SMOTE-Based Weighted Deep Rotation Forest for the Imbalanced Hyperspectral Data Classification

 ,
,  ,
, 
Abstract
:1. Introduction
- Undersampling methods: Undersampling alters the size of training sets by sampling a smaller majority class, which reduces the level of imbalance [37] and is easy to perform and have been shown to be useful in imbalanced problems [39,40,41,42]. The major superiority of undersampling is that all training instances are real [35]. Random undersampling (RUS) is a popular method that is designed to balance class distribution by eliminating the majority class instances randomly. However, the main disadvantage of undersampling is that it may neglect potentially useful information, which could be significant for the induction process.
- Oversampling methods: Over-sampling algorithms increase the number of samples either by randomly choosing instances from the minority class and appending them to the original dataset or by synthesizing new examples [43], which can reduce the degree of imbalanced distribution. Random oversampling is simply copying the sample of the minority class, which easily leads to overfitting [44] and has little effect on improving the classification accuracy of the minority class. The synthetic minority oversampling technique (SMOTE) is a powerful algorithm that was proposed by Chawla [29] and has shown a great deal of success in various applications [45,46,47]. SMOTE will be described in detail in Section 2.1.
- Active learning methods: Traditional active learning methods are utilized to deal with problems with the unlabeled training dataset. In recent years, various algorithms on active learning from imbalanced data problems have been presented [48,52,53]. Active learning is a kind of learning strategy that selects samples from a random set of training data. It can choose more worthy instances and discard the instances which have less information, so as to enhance the classification performance. The large computation cost for large datasets is the primary disadvantage of these approaches [48].
- Cost-sensitive learning methods: Cost-sensitive learning solves class imbalance problems by using different cost matrices [50]. Currently, there are three commonly used cost-sensitive strategies. (1) The cost-sensitive sample weighting: converting the cost of misclassification into the sample weights on the original data set. (2) The cost-sensitive function is directly incorporated into the existing classification algorithm, which will ameliorate internal structure of the algorithm. (3) The cost-sensitive ensemble: cost-sensitive factors are integrated into the existing classification methods and combine with ensemble learning. Nevertheless, cost-sensitive learning methods require the knowledge of misclassification costs, which are hard to obtain in the datasets in the real world [54,55].
- Kernel-based learning methods: Kernel-based learning is focused on the theories of statistical learning and Vapnik-Chervonenkis (VC) dimensions [56]. The support vector machines (SVMs), which is a typical kernel-based learning method, can obtain the relatively robust classification accuracy for imbalanced data sets [51,57]. Many methods that combine sampling and ensemble techniques with SVM have been proposed [58,59] and effectively improve performance in the case of imbalanced class distribution. For instance, a novel ensemble method, called Bagging of Extrapolation Borderline-SMOTE SVM (BEBS) was proposed to incorporate the borderline information [60]. However, as this method is based on SVM, it is difficult to implement in a large dataset.
- (1)
- The proposed SMOTE-WDRoF based on deep ensemble learning combines deep rotating forest and SMOTE internally. It can obtain higher accuracy and faster training speed for the imbalanced hyperspectral data.
- (2)
- Besides, the introduction of the adaptive weight function can alleviate the defect of SMOTE, which is that SMOTE would generate additional noise when synthesizing new samples.
2. Related Works
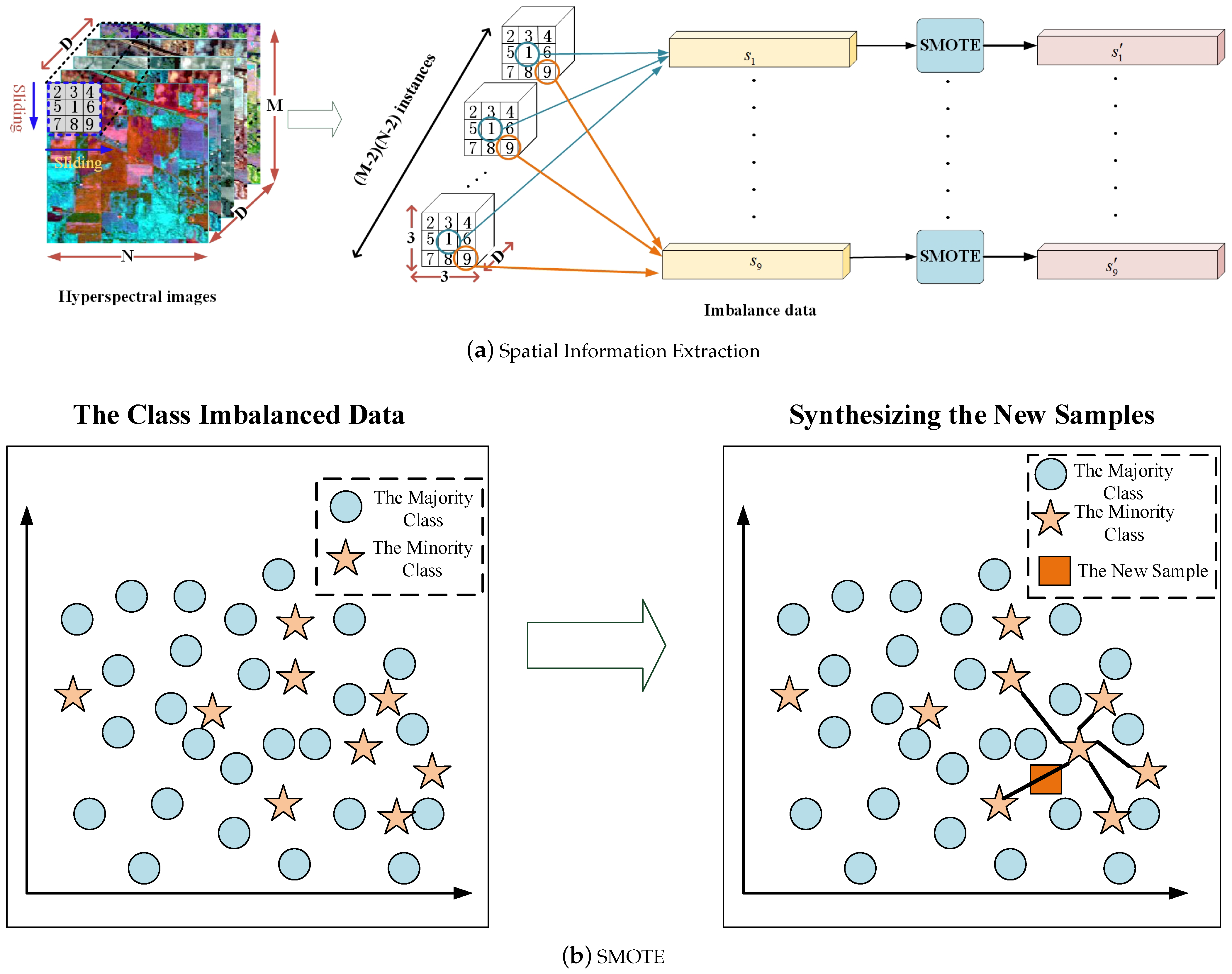
2.1. Synthetic Minority Over-Sampling Technique (SMOTE)
- (1)
- Calculate k nearest neighbors with minority class samples in accordance with Euclidean distance for each minority instance .
- (2)
- A neighbor is randomly chosen from the k nearest neighbors of .
- (3)
- Create a new instances between and :where is the random number between 0 and 1.
2.2. Random Forest (RF)
2.3. Rotation Forest (RoF)
- (1)
- Firstly, the feature space is split into K feature sets which are disjoint and each subset includes number of features.
- (2)
- Secondly, a new training set is obtained by using bootstrap algorithm to randomly selected the 75% of the training data.
- (3)
- Then, the coefficients is obtained by employing the principal component analysis (PCA) on each subspace and the coefficients of all subspaces are organized in a sparse “rotation” matrix .
