
Hyperspectral Image Classification Based on Multi-Scale Residual Network with Attention Mechanism

Abstract

1. Introduction
2. Multi-Scale Residual Network Model Integrating Attention Mechanism
2.1. ECA-NET Block
2.2. S2A Block
2.3. Residual Convolutional Layer Structure (ECA_Residual_NET)
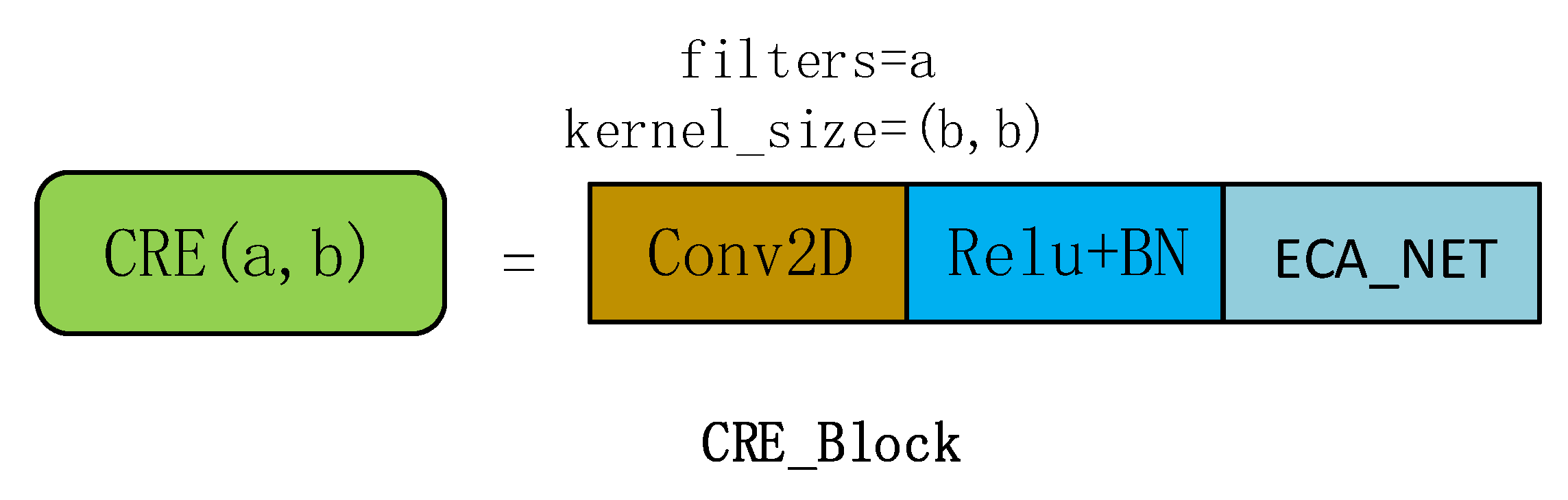
2.4. CRE_Block
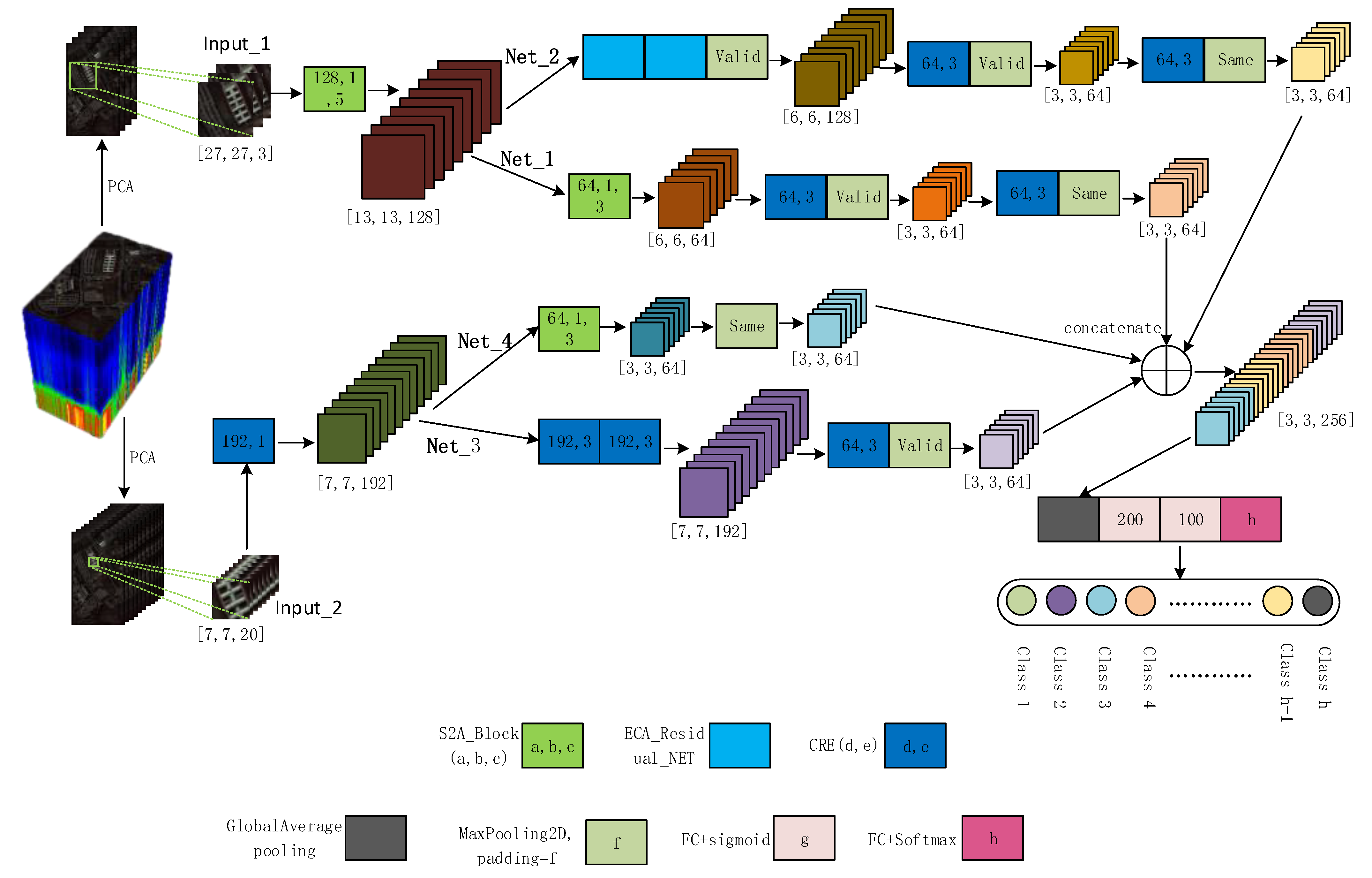
2.5. Overall Network Structure of the Suggested Deep Classification Technique
3. Experimental Platform and Experimental Result
3.1. Introduction of the Dataset
3.1.1. Pavia University Dataset
3.1.2. KSC Dataset
3.1.3. Indian Pines Dataset
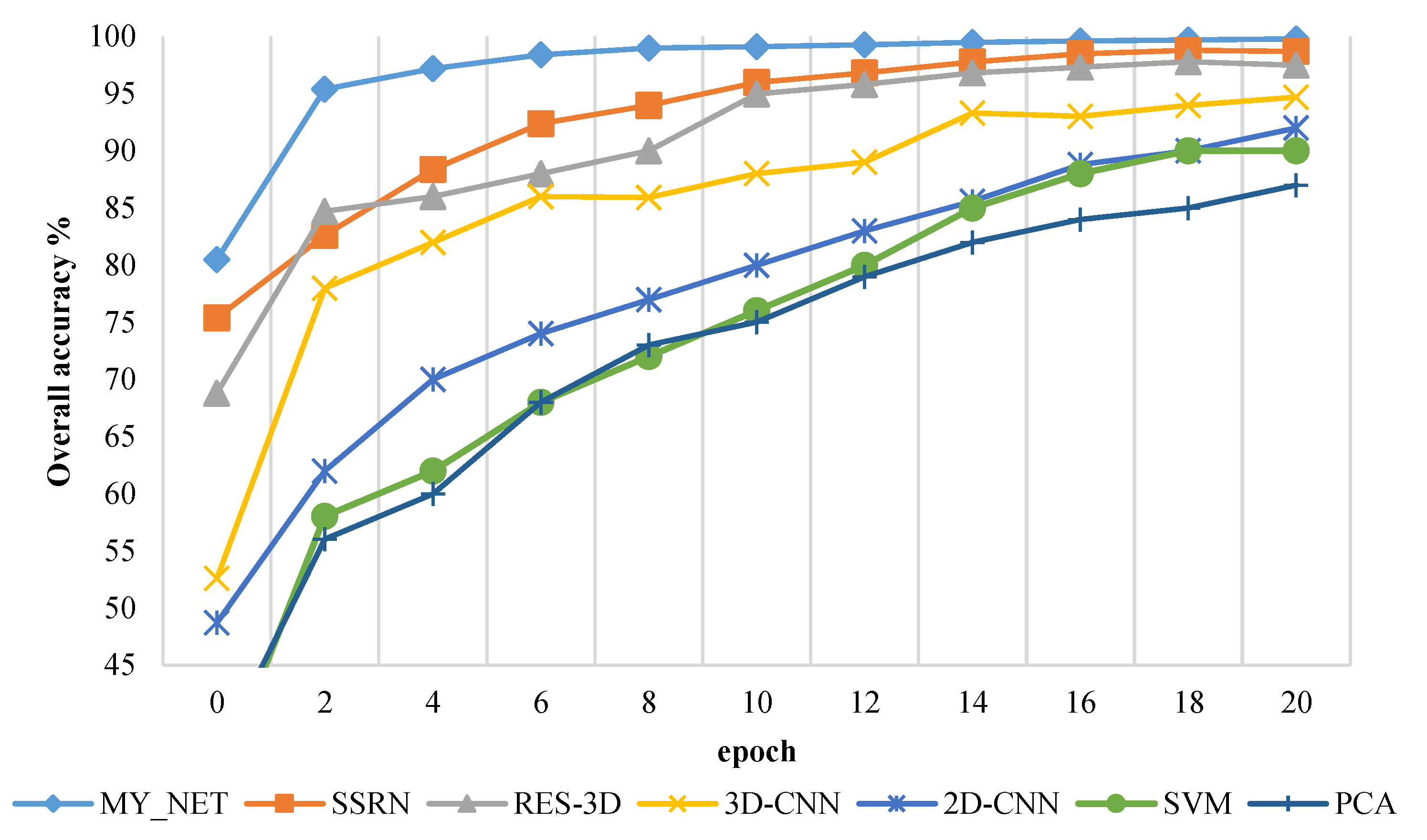
3.2. Analysis of Experimental Results
3.2.1. Parameter Setting
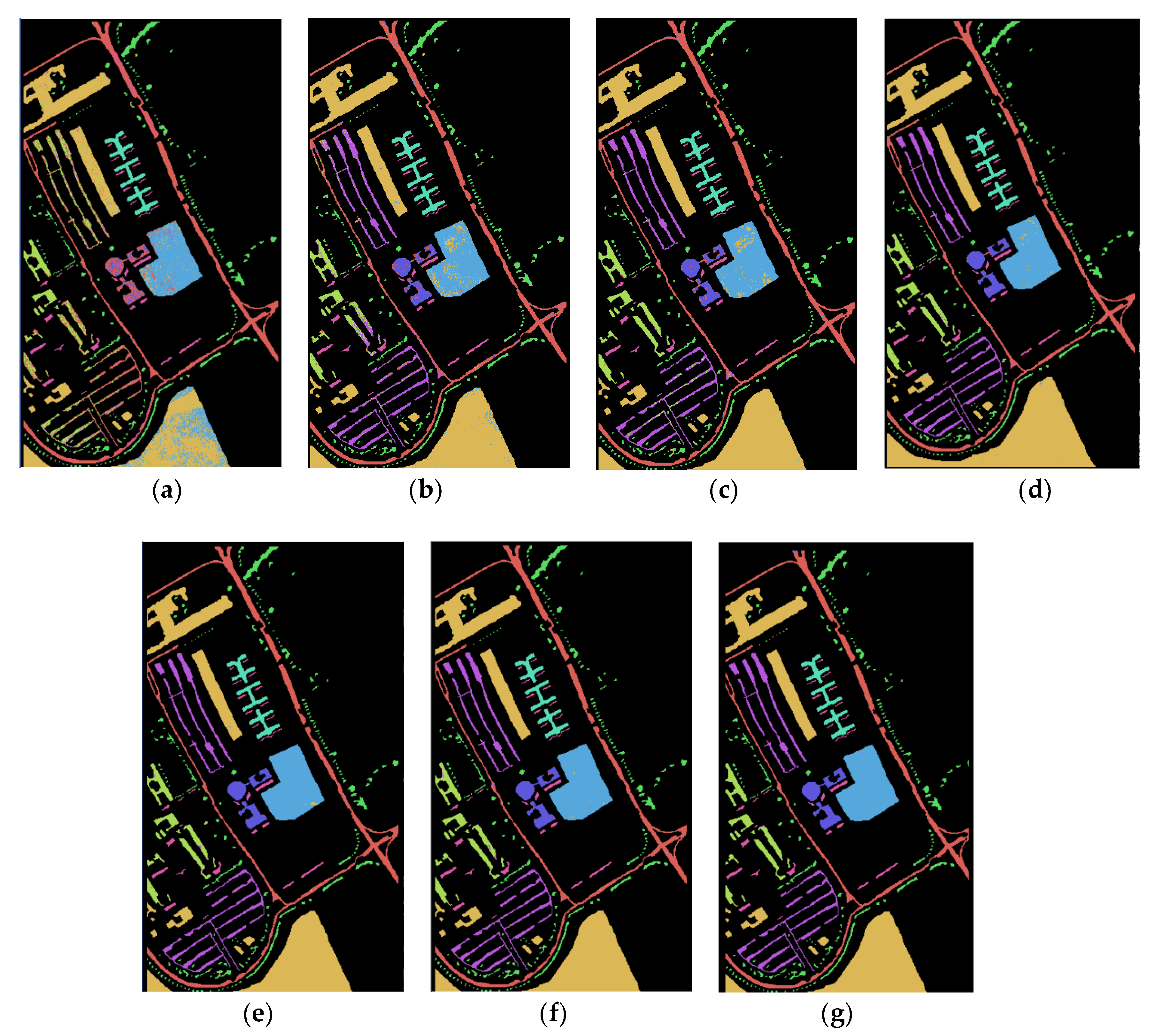
3.2.2. Pavia University Dataset
3.2.3. KSC Dataset
3.2.4. Indian Pines Dataset
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Bioucas-dias, J.M.; Plaza, A.; Camps-valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral Remote Sensing Data Analysis and Future Challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef]
- Li, W.; Wu, G.; Zhang, F.; Du, Q. Hyperspectral image classification using deep pixel-pair features. IEEE Trans. Geosci. Remote Sens. 2016, 55, 844–853. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef]
- Maghsoudi, Y.; Zoej, M.J.V.; Collins, M. Using class-based feature selection for the classification of hyperspectral data. Int. J. Remote Sens. 2011, 32, 4311–4326. [Google Scholar] [CrossRef]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.; Plaza, A. Spectral–spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2012, 50, 809–823. [Google Scholar] [CrossRef]
