
Optimal Grid-Based Filtering for Crop Phenology Estimation with Sentinel-1 SAR Data


Abstract
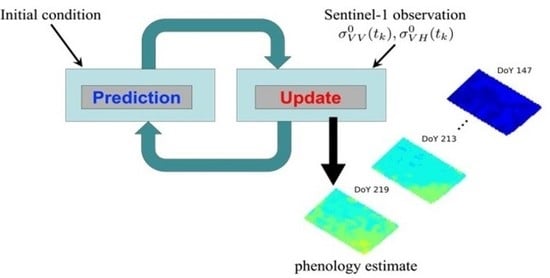
1. Introduction
2. Methodology
2.1. Background
- 1.
- Neither modeling and , nor making assumptions on the noise distributions is required.
- 2.
- Considering phenology as a discrete and finite state variable, the proposed GBF approach is the only method to provide optimal phenology estimates. In contrast, when dealing with continuous variables, EKF and PF are approximate nonlinear BF that provide suboptimal estimates [26].
- 3.
- The transition matrix is a widely used formulation in many fields (robotics, speech recognition, bioinformatics, etc.). This general framework is simpler to implement than EKF and PF algorithms. In addition, it is straightforward to train the prediction model in real time by updating the transition probabilities.
2.2. Grid-Based Filter for SAR-Based Phenology Estimation
2.3. GBF Modeling
2.3.1. Initial Distribution
2.3.2. Prediction Model
2.3.3. State Space
2.3.4. Observation Model
3. Test Site and Data Sets
3.1. Ground Campaign Data
3.1.1. BBCH Scale of Rice
3.2. Sentinel-1 Data and Processing
- 1.
- Apply orbit files.
- 2.
- Thermal noise removal.
- 3.
- Subset to the area of interest.
- 4.
- Radiometric calibration to backscattering coefficient ().
- 5.
- Speckle filter: IDAN with window size equal to 20.
- 6.
- Conversion from linear to dB.
- 7.
- Orthorectification (step named Terrain Correction in SNAP) to a cartographic grid with pixel size equal to 10 m.
4. Experiments
4.1. Testing and Training Data
4.2. GBF Modeling
4.2.1. Initial Distribution
4.2.2. Prediction Model and State Space
- 1.
- Interpolation. For each parcel of each training year, since ground data are provided on a weekly basis, we assume local linearity between phenology and time. Accordingly, the measured BBCH stages are linearly interpolated to obtain values on a one-day basis.
- 2.
- Discretization. The interpolated values are discretized to obtain values belonging to the BBCH scale (see Table 3).
- 3.
- Computation of the one-day transition probabilities. The discretized BBCH stages are used to compute the probability of transiting from stage to stage in one day, . For a given stage , the total number of parcels transiting to among all the training years is considered. Then, is given by (17).
4.2.3. Observation Model
- 1.
- Interpolation. For each parcel of each training year, the measured BBCH stages are linearly interpolated to obtain the BBCH codes at the radar acquisition dates.
- 2.
- Discretization. The interpolated values are discretized to obtain values belonging to the BBCH scale.
- 3.
- Stacking. For each polarimetric channel, the values of all the pixels extracted from the parcels polygons of all the training years are stacked according to the discretized stages. These stacked values are the training samples of the backscattered powers at each stage of the BBCH scale.
- 4.
