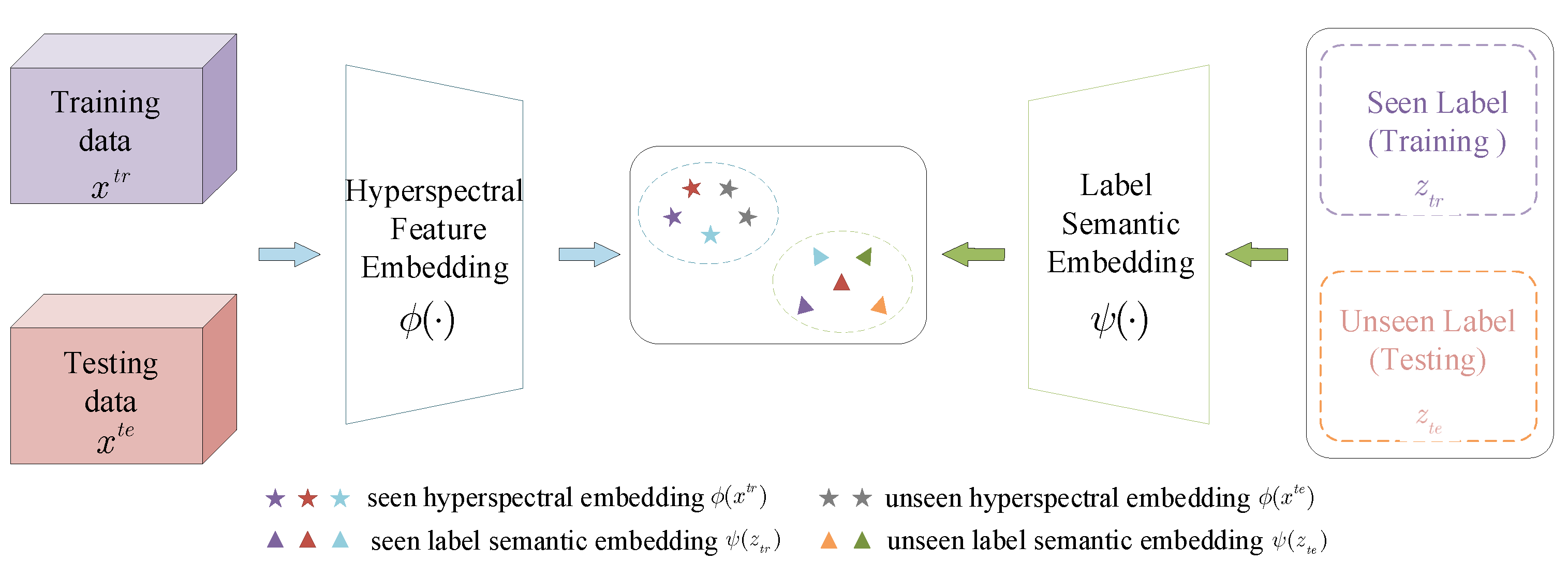
5.1. Datasets
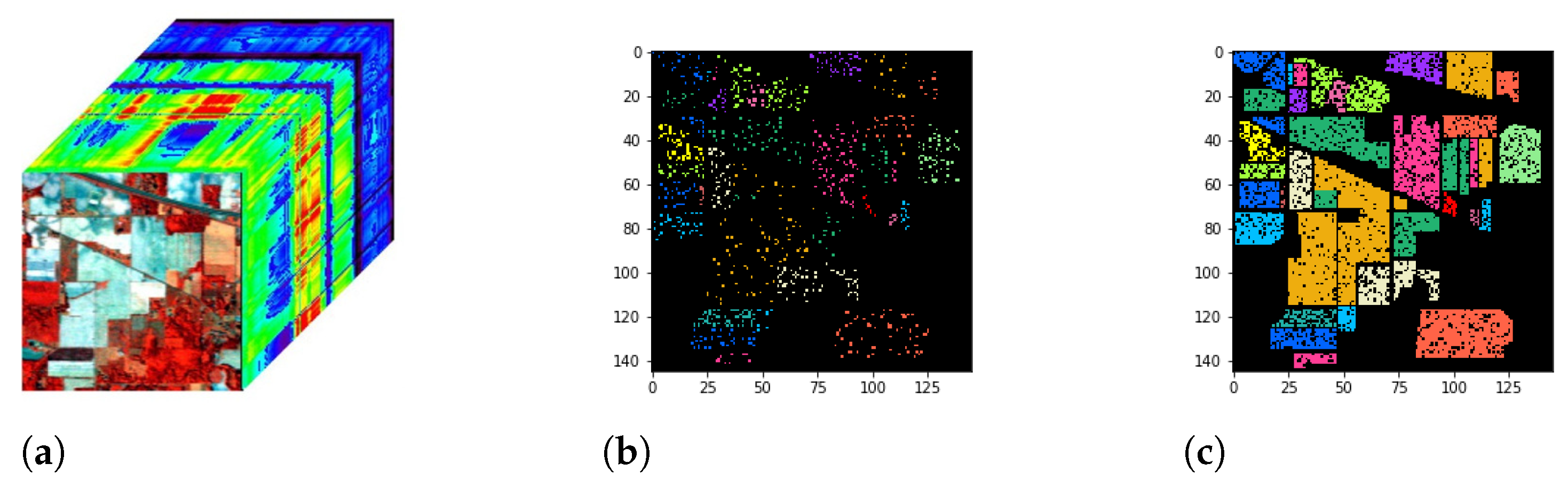
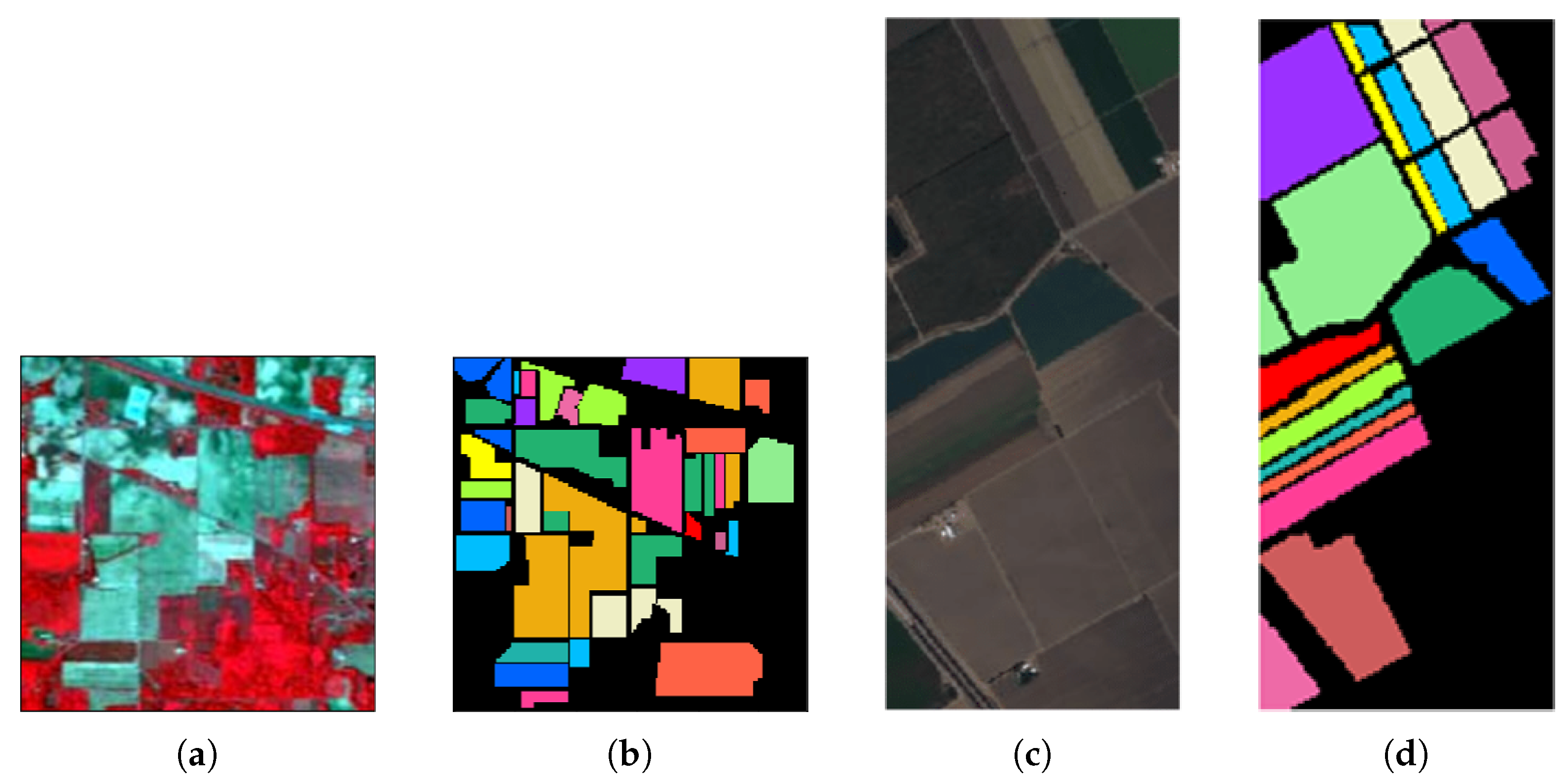
We complete a set of experiments on a pair of datasets collected by the same hyperspectral sensor. The reason for this selection is that different hyperspectral sensors have significant spectral gaps in hyperspectral imaging due to differences in wavelength range and spectral resolution. Our choice of pair datasets acquired by the same hyperspectral sensor can maintain greater consistency in the physical meaning of the spectra. So, we select four public hyperspectral datasets, including Indian Pines (IP), Salinas (SA), Pavia Center (PC), and Pavia University (PU). The false color images and the corresponding groundtruth maps are shown in
Figure 8 and
Figure 9, respectively. According to the hyperspectral sensor type of collecting data, we divide them into two groups, A and B. Each group has two datasets to form a pair of training set and testing set.
