2.1. Improved Conditional Entropy Model
Target detection can be expressed as the following hypothesis testing problem:
where
and
represent clutter and target components, as shown in Equation (
1), the part containing only background clutter is verified by hypothesis
. On the contrary,
represents that the region is composed both of targets and clutter. Under the condition that the observed ground features is
, the hypothesis testing process is expressed as the ratio of posterior probabilities as follows:
where
is the detection threshold, when the ratio on the left is not less than the threshold, accept
, otherwise accept
. However, the posterior probability may be very complex in the real problem, so the following changes can be obtained from Bayesian formula:
Under the assumption that the features of the region are only represented by the scattering intensity, and the scattering of pixels is independent. We can use Equation (
3) to represent the target detection problem. On the basis of LRT model, some models such as self-information and relative entropy (Equation (
4)) are also proposed, which can be directly used for target detection.
where
.
is the number of pixels corresponding to the
l-th gray scale in the area, which defines as
, for
.
is the final pixel set of the
n-th superpixel defined as
.
is the background normalized histogram.
However, Information entropy models (including self information and relative entropy) all take the whole superpixel area as background or target for calculation, which does not conform to the actual situation. In fact, part of the target’s superpixels contain both target and background pixels, and the whole histograms are mixed by target and background distributions. Therefore, the deviation caused by background distribution may reduce the detection effect. Aiming at this problem, we propose an improved conditional entropy model.
Under the target hypothesis
, the pixel whose scattering gray scale is greater than the threshold
is regarded as the target, and the number of these pixels is denoted as
. Then the normalized histogram can be composed of the histograms of background and target.
where
and
, respectively, represent normalized background and target pixels histogram. For Equation (
5), We can calculate the number of background pixels in the
L-th gray scale from the first item of denominator
. Similarly, the second item of denominator
represents the number of target pixels in the
L-th gray scale. After adding the two items, we can get the number of all pixels in the
L-th gray scale. Then, divide it by the total number of pixels, we can get the result
.
When Equation (
5) is substituted into Equation (
4), the addition term is difficult to be decomposed from the logarithm. Besides,
is an unknown parameter. Therefore, it is difficult to directly use the joint histogram to simplify the relative entropy.
To solve this problem, it is assumed that some pixels in the region whose scattering gray level is greater than a certain threshold belong to the target, and their total number is . In addition, under the assumption of target, the interference of background distribution can be properly ignored while the distribution of target are focused.
Therefore, the statistical features of regional scattering are expressed as piece-wise functions, where the gray level greater than the threshold is represented as the target histogram, otherwise it means the background histogram, and the latter is replaced by the histogram of the whole background region:
where
.
For most of the SAR images, the scatterings of targets are often stronger than those of the background, so the above model can approximate the target area. The choice of two parameters,
and
, is crucial to the effectiveness of the model. In order to analyze the influence of
on relative entropy detection, the segmented histogram is introduced into Equation (
4).
Equation (
7) shows that the relative entropy of the piece-wise histogram can be transformed into the sum of the two terms: The first term is the partial relative entropy
of
target pixels, which is called conditional entropy; The other term is equivalent to the binomial distribution entropy
of
. The specific expressions of the two are as follows:
The two terms in the above equation are functions of and .