- (4)
- The columns of is rearranged by matching the order of original features F to build the rotation matrix . Then, construct the new training set , which is used to train an individual classifier.
- (5)
- Repeat the aforementioned process on all diverse training sets and generate a series of individual classifiers. Finally, the results are obtained by the majority vote rule.
2.4. Rotation-Based Deep Forest (RBDF)
3. Method
3.1. Spatial Information Extraction and Balanced Datasets Generation
3.2. Weighted Deep Rotation Forest (WDRoF)
- (1)
- The datasets that have been generated by SMOTE are fed into the RoF models where . The can be written as , where K stands for the number of instances. In RoF, we apply PCA for features transformation which is a mathematical transformation method that transforms a set of variables into a set of unrelated ones. Its goal is to obtain the projection matrix :First of all, the self-correlation matrix for is computed:where is the expected number of and represents transposition. Second, eigen decomposition is applied on to calculate its eigenvalues: and corresponding eigenvectors: . Finally, the principal component coefficient can be calculated by the following:Construct the rotation matrix with Equation (2) and then generate the rotation feature vectors by the RoF.
- (2)
- The rotation feature vectors are fed into the first level of the random forest and the weight of the sample is set to 1. In level 1, each RF will generate the classification probability and classification error information of each instance for the dataset. All the classification probabilities vector of level 1 are averaged to obtain a robust estimation :where represents the ith decision tree output and stands for number of decision tree in RF. In addition, according to the classification error, the weights of the sample can be computedwhere is the number of votes of any other class with the wth RF model. The weight of a sample will be increased if it is misclassified by the previous level, which makes the sample play a more significant role in the next level and forces the classifier to focus attention on the misclassified samples.
- (3)
- In the last level, after the average probability vector is calculated, the prediction label is acquired by finding the maximum probability.
| Algorithm 1: SMOTE-Based Weighted Deep Rotation Forest (SMOTE-WDRoF) | |
| 1 | Input: : the hyperspectral image; M: the height of the image; N: the width of the image; D: the spectral bands of the image; : the size of sliding window; ; |
| 2 | Process: |
| 3 | form = 1:M do |
| 4 | for n = 1:N do |
| 5 | Obtain K patches by scanning the image using the sliding |
| window with (3) | |
| 6 | end for |
| 7 | end for |
| 8 | forw = 1: do |
| 9 | Acquire the imbalanced data by extracting the pixels of corresponding |
| positions in K patches | |
| 10 | Input into the SMOTE algorithm |
| 11 | Construct the balanced data |
| 12 | end for |
| 13 | Get the balanced datasets |
| Classification: | |
| 14 | forl = 1: do |
| 15 | for w = 1: do |
| 16 | Construct the rotation feature vector by utilizing RoF algorithm |
| 17 | Train the RF model with |
| 18 | Update each sample weight: with (8) |
| 19 | Calculate the the classification probability |
| 20 | end for |
| 21 | Obtain the average probability vector with (7) |
| 22 | Concatenate with the input feature vector to constitute input of the next |
| level | |
| 23 | end for |
| 24 | Output: The prediction label |
4. Experimental Results
4.1. Datasets
- Indian Pines AVRIS were obtained employing the National Aeronautics and Space Administration’s Airborne Visible/Infrared Imaging Spectrometer (AVIRIS) sensor and gathered over northwest Indiana’s Indian Pine test site in June 1992. As the high imbalance dataset, Indian Pines AVRIS consists of pixels and 220 bands covering the range from 0.4 to 2.5 m with a spatial resolution of 20 m. There are 16 different land-cover classes and 10,249 samples in the original ground truth. 30% of original reference data are chosen randomly to constitute training dataset and the remaining part constructs test dataset. For Indian Pines AVRIS, if the number of samples is less than 100, such as Oats, half of the samples are randomly chosen to construct training sets. The IR on the training set is 73.6.
- KSC was acquired by the Airborne Visible/Infrared Imaging Spectrometer instrument over the Kennedy Space Center (KSC), Florida, on 23 March 1996. The image consists of pixels with a spatial resolution of 18 m. After removing noisy bands, 176 spectral bands were used for the analysis. Approximately 5208 instances with 13 classes from the ground-truth map. Similar to the setup in the Indian Pines AVRIS image, 30% of pixels per class are randomly selected to constitute the training set, and the others are utilized to construct the test set. The IR on the training set is 8.71.
- Salinas was gathered by the AVIRIS sensor over Salinas Valley, California with 224 spectral bands. This image consists of pixels with a spatial resolution of 20 m. The original ground truth also has 16 classes mainly including vegetables, vineyard fields, and bare soils. Training sets are constructed by 8% of its samples chosen randomly from original reference data. The IR on the training set is 12.51.
- University of Pavia scenes covering the city of Pavia, Italy, was gathered by the reflective optics system imaging spectrometer sensor. The data sets consist of pixels covering the range from 0.43 to 0.86 m with a spatial resolution of 1.3 m. There are 16 classes and 42,776 instances in the original ground truth. The training dataset is constituted by 8% of samples that are chosen randomly from original data without replacement. The IR on the training set is 19.83.
4.2. Experiment Settings
4.3. Assessment Metric
- Precision: Precision is employed to measure the classification accuracy of each class in the imbalanced data. The measures the prediction rate when testing only samples of class iwhere and stand for the true prediction of the ith class and the false prediction of the ith class into ith class, respectively.
- Average Accuracy (AA): As a performance metric, AA provides the same weight to each of the classes in the data, independently of the number of instances it has. It can be defined as
- Recall: True Positive Rate is defined as recall denoting the percentage of instances that are correctly classified. Recall is particularly suitable for evaluating classification algorithms that deal with multiple classes of imbalanced data [73]. It can be computed as the following equation:where stand for the false prediction of the ith class into jth class.
- F-measure: F-measure, an evaluation index obtained by integrating precision and Recall, has been widely used in the imbalance data classification [55,74,75]. In the process of classification, precision is expected to be as high as possible, and it is also expected to Recall as large as possible. In fact, however, the two metrics are negatively correlated in some cases. The introduction of F-measure synthesizes the two, and the higher F-measure is, the better the performance of the classifier is. F-measure can be calculated as the following equation:where can be calculated by .
- Kappa: The metric that assesses the consistency of the predicted results is Kappa, which checks if the consistency is caused by chance. And the higher Kappa is, the better the performance of the classifier is Kappa can be defined aswhere and stand for the actual sample size of class i and the predicted sample size of class i, respectively.