- Licciardi, G.; Marpu, P.; Chanussot, J.; Benediktsson, J. Linear versus nonlinear PCA for the classification of hyperspectral data based on the extended morphological profiles. IEEE Geosci. Remote Sens. Lett. 2012, 9, 447–451. [Google Scholar] [CrossRef]
- Deng, Y.J.; Li, H.C.; Pan, L.; Shao, L.Y.; Du, Q.; Emery, W.J. Modified tensor locality preserving projection for dimensionality reduction of hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2018, 15, 277–281. [Google Scholar] [CrossRef]
- Villa, A.; Benediktsson, J.A.; Chanussot, J.; Jutten, C. Hyperspectral Image Classification With Independent Component Discriminant Analysis. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4865–4876. [Google Scholar] [CrossRef]
- Liu, J.; Wu, Z.; Wei, Z.; Xiao, L.; Sun, L. Spatial-spectral kernel sparse representation for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2462–2471. [Google Scholar] [CrossRef]
- Gao, L.; Hong, D.; Yao, J.; Zhang, B.; Gamba, P.; Chanussot, J. Spectral Superresolution of Multispectral Imagery with Joint Sparse and Low-Rank Learning. IEEE Trans. Geosci. Remote Sens. 2020, 1–12. [Google Scholar] [CrossRef]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Hu, W.; Huang, Y.Y.; Wei, L.; Zhang, F.; Li, H.C. Deep Convolutional Neural Networks for Hyperspectral Image Classification. J. Sens. 2015, 2015, 1–12. [Google Scholar] [CrossRef]
- Hao, S.; Wang, W.; Ye, Y.; Nie, T.; Bruzzone, L. Two-stream deep architecture for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 2349–2361. [Google Scholar] [CrossRef]