Table 1 shows the detailed information of these four datasets. In addition, the name of categories and the corresponding number of samples of these two groups are shown in
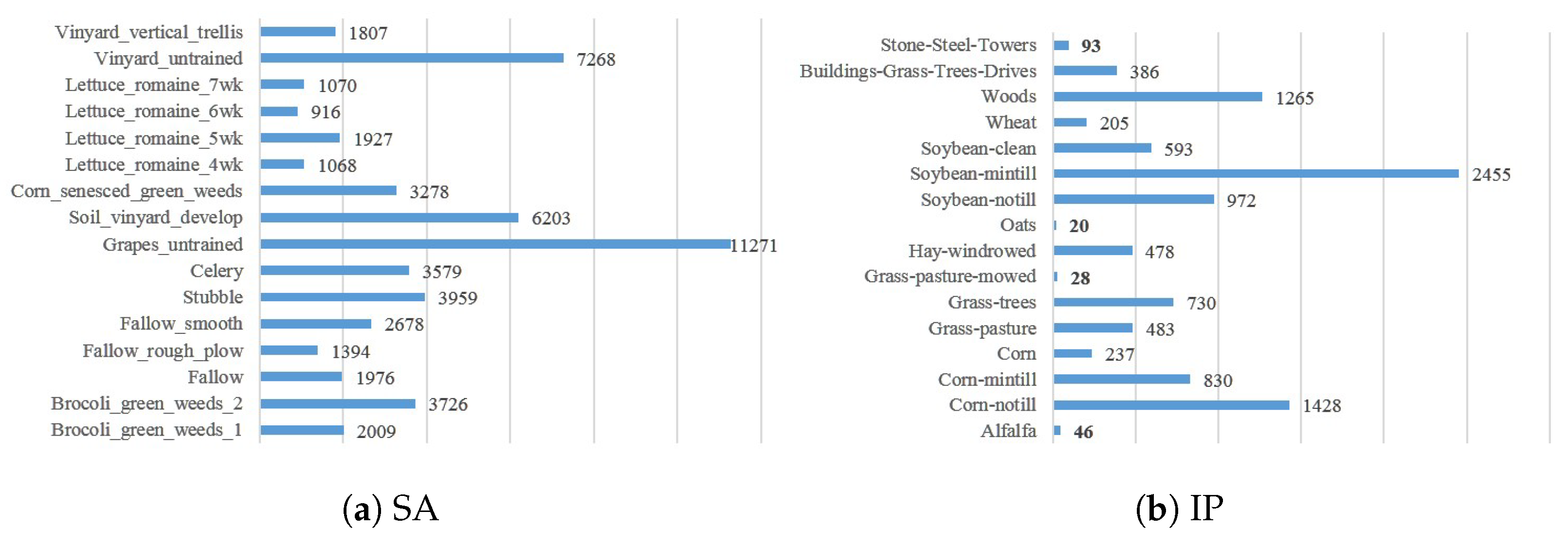
Figure 10 and
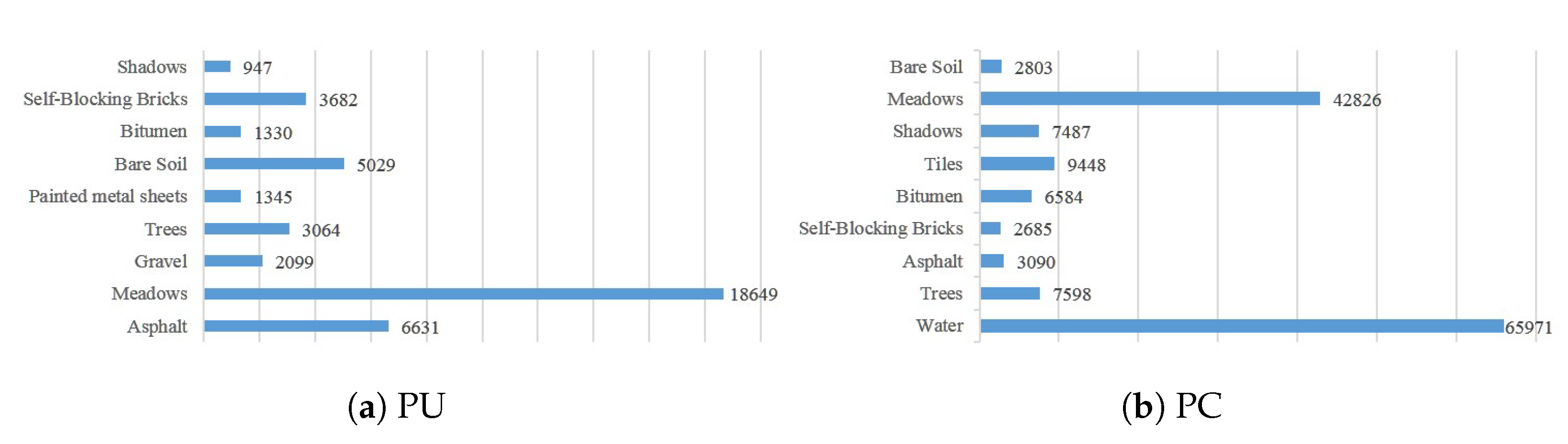
Figure 11, separately.
For HSI classification across different datasets, it is important to choose the appropriate combination of training and test sets. We split the selected datasets into the following 2 groups.
Group A: The Indian Pines dataset and the Salinas dataset. Both datasets were acquired by the AVIRIS sensor. To keep the input dimension of spectral consistent, we removed the last four bands from the Salinas dataset. Both of these two datasets has 16 different categories, but there are too few samples of some categories in this dataset, which will cause serious problems of category imbalance, so we exclude categories with less than 200 samples, including Alfalfa, Grass-pasture-mowed, Oats and Stone-Steel-Towers. The final selected categories of the training and testing sets are listed in
Table 2. We design two cases of training and testing set as follows:
Case 1: IP-SA
Training Set—Indian Pines dataset with 12 categories.
Testing Set—Salinas dataset 16 categories.
Case 2: SA-IP
Training Set—Salinas dataset with 12 categories.
Testing Set—Indian Pines dataset 16 categories.
Group B: The Pavia Center dataset and the Pavia University dataset. Both datasets were acquired by the ROSIS sensor. To keep the input dimension of spectral consistent, we remove the last band from the Pavia University dataset. Each dataset covers 9 different categories, but 6 categories are the same between these two datasets. In order to keep the categories of training and testing set disjoint, we choose 5 categories of Pavia Center dataset and 6 categories of Pavia University dataset to form the combinations, which listed in
Table 3. We design two cases of training and testing set as follows:
Case 3: PU-PC
Training Set—Pavia University dataset with 6 categories.
Testing Set—Pavia Center dataset 5 categories.
Case 4: PC-PU
Training Set—Pavia Center dataset with 5 categories.
Testing Set—Pavia University dataset 6 categories.
Besides, considering that the hyperspectral images of two different regions actually collected are likely to have duplicate land-cover categories, so we also perform experiments on dataset-pairs with duplicate categories in another two cases as follows:
Case 5: PU’-PC’
Training Set—Pavia University dataset with 9 categories.
Testing Set—Pavia Center dataset 9 categories.
Case 6: PC’-PU’
Training Set—Pavia Center dataset with 9 categories.
Testing Set—Pavia University dataset 9 categories.