4.4. Performance Comparative Analysis
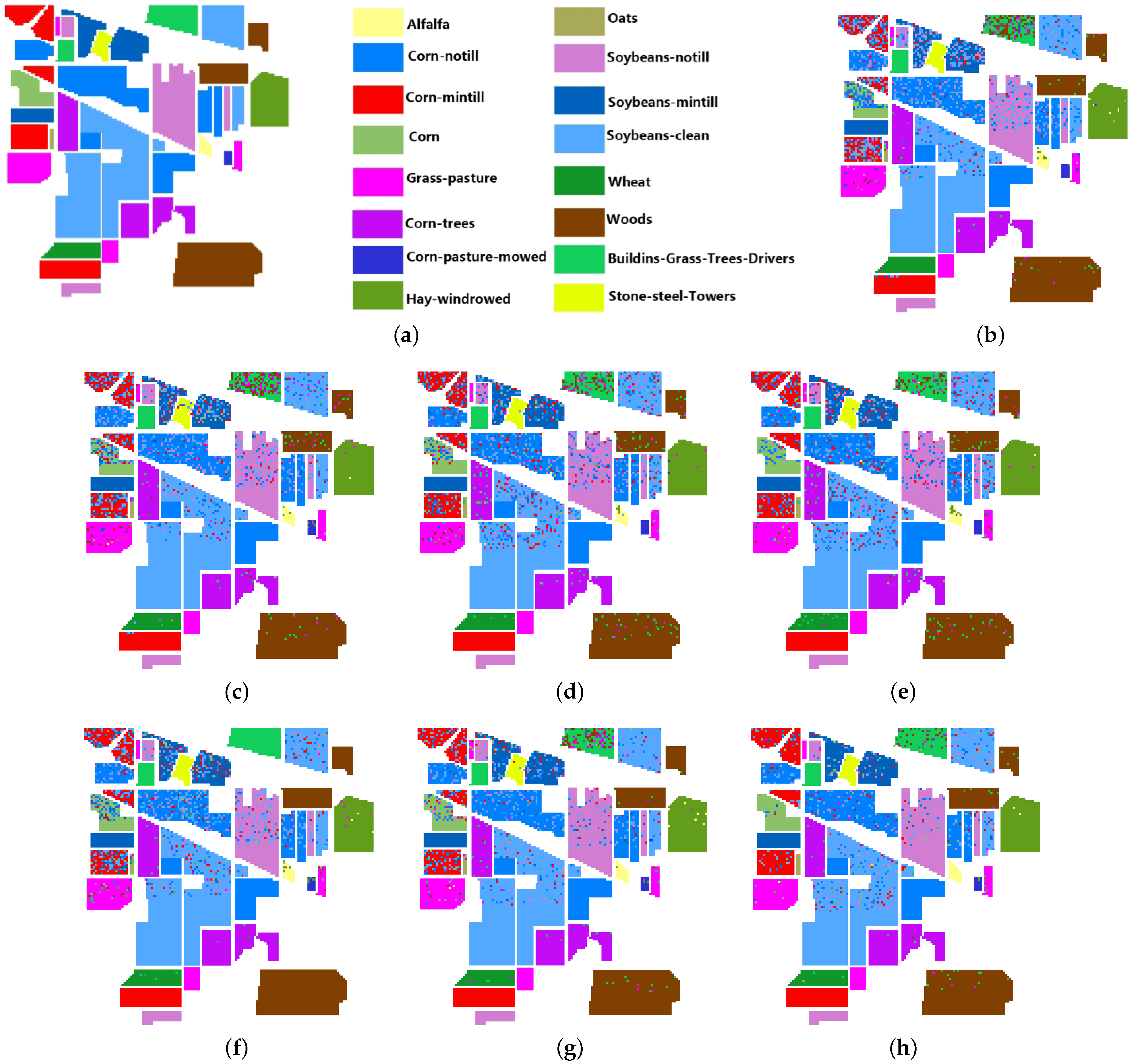
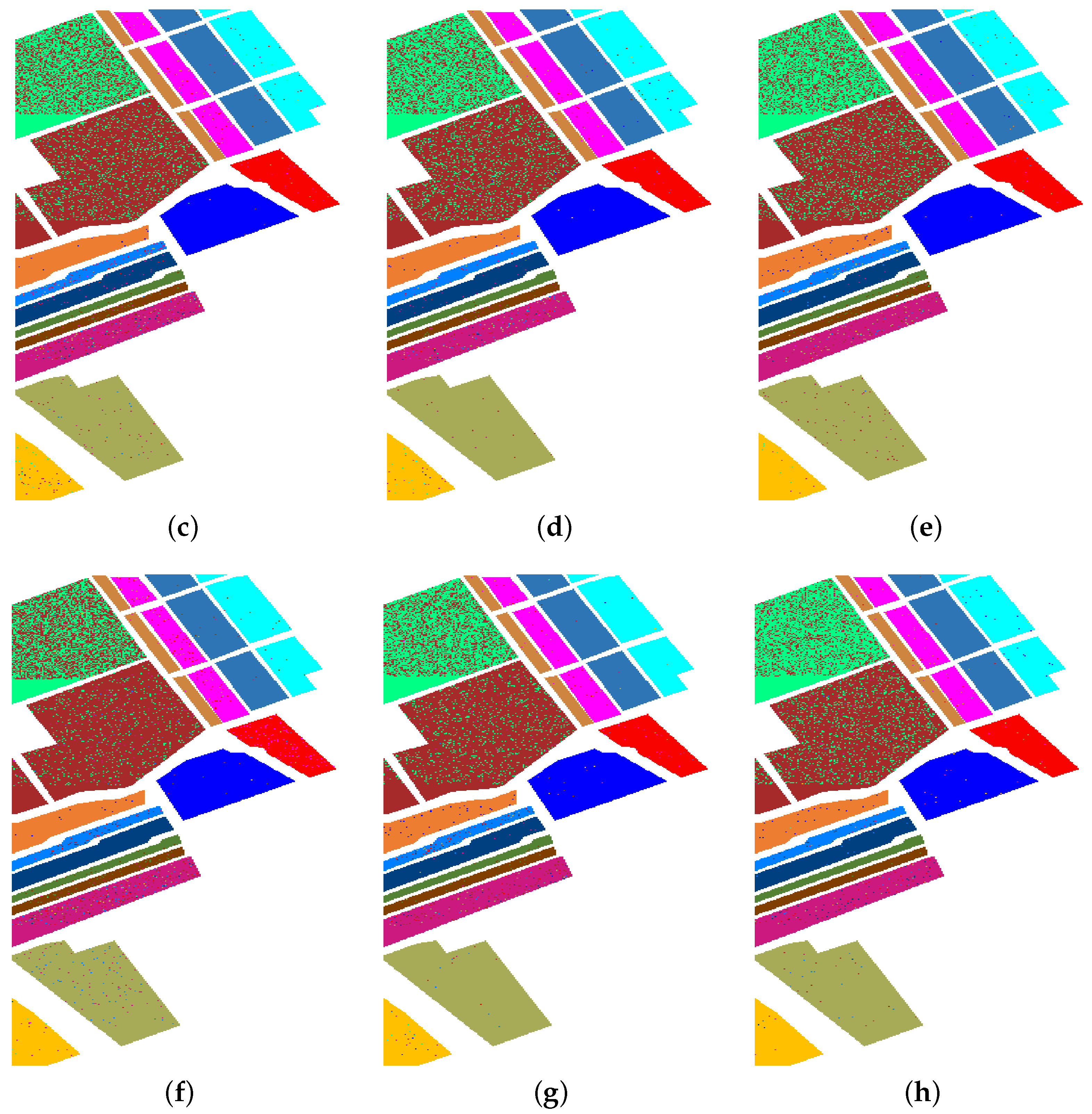
4.4.1. Experimental Results on Indian Pines AVRIS
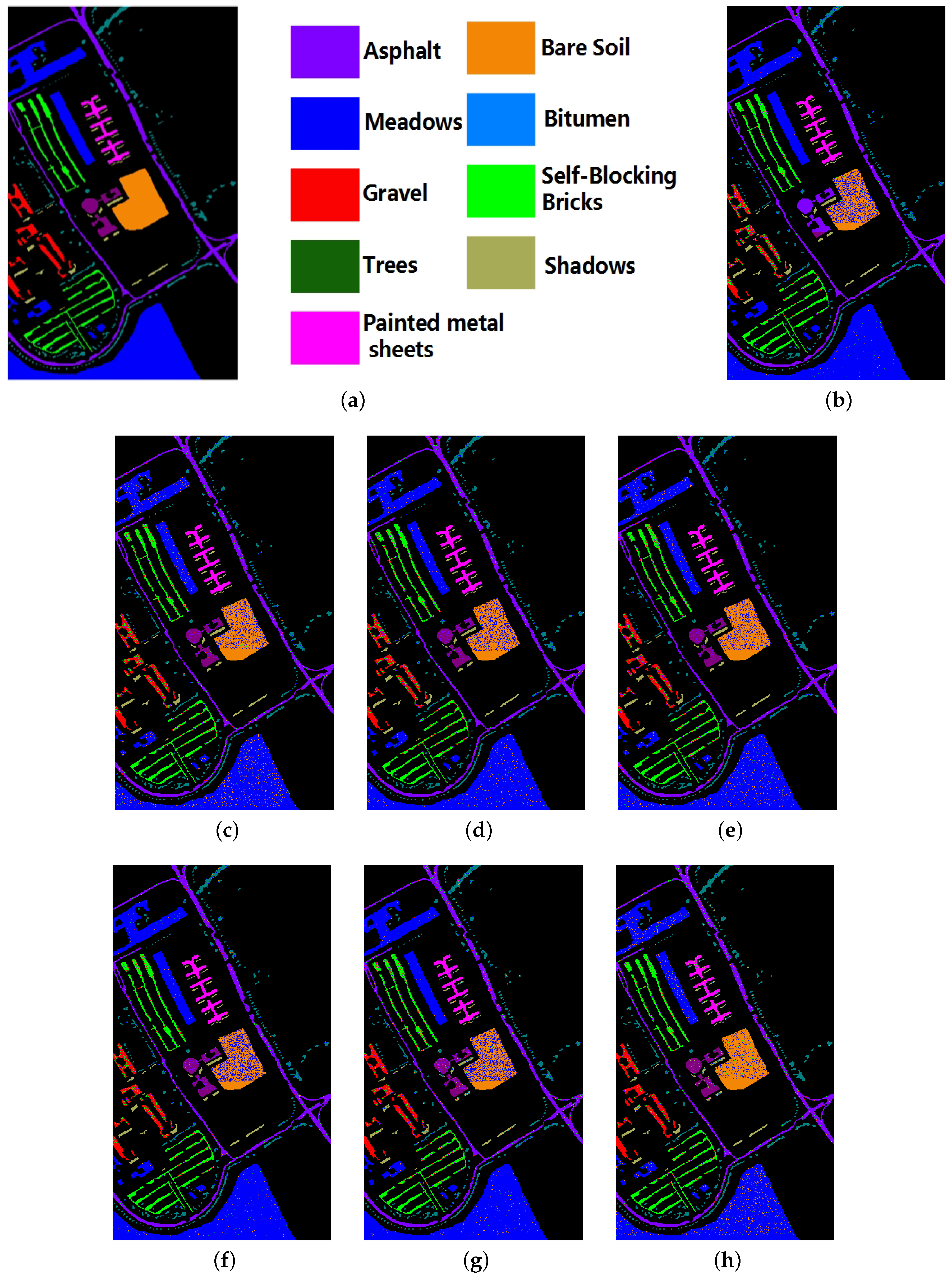
4.4.2. Experimental Results on KSC
4.4.3. Experimental Results on Salinas
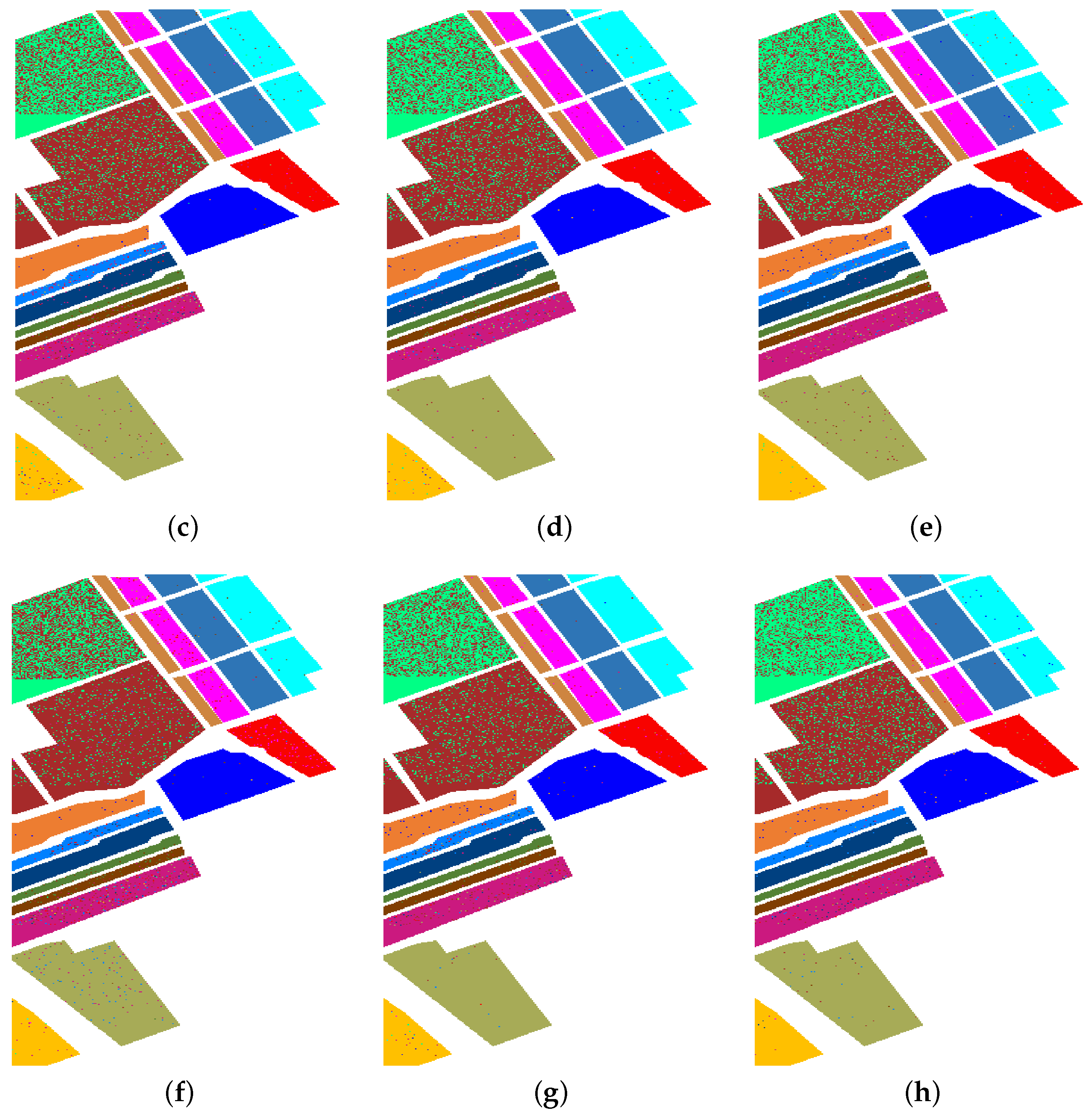
4.4.4. Experimental Results on University of Pavia scenes
4.4.5. Training Time of Different Deep Learning Methods
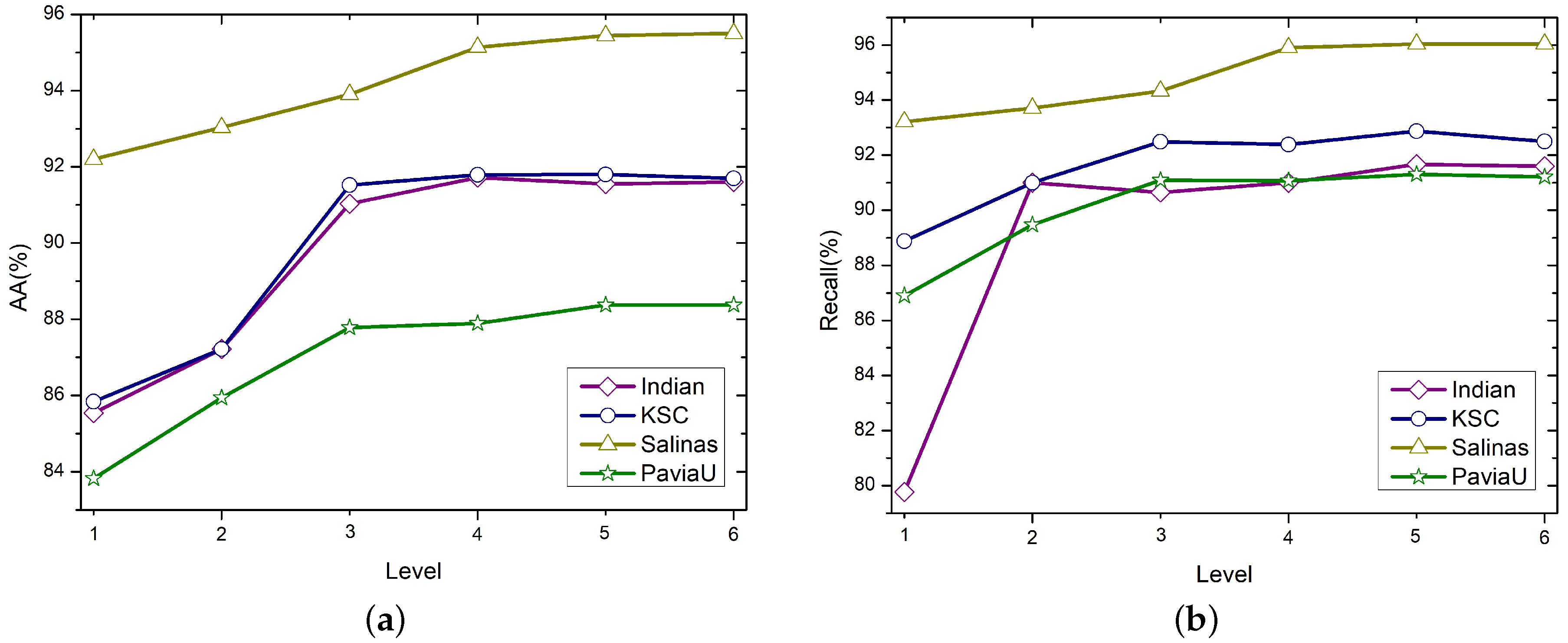
4.5. Influence of Model Parameters on Classification Performance
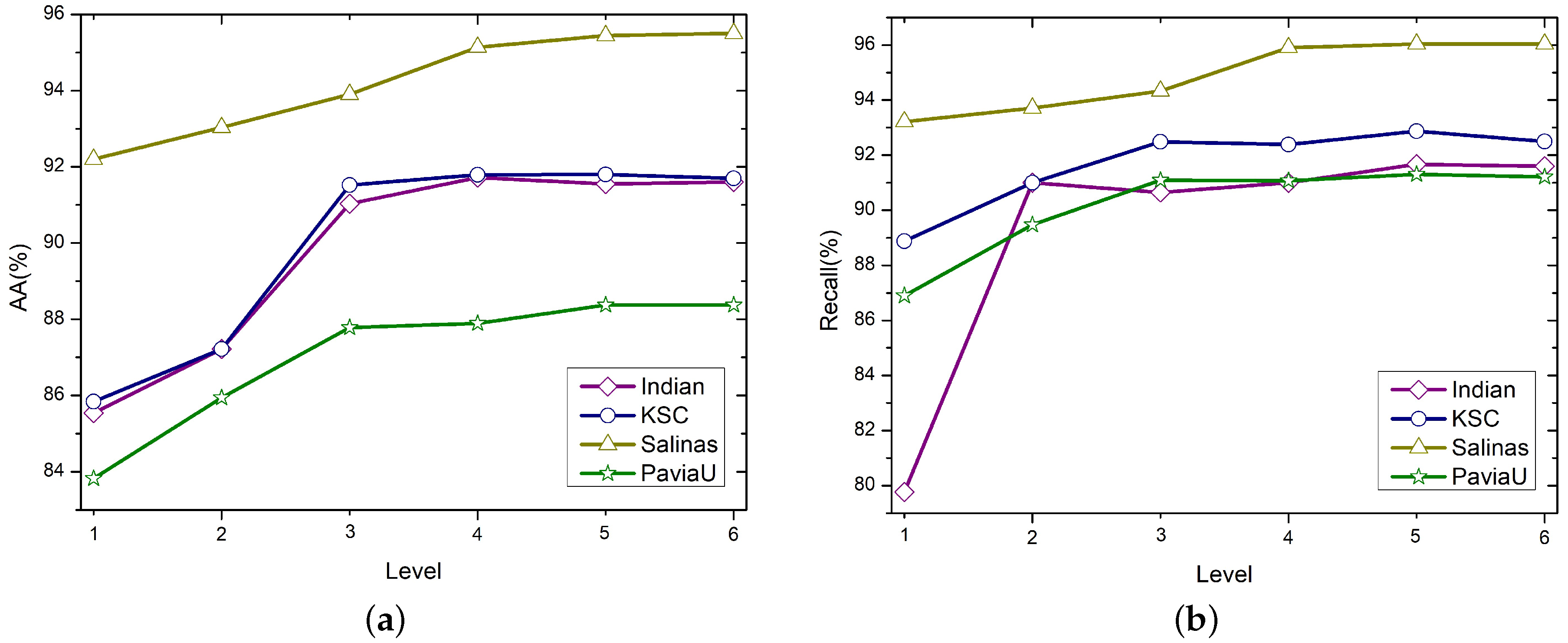
4.5.1. Influence of Level
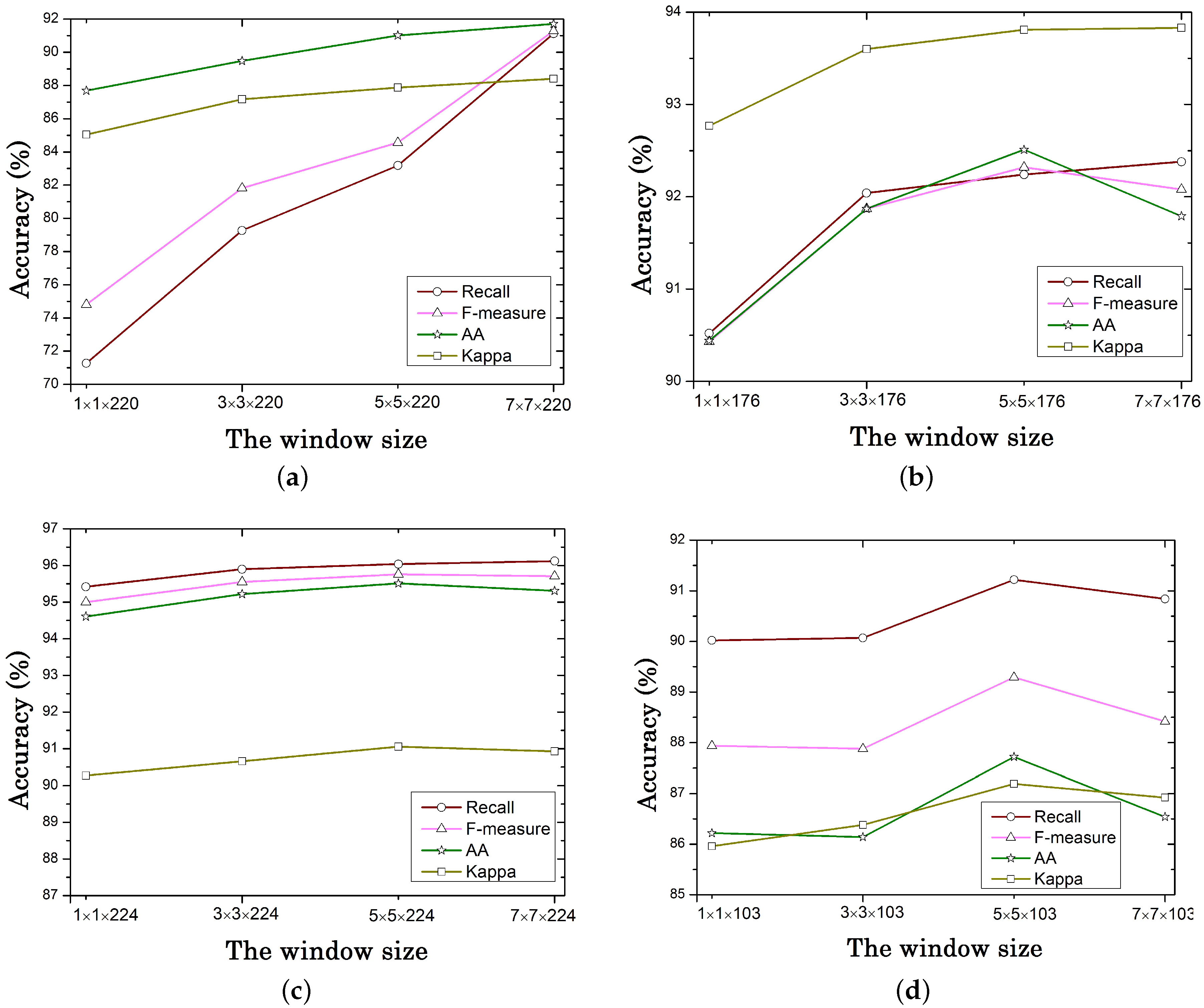
4.5.2. Influence of the Window Size
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, M.; Li, W.; Du, Q. Diverse Region-Based CNN for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Landgrebe, D. Hyperspectral image data analysis. IEEE Signal Process. Mag. 2002, 19, 17–28. [Google Scholar] [CrossRef]
- Li, H.; Song, Y.; Chen, C.P. Hyperspectral Image Classification Based on Multiscale Spatial Information Fusion. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5302–5312. [Google Scholar] [CrossRef]
- Zheng, X.; Yuan, Y.; Lu, X. Dimensionality Reduction by Spatial–Spectral Preservation in Selected Bands. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5185–5197. [Google Scholar] [CrossRef]
- Lin, L.; Song, X. Using CNN to Classify Hyperspectral Data Based on Spatial-spectral Information. Adv. Intell. Inf. Hiding Multimed. Signal Process. 2017, 64, 61–68. [Google Scholar]
- Yuan, Y.; Feng, Y.; Lu, X. Projection-Based NMF for Hyperspectral Unmixing. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2632–2643. [Google Scholar] [CrossRef]
- Feng, W.; Huang, W.; Bao, W. Imbalanced Hyperspectral Image Classification with an Adaptive Ensemble Method Based on SMOTE and Rotation Forest with Differentiated Sampling Rates. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1879–1883. [Google Scholar] [CrossRef]
- Quan, Y.; Zhong, X.; Feng, W.; Dauphin, G.; Xing, M. A Novel Feature Extension Method for the Forest Disaster Monitoring Using Multispectral Data. Remote Sens. 2020, 12, 2261. [Google Scholar] [CrossRef]
- Jiang, M.; Fang, Y.; Su, Y.; Cai, G.; Han, G. Random Subspace Ensemble With Enhanced Feature for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 1373–1377. [Google Scholar] [CrossRef]
- Zhao, Q.; Jia, S.; Li, Y. Hyperspectral remote sensing image classification based on tighter random projection with minimal intra-class variance algorithm. Pattern Recognit. 2020, 111, 107635. [Google Scholar] [CrossRef]
- Shi, T.; Liu, H.; Chen, Y.; Wang, J.; Wu, G. Estimation of arsenic in agricultural soils using hyperspectral vegetation indices of rice. J. Hazard. Mater. 2016, 308, 243–252. [Google Scholar] [CrossRef] [PubMed]
- Obermeier, W.A.; Lehnert, L.W.; Pohl, M.J.; Gianonni, S.M.; Silva, B.; Seibert, R.; Laser, H.; Moser, G.; Müller, C.; Luterbacher, J.; et al. Grassland ecosystem services in a changing environment: The potential of hyperspectral monitoring. Remote Sens. Environ. 2019, 232, 111273. [Google Scholar] [CrossRef]
