
ACFNet: A Feature Fusion Network for Glacial Lake Extraction Based on Optical and Synthetic Aperture Radar Images



Abstract
:1. Introduction
2. Study Area and Dataset
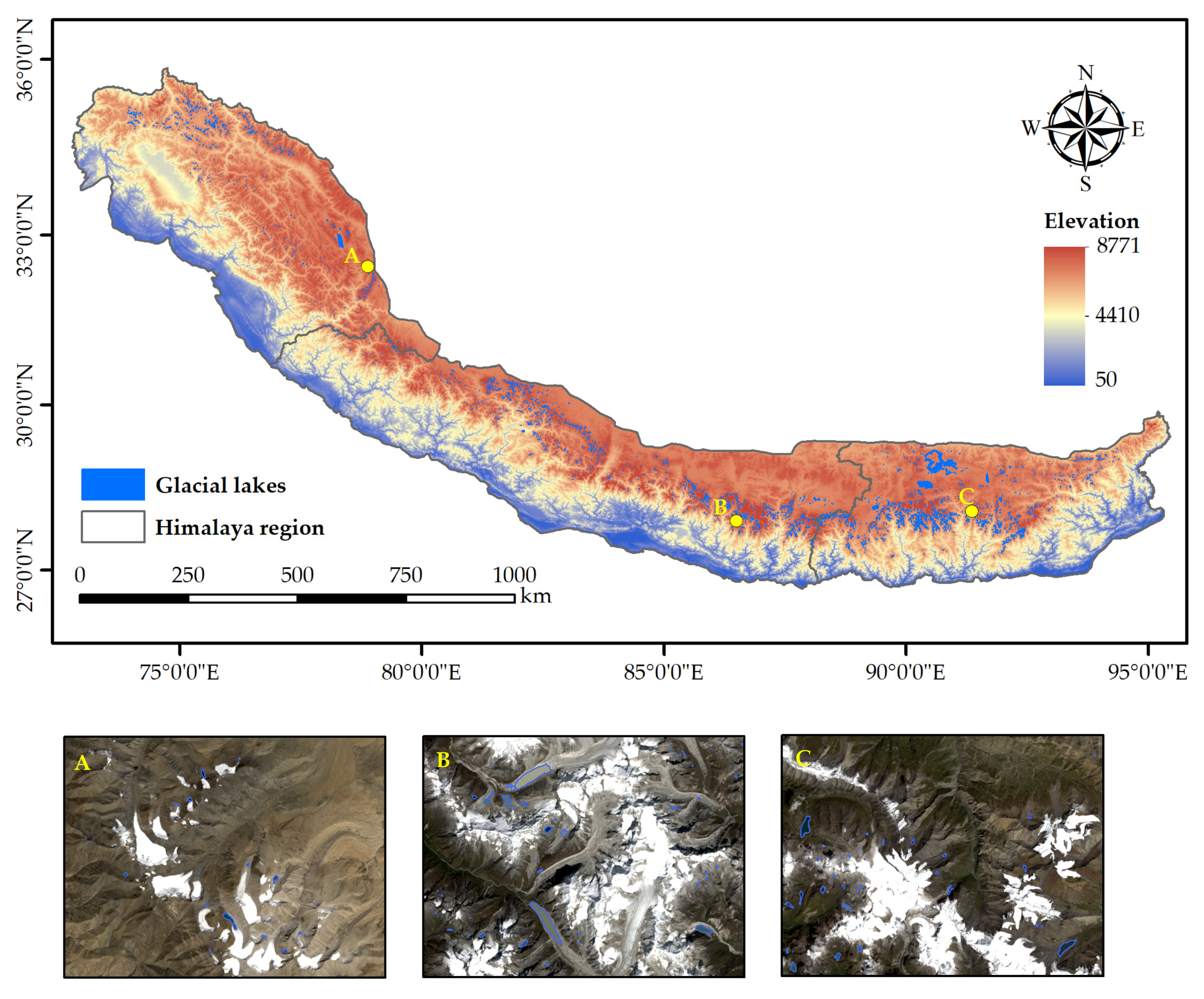
2.1. Study Area
2.2. Optical Dataset
2.3. SAR Dataset
3. Methodology
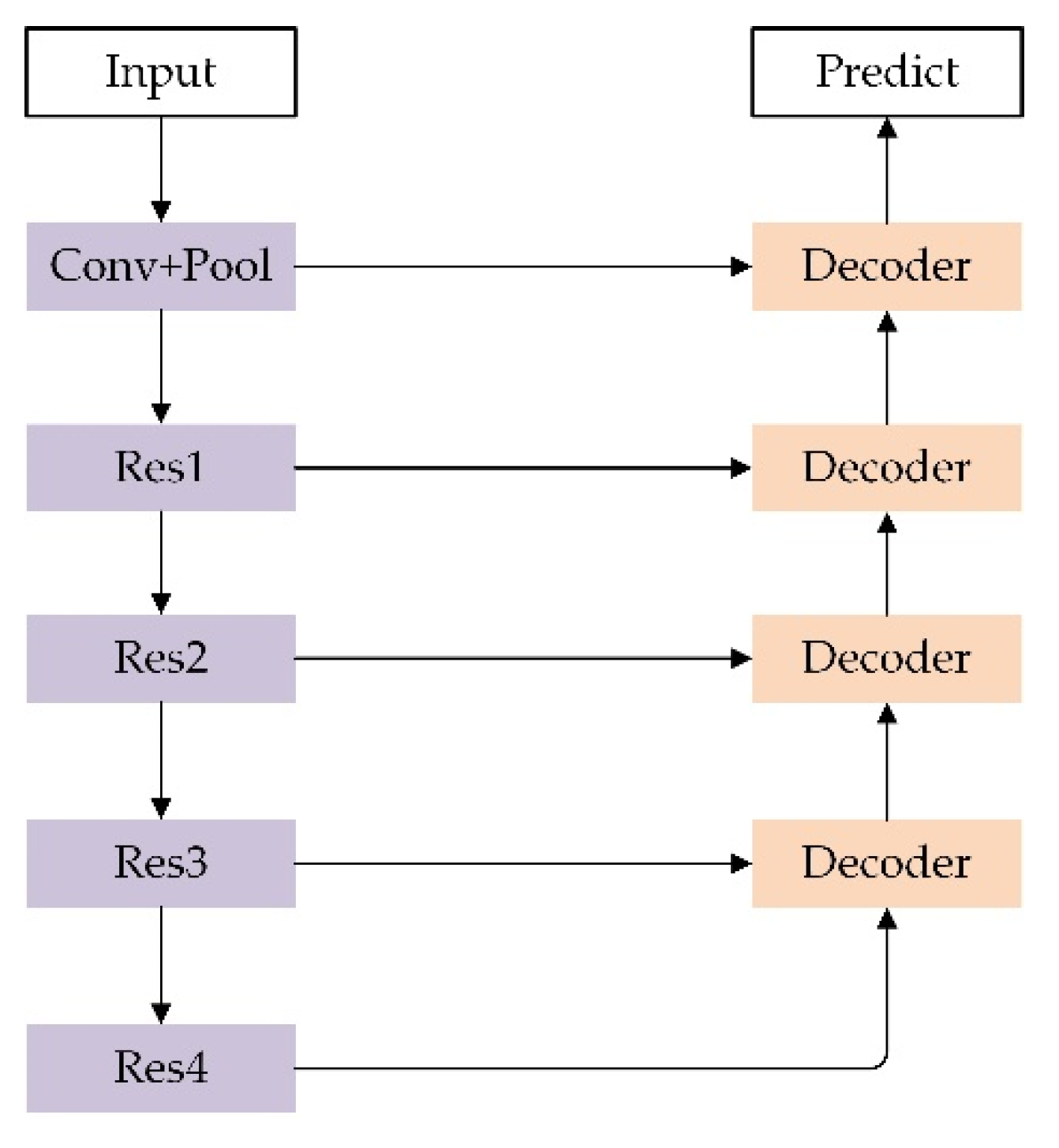
3.1. U-Net Structure
3.2. ResNet Backbone
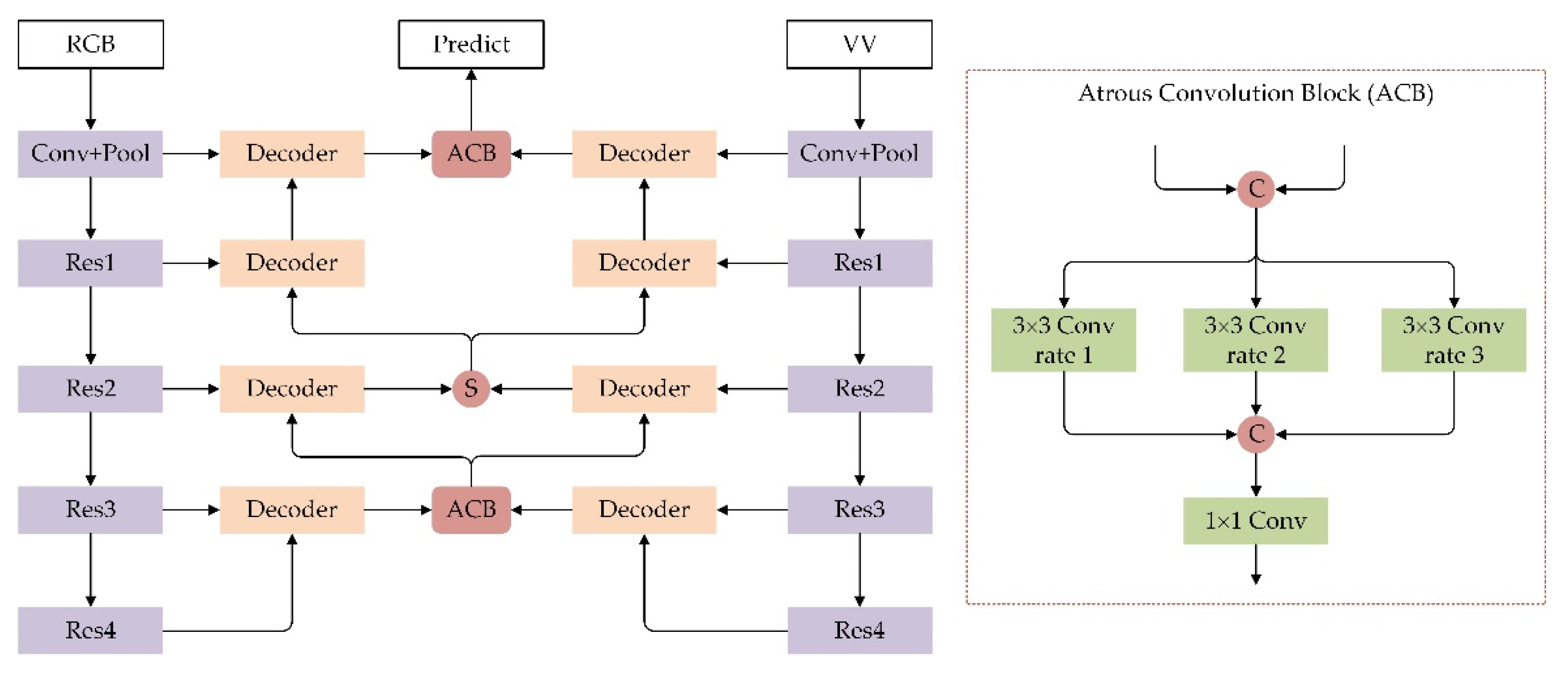
3.3. ACFNet Architecture
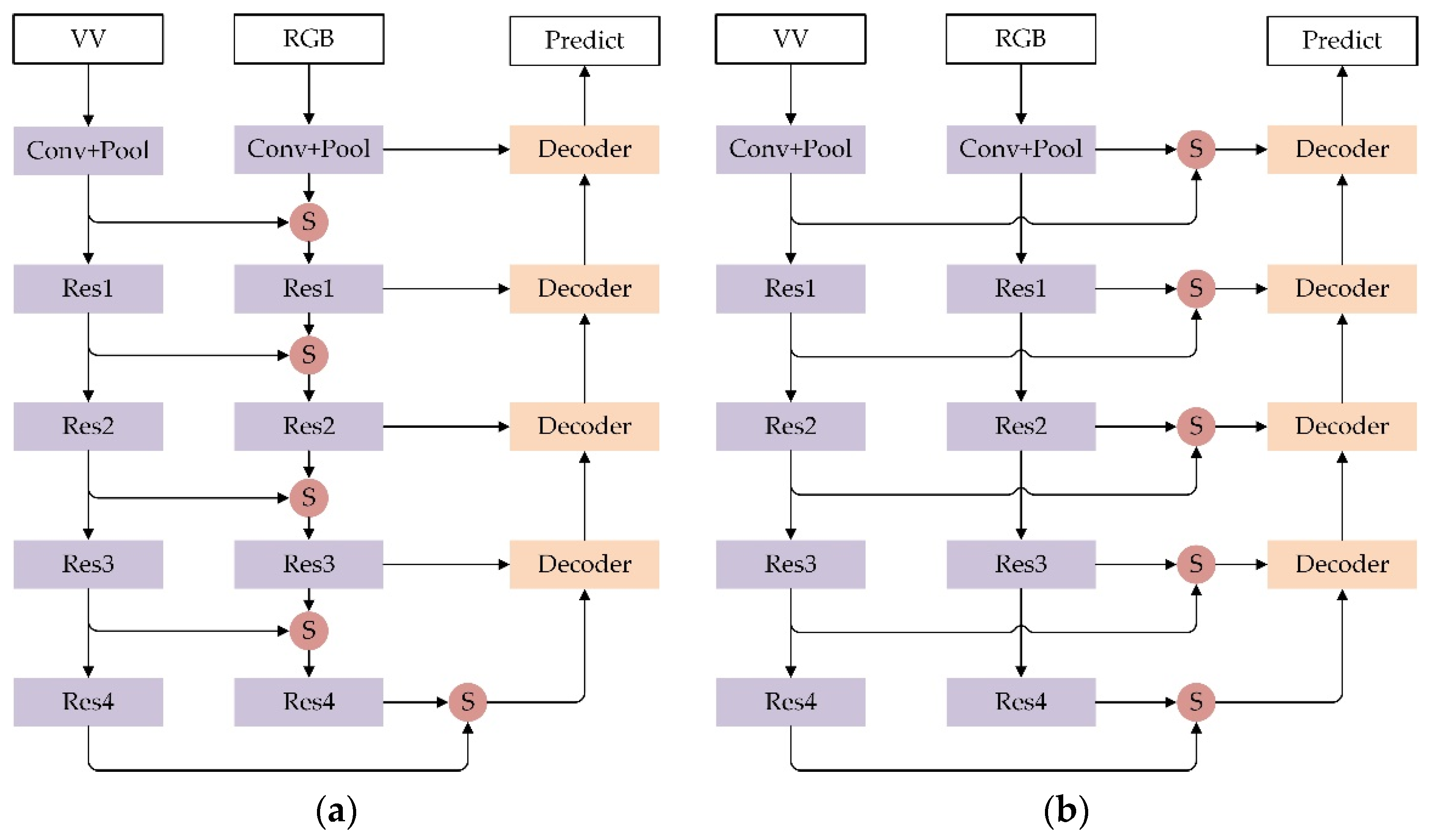
3.4. Fusion Methods in the Encoder–Decoder Structure
4. Experiment and Results
4.1. Implementation Details
4.2. Loss Function and Evaluation Metrics
4.3. Results
5. Discussion
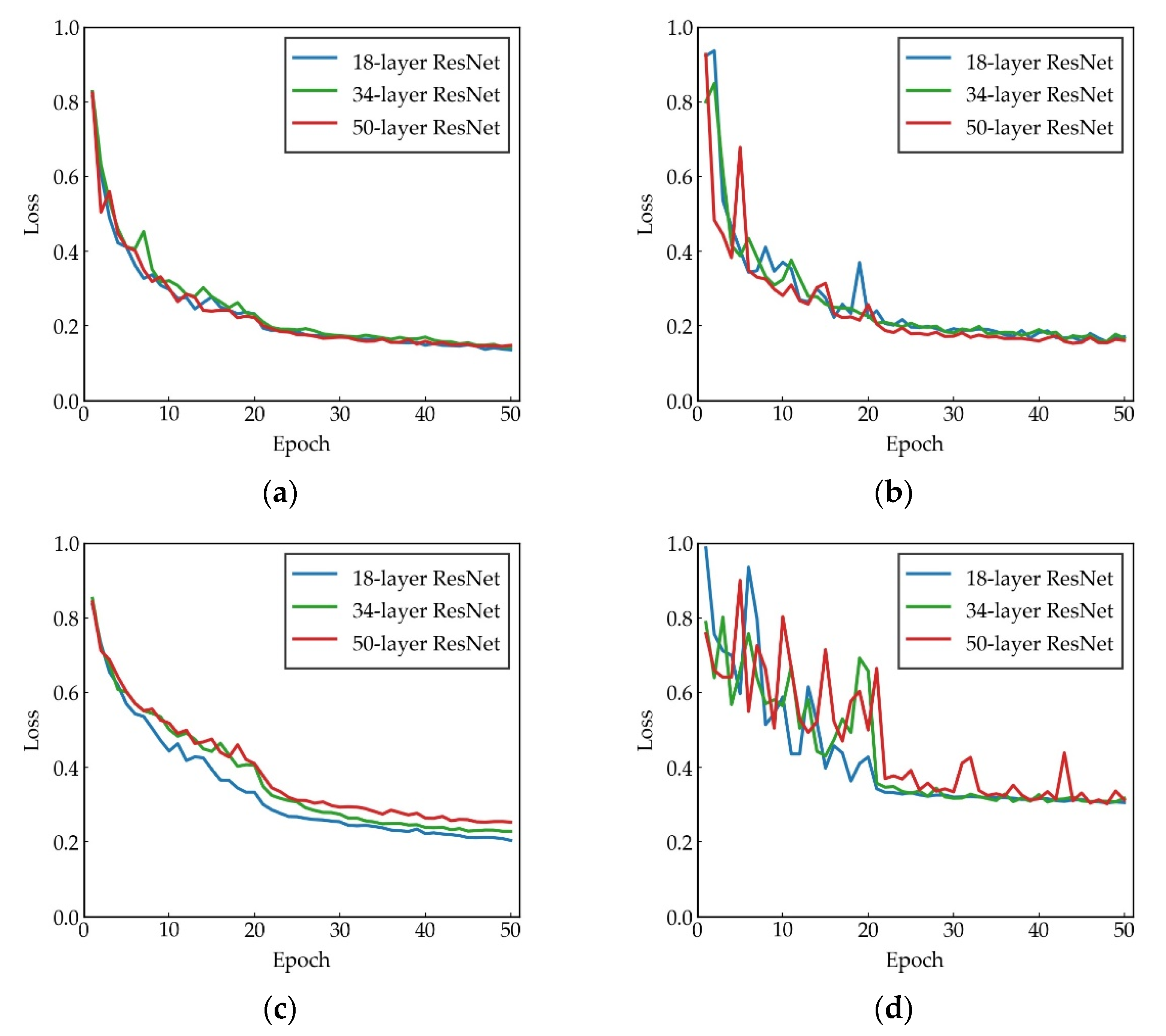
5.1. Backbone Depth for RGB and VV Data
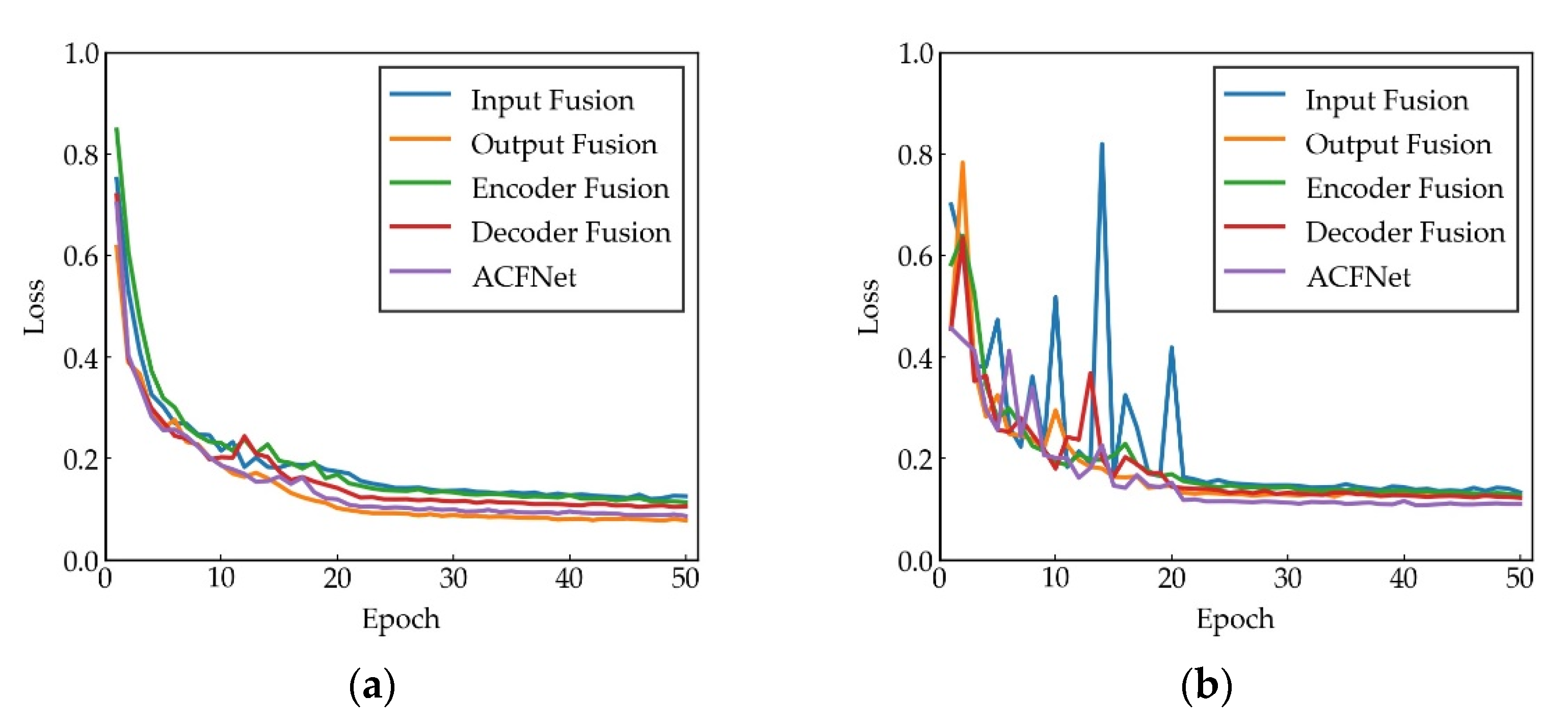
5.2. Effects of Fusion Methods
5.3. Comparisons with Other Models
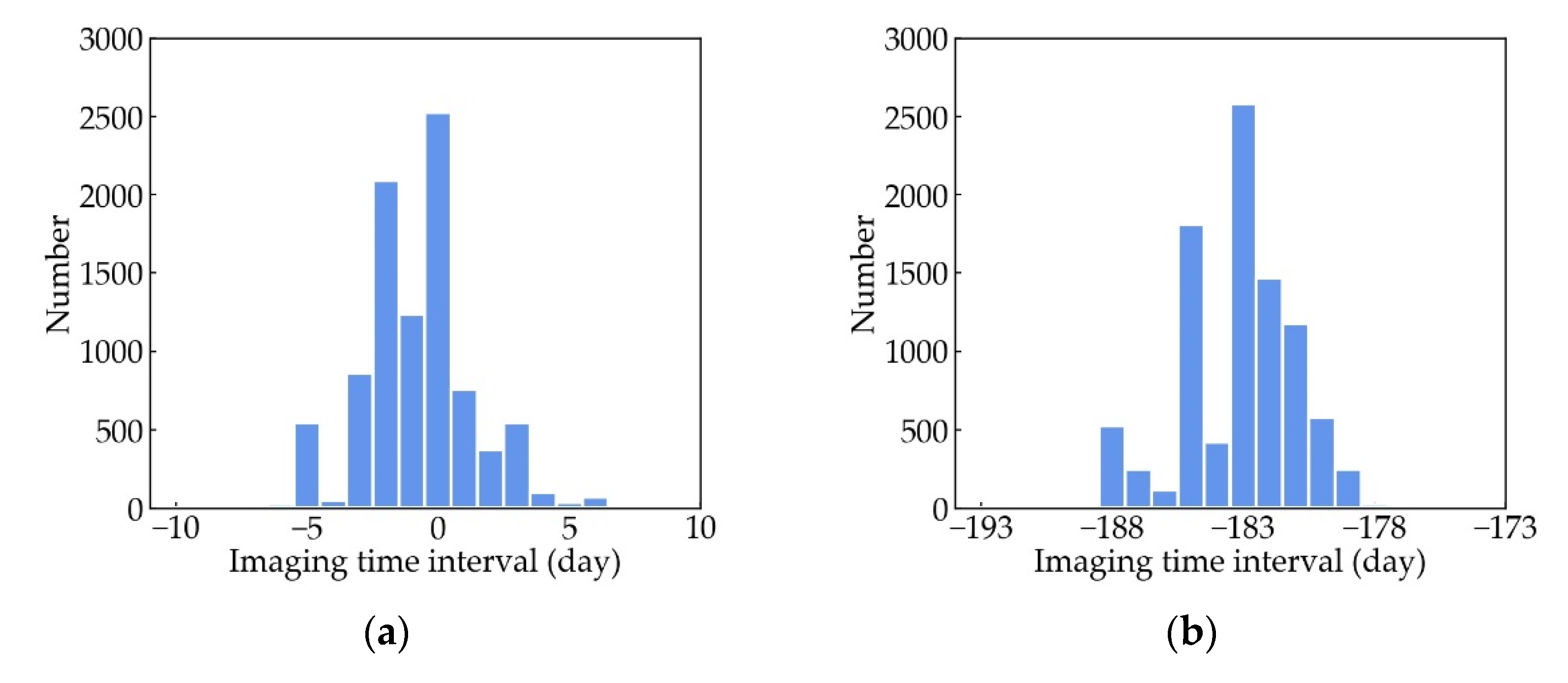
5.4. Impacts of Imaging Time Intervals between SAR and Optical Images
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zemp, M.; Huss, M.; Thibert, E.; Eckert, N.; McNabb, R.; Huber, J.; Barandun, M.; Machguth, H.; Nussbaumer, S.U.; Gartner-Roer, I.; et al. Global glacier mass changes and their contributions to sea-level rise from 1961 to 2016. Nature 2019, 568, 382–386. [Google Scholar] [CrossRef]
- Shugar, D.H.; Burr, A.; Haritashya, U.K.; Kargel, J.S.; Watson, C.S.; Kennedy, M.C.; Bevington, A.R.; Betts, R.A.; Harrison, S.; Strattman, K. Rapid worldwide growth of glacial lakes since 1990. Nat. Clim. Chang. 2020, 10, 939–945. [Google Scholar] [CrossRef]
- Wang, X.; Guo, X.; Yang, C.; Liu, Q.; Wei, J.; Zhang, Y.; Liu, S.; Zhang, Y.; Jiang, Z.; Tang, Z. Glacial lake inventory of high-mountain Asia in 1990 and 2018 derived from Landsat images. Earth Syst. Sci. Data 2020, 12, 2169–2182. [Google Scholar] [CrossRef]
- Chen, F.; Zhang, M.; Guo, H.; Allen, S.; Kargel, J.S.; Haritashya, U.K.; Watson, C.S. Annual 30 m dataset for glacial lakes in High Mountain Asia from 2008 to 2017. Earth Syst. Sci. Data 2021, 13, 741–766. [Google Scholar] [CrossRef]
- King, O.; Dehecq, A.; Quincey, D.; Carrivick, J. Contrasting geometric and dynamic evolution of lake and land-terminating glaciers in the central Himalaya. Glob. Planet. Chang. 2018, 167, 46–60. [Google Scholar] [CrossRef]
