1. Introduction
In recent years, Unmanned Aerial Vehicles (UAVs) have rapidly gained popularity as a remote sensing platform that can provide higher spatial and temporal resolution images relative to traditional media such as satellites. An increasing number of studies have utilized UAV-based near-ground remote sensing [
1,
2,
3,
4], taking advantage of their flexibility, ease of use, and ability to measure at lower altitudes in comparison with airborne sensors. The civil applications of UAV for high-resolution image acquisition have emerged as an attractive option for agriculture [
5,
6,
7] and environmental monitoring [
8,
9]. Hence, they were widely used in recent studies involving quantitative remote sensing applications due to their versatility. For example, different groups used hyperspectral for ground object classification and biochemical analysis [
10,
11,
12,
13], monitored ground plant diseases in an orchard or plant vegetation by using miniature thermal cameras [
14,
15,
16], and used narrow-band multispectral imagery for crop water stress monitoring [
17,
18]. Integrating different data types to meet the diverse need of ground surveying is becoming a new research focus.
Vegetation indices have long been used in remote sensing [
19,
20,
21] because they are simple, intuitionistic, and effective ways to model the ground cover reflectance. However, in drone-based remote sensing, although sensor and ground resolution are improved, vegetation indices alone cannot provide sufficient accuracy for classification [
22]. Instead, new methods are needed to fully exploit the information contained within reflectance. The majority of vegetation indices were designed to enhance the difference among different land covers. For example, the normalized difference vegetation index (NDVI), the most commonly-used vegetation index in remote sensing for monitoring plant growth status, calculates the ratio of the differences and sum of the near-infrared (NIR) and red bands to represent the nonlinear structural relations between different bands. Green NDVI uses the green channel to replace red in the NDVI formula, and also represents the nonlinear relations between all multispectral channels. While many studies used machine learning methods to build models based on spectral bands for ground classification [
23], the nonlinear information contained in vegetation indexes has barely been fused into ground classification models. However, the unstructured information contained within vegetation indices may help with improving classification accuracy.
Shadow is a significant factor in remote sensing. [
24] took shadow reflective features into consideration during image segmentation and extracted shadows according to the statistical characteristics of the images. The authors used a set threshold to detect shade, which decreased its practicability. [
25] studied the relationship between field-measured stem volume and tree crown area and tree shadow area. Shadow influences the reflectance of soil and may lead to miscalculation of some parameter retrievals, like soil organic carbon and textures [
26], as well as soil moisture [
27]. Moreover, shadows may lead to errors in other ground plant measurements, like tree size, crown height [
28]. Therefore, a rapid and accurate shadow classification is needed for almost all remote sensing platforms, including satellite, aircraft, and UAVs.
Machine learning is widely adopted in remote sensing for ground classification, texture segmentation. Selecting features for model training input is as important as selections of samples and methods. Inclusion of a greater number of features improves the ability of the model to differentiate among species and categories. Consequently, a key goal is to find as many spatial features as possible, then use redundancy reduction or feature selection methods like Principal Component Analysis (PCA), Uninformative variables elimination (UVE), Independent Component Analysis (ICA), and lastly select different classifiers using methods such as Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Linear Discriminant Analysis (LDA) to build a statistical model for fast classification applications. Feature selection is often regarded as a process that obtains a subset from the original features set based on certain selection criteria. Usually, the dimensions of the features are reduced. Before feature selection is performed, vectors that contain normalized feature variables need to be built.
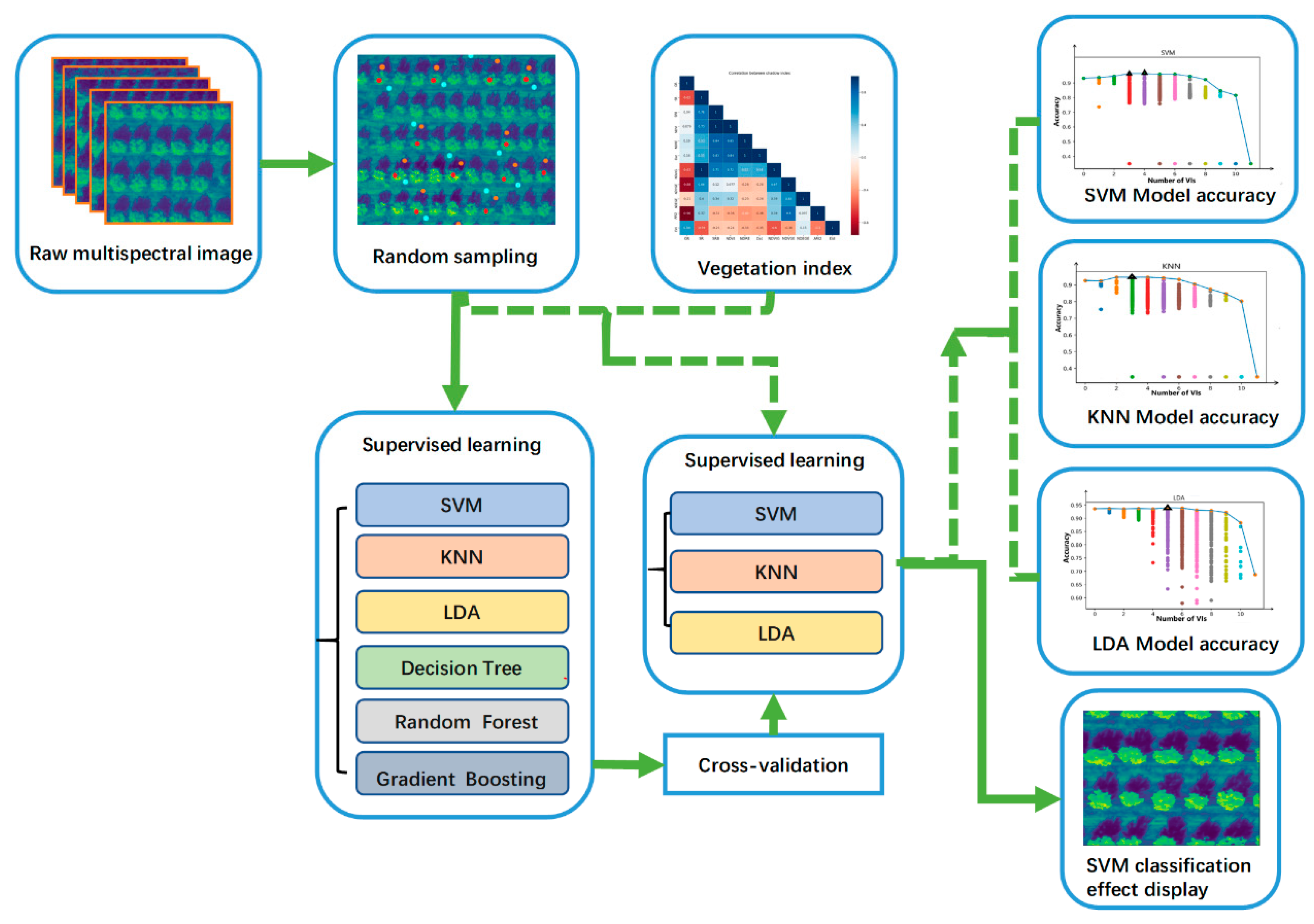
In this study, a UAV mounted with a five-band multispectral camera was used to measure an almond plantation. After the orthoimage was acquired, we first tested the classification of three surface types (tree, shadow, and soil) using different machine learning methods, namely SVM, LDA, KNN, Random forest, Decision Trees, Gradient Boost, to determine which method obtained the best performance. Secondly, we developed a fusion pipeline incorporating both spectral bands and normalized vegetation indices into the machine learning process. Thirdly, we assessed the impact of fusing spectral bands and vegetation indexes on the performance of the machine learning models. Lastly, we comprehensively compared the results trained with vegetation indexes and determined the proper selection protocol for classification.