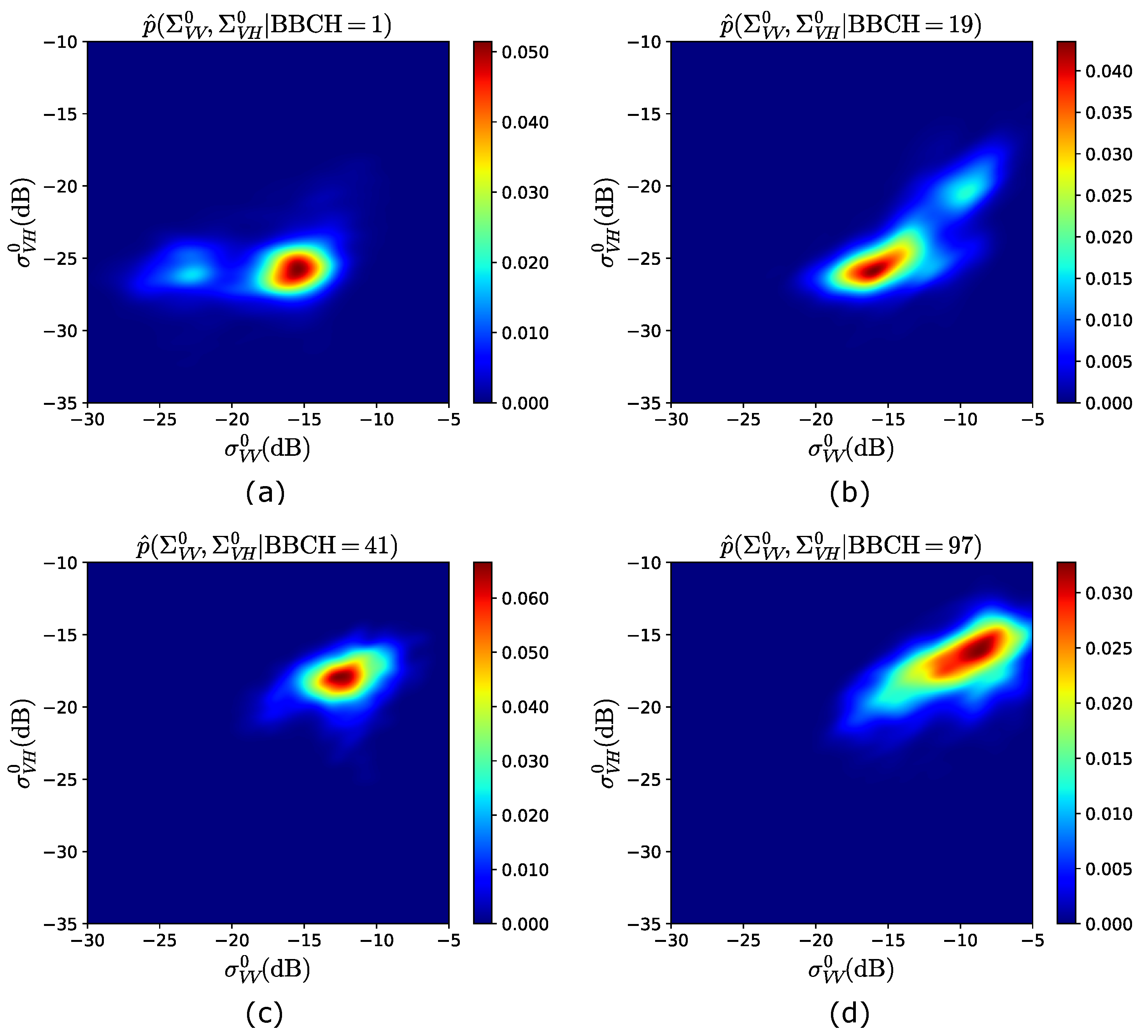
- KDE. For each BBCH stage, KDE (15) is applied to these samples to estimate the joint pdf of and , using the multivariate Gaussian kernel [29] to model . This results in estimated pdfs, i.e.; , . This set of distributions consists of the observation model to be used when the GBF is implemented on the testing data.
4.3. GBF Implementation
4.4. Estimation Results
5. Discussion
5.1. Analysis of the Estimation Performance
5.2. Illustration of Pixel-Level Phenology Estimates
6. Conclusions
- When rice fields are at stages BBCH 1–40, on average, the final estimation, provided by the S1 observation through the likelihood (update step), outperforms the prediction.
