1. Introduction
Object detection of remote sensing images plays an important role in military and national defense. With object detection techniques, the categories and positions of military objects can be obtained, and the battlefield situation and environment can be evaluated. Since the 1990s, remote sensing image object detection has also played an important role in civilian fields, such as the detection of vehicles and buildings, serving urban road planning, parking lot site selection, and traffic management.
Convolutional neural networks have moved object detection to a new level. Since traditional object detection methods perform badly both in detection precision and rate, researchers have begun to study object detection methods based on deep learning. The core of deep learning-based object detection methods is the convolutional neural network. Compared with traditional feature extraction methods, convolutional neural networks have unique characteristics of weight sharing, local connection, and down-sampling. These decrease the number of parameters and perform well in feature extraction. Commonly used feature extraction networks include VGG-16 [
1], GoogleNet [
2], and AlexNet [
3]. With the advent of the residual block, deeper convolutional networks have emerged, such as ResNet [
4] and DenseNet [
5]. Deep networks can extract features with more semantic information, and ResNet is well known in the object detection field.
The network used in the object detection method based on deep learning can be divided into a single-stage detection method and two-stage detection method, according to different implementation methods. The two-stage detection method, which is based on area recommendation, first extracts some regions of interest (RoIs) that may contain objects, and then classifies and regresses bounding boxes. The precision is higher than that of the single-stage method, but the detection rate is lower. The first proposed two-stage detection network was the Region-based Convolutional Neural Network (R-CNN) [
6]. Based on R-CNN, more typical area-based object detection networks have been proposed, including Fast R-CNN [
7], Faster R-CNN [
8], R-FCN [
9], Mask R-CNN [
10], and Cascade R-CNN [
11].
The single-stage methods are based on regression and classification. They generate a series of bounding boxes at various positions on the image, and predict and classify them, without generating RoIs in advance [
12,
13,
14]. Typical regression-based object detection networks mainly include YOLO (You Only Look Once) [
15], SSD (Single Shot Multi-Box Detector) [
16], and RetinaNet [
17]. Based on the YOLO network, the extended object detection networks include YOLOv2 [
18] and YOLOv3 [
19]. The improved networks based on SSD are DSOD [
20], RFBNet [
21], ASSD [
22], etc. In addition, G-CNN [
23] and AttentionNet [
24] are also commonly used single-stage object detection networks.
However, compared to objects of natural images, objects of remote sensing images have greater scale diversity, arbitrary directivity, and dense arrangement. In response to these problems, predecessors used methods of feature fusion, extracting rotation invariant features, using oriented detection bounding boxes, designing double detection heads, and so on, to reconstruct the prior network model.
To detect scale diversity objects, in 2016, Lin et al. proposed the classic feature pyramid network (FPN) [
25]. An FPN provides more feature maps for objects with various scales by feature fusion. Based on the FPN, more networks were proposed by reconstruction. In 2019, Chen et al. proposed the scene-contextual feature pyramid network (SCFPN), which detected objects by fusing the whole image’s feature map with the proposal box’s feature [
26]. In 2020, Qian et al. proposed a remote sensing image object detection method based on multilevel feature fusion [
27].
For the arbitrary directivity problem, some researchers tried to design rotated anchors in a region proposal network (RPN) and extract rotation invariant features. In 2018, Li et al. proposed a contextual feature fusion network with rotation invariance [
28]. By generating multiscale anchor frames based on RPN, multiangle anchor frames were added to detect oriented objects. In 2020, Zhang et al. proposed a double network [
29], which contained multiple CNN channels, where each channel was responsible for a specific rotation direction. However, designed anchors cannot involve all angles, and many anchors need too much calculation, which leads to a low detection rate. Other researchers began to improve the method by changing the regression method or turning the regression problem into a classification problem. In 2019, Ding et al. proposed an RoI converter to achieve oriented object detection [
30]. By converting the horizontal region of interest (HRoI) into a rotated region of interest (RRoI), based on the RRoIs, a rotational position-sensitive RoI Align module was proposed. It was used to extract rotation-invariant features. In August 2019, Yang et al. proposed a novel multiclass oriented detector SCRDet (small, cluttered, and rotated detector) [
31], which was suitable for detection of small, dense, and rotating objects. In 2020, Fu et al. built a fused framework based on a two-stage convolutional neural network for arbitrary directions and multiscale object detection in remote sensing images [
32]. In this paper, a rotation-aware object detector is constructed, which uses an oriented frame to locate objects in remote sensing images. In 2021, Xu et al. proposed a simple and effective framework to detect directional objects [
33]. The network used Faster R-CNN as the backbone network and realized oriented bounding box detection by regressing four sliding offsets and a tilt factor. In 2021, Yang et al. proposed an end-to-end refined single-stage rotation detector, R3Det [
34], to quickly and accurately locate objects. In the text detection field, the rotational region convolutional neural network (R2CNN) is an effective and simple network [
35].
Previous studies have found that the features of interest are different for classification tasks and localization tasks. Therefore, predecessors solved this problem by assigning different detection heads to the different tasks. In 2020, Wu et al. proposed a double head structure [
36], which used a fully connected head for the classification task and a convolutional head for the localization task. The convolutional head was made of one residual block, some bottleneck blocks [
4], and the same number of nonlocal blocks [
37]. In this paper, the authors also fused the classification scores from double heads. Song et al. proposed a simple operator called task-aware spatial disentanglement (TSD) [
38]. TSD decouples classification and regression from the spatial dimension by generating two disentangled proposals for them, which are estimated by the shared proposal.
In our experiments, we validated that the R2CNN network cannot perform well for slender objects with arbitrary directivity. Furthermore, the convolutional head requires calculation and leads to a low detection rate. Moreover, it is difficult to train. Therefore, this paper proposes a simple and effective network for oriented object detection in remote sensing images, namely TPR-R2CNN, which is based on a double fully connected head structure and a three-point regression method. The proposed TPR-R2CNN network applies a double fully connected head for classification and localization. One head is followed by a classification layer and a horizontal bounding box regression layer, and the other is followed by a classification layer and an oriented bounding box regression layer. The three-point regression method is used in the oriented bounding box regression layer, which is a fully connected layer, to regress the center point’s coordinate and two vertices’ coordinates of the bounding box. The main contributions of this paper are as follows:
- (1)
The paper applies a double fully connected head with classification fusion, one for classification and horizontal bounding box regression tasks, the other for classification and oriented bounding box regression tasks. The outputs of the two classification layers are fused as the final classification score.
- (2)
The paper proposes a three-point regression method (TPR) to enhance the detection precision for remote sensing objects, which are slender and have arbitrary directions. The new regression method increases the fault tolerance rate of the detection network.
We performed comparative experiments to validate the proposed method. Extensive experimental results from the DOTA-v1.5 and HRSC2016 datasets showed better performance of our detector than the regression method of the R2CNN network. The paper is organized as follows.
In
Section 2, we detail the proposed method, including the backbone, the basic algorithm of TPR, the structure of the double detection head, and the new loss function based on TPR. In
Section 3, we detail the experiments, including the introduction and preprocessing of the DOTA-v1.5 and HRSC2016 datasets, the evaluation metrics, and the parameter settings in the training process.