- Zheng, G.; Allen, S.K.; Bao, A.; Ballesteros-Cánovas, J.A.; Huss, M.; Zhang, G.; Li, J.; Yuan, Y.; Jiang, L.; Yu, T.; et al. Increasing risk of glacial lake outburst floods from future Third Pole deglaciation. Nat. Clim. Chang. 2021, 11, 411–417. [Google Scholar] [CrossRef]
- Dubey, S.; Goyal, M.K. Glacial Lake Outburst Flood Hazard, Downstream Impact, and Risk Over the Indian Himalayas. Water Resour. Res. 2020, 56, e2019WR026533. [Google Scholar] [CrossRef]
- Ashraf, A.; Naz, R.; Roohi, R. Glacial lake outburst flood hazards in Hindukush, Karakoram and Himalayan Ranges of Pakistan: Implications and risk analysis. Geomat. Nat. Hazards Risk 2012, 3, 113–132. [Google Scholar] [CrossRef] [Green Version]
- Khanal, N.R.; Mool, P.K.; Shrestha, A.B.; Rasul, G.; Ghimire, P.K.; Shrestha, R.B.; Joshi, S.P. A comprehensive approach and methods for glacial lake outburst flood risk assessment, with examples from Nepal and the transboundary area. Int. J. Water Resour. Dev. 2015, 31, 219–237. [Google Scholar] [CrossRef] [Green Version]
- Petrov, M.A.; Sabitov, T.Y.; Tomashevskaya, I.G.; Glazirin, G.E.; Chernomorets, S.S.; Savernyuk, E.A.; Tutubalina, O.V.; Petrakov, D.A.; Sokolov, L.S.; Dokukin, M.D.; et al. Glacial lake inventory and lake outburst potential in Uzbekistan. Sci. Total Environ. 2017, 592, 228–242. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prakash, C.; Nagarajan, R. Glacial lake changes and outburst flood hazard in Chandra basin, North-Western Indian Himalaya. Geomat. Nat. Hazards Risk 2018, 9, 337–355. [Google Scholar] [CrossRef] [Green Version]
- Brun, F.; Wagnon, P.; Berthier, E.; Jomelli, V.; Maharjan, S.B.; Shrestha, F.; Kraaijenbrink, P.D.A. Heterogeneous Influence of Glacier Morphology on the Mass Balance Variability in High Mountain Asia. J. Geophys. Res. Earth Surf. 2019, 124, 1331–1345. [Google Scholar] [CrossRef]
- King, O.; Bhattacharya, A.; Bhambri, R.; Bolch, T. Glacial lakes exacerbate Himalayan glacier mass loss. Sci. Rep. 2019, 9, 18145. [Google Scholar] [CrossRef] [Green Version]
- Carrivick, J.L.; Tweed, F.S. Proglacial lakes: Character, behaviour and geological importance. Quat. Sci. Rev. 2013, 78, 34–52. [Google Scholar] [CrossRef] [Green Version]