- Zhang, M.; English, D.; Hu, C.; Carlson, P.; Muller-Karger, F.E.; Toro-Farmer, G.; Herwitz, S.R. Short-term changes of remote sensing reflectancein a shallow-water environment: Observations from repeated airborne hyperspectral measurements. Int. J. Remote Sens. 2016, 37, 1620–1638. [Google Scholar] [CrossRef]
- Li, Q.; Feng, W.; Quan, Y.H. Trend and forecasting of the COVID-19 outbreak in China. J. Infect. 2020, 80, 469–496. [Google Scholar]
- Pontius, J.; Hanavan, R.P.; Hallett, R.A.; Cook, B.D.; Corp, L.A. High spatial resolution spectral unmixing for mapping ash species across a complex urban environment. Remote Sens. Environ. 2017, 199, 360–369. [Google Scholar] [CrossRef]
- Richards, J.A.; Jia, X. Using Suitable Neighbors to Augment the Training Set in Hyperspectral Maximum Likelihood Classification. IEEE Geosci. Remote Sens. Lett. 2008, 5, 774–777. [Google Scholar] [CrossRef]
- Guo, X.; Huang, X.; Zhang, L.; Zhang, L.; Plaza, A.; Benediktsson, J.A. Support Tensor Machines for Classification of Hyperspectral Remote Sensing Imagery. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3248–3264. [Google Scholar] [CrossRef]
- Meher, S.K. Knowledge-Encoded Granular Neural Networks for Hyperspectral Remote Sensing Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2439–2446. [Google Scholar] [CrossRef]
- Li, J.; Du, Q.; Li, Y.; Li, W. Hyperspectral Image Classification with Imbalanced Data Based on Orthogonal Complement Subspace Projection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3838–3851. [Google Scholar] [CrossRef]
- Mi, Y. Imbalanced Classification Based on Active Learning SMOTE. Res. J. Appl. Eng. Technol. 2013, 5, 944–949. [Google Scholar] [CrossRef]
- Taherkhani, A.; Cosma, G.; McGinnity, T.M. AdaBoost-CNN: An Adaptive Boosting algorithm for Convolutional Neural Networks to classify Multi-Class Imbalanced datasets using Transfer Learning. Neurocomputing 2020, 404, 351–366. [Google Scholar] [CrossRef]
- Zhang, X.; Zhuang, Y.; Wang, W.; Pedrycz, W. Transfer Boosting With Synthetic Instances for Class Imbalanced Object Recognition. IEEE Trans. Cybern. 2016, 48, 357–370. [Google Scholar] [CrossRef] [PubMed]
- Anand, A.; Pugalenthi, G.; Fogel, G.B.; Suganthan, P.N. An approach for classification of highly imbalanced data using weighting and undersampling. Amino Acids 2010, 39, 1385–1391. [Google Scholar] [CrossRef] [PubMed]
- Lin, M.; Tang, K.; Yao, X. Dynamic Sampling Approach to Training Neural Networks for Multiclass Imbalance Classification. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 647–660. [Google Scholar]
- Feng, W.; Huang, W.; Ren, J. Class Imbalance Ensemble Learning Based on the Margin Theory. Appl. Sci. 2018, 8, 815. [Google Scholar] [CrossRef] [Green Version]
- Feng, W.; Dauphin, G.; Huang, W.; Quan, Y.; Liao, W. New Margin-Based Subsampling Iterative Technique In Modified Random Forests for Classification. Knowl. Based Syst. 2019, 182, 104845. [Google Scholar] [CrossRef]
- Feng, W.; Bao, W. Weight-Based Rotation Forest for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2167–2171. [Google Scholar] [CrossRef]
- Castellanos, F.J.; Valero-Mas, J.J.; Calvo-Zaragoza, J.; Rico-Juan, J.R. Oversampling imbalanced data in the string space. Pattern Recognit. Lett. 2018, 103, 32–38. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Blaszczynski, J.; Stefanowski, J. Neighbourhood sampling in bagging for imbalanced data. Neurocomputing 2015, 150, 529–542. [Google Scholar] [CrossRef]
