
Vision Transformers for Remote Sensing Image Classification




Abstract
1. Introduction
2. Materials and Methods
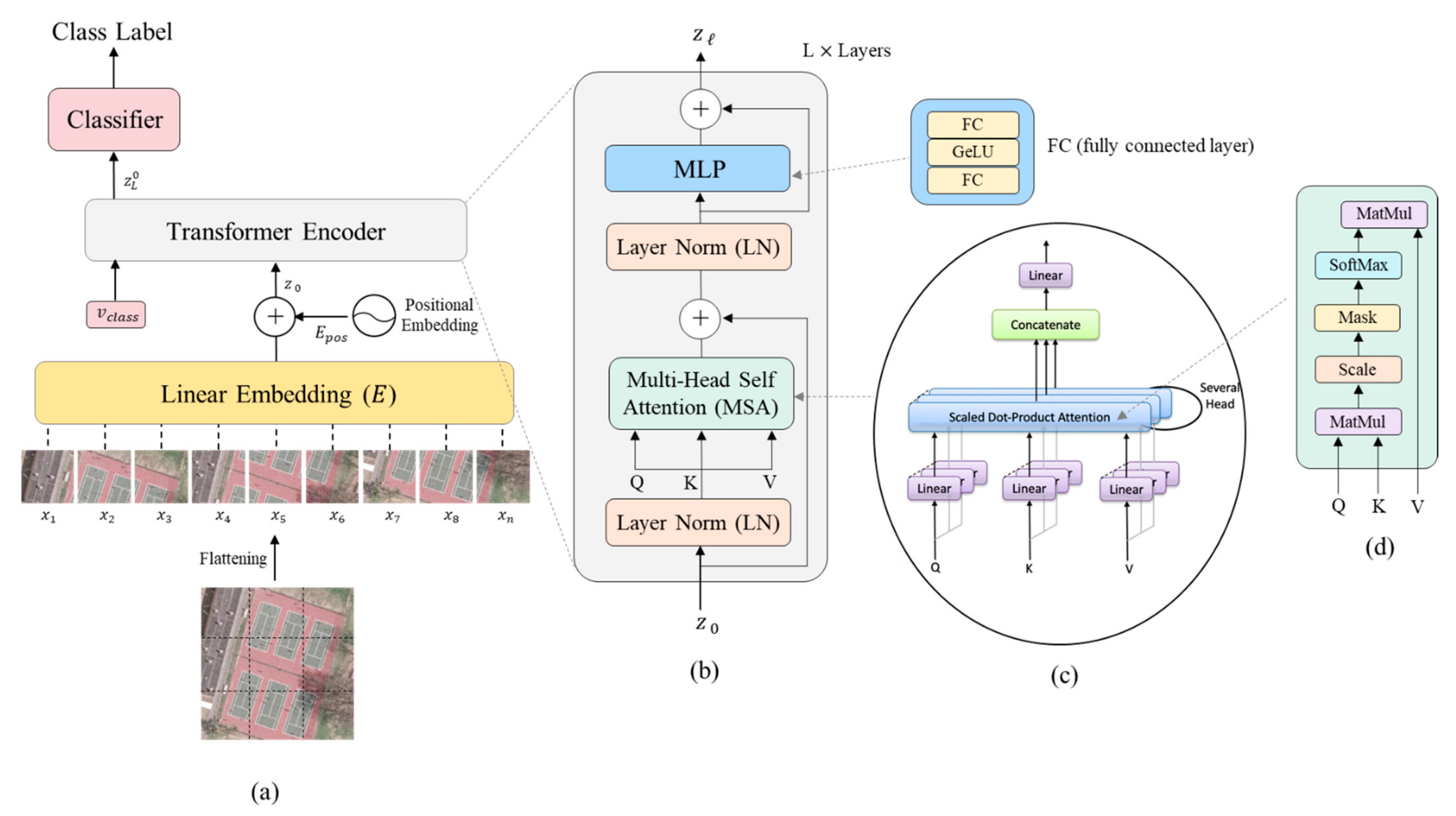
2.1. Vision Transformer
2.1.1. Linear Embedding Layer
2.1.2. Vision Transformer Encoder
2.1.3. Vision Transformer Variants
2.2. Data Augmentation Strategies
2.3. Network Compression
| Algorithm 1: Vision Transformer |
| Input: Training images: |
Output: predicted labels of the test set.