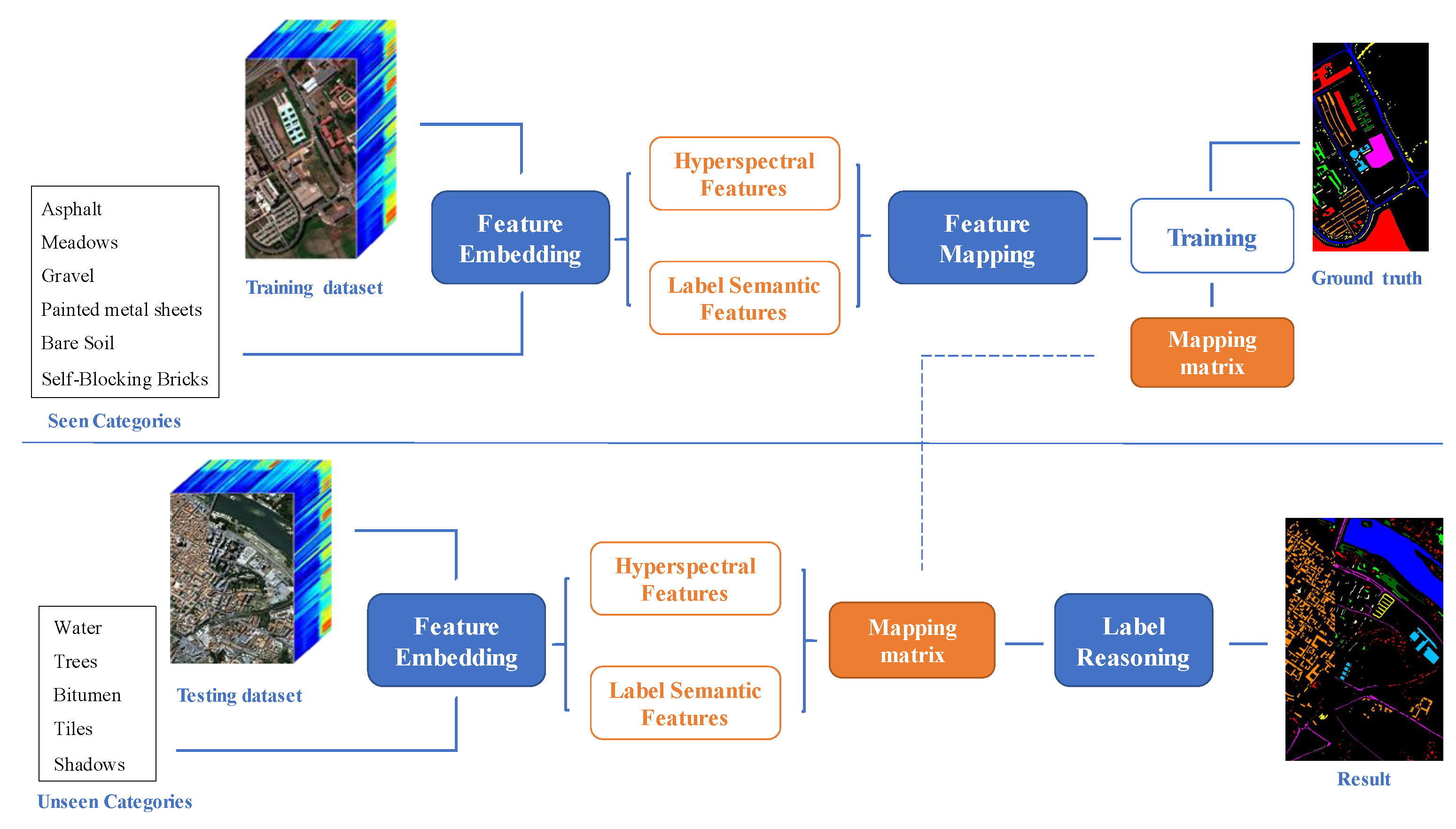
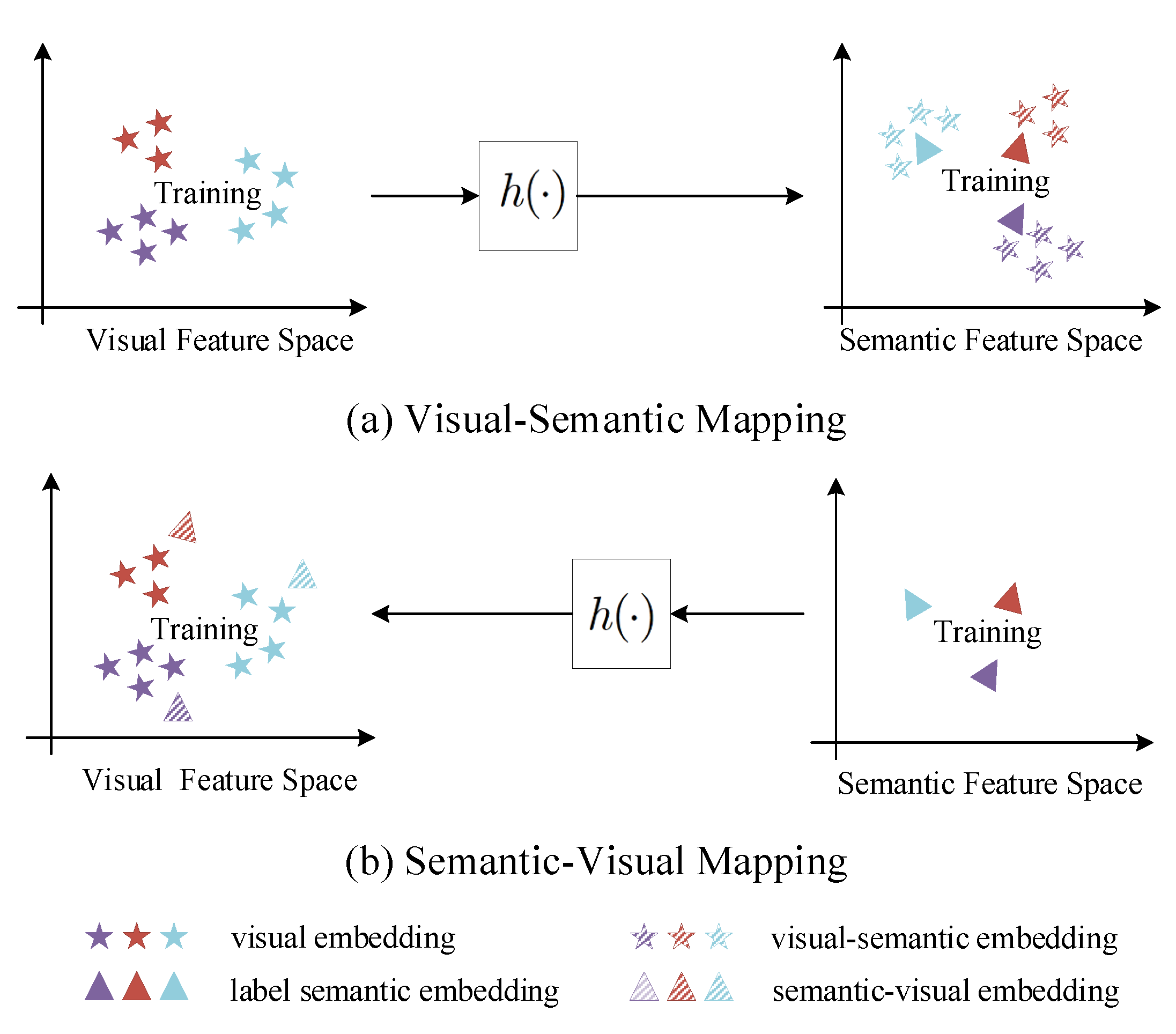
5.3. Implementation Details
5.3.1. Visual Embeddings
We obtain visual embeddings from the aforementioned HSI classification models. For each combination of training and testing sets, we retrain and optimal the model for each training set and save its model parameters as a pre-trained model. We finally load the pre-trained model without the softmax layer of the original classifier and get the visual embeddings.
For the bands-grouping RNN, we group 10 bands for each time step. The hidden layer units of RNN is set to 256, and the size of latter fully-connected layer is set to 128. For the ResNet18, it contains 