- Mei, S.; Ji, J.; Bi, Q.; Hou, J.; Du, Q.; Li, W. Integrating spectral and spatial information into deep convolutional neural networks for hyperspectral classification. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 5067–5070. [Google Scholar]
- Chen, C.; Zhang, J.; Zheng, C.; Yan, Q.; Xun, L. Classification of hyperspectral data using a multi-channel convolutional neural network. In Proceedings of the 14th International Conference on Intelligent Computing (ICIC), Wuhan, China, 15–18 August 2018; pp. 81–92. [Google Scholar]
- Gao, F.; Huang, T.; Sun, J.; Wang, J.; Hussain, A.; Yang, E. A New Algorithm of SAR Image Target Recognition Based on Improved Deep Convolutional Neural Network. Cogn. Comput. 2019, 11, 809–824. [Google Scholar] [CrossRef]
- Rao, M.; Tang, P.; Zhang, Z. A Developed Siamese CNN with 3D Adaptive Spatial-Spectral Pyramid Pooling for Hyperspectral Image Classification. Remote Sens. 2020, 12, 1964. [Google Scholar] [CrossRef]
- Lee, H.; Kwon, H. Going deeper with contextual CNN for hyperspectral image classification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral-spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2018, 56, 847–858. [Google Scholar] [CrossRef]
- Wu, P.; Cui, Z.; Gan, Z.; Liu, F. Residual Group Channel and Space Attention Network for Hyperspectral Image Classification. Remote Sens. 2020, 12, 2035. [Google Scholar] [CrossRef]
- Mou, L.; Zhu, X.X. Learning to Pay Attention on Spectral Domain: A Spectral Attention Module-Based Convolutional Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 58, 110–122. [Google Scholar] [CrossRef]