2. Materials and Methods
2.1. Study Area
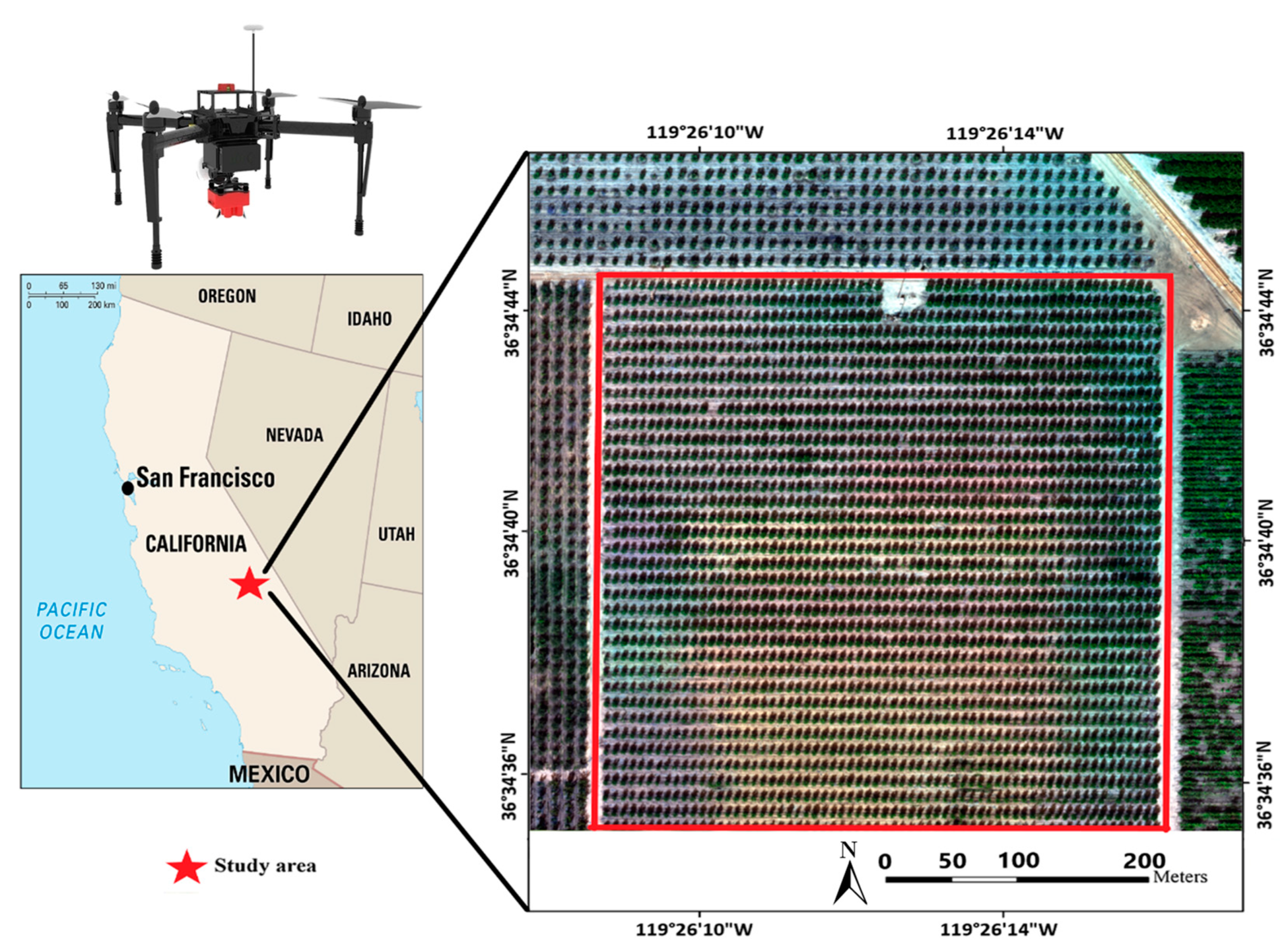
The experiment site (36°34′42.67″N,119°26′14.01″W) is located at Reedley, CA, USA. The terrain of the experimental area is generally flat, with elevation ranging from 340 to 350 feet. A total of 20 acres of almond plantation were used for experiment. Row spacing of 2 rows was about 5.14 m, and column spacing was about 9.3 m.
2.2. Data Collection and Image Selection
A DJI M100 quadrotor drone was equipped with a RedEdge-M (MicaSense Inc., Washington, DC, USA) multispectral camera, and GPS (ublox AG, Swiss), and Downwelling Light Sensors (MicaSense Inc, USA) for this research. The drone was powered by a 5700-mAh LiPo battery, which provides an average flight duration of ~30 minutes. The RedEdge-M acquires images with 1280 × 960 pixels resolution at five spectral bands including blue (475 nm), green (560 nm), red (668 nm), red edge (717 nm), and near-infrared (840 nm). The focal length of the lens was 5.4 mm and images were stored as 16-bit TIFF RAW format.
The experiment was carried out in mid-October. Multispectral images were collected at the height of 200 meters above the ground level. A high side and forward overlap rate of 80% was adopted to assure high map quality. Multispectral images were stitched together using Structure from Motion (SfM) functions in Photoscan software (Agisoft LLC, Russia) to generate an orthoimage map (
Figure 1). Within the map, a region of interest was selected for analysis (
Figure 1, red highlight) which contained even tree distribution and omitted signal interference from nearby road and bare soil patches.
2.3. Selection of Spectra
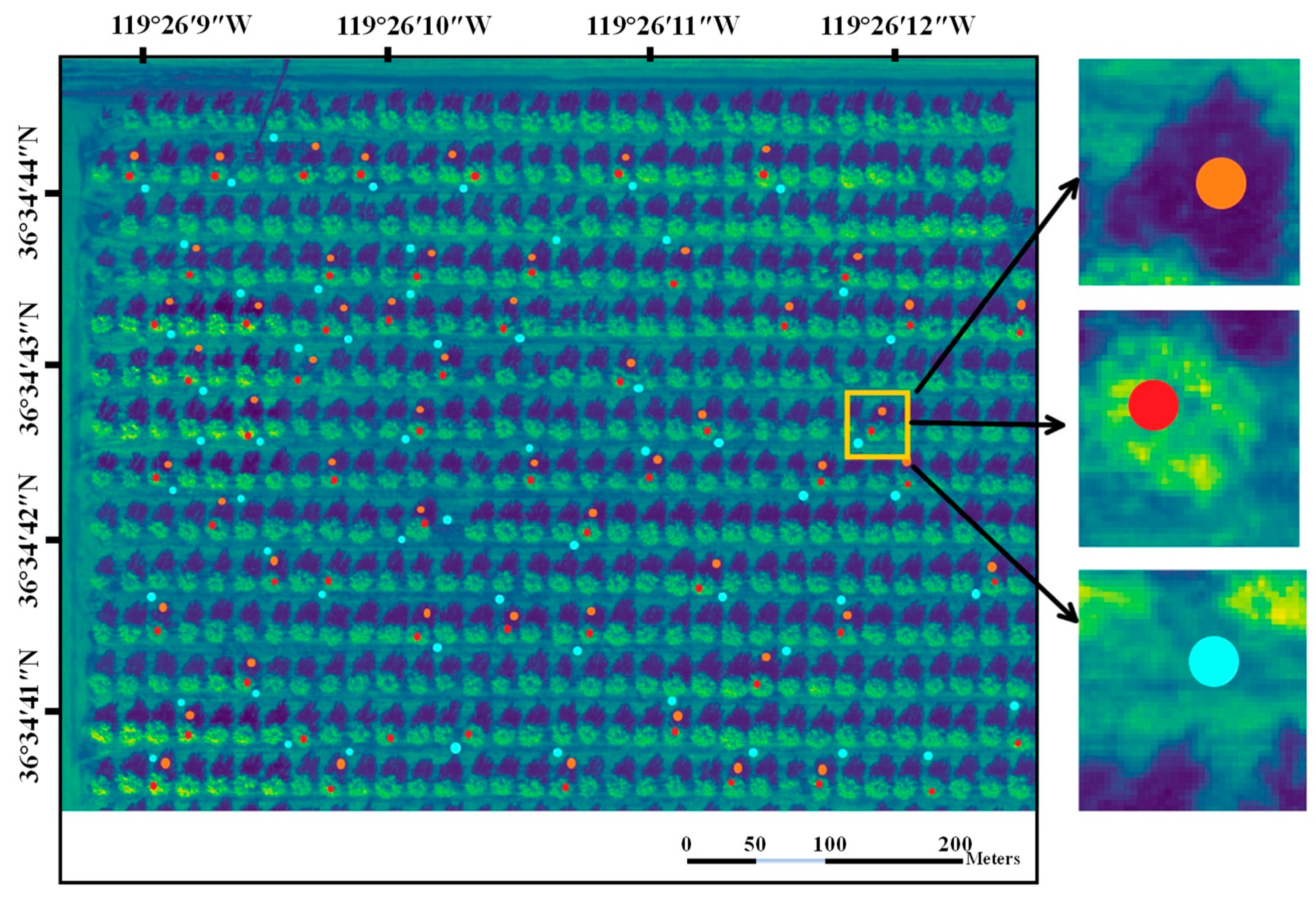
As classification is based on spectral features, it is crucial to properly collect multiple spectral information in different areas to form training data sets. Sampling was performed as follows: The region of interest was split into three categories: almond tree, sunlit soil, and shade-covered soil. Circular points, consisting of a 4-pixel radius, were randomly sampled within the region of interest. The points were sampled such that the whole circle fit within a single category. The feature vector of each point was calculated as the mean value of reflectance within the circle. The whole process is as the
Figure 2 shows.