17 convolutional layers and a fully connected layer. The size of spatial region for each pixel is set to , and the last fully connected layer output a 512-dimensional visual feature vector. For the SSAN, the size of spatial region for each pixel is set to , and the output of fully connected layer is 1024-dimensional. In addition, we employ L2 regularization and a dropout parameter set to 0.4 to avoid overfitting.
These three methods also have some common parameters in training, the batch size of the pre-training stage is set to 256 and the learning rate is 0.001.
5.3.2. Semantic Label Embeddings
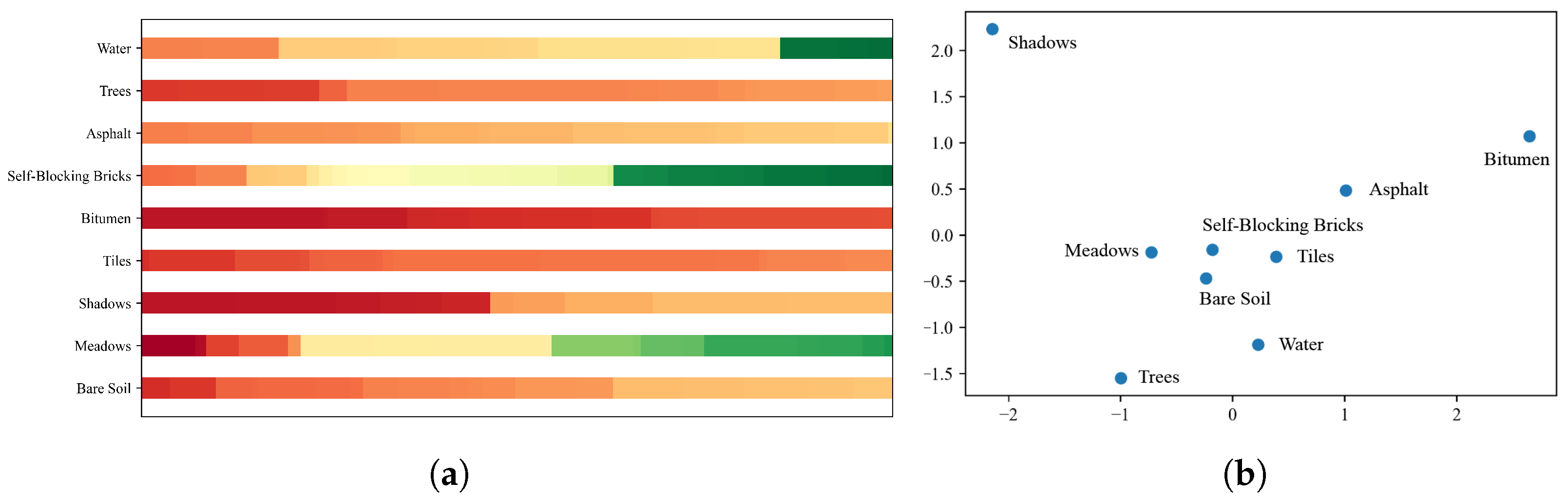
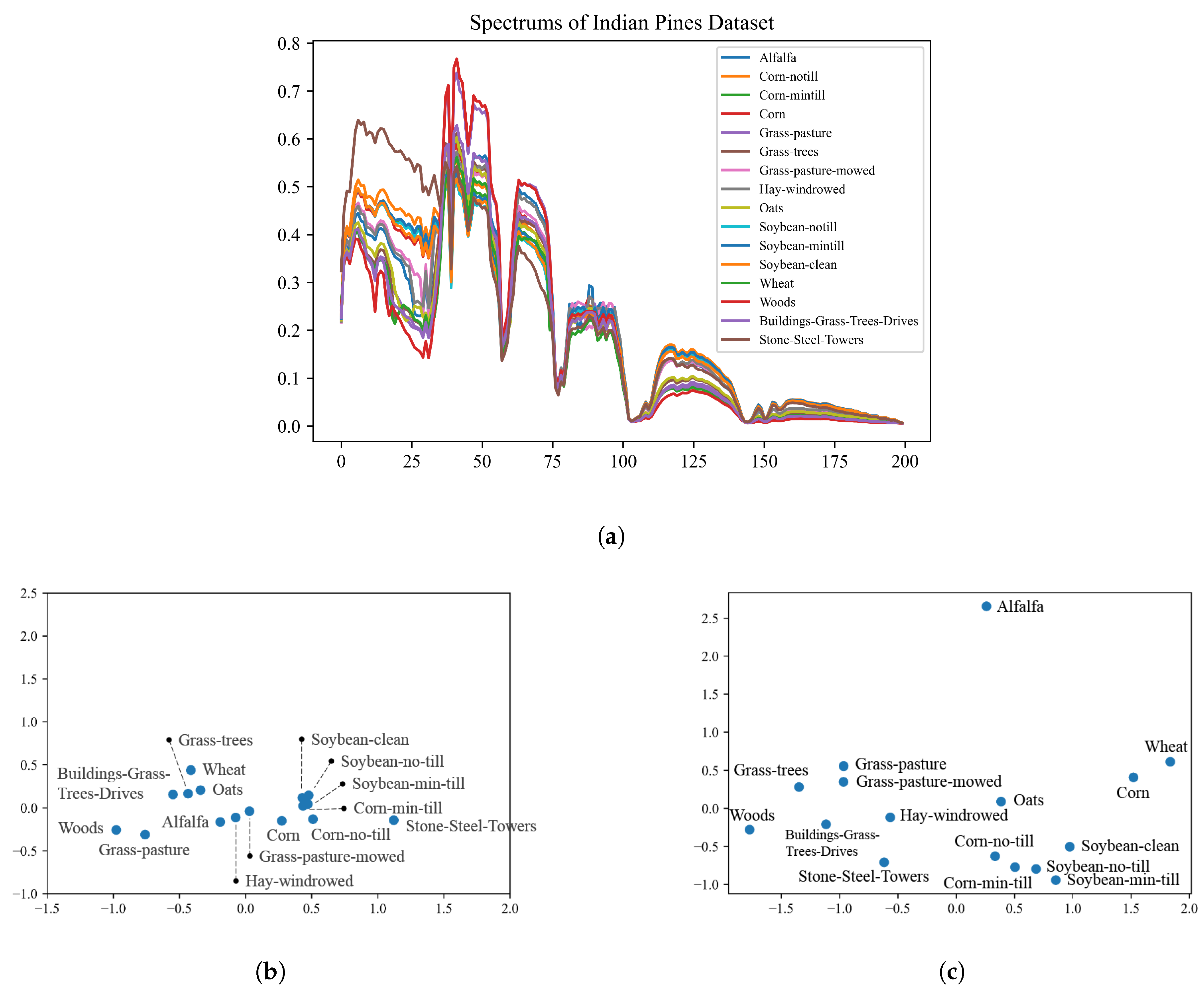
As illustrated in