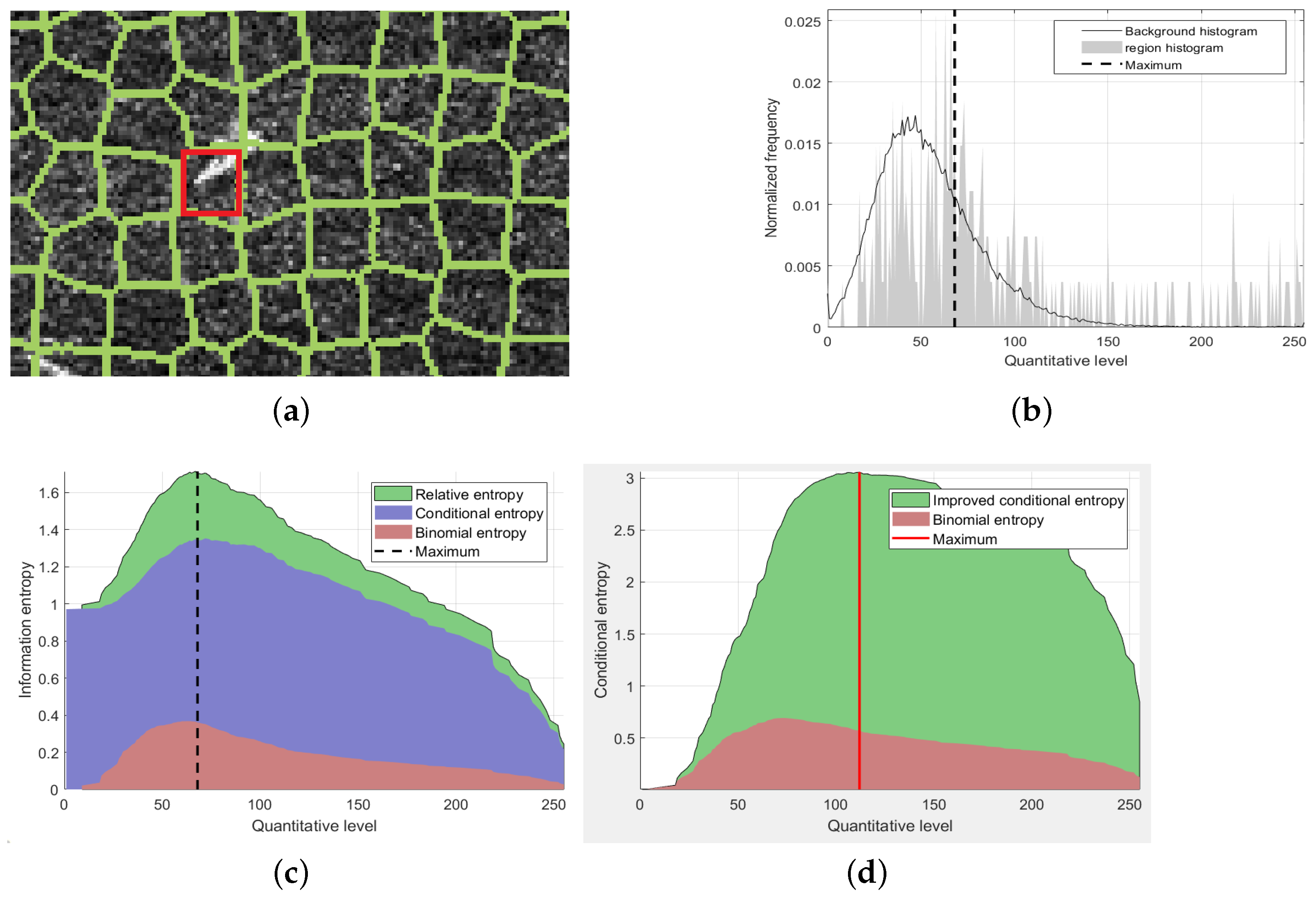
In order to further analyze the change law of the two functions, the values of the above equation are calculated for the target super-pixel shown in the red box in
Figure 2a. The brighter pixels in the region belong to the target, while the rest of them are backgrounds. In
Figure 2b, the gray area shows the normalized histogram of this area, and the black curve shows the normalized histogram of the whole SAR image. The horizontal axis quantitative level means 256 gray scales. Therefore,
Figure 2b shows the frequency of pixels in each gray level. In
Figure 2c, the horizontal axis is the value of
, while the vertical axis is the corresponding conditional entropy,
, and the sum of them. When
is the quantization level on the leftmost side of the horizontal axis, the corresponding ordinate value is the relative entropy. With the increase of
, it can be seen that both conditional entropy and
will increase at first but then decrease, and the maximum value of the sum is reached from the position shown by the vertical line in
Figure 2c.
Besides, it can be shown from Equation (
8) that when
,
reaches the maximum value, which means that this item will potentially make the target pixels close to the number of background pixels. Reflected in the figure, the position of the maximum value in the red area represents that the proportion of target and background is the same. In
Figure 2c, this position is very close to the maximum position (the vertical line), indicating that the maximum position is also close to
. However, in
Figure 2a, in the red box, the target area is significantly less than the background areas. Therefore, this result is inaccurate. In fact, in the normal image region, the pixel proportion of the target and the background are rarely equal. Thus, the binomial entropy
, which is independent of the target, can be ignored. This section proposes an improved model for conditional entropy. The result is shown in the
Figure 2d.
