
Improving the Estimation of Weighted Mean Temperature in China Using Machine Learning Methods



Abstract

1. Introduction
2. Study Area and Data
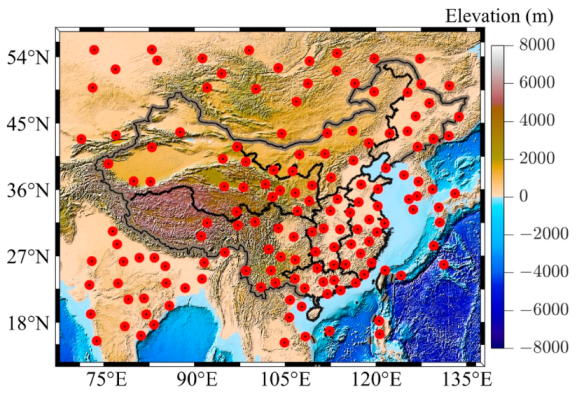
2.1. Study Area
2.2. Data
2.2.1. Radiosonde Data
2.2.2. GPT3 Model Predictions
3. Methods
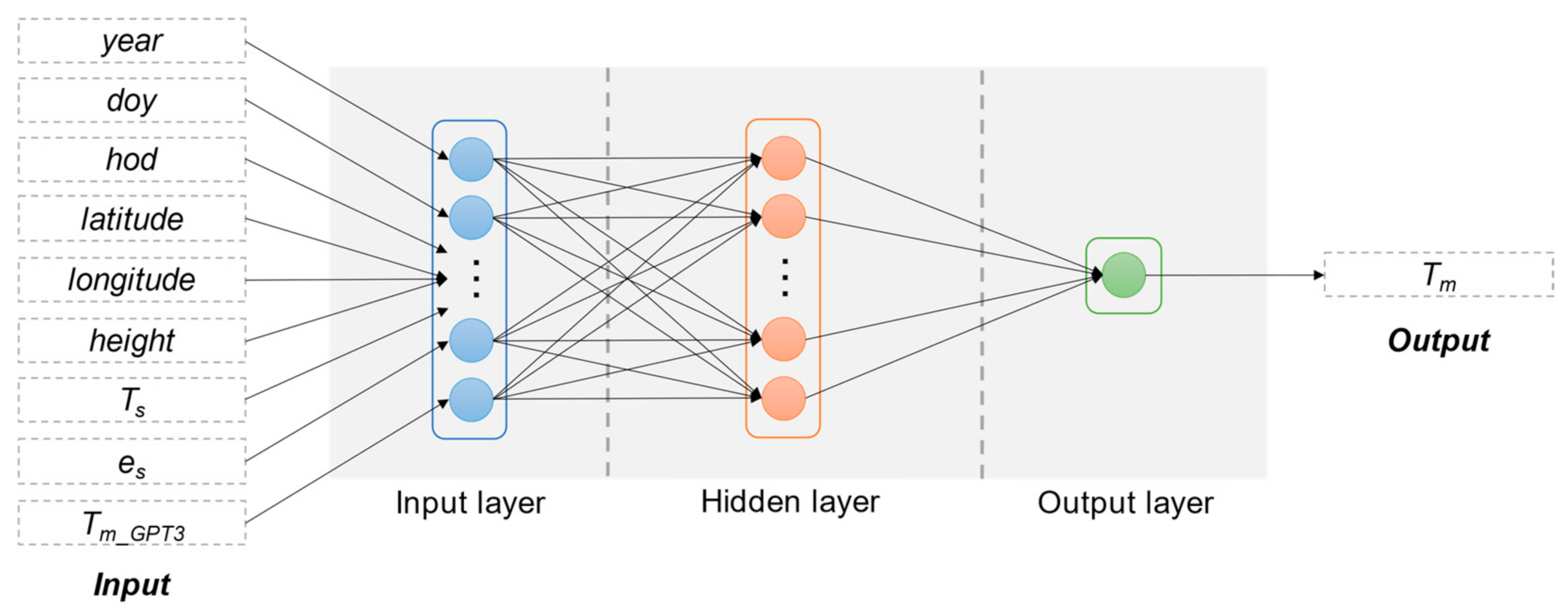
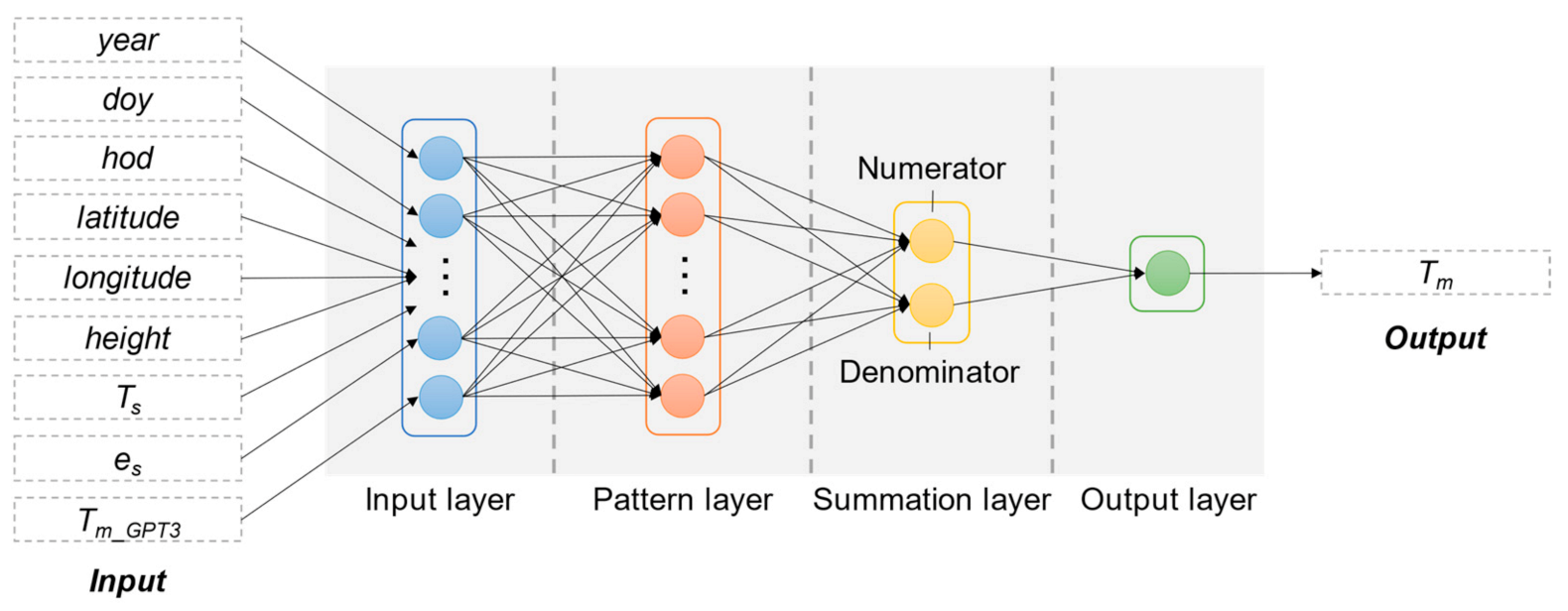
3.1. Selection of Input and Output
3.2. Machine Learning Structures
3.2.1. Random Forest (RF)
3.2.2. Backpropagation Neural Network (BPNN)
3.2.3. Generalized Regression Neural Network (GRNN)
3.3. Model Evaluation
4. Results
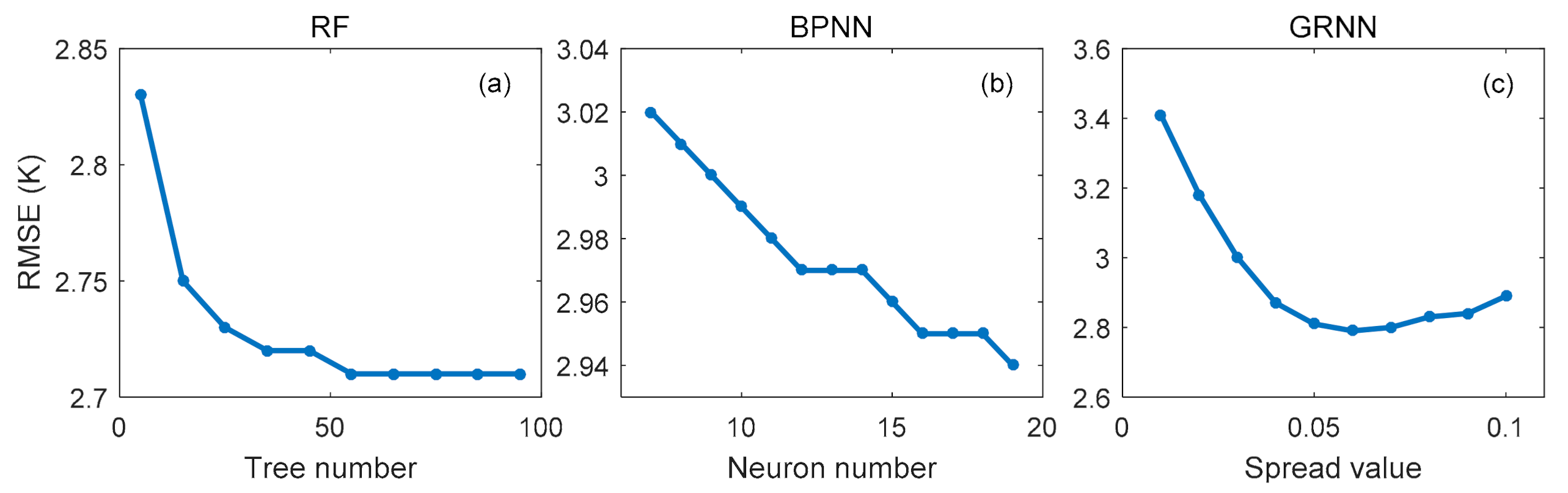
4.1. Determining the Hyperparameter
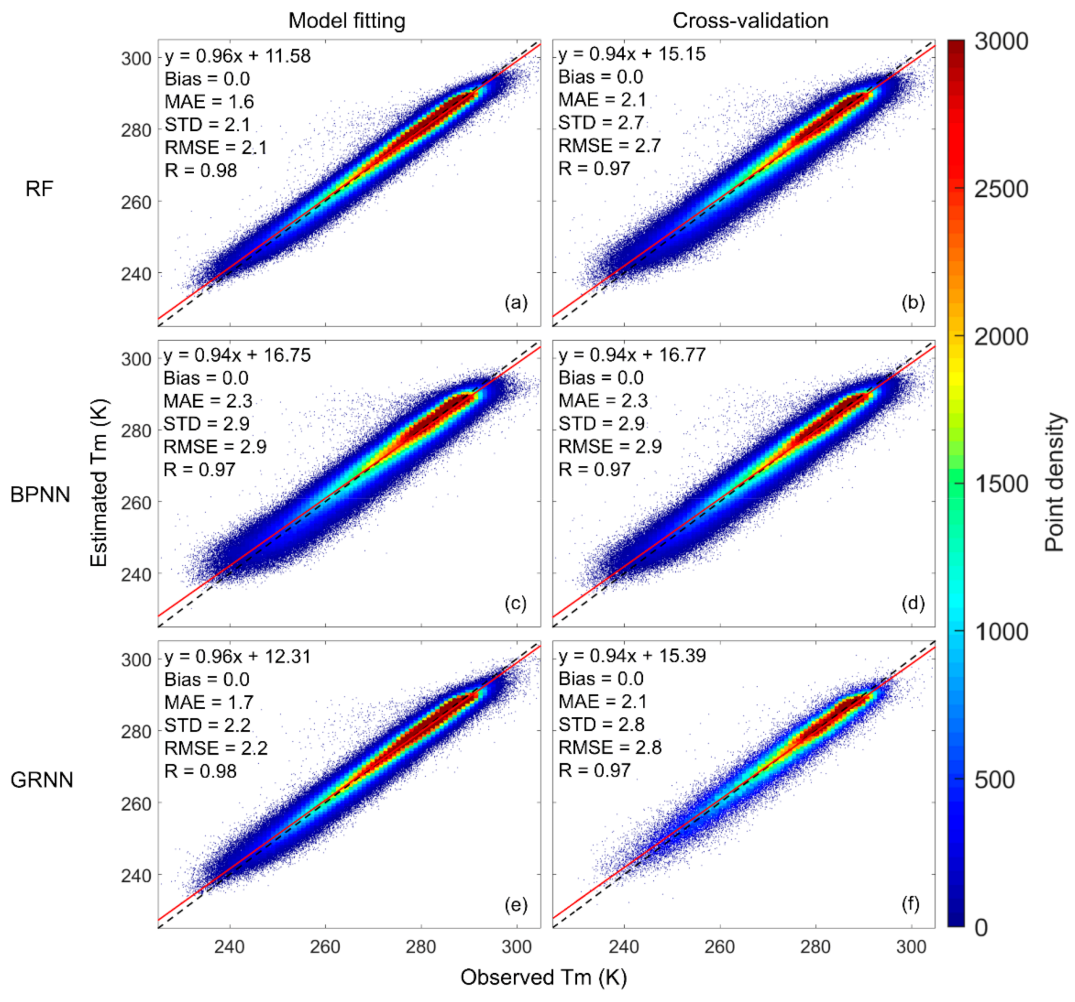
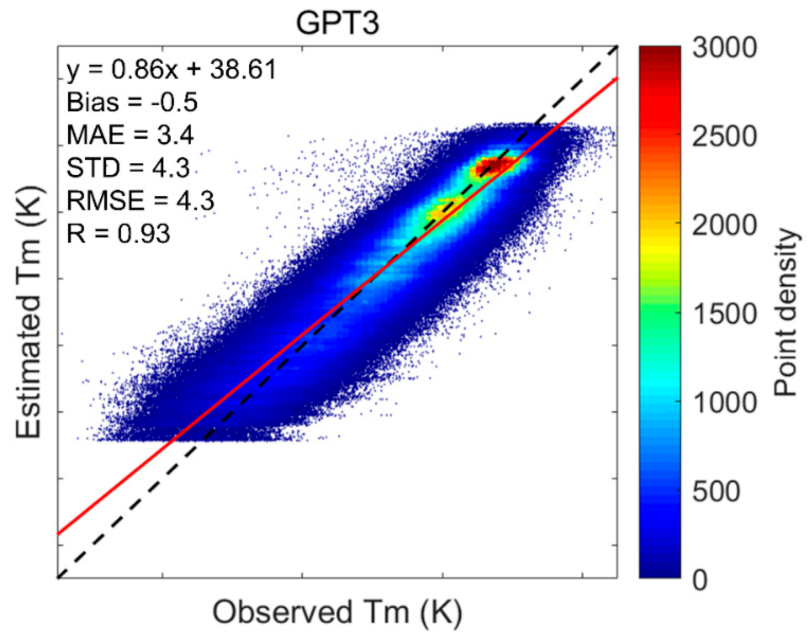
4.2. Overall Performance of the Model
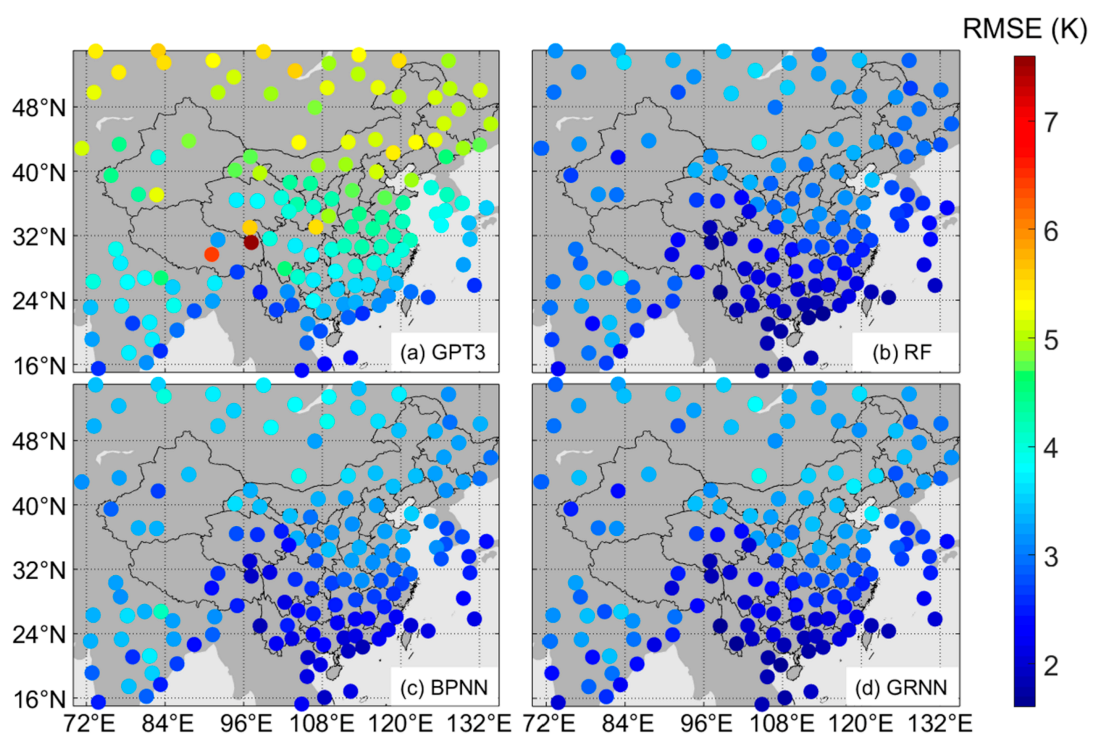
4.3. The Spatial Performance of the Models
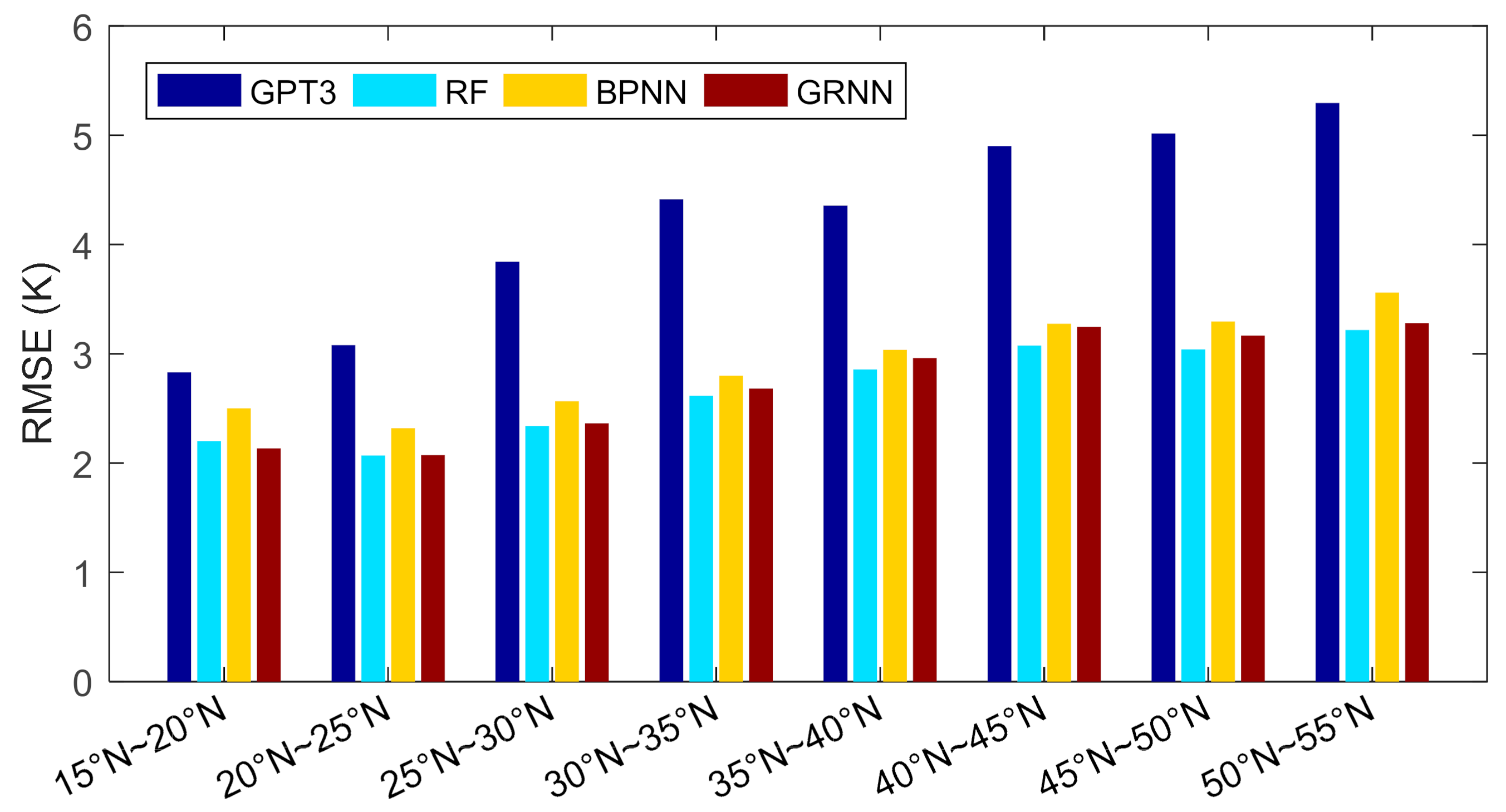
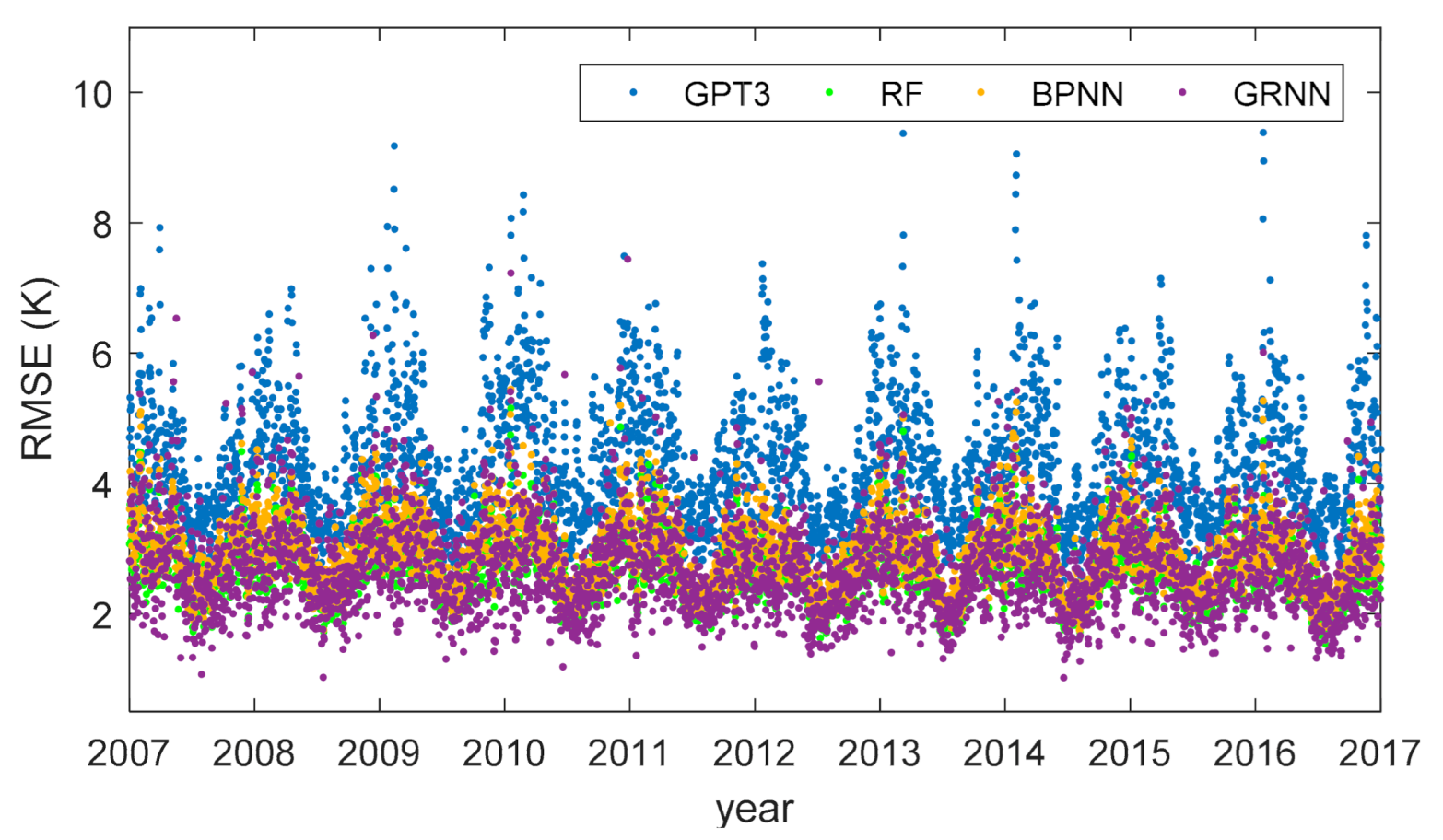
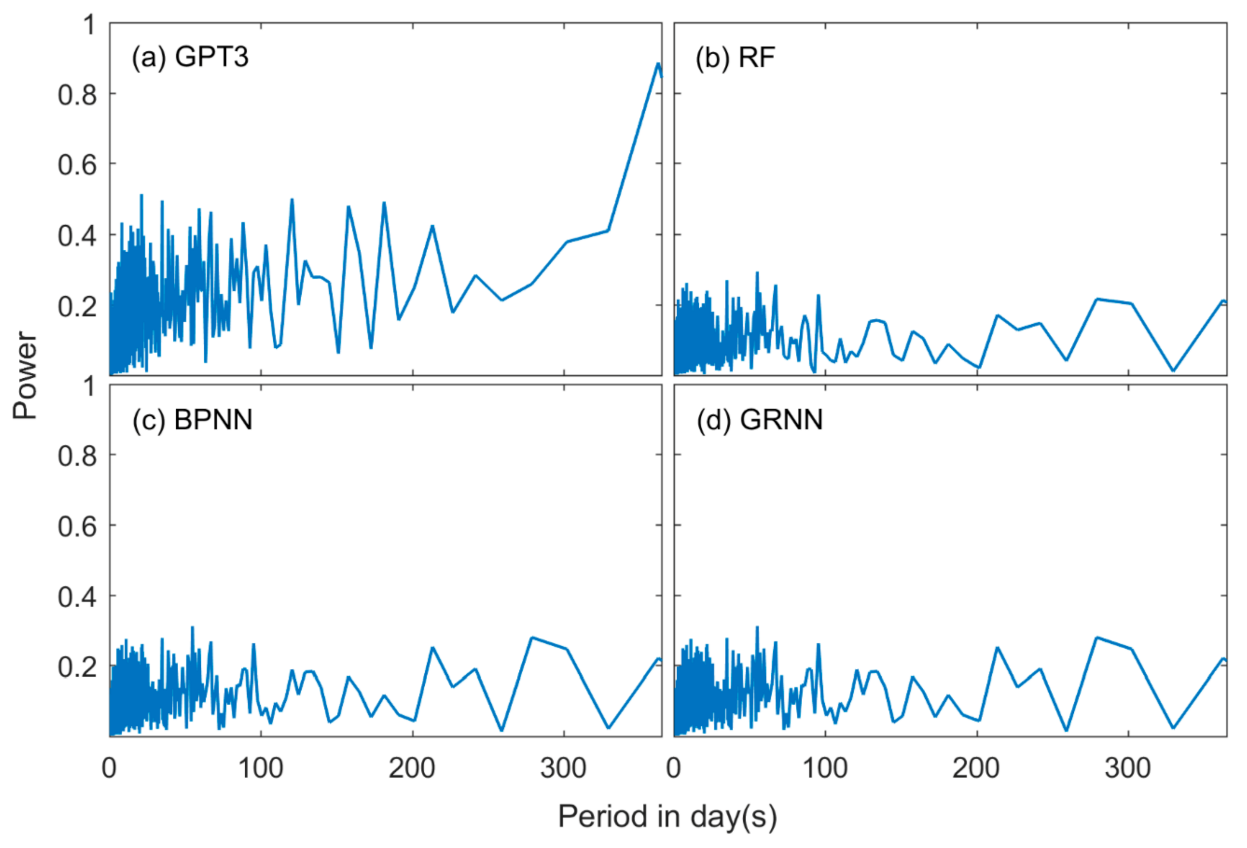
4.4. The Temporal Performance of the Models
5. Discussion
5.1. The Reason for Accuracy Improvement of Machine Learning Models
