1. Introduction
Synthetic aperture radar (SAR) images are images of the Earth’s surface obtained by the observation tool (SAR systems) under any weather condition. However, SAR images are inevitably obscured by speckle noise due to their coherent imaging mechanism, which makes it extremely difficult for computer vision systems to automatically interpret SAR data. Removing speckle is an essential step before applying SAR images to various tasks [
1].
Conventional methods remove speckle, either in the spatial domain, such as Lee [
2], Kuan [
3] and Frost [
4], which operate on the pixels by sliding a window over the entire image, or in the frequency domain, where some transforms that can sparsely represent images, such as wavelets [
5] and contourlets [
6], are employed to reduce speckle by thresholding the small coefficients of the frequency domain. The frequency domain methods improve the performance of speckle reduction in the following two aspects: representing SAR image features more sparsely and more accurately distinguishing the transformation coefficients of the image content from the speckle. The former analyzes geometrical structures in SAR images from the multiscale and multidirection of the transform and represents many detailed features with fewer high-magnitude transform coefficients [
7,
8]. The goal of the latter is to optimize the threshold determination strategy to identify the coefficients representing the image content from all the transform coefficients as accurately as possible [
9].
In the past decade, non-local self-similarity (NSS)-based methods [
10,
11,
12,
13] for speckle reduction have received wide attention due to their ability to eliminate speckle while sacrificing fewer image details. Deledalle et al. [
10] proposed the first nonlocal patch-based despeckling method, where each despeckled pixel is a weighted average of pixels centered at some blocks that are similar to the block centered at the current pixel. Two perfect variants of this kind of method are NL-SAR [
12] and SAR-BM3D [
13], which can obtain a desired result for the SAR images with regular and repetitive textures. However, it is difficult for this kind of method to create an optimal balance between preserving SAR image features and removing artifacts because the NSS models are sensitive to the spatial features of SAR images.
Inspired by the success of deep convolutional neural networks (CNNs) in the field of optical image denoising, Chierchia et al. [
14] first proposed a residual CNN for subtracting speckle noise from SAR images. Considering that speckle noise is assumed to be multiplicative, the method first transforms multiplicative speckle into an additive form and then regards the additive speckle as the residual of the network. The ID-CNN [
15] can directly train SAR images without requiring a homomorphic transformation. In this method, the SAR image subtracts the learned speckle through skip connections, thus yielding a clean SAR image. SAR-DRN [
16] employs dilated convolutions and a combination structure of skip connections with a residual learning. Similar to [
15], SAR-DRN is also trained in an end-to-end way. Yue et al. [
17] exploited a deep neural network architecture to extract image features and reconstruct the probability density function (PDF) of the radar cross section (RCS) that is obscured by speckle noise. Lattari et al. [
18] proposed a deep encoder-decoder CNN based on the architecture of the U-Net to capture speckle statistical features. Cozzolino et al. [
19] proposed a nonlocal despeckling method for SAR images, in which the weight of the target pixel is estimated using a convolutional neural network.
From the above deep-learning-based despeckling methods, it can be seen that these methods all employ CNNs with a single-stream structure for training, either outputting a clean image in an end-to-end fashion or learning the underlying noise model. However, it is very difficult for models that adopt a single-stream structure to capture the multidirectional features of images, which will result in the loss of many detailed edge and textural features in the process of removing speckle noise.
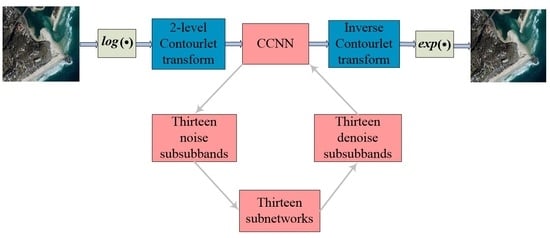
In this paper, we propose a multiscale and multidirectional CNN (CCNN) model to capture image features and to achieve better performance in suppressing speckle noise. The CCNN consists of multiple independent subnetworks (shown in
Figure 1), each of which adopts a network structure and a loss function according to the characteristic of the subband. Each subnetwork captures feature details and removes speckle noise from a specific direction and a specific scale. When the loss function of each subnetwork reaches the optimal value, the despeckled SAR image is obtained in a coarse-to-fine manner through the in-verse Contourlet transform.