- Wang, L.; Peng, J.T.; Sun, W.W. Spatial–Spectral Squeeze-and-Excitation Residual Network for Hyperspectral Image Classification. Remote Sens. 2019, 11, 884. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Clausi, D.A.; Wong, A. Generative Adversarial Networks and Conditional Random Fields for Hyperspectral Image Classification. IEEE Trans. Cybern. 2020, 50, 3318–3329. [Google Scholar] [CrossRef] [PubMed]
- Yuan, Y.; Zheng, X.T.; Lu, X.Q. Hyperspectral image superresolution by transfer learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 1963–1974. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3-D-2-D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 17, 277–281. [Google Scholar] [CrossRef]
- Niu, R. HMANet: Hybrid Multiple Attention Network for Semantic Segmentation in Aerial Images. arXiv 2020, arXiv:2001.02870. [Google Scholar]
- Zhang, M.; Li, W.; Du, Q. Diverse region-based CNN for hyperspectral image classification. IEEE Trans. Image Process. 2018, 27, 2623–2634. [Google Scholar] [CrossRef] [PubMed]
- Fang, L.Y.; LI, S.T.; Kang, X.D.; Jon, A. Spectral spatial classification of hyperspectral images with a superpixel-based discriminative sparse model. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4186–4201. [Google Scholar] [CrossRef]
- Wang, Q.L.; Wu, B.G.; Zhu, P.F.; Li, P.H.; Zuo, W.M.; Hu, Q.H. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E.H. Squeeze-and-Excitation Networks. arXiv 2018, arXiv:1709.01507v4. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Li, L.; Yin, J.H.; Jia, X.P.; Li, S.; Han, B.N. Joint Spatial-Spectral Attention Network for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2020, 130, 38–45. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Paris, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814. [Google Scholar]