5.2. Comparison of Computational Costs of Machine Learning Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Leick, A. GPS satellite surveying. J. Geol. 1990, 22, 181–182. [Google Scholar]
- Askne, J.; Nordius, H. Estimation of Tropospheric Delay for Mircowaves from SurfaceWeather Data. Radio Sci. 1987, 22, 379–386. [Google Scholar] [CrossRef]
- Davis, J.L.; Herring, T.A.; Shapiro, I.I.; Rogers, A.E.E.; Elgered, G. Geodesy by radio interferometry: Effects of atmospheric modeling errors on estimates of baseline length. Radio Sci. 1985, 20, 1593–1607. [Google Scholar] [CrossRef]
- Bevis, M.; Businger, S.; Herring, T.A.; Rocken, C.; Anthes, R.A.; Ware, R.H. GPS meteorology: Remote sensing of atmospheric water vapor using the global positioning system. J. Geophys. Res. Atmos. 1992, 97, 15787–15801. [Google Scholar] [CrossRef]
- Bevis, M.; Businger, S.; Chiswell, S.; Herring, T.A.; Anthes, R.A.; Rocken, C.; Ware, R.H. GPS meteorology: Mapping zenith wet delays onto precipitable water. J. Appl. Meteorol. Clim. 1994, 33, 379–386. [Google Scholar] [CrossRef]
- Yao, Y.; Zhu, S.; Yue, S. A globally applicable, season-specific model for estimating the weighted mean temperature of the atmosphere. J. Geod. 2012, 86, 1125–1135. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, B.; Yue, S.; Xu, C.; Peng, W. Global empirical model for mapping zenith wet delays onto precipitable water. J. Geod. 2013, 87, 439–448. [Google Scholar] [CrossRef]
