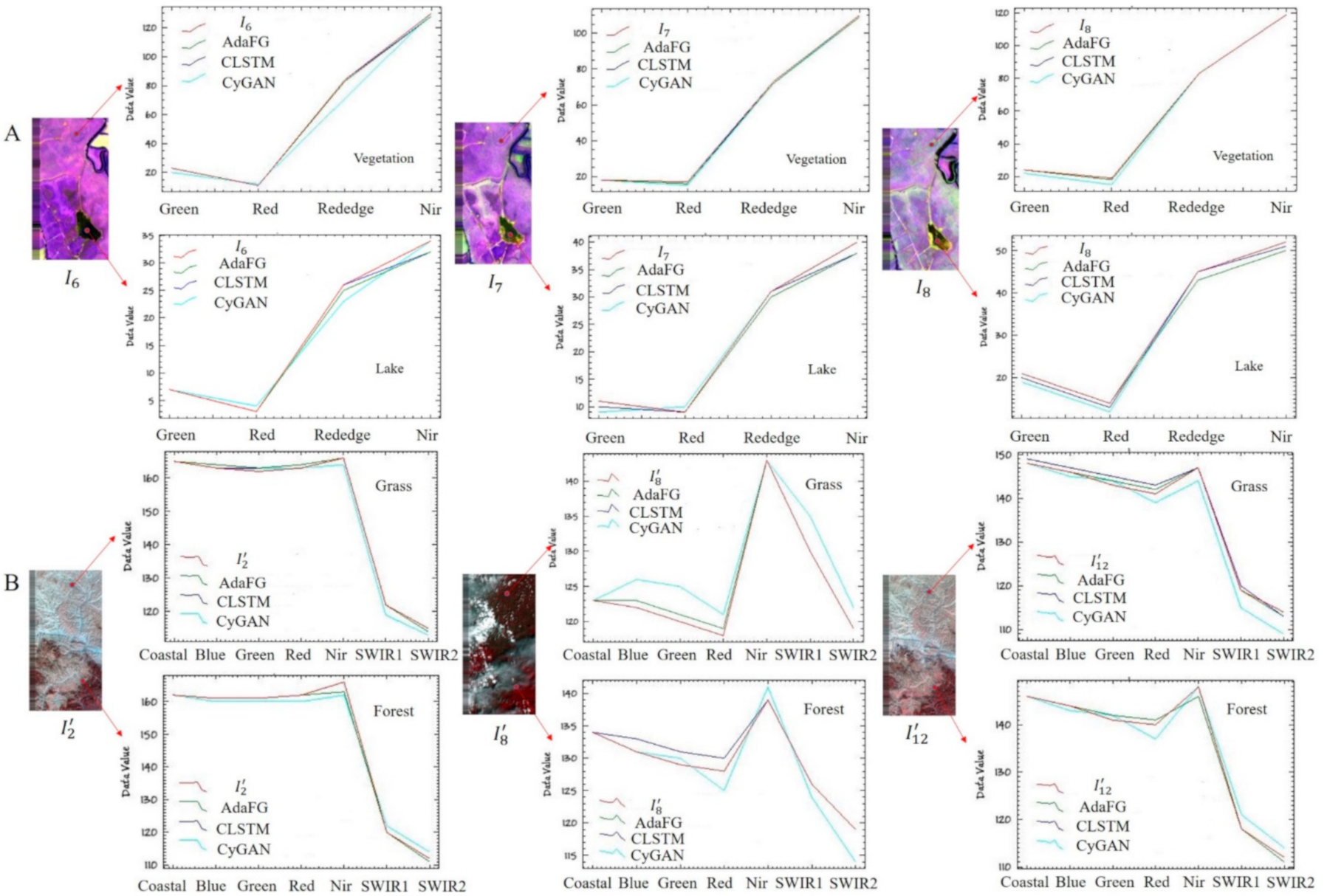
Figure 9 shows the spectral curves between the generated result and reference image using different networks at different coordinates (vegetation, lake, grass, forest) and illustrates that using different networks could maintain better spectral features between the generated result and the reference image in both datasets.