Section 4 presents the results of our method compared to R2CNN and analyzes the results on two datasets. Finally, we discuss the limitations of the proposed method and suggest future research directions.
Section 5 concludes the paper.
2. Proposed Method
The basic network structure diagram of the proposed TPR-R2CNN is shown in
Figure 1. An oriented box regression layer was set parallel to the classification layer and the horizontal box regression layer. A double head structure was used in the detection stage. The double fully connected head was made of two single fully connected heads, one of which was followed by a classification layer and the horizontal bounding box regression layer, while the other was followed by a classification layer and oriented box regression layer. The outputs of these classification layers were added together as the final result, which was then put into the Softmax function to calculate the scores. The structures of different detection heads will be explained in detail in
Section 2.3.
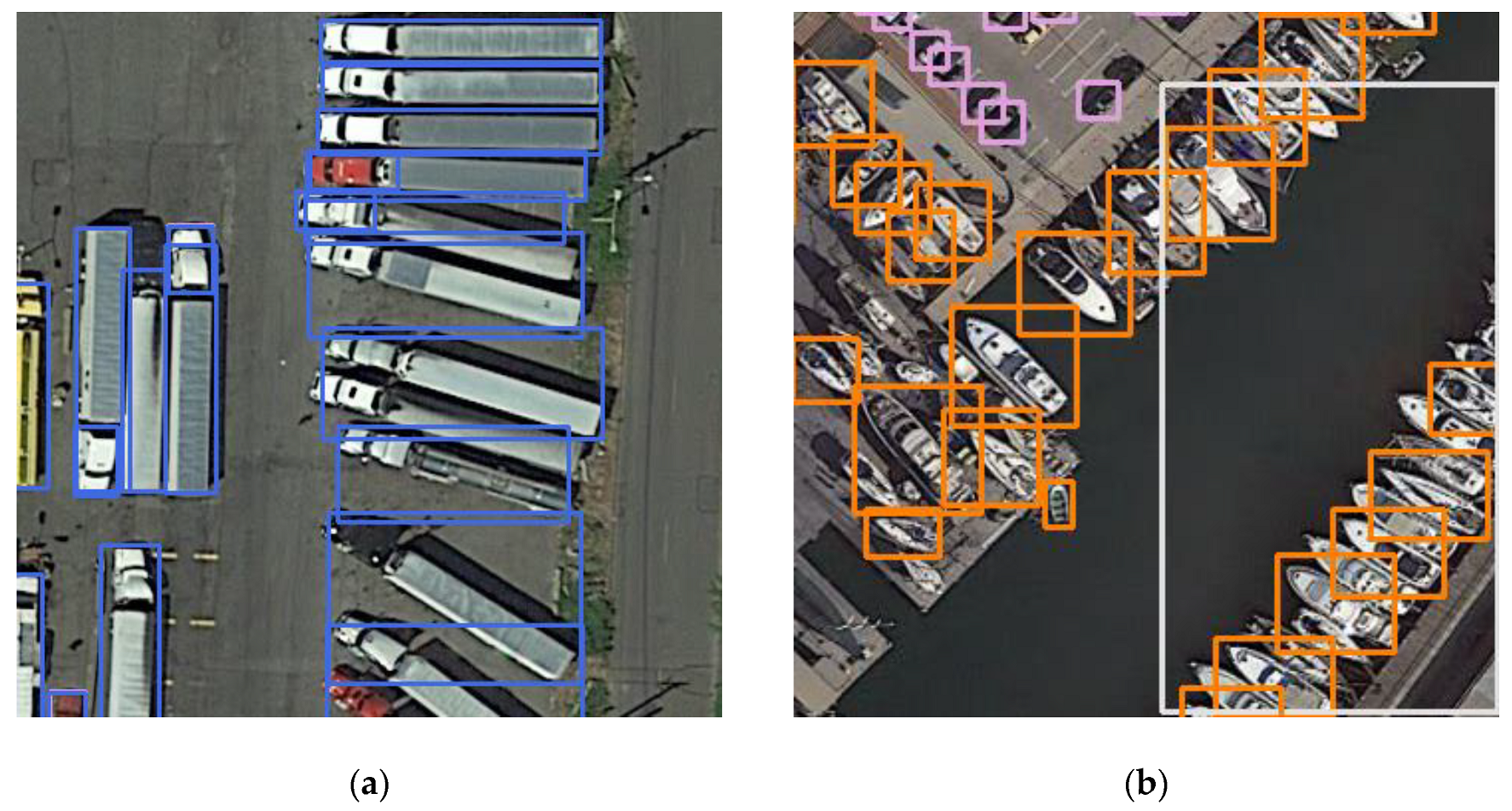
We proposed this detection method because using a horizontal box for detection has certain drawbacks. A horizontal box contains some redundant information for oblique objects, and it cannot accurately represent the position of all kinds of objects. In the final non-maximum suppression (NMS) stage, for slender and densely arranged objects with arbitrary directivity, such as vehicles and ships, the correct bounding boxes may be deleted by mistake. This will result in a decrease in detection precision. As shown in
Figure 2, due to the influence of non-maximum suppression, the detection results miss some correct objects. Using an oriented bounding box for detection is an effective way to solve the problem.
In order to realize object detection with an oriented bounding box, researchers added some rotated anchor frames in the RPN stage. However, a large number of anchor frames caused a sharp increase in the amount of calculation and introduced difficulties in training and detecting. Then, researchers began to use the regression method for oriented object detection with oriented bounding boxes. R2CNN [
35] is an effective network for text detection. However, the regression method cannot perform very well in remote sensing object detection, especially for slender objects with arbitrary directions. Through our experiments, we showed that the problem was mainly caused by the original regression method, which is explained in detail in
Section 2.2.
2.1. Backbone
The oriented object detection network frame was based on the Faster R-CNN network. The backbone used in this research was ResNet-50 [
4] with FPN [
25]. The focus of the ResNet network is to propose a residual module, which can solve the problems of gradient disappearance and gradient explosion in ultra-deep networks. In addition, the ResNet network uses batch normalization (BN) instead of dropout, which speeds up the network training process.
As remote sensing objects have the characteristics of scale diversity, FPN was used in the network.
Figure 3 shows the basic structure of the FPN network, which mainly included three parts: a bottom-up feature extraction network, a top-down reconstruction of the feature pyramid path, and a horizontal feature connection path.
The bottom-up network produced feature maps of different sizes and levels. The low-level feature maps had higher resolution but contained low-level semantic information, and the high-level feature maps contained more abstract high-level features but lost resolution. The top-down path reconstructed larger feature maps by up-sampling. In the horizontal connection stage, the original feature map was operated by a 1×1 convolution layer, which could unify the number of feature map channels. Then, the feature map was added by element with the previous fused feature map, and the new fused feature map was obtained.
In this way, the fused feature maps
both had high resolution and deep semantic information to a certain extent. In the anchor setting,
correspond to the anchor scales of
, respectively. The corresponding level of feature map
is calculated by Equation (1):
where
is 4 and
and
are the width and height of the proposal, respectively.
