3.1. Framework of the Proposed Method
The proposed method consists of three parts, clutter suppression, 3D TBD, and 2D HT. The processing flowchart is presented in
Figure 1. The three components are highlighted by blue, green, and red boxes. Firstly,
detection bins are built [
21], each detection bin corresponding to a 3D vector. In [
2,
19,
21], the 3 dimensions in 3D TBD regard the X axis, Y axis, and time, respectively. A total of 140 3D vectors are selected for the limitation of target velocity [
2]. However, the three dimensions here are the X axis, Y axis, and Z axis. Without the limitation of the target motion model, 1217 3D vectors covering all directions are exploited, and 1217 detection bins are built. The 3D vectors are built based on tessellation of Platonic solids in [
32].
In clutter suppression, history measurements are firstly rotated and then projected to get a score map. Clutter density of background and clutter regions in the detection bin is denoted by the score map, so we called the score map “clutter map”. Each detection bin corresponds to one clutter map, and 1217 clutter maps are obtained in total. Then, in track detection processing, the current measurements are rotated by the same 3D vector and generate a current score map in the same way. In each detection bin, the current score map is subtracted by the clutter map. The reserved votes are regarded as target votes. The 3D TBD method introduced the 3D rotation, voting strategy for maps, and backtrace for the candidates whose score exceeds threshold .
In the third part, each candidate contains one track at most. Therefore, three HT are performed on X-axis versus time, Y-axis versus time and Z-axis versus time respectively. The intersection of the point set obtained by the 3 Hough transformations is tested with the second threshold
. The intersection is confirmed as a target track if its score is larger than
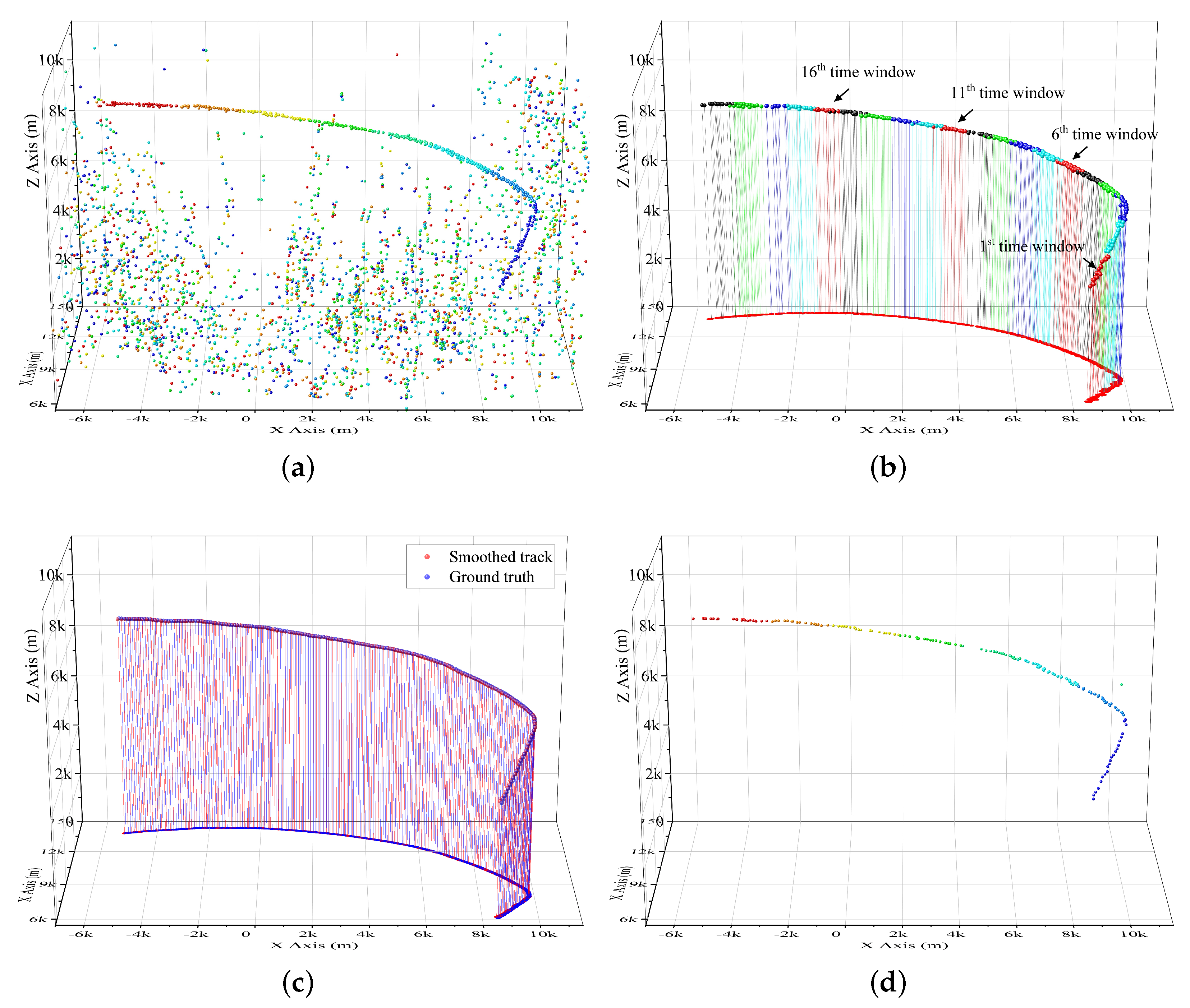
. In maneuvering target tracking scenarios, tracklets can be detected by the proposed method firstly, and the whole trajectory can be then obtained by associating the tracklets [
21,
33].
3.3. The 4D TBD
After obtaining the clutter map in
detection bins, we detect the current tracks by the latest measurements. The latest measurement point set is represented by
.
denote the time window in which the target track exists. The
is also rotated by
3D vectors in each detection bin. Each detection bin generates a current projected map. Corresponding to the
clutter map, the
current projected map is represented by
. Current projected map
is obtained by (
7)–(
9) and (
12) using measurements
.