- Ukita, J.; Narama, C.; Tadono, T.; Yamanokuchi, T.; Tomiyama, N.; Kawamoto, S.; Abe, C.; Uda, T.; Yabuki, H.; Fujita, K. Glacial lake inventory of Bhutan using ALOS data: Methods and preliminary results. Ann. Glaciol. 2011, 52, 65–71. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Siegert, F.; Zhou, A.-g.; Franke, J. Glacier and glacial lake changes and their relationship in the context of climate change, Central Tibetan Plateau 1972–2010. Glob. Planet. Chang. 2013, 111, 246–257. [Google Scholar] [CrossRef]
- Wang, W.; Xiang, Y.; Gao, Y.; Lu, A.; Yao, T. Rapid expansion of glacial lakes caused by climate and glacier retreat in the Central Himalayas. Hydrol. Process. 2015, 29, 859–874. [Google Scholar] [CrossRef]
- Zhang, G.; Yao, T.; Xie, H.; Wang, W.; Yang, W. An inventory of glacial lakes in the Third Pole region and their changes in response to global warming. Glob. Planet. Chang. 2015, 131, 148–157. [Google Scholar] [CrossRef]
- Raj, K.B.G.; Kumar, K.V. Inventory of Glacial Lakes and its Evolution in Uttarakhand Himalaya Using Time Series Satellite Data. J. Indian Soc. Remote Sens. 2016, 44, 959–976. [Google Scholar] [CrossRef]
- Senese, A.; Maragno, D.; Fugazza, D.; Soncini, A.; D’Agata, C.; Azzoni, R.S.; Minora, U.; Ul-Hassan, R.; Vuillermoz, E.; Asif Khan, M.; et al. Inventory of glaciers and glacial lakes of the Central Karakoram National Park (CKNP–Pakistan). J. Maps 2018, 14, 189–198. [Google Scholar] [CrossRef]
- McFeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. Int. J. Remote Sens. 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Worni, R.; Huggel, C.; Stoffel, M. Glacial lakes in the Indian Himalayas--from an area-wide glacial lake inventory to on-site and modeling based risk assessment of critical glacial lakes. Sci. Total Environ. 2013, 468–469, S71–S84. [Google Scholar] [CrossRef] [PubMed]
- Xin, W.; Shiyin, L.; Wanqin, G.; Xiaojun, Y.; Zongli, J.; Yongshun, H. Using Remote Sensing Data to Quantify Changes in Glacial Lakes in the Chinese Himalaya. Mt. Res. Dev. 2012, 32, 203–212. [Google Scholar] [CrossRef]
- Huggel, C.; Kääb, A.; Haeberli, W.; Teysseire, P.; Paul, F. Remote sensing based assessment of hazards from glacier lake outbursts: A case study in the Swiss Alps. Can. Geotech. J. 2002, 39, 316–330. [Google Scholar] [CrossRef] [Green Version]