2.2. Three-Point Regression
Based on the original Faster R-CNN network structure, this paper added an oriented bounding box regression layer in parallel to the final prediction layers. This oriented bounding box regression layer predicted the position offset information of the proposed horizontal boxes. The proposed network contained the regression layer of the horizontal box, because the authors of R2CNN [
35] pointed out that the existence of the horizontal bounding box regression layer can help improve detection precision. In the detection stage, the horizontal bounding box NMS processing was changed to oriented bounding box NMS processing, and the IoU threshold was set to 0.3.
Specifically, in the oriented bounding box regression stage, the R2CNN network predicted the coordinate offsets of the first two points (upper left corner and upper right corner) and the height of the oriented bounding box. This was effective for text detection with a small angle of tilt. However, objects of remote sensing images are often accompanied by large rotation angles, and the directions are arbitrary. For these objects, this method of regression had a low error tolerance rate in the detection stage.
On the one hand, even if the predicted two vertices were only slightly different from the vertices of the ground truth, the other two points’ coordinates could be quite different from the true value. That is because they rely on the rotated angle of the oriented box, the predicted vertices’ coordinates, and the height of the object. When the object has a large aspect ratio in shape, the greater height and a small angle deviation will cause a large deviation to the other two vertices. Hence, the predicted bounding box would probably be deleted.