- Liu, B.; Yu, X.; Zhang, P.; Tan, X. Deep 3D convolutional network combined with spatial-spectral features for hyperspectral image classification. Acta Geod. Cartogr. Sin. 2019, 48, 53–63. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | Class | Training | Validation | Test | Total Samples |
|---|---|---|---|---|---|
| 1 | Asphalt | 663 | 663 | 5305 | 6631 |
| 2 | Meadows | 1864 | 1864 | 14,921 | 18,649 |
| 3 | Gravel | 209 | 209 | 1681 | 2099 |
| 4 | Trees | 306 | 306 | 2452 | 3064 |
| 5 | Sheets | 134 | 134 | 1077 | 1345 |
| 6 | Bare Soil | 502 | 502 | 4025 | 5029 |
| 7 | Bitumen | 133 | 133 | 1064 | 1330 |
| 8 | Bricks | 368 | 368 | 2946 | 3682 |
| 9 | Shadows | 94 | 94 | 759 | 947 |
| Total | 4273 | 4273 | 34,230 | 42,776 |
| Number | Class | Training | Validation | Test | Total Samples |
|---|---|---|---|---|---|
| 1 | Scrub | 152 | 76 | 533 | 761 |
| 2 | Willow swamp | 48 | 24 | 171 | 243 |
| 3 | Cabbage palm | 50 | 25 | 181 | 256 |
| 4 | Cabbage oak | 50 | 25 | 177 | 252 |
| 5 | Slash pine | 32 | 16 | 113 | 161 |
| 6 | Oak hammock | 46 | 23 | 160 | 229 |
| 7 | Hardwood swamp | 20 | 10 | 75 | 105 |
| 8 | Graminoid marsh | 86 | 43 | 302 | 431 |
| 9 | Spartina marsh | 104 | 52 | 364 | 520 |
| 10 | Cattail marsh | 80 | 40 | 284 | 404 |
| 11 | Salt marsh | 84 | 42 | 293 | 419 |
| 12 | Mud flats | 100 | 50 | 353 | 503 |
| 13 | Water | 186 | 93 | 648 | 927 |
| Total | 1038 | 519 | 3654 | 5211 |
| Number | Class | Training | Validation | Test | Total Samples |
|---|---|---|---|---|---|
| 1 | Alfalfa | 8 | 4 | 34 | 46 |
| 2 | Corn—no till | 284 | 142 | 1002 | 1428 |
| 3 | Corn—min till | 166 | 83 | 581 | 830 |
| 4 | Corn | 46 | 23 | 168 | 237 |
| 5 | Grass/pasture | 146 | 73 | 511 | 730 |