- Bolch, T.; Buchroithner, M.F.; Peters, J.; Baessler, M.; Bajracharya, S. Identification of glacier motion and potentially dangerous glacial lakes in the Mt. Everest region/Nepal using spaceborne imagery. Nat. Hazards Earth Syst. Sci. 2008, 8, 1329–1340. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Liu, Q.; Liu, S.; Wei, J.; Jiang, Z. Heterogeneity of glacial lake expansion and its contrasting signals with climate change in Tarim Basin, Central Asia. Environ. Earth Sci. 2016, 75, 696. [Google Scholar] [CrossRef]
- Wang, X.I.N.; Chai, K.; Liu, S.; Wei, J.; Jiang, Z.; Liu, Q. Changes of glaciers and glacial lakes implying corridor-barrier effects and climate change in the Hengduan Shan, southeastern Tibetan Plateau. J. Glaciol. 2017, 63, 535–542. [Google Scholar] [CrossRef] [Green Version]
- Shukla, A.; Garg, P.K.; Srivastava, S. Evolution of Glacial and High-Altitude Lakes in the Sikkim, Eastern Himalaya Over the Past Four Decades (1975–2017). Front. Environ. Sci. 2018, 6, 81. [Google Scholar] [CrossRef]
- Gardelle, J.; Arnaud, Y.; Berthier, E. Contrasted evolution of glacial lakes along the Hindu Kush Himalaya mountain range between 1990 and 2009. Glob. Planet. Chang. 2011, 75, 47–55. [Google Scholar] [CrossRef] [Green Version]
- Bhardwaj, A.; Singh, M.K.; Joshi, P.K.; Snehmani; Singh, S.; Sam, L.; Gupta, R.D.; Kumar, R. A lake detection algorithm (LDA) using Landsat 8 data: A comparative approach in glacial environment. Int. J. Appl. Earth Obs. Geoinf. 2015, 38, 150–163. [Google Scholar] [CrossRef]
- Li, J.; Sheng, Y.; Luo, J. Automatic extraction of Himalayan glacial lakes with remote sensing. Yaogan Xuebao-J. Remote Sens. 2011, 15, 29–43. [Google Scholar]
- Song, C.; Sheng, Y.; Ke, L.; Nie, Y.; Wang, J. Glacial lake evolution in the southeastern Tibetan Plateau and the cause of rapid expansion of proglacial lakes linked to glacial-hydrogeomorphic processes. J. Hydrol. 2016, 540, 504–514. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Zhang, M.; Tian, B.; Li, Z. Extraction of Glacial Lake Outlines in Tibet Plateau Using Landsat 8 Imagery and Google Earth Engine. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4002–4009. [Google Scholar] [CrossRef]
- Zhao, H.; Chen, F.; Zhang, M. A Systematic Extraction Approach for Mapping Glacial Lakes in High Mountain Regions of Asia. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2788–2799. [Google Scholar] [CrossRef]
- Jain, S.K.; Sinha, R.K.; Chaudhary, A.; Shukla, S. Expansion of a glacial lake, Tsho Chubda, Chamkhar Chu Basin, Hindukush Himalaya, Bhutan. Nat. Hazards 2014, 75, 1451–1464. [Google Scholar] [CrossRef]