- Yao, Y.; Xu, C.; Zhang, B.; Cao, N. GTm-III: A new global empirical model for mapping zenith wet delays onto precipitable water vapour. Geophys. J. Int. 2014, 197, 202–212. [Google Scholar] [CrossRef]
- Chen, P.; Yao, W.; Zhu, X. Realization of global empirical model for mapping zenith wet delays onto precipitable water using NCEP re-analysis data. Geophys. J. Int. 2014, 198, 1748–1757. [Google Scholar] [CrossRef]
- He, C.; Wu, S.; Wang, X.; Hu, A.; Wang, Q.; Zhang, K. A new voxel-based model for the determination of atmospheric weighted mean temperature in GPS atmospheric sounding. Atmos. Meas. Tech. 2017, 10, 2045–2060. [Google Scholar] [CrossRef]
- Zhang, H.; Yuan, Y.; Li, W.; Ou, J.; Li, Y.; Zhang, B. GPS PPP derived precipitable water vapor retrieval based on Tm/Ps from multiple sources of meteorological data sets in China. J. Geophys. Res. Atmos. 2017, 122, 4165–4183. [Google Scholar] [CrossRef]
- Huang, L.; Jiang, W.; Liu, L.; Chen, H.; Ye, S. A new global grid model for the determination of atmospheric weighted mean temperature in GPS precipitable water vapor. J. Geod. 2019, 93, 159–176. [Google Scholar] [CrossRef]