Benefiting from the multiscale and multidirectional decomposition of the Contourlet transform, the CCNN can capture the detailed features in multiscales and multidirections, thus preserving image resolution while suppressing speckle noise. Compared with state-of-the-art despeckling methods, the CCNN can preserve relatively more detailed features while suppressing speckle noise.
In summary, the main contributions of the proposed method are fourfold: (1) the CCNN uses the Contourlet transform to divide a problem of SAR image despeckling into multiple subproblems and then suppresses speckle noises of the Contourlet sub-bands using multiple independent subnetworks, which means that our proposed CCNN can provide sufficient convolutional layers for capturing the image features, but overcome the problem of vanishing/exploding gradients; (2) each subnetwork has its structure and loss function, which ensures that each sub-band is the most similar to the corresponding sub-bands of the clean SAR image; (3) the features in each sub-band are concentrated in the horizontal or vertical or diagonal direction, etc., which reduces the requirement of a convolutional neural network, that is, each sub-band does not require too many convolution layers or a complex network to capture SAR image features and suppress speckle noise; (4) the subnetwork used to train each sub-band is independent and can run in parallel, thus shortening the training time.
This paper is organized as follows:
Section 2 briefly introduces the related work on CNN-based despeckling and the Contourlet analysis. The architecture of the proposed CCNN and the adopted loss functions are described in detail in
Section 3. We describe and discuss experimental results for synthetic and real-world SAR data in
Section 4. Finally,
Section 5 concludes and outlines future work.
2. Related Work
Many schemes for improving the visual quality of SAR image despeckling have been developed. Here, we focus on the schemes that are relative to the proposed CCNN.
With the success of AlexNet [
20] in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC-2012), CNNs have attracted great attention in the field of SAR image despeckling. In the last two years, a surge in SAR image despeckling methods based on CNNs has been presented, which adopted the architecture of U-Net [
21], ResNet [
22], or DenseNet [
23]. These CNN architectures are designed with many convolutional layers to make them deep enough to capture abundant enough features for images. To alleviate the problem of vanishing/exploding gradients caused by deepening the networks, the common characteristic of these networks is that not only neighboring layers, but also any other two layers, are linked by using skip connections. U-Net uses skip connections to concatenate feature mapping from the first convolutional layer to the last, second to second to last, etc. In ResNet, the input of convolutional blocks (containing multiple convolutional layers) is added to their output via skip connections. In DenseNet, all preceding convolutional layers were connected to their subsequent layers, which can overcome the shortcomings of ResNet, such as some layers being selectively discarded, or information being blocked. The basic idea of such a design is that only the deep network with a greater number of convolution layers can capture as many features as possible, helping to upgrade the visual quality of SAR image despeckling.
However, SAR image resolution is inferior to that of optical images. If capturing the detailed features of SAR images by only increasing the network depth, network training will become quite difficult and fail to capture some feature details. Multiscale and multidirection are natural attributes of an image. Analyzing the characteristics of multiscale and multidirectional images can reveal more essences of SAR images [
24]. The Contourlet transform plays an important role in the multiscale and multidirectional analysis of images and can produce large magnitude coefficients for image details in a certain scale and direction, which can effectively analyze and sparsely represent the edges and textures of SAR images. This helps us to improve the despeckling performance of the CNN-based method.