- Qi, K.; Yang, H.; Hu, Q.; Yang, D. A new adaptive weighted imbalanced data classifier via improved support vector machines with high-dimension nature. Knowl. Based Syst. 2019, 185, 104933. [Google Scholar] [CrossRef]
- Zhou, Z.H.; Liu, X.Y. Training cost-sensitive neural networks with methods addressing the class imbalance problem. IEEE Trans. Knowl. Data Eng. 2006, 18, 63–77. [Google Scholar] [CrossRef]
- Datta, A.; Ghosh, S.; Ghosh, A. Combination of Clustering and Ranking Techniques for Unsupervised Band Selection of Hyperspectral Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2814–2823. [Google Scholar] [CrossRef]
- Galar, M. A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2012, 42, 463–484. [Google Scholar] [CrossRef]
- Ng, W.W.Y.; Hu, J.; Yeung, D.S.; Yin, S.; Roli, F. Diversified Sensitivity-Based Undersampling for Imbalance Classification Problems. IEEE Trans. Cybern. 2017, 45, 2402–2412. [Google Scholar] [CrossRef]
- Ming, G.; Xia, H.; Sheng, C.; Harris, C.J. A combined SMOTE and PSO based RBF classifier for two-class imbalanced problems. Neurocomputing 2011, 74, 3456–3466. [Google Scholar]
- Liu, X.Y.; Wu, J.; Zhou, Z.H. Exploratory undersampling for class-imbalance learning. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2008, 39, 539–550. [Google Scholar]
- Barandela, R.; Valdovinos, R.M.; Sánchez Garreta, J.S.; Ferri, F.J. The Imbalance Training Sample Problem: Under or over Sampling. In Joint IAPR International Workshops on Statistical Techniques in Pattern Recognition (SPR) and Structural and Syntactic Pattern Recognition (SSPR); Springer: Berlin/Heidelberg, Germany, 2004; Volume 3138, pp. 806–814. [Google Scholar]
- Liu, B.; Tsoumakas, G. Dealing with class imbalance in classifier chains via random undersampling. Knowl. Based Syst. 2020, 192, 105292.1–105292.13. [Google Scholar] [CrossRef]
- Akkasi, A.; Varolu, E.; Dimililer, N. Balanced undersampling: A novel sentence-based undersampling method to improve recognition of named entities in chemical and biomedical text. Appl. Intell. 2017, 48, 1–14. [Google Scholar] [CrossRef]
- Kang, Q.; Chen, X.S.; Li, S.S.; Zhou, M.C. A Noise-Filtered Under-Sampling Scheme for Imbalanced Classification. IEEE Trans. Cybern. 2017, 47, 4263–4274. [Google Scholar] [CrossRef]
- Ng, W.W.Y.; Xu, S.; Zhang, J.; Tian, X.; Rong, T.; Kwong, S. Hashing-Based Undersampling Ensemble for Imbalanced Pattern Classification Problems. IEEE Trans. Cybern. 2020, 1–11. [Google Scholar] [CrossRef] [PubMed]
- De Morais, R.F.A.B.; Vasconcelos, G.C. Boosting the Performance of Over-Sampling Algorithms through Under-Sampling the Minority Class. Neurocomputing 2019, 343, 3–18. [Google Scholar] [CrossRef]
- Batista, G.E.A.P.A.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Prusty, M.R.; Jayanthi, T.; Velusamy, K. Weighted-SMOTE: A modification to SMOTE for event classification in sodium cooled fast reactors. Prog. Nucl. Energy 2017, 100, 355–364. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Fonseca, J.; Khudinyan, M. Imbalanced Learning in Land Cover Classification: Improving Minority Classes’ Prediction Accuracy Using the Geometric SMOTE Algorithm. Remote Sens. 2019, 11, 3040. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Lang, J.; Fujita, H.; Li, H. Imbalanced enterprise credit evaluation with DTE-SBD: Decision tree ensemble based on SMOTE and bagging with differentiated sampling rates. Inf. Sci. 2018, 425, 76–91. [Google Scholar] [CrossRef]