- Yang, F.; Guo, J.; Meng, X.; Shi, J.; Zhang, D.; Zhao, Y. An improved weighted mean temperature (Tm) model based on GPT2w with T m lapse rate. GPS Solut. 2020, 24, 1–13. [Google Scholar] [CrossRef]
- Schüler, T. The TropGrid2 standard tropospheric correction model. GPS Solut. 2014, 18, 123–131. [Google Scholar] [CrossRef]
- Landskron, D.; Böhm, J. VMF3/GPT3: Refined discrete and empirical troposphere mapping functions. J. Geod. 2018, 92, 349–360. [Google Scholar] [CrossRef]
- Balidakis, K.; Nilsson, T.; Zus, F.; Glaser, S.; Heinkelmann, R.; Deng, Z.; Schuh, H. Estimating integrated water vapor trends from VLBI, GPS, and numerical weather models: Sensitivity to tropospheric parameterization. J. Geophys. Res. Atmos. 2018, 123, 6356–6372. [Google Scholar] [CrossRef]
- Sun, Z.; Zhang, B.; Yao, Y. A global model for estimating tropospheric delay and weighted mean temperature developed with atmospheric reanalysis data from 1979 to 2017. Remote Sens. 2019, 11, 1893. [Google Scholar] [CrossRef]
- Ding, M. A neural network model for predicting weighted mean temperature. J. Geod. 2018, 92, 1187–1198. [Google Scholar] [CrossRef]