Using Equation (1), we can calculate the actual distance of the captured object in an image,
x, as:
where
f represents the focal length of 5.4 mm,
p represents the pixel size of 0.00375 mm
2, and
h represents the height above target of 200 m. Thus, the actual distance corresponding to each pixel is 0.139 m, and the actual radius of the sampling circle is about 0.554 m.
The points’ spot selection is very important in forming the dataset. If the collected areas are mostly the central area of trees, shadows, and ground, the difference between them can be ignored. However, for random selection of sample points adopted to represent the species better, it is important to collect some edge data to increase sample points’ diversity. The sampling point size was designed with 4 × 4 pixels, which can represent the different reflectance of the species. The sampling circles where the tree is located were randomly selected. Each circle sampling area consisted of 4 × 4 band reflections. Inspired by the idea of averaging, the overall band reflection of it can be represented by the band reflection mean value. At the same time, the influence of noise can be avoided. Then, we labeled these 593 sample data tags as ’tree.’ In the same way, we sampled the reflectance of the ground and shadows.
As shown in
Table 1, we randomly extracted 400 data as a training set, 80 data as a validation set, and 113 data as the test set.
Figure 3 is an orthoimage representing about 1/4 of the entire study area, enlarged to demonstrate how the sampling was performed.
2.4. Performance Evalution
A variety of machine learning methods were employed here, including SVM, KNN, LDA, to investigate all possible models for classification fully. Some machine learning algorithms, like random forest and genetic algorithm, which have been used in a lot of machine learning researches, were not discussed in the fusion section. This was because these methods may have inconsistent results every time the training process was done. From this angle, they were not suitable for the goals to cross evaluate different machine learning methods. It is desirable to use methods that are consistent in performance to explore the feasibility of fusing vegetation indexes into a classification model.