- For years 2017–2019, the within fields variability detected by GBF, more pronounced at stages BBCH 40–80, is in agreement with the heterogeneous development present in ground data.
- Due to the recursive nature of the filter, worse estimates at a given time could severally affect the estimations at successive time epochs. This is especially true at approximately BBCH 40–80, where the extinction phenomena caused by the elongating vertical stems might affect the likelihood function and then result in large estimation errors.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Atzberger, C. Advances in Remote Sensing of Agriculture: Context Description, Existing Operational Monitoring Systems and Major Information Needs. Remote Sens. 2013, 5, 949–981. [Google Scholar] [CrossRef]
- FAO. GIEWS Update-Bangladesh. GIEWS. 2017. Available online: https://www.fao.org/3/i7876e/i7876e.pdf (accessed on 21 October 2021).
- Liu, F.; Chen, Y.; Shi, W.; Zhang, S.; Tao, F.; Ge, Q. Influences of agricultural phenology dynamic on land surface biophysical process and climate feedback. J. Geogr. Sci. 2017, 27, 1085–1099. [Google Scholar] [CrossRef]
- Steele-Dunne, S.C.; McNairn, H.; Monsivais-Huertero, A.; Judge, J.; Liu, P.; Papathanassiou, K. Radar Remote Sensing of Agricultural Canopies: A Review. IEEE J. Sel. Topics Appl. Earth. Observ. Remote Sens. 2017, 10, 2249–2272. [Google Scholar] [CrossRef]
- Mestre-Quereda, A.; Lopez-Sanchez, J.M.; Vicente-Guijalba, F.; Jacob, A.W.; Engdahl, M.E. Time-Series of Sentinel-1 Interferometric Coherence and Backscatter for Crop-Type Mapping. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2020, 13, 4070–4084. [Google Scholar] [CrossRef]
- Yang, H.; Pan, B.; Li, N.; Wang, W.; Zhang, J.; Zhang, X. A systematic method for spatio-temporal phenology estimation of paddy rice using time series Sentinel-1 images. Remote Sens. Environ. 2021, 259. [Google Scholar] [CrossRef]
- Mandal, D.; Kumar, V.; Ratha, D.; Dey, S.; Bhattacharya, A.; Lopez-Sanchez, J.M.; McNairn, H.; Rao, Y.S. Dual polarimetric radar vegetation index for crop growth monitoring using Sentinel-1 SAR data. Remote Sens. Environ. 2020, 247, 2020. [Google Scholar] [CrossRef]
- European Space Agency. Sentinel-1 User Handbook; European Space Agency: Paris, France, 2013. [Google Scholar]
- Joint Research Center. Concept Note: Towards Future Copernicus Service Components in Support to Agriculture? Available online: https://www.copernicus.eu/sites/default/files/2018-10/AGRI_Conceptnote.pdf (accessed on 15 September 2021).