Figure 12, first of all,
Figure 12a indicates that some categories in Indian Pines dataset are hard to classify in the origin spectral dimension, especially “Soybean-clean”, “Soybean-no-till”, “Soybean-min-till” and “Corn-min-till” according to
Figure 12b. Relatively speaking, as PCA 2D projection of word2vec vectors in
Figure 12c, it shows that label semantic representations have good separability of categories. It also proves the effectiveness of word2vec vectors.
In addtion, many categories of names in the HSI dataset are composed of multiple words, so we load and average the word vectors corresponding to each category. Secondly, not all words of category names can be found in this corpus. Thus, we have modified the names of categories slightly without violating the original meaning. For instance, “Lettuce_romanine_4wk” refers to the lettuce that grows in the fourth week, but “4wk” is not a word, so we change it to “Lettuce_romanine_4”. The same operation applies to other categories.
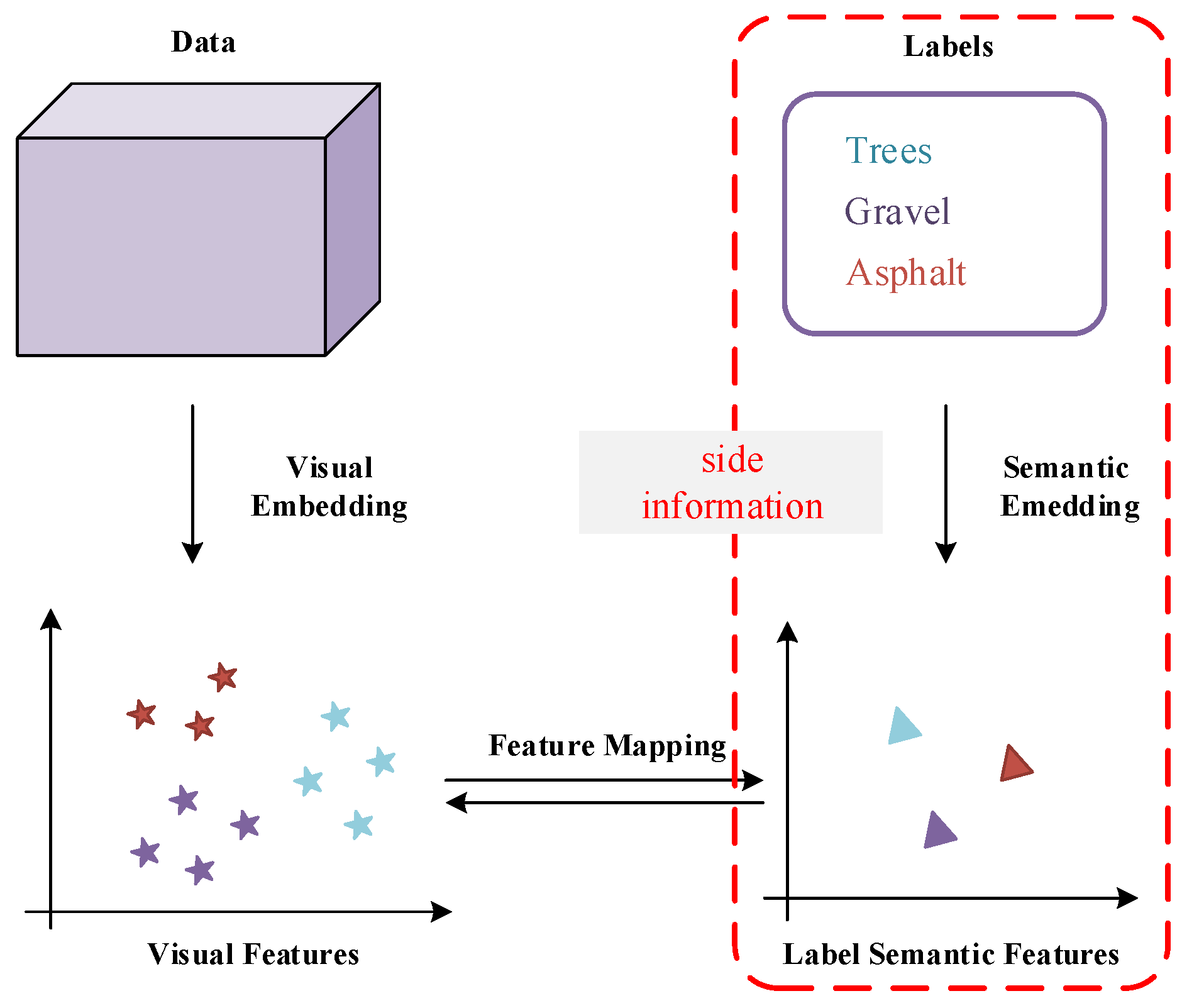
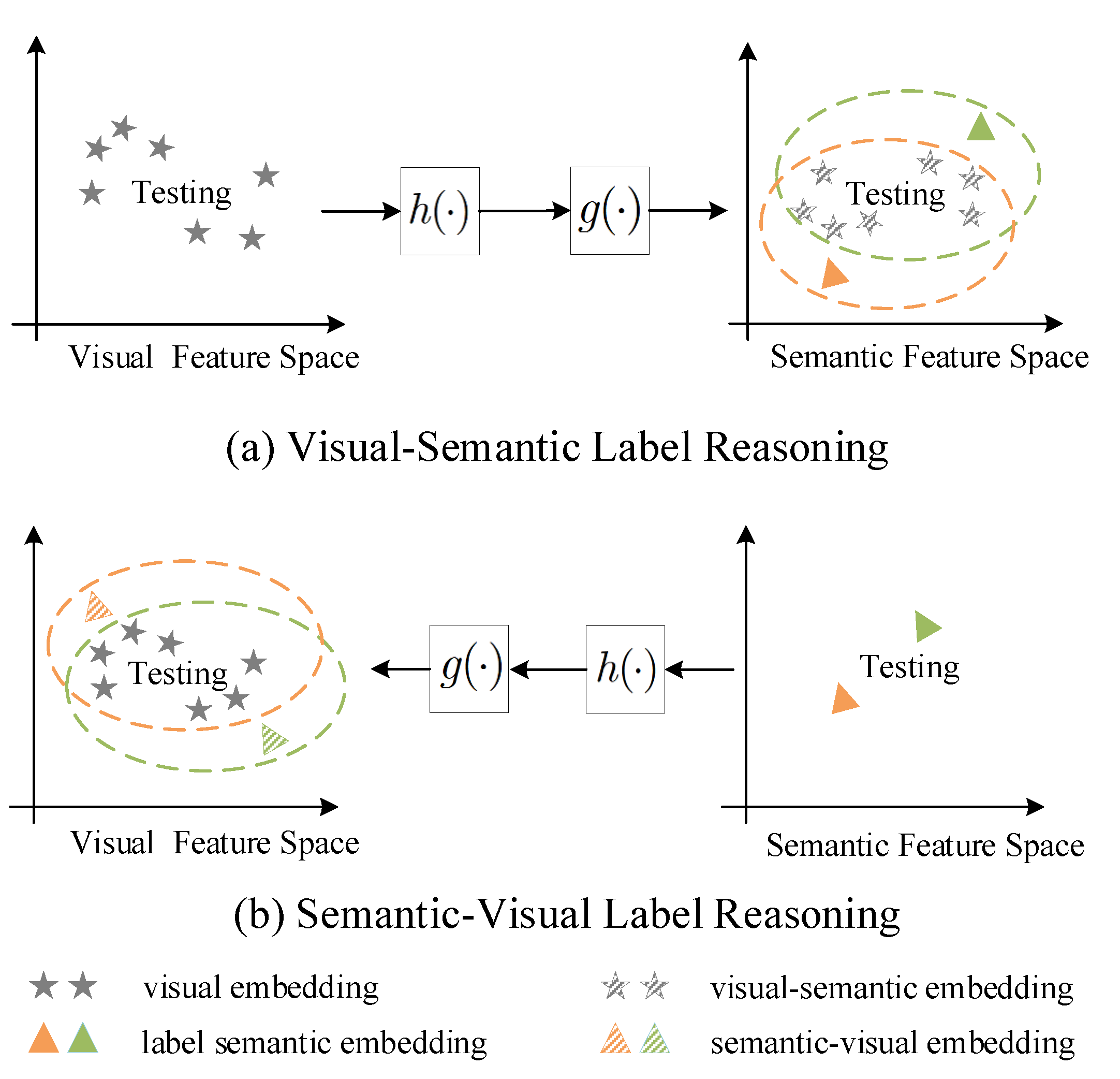
5.3.3. Visual-Semantic Alignment
Many classic zero-shot learning methods make use of category attributes provided by the public dataset, but there is no corresponding attributes data in the hyperspectral dataset. Therefore, we choose some models that only used word embeddings as the category reference data.