| 6 | Grass/tress | 96 | 48 | 339 | 483 |
| 7 | Grass/pasture—mowed | 6 | 3 | 19 | 28 |
| 8 | Hay—windrowed | 94 | 47 | 337 | 478 |
| 9 | Soybeans—no till | 194 | 97 | 681 | 972 |
| 10 | Soybeans—min till | 490 | 245 | 1720 | 2455 |
| 11 | Soybeans—clean till | 118 | 59 | 416 | 593 |
| 12 | Wheat | 40 | 20 | 145 | 205 |
| 13 | Woods | 252 | 126 | 887 | 1265 |
| 14 | Buildings–grass–trees | 76 | 38 | 272 | 386 |
| 15 | Stone–steel towers | 18 | 9 | 66 | 93 |
| 16 | Oats | 4 | 2 | 14 | 20 |
| Total | 2038 | 1019 | 7192 | 10,249 |
| Class | PCA | SVM | 2D-CNN | 3D-CNN | RES-3D | SSRN | My_Net |
|---|---|---|---|---|---|---|---|
| Asphalt | 76.65 | 85.57 | 93.80 | 0.97.15 | 96.18 | 98.84 | 98.74 |
| Meadows | 88.86 | 86.56 | 89.43 | 93.43 | 98.10 | 97.23 | 100.00 |
| Gravel | 92.24 | 89.43 | 92.27 | 94.48 | 97.21 | 99.82 | 99.56 |
| Trees | 90.38 | 92.17 | 94.13 | 92.39 | 95.31 | 98.15 | 100.00 |
| Metal | 87.56 | 85.68 | 90.51 | 94.37 | 99.64 | 99.43 | 98.83 |
| Soil | 85.52 | 94.79 | 92.34 | 96.68 | 97.72 | 96.17 | 100.00 |
| Bitumen | 88.67 | 90.65 | 94.72 | 93.48 | 96.31 | 96.56 | 99.32 |
| Bricks | 91.73 | 92.43 | 95.78 | 97.76 | 98.48 | 100.00 | 100.00 |
| Shadows | 89.86 | 92.79 | 91.56 | 94.34 | 100.00 | 98.34 | 99.67 |
| OA (%) | 87.23 | 90.53 | 93.33 | 94.68 | 97.78 | 98.17 | 99.82 |
| AA (%) | 88.15 | 90.25 | 94.17 | 95.37 | 98.17 | 98.64 | 99.59 |
| Kappa×100 | 85.23 | 89.24 | 92.48 | 94.46 | 97.25 | 98.76 | 99.71 |
| Class | PCA | SVM | 2D-CNN | 3D-CNN | RES-3D | SSRN | My_Net |
|---|---|---|---|---|---|---|---|
| Scrub | 66.75 | 90.28 | 84.42 | 97.19 | 97.96 | 98.46 | 99.37 |
| Willow swamp | 93.51 | 81.96 | 79.61 | 82.38 | 96.27 | 96.17 | 99.82 |