To evaluate the model performance, we compared the output array with the test array. It was easy to tell how it performed by seeing that the output array from the predictive function was almost the same as the test array. In order to see the generalization of the model, the trained models were not only tested on the test set data but also applied to map the classification result of the entire research area. The trained model was used for pixel-wise classification, and the classification results are displayed in different colors. This was done to demonstrate the performance of the model. To visualize the classification result may not show too many details like the confuse matrix or outliers due to lack of ground truth data.
2.5. Vegetation Index
In this study, 11 VIs were used to improve classification accuracy. As the most prevailing VI, the sample radio (SR) is around 1, and SR is usually used for soil and vegetation segmentation since bare soils generally were near 1 and the number of green vegetation increased in a pixel (picture element), the SR increased. In other words, SR may contribute to the classification of the ground and the tree.
In the NDVI, the difference between the near-infrared and red reflectances is divided by their sum. Data from vegetated areas will yield positive values for the NDVI due to high near-infrared and low red or visible reflectances. As the amount of green vegetation cover increases in pixels, NDVI increases in value up to nearly 1. In contrast, bare soil and rocks generally show similar reflectance in the near-infrared and red or visible, generating positive but lower NDVI values close to 0. The red or visible reflectance of clouds, shadows are larger than their near-infrared reflectance, so scenes containing these materials produce negative NDVIs.
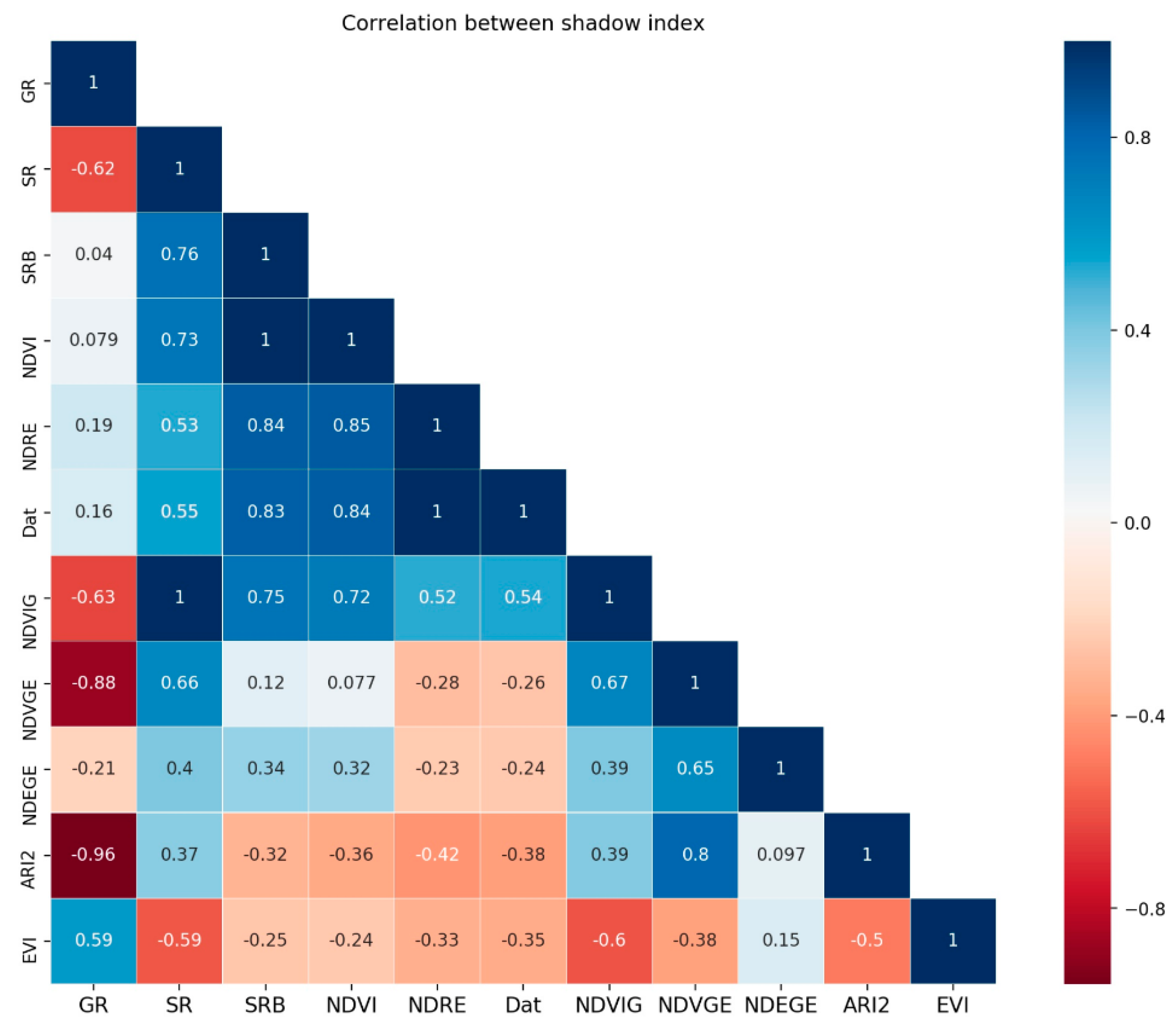
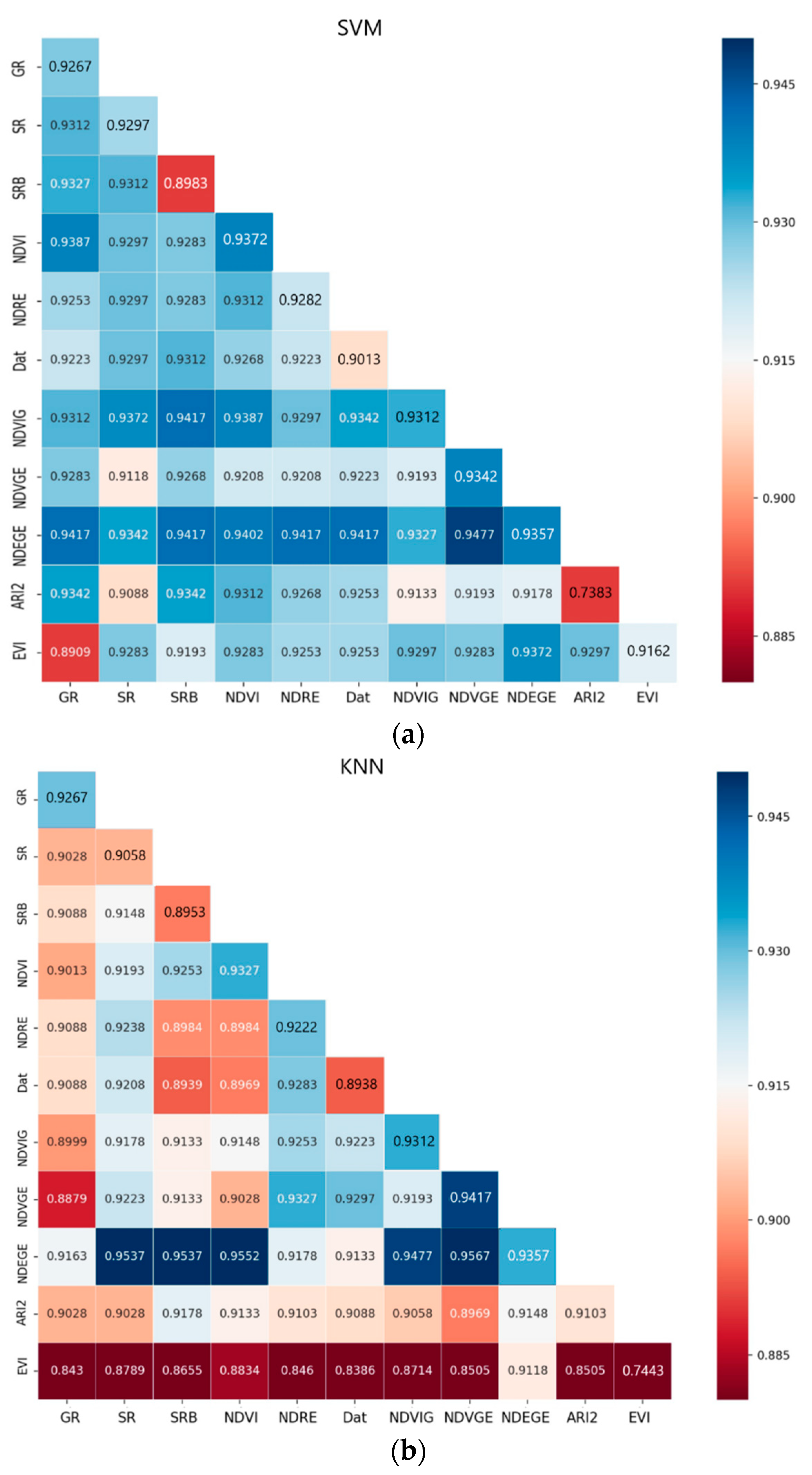
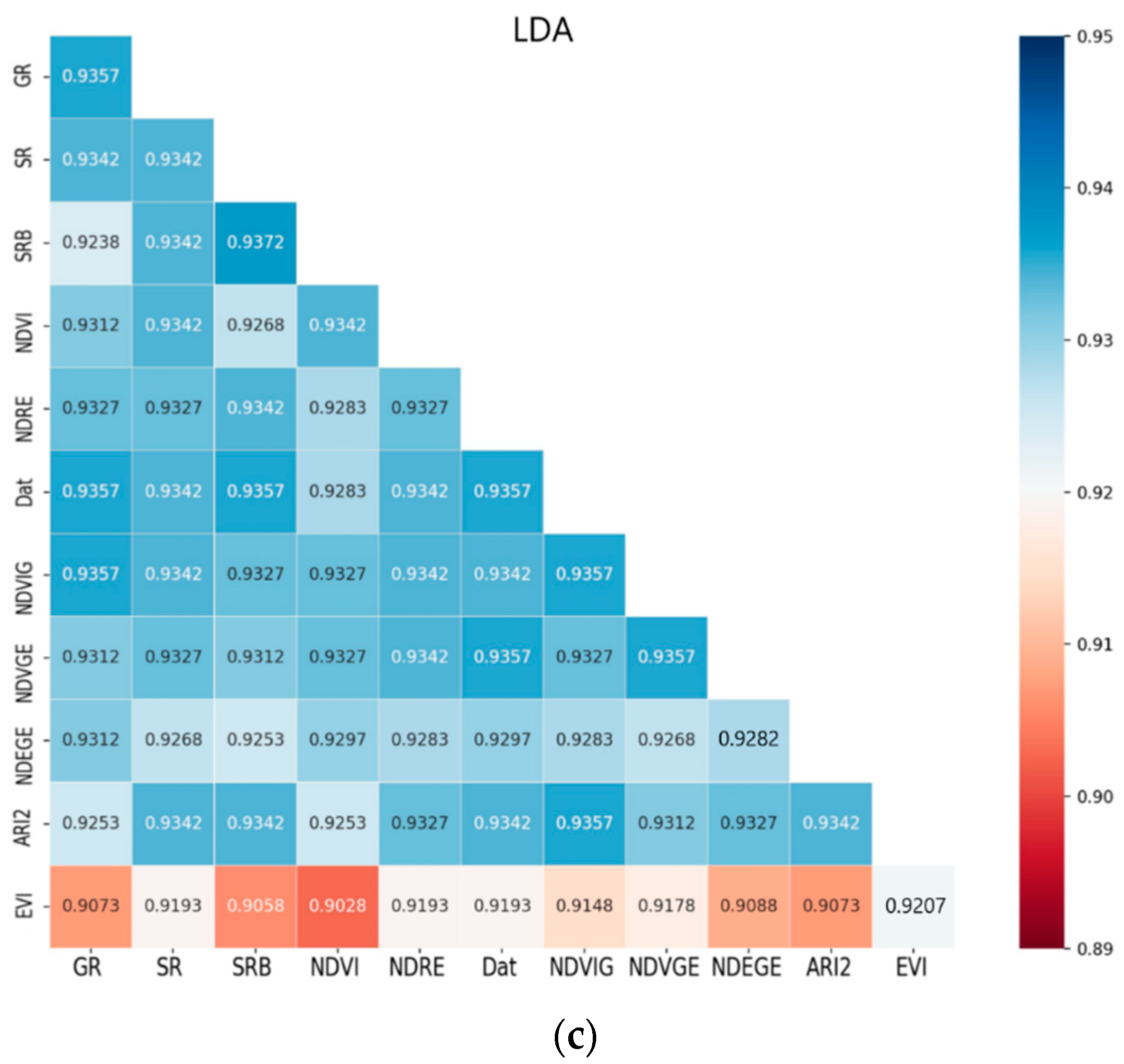
As shown in
Table 2, all 11 types of VIs used in this study are listed. Before the data was used in further process, it needs to be normalized to the same scale. Their mutual relevances were studied, as
Figure 4 shows. The closer the correlation coefficient was to 1 or −1, the more positively or negatively relevant they were and the darker the color got. The negative correlation and positive correlation were both taken into consideration. Dat and NDVI showed a high correlation
R2 = 1. SR and NDVRG were also the same. In general, their relevance was not very high. Nearly three-quarters of the vegetation index had a correlation coefficient below 0.5. We also hoped that the vegetation index correlation coefficient was lower so that different vegetation indices can play different roles.