Table 1 shows the IoUs of frames with different aspect ratios under various angles. When the aspect ratio reaches 4:1, the predicted bounding box will be deleted if the angle deviation is more than 10 degrees. As the aspect ratio increases, there are higher requirements for the positioning precision of the first two vertices.
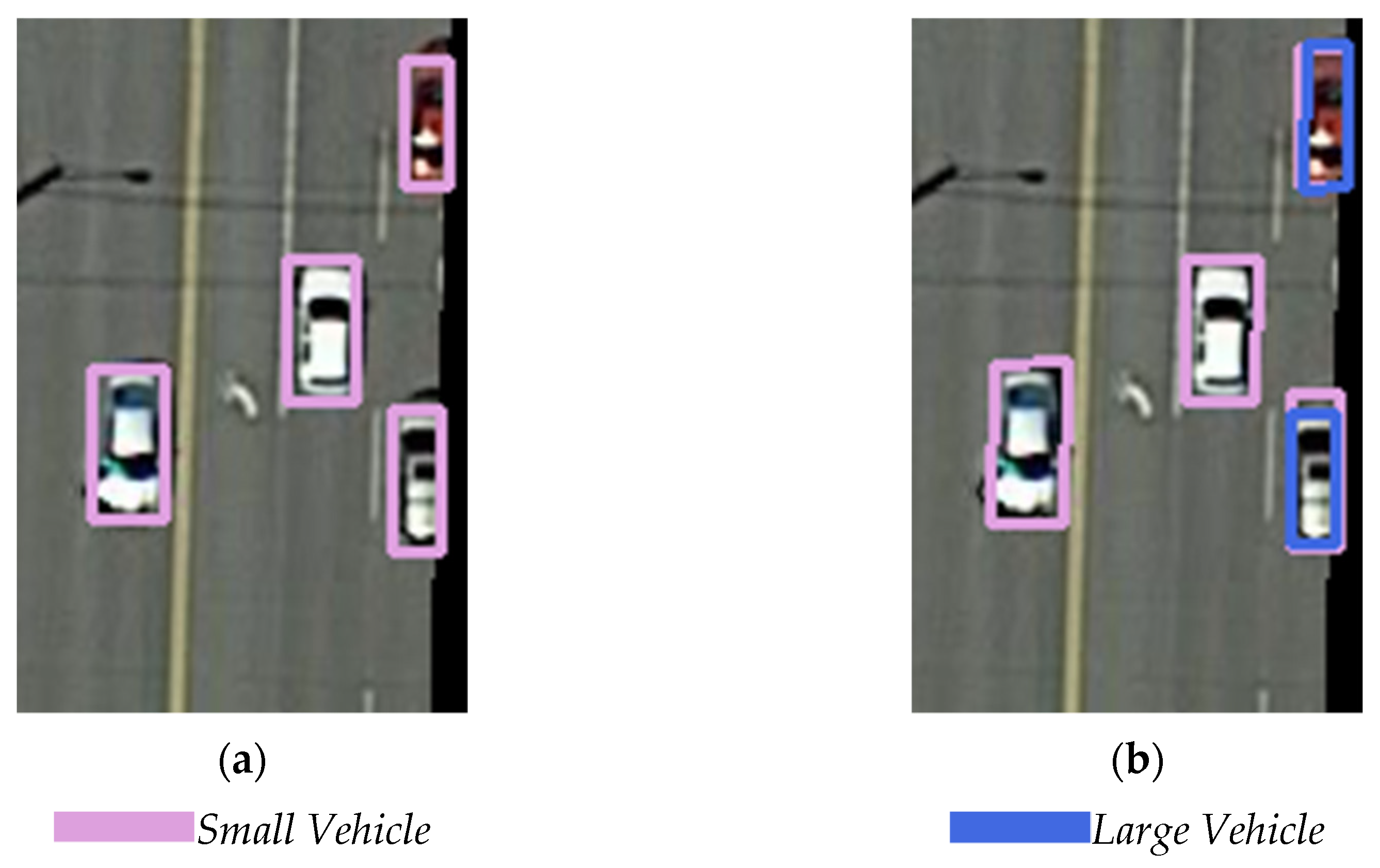
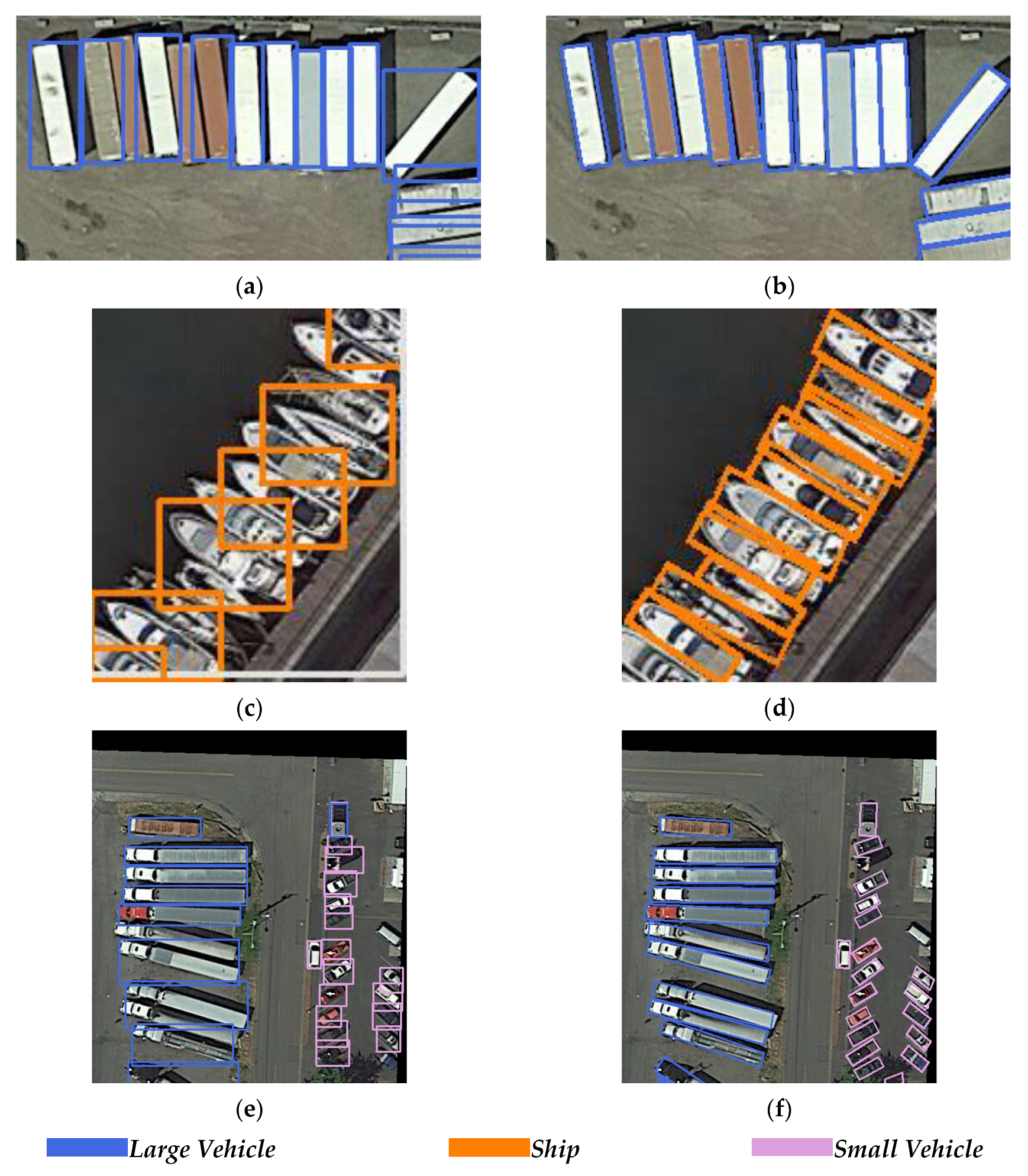
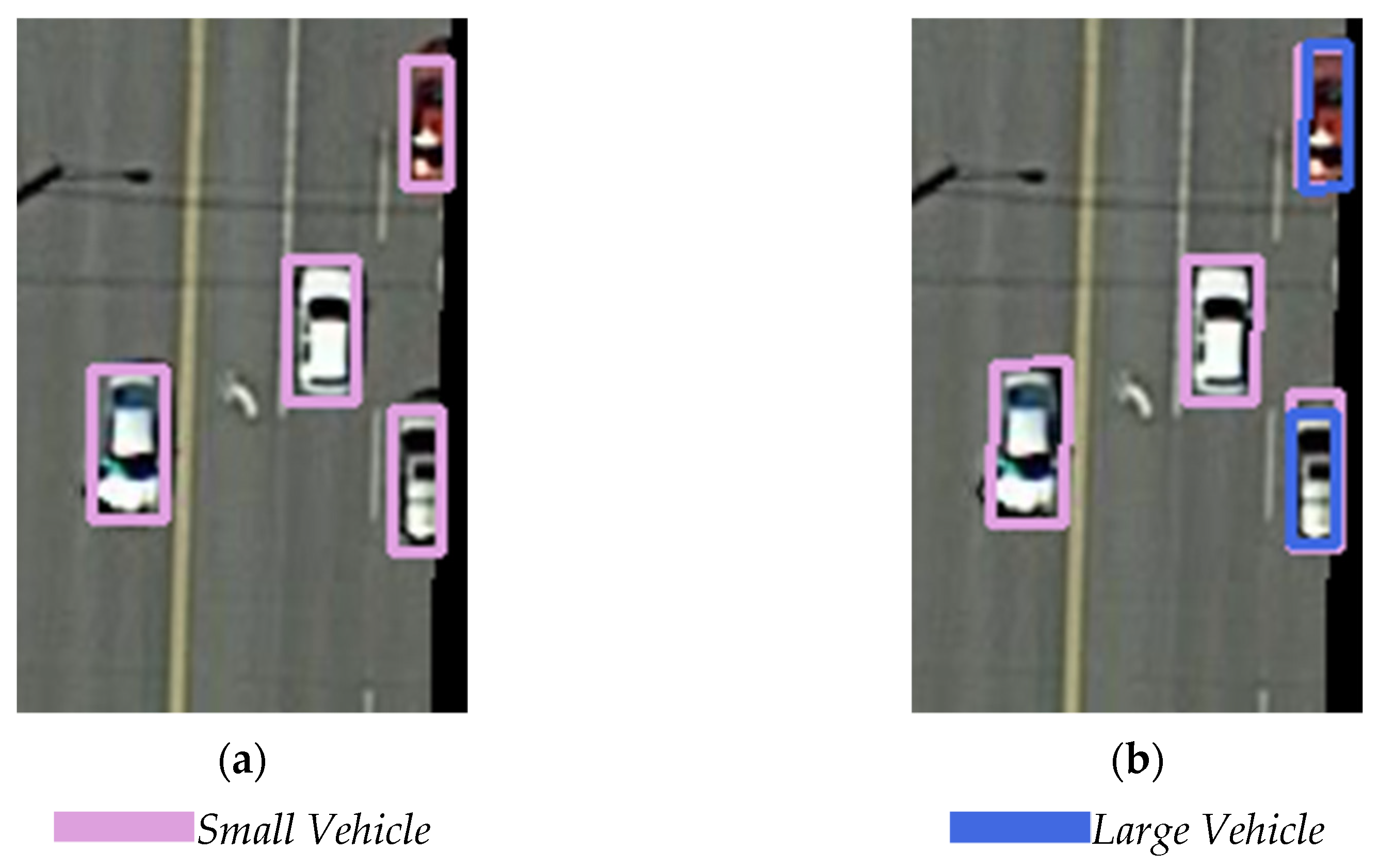
On the other hand, in some cases, the network may generate several predicted bounding boxes at various directions for one ground truth. The IoUs between them and the ground truth all reached 0.5, while the IoU values between some of them could not reach the 0.3 threshold, and then there was not one predicted bounding box generated for one object, thus decreasing the detection precision. This situation is shown in
Figure 4.
Figure 4a shows the detection result of R2CNN. For the same large vehicle object, two detection bounding boxes were generated, one of which was closer to the ground truth. The IoU value did not reach the threshold of 0.3, so the relatively incorrect predicted bounding box was not deleted.
In order to resolve this problem, we modified the original regression method by regressing the coordinates of the first two vertices and the coordinates of the center points. The coordinates of the other two vertices could be calculated from these three points. Once the coordinates of the center point were located, a small deviation of the vertices would not influence the location of the entire bounding box, and the fault tolerance was improved. Although the predicted bounding box might not be a standard rectangle, the precision of the position can be guaranteed to a certain extent, and the wrong boxes can be deleted easily through NMS processing. This regression method is named the three-point regression method (TPR).
Figure 4b shows an example of the detection result with TPR-R2CNN. Compared with R2CNN, the predicted position of this large vehicle was more precise.