| Cabbage palm | 74.43 | 75.65 | 89.34 | 94.24 | 94.17 | 98.42 | 99.86 |
| Cabbage oak | 92.38 | 81.35 | 94.91 | 90.18 | 96.76 | 99.49 | 100.00 |
| Slash pine | 83.63 | 92.83 | 66.48 | 70.64 | 98.32 | 96.34 | 99.58 |
| Oak hammock | 69.43 | 74.51 | 73.34 | 70.37 | 94.51 | 100.00 | 100.00 |
| Hardwood swamp | 77.28 | 79.62 | 69.64 | 74.15 | 99.34 | 99.37 | 100.00 |
| Graminoid marsh | 76.72 | 95.83 | 81.72 | 90.46 | 98.94 | 99.82 | 99.57 |
| Spartina marsh | 82.79 | 91.92 | 90.16 | 95.37 | 97.85 | 97.71 | 100.00 |
| Cattail marsh | 81.56 | 88.14 | 91.87 | 98.48 | 100.00 | 99.42 | 100.00 |
| Salt marsh | 73.92 | 91.42 | 93.16 | 99.16 | 98.42 | 99.45 | 100.00 |
| Mud flats | 69.34 | 84.48 | 88.64 | 98.49 | 100.00 | 97.18 | 99.75 |
| Water | 85.16 | 86.94 | 95.54 | 100.00 | 100.00 | 100.00 | 100.00 |
| OA (%) | 82.09 | 88.76 | 90.25 | 93.52 | 97.47 | 98.16 | 99.81 |
| AA (%) | 81.56 | 89.17 | 91.32 | 94.20 | 97.25 | 98.13 | 99.74 |
| Kappa×100 | 81.72 | 88.56 | 91.92 | 94.77 | 97.25 | 98.64 | 99.52 |
| Class | PCA | SVM | 2D-CNN | 3D-CNN | RES-3D | SSRN | My_Net |
|---|---|---|---|---|---|---|---|
| Alfalfa | 72.46 | 78.53 | 74.37 | 91.62 | 97.38 | 97.48 | 100.00 |
| Corn—no till | 69.35 | 82.61 | 86.61 | 89.33 | 95.37 | 100.00 | 100.00 |
| Corn—min till | 71.58 | 74.84 | 91.49 | 93.97 | 98.64 | 99.46 | 99.25 |
| Corn | 81.62 | 79.71 | 90.82 | 95.94 | 97.92 | 96.56 | 100.00 |
| Grass—pasture | 67.34 | 72.67 | 73.58 | 82.34 | 97.97 | 97.76 | 100.00 |
| Grass—tress | 81.29 | 85.42 | 82.65 | 96.72 | 99.48 | 99.48 | 98.56 |
| Grass—pasture | 75.52 | 81.19 | 79.37 | 81.61 | 95.19 | 100.00 | 100.00 |