The Contourlet transform [
6] is an efficient multiresolution image representation, which has properties such as multiresolution, multiscale, multidirectionality, and anisotropy. The original image can be decomposed into lossless multiscale sub-bands in different directions and different frequency bands through Contourlet transform. In Contourlet transform, the Laplacian pyramid (LP) [
6] is first used to decompose an image into a bandpass sub-band and a lowpass sub-band. The bandpass sub-bands from the LP are then fed into a directional filter bank (DFB) [
6] to decompose into bandpass sub-bands with specific directional features. The process can be iterated on the lowpass sub-band, generating multiple sub-bands with different scales and different directions. These sub-bands use a few high-magnitude coefficients to represent image features along specific directions, while noise is generally represented by smaller coefficients [
25]. Through Contourlet decomposition, we can divide the problem of requiring a deep and complicated CNN to handle SAR image despeckling into multiple small problems, each of which, using a simple CNN, trains the features of a Contourlet sub-band with a specific scale and direction. The features in the Contourlet sub-bands are concentrated in a specific direction, and their feature coefficients are large; the subnetwork that has a relatively simple structure and fewer convolutional layers will be sufficient to fully learn the feature details of each sub-band and effectively suppress speckle noise.
4. Results
We carried out experiments on both synthetic and real SAR images. The motivation for designing the CCNN was to improve the performance of suppressing convolutional neural network speckle while shortening the training time. To this end, multiple experiments were conducted to evaluate the performance of the CCNN. First, we investigated the advantages of each independently learned Contourlet sub-band. Second, we examined the impacts of the different structures of the subnetworks on the despeckling quality of the SAR images. Third, we investigated the effect of different subnetworks with different loss functions. These experiments belong to our ablation studies, displaying the impact of each basic component on the performance of the CCNN. Finally, we selected four representative despeckling methods as the comparison baselines to compare and comprehensively analyze the performance of the proposed CCNN method: three CNN-based methods (SAR-CNN [
14], ID-CNN [
15], and SAR-UNet [
18]), and the representative traditional method (SAR-BM3D [
13]).
We used the PSNR to evaluate the despeckling results of the synthetic SAR images. In addition, the structural similarity (SSIM) [
38] was used to evaluate the ability to retain the image details. Sheikh et al. [
39] discussed many quantitative metrics for the estimated images and stated that the SSIM index is good at assessing the fidelity of detailed features. The higher the values, the more similar the local feature of the image will be, and the better the fidelity of the image. For SAR images from real-world scenarios, speckle suppression ability is measured objectively using no-reference image quality evaluation such as the natural image quality evaluator (NIQE) [
40] and the equivalent number of looks (ENL) [
41], which are calculated on homogeneous regions of the despeckled SAR images. The former can objectively measure the ability to suppress speckle noise in the absence of clean reference images, and the latter is sensitive to the content sharpness, texture diversity, and detail contrast of the images. Therefore, they are suitable for evaluating the speckle suppressing results of SAR images from real-world scenarios. The larger the NIQE and the larger the ENL, the better the preserved image details will be, and the speckle results will be suppressed.
4.1. Ablation Studies
4.1.1. Subband Training
In this section, we aim to verify that each Contourlet sub-band being trained independently not only shortens the training time but is also helpful for enhancing the denoising quality. One of the advantages of the CCNN is that it can be divided into several subnetworks. These subnetworks can learn the feature mapping of each Contourlet subband on multiple computers in parallel, and the well-trained sub-band can then be integrated to obtain a clean image through the inverse Contourlet. The CCNN that is trained in this way is denoted as CCNN-1. The CCNN learns its feature mapping on a single computer. Here, we compare the CCNN with the SAR-BM3D [
13], SAR-CNN [
14], ID-CNN [
15], and SAR-UNet [
18], despeckling benchmark methods. The results of these methods, shown in
Table 1, come from their paper or cite their paper.