2.3. Double Detection Head
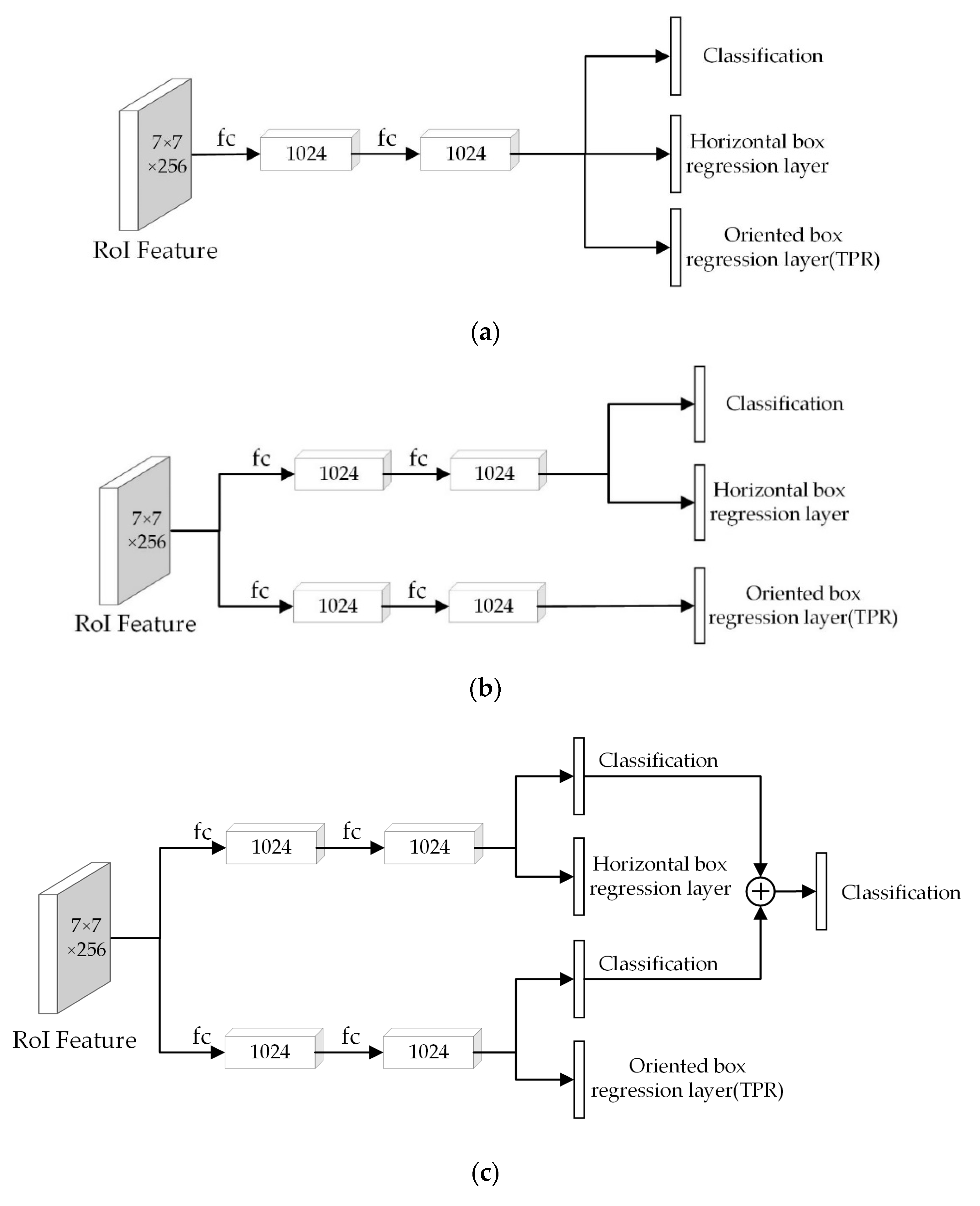
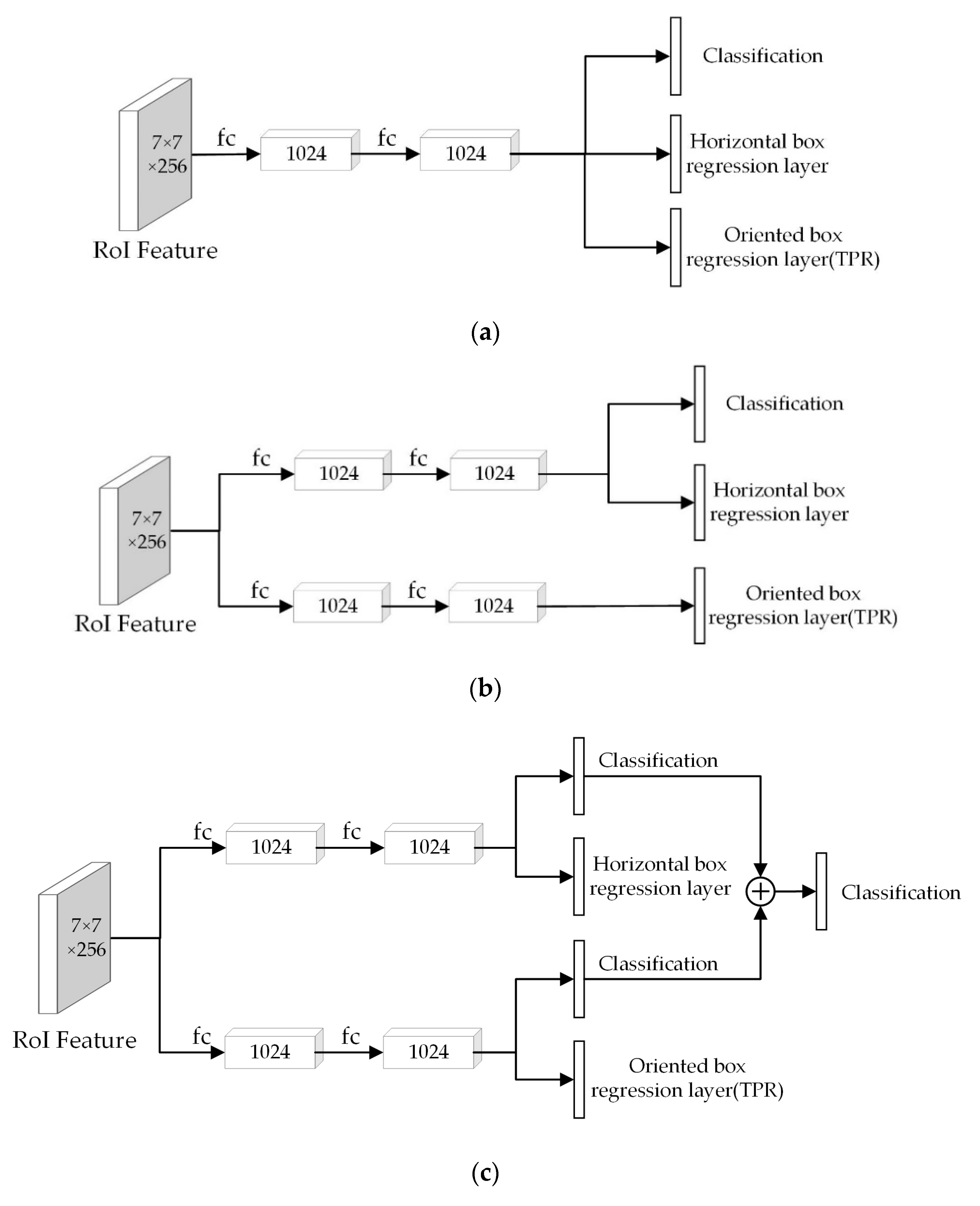
Figure 5 shows the structures of three different detection heads.