|
3. Experimental Results
3.1. Dataset Description
3.2. Experimental Setup
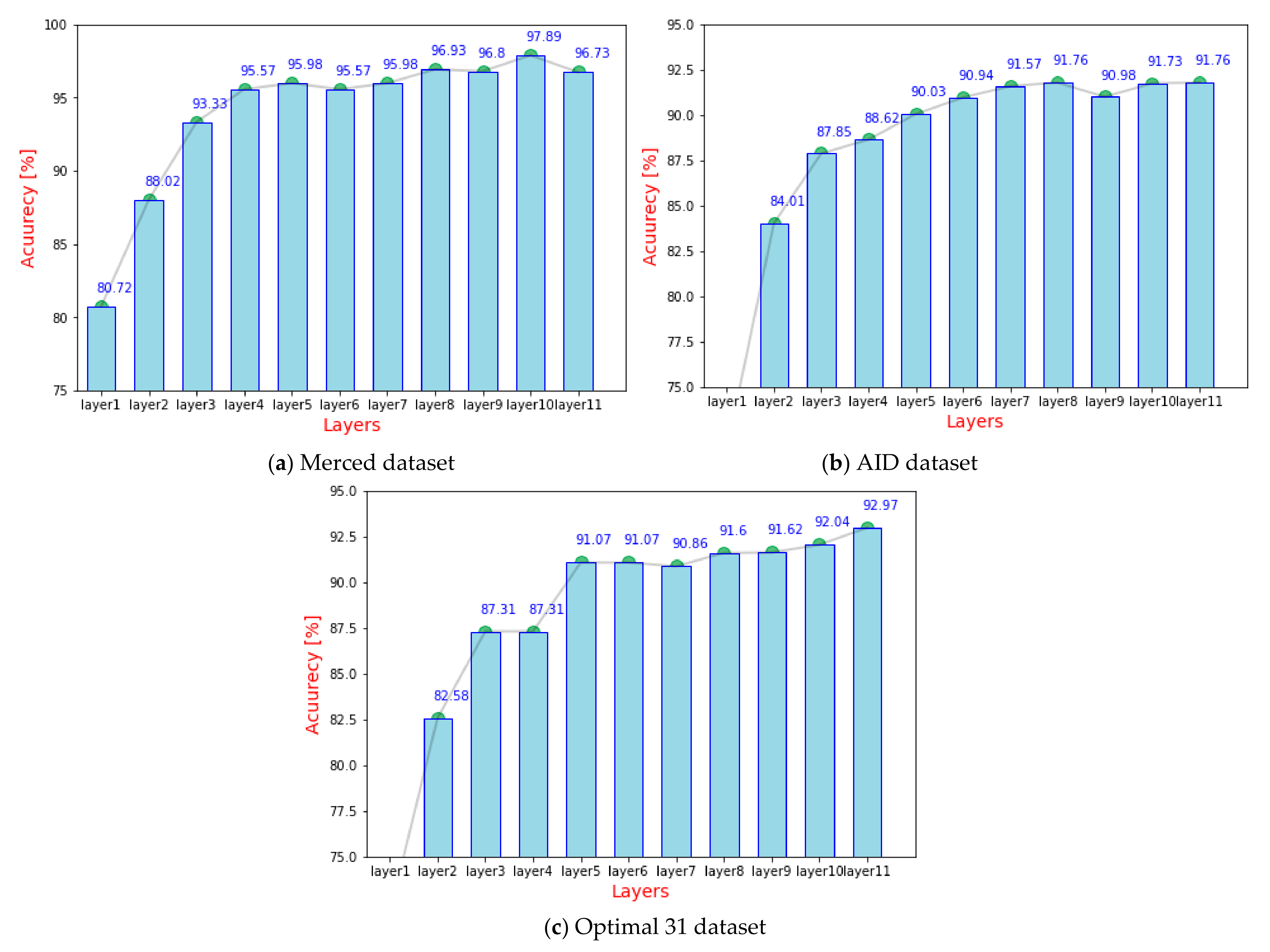
3.3. Experiment 1: Preliminary Analysis
3.4. Experiment 2: Network Compression
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hu, Q.; Wu, W.; Xia, T.; Yu, Q.; Yang, P.; Li, Z.; Song, Q. Exploring the use of google earth imagery and object-based methods in land use/cover mapping. Remote Sens. 2013, 5, 6026–6042. [Google Scholar] [CrossRef]
- Toth, C.; Jóźków, G. Remote sensing platforms and sensors: A survey. ISPRS J. Photogramm. Remote Sens. 2016, 115, 22–36. [Google Scholar] [CrossRef]
- Hoogendoorn, S.P.; Van Zuylen, H.J.; Schreuder, M.; Gorte, B.; Vosselman, G. Microscopic traffic data collection by remote sensing. Transp. Res. Rec. 2003, 1855, 121–128. [Google Scholar] [CrossRef]
- Valavanis, K.P. Advances in Unmanned Aerial Vehicles: State of the Art and the Road to Autonomy; Springer Science & Business Media: Berlin, Germany, 2008; ISBN 978-1-4020-6114-1. [Google Scholar]
- Sheppard, C.; Rahnemoonfar, M. Real-time scene understanding for UAV imagery based on deep convolutional neural networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2243–2246. [Google Scholar]
- Al-Najjar, H.A.H.; Kalantar, B.; Pradhan, B.; Saeidi, V.; Halin, A.A.; Ueda, N.; Mansor, S. Land cover classification from fused DSM and UAV images using convolutional neural networks. Remote Sens. 2019, 11, 1461. [Google Scholar] [CrossRef]
- Liu, T.; Abd-Elrahman, A.; Zare, A.; Dewitt, B.A.; Flory, L.; Smith, S.E. A fully learnable context-driven object-based model for mapping land cover using multi-view data from unmanned aircraft systems. Remote Sens. Environ. 2018, 216, 328–344. [Google Scholar] [CrossRef]
- Bazi, Y. Two-branch neural network for learning multi-label classification in UAV imagery. In Proceedings of the IGARSS 2019—2019 IEEE International Geoscience and Remote Sensing Symposium, Yokohama, Japan, 28 July–2 August 2019; pp. 2443–2446. [Google Scholar]
- Skidmore, A.K.; Bijker, W.; Schmidt, K.; Kumar, L. Use of remote sensing and GIS for sustainable land management. ITC J. 1997, 3, 302–315. [Google Scholar]