Table 1 displays the averages of PSNRs/SSIMs/NIQEs/ENLs and the GPU runtime when the CCNN and the four comparison methods handle the 100 images from the BSD 500 (added with the speckle noise of
and the PatternNet dataset. The CCNN-1 and the CCNN both achieved the best metric values, with a relatively shorter execution time when compared with state-of-the-art image despeckling methods. It can also be seen that the execution time and training time of the CCNN were slightly greater than those of CCNN-1. This is because the subnetworks of CCNN-1 can be independently trained on multiple computers in parallel. The subnetworks of the CCNN are confined to running on a single computer. Due to the multiscale and multidirectional decomposition of Contourlets, the sub-bands of the Contourlet can not only intensively represent common characteristics in a certain direction, but also use larger coefficients than those of the noise to represent these features (for example, the coefficients of the horizontal directional edges in the LH sub-bands are larger). Each sub-band does not lose any detailed features because it does not require clipping. Therefore, each subnetwork does not require a deep CNN with many convolution layers to capture the characteristics of these sub-bands; moreover, each subnetwork has a loss function, which can control and adjust the parameters of the subnetwork, to ensure that each sub-band is most similar to that of the clean SAR image. These measures ensure that the proposed CCNN can achieve better PSNR/SSIM/NIQE/ENL metrics than those of other comparison methods at a relatively faster speed, even if the CCNN works on a single computer.
4.1.2. The Structure of the Subnetwork
Here, we verify that the mechanism, i.e., each subnetwork that adopts a training structure to suit the characteristic of each sub-band, is helpful for improving the performance of the CCNN. In the CCNN, the structure of the subnetwork that is responsible for training each Contourlet sub-band can be different. We explore a CNN architecture that is fit for them according to each of their Contourlet sub-band attributes. The common feature of these subnetworks is that they all have few convolutional layers, which means that our proposed CCNN can have enough convolutional layers to capture the image features without causing the problem of vanishing/exploding gradients. The directional sub-bands in the low level contain most of the speckle noise of an SAR image and the size is larger. We adopt the ResNet structure to capture the speckle noise features from the sub-bands and learn