2.6. Supervised Learning Methods
Different supervised learning methods were implemented using the open-source Python Scikit-Learn toolkit. Support vector machine (SVM) and Kernel SVM are supervised machine learning classification algorithms. SVMs were introduced initially in the 1960s and were later refined in the 1990s. After 20 years of development, they are becoming extremely popular, owing to their ability to achieve outstanding results.
The training set contains five features, so it is very important to choose the appropriate kernel function. Various kernel functions were implemented, such as linear, nonlinear, polynomial, Gaussian kernel, Radial basis function (RBF), sigmoid. The trained model was used to predict all the raw data directly, and finally adopt linear as SVM kernel. The linear kernel function can effectively distinguish between trees and tree shadows, while other kernel functions work poorly.
K-NN is a type of instance-based learning, or lazy learning, where the function is only approximated locally, and all computation is deferred until classification. A peculiarity of the K-NN algorithm is that it is sensitive to the local structure of the data. The best choice of k depends upon the data; generally, larger values of k reduces the effect of the noise on the classification, but make boundaries between classes less distinct. The special case where the type is predicted to be the class of the closest training sample is called the nearest neighbor algorithm. We will set k to 1.
Linear Discriminant Analysis (LDA) is most commonly used as a dimensionality reduction technique in the pre-processing step for pattern-classification and machine learning applications. It has been used as a linear classifier to project a feature space (an n-dimensional dataset sample) onto a smaller subspace 𝑘 while maintaining the biggest class-discriminatory direction.
Decision tree learning is a method commonly used in data mining. The goal is to create a model that predicts the value of a target variable based on several input variables. Random forests or random decision forests are an ensemble learning method for classification, regression, and other tasks that operate by constructing a multitude of decision trees at training time and outputting the class that is the mode of the types (classification) or mean prediction (regression) of the individual trees. Random decision forests correct for decision trees’ habit of overfitting to their training set
The idea of gradient boosting originated in Leo Breiman’s observation that boosting can be interpreted as an optimization algorithm on a suitable cost function. Jerome H. Friedman subsequently developed explicit regression gradient boosting algorithms.
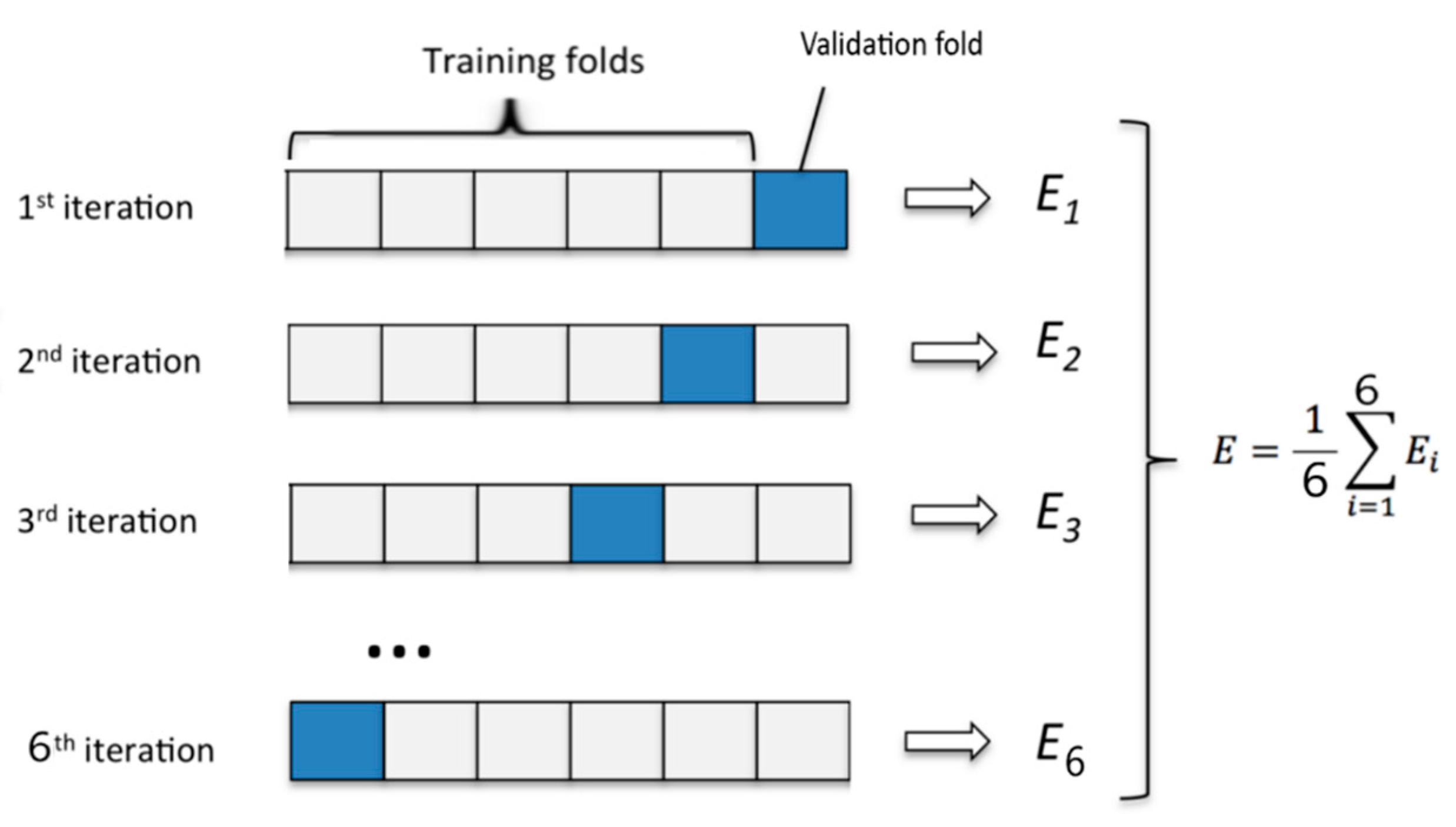
The model was trained firstly with the training set. To assess the performance of machine learning models, cross validation was used. This helps to know the machine learning model would generalize to an independent data set. K-fold cross validation is a common type of cross validation. As shown in
Figure 5, firstly, the original training data set was partitioned into 6 equal subsets. Each subset was called a fold. Let the folds be named as f1, f2, …, f6. Secondly, keep the fold fi (i = 0, …, 6) as validation fold and keep all the remaining 5 folds in the cross validation training set. Lastly, we will estimate the accuracy of the machine learning model by averaging the accuracies derived in all the k cases of cross validation, and it is expressed by the symbol E. mean-square error can measure the average of the squares of the errors. MSE will also be an important indicator of the evaluation model.
Cross validation results are shown in
Table 3, MSE is the mean squared error. In the supervised learning method, the E value of LDA was higher, and the MSE value was lower. SVM and KNN models were acceptable. The remaining supervised learning methods had lower E values, and MSE was not ideal. In the following research, we will focus on SVM, KNN, and LDA. The table shows the mean square error and the average correct rate under different supervised learning methods.
2.7. VIs’ Normalization for Fusion Study
Test sets were used to predict SVM model accuracy, which was up to 93.27%, and the model was quite good. In order to improve the accuracy of the model, the VI referenced above was used to expand the dimension of the training set. We regarded the original training set as a reference object and compared it with the training set with the VI.
Because the SVM was sensitive to the data’s size, it was necessary to find a normalization method to put the data in the same range. In this research, we proposed a new formula to normalize the data. The formula (2) and (3) was as follows:
This formula can extend the VI to the same order of magnitude. Then the VI and other band set from a training data set were combined to train the model.