- Xiao, Y.; Zhan, Q. A review of remote sensing applications in urban planning and management in China. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; pp. 1–5. [Google Scholar]
- Daldegan, G.A.; Roberts, D.A.; de Ribeiro, F.F. Spectral mixture analysis in google earth engine to model and delineate fire scars over a large extent and a long time-series in a rainforest-savanna transition zone. Remote Sens. Environ. 2019, 232, 111340. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikainen, M. Face description with local binary patterns: Application to face recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 2037–2041. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: San Diego, CA, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Li, Q.; Qi, S.; Shen, Y.; Ni, D.; Zhang, H.; Wang, T. Multispectral image alignment with nonlinear scale-invariant keypoint and enhanced local feature matrix. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1551–1555. [Google Scholar] [CrossRef]
- Sivic, J.; Russell, B.C.; Efros, A.A.; Zisserman, A.; Freeman, W.T. Discovering objects and their location in images. In Proceedings of the Tenth IEEE International Conference on Computer Vision (ICCV’05), Beijing, China, 17–21 October 2005; Volume 1, pp. 370–377. [Google Scholar]
- Huang, L.; Chen, C.; Li, W.; Du, Q. Remote sensing image scene classification using multi-scale completed local binary patterns and fisher vectors. Remote Sens. 2016, 8, 483. [Google Scholar] [CrossRef]
- Imbriaco, R.; Sebastian, C.; Bondarev, E.; de With, P.H.N. Aggregated deep local features for remote sensing image retrieval. Remote Sens. 2019, 11, 493. [Google Scholar] [CrossRef]
- Diao, W.; Sun, X.; Zheng, X.; Dou, F.; Wang, H.; Fu, K. Efficient saliency-based object detection in remote sensing images using deep belief networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 137–141. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Nogueira, K.; Miranda, W.O.; Santos, J.A.D. Improving spatial feature representation from aerial scenes by using convolutional networks. In Proceedings of the 2015 28th SIBGRAPI Conference on Graphics, Patterns and Images, Salvador, Brazil, 26–29 August 2015; pp. 289–296. [Google Scholar]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using imagenet pretrained networks. IEEE Geosci. Remote Sens. Lett. 2016, 13, 105–109. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Lakhal, M.I.; Çevikalp, H.; Escalera, S.; Ofli, F. Recurrent neural networks for remote sensing image classification. IET Comput. Vis. 2018, 12, 1040–1045. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative adversarial networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Feng, J.; Yu, H.; Wang, L.; Cao, X.; Zhang, X.; Jiao, L. Classification of hyperspectral images based on multiclass spatial–spectral generative adversarial networks. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5329–5343. [Google Scholar] [CrossRef]
- Mou, L.; Lu, X.; Li, X.; Zhu, X.X. Nonlocal graph convolutional networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 1–12. [Google Scholar] [CrossRef]
- Hu, W.; Li, H.; Pan, L.; Li, W.; Tao, R.; Du, Q. Spatial–spectral feature extraction via deep ConvLSTM neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4237–4250. [Google Scholar] [CrossRef]
- Bi, Q.; Qin, K.; Li, Z.; Zhang, H.; Xu, K.; Xia, G.-S. A multiple-instance densely-connected ConvNet for aerial scene classification. IEEE Trans. Image Process. 2020, 29, 4911–4926. [Google Scholar] [CrossRef]
- Yu, Y.; Li, X.; Liu, F. Attention GANs: Unsupervised deep feature learning for aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 519–531. [Google Scholar] [CrossRef]
- Bazi, Y.; Al Rahhal, M.M.; Alhichri, H.; Alajlan, N. Simple yet effective fine-tuning of deep CNNs using an auxiliary classification loss for remote sensing scene classification. Remote Sens. 2019, 11, 2908. [Google Scholar] [CrossRef]
- Sun, H.; Li, S.; Zheng, X.; Lu, X. Remote sensing scene classification by gated bidirectional network. IEEE Trans. Geosci. Remote Sens. 2019, 1–15. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.; Ding, L. Scene classification based on two-stage deep feature fusion. IEEE Geosci. Remote Sens. Lett. 2018, 15, 183–186. [Google Scholar] [CrossRef]
- Yu, Y.; Liu, F. A Two-Stream Deep Fusion Framework for High-Resolution Aerial Scene Classification. Available online: https://www.hindawi.com/journals/cin/2018/8639367/ (accessed on 20 November 2020).