Figure 5a is the single fully connected head, which is made of two fully connected layers, with the size of 12,544 × 1024 and 1024 × 1024, respectively. In the single fully connected head structure, the classification layer, horizontal box regression layer, and oriented box regression layer share the one head.
Figure 5b shows the structure of the double fully connected head. It is made of two single fully connected heads, one of which is used for the oriented box regression task.
Based on the double fully connected head,
Figure 5c shows a new double fully connected head, which contains two classification layers. For each predicted bounding box, the outputs of the two classification layers were added element-wise to obtain a new output vector. The Softmax function was applied to the new vector to obtain the final classification score vector.
2.4. Loss Function
In this paper, the loss function is shown as in Equation (2). The total loss function consists of three parts: the first is the object classification loss, which uses the cross-entropy loss; the second is the horizontal box regression loss, which includes the regression loss of the center point coordinates and the width and height of the box; and the third is the newly added oriented box regression loss, including the regression loss of center point coordinates and the first two vertices’ coordinates.
,
, and
were set to 2, 1, and 1, respectively.
Here,
is the total loss function;
,
, and
are the loss functions of classification, horizontal bounding box regression, and oriented bounding box regression; and
is the number of proposals.
Here, is the kth element of the classification vector obtained by the classification layer, is the final classification score vector of the ith proposal, is the actual classification score vector, and is the number of categories. and are the predicted regression values of the ith proposal.
Specifically, the classification loss was calculated by Equations (3) and (4). Both the horizontal box and the oriented box regression loss were calculated using Smooth L1 Loss. The formulas for calculating the regression value of the oriented bounding box are shown in Equations (5) and (6):
where
and
are the width and height of the proposal and (
,
), (
,
), and (
,
) are the predicted coordinates of the first vertices and center point. (
,
), (
,
), and (
,
) are the coordinates of proposed bounding box.
In the calculation of the oriented bounding box regression loss, the weights of the six offsets in Equation (5) were set to 5, 5, 5, 5, 10, and 10. For the horizontal bounding box regression loss, the weights were set to 10, 10, 5, and 5.
3. Experiment
To evaluate the performance of the proposed method, we performed experiments on two publicly available and challenging datasets: the DOTA-v1.5 dataset [
12] and the HRSC2016 [
39] dataset. The dataset preprocessing, evaluation metrics, and training details are described in this section.
3.1. Dataset and Preprocessing
For the experiments, two datasets were chosen, DOTA-v1.5 and HRSC2016, for oriented bounding box object detection in aerial images.
3.1.1. DOTA-v1.5
The DOTA-v1.5 dataset contains 2806 remote sensing images and 403,318 instances, covering 16 categories: airplane, ship, storage tank, baseball diamond, tennis court, basketball court, ground track field, harbor, bridge, small vehicle, large vehicle, helicopter, roundabout, football field, swimming pool, and container crane. DOTA-v1.5 is an updated version of DOTA-v1.0. Both of them use the same aerial images but DOTA-v1.5 has revised and updated the annotation of objects, where many small object instances about or below 10 pixels that were missed in DOTA-v1.0 have been additionally annotated. In addition, DOTA-v1.5 added the category of container crane. Consistent with DOTA-v.1.0, the images in DOTA-v1.5 mainly came from China’s resource satellites Jilin-1, Gaofen-2, and Google Earth. The width and height of the DOTA-v1.5 images range from 800 to 4000 pixels, and the spatial resolution is 0.1 m to 4.5 m. It is divided into a training set, validation set, and test set, according to the ratios of 1/2, 1/6, and 1/3, respectively.
In the dataset, the position of each instance is represented by a quadrilateral bounding box. The bounding box can be expressed as “x1, y1, x2, y2, x3, y3, x4, y4”. The vertices are arranged in clockwise order. For the horizontal box, the starting point is the upper left vertex, and for the oriented box, the starting point is the front left vertex in the physical sense of the object. Through experiments, we found this method of labeling was hard to train. Therefore, in our experiments, we set the point that was the nearest to the upper left vertex of the horizontal bounding box as the starting point, and the vertices were arranged in clockwise order.
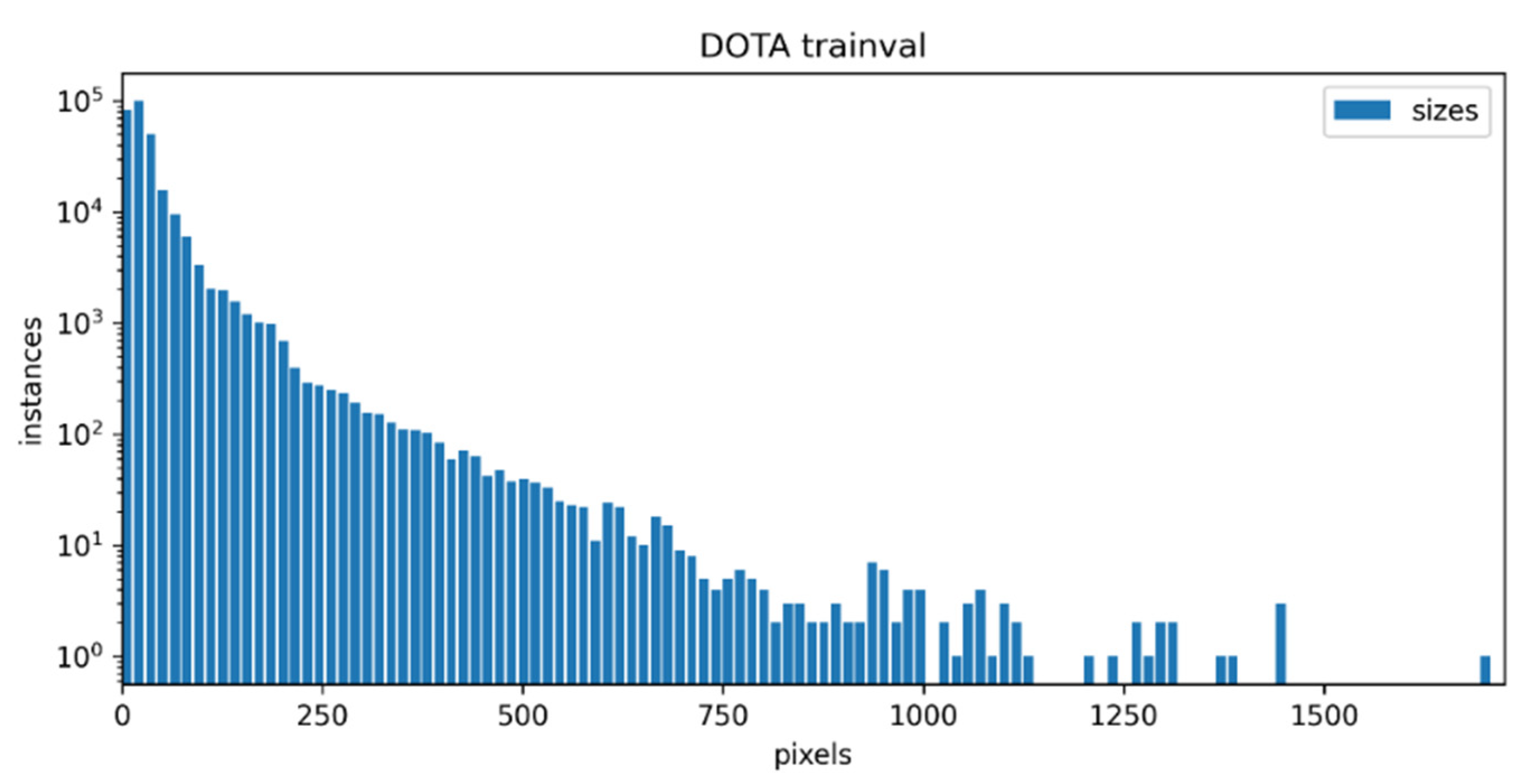
We used the training set in the dataset for training and the validation set for testing and evaluating the network. We separately counted the size information of all objects in the training set and validation set, according to the horizontal bounding boxes. As shown in
Figure 6, the object sizes of the training set and validation set of DOTA-v1.5 were concentrated within 200 pixels, the number of small targets was large, and the proportion was high. There were nearly 100,000 small objects within 15 pixels of DOTA-v1.5, and the smallest object area was only 8 square pixels.