3. Results and Discussion
3.1. The Performance of A Single VI
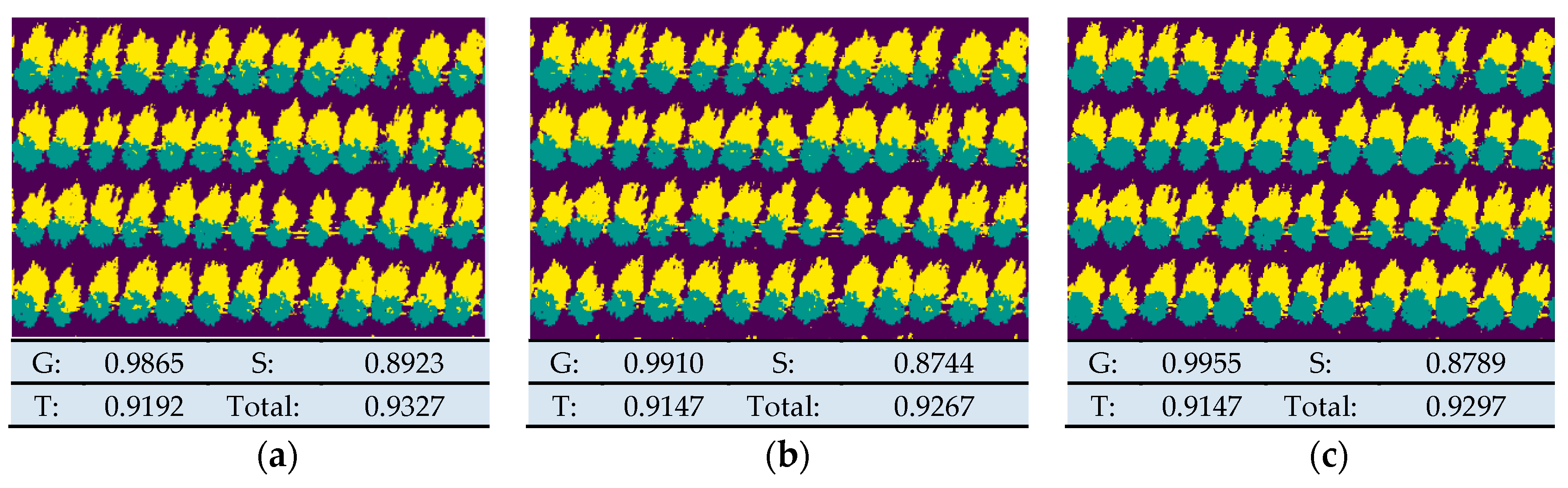
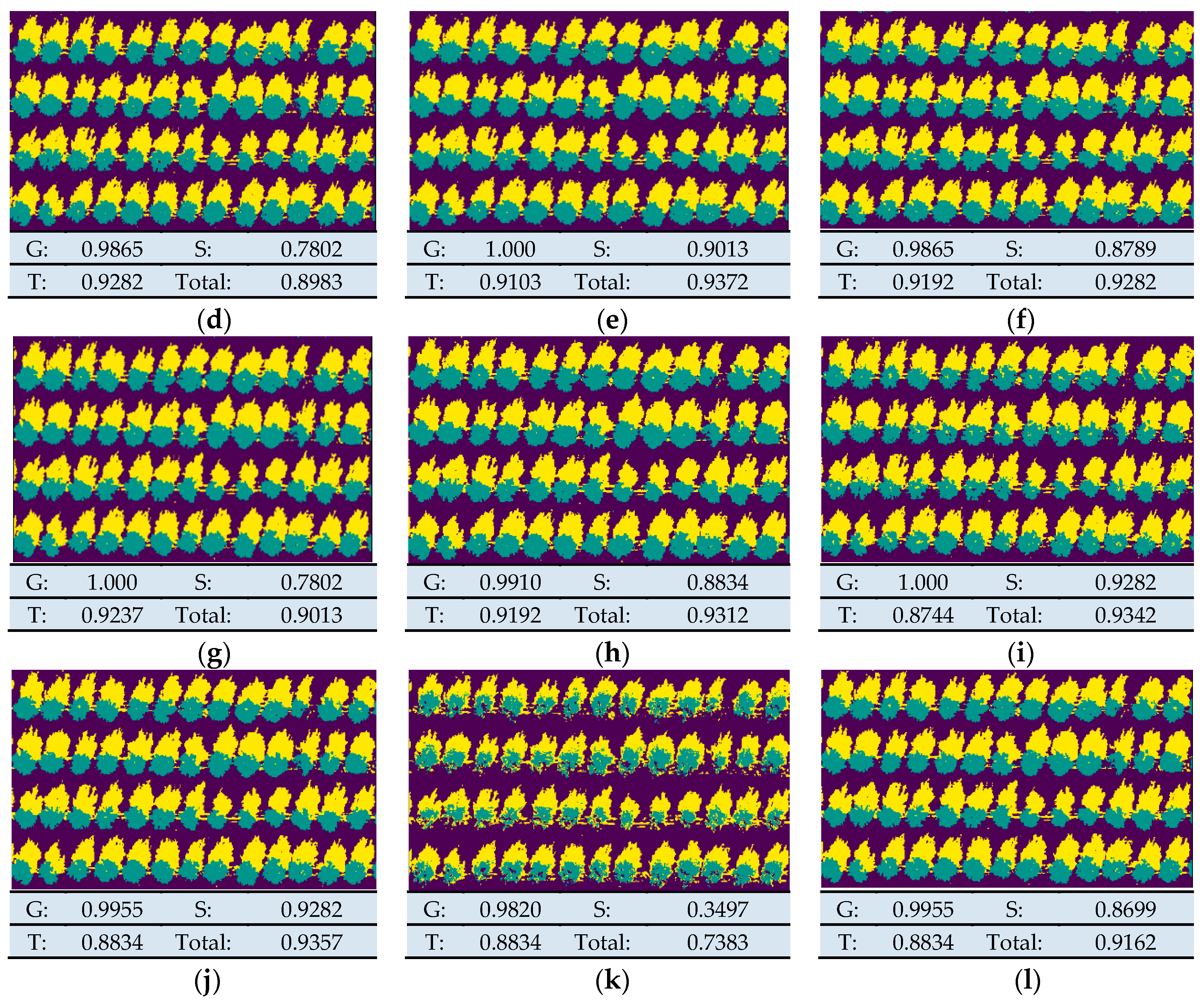
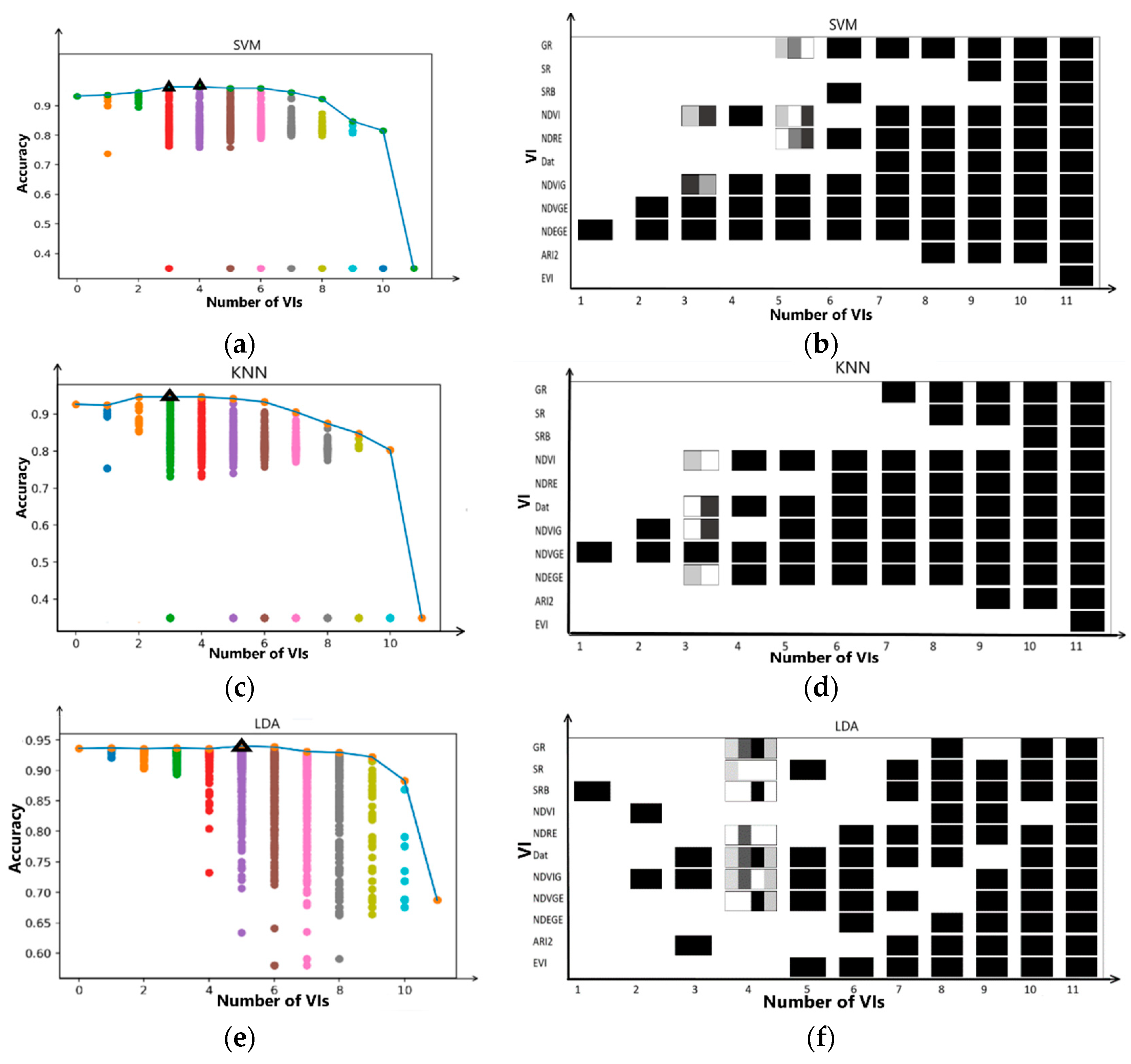
As shown in
Figure 6,
Figure 6a shows the performance of the five-band training model. It will be treated as a reference in the following sections. Others show model validation results for five bands and different vegetation indices as a data set. Results showed that VIs influenced the accuracy of the classification model, and the model based on extended features, including Red Edge NDVI, RedEdge Green NDVI, and NDVI, was better trained than the original multispectral data set. By comparing (e), (i), and (j), the total correct rate of them was over the 5-band model.