| Hay—windrowed | 77.43 | 83.51 | 87.51 | 79.37 | 99.41 | 99.56 | 100.00 |
| Oats | 86.96 | 83.37 | 90.43 | 93.19 | 97.76 | 99.12 | 100.00 |
| Soybeans—no till | 80.84 | 88.28 | 93.16 | 97.64 | 98.84 | 100.00 | 99.17 |
| Soybeans—min till | 82.61 | 74.76 | 95.19 | 93.28 | 97.19 | 99.14 | 100.00 |
| Soybeans—clean till | 76.39 | 86.51 | 94.72 | 98.76 | 100.00 | 98.08 | 100.00 |
| Wheat | 85.64 | 82.43 | 92.49 | 99.24 | 96.15 | 97.58 | 100.00 |
| Woods | 77.52 | 75.97 | 90.84 | 94.49 | 98.76 | 100.00 | 99.38 |
| Buildings–grass–trees | 84.48 | 88.91 | 87.37 | 89.19 | 96.14 | 99.67 | 98.89 |
| Stone–steel towers | 73.47 | 71.58 | 86.64 | 94.64 | 99.39 | 98.84 | 99.38 |
| OA (%) | 75.32 | 80.56 | 86.15 | 94.28 | 97.58 | 98.27 | 99.37 |
| AA (%) | 75.43 | 81.43 | 85.23 | 93.97 | 97.36 | 98.28 | 99.45 |
| Kappa×100 | 75.87 | 80.26 | 85.64 | 94.15 | 97.44 | 98.52 | 99.61 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qing, Y.; Liu, W. Hyperspectral Image Classification Based on Multi-Scale Residual Network with Attention Mechanism. Remote Sens. 2021, 13, 335. https://doi.org/10.3390/rs13030335
Qing Y, Liu W. Hyperspectral Image Classification Based on Multi-Scale Residual Network with Attention Mechanism. Remote Sensing. 2021; 13(3):335. https://doi.org/10.3390/rs13030335
Chicago/Turabian StyleQing, Yuhao, and Wenyi Liu. 2021. "Hyperspectral Image Classification Based on Multi-Scale Residual Network with Attention Mechanism" Remote Sensing 13, no. 3: 335. https://doi.org/10.3390/rs13030335
APA StyleQing, Y., & Liu, W. (2021). Hyperspectral Image Classification Based on Multi-Scale Residual Network with Attention Mechanism. Remote Sensing, 13(3), 335. https://doi.org/10.3390/rs13030335