The selected comparative methods are DeVise, WLE, SAE, DEM and RN. All of them have been briefly introduced previously. Specifically, Word2Vec Label Embedding (WLE) is a variant of Attribute Label Embedding (ALE) model that uses word2vec instead of attributes. In these methods, DeVise and WLE align two parts of embeddings in the semantic space, and DEM and relation network are mapping the label semantic embeddings to the visual space. Moreover, SAE can be applied in both two space. The parameter settings are listed in
Table 4.
5.4. Analysis of Experimental Results
We take the training and testing set in six cases with their selected categories, and report the experimental results using visual features obtained from bands-grouping RNN, ResNet18 and SSAN, respectively.
Table 5 list results on GroupA datasets with case 1 and case 2 (IP and SA),
Table 6 present the results on GroupB datasets with case 3 and case 4 (PU and PC), and
Table 7 shows results on GroupB datasets with case 5 and case 6 (PU’ and PC’). The reports list the average results of 5 runs.
The comparison of experimental results using different feature extraction networks show that the source of visual embeddings has a considerable effect on the experimental results. The results indicate that the performance of SSAN which extracts joint spatial-spectral features is better than both the bands-grouping RNN which only focuses on the spectral feature and ResNet18 which concentrates on the spatial information. It is consistent with the trend in ordinary hyperspectral classification methods. For Group A, this is because IP and SA are collected from rural areas which mostly covered with crops, and the crops usually have a homogeneous distribution in the spatial domain. In contrast, Group B datasets have intricate distribution spatially. PC and PU provide data from the urban area, some category distributions here are decentralized, and some are mixed together. The advantage of HSI is the rich spectral information, also the introduction of complex spatial distribution has a positive impact on the performance of the classification or recognition task. Therefore, the superiority of hyperspectral data can be brought into play only by combining and fully mining the spectral and spatial information.
As we can observe, Group A is underperformed, especially the IP-SA case. The results of SAE and WLE with visual feature embedding under bands-grouping RNN are even nearly close to random classification performance. The poor performance may be caused by the reason that the categories in Group A mainly are crops, some of which only have a slight difference in terms of the name. For example, “Brocoli_green_weeds_1” and “Brocoli_green_weeds_2” in Salinas dataset, or “Soybean-no till”, “Soybean-min till” and “Soybean-clean” in Indian Pines dataset. They belong to the same type of land cover, but they have different spectra in hyperspectral data because they are under different conditions. Therefore, in the HSI data set, they are usually distinguished by adding other words or numbers. In zero-shot learning, we employ label semantic representation as side information, but for these categories which are only slightly different in name, they are difficult to distinguish semantically. It has a certain negative impact on classification performance.
Focusing on case 3 and case 4 of Group B (see
Table 6), it can be noticed that only the results of the WLE and RN perform beyond the random classification performance in the PU-PC case. This is in stark contrast to the results of another case PC-PU, in which all zero-shot learning methods perform better. The huge difference between the number of labeled samples for training and testing comes to the first reason for this situation. It can be seen in
Table 3, the PC dataset has 91,775 labeled samples while the PU dataset only has 36,817 in case 3 and case 4. The second reason is the unbalanced categories. Both of them have severely uneven data distribution. For example, the number of “Waters” in the PC dataset is 65,571 and “Meadows” has 18,449 samples in PU dataset while the other categories only have a few thousand. Group A has a similar situation. Besides, Group B covers the scene captured from the urban area, where most of the categories have a scattered and complex spatial distribution.
The “” item in the tables indicate the choice of embedding space. Among all the zero-shot learning methods, the results in SAE are unsatisfactory, and several items of accuracy are even lower than the performance of random prediction. It suggests that there is no linear relationship between the visual feature embedding and the label semantic embedding. Besides, the performance of DeVise and WLE also prove that, both of which employ bi-linear compatibility function to connect the visual feature embedding and the label semantic embedding. So this kind of method cannot generalized well in the HSI classification task. Through these comparative experiments, it can be found that the “” method shows better results no matter under different visual feature extraction models or in different combinations of training and testing datasets, especially RN. It implies that treat visual space as an embedding space is a better choice for the application of zero-shot learning in HSI classification.
Case 5 and case 6 where the training set and the testing set shared some categories are attempts for generalized zero-shot learning.
Table 7 shows the experimental results. Compared with previous experiments, the top-k accuracy has no significant improvement with the existence of common categories. There are two main reasons. First of all, both datasets have 9 categories, but their distribution of each category is visibly different, even the same categories in PC or PU has a significant difference in distribution. For example, the entire PC dataset contains 148,152 labeled samples and the PU dataset contains 42,776 labeled samples in total. What’s more, as shown in
Figure 11, “Meadows” has 18,649 labeled samples in the PU dataset but has 42,826 in the PC dataset.“Self-Blocking Bricks” is the category with the fewest samples in the PC dataset, and there are only 2685 samples, but it ranks fifth in the number of samples in the PU dataset, with 3682 samples. Secondly, it is worth mentioning that the spectra of the same land-cover may not be fully consistent. The spectral curves of the same type of land-cover in the same dataset may have a certain range of fluctuation due to the spatial distribution or occlusion. Moreover, for these two datasets collected by the same sensor, the differences in the imaging environment, such as different weather conditions or lighting effects, may cause some variations in the spectrum of the same category. These also have a certain interference on the performance of classification. Besides, the experimental result of case 5 and case 6 are also consistent with the trends of the previous experiments.
In addition, in order to prove the positive effect of generalized zero-shot learning, we add a comparison with the ordinary hyperspectral classification in cases 5 and case 6,
Figure 13 shows the top-1 accuracy of each comparative methods. As we can see, the DEM and RN perform more robust and superior.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}