- Veh, G.; Korup, O.; Roessner, S.; Walz, A. Detecting Himalayan glacial lake outburst floods from Landsat time series. Remote Sens. Environ. 2018, 207, 84–97. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Yu, B.; Chen, F.; Xu, C. Landslide detection based on contour-based deep learning framework in case of national scale of Nepal in 2015. Comput. Geosci. 2020, 135, 104388. [Google Scholar] [CrossRef]
- Yu, B.; Yang, L.; Chen, F. Semantic segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3252–3261. [Google Scholar] [CrossRef]
- Chen, Y.; Li, L.; Whiting, M.; Chen, F.; Sun, Z.; Song, K.; Wang, Q. Convolutional neural network model for soil moisture prediction and its transferability analysis based on laboratory Vis-NIR spectral data. Int. J. Appl. Earth Obs. Geoinf. 2021, 104, 102550. [Google Scholar] [CrossRef]
- Guo, H.; Chen, F.; Sun, Z.; Liu, J.; Liang, D. Big Earth Data: A practice of sustainability science to achieve the Sustainable Development Goals. Sci. Bull. 2021, 66, 1050–1053. [Google Scholar] [CrossRef]
- Shamshirband, S.; Rabczuk, T.; Chau, K.-W. A survey of deep learning techniques: Application in wind and solar energy resources. IEEE Access 2019, 7, 164650–164666. [Google Scholar] [CrossRef]
- Fan, Y.; Xu, K.; Wu, H.; Zheng, Y.; Tao, B. Spatiotemporal modeling for nonlinear distributed thermal processes based on KL decomposition, MLP and LSTM network. IEEE Access 2020, 8, 25111–25121. [Google Scholar] [CrossRef]
- Qayyum, N.; Ghuffar, S.; Ahmad, H.; Yousaf, A.; Shahid, I. Glacial Lakes Mapping Using Multi Satellite PlanetScope Imagery and Deep Learning. ISPRS Int. J. Geo-Inf. 2020, 9, 560. [Google Scholar] [CrossRef]
- Chen, F. Comparing Methods for Segmenting Supra-Glacial Lakes and Surface Features in the Mount Everest Region of the Himalayas Using Chinese GaoFen-3 SAR Images. Remote Sens. 2021, 13, 2429. [Google Scholar] [CrossRef]
- Wu, R.; Liu, G.; Zhang, R.; Wang, X.; Li, Y.; Zhang, B.; Cai, J.; Xiang, W. A Deep Learning Method for Mapping Glacial Lakes from the Combined Use of Synthetic-Aperture Radar and Optical Satellite Images. Remote Sens. 2020, 12, 4020. [Google Scholar] [CrossRef]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European conference on computer vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Song, C.; Sheng, Y.; Wang, J.; Ke, L.; Madson, A.; Nie, Y. Heterogeneous glacial lake changes and links of lake expansions to the rapid thinning of adjacent glacier termini in the Himalayas. Geomorphology 2017, 280, 30–38. [Google Scholar] [CrossRef] [Green Version]