Firstly, the conditional entropy is simplified by referring to the method in literature [
20], the number of quantization levels that satisfying the condition
and
are set as
q. So we can substitute
for the original conditional entropy, and ignore the effect of
. At the same time, the coefficient
of the original conditional entropy has a strong constraint on its value, which results in
approaching
. Therefore, we add the logarithmic term
as the coefficient. The final improved conditional entropy model is shown as (
9):
The improved conditional entropy is still a function of
or
. Similar to the analysis of the relative entropy,
is taken as a parameter to calculate the maximum value of the improved condition entropy, and the corresponding
is obtained as:
is taken as the Maximum Likelihood Estimation (MLE) [
29,
30] result of the number of target pixels, and the maximum value is defined as
. This value will maximize the LRT of the target superpixel.
In the experiment of the same superpixels in
Figure 2a, the value of the improved conditional entropy is shown in
Figure 2d. The quantization level corresponding to the maximum value is shown by the red vertical line. Compared with the position of the maximum value in
Figure 2c,
is more shifted to the right side, that is, less than
, which is closer to the real proportion of the target pixel in the super-pixel region.
In order to make the description simple, the conditional entropy in the following refers to the function . For the scattering features of superpixel region, the proposed piece-wise histogram takes into account the mixing of target and background, which is more consistent with the actual situation, and the scattering features of the target and the background are further enhanced.
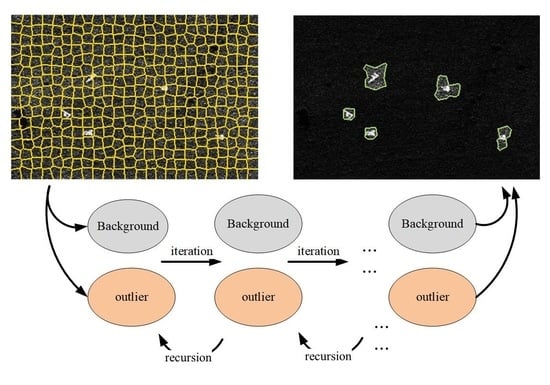
2.2. Iterative Outlier Detection
Although the conditional entropy of superpixels can be directly applied to discriminate targets and backgrounds, the detection effect is affected by two factors: the selection of detection threshold and background region. The former determines the detection performance, while the latter is related to the measure of conditional entropy and the accuracy of detection. The problem is that the prior information of both is usually unknown. In order to improve the adaptability of the detection algorithm, iterating outlier detection is proposed in this section. In each iteration, the background region is adjusted according to the last detection result, and the relative detection threshold also changes due to the change of background, so the results of multiple iterations can realize an effective background selection and detection threshold design.
Generally speaking, most of the superpixels in SAR images belong to the background, while there are only a small number of target superpixels. When the background is a uniform ground scene, and its scattering also satisfies the homogeneity assumption, then the overall background region and the local background superpixel have similar scattering statistical features. Based on these two assumptions, the conditional entropy of most of the superpixels in SAR image also satisfies the similarity, while only a small number of background and target superpixels do not have the similarity. These special pixels are called outliers. Therefore, a simple statistical outlier detection method is adopted, which centers on the mean value of all the superpixel conditional entropy and expresses the deviation degree by its standard deviation. The detection process of outliers is as follows:
(1) Select the background area and use its histogram to calculate the conditional entropy ;
(2) Calculate the sample mean
and variance
of conditional entropy in this set;
(3) Normalize the conditional entropy;
(4) Detect outliers based on threshold
.
A suitable threshold is set to distinguish background from outliers. When the left side of the above equation is greater than or equal to , the -th superpixel is considered to be an outlier, otherwise it belongs to the background.
In general, single outlier detection has the advantages of simplicity and high efficiency, but it may face two difficulties when detecting complex high-resolution SAR images: (1) when the imaging region contains multiple types of ground objects, the superpixels of different scenes may cause the center of conditional entropy deviation. Because of this problem, some superpixels of the scene will be detected as outliers, forming a large number of false alarms; (2) The variance of conditional entropy of superpixels in complex scenes are larger, which leads to the decrease of conditional entropy after standardization.It is easy to cause missing detection.