the speckle noise feature mappings. Although these sub-bands are large, the subnetworks train the speckle noise features rather than the image content by using residual learning, which is not only easy to train but also reduces the learned parameters. This is based on the fact that there are far fewer contents to be learned from the noise than from an image. For the directional sub-bands in the highest level, the sub-bands contain more detailed features and less noise, and these detailed features may be very thin, which requires that the fine features extracted from the previous convolution layers can be passed to the subsequent convolution layers. Therefore, the subnetworks that are in charge of the directional sub-bands at the second level adopt the U-Net structure. Symmetric connections are added between the convolution layers and their corresponding layers, ensuring that the overall features captured by the previous convolution layers are passed into the subsequent feature maps. Furthermore, we also utilize dilate convolutions to enlarge the receptive field of the convolutional layers and to capture the thin features. For the coarse sub-bands in the highest level, the sub-bands contain much more overall image information, fewer detailed features and the least noise. The S-CNN that contains fewer mixed convolutional layers and has a skip connection will be competent enough to capture and learn the overall features of the coarse sub-bands.
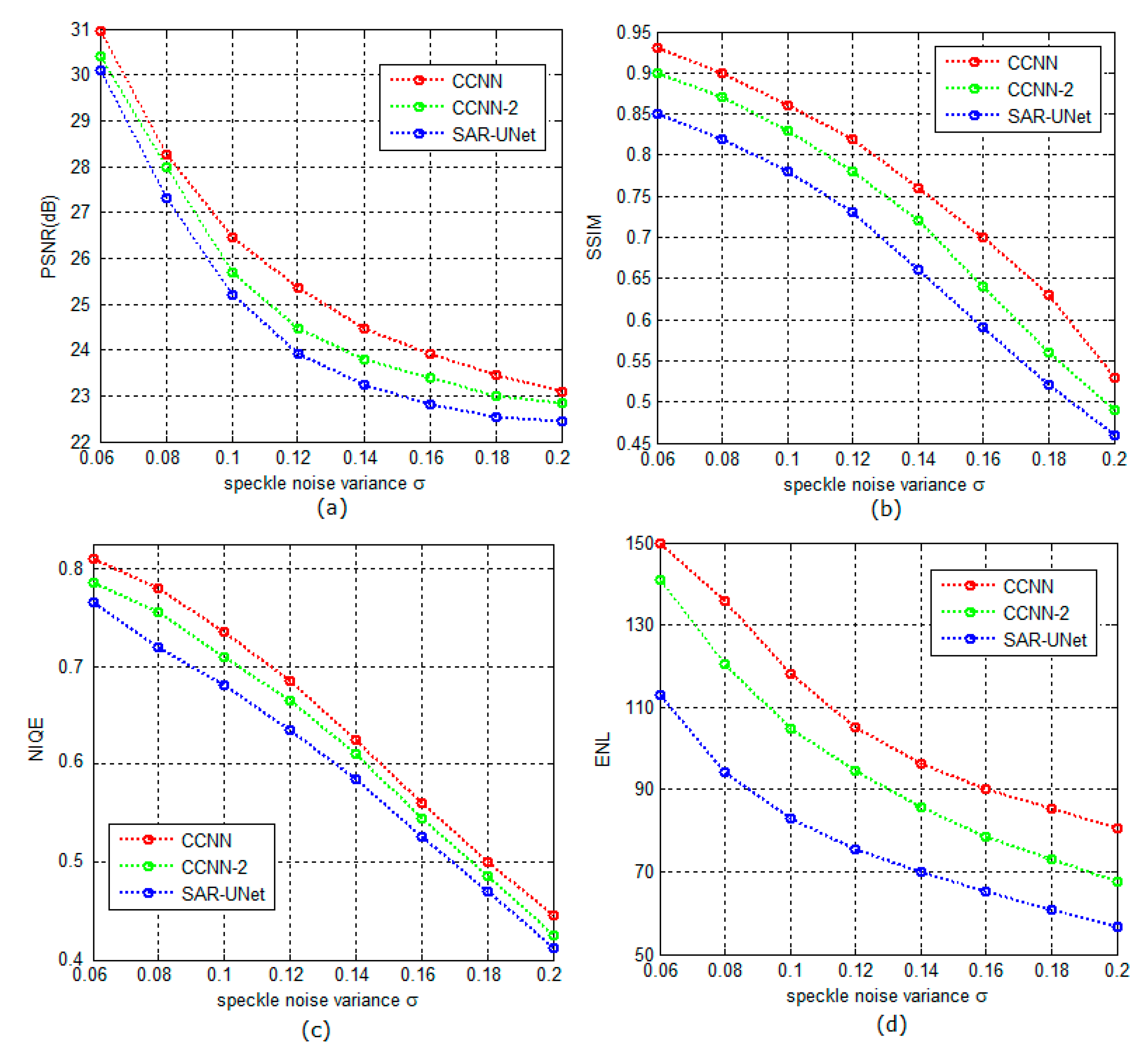
Figure 3 shows the positive impact of the subnetwork structures on the performance of the CCNN. The CCNN-2 represents a variant of the CCNN in which all the subnetworks are designed with the ResNet structure (i.e., the structure shown in
Figure 2a) and each subnetwork has eight convolutional layers. We consider SAR-UNet [
18] as a comparison baseline because it uses the same structure to extract detailed features at different scales. The comparison of the proposed CCNN method, the CCNN-2 method and the SAR-UNet method in terms of PSNRs/SSIMs/NIQEs/ENLs is shown in
Figure 3a,d. These data are from the average of the 100 synthetic SAR images that included speckle noise with the variance σ = 0.06, 0.08, …, 0.2.
Figure 3 illustrates that the performance of the CCNN is significantly superior to that of SAR-UNet. Additionally, the performance of CCNN-2 slightly surpasses that of the SAR-UNet method. This indicates that the strategy that uses the different CNN structures to train the different sub-bands can significantly improve the performance of suppressing speckles of the CCNN.