- Lopez-Sanchez, J.M.; Cloude, S.R.; Ballester-Berman, J.D. Rice phenology monitoring by means of SAR polarimetry at X-band. IEEE Trans. Geosci. Remote Sens. 2012, 50, 2695–2709. [Google Scholar] [CrossRef]
- Lopez-Sanchez, J.M.; Vicente-Guijalba, F.; Ballester-Berman, J.D.; Cloude, S.R. Estimating phenology of agricultural crops from space. In ESA Living Planet Symp.; European Space Agency: Edinburgh, UK, 2013; ESA-SP 722. [Google Scholar]
- Lopez-Sanchez, J.M.; Vicente-Guijalba, F.; Ballester-Berman, J.D.; Cloude, S.R. Polarimetric response of rice fields at C-band: Analysis and phenology retrieval. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2977–2993. [Google Scholar] [CrossRef]
- Yang, Z.; Li, K.; Liu, L.; Shao, Y.; Brisco, B.; Li, W. Rice growth monitoring using simulated compact polarimetric C band SAR. Radio Sci. 2014, 49, 1300–1315. [Google Scholar] [CrossRef]
- Mascolo, L.; Lopez-Sanchez, J.M.; Vicente-Guijalba, F.; Mazzarella, G.; Nunziata, F.; Migliaccio, M. Retrieval of phenological stages of onion fields during the first year of growth by means of C-band polarimetric SAR measurements. Int. J. Remote Sens. 2015, 36, 3077–3096. [Google Scholar] [CrossRef]
- Yuzugullu, O.; Erten, E.; Hajnsek, I. Rice growth monitoring by means of X-band co-polar SAR: Feature clustering and BBCH scale. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1218–1222. [Google Scholar] [CrossRef]
- Lopez-Sanchez, J.M.; Vicente-Guijalba, F.; Ballester-Berman, J.D.; Cloude, S.R. Influence of incidence angle on the coherent copolar polarimetric response of rice at X-band. IEEE Geosci. Remote Sens. Lett. 2015, 12, 249–253. [Google Scholar] [CrossRef]
- Mascolo, L.; Lopez-Sanchez, J.M.; Vicente-Guijalba, F.; Nunziata, F.; Migliaccio, M.; Mazzarella, G. A complete procedure for crop phenology estimation with PolSAR data based on the complex Wishart classifier. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6505–6515. [Google Scholar] [CrossRef]
- Kucuk, C.; Taskin, G.; Erten, E. Paddy-rice phenology classification based on machine-learning methods using multitemporal co-polar X-band SAR images. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2016, 9, 2509–2519. [Google Scholar] [CrossRef]
- Vicente-Guijalba, F.; Martinez-Marin, T.; Lopez-Sanchez, J.M. Crop phenology estimation using a multitemporal model and a Kalman filtering strategy. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1081–1085. [Google Scholar] [CrossRef]
- Vicente-Guijalba, F.; Martinez-Marin, T.; Lopez-Sanchez, J.M. Dynamical approach for real-time monitoring of agricultural crops. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3278–3293. [Google Scholar] [CrossRef]
- De Bernardis, C.; Vicente-Guijalba, F.; Martinez-Marin, T.; Lopez-Sanchez, J.M. Estimation of key dates and stages in rice crops using dual-polarization SAR time series and a particle filtering approach. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2015, 8, 1008–1018. [Google Scholar] [CrossRef]
- De Bernardis, C.; Vicente-Guijalba, F.; Martinez-Marin, T.; Lopez-Sanchez, J.M. Contribution to real-time estimation of crop phenological states in a dynamical framework based on NDVI time series: Data fusion with SAR and temperature. IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens. 2016, 9, 3512–3523. [Google Scholar] [CrossRef]
- McNairn, H.; Jiao, X.; Pacheco, A.; Sinha, A.; Tan, W.; Li, Y. Estimating canola phenology using synthetic aperture radar. Remote Sens. Environ. 2018, 219, 196–205. [Google Scholar] [CrossRef]