In some CFAR detection algorithms [
31,
32], the iterative method is used to optimize the selection of background pixels. In these methods, with the increase of iterations, a growing number of pixels are detected as targets and excluded from the background area. This process gradually improves the accuracy of background estimation and helps to improve the detection effect. Therefore, for the background selection problem of single outlier detection, the iterative strategy is also applied.
Specifically, at the beginning of the iteration, the background may contain complex scenes and some target superpixels. Although the influence of them on the histogram may be small, the background area is still changed after detecting the partial segregating group value by the empirical threshold. In the subsequent iterations, the set of background superpixels will be gradually divided into outliers and background. The expected stop conditions will be achieved, until the maximum number of iterations, or when the number of new outliers is less than the set value.
We adopt the superposition strategy to realize iterative detection, that is, to assign label
to the superpixel. In the iteration, the label of the outlier is superimposed. Let the initial background be the set of all superpixels:
. The superscript indicates that the initial labels of the superpixels is all 0. In iterative detection, superpixels with the same label belong to the same background set, Outlier detection is performed on each set respectively, and the label of outlier superpixels is updated:
where
is used to achieve the division of background and outliers.
The label of the outlier increases by 1, indicating that the superpixel is added to the background set corresponding to the next label. Conversely, the label of the background superpixel remains the same. In addition, the label of any superpixel does not exceed the current iteration number i. Then, an iteration is completed after detecting outliers and updating the label for the background set with labels 0 to , respectively.
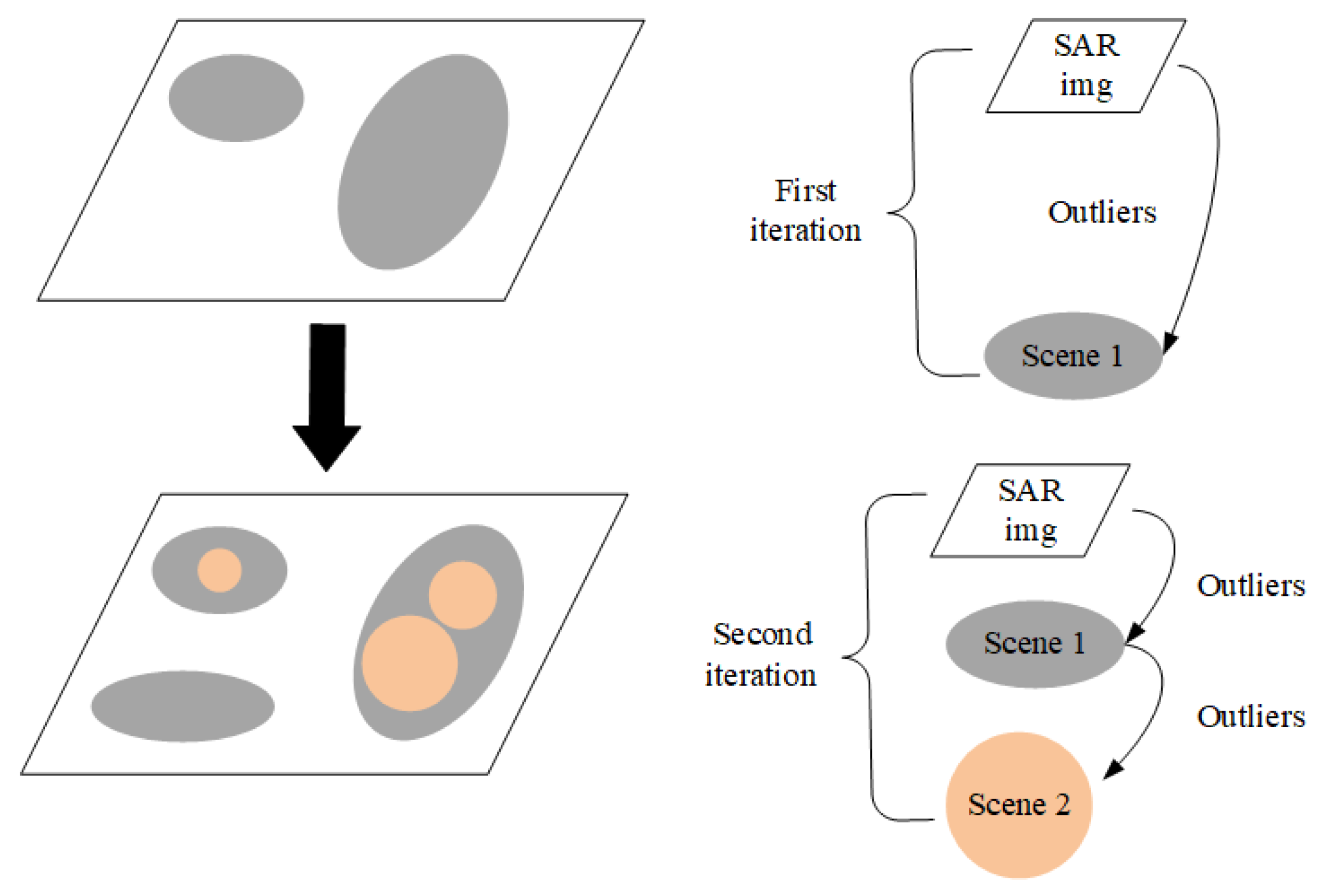
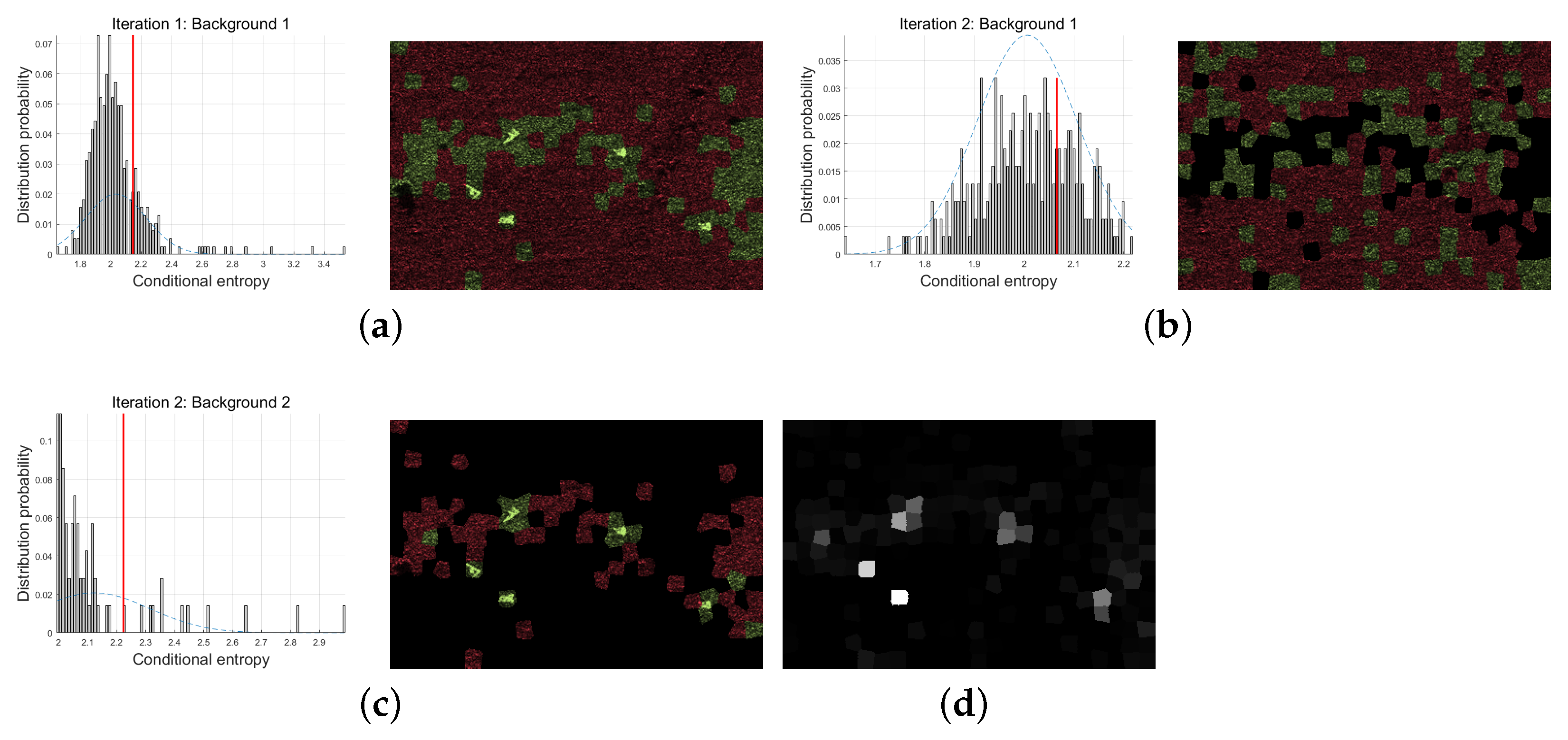
A simple example of two iterations is shown in