- Cheng, G.; Yang, C.; Yao, X.; Guo, L.; Han, J. When deep learning meets metric learning: Remote sensing image scene classification via learning discriminative CNNs. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2811–2821. [Google Scholar] [CrossRef]
- Xue, W.; Dai, X.; Liu, L. Remote sensing scene classification based on multi-structure deep features fusion. IEEE Access 2020, 8, 28746–28755. [Google Scholar] [CrossRef]
- Wang, Q.; Li, B.; Xiao, T.; Zhu, J.; Li, C.; Wong, D.F.; Chao, L.S. Learning deep transformer models for machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Fortezza da Florence, Italy, 28 July–2 August 2019; pp. 1810–1822. [Google Scholar]
- Dai, Z.; Yang, Z.; Yang, Y.; Carbonell, J.; Le, Q.; Salakhutdinov, R. Transformer-XL: Attentive language models beyond a fixed-length context. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Fortezza da Florence, Italy, 28 July–2 August 2019; pp. 2978–2988. [Google Scholar]
- Chen, N.; Watanabe, S.; Villalba, J.A.; Zelasko, P.; Dehak, N. Non-autoregressive transformer for speech recognition. IEEE Signal Process. Lett. 2020, 28, 121–125. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 5998–6008. [Google Scholar]
- Bello, I.; Zoph, B.; Vaswani, A.; Shlens, J.; Le, Q.V. Attention Augmented Convolutional Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 3285–3294. [Google Scholar]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1155–1167. [Google Scholar] [CrossRef]
- Wu, B.; Xu, C.; Dai, X.; Wan, A.; Zhang, P.; Tomizuka, M.; Keutzer, K.; Vajda, P. Visual transformers: Token-based image representation and processing for computer vision. arXiv 2020, arXiv:2006.03677. [Google Scholar]
- Ramachandran, P.; Parmar, N.; Vaswani, A.; Bello, I.; Levskaya, A.; Shlens, J. Stand-alone self-attention in vision models. arXiv 2019, arXiv:1906.05909. [Google Scholar]
- Chen, M.; Radford, A.; Child, R.; Wu, J.; Jun, H.; Luan, D.; Sutskever, I. Generative pretraining from pixels. In Proceedings of the 37th International Conference on Machine Learning, Vienna, Austrlia, 12–18 July 2020; pp. 1691–1703. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- He, J.; Zhao, L.; Yang, H.; Zhang, M.; Li, W. HSI-BERT: Hyperspectral image classification using the bidirectional encoder representation from transformers. IEEE Trans. Geosci. Remote Sens. 2020, 58, 165–178. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MI, USA, 2–7 June 2019; Long and Short Papers. Volume 1, pp. 4171–4186. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning augmentation strategies from data. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019; IEEE: Long Beach, CA, USA, 2019; pp. 113–123. [Google Scholar]
- Jackson, P.T.; Atapour-Abarghouei, A.; Bonner, S.; Breckon, T.P.; Obara, B. Style Augmentation: Data Augmentation via Style Randomization. In Proceedings of the 2019 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Bowles, C.; Chen, L.; Guerrero, R.; Bentley, P.; Gunn, R.; Hammers, A.; Dickie, D.A.; Hernández, M.V.; Wardlaw, J.; Rueckert, D. GAN augmentation: Augmenting training data using generative adversarial networks. arXiv 2018, arXiv:1810.10863. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical risk minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Yun, S.; Han, D.; Chun, S.; Oh, S.J.; Yoo, Y.; Choe, J. CutMix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 6022–6031. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2016, arXiv:1510.00149. [Google Scholar]
- Wu, J.; Leng, C.; Wang, Y.; Hu, Q.; Cheng, J. Quantized Convolutional Neural Networks for Mobile Devices. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 4820–4828. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems—GIS ’10, San Jose, CA, USA, 2–5 November 2010; p. 270. [Google Scholar]