Then, we can get the projected map after clutter region suppression,
, by subtraction of the two maps.
Then the cells whose score is larger than a threshold in map are found out. These cells are candidates potentially containing a target track. Therefore, these cells are called “candidate cell”. If all the cells in are smaller than the , it infers that no target whose direction close to the 3D vector of this detection bin exists. It is unnecessary to do further processing on this detection bin.
The candidate cells in the same score map are firstly clustered into sets to get the candidate regions by the region growing method in [
33,
34]. Each candidate cell set potentially contains a target track. It assumes that
candidate regions are obtained in the
. Further detection will be performed on each set. The cardinality of a candidate cell set is denoted by
. Candidate region set
can be expressed by
The processing of each region in follows three steps.
Firstly, the points voting for the candidate cell set are backtracked. The 3D straight line which corresponds to a candidate cell
can be expressed by
If the distance
between the 3D line (
17) and a rotated point
is smaller than cell width
, the point
should vote for the cell
. The expressions for the distance
are available in [
19]. The point set voting for the
is denoted by
. Then, the corresponding point set of the candidate region
can be expressed by the union of
point set, i.e.,
The parameter r denotes the index of the candidate regions in . Each set is promising and contains one track.
Secondly, three 2D HT are performed according to (
1). On the X axis, a parameter space map of
is built. The parameter space map has
bins for
and
bins for
. The parameter space map can be denoted by
. The bin width of
and
is
and
, respectively. The voting process corresponding to the X axis can be expressed by
The maximum score of parameter space map,
, can be obtained by enumeration. Similarly, on the Y axis and Z axis, 2D HT is also performed for the
and
. If all three maximums,
,
, and
, are larger than a fixed threshold
, we believe that one track exits in the point set
, i.e.,
The points which were voting for the cell of maximum vote
are represented by
. Similarly, we can get the point sets
and
. The obtained tracklet in
is exactly the intersection of the three point set, i.e.,
Thirdly, track fusion is necessary to avoid duplicate detection. The same track may be detected in more than one detection bin if 3D vectors of detection bins are very close. Therefore, if two 3D vectors,
and
, meet the expression in (
23), the tracks detected in the two detection bins are attempted for fusion.