For the DOTA-v1.5 dataset, the sizes of most images were too large. Considering the problem of memory occupation, the original images were split into 800 × 800 patches with a stride of 640. Because both the horizontal and the oriented boxes’ information of objects needed to be used, we comprehensively considered the selection criteria of the cropped horizontal boxes and the oriented boxes. We ensured that the horizontal boxes of the objects in the cropped images corresponded to the label information of the oriented boxes one by one, and we contained the cropped objects with areas more than 90% of the original total area. The number of images after splitting was 20,287, among which there were 15,340 images in the training set and 4947 images in the validation set, respectively.
In the horizontal box and directed box labeling information, the incorrect labeling information with an area of 0 was uniformly eliminated. Then, the annotation format of the picture was converted to Pascal VOC format, which contained the information on the horizontal frame and the directed frame. The horizontal annotations were expressed in the form of “(xmin, ymin), (xmax, ymax)”, and the oriented annotations were expressed in the form of “x1, y1, x2, y2, x3, y3, x4, y4”, which was different from DOTA-v1.5. In the original labeling method of the data set, the coordinates of the starting point here were unified as the coordinates of the top-left vertex, rather than the “top-left corner” in the physical sense. Similarly, the DOTA-v1.5 data set images were also standardized before being sent to the model. During the training process, half of the training images were also randomly flipped for data augmentation.
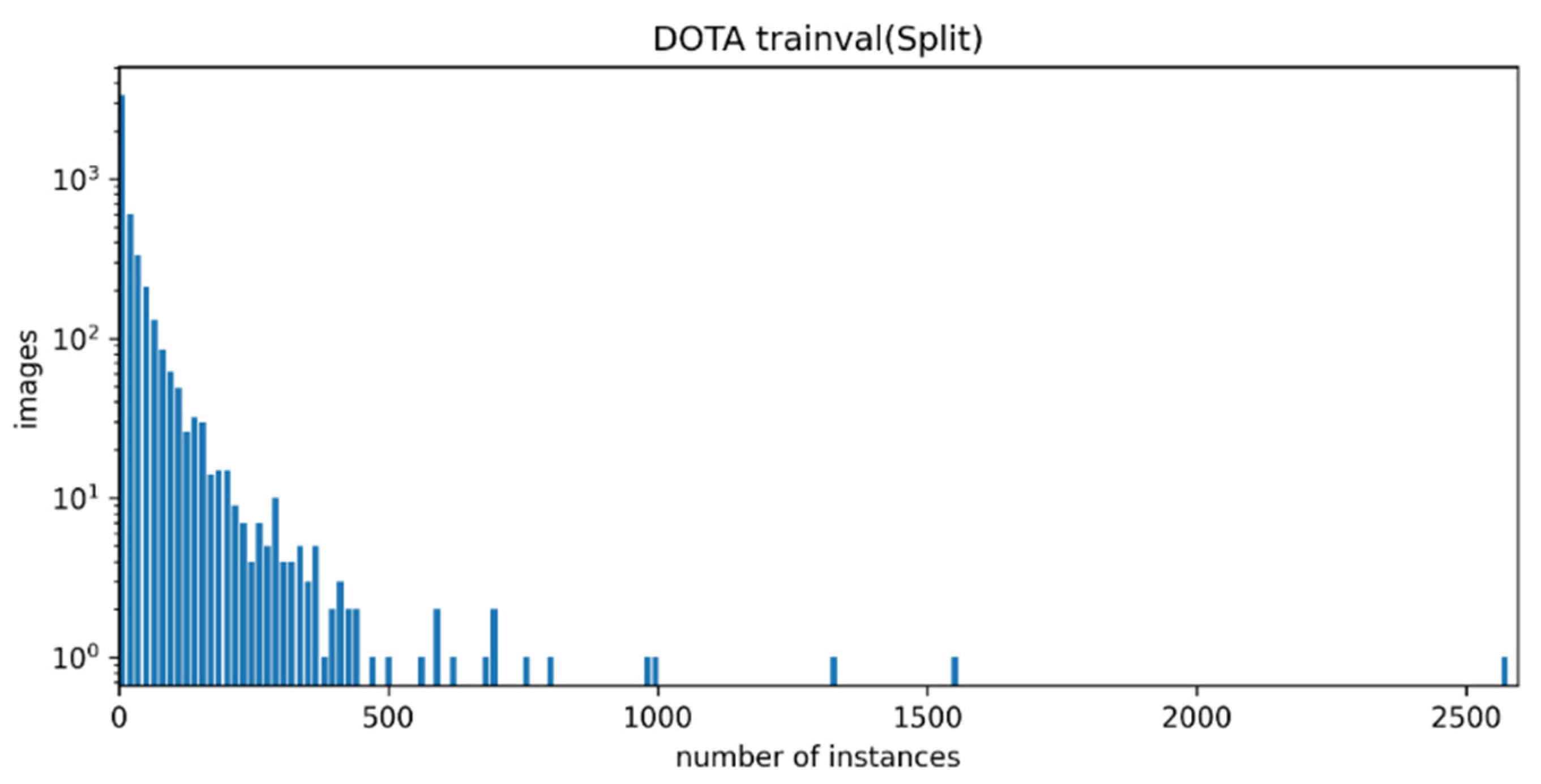
After the preprocessing of the DOTA-v1.5 dataset, the number of objects contained was counted in each image of the dataset, as shown in
Figure 7. The abscissa was the number of objects in each image, the interval was 15, and the ordinate was the number of images.