- Ertekin, S.; Huang, J.; Bottou, L.; Giles, C.L. Learning on the border: Active learning in imbalanced data classification. In Proceedings of the Sixteenth ACM Conference on Information & Knowledge Management, Lisbon, Portugal, 6–10 November 2007; Association for Computing Machinery: New York, NY, USA, 2007; pp. 127–136. [Google Scholar]
- Sun, Y.; Kamel, M.S.; Wong, A.K.C.; Wang, Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit. 2007, 40, 3358–3378. [Google Scholar] [CrossRef]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar]
- Ding, S.; Mirza, B.; Lin, Z.; Cao, J.; Sepulveda, J. Kernel based online learning for imbalance multiclass classification. Neurocomputing 2017, 277, 139–148. [Google Scholar] [CrossRef]
- Yu, H.; Yang, X.; Zheng, S.; Sun, C. Active Learning From Imbalanced Data: A Solution of Online Weighted Extreme Learning Machine. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 1088–1103. [Google Scholar] [CrossRef]
- Zhang, H.; Liu, W.; Shan, J.; Liu, Q. Online Active Learning Paired Ensemble for Concept Drift and Class Imbalance. IEEE Access 2018, 6, 73815–73828. [Google Scholar] [CrossRef]
- Sun, T.; Jiao, L.; Feng, J.; Liu, F.; Zhang, X. Imbalanced Hyperspectral Image Classification Based on Maximum Margin. IEEE Geosci. Remote Sens. Lett. 2015, 12, 522–526. [Google Scholar] [CrossRef]
- Feng, W.; Dauphin, G.; Huang, W.; Quan, Y.; Bao, W.; Wu, M.; Li, Q. Dynamic Synthetic Minority Over-Sampling Technique-Based Rotation Forest for the Classification of Imbalanced Hyperspectral Data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 2159–2169. [Google Scholar] [CrossRef]
- Vapnik, V.N. The Nature of Statistical Learning Theory; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Japkowicz, N.; Stephen, S. The class imbalance problem: A systematic study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Akbani, R.; Kwek, S.S.; Japkowicz, N. Applying Support Vector Machines to Imbalanced Datasets; Springer: Berlin/Heidelberg, Germany, 2004; pp. 39–50. [Google Scholar]
- Kang, P.; Cho, S. EUS SVMs: Ensemble of Under-Sampled SVMs for Data Imbalance Problems. In Proceedings of the International Conference on Neural Information Processing; Springer: Berlin/Heidelberg, Germany, 2006; pp. 837–846. [Google Scholar]
- Qi, W.; Luo, Z.H.; Huang, J.C.; Feng, Y.H.; Zhong, L. A Novel Ensemble Method for Imbalanced Data Learning: Bagging of Extrapolation-SMOTE SVM. Comput. Intell. Neurosci. 2017, 2017, 1827016. [Google Scholar]
- Ying, L.; Haokui, Z.; Qiang, S. Spectral–Spatial Classification of Hyperspectral Imagery with 3D Convolutional Neural Network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef] [Green Version]