4.1.3. Loss Function
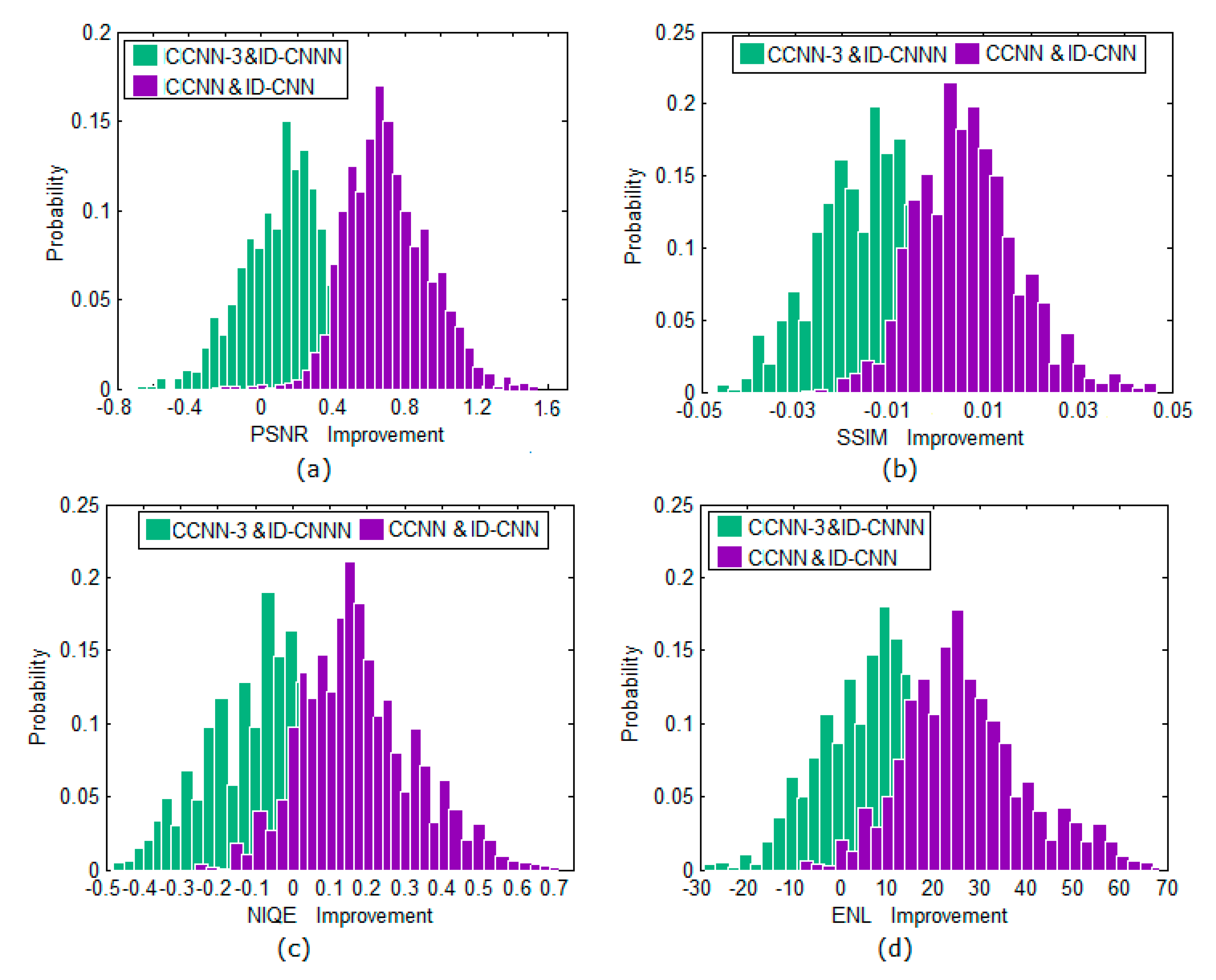
In the CCNN, the subnetwork used to independently train each Contourlet sub-band has not only its own structure but also its own loss function. As is known, the image contents and noise can be partially separated through multidirectional and multiscale Contourlet decomposition. The correlation of the image information is large, and the correlation of the noise information is small. Therefore, the amplitudes of most coefficients of the image details are higher than those of most of the noise coefficients, even if the noise intensity is high. Therefore, in the directional sub-bands, the high-magnitude coefficients convey most of the image detail energy and most of the low-magnitude coefficients are due to noise. If the high-magnitude coefficients can play a leading role in the loss function, it is conducive to the learning and preservation of image details and suppressing noise. Considering this point, we introduce a weight factor λ into the loss function of the directional sub-bands. The weight factor λ is set to two different values according to the coefficient values of the directional sub-band. Only coefficients greater than the average of the coefficients of each directional sub-band are assigned a higher λ value, and the rest are assigned a lower λ. However, the averages of the coefficients of each directional sub-band are bound to be different, which means that the objective function of each subnetwork has its own standard. This mechanism is helpful for suppressing speckle noise while preserving the feature details. To verify the effectiveness of this scheme, we conducted the following experiments: each subnetwork uses the same loss function, i.e., weight factor λ of Equation (1) is set to 1, to learn its feature mapping, and this CCNN is denoted as CCNN-3. Here, we consider the ID-CNN [
15] as a comparison baseline because its weight factor λ of the loss function is also a constant.