- Ding, M. A second generation of the neural network model for predicting weighted mean temperature. GPS Solut. 2020, 24, 1–6. [Google Scholar] [CrossRef]
- Yang, L.; Chang, G.; Qian, N.; Gao, J. Improved atmospheric weighted mean temperature modeling using sparse kernel learning. GPS Solut. 2021, 25, 1–10. [Google Scholar] [CrossRef]
- Long, F.; Hu, W.; Dong, Y.; Wang, J. Neural Network-Based Models for Estimating Weighted Mean Temperature in China and Adjacent Areas. Atmosphere 2021, 12, 169. [Google Scholar] [CrossRef]
- Yao, Y.; Zhang, B.; Xu, C.; Yan, F. Improved one/multi-parameter models that consider seasonal and geographic variations for estimating weighted mean temperature in ground-based GPS meteorology. J. Geod. 2014, 88, 273–282. [Google Scholar] [CrossRef]
- Wang, J.; Zhang, L.; Dai, A. Global estimates of water-vapor-weighted mean temperature of the atmosphere for GPS applications. J. Geophys. Res. Atmos. 2005, 110. [Google Scholar] [CrossRef]
- Wang, X.; Zhang, K.; Wu, S.; Fan, S.; Cheng, Y. Water vapor weighted mean temperature and its impact on the determination of precipitable water vapor and its linear trend. J. Geophys. Res. Atmos. 2016, 121, 833–852. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.; Stone, C.J.; Olshen, R.A. Classification and Regression Trees; CRC Press: Boca Raton, FL, USA, 1984. [Google Scholar]