- Xia, G.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- He, N.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Remote sensing scene classification using multilayer stacked covariance pooling. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6899–6910. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Number of Layers | Hidden Size D | MLP Size | Heads | Number of Parameters |
|---|---|---|---|---|---|
| ViT-Base | 12 | 768 | 3072 | 12 | 86 M |
| ViT-Large | 24 | 1024 | 4096 | 16 | 307 M |
| ViT-Huge | 32 | 1280 | 5120 | 16 | 632 M |
| Dataset | Number of Classes | Number of Images per Class | Image Size | Year |
|---|---|---|---|---|
| Merced | 21 | 100 | 256 × 256 | 2010 |
| AID | 30 | 220~420 | 600 × 600 | 2017 |
| Optimal 31 | 31 | 60 | 256 × 256 | 2019 |
| With Augmentation | |||||
|---|---|---|---|---|---|
| Dataset | Clean Images | Standard | CutMix | Cutout | Hybrid |
| Merced | 94.55 | 96.32 | 96.66 | 95.44 | 96.73 |
| AID | 89.31 | 92.06 | 90.50 | 91.62 | 91.76 |
| Optimal31 | 88.27 | 91.43 | 92.44 | 92.25 | 92.97 |
| Average | 90.71 | 93.27 | 93.20 | 93.30 | 93.82 |
| Dataset | 224 × 224 | 384 × 384 |
|---|---|---|
| Merced | 96.73 30 min | 97.43 46 min |
| AID | 91.76 43 min | 92.94 88 min |
| Optimal31 | 92.76 25 min | 92.79 68 min |
| Average | 93.45 32.66 min | 94.38 67.33 min |
| Datasets | ||||
|---|---|---|---|---|
| Method | Merced (50% Train) | AID (20% Train) | Optimal31 (80% Train) | NWPU (10% Train) |
| ARCNet-VGG16 [41] | 96.81 ± 0.14 | 88.75 ± 0.40 | 92.70 ± 0.35 | - |
| ARCNet- AlexNet [41] | - | - | 85.75 ± 0.35 | - |
| ARCNet- ResNet [41] | - | - | 91.28 ± 0.45 | - |
| GoogLeNet+SVM [58] | 92.70 ± 0.60 | 83.44 ± 0.40 | - | - |
| GBNet + global feature [31] | 97.05 ± 0.19 | 92.20 ± 0.23 | 93.28 ± 0.27 | - |
| VGG-16+MSCP [59] | 98.36 ± 0.58 | 91.52 ± 0.21 | - | - |
| Fine-tuning VGG16 [31] | 96.57 ± 0.38 | 89.49 ± 0.34 | 89.52 ± 0.26 | 87.15 ± 0.45 |
| Fine-tuning GoogLeNet [60] | - | - | 82.57 ± 0.12 | 82.57 ± 0.12 |
| Inception-v3-aux [30] | 97.63 ± 0.20 | 93.52 ± 0.21 | 94.13 ± 0.35 | 89.32 ± 0.33 |
| GoogLeNet-aux [30] | 97.90 ± 0.34 | 93.25 ± 0.33 | 93.11 ± 0.55 | 89.22 ± 0.25 |
| EfficientNetB0-aux [30] | 98.01 ± 0.45 | 93.69± 0.11 | 93.97 ± 0.13 | 89.96 ± 0.27 |
| EfficientNetB3-aux [30] | 98.22 ± 0.49 | 94.19 ± 0.15 | 94.51 ± 0.75 | 91.08 ± 0.14 |
| Proposed V32_21k [384 × 384] | 97.74 ± 0.10 | 95.51 ± 0.57 | 94.62 ± 0.38 | 92.81 ± 0.17 |
| Proposed V16_21k [224 × 224] | 98.14 ± 0.47 | 94.97 ±0.01 | 95.07 ± 0.12 | 92.60 ± 0.10 |
| Proposed V16_21k [384 × 384] | 98.49 ± 0.43 | 95.86 ± 0.28 | 95.56 ± 0.18 | 93.83 ± 0.46 |
| Proposed V16_21k [384 × 384] [pruning 50%] | 97.90 ± 0.10 | 94.27 ± 1.41 | 95.30 ± 0.58 | 93.05 ± 0.46 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bazi, Y.; Bashmal, L.; Rahhal, M.M.A.; Dayil, R.A.; Ajlan, N.A. Vision Transformers for Remote Sensing Image Classification. Remote Sens. 2021, 13, 516. https://doi.org/10.3390/rs13030516
Bazi Y, Bashmal L, Rahhal MMA, Dayil RA, Ajlan NA. Vision Transformers for Remote Sensing Image Classification. Remote Sensing. 2021; 13(3):516. https://doi.org/10.3390/rs13030516
Chicago/Turabian StyleBazi, Yakoub, Laila Bashmal, Mohamad M. Al Rahhal, Reham Al Dayil, and Naif Al Ajlan. 2021. "Vision Transformers for Remote Sensing Image Classification" Remote Sensing 13, no. 3: 516. https://doi.org/10.3390/rs13030516
APA StyleBazi, Y., Bashmal, L., Rahhal, M. M. A., Dayil, R. A., & Ajlan, N. A. (2021). Vision Transformers for Remote Sensing Image Classification. Remote Sensing, 13(3), 516. https://doi.org/10.3390/rs13030516