Figure 4 shows the probability distributions of the PSNR, SSIM, NIQE, and ENL gains of these 200 SAR images (100 synthetic and 100 real images). These gain values were obtained from the CCNN and CCNN-3 relative to the ID-CNN baseline. The PSNR/SSIM/NIQE/ENL gains shown in
Figure 4 illustrate that the performance of the CCNN exceeds those of the ID-CNN by a large margin and that CCNN-3 is slightly superior to the ID-CNN, which demonstrates that using different loss functions to supervise learning of each sub-band is helpful for improving the despeckling performance of the CCNN.
4.2. The CCNN Performance
To comprehensively verify the CCNN performance, we investigate the despeckling results of the CCNN and the four comparison methods on synthetic SAR images and real SAR images. In particular, we also investigate the performance of the CCNN+, a variant of the CCNN, in which the number of convolutional layers increases to 10 or the number of the mixed convolution layers increases to five in each subnetwork. The regions of interest (ROIs) in each despeckled image are enlarged by two times using bicubic interpolation and are shown in the corners to highlight the details obtained from different methods.
4.2.1. Results on Synthetic SAR Images
The 100 test images were randomly selected from the BSD500 and speckle noise was added with variance σ = 0.06, 0.08, …, and 0.2. Among them, the representatives of grayscale and color images and their corresponding single-look speckle synthetic images are shown in
Figure 5. The two assessment values in terms of PSNR and SSIM (averaging values of 100 synthetic images obtained from these methods are presented in
Table 2. The visual quality of the despeckled images is shown in
Figure 6 and
Figure 7.
The assessment values from the methods shown in
Table 2 are high, illustrating that these methods all yield good speckle-suppressing results. High PSNR values indicate that the despeckled image is closest to the original clean image; high SSIM values demonstrate that the methods can retain the edge and texture details while suppressing speckle noise.
Overall, the assessment values obtained from the CNN-based methods (SAR-CNN,ID-CNN,SAR-UNet and CCNN) are superior to those of the traditional method (SAR-BM3D).This is because the traditional despeckling method distinguishes the image energy from the speckle noise based on image similarity and sparse representation, while the CNN-based methods can extract useful end-to-end data by integrating multiple convolutional layers and/or convolutional blocks, thus having a powerful learning capability and providing accurate predictive features for the estimated images.
Figure 6 and
Figure 7 indicate that the visual quality of images obtained from the traditional despeckling methods is indeed inferior to the image quality obtained from the CNN-based methods. There are significant block artifacts around the edges of images obtained from the SAR-BM3D method. With the help of residual learning, the SAR-CNN and the ID-CNN can retain the edge and texture details well while removing noise and they generate slight artifacts only at the sharp edges. In contrast, the visual results of the ID-CNN are surperior to those of the SAR-CNN, perhaps benefiting from the ID-CNN using the improved loss function. Due to introducing downscaling and upscaling convolutional layers, the numerical results of the despeckled images from SAR-UNet are relatively better; most of the details are preserved, although the details in the textural regions are lost. The CCNN learns the deep characteristics of the images in multiple scales and multiple directions by using the Contourlet transform to build a multiple-stream structure, thus estimating fully detailed image information. The obtained numerical results from the CCNN are desired and have not only the highest PSNR mean values, but also relatively high SSIMs. Additionally, the visual quality obtained from the CCNN is also outstanding, with few slight artifacts appearing only at some edges. Moreover, when the number of convolutional layers of the CCNN increases, namely, CCNN+, the obtained metrics are better in terms of the PSNRs/SSIMs. This indicates that there is still room for improvement in the structure and the performance of the CCNN.