- Sellami, A.; Abbes, A.B.; Barra, V.; Farah, I.R. Fused 3-D spectral-spatial deep neural networks and spectral clustering for hyperspectral image classification. Pattern Recognit. Lett. 2020, 138, 594–600. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Wang, Y.; Gu, Y.; He, X.; Ghamisi, P.; Jia, X. Deep Learning Ensemble for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 1882–1897. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Qin, H.; Hao, A. Deep variance network: An iterative, improved CNN framework for unbalanced training datasets. Pattern Recognit. J. Pattern Recognit. Soc. 2018, 81, 294–308. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. Off. J. Int. Neural Netw. Soc. 2018, 106, 249–259. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cao, X.; Wen, L.; Ge, Y.; Zhao, J.; Jiao, L. Rotation-Based Deep Forest for Hyperspectral Imagery Classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1105–1109. [Google Scholar] [CrossRef]
- Breiman, L. Bagging Predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Rodriguez, J.J.; Kuncheva, L.I.; Alonso, C.J. Rotation Forest: A New Classifier Ensemble Method. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 1619–1630. [Google Scholar] [CrossRef] [PubMed]
- Hu, W.; Huang, Y.; Li, W.; Zhang, F.; Li, H. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Fernández, A.; López, V.; Galar, M.; del Jesus, M.J.; Herrera, F. Analysing the classification of imbalanced data-sets with multiple classes: Binarization techniques and ad-hoc approaches. Knowl. Based Syst. 2013, 42, 97–110. [Google Scholar] [CrossRef]
- Sáez, J.A.; Krawczyk, B.; Woźniak, M. Analyzing the oversampling of different classes and types of examples in multi-class imbalanced datasets. Pattern Recognit. 2016, 57, 164–178. [Google Scholar] [CrossRef]
- Xu, X.; Chen, W.; Sun, Y. Over-sampling algorithm for imbalanced data classification. J. Syst. Eng. Electron. 2019, 30, 1182–1191. [Google Scholar] [CrossRef]
- Yan, Y.; Liu, R.; Ding, Z.; Du, X.; Chen, J.; Zhang, Y. A Parameter-free Cleaning Method for SMOTE in Imbalanced Classification. IEEE Access 2019, 7, 23537–23548. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| The Dataset | Indian Pines AVRIS | Salinas | ||||
| Class No. | Train | Test | Class No. | Train | Test | |
| 1 | Alfalfa | 23 | 23 | Brocoli_green_weeds_1 | 100 | 1909 |
| 2 | Corn-notill | 428 | 1000 | Brocoli_green_weeds_2 | 186 | 3540 |
| 3 | Corn-mintill | 249 | 581 | cFallow | 98 | 1878 |
| 4 | Corn | 71 | 166 | cFallow_rough_plow | 68 | 1325 |
| 5 | Grass-pasture | 144 | 339 | Fallow_smooth | 133 | 2545 |
| 6 | Corn-trees | 219 | 511 | Stubble | 197 | 3762 |
| 7 | Corn-pasture-mowed | 14 | 14 | Celery | 178 | 3401 |
| 8 | Hay-windrowed | 143 | 335 | Grapes_untrained | 563 | 10,708 |
| 9 | Oats | 10 | 10 | Soil_vinyard_develop | 310 | 5893 |
| 10 | Soybeans-notill | 291 | 681 | Corn_senesced_green_weeds | 163 | 3115 |
| 11 | Soybeans-mintill | 736 | 1719 | Lettuce_romaine_4wk | 53 | 1015 |
| 12 | Soybeans-clean | 177 | 416 | Lettuce_romaine_5wk | 96 | 1831 |
| 13 | Wheat | 61 | 144 | Lettuce_romaine_6wk | 45 | 871 |
| 14 | Woods | 379 | 886 | Lettuce_romaine_7wk | 53 | 1017 |
| 15 | Buildings-Grass-Trees-Drivers | 115 | 271 | Vinyard_untrained | 363 | 6905 |
| 16 | Stone-steel-Towers | 46 | 47 | Vinyard_vertical_trellis | 90 | 1717 |
| Total | 3106 | 7143 | 2697 | 51,432 | ||
| The Dataset | KSC | University of Pavia ROSIS | ||||
| Class No. | Train | Test | Class No. | Train | Test | |