3.3.2. Single Network Datasets
In the second aspect, we constructed single network datasets according to the characteristics of different deep convolutions networks and existing images in both datasets. There were no reference images in this aspect.
Figure 10 shows the generated results of UAV images using the AdaFG network from 2017 to 2019 and the visual effects of three-level generation according to the construction strategy in
Table 3.
Figure 11 shows the generated results of Landsat-8 images using the CyGAN network from 2013 to 2015 and the visual effects of two-level generation according to the construction strategy in
Table 4. It appears that as the level of generation increased, the spectral features of the generated result became worse. This may be caused by the propagation of pixel error as the level of generation increased.
3.3.3. Multiple Network Datasets
In the third aspect, we constructed multiple network datasets to reduce the pixel error of the generated result caused by a single network. There were no reference images in this aspect.
Figure 12 shows the generated results of UAV images using AdaFG, CLSTM, and CyGAN network from 2017 to 2019 and the visual effects of the generated results according to the construction strategy in
Table 5.
Figure 13 shows the generated results of Landsat-8 images using AdaFG, CLSTM, and CyGAN network from 2013 to 2015 and the visual effects of the generated results according to the construction strategy in
Table 6. It appears that the visual effects of multiple network datasets are better than a single network.
3.3.4. Comparisons Between Single and Multiple Networks Datasets
In the second and third aspects, we conducted quantitative indicator evaluation between single network datasets and multiple network datasets.
Table 8 shows the quantitative evaluation indicator between the generated results using a single network (AdaFG, CyGAN) and multiple networks. The table shows that the RMSE value produced by using a single network (AdaFG, CyGAN) was higher than that using multiple networks in both datasets.
5. Conclusions
The paper provides a remote-sensing sequence image construction scheme that can transform spectral mapping estimation and pixel synthesis into an easier process of using different deep convolution networks to construct remote-sensing sequence datasets. The major conclusions of this paper can be summarized as follows:
(1) The proposed AdaFG model provides a new method of generating remote-sensing images, especially for high-spatial-resolution images. CLSTM and CyGAN models can make up for the shortcoming of the AdaFG network model, which only performs single-scene generation and is affected by the missing degree of sequence images. The models can better capture and simulate complex and diverse nonlinear spectral transformation between different temporal images, and get better-generated images based on the models.
(2) Using separable convolution kernel of size 11 in AdaFG network, stacks of 3 × 3 CLSTM network layer, and 350, 1/32 in CyGAN network lead to better-generated results. Experiments show that the deep convolution network models can be used to get generated images to fill in missing areas of sequence images and produce remote-sensing sequence datasets.
The proposed AdaFG model is an image transformation method based on triple samples according to its structure, and its structure uses an adaptive separable convolution kernel. The spectral transformation ability of this model is higher than CLSTM and CyGAN models. However, this method only performs single-scene generation and its results are affected by the missing degree of sequence images. The proposed CLSTM model is an image transformation method based on multi-tuple samples according to its structure, and its structure is single-step stacked prediction. This model can perform predictions based on the state information of the time-series data. However, its results are affected by the length and missing degree of sequence images. The proposed CyGAN model is an image transformation method based on two-tuple samples according to its structure, and its structure uses cycle-consistent strategy and variable proportional hyper-parameters. This model can perform bidirectional transformation between different pictures, and its generated results are not affected by the degree of missing sequence images. However, the spectral transformation ability of this method is weak and its results are affected by the noise degree of sequence images.
When constructing remote-sensing time-series image datasets, it is necessary to make full use of the advantages of different deep convolution networks. When the missing degree of the sequence is small, using AdaFG and CLSTM model constructs the construction of remote-sensing time-series image datasets. When the missing degree of the sequence is larger, using the CyGAN model constructs the construction of remote-sensing time-series image datasets. Regardless of the quality and missing degree of sequence images, it is necessary to use the AdaFG model for the construction of remote-sensing time-series image datasets. In future work, we will make full use of the advantages of different deep convolution networks to construct a larger area remote-sensing sequence datasets.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}