- Bolch, T.; Kulkarni, A.; Kääb, A.; Huggel, C.; Paul, F.; Cogley, J.G.; Frey, H.; Kargel, J.S.; Fujita, K.; Scheel, M. The state and fate of Himalayan glaciers. Science 2012, 336, 310–314. [Google Scholar] [CrossRef] [Green Version]
- Brun, F.; Berthier, E.; Wagnon, P.; Kaab, A.; Treichler, D. A spatially resolved estimate of High Mountain Asia glacier mass balances, 2000–2016. Nat. Geosci. 2017, 10, 668–673. [Google Scholar] [CrossRef] [PubMed]
- Bookhagen, B.; Burbank, D.W. Toward a complete Himalayan hydrological budget: Spatiotemporal distribution of snowmelt and rainfall and their impact on river discharge. J. Geophys. Res. 2010, 115. [Google Scholar] [CrossRef] [Green Version]
- Nie, Y.; Sheng, Y.; Liu, Q.; Liu, L.; Liu, S.; Zhang, Y.; Song, C. A regional-scale assessment of Himalayan glacial lake changes using satellite observations from 1990 to 2015. Remote Sens. Environ. 2017, 189, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Chen, F.; Yu, B.; Li, B. A practical trial of landslide detection from single-temporal Landsat8 images using contour-based proposals and random forest: A case study of national Nepal. Landslides 2018, 15, 453–464. [Google Scholar] [CrossRef]
- Wang, N.; Chen, F.; Yu, B.; Qin, Y. Segmentation of large-scale remotely sensed images on a Spark platform: A strategy for handling massive image tiles with the MapReduce model. ISPRS J. Photogramm. Remote Sens. 2020, 162, 137–147. [Google Scholar] [CrossRef]
- Schmitt, M.; Hughes, L.H.; Zhu, X.X. The SEN1-2 dataset for deep learning in SAR-optical data fusion. arXiv 2018, arXiv:1807.01569. [Google Scholar] [CrossRef] [Green Version]
- Versaci, M.; Calcagno, S.; Morabito, F.C. Fuzzy geometrical approach based on unit hyper-cubes for image contrast enhancement. In Proceedings of the 2015 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 19–21 October 2015; pp. 488–493. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Banan, A.; Nasiri, A.; Taheri-Garavand, A. Deep learning-based appearance features extraction for automated carp species identification. Aquac. Eng. 2020, 89, 102053. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic image segmentation with deep convolutional nets and fully connected crfs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Couprie, C.; Farabet, C.; Najman, L.; LeCun, Y. Indoor semantic segmentation using depth information. arXiv 2013, arXiv:1301.3572. [Google Scholar]
- Hazirbas, C.; Ma, L.; Domokos, C.; Cremers, D. FuseNet: Incorporating depth into semantic segmentation via fusion-based CNN architecture. In Computer Vision–ACCV 2016; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2017; pp. 213–228. [Google Scholar]
- Ha, Q.; Watanabe, K.; Karasawa, T.; Ushiku, Y.; Harada, T. MFNet: Towards real-time semantic segmentation for autonomous vehicles with multi-spectral scenes. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5108–5115. [Google Scholar]
- Adriano, B.; Yokoya, N.; Xia, J.; Miura, H.; Liu, W.; Matsuoka, M.; Koshimura, S. Learning from multimodal and multitemporal earth observation data for building damage mapping. ISPRS J. Photogramm. Remote. Sens. 2021, 175, 132–143. [Google Scholar] [CrossRef]
- Park, S.-J.; Hong, K.-S.; Lee, S. Rdfnet: Rgb-d multi-level residual feature fusion for indoor semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4980–4989. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of COMPSTAT’2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 177–186. [Google Scholar]
- Milletari, F.; Navab, N.; Ahmadi, S.-A. V-Net: Fully convolutional neural networks for volumetric medical image segmentation. In Proceedings of the 2016 Fourth International Conference on 3D Vision (3DV), Stanford, CA, USA, 25–28 October 2016; pp. 565–571. [Google Scholar]
- Li, X.; Sun, X.; Meng, Y.; Liang, J.; Wu, F.; Li, J. Dice loss for data-imbalanced NLP tasks. arXiv 2019, arXiv:1911.02855. [Google Scholar]
- Yu, B.; Chen, F.; Xu, C.; Wang, L.; Wang, N. Matrix SegNet: A Practical Deep Learning Framework for Landslide Mapping from Images of Different Areas with Different Spatial Resolutions. Remote Sens. 2021, 13, 3158. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Input | U-Net Backbone | Precision | Recall | F1 | IOU |
|---|---|---|---|---|---|
| RGB | 18-layer ResNet | 0.9269 | 0.8139 | 0.8667 | 0.7649 |
| 34-layer ResNet | 0.9141 | 0.8174 | 0.863 | 0.7591 | |