In general, the recognition rate of the ground was high, while the recognition rate of the tree was not that high. It can be seen from the results shown in the
Figure 7c, tree recognition rate could be improved by bringing in a suitable VI.
Meanwhile, it can be seen that some VIs could increase the recognition rate of shadows. Although the recognition rate of trees and shadows increased, the degree of the increase was not very large, and there was still a significant gap in the recognition rate.
As shown in
Table 4, KNN and LDA model accuracy was obtained from the test set. VI could improve the accuracy of the KNN model; however, VI could not enhance the accuracy of the LDA model. Most of the VIs that could improve the SVM and KNN were the same. NDVI, NDVGE, and NDEGE were all conducive to the improvement of SVM and KNN model accuracy. NDVIG alone affected KNN model improvement. SRB did not affect the accuracy of the LDA model. Other VIs reduced the accuracy of the LDA model.
ARI2 greatly impacted the accuracy of the SVM model, just as EVI to the KNN model. However, the VI index had little effect on the accuracy of the LDA model. So, appropriate VI could increase the accuracy of the SVM and KNN models, but VI had little impact on the LDA model.
3.3. The Performance of Multiple VIs
To explore the influence of the input number of VIs on the accuracy of the model, different vegetation indices were extracted to form a new feature set to train the classification model. The result is shown in
Figure 8a,c,e. The horizontal indicates the number of VIs used in the training set, and the vertical indicates the accuracy of the model. The scatter points in each vertical row are the models’ accuracy under the same number of VIs. The plot was formed by the best model accuracy using different numbers of VIs.
When the number of VIs was up to three or four, the highest SVM model precision was 96.41%. Compared with the accuracy of the original five-band model, it improved by 3%. However, when using all VIs, accuracy was only 34.9%. When observing the single VI model, one of the indices could reduce the overall accuracy. When the index was combined with other indices to form a training set, many low-precision models were produced, which leads to lower performance.
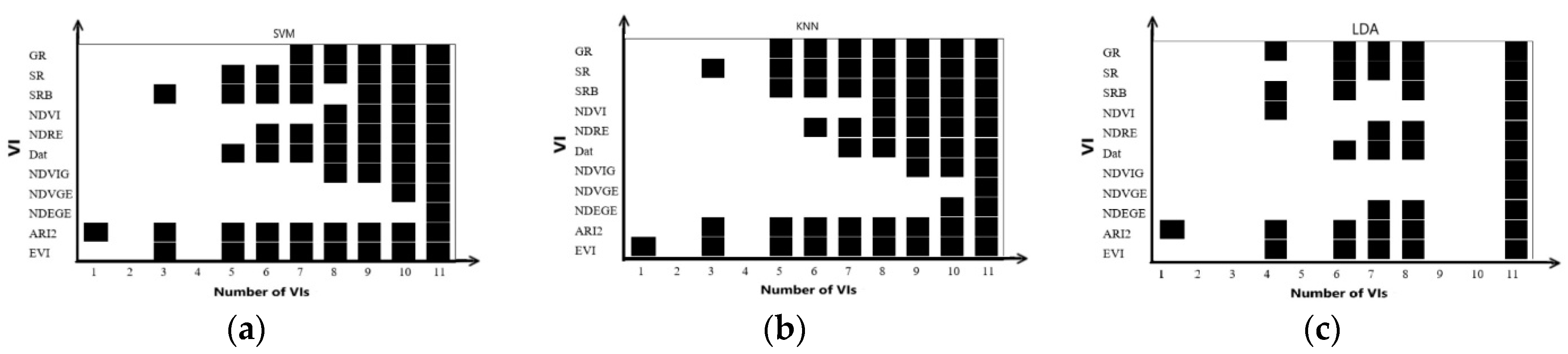
Figure 9 illustrates the outlier points in
Figure 8a,c,e.
As shown in
Figure 8b,d,f, the best accuracy of the model was initially increasing and then decreasing with the number of VIs. When the number of VIs were up to 3, KNN model achieved the highest precision. When the number of VIs was up to 3 or 4, SVM model achieved the highest precision.
As shown in
Figure 8b,d,f, the horizontal indicates the number of VIs in the training set, and the vertical indicates all the VIs. These three graphs show the VI distribution of the best-trained model among all VI combinations. As it shows, VI fusion had mostly improved the accuracy of SVM and KNN models, but did not have much effect on the LDA trained model.
In the best SVM model, the NDEGE index appeared most frequently. In the single vegetation index SVM model, the NDEGE index could train the best model. NDEGE and NDVGE indices could train the best model in the two-VI SVM model. In three-VI SVM models, NDEGE, NDVGE, and NDVIG indices had the same effect as NDEGE, NDVGE, and NDVI indices. A combination of NDEGE, NDVGE, NDVIG, and NDVI indices could train the optimal model. It can be concluded that the NDEGE, NDVGE, NDVIG, and NDVI indexes were beneficial to improve the accuracy of the SVM model.
In the best KNN model, the NDVGE index appeared most frequently, In the single vegetation index KNN model, the NDVGE index could train the best model. NDVIG and NDVGE indices could train the best model in the two-VI SVM model. In three-VI KNN models, a combination of Dat, NDVGE, and NDVIG indices had the same effect as NDEGE, NDVGE, and NDVI indices, reaching an overall accuracy of 95.92%.
This study showed that a properly selected combination of Vis with original multispectral bands could improve the accuracy of the trained model, and a reasonable VI combination could further improve it.
To better understand the relationship between VIs and machine learning models. As
Figure 9 shows, NDEGE and NDVGE were the two least occurred VIs among all combinations. The blank in each machine learning method was due to the lowest points and was not treated as an outlier.