- Hecht-Nielsen, R. Theory of the backpropagation neural network. In Neural Networks for Perception; Academic Press: Cambridge, MA, USA, 1992; pp. 65–93. [Google Scholar]
- Specht, D.F. A general regression neural network. IEEE Trans. Neural Netw. 1991, 2, 568–576. [Google Scholar] [CrossRef] [PubMed]
- Rodriguez, J.; Perez, A.; Lozano, J. Sensitivity analysis of k-fold cross-validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Gardner, M.; Dorling, S.R. Artificial neural networks (the multilayer perceptron)—A review of applications in the atmospheric sciences. Atmos. Environ. 1998, 32, 2627–2636. [Google Scholar] [CrossRef]
- Reich, S.; Gomez, D.; Dawidowski, L. Artificial neural network for the identification of unknown air pollution sources. Atmos. Environ. 1999, 33, 3045–3052. [Google Scholar] [CrossRef]
- Yuan, Q.; Xu, H.; Li, T.; Shen, H.; Zhang, L. Estimating surface soil moisture from satellite observations using a generalized regression neural network trained on sparse ground-based measurements in the continental US. J. Hydrol. 2020, 580, 124351. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Model Fitting | Cross-Validation | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Bias | MAE | STD | RMSE | R | Bias | MAE | STD | RMSE | R | |
| GPT3 | −0.5 | 3.4 | 4.3 | 4.3 | 0.93 | |||||
| RF | 0.0 | 1.6 | 2.1 | 2.1 | 0.98 | 0.0 | 2.1 | 2.7 | 2.7 | 0.97 |
| BPNN | 0.0 | 2.3 | 2.9 | 2.9 | 0.97 | 0.0 | 2.3 | 2.9 | 2.9 | 0.97 |
| GRNN | 0.0 | 1.7 | 2.2 | 2.2 | 0.98 | 0.0 | 2.1 | 2.8 | 2.8 | 0.97 |
| Latitude Band | RMSE (K) | |||
|---|---|---|---|---|
| GPT3 | RF | BPNN | GRNN | |
| 15°N~20°N | 2.8 | 2.2 | 2.5 | 2.1 |
| 20°N~25°N | 3.1 | 2.1 | 2.3 | 2.1 |
| 25°N~30°N | 3.8 | 2.3 | 2.6 | 2.4 |
| 30°N~35°N | 4.4 | 2.6 | 2.8 | 2.7 |
| 35°N~40°N | 4.4 | 2.9 | 3.0 | 3.0 |
| 40°N~45°N | 4.9 | 3.1 | 3.3 | 3.2 |
| 45°N~50°N | 5.0 | 3.0 | 3.3 | 3.2 |
| 50°N~55°N | 5.3 | 3.2 | 3.6 | 3.3 |
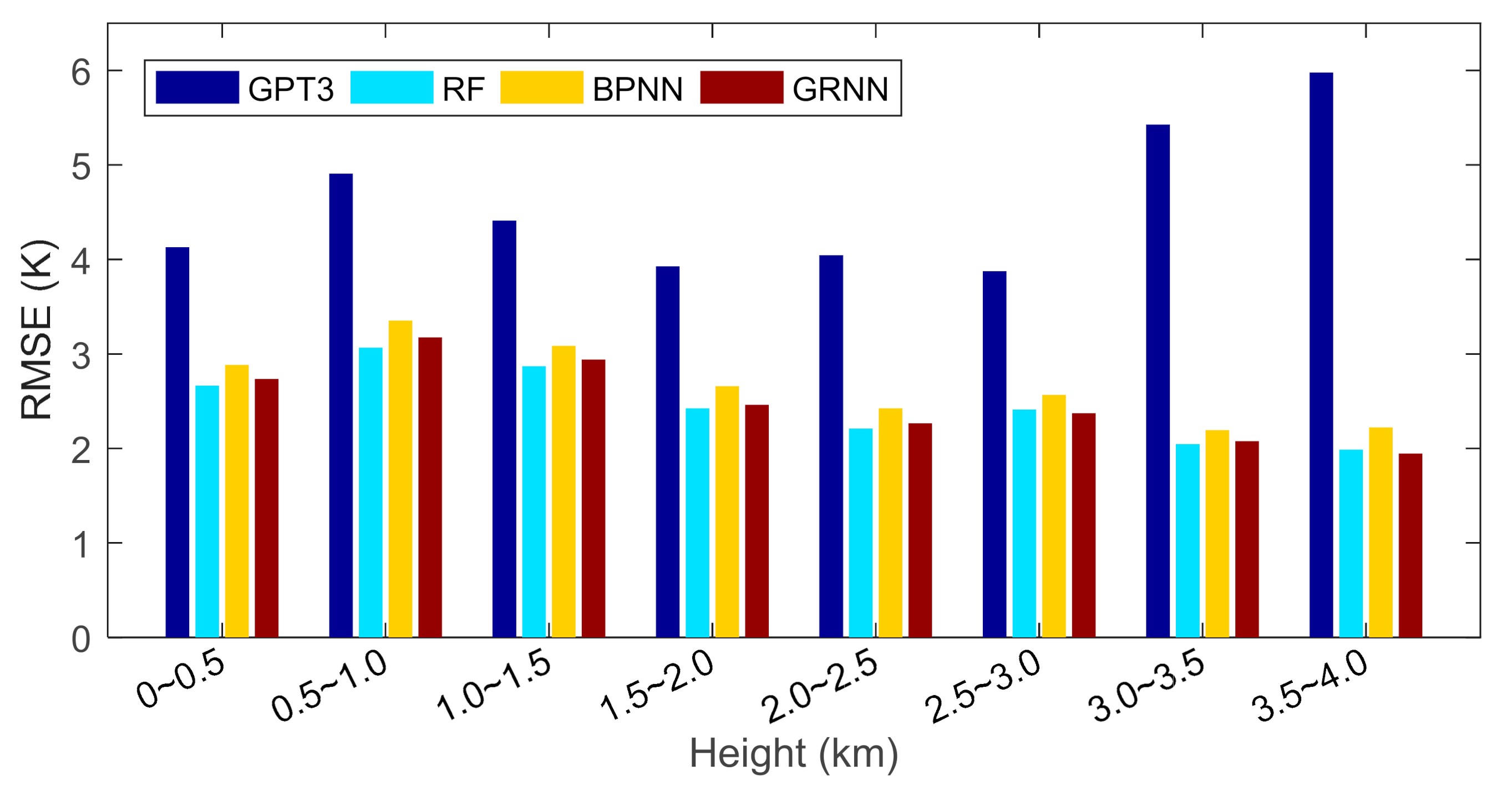
| Height Layer | RMSE (K) | |||
|---|---|---|---|---|
| GPT3 | RF | BPNN | GRNN | |
| 0 km~0.5 km | 4.1 | 2.7 | 2.9 | 2.7 |
| 0.5 km~1.0 km | 4.9 | 3.1 | 3.4 | 3.2 |
| 1.0 km~1.5 km | 4.4 | 2.9 | 3.1 | 2.9 |
| 1.5 km~2.0 km | 3.9 | 2.4 | 2.7 | 2.5 |
| 2.0 km ~2.5 km | 4.0 | 2.2 | 2.4 | 2.3 |