Figure 3. In the first iteration, the whole SAR image is taken as the background. As indicated in the brackets on the right, we use the white parallelogram to represent the whole SAR image. The detected outliers called Scene 1 are shown as the gray area (two gray ellipses) in the first parallelogram. In the second iteration, the region outside Scene 1 in the SAR image is taken as a background set. The outliers detected again are shown by the third gray ellipse in the lower left corner of the second quadrangle. Then, taking the corresponding area of Scene 1 as another background set, outliers are detected, as shown in the orange circles below the arrow. In the second iteration, when the outlier label is updated, ellipse in the the lower left corner of the right side is added to Scene 1. Then, the circles in ellipses are updated to Scene 2. Repeat the above process to achieve iterative outlier detection, we need to pay attention to update the outlier labels after finishing detection of each scene, so as to avoid changing the background set in a single iteration.
It can be seen from the above recursive method that the iterative detection based on superposition strategy has the following features:
(1) After outliers are detected and labeled, the complexity of background set is reduced;
(2) Adding outliers as a new background set is equivalent to a smaller outlier detection problem;
(3) After the superpixels of the target are detected as outliers for many times, their labels overlay is higher, which makes them more saliency than the background. Therefore, the superposition of superpixel outlier degree can be provided as a saliency for subsequent steps.
By continuously adjusting the division of background set, the uniform background region in SAR image is gradually screened out, which improves the accuracy of background selection.
2.3. Recursing Saliency Depth
Outliers reflect the superpixels which differ from the background. The more different the superpixels are, the more attention we will pay. Therefore, in the iterative process, when the background and outliers vary wildly, it is generally considered that the corresponding scene is more likely to contain the target of interest. S. Liu proposed the concept of saliency depth to evaluate the possibility of targets in multi-class scenes [
27]. The method in this subsection does not use scene classification in detection, but represents different scenes through iterative detection of background set, so it can also use saliency depth analysis to analyze the possibility of target existence.
In this section, the saliency of outliers in iteration is evaluated by the saliency depth of recursion. The high saliency outliers are retained, and the low saliency superpixels are suppressed to achieve saliency correction.
First, calculate the degree of deviation of outliers in the scene, denoted as initial salience:
where
is the number of outlier superpixels,
is the regional features measure of outliers after standardized processing, such as self information or conditional entropy.
represents the degree of outlier deviating from the threshold. In the initial saliency
, we want to highlight the outliers far from the threshold. Therefore, we use power 3 to deal with the degree of outlier. The experiment of S. Liu [
27] shows that the scene containing targets has higher initial saliency, while for the pure background SAR image with Equivalent Number of Looks (ENL, a parameter commonly used to measure the speckle suppression of different SAR/OCT image filters) greater than 1, its initial saliency is often smaller.
After excluding the current outlier in the scene, the outlier is detected again and the salience is calculated using Equation (
15), which is called the predicted salience
. If some salient targets in the scene are not detected as outliers, the prediction saliency may be high, which means that the background area needs to be further detected and divided. On the other hand, assuming that all salient targets have been included in the outliers, after excluding the outliers, the saliency of the background superpixel set is lower than the initial case, which means that further detection of the background region may be unnecessary.
In the experiment, it is found that the prediction saliency of the non-target scene itself may also be higher than the initial saliency. In order to calculate the saliency depth, we set , to widen the gap between the initial value and the predicted value. Finally, the depth of salience is defined as . These two values measure the complexity of the background set, while depth indicates whether outlier detection is effective in reducing the complexity of the background.
The saliency depth requires the calculation of two salience, and the difference between the two is determined by outlier screening. The saliency depth of iterative detection is calculated by the following equation:
where
represents the saliency depth of the set labeled
b in the
i-th iteration, and
represents the initial salience of the set. In addition, the initial salience corresponding to all labels and number of iterations can be combined into matrix
, where the rows represent number of iterations and the columns represent number of labels;
is the result of row difference of matrix
. This step is called recursing saliency depth, because it uses the salience provided by the next iteration.