3.4. Classification Accuracy
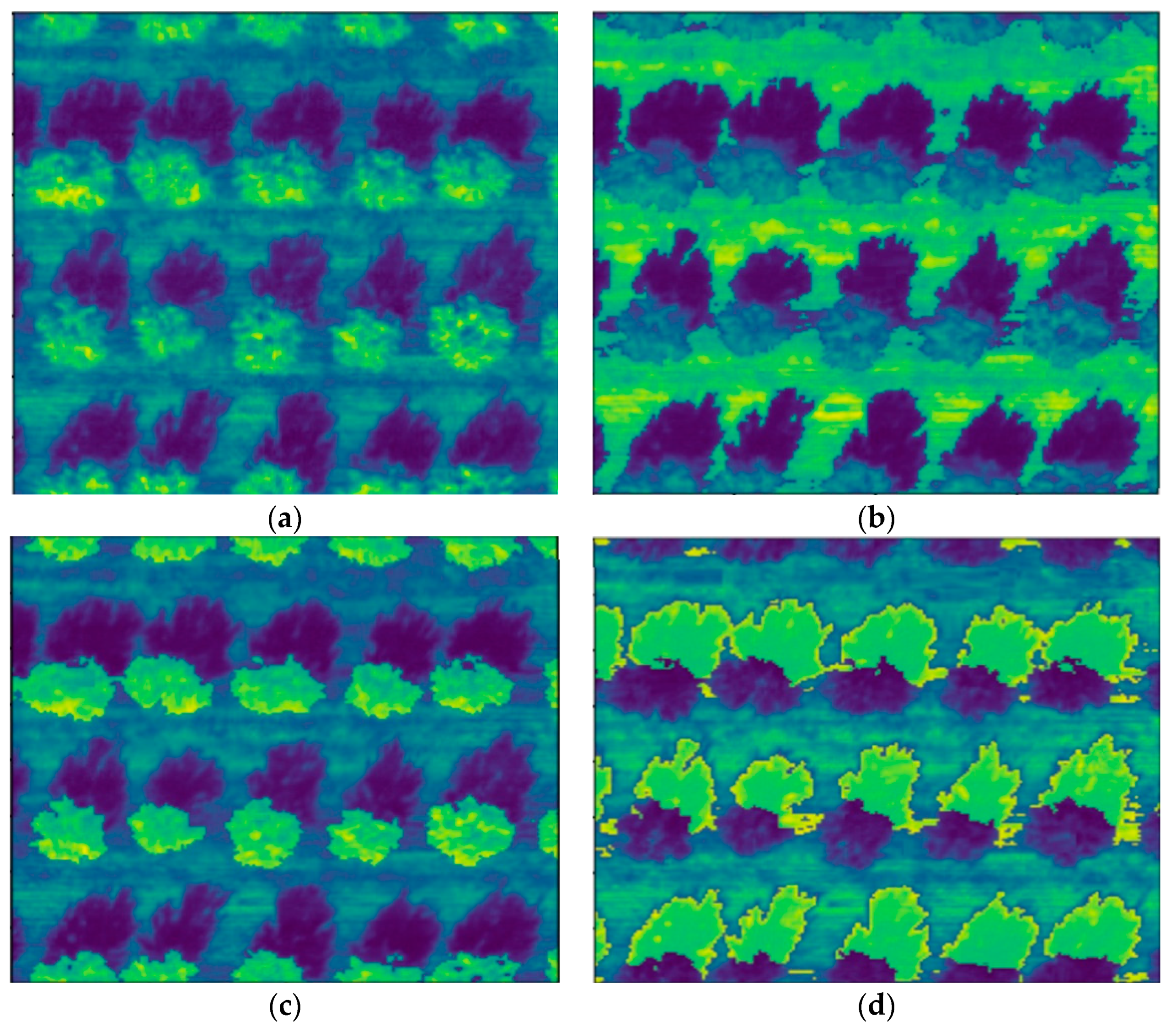
The trained model was applied to the entire orthoimage to demonstrate its classification accuracy. The set of original multispectral bands and added VIs were normalized as in the training process and put into the trained machine learning model. The best two-VI SVM models were selected for this demonstration. The refractive indices of different classes in the same band are highlighted.
The best two-VI SVM models used for prediction were multi-spectrals combined with NDEGE and NDVGE. The segmentation result is shown in
Figure 10. The classification effect showed it worked well, and the tree, shadow, and ground could be effectively distinguished.
4. Discussions
Our results showed that the fusion of multispectral bands and VIs could improve the classification model accuracy if proper VIs were selected. In particular, three to four VIs could reach the optimal fusion result. All the results above could be attributed to three reasons to the best of our knowledge. First, the information in VIs could help enlarge the difference among ground covers. As discussed above, VIs were first introduced to describe the difference among ground covers so as to do tasks like classification, segmentation, monitoring. They contained nonlinear correlations between spectral bands that had not been introduced into machine learning-based remote sensing classification.
Second, different training methods were sensitive to different VIs. The selected training methods in this research were kernel-based SVM, distance-based KNN, linear transformation-based LDA. SVM, NDEGE, NDVIG, and NDVGE had a positive effect on building models. To KNN, the result was almost the same, NDEGE, NDVGE, and NDVI had a positive effect in improving model accuracy. To these two training methods, adding VIs created an apparent improvement. SVM was designed to find the hyperplane for class separation, so adding classes related features could improve the hyperplane performance. Meanwhile, the KNN separated types based on distance between new samples and known samples. KNN did not require training, but calculated distances every time, so it tended to be very slow when the data set was large. From this point of view, adding VIs could increase the class distance to improve performance. One more thing was that all the VIs mentioned above were loosely correlated with each other, as is shown in
Figure 4. For example, correlation coefficient between NDEGE and NDVIG was 0.39, NDVI and NDEGE was 0.32, NDVI and NDVGE was 0.077, NDVGE and NDEGE was 0.65. This may have been why the performance increased with more VIs, as
Figure 8a,c shows.
However, LDA was different from the former two methods. LDA was based on linear transformation, and it was designed to project at the largest separation plane. So the performance was unlikely to change with the number increases because new information was unlikely to have influence on LDA projection. It can be concluded that LDA was not fit for information purposes.
Although combining spectral bands and VIs could improve the performance of the classification model, more was not better, and some VIs had a reverse effect. As it shows, the performance decreased when more than 4 VIs were added and dramatically dropped when all 11 VIs were added. Additionally, it can be seen there were points significantly lower than other points of the same column. We noticed that there were height-related indexes, such as CHM [
39]. It could be used when the images were acquired at low altitude and the height was obvious in DSM. However, in our experiment, the altitude was 200 meters and the generated DSM had nearly no height information. Moreover, the resolution of multispectral camera was much lower than RGB cameras used in height-related studies. So, the DSM was flat and wasn’t taken into further studies.
Moreover, the way to normalize VIs still needs more exploration. In this study, VIs were normalized to zero to one according to the minimum and maximum value of all pixels. This was because some VIs could not be normalized to a particular range. For example, SRB was the rate of NIR and Red, so it could be very big. There was hardly any other way to normalize it to a certain value range except the proposed method in this research. Meanwhile, this method could maximize the influence of other normalized VIs. For example, NDVI was an index already normalized between minus one and one, but in the normalized method used in this research, the value was normalized to the scale of minimum and maximum value of all pixels. In this way, the VI value was considered to be larger than it was.
5. Conclusions
This paper describes the application of a UAV-based five-band multispectral camera for the classification of three different ground covers, trees, soil, and shadow at first. To further utilize the nonlinear information between multispectral bands, a fusion method was developed to see if it can improve the performance of the classification model. The classification results based on the original five bands were 0.9327 for SVM, 0.9267 for KNN, and 0.9372 for LDA. It can be concluded that mixed ground cover like shadow can be properly distinguished. This result can be helpful in research using shadow-based measurement.
Secondly, 11 VIs were calculated and integrated with the original five bands to train models using three supervised learning algorithms, namely SVM, KNN, and LDA. After gradually adding VIs into feature space, it was found that three to four VIs could improve the classification performance when using SVM and KNN, and it decreased if more were added. VIs had little influence on LDA-based classification. It can be concluded that fusing multispectral bands and VIs in supervised learning can improve classification performance. Among all 11 proposed VIs, NDEGE, NDVIG, NDVGE, and NDVI positively affected information fusion.
At present, only VIs have been used and proved effective in remote sensing for information fusion in this research. The constructed VIs is limited due to limited bands of multispectral camera that can be mounted on a UAV. In this research, a five-band multispectral camera was used. In the future, with the development of spectral sensor technology, cameras with more bands can bring more VIs. Meanwhile, only several linear machine learning methods were cross-compared. This was to guarantee the consistency of the trained model. In the future, far more complicated machine learning algorithms can be used to verify this research. At last, the classification result based on original bands was pretty good, and information fusion can improve the accuracy. It was more desirable to explore the effect of fusion in cases in which the classification result was bad based on the spectral bands’ original information.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}