3.1.2. HRSC2016
The HRSC2016 dataset contains images from two scenarios, including ships at sea and ships inshore. The images were collected from Google Earth. The images sizes range from 300 × 300 to 1500 × 900, and most of them are larger than 1000 × 600. There are more than 25 types of ships with large varieties in scale, position, rotation, shape, and appearance. The training and validation datasets in our experiments contained 617 images and 438 images, respectively. For data augmentation, we adopted horizontal flipping. The images were resized to (512, 800), where 512 represents the length of the short side and 800 the maximum length of an image.
3.2. Evaluation Metrics
Object detection accuracy evaluation indicators include the missing alarm rate (MAR), false alarm rate (FAR), average precision (AP), and mean average precision (mAP) for all categories. These metrics are related to each other.
The precision reflects the number of positive samples that are found and correct, and the recall reflects how many positive samples are found. By setting different confidence thresholds, multiple sets of precision and recall can be obtained, which can be calculated from
Table 2 and Equation (7).
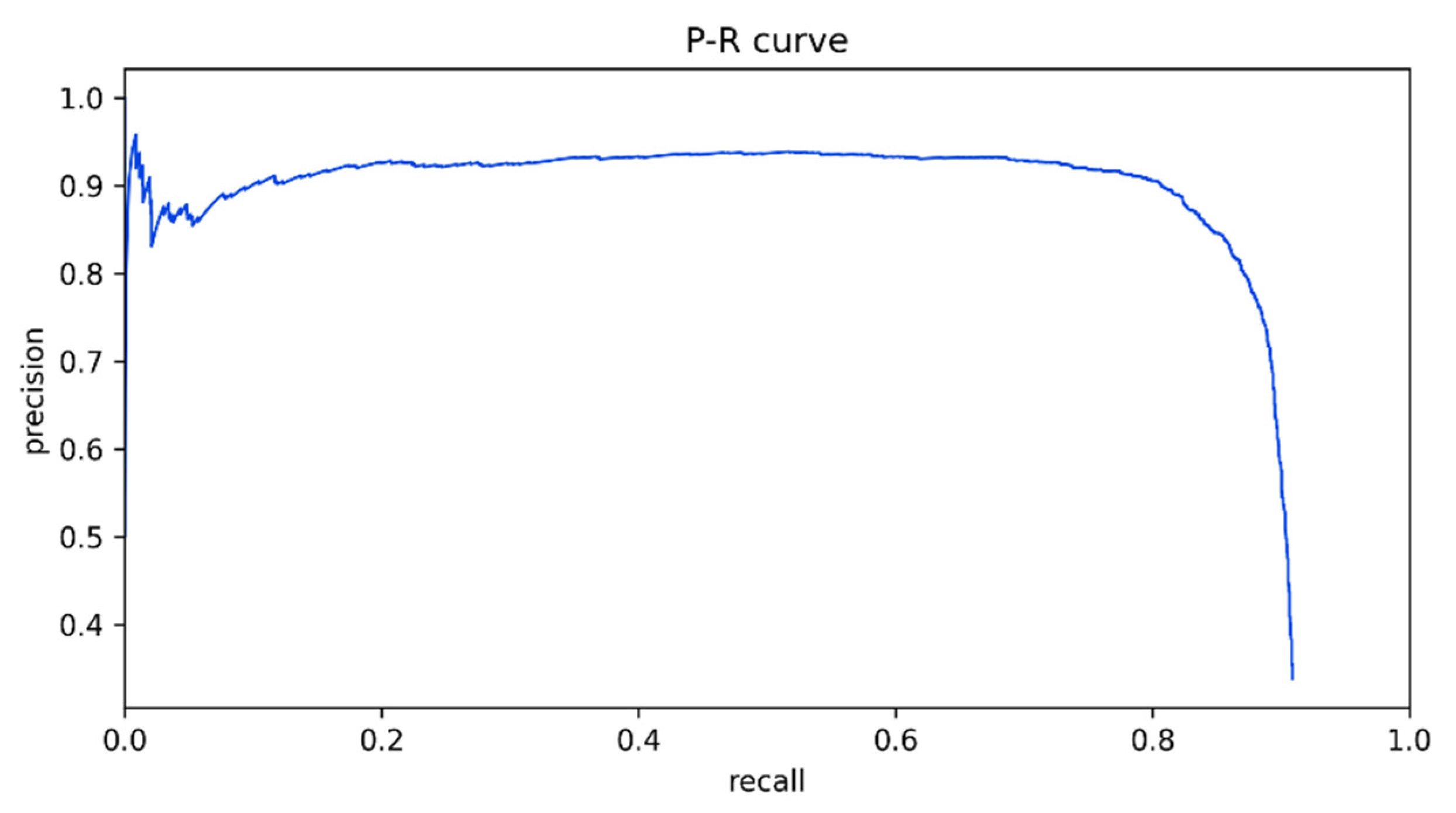
The P–R (precision–recall) curve was composed of recall values, which formed the horizontal axis, and precision values, which formed the vertical axis, as shown by
Figure 8. Integrating the P–R curve, the average precision (
AP) value was calculated. However, in practical applications, integrating the P–R curve is not commonly used; smoothing the P–R curve is more common. Specifically, for each point on the P–R curve, the value of precision takes the value of the greatest precision on the right side of the point, as shown in Equation (8). mAP is the average of the average precisions of all categories.
The evaluation metrics used in this paper were AP and mAP. The classification standard for positive and negative samples is whether the IoU value reaches 0.5. If the IoU value between the predicted box and any ground truth is greater than 0.5, the predicted box is classified as a positive sample; otherwise, it is a negative sample.
In this research, the object detection speed evaluation metrics were the number of images detected per second (FPS, frames per second), which was calculated on a graphics card. Specifically, the model time was used to evaluate the detection effectiveness of this model.
where
is the P–R curve and
AP is the average precision.
3.3. Training Details
The experiments in this paper were trained on a server, which had an RTX3090 GPU with 24 GB RAM. This research used the pretrained weights, which were trained on ImageNet. In the training processing, the low-level weights conv1 and conv2_x in ResNet-50 were frozen, and only the high-level weights were trained.
During the training process, the batch size (the number of images input to the network each time) was set to 8 and 16 for the DOTA-v1.5 dataset and HRSC2016 dataset, respectively, and the batch size of RPN was set to 256. The optimizer was the stochastic gradient descent method with momentum, and the momentum was set as 0.9, which is commonly used; the initial learning rate was set to 0.005. When the validation loss was stable or over-fitting occurred, the learning rate was reduced to 1/3 of the original. After the mAP value stabilized, the training was stopped. In the validation stage, the objects with confidence above 0.05 were contained.
For the DOTA-v1.5 dataset, there were 8000 RoIs from RPN before NMS and 2000 RoIs after NMS processing. We used 3 aspect ratios for anchors. After oriented bounding box NMS (IoU threshold = 0.3), the maximum number of detection boxes retained per image in the DOTA-v1.5 dataset was 2000. For HRSC2016, there were 8000 RoIs from PRN before NMS and 1000 RoIs after NMS. The aspect ratios of anchors were set to , because there were more aspect ratio variations in HRSC2016. For the DOTA-v1.5 and HRSC2016 datasets, the maximum numbers of detection boxes retained per image were 2000 and 100.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}