| 1 | Scrub | 229 | 532 | Asphalt | 331 | 6300 |
| 2 | Willow swamp | 73 | 170 | Meadows | 932 | 17,717 |
| 3 | Cabbage palm ham | 80 | 179 | Gravel | 104 | 1995 |
| 4 | Cabbage palm/oak ham | 76 | 176 | Trees | 153 | 2911 |
| 5 | Slash pine | 49 | 112 | Painted metal sheets | 67 | 1278 |
| 6 | Oak/broadleaf ham | 69 | 160 | Bare Soil | 251 | 4778 |
| 7 | Hardwood swamp | 32 | 73 | Bitumen | 66 | 1264 |
| 8 | Graminoid marsh | 130 | 301 | Self-Blocking Bricks | 184 | 3498 |
| 9 | Spartina marsh | 157 | 363 | Shadows | 47 | 900 |
| 10 | Cattail marsh | 122 | 282 | |||
| 11 | Salt marsh | 126 | 293 | |||
| 12 | Mud flats | 151 | 352 | |||
| 13 | Water | 279 | 648 | |||
| Total | 1573 | 3635 | 2135 | 40,641 | ||
| IR: 73.6 | SVM | RF | RoF | SMOTE-RoF | CNN | RBDF | SMOTE-WDRoF |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 | |||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| 10 | |||||||
| 11 | |||||||
| 12 | |||||||
| 13 | |||||||
| 14 | |||||||
| 15 | |||||||
| 16 | |||||||
| AA (%) | |||||||
| Recall (%) | |||||||
| F-measure (%) | |||||||
| Kappa (%) |
| IR: 8.71 | SVM | RF | RoF | SMOTE-RoF | CNN | RBDF | SMOTE-WDRoF |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 | |||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| 10 | |||||||
| 11 | |||||||
| 12 | |||||||
| 13 | |||||||
| AA (%) | |||||||
| Recall (%) | |||||||
| F-measure (%) | |||||||
| Kappa (%) |
| IR: 12.51 | SVM | RF | RoF | SMOTE-RoF | CNN | RBDF | SMOTE-WDRoF |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 | |||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| 10 | |||||||
| 11 | |||||||
| 12 | |||||||
| 13 | |||||||
| 14 | |||||||
| 15 | |||||||
| 16 | |||||||
| AA (%) | |||||||
| Recall (%) | |||||||
| F-measure (%) | |||||||
| Kappa (%) |
| IR: 19.83 | SVM | RF | RoF | SMOTE-RoF | CNN | RBDF | SMOTE-WDRoF |
|---|---|---|---|---|---|---|---|
| 1 | |||||||
| 2 | |||||||
| 3 | |||||||
| 4 | |||||||
| 5 | |||||||
| 6 | |||||||
| 7 | |||||||
| 8 | |||||||
| 9 | |||||||
| AA (%) | |||||||
| Recall (%) | |||||||
| F-measure (%) | |||||||
| Kappa (%) |
| Data | Indian Pines AVRIS | KSC | Salinas | University of Pavia Scenes |
|---|---|---|---|---|
| CNN | 30,830 | 5958 | 11,430 | 21,030 |
| SMOTE-WDRoF | 3942 | 1389 | 1809 | 1752 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Quan, Y.; Zhong, X.; Feng, W.; Chan, J.C.-W.; Li, Q.; Xing, M. SMOTE-Based Weighted Deep Rotation Forest for the Imbalanced Hyperspectral Data Classification. Remote Sens. 2021, 13, 464. https://doi.org/10.3390/rs13030464
Quan Y, Zhong X, Feng W, Chan JC-W, Li Q, Xing M. SMOTE-Based Weighted Deep Rotation Forest for the Imbalanced Hyperspectral Data Classification. Remote Sensing. 2021; 13(3):464. https://doi.org/10.3390/rs13030464
Chicago/Turabian StyleQuan, Yinghui, Xian Zhong, Wei Feng, Jonathan Cheung-Wai Chan, Qiang Li, and Mengdao Xing. 2021. "SMOTE-Based Weighted Deep Rotation Forest for the Imbalanced Hyperspectral Data Classification" Remote Sensing 13, no. 3: 464. https://doi.org/10.3390/rs13030464
APA StyleQuan, Y., Zhong, X., Feng, W., Chan, J. C.-W., Li, Q., & Xing, M. (2021). SMOTE-Based Weighted Deep Rotation Forest for the Imbalanced Hyperspectral Data Classification. Remote Sensing, 13(3), 464. https://doi.org/10.3390/rs13030464