4.2.2. Results on Real SAR Images
The experiments on the synthetic images cannot adequately validate the effectiveness of the proposed method since the synthetic images in the simulation experiments are not acquired in a real degradation way. Here, we repeat the experiments on real SAR images to illustrate the feasibility and robustness of the proposed CCNN in some real-world scenarios.
We selected eight SAR images that have multilooked images from the PatternNet dataset to test the CCNN. Two of these SAR images and their corresponding multilook references are shown in
Figure 8. The red boxes on the multilooked images represent the regions used to compute the ENL. In this experiment, temporal multilooking was used as the reference image for training. This reference is quite different from the ideal “clean” image, which implies that the speckle noise cannot be completely suppressed. Therefore, we focus on the comparisons of the quantitative indicators NIQE and ENL.
The quantitative evaluation of the baseline methods and our CCNN are shown in
Table 3. The metric NIQE can measure the quality of the despeckled images and is expressed as a simple distance between the despeckled images and the model that is constructed via statistical features collected from many real SAR images. The larger the metric NIQE is, the better the image detail preservation will be. The index ENL indicates the smooth degree of the despeckled image by calculating the mean and standard deviation of a homogeneous region. The larger the ENL is, the smoother the region will be and the better the speckle noise suppression.
In
Table 3, the ENL of the SAR-CNN method is the lowest while the NIQE of the SAR-BM3D network is the lowest, which indicates that the former cannot effectively suppress speckle noise and the latter cannot preserve fine details in the textural region. Overall, the metrics obtained from the CCNN on the eight SAR images (#1, #2, …, #8) are the most satisfactory and have the highest ENL and NIQE, which indicates that the CCNN can effectively suppress speckle noise without significantly impairing the image resolution.
Figure 9 and
Figure 10 show the visual qualities of the despeckled images obtained from the baseline methods and the proposed CCNN. In contrast, we observe that the SAR-BM3D, SAR-CNN, ID-CNN, and SAR-UNet lose details to some extent, blur some texture details and edges, or have a large level of residual speckle noise, while our proposed CCNN and the CCNN+ preserve most details well, even for thin lines and complex textures. Additionally, very few speckle noises are left and very few artifacts are introduced.
5. Discussion
In summary, the proposed CCNN provides very satisfying results considering despeckling performance and detail preservation. For real-world SAR images, we observe the same results with the synthetic SAR images as before, only less pronounced. This probably has to do with the imperfect reference images used for training the CCNN. In fact, a 25-look image (obtained by averaging a series of 25 SAR images) is not a true clean SAR image, but only an approximation of it, based on temporal multilooking. The regions characterized by a different average intensity from the rest of the image probably correspond to regions where the despeckled image approaches the reference image but not the original noisy image. Thus, the CCNN behaves as instructed to do based on bad examples. With this premise, the reference multilooking images can only provide bad results. If our conjecture is right, the CCNN performance will be further improved when better reference data are available.
The CCNN can be extended to higher level of Contourlet decomposition. Nevertheless, higher level inevitably results in deeper network and heavier computational burden. Thus, a suitable level is required to balance efficiency and performance. We examined the PSNR and runtime results of CCNNs with the levels of 1 to 3. We observed that CCNN with 2-level architecture performs much better than CCNN with 1-level, while CCNN with 3-level architecture only performs negligibly better than CCNN with 2-level in terms of the PSNR metric. Moreover, the speed of CCNN with 2-level is also moderate compared with many more decomposition levels. Taking both efficiency and performance gain into account, we choose CCNN with 2-level as the default setting.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}