From Equation (
16), if
is large, it means that the background superpixel after outlier screening has uniformity and does not need to be further detected; otherwise, it means that the background set after outlier screening has little difference from the previous background set, which may have been a pure background or there is a target to be detected. Therefore, we need to find the maximum value for each column of the matrix
:
The background of label b reaches its maximum depth of salience at iteration .
In order to optimize the detection results, the effective outliers in different backgrounds should be enhanced, and the effective background regions should be suppressed to generate a reasonable global salience map. We proposed a fusion method based on saliency depth. Firstly, the outlier degree and background corresponding to the maximum saliency depth are used for enhancement and suppression, respectively:
In the
-th iteration, the set of label
b corresponds to the maximum saliency depth, and the salience value of the outlier is positive
, whereas the salience value of the background is equal to its negative value. Then, combining with the salience value of the outlier itself, that is, adding the loss item of Hinge, the final salience value
is obtained:
where
is the Hinge loss term with a positive value. In order to avoid missed detection, for the superpixel with positive salience value, its mean salience value
and standard deviation
are used for global detection:
where
is the total number of positive outliers.
Then, the empirically selected global detection threshold
is used to determine whether the superpixel belongs to the potential target or background:
If is true, it indicates that the n-th superpixel is the potential target region, otherwise, it belongs to the background region.
However, in order to avoid missed detection, the outlier threshold and global detection threshold are usually set with very small value, so there are still a few false alarms. When the target pixel proportion is very low, it will result in the loss of target information. To solve the above problems, local information is used to optimize the detection results.
2.4. Local Salience Optimization
The arrangement of the centers of superpixels is usually irregular, so it is necessary to build a graph model with superpixels as nodes, and make local access through the edges of adjacent superpixels. When a node has a short path to a background (target) seed node, then this node is also classified as a background (target).
Considering the complexity of calculation, a graph model is established only for the local neighborhood of each potential target superpixel, denoted as
, where
is the set of
M superpixel nodes. The adjacency matrix
represents the
edges. Since only adjacent superpixels have effective edges, the edge weight is calculated by the following equation:
where
is the node set adjacent to the
m-th node, and the edge weight between adjacent nodes is
, the edge weight between disconnected nodes is infinite. In addition, the edge of the superpixel is made to satisfy symmetry, that is,
.
In order to detect the target superpixels that the conditional entropy cannot distinguish and filter out the false alarm, the KS (Kolmogorov-Smirnov) test value is calculated only by using the first
K non-zero gray levels in the adjacent superpixels:
where
is the CDF (Cumulative Distribution Function) of the first
K gray levels of the
m-th superpixel, and
,
. KS test is similar to conditional entropy in that it restricts strongly scattered pixels, but KS test has symmetry, so it is more in line with local detection requirements.
For the target split into adjacent superpixels, the centroid of mass of strongly scattered pixels in superpixel is extracted. In the adjacent background superpixel, the distance between the centroid of mass is long, but in the adjacent target superpixel, the distance is short. Therefore, we calculate the euclidean distance
of the centroid of mass of strong scattering in the adjacent superpixel and introduce it into the edge weight:
Then, the potential target superpixels in the global detection results are taken as the target seeds, and the rest are the background seeds. At the same time, the potential target superpixels are sorted according to the salience value, and the target seeds with high salience value are given priority for local detection.
q is used to represent the ordinal number of the potential target superpixel after sorting, which satisfies the following order inequality:
Therefore, when local detection is carried out on the q-th superpixel, its adjacent node set is checked. When contains only the potential target, we can appropriately expand the scope of its neighborhood until it includes the background seed. When only contains the background, a virtual target seed can be assumed: its histogram is replaced by the average histogram of the first q target seeds, and then the distance between and KS is calculated. The distance between and its center of mass is replaced by the maximum distance from the pixel to its own center of mass in the superpixel . is used to build the local graph model, and the weights of the middle edges are assigned.
According to the distance between and , the nodes with the shortest distance are assigned to to achieve local detection. After Q potential targets are processed in order of salience value from high to low, local salience optimization is completed.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}