| 50-layer ResNet | 0.9144 | 0.8326 | 0.8715 | 0.7724 | |
| VV | 18-layer ResNet | 0.81 | 0.6824 | 0.7407 | 0.5883 |
| 34-layer ResNet | 0.7927 | 0.6813 | 0.7328 | 0.5783 | |
| 50-layer ResNet | 0.7582 | 0.6986 | 0.7272 | 0.5714 |
| Input | Model | Precision | Recall | F1 | IOU |
|---|---|---|---|---|---|
| RGB, VV | Wu’s Model | 0.886 | 0.8745 | 0.8802 | 0.7861 |
| ACFNet | 0.9198 | 0.8921 | 0.9057 | 0.8278 | |
| Output Fusion | 0.9283 | 0.8602 | 0.893 | 0.8067 | |
| Decoder Fusion | 0.9215 | 0.8737 | 0.897 | 0.8132 | |
| Encoder Fusion | 0.8946 | 0.8764 | 0.8854 | 0.7944 | |
| RGB+VV | Input Fusion | 0.8476 | 0.8798 | 0.8634 | 0.7596 |
| SegNet | 0.8625 | 0.816 | 0.8386 | 0.7221 | |
| DeepLabV3+ | 0.8557 | 0.8441 | 0.8498 | 0.7389 |
| Input | Model | Precision | Recall | F1 | IOU | IOU Decrease (%) |
|---|---|---|---|---|---|---|
| RGB, VV | Wu’s Model | 0.9083 | 0.8474 | 0.8768 | 0.7807 | 0.54 |
| ACFNet | 0.9061 | 0.8502 | 0.8772 | 0.7814 | 4.64 | |
| Output Fusion | 0.921 | 0.8181 | 0.8665 | 0.7645 | 4.22 | |
| Decoder Fusion | 0.9106 | 0.8436 | 0.8758 | 0.7791 | 3.41 | |
| Encoder Fusion | 0.8869 | 0.8516 | 0.8689 | 0.7682 | 2.62 | |
| RGB+VV | Input Fusion | 0.876 | 0.8432 | 0.8593 | 0.7533 | 0.63 |
| SegNet | 0.8405 | 0.7626 | 0.7996 | 0.6662 | 5.59 | |
| DeepLabV3+ | 0.8855 | 0.8028 | 0.8421 | 0.7273 | 1.16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Chen, F.; Zhang, M.; Yu, B. ACFNet: A Feature Fusion Network for Glacial Lake Extraction Based on Optical and Synthetic Aperture Radar Images. Remote Sens. 2021, 13, 5091. https://doi.org/10.3390/rs13245091
Wang J, Chen F, Zhang M, Yu B. ACFNet: A Feature Fusion Network for Glacial Lake Extraction Based on Optical and Synthetic Aperture Radar Images. Remote Sensing. 2021; 13(24):5091. https://doi.org/10.3390/rs13245091
Chicago/Turabian StyleWang, Jinxiao, Fang Chen, Meimei Zhang, and Bo Yu. 2021. "ACFNet: A Feature Fusion Network for Glacial Lake Extraction Based on Optical and Synthetic Aperture Radar Images" Remote Sensing 13, no. 24: 5091. https://doi.org/10.3390/rs13245091
APA StyleWang, J., Chen, F., Zhang, M., & Yu, B. (2021). ACFNet: A Feature Fusion Network for Glacial Lake Extraction Based on Optical and Synthetic Aperture Radar Images. Remote Sensing, 13(24), 5091. https://doi.org/10.3390/rs13245091