| 2.5 km~3.0 km | 3.9 | 2.4 | 2.6 | 2.4 |
| 3.0 km~3.5 km | 5.4 | 2.0 | 2.2 | 2.1 |
| 3.5 km~4.0 km | 6.0 | 2.0 | 2.2 | 1.9 |
| Machine Learning Model | Time Cost | Model Size | |
|---|---|---|---|
| Model Fitting | Prediction | ||
| RF | 3′13′′ | 0′52′′ | 5889.6 MB |
| BPNN | 8′54′′ | 0′05′′ | 23.6 MB |
| GRNN | 0′01′′ | 11h33′54′′ | 39.2 MB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, Z.; Zhang, B.; Yao, Y. Improving the Estimation of Weighted Mean Temperature in China Using Machine Learning Methods. Remote Sens. 2021, 13, 1016. https://doi.org/10.3390/rs13051016
Sun Z, Zhang B, Yao Y. Improving the Estimation of Weighted Mean Temperature in China Using Machine Learning Methods. Remote Sensing. 2021; 13(5):1016. https://doi.org/10.3390/rs13051016
Chicago/Turabian StyleSun, Zhangyu, Bao Zhang, and Yibin Yao. 2021. "Improving the Estimation of Weighted Mean Temperature in China Using Machine Learning Methods" Remote Sensing 13, no. 5: 1016. https://doi.org/10.3390/rs13051016
APA StyleSun, Z., Zhang, B., & Yao, Y. (2021). Improving the Estimation of Weighted Mean Temperature in China Using Machine Learning Methods. Remote Sensing, 13(5), 1016. https://doi.org/10.3390/rs13051016