The
is a constant set to
in our experiments. Each pair of the tracklets obtained in
-th and
-th detection bins are compared. Two tracks are fused if they are sharing the same points, and the fusion can be expressed by (
24)
where the constant parameter
is set to 0.5 in the experiments.
3.4. Theoretical Model
After the introduction of methods in each stage, an integrated theoretical model of the whole algorithm is given.
The measurements during a time period are projected, rotated firstly. Then, a map voted by the rotated points is obtained in each detection bin. Each map contains
grid cells which are sized
. The votes in a map cell consist of three parts when a track exists, i.e., the votes of the target, background, and clutter region. The expectation of the three components all follow a Poisson distribution, and their expectation is
The
means the radar coverage range. The historical measurement
is exactly used to estimate the clutter components, i.e., (
26) and (
27). The clutter components in each grid cell and in
detection bins (
) are estimated by (
7)–(
12).
If a target exists in a cell, the expectation of the points voting for the cell is the summation of (
25) and (
26) (target not in a clutter region) or the summation of (
25)–(
27) (target in a clutter region). The map is precisely the
, which is estimated by
by using (
7)–(
12).
In
and
, the distributions of false alarm points in each cell generated by background (
26) and clutter regions (
27) are the same, as the variation of clutter is quite slow compared with that of the target cell. Therefore, after the subtraction of
and
(
15), only the components of target (
25) are reserved in
, and it is much larger than the residual error of subtraction in (
15). Therefore, target detection in
is quite easy, and the subtraction in each detection bin is the theoretical basis of our improvements.
The distribution of the quantity of the points in a target cell can be expressed by (
28) because the summation of several individual Poisson processes also follows a Poisson distribution.
Similarly, the distribution of a cell in which a target is absent can be written as
The vote of cell in clutter map
is the expectation of clutter components, i.e.,
. If the threshold equals
, the false alarm detection probability of a cell
can be written as
The false alarm rate is the summation of the probability of votes more than
. According to (
30), the estimated clutter
and the component
in (
29) are canceled out. Therefore, the summation is usually very low in using an appropriate
.
According to (
28), the detection rate can be written as
For the contribution of target component, , exceeding is quite easy for the . It provides a remarkable detection rate of the target tracklet.
Even if a false alarm tracklet is built by the 3D HT, three 2D HT are performed to further verify the tracklet. In the 2D HT, the parameter space is divided into
grid cells. Each point would vote for all
speed bins in 2D Hough map
, each velocity bin one vote. Therefore, the map
has
votes in total. If a cell has been correctly confirmed as a tracklet candidate, it contains
points, at least. The point cardinality of the set
follows the distribution:
Similarly, the point cardinality of set
in which no target points exist but has been falsely confirmed as a candidate follows the distribution:
If the clutter points randomly vote for the
cells in map
, the expectation of vote in each cell can be expressed by
According to (
33), the vote distribution of a cell in map
if no target exits can be expressed by
Then, the false alarm rate of
in map
can be written as
Similarly, the distributions
and
, which correspond to
and
, are available, and the three distributions are individual with each other. Therefore, according to (
21), the overall false alarm rate of track detection can be expressed by
The
is usually very low because the score is hard to exceed
if the point set originates from clutter and the points are randomly voting for the cells. Meanwhile, according to (
37), even if the false alarm arises in one 2D HT map, the false alarm track is very hard to pass the three 2D HT map detection at the same time. Therefore, (
36) and (
37) grant our method an extremely low false track detection rate.
If the target points exist in a cell, the clutter points randomly vote for the
cells in map
. However, all the target points would vote for the one cell, and the vote expectation of the cell can be expressed by
According to (
32), the distribution of votes in a cell of map
when the target actually exists can be expressed by
The detection rate of
in map
can be written as
According to (
21), the track can be confirmed only if it is detected in all three 2D Hough maps. Therefore, the overall track detection rate can be expressed by
For the component of target points, , the vote is very easy to exceed , and the is close to 1. Similarly, a high detection rate of target track can be achieved.