- De Bernardis, C.; Vicente-Guijalba, F.; Martinez-Marin, T.; Lopez-Sanchez, J.M. Particle Filter Approach for Real-Time Estimation of Crop Phenological States Using Time Series of NDVI Images. Remote Sens. 2016, 8, 610. [Google Scholar] [CrossRef]
- Grewal, M.S.; Andrews, A.P. Kalman Filtering: Theory and Practice Using MATLAB, 2nd ed.; Wiley: Hoboken, NJ, USA, 2001. [Google Scholar]
- Arulampalam, M.S.; Maskell, S.; Gordon, N.; Clapp, T. A tutorial on particle filters for online nonlinear/non-Gaussian Bayesian tracking. IEEE Trans. Signal Process. 2002, 50, 174–188. [Google Scholar] [CrossRef]
- Meier, U. (Ed.) Growth Stages of Mono- and Dicotyledonous Plants. BBCH Monograph, 2nd ed.; Federal Biological Research Centre for Agriculture and Forestry: Braunschweig, Germany, 2001. [Google Scholar]
- Bowerman, B.L. Nonstationary Markov Decision Processes and Related Topics in Nonstationary Markov Chains. Ph.D. Thesis, Iowa State University, Ames, IA, USA, 1974. [Google Scholar]
- Minnotte, M.C.; Sain, S.R.; Scott, D.W. Multivariate Visualization by Density Estimation. In Handbook of Data Visualization; Chen, C., Härdle, W., Unwin, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; pp. 389–416. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Filter | Prediction/Observation Model | Noise Model | Optimality |
|---|---|---|---|
| KF | Linear equation | Gaussian | Optimal |
| EKF | Linearization | Gaussian | Sub-optimal |
| PF | Curve fitting | No restriction | Sub-optimal |
| Grid-based filter | No restriction | No restriction | Optimal |
| Year | Number of Parcels | Ground Measurements |
|---|---|---|
| 2009 | 6 | 115 |
| 2010 | 7 | 151 |
| 2011 | 6 | 114 |
| 2013 | 6 | 131 |
| 2014 | 6 | 135 |
| 2015 | 4 | 77 |
| 2016 | 7 | 142 |
| 2017 | 7 | 134 |
| 2018 | 7 | 141 |
| 2019 | 5 | 101 |
| 2020 | 6 | 121 |
| Total | 67 | 1362 |
| Principal Growth Stage | Secondary Growth Stages (BBCH Codes) |
|---|---|
| 0: Germination | 00, 01, 03, 05, 06, 07, 09 |
| 1: Leaf development | 10–19 |
| 2: Tillering | 21–29 |
| 3: Stem elongation | 30, 32, 34, 37, 39 |
| 4: Booting | 41, 43, 45, 47, 49 |
| 5: Inflorescence emergence, heading | 51–59 |
| 6: Flowering, anthesis | 61, 65, 69 |
| 7: Development of fruit | 71, 73, 75, 77 |
| 8: Ripening | 83, 85, 87, 89 |
| 9: Senescence | 92, 97, 99 |
| Experiment No. | Testing Year | Training Years for the Prediction Model (Available Ground Data) | Training Years for the Observation Model (Available S1 Data) |
|---|---|---|---|
| 1 | 2020 | 2009–2019 | 2017, 2018, 2019 |
| 2 | 2019 | 2009–2018, 2020 | 2017, 2018, 2020 |
| 3 | 2018 | 2009–2017, 2019, 2020 | 2017, 2019, 2020 |
| 4 | 2017 | 2009–2016, 2018–2020 | 2018, 2019, 2020 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mascolo, L.; Martinez-Marin, T.; Lopez-Sanchez, J.M. Optimal Grid-Based Filtering for Crop Phenology Estimation with Sentinel-1 SAR Data. Remote Sens. 2021, 13, 4332. https://doi.org/10.3390/rs13214332
Mascolo L, Martinez-Marin T, Lopez-Sanchez JM. Optimal Grid-Based Filtering for Crop Phenology Estimation with Sentinel-1 SAR Data. Remote Sensing. 2021; 13(21):4332. https://doi.org/10.3390/rs13214332
Chicago/Turabian StyleMascolo, Lucio, Tomas Martinez-Marin, and Juan M. Lopez-Sanchez. 2021. "Optimal Grid-Based Filtering for Crop Phenology Estimation with Sentinel-1 SAR Data" Remote Sensing 13, no. 21: 4332. https://doi.org/10.3390/rs13214332
APA StyleMascolo, L., Martinez-Marin, T., & Lopez-Sanchez, J. M. (2021). Optimal Grid-Based Filtering for Crop Phenology Estimation with Sentinel-1 SAR Data. Remote Sensing, 13(21), 4332. https://doi.org/10.3390/rs13214332