3.5. Implementation of the Whole Algorithm
The implementation of the proposed method is explained by the Pseudocode in Algorithm 1. In the Pseudocode, lines 1–3 present the clutter map
estimation using
in
detection bins. In lines 5 and 6, target map
is calculated, and only the component of target (
25) is reserved. In line 7,
target regions are easily obtained. In lines 9–12, three 2D HT are performed. In lines 13–15, the target tracklet is confirmed. After getting all the tracklets in
detection bins in lines 4–17, tracklet fusion is performed in line 18.
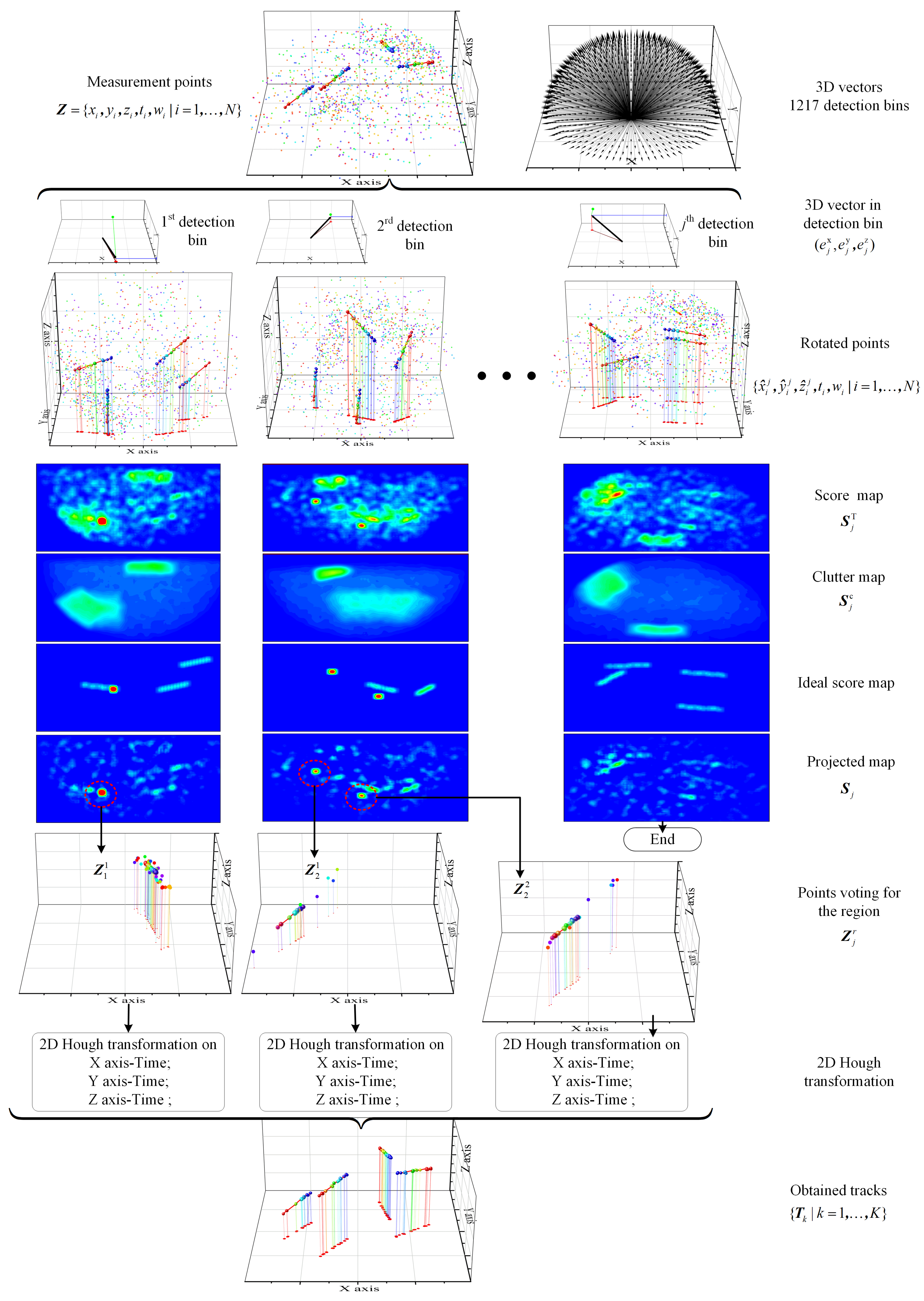
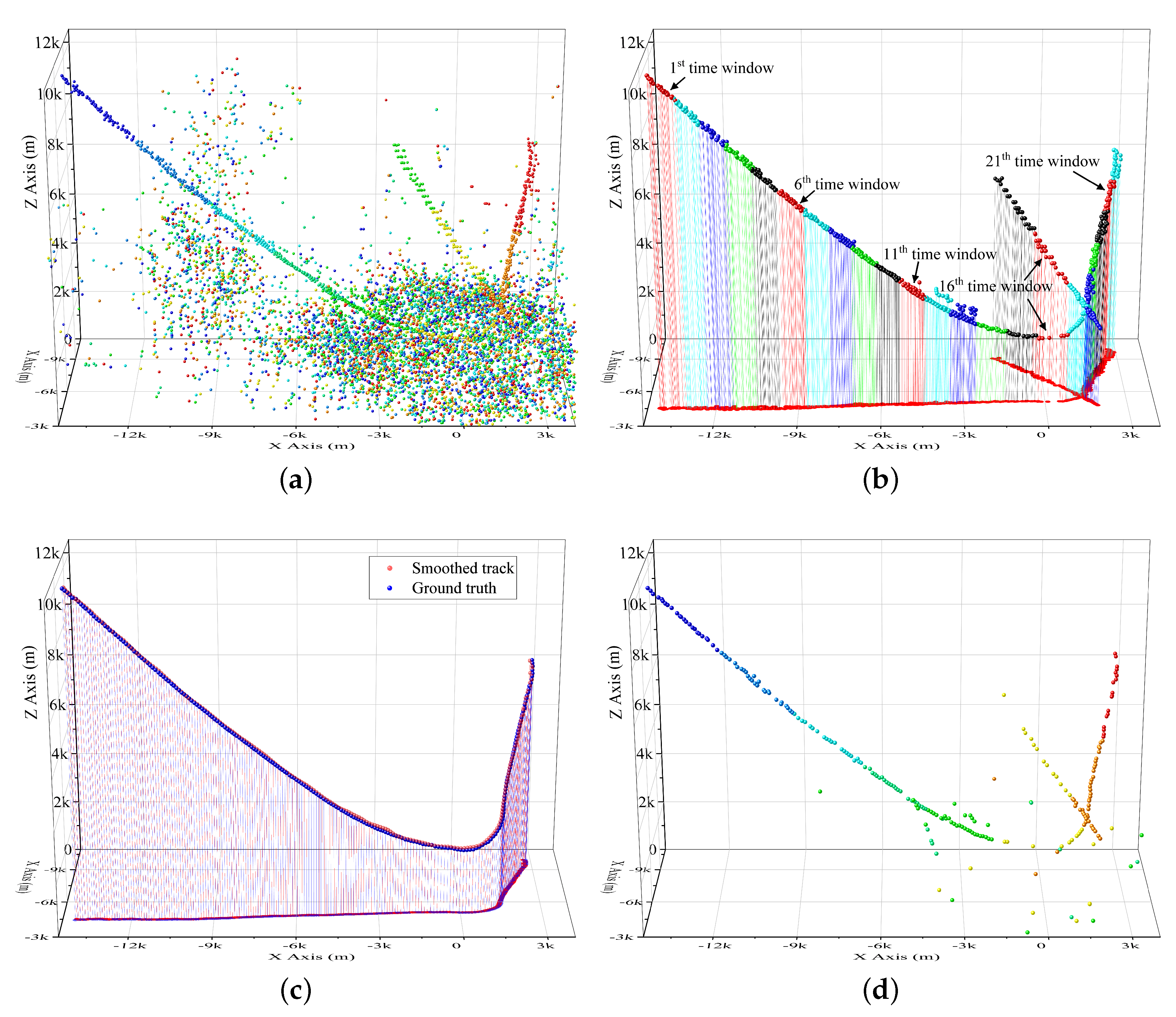
A diagram presenting the whole process is given in
Figure 2 to make our method more understandable. The two sub-figures in the first line present the measurement points
in the example and the 3D vectors
. They are the inputs to detect the four target tracklets. The measurements include the target points and false alarm points originating in the background and two clutter regions. The weight of all points is the same at the beginning. The target points are labeled by larger balls for distinction. The blue to red points denote the initial points to most recently obtained points. In the second line, three 3D vectors are presented as examples. Each vector regards a detection bin. In the third line, points after projection (
7) and two rotation (
8) and (
9), i.e.,
, in the three detection bins are presented. In the first detection bin, one target track is perpendicular to the current X-Y plane. Two target tracks are perpendicular to the plane in the subfigure in line 3, column 2. In the fourth line, the score maps before clutter suppression
in the three detection bins are presented. The vote of two clutter regions is quite outstanding. The clutter map
, which is built by history measurements
, is presented by the subfigures in the fifth line. Subfigures in the sixth line and seventh line present the projected map when the false alarm points are absent and present, respectively. In the projected map
, the target region is much easier to be detected. The target region in the first detection bin is outstanding in subfigure of line 7, column 1. The points in set
, which vote for the target region, are presented in the subfigure of line 8, column 1. Then, one tracklet can be obtained after 2D HT in the subfigure of line 9, column 1. Similarly, in the second detection bin, two target regions are detected in the subfigures of line 7, column 2. Two tracklets can be then obtained after two individual 2D HT processing. In the third column (
detection bin), no target regions can be obtained in subfigures of line 7, column 3. That means no tracklet can be obtained in this detection bin. The subfigures in the bottom (line 10) present all the tracklets obtained by the
detection bins.
| Algorithm 1: The 4D Track-before-detect method. |
 |
An example of 2D HT is presented in
Figure 3. The subfigure in the first line presents the point set of a target region,
. It shows that the point of a target tracklet and a few false alarm points exist. In the second line, the maps of HT in X axis-time, Y axis-time, and Z axis-time are present. The target region in each 2D HT map (
,
and
) is highlighted by a red circle. As is presented in the three subfigures in the third line, the points which were voting for the target region in each 2D HT map are extracted, i.e.,
,
, and
. In the three point sets, both the target points and a few false alarm points are included. At the bottom of
Figure 3, the intersection of three point set, also the obtained track, is presented. It shows that all the target points are detected in the track
, and false alarm points have been filtered out.
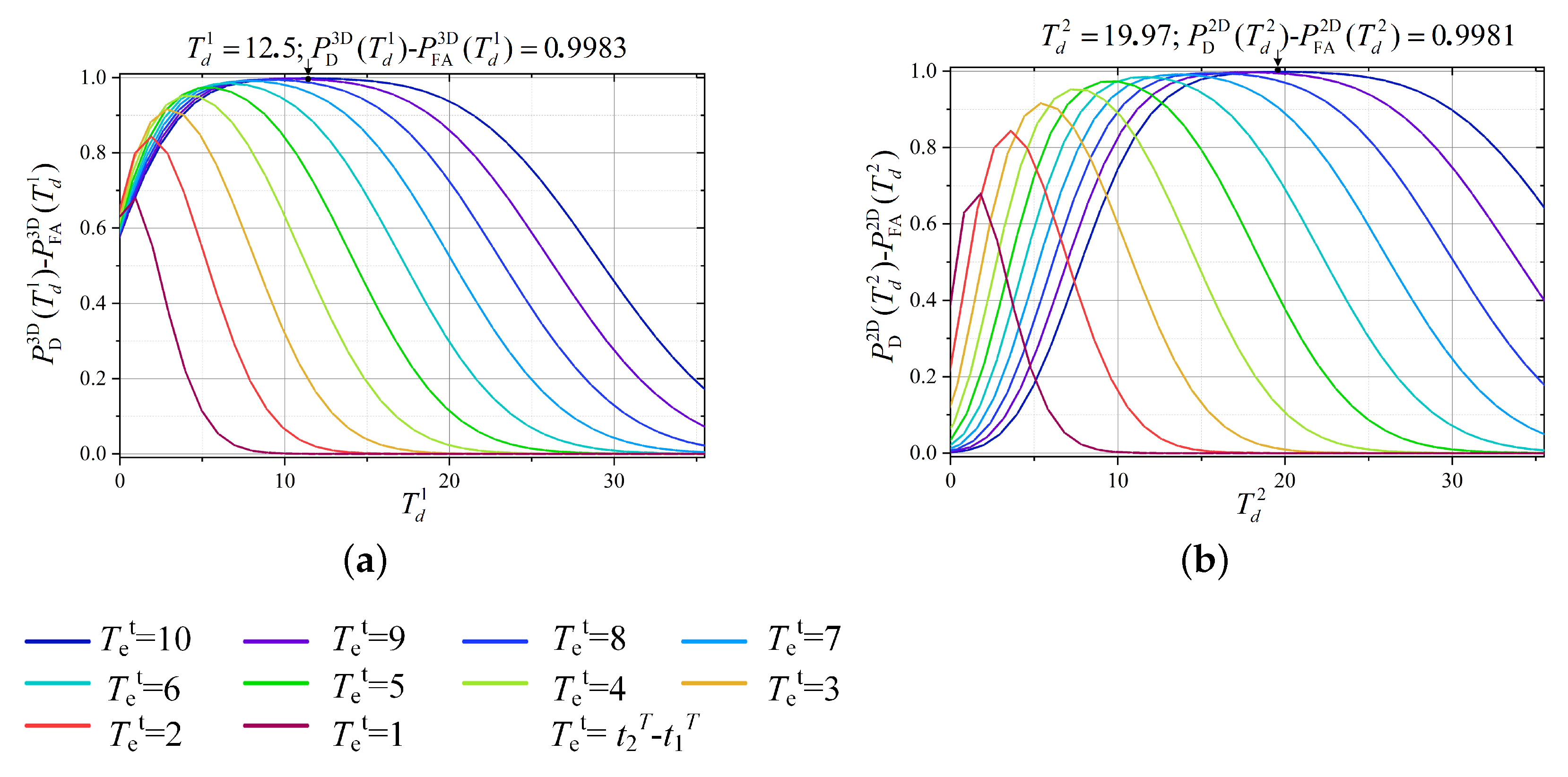
3.6. Discussion of Thresholds
The tracking performance is closely related to the detection thresholds
in (
16) and
in (
21). The optimal values of the two thresholds are decided by the parameters of targets and measurement environment.
The
is applied to confirm the candidate target region in the 3D voting process. The optimal threshold
can be defined by (
42) according to (
30) and (
31)
The track is easier to be detected if more target points and fewer clutter points are voting for the cell, i.e.,
In (
43),
and
are the constants in the radar system. The
,
, and
are related to targets and measurement environment and are out of our control. The
should match with the measurement position error of radar systems, otherwise not all the target points would vote for the cell. Therefore, the most simple approach to improve the target track detection performance is to enhance the time period, i.e.,
. However, it is worth noting that the discussion in this section is built on the target model in (
17). Therefore, a very large value of
is unsuitable because the target may be maneuvering during
to
. The (
43) also proves that the merit of track-before-detect method comes from accumulating the target “votes” according to the target motion model during a long enough time.
The
is applied to confirm the candidate target region in the 2D voting process. Similarly, the optimal threshold
can be defined by
With using and , a high target track detection rate and a very low false alarm track